1. Introduction
Failure on rolling bearings is one of the most frequent system failures, resulting in huge losses of productivity in drivetrains installed in remote and harsh environment areas. Defects on bearings contribute to over 40% of faults in rotating machinery [
1]. If a bearing fault is well predicted, the risk of long-term system breakdown can be prevented, and a replacement of the faulty bearing will be done at the right time. Faulty bearings can be detected by analyzing current, vibration, or acoustic emission signals. Current signature analysis can be useful to detect limited faults on bearings, which need to be connected to a shaft driven by an electric motor. Vibration analysis is preferred to monitor conditions of bearings in most mechanical systems, where accelerometers are usually installed in place. In critical applications, acoustic emission signals can be used to detect bearing faults at an early stage due to its higher sensitivity and convenient installation without being involved in the system.
Processing data and understanding faulty features in vibration and acoustic emission analysis need skilled manpower with advanced knowledge of bearing faults [
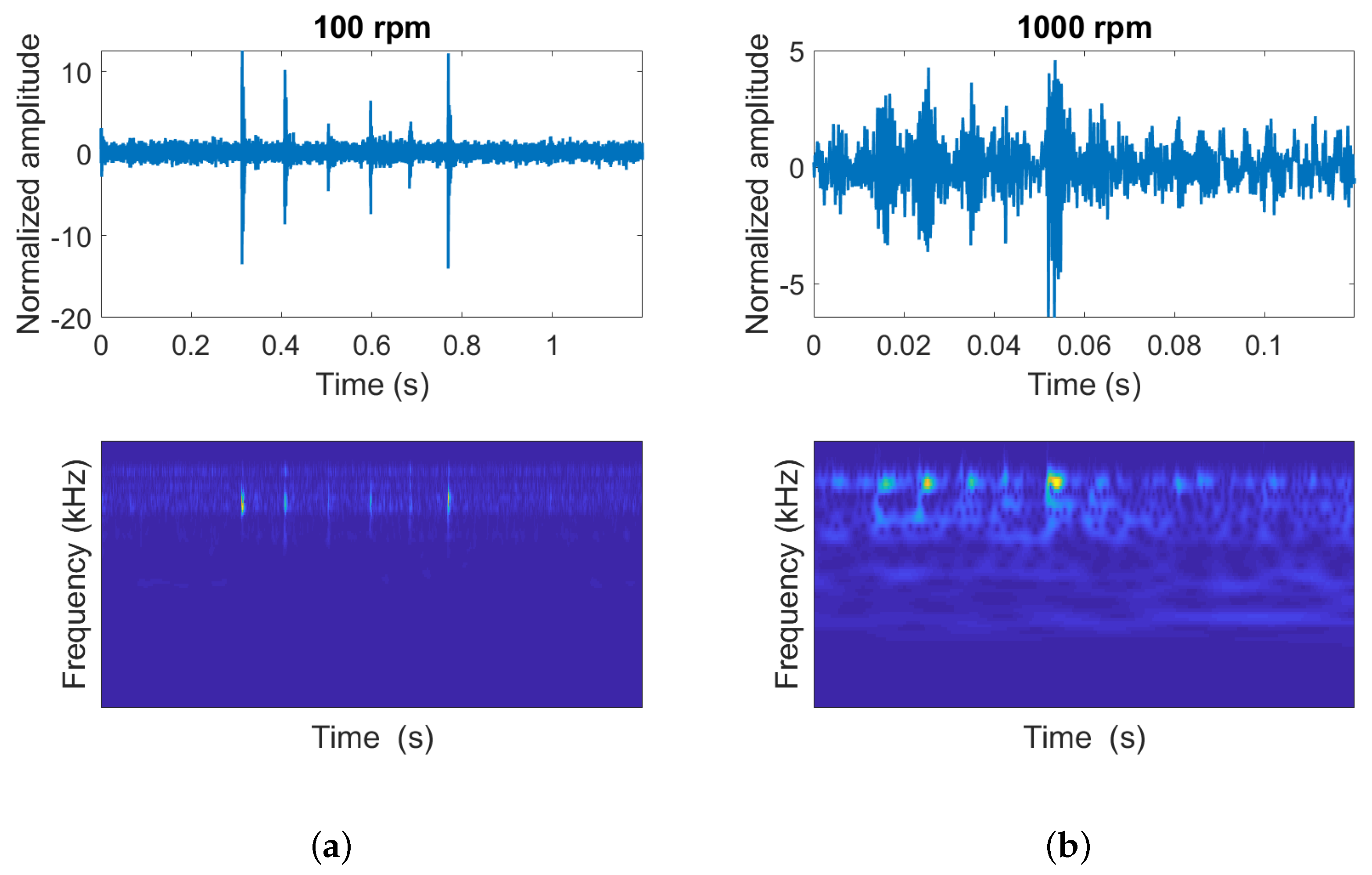
2]. Vibration signals associated with faults typically originates from high-frequency resonance in the housing structure excited by low-frequency impacts related to the contact between a fault and other bearing components. The accelerometers installed on the bearing housing are very sensitive to any forces generated in a system. This makes collected signals from the accelerometers very complicated due to the interference of noise. The complexity of the output signals from the collected acoustic emission sensors can be even worse due to its higher sensitivity and is worse in highly disturbed environments.
