1. Introduction
Physical unclonable functions or PUFs [
1,
2] utilize inherent manufacturing variations to produce hardware tokens that can be used as building blocks for authentication protocols. Many different physical phenomena have been proposed to provide PUF behavior including Ring Oscillators (ROs) [
2,
3,
4], cross-coupled latches or flip-flops [
5], capacitive particles in a coating [
6], and beads in an optical card [
1]. PUFs can be categorized by the type of functionality they provide: Weak PUFs, also called Physically Obfuscated Keys (POKs), are used for secure key storage. Strong PUFs implement (pseudo) random functions based on exploiting manufacturing variations that vary from PUF instance to PUF instance; strong PUFs are used for device identification and authentication. The primary advantage of using a strong PUF is that the communication between the authenticator and the physical device need not be protected. This is because each authentication uses a distinct input to the “pseudorandom function”.
In this work, we deal with the design and implementation of strong PUFs. A strong PUF is a physical token that implements a function that translates
challenges into
responses. The
reliability property of a strong PUF says that if the same challenge is provided multiple times, the responses should be close (according to some distance metric) but not necessarily the same. The
security property is that an adversary with access to the PUF (and the ability to see responses for chosen queries) should not be able to predict the response for an unqueried challenge. Recently, attacks in this model allow creation of accurate models for many proposed strong PUFs [
7,
8,
9,
10,
11]. We only consider attacks using the input and output behavior. An additional required security property is that the adversary should not be able to physically clone the device to create a device with similar behavior (see [
12] for more on required properties).
These attacks can be mitigated by designing new PUFs or adding protections to the PUF challenge-response protocol. Our focus is on improving the challenge-response protocol. A natural way to prevent learning attacks is to apply a one-way hash to the output. However, the PUF reliability property only says that responses are noisy: they are close, not identical. Fuzzy extractors [
13] can remove noise at the cost of leaking information about the response. This information leakage prevents fuzzy extractors from being reused across multiple challenges [
14,
15,
16,
17]. Computational fuzzy extractors do not necessarily leak information [
18] and some constructions may be reusable [
19]. Herder et al. have designed a new computational fuzzy extractor and PUF challenge-response protocol designed to defeat modeling attacks [
20]. Their construction is based on the learning parity with noise (LPN) problem [
21], a well-studied cryptographic problem. Essentially, the LPN problem states that a product of a secret vector and a random matrix plus noise is very hard to invert. However, their work did not implement the protocol, leaving its viability unclear.
Our Contribution: We provide the first implementation of a challenge-response protocol based on computational fuzzy extractors. Our implementation allows for arbitrary interleaving of challenge creation, called
, and the challenge response protocol, called
, and is stateless. Our implementation builds on a Ring Oscillator (RO) PUF on a Xilinx Zynq All Programmable SoC (System on Chip) [
22], which has an FPGA (Field Programmable Gate Array) and a co-processor communicating with each other.
Our approach is based on the LPN problem, like the construction of Herder et al. [
20], with the following fundamental differences:
In order to minimize area overhead so that all control logic and other components fit well inside the FPGA, we reduce storage (by not storing the whole multiplication matrix of the LPN problem, but only storing its hash) and, most importantly, we outsource Gaussian elimination to the co-processor.
We keep the same adversarial model: we only trust the hardware implementation of
and
in FPGA, i.e., we do not trust the co-processor. In fact, we assume that the adversary controls the co-processor and its interactions with the trusted FPGA logic; in particular, the adversary observes exactly what the co-processor receives from the trusted FPGA logic and the adversary may experiment with the trusted FPGA logic through the communication interface. As in Herder et al. [
20], we assume that an adversary can not be successful by physically attacking the trusted FPGA logic with its underlying RO PUF. We notice that in order to resist side channel attacks on the FPGA logic itself, the logic needs to be implemented with side channel counter measures in mind. This paper gives a first proof-of-concept without such counter measures added to its implementation.
In order to outsource Gaussian elimination to the co-processor, the trusted FPGA logic reveals so-called “confidence information” about the RO PUF to the co-processor, which is controlled by the adversary. This fundamentally differs from Herder et al. [
20] where confidence information is kept private.
To prove security of our proposal, we introduce a mild assumption on the RO PUF output bits: we need to assume that the RO PUF output bits are represented by an “LPN-admissible” distribution for which the LPN problem is still conjectured to be hard. We argue that the RO PUF output distribution is LPN-admissible for two reasons (see Definition 1 and discussion after Theorem 1):
Since we reveal the “confidence information”, we can implement a masking trick which, as a result, only reveals a small number of equations, making the corresponding LPN problem very short; we know that very short LPN problems are harder to solve than long ones.
Studies have shown that the RO pairs which define the RO PUF on FPGA can be implemented in such a way that correlation among RO pairs can be made extremely small; this means that the RO PUF creates almost identical independent distributed (i.i.d.) noise bits in the LPN problem and we know that, for i.i.d. noise bits, the LPN problem has been well-studied and conjectured to be hard for decades.
Our main insight is that “confidence information” does not have to be kept private—this is opposed to what has been suggested in Herder et al. [
20]. As a result of our design decisions:
The area of our implementation on FPGA is 49.1 K LUTs (Look-up Tables) and 58.0 K registers in total. This improves over the estimated area overhead of 65.7 K LUT and 107.3 K registers for the original construction of Herder et al. [
20].
The throughput of our implementation is 1.52 K executions per second and 73.9 executions per second.
According to our experiments on real devices, even though the underlying RO PUF has a measured maximum error rate (i.e., the fraction of RO pairs producing a wrong response bit) of 8% for temperatures from 0 to 70 degree Celsius, correctly reconstructed responses for 1000 measurements.
Organization: This paper is organized as follows: In
Section 2, we introduce the necessary background and the original LPN-based PUF design of [
20]. Our simplified and implementation friendly LPN-based PUF construction is described in
Section 3. The implementation details and security analysis with discussion on admissible LPN distributions are provided in
Section 4 and
Section 5, respectively. We compare our work with related work in
Section 6. The paper concludes in
Section 7.
