
Associative Blockchain for Decentralized PKI Transparency


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
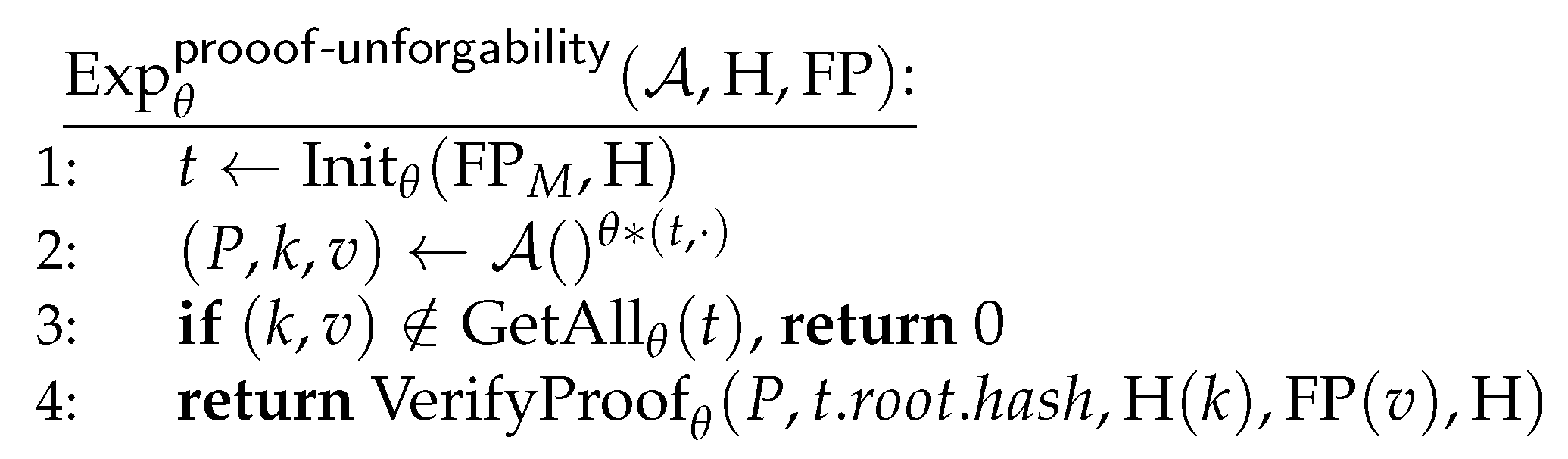{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Our Contribution
1.1.1. Properties and Design Goals
- Transparency: Provide a publicly auditable system that enables anyone who connects to verify certificates or detect misbehaviour.
- Multiple certificates: Allow an entity to register multiple certificates per domain, mapping one identity to multiple public keys.
- Multiple domain names: Handle multiple domain names on a single certificate.
- No single point of failure: No centralisation or federation of any kind.
- Scalability: Remain efficient as more and more identities are recorded.
- Efficiency: Have low impact on TLS servers and minimal client storage/processing.
- Client privacy: Keep end-user browsing habits maximally private from observers and third parties.
- Revocation: Provide a reliable revocation system.
1.1.2. Overview of Our Construction
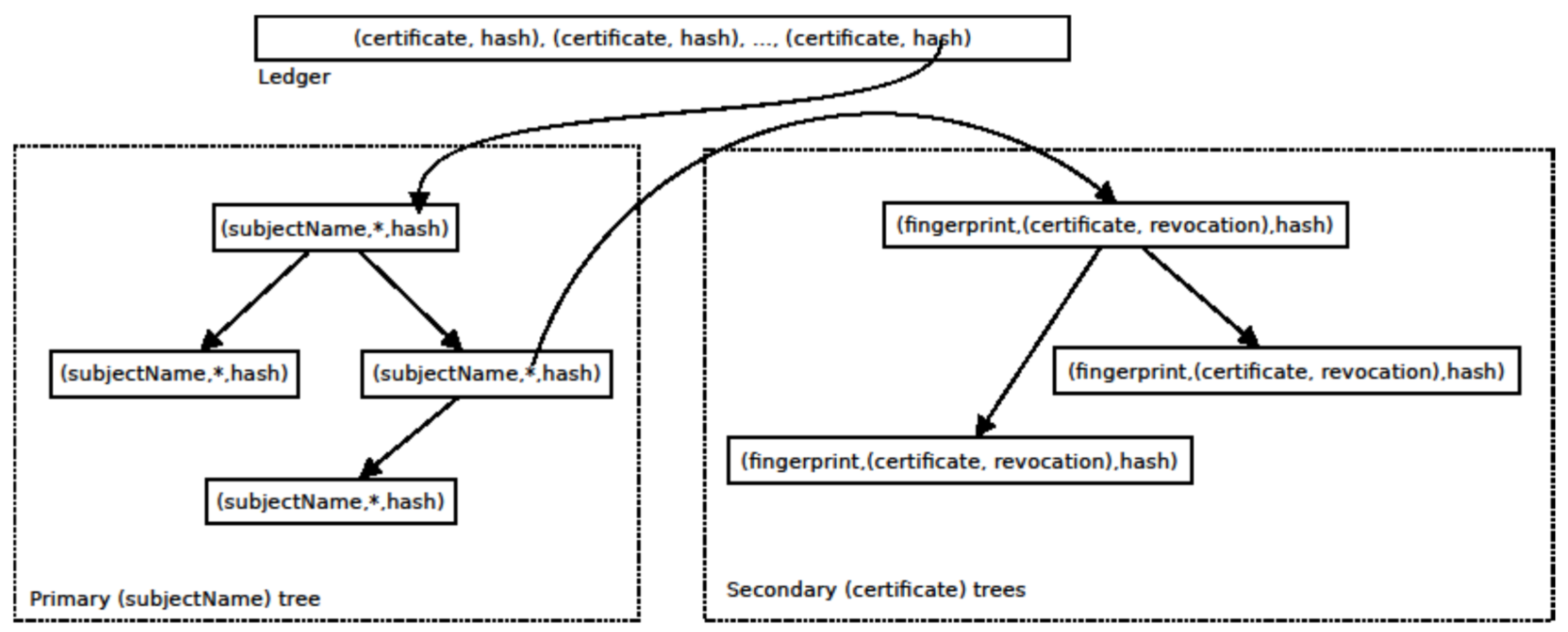
- Certificate trees: A set of Merkle binary search trees (described in Section 2.1)—one per subject name—that stores all certificates associated with that subject name. Revocations are stored alongside the associated certificate. Certificates are indexed by the fingerprint and revocations