
Foundations of Programmable Secure Computation


{kind=link}
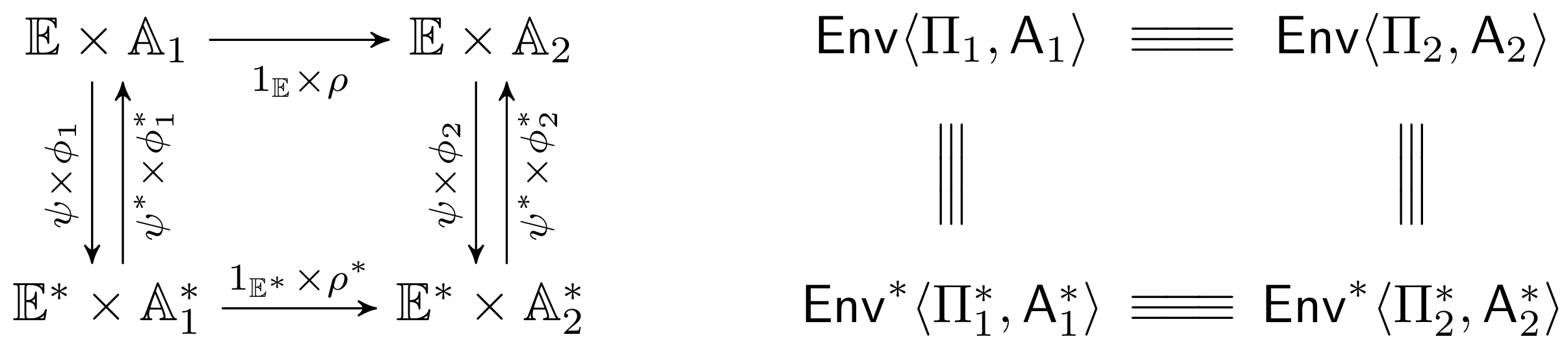{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
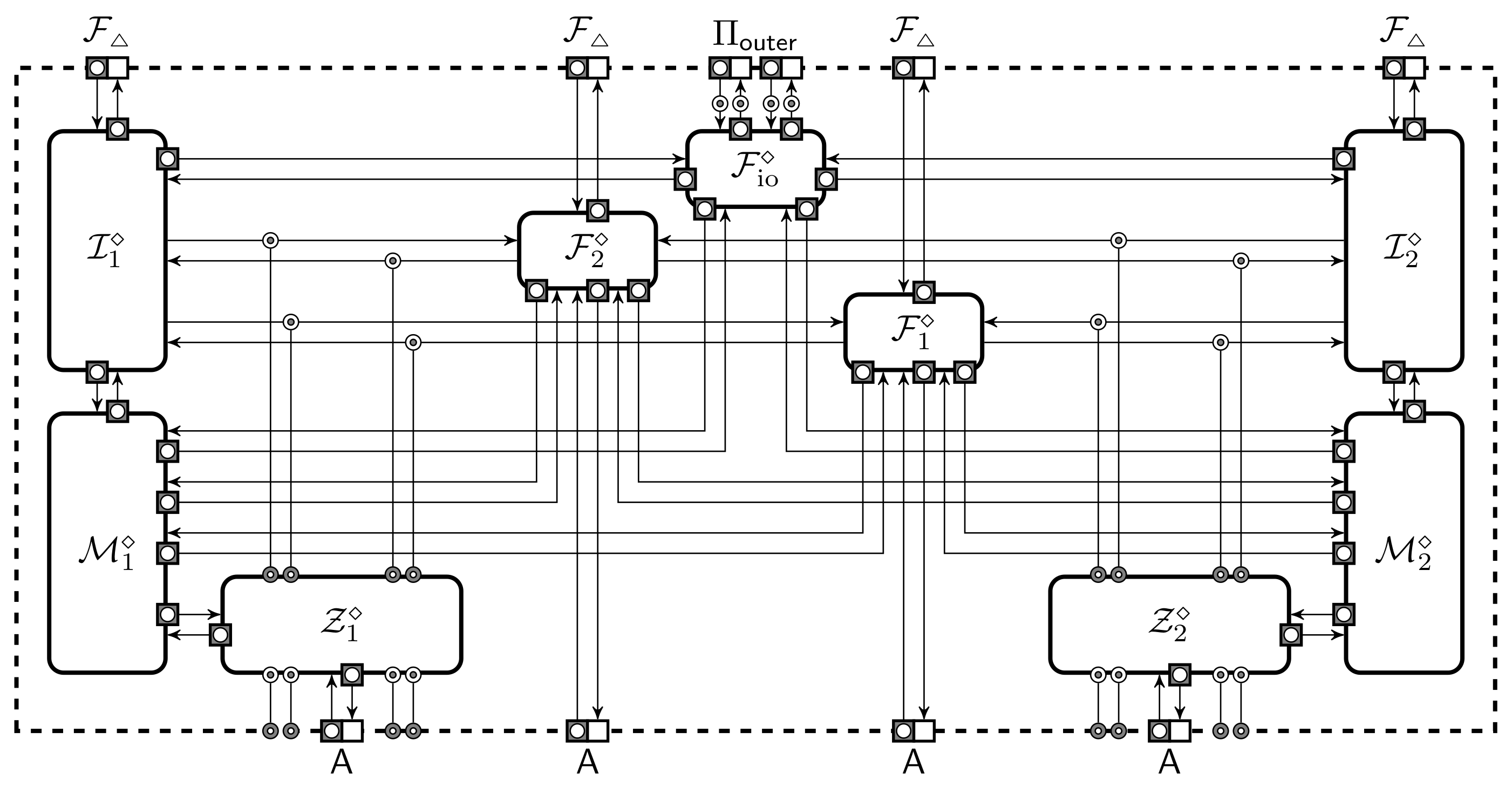{kind=link}
{kind=link}
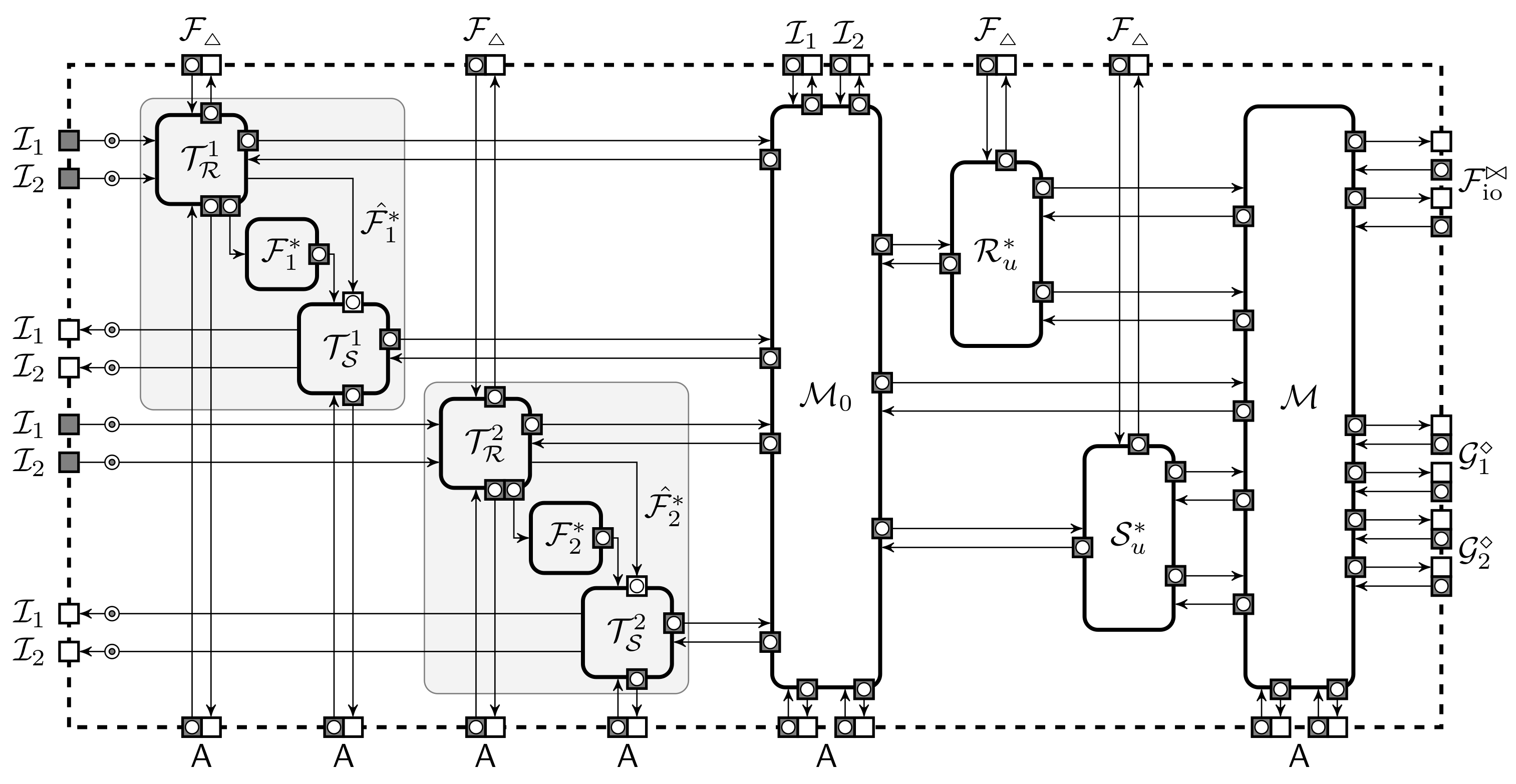{kind=link}
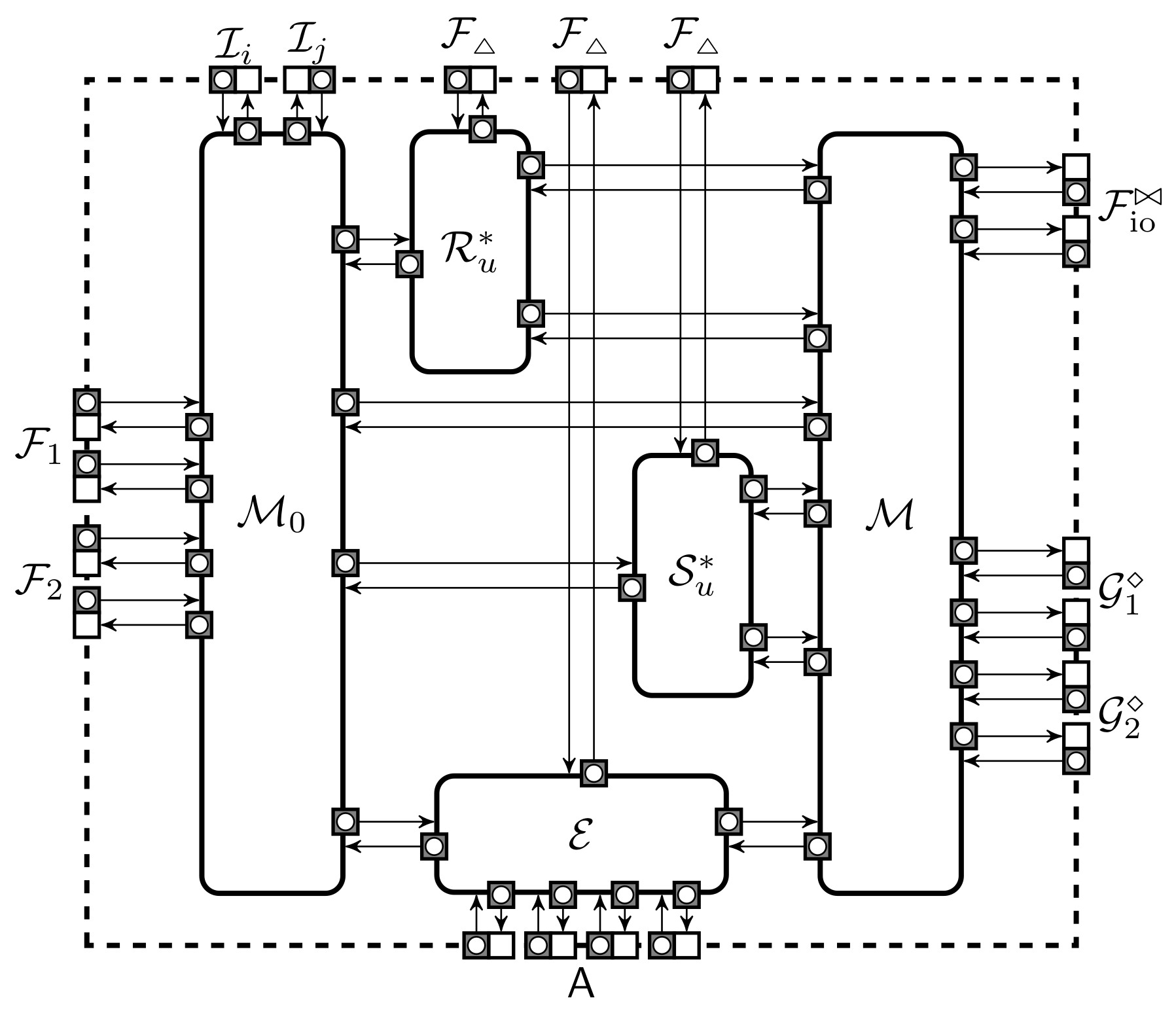{kind=link}
{kind=link}
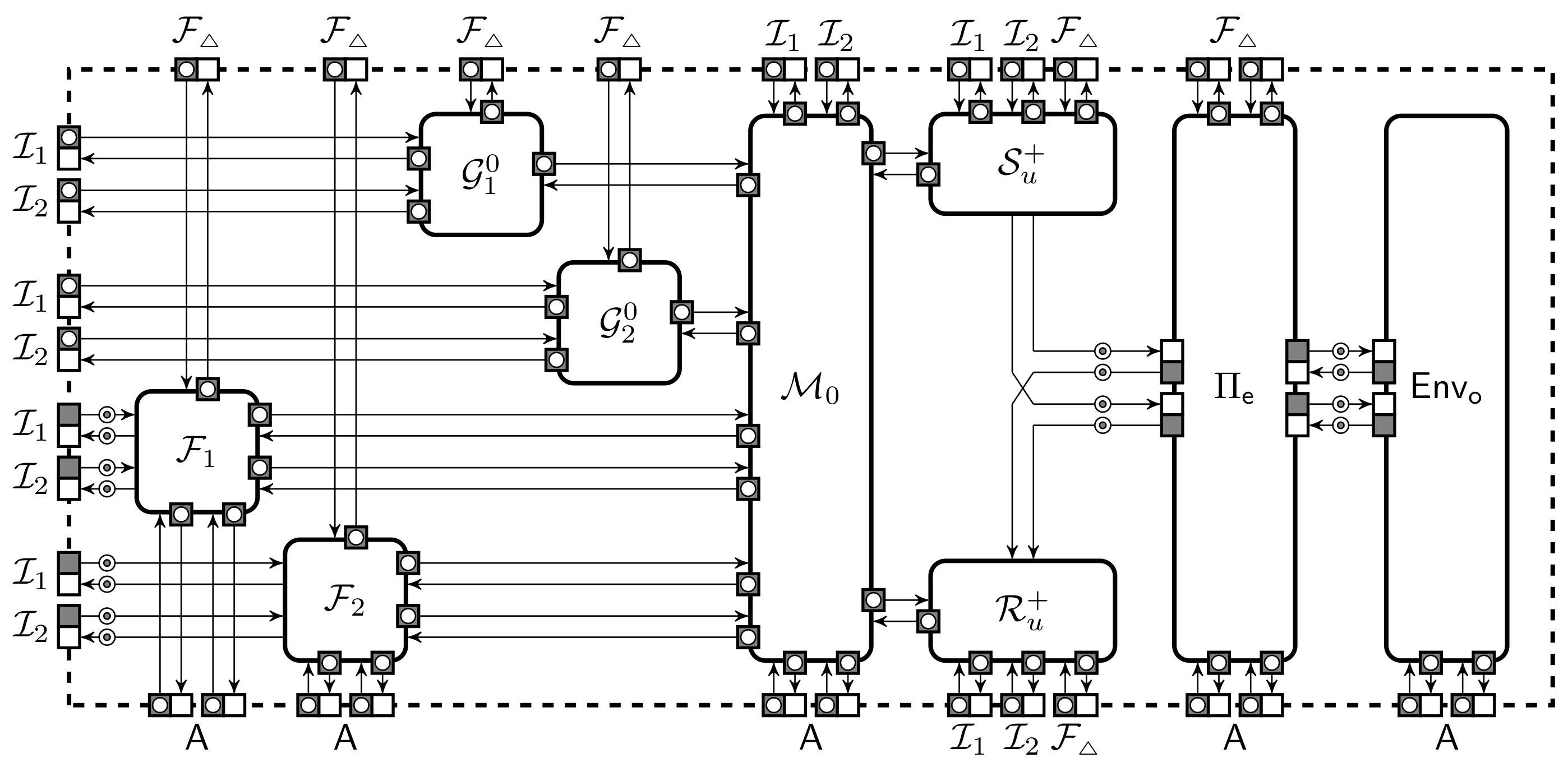{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
| Algorithm 1 Equality Check |
| Input: Two shared values and Output: 0 if , non-zero value otherwise Generate a shared random non-zero value . Compute . Publish as z. return z |
| Algorithm 2 Two-element Comparison-Based Sorting |
| Input: Two shared values and Output: Return fresh shares of x and y so that larger is the first Shuffle and to learn , where . Compute private comparison , where if . Publish as b. return if else |