3. Our Construction
It costs significant area overhead to perform Gaussian elimination in hardware. For this reason, we propose a hardware software co-design of LPN-based PUFs where Gaussian elimination is pushed to the untrusted software, i.e., only the hardware components are assumed to be trusted in that they are not tampered with and an adversary can only observe the interactions between hardware and software.
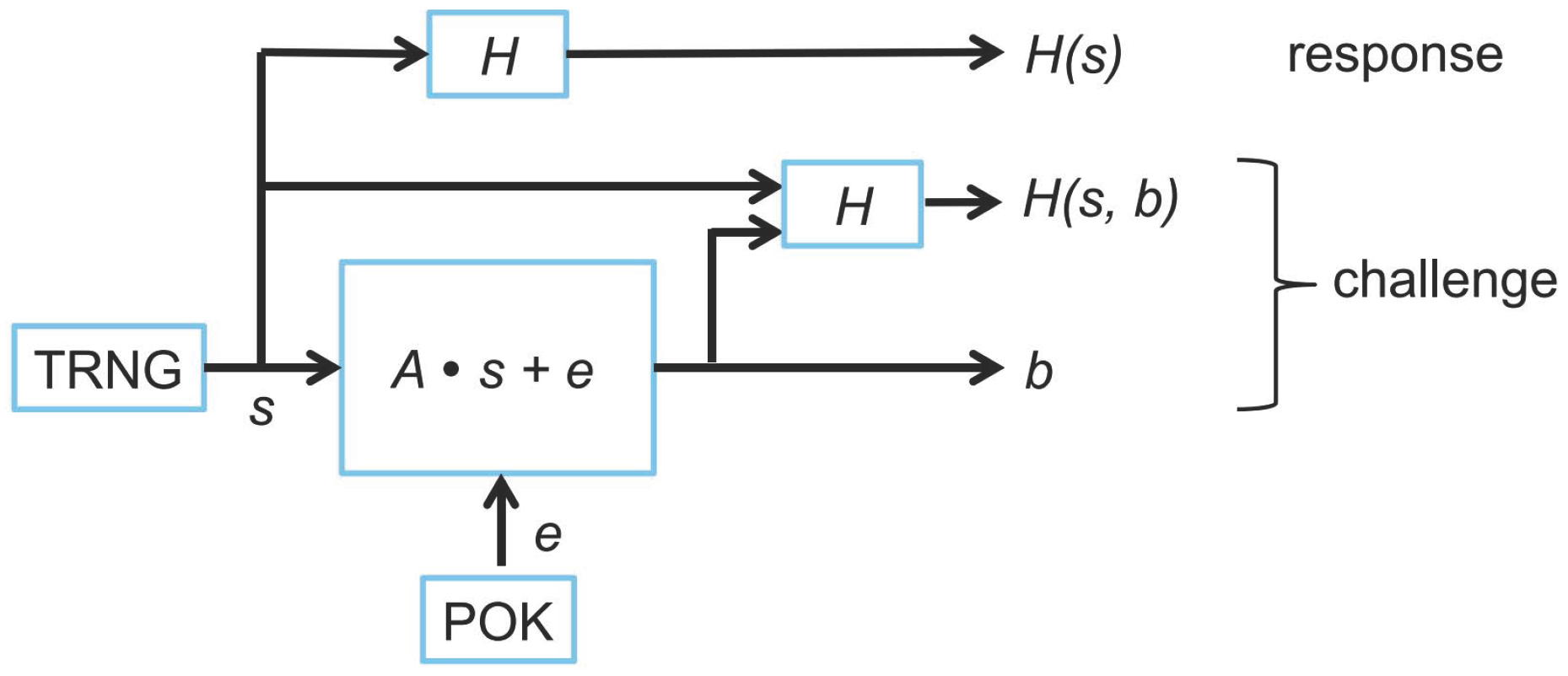
As in the original construction, our LPN-based PUF has a Physical Obfuscated Key (POK), which always measures the same response, at its core. It also has two modes of operation:
(
Figure 3) and
(
Figure 4). Each instance of
creates a challenge-response pair. If a correctly created challenge is given to the LPN-based PUF operating in
mode, then the corresponding response is regenerated. In
Figure 3 and
Figure 4, the functions in white boxes are implemented in hardware and are trusted. The processor (in the grey box) and the software running on it are considered to be untrusted; therefore, all of the computation executed by the software should be verified by the trusted hardware in the diamond shaped boxes.
Generation : Matrix is selected at random by the manufacturer, and it can be the same for all the devices. Therefore, its hash value can be completely hard coded into the circuit to prevent adversaries from manipulating matrix . In our construction, a POK is implemented by m Ring Oscillator pairs (RO pairs), where m is the number of rows in matrix . Note that we use a POK, but our protocol supports a large number of challenge-response pairs yielding a strong PUF overall.
The POK generates a vector with count differences coming from the RO pairs. The sign of each entry in gives a binary vector , and the absolute value of the entries in represents confidence information . selects a set of bits from where the corresponding confidence information is at least some predefined threshold .
The processor feeds the rows of one by one into the hardware. By using a bit select module based on set , the hardware extracts and feeds the rows of to a hardware matrix-vector multiplier. The hardware matrix-vector multiplier takes input matrix , an input vector generated by a True Random Number Generator (TRNG), and , and computes . We set all bits for to generate the complete vector of m bits. This masking trick has the advantage that no unnecessary information is given to the adversary (and will allow us to have a reduction to a very short LPN-problem). After is constructed, hash values and are computed. The challenge is with response .
Since any software computation is considered untrusted, the hardware needs to verify the hash of . This circuitry (with hash embedded) is used in mode to verify that the (untrusted) processor provides the correct specified by the manufacturer, instead of an adversarially designed matrix. This is needed because the underlying LPN problem is only hard if is a randomly chosen matrix; an adversarially designed could leak the POK behavior. Similarly, matrix also needs to be verified in for the same reason.
