
Classification of Different Recycled Rubber-Epoxy Composite Based on Their Hardness Using Laser-Induced Breakdown Spectroscopy (LIBS) with Comparison Machine Learning Algorithms




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
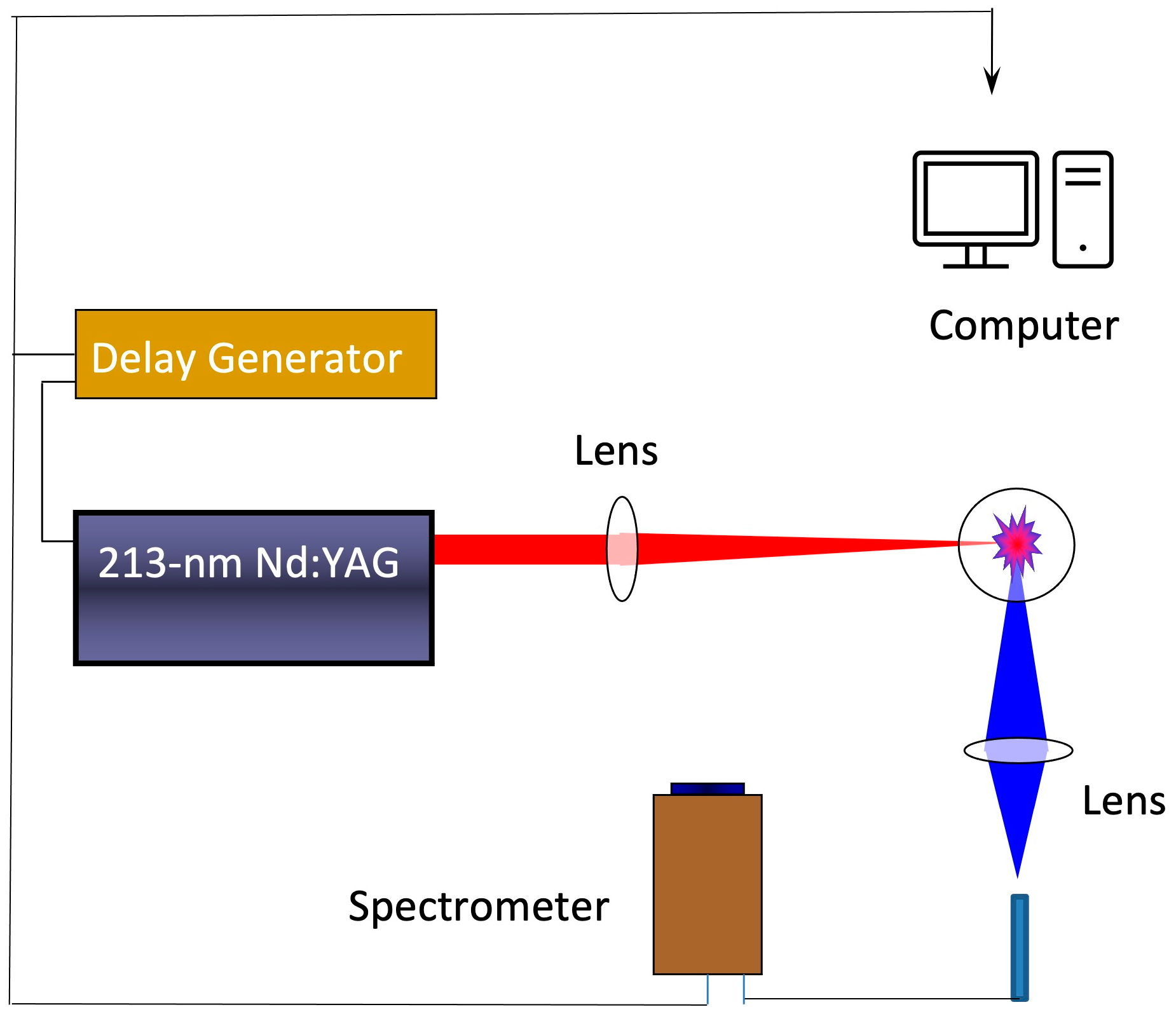
2. Experimental Procedure
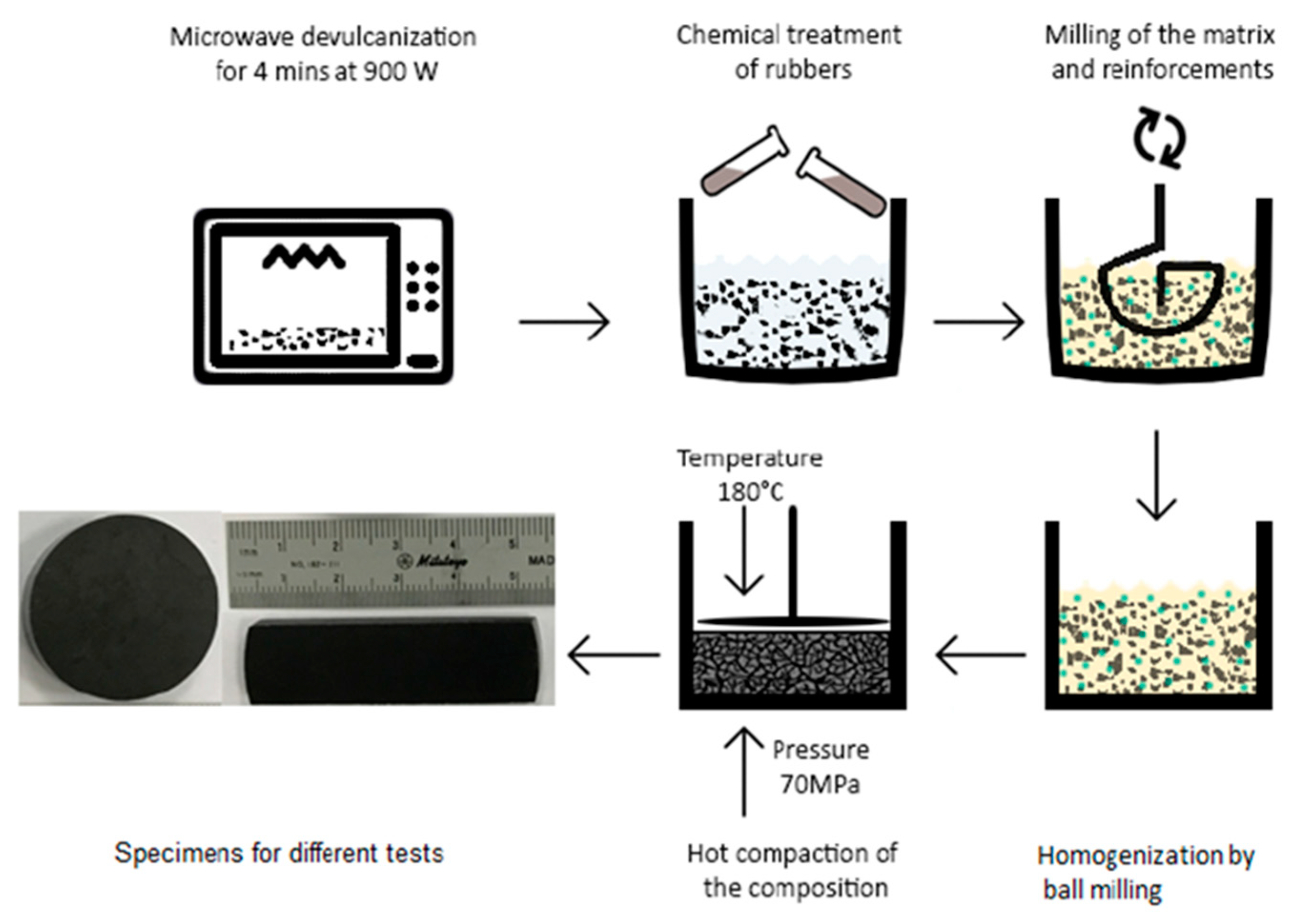
2.1. Sample Preparation
2.2. ML Methods for LIBS
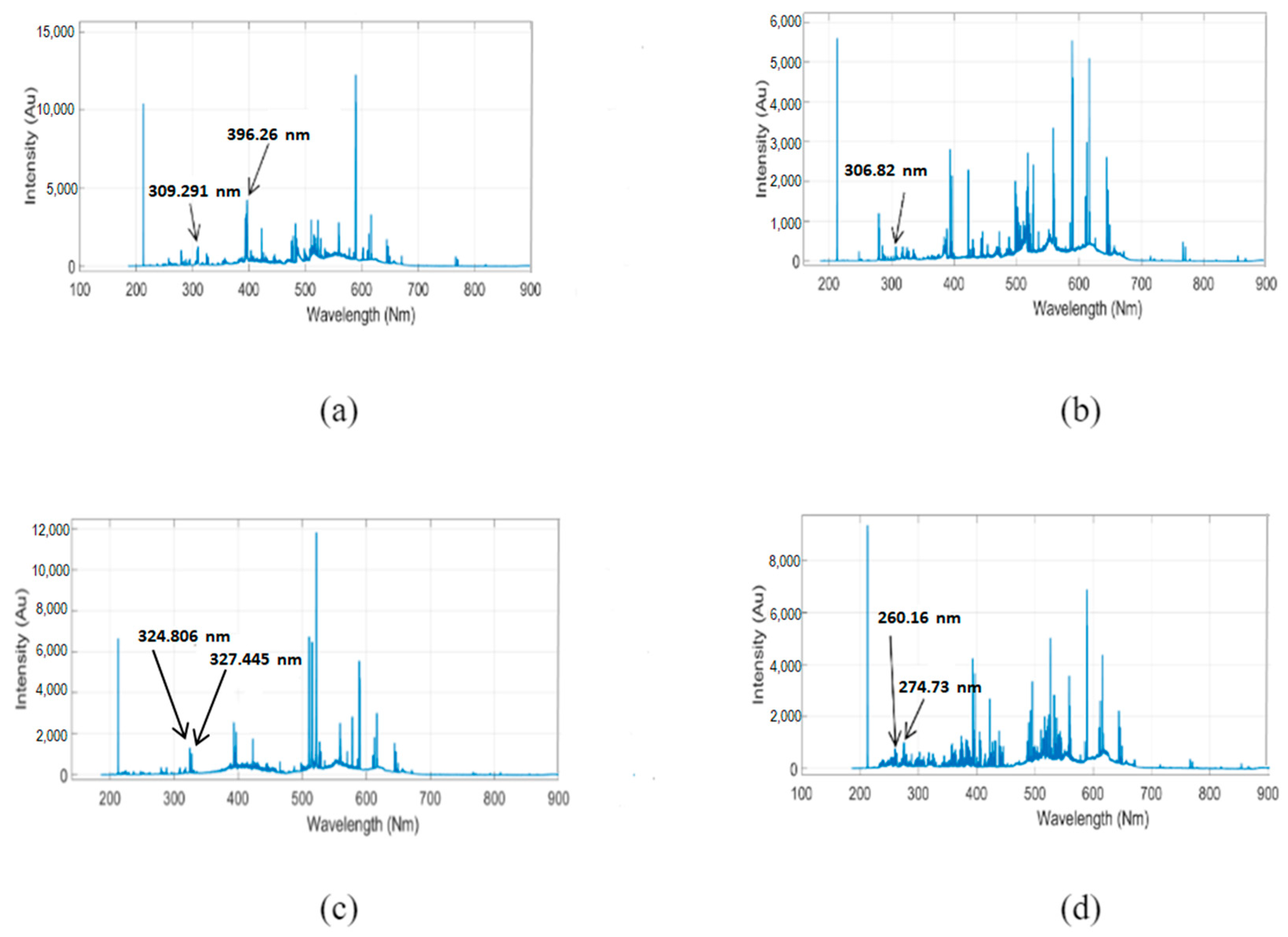
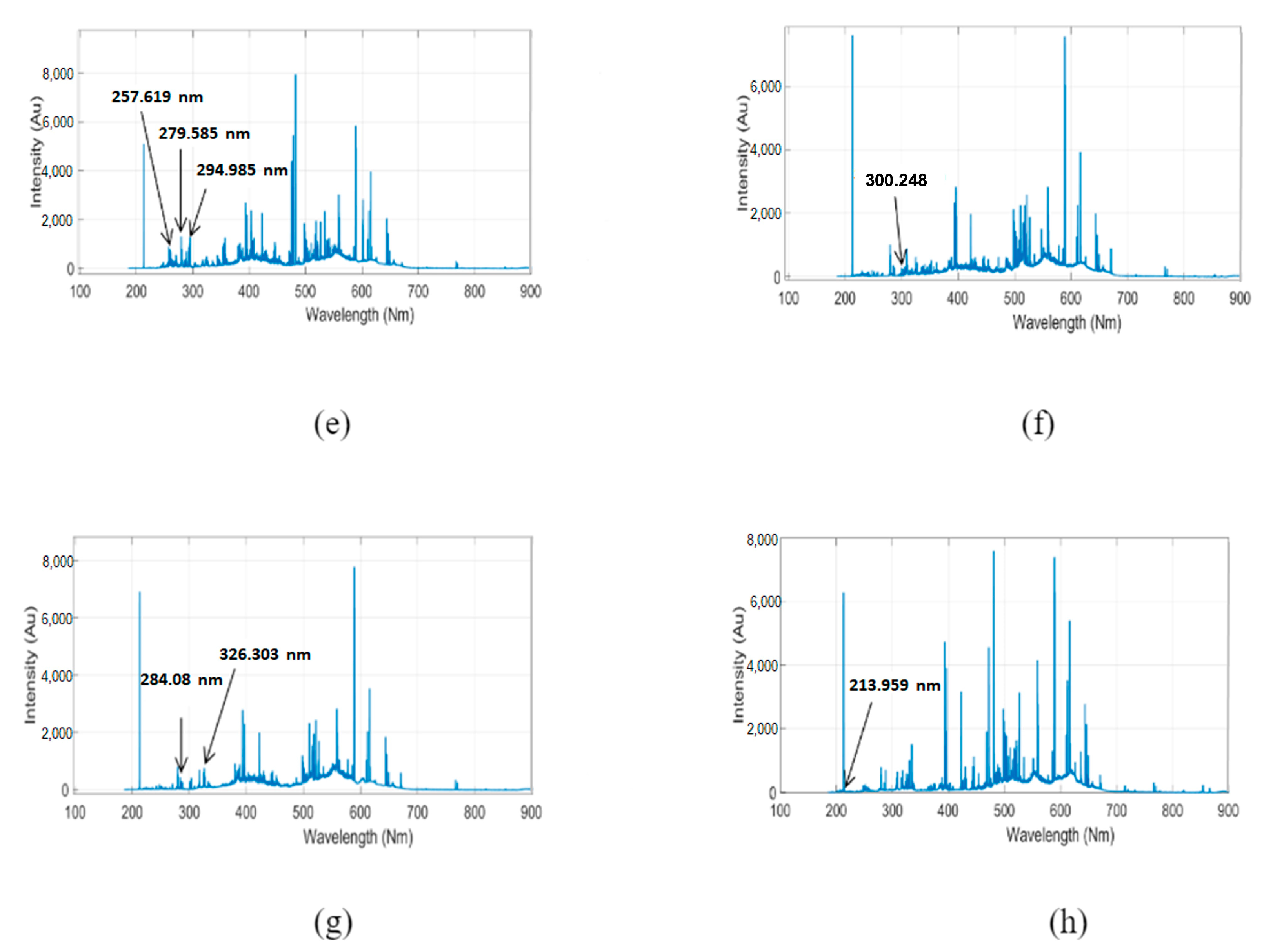
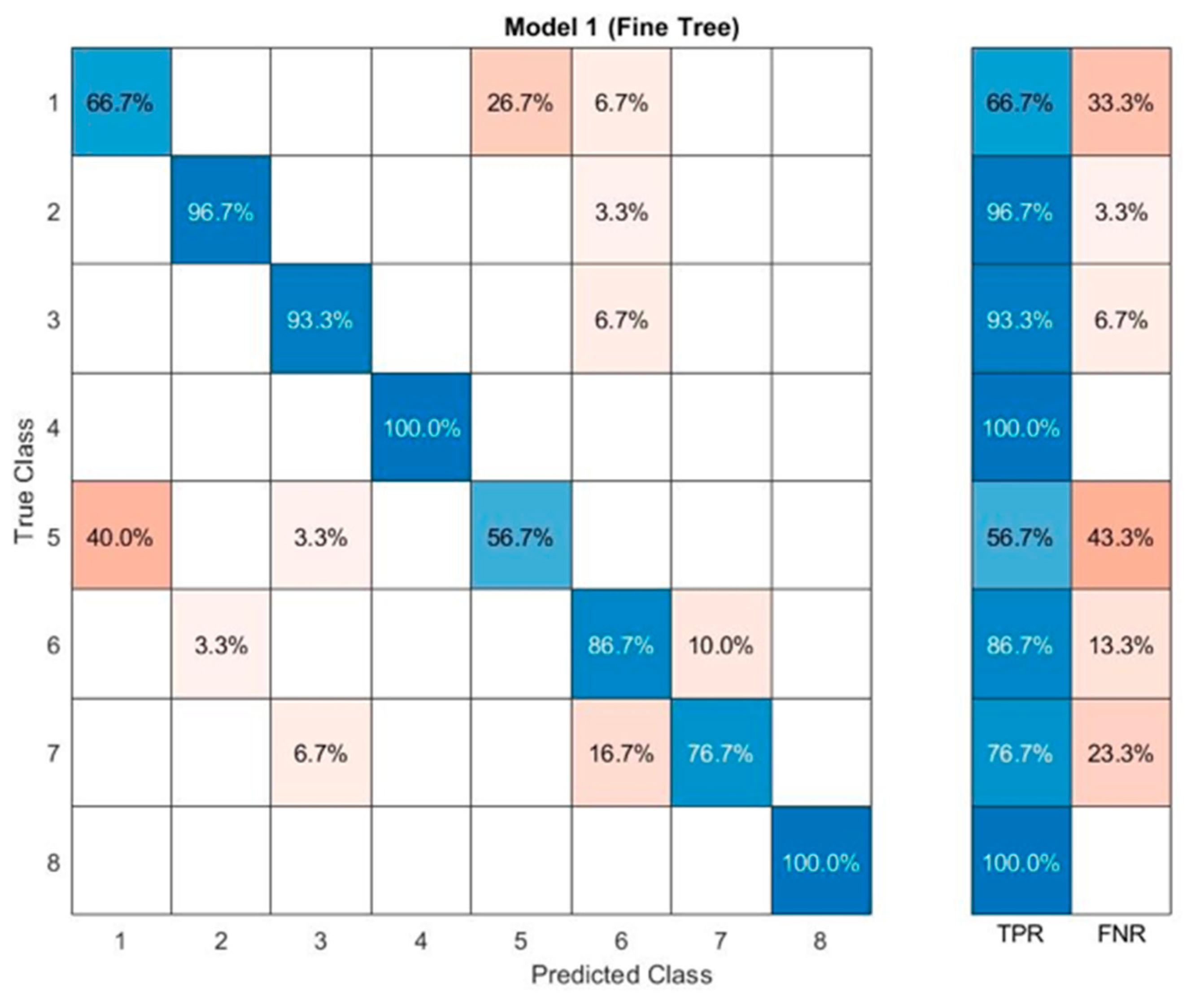
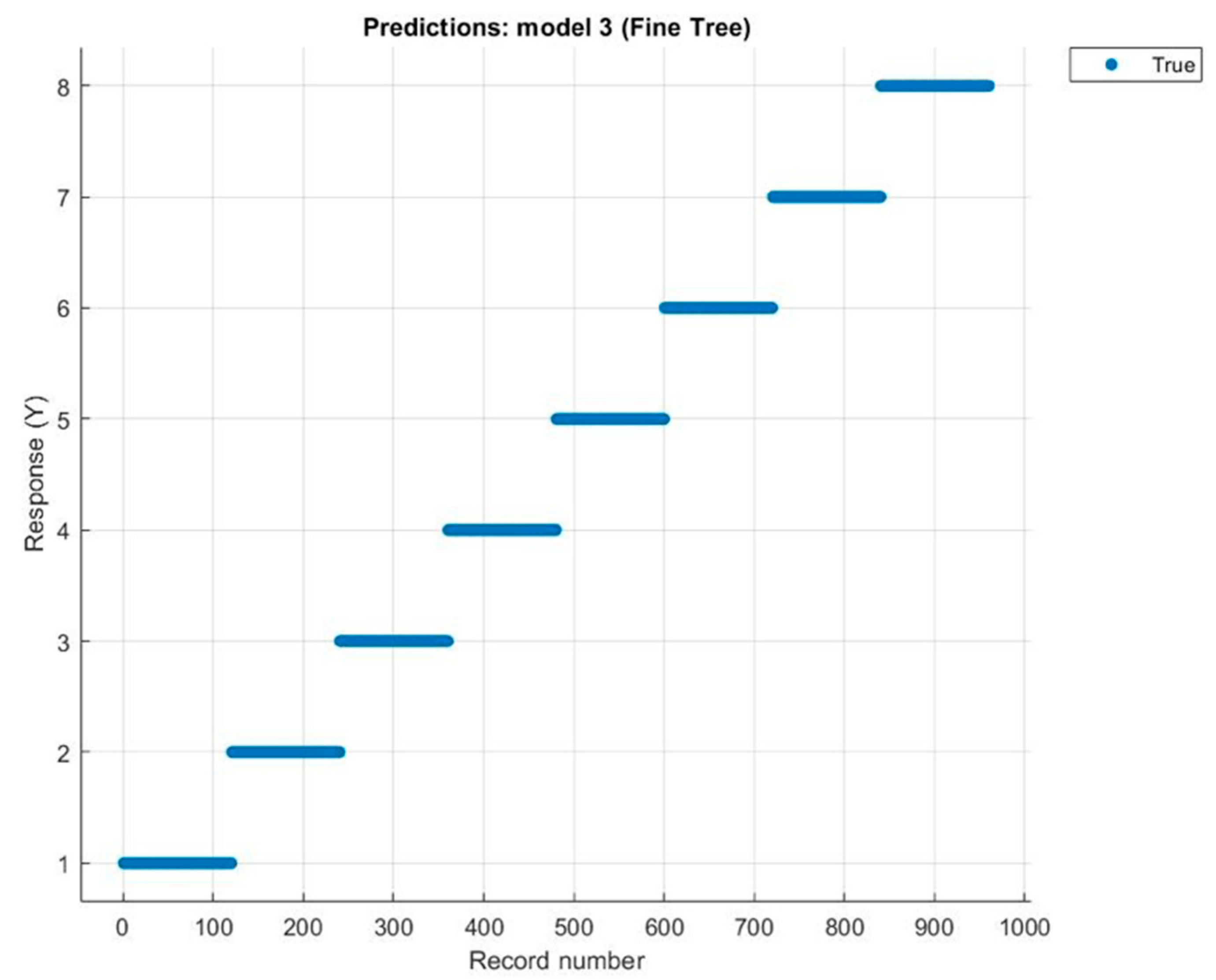
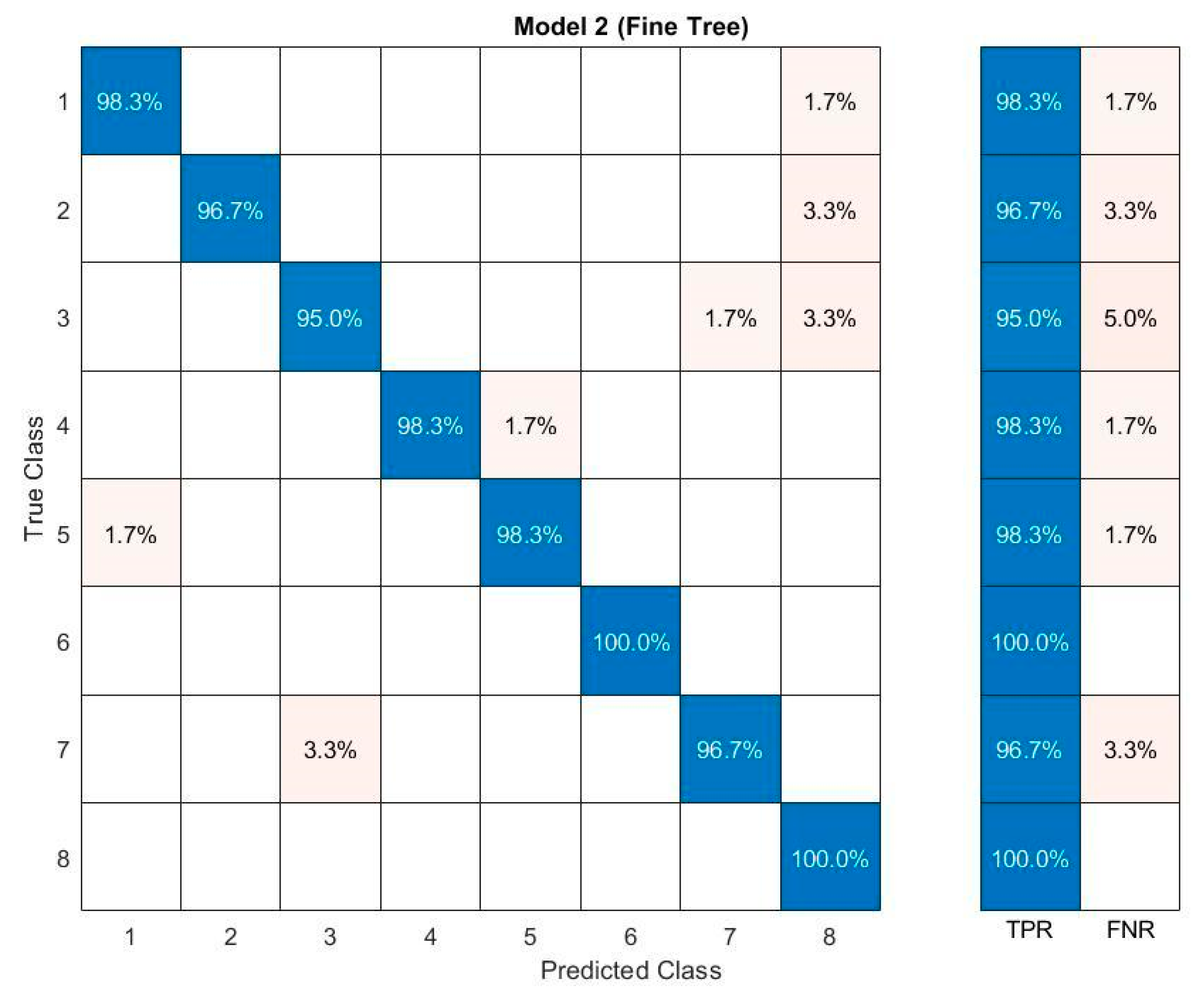
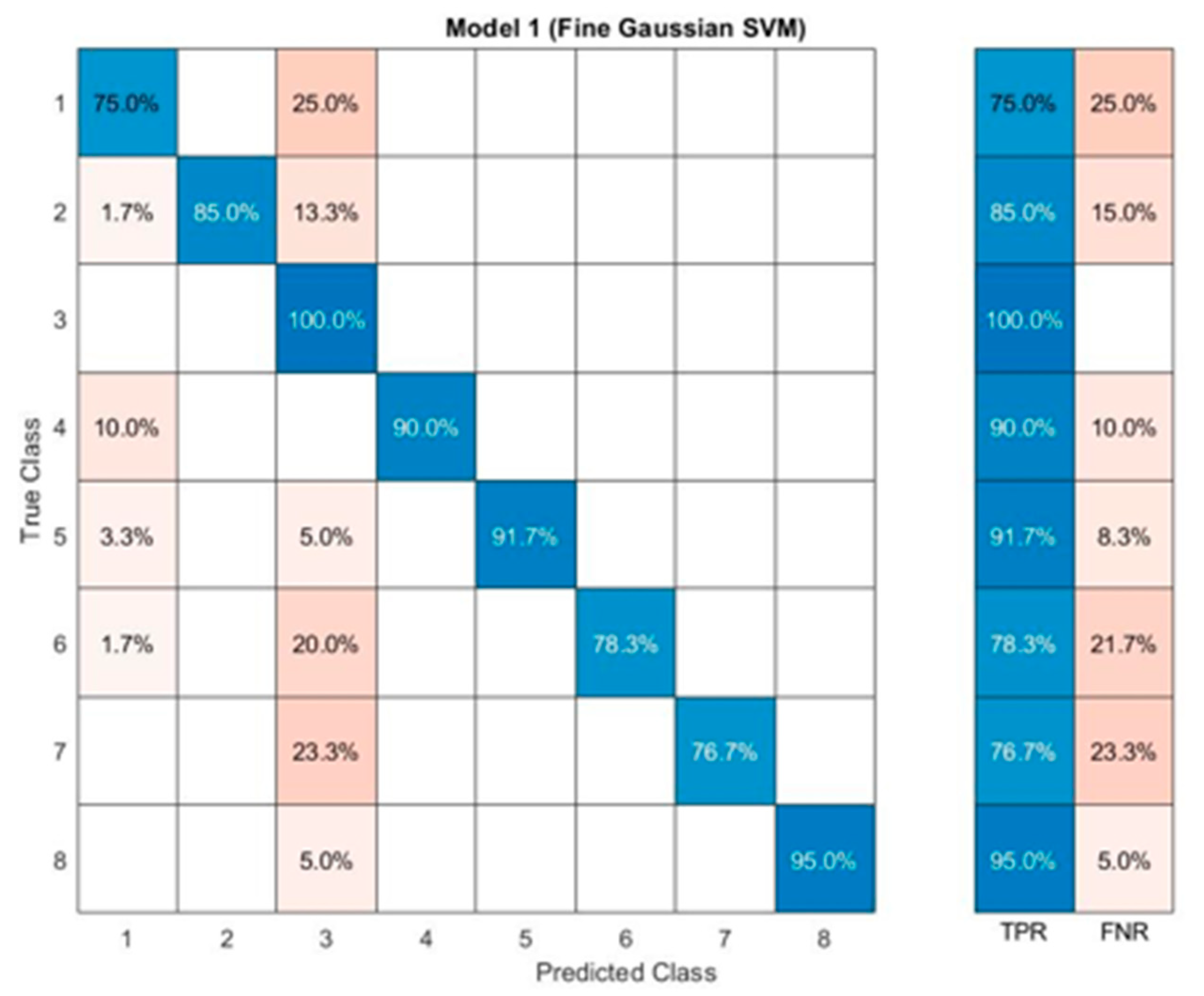
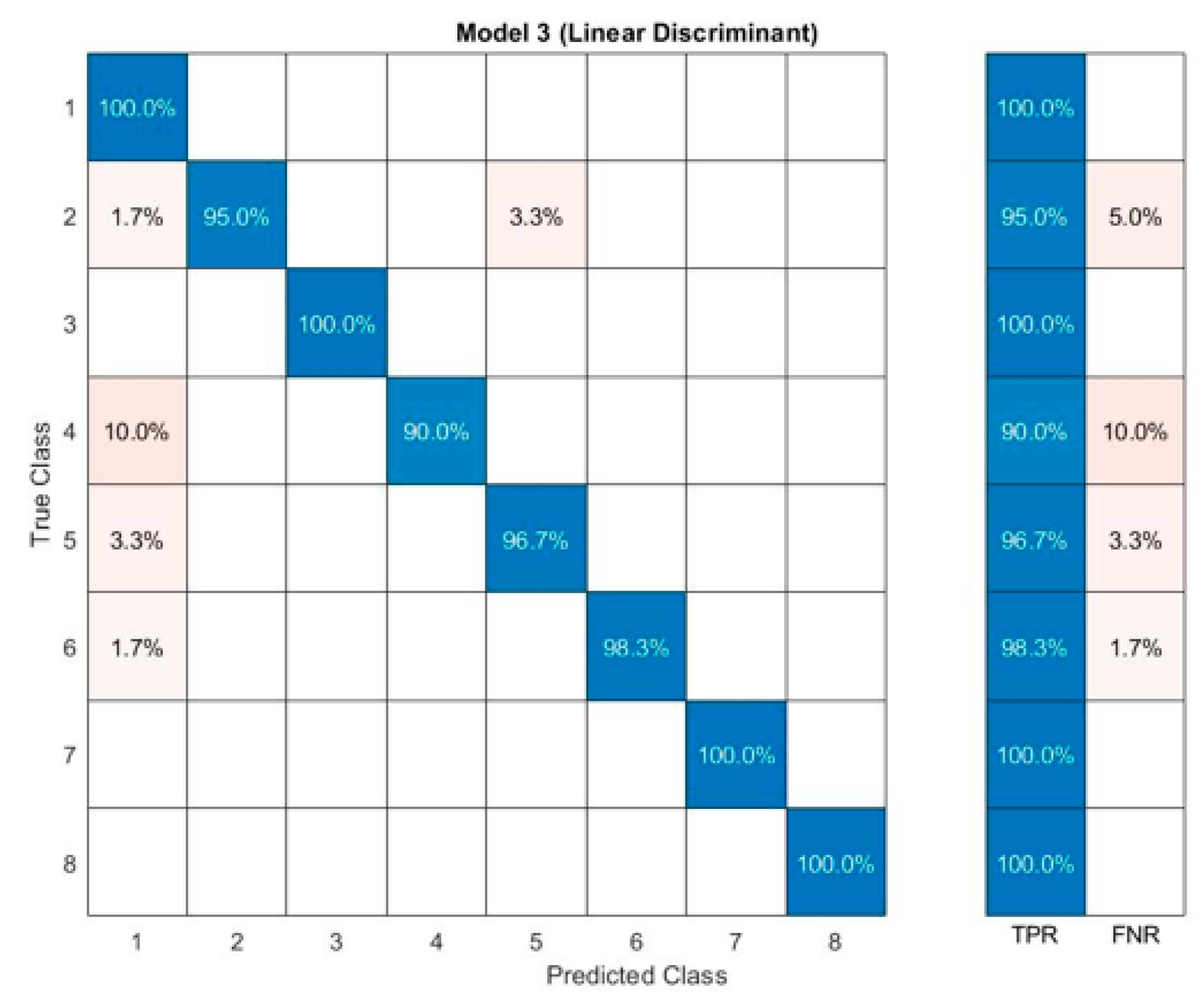
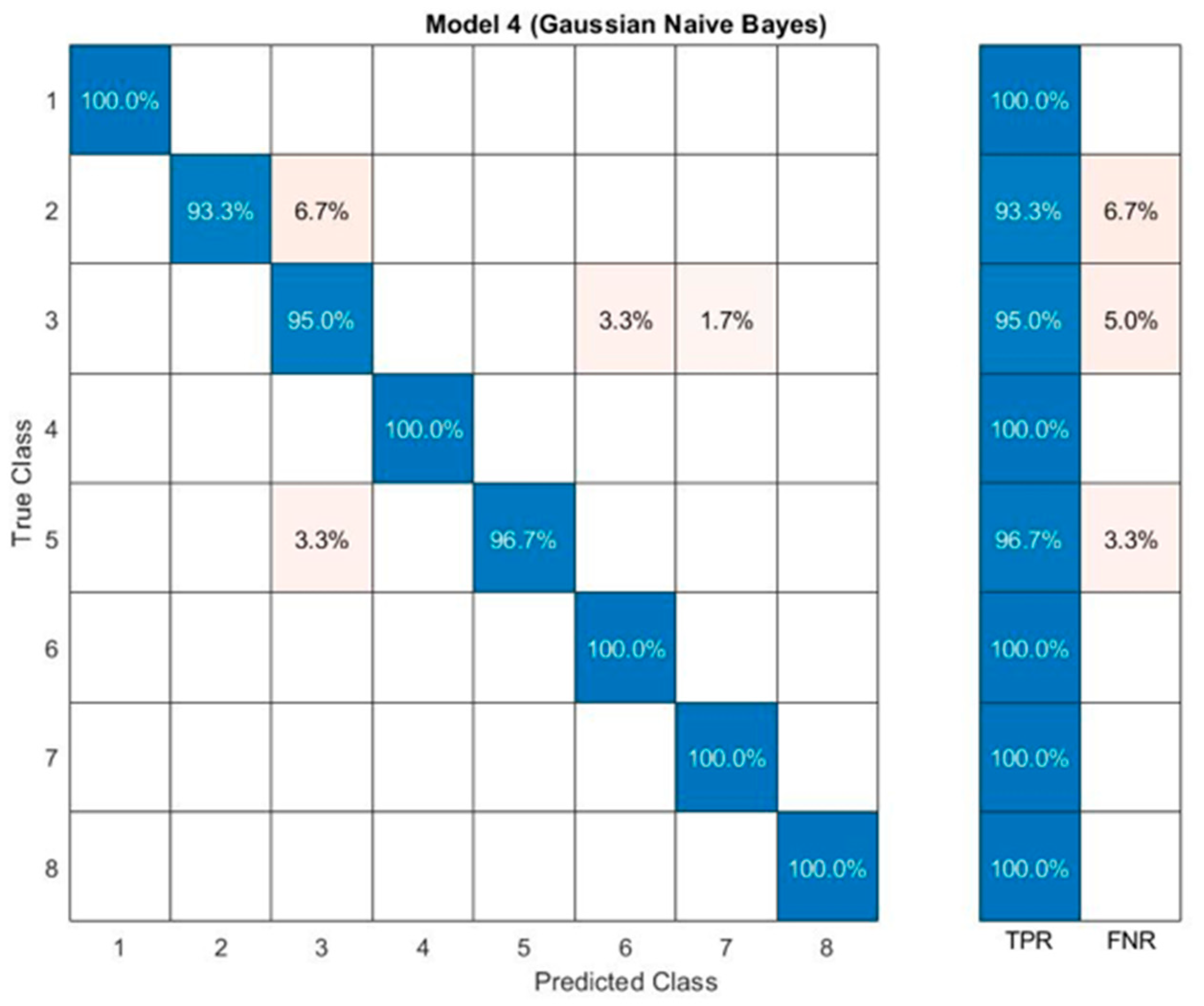
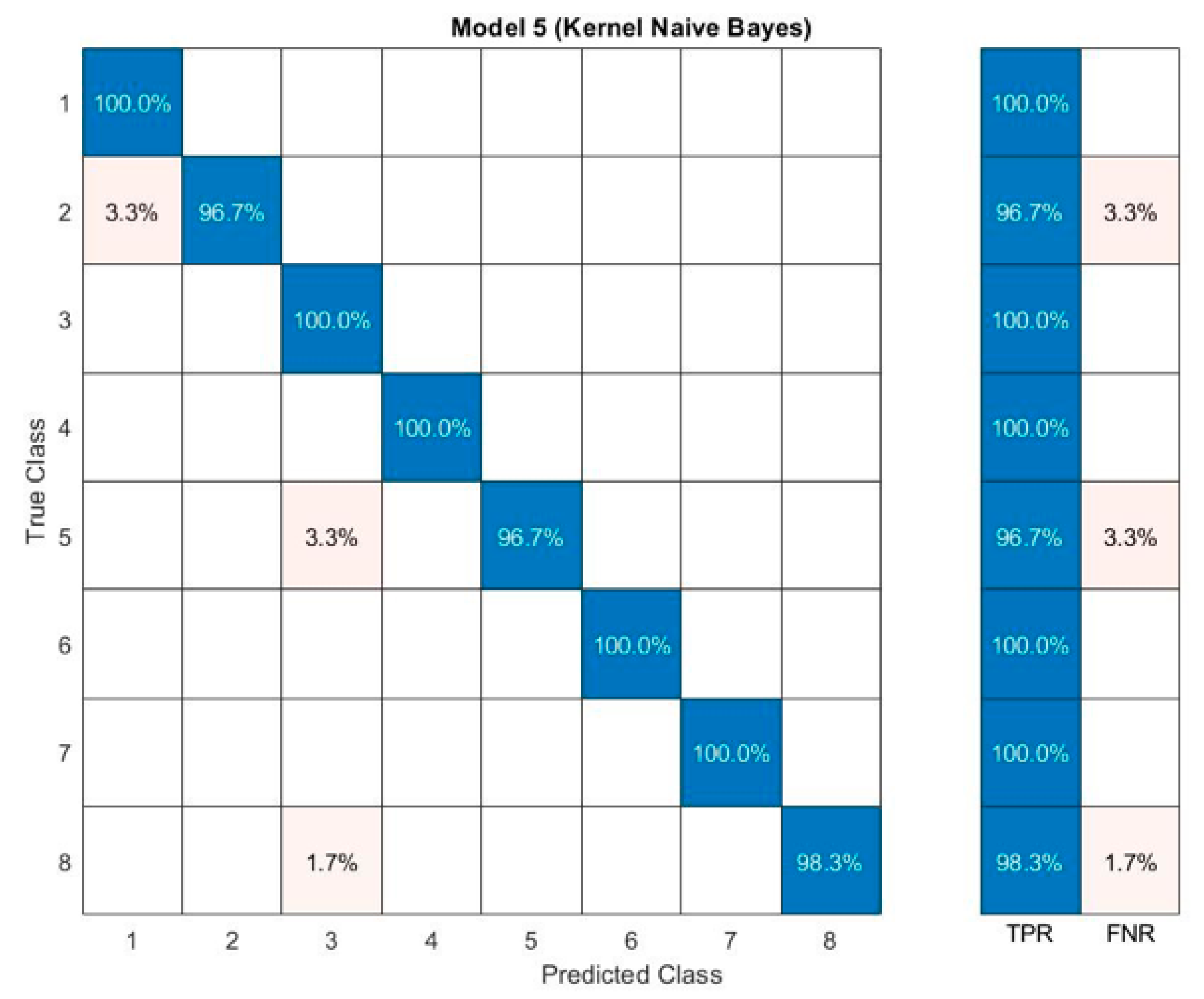
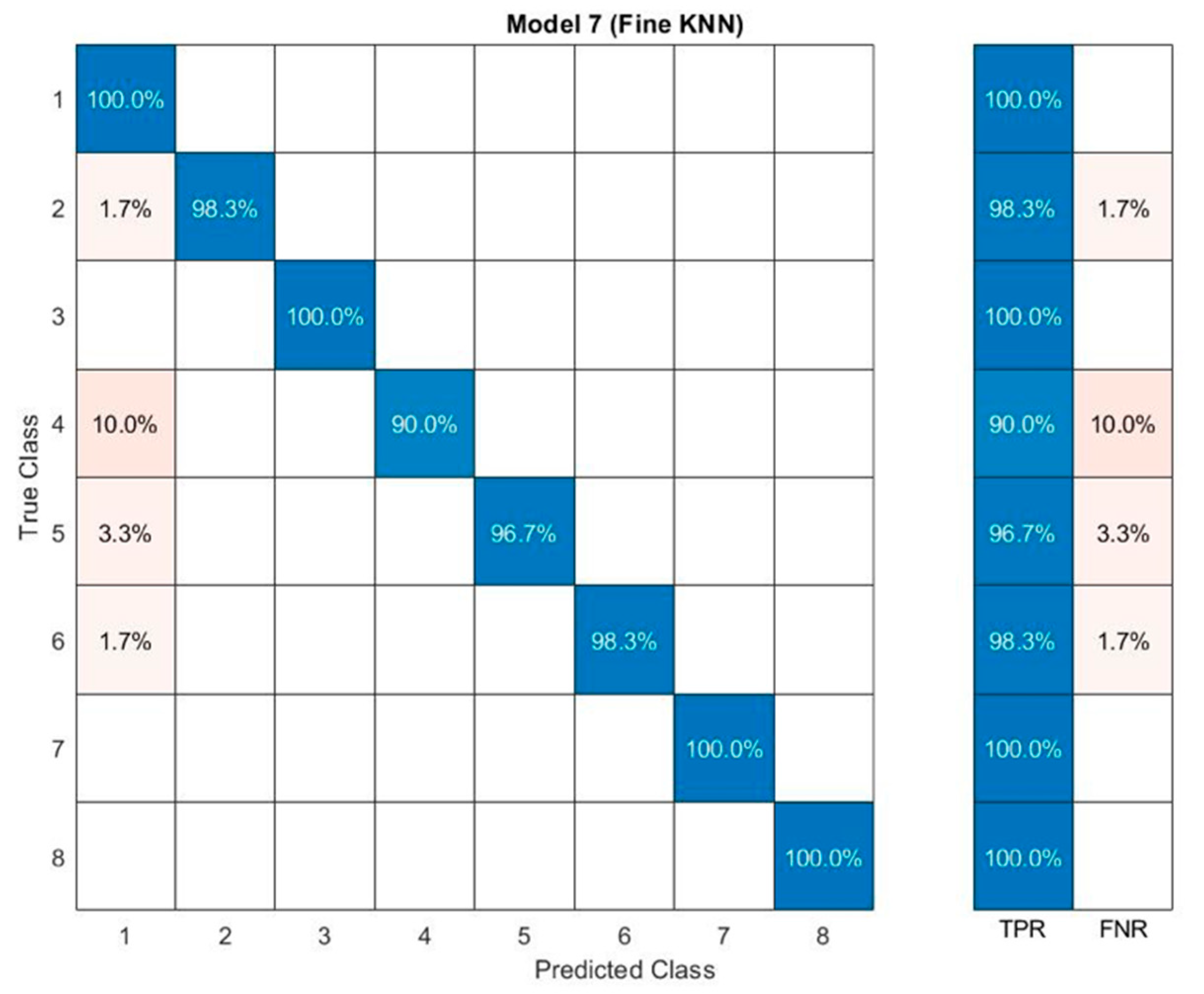
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, K.; Qiu, C.; Tian, D.; Yang, G.; Li, Y.; Han, X. Laser-Induced Breakdown Spectroscopy for Plastic Classification. Spectrosc. Spectr. Anal. 2017, 37, 3600–3605. [Google Scholar]
