Frequency-Domain Joint Motion and Disparity Estimation Using Steerable Filters




Abstract
:1. Introduction
1.1. Previous Relevant Work
1.2. Summary of Contributions
- Theoretical foundations for frequency-domain joint depth and motion estimation are given. Additionally, the construction of spatiotemporal steerable filters in the frequency domain, appropriate for the joint estimation task, is presented.
- Based on the above theoretical developments, a novel algorithm for joint disparity and motion estimation is formulated. Due to the computational efficiency of the steerable filters, the proposed method presents relatively low computational effort given the high complexity of the problem, while it is appropriate for parallel GPU implementation.
- To the best of the authors knowledge, the proposed approach constitutes the first attempt towards simultaneous depth and motion estimation using frequency-domain considerations. The presented ideas provide a novel paradigm for frequency-domain, filter-based coupled disparity-motion estimation and could constitute the basis for new developments.
- Finally, in the proposed algorithm, the semi-global scan-line optimization approach for stereo matching [18] is extended and successfully applied in the joint motion-disparity estimation problem.
2. Theoretical Developments
2.1. Motion and Disparity Model in the Frequency Domain
2.1.1. Model in the Frequency Domain
2.1.2. Definitions of Energy Functions for Joint Motion-Disparity Estimation
2.2. Steerable 3D Filters for Joint Motion-Disparity Estimation
2.2.1. Directional Filters and Filter “Replicas”
2.2.2. “Steerability” Property
2.3. Definition of Appropriate Energy Functions
- Find direction vectors, notated as , that are equally distributed and lie on the candidate motion plane.
- The “max-steering” distribution is defined from:
2.3.1. Functions for Joint Motion-Disparity Estimation
2.3.2. Functions for Pixel-Wise (Local) Estimation
2.3.3. Combined Cost Function for Motion-Disparity Estimation
2.3.4. Handling Responses of Shifted Filter Replicas: Sub-Pixel Accuracy
3. Algorithmic Developments
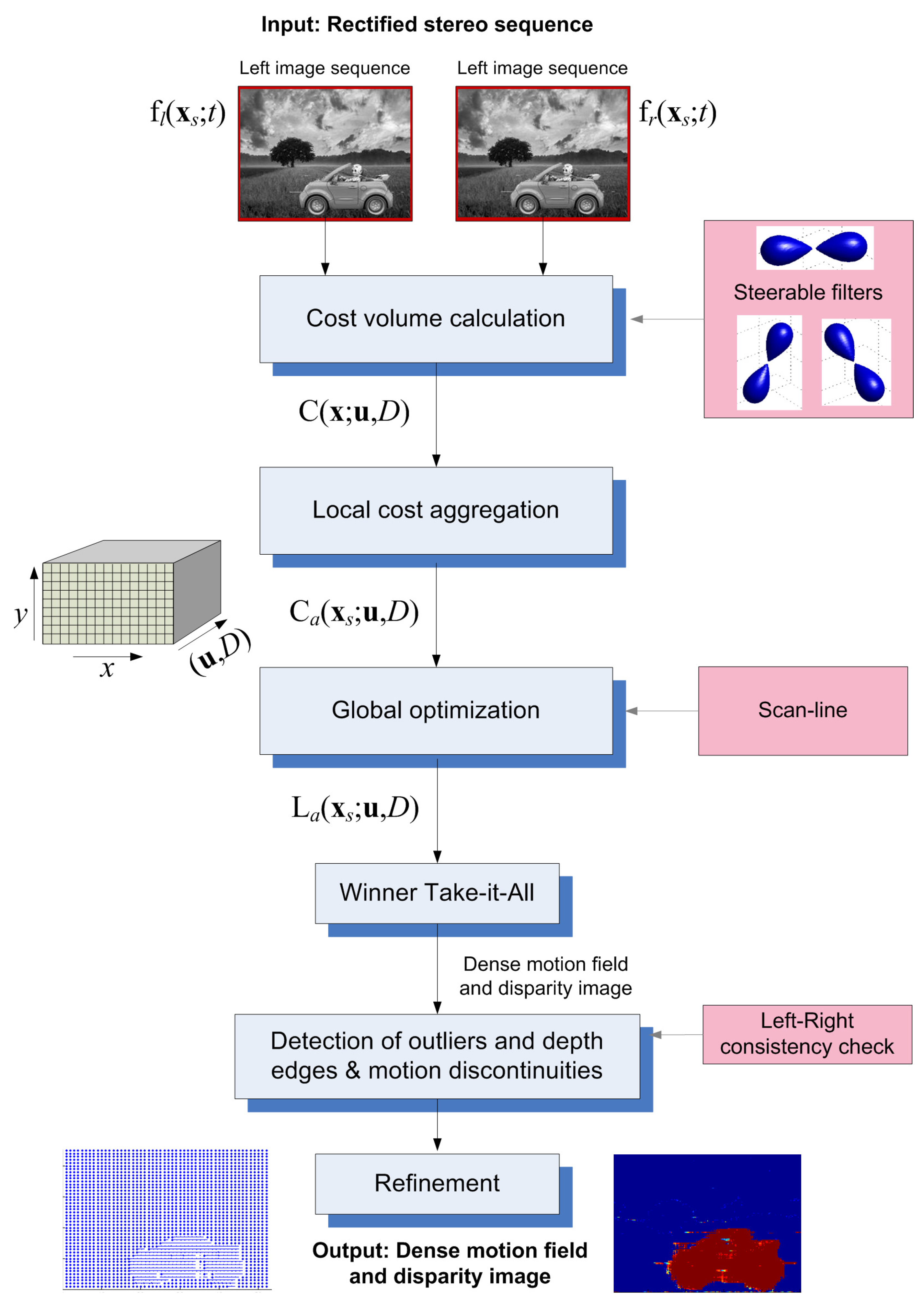
3.1. Outline of the Main Algorithm
- (Matching) Cost volume computation: Based on our theoretical steerable filters-based developments, this step calculates a cost hyper-volume .
- Cost (support) aggregation: The cost hyper-volume is spatially aggregated in a local region around each pixel, using a window, to produce the hyper-volume . A Gaussian window of size or and standard deviation equal to W is used.
- (Semi-)global optimization: In our case, where the cost hyper-volume is defined over the 5D (2D space + 2D velocity + disparity) space, global optimization [41] would be very slow, even with modern efficient methods, such as graph-cuts [42] or belief propagation [31]. We extend and use a semi-global optimization [18].
- Disparity-velocity refinement: This step performs refinement of the estimates, by detecting and correcting outlier estimates.
3.2. Cost Volume Calculation and Local Aggregation
3.2.1. Cost Volume Calculation
- Construct a 3D steerable filter basis in the frequency domain, at the basic orientations . This step is independent of the input sequence, and therefore, the filter basis can be constructed off-line.
- Compute the spatiotemporal FT of the input sequences to obtain and .
- Pre-processing: Since most natural images have strong low spatial-frequency characteristics, we amplify the medium-frequency components via band-pass pre-filtering, as in [10].
- Multiply and with each basic filter , to obtain the basic responses and , respectively. If sub-pixel accuracy is wanted (see Section 2.3.4), calculate also the sub-pixel shifted responses .
- Apply 3D IFT to each and to get the basic responses in the original space-time domain and . From Equation (20), the responses are available for all candidate shifts D, with the wanted sub-pixel accuracy.
- Calculate the quadratic terms , and , defined in Section 2.3.1 (Equation (17)), for each candidate disparity D.
- The quadratic terms are aggregated along the T input frames using a 1D Gaussian window , i.e., . Similar equations are used for and . Experimentally, it was found that a good choice for the extent (standard deviation) of this window is .
- Calculate the distributions , as described in Section 2.3.1 and Section 2.3.2. Then, calculate the combined cost function from (19).
