Deep Learning Based Surveillance System for Open Critical Areas


Abstract
:1. Introduction and Related Work
- Abnormal car behaviour detection (with specific attention to off-spot parking and wrong direction movement).
- Parking duration understanding.
- Generic anomaly detection and localization for non-car objects based on statistical model learning.
- Accurately estimating the number of objects (cars, people, etc.) in the area of interest.
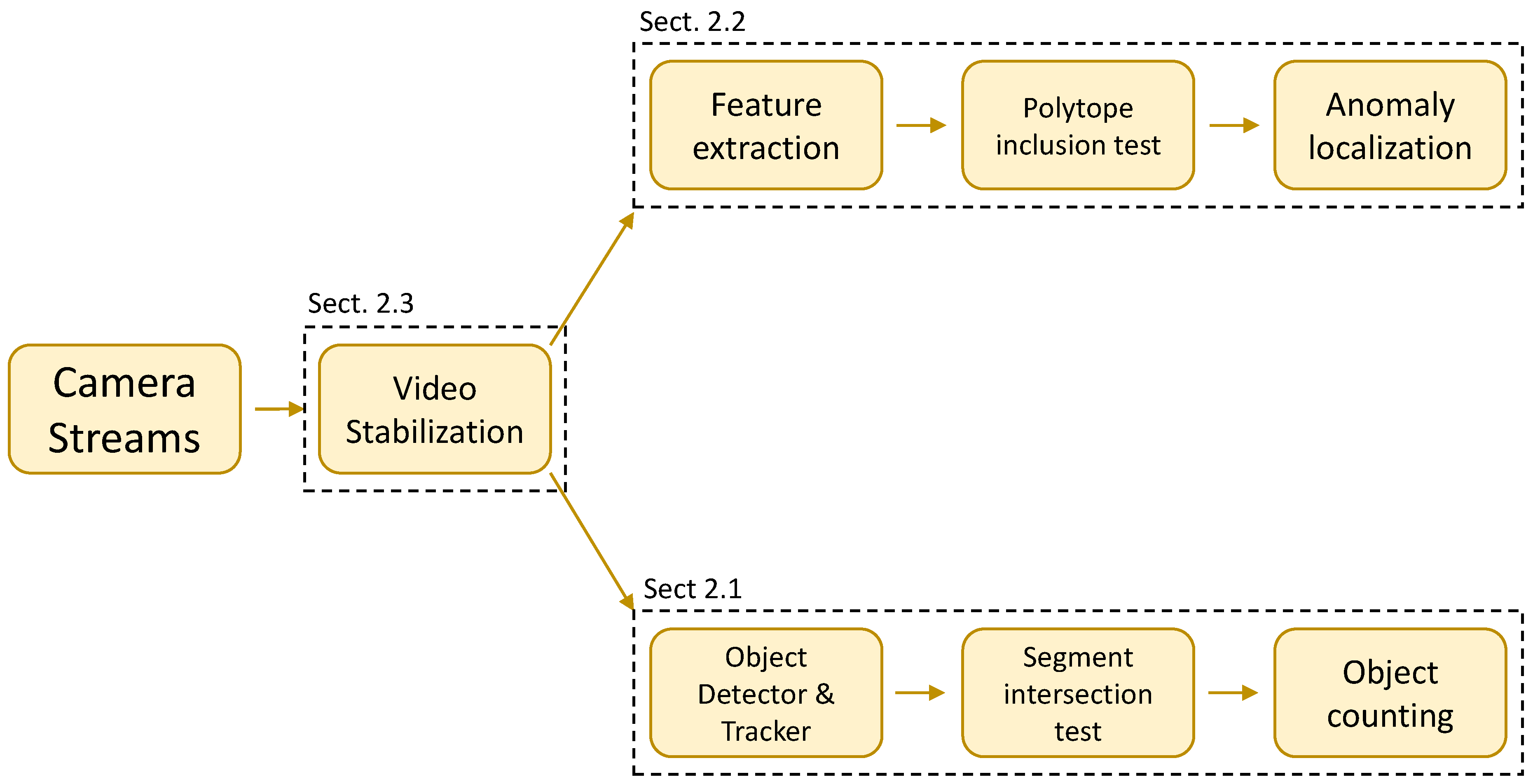
2. Surveillance System
2.1. Object Detection, Tracking, and Counting
2.1.1. Detection
2.1.2. Tracking
| Algorithm 1: Data association algorithm. We associate tracks and unassociated detection if and remove a track if it is “dead” for frames. Matrix keeps track of associations and vector counts the number of frames in which a track i is not associated with any detection. |
 |
2.1.3. Counting
2.2. Anomaly Detection
2.2.1. Constructing the Model
2.2.2. Robust Convex Hull
2.2.3. Ensembles of Polytopes
2.2.4. Anomaly Localization
2.3. Camera Stabilization
3. Case Studies
3.1. Pier
3.2. Parking Lot
4. Results
4.1. Object Counting
4.2. Parking Lot Analysis
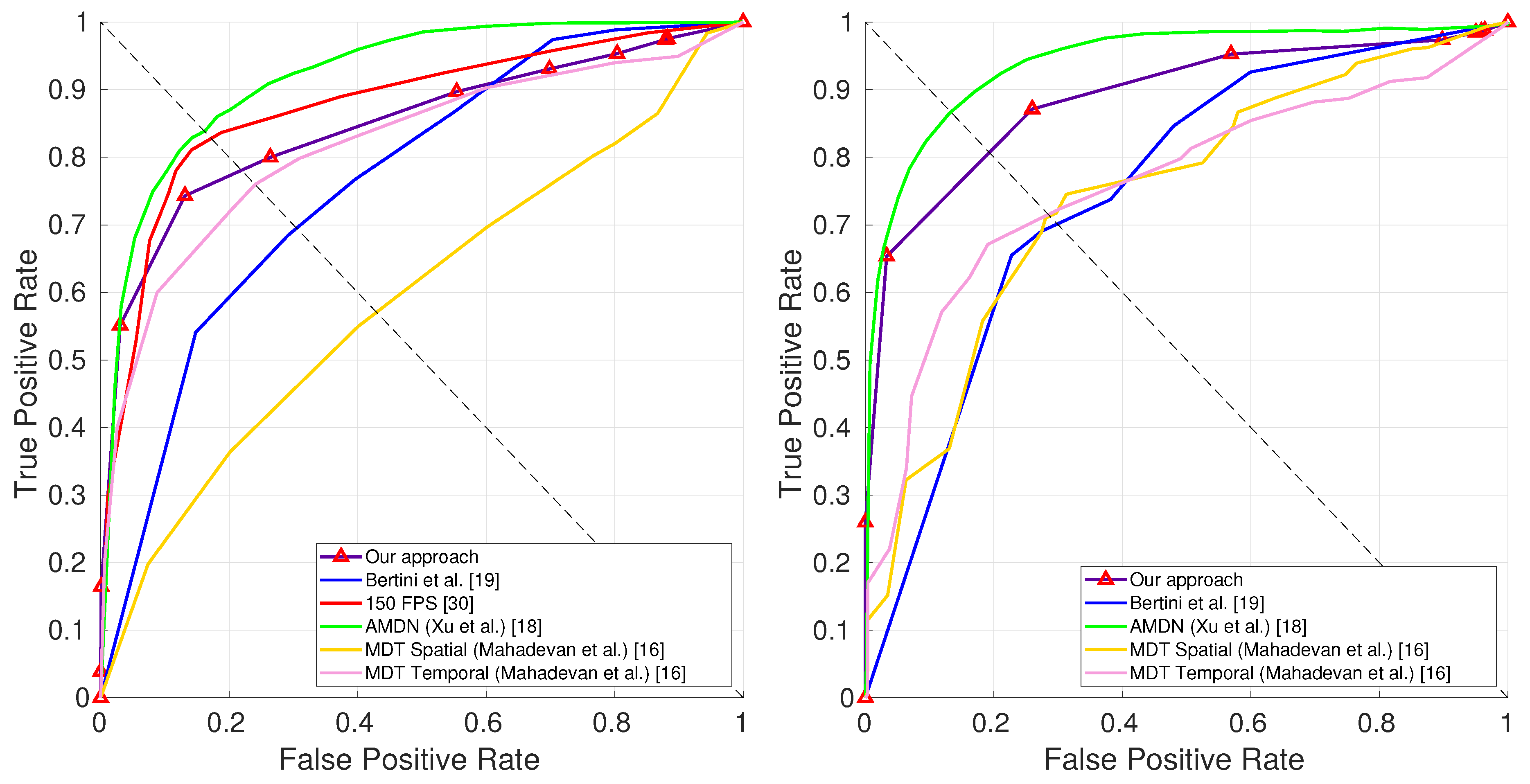
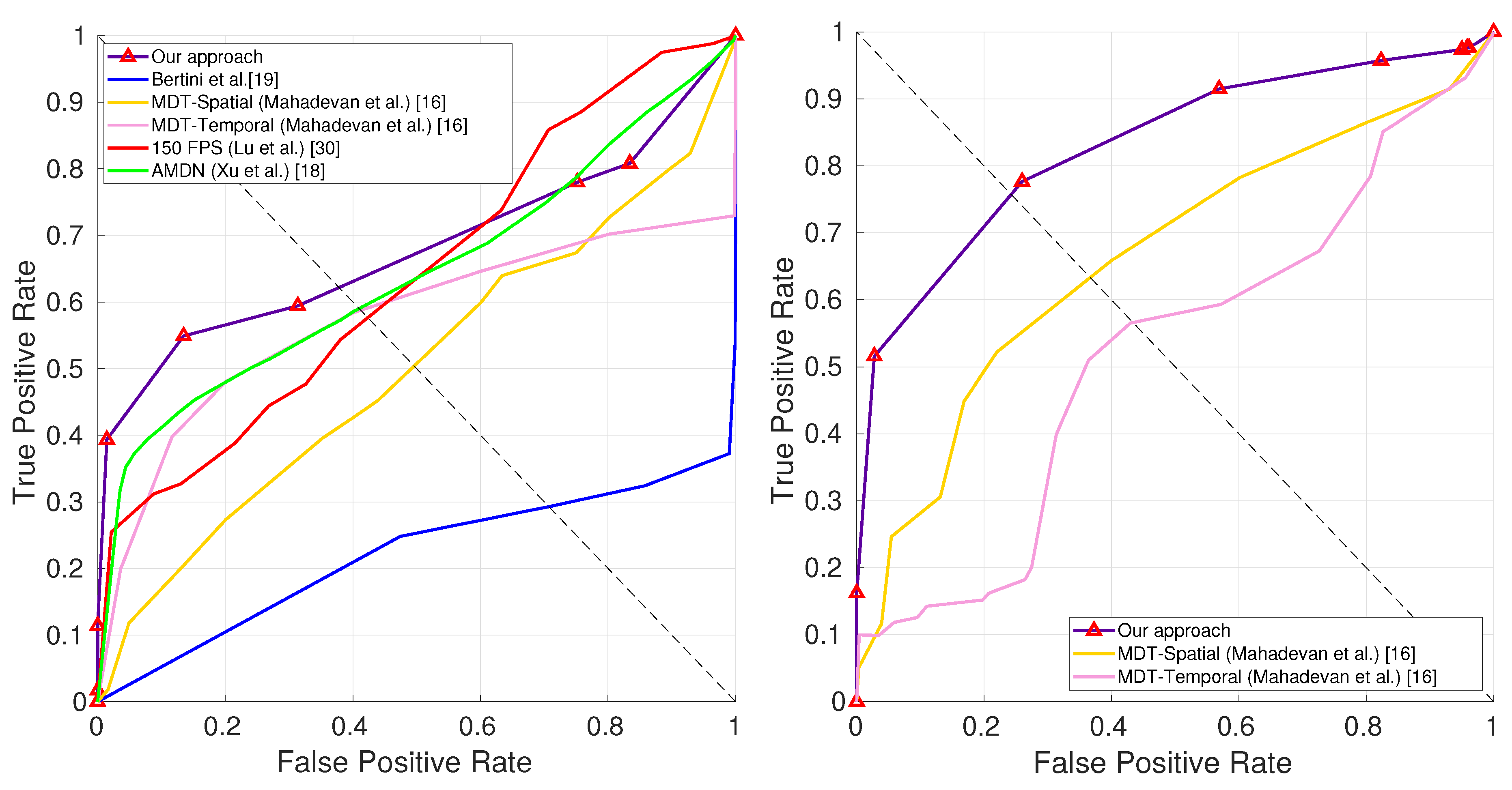
4.3. Anomaly Detection
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Manic, M.; Amarasinghe, K.; Rodriguez-Andina, J.J.; Rieger, C. Intelligent buildings of the future: Cyberaware, deep learning powered, and human interacting. IEEE Ind. Electron. Mag. 2016, 10, 32–49. [Google Scholar] [CrossRef]
- Martinel, N.; Micheloni, C. Re-identify people in wide area camera network. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Providence, RI, USA, 16–21 June 2012; pp. 31–36. [Google Scholar]