To predict bearing faults based on the mentioned signals, common processing, i.e., fast Fourier transform (FFT), short-time Fourier transform (STFT), and continuous Wavelet transform (CWT) in [
3], and wavelet transform (WT) with kurtosis [
4], could be used to detect signals associated with the faults. Such a signal processing technique is useful to observe characteristic frequencies in time and frequency representations. However, missing a harmonic in a spectrum or the appearance of harmonics at characteristic frequencies due to noise might cause misclassification. Further, the effectiveness of this conventional approach strongly depends on manpower skill, training, and relevant experience.
Unlike conventional bearing faults such as spalling on races or rolling elements, roller-end wear in axial roller bearings might not produce periodic harmonic components associated with faults. In a previous study by the authors [
5], scratches on an axial bearing were observed on roller ends of a tapered axial roller bearing in an offshore drilling machine, but no particular bearing frequency was steadily detected in the spectrum. However, acoustic emission data showed an energy increase with higher damage severities. Detecting bearing defects without a characteristic frequency or predefined knowledge of the fault signature is a big challenge in fault diagnosis.
To address the mentioned challenges, an automatic system for fault detection and classification applicable to both vibration and acoustic emission signals can reduce the manpower dependence and time consumption for condition monitoring of the roller bearing in industry. As argued in [
