Power Side-Channel Attack Analysis: A Review of 20 Years of Study for the Layman

Abstract
:1. Introduction
2. Measuring Power Consumption
3. Direct Observation: Simple Power Analysis
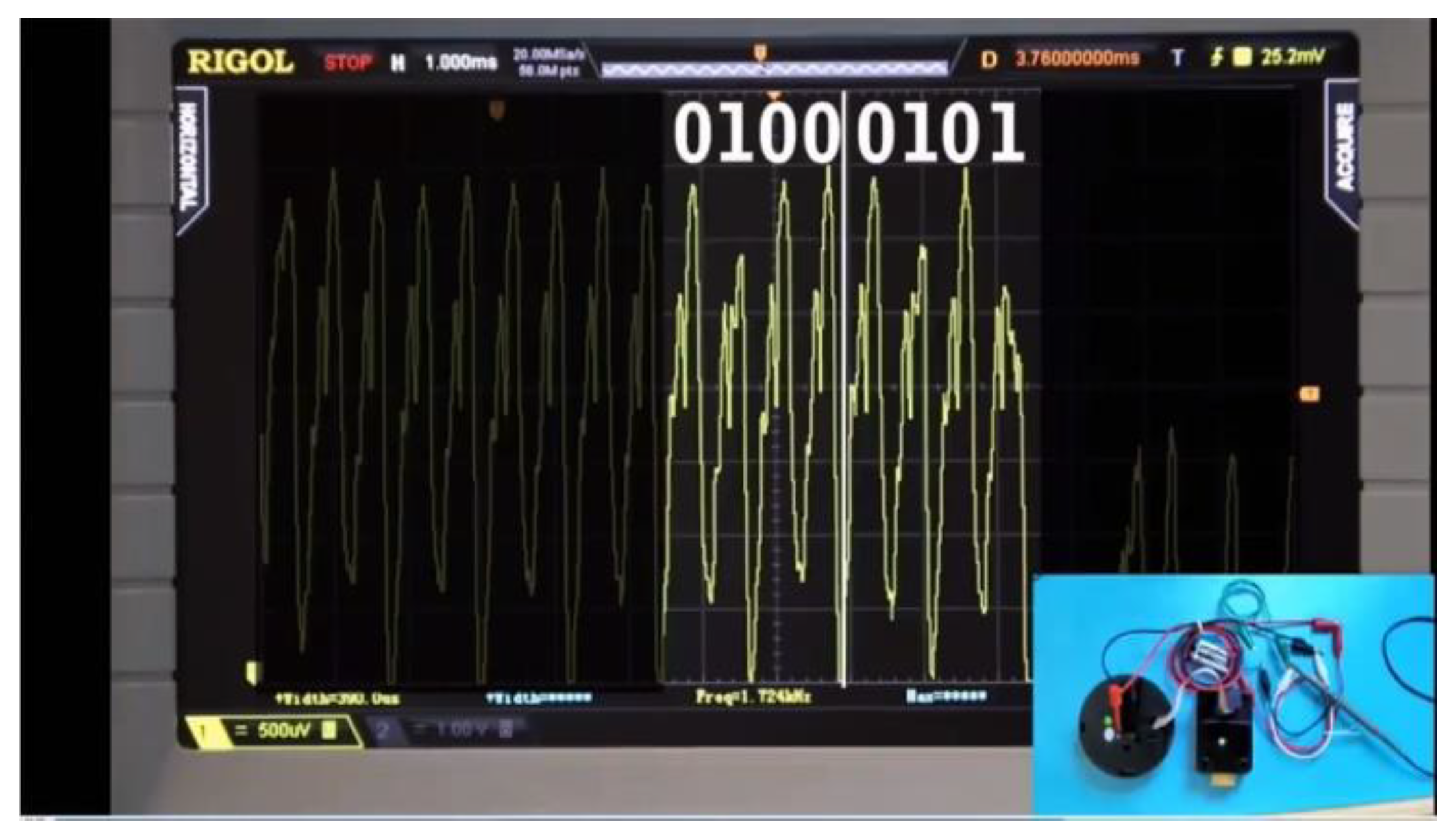
3.1. Simple Power Analysis and Timing Attacks
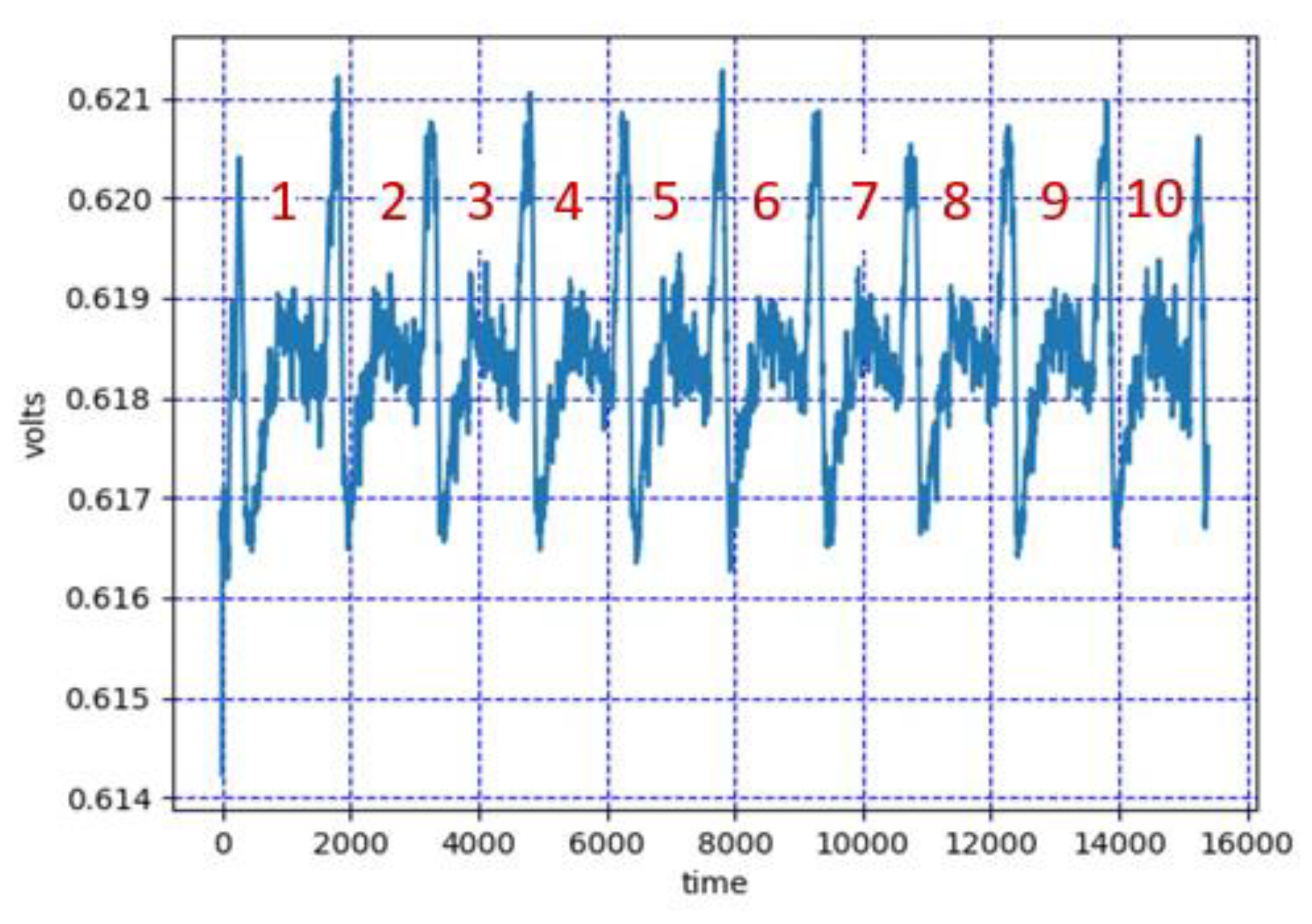
3.1.1. Classic RSA Attack
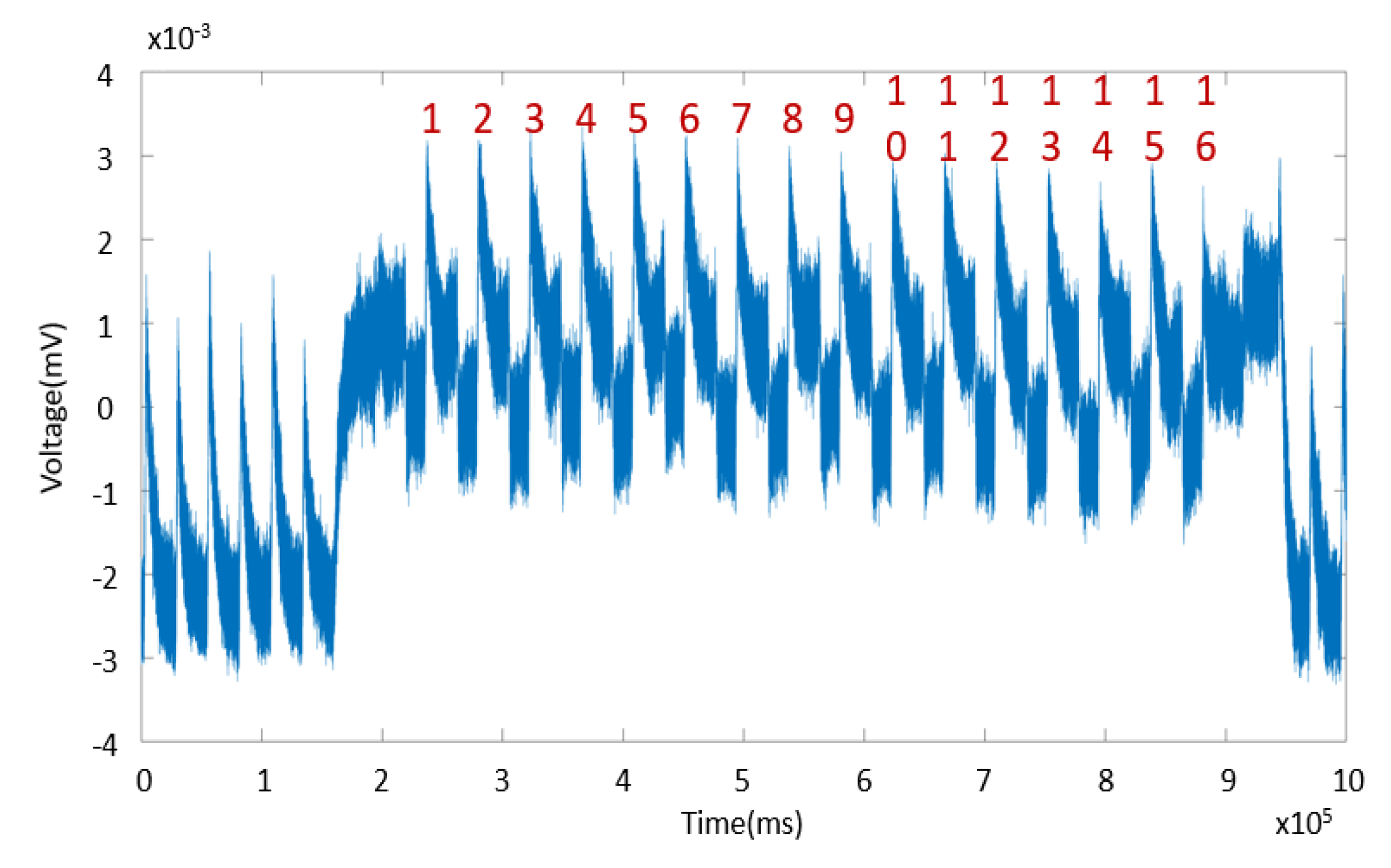
3.1.2. Breaking a High-Security Lock
4. Milestones in the Development of Power Side-Channel Analysis and Attacks
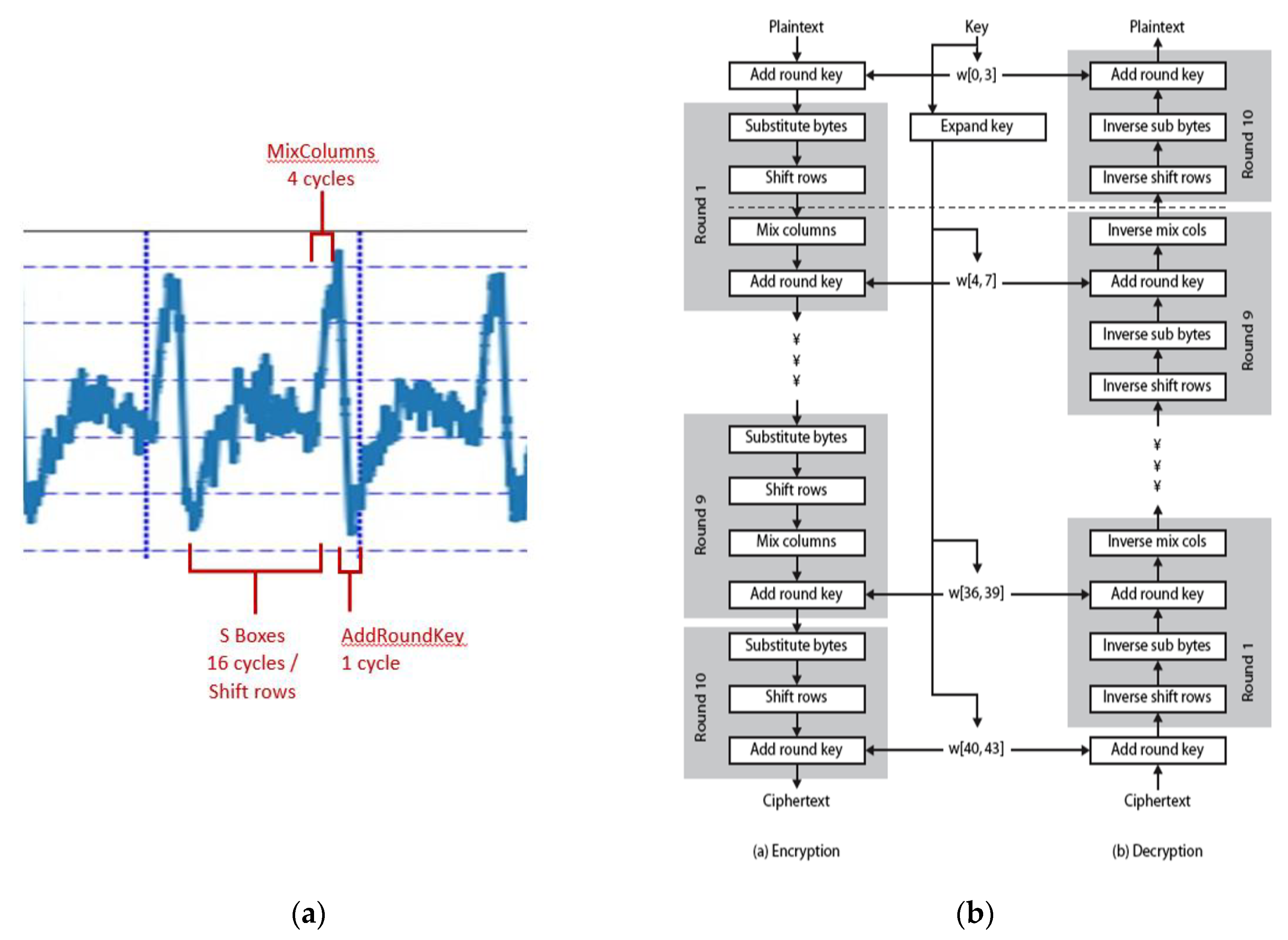
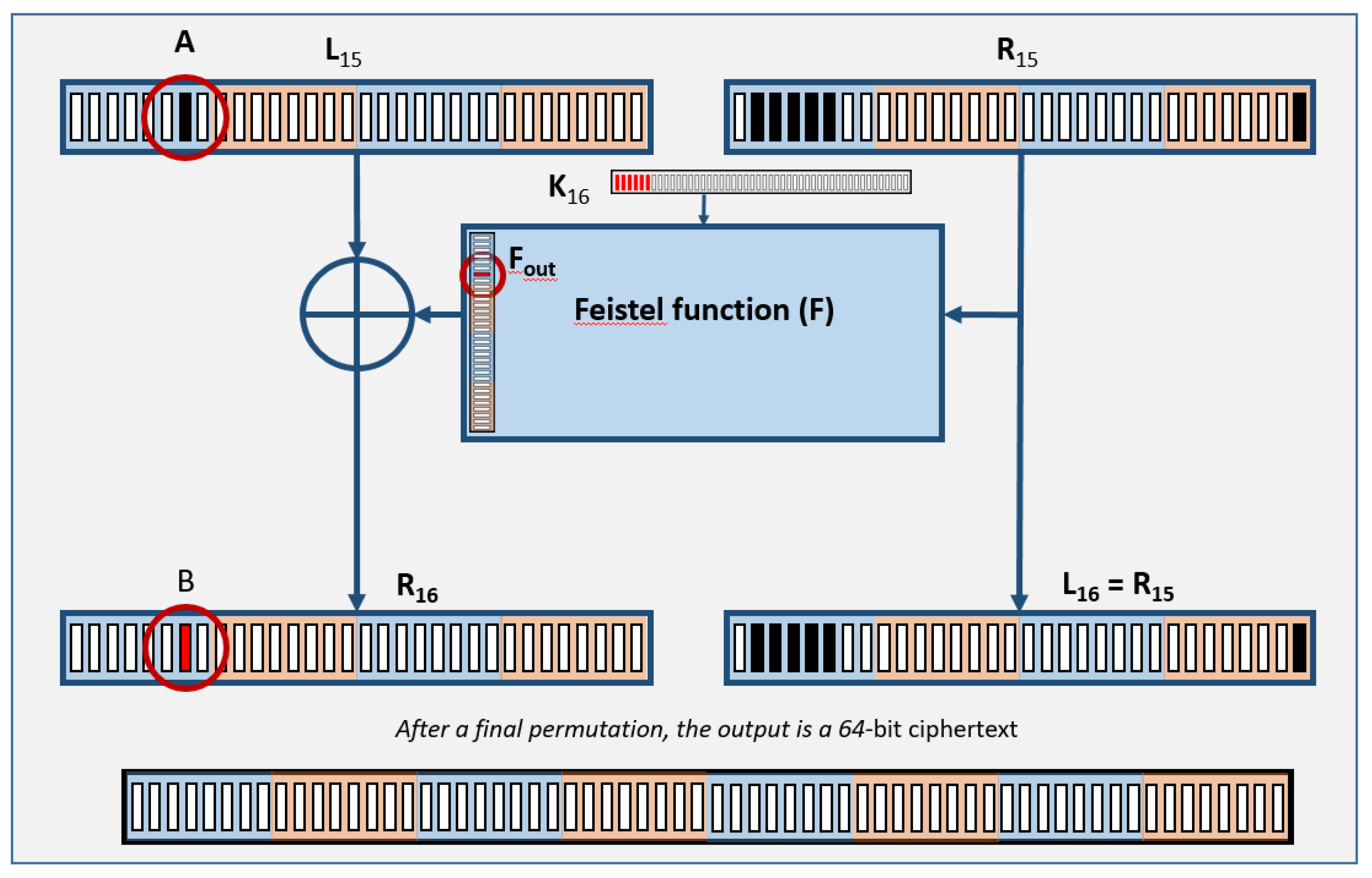
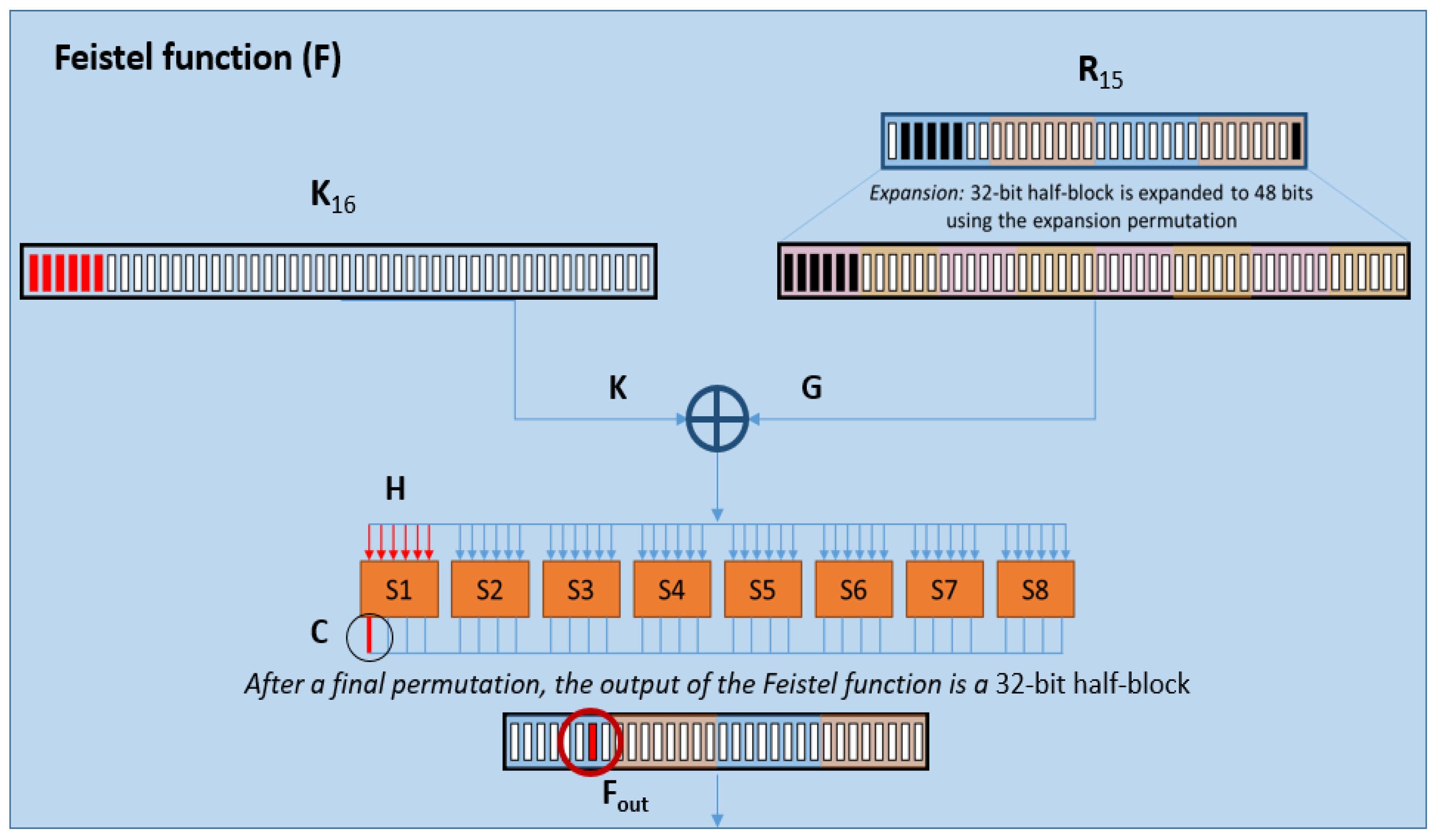
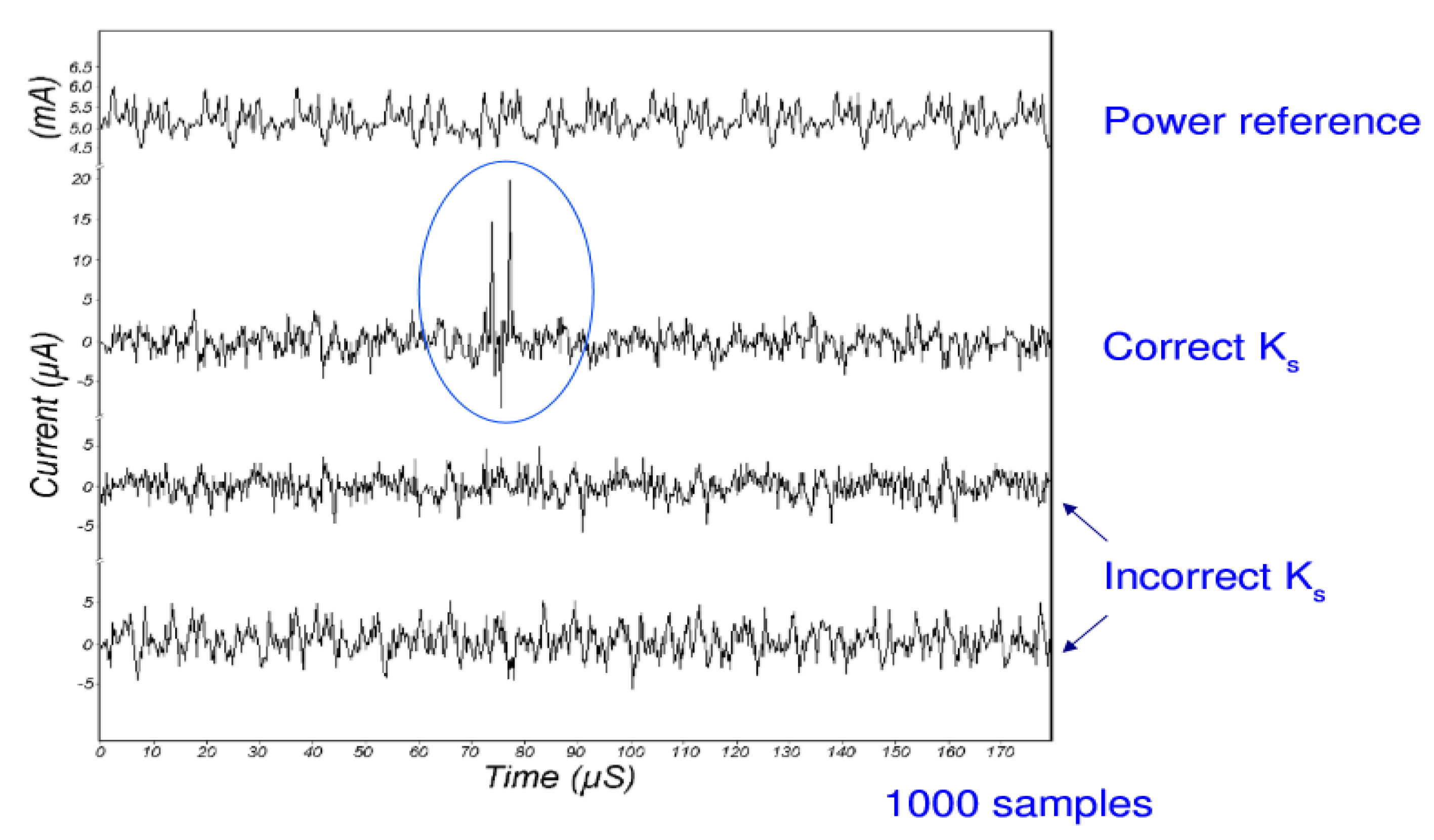
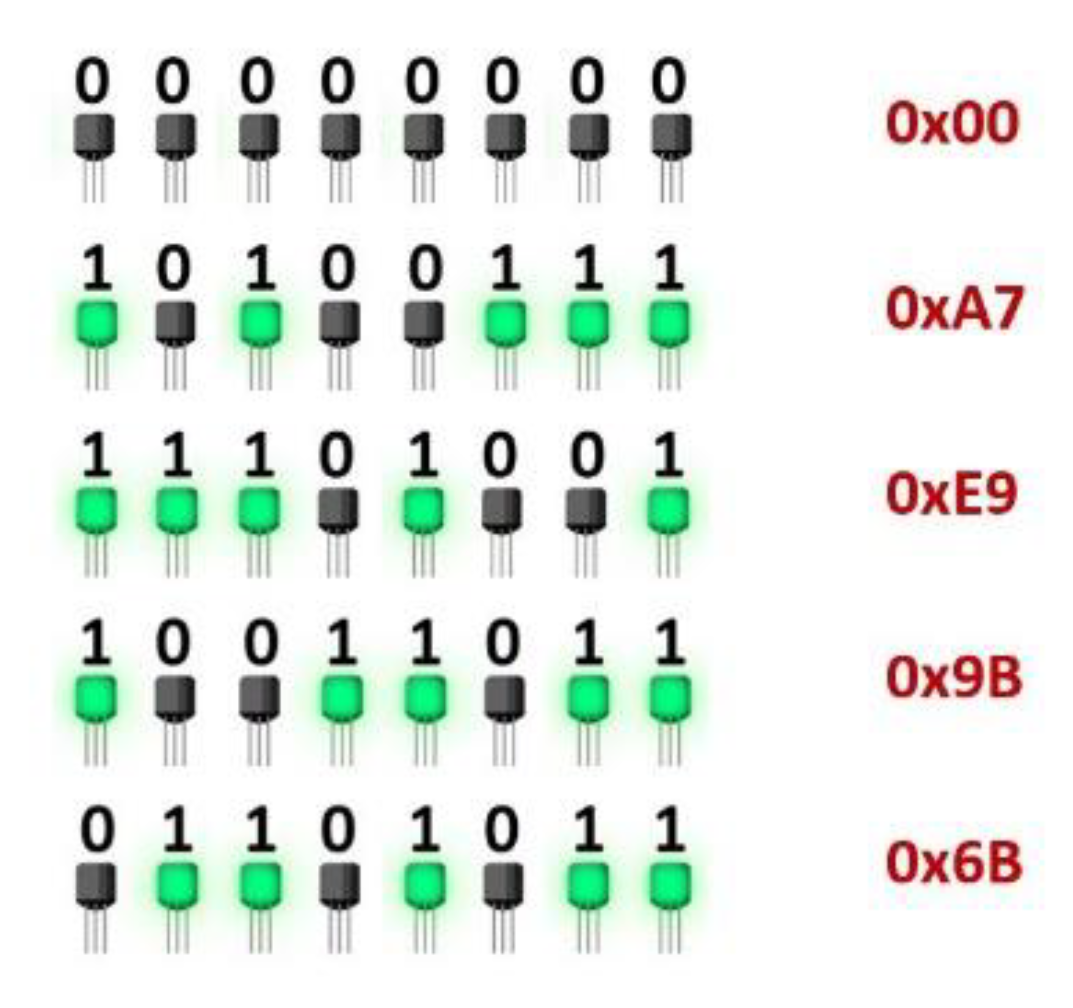
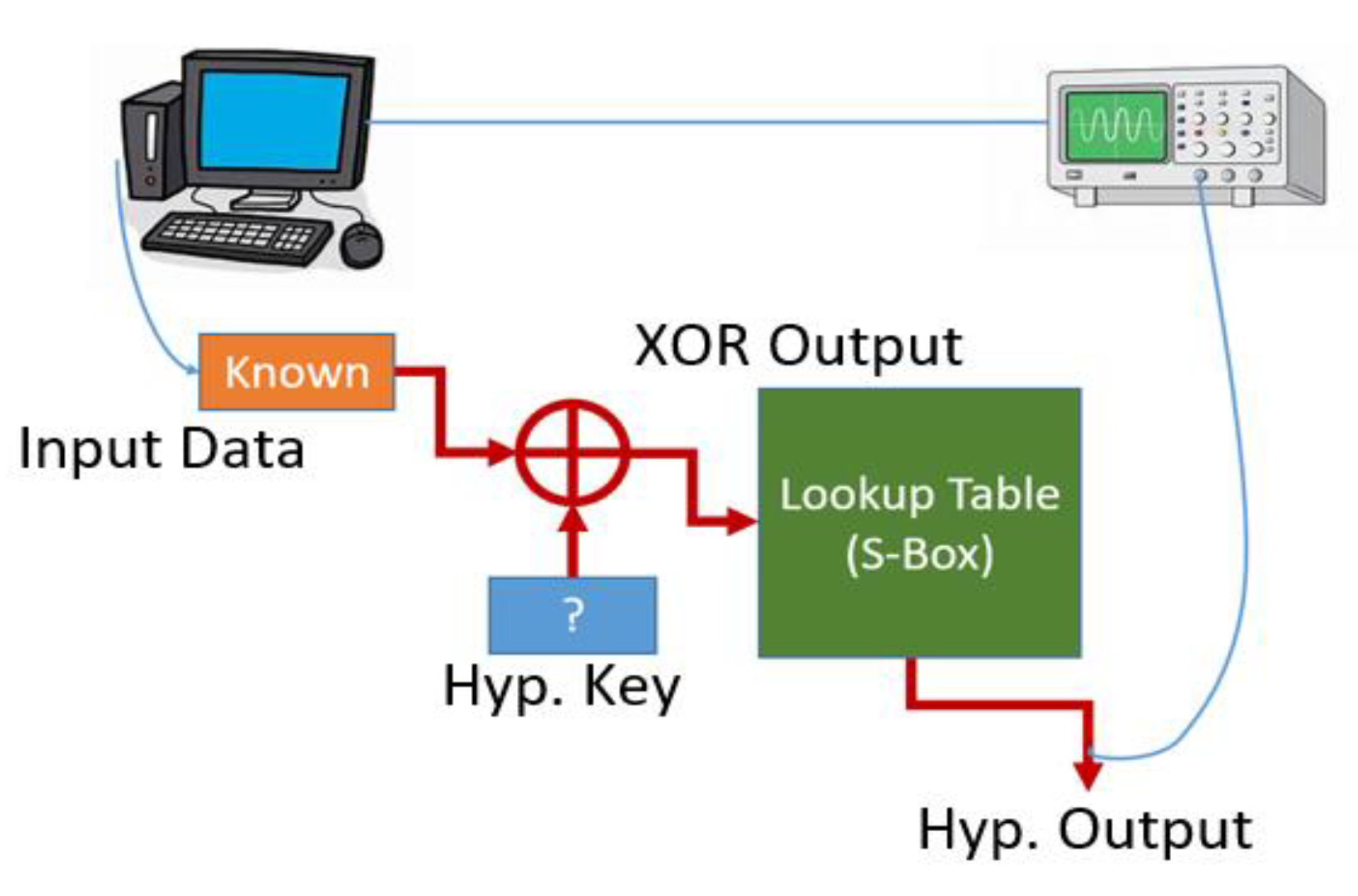
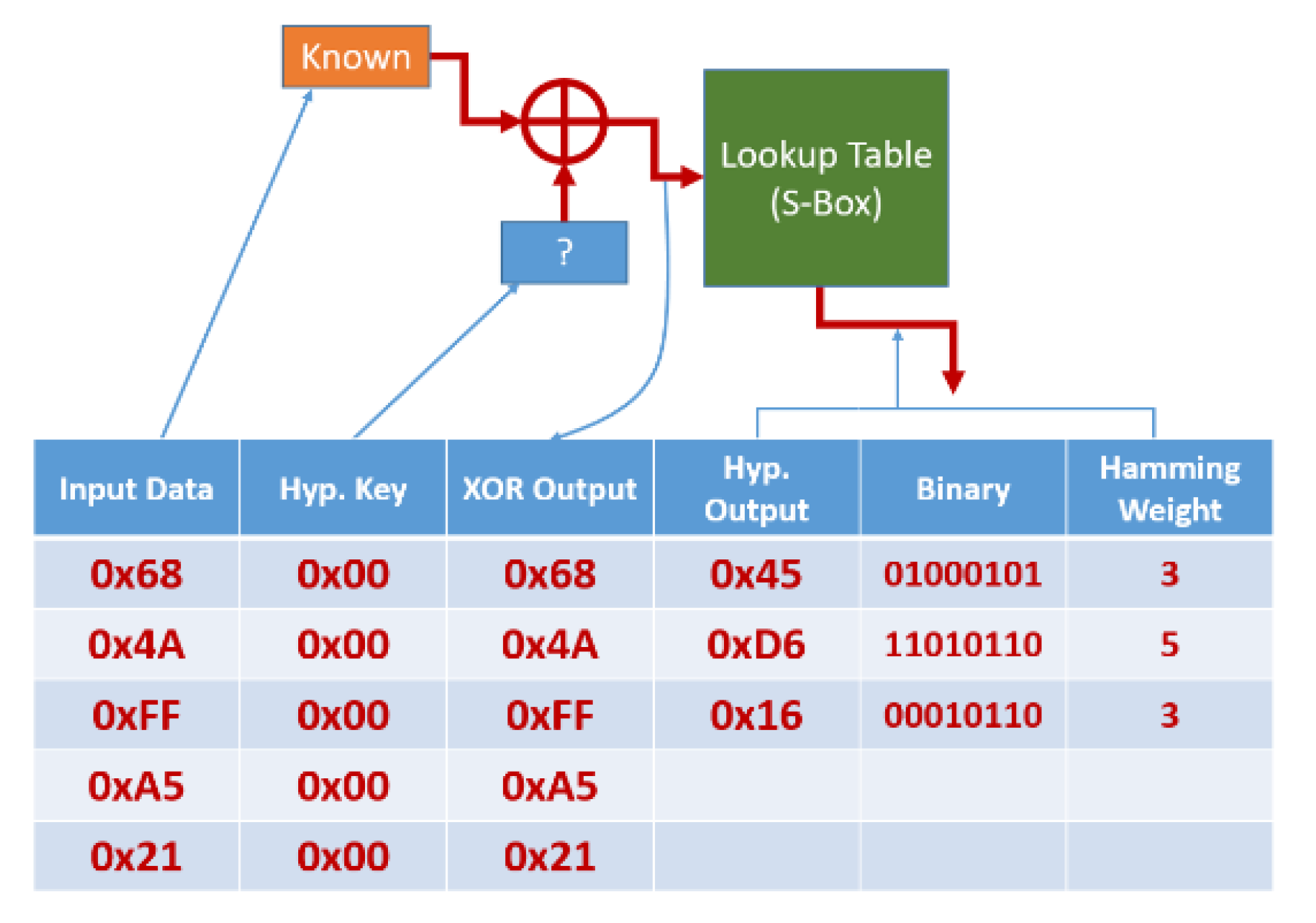
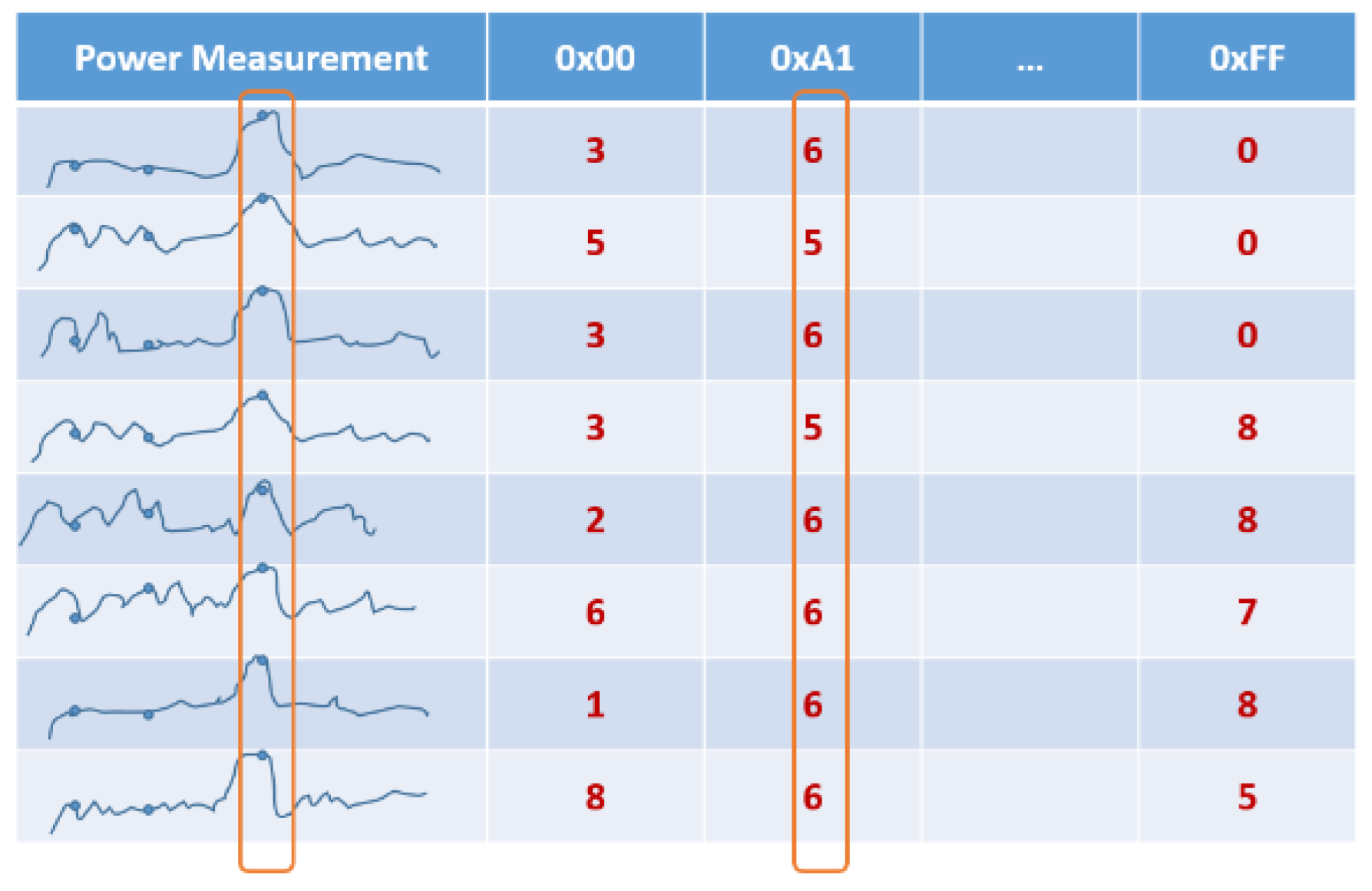
4.1. Differential Power Analysis
4.1.1. Theory
4.1.2. Practice
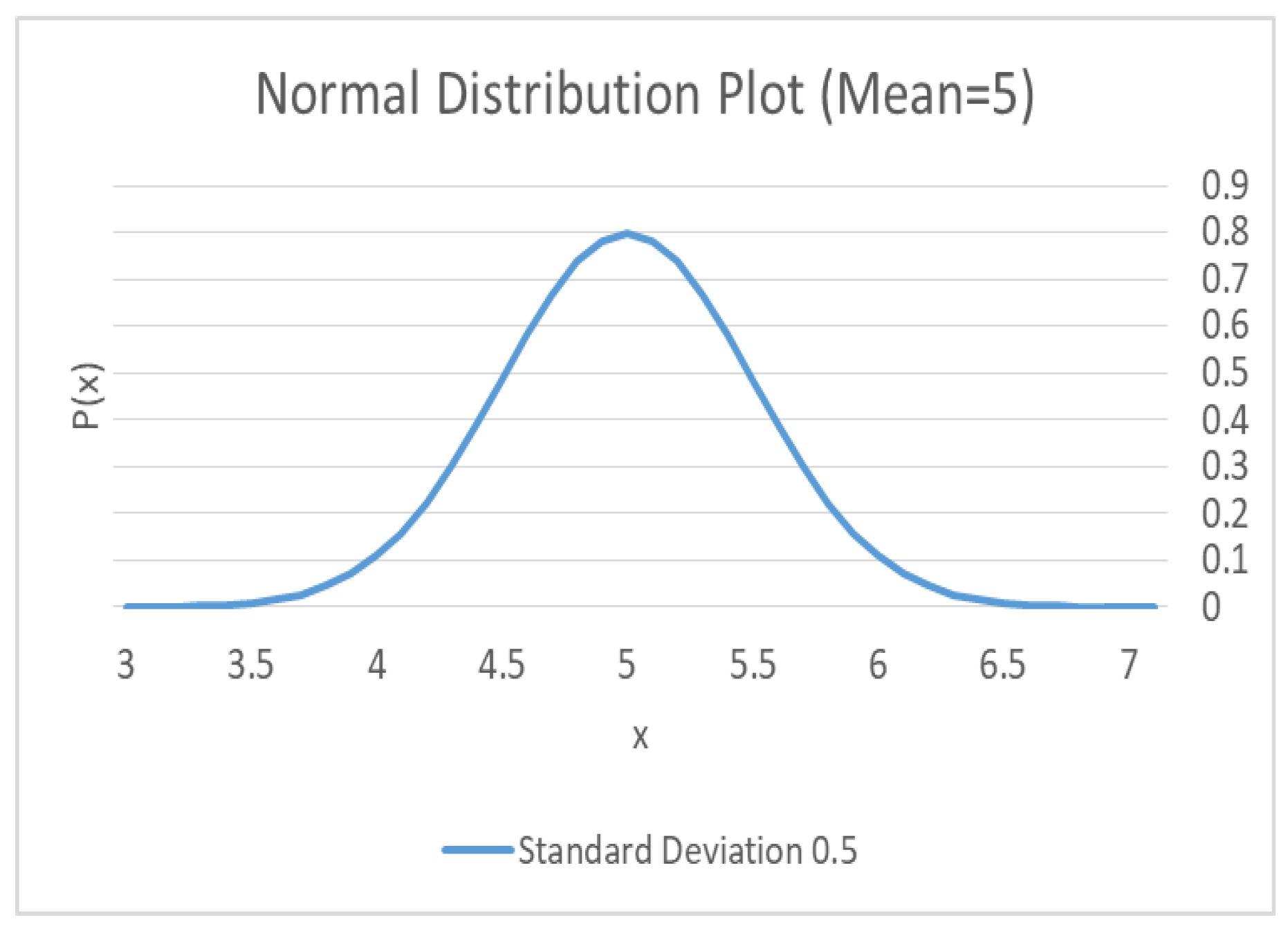
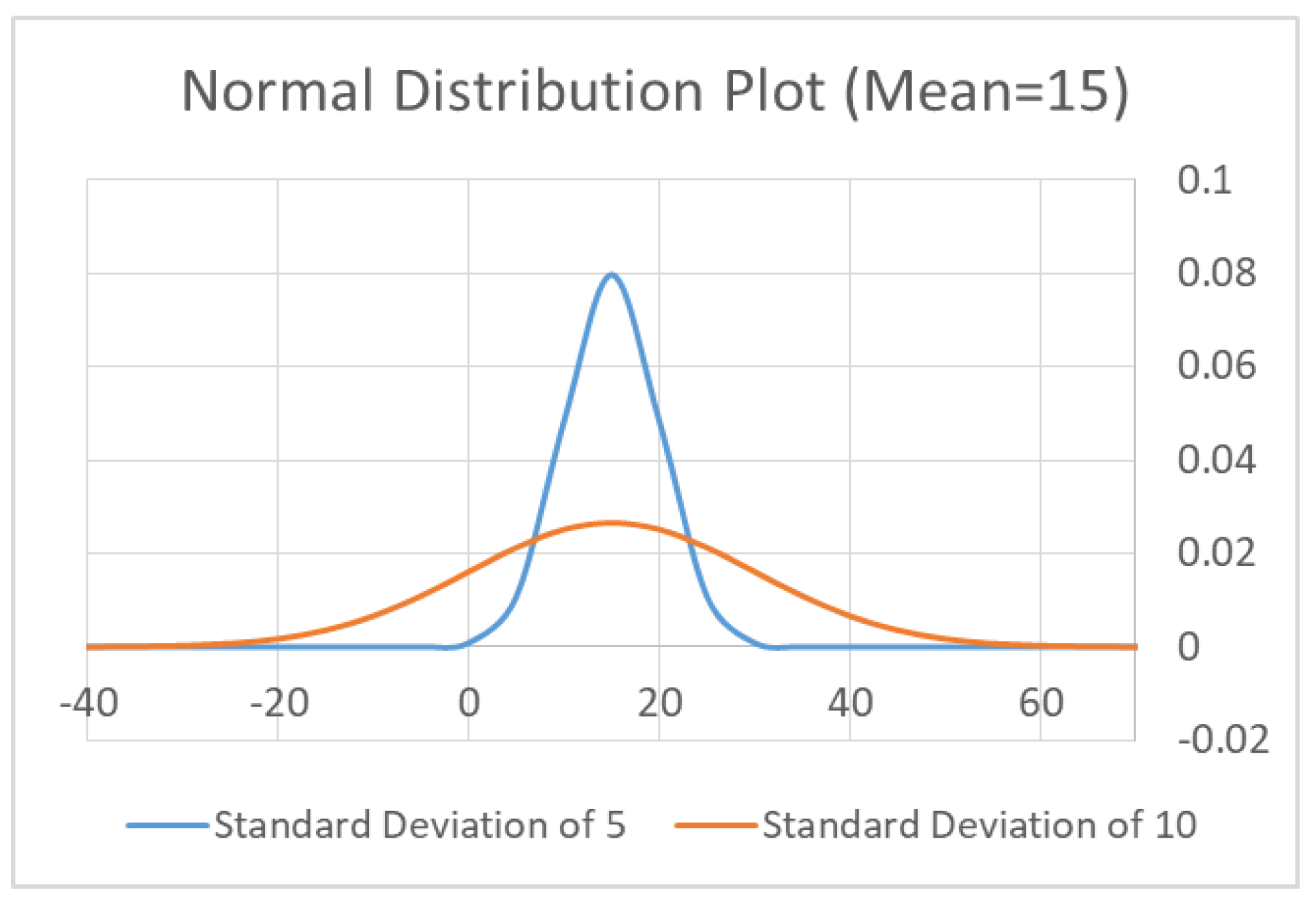
4.1.3. Statistics: Univariate Gaussian Distribution
4.1.4. A Brief Look at Countermeasures
4.1.5. Statistics: Multivariate Gaussian Distribution
4.2. Template Attacks
4.2.1. Theory
- Using a clone of the victim device, use combinations of plaintexts and keys and gather a large number of power traces. Record enough traces to distinguish each subkey’s value.
