
Solid Waste Image Classification Using Deep Convolutional Neural Network



Abstract
:1. Introduction
- The provision of a reconstructed and represented version of an existing dataset for solid waste classification [24] (including source code) such that it can be used by other researchers to reproduce the experiments, improve results, and compare performance;
- The proposal of a bespoke, lightweight CNN framework based on image size reduction for waste classification, with low time and computation requirements and relatively high performance.
2. Background and Related Research
3. Materials and Methods
3.1. Dataset
3.2. Image Data Augmentation
3.3. Method
- To show how image resizing can be used to address the requirements of different applications, namely: a light-weight application for low-cost device with limited memory capacity and low-resolution camera and a robust application using high-resolution camera without memory restriction.
- To investigate the variation in performance between the two models. The idea is to determine if smaller image resolution can achieve a relatively high performance, thus avoiding unnecessary waste of system resources in terms of model size and computational time.
3.4. Experimental Setup
4. Results
- The standard CNN architectures were developed as part of the annual ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [69], where researchers compete to correctly detect and/or classify objects and scenes in a large database consisting of 14,197,122 images organised into 21,841 categories. As such, the pre-trained models are inherently very large.
- Self-reported model size and development time will vary among research studies due to variations in the computer system specification, purpose of experiments, data size, etc. For example, Hang et al. [23] used nine standard CNN architectures (with some modifications, such as layer freezing) to classify plant leaf diseases, and compared model size and training time. InceptionNet-v2 [46] produced the smallest model size of 45.1 MB within 2187.3 s. This is super-fast when compared to the 6.40 h used to train our smaller bespoke CNN model that is only 1.08 MB. Their experiment was faster due to higher system specification (i.e., i7-8700k processor and 32GB RAM, accelerated by two NVIDIA GTX 1080TI GPUs).
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Meng, X.; Tan, X.; Wang, Y.; Wen, Z.; Tao, Y.; Qian, Y. Investigation on decision-making mechanism of residents’ household solid waste classification and recycling behaviors. Resour. Conserv. Recycl. 2019, 140, 224–234. [Google Scholar] [CrossRef]
- Guo, X.-x.; Liu, H.-t.; Zhang, J. The role of biochar in organic waste composting and soil improvement: A review. Waste Manag. 2020, 102, 884–899. [Google Scholar] [CrossRef] [PubMed]
- Sharma, B.; Vaish, B.; Monika; Singh, U.K.; Singh, P.; Singh, R.P. Recycling of Organic Wastes in Agriculture: An Environmental Perspective. Int. J. Environ. Res. 2019, 13, 409–429. [Google Scholar] [CrossRef]
- Dhiman, S.S.; Shrestha, N.; David, A.; Basotra, N.; Johnson, G.R.; Chadha, B.S.; Gadhamshetty, V.; Sani, R.K. Producing methane, methanol and electricity from organic waste of fermentation reaction using novel microbes. Bioresour. Technol. 2018, 258, 270–278. [Google Scholar] [CrossRef]
- Taleb, M.A.; Al Farooque, O. Towards a circular economy for sustainable development: An application of full cost accounting to municipal waste recyclables. J. Clean. Prod. 2021, 280, 124047. [Google Scholar] [CrossRef]
- Ferronato, N.; Torretta, V. Waste Mismanagement in Developing Countries: A Review of Global Issues. Int. J. Environ. Res. Public Health 2019, 16, 1060. [Google Scholar] [CrossRef] [Green Version]
- Dzhanova, Y. Sanitation Workers Battle Higher Waste Levels in Residential Areas as Coronavirus Outbreak Persists; CNBC Politics: New York, NY, USA, 2020; Available online: https://www.cnbc.com/2020/05/16/coronavirus-sanitation-workers-battle-higher-waste-levels.html (accessed on 21 January 2022).