6], increasing the performance of the detection system might be more important than looking for highly reliable features. Model-based, data-driven, or hybrid algorithms are common in automatic fault diagnosis [
7,
8,
9,
10]. The model-based diagnosis needs both a detailed physical model of the system and its accurate parameters, which are very hard to obtain in reality. Without a physical model [
11], the data-driven approach using statistical or machine learning algorithms is attractive for an automatic diagnosis system. To enhance the accuracy of fault detection, statistics methods should be based on the frequency spectrum to reduce false and missing alarms [
12]. Alternatively, machine learning methods, namely support vector machine (SVM) [
13,
14], decision tree (DT) [
15], and various neural network architectures [
16,
17] combined with advanced signal processing can be used to find the complex relations on the feature space by using predefined time-frequency features, being based on fault characteristic frequencies. However, without the characteristic frequencies, the mentioned methods have great difficulty in classifying bearing faults [
18].
This work focuses on developing a simple automatic fault diagnosis method for roller bearings, requiring less human intervention or domain knowledge of features. Using transfer learning (TL) allows us to reduce the time and complexity of generating features for fault classification. Further, TL is very helpful for a bearing fault diagnosis if the available data for training and validation are limited in industry [
16]. Within this work, a pretrained version of the well-known AlexNet convolutional neural network (CNN) architecture [
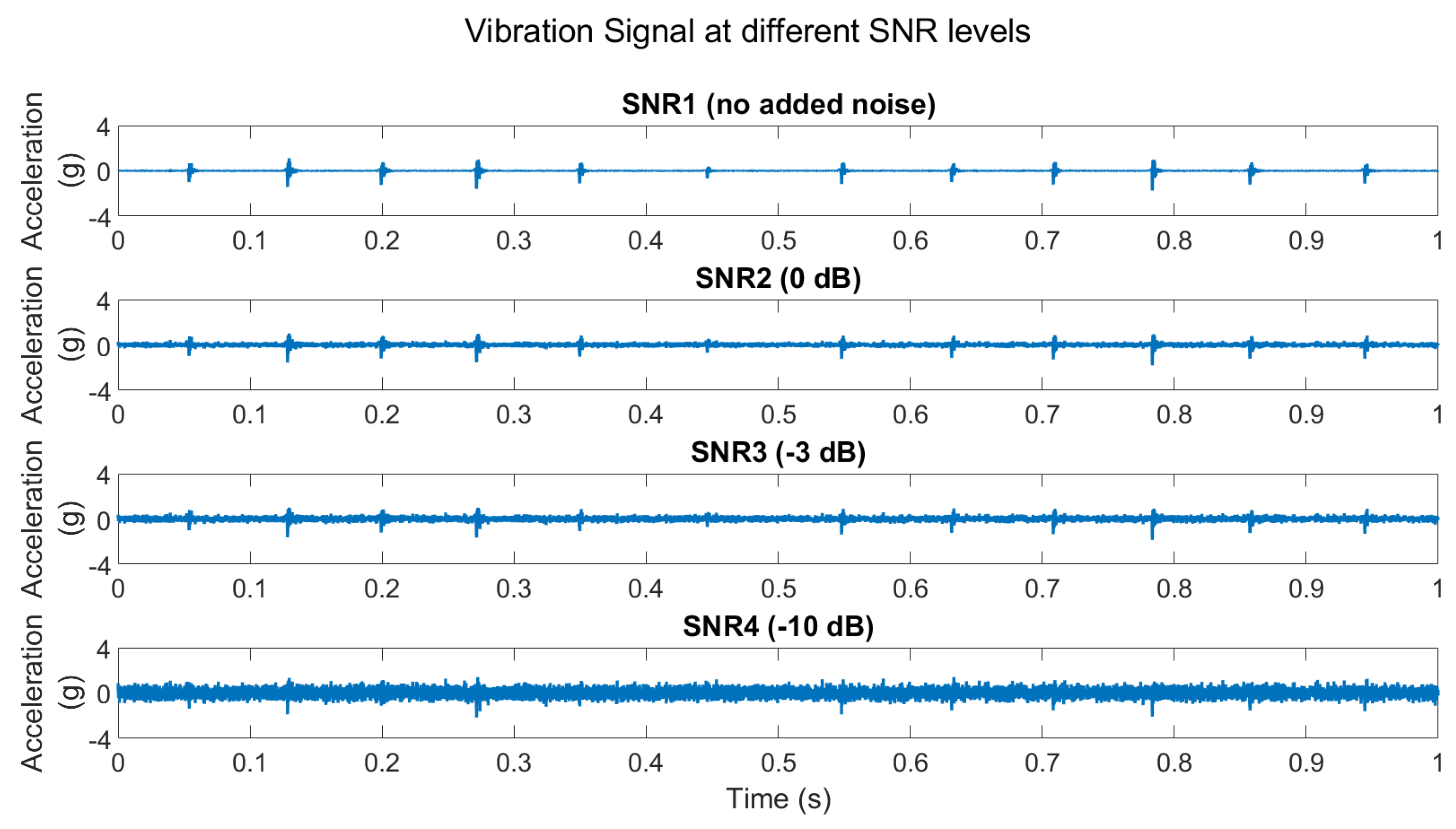