- Create a template of the device’s operation. This template will highlight select “points of interest” in the traces and derive a multivariate distribution of the power traces for this set of points.
- Collect a small number of power traces from the victim device.
- Apply the template to the collected traces. Examine each subkey and compute values most likely to be correct by how well they fit the model (template). Continue until the key is fully recovered.
4.2.2. Practice
4.3. Correlation Power Analysis
4.3.1. Theory
4.3.2. Practice
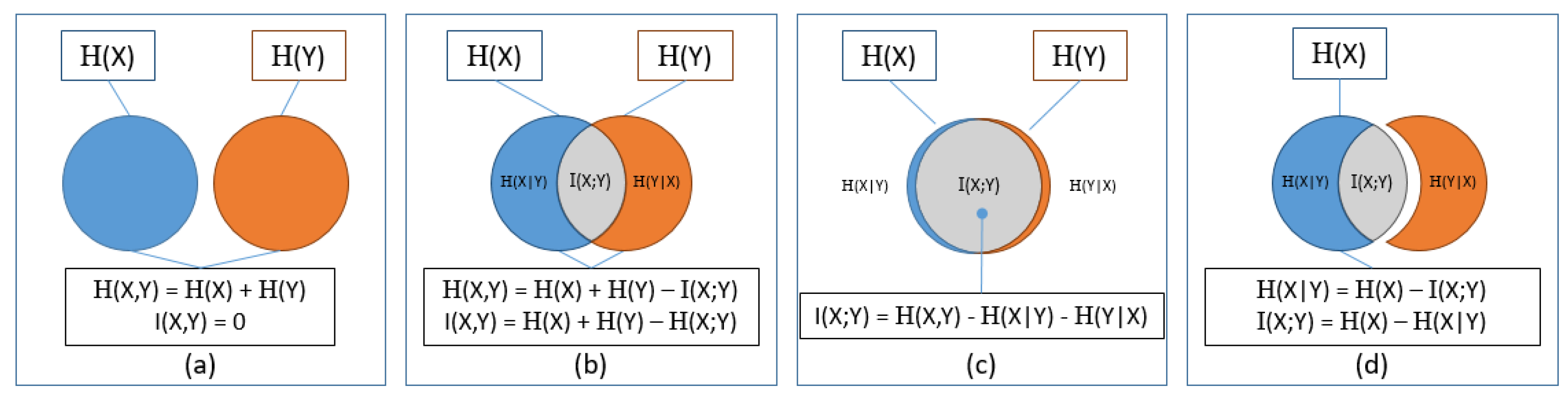
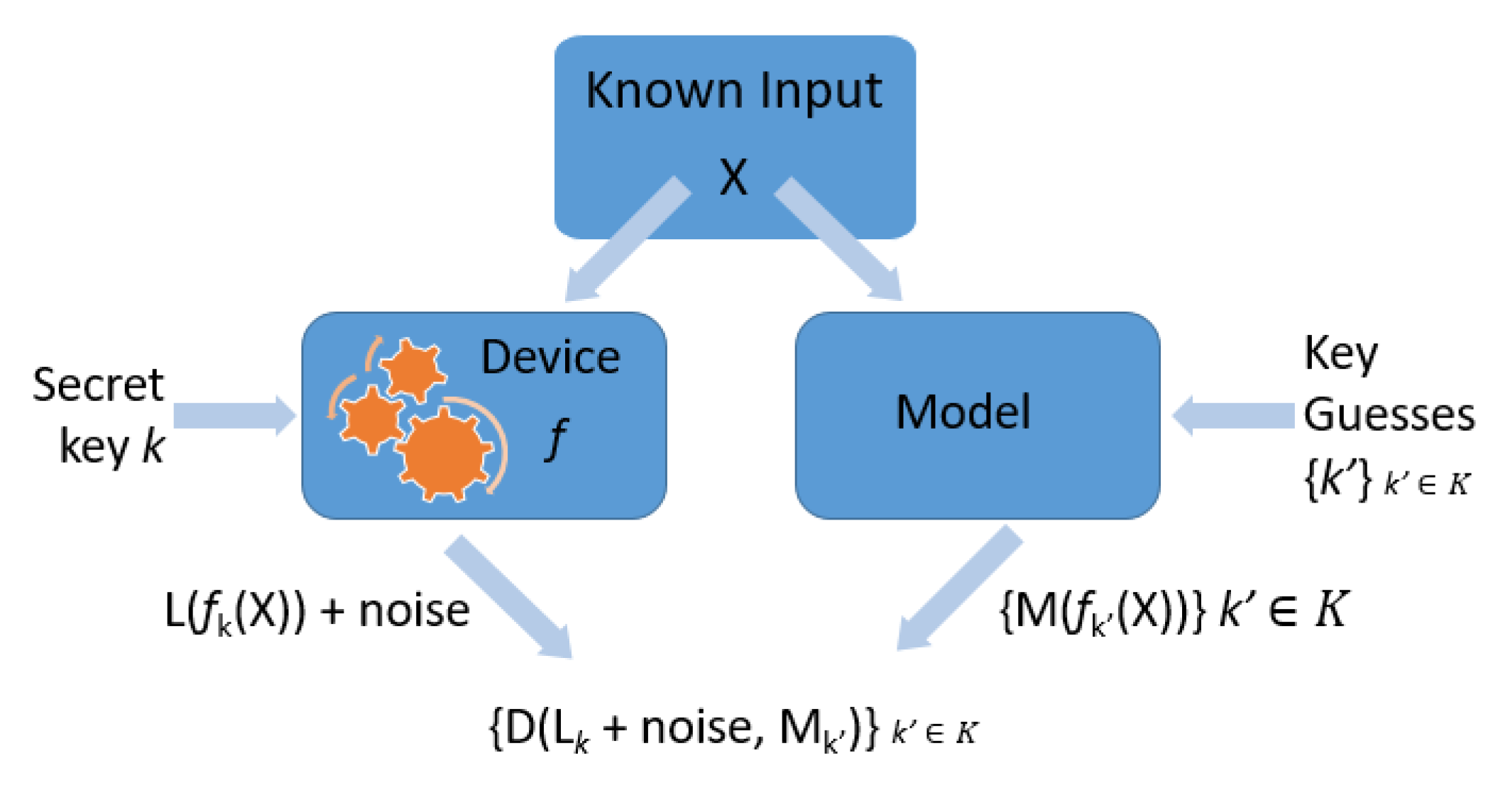
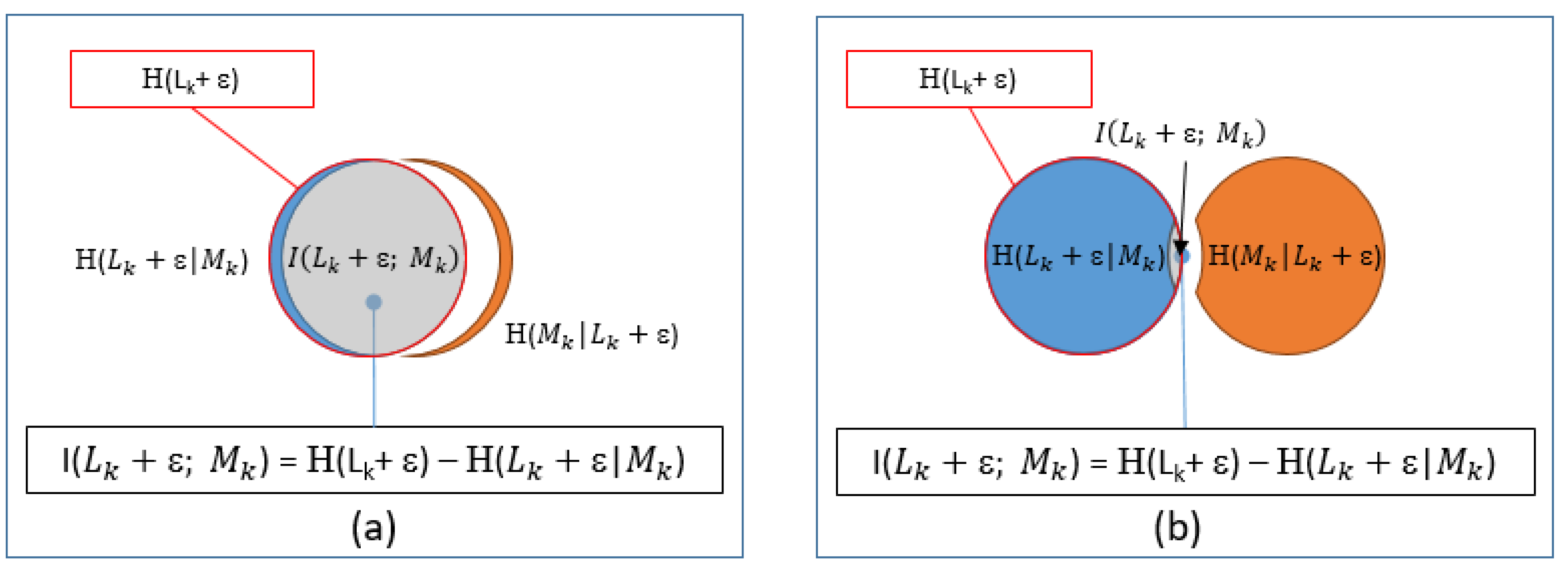
4.4. Mutual Information Analysis
4.4.1. Theory
4.4.2. Statistics: Information Theory
4.4.3. Practice
5. An Expanding Focus and Way Ahead
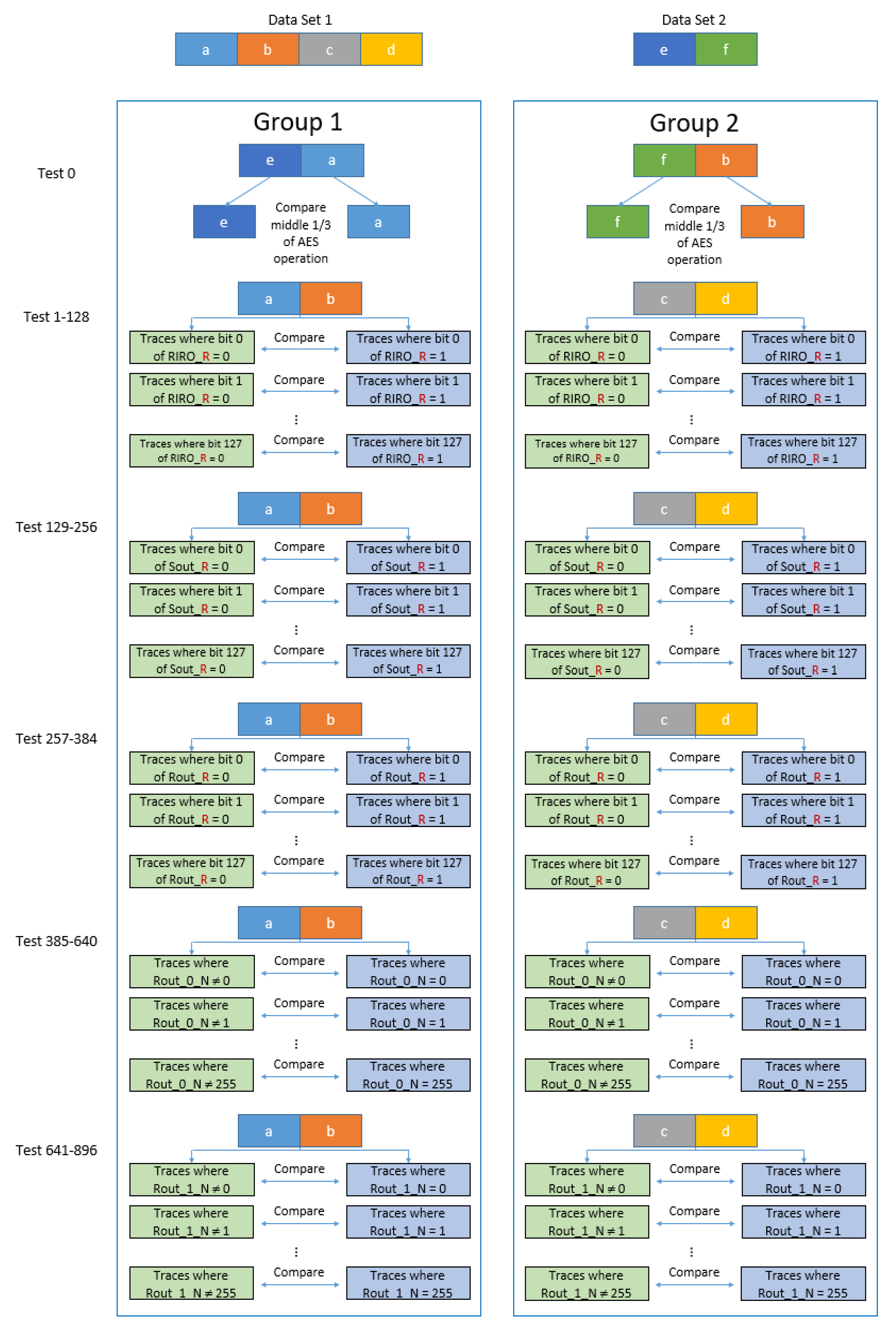
5.1. Test Vector Leakage Assessment
5.1.1. Theory
5.1.2. Practice
5.1.3. Statistics: Welch’s t-Test
5.1.4. Statistics: Pearson’s χ2-Test
6. Summary
Author Contributions
Funding
Conflicts of Interest
Appendix A. Descriptive Statistics
References