- Godoi, Q.; Leme, F.O.; Trevizan, L.C.; Pereira Filho, E.R.; Rufini, I.A.; Santos, D., Jr.; Krug, F.J. Laser-induced breakdown spectroscopy and chemometrics for classification of toys relying on toxic elements. Spectrochim. Acta Part B At. Spectrosc. 2011, 66, 138–143. [Google Scholar] [CrossRef]
- Wang, W.; Sun, L.; Lu, Y.; Qi, L.; Wang, W.; Qiao, H. Laser induced breakdown spectroscopy online monitoring of laser cleaning quality on carbon fiber reinforced plastic. Opt. Laser Technol. 2022, 145, 107481. [Google Scholar] [CrossRef]
- Brunnbauer, L.; Larisegger, S.; Lohninger, H.; Nelhiebel, M.; Limbeck, A. Spatially resolved polymer classification using laser induced breakdown spectroscopy (LIBS) and multivariate statistics. Talanta 2020, 209, 120572. [Google Scholar] [CrossRef]
- Costa, V.C.; Aquino, F.W.B.; Paranhos, C.M.; Pereira-Filho, E.R. Identification and classification of polymer e-waste using laser-induced breakdown spectroscopy (LIBS) and chemometric tools. Polym. Test. 2017, 59, 390–395. [Google Scholar] [CrossRef]
- Anzano, J.; Bonilla, B.; Montull-Ibor, B.; Lasheras, R.-J.; Casas-Gonzalez, J. Classifications of Plastic Polymers based on Spectral Data Analysis with leaser induced Breakdown Spectroscopy. J. Polym. Eng. 2010, 30, 177–188. [Google Scholar] [CrossRef]