19] is applied to CWT spectrograms of vibration and acoustic emission signals. Then, the CNN is either fine-tuned to perform classification directly or to extract features used to train and validate two classifiers using SVM and sparse autoencoder-based SVM (SAE-SVM). The robustness of the proposed method is tested at different signal-to-noise ratio (SNR) levels.
The remainder of the article is organized as follows. In
Section 2, the proposed methods are detailed. In
Section 3, the experimental setup and preprocessing are presented. In
Section 4, the results of the fault detection and classification are presented. Further, the discussion of the presented results is detailed in
Section 5. Finally, the paper is concluded in
Section 6.
2. The Proposed Method
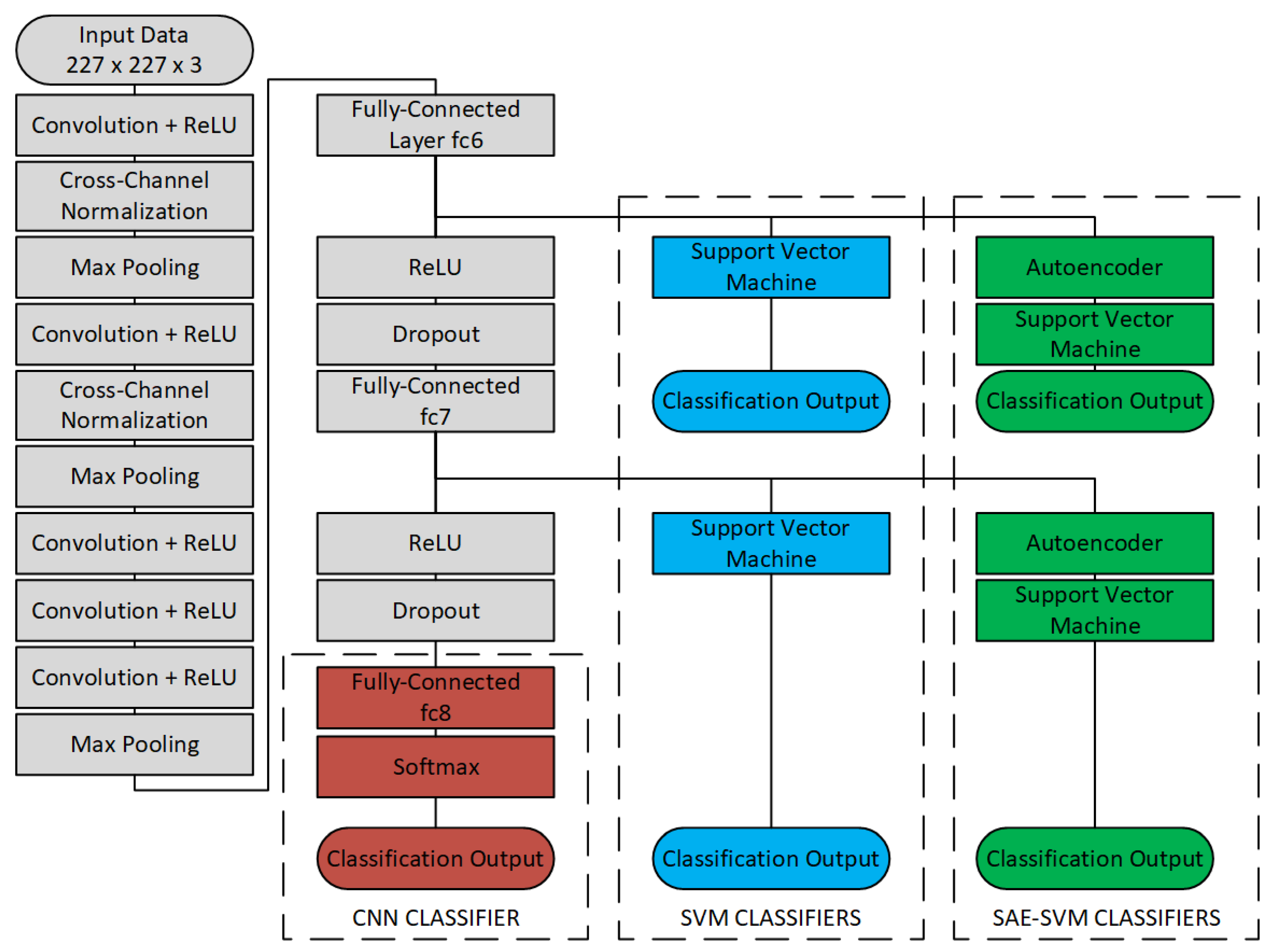
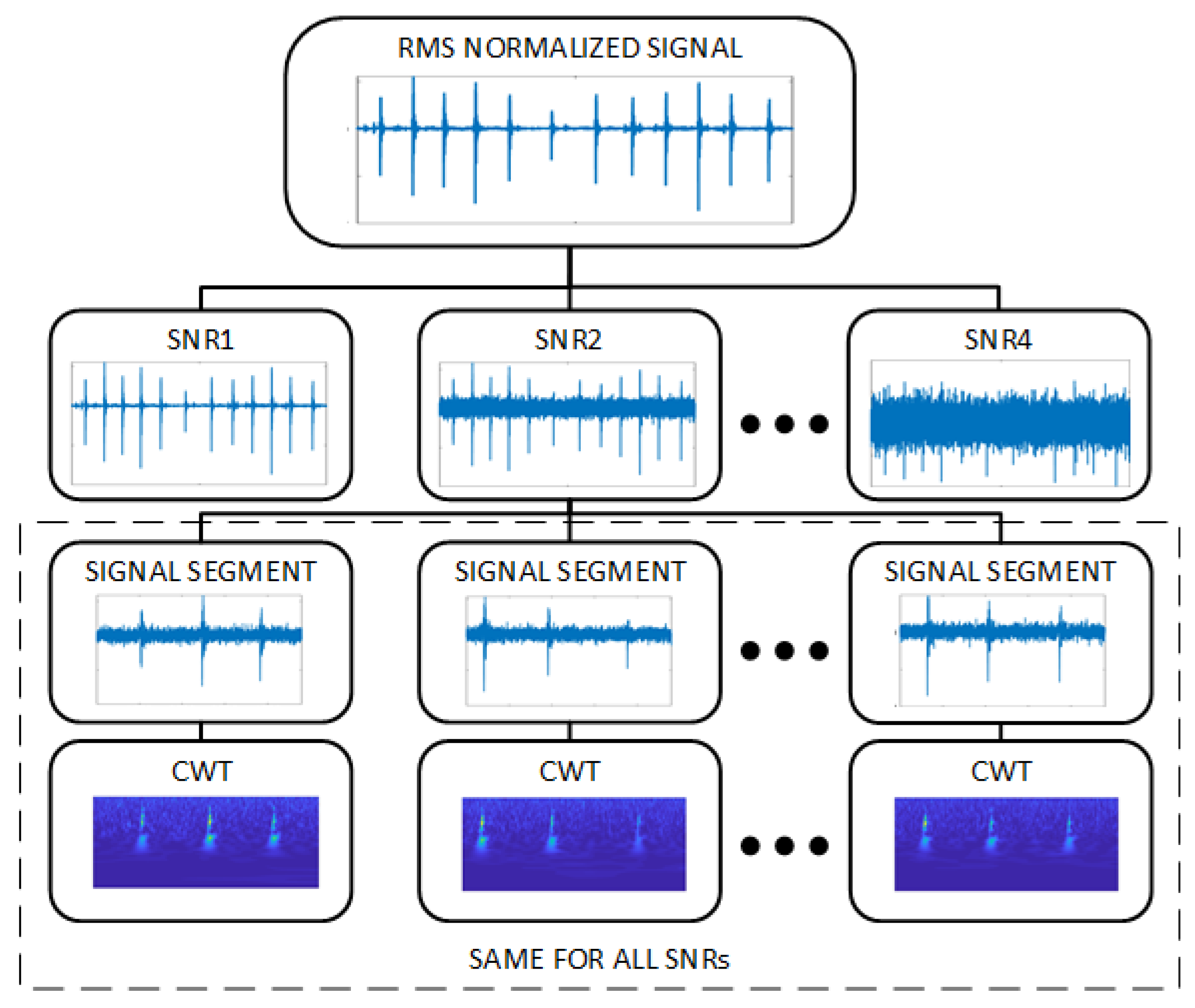
A diagram of the proposed fault classification is shown in
Figure 1. The vibration signals need to be converted to images as pixels or a matrix (227 × 227 × 3, height by width by depth) before feeding them to the AlexNet architecture. Within this process, images or spectrograms of vibration signals are formed by three channels (red, green, and blue (RGB)), resulting in a depth of three. The spectrograms go though several convolutional layers, acting as learnable filters to detect the presence of specific features from the input, and produce matrices (
) with
and
L-size filters. This work utilizes a pretrained version of the AlexNet architecture [
19], obtained from the Berkeley Vision and Learning Center caffe repository on GitHub [
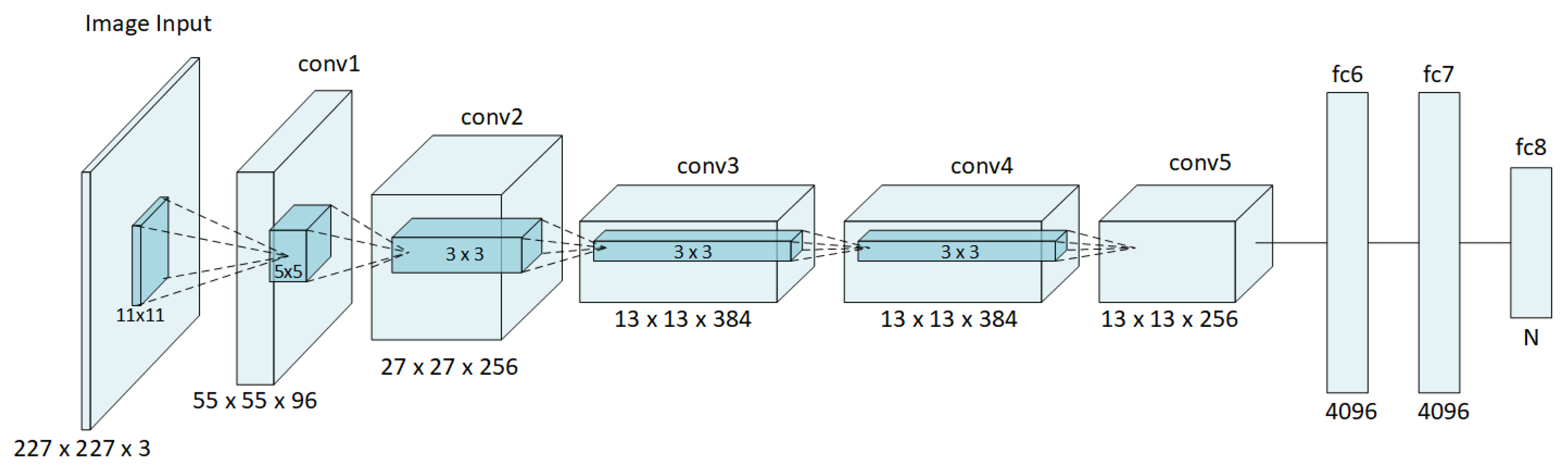
20], through the MATLAB Deep Learning Toolbox. AlexNet consists of five convolutional (conv1–conv5) and three fully-connected (fc6–fc8) layers, as illustrated in