- Biham, E.; Shamir, A. Differential cryptanalysis of DES-like cryptosystems. In Proceedings of the Advances in Cryptology—CRYPTO’90, Berlin, Germany, 11–15 August 1990; pp. 2–21. [Google Scholar]
- Miyano, H. A method to estimate the number of ciphertext pairs for differential cryptanalysis. In Advances in Cryptology—ASIACRYPT’91, Proceedings of the International Conference on the Theory and Application of Cryptology, Fujiyosida, Japan, 11–14 November 1991; Springer: Berlin, Germany, 1991; pp. 51–58. [Google Scholar]
- Jithendra, K.B.; Shahana, T.K. Enhancing the uncertainty of hardware efficient Substitution box based on differential cryptanalysis. In Proceedings of the 6th International Conference on Advances in Computing, Control, and Telecommunication Technologies (ACT 2015), Trivandrum, India, 31 October 2015; pp. 318–329. [Google Scholar]
- Matsui, M. Linear cryptanalysis method for DES cipher. In Advances in Cryptology—EUROCRYPT’93, Proceedings of the Workshop on the Theory and Application of Cryptographic Techniques, Lofthus, Norway, 23–27 May 1993; Springer: Berlin, Germany, 1993; pp. 386–397. [Google Scholar]
- Courtois, N.T. Feistel schemes and bi-linear cryptanalysis. In Advances in Cryptology—CRYPTO 2004, Proceedings of the 24th Annual International Cryptology Conference, Santa Barbara, CA, USA, 15–19 August 2004; Springer: Berlin, Germany, 2004; pp. 23–40. [Google Scholar]