are indexed by the fingerprint of the certificate they revoke. These structures provide short proofs of membership. Since revocations are stored alongside certificates, a proof of membership for a certificate reveals whether a revocation exists in the store.
- Primary tree: A Merkle Binary Search tree which stores pointers to certificate trees, indexed by subject names. Note that it is possible to paste together membership proofs from these two trees to prove the membership of a certificate in the overall store.
- A distributed ledger (described in Section 2.2) which is used to store updates to the trees in the form of the new root hash of the primary tree, along with any certificates and revocations that have been added since the last ledger entry.
1.2. Background and Related Work
1.2.1. PKI Transparency
1.2.2. Blockchain-Based PKI
1.2.3. Traditional PKI Augmented with Blockchain
1.2.4. PKI Threat Models
1.3. Structure of the Paper
2. Preliminaries
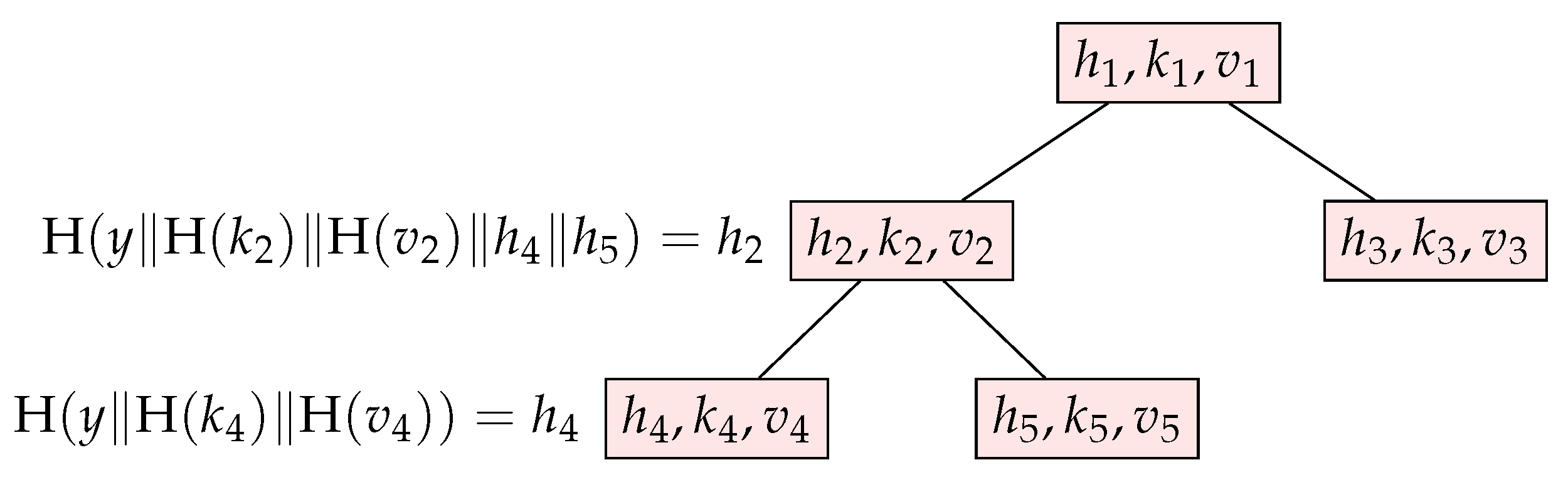
2.1. Merkle Hash Trees, Binary Search Trees, and Merkle-BST
2.1.1. Merkle Hash Trees
2.1.2. Binary Search Trees
2.1.3. Merkle-BST and Security Properties
2.2. Distributed Ledgers and Blockchains
3. Decentralised PKI Transparency
3.1. Entities, Operations and Functionalities
- Certificate authorities: issue certificates for domains, and revocations.