- Xu, L.; Liang, L.; Zhang, T.; Tang, H.; Wang, K.; Li, H. A method of improving classification precision based on model population analysis of steel material for laser-induced breakdown spectroscopy. Anal. Methods 2014, 6, 8374–8379. [Google Scholar] [CrossRef]
- Jull, H.; Bier, J.; Künnemeyer, R.; Schaare, P. Classification of recyclables using laser-induced breakdown spectroscopy for waste management. Spectrosc. Lett. 2018, 51, 257–265. [Google Scholar] [CrossRef]
- Junjuri, R.; Zhang, C.; Barman, I.; Gundawar, M.K. Identification of post-consumer plastics using laser-induced breakdown spectroscopy. Polym. Test. 2019, 76, 101–108. [Google Scholar] [CrossRef]
- Guo, Y.; Tang, Y.; Du, Y.; Tang, S.; Guo, L.; Li, X.; Lu, Y.; Zeng, X. Cluster analysis of polymers using laser-induced breakdown spectroscopy with K-means. Plasma Sci. Technol. 2018, 20, 065505. [Google Scholar] [CrossRef] [Green Version]
- Stefas, D.; Gyftokostas, N.; Bellou, E.; Couris, S. Laser-Induced Breakdown Spectroscopy Assisted by Machine Learning for Plastics/Polymers Identification. Atoms 2019, 7, 79. [Google Scholar] [CrossRef] [Green Version]