2. Materials and Methods
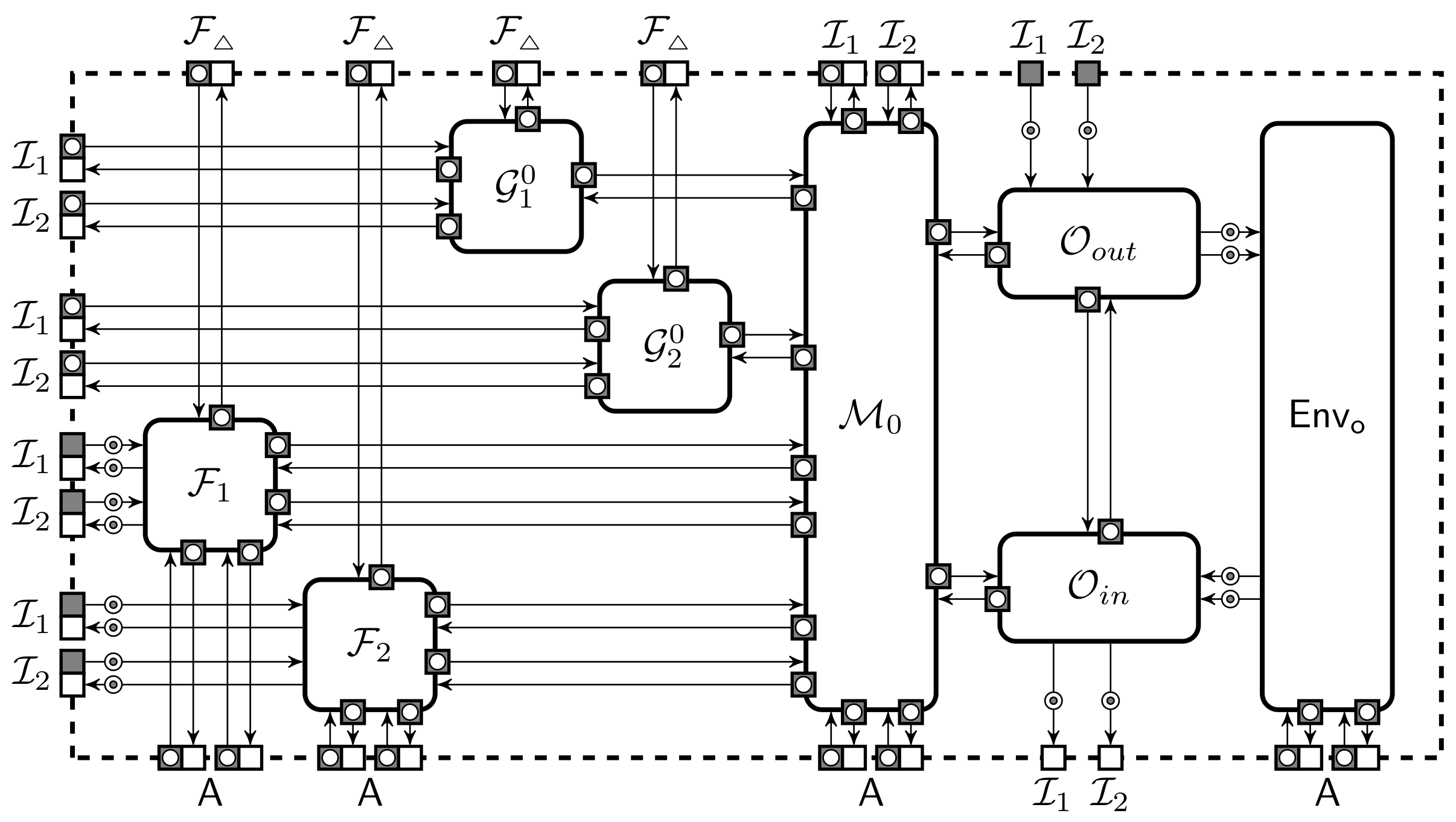
2.1. Asynchronous Systems and Visual Notation
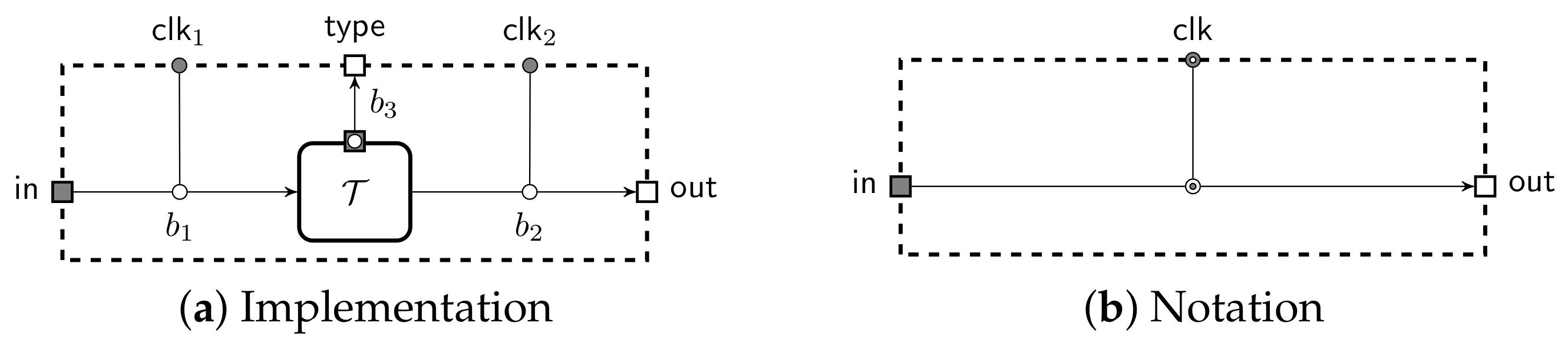
 ). We extend this model by adding buffers which leak information to the machine that clocks it. These can be used to ensure that the adversary learns some meta information about the messages, such as the subprotocol instance that receives the message. For visual clarity, we omit these details and use an arrow with a dotted bullet (
). We extend this model by adding buffers which leak information to the machine that clocks it. These can be used to ensure that the adversary learns some meta information about the messages, such as the subprotocol instance that receives the message. For visual clarity, we omit these details and use an arrow with a dotted bullet (  ) for the leaky buffer. We use a dedicated notation for sender-clocked (
) for the leaky buffer. We use a dedicated notation for sender-clocked (  ) and receiver-clocked (
) and receiver-clocked (  ) buffers and omit port squares if they are deducible from context. By default all buffers are clocked by the adversary. The notation is illustrated in Figure 1. A message written to the input port of a buffer is appended to an internal queue of messages . A leaky buffer also has a corresponding queue of leaks that is kept in sync. Leaks can be fetched using a dedicated port, thus the clocking machine must have at least one input port to receive the leakage. The full construction of it can be found in Appendix A. An input to standard clocking port causes to be removed from the queue and written to the output port. An empty output is written to the output if the input is out of range.
