
Using Shallow and Deep Learning to Automatically Detect Hate Motivated by Gender and Sexual Orientation on Twitter in Spanish





{kind=link}
{kind=link}
Abstract
:1. Introduction
Online Hate Detection Based on Reasons of Gender and Sexual Orientation
2. Materials and Methods
2.1. Creation of the Training Corpus
2.1.1. Creation of a Filter Dictionary and Downloading of the Filtered Tweets
- -
- word = [‘comerabo’, ‘comepolla’, ‘chupapolla’, ‘muerdealmohada’, ‘machirul’, ‘marimach’, ‘hermafrodit’, ‘travelo’, ‘gay\nvicio’, ‘gay\ndesviac’, ‘gay\ndesviad’, ‘gay\npervert’, ‘gay\npervers’, ‘gay\ndepravac’, ‘gay\ndepravad’, ‘gay\npromiscu’, ‘gay\nlibertin’, ‘gay\nenferm’, ‘gay\nput’, ‘gay\nmaldit’, ‘gay\nsuci’, ‘gay\npluma’, ‘gay\ntijer’, ‘gay\ncoño’, ‘gay\npotorro’, ‘gay\npierdeaceit’, ‘gay\nmierda’, ‘gay\nbasura’, ‘gay\ngentuza’, ‘gay\nasco’, ‘gay\nlacra’, ‘gay\nescoria’, ‘gay\ncontagi’, ‘gay\ndestroz’, ‘gay\nreventar’, ‘gay\nrevient’, ‘gay\nmata’, ‘gay\nextermin’, ‘maric\ndesviac’, ‘maric\ndesviad’, ‘maric\npervert’, ‘maric\npervers’, ‘maric\ndepravac’, ‘maric\ndepravad’, ‘maric\npromiscu’, ‘maric\nlibertin’, ‘maric\nenferm’, ‘maric\nput’, ‘maric\nmaldit’, ‘maric\nsuci’, ‘maric\npluma’, ‘maric\ntijer’, ‘maric\ncoño’, ‘maric\npotorro’, ‘maric\npierdeaceit’, ‘maric\nmierda’, ‘maric\nbasura’, ‘maric\ngentuza’, ‘maric\nasco’, ‘maric\nlacra’, ‘maric\nescoria’, ‘maric\ncontagi’, ‘maric\ndestroz’, ‘maric\nreventar’, ‘maric\nrevient’, ‘maric\nmata’, ‘maric\nextermin’ ‘mariq\ndesviac’, ‘mariq\ndesviad’, ‘mariq\npervert’, ‘mariq\npervers’, ‘mariq\ndepravac’, ‘mariq\ndepravad’, ‘mariq\npromiscu’, ‘mariq\nlibertin’, ‘mariq\nenferm’, ‘mariq\nput’, ‘mariq\nmaldit’, ‘mariq\nsuci’, ‘mariq\npluma’, ‘mariq\ntijer’, ‘mariq\ncoño’, ‘mariq\npotorro’, ‘mariq\npierdeaceit’, ‘mariq\nmierda’, ‘mariq\nbasura’, ‘mariq\ngentuza’, ‘mariq\nasco’, ‘mariq\nlacra’, ‘mariq\nescoria’, ‘mariq\ncontagi’, ‘mariq\ndestroz’, ‘mariq\nreventar’, ‘mariq\nrevient’, ‘mariq\nmata’, ‘mariq\nextermin’, ‘lesbi\ndesviac’, ‘lesbi\ndesviad’, ‘lesbi\npervert’, ‘lesbi\npervers’, ‘lesbi\ndepravac’, ‘lesbi\ndepravad’, ‘lesbi\npromiscu’, ‘lesbi\nlibertin’, ‘lesbi\nenferm’, ‘lesbi\nput’, ‘lesbi\nmaldit’, ‘lesbi\nsuci’, ‘lesbi\npluma’, ‘lesbi\ntijer’, ‘lesbi\ncoño’, ‘lesbi\npotorro’, ‘lesbi\npierdeaceit’, ‘lesbi\nmierda’, ‘lesbi\nbasura’, ‘lesbi\ngentuza’, ‘lesbi\nasco’, ‘lesbi\nlacra’, ‘lesbi\nescoria’, ‘lesbi\ncontagi’, ‘lesbi\ndestroz’, ‘lesbi\nreventar’, ‘lesbi\nrevient’, ‘lesbi\nmata’, ‘lesbi\nextermin’, ‘trans\ndesviac’, ‘trans\ndesviad’, ‘trans\npervert’, ‘trans\npervers’, ‘trans\ndepravac’, ‘trans\ndepravad’, ‘trans\npromiscu’, ‘trans\nlibertin’, ‘trans\nenferm’, ‘trans\nput’, ‘trans\nmaldit’, ‘trans\nsuci’, ‘trans\npluma’, ‘trans\ntijer’, ‘trans\ncoño’, ‘trans\npotorro’, ‘trans\npierdeaceit’, ‘trans\nmierda’, ‘trans\nbasura’, ‘trans\ngentuza’, ‘trans\nasco’, ‘trans\nlacra’, ‘trans\nescoria’, ‘trans\ncontagi’, ‘trans\ndestroz’, ‘trans\nreventar’, ‘trans\nrevient’, ‘trans\nmata’, ‘trans\nextermin’, ‘drag\ndesviac’, ‘drag\ndesviad’, ‘drag\npervert’, ‘drag\npervers’, ‘drag\ndepravac’, ‘drag\ndepravad’, ‘drag\npromiscu’, ‘drag\nlibertin’, ‘drag\nenferm’, ‘drag\nput’, ‘drag\nmaldit’, ‘drag\nsuci’, ‘drag\npluma’, ‘drag\ntijer’, ‘drag\ncoño’, ‘drag\npotorro’, ‘drag\npierdeaceit’, ‘drag\nmierda’, ‘drag\nbasura’, ‘drag\ngentuza’, ‘drag\nasco’, ‘drag\nlacra’, ‘drag\nescoria’, ‘drag\ncontagi’, ‘drag\ndestroz’, ‘drag\nreventar’, ‘drag\nrevient’, ‘drag\nmata’, ‘drag\nextermin’ (…)].