- Kaza, S.; Yao, L.C.; Bhada-Tata, P.; Van Woerden, F. What a Waste 2.0: A Global Snapshot of Solid Waste Management to 2050; Urban Development: Washington, DC, USA, 2018. [Google Scholar]
- Yadav, H.; Kumar, P.; Singh, V.P. Hazards from the Municipal Solid Waste Dumpsites: A Review. In Proceedings of the 1st International Conference on Sustainable Waste Management through Design; Springer: Cham, Switzerland, 2019; Volume 21, pp. 336–342. [Google Scholar] [CrossRef]
- Forti, V.; Balde, C.P.; Kuehr, R.; Bel, G. The Global E-Waste Monitor 2020: Quantities, Flows and the Circular Economy Potential; United Nations University/United Nations Institute for Training and Research: Bonn, Germany; International Telecommunication Union: Geneva, Switzerland; International Solid Waste Association: Rotterdam, The Netherland, 2020. [Google Scholar]
- Ellen MacArthur Foundation. The New Plastics Economy: Rethinking the Future of Plastics and Catalysing Action. Available online: https://emf.thirdlight.com/link/cap0qk3wwwk0-l3727v/@/#id=1 (accessed on 21 January 2022).
- Xia, W.; Jiang, Y.; Chen, X.; Zhao, R. Application of machine learning algorithms in municipal solid waste management: A mini review. Waste Manag. Res. J. Sustain. Circ. Econ. 2021, 0734242X2110337. [Google Scholar] [CrossRef]
- Li, W.; Tse, H.; Fok, L. Plastic waste in the marine environment: A review of sources, occurrence and effects. Sci. Total Environ. 2016, 566–567, 333–349. [Google Scholar] [CrossRef]
- Ye, Z.; Yang, J.; Zhong, N.; Tu, X.; Jia, J.; Wang, J. Tackling environmental challenges in pollution controls using artificial intelligence: A review. Sci. Total Environ. 2020, 699, 134279. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. Evolving Deep Convolutional Neural Networks for Image Classification. IEEE Trans. Evol. Comput. 2020, 24, 394–407. [Google Scholar] [CrossRef] [Green Version]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Liang, S.; Gu, Y. A deep convolutional neural network to simultaneously localize and recognize waste types in images. Waste Manag. 2021, 126, 247–257. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2012; Volume 25. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Hang, J.; Zhang, D.; Chen, P.; Zhang, J.; Wang, B. Classification of Plant Leaf Diseases Based on Improved Convolutional Neural Network. Sensors 2019, 19, 4161. [Google Scholar] [CrossRef] [Green Version]
- Sekar, S. Waste Classification Data, Version 1. Available online: https://www.kaggle.com/techsash/waste-classification-data (accessed on 18 January 2022).
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Toğaçar, M.; Ergen, B.; Cömert, Z. Waste classification using AutoEncoder network with integrated feature selection method in convolutional neural network models. Measurement 2020, 153, 107459. [Google Scholar] [CrossRef]
- Mulim, W.; Revikasha, M.F.; Rivandi; Hanafiah, N. Waste Classification Using EfficientNet-B0. In Proceedings of the IEEE Institute of Electrical and Electronics Engineers, Jakarta, Indonesia, 28 October 2021; pp. 253–257. [Google Scholar] [CrossRef]
- Mallikarjuna, M.G.; Yadav, S.; Shanmugam, A.; Hima, V.; Suresh, N. Waste Classification and Segregation: Machine Learning and IOT Approach; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2021; pp. 233–238. [Google Scholar] [CrossRef]
- Gupta, T.; Joshi, R.; Mukhopadhyay, D.; Sachdeva, K.; Jain, N.; Virmani, D.; Garcia-Hernandez, L. A deep learning approach based hardware solution to categorise garbage in environment. Complex Intell. Syst. 2021, 1–24. [Google Scholar] [CrossRef]
- Masand, A.; Chauhan, S.; Jangid, M.; Kumar, R.; Roy, S. ScrapNet: An Efficient Approach to Trash Classification. IEEE Access 2021, 9, 130947–130958. [Google Scholar] [CrossRef]
- Hoque, M.A.; Azad, M.; Ashik-Uz-Zaman, M. IoT and Machine Learning Based Smart Garbage Management and Segregation Approach for Bangladesh; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Mollá, I.F. Inorganic Waste Classifier Using Artificial Intelligence. Ph.D. Thesis, LAB University of Applied Sciences, Lahti, Finland, 2021. [Google Scholar]
- Faria, R.; Ahmed, F.; Das, A.; Dey, A. Classification of Organic and Solid Waste Using Deep Convolutional Neural Networks. In Proceedings of the 2021 IEEE 9th Region 10 Humanitarian Technology Conference (R10-HTC), Bangalore, India, 30 September–2 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python, 1st ed.; Manning Publications: Shelter Island, NY, USA, 2018. [Google Scholar]
- Chollet, F. Training and Evaluation with the Built-In Methods. Available online: https://keras.io/guides/training_with_built_in_methods/ (accessed on 20 January 2022).