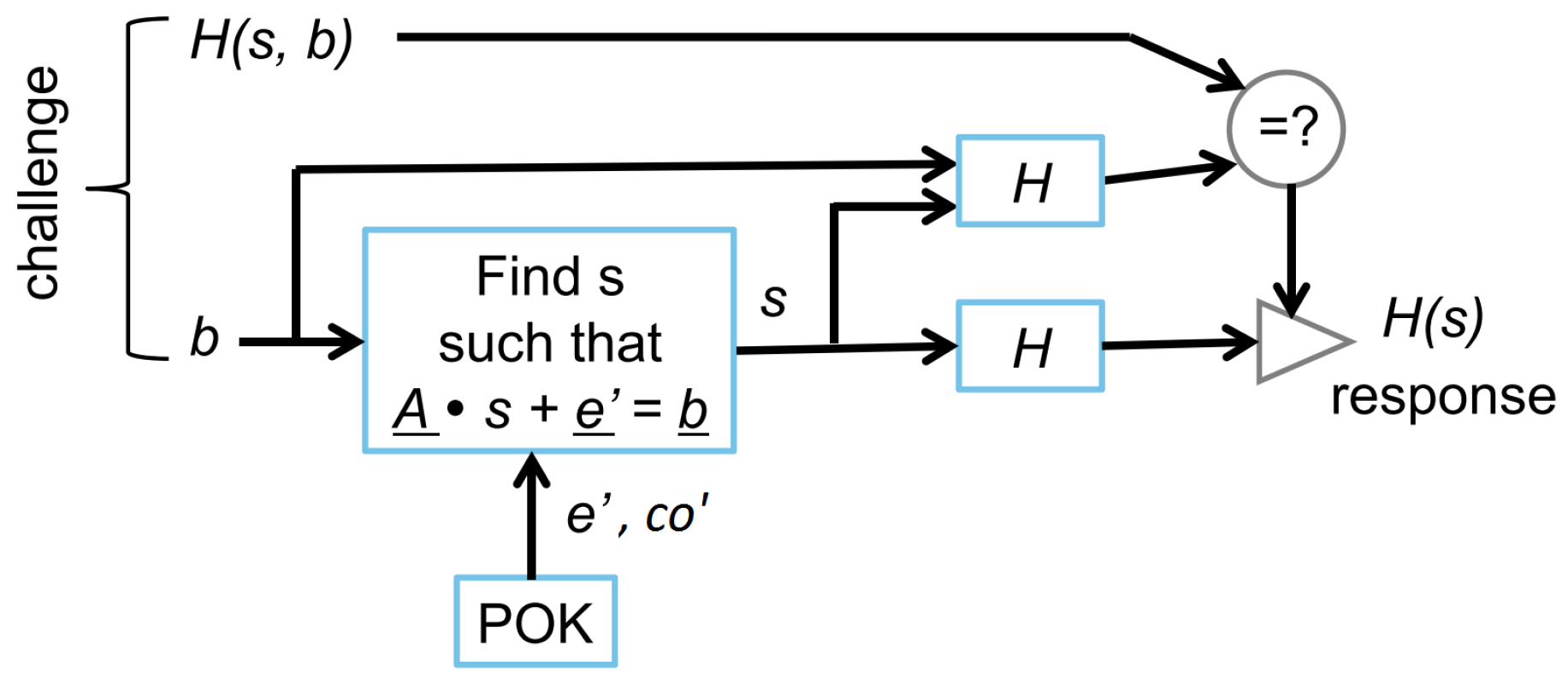
Verification : In mode, the adversary inputs a possibly corrupted or maliciously generated challenge ( in , we denote all the variables, which should have the same values as the corresponding variables used in , as the original variable followed with a single quotation mark (). e.g., in should be equal to in , if it is not maliciously manipulated by adversaries). Before a corresponding response will be reconstructed, the hardware in mode needs to check whether was previously generated in mode.
The POK measures again count differences from its RO pairs and obtains and . There are some errors in , so . For indices i corresponding to high confidence, we expect with (very) small probability. We use this fact to remove (almost all of) the noise from the linear system.
The POK observes which i corresponds to a bit that has high confidence value; we call the set of reliable bit positions , which should have a similar size as that of . The POK then sends to the processor. The processor takes input challenge and picks a subset with such that matrix has full-rank. We notice that, by using a subset of both and the probability for is much smaller than for or .
The processor computes and transmits to the hardware matrix-vector multiplier the inverse matrix
of matrix
. Next, the rows of matrix
are fed one by one into the hardware and its hash is computed and verified against
. The rows corresponding to submatrix
are extracted (using a bit select functionality based on
) and the columns of
are fed into the hardware matrix-vector multiplier one by one. This verifies that
and
are inverses of one another (the equal identity matrix box in
Figure 4 verifies that the columns of the identity matrix are being produced one after another). The correctness of matrix
is guaranteed by checking whether the hash of matrix
matches the hash value
(as was done in
). The correctness of
implies the correctness of
(since
was fed as part of
into the hardware). Therefore, if all checks pass, then
is indeed the inverse of a properly corresponding submatrix of the matrix
used in
. (The reason why this conclusion is important is explained in
Section 5.).
Next, the hardware computes the vector
and multiplies this vector with matrix
using the hardware matrix-vector multiplier:
The (non-malleable) hash value is compared with the input value from the challenge.
Suppose that input was generated as for some and . If , we conclude that is correct in that it is equal to input which was hashed into when was generated, and is correct in that it is equal to input which was hashed into when was generated.
Since the adversary is not able to solve the LPN problem, the check
together with the conclusion that
led to a proper solution
of the LPN problem by using the bits in the POK-generated vector
implies that only the LPN-based PUF itself could have generated
and, hence, the challenge. This means that the LPN-based PUF must have selected
and produced the inputted challenge with
during an execution of
. We notice that vector
can only be recovered if
in the execution of
equals
in (
1). We conclude that
is now able to generate the correct response
(since
must have been the response that was generated by the LPN-based PUF when it computed the challenge with
).