- Gajarska, Z.; Brunnbauer, L.; Lohninger, H.; Limbeck, A. Identification of 20 polymer types by means of laser-induced breakdown spectroscopy (LIBS) and chemometrics. Anal. Bioanal. Chem. 2021, 413, 6581–6594. [Google Scholar] [CrossRef]
- Zeng, Q.; Sirven, J.-B.; Gabriel, J.-C.P.; Tay, C.Y.; Lee, J.-M. Laser induced breakdown spectroscopy for plastic analysis. TrAC Trends Anal. Chem. 2021, 140, 116280. [Google Scholar] [CrossRef]
- Tang, Y.; Guo, Y.; Sun, Q.; Tang, S.; Li, J.; Guo, L.; Duan, J. Industrial polymers classification using laser-induced breakdown spectroscopy combined with self-organizing maps and K-means algorithm. Optik 2018, 165, 179–185. [Google Scholar] [CrossRef]
- Dastjerdi, M.V.; Mousavi, S.J.; Soltanolkotabi, M.; Zadeh, A.N. Identification and Sorting of PVC Polymer in Recycling Process by Laser-Induced Breakdown Spectroscopy (LIBS) Combined with Support Vector Machine (SVM) Model. Iran. J. Sci. Technol. Trans. A Sci. 2018, 42, 959–965. [Google Scholar] [CrossRef]