- Troscianko, T.; Holmes, A.; Stillman, J.; Mirmehdi, M.; Wright, D.; Wilson, A. What happens next? The predictability of natural behaviour viewed through CCTV cameras. Perception 2004, 33, 87–101. [Google Scholar] [CrossRef] [PubMed]
- Haering, N.; Venetianer, P.L.; Lipton, A. The evolution of video surveillance: An overview. Mach. Vis. Appl. 2008, 19, 279–290. [Google Scholar] [CrossRef]
- Valera, M.; Velastin, S.A. Intelligent distributed surveillance systems: A review. IEE Proc. Vis. Image Signal Process. 2005, 152, 192–204. [Google Scholar] [CrossRef]
- Denman, S.; Kleinschmidt, T.; Ryan, D.; Barnes, P.; Sridharan, S.; Fookes, C. Automatic surveillance in transportation hubs: No longer just about catching the bad guy. Expert Syst. Appl. 2015, 42, 9449–9467. [Google Scholar] [CrossRef] [Green Version]
- Sabeur, Z.; Doulamis, N.; Middleton, L.; Arbab-Zavar, B.; Correndo, G.; Amditis, A. Multi-modal computer vision for the detection of multi-scale crowd physical motions and behavior in confined spaces. In International Symposium on Visual Computing; Springer: Berlin, Germany, 2015; pp. 162–173. [Google Scholar]
- Hashemzadeh, M.; Farajzadeh, N. Combining keypoint-based and segment-based features for counting people in crowded scenes. Inform. Sci. 2016, 345, 199–216. [Google Scholar] [CrossRef]
- Yang, B.; Cao, J.; Wang, N.; Zhang, Y.; Zou, L. Counting challenging crowds robustly using a multi-column multi-task convolutional neural network. Signal Process. Image Commun. 2018, 64, 118–129. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shah, M. Real-world Anomaly Detection in Surveillance Videos. arXiv, 2018; arXiv:1801.04264. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Stateline, NV, USA, 3–8 December 2012. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Washington, DC, USA, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Las Vegas Valley, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv, 2018; arXiv:1804.02767. [Google Scholar]