- Domain owners: obtain certificates from CAs, control servers, and (optionally) monitor the DPKIT for any suspicious activity.
- Servers: allow clients to connect, and (optionally, if DPKIT-aware) request proofs of certificate membership from DPKIT peers.
- Clients: initiate TLS connections with servers, accept or reject server certificates based on DPKIT information provided by the server and peers.
- Peers: maintain the DPKIT data structure, record certificates, supply servers with proofs of certificate membership, provide auditing functionality.
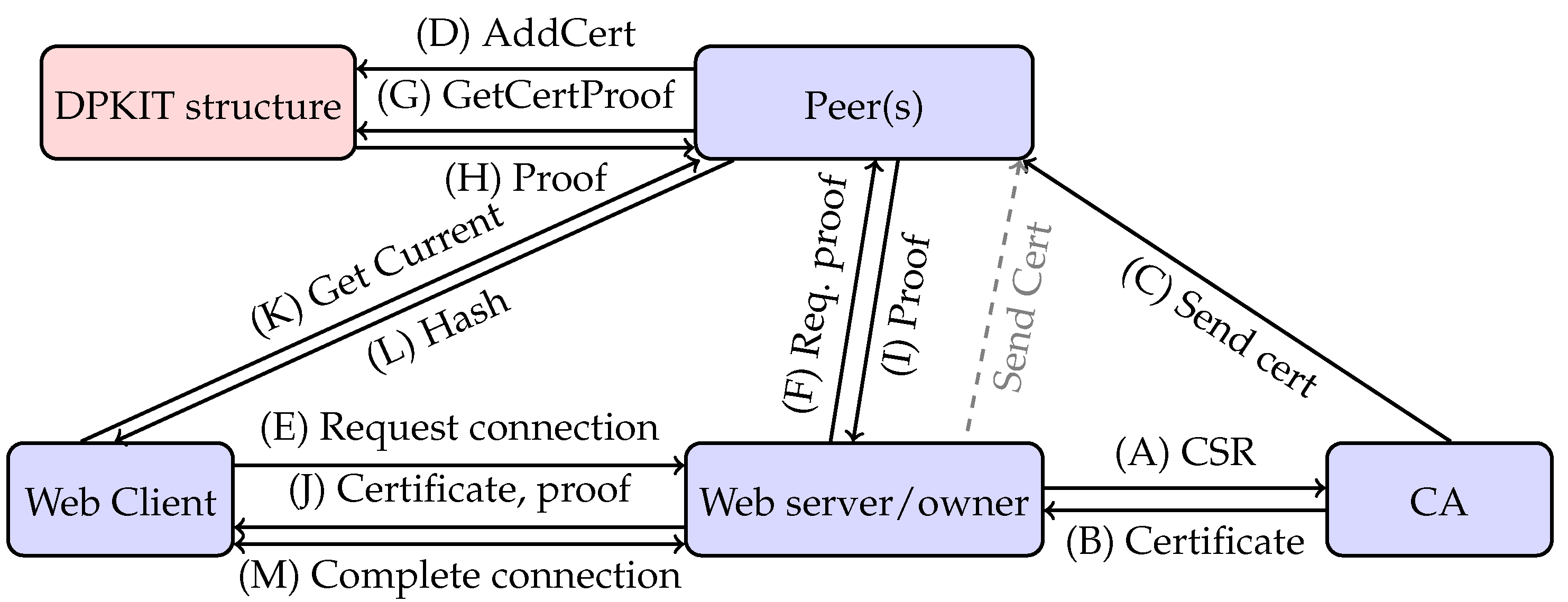
- A domain owner requests a certificate from a CA. The CA applies its vetting policies and issues a certificate to the domain owner (steps A and B).