- Murphy, K.P. Machine Learning: A Probabilistic Perspective. In Adaptive Computation and Machine Learning Series; Bach, F., Ed.; MIT Press: London, UK, 2012. [Google Scholar]
- Nnamoko, N.; Barrowclough, J.; Procter, J. Waste Classification Dataset. Mendeley Data 2022, V2. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Thung, G.; Yang, M. Classification of Trash for Recyclability Status; Leland Stanford Junior University: Palo Alto, CA, USA, 2016; Available online: http://cs229.stanford.edu/proj2016/report/ThungYang-ClassificationOfTrashForRecyclabilityStatus-report.pdf (accessed on 19 January 2022).
- Srinilta, C.; Kanharattanachai, S. Municipal Solid Waste Segregation with CNN. In Proceedings of the 2019 5th International Conference on Engineering, Applied Sciences and Technology (ICEAST), Luang Prabang, Laos, 2–5 July 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Dewulf, V. Application of Machine Learning to Waste Management: Identification and Classification of Recyclables; Technical Report; Imperial College: London, UK, 2017. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Wang, H.; Li, Y.; Dang, L.M.; Ko, J.; Han, D.; Moon, H. Smartphone-based bulky waste classification using convolutional neural networks. Multimed. Tools Appl. 2020, 79, 29411–29431. [Google Scholar] [CrossRef]
- Castellano, G.; Carolis, B.D.; Macchiarulo, N.; Rossano, V. Learning waste Recycling by playing with a Social Robot. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 3805–3810. [Google Scholar] [CrossRef]
- Radhika, D.A. Real Life Smart Waste Management System [Dry, Wet, Recycle, Electronic and Medical]. Int. J. Sci. Res. Sci. Technol. 2021, 7, 631–640. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Rahman, M.W.; Islam, R.; Hasan, A.; Bithi, N.I.; Hasan, M.M.; Rahman, M.M. Intelligent waste management system using deep learning with IoT. J. King Saud Univ.—Comput. Inf. Sci. 2020. [Google Scholar] [CrossRef]
- Siva Kumar, A.P.; Buelaevanzalina, K.; Chidananda, K. An efficient classification of kitchen waste using deep learning techniques. Turk. J. Comput. Math. Educ. 2021, 12, 5751–5762. [Google Scholar]
- Kusrini; Saputra, A.P. Waste Object Detection and Classification using Deep Learning Algorithm: YOLOv4 and YOLOv4-tiny. Turk. J. Comput. Math. Educ. 2021, 12, 1666–1677. [Google Scholar]
- Teh, J. Household Waste Segregation Using Intelligent Vision System. Ph.D. Thesis, Universiti Tunku Abdul Rahman, Perak, Malaysia, 2021. Available online: http://eprints.utar.edu.my/4220/ (accessed on 19 January 2022).
- Alonso, S.L.N.; Forradellas, R.F.R.; Morell, O.P.; Jorge-Vazquez, J. Digitalization, circular economy and environmental sustainability: The application of artificial intelligence in the efficient self-management of waste. Sustainability 2021, 13, 92. [Google Scholar] [CrossRef]
- Majchrowska, S.; Mikołajczyk, A.; Ferlin, M.; Klawikowska, Z.; Plantykow, M.A.; Kwasigroch, A.; Majek, K. Deep learning-based waste detection in natural and urban environments. Waste Manag. 2022, 138, 274–284. [Google Scholar] [CrossRef]
- Sivakumar, M.; Renuka, P.; Chitra, P.; Karthikeyan, S. IoT incorporated deep learning model combined with SmartBin technology for real-time solid waste management. Comput. Intell. 2021. [Google Scholar] [CrossRef]
- Chollet, F. Building Powerful Image Classification Models Using Very Little Data. Available online: https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html (accessed on 19 January 2022).