- Soleimany, H.; Nyberg, K. Zero-correlation linear cryptanalysis of reduced-round LBlock. Des. Codes Cryptogr. 2014, 73, 683–698. [Google Scholar] [CrossRef] [Green Version]
- Kocher, P.; Jaffe, J.; Jun, B. Differential power analysis. In Proceedings of the 19th Annual International Cryptology Conference (CRYPTO 1999), Santa Barbara, CA, USA, 15–19 August 1999; pp. 388–397. [Google Scholar]
- Mangard, S.; Oswald, E.; Popp, T. Power Analysis Attacks: Revealing the Secrets of Smart Cards; Springer: Berlin, Germany, 2007; p. 338. [Google Scholar] [CrossRef]
- Agrawal, D.; Archambeault, B.; Rao, J.R.; Rohatgi, P. The EM sidechannel(s). In Proceedings of the 4th International Workshop on Cryptographic Hardware and Embedded Systems (CHES 2002), Redwood Shores, CA, USA, 13–15 August 2002; pp. 29–45. [Google Scholar]
- Gandolfi, K.; Mourtel, C.; Olivier, F. Electromagnetic analysis: Concrete results. In Proceedings of the 3rd International Workshop on Cryptographic Hardware and Embedded Systems (CHES 2001), Paris, France, 14–16 May 2001; pp. 251–261. [Google Scholar]