- Hussain, L. Detecting epileptic seizure with different feature extracting strategies using robust machine learning classification techniques by applying advance parameter optimization approach. Cogn. Neurodyn. 2018, 12, 271–294. [Google Scholar] [CrossRef]
- Wahab, A.H.B.A.; Zahari, R.; Lim, T.H. Detecting diseases in Chilli Plants Using K-Means Segmented Support Vector Machine. In Proceedings of the 2019 3rd International Conference on Imaging, Signal Processing and Communication (ICISPC), Singapore, 27–29 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 57–61. [Google Scholar] [CrossRef]
- Joshi, S.; Joshi, F. Human Emotion Classification based on EEG Signals Using Recurrent Neural Network And KNN. arXiv 2022, arXiv:2205.08419. [Google Scholar]
- Santhiya, R.; GeethaPriya, C. Machine Learning Techniques for Intelligent Transportation Systems-An overview. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–7. [Google Scholar]
- Rathore, D.S.; Ram, B.; Pal, B.L.; Malviya, S. Analysis of classification algorithms for insect detection using MATLAB. In Proceedings of the 2nd International Conference on Advanced Computing and Software Engineering (ICACSE), Sultanpur, India, 8–9 February 2019. [Google Scholar]
- Zhang, D.; Zhang, H.; Zhao, Y.; Chen, Y.; Ke, C.; Xu, T.; He, Y. A brief review of new data analysis methods of laser-induced breakdown spectroscopy: Machine learning. Appl. Spectrosc. Rev. 2022, 57, 89–111. [Google Scholar] [CrossRef]
- Dong, R.; Wang, J.; Weng, S.; Yuan, H.; Yang, L. Field determination of hazardous chemicals in public security by using a hand-held Raman spectrometer and a deep architecture-search network. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 258, 119871. [Google Scholar] [CrossRef] [PubMed]
- Niu, C.; Cheng, X.; Zhang, T.; Wang, X.; He, B.; Zhang, W.; Feng, Y.; Bai, J.; Li, H. Novel Method Based on Hollow Laser Trapping-LIBS-Machine Learning for Simultaneous Quantitative Analysis of Multiple Metal Elements in a Single Microsized Particle in Air. Anal. Chem. 2021, 93, 2281–2290. [Google Scholar] [CrossRef]
- Chen, T.; Zhang, T.; Li, H. Applications of laser-induced breakdown spectroscopy (LIBS) combined with machine learning in geochemical and environmental resources exploration. TrAC Trends Anal. Chem. 2020, 133, 116113. [Google Scholar] [CrossRef]
