
Detect Megaregional Communities Using Network Science Analytics


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Literature Review
3. Methods
3.1. Data Sources
3.2. Analytical Methods
4. Results
4.1. Visualizing Commuting Flows
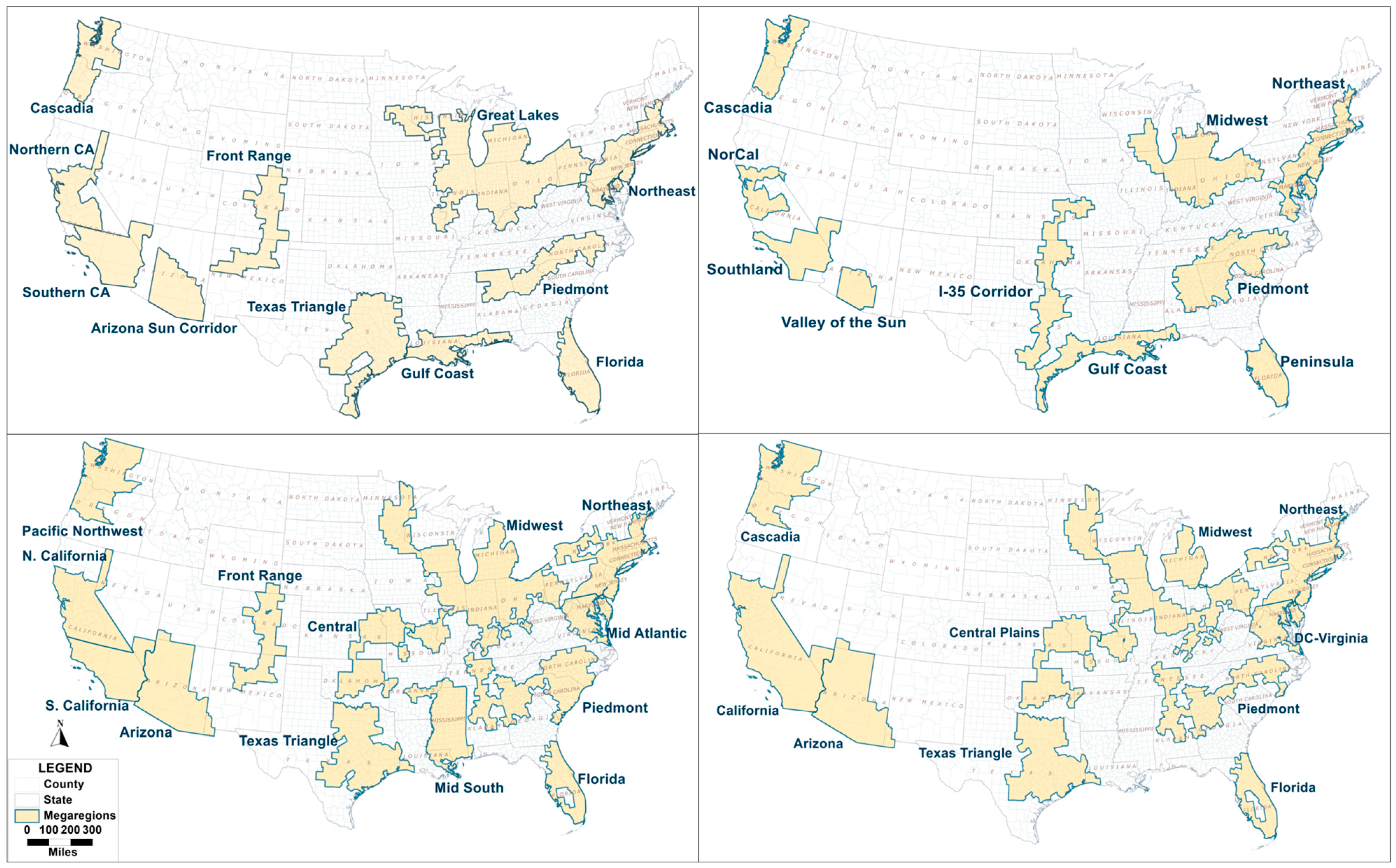
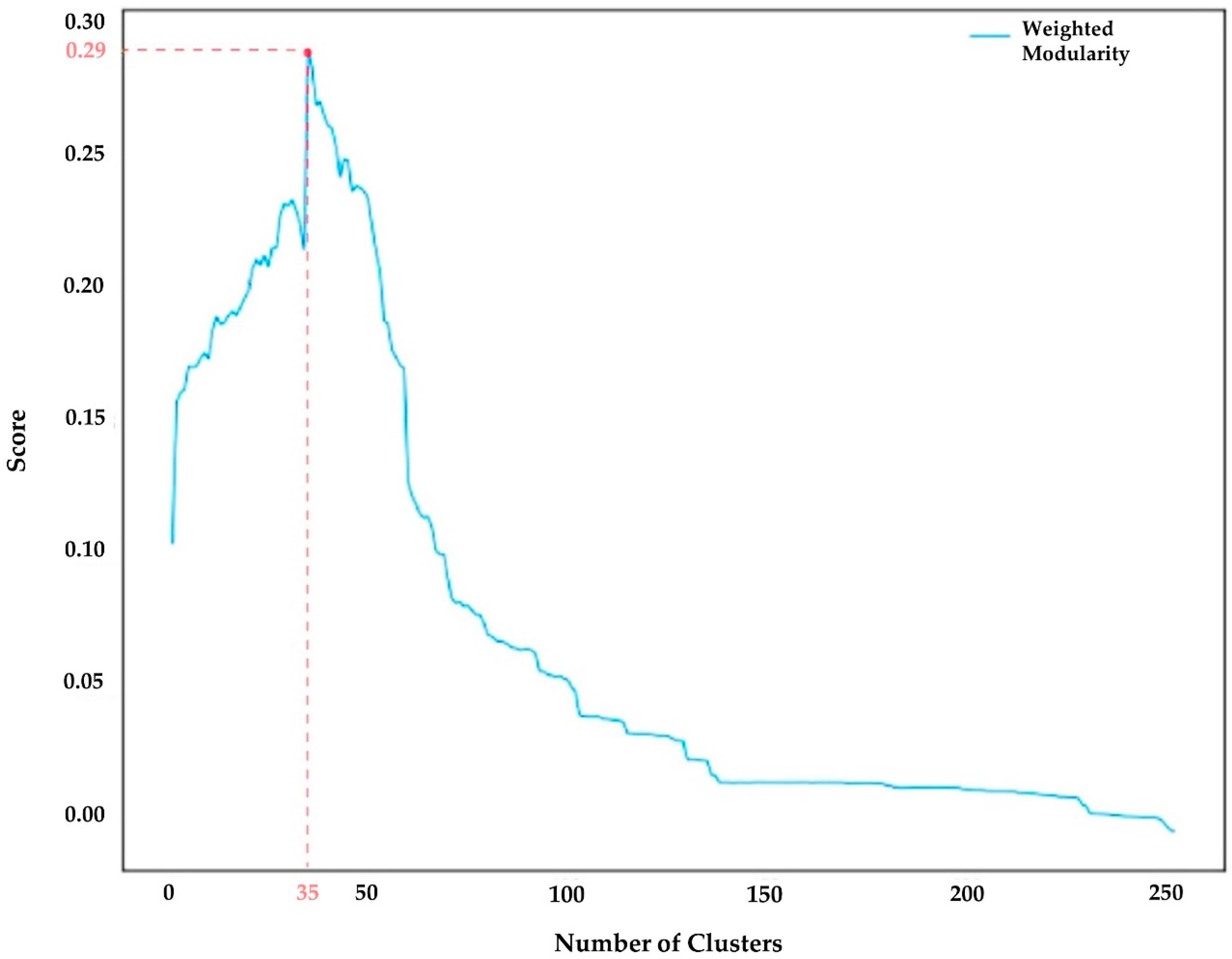
4.2. Gephi Analysis Results
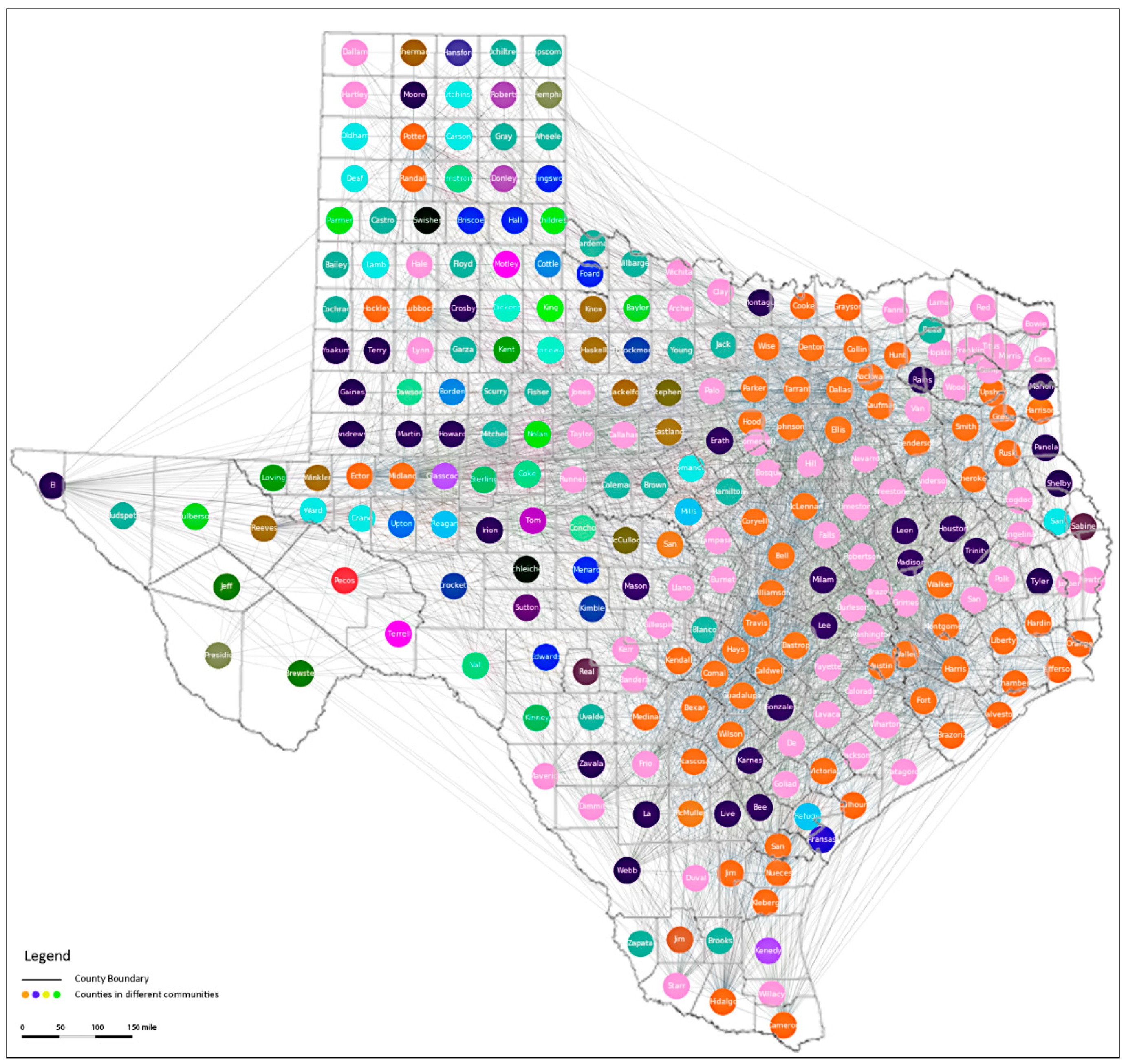
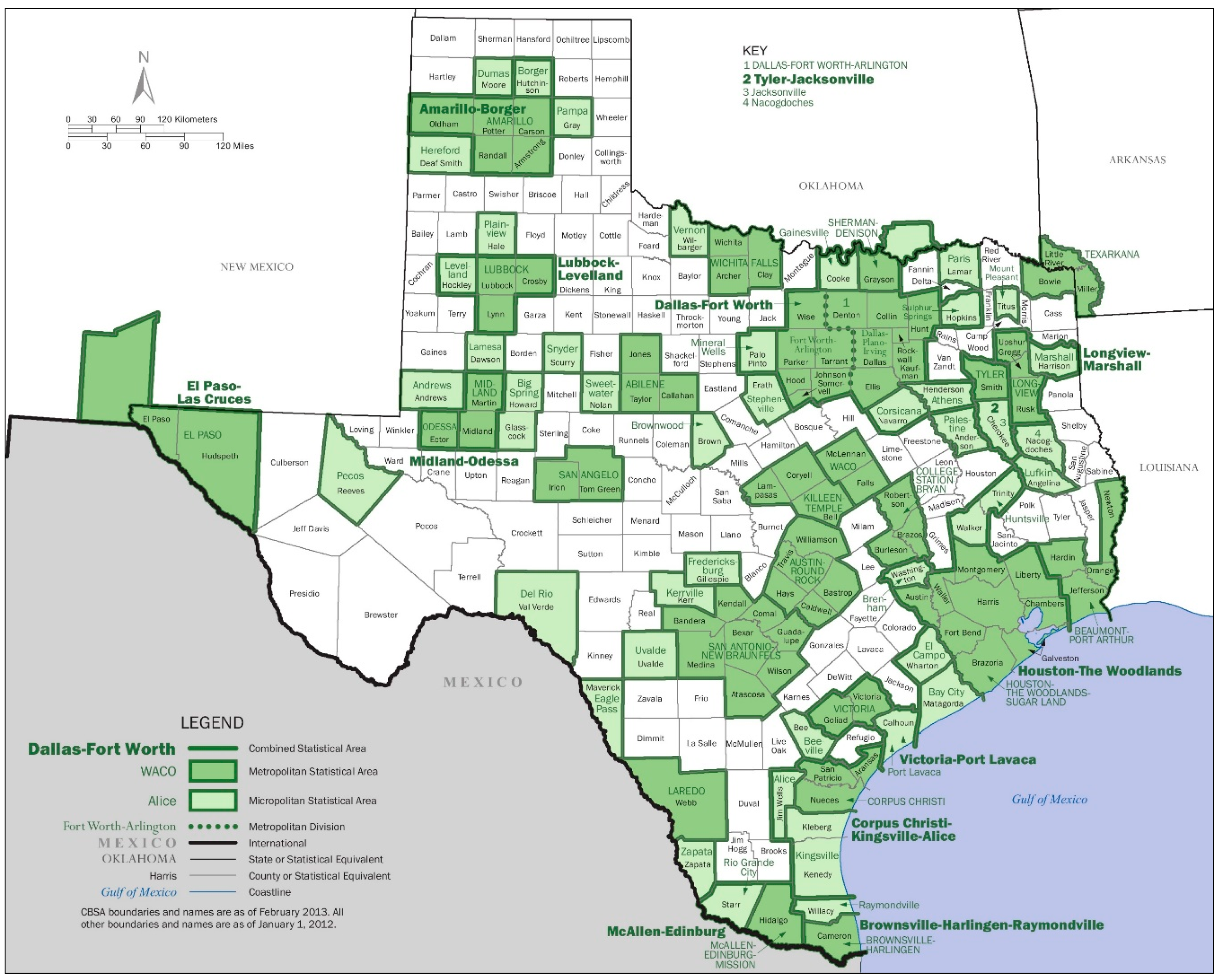
4.3. The Texas Analysis
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Batty, M. Modelling Cities as Dynamic Systems. Nature 1971, 231, 425–428. [Google Scholar] [CrossRef]