- Optionally, the domain owner or the CA sends the certificate to a DPKIT peer, who adds the certificate to the DPKIT data structure. The domain owner supplies the certificate to the domain TLS server (steps C and D).
- A client requests a connection to the server. Optionally, the server requests a proof of certificate membership for its certificate from the DPKIT peer, which the peer provides. The server sends its certificate and optionally the proof to the client (steps E, F, G, H, I and J).
- The client requests the latest root hash from a DPKIT peer and uses it to check the proof of certificate membership. It can also obtain the proof itself from the peer if not provided by the server. Depending on its security policy, the client may then complete the connection to the server (steps K, L and M).
- Revocation certificates may also be submitted to DPKIT peers. The revocation is recorded, and its presence is noted in proofs of certificate membership. Hence, clients will be made aware of any relevant revocations when verifying the proof of membership for a certificate.
- Any entity may submit a certificate to a DPKIT peer, and peers should add onto the DPKIT any missing valid certificates for which a proof is requested. This means that clients may contribute certificates that they have found which are missing from the DPKIT, increasing the probability that rare certificates are discovered and recorded.
- DPKIT peers also supply auditing functionality, including enumerations over all certificates for a domain, or over all domains, and indications whether certificates have been revoked.
- : returns a list l of subject names for which the certificate c applies.
- : returns a fingerprint of the certificate or revocation.
- : returns a bit indicating whether or not c is a revocation certificate.
- : if c is a revocation, returns the fingerprint of the certificate being revoked.
- : returns a bit indicating whether or not this is a proper (e.g., X.509) certificate.
- : deterministic algorithm that outputs an initial data structure d.
- or ⊥: deterministic algorithm taking a certificate c and a data structure d as input and outputs an updated data structure or ⊥ if not valid.
- or ∅: deterministic algorithm that takes a data structure d and a subject name N and outputs a data structure representing all certificates for N or ∅ if N is not present.
- or ⊥: deterministic algorithm that takes a data structure s and a certificate fingerprint F and outputs a certificate and revocation tuple , either of which may be ⊥, or ⊥ if both not present.
- or ⊥: deterministic algorithm that takes a certificate c and a data structure d and outputs a membership proof P or an error ⊥.
- or ⊥: deterministic algorithm that takes an object d and outputs an ordered list of entries or an error symbol ⊥.
- : deterministic algorithm that takes a data structure d and returns a fingerprint F that captures all entries in the structure.
- : deterministic algorithm that, given a certificate c, fingerprint F and membership proof P, outputs a bit .
- : deterministic algorithm that takes as input a membership proof P and outputs a bit .
3.2. DPKIT Construction
4. Security Analysis and Evaluation
4.1. Security Goals
- Non-removability,
- per Experiment , demands that it is hard for an adversary to remove an entry once logged through honest functionalities.
- Proof consistency,
- per Experiment , entails that it is hard for an adversary to provide a valid membership proof for an entry that is invalid or not yet logged.
- Revocation reveal,
- per Experiment , demands that it is hard for an adversary to hide an entry’s revocation information if it exists in the log.
- 1.
- If has not been called on certificate c,then
- 2.
- If has been called on a certificate c, then we always have
- 3.
- For a certificate c, if has never been called on any revocation r bearing onto c, that is, s.t. , then we always have
4.2. Proofs of Security
5. Discussion
5.1. Design Goals Revisited
- Transparency: When implemented using a public blockchain for the ledger, all information is publicly available. When proper incentives are used, certificates and revocations will be aggressively added to the ledger when they begin to circulate, meaning that maximum information is available in one common, publicly accessible place. Certificates and revocations cannot be removed from the ledger (non-removable entry security property). Additionally, participating clients obtain guarantees that certificates have been logged (proof consistency property).
- Multiple certificates: This is handled by using certificate subtrees for each subject name
- Multiple domain names: This is handled by adding each certificate to the tree under all of its subject names
- No single point of failure: This is achieved by through the decentralized ledger, and hence is sensitive to the ledger used.
- Scalability: The efficiency of operations and proofs in Merkle-BSTs allows for efficient operations. The scalability of the system as a whole thus depends mostly on the ledger being used. Note that issuing certificates happens at a much slower pace than financial transactions, so the scalability needs are much more modest than what is required for crypto-currency ledgers.