- Syazwani, R.W.N.; Asraf, H.M.; Amin, M.M.S.; Dalila, K.N. Automated image identification, detection and fruit counting of top-view pineapple crown using machine learning. Alex. Eng. J. 2022, 61, 1265–1276. [Google Scholar] [CrossRef]
- Seyidbayli, C.; Salhi, F.; Akdogan, E. Comparison of machine learning algorithms for EMG signal classification. Period. Eng. Nat. Sci. (PEN) 2020, 8, 1165–1176. [Google Scholar]
- Syed, S.A.; Rashid, M.; Hussain, S.; Imtiaz, A.; Abid, H.; Zahid, H. Inter classifier comparison to detect voice pathologies. Math. Biosci. Eng. 2021, 18, 2258–2273. [Google Scholar] [CrossRef] [PubMed]
- Arslan, H.; Orhan, E.R. A Comparative Study on COVID-19 Prediction Using Deep Learning and Machine Learning Algorithms: A Case Study on Performance Analysis. Sak. Univ. J. Comput. Inf. Sci. 2022, 5, 71–83. [Google Scholar] [CrossRef]















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yılmaz, V.S.; Eseller, K.E.; Aslan, O.; Bayraktar, E. Classification of Different Recycled Rubber-Epoxy Composite Based on Their