) buffers and omit port squares if they are deducible from context. By default all buffers are clocked by the adversary. The notation is illustrated in Figure 1. A message written to the input port of a buffer is appended to an internal queue of messages . A leaky buffer also has a corresponding queue of leaks that is kept in sync. Leaks can be fetched using a dedicated port, thus the clocking machine must have at least one input port to receive the leakage. The full construction of it can be found in Appendix A. An input to standard clocking port causes to be removed from the queue and written to the output port. An empty output is written to the output if the input is out of range.2.2. Security through Observational Equivalence
2.3. Soundness and Completeness Theorems
2.4. Programmable Multiparty Computation
2.4.1. Security of Distributed Storage Domains
2.4.2. Canonical Description of Ideal Functionalities
2.4.3. Canonical Description of Local Functionalities
2.4.4. Security of Protection Domains
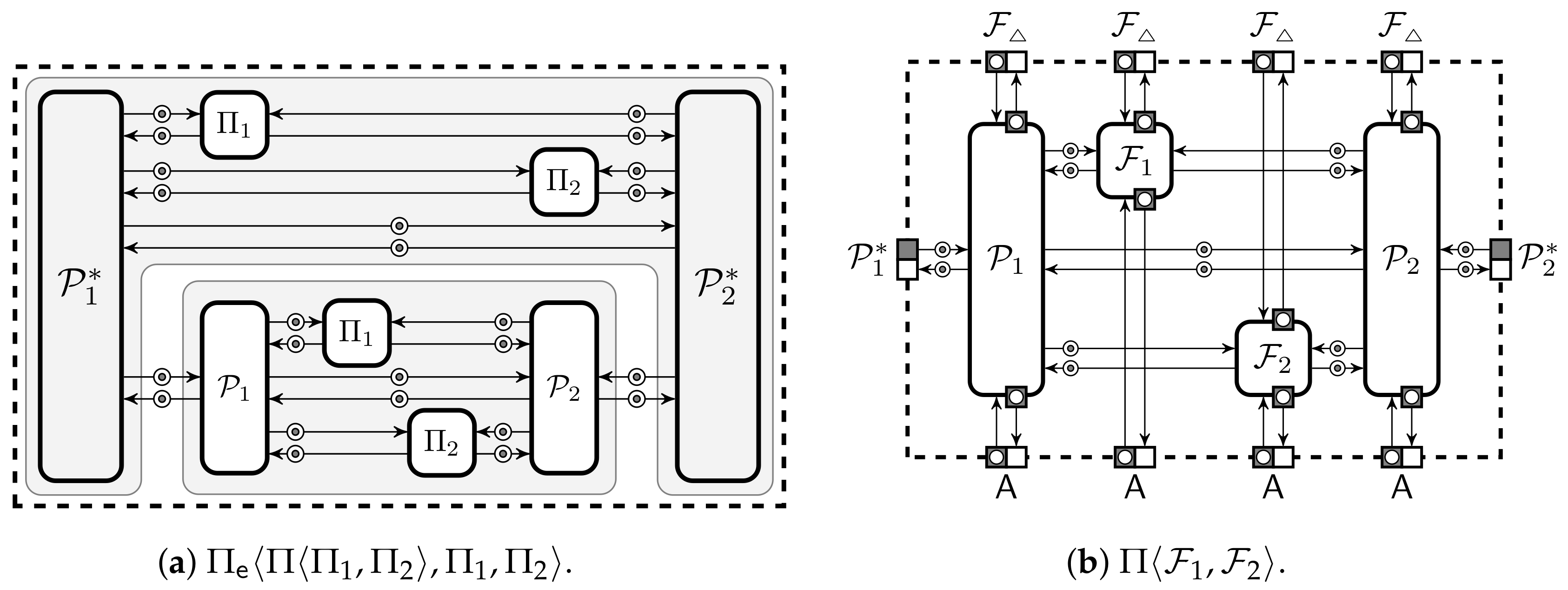
2.4.5. Secure Extension of Protection Domains
2.4.6. Restrictions to Environments and Adversaries
3. Results
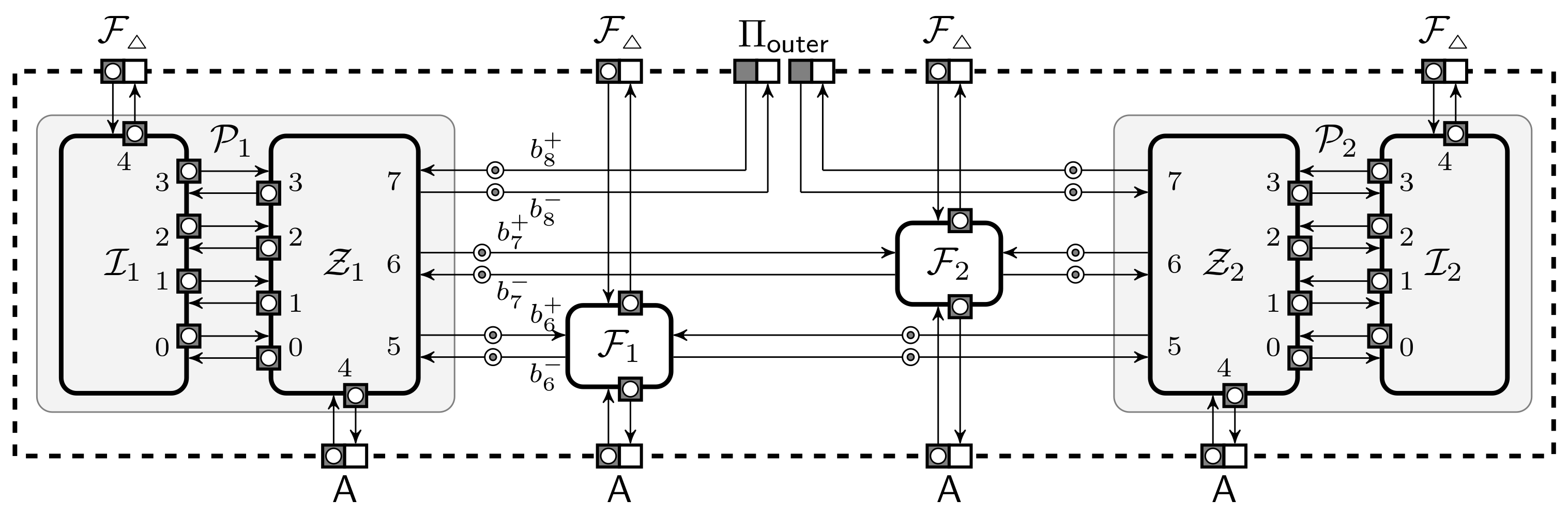
3.1. Minimal Requirements to Message Scheduling
3.1.1. Basics of Protocol Execution
3.1.2. Tight Message Scheduling
3.1.3. Robustness against Malformed Inputs
- (a)
- The adversary clocks any outgoing buffer and any incoming buffer connected to an honest party only when all incoming buffers connected to corrupted parties are empty.