- Kasuya, M.; Machida, T.; Sakiyama, K. New metric for side-channel information leakage: Case study on EM radiation from AES hardware. In Proceedings of the 2016 URSI Asia-Pacific Radio Science Conference (URSI AP-RASC), Piscataway, NJ, USA, 21–25 August 2016; pp. 1288–1291. [Google Scholar]
- Gu, P.; Stow, D.; Barnes, R.; Kursun, E.; Xie, Y. Thermal-aware 3D design for side-channel information leakage. In Proceedings of the 34th IEEE International Conference on Computer Design (ICCD 2016), Scottsdale, AZ, USA, 2–5 October 2016; pp. 520–527. [Google Scholar]
- Hutter, M.; Schmidt, J.-M. The temperature side channel and heating fault attacks. In Proceedings of the 12th International Conference on Smart Card Research and Advanced Applications (CARDIS 2013), Berlin, Germany, 27–29 November 2013; pp. 219–235. [Google Scholar]
- Masti, R.J.; Rai, D.; Ranganathan, A.; Muller, C.; Thiele, L.; Capkun, S. Thermal Covert Channels on Multi-core Platforms. In Proceedings of the 24th USENIX Security Symposium, Washington, DC, USA, 12–14 August 2015; pp. 865–880. [Google Scholar]
- Ferrigno, J.; Hlavac, M. When AES blinks: Introducing optical side channel. IET Inf. Secur. 2008, 2, 94–98. [Google Scholar] [CrossRef]