3.3. Adapted Scan-Line Optimization
3.4. WTA, Outliers’ Detection and Refinement
3.4.1. Outliers’ Detection, Refinement and Confidence Map
3.5. Estimation Confidence Map
4. Experimental Results
4.1. Prerequisites
4.2. Experimental Results: Artificial Sequences
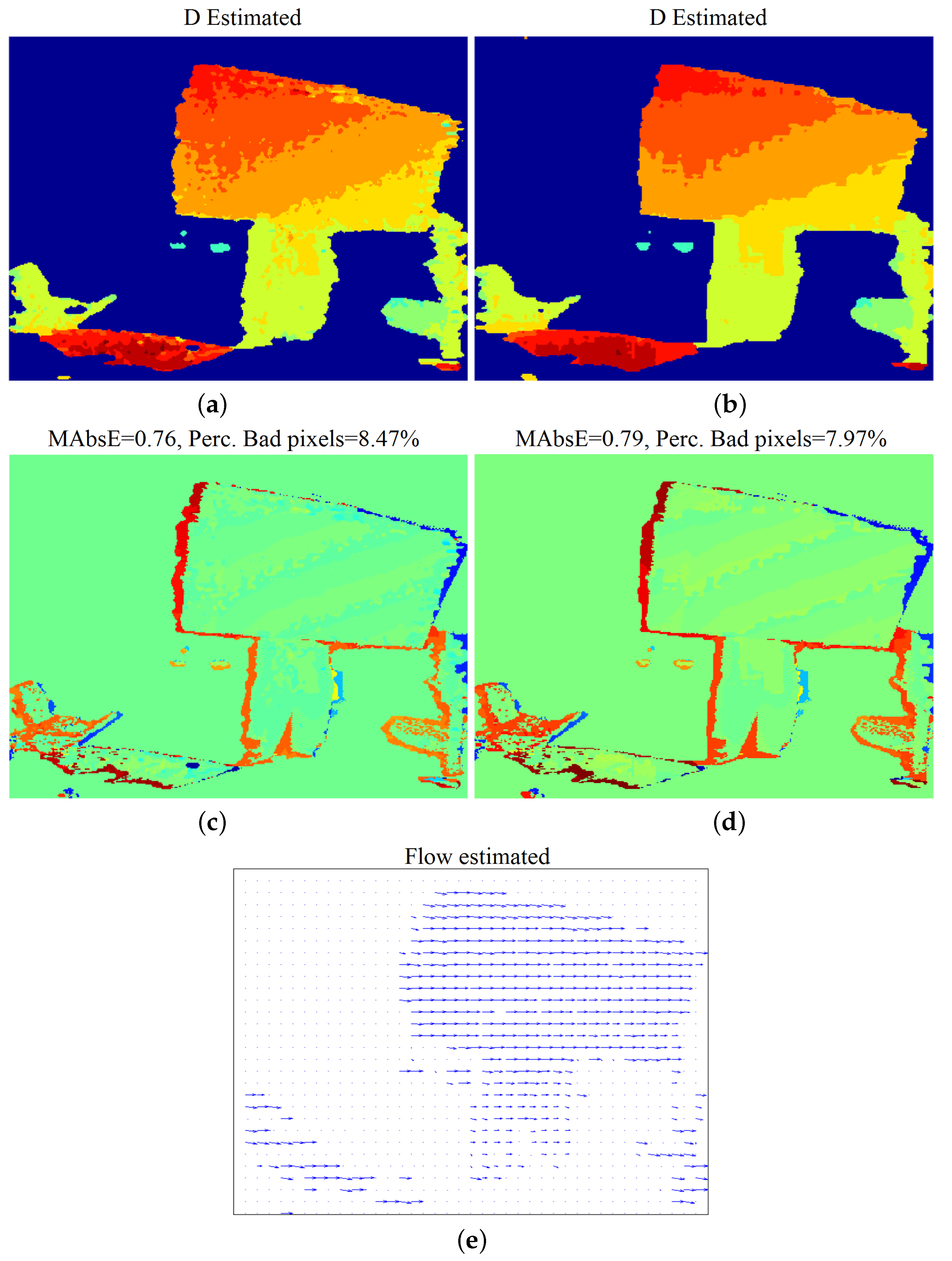
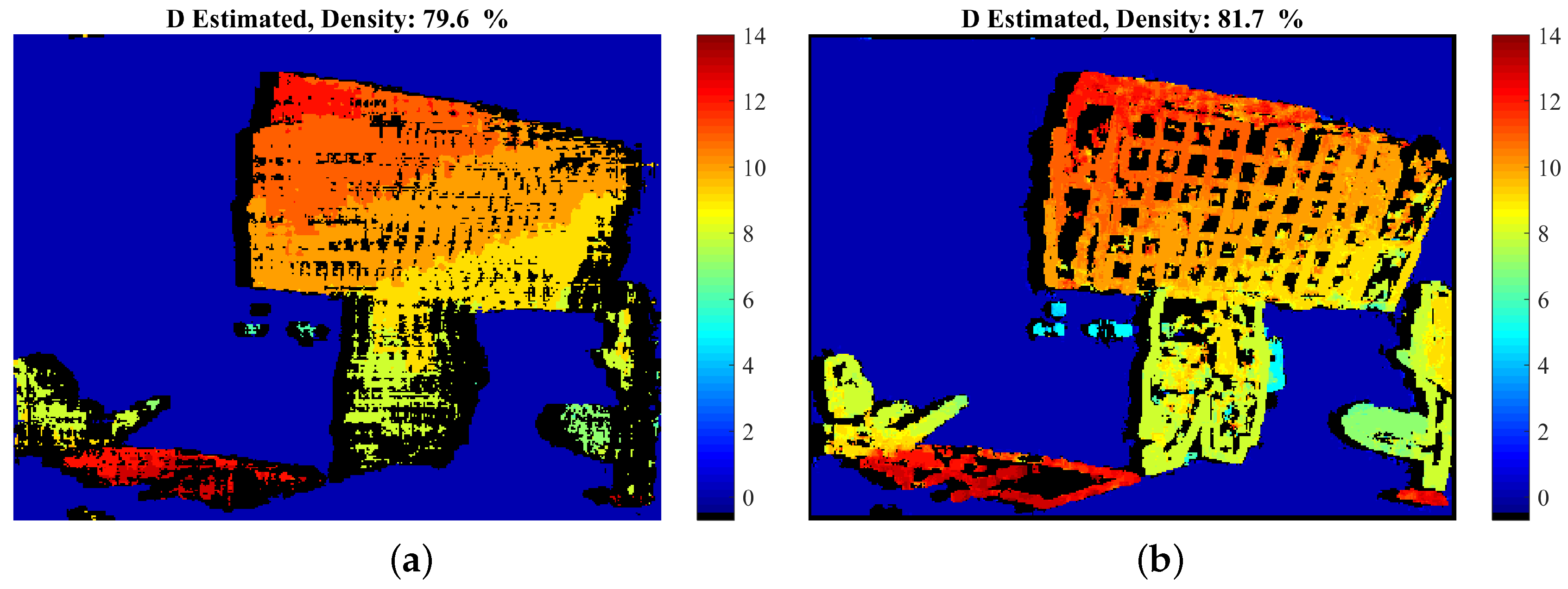
4.2.1. “Car-Tree” Sequence
4.2.2. “Futuristic White-Tower” Sequence
4.2.3. “Rotating Lenna Plane” Sequence
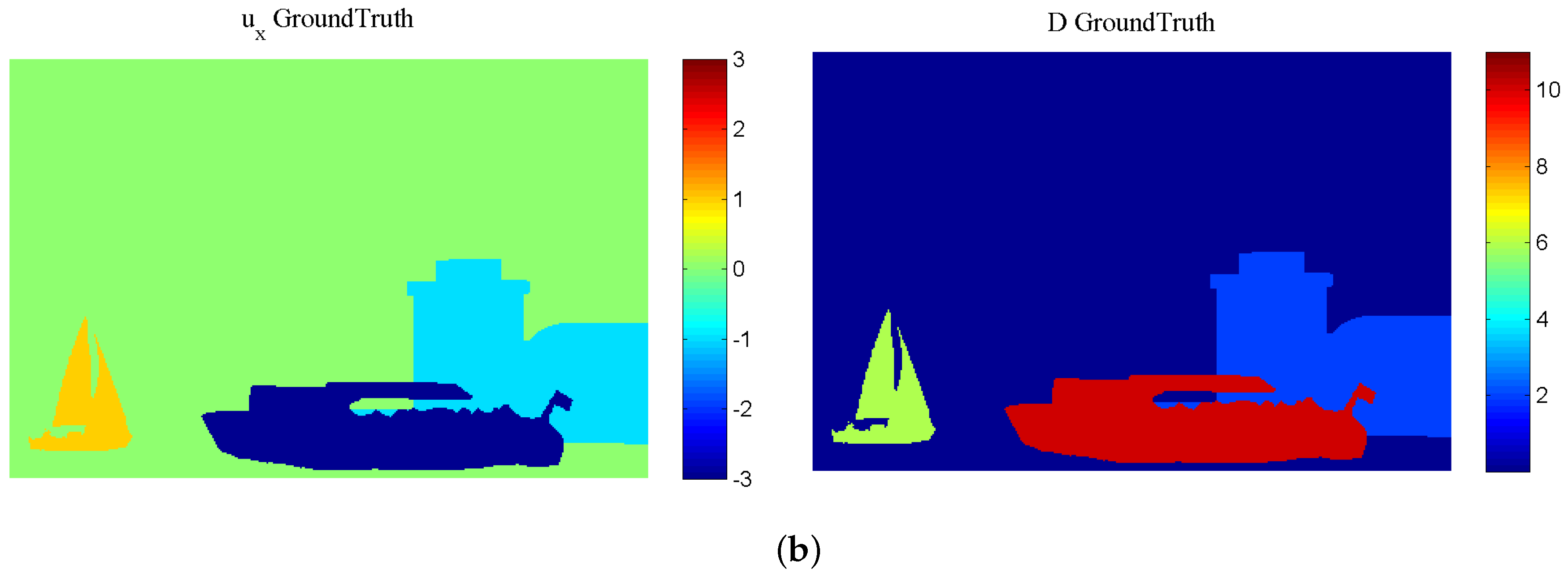
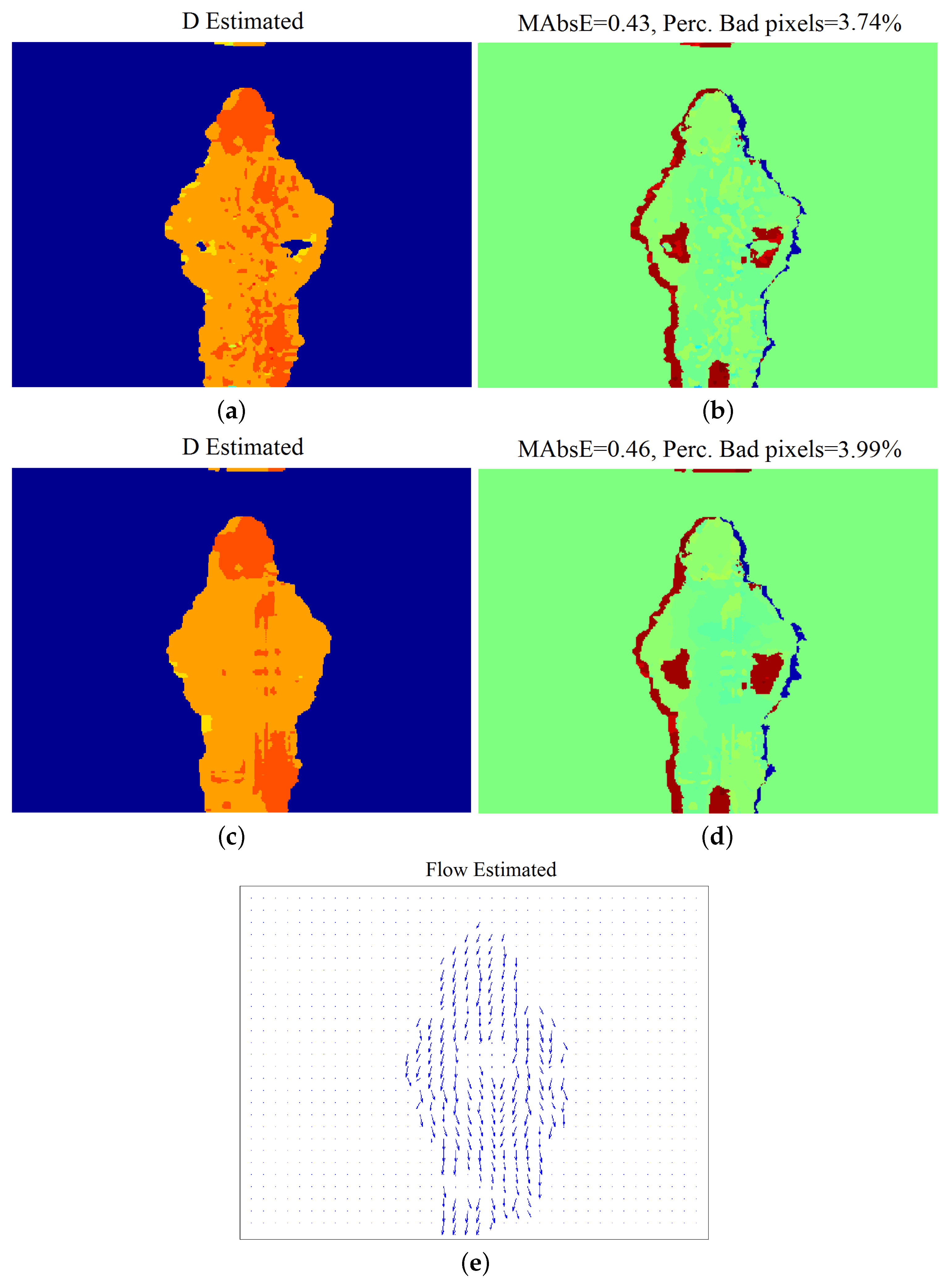
4.3. Experimental Results: Natural Sequences with Known Disparity GT
4.3.1. “Dimitris-Chessboard” Sequence
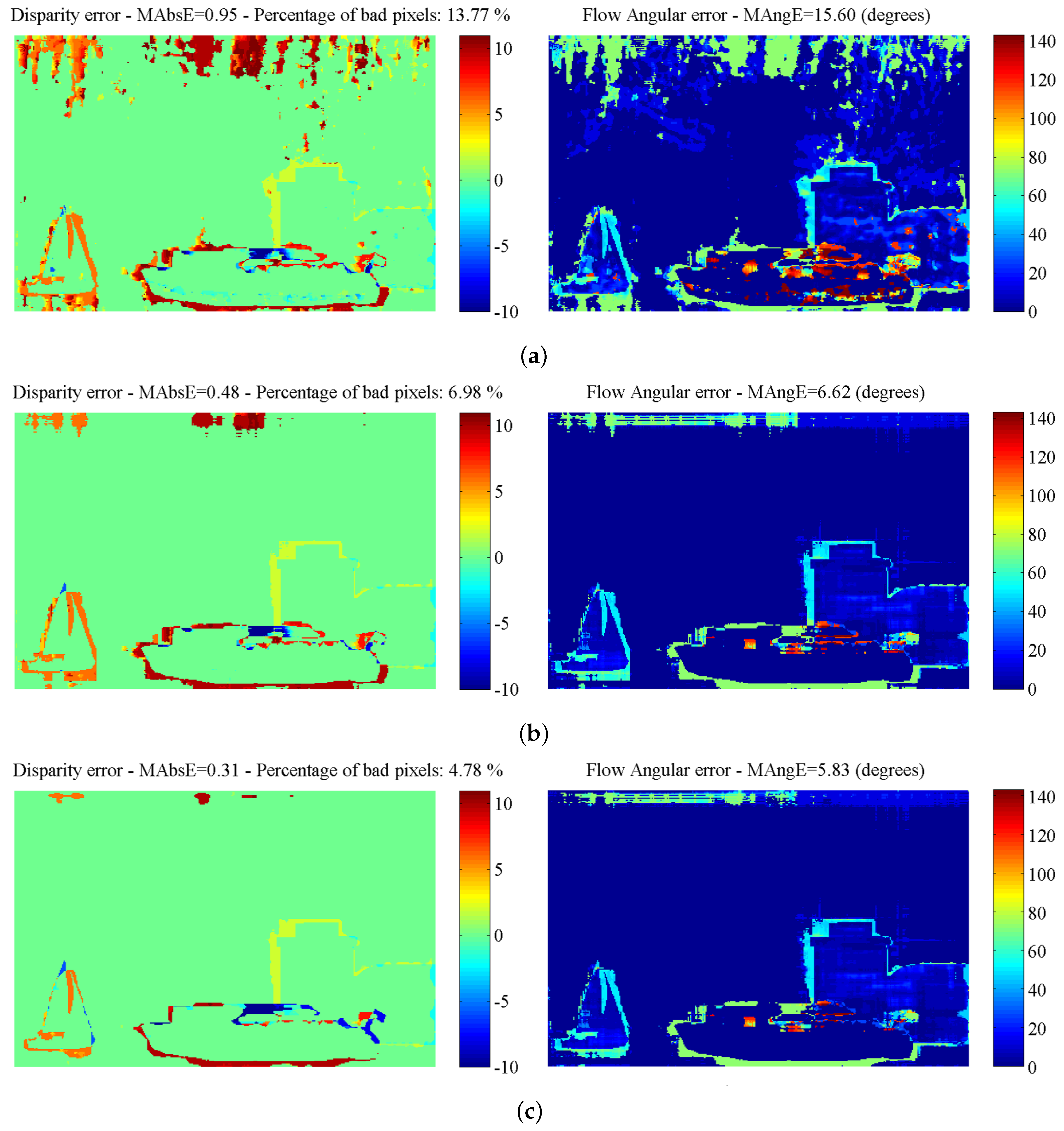
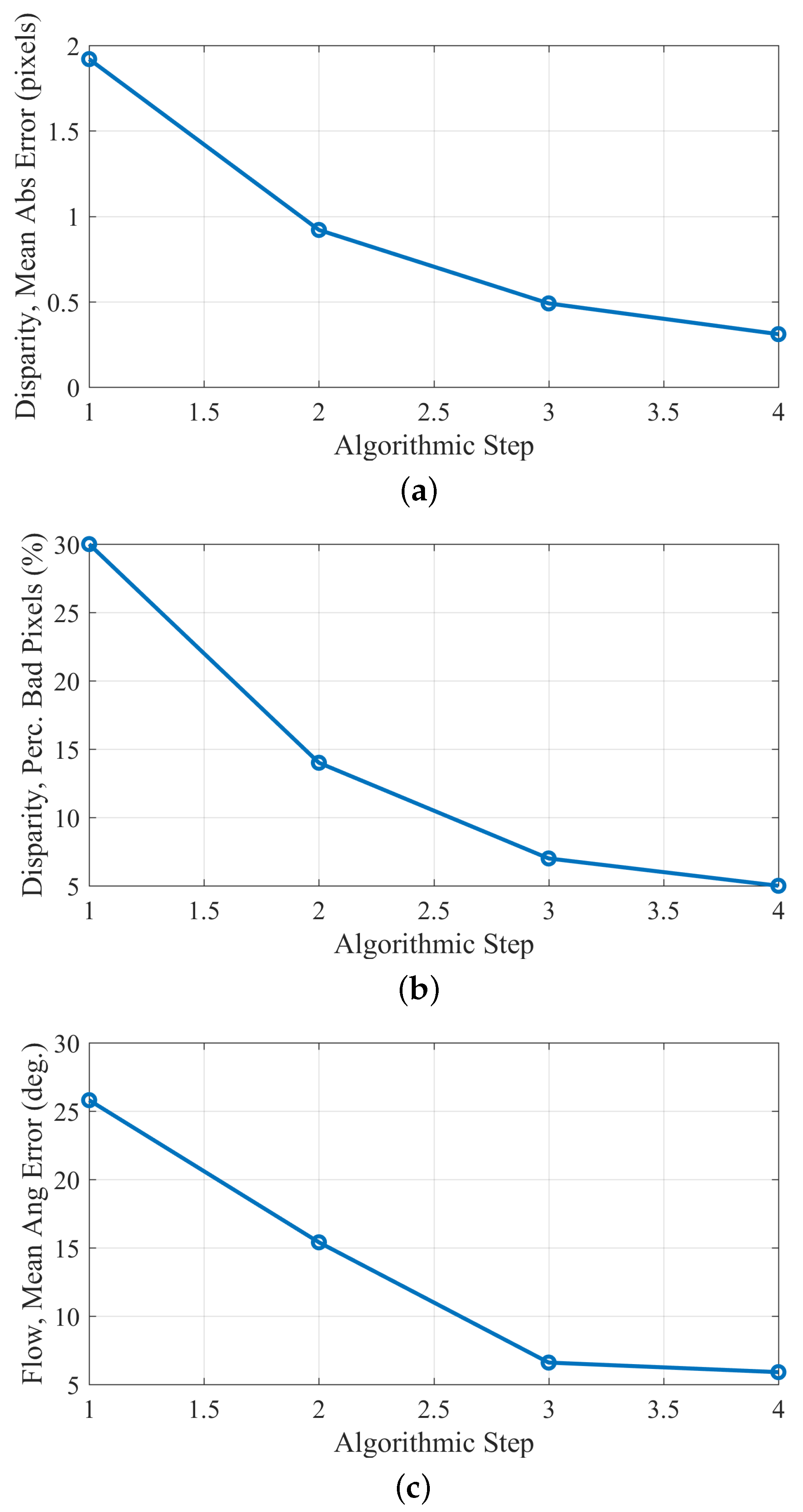
4.3.2. “Xenia” Sequence
5. Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| DOG | Derivatives of Gaussian |
| MRF | Markov Random Field |
| NSSD | Normalized Sum of Squares Difference |
| GPU | Graphics Processing Unit |
| (F)FT | (Fast) Fourier Transform |
| SO | Scan-line Optimization |
| (M)AE | (Mean) Angular Error |
| WTA | Winner Take-it-All |
References
- Smolic, A. 3D video and free viewpoint video-From capture to display. Pattern Recognit. 2011, 44, 1958–1968. [Google Scholar] [CrossRef]
- Vedula, S.; Baker, S.; Rander, P.; Collins, R.; Kanade, T. Three-dimensional scene flow. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 475–480. [Google Scholar] [CrossRef] [PubMed]
- Ottonelli, S.; Spagnolo, P.; Mazzeo, P.L. Improved video segmentation with color and depth using a stereo camera. In Proceedings of the IEEE International Conference on Industrial Technology (ICIT), Cape Town, South Africa, 25–28 Febtuary 2013; pp. 1134–1139. [Google Scholar]