- (b)
- Upon receiving a message from that comes from , the adversary immediately orders to forward it to without changes.
- (c)
- The adversary can send arbitrary messages to on behalf of .
- (d)
- The adversary can fetch the state of .
- (e)
- The adversary gives no other orders to .
3.1.4. Security against Rushed Execution
- (a)
- The round π is not in the program code of the interpreter .
- (b)
- The interpreter needs an input from to submit an input to π.
- (c)
- The interpreter needs an output from a round of computation to submit an input to π and is executed concurrently or after π.
3.2. Shared Memory and Simplistic Adversaries
3.2.1. Interpreter Specification
- (a)
- Each memory location can be assigned only once.
- (b)
- No instruction can read a memory location before it is initialised.
- (c)
- A new message with tag is never written to the output port p to before reading a message with tag from the input port p from .
- (d)
- For instructionsDmaCallandSend, no other program instruction can read memory locations in the vector α and write the memory location β.
3.2.2. Shared Memory Model for Communication
- (a)
- The adversary clocks any outgoing buffer and any incoming buffer to an honest party only when all incoming buffers to corrupted parties are empty.
- (b)
- The adversary can modify the state of the corrupted party only in the locations α of pendingDmaCallandSendinstructions. These changes are done before the corresponding tuple is clocked to and each value is modified at most once.
3.2.3. Memory Alignment and Protocol Specification
- (a)
- all conditional jumps are based on local values,
- (b)
- the remaining local operations are implemented with and
- (c)
- all ideal functionalities are used in memory-aligned manner.
3.3. Reduction to Abstract Memory Model
3.3.1. Introduction of Abstract Memory
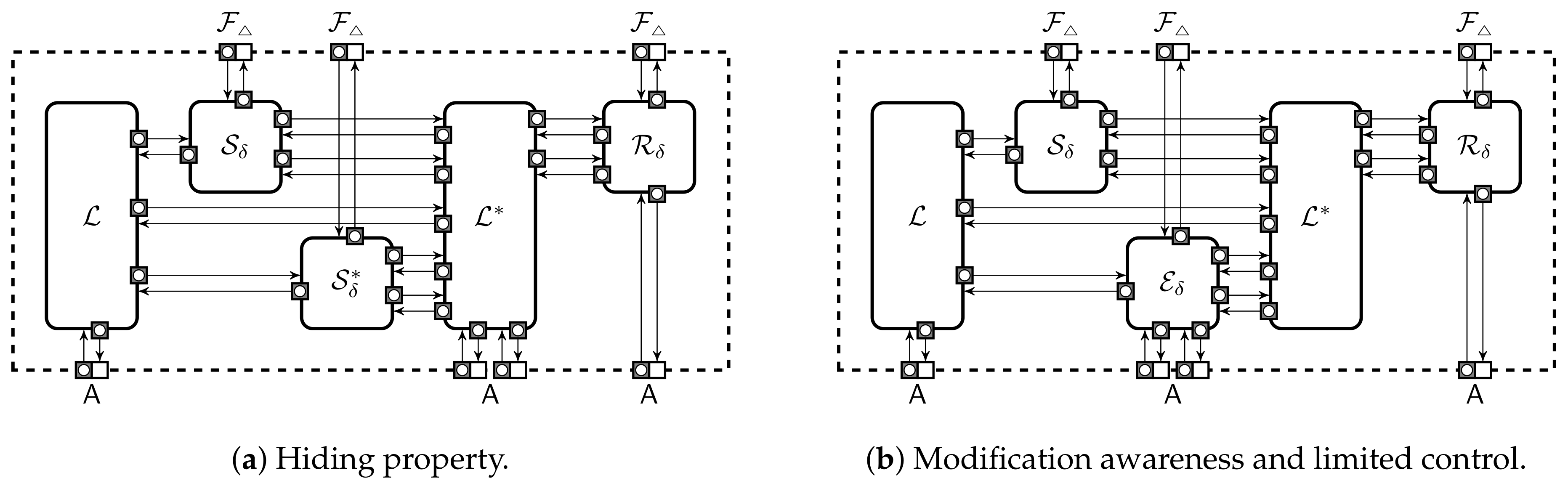
3.3.2. Extended Modification-Awareness
3.3.3. Meaningful Local Operations
3.3.4. Isolation of Protocol Outputs
3.3.5. Complete Memory Isolation
3.3.6. From Limited Control to the Hybrid Model
3.4. Abstract Model
3.4.1. Abstract Execution Environment
3.4.2. Security in the Abstract Model
- is well-formed (Definition 18) and in a canonical form (Definition 21),
- is robust against malformed inputs (Definition 14),
- is secure against rushing (Definition 16),
- is output-isolated (Definition 24)
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| MPC | Secure multiparty computation |
| ABB | Arithmetic black box |
| RSIM | Reactive simulatability |
| UC | Universal composability |
| Secret sharing of value x | |
| Environment | |
| Class of environments | |
| Adversary | |
| Class of adversaries | |
| Protocol | |
| Inner environment representing computations in the secure computation framework | |
| Class of protocols | |
| Protocol participant i | |
| Code interpreter of | |
| Corruption manager for | |
| Secure setup functionality | |
| Ideal functionality | |
| Ideal functionality of a protection domain | |
| Input–output functionality | |
| Local functionality p for | |
| Local functionality on values | |
| Secret sharing functionality | |
| Reconstruction functionality | |
| Machine inside that manages timing of | |
| Machine inside that manages timing of | |
| Machine inside that manages access to | |
| Extractor | |
| Storage of values in a storage domain | |
| Storage of shares in a storage domain | |
| Memory | |
| Memory holding only values | |
| Internal state of the protocol participant | |
| Global state combining of all participants | |
| State kept in | |
| m | Protocol message |
| Transformations of the adversary | |
| Transformations of the environment | |
| Transformation defined in the security proof | |
| Storage domain called | |
| Adversary structure for storage domain | |
| Modification operator in storage domain | |
| ⊥ | Failure symbol denoting invalid values |
| Configuration i |
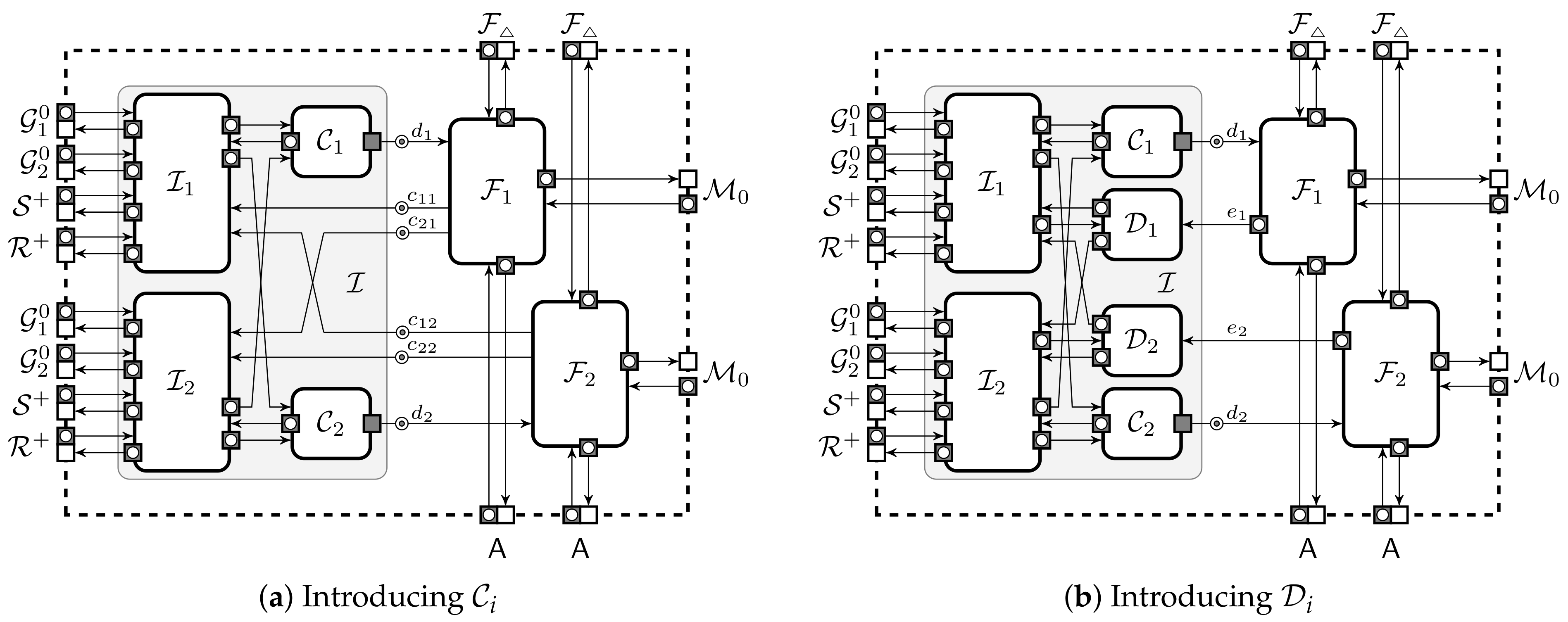
Appendix A. Buffers Leaking Message Annotations

Appendix B. Two Ways to Specify Ideal Functionalities

Appendix C. Combined Interpreter with Simplified Clocking

References
- Bogdanov, D.; Laur, S.; Willemson, J. Sharemind: A Framework for Fast Privacy-Preserving Computations. In Lecture Notes in Computer Science, Proceedings of the Computer Security—ESORICS 2008, 13th European Symposium on Research in Computer Security, Málaga, Spain, 6–8 October 2008; Jajodia, S., López, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5283, pp. 192–206. [Google Scholar] [CrossRef] [Green Version]
- Damgård, I.; Pastro, V.; Smart, N.P.; Zakarias, S. Multiparty Computation from Somewhat Homomorphic Encryption. In Lecture Notes in Computer Science, Proceedings of the Advances in Cryptology—CRYPTO 2012—32nd Annual Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2012; Safavi-Naini, R., Canetti, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7417, pp. 643–662. [Google Scholar] [CrossRef] [Green Version]
- Bogdanov, D. Sharemind: Programmable Secure Computations with Practical Applications. Ph.D. Thesis, University of Tartu, Tartu, Estonia, 2013. [Google Scholar]
- Demmler, D.; Schneider, T.; Zohner, M. ABY—A Framework for Efficient Mixed-Protocol Secure Two-Party Computation. In Proceedings of the 22nd Annual Network and Distributed System Security Symposium, NDSS 2015, San Diego, CA, USA, 8–11 February 2015. [Google Scholar]
- Alexandra Institute. FRESCO—A Framework for Efficient Secure Computation. Available online: http://github.com/aicis/fresco (accessed on 20 August 2021).