- Stellari, F.; Tosi, A.; Zappa, F.; Cova, S. CMOS circuit analysis with luminescence measurements and simulations. In Proceedings of the 32nd European Solid State Device Research Conference, Bologna, Italy, 24–26 September 2002; pp. 495–498. [Google Scholar]
- Brumley, D.; Boneh, D. Remote timing attacks are practical. Comput. Netw. 2005, 48, 701–716. [Google Scholar] [CrossRef]
- Kocher, P.C. Timing Attacks on Implementations of Diffie-Hellman, RSA, DSS, and Other Systems. In Advances in Cryptology—CRYPTO ’96 Proceedings of the 16th Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 1996; Springer: Berlin/Heidelberg, Germany, 1996; pp. 104–113. [Google Scholar]
- Toreini, E.; Randell, B.; Hao, F. An Acoustic Side Channel Attack on Enigma; Newcastle University: Newcastle, UK, 2015. [Google Scholar]
- Standards, N.B.O. Data Encryption Standard; Federal Information Processing Standards Publication (FIPS PUB) 46: Washington, DC, USA, 1977. [Google Scholar]
- Standards, N.B.O. Advanced Encryption Standard (AES); Federal Information Processing Standards Publication (FIPS PUB) 197: Washington, DC, USA, 2001. [Google Scholar]
- Cryptographic Engineering Research Group (CERG), Flexible Open-Source Workbench for Side-Channel Analysis (FOBOS). Available online: https://cryptography.gmu.edu/fobos/ (accessed on 1 March 2020).
