The application of the CRF-inequality to heteroscedastic least-squares fit for straight tracks adds other complications. Two parameters must be handled. The first parameter is the constant
, the impact point of the track in the reference plane. The second is
, the angular shift of the track in the plane distant
from the reference plane. Also here, the heteroscedasticity eliminates any easy rule with the increase of the number (
N) of the observations for two different reasons. One is again the differences of the
; the new one is due to the constraint of the fixed length of the tracker. Each insertion of a new detecting plane requires a repositioning of all the others. We will study our Gaussian model with the condition
, this introduces some simplification on standard least-squares equations. The likelihood function is similar to that of Equation (
14), but now, the order of the PDFs must be conserved. The parameter
orders the measuring planes:
The Fisher information
becomes the
matrix:
The CRF-inequality assumes the form of a matrix inequality, we limit to relations among variances:
where
and
are the variances of any estimators for
and
:
and:
The Gaussian model is efficient because its variances are equal to the diagonal of
(here and in the following the indications
of the used PDFs will be subtended). The unbiased efficient estimators of
and
for the model of Equation (
25) are given by
(similar to those for a single parameter):
The last equation allows the extraction of the formal expressions of the unbiased efficient estimators for this model (and are identical to those reported everywhere, for example, in ref. [
8]). The mean values of products of logarithmic derivatives are obtained by the mean values of double derivative of a single logarithmic function (as in Equation (
6)), and due to Equation (
28) gives:
The second equation uses the first equation giving the Fisher information and the symmetry . The diagonal terms are the variances of the efficient estimators for and . It is evident the privileged position of the Gaussian PDFs in the CRF-inequality.
4.1. The Standard Least-Squares Equations with Heteroscedastic Likelihood
We defined standard least-squares equations the estimators (for
and
) obtained with a homoscedastic model. It is easy to prove that the standard least-squares estimators are efficient estimators for a Gaussian model with identical
s. The extension of Equations (
13) to the case for two parameters shows immediately this property. The condition
simplifies the forms of the estimators. In the case of identical
s the CRF-inequality states that any other estimator has a greater variance compared to the efficient estimators. It is evident that the efficiency of an estimator is strictly bound to the likelihood model of its definition (in a given model the efficient estimator of a parameter is unique). We could derive the forms of the standard least-squares estimators as the efficient estimators for the Gaussian model with identical
, but the usual derivation is faster. The estimators of
and
of the standard least squares are:
For an easy check of the forms of the estimators, we report the least-squares equations that give their expressions (after inserting
). The heteroscedastic likelihood
destroys their efficiency (optimality) and the new variances are different from those in the homoscedastic model (
and
):
and, due to the differences from the variances of the efficient estimators, the CRF inequalities of Equations (
32) and (
33) impose to them to be grater. We will extensively prove this property as a prototype of demonstration [
9] that will be used even for the momentum variances.
First, it is required the joint variance-covariance matrix of
with the efficient estimators
. This matrix is positive semi-definite (symmetrical with the variances in the diagonal). Let
be this matrix,
T the column vector
and with
the average on the likelihood of Equation (
25). The matrix
is the variance-covariance matrix of the efficient estimators (Equation (
35))
It is easy to show the following general property of the covariance of the unbiased estimator
with the efficient estimators. By definition, the mean value of an unbiased estimator is always zero as any of its derivative:
The derivative of the likelihood is the first component of
of Equation (
27), and this correlation (the integral term) becomes equal to one. The derivative in
of the mean value of
has no one and the sought correlation is zero. Similarly, for the other estimator
. Hence the matrix
is:
The matrix
is symmetric. The properties (positive semi-definite) of
-matrix are conserved even with transformation
with
any real matrix of four lines and two columns (a few details about the positive semi-definite matrices are reported in
Appendix A):
The last of Equation (
41) is Equation (
31) as a matrix relation. The equality is eliminated being evidently impossible. For the definition of positive semi-definite matrices, it is straightforward to extract the relations among the variances. The Equations (
31)–(
41) will be extended the estimators of the momentum reconstructions.
Equations (
41) were demonstrated with heteroscedastic Gaussian model; however, the variances of
T remain always greater also for heteroscedastic irregular models with equivalent set of
. The efficient estimators of heteroscedastic models continue to be efficient even for homoscedastic models, converging to them when all the
become identical.
This set of demonstrations for heteroscedastic model is addressed to each given chain of PDFs with a defined order of
. Their variances of Equations (
32) and (
33) are strongly modified by the differences among the
without any evident
N limitation. Instead, the variances of the standard least squares are weakly modified, and they save explicit
N limitations. For example, the variances of the
parameter has averages
.