If , then likely and only differ in a few positions (if there is no adversary). By flipping up to t bits in (in a fixed pattern, first all single bit flips, next all double bit flips, etc.), new candidate vectors can be computed. When the hash verifies, the above reasoning applies and with the correct response . Essentially, since the bits we are using for verification are known to be reliable, if the system is not under physical attacks, then very likely there are no more than t bit errors in . Internally, we can try all the possible error patterns on with at most t bit flips, and check the resulted against to tell whether the current was used in or not.
If none of the t bit flip combinations yields the correct hash value , then the exception ⊥ is output. This decoding failure can be caused by attackers who feed invalid CRPs, or a very large environmental change that results in more than t bit errors in , which can also be considered as a physical attack. We notice that allowing t-bit error reduces the security parameter with ≈t bits since an adversary only needs to find within t bit errors from . In order to speed up the process of searching for the correct , we use a pipelined structure which keeps on injecting possible (with at most t bit flips) to the hardware matrix-vector multiplier.
Being able to recover
is only possible if
in the execution of
and
in Equation (
1) are equal up to
t bit flips. This is true with high probability if
is large enough and
was properly selected as a subset of
. As explained by Herder et al. [
20],
m should be large enough so that an appropriate
can be selected with the property that, when the RO pairs are measured again, there will be a set
of
n reliable bits: in particular, according to the theorical analysis in [
20], for
, this corresponds to
m at most 450 RO pairs for operating temperature from 0 to 70 degrees Celsius and error probability (of not being able to reconstruct
) less than
. Readers are referred to Equation (2) in [
20] for an estimation of
given the distribution of RO outputs and the desired error rate.
Comparison with previous work: Our approach differs from the construction of Herder et al. in [
20] in the following ways:
We output the indices of reliable bits to the untrusted processor, instead of keeping the positions of these reliable bits private inside the hardware. In
Section 5, we argue that the distribution of
and, in general,
are still LPN-admissible.
By masking (i.e., making all-zero outside ), we can reduce the security to a very short LPN problem with equations (corresponding to set ).
By revealing and to the processor, the processor can select a submatrix with which is a full rank matrix. This would consume more area if done in hardware.
Since the processor knows the selected submatrix , the processor can compute the inverse matrix. Hence, we do not need a complex Gaussian eliminator in hardware and we reuse the matrix-vector multiplier used in mode.
Because the processor with executing software is considered to be untrusted, we add mechanisms to check manipulation of and .
Matrix does not need to be hard-coded in circuitry. Instead, a hash-of--checking circuitry is hard coded in hardware giving less area overhead.
4. Implementation
We implemented our construction on Xilinx Zynq All programmable SoC [
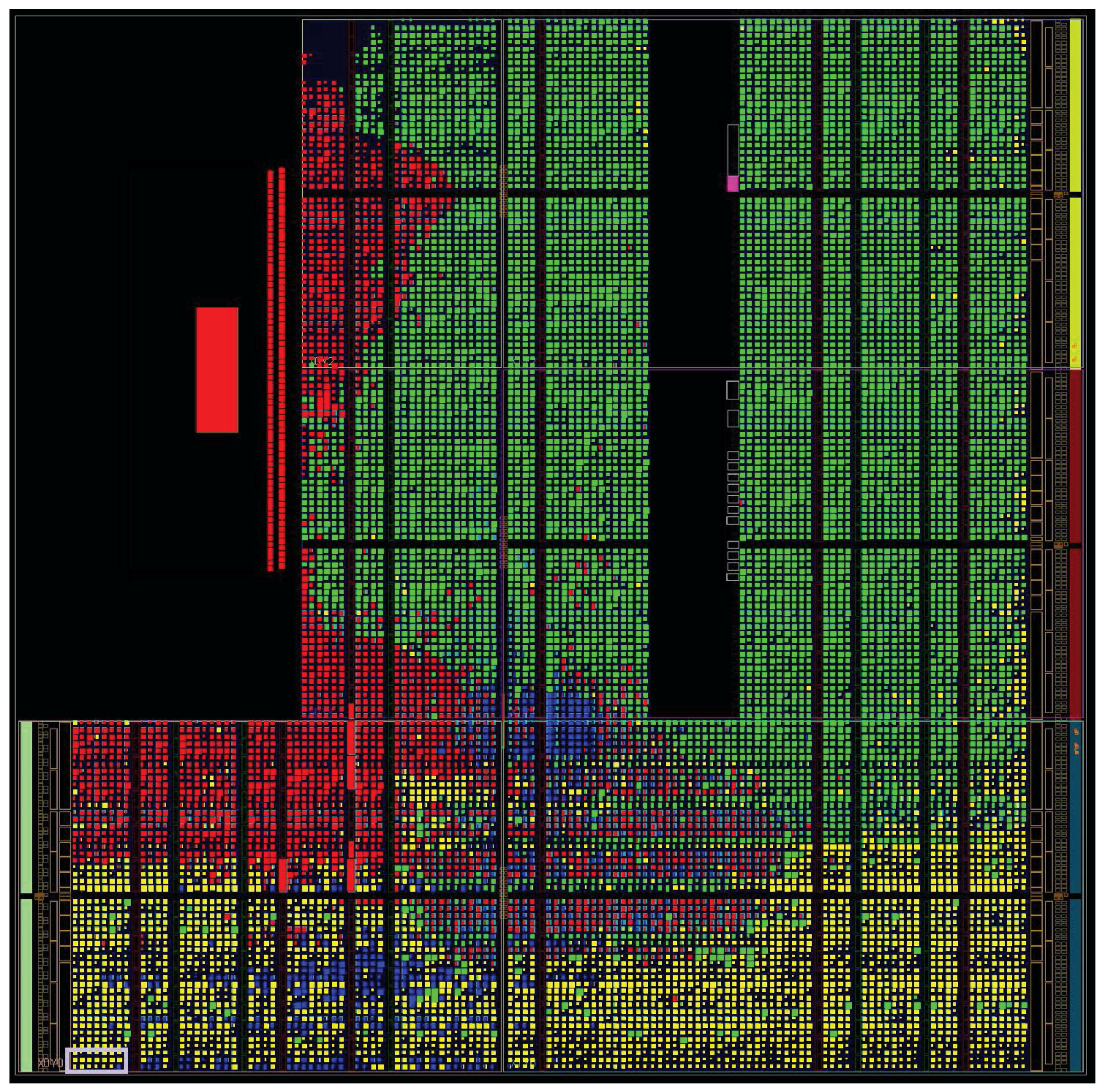
22]. The Zynq platform contains an ARM-based programming system with some programmable logic around it. Having a hard core embedded, this platform makes our software hardware co-design implementation easier and more efficient in software execution. We implemented the software units on the ARM core and the hardware units in the programmable logic. The communication between these two parts is over an AXI Stream Interface in order to maximize the communication throughput. The FPGA layout of the implemented LPN-based PUF is shown in
Figure 5.