2.1.2. Manual Peer Classification
2.1.3. Checking the Intercoder Agreement
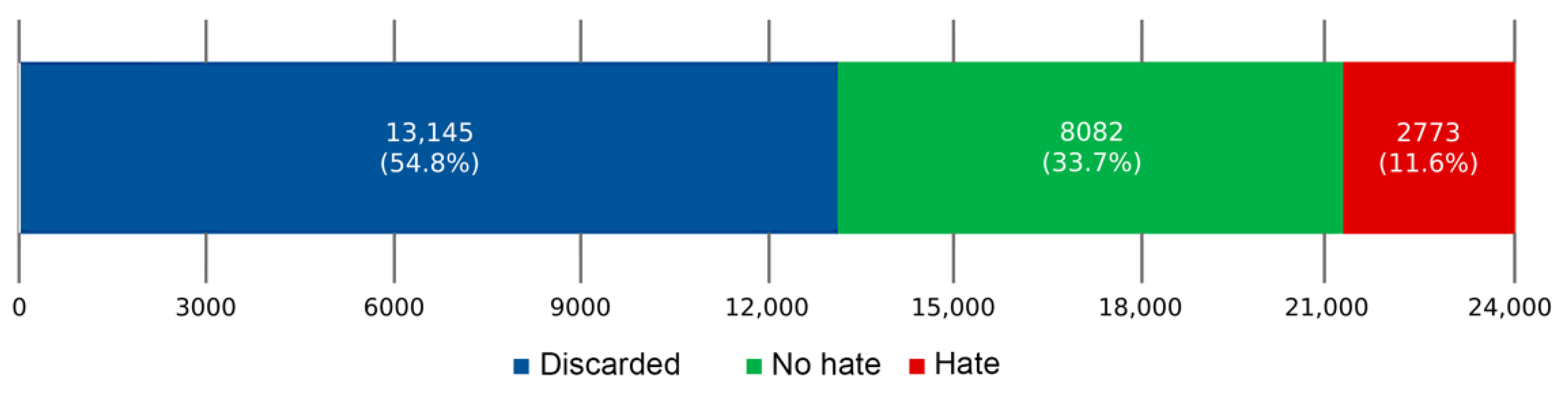
2.1.4. Cleaning and Compilation of the Final Database
2.2. Generation of the Predictive Models
2.2.1. Shallow Modeling
2.2.2. Deep Modeling
- The first input layer converted each word into embeddings, which were dense vectors that represented the categorical value of any given word. The embeddings were trained using the 10,000 most common words of the created vocabulary plus 1000 out-of-vocabulary buckets. Thus, the matrix of embeddings included one row for each of these 11,000 words and one column for each of the six embedding dimensions (this hyperparameter was tuned several times and obtained the best performance with size = 6).
- The second and the third hidden layers included were gated recurrent unit (GRU) layers with 128 neurons each. GRUs are simplified versions of traditional LSTM cells. Despite the fact that both perform quite well for text classification (converging quickly and detecting long-term dependencies), we decided to use GRUs instead of LSTM given that the simplified version performs as well as the original one.
- The last output layer consisted of a dense layer with just one neuron, and it used sigmoid activation to predict the probability of a message being a hateful message.
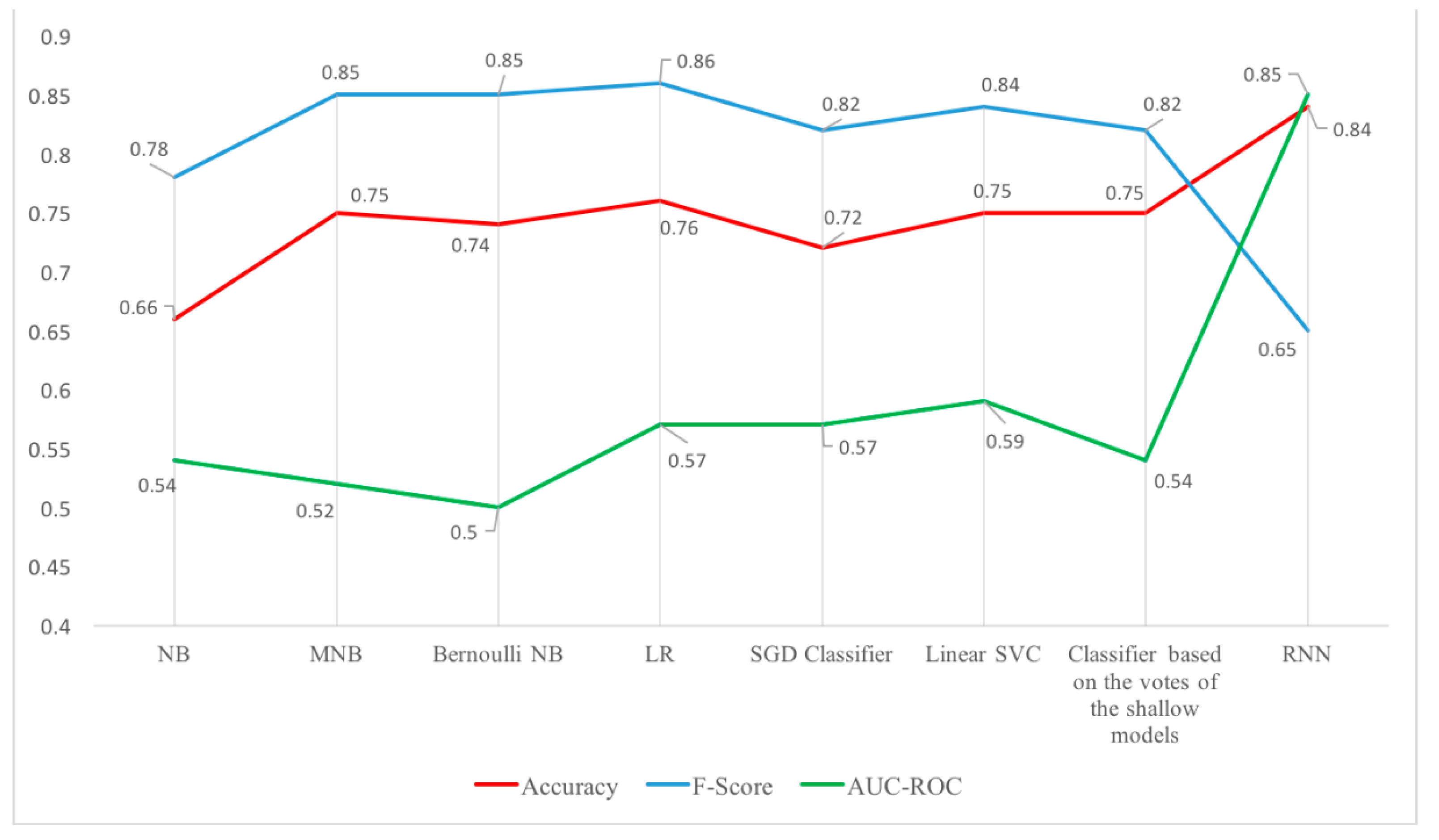
3. Results
- -
- Vaya cara de chupapollas que tienes perra (what a cocksucker face you have bitch);
- -
- >Maricones más tóxicos que Chernobyl no, gracias (fags more toxic than Chernobyl, no thanks);
- -
- Yo veo a alguien que es gay un hombre que le da por homofobico o algo y lo corto en pedazos (I see someone who is a gay, a man who thinks he is homophobic or something and I cut him to pieces);