- Cryptographic Engineering Research Group (CERG), eXtended eXtensible Benchmarking eXtension (XXBX). Available online: https://cryptography.gmu.edu/xxbx/ (accessed on 1 March 2020).
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Joye, M.; Sung-Ming, Y. The Montgomery powering ladder. In Cryptographic Hardware and Embedded Systems—CHES 2002, Proceedings of the 4th International Workshop, Redwood Shores, CA, USA, 13–15 August 2002; Revised Papers; Springer: Berlin, Germany, 2002; pp. 291–302. [Google Scholar]
- Rohatgi, P. Protecting FPGAs from Power Analysis. Available online: https://www.eetimes.com/protecting-fpgas-from-power-analysis (accessed on 21 April 2020).
- Messerges, T.S.; Dabbish, E.A.; Sloan, R.H. Power analysis attacks of modular exponentiation in smartcards. In Proceedings of the 1st Workshop on Cryptographic Hardware and Embedded Systems (CHES 1999), Worcester, MA, USA, 12–13 August 1999; pp. 144–157. [Google Scholar]
- Plore. Side Channel Attacks on High Security Electronic Safe Locks. Available online: https://www.youtube.com/watch?v=lXFpCV646E0 (accessed on 15 January 2020).
- Aucamp, D. Test for the difference of means. In Proceedings of the 14th Annual Meeting of the American Institute for Decision Sciences, San Francisco, CA, USA, 22–24 November 1982; pp. 291–293. [Google Scholar]
- Cohen, A.E.; Parhi, K.K. Side channel resistance quantification and verification. In Proceedings of the 2007 IEEE International Conference on Electro/Information Technology (EIT 2007), Chicago, IL, USA, 17–20 May 2007; pp. 130–134. [Google Scholar]
- Brier, E.; Clavier, C.; Olivier, F. Correlation power analysis with a leakage model. In Proceedings of the 6th International Workshop on Cryptographic Hardware and Embedded Systems (CHES 2004), Cambridge, MA, USA, 11–13 August 2004; pp. 16–29. [Google Scholar]
- Souissi, Y.; Bhasin, S.; Guilley, S.; Nassar, M.; Danger, J.L. Towards Different Flavors of Combined Side Channel Attacks. In Topics in Cryptology–CT-RSA 2012, Proceedings of the Cryptographers’ Track at the RSA Conference 2012, San Francisco, CA, USA, 27 February–2 March 2012; Springer: Berlin, Germany, 2012; pp. 245–259. [Google Scholar]
- Zhang, H.; Li, J.; Zhang, F.; Gan, H.; He, P. A study on template attack of chip base on side channel power leakage. Dianbo Kexue Xuebao/Chin. J. Radio Sci. 2015, 30, 987–992. [Google Scholar] [CrossRef]
- Socha, P.; Miskovsky, V.; Kubatova, H.; Novotny, M. Optimization of Pearson correlation coefficient calculation for DPA and comparison of different approaches. In Proceedings of the 2017 IEEE 20th International Symposium on Design and Diagnostics of Electronic Circuits & Systems (DDECS), Los Alamitos, CA, USA, 19–21 April 2017; pp. 184–189. [Google Scholar]
- Chari, S.; Rao, J.R.; Rohatgi, P. Template attacks. In Proceedings of the 4th International Workshop on Cryptographic Hardware and Embedded Systems (CHES 2002), Redwood Shores, CA, USA, 13–15 August 2002; pp. 13–28. [Google Scholar]
- Chen, L.; Wang, S. Semi-naive bayesian classification by weighted kernel density estimation. In Proceedings of the 8th International Conference on Advanced Data Mining and Applications (ADMA 2012), Nanjing, China, 15–18 December 2012; pp. 260–270. [Google Scholar]
- Gierlichs, B.; Batina, L.; Tuyls, P.; Preneel, B. Mutual information analysis: A generic side-channel distinguisher. In Cryptographic Hardware and Embedded Systems—CHES 2008, Proceedings of the 10th International Workshop, Washington, DC, USA, 10–13 August 2008; Springer: Berlin, Germany, 2008; pp. 426–442. [Google Scholar]
- Souissi, Y.; Nassar, M.; Guilley, S.; Danger, J.-L.; Flament, F. First principal components analysis: A new side channel distinguisher. In Proceedings of the 13th International Conference on Information Security and Cryptology (ICISC 2010), Seoul, Korea, 1–3 December 2010; pp. 407–419. [Google Scholar]
- Whitnall, C.; Oswald, E.; Standaert, F.X. The myth of generic DPA...and the magic of learning. In Topics in Cryptology—CT-RSA 2014, Proceedings of the Cryptographer’s Track at the RSA Conference, San Francisco, CA, USA, 25–28 February 2014; Springer: Berlin, Germany, 2014; pp. 183–205. [Google Scholar]
- Wong, D. Explanation of DPA: Differential Power Analysis (from the paper of Kocher et al); YouTube: San Bruno, CA, USA, 2015. [Google Scholar]
- Aigner, M.; Oswald, E. Power Analysis Tutorial; Institute for Applied Information Processing and Communication; University of Technology Graz: Graz, Austria, 2008. [Google Scholar]
- Messerges, T.S.; Dabbish, E.A.; Sloan, R.H. Examining smart-card security under the threat of power analysis attacks. IEEE Trans. Comput. 2002, 51, 541–552. [Google Scholar] [CrossRef] [Green Version]
- Messerges, T.S.; Dabbish, E.A.; Sloan, R.H. Investigations of power analysis attacks on smart cards. In Proceedings of the USENIX Workshop on Smartcard Technology, Berkeley, CA, USA, 10–11 May 1999; pp. 151–161. [Google Scholar]
- Kiyani, N.F.; Harpe, P.; Dolmans, G. Performance analysis of OOK modulated signals in the presence of ADC quantization noise. In Proceedings of the IEEE 75th Vehicular Technology Conference, VTC Spring 2012, Yokohama, Japan, 6 May–9 June 2012. [Google Scholar]
- Le, T.H.; Clediere, J.; Serviere, C.; Lacoume, J.L. Noise reduction in side channel attack using fourth-order cumulant. IEEE Trans. Inf. Forensics Secur. 2007, 2, 710–720. [Google Scholar] [CrossRef]
- Ott, R.L.; Longnecker, M. An Introduction to Statistical Methods & Data Analysis, Seventh ed.; Cengage Learning: Boston, MA, USA, 2016; p. 1179. [Google Scholar]
- Messerges, T.S. Using second-order power analysis to attack DPA resistant software. In Cryptographic Hardware and Embedded Systems—CHES 2000, Proceedings of the Second International Workshop, Worcester, MA, USA, 17–18 August 2000; Springer: Berlin, Germany, 2000; pp. 238–251. [Google Scholar]
- Oswald, E.; Mangard, S.; Herbst, C.; Tillich, S. Practical second-order DPA attacks for masked smart card implementations of block ciphers. In Topics in Cryptology-CT-RSA 2006, Proceedings of the Cryptographers’ Track at the RAS Conference 2006, San Jose, CA, USA, 13–17 February 2006; Springer: Berlin, Germany, 2006; pp. 192–207. [Google Scholar]
- Clavier, C.; Coron, J.-S.; Dabbous, N. Differential power analysis in the presence of hardware countermeasures. In Proceedings of the 2nd International Workshop on Cryptographic Hardware and Embedded Systems (CHES 2000), Worcester, MA, USA, 17 August 2000; pp. 252–263. [Google Scholar]
- Debande, N.; Souissi, Y.; Nassar, M.; Guilley, S.; Thanh-Ha, L.; Danger, J.L. Re-synchronization by moments: An efficient solution to align Side-Channel traces. In Proceedings of the 2011 IEEE International Workshop on Information Forensics and Security (WIFS 2011), Piscataway, NJ, USA, 29 November–2 December 2011; p. 6. [Google Scholar]
- Qizhi, T.; Huss, S.A. A general approach to power trace alignment for the assessment of side-channel resistance of hardened cryptosystems. In Proceedings of the 2012 Eighth International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP), Los Alamitos, CA, USA, 18–20 July 2012; pp. 465–470. [Google Scholar]
- Thiebeauld, H.; Gagnerot, G.; Wurcker, A.; Clavier, C. SCATTER: A New Dimension in Side-Channel. In Constructive Side-Channel Analysis and Secure Design, Proceedings of the 9th International Workshop (COSADE 2018), Singapore, 23–24 April 2018; Springer: Berlin, Germany, 2008; pp. 135–152. [Google Scholar]
- Shamir, A. Protecting smart cards from passive power analysis with detached power supplies. In Cryptographic Hardware and Embedded Systems—CHES 2000, Proceedings of the Second International Workshop, Worcester, MA, USA, 17–18 August 2000; Springer: Berlin, Germany, 2000; pp. 71–77. [Google Scholar]
- Coron, J.-S. Resistance against differential power analysis for elliptic curve cryptosystems. In Proceedings of the 1st Workshop on Cryptographic Hardware and Embedded Systems (CHES 1999), Worcester, MA, USA, 12–13 August 1999; pp. 292–302. [Google Scholar]
- Waddle, J.; Wagner, D. Towards efficient second-order power analysis. In Proceedings of the 6th International Workshop on Cryptographic Hardware and Embedded Systems (CHES 2004), Cambridge, MA, USA, 11–13 August 2004; pp. 1–15. [Google Scholar]
- ChipWhisperer®. Template Attacks. Available online: https://wiki.newae.com/Template_Attacks (accessed on 3 April 2020).