- Alexiadis, D.; Chatzitofis, A.; Zioulis, N.; Zoidi, O.; Louizis, G.; Zarpalas, D.; Daras, P. An integrated platform for live 3D human reconstruction and motion capturing. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 798–813. [Google Scholar] [CrossRef]
- Newcombe, R.; Fox, D.; Seitz, S. DynamicFusion: Reconstruction and Tracking of Non-rigid Scenes in Real-Time. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, Y.; Ostermann, J.; Zhang, Y. Video Processing and Communications; Prentice Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two frame stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Barron, J.; Fleet, D.; Beauchemin, S. Performance of optical flow techniques. Int. J. Comput. Vis. 1994, 12, 43–77. [Google Scholar] [CrossRef]
- Black, M.J.; Anandan, P. The robust estimation of multiple motions: Parametric and piecewise-smooth flow fields. Comput. Vis. Image Underst. 1996, 63, 75–104. [Google Scholar] [CrossRef]
- Alexiadis, D.S.; Sergiadis, G.D. Narrow directional steerable filters in motion estimation. Comput. Vis. Image Underst. 2008, 110, 192–211. [Google Scholar] [CrossRef]
- Freeman, W.T.F.; Adelson, E.H. The design and use of steerable filters. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 891–906. [Google Scholar] [CrossRef]
- DeAngelis, C.; Ohzawa, I.; Freeman, R.D. Depth is encoded in the visual cortex by a specialized receptive field structure. Nature 1991, 352, 156–159. [Google Scholar] [CrossRef] [PubMed]