Figure 2, in which numbers outside the boxes illustrate the dimension in each layer and numbers inside the boxes indicate the filter sizes of the convolutions. The architecture uses rectified linear units (ReLU) as activation functions and dropout layers to prevent overfitting. Three classifiers will be described in this section: CNN, SVM, and SAE-SVM. For the two latter, features from the pretrained network will be extracted at both layer fc6 and fc7 and used to train two instances of the classifiers.
2.1. Convolutional Neural Network-Based Fault Classifiers or Retrained CNN
Given the performance of CNNs in image classification, they can be fully trained to classify patterns or spectrograms generated by CWT correctly [
21]. However, training a network from scratch is very time consuming, requiring GPU programming, tuning of hyperparameters, etc. The first classifier uses transfer learning through fine-tuning of a pretrained CNN, e.g., the AlexNet architecture, to reduce the complexity of the training process. Instead of retraining the complete network from scratch, only the final classification layer is replaced, which maintains most of the already gathered information from the training on the imageNet database. To make sure most of the pretrained weights are maintained, the learning rate for the classification layer fc8 is increased to 20-times the overall learning rate. After replacing fc8 with a fully-connected layer of size 2 (equal to the number of classes), the network has approximately 60 million trainable parameters. Because of pre-training, fine-tuning the CNN to classify new data can then be done by using a smaller dataset of CWT spectrograms. This adaptation of a pretrained network is time-saving and very helpful for inexperienced users.
Table 1 describes the parameter setting for the CNN-classifier.
