
Sensitivity Analysis of Artificial Neural Networks Identifying JWH Synthetic Cannabinoids Built with Alternative Training Strategies and Methods


Abstract
:1. Introduction
2. Materials and Methods
3. Results
4. Discussion
5. Conclusions
- Accuracy [(true positives + true negatives)/total instances]:
- 2.
- Sensitivity, or true positive rate (true positives/positive instances):
- 3.
- Specificity, or true negative rate (specificity = true negative/negative instances):
- 4.
- Error rate [accuracy = (false positives + false negatives)/total instances]:
- Activation function: hyperbolic tangent, Softmax;
- Loss index: normalized squared error;
- Regularization: L2;
- Neuron selection: growing neurons;
- Inputs selection: growing inputs;
- Optimization algorithm: Adaptive Moment Estimation.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Benitez, J.M.; Castro, J.L.; Requena, I. Are artificial neural networks black boxes? IEEE Trans. Neural. Netw. 1997, 8, 1156–1164. [Google Scholar] [CrossRef] [PubMed]
- Doulamis, A.D.; Doulamis, N.D.; Kollias, S.D. On-line retrainable neural networks: Improving the performance of neural networks in image analysis problems. IEEE Trans. Neural. Netw. 2000, 11, 137–155. [Google Scholar] [CrossRef] [PubMed]
- Yeung, D.S.; Cloete, I.; Shi, D.; Ng, W.W.Y. Sensitivity Analysis for Neural Networks; Springer: Berlin/Heidelberg Germany, 2010. [Google Scholar]
- Montano, J.J.; Palmer, A. Numeric sensitivity analysis applied to feedforward neural networks. Neural. Comput. Appl. 2003, 12, 119–125. [Google Scholar] [CrossRef]
- Burlacu, C.M.; Burlacu, A.C.; Praisler, M. Physico-chemical analysis, systematic benchmarking, and toxicological aspects of the JWH aminoalkylindole class-derived synthetic JWH cannabinoids. Ann. Univ. Dunarea Jos Galati Fascicle II Math. Phys. Theor. Mech. 2021, 44, 34–45. [Google Scholar] [CrossRef]
- Todeschini, R.; Consonni, V. Handbook of Molecular Descriptors; Wiley: Weinheim, Germany, 2000; pp. 1–667. [Google Scholar]
- Burlacu, C.M.; Gosav, S.; Burlacu, B.A.; Praisler, M. Convolutional Neural Network detecting synthetic cannabinoids. In Proceedings of the 2021 International Conference on e-Health and Bioengineering (EHB), Iasi, Romania, 18–19 November 2021; pp. 1–4. [Google Scholar]