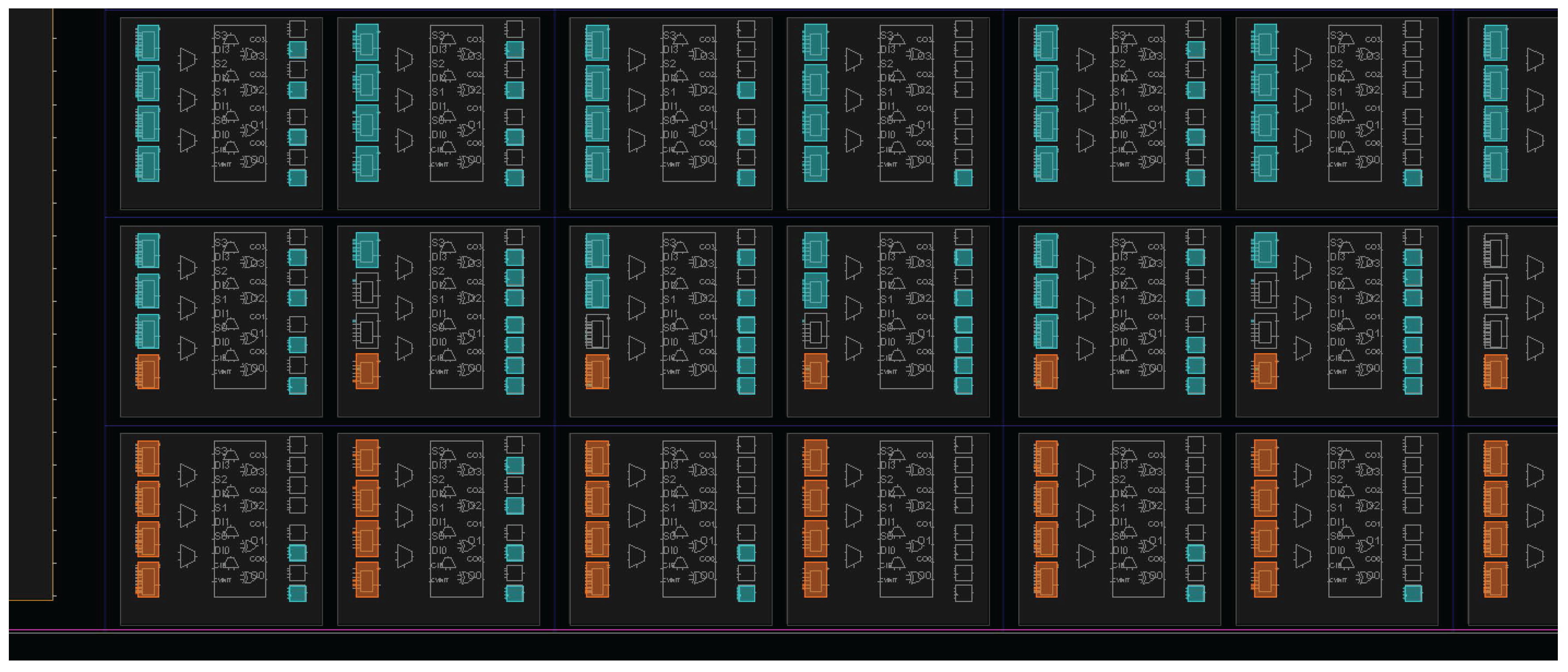
We have 450 RO pairs for generating
with confidence information
as depicted in
Figure 3 and
Figure 4. Each RO has five stages, and the two ROs in each RO pair are manually placed at adjacent columns on the FPGA to minimize the systematic effects [
33] (see
Figure 6). We measure the toggles at the output of each RO for 24 clock cycles to generate
and
. In
mode, module Index Selection compares vector
with a threshold
to produce an index vector, which indicates the positions of all the reliable bits. This is used in module Bit Selection to condense the 450-bit vector
to a 256-bit vector
by selecting 256 bits out of all the reliable bits. Set
restricted to these 256 bits is sent to the processor as part of the generated challenge.
Next, the processor sends matrix
(450 rows times 128 columns) to the hardware row by row. All the rows will be fed into the hash function to compute
to verify the correctness of
. Only the rows in
, which will be used later in a matrix multiplication, are selected and stored by the Row Selection module. Since we implemented a pipelined matrix-vector multiplier for multiplying a
matrix with a 128-bit vector,
multiplies the
submatrix
of
with a randomly generated vector
by loading this submatrix in two parts. After XORing
, we obtain a 256-bit vector
. Module Bit Expand adds zeroes to create the full 450-bit vector
. After Bit Expand, we feed the 450 bits of
and the 128 bits of
to the hash module to compute
and
. We implemented a multiple ring oscillator based true random number generator [
34] to generate the 128-bit vector
, and SHA-256 [
35] is implemented as the hash function.