2.2. Support Vector Machine-Based Fault Classifier
Support vector machines are supervised learning models for data classification. Given a set of training data of dimension
K, the algorithm finds the hyperplane, a subset of the feature space of dimension
, which provides the best separation between classes in the training data [
14]. This is a quadratic optimization problem, which also removes the local minima being present in neural networks [
22]. Each input image generates a set of features at each layer throughout the network. Instead of retraining the final classification layers like in
Section 2.1, this classifier extracts the features directly at a higher level. This method is built on on the assumption that filters in the convolutional layers are trained to detect features that are also suited to discriminate features associated with the bearing faults.
The generated feature space from AlexNet has dimension
for both layer fc6 and fc7. The objective of using data at fc6 or fc7 is to study whether the extra ReLU, dropout, and fully-connected layer from TL affects the accuracy of SVM classifications or not. By using the pretrained network to generate features, it is not necessary to design any features tailor-made to the application. Instead, the SVM is trained as set in
Table 2.
2.3. Sparse Autoencoder Combined with SVM Classifier
The autoencoder is designed to replicate its input at its output in an unsupervised fashion, which can be used for both unsupervised feature extraction and image denoising [
23]. An autoencoder is basically a single fully-connected layer of size
P, referred to as the hidden layer, that is trained to reconstruct its input by minimizing error over the training dataset. Labels are not considered during training. One could assume that not all these features are equally important or necessary in order to perform classification. However, computational burden is a product of feature space dimension,
N, and hidden layer size,
P. By using the features from fc6 or fc7 instead of the input image,
N is reduced from 154,587 to 4096, dramatically reducing the computational burden. Denoising AEs and sparse AEs are commonly used in literature. The denoising AEs are to partially corrupt input data and capture the original data removing noise, while the sparse AEs are to learn the features and structures within the input data. With a hidden layer size of
, the SAE is used in this paper with a sparsity proportion of
to identify features from fc6 or fc7. The identified individual features are classified by SVM as described in
Section 2.2. Detailed settings of the SAE parameters are given in
Table 3.
5. Discussions
Table 10 shows accuracy averaged across SNR levels and results for different amounts of test data, the overall accuracy in both datasets. The SVM classifier had the highest accuracy, followed by CNN and SAE-SVM, respectively. The SAE-SVM score was heavily affected by poor performance in analyzing features fc7 in Dataset 2.
While accuracy is an indicator of classifier performance, detection rate and of false alarm rate will further justify performance evaluation.
Table 11 shows the probability of false alarm (PFA) and probability of detection (POD) averaged across SNR level and training data size. Additionally, the mean value across both datasets is included. These metrics are summarized and color coded using dark green (best), light green, yellow, light red, and dark red (worst) for each dataset. Ideally, a classifier has a high POD combined with a low PFA.
Evaluation of the classifiers was done qualitatively with respect to classification performance, robustness, ease of implementation, and computational demand. When ranking performance between classifiers, the notation of was used, as five different variations have been tested where X is the ranking of the performance, e.g., indicates the best performance.
5.1. CNN Classifier
As seen in
Table 10, the CNN classifier had an overall accuracy of 96.93%, which was ranked
of the tested cases. Closer examination of
Table 8 and
Table 12 reveals that accuracy with 25% training data in Dataset 1 had the most negative impact on overall score. Its PFA ranked
, while its POD
. Its POD ranked
for Dataset 1, FT1, but still over 95%. The implementation was easy, but required training the network. The performance with 25% training data suggests that more training data are required compared to other classifiers. The CNN classifier also scaled well to multi-class classification problems by simply increasing the number of neurons in the final layers.
5.2. SVM Classifier
The SVM classifier was the easiest to implement. Filters and weights from the pretrained network were not modified, and the features input to the SVM were available without any fine-tuning of the network. The major tuning parameter was from which layer to extract the features. In this paper, features at layers fc6 and fc7 were used, but fc6 showed a better accuracy, lower PFA, and higher POD for all datasets except POD for Dataset 2. Additionally, both mean accuracy, PFA, and POD ranked overall. Tuning of SVM parameters and different kernels will affect performance, but training the SVM is less computationally heavy than training the CNN or autoencoders. Overall, the SVM classifier on features fc6 had the best performance among the tested classifiers.
5.3. SAE-SVM Classifier
The sparse autoencoder added to the SVM classifier became an SEA-SVM classifier. While unsupervised extraction of important parameters seems favorable, the methods showed no consistent advantage over the SVM classifier in terms of classification performance. As illustrated by the results in Dataset 2, the autoencoder might even fail to extract useful features for discriminating between classes where the SVM classifier succeeds. Extracting features at fc7 ranked in accuracy, PFA, and POD, mainly due to performance on the axial roller bearing dataset. In contrast, the SAE-SVM using fc6 was ranked in PFA in fault classification for the axial roller bearing, but this result was accompanied by a rank in POD. Introducing the autoencoder in addition to the SVM adds complexity in terms of tuning parameters and requires time and computational power to train. Combined with the results, this method is not recommended for classifying faults in roller bearings if using simple transfer learning.