- Egger, J.; Pepe, A.; Gsaxner, C.; Jin, Y.; Li, J.; Kern, R. Deep learning-a first meta-survey of selected reviews across scientific disciplines, their commonalities, challenges and research impact. PeerJ Comput. Sci. 2021, 7, e773. [Google Scholar] [CrossRef] [PubMed]
- Gupta, R.; Srivastava, D.; Sahu, M.; Tiwari, S.; Ambasta, R.K.; Kumar, P. Artificial intelligence to deep learning: Machine intelligence approach for drug discovery. Mol. Divers. 2021, 25, 1315–1360. [Google Scholar] [CrossRef] [PubMed]
- Jing, Y.; Bian, Y.; Hu, Z.; Wang, L.; Xie, X.Q.S. Deep learning for drug design: An artificial intelligence paradigm for drug discovery in the big data era. AAPS J. 2018, 20, 1–10. [Google Scholar]
- Smith, S.L.; Dherin, B.; Barrett, D.G.T.; De, S. On the origin of implicit regularization in stochastic gradient descent. arXiv 2021, arXiv:2101.12176. [Google Scholar]
- Wang, M.; Xu, X.; Yan, Z.; Wang, H. An online optimization method for extracting parameters of multi-parameter PV module model based on adaptive Levenberg-Marquardt algorithm. Energy Convers. Manag. 2021, 245, 114611. [Google Scholar] [CrossRef]
- Singarimbun, R.N.; Nababan, E.B.; Sitompul, O.S. Adaptive moment estimation to minimize square error in backpropagation algorithm. In Proceedings of the 2019 International Conference of Computer Science and Information Technology (ICoSNIKOM), Medan, Indonesia, 28–29 November 2019; pp. 1–7. [Google Scholar]
- Powers, D.M.W. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2011, arXiv:2010.16061. [Google Scholar]



{kind=link}
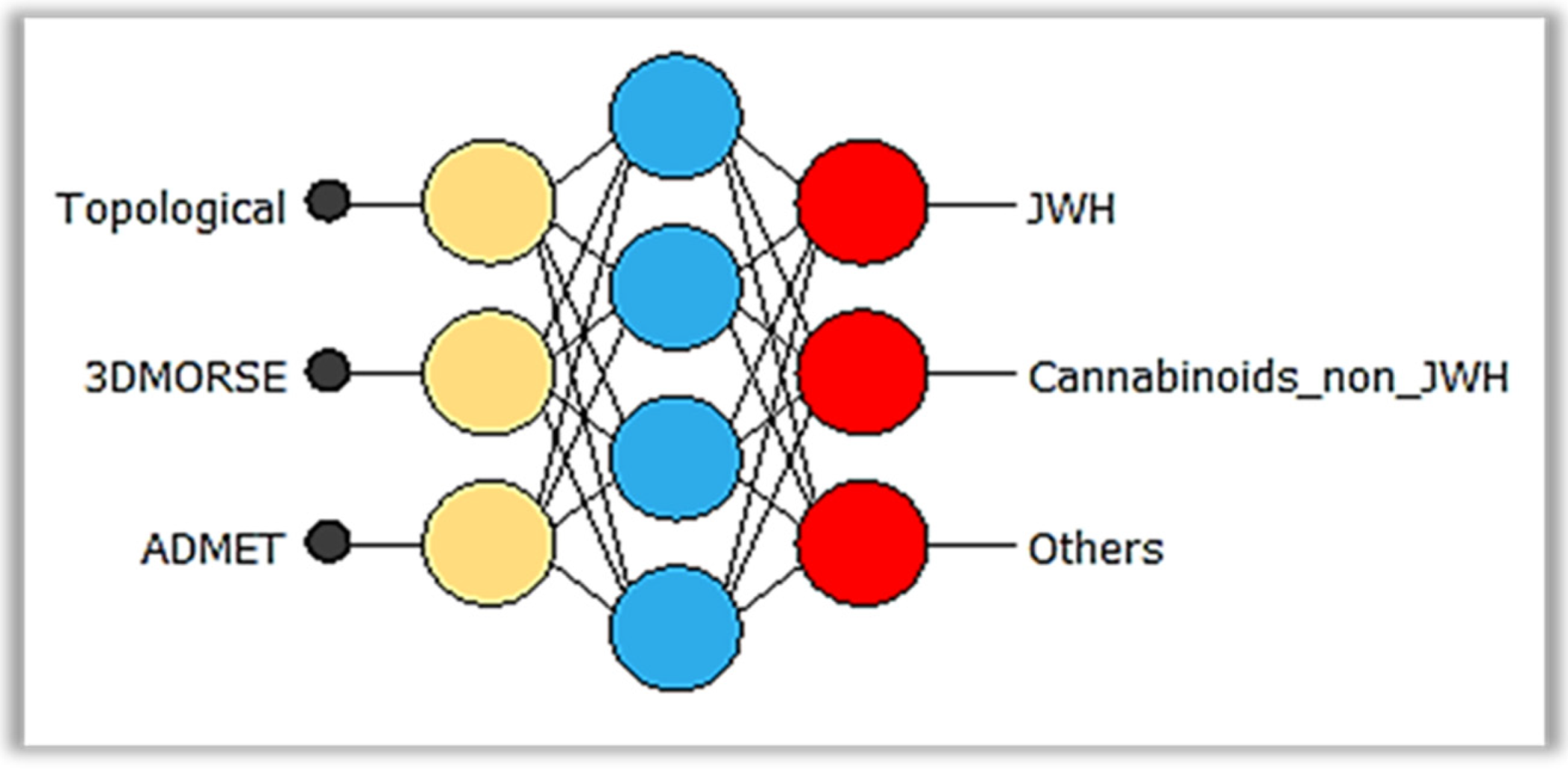{kind=link}
| Input | Minimum | Maximum | Mean | Deviation | Scaler |
|---|---|---|---|---|---|
| Topological | 4.300000 | 7.900000 | 5.843330 | 0.828066 | Mean St. Dev. |
| 3D-MoRSE | 2.000000 | 4.400000 | 3.054000 | 0.433594 | Mean St. Dev. |
| ADMET | 1.000000 | 6.900000 | 3.758670 | 1.764420 | Mean St. Dev. |
| Predicted JWH | Predicted Non-JWH Cannabinoids | Predicted Others | |
|---|---|---|---|
| Real JWH Cannabinoids | 10 | 0 | 0 |
| Real non-JWH Cannabinoids | 0 | 7 | 0 |
| Real Others | 0 | 1 | 12 |
| Predicted JWH | Predicted Non-JWH Cannabinoids | Predicted Others | |
|---|---|---|---|
| Real JWH Cannabinoids | 8 | 0 | 0 |
| Real non-JWH Cannabinoids | 0 | 9 | 1 |