- Efficiency: TLS clients and servers need only to process proofs of membership, which are short. Hence, the impact is low. Servers can cache proofs for greater efficiency.
- Client privacy: The only information revealed by a client to other entities is to peers, from which they only obtain recent root hashes, and hence only reveal their participation in the scheme, and TLS servers, which they need to contact anyways to access their services.
- Revocation: Revocations are stored, and proofs of membership reveal their existence to clients (Revocation reveal security property.)
5.2. Considerations around Ledgers and Participants
5.2.1. Participants and Incentives
- Clients: Clients have two main goals in our model: to avoid impersonation attacks and to avoid leaking information to third parties. While the first is best served by having a complete record of certificates and revocations, a client may choose not to log new certificates that they see to avoid leaking their browsing information to peers.
- Domain owners and servers: Domain owners have an incentive to prevent impersonators from capturing business or driving away customers. Again, this is served by a complete record, but domain owners are only interested in their own domains, and hence only have an incentive to report certificates for their domains. In some circumstances, they may be incentivized to suppress knowledge of successful attacks—possibly to prevent harm to their reputation—and so may in fact not want false certificates to be logged. If clients insist on only connecting to sites with logged certificates (much as today they more or less insist on only connecting to sites with valid certificates), then domain owners will be strongly incentivized to have their legitimate certificates logged or lose business.
- Certificate authorities: Certificate authorities, as trusted entities, only stay in business for as long as they remain trustworthy. While participation in logging schemes may improve the perception of their security, any evidence of security failures reduces their perceived trustworthiness and hence disincentivizes logging problematic certificates. If domain owners insist on having their legitimate certificates logged, then certificate authorities will be incentivized to do this or lose business.
- Peers: Peers’ main role is to contribute to the storage and computational power required to maintain the ledger. Although they may also play one of the above roles, the role of peer does not bring with it any special incentives.
5.2.2. Maintaining the Ledger
- Groups of clients, web browser vendors, governments, or other organisations that have an overall desire for security on (parts of) the Internet
- Domain owners or Certificate authorities who are forced to log their own legitimate certificates by client policies
- Domain owners who wish to know about fraudulent certificates for their domains so that they can take necessary security actions
- Certificate authorities who are interested in testing the security claims of their competitors
- Certificate authorities who wish to present a positive security image by advertising proactive security policies
- Insurance agencies who insure companies against cyber threats, that want to mitigate damage as quickly as possible, and who want to catch untrustworthy certificate authorities who increase the chances of security threats against their insurees.
5.3. Usage
5.3.1. What Goes on the Ledger?
- A certificate appears in the store that the domain owner did not apply for. This check must be done by the domain owner or someone with sufficient knowledge to recognise certificates that they have requested. In order for the certificate store to be useful in this manner, as many certificates as possible must be logged, since those collecting certificates do not typically have the required knowledge to decide fraudulent certificates from authentic ones.
- A certificate is presented to a client that does not exist on the log. In this case, the client may decide not to connect. A certificate that is not logged may mean that the domain owner is not aware of it and hence not able to take appropriate actions against the certificate, such as seeking a revocation from the issuing CA. Hence, it should be standard practice to log certificates as soon as they are issued.
- A certificate is presented to a client whose revocation exists on the log. In this case, the client should not connect. In order for this to be useful, as many revocations as possible must be logged, whether or not the corresponding certificate has been. Hence, it should be standard practice to log revocations soon as they are issued.
5.3.2. Privacy
- In the honest case, which is the vast majority of traffic, certificates will already be logged and there is no need for clients to submit certificates. Hence, for most clients, it is rare to encounter an unlogged certificate.
- A client may opt to contribute an unlogged certificate when they find one. The client may prompt the user to make a decision, and it may be the case that most people will choose to log the certificate in most scenarios.
- An anonymising layer, similar to TOR, may be added to the communication between clients and peers. Such a system could be simple to implement, since there is no need for the client to receive a reply from the peer. It may be that blockchain technologies will incorporate such anonymous transactions themselves in the near future, with some already providing some level of anonymity [40].
- If bounties are used, as proposed above, clients may willingly accept the fee for their breach of privacy, or some clients may go out of their way to collect and report certificates in order to collect bounties. However, bounty hunters will likely not encounter certificates that are part of attacks targeted at particular users.