- KU Leuven. SCALE-MAMBA Software. Available online: https://github.com/KULeuven-COSIC/SCALE-MAMBA (accessed on 20 August 2021).
- Keller, M. MP-SPDZ: A Versatile Framework for Multi-Party Computation. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security—CCS’20, Virtual Event, 9–13 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1575–1590. [Google Scholar] [CrossRef]
- Bogetoft, P.; Christensen, D.L.; Damgård, I.; Geisler, M.; Jakobsen, T.P.; Krøigaard, M.; Nielsen, J.D.; Nielsen, J.B.; Nielsen, K.; Pagter, J.; et al. Secure Multiparty Computation Goes Live. In Lecture Notes in Computer Science, Proceedings of the Financial Cryptography and Data Security, 13th International Conference, FC 2009, Accra Beach, Barbados, 23–26 February 2009; Revised Selected Papers; Dingledine, R., Golle, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5628, pp. 325–343. [Google Scholar] [CrossRef] [Green Version]
- Mohassel, P.; Zhang, Y. SecureML: A System for Scalable Privacy-Preserving Machine Learning. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, SP 2017, San Jose, CA, USA, 22–26 May 2017; pp. 19–38. [Google Scholar] [CrossRef]
- Bogdanov, D.; Kamm, L.; Kubo, B.; Rebane, R.; Sokk, V.; Talviste, R. Students and Taxes: A Privacy-Preserving Study Using Secure Computation. PoPETs 2016, 2016, 117–135. [Google Scholar] [CrossRef] [Green Version]
- Archer, D.W.; Bogdanov, D.; Lindell, Y.; Kamm, L.; Nielsen, K.; Pagter, J.I.; Smart, N.P.; Wright, R.N. From Keys to Databases—Real-World Applications of Secure Multi-Party Computation. Comput. J. 2018, 61, 1749–1771. [Google Scholar] [CrossRef] [Green Version]
- Mohassel, P.; Rindal, P. ABY3: A Mixed Protocol Framework for Machine Learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, CCS 2018, Toronto, ON, Canada, 15–19 October 2018; Lie, D., Mannan, M., Backes, M., Wang, X., Eds.; ACM: New York, NY, USA, 2018; pp. 35–52. [Google Scholar] [CrossRef]
- Laud, P.; Pankova, A. Privacy-preserving record linkage in large databases using secure multiparty computation. BMC Med. Genom. 2018, 11, 35–55. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Canetti, R. Universally Composable Security: A New Paradigm for Cryptographic Protocols. In Proceedings of the 42nd Annual Symposium on Foundations of Computer Science, FOCS 2001, Las Vegas, NV, USA, 14–17 October 2001; pp. 136–145. [Google Scholar] [CrossRef] [Green Version]
- Damgård, I.; Nielsen, J.B. Universally Composable Efficient Multiparty Computation from Threshold Homomorphic Encryption. In Lecture Notes in Computer Science, Proceedings of the Advances in Cryptology—CRYPTO 2003, 23rd Annual International Cryptology Conference, Santa Barbara, CA, USA, 17–21 August 2003; Boneh, D., Ed.; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2729, pp. 247–264. [Google Scholar] [CrossRef] [Green Version]
- Lipmaa, H.; Toft, T. Secure Equality and Greater-Than Tests with Sublinear Online Complexity. In Lecture Notes in Computer Science, Proceedings of the Automata, Languages, and Programming—40th International Colloquium, ICALP 2013, Riga, Latvia, 8–12 July 2013; Fomin, F.V., Freivalds, R., Kwiatkowska, M.Z., Peleg, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7966, pp. 645–656. [Google Scholar] [CrossRef]
- Escudero, D.; Ghosh, S.; Keller, M.; Rachuri, R.; Scholl, P. Improved Primitives for MPC over Mixed Arithmetic-Binary Circuits. In Lecture Notes in Computer Science, Proceedings of the Advances in Cryptology—CRYPTO 2020—40th Annual International Cryptology Conference, CRYPTO 2020, Santa Barbara, CA, USA, 17–21 August 2020; Micciancio, D., Ristenpart, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12171, pp. 823–852. [Google Scholar] [CrossRef]
- Damgård, I.; Escudero, D.; Frederiksen, T.K.; Keller, M.; Scholl, P.; Volgushev, N. New Primitives for Actively-Secure MPC over Rings with Applications to Private Machine Learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy, SP 2019, San Francisco, CA, USA, 19–23 May 2019; pp. 1102–1120. [Google Scholar] [CrossRef]
- Kamm, L.; Willemson, J. Secure Floating-Point Arithmetic and Private Satellite Collision Analysis. Int. J. Inf. Secur. 2015, 14, 531–548. [Google Scholar] [CrossRef] [Green Version]
- Veugen, T.; Abspoel, M. Secure integer division with a private divisor. Proc. Priv. Enhancing Technol. 2021, 2021, 339–349. [Google Scholar] [CrossRef]
- Catrina, O.; de Hoogh, S. Improved Primitives for Secure Multiparty Integer Computation. In Lecture Notes in Computer Science, Proceedings of the Security and Cryptography for Networks, 7th International Conference, SCN 2010, Amalfi, Italy, 13–15 September 2010; Garay, J.A., Prisco, R.D., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6280, pp. 182–199. [Google Scholar] [CrossRef]
- Nishide, T.; Ohta, K. Multiparty Computation for Interval, Equality, and Comparison Without Bit-Decomposition Protocol. In Lecture Notes in Computer Science, Proceedings of the Public Key Cryptography—PKC 2007, 10th International Conference on Practice and Theory in Public-Key Cryptography, Beijing, China, 16–20 April 2007; Okamoto, T., Wang, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4450, pp. 343–360. [Google Scholar] [CrossRef] [Green Version]