| Real Others | 0 | 2 | 10 |
| Predicted JWH | Predicted Non-JWH Cannabinoids | Predicted Others | |
|---|---|---|---|
| Real JWH Cannabinoids | 8 | 0 | 0 |
| Real Non-JWH Cannabinoids | 0 | 9 | 1 |
| Real Others | 0 | 3 | 9 |
| Predicted JWH | Predicted Non-JWH Cannabinoids | Predicted Others | |
|---|---|---|---|
| Real JWH Cannabinoids | 8 | 0 | 0 |
| Real non-JWH Cannabinoids | 0 | 10 | 0 |
| Real Others | 0 | 3 | 9 |
| Root Mean Squared Error | ||||
|---|---|---|---|---|
| Number of Nodes in the Hidden Layer | ANN | Training Set | Selection Set | Testing Set |
| 1 | Version 3 | 0.187558 | 0.276155 | 0.284885 |
| 3 | Version 2 | 0.180618 | 0.276762 | 0.284408 |
| 4 | Version 1 | 0.178430 | 0.241047 | 0.213058 |
| 6 | Version 4 | 0.173380 | 0.268222 | 0.280003 |
| Weighted Average | ||||
|---|---|---|---|---|
| Number of Nodes in the Hidden Layer | ANN | Accuracy | Recall | F1 Score |
| 1 | Version 3 | 0.876667 | 0.866667 | 0.866667 |
| 3 | Version 2 | 0.903030 | 0.900000 | 0.900207 |
| 4 | Version 1 | 0.970833 | 0.966667 | 0.967111 |
| 6 | Version 4 | 0.923077 | 0.900000 | 0.899379 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Burlacu, C.M.; Burlacu, A.C.; Praisler, M. Sensitivity Analysis of Artificial Neural Networks Identifying JWH Synthetic Cannabinoids Built with Alternative Training Strategies and Methods. Inventions 2022, 7, 82. https://doi.org/10.3390/inventions7030082
Burlacu CM, Burlacu AC, Praisler M. Sensitivity Analysis of Artificial Neural Networks Identifying JWH Synthetic Cannabinoids Built with Alternative Training Strategies and Methods. Inventions. 2022; 7(3):82. https://doi.org/10.3390/inventions7030082
Chicago/Turabian StyleBurlacu, Catalina Mercedes, Adrian Constantin Burlacu, and Mirela Praisler. 2022. "Sensitivity Analysis of Artificial Neural Networks Identifying JWH Synthetic Cannabinoids Built with Alternative Training Strategies and Methods" Inventions 7, no. 3: 82. https://doi.org/10.3390/inventions7030082
APA StyleBurlacu, C. M., Burlacu, A. C., & Praisler, M. (2022). Sensitivity Analysis of Artificial Neural Networks Identifying JWH Synthetic Cannabinoids Built with Alternative Training Strategies and Methods. Inventions, 7(3), 82. https://doi.org/10.3390/inventions7030082