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Irving, B. A Gentle Autoencoder Tutorial (with Keras); GitHub: San Francisco, CA, USA, 2016; Available online: https://github.com/benjaminirving/mlseminars-autoencoders/blob/master/Autoencoders.ipynb (accessed on 19 January 2022).
- Alaslani, M.G.; Elrefaei, L.A. Convolutional Neural Network Based Feature Extraction for IRIS Recognition. Int. J. Comput. Sci. Inf. Technol. 2018, 10, 65–78. [Google Scholar] [CrossRef] [Green Version]
- Bansal, V.; Libiger, O.; Torkamani, A.; Schork, N.J. Statistical analysis strategies for association studies involving rare variants. Nat. Rev. Genet. 2010, 11, 773–785. [Google Scholar] [CrossRef] [Green Version]
- Keim, R. Understanding Color Models Used in Digital Image Processing. Available online: https://www.allaboutcircuits.com/technical-articles/understanding-color-models-used-in-digital-image-processing/ (accessed on 19 January 2022).
- Provenzi, E. Color Image Processing; MDPI: Basel, Switzerland, 2018. [Google Scholar] [CrossRef]
- Dertat, A. Applied Deep Learning—Part 4: Convolutional Neural Networks. Available online: https://towardsdatascience.com/applied-deep-learning-part-4-convolutional-neural-networks-584bc134c1e2 (accessed on 19 January 2022).
- Brownlee, J. A Gentle Introduction to Dropout for Regularizing Deep Neural Networks; Publisher: Machine Learning Mastery. 2018. Available online: https://machinelearningmastery.com/dropout-for-regularizing-deep-neural-networks/ (accessed on 19 January 2022).
- Brownlee, J. How to Choose Loss Functions When Training Deep Learning Neural Networks; Publisher: Machine Learning Mastery. 2019. Available online: https://machinelearningmastery.com/how-to-choose-loss-functions-when-training-deep-learning-neural-networks/ (accessed on 19 January 2022).