- -
- Esos maricones de mierda, son escorias (those shitty fags, they’re slag);
- -
- Hermosa en tus sueños pedazo de travesti eres un asco! (beautiful in your dreams piece of transvestite you are disgusting!);
- -
- Que asco son lesbianas ojalá las quemen como hacía Hitler (how disgusting they are lesbians, I hope they burn them like Hitler did);
- -
- Que te haces la pacifista puta de mierda travesti política (you play the pacifist political transvestite fucking whore);
- -
- Es un comepollas de primera... como su mujer, que le caben cuatro de golpe en la boca (he is a first-rate cocksucker... like his wife, who can fit four at once in her mouth);
- -
- No me vayas a contagiar tu enfermedad lesbiana asquerosa (don’t give me your disgusting lesbian disease);
- -
- Muerete puta Lesbiana de mierda (die fucking lesbian whore);
- -
- Deja de llorar puto maricon de mierda (stop crying you fucking fag shit);
- -
- Puta por que le contabas a mi madre las pollas que te chupabas y como follabas con los tios eh puta chupapollas Hija de puta culera jodete perra puta guarra (you are a whore because you told my mother about the cocks you sucked and how you fucked with the guys, eh whore cocksucker daughter of a bitch fuck you slut, whore, hooker);
- -
- Que no te pille por ahí maricona de mierda que te reviento (better that I don’t catch you out there, you fucking faggot I’ll bust you);
- -
- Al punto que llegan estos Progres....realmente una vergüenza esta tropa de Travestis (to the point that these progressives come... they really are a shame this troop of transvestites);
- -
- Tu lo q eres es una puta marica pasiva (what you are is a bottom faggot whore).