- Damgård, I.; Fitzi, M.; Kiltz, E.; Nielsen, J.B.; Toft, T. Unconditionally Secure Constant-Rounds Multi-party Computation for Equality, Comparison, Bits and Exponentiation. In Lecture Notes in Computer Science, Proceedings of the Theory of Cryptography, Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, 4–7 March 2006; Halevi, S., Rabin, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3876, pp. 285–304. [Google Scholar] [CrossRef] [Green Version]
- Canetti, R.; Rabin, T. Universal Composition with Joint State. In Lecture Notes in Computer Science, Proceedings of the Advances in Cryptology—CRYPTO 2003, 23rd Annual International Cryptology Conference, Santa Barbara, CA, USA, 17–21 August 2003; Boneh, D., Ed.; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2729, pp. 265–281. [Google Scholar] [CrossRef] [Green Version]
- Pfitzmann, B.; Waidner, M. A Model for Asynchronous Reactive Systems and its Application to Secure Message Transmission. In Proceedings of the 2001 IEEE Symposium on Security and Privacy—SP’01, Oakland, CA, USA, 14–16 May 2001; pp. 184–200. [Google Scholar]
- Backes, M.; Pfitzmann, B.; Waidner, M. A General Composition Theorem for Secure Reactive Systems. In Lecture Notes in Computer Science, Proceedings of the Theory of Cryptography, First Theory of Cryptography Conference, TCC 2004, Cambridge, MA, USA, 19–21 February 2004; Naor, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 2951, pp. 336–354. [Google Scholar] [CrossRef] [Green Version]
- Backes, M.; Pfitzmann, B.; Waidner, M. The reactive simulatability (RSIM) framework for asynchronous systems. Inf. Comput. 2007, 205, 1685–1720. [Google Scholar] [CrossRef] [Green Version]
- Goldreich, O. The Foundations of Cryptography—Volume 2: Basic Applications; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar] [CrossRef]
- Canetti, R. Security and Composition of Multiparty Cryptographic Protocols. J. Cryptol. 2000, 13, 143–202. [Google Scholar] [CrossRef]
- Micali, S.; Rogaway, P. Secure Computation (Abstract). In Lecture Notes in Computer Science, Proceedings of the Advances in Cryptology—CRYPTO’91, 11th Annual International Cryptology Conference, Santa Barbara, CA, USA, 11–15 August 1991; Feigenbaum, J., Ed.; Springer: Berlin/Heidelberg, Germany, 1991; Volume 576, pp. 392–404. [Google Scholar] [CrossRef] [Green Version]
- Beaver, D. Secure Multiparty Protocols and Zero-Knowledge Proof Systems Tolerating a Faulty Minority. J. Cryptol. 1991, 4, 75–122. [Google Scholar] [CrossRef]
- Canetti, R.; Feige, U.; Goldreich, O.; Naor, M. Adaptively Secure Multi-Party Computation. In Proceedings of the Twenty-Eighth Annual ACM Symposium on the Theory of Computing, Philadelphia, PA, USA, 22–24 May 1996; Miller, G.L., Ed.; ACM: New York, NY, USA, 1996; pp. 639–648. [Google Scholar] [CrossRef]
- Zikas, V.; Hauser, S.; Maurer, U.M. Realistic Failures in Secure Multi-party Computation. In Lecture Notes in Computer Science, Proceedings of the Theory of Cryptography, 6th Theory of Cryptography Conference, TCC 2009, San Francisco, CA, USA, 15–17 March 2009; Reingold, O., Ed.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5444, pp. 274–293. [Google Scholar] [CrossRef] [Green Version]
- Gordon, S.D.; Katz, J. Complete Fairness in Multi-party Computation without an Honest Majority. In Lecture Notes in Computer Science, Proceedings of the Theory of Cryptography, 6th Theory of Cryptography Conference, TCC 2009, San Francisco, CA, USA, 15–17 March 2009; Reingold, O., Ed.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5444, pp. 19–35. [Google Scholar] [CrossRef] [Green Version]
- Cohen, R.; Lindell, Y. Fairness Versus Guaranteed Output Delivery in Secure Multiparty Computation. J. Cryptol. 2017, 30, 1157–1186. [Google Scholar] [CrossRef]
- Kiraz, M.; Schoenmakers, B. A protocol issue for the malicious case of Yao’s garbled circuit construction. In Proceedings of the 27th Symposium on Information Theory in the Benelux, Noordwijk, The Netherlands, 8–9 June 2006; pp. 283–290. [Google Scholar]
- Mohassel, P.; Franklin, M.K. Efficiency Tradeoffs for Malicious Two-Party Computation. In Lecture Notes in Computer Science, Proceedings of the Public Key Cryptography—PKC 2006, 9th International Conference on Theory and Practice of Public-Key Cryptography, New York, NY, USA, 24–26 April 2006; Yung, M., Dodis, Y., Kiayias, A., Malkin, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3958, pp. 458–473. [Google Scholar] [CrossRef] [Green Version]
- Aumann, Y.; Lindell, Y. Security Against Covert Adversaries: Efficient Protocols for Realistic Adversaries. In Lecture Notes in Computer Science, Proceedings of the Theory of Cryptography, 4th Theory of Cryptography Conference, TCC 2007, Amsterdam, The Netherlands, 21–24 February 2007; Vadhan, S.P., Ed.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4392, pp. 137–156. [Google Scholar] [CrossRef] [Green Version]
- Küsters, R.; Datta, A.; Mitchell, J.C.; Ramanathan, A. On the Relationships between Notions of Simulation-Based Security. J. Cryptol. 2008, 21, 492–546. [Google Scholar] [CrossRef]
- Goyal, V.; Gupta, D.; Sahai, A. Concurrent Secure Computation via Non-Black Box Simulation. In Lecture Notes in Computer Science, Proceedings of the Advances in Cryptology—CRYPTO 2015—35th Annual Cryptology Conference, Santa Barbara, CA, USA, 16–20 August 2015; Gennaro, R., Robshaw, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9216, pp. 23–42. [Google Scholar] [CrossRef]
- Kiyoshima, S. Non-black-box Simulation in the Fully Concurrent Setting, Revisited. J. Cryptol. 2019, 32, 393–434. [Google Scholar] [CrossRef]