- Li, W.; Mahadevan, V.; Vasconcelos, N. Anomaly detection and localization in crowded scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 18–32. [Google Scholar] [PubMed]
- Kim, J.; Grauman, K. Observe locally, infer globally: A space-time MRF for detecting abnormal activities with incremental updates. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Miami Beach, FL, USA, 20–25 June 2009; pp. 2921–2928. [Google Scholar]
- Xu, D.; Ricci, E.; Yan, Y.; Song, J.; Sebe, N. Learning deep representations of appearance and motion for anomalous event detection. Comput. Vis. Image Understand. 2015, 156, 117–127. [Google Scholar] [CrossRef]
- Alom, M.Z.; Bontupalli, V.; Taha, T.M. Intrusion detection using deep belief networks. In Proceedings of the Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 June 2015; pp. 339–344. [Google Scholar]
- Bertini, M.; Del Bimbo, A.; Seidenari, L. Multi-scale and real-time non-parametric approach for anomaly detection and localization. Comput. Vis. Image Understand. 2012, 116, 320–329. [Google Scholar] [CrossRef]
- Breitenstein, M.D.; Grabner, H.; Van Gool, L. Hunting nessie-real-time abnormality detection from webcams. In Proceedings of the International Conference on Computer Vision Workshops (ICCVW), Kyoto, Japan, 27 September–4 October 2009; pp. 1243–1250. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. arXiv, 2016; arXiv:1612.08242. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Boissonnat, J.; Preparata, F. Robust Plane Sweep for Intersecting Segments. SIAM J. Comput. 2000, 29, 1401–1421. [Google Scholar] [CrossRef]