- Fleet, D.; Wagner, H.; Heeger, D. Neural Encoding of Binocular Disparity: Energy Models, Position Shifts and Phase Shifts. Vis. Res. 1996, 36, 1839–1857. [Google Scholar] [CrossRef]
- Adelson, E.H.; Bergen, J.R. Spatiotemporal energy models for the perception of motion. J. Opt. Soc. Am. A 1985, 2, 284–299. [Google Scholar] [CrossRef] [PubMed]
- Watson, A.B.; Ahumada, A.J. Model of human visual-motion sensing. J. Opt. Soc. Am. A 1985, 2, 322–341. [Google Scholar] [CrossRef] [PubMed]
- Qian, N. Computing Stereo Disparity and Motion with Known Binocular Cell Properties; Technical Report; MIT: Cambridge, MA, USA, 1993. [Google Scholar]
- Qian, N.; Andersen, R.A. A Physiological Model for Motion-stereo Integration and a Unified Explanation of Pulfrich-like Phenomena. Vis. Res. 1997, 37, 1683–1698. [Google Scholar] [CrossRef]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Cech, J.; Matas, J.; Perdoch, M. Efficient Sequential Correspondence Selection by Cosegmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1568–1581. [Google Scholar] [CrossRef] [PubMed]
- Kordelas, G.; Alexiadis, D.; Daras, P.; Izquierdo, E. Enhanced disparity estimation in stereo images. Image Vis. Comput. 2015, 35, 31–49. [Google Scholar] [CrossRef]
- Kordelas, G.; Alexiadis, D.; Daras, P.; Izquierdo, E. Content-based guided image filtering, weighted semi-global optimization and efficient disparity refinement for fast and accurate disparity estimation. IEEE Trans. Multimed. 2016, 18, 155–170. [Google Scholar] [CrossRef]
- Viola, P.; Wells, W.M. Alignment by maximization of mutual information. Int. J. Comput. Vis. 1997, 24, 137–154. [Google Scholar] [CrossRef]