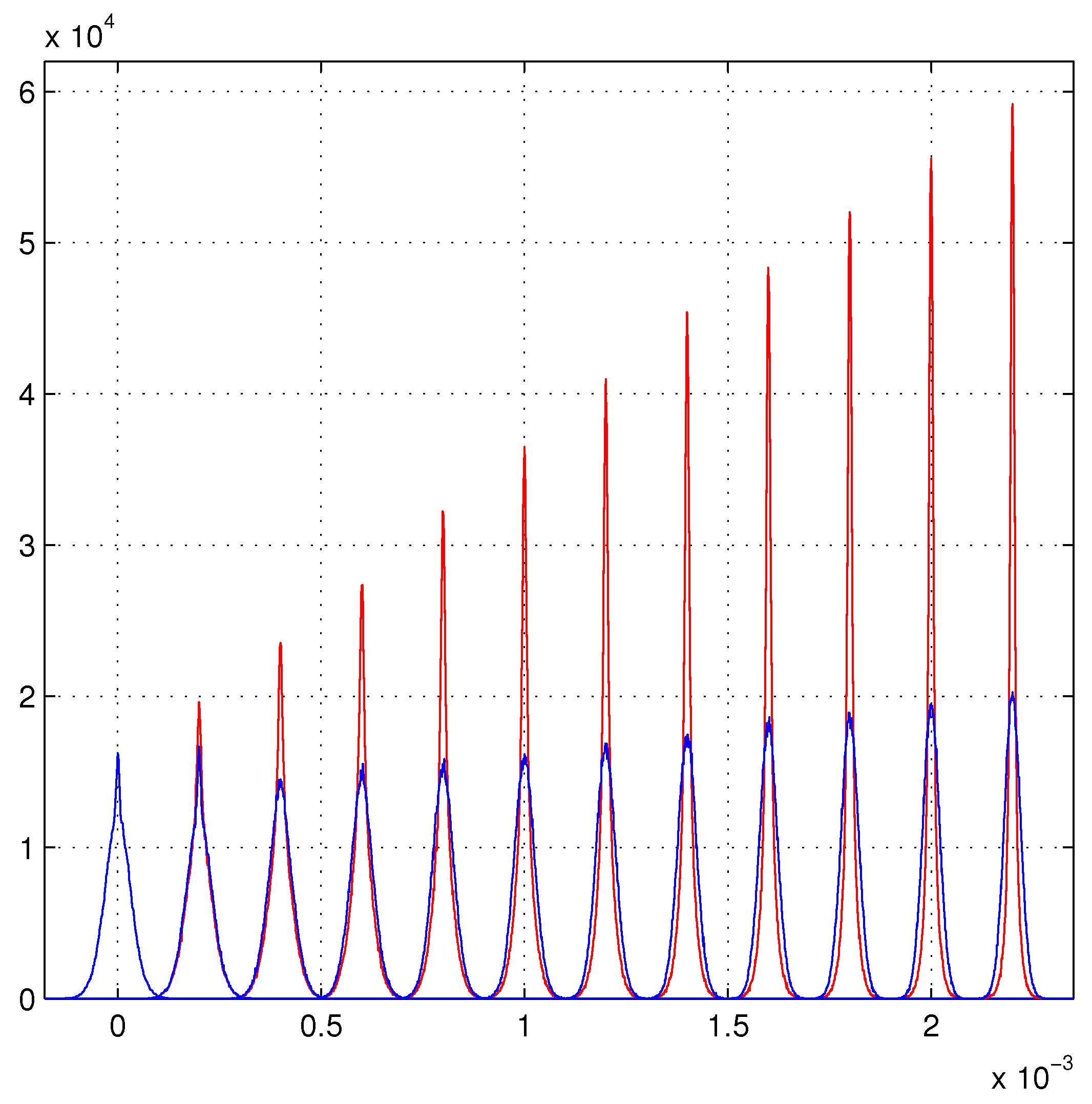
Figure 1 illustrates these limits for the
estimator (the blue distributions) also
cannot grow faster than
N for the fixed length of the tracker. The large modifications of the variances of the chains of PDFs, render the track fitting strongly dependent from other PDFs. For example, those that select the chains among the possible set of chains. These PDFs are introduced by the properties of the measuring devices. As we said above, a binomial PDF suffices in the disordered tracker detector for the models of refs. [
2,
3], just a mean disorder of half strip (≈30
m) is enough for this. The use of standard least-squares method in heteroscedastic models has enormous simplifications, because it does not need the knowledge of the
for each observation. Unfortunately, it amounts to a large loss of resolution. Our models of ref. [
3] illustrate in evident way the amplitude of this loss. In any case the lucky model of ref. [
3] can be an economic way to introduce effective
.