- If a fraudulent certificate is used in a targeted attack on a small set of clients, then the extent of the attack is necessarily limited. While not ideal, an unlogged certificate in this scenario will do little immediate damage. However, the more clients are involved, or the more fraudulent certificates that are issued in the same manner, the more likely it is that at least one client is willing to log the certificate. So, there is at least a positive correlation between the scale of an attack and the likelihood that it is detected by these mechanisms.
5.3.3. Forks and Out of Date Peers
- Each peer keeps copies of the trees for all recent blocks back to the most recent block that is more than t seconds old (according to the peer). Note that this can be done efficiently: most nodes in a tree do not change with the addition of a certificate, and hence these nodes can be kept in common for all the blocks’ trees if pointers or references are used. Only nodes along the path from the root to the new certificate need to be changed with the addition of a new certificate, and these are what needs to be stored for each block.
- The client will keep a list of root hashes, including all root hashes that are, at most, seconds old (according to its peer(s)), plus the next most recent root hash.
- The server requests a proof from a peer from the peer’s oldest data structure and offers it to the client
5.4. What Ledger to Use
5.5. Comparison to Other Schemes
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Construction of Merkel-BST
- : deterministic algorithm that give a value fingerprinting hash function and a hash function , outputs an initial data structure t.
- : deterministic algorithm that takes a key-value entry , a data structure t, and returns 1 if successful or 0 on error.
- : deterministic algorithm that takes a key-value entry , a data structure t, and returns 1 if successful or 0 on error.
- or ⊥: A deterministic algorithm that takes an entry key k and a data structure t, and outputs a value v or ⊥.
- : deterministic algorithm that takes a data structure t and outputs a fingerprint F, representing the complete list of entries.
- : deterministic algorithm that takes a data structure t and outputs an ordered list of entries E.
- or ⊥: deterministic algorithm that takes as inputs an entry key k and a data structure t and outputs a membership proof P or ⊥ if the key is not present.
- : A deterministic algorithm that takes as inputs an entry key hash , a value fingerprint , a data-structure fingerprint F, a membership proof P, and a hash function H and outputs a bit .
- 1.
- If is called, has not been called previously, and has not been called since, then any subsequent call will return a list that contains the pair .
- 2.
- If is called, is called, and has not been called since, then any subsequent call will return a list that contains the pair .
- 3.
- Any call will return the value v corresponding to the first call or the most recent call to after a call to with matching key k, or an error symbol ⊥ if no such call had been made.
- 4.
- Under the same conditions as above, it is always the case that.




References
- Dierks, T.; Rescorla, E. The Transport Layer Security (TLS) Protocol Version 1.1. Internet Engineering Task Force (IETF). 2006, RFC 4346. Available online: https://tools.ietf.org/id/draft-ietf-tls-oldversions-deprecate-02.html (accessed on 21 March 2021).
- Cooper, D.; Santesson, S.; Farrell, S.; Boeyen, S.; Housley, R.; Polk, W. Internet X. 509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile. RFC 5280 (Proposed Standard), 2008. Updated by RFC 6818. 2008. Available online: https://datatracker.ietf.org/doc/rfc5280 (accessed on 21 March 2021).
- Fox IT. Black Tulip: Report of the Investigation into the DigiNotar Certificate Authority Breach. 2012. Available online: http://www.rijksoverheid.nl/bestanden/documenten-en-publicaties/rapporten/2012/08/13/black-tulip-update/black-tulip-update.pdf (accessed on 21 March 2021).
- Comodo Group. Comodo Fraud Incident: Update 31-Mar-2011. 2011. Available online: https://www.comodo.com/Comodo-Fraud-Incident-2011-03-23.html (accessed on 21 March 2021).
- Ducklin, P. The TURKTRUST SSL Certificate Fiasco—What really Happened, and What Happens Next? Available online: https://nakedsecurity.sophos.com/2013/01/08/the-turktrust-ssl-certificate-fiasco-what-happened-and-what-happens-next/ (accessed on 21 March 2021).
- Somogyi, S.; Eijdenberg, A. Improved Digital Certificate Security. 2015. Available online: http://googleonlinesecurity.blogspot.de/2015/09/improved-digital-certificate-security.html (accessed on 21 March 2021).
- Solo, D.; Housley, R.; Ford, W. Internet X. 509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile. Internet Engineering Task Force (IETF) 2002, RFC 3280. Available online: https://www.ietf.org/rfc/rfc3280.txt (accessed on 21 March 2021).
- Eastlake, D. Transport Layer Security (TLS) Extensions: Extension Definitions. Internet Engineering Task Force (IETF) January, 2011, RFC 6066. Available online: https://datatracker.ietf.org/doc/html/rfc6066 (accessed on 21 March 2021).