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Good Accuracy Despite High Loss Value. Cross Validated. Version: 25 May 2017. Available online: https://stats.stackexchange.com/q/281651 (accessed on 19 January 2022).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Class ID | Original Image | Augmented Image |
|---|---|---|---|
| Organic | 1 | 13,880 | 194,320 |
| Recyclable | 0 | 10,825 | 151,550 |
| Total | 24,705 | 345,870 |
| Class Name | Training | Validation | Testing |
|---|---|---|---|
| Organic | 116,592 | 29,148 | 48,580 |
| Recyclable | 90,930 | 22,732 | 37,888 |
| Total | 207,522 | 51,880 | 86,468 |
| Input Resolution (pixel) | Epochs | Dev. Time (hour) | Model Size (MB) | Loss | Accuracy | ||||
|---|---|---|---|---|---|---|---|---|---|
| Training | Validation | Testing | Training | Validation | Testing | ||||
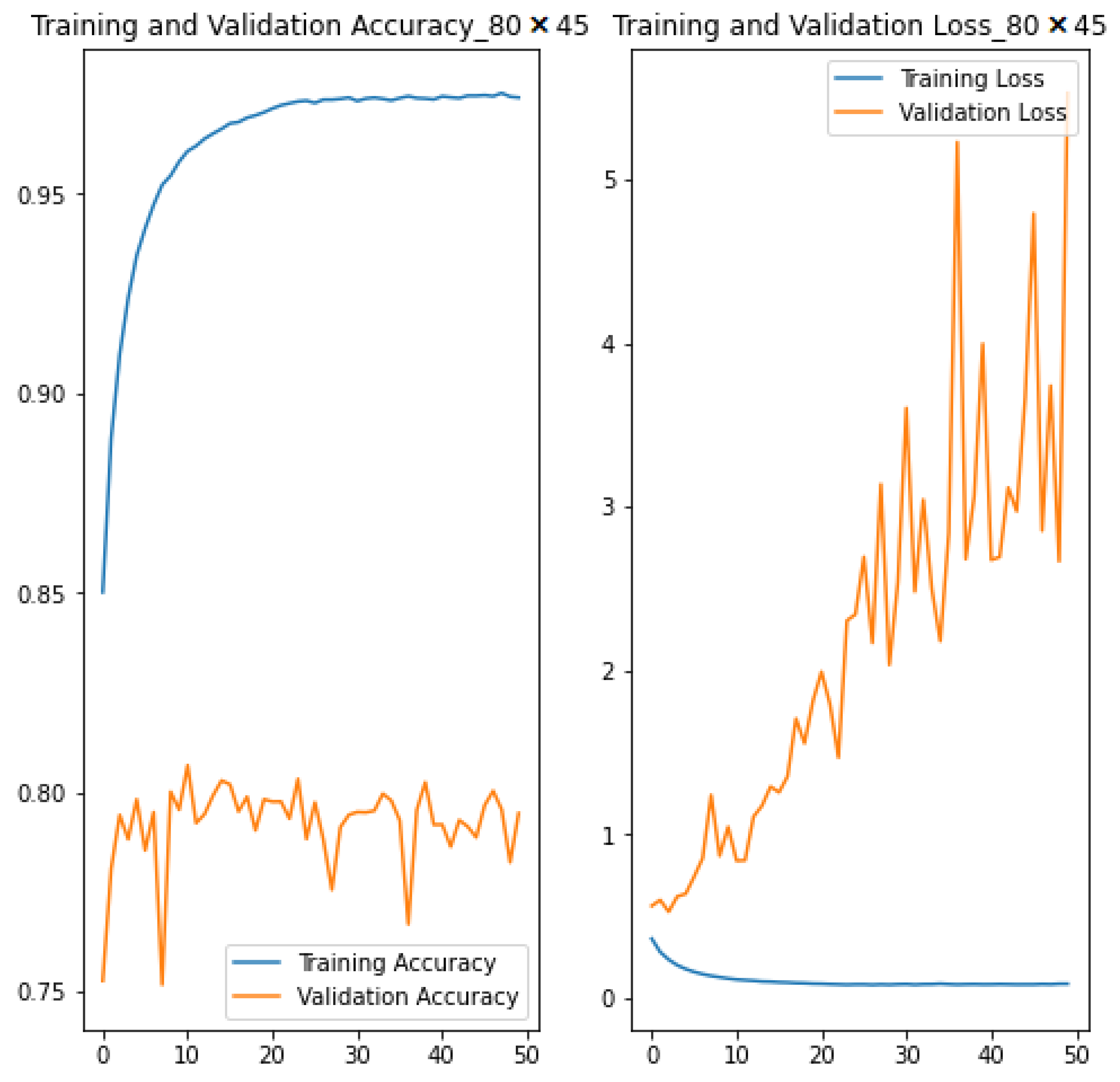
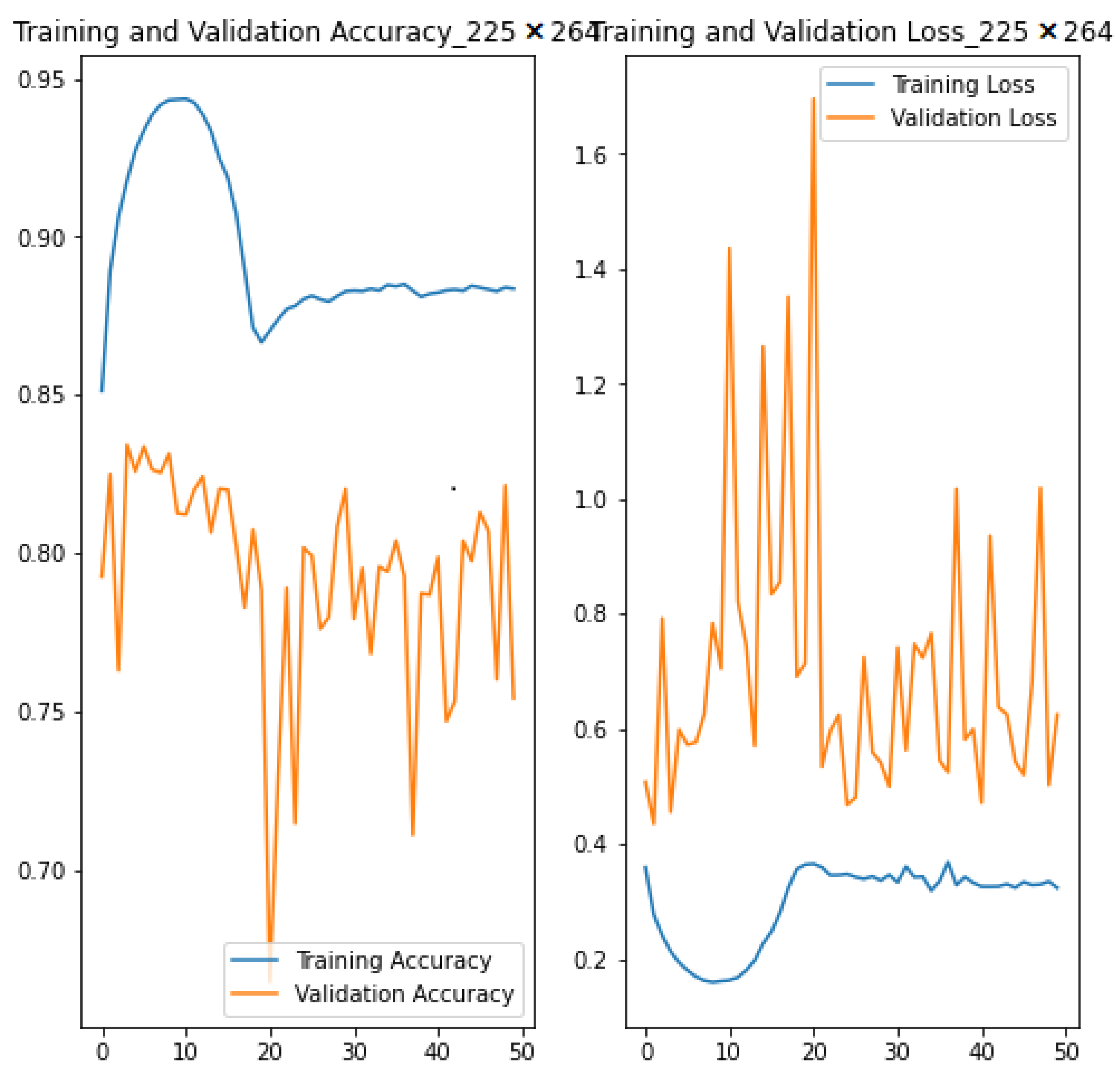
| 50 | 65.46 † | 2.35 † | 0.2954 | 0.7083 | 0.5692 | 0.8956 | 0.7921 | 0.7619 | |
| 50 | 6.40 † | 1.08 † | 0.1073 | 2.1885 | 5.4401 | 0.9628 | 0.7921 | 0.8088 | |
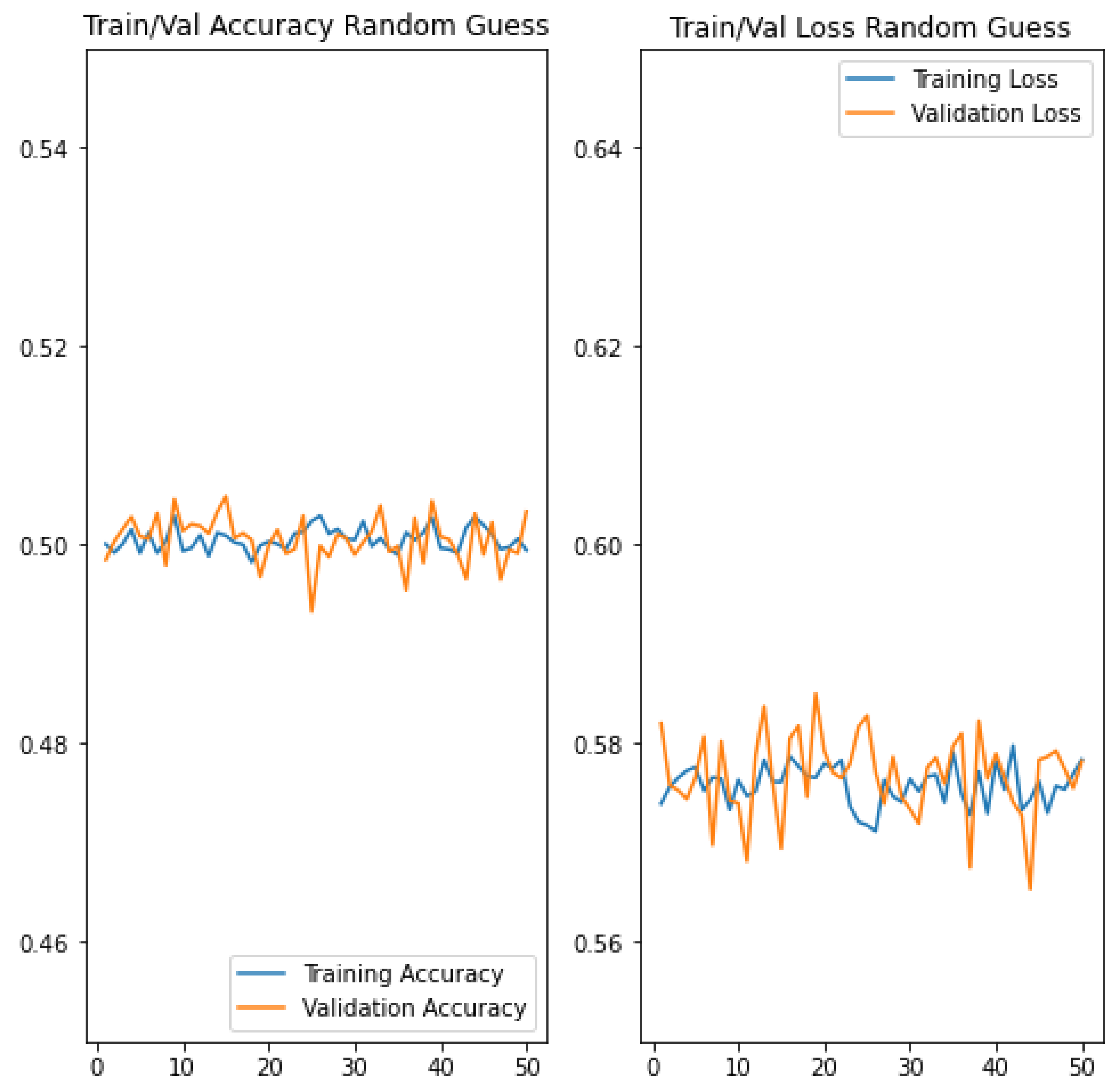
| Baseline | 50 | - | - | 0.5758 | 0.5768 | 0.5767 | 0.5005 | 0.5005 | 0.5005 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nnamoko, N.; Barrowclough, J.; Procter, J. Solid Waste Image Classification Using Deep Convolutional Neural Network. Infrastructures 2022, 7, 47. https://doi.org/10.3390/infrastructures7040047
Nnamoko N, Barrowclough J, Procter J. Solid Waste Image Classification Using Deep Convolutional Neural Network. Infrastructures. 2022; 7(4):47. https://doi.org/10.3390/infrastructures7040047
Chicago/Turabian StyleNnamoko, Nonso, Joseph Barrowclough, and Jack Procter. 2022. "Solid Waste Image Classification Using Deep Convolutional Neural Network" Infrastructures 7, no. 4: 47. https://doi.org/10.3390/infrastructures7040047
APA StyleNnamoko, N., Barrowclough, J., & Procter, J. (2022). Solid Waste Image Classification Using Deep Convolutional Neural Network. Infrastructures, 7(4), 47. https://doi.org/10.3390/infrastructures7040047