- Batty, M. Building a science of cities. Cities 2012, 29, S9–S16. [Google Scholar] [CrossRef] [Green Version]
- Bettencourt, L.M.A. The Origins of Scaling in Cities. Science 2013, 340, 1438–1441. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rybski, D.; Arcaute, E.; Batty, M. Urban scaling laws. In Environment and Planning B: Urban Analytics and City Science; SAGE Publications Sage UK: London, UK, 2018; Volume 46. [Google Scholar] [CrossRef]
- Finance, O.; Swerts, E. Scaling laws in urban geography. Linkages with urban theories, challenges and limitations. In Theories and Models of Urbanization; Springer: Cham, Switzerland, 2020; pp. 67–96. [Google Scholar]
- Bettencourt, L.M.A.; Yang, V.C.; Lobo, J.; Kempes, C.P.; Rybski, D.; Hamilton, M.J. The interpretation of urban scaling analysis in time. J. R. Soc. Interface 2020, 17, 20190846. [Google Scholar] [CrossRef] [Green Version]
- Molinero, C.; Thurner, S. How the geometry of cities determines urban scaling laws. J. R. Soc. Interface 2021, 18, 20200705. [Google Scholar] [CrossRef]
- Acuto, M.; Parnell, S.; Seto, K.C. Building a global urban science. Nat. Sustain. 2018, 1, 2–4. [Google Scholar] [CrossRef]