- Galperin, S.; Santesson, S.; Myers, M.; Malpani, A.; Adams, C.X. 509 Internet Public Key Infrastructure Online Certificate Status Protocol-OCSP. Internet Engineering Task Force (IETF) 2013, RFC 6960. Available online: https://datatracker.ietf.org/doc/html/rfc2560 (accessed on 21 March 2021).
- Boneh, D.; Franklin, M. Identity-Based Encryption from the Weil Pairing. In Advances in Cryptology—CRYPTO 2001; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2139, pp. 213–229. [Google Scholar]
- Eckersley, P.; Burns, J. The EFF SSL Observatory. 2010. Available online: https://www.eff.org/observatory (accessed on 21 March 2021).
- Laurie, B.; Langley, A.; Kasper, E. Certificate Transparency. RFC 6962 (Experimental). 2013. Available online: https://datatracker.ietf.org/doc/html/rfc6962 (accessed on 21 March 2021).
- Laurie, B. Certificate Transparency. ACM Queue Secur. 2014, 12, 10. Available online: https://queue.acm.org/detail.cfm?id=2668154 (accessed on 21 March 2021). [CrossRef]
- Dowling, B.; Günther, F.; Herath, U.; Stebila, D. Secure logging schemes and Certificate Transparency. In ESORICS; Springer: Berlin/Heidelberg, Germany, 2016; pp. 140–158. [Google Scholar]
- Basin, D.A.; Cremers, C.J.F.; Kim, T.H.; Perrig, A.; Sasse, R.; Szalachowski, P. ARPKI: Attack Resilient Public-Key Infrastructure. In ACM CCS 2014; Ahn, G., Yung, M., Li, N., Eds.; ACM: New York, NY, USA, 2014; pp. 382–393. [Google Scholar] [CrossRef]
- Kim, T.H.; Huang, L.; Perrig, A.; Jackson, C.; Gligor, V.D. Accountable key infrastructure. In WWW 2013; Schwabe, D., Almeida, V.A.F., Glaser, H., Baeza-Yates, R., Moon, S.B., Eds.; International World Wide Web Conferences Steering Committee/ACM: New York, NY, USA, 2013; pp. 679–690. [Google Scholar]
- Yu, J.; Cheval, V.; Ryan, M. DTKI: A new formalized PKI with verifiable trusted parties. Comput. J. 2016, 59, 1695–1713. [Google Scholar] [CrossRef] [Green Version]
- Brunner, C.; Knirsch, F.; Unterweger, A.; Engel, D. A Comparison of Blockchain-based PKI Implementations. In ICISSP; Science and Technology Publications: Setúbal, Portugal, 2020; pp. 333–340. [Google Scholar]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2008. Available online: bitcoin.org (accessed on 21 March 2021).
- Fromknecht, C.; Velicanu, D.; Yakoubov, S. A Decentralized Public Key Infrastructure with Identity Retention. IACR Cryptol. ePrint Arch. 2014, 2014, 803. [Google Scholar]
- Leiding, B.; Cap, C.H.; Mundt, T.; Rashidibajgan, S. Authcoin: Validation and Authentication in Decentralized Networks. arXiv 2016, arXiv:1609.04955. Available online: http://xxx.lanl.gov/abs/1609.04955 (accessed on 21 March 2021).
- Fredriksson, B. A Distributed Public Key Infrastructure for the Web Backed by a Blockchain. 2017. Available online: http://www.diva-portal.org/smash/get/diva2:1121040/FULLTEXT01.pdf (accessed on 21 March 2021).
- Qin, B.; Huang, J.; Wang, Q.; Luo, X.; Liang, B.; Shi, W. Cecoin: A decentralized PKI mitigating MitM attacks. FGCS 2017, 107, 805–815. [Google Scholar] [CrossRef]
- Project, T.E. Modified Merkle Patricia Trie Specification. Available online: https://github.com/ethereum/wiki/wiki/Patricia-Tree (accessed on 21 March 2021).