- Vedaldi, A.; Soatto, S. Local features, all grown up. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Huguet, F.; Devernay, F. A Variational Method for Scene Flow Estimation from Stereo Sequences. In Proceedings of the 11th IEEE ICCV conference, Rio de Janeiro, Brazil, 14–21 Octemner 2007; pp. 1–7. [Google Scholar]
- Valgaerts, L.; Bruhn, A.; Zimmer, H.; Weickert, J.; Stoll, C.; Theobalt, C. Joint Estimation of Motion, Structure and Geometry from Stereo Sequences. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010. [Google Scholar]
- Cech, J.; Sanchez-Riera, J.; Horaud, R.P. Scene Flow Estimation by Growing Correspondence Seeds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; IEEE Computer Society Press: Los Alamitos, CA, USA, 2011; pp. 49–56. [Google Scholar]
- Liu, J.; Skerjanc, R. Stereo and motion correspondence in a sequence of stereo images. Signal Process. Image Commun. 1993, 5, 305–318. [Google Scholar] [CrossRef]
- Patras, I.; Alvertos, N.; Tziritasy, G. Joint Disparity and Motion Field Estimation in Stereoscopic Image Sequences; Technical Report TR-157; FORTH-ICS: Heraklion, Greece, 1995. [Google Scholar]
- Sizintsev, M.; Wildes, R.P. Spatiotemporal stereo and scene flow via stequel matching. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1206–1219. [Google Scholar] [CrossRef] [PubMed]
- Sizintsev, M.; Wildes, R.P. Spacetime Stereo and 3D Flow via Binocular Spatiotemporal Orientation Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2241–2254. [Google Scholar] [CrossRef] [PubMed]