- Regional Plan Association. America 2050: A Prospectus [Internet]. Regional Plan Association. 2006. Available online: https://s3.us-east-1.amazonaws.com/rpa-org/pdfs/2050-Prospectus.pdf (accessed on 1 October 2021).
- Peter, H.; Kathy, P. The Polycentric Metropolis: Learning from Mega-City Regions in Europe; Routledge & CRC Press: London, UK, 2006; Available online: https://www.routledge.com/The-Polycentric-Metropolis-Learning-from-Mega-City-Regions-in-Europe/Hall-Pain/p/book/9781844077472 (accessed on 22 December 2021).
- Nelson, A.C.; Lang, R. Megapolitan America: A New Vision for Understanding America’s Metropolitan Geography; APA Planners: Chicago, IL, USA; Taylor & Francis [distributor]: London, UK, 2011; p. 278. [Google Scholar]
- Megaregions: Globalization’s New Urban form? Harrison, J.; Hoyler, M. (Eds.) Edward Elgar: Cheltenham, UK, 2015; p. 270. [Google Scholar]
- Groff, S.P.; Stefan, R. China’s City Clusters: Pioneering Future Mega-Urban Governance. Am. Aff. URL 2019, 3, 134–150. Available online: https://americanaffairsjournal.org/issue/summer-2019/ (accessed on 1 October 2021).