- Lerman, L.; Bontempi, G.; Markowitch, O. Power analysis attack: An approach based on machine learning. Int. J. Appl. Cryptogr. 2014, 3, 97–115. [Google Scholar] [CrossRef] [Green Version]
- Markowitch, O.; Lerman, L.; Bontempi, G. Side Channel Attack: An Approach Based on Machine Learning; Center for Advanced Security Research Darmstadt: Darmstadt, Germany, 2011. [Google Scholar]
- Hospodar, G.; Gierlichs, B.; De Mulder, E.; Verbauwhede, I.; Vandewalle, J. Machine learning in side-channel analysis: A first study. J. Cryptogr. Eng. 2011, 1, 293–302. [Google Scholar] [CrossRef]
- Ramezanpour, K.; Ampadu, P.; Diehl, W. SCAUL: Power Side-Channel Analysis with Unsupervised Learning. arXiv e-Prints 2020, arXiv:2001.05951. [Google Scholar]
- Hettwer, B.; Gehrer, S.; Guneysu, T. Applications of machine learning techniques in side-channel attacks: A survey. J. Cryptogr. Eng. 2019. [Google Scholar] [CrossRef]
- Lerman, L.; Martinasek, Z.; Markowitch, O. Robust profiled attacks: Should the adversary trust the dataset? IET Inf. Secur. 2017, 11, 188–194. [Google Scholar] [CrossRef]
- Martinasek, Z.; Iglesias, F.; Malina, L.; Martinasek, J. Crucial pitfall of DPA Contest V4.2 implementation. Secur. Commun. Netw. 2016, 9, 6094–6110. [Google Scholar] [CrossRef]
- Martinasek, Z.; Zeman, V.; Malina, L.; Martinásek, J. k-Nearest Neighbors Algorithm in Profiling Power Analysis Attacks. Radioengineering 2016, 25, 365–382. [Google Scholar] [CrossRef]
- Golder, A.; Das, D.; Danial, J.; Ghosh, S.; Sen, S.; Raychowdhury, A. Practical Approaches toward Deep-Learning-Based Cross-Device Power Side-Channel Attack. IEEE Trans. Very Large Scale Integr. (Vlsi) Syst. 2019, 27, 2720–2733. [Google Scholar] [CrossRef] [Green Version]
- Jin, S.; Kim, S.; Kim, H.; Hong, S. Recent advances in deep learning-based side-channel analysis. ETRI J. 2020, 42, 292–304. [Google Scholar] [CrossRef] [Green Version]
- Libang, Z.; Xinpeng, X.; Junfeng, F.; Zongyue, W.; Suying, W. Multi-label Deep Learning based Side Channel Attack. In Proceedings of the 2019 Asian Hardware Oriented Security and Trust Symposium (AsianHOST), Piscataway, NJ, USA, 16–17 December 2019; p. 6. [Google Scholar]
- Yu, W.; Chen, J. Deep learning-assisted and combined attack: A novel side-channel attack. Electron. Lett. 2018, 54, 1114–1116. [Google Scholar] [CrossRef]
- Wang, H.; Brisfors, M.; Forsmark, S.; Dubrova, E. How Diversity Affects Deep-Learning Side-Channel Attacks. In Proceedings of the 5th IEEE Nordic Circuits and Systems Conference, NORCAS 2019: NORCHIP and International Symposium of System-on-Chip, SoC 2019, Helsinki, Finland, 29–30 October 2019; IEEE Circuits and Systems Society (CAS). Tampere University: Tampere, Finland, 2019. [Google Scholar]
- Batina, L.; Gierlichs, B.; Prouff, E.; Rivain, M.; Standaert, F.-X.; Veyrat-Charvillon, N. Mutual information analysis: A comprehensive study. J. Cryptol. 2011, 24, 269–291. [Google Scholar] [CrossRef] [Green Version]
- Prouff, E.; Rivain, M. Theoretical and practical aspects of mutual information based side channel analysis. In Proceedings of the 7th International Conference on Applied Cryptography and Network Security (ACNS 2009), Paris-Rocquencourt, France, 2–5 June 2009; pp. 499–518. [Google Scholar]
- Standaert, F.-X.; Gierlichs, B.; Verbauwhede, I. Partition vs. comparison side-channel distinguishers: An empirical evaluation of statistical tests for univariate side-channel attacks against two unprotected CMOS devices. In Proceedings of the 11th International Conference on Information Security and Cryptology (ICISC 2008), Seoul, Korea, 3–5 December 2008; pp. 253–267. [Google Scholar]
- Veyrat-Charvillon, N.; Standaert, F.-X. Mutual information analysis: How, when and why? In Proceedings of the 11th International Workshop on Cryptographic Hardware and Embedded Systems (CHES 2009), Lausanne, Switzerland, 6–9 September 2009; pp. 429–443. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Carbone, M.; Teglia, Y.; Ducharme, G.R.; Maurine, P. Mutual information analysis: Higher-order statistical moments, efficiency and efficacy. J. Cryptogr. Eng. 2017, 7, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Whitnall, C.; Oswald, E. A Comprehensive Evaluation of Mutual Information Analysis Using a Fair Evaluation Framework. In Advances in Cryptology—CRYPTO 2011, Proceedings of the 31st Annual Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2011; Springer: Berlin, Germany, 2011; pp. 316–334. [Google Scholar]
- Fan, H.-F.; Yan, Y.-J.; Xu, J.-F.; Ren, F. Simulation of correlation power analysis against AES cryptographic chip. Comput. Eng. Des. 2010, 31, 260–262. [Google Scholar]
- Socha, P.; Miskovsky, V.; Kubatova, H.; Novotny, M. Correlation power analysis distinguisher based on the correlation trace derivative. In Proceedings of the 21st Euromicro Conference on Digital System Design (DSD 2018), Prague, Czech Republic, 29–31 August 2018; pp. 565–568. [Google Scholar]
- Raatgever, J.W.; Duin, R.P.W. On the variable kernel model for multivariate nonparametric density estimation. In Proceedings of the COMPSTAT 1978 Computational Statistics; Physica: Wien, Austria, 1978; pp. 524–533. [Google Scholar]
- Batina, L.; Gierlichs, B.; Lemke-Rust, K. Differential cluster analysis. In Proceedings of the 11th International Workshop on Cryptographic Hardware and Embedded Systems (CHES 2009), Lausanne, Switzerland, 6–9 September 2009; pp. 112–127. [Google Scholar]
- Silva, J.; Narayanan, S.S. On data-driven histogram-based estimation for mutual information. In Proceedings of the 2010 IEEE International Symposium on Information Theory (ISIT 2010), Piscataway, NJ, USA, 13–18 June 2010; pp. 1423–1427. [Google Scholar]
- Lange, M.; Nebel, D.; Villmann, T. Partial Mutual Information for Classification of Gene Expression Data by Learning Vector Quantization. In Advances in Self-Organizing Maps and Learning Vector Quantization, Proceedings of the 10th International Workshop (WSOM 2014), Mittweida, Germany, 2–4 July 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 259–269. [Google Scholar]
- Goodwill, G.; Jun, B.; Jaffe, J.; Rohatgi, P. A testing methodology for side-channel resistance validation. In Nist Non-Invasive Attack Testing Workshop; NIST: Gaithersburg, MA, USA, 2011. [Google Scholar]
- Mather, L.; Oswald, E.; Bandenburg, J.; Wojcik, M. Does my device leak information? An a priori statistical power analysis of leakage detection tests. In Proceedings of the 19th International Conference on the Theory and Application of Cryptology and Information Security (ASIACRYPT 2013), Bengaluru, India, 1–5 December 2013; pp. 486–505. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
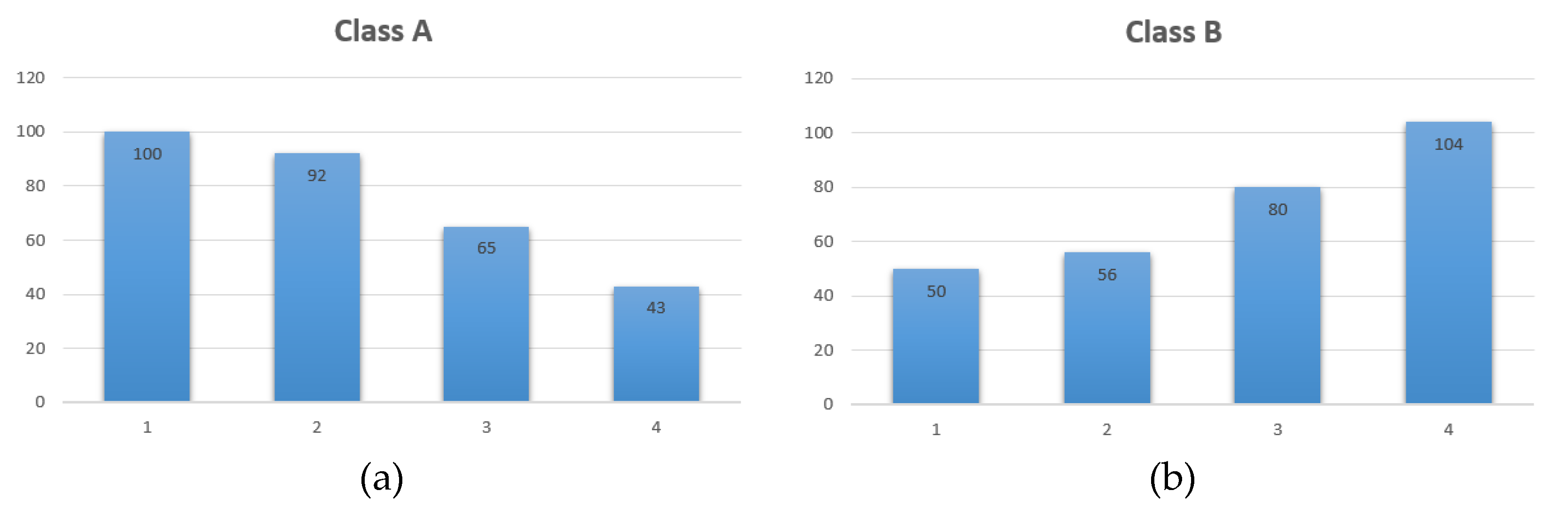
| Fi,j | j = 0 | j = 1 | j = 2 | j = 3 | Total |
|---|---|---|---|---|---|
| i = 0 | 100 | 92 | 65 | 43 | 300 |
| i = 1 | 50 | 56 | 80 | 104 | 290 |
| Total | 150 | 148 | 145 | 147 | 590 |
| Eij | j = 0 | j = 1 | j = 2 | j = 3 |
|---|---|---|---|---|
| i = 0 | 76.27 | 75.25 | 73.73 | 74.75 |
| i = 1 | 73.73 | 72.75 | 71.27 | 72.25 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Randolph, M.; Diehl, W. Power Side-Channel Attack Analysis: A Review of 20 Years of Study for the Layman. Cryptography 2020, 4, 15. https://doi.org/10.3390/cryptography4020015
Randolph M, Diehl W. Power Side-Channel Attack Analysis: A Review of 20 Years of Study for the Layman. Cryptography. 2020; 4(2):15. https://doi.org/10.3390/cryptography4020015
Chicago/Turabian StyleRandolph, Mark, and William Diehl. 2020. "Power Side-Channel Attack Analysis: A Review of 20 Years of Study for the Layman" Cryptography 4, no. 2: 15. https://doi.org/10.3390/cryptography4020015
APA StyleRandolph, M., & Diehl, W. (2020). Power Side-Channel Attack Analysis: A Review of 20 Years of Study for the Layman. Cryptography, 4(2), 15. https://doi.org/10.3390/cryptography4020015