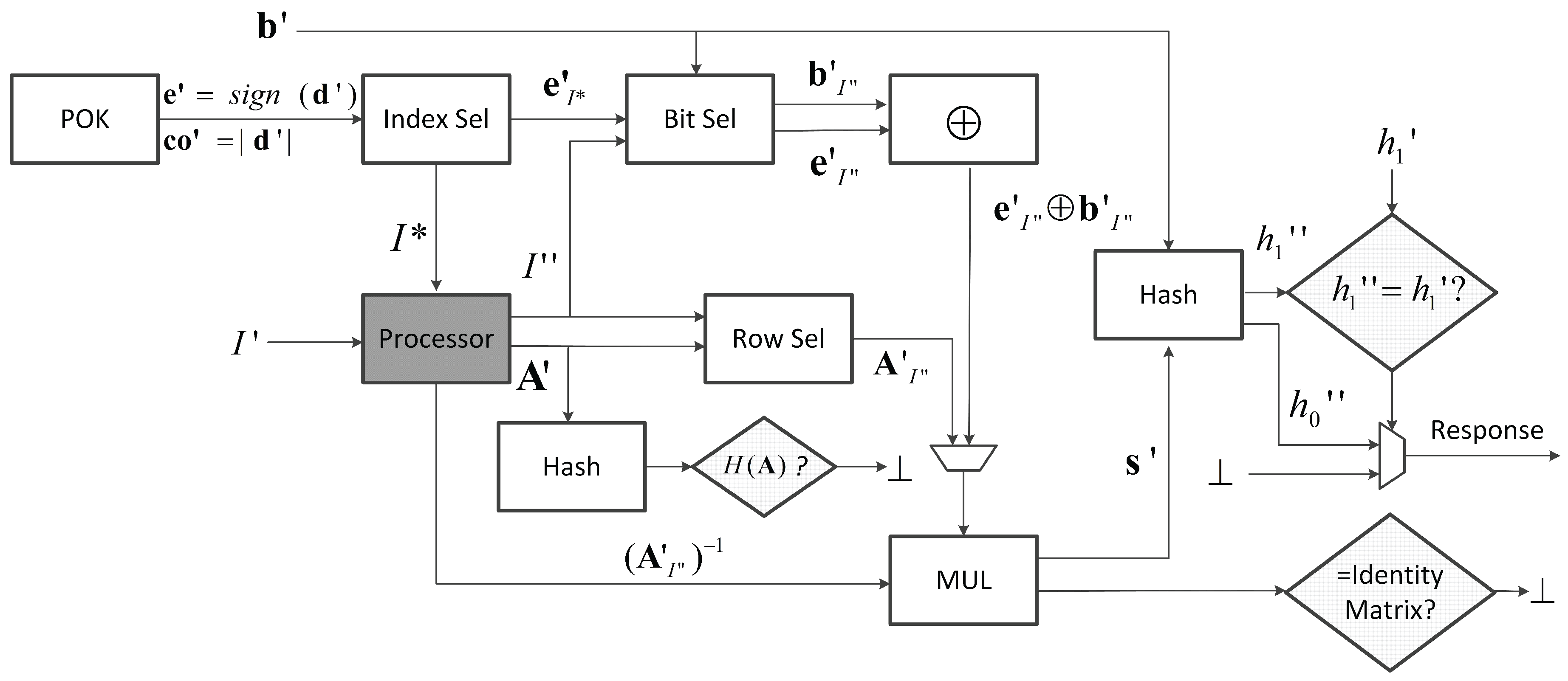
In mode, 450 RO pairs are evaluated in the same way as in . Now, the module Index Selection generates index set , which is sent to the processor. A correctly and non-maliciously functioning processor should take the intersection of and the correct set , which was produced by . From this intersection, the processor selects an index set such that the submatrix is invertible. Since a randomly selected 128 × 128 submatrix may not be invertible, it may require the processor to try a couple of times until finding an invertible matrix. Matrix is streamed to the hardware row by row and is stored in registers, which will be the matrix input for the matrix-vector multiplier.
Next, the processor streams into the hardware row by row. All the rows will be fed into the hash function to compute to verify the correctness of . At the same time, the rows of are fed into the Row Selection module for selecting the 128 × 128 submatrix . All the rows in are temporarily saved in an array of shift registers. After all the rows of are streamed in, the array of shift registers can shift out column by column and reuse the pipelined matrix-vector multiplier in to check whether the product of and each column of is a column of the identity matrix or not.
If the above two checks pass, then the inverse matrix
will be multiplied with
to recover
. Here, the processor should have given
to the hardware so that the Bit Selection module can be used to obtain
(with
). The recovered
is further verified by computing
. If
; then, the hardware computes and outputs
. According to the calculation in [
20], we set
. This means that we need to exhaustively try all the one bit flips. This means that there are 129 possible possible
in total (these can be fed one by one into the pipelined matrix-vector multiplier). If none of these yields a correct
, then the hardware will output an all-zero vector to indicate a ⊥ response. Similarly, if any of the above checks (of the hash of
and of the inverse matrix) fails, then the hardware will output the all-zero vector as well.
Our implementation results. The area of our full design on FPGA is 49.1 K LUTs and 58.0 K registers in total. The area utilization of each part is shown in
Table 1. The three most costly components are two 128 × 128 register arrays and the 450 RO pairs, which form together the underlying RO PUF. The dynamic power consumption of the complete implementation is 1.753 W, and its static power consumption is 0.163 W.
The throughput of our implementation is measured as 1.52 K executions per second and 73.9 executions per second. The execution time of is dominated by the matrix transmission, which takes 91% of the overall execution time. However, is dominated by the software Gaussian elimination, where each Gaussian elimination takes about 3880 s to finish, and each requires 3.47 Gaussian eliminations on average.