- Liu, Z.; Zhang, M.; Liu, L. Benchmark of the Trends of Spatial Inequality in World Megaregions. Sustainability 2021, 13, 6456. [Google Scholar] [CrossRef]
- Seto, K.C.; Golden, J.S.; Alberti, M.; Turner, B.L., II. Sustainability in an urbanizing planet. Proc. Natl. Acad. Sci. USA 2017, 114, 8935–8938. [Google Scholar] [CrossRef] [Green Version]
- Dewar, M.; Epstein, D. Planning for “megaregions” in the United States. J. Plan. Literature 2007, 22, 108–124. [Google Scholar]
- Megaregions: Planning for Global Competitiveness; Ross, C.L. (Ed.) Island Press: Washington, DC, USA, 2009; p. 307. [Google Scholar]
- Bettencourt, L.M.A.; Lobo, J.; Strumsky, D.; West, G.B. Urban Scaling and Its Deviations: Revealing the Structure of Wealth, Innovation and Crime across Cities. PLoS ONE 2010, 5, e13541. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lobo, J.; Bettencourt, L.M.A.; Strumsky, D.; West, G.B. Urban Scaling and the Production Function for Cities. PLoS ONE 2013, 8, e58407. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berry, B.J.; Okulicz-Kozaryn, A. The city size distribution debate: Resolution for US urban regions and megalopolitan areas. Cities 2012, 29, S17–S23. [Google Scholar] [CrossRef]
- Carbonell, A.; Yaro, R.D. American spatial development and the new megalopolis. Land Lines 2005, 17, 1–4. [Google Scholar]
- Gottmann, J. Megalopolis or the Urbanization of the Northeastern Seaboard. Econ. Geogr. 1957, 33, 189. [Google Scholar] [CrossRef]
- Lang, R.E.; Dhavale, D. Beyond megalopolis: Exploring america’s new “megapolitan” geography. Metrop. Inst. Census Rep. Ser. 2005, 5, 1–35. [Google Scholar]
- FHWA. Megaregions and National Economic Partnerships [Internet]. 2018. Available online: https://www.fhwa.dot.gov/planning/megaregions/ (accessed on 25 December 2021).
- Zhang, M.; Steiner, F.; Butler, K. Connecting the Texas Triangle: Economic integration and transportation coordination. In The Healdsburg Research Seminar on Megaregions; Regional Plan Association: New York, NY, USA, 2007; pp. 21–36. [Google Scholar]
- Bright, E. Viewpoint: Megas? Maybe not. Plan. Mag. 2007, 73, 46. [Google Scholar]
- Florida, R.; Gulden, T.; Mellander, C. The rise of the mega-region. Camb. J. Reg. Econ. Soc. 2008, 1, 459–476. [Google Scholar] [CrossRef]
- Taubenböck, H.; Wiesner, M.; Felbier, A.; Marconcini, M.; Esch, T.; Dech, S. New dimensions of urban landscapes: The spa-tio-temporal evolution from a polynuclei area to a mega-region based on remote sensing data. Appl. Geogr. 2014, 47, 137–153. [Google Scholar] [CrossRef]
- Taubenböck, H.; Wiesner, M. The spatial network of megaregions-Types of connectivity between cities based on settle-ment patterns derived from EO-data. Comput. Environ. Urban Syst. 2015, 54, 165–180. [Google Scholar] [CrossRef]
- Taubenbock, H.; Bauer, P.; Geiss, C.; Wurm, M. Mega-regions in China. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Institute of Electrical and Electronics Engineers (IEEE), Dubai, United Arab Emirates, 6–8 March 2017; pp. 1–4. [Google Scholar]
- Glocker, D. The Rise of Megaregions: Delineating a New Scale of Economic Geography. OECD Regional Development Working Papers 2018/04. 2018. Available online: https://www.oecd-ilibrary.org/docserver/f4734bdd-en.pdf?expires=1644977918&id=id&accname=guest&checksum=61093A0D60BDB50C7D0C6C3673DFC977 (accessed on 24 December 2021).