- Feng, T.; Chen, W.; Zhang, D.; Liu, C. One-Stop Efficient PKI Authentication Service Model Based on Blockchain. In Blockchain Technology and Application; Si, X., Jin, H., Sun, Y., Zhu, J., Zhu, L., Song, X., Lu, Z., Eds.; Springer: Singapore, 2020; pp. 31–47. [Google Scholar] [CrossRef]
- Kubilay, M.Y.; Kiraz, M.S.; Mantar, H.A. CertLedger: A new PKI model with Certificate Transparency based on blockchain. Comput. Secur. 2019, 85, 333–352. [Google Scholar] [CrossRef] [Green Version]
- Madala, D.S.V.; Jhanwar, M.P.; Chattopadhyay, A. Certificate Transparency Using Blockchain. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 71–80. [Google Scholar] [CrossRef]
- Wang, Z.; Lin, J.; Cai, Q.; Wang, Q.; Zha, D.; Jing, J. Blockchain-based Certificate Transparency and Revocation Transparency. IEEE Trans. Dependable Secur. Comput. 2020, 1. [Google Scholar] [CrossRef]
- Zhao, J.; Lin, Z.; Huang, X.; Zhang, Y.; Xiang, S. TrustCA: Achieving Certificate Transparency through Smart Contract in Blockchain Platforms. In Proceedings of the 2020 International Conference on High Performance Big Data and Intelligent Systems (HPBD IS), Shenzhen, China, 23 May 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Yakubov, A.; Shbair, W.M.; Wallbom, A.; Sanda, D.; State, R. A blockchain-based PKI management framework. In Proceedings of the NOMS 2018—2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Kent, S. Attack Model and Threat for Certificate Transparency. Internet Engineering Task Force (IETF). 2015. Available online: https://datatracker.ietf.org/doc/html/draft-ietf-trans-threat-analysis (accessed on 21 March 2021).
- Wood, G. Ethereum: A secure decentralised generalised transaction ledger. Ethereum Proj. Yellow Pap. 2014, 151, 1–32. [Google Scholar]
- Merkle, R.C. A Certified Digital Signature. In CRYPTO’89; Brassard, G., Ed.; Springer: Berlin/Heidelberg, Germany, 1990; Volume 435, pp. 218–238. [Google Scholar] [CrossRef] [Green Version]
- Merkle, R.C. Secrecy, Authentication, and Public Key Systems. 1979. Available online: https://www.merkle.com/papers/Thesis1979.pdf (accessed on 21 March 2021).
- Cormen, T.H. Introduction to Algorithms, 3rd ed.; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Barber, S.; Boyen, X.; Shi, E.; Uzun, E. Bitter to better—how to make bitcoin a better currency. In FC’12; Springer: Berlin/Heidelberg, Germany, 2012; pp. 399–414. [Google Scholar]
- Eyal, I.; Sirer, E.G. Majority is not enough: Bitcoin mining is vulnerable. In FC’14; Springer: Berlin/Heidelberg, Germany, 2014; pp. 436–454. [Google Scholar]
- Li, X.; Jiang, P.; Chen, T.; Luo, X.; Wen, Q. A survey on the security of blockchain systems. Future Gener. Comput. Syst. 2020, 107, 841–853. [Google Scholar] [CrossRef] [Green Version]
- Conti, M.; Sandeep Kumar, E.; Lal, C.; Ruj, S. A Survey on Security and Privacy Issues of Bitcoin. IEEE Commun. Surv. Tutor. 2018, 20, 3416–3452. [Google Scholar] [CrossRef] [Green Version]
- Feng, Q.; He, D.; Zeadally, S.; Khan, M.K.; Kumar, N. A survey on privacy protection in blockchain system. J. Netw. Comput. Appl. 2019, 126, 45–58. [Google Scholar] [CrossRef]
- Bitcoin difficulty. Available online: https://en.bitcoin.it/wiki/Difficulty (accessed on 8 March 2019).
- Hallam-Baker, P.; Stradling, R. DNS Certification Authority Authorization (CAA) Resource Record. Technical Report. 2013. Available online: https://datatracker.ietf.org/doc/rfc6844/?include_text=1 (accessed on 21 March 2021).






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boyen, X.; Herath, U.; McKague, M.; Stebila, D. Associative Blockchain for Decentralized PKI Transparency. Cryptography 2021, 5, 14. https://doi.org/10.3390/cryptography5020014
Boyen X, Herath U, McKague M, Stebila D. Associative Blockchain for Decentralized PKI Transparency. Cryptography. 2021; 5(2):14. https://doi.org/10.3390/cryptography5020014
Chicago/Turabian StyleBoyen, Xavier, Udyani Herath, Matthew McKague, and Douglas Stebila. 2021. "Associative Blockchain for Decentralized PKI Transparency" Cryptography 5, no. 2: 14. https://doi.org/10.3390/cryptography5020014
APA StyleBoyen, X., Herath, U., McKague, M., & Stebila, D. (2021). Associative Blockchain for Decentralized PKI Transparency. Cryptography, 5(2), 14. https://doi.org/10.3390/cryptography5020014