- Isard, M.; MacCormick, J. Dense Motion and Disparity Estimation Via Loopy Belief Propagation. In Proceedings of the Computer Vision—ACCV 2006, Lecture Notes in Computer Science, Hyderabad, India, 13–16 January 2006; Volume 3852, pp. 32–41. [Google Scholar]
- Liu, F.; Philomin, V. Disparity Estimation in Stereo Sequences using Scene Flow. In Proceedings of the British Machine Vision Association, London, UK, 7–10 September 2009. [Google Scholar]
- Zitnick, C.L.; Kang, S.B. Stereo for image-based rendering using image over-segmentation. Int. J. Comput. Vis. 2007, 75, 49–65. [Google Scholar] [CrossRef]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Wedel, A.; Brox, T.; Vaudrey, T.; Rabe, C.; Franke, U.; Cremers, D. Stereoscopic Scene Flow Computation for 3D Motion Understanding. Int. J. Comput. Vis. 2011, 95, 29–51. [Google Scholar] [CrossRef]
- Yamaguchi, K.; McAllester, D.; Urtasun, R. Efficient Joint Segmentation, Occlusion Labeling, Stereo and Flow Estimation. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Taniai, T.; Sinha, S.N.; Sato, Y. Fast multi-frame stereo scene flow with motion segmentation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Walk, S.; Schindler, K.; Schiele, B. Disparity statistics for pedestrian detection: Combining appearance, motion and stereo. In Proceedings of the European Conference Computer Vision, Heraklion, Crete, 5–11 September 2010; pp. 182–195. [Google Scholar]
- Seguin, G.; Alahari, K.; Sivic, J.; Laptev, I. Pose Estimation and Segmentation of Multiple People in Stereoscopic Movies. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1643–1655. [Google Scholar] [CrossRef] [PubMed]