- Pass, R. Simulation in Quasi-Polynomial Time, and Its Application to Protocol Composition. In Lecture Notes in Computer Science, Proceedings of the Advances in Cryptology—EUROCRYPT 2003, International Conference on the Theory and Applications of Cryptographic Techniques, Warsaw, Poland, 4–8 May 2003; Biham, E., Ed.; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2656, pp. 160–176. [Google Scholar] [CrossRef] [Green Version]
- Barak, B.; Sahai, A. How To Play Almost Any Mental Game Over The Net—Concurrent Composition via Super-Polynomial Simulation. In Proceedings of the 46th Annual IEEE Symposium on Foundations of Computer Science (FOCS 2005), Pittsburgh, PA, USA, 23–25 October 2005; pp. 543–552. [Google Scholar] [CrossRef]
- Oren, Y. On the Cunning Power of Cheating Verifiers: Some Observations about Zero Knowledge Proofs (Extended Abstract). In Proceedings of the 28th Annual Symposium on Foundations of Computer Science, Los Angeles, CA, USA, 27–29 October 1987; pp. 462–471. [Google Scholar] [CrossRef]
- Canetti, R. Universally Composable Security: A New Paradigm for Cryptographic Protocols. Cryptology ePrint Archive, Report 2000/067. 2000. Available online: https://eprint.iacr.org/2000/067 (accessed on 20 August 2021).
- Maurer, U.; Renner, R. Abstract Cryptography. In Proceedings of the Innovations in Computer Science—ICS 2011, Beijing, China, 7–9 January 2011; Chazelle, B., Ed.; Tsinghua University Press: Beijing, China, 2011; pp. 1–21. [Google Scholar]
- Küsters, R. Simulation-Based Security with Inexhaustible Interactive Turing Machines. In Proceedings of the 19th IEEE Computer Security Foundations Workshop, (CSFW-19 2006), Venice, Italy, 5–7 July 2006; pp. 309–320. [Google Scholar] [CrossRef]
- Hofheinz, D.; Shoup, V. GNUC: A New Universal Composability Framework. J. Cryptol. 2015, 28, 423–508. [Google Scholar] [CrossRef] [Green Version]
- Böhl, F.; Unruh, D. Symbolic universal composability. J. Comput. Secur. 2016, 24, 1–38. [Google Scholar] [CrossRef]
- Camenisch, J.; Krenn, S.; Küsters, R.; Rausch, D. iUC: Flexible Universal Composability Made Simple. In Lecture Notes in Computer Science, Proceedings of the Advances in Cryptology—ASIACRYPT 2019—25th International Conference on the Theory and Application of Cryptology and Information Security, Kobe, Japan, 8–12 December 2019; Galbraith, S.D., Moriai, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11923, pp. 191–221. [Google Scholar] [CrossRef]
- Barak, B.; Canetti, R.; Lindell, Y.; Pass, R.; Rabin, T. Secure Computation Without Authentication. In Lecture Notes in Computer Science, Proceedings of the Advances in Cryptology—CRYPTO 2005: 25th Annual International Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2005; Shoup, V., Ed.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3621, pp. 361–377. [Google Scholar] [CrossRef] [Green Version]
- Canetti, R.; Cohen, A.; Lindell, Y. A Simpler Variant of Universally Composable Security for Standard Multiparty Computation. In Lecture Notes in Computer Science, Proceedings of the Advances in Cryptology—CRYPTO 2015—35th Annual Cryptology Conference, Santa Barbara, CA, USA, 16–20 August 2015; Gennaro, R., Robshaw, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9216, pp. 3–22. [Google Scholar] [CrossRef] [Green Version]
- Yao, A.C. Protocols for Secure Computations (Extended Abstract). In Proceedings of the 23rd Annual Symposium on Foundations of Computer Science, Chicago, IL, USA, 3–5 November 1982; pp. 160–164. [Google Scholar] [CrossRef]
- Beaver, D. Foundations of Secure Interactive Computing. In Lecture Notes in Computer Science, Proceedings of the Advances in Cryptology—CRYPTO’91, 11th Annual International Cryptology Conference, Santa Barbara, CA, USA, 11–15 August 1991; Feigenbaum, J., Ed.; Springer: Berlin/Heidelberg, Germany, 1991; Volume 576, pp. 377–391. [Google Scholar] [CrossRef] [Green Version]
- Bellare, M.; Rogaway, P. Robust Computational Secret Sharing and a Unified Account of Classical Secret-Sharing Goals. In Proceedings of the 14th ACM Conference on Computer and Communications Security—CCS’07, Alexandria, VA, USA, 2 November–31 October 2007; Association for Computing Machinery: New York, NY, USA, 2007; pp. 172–184. [Google Scholar] [CrossRef] [Green Version]
- Damgård, I.; Nielsen, J.B. Adaptive versus static security in the UC model. In Proceedings of the International Conference on Provable Security, Hong Kong, China, 9–10 October 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 10–28. [Google Scholar]
- Genkin, D.; Ishai, Y.; Prabhakaran, M.; Sahai, A.; Tromer, E. Circuits resilient to additive attacks with applications to secure computation. In Proceedings of the Symposium on Theory of Computing, STOC 2014, New York, NY, USA, 31 May–3 June 2014; Shmoys, D.B., Ed.; ACM: New York, NY, USA, 2014; pp. 495–504. [Google Scholar] [CrossRef] [Green Version]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Laur, S.; Pullonen-Raudvere, P. Foundations of Programmable Secure Computation. Cryptography 2021, 5, 22. https://doi.org/10.3390/cryptography5030022
Laur S, Pullonen-Raudvere P. Foundations of Programmable Secure Computation. Cryptography. 2021; 5(3):22. https://doi.org/10.3390/cryptography5030022
Chicago/Turabian StyleLaur, Sven, and Pille Pullonen-Raudvere. 2021. "Foundations of Programmable Secure Computation" Cryptography 5, no. 3: 22. https://doi.org/10.3390/cryptography5030022
APA StyleLaur, S., & Pullonen-Raudvere, P. (2021). Foundations of Programmable Secure Computation. Cryptography, 5(3), 22. https://doi.org/10.3390/cryptography5030022