- Casale, P.; Pujol, O.; Radeva, P. Approximate polytope ensemble for one-class classification. Pattern Recognit. 2014, 47, 854–864. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Oneata, D.; Verbeek, J.; Schmid, C. A robust and efficient video representation for action recognition. Int. J. Comput. Vis. 2016, 119, 219–238. [Google Scholar] [CrossRef] [Green Version]
- Mair, E.; Hager, G.D.; Burschka, D.; Suppa, M.; Hirzinger, G. Adaptive and generic corner detection based on the accelerated segment test. In Proceedings of the European Conference on Computer Vision (ECCV), Heraklion, Crete, Greece, 5–11 September 2010; pp. 183–196. [Google Scholar]
- Shi, J.; Tomasi, C. Good features to track. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Lu, C.; Shi, J.; Jia, J. Abnormal event detection at 150 fps in matlab. In Proceedings of the International Conference on Computer Vision (ICCV), Darling Harbour, Sydney, 1–8 December 2013; pp. 2720–2727. [Google Scholar]
- Mehran, R.; Oyama, A.; Shah, M. Abnormal crowd behavior detection using social force model. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 935–942. [Google Scholar]
- Adam, A.; Rivlin, E.; Shimshoni, I.; Reinitz, D. Robust real-time unusual event detection using multiple fixed-location monitors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 555–560. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Precision | Recall | F1 |
|---|---|---|---|
| Person | 0.81 | 0.56 | 0.66 |
| Car | 0.76 | 0.88 | 0.81 |
| Truck | 0.62 | 0.91 | 0.74 |
| Moto | 0.76 | 0.29 | 0.42 |
| Sequence | Class | Count | GT |
|---|---|---|---|