Comparison. The original construction in [
20] would need a hardware Gaussian eliminator in an implementation. The most efficient implementation of a pipelined Gaussian eliminator takes 16.6 K LUT and 32.9 K registers on FPGA for a 128 row matrix [
36]. In our design, we save this area by pushing the computation to the software.
One may argue that, in order to push Gaussian elimination to untrusted software, we have to add extra hardware to check for the correctness of the inverse matrix. Notice, however, for checking this inverse matrix, we reuse the matrix-vector multiplier in . Therefore, the only additional hardware overhead is one 128 × 128 register array. If we do Gaussian elimination in hardware, then we need registers to store the whole matrix of size 128 × 256 and the output matrix of the Gaussian elimination, which is another 128 × 128 bits: this is because a random matrix constructed by 128 rows in may not have full rank. As a result, the hardware may need to try a couple of times in order to find an invertible submatrix of . For these reasons, compared to our implementation in this paper, Gaussian elimination in hardware will cost an additional 128 × 128 register utilization together with the control logic for randomly selecting 128 rows out of a 256-row matrix.
If we would implement the original construction in hardware, then its area overhead without additional control logic is estimated at 65.7 K LUT (49.1 K + 16.6 K) and 107.3 K register (58.0 K + 32.9 K + 16.4 K). This resource utilization would be larger than the available resources on our FPGA (53.2 K LUT and 106.4 K registers).
Experimental Results. We characterized the error rate of RO pairs defined as the percentage of error bits generated in one 450 bit vector
. The error rate of the implemented 450 RO pairs at room temperature is
, which is in the range (2∼
) that has been reported in a large scale characterization of ring oscillators [
4]. We measured the error rate of 450 RO pairs under different temperatures from 0 to 70 degrees Celsius where the output of the 450 RO pairs is compared to a reference output vector
generated at 25 degrees Celsius. We observed a maximum error rate of 8% (36 out of 450) over 1000 repeated measurements. This error rate is within the range of the error correction bound (9%) estimated in [
20]. We also characterized the bias of all the RO pair outputs,
for our implementation.
We experimented with the whole system under different temperatures (at
C,
C and
C). This showed that
was always able to reconstruct the proper response. No failure was observed over 1000 measurements under different tempratures. We did not perform testing on voltage variation and aging because the overall error rate is only affected by the error rate of the RO pair output bits. As long as the error rate of RO outputs is lower than 9% [
20], given the current implementation, we can have a large probability to regenerate the correct response. The overall error rate will not be affected by how we introduce the errors in RO pairs.
If a TRNG has already been implemented in the system, then the TRNG can be reused for the LPN-based PUF as well. As a part of a proof-of-concept implementation of the LPN-based PUF, we did not perform a comprehensive evaluation of our implemented TRNG.
Future Direction. In our implementation, the area of LPN core mainly consists of two 128 × 128 bit register arrays for storing two matrices. It is possible to eliminate storage of these two matrices in order to significantly reduce the area at the cost of paying a performance penalty.
The proposed alternative implementation works as follows: instead of storing two matrices for checking (in ) whether and are indeed inverse matrices of one another, we only store at most one row or one column in the hardware at the same time. In , we will need to first feed in matrix , and let the hardware check its hash. At the same time, the rows in are selected and fed into another hash engine to compute which is separately stored. However, the hardware does not store any of the rows of (and this avoids the need for a 128 × 128 bit register array). Notice that after this process the authenticity of matrix has been verified, and, as a result, we know that the rows of are equal to the rows of , hence, the stored hash which can now be used to verify the submatrix whenever it is loaded again into the hardware.
Next, matrix is fed into the hardware column by column. When a column is fed into the hardware, e.g., the i-th column, we store it in the hardware temporarily. Then, the processor sends the whole matrix to the hardware row by row. Its hash is computed on the fly and in the end compared with the stored hash . At the same time, each received row of is multiplied (inner product) with the current stored i-th column of . This is used to check if the product is indeed equal to the corresponding bit in the i-th column of the identity matrix. If this check passes for all rows of and the hash verifies as well, then this column will be added to the intermediate value register of , based on whether i-th bit of equals 1 or not.
In the above protocol, we also hash all received columns of and store the hash in a separate register. If the above checks pass for all columns, then we know that this hash must correspond to . This will facilitate the process of trying other possible versions of in the future (where the processor again feeds matrix column by column so that its hash and at the same time can be computed).
The first trial/computation of requires the processor to feed in matrix (450 × 128 bits) once, matrix (128 × 128 bits) 128 times (since it needs to be fed in once after each column of is fed in), and (128 × 128 bits) once. If the first trial on fails, we will need to feed in a few more times until it recovers the correct ; now, only needs to be checked, hence, does not need to be sent again and again. Therefore, we can estimate the throughput upper bound of this new implementation by our time measurement in our current implementation. Since the hardware computation time in our implementation does not dominate the overall computation time, we can estimate the performance of the new alternative implementation by only counting software computation time and data transmission time. In , this alternative implementation will have a similar execution time because the matrix can be multiplied with vector row by row and output bit by bit. in this alternative implementation will require transmitting 2,171,136 bits for the first trial/computation of . Knowing that it takes about 600 s to send 57,600 bits in our implementation, transmitting 2,171,136 will require about 22,626 s, and on average we will need to try Gaussian elimination 3.472 times to find an invertible matrix, which will take about 13,471s. The throughput upper bound of this alternative implementation would be 27.0 per second.
To implement this alternative solution, we can reuse some of the current components: Bit Select, Index Select, Bit Expand, ROs, TRNG and Communication (technically, Row Select can be reused as well, but in our current implementation, Row Select is highly integrated with matrix registers. Therefore, we cannot get a separate area utilization number of Row Select without matrix registers). We will need to double the size of the hash circuitry because we will always need two hash engines to run at the same time. The area of LPN core can be reduced significantly, the lower bound (without the state machine for controlling all the components) of the area utilization would be 2 K LUTs and 4.8 K registers. Adding to this the utilization of the other components, the total size would be at least 23.4 K LUTs and 24.8 K registers.