Hardness Using Laser-Induced Breakdown Spectroscopy (LIBS) with Comparison Machine Learning Algorithms. Inventions 2023, 8, 54. https://doi.org/10.3390/inventions8020054
Yılmaz VS, Eseller KE, Aslan O, Bayraktar E. Classification of Different Recycled Rubber-Epoxy Composite Based on Their Hardness Using Laser-Induced Breakdown Spectroscopy (LIBS) with Comparison Machine Learning Algorithms. Inventions. 2023; 8(2):54. https://doi.org/10.3390/inventions8020054
Chicago/Turabian StyleYılmaz, Vadi Su, Kemal Efe Eseller, Ozgur Aslan, and Emin Bayraktar. 2023. "Classification of Different Recycled Rubber-Epoxy Composite Based on Their Hardness Using Laser-Induced Breakdown Spectroscopy (LIBS) with Comparison Machine Learning Algorithms" Inventions 8, no. 2: 54. https://doi.org/10.3390/inventions8020054
APA StyleYılmaz, V. S., Eseller, K. E., Aslan, O., & Bayraktar, E. (2023). Classification of Different Recycled Rubber-Epoxy Composite Based on Their Hardness Using Laser-Induced Breakdown Spectroscopy (LIBS) with Comparison Machine Learning Algorithms. Inventions, 8(2), 54. https://doi.org/10.3390/inventions8020054