Table 12 gives a comparative evaluation of the proposed fault classifiers for roller bearings, where + and
indicate good and very good relative performance, while − and
are the negative equivalents.
5.4. Comparison with Envelope Analysis
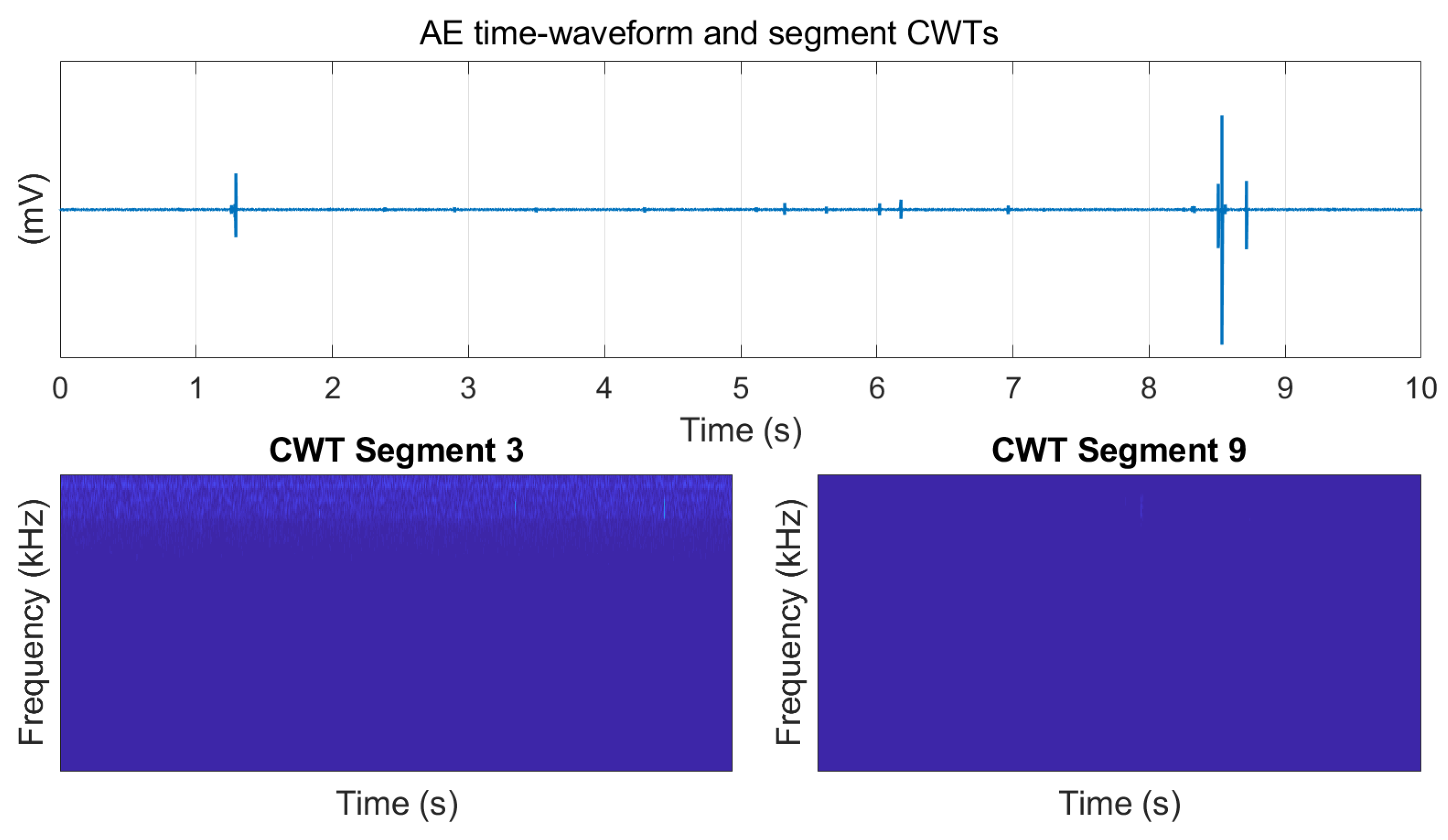
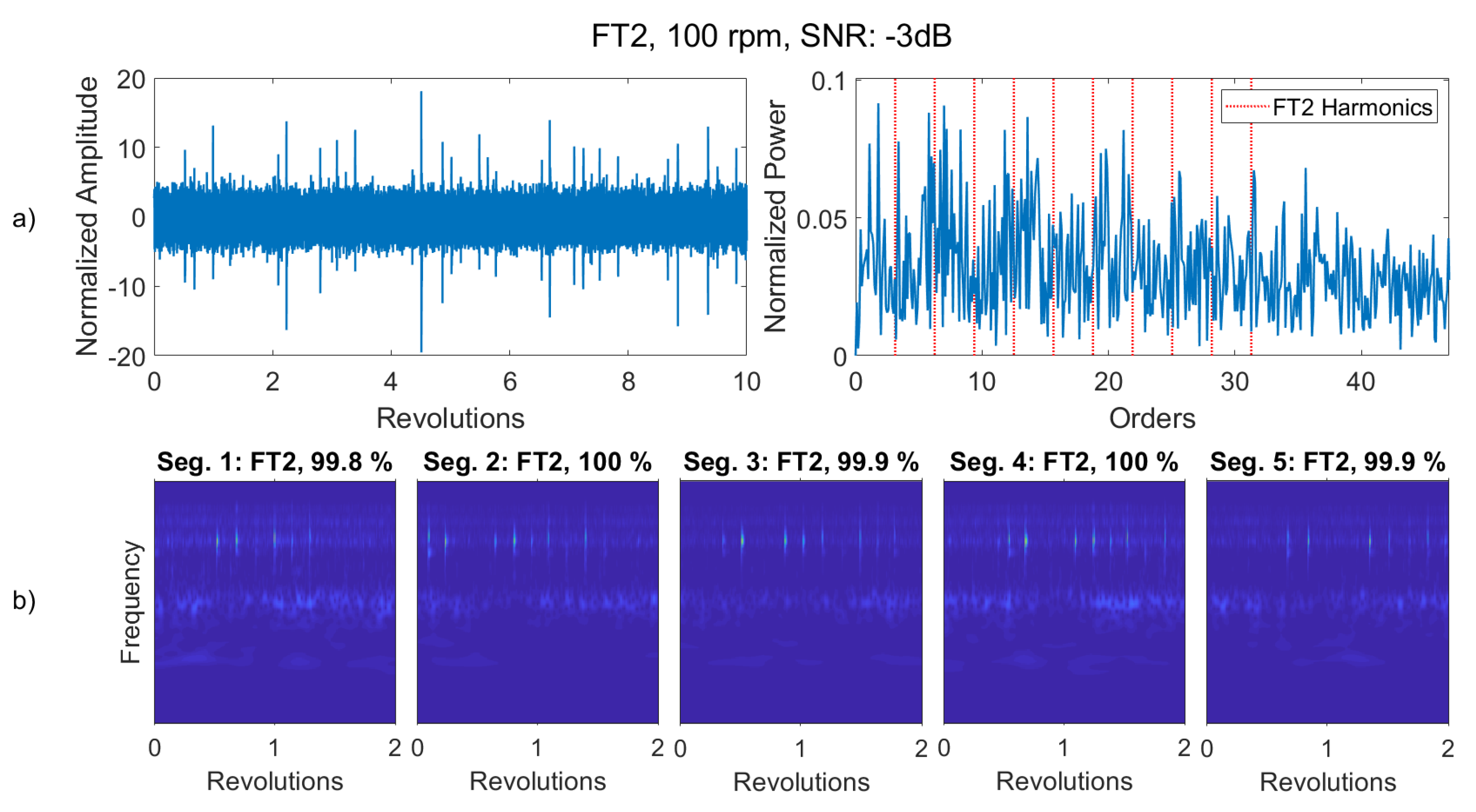
Envelope analysis has been commonly used in detecting bearing faults in industry. The performance of the proposed algorithms using machine learning was compared to those of using envelope analysis. In Dataset 1, the roller element fault (FT2) was more difficult to detect than the outer race fault; thus, we provide an example where FT2 at the lowest speed (100 rpm) was analyzed using envelope analysis. In the proposed classifiers, segments of two revolutions were used. To improve resolution in the envelope spectrum, five segments were combined so that total segment length was extended to 10 revolutions. As shown in
Figure 13, even though transients were visible in the time domain waveform, no clear peak was visible in the envelope spectrum without further processing. However, the proposed method, here illustrated by the CNN classifier, can predict the correct class with above 99% probability. Envelope analysis would in this case require a certain expertise to perform further analysis.
6. Conclusions
A transfer learning approach to bearing fault classification using a pretrained convolution neural network (CNN) was proposed in this work. It was shown that the pretrained network can be fine tuned, or used to generate features for detecting bearing faults by other machine learning-based classifiers. Three classifiers based on CNN, support vector machine (SVM) and combined sparse autoencoder (SAE) and SVM algorithms were used to classify faults in axial and radial roller bearings using both vibration and acoustic emission signals.
The performance and robustness of the proposed method were investigated under different fault types, operating speed, and noise levels. The investigation shows that extracting features from the pretrained CNN directly, then using the SVM for classification, is the best option to detect faults in roller bearings in terms of robustness, easy implementation, and computational burden. Fine-tuning of the CNN scales well to multiclass classification problems, but yields lower accuracy than the SVM classifier. Combined with increased computational burden and more tunable hyperparameters, the CNN-based classifier is ranked as the second best option. Unsupervised dimensionality reduction using SEA to the extracted features from the pretrained CNN increases the computational burden and complexity of the SAE-SVM classifier for this application. It also has a negative effect on robustness and thus the accuracy of the classification.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}