| 1 | Person | 29 | 36 |
| Car | - | - | |
| Truck | - | - | |
| Moto | 0 | 6 | |
| 2 | Person | 79 | 83 |
| Car | 22 | 21 | |
| Truck | 6 | 5 | |
| Moto | - | - | |
| 3 | Person | 24 | 20 |
| Car | 1 | 1 | |
| Truck | 10 | 10 | |
| Moto | 1 | 6 |
| Spot Accuracy | Abnormal Parking Recall | Abnormal Parking Precision |
|---|---|---|
| 93.88% | 79.27% | 60.75% |
| Method | Ped1 | Ped2 | ||
|---|---|---|---|---|
| Frame | Pixel | Frame | Pixel | |
| Ours | 78.1 | 62.2 | 80.7 | 75.7 |
| Xu et al. [20] | 78.0 | 59.9 | 83.0 | - |
| MDT Spatial [18] | 56.2 | 54.2 | 71.3 | 63.4 |
| MDT Temporal [18] | 77.1 | 48.2 | 72.1 | 56.8 |
| 150 fps [33] | 85.0 | 59.1 | - | - |
| Bertini et al. [22] | 66.0 | 29.0 | 68.0 | - |
| Mehran et al. [34] | 63.5 | 40.9 | 65.0 | 27.6 |
| Kim et al. [19] | 64.4 | 23.2 | 64.2 | 22.4 |
| Adam et al. [35] | 61.1 | 32.6 | 54.2 | 22.4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Turchini, F.; Seidenari, L.; Uricchio, T.; Del Bimbo, A. Deep Learning Based Surveillance System for Open Critical Areas. Inventions 2018, 3, 69. https://doi.org/10.3390/inventions3040069
Turchini F, Seidenari L, Uricchio T, Del Bimbo A. Deep Learning Based Surveillance System for Open Critical Areas. Inventions. 2018; 3(4):69. https://doi.org/10.3390/inventions3040069
Chicago/Turabian StyleTurchini, Francesco, Lorenzo Seidenari, Tiberio Uricchio, and Alberto Del Bimbo. 2018. "Deep Learning Based Surveillance System for Open Critical Areas" Inventions 3, no. 4: 69. https://doi.org/10.3390/inventions3040069
APA StyleTurchini, F., Seidenari, L., Uricchio, T., & Del Bimbo, A. (2018). Deep Learning Based Surveillance System for Open Critical Areas. Inventions, 3(4), 69. https://doi.org/10.3390/inventions3040069