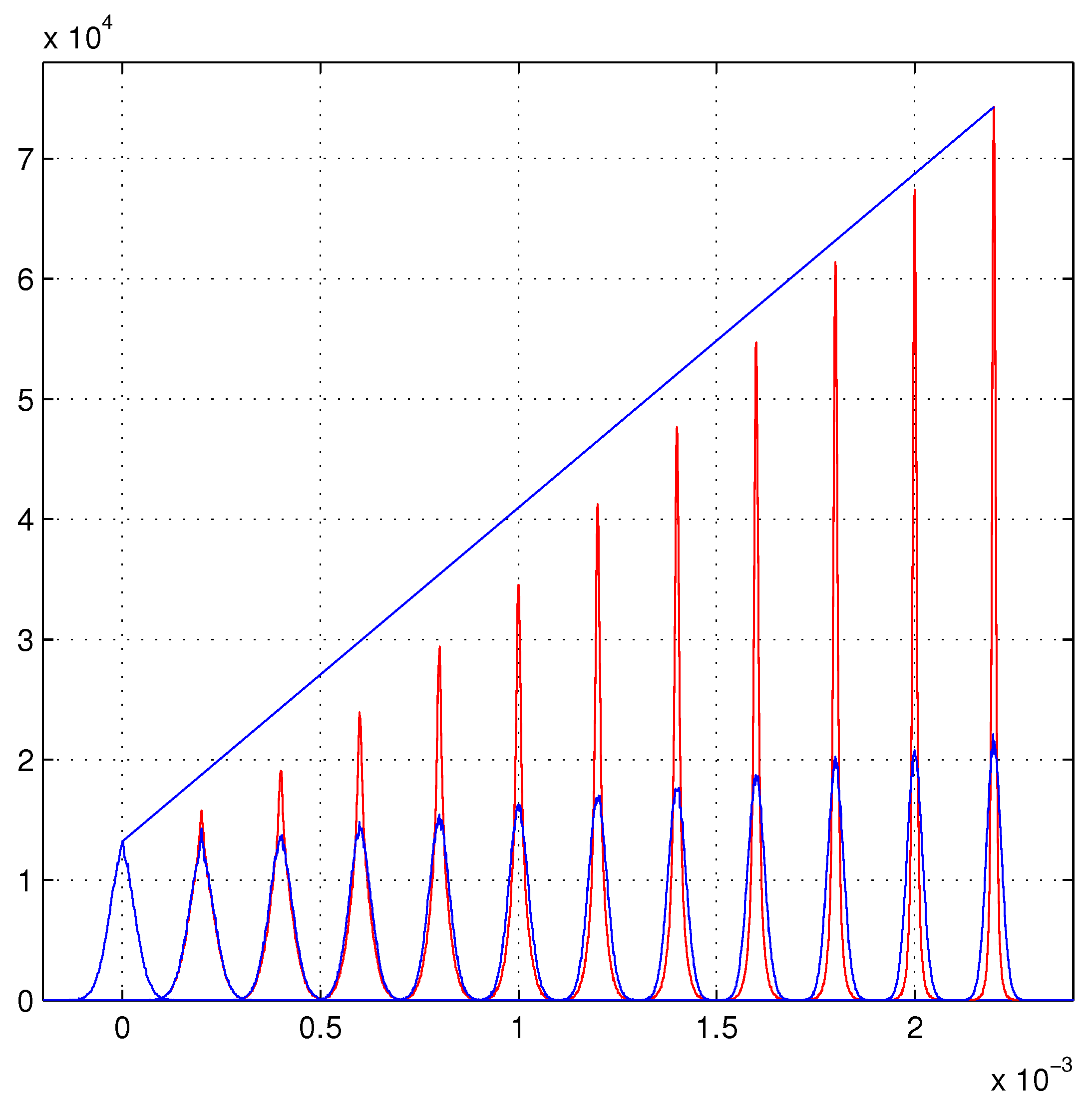
For our pleasure, in
Figure 2, we invented a faster growth than that of the Gaussian model of ref. [
3]. The quality of the detectors increases with the number N of detecting layers, each inserted layer is better than the previous one. The bleu straight line shows an evident deviation from a linear growth with an almost parabolic growth (with the variances going down as
). The blue distributions are practically insensible to these changes. With appropriate selection of the detector quality many types of growth can be implemented.



{kind=link}
{kind=link}