If area size needs to be further reduced, we recommend implementing the alternative solution at the cost of a 1/3 lower throughput of .
The comparison between our implementation and the estimation of the previous construction and an alternative implementation is summarized in
Table 2.
5. Security Analysis
We adopt the following security definition from Herder et al. [
20]:
Definition 2. A PUF defined by two modes and is ϵ-secure with error δ ifand for all probabilistic polynomial time (PPT) adversaries , , which is defined in terms of the following experiment [20]. | Algorithm 1 Stateless PUF Strong Security |
- 1:
procedure - 2:
makes polynomial queries to and . - 3:
When the above step is over, will return a pair - 4:
if returns such that: - 5:
then return 1 - 6:
else return 0 - 7:
end procedure
|
The advantage of is defined as For our construction (reusing the proof in [
20]), the security game in Definition 2 is equivalent to that where the adversary
does not make any queries to
.
The adversary in control of the processor can repeatedly execute and and receive various instances of sets and . This information can be used to estimate confidence information and this gives information about to the adversary. Therefore, we assume the strongest adversary, who has full knowledge about in the following theorem.
Theorem 1. Let be the conditional distribution of given and given index set with and . If the distribution is LPN-admissible, then the proposed PUF construction has negligible in n under the random oracle model.
The proof uses similar arguments to those found in sections VIII.A and VII.C.2 of [
20], with three differences: (1) the adversary who wants to break LPN problems takes an LPN instance
, where
and
. Thus, the related LPN problem is restricted to only
equations, instead of
m equations (m > 2n) in [
20]; (2) the distribution of
is from
which is conditioned on
, instead of
in [
20]; (3) in our construction, the querries to the random oracle are
and
, which are different from
and
used in the original construction. But this does not affect the capability of recovering
from the look up table constructed in the original proof in [
20].
The above theorem talks about LPN-admissible distributions for very short LPN problems (i.e., the number of linear equations is
, twice the length of
). Short LPN problems are harder to solve than longer LPN problems [
32]. Thus, we expect a larger class of LPN-admissible distributions in this setting.
In our implementation,
is generated by RO pairs on the FPGA. It has been shown in [
33] that, across FPGAs, the behavior of ROs correlate, i.e., if one depicts the oscillating frequency as a function of the spatial location of the RO, then this mapping looks the same across FPGAs. This means that different RO pairs among different FPGAs with the same spatial location behave in a unique way: an adversary may still program its own FPGAs from the same vendor and measure how the output of RO pairs depend on spatial locality its on its own FPGAs (which is expected to be similar across FPGAs).
The spatial locality of one RO pair does not influence the behavior of another RO pair on the same FPGA. However, if the output of one RO pair is known, the adversary is able to refine its knowledge about spatial locality dependence. In this sense, RO pairs with different spatial locations on the same FPGA become correlated. However, since the two neighboring ROs are affected almost the same by systematic variations, the correlation (even with knowledge of confidence information) between the RO pair outputs generated by physically adjacent ROs is conjectured to be very small. This claim is also verified experimentally in [
33]. We can conclude that different RO pairs will show almost i.i.d. behavior, if all the bits are generated by comparing neighboring ROs. However, even though the larger part of spatial locality is canceled out, conditioned on the adversary’s knowledge of how spatial locality influences RO pairs, an RO pair’s output does not look completely unbiased with
. In general, however,
(this corresponds to the inter Hamming distance between RO PUFs) [
20,
33]. Hence, the 450 RO pairs seem to output random independent bits, i.e., Bernoulli distributed with a bias
. Since we conjecture the hardness of LPN stating that Bernoulli distributions (with much smaller bias) are LPN-admissible, this makes it very likely that in our implementation an LPN-admissible distribution is generated.
As a final warning, we stress that replacing the 450 RO pairs by, e.g., a much smaller (in area) ring oscillating arbiter PUF introduces correlation, which is induced by how such a smaller PUF algorithmically combines a small pool of manufacturing variations into a larger set of challenge response pairs. This type of correlation will likely not give rise to a LPN-admissible distribution (the confidence information may be used by the attacker to derive an accurate software model of the smaller PUF which makes —as perceived by the adversary—a low entropy source distribution).
Including and in the hash computation. We analyze the reasons why and must be included in :
Parameter . is the only dynamic variable in the design so it ensures that challenge-response pairs are unpredictable. (We cannot directly use as a part of the challenge or response itself as this would provide information about to the adversary.)
Parameter . This inclusion is because of a technicality regarding Definition 2 (one bit flip in likely gives a new valid challenge-response pair).
Checking the hash of . We note that
checks if the adversary provides the correct matrix
as input by verifying the hash of
. If this check is not done, then the adversary can manipulate matrix
, and, in particular, submatrix
and its inverse
in
. This leads to the following attack: suppose the inverse of the manipulated matrix is close to the original inverse
with only one bit flipped in column
j. Let
be an all-zero matrix with only the one bit flipped in the
j-th column. Then,
computes
Since repeats this computation by flipping at most t bits in , we may assume that the term will be equal to zero for one of these computations. This means that outputs the correct response based on only if . Due to the specific choice for this happens if and only if the j-th row of has inner product zero with . By observing whether outputs a valid response or ⊥, the adversary is able to find out whether this inner product is equal to 0 or 1 and this leaks information about .
Machine Learning Resistance. Current strong PUF designs are delay-based and vulnerable to Machine Learning (ML) attacks. In order to obtain a strong PUF design with provable security, we bootstrap a strong PUF from a weak PUF (also called POK) by including a digital interface within the trusted computing base. This makes the new LPN-based strong PUF from [
20] provably secure as its security is reduced to the hardness of the LPN problem (at the price of not being lightweight due to the larger digital interface). In other words, no ML attack can ever attack the LPN-based PUF unless an ML approach can solve LPN.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}