- Simoncelli, E.P. Distributed Representation and Analysis of Visual Motion. Ph.D. Thesis, Department of Electrical Engineering and Computer Science, Massachusetts Institute of Technology, Cambridge, MA, USA, 1993. [Google Scholar]
- Terzopoulos, D. Regularization of inverse visual problems involving discontinuities. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 413–424. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Hosni, A.; Rhemann, C.; Bleyer, M.; Rother, C.; Gelautz, M. Fast Cost-Volume Filtering for Visual Correspondence and Beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 504–511. [Google Scholar] [CrossRef] [PubMed]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence: “Futur.WT” | Resolution: | No. of Frames: 6 | ||
|---|---|---|---|---|
| Parameters | ||||
| Filters | Candidate | Candidate | ||
| Order | Velocities | Disparities | ||
| Algorithmic Part | Computational Time (ms) | GPU | ||
| CPU Impl. | GPU Impl. | Speed-Up | ||
| Init. cost volume calculation | 27,156 | 7423 | 3.65:1 | |
| Scan-line optimization | 433,794 | 103,899 | 4.18:1 | |
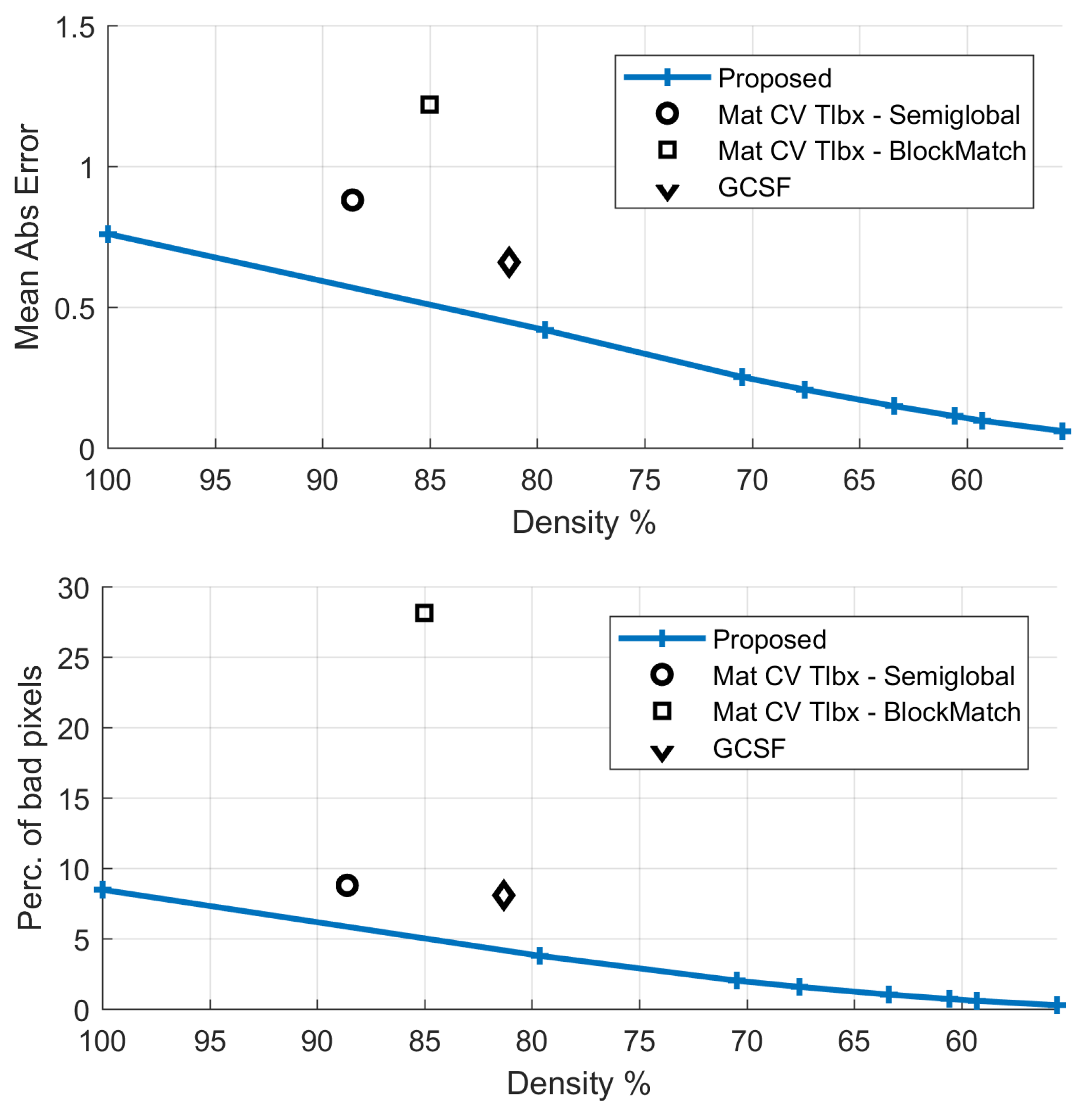
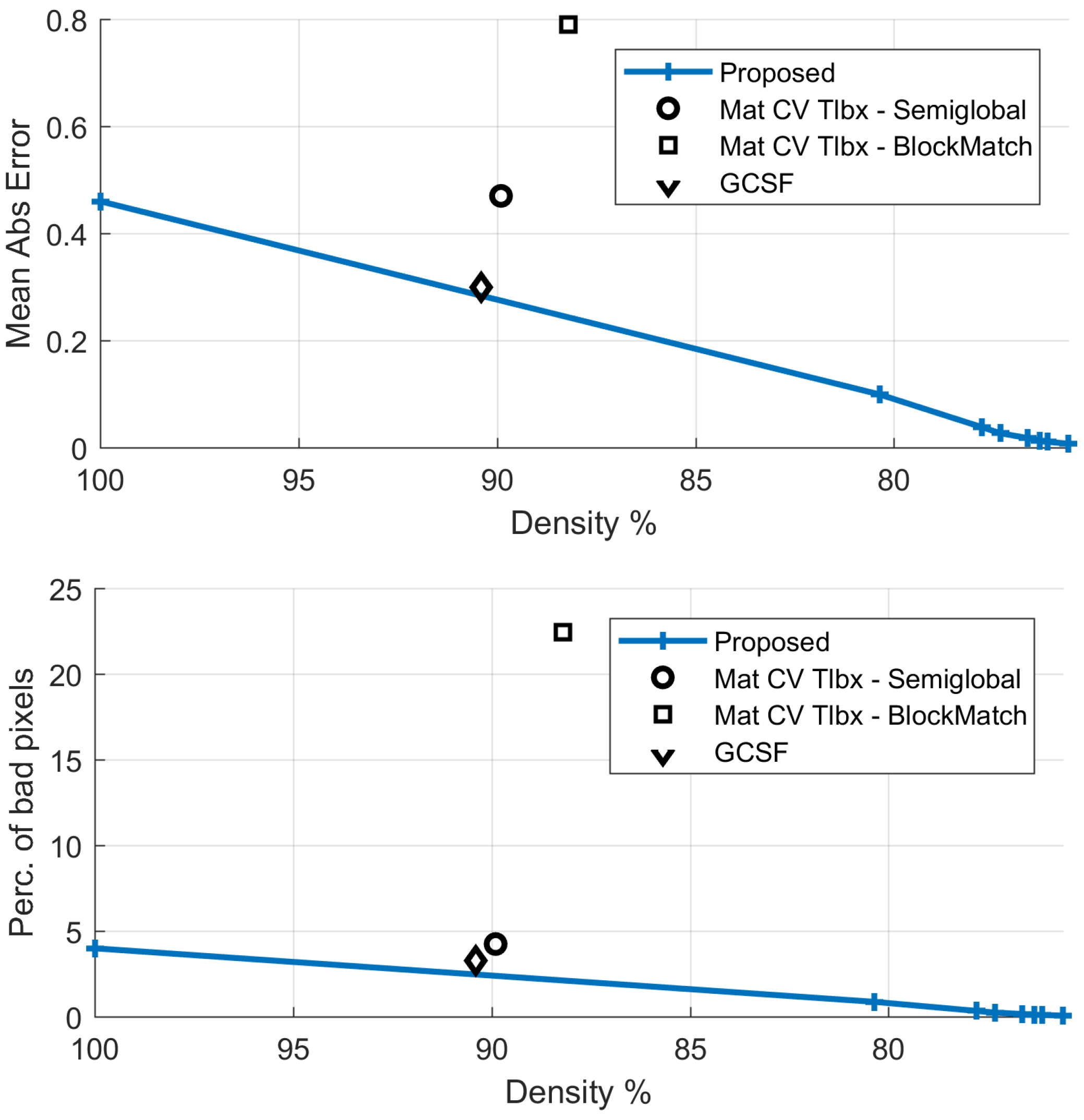
| Method | Dispar.Density | Mean AbsError | Perc.Bad Pixels | Flow Density | Mean Angul.Error |
|---|---|---|---|---|---|
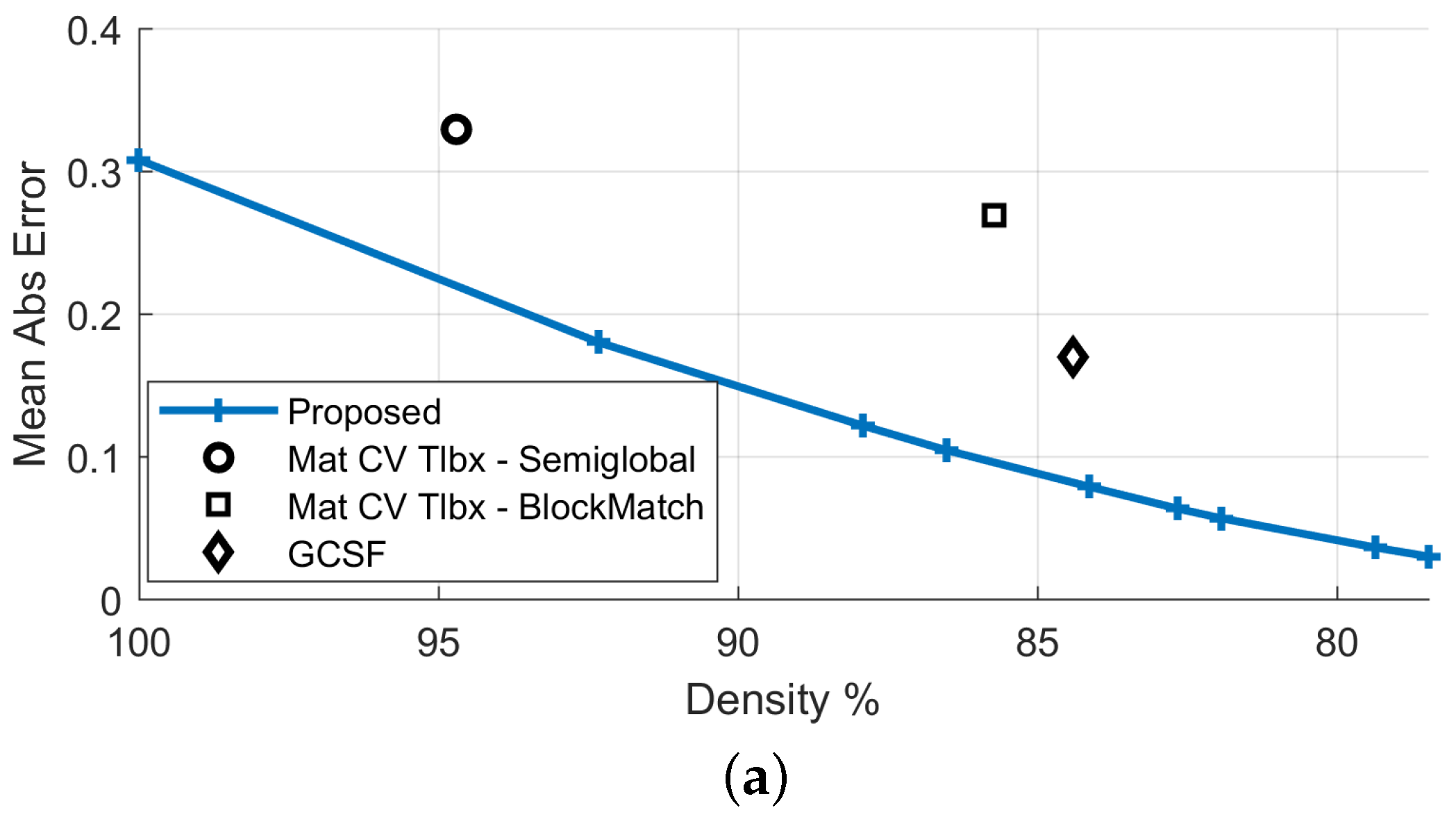
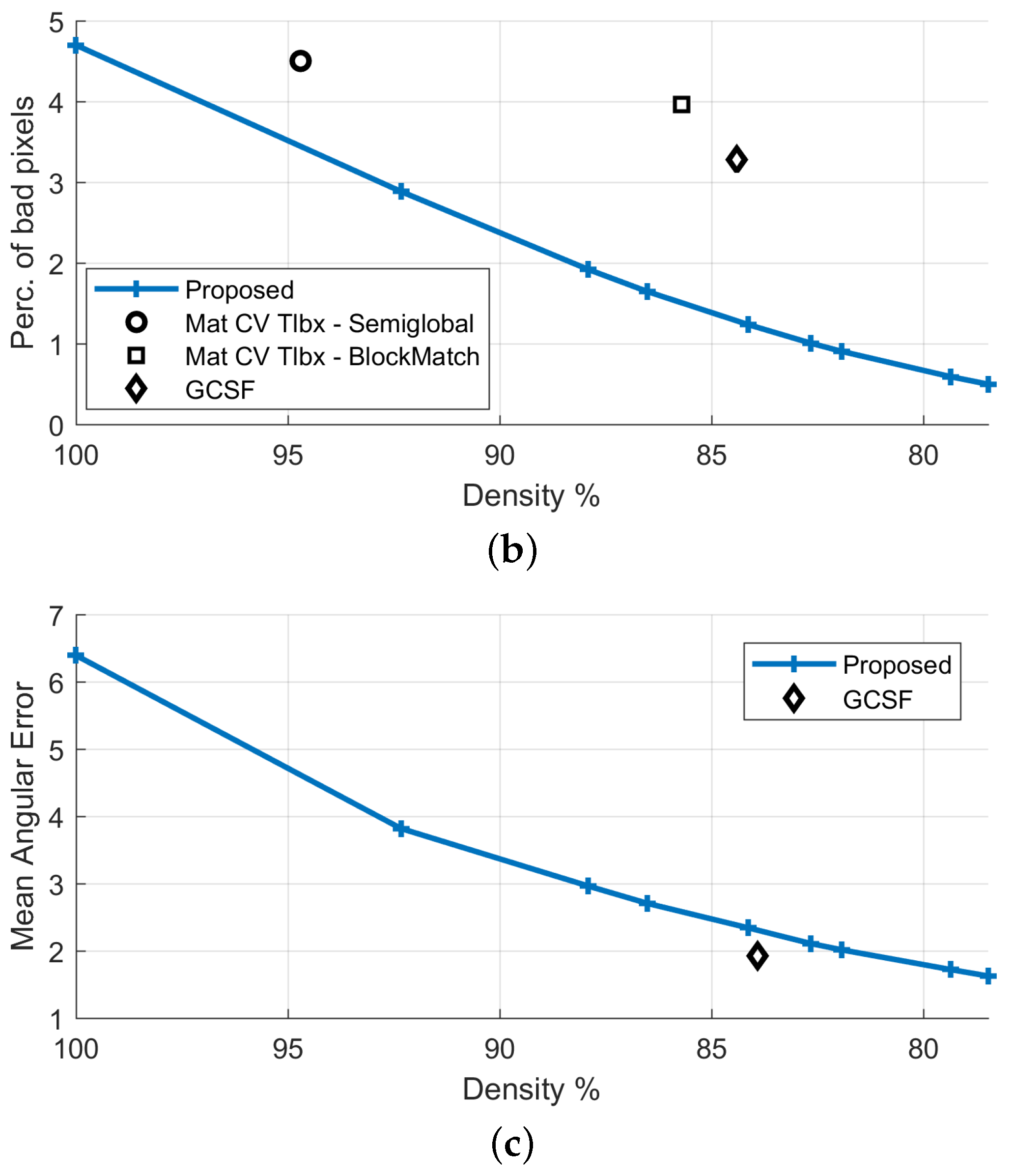
| Proposed (FD) | 100% | 0.31 | 4.78% | 100% | 5.83 |
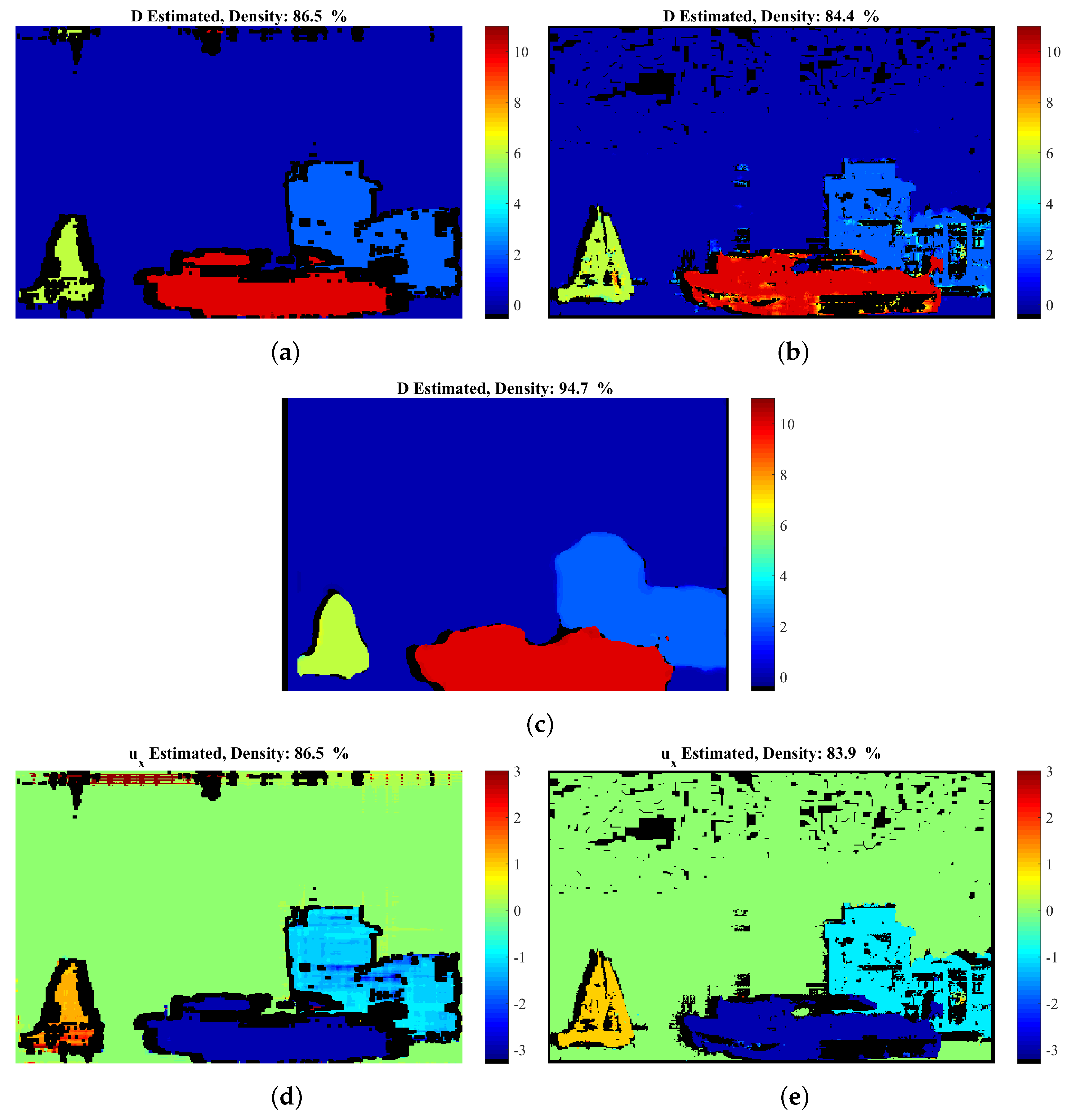
| Proposed | 86.5% | 0.10 | 1.65% | 86.5% | 2.71 |
| GCSF [26] | 84.4% | 0.17 | 3.28% | 83.9% | 1.93 |
| MatCVTlbx-SemiG [18] | 94.7% | 0.33 | 4.50% | - | - |
| MatCVTlbx-Block | 85.7% | 0.27 | 3.96% | - | - |