- Marull, J.; Font, C.; Boix, R. Modelling urban networks at mega-regional scale: Are increasingly complex urban systems sustainable? Land Use Policy 2015, 43, 15–27. [Google Scholar] [CrossRef]
- He, M.; Glasser, J.; Pritchard, N.; Bhamidi, S.; Kaza, N. Demarcating geographic regions using community detection in commuting networks with significant self-loops. PLoS ONE 2020, 15, e0230941. [Google Scholar] [CrossRef] [PubMed]
- Nelson, G.D.; Rae, A. An Economic Geography of the United States: From Commutes to Megaregions. PLoS ONE 2016, 11, e0166083. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- US Census Bureau UC. 2011–2015 5-Year ACS Commuting Flows [Internet]. Census.gov. 2021. Available online: https://www.census.gov/data/tables/2015/demo/metro-micro/commuting-flows-2015.html (accessed on 24 December 2021).
- Office of Management and Budget. 2010 Standards for Delineating Metropolitan and Micropolitan Statistical Areas; Notice. Fed. Regist. 2010, 75, 37246–37252. [Google Scholar]
- Radicchi, F.; Castellano, C.; Cecconi, F.; Loreto, V.; Parisi, D. Defining and identifying communities in networks. Proc. Natl. Acad. Sci. USA 2004, 101, 2658–2663. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [Green Version]
- Cherven, K. Network Graph Analysis and Visualization with Gephi; Packt Publishing Ltd: Birmingham, UK, 2013. [Google Scholar]
- NetworkX Developers. NetworkX—Network Analysis in Python [Internet]. 2021. Available online: https://networkx.org/ (accessed on 24 December 2021).
- Banerjee, T. Megaregions or Megasprawls? Issues of Density, Urban Design and Quality Growth. In Megaregions: Planning for Global Competitiveness; Island Press: Washington, DC, USA, 2009; pp. 83–106. [Google Scholar]
- Blondel, V.D.; Guillaume, J.-L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef] [Green Version]
- Haughey, J. Census Bureau: New Yorkers come to Florida to work, New Englanders to retire [Internet]. The Center Square. 2019. Available online: https://www.thecentersquare.com/florida/census-bureau-new-yorkers-come-to-florida-to-work-new-englanders-to-retire/article_bf861aa0-fcdf-11e9-997a-0b2cc9818e66.html (accessed on 24 December 2021).
- US Census Bureau. TEXAS—Core Based Statistical Areas (CBSAs) and Counties [Internet]. 2013. Available online: https://www2.census.gov/geo/maps/metroarea/stcbsa_pg/Feb2013/cbsa2013_TX.pdf (accessed on 24 December 2021).
- Seltzer, E.; Carbonell, A. Regional planning in America: Planning regions. In Regional Planning in America: Practice and Prospect; Lincoln Institute of Land Policy: Cambridge, MA, USA, 2011; pp. 1–16. [Google Scholar]
- Wheeler, S.M. Five reasons why megaregional planning works against sustainability. In Megaregions; Edward Elgar Publishing: Glasgow, UK, 2015; pp. 97–118. [Google Scholar]
- Burger, M.J.; Meijers, E.J. Agglomerations and the rise of urban network externalities. Pap. Reg. Sci. 2016, 95, 5–15. [Google Scholar] [CrossRef]
- Pflieger, G.; Rozenblat, C. Introduction. Urban Networks and Network Theory: The City as the Connector of Multiple Networks. Urban Stud. 2010, 47, 2723–2735. [Google Scholar] [CrossRef] [Green Version]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Lan, B. Detect Megaregional Communities Using Network Science Analytics. Urban Sci. 2022, 6, 12. https://doi.org/10.3390/urbansci6010012
Zhang M, Lan B. Detect Megaregional Communities Using Network Science Analytics. Urban Science. 2022; 6(1):12. https://doi.org/10.3390/urbansci6010012
Chicago/Turabian StyleZhang, Ming, and Bolin Lan. 2022. "Detect Megaregional Communities Using Network Science Analytics" Urban Science 6, no. 1: 12. https://doi.org/10.3390/urbansci6010012
APA StyleZhang, M., & Lan, B. (2022). Detect Megaregional Communities Using Network Science Analytics. Urban Science, 6(1), 12. https://doi.org/10.3390/urbansci6010012