| Method | Dispar.Density | Mean Abs Error | Perc. Bad Pixels | Flow Density | Mean Angul. Error |
|---|---|---|---|---|---|
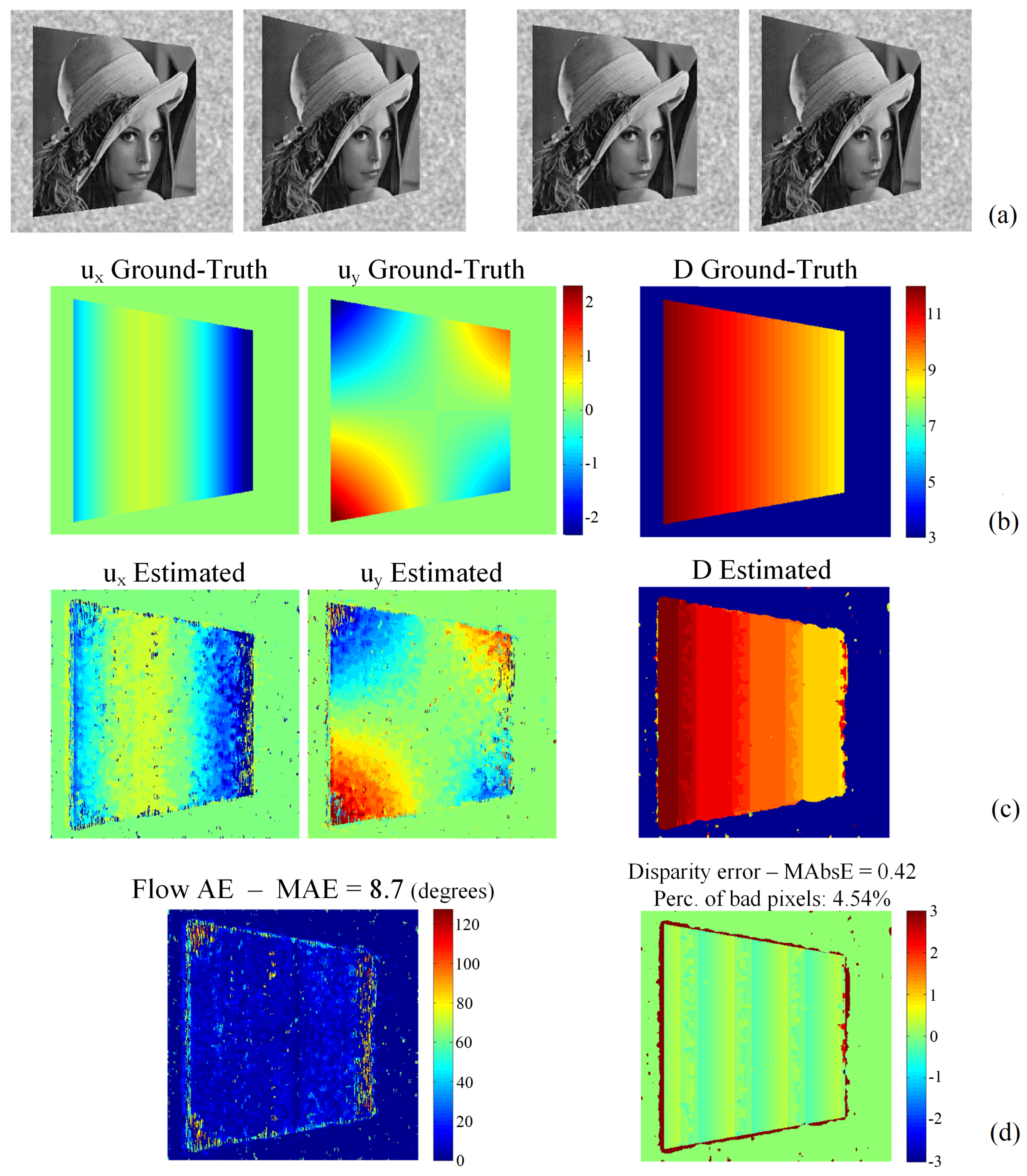
| Proposed-Step 2 (FD) | 100% | 0.42 | 4.54% | 100% | 8.70 |
| GCSF [26] | 89.1% | 0.31 | 3.71% | 87.5% | 10.18 |
| MatCVTlbx-SemiG [18] | 93.9% | 0.38 | 5.38% | - | - |
| MatCVTlbx-Block | 87.5% | 0.47 | 6.69% | - | - |
| Sequence: “Dimitris” | Resolution: | No. of Frames: 6 | ||
|---|---|---|---|---|
| Parameters | ||||
| Filters | Candidate | Candidate | ||
| Order | Velocities | Disparities | ||
| Algorithmic Part | Computational Time (ms) | GPU | ||
| CPU Impl. | GPU Impl. | Speed-Up | ||
| Init. cost volume calculation | 30,283 | 7564 | 4.00:1 | |
| Scan-line optimization | 405,071 | 86,295 | 4.69:1 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alexiadis, D.; Mitianoudis, N.; Stathaki, T. Frequency-Domain Joint Motion and Disparity Estimation Using Steerable Filters. Inventions 2018, 3, 12. https://doi.org/10.3390/inventions3010012
Alexiadis D, Mitianoudis N, Stathaki T. Frequency-Domain Joint Motion and Disparity Estimation Using Steerable Filters. Inventions. 2018; 3(1):12. https://doi.org/10.3390/inventions3010012
Chicago/Turabian StyleAlexiadis, Dimitrios, Nikolaos Mitianoudis, and Tania Stathaki. 2018. "Frequency-Domain Joint Motion and Disparity Estimation Using Steerable Filters" Inventions 3, no. 1: 12. https://doi.org/10.3390/inventions3010012
APA StyleAlexiadis, D., Mitianoudis, N., & Stathaki, T. (2018). Frequency-Domain Joint Motion and Disparity Estimation Using Steerable Filters. Inventions, 3(1), 12. https://doi.org/10.3390/inventions3010012