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Müller, K.; Schwarz, C. Fanning the Flames of Hate: Social Media and Hate Crime. J. Eur. Econ. Assoc. 2021, 19, 2131–2167. [Google Scholar] [CrossRef]
- Anti-Defamation League. Online Hate and Harassment. The American Experience 2020. The ADL Center for Technology and Society: 2020. Available online: https://www.adl.org/media/14643/download (accessed on 15 February 2021).
- Anti-Defamation League. Online Hate and Harassment. The American Experience 2021. The ADL Center for Technology and Society: 2021. Available online: https://www.adl.org/media/16033/download (accessed on 29 May 2021).
- Hate Crime Reporting. Available online: https://hatecrime.osce.org (accessed on 31 May 2021).
- Movimiento contra la Intolerancia. Informe Raxen: Racismo, Xenofobia, Antisemitismo, Islamofobia, Neofascismo y Otras Manifestaciones de Intolerancia A Través de los Hechos. Especial 2019. Por un Pacto de Estado Contra la Xenofobia y la Intolerancia; Movimiento contra la Intolerancia: Madrid, Spain, 2019. [Google Scholar]
- Ministerio del Interior de España. Informe de Evolución de los Delitos de Odio en España. 2020. Available online: http://www.interior.gob.es/documents/642012/3479677/Informe+sobre+la+evolución+de+delitos+de+odio+en+España%2C%20año+2019/344089ef-15e6-4a7b-8925-f2b64c117a0a (accessed on 6 February 2021).
- Arcila-Calderón, C.; Blanco-Herrero, D.; Valdez-Apolo, M.B. Rechazo y discurso de odio en Twitter: Análisis de contenido de los tuits sobre migrantes y refugiados en español. REIS Rev. Española Investig. Sociológicas 2020, 172, 21–40. [Google Scholar] [CrossRef]
- Valdez-Apolo, M.B.; Arcila-Calderón, C.; Amores, J.J. El discurso del odio hacia migrantes y refugiados a través del tono y los marcos de los mensajes en Twitter. Rev. Asoc. Española Investig. Comun. 2019, 6, 361–384. [Google Scholar] [CrossRef]
- Amores, J.J.; Blanco-Herrero, D.; Sánchez-Holgado, P.; Frías-Vázquez, M. Detectando el odio ideológico en Twitter. Desarrollo y evaluación de un detector de discurso de odio por ideología política en tuits en español. Cuadernos.Info 2021, 49, 98–124. [Google Scholar] [CrossRef]
- Council of Europe. Recommendation No. R (97) 20 of the Committee of Ministers to Member States on “Hate Speech”. Council of Europe: Strasbourg, France, 1997. [Google Scholar]
- European Commission against Racism and Intolerance. ECRI General Policy Recommendation N° 15 on Combating Hate Speech; Council of Europe: Strasbourg, France, 2016. [Google Scholar]
- Gagliardone, I.; Gal, D.; Alves, T.; Martinez, G. Countering Online Hate Speech; Unesco Publishing: Paris, France, 2015. [Google Scholar]
- Moretón Toquero, M.A. El «ciberodio», la nueva cara del mensaje de odio: Entre la cibercriminalidad y la libertad de expresión. Rev. Jurídica Castilla León 2012, 27. Available online: https://dialnet.unirioja.es/servlet/articulo?codigo=4224783 (accessed on 12 December 2020).
- Malmasi, S.; Zampieri, M. Detecting hate speech in social media. arXiv 2017, arXiv:1712.06427. Available online: https://arxiv.org/abs/1712.06427 (accessed on 8 November 2020).
- Salminen, J.; Hopf, M.; Chowdhury, S.A.; Jung, S.G.; Almerekhi, H.; Jansen, B.J. Developing an online hate classifier for multiple social media platforms. Hum. -Cent. Comput. Inf. Sci. 2020, 10, 1–34. [Google Scholar] [CrossRef]
- Pereira-Kohatsu, J.C.; Quijano-Sánchez, L.; Liberatore, F.; Camacho-Collados, M. Detecting and monitoring hate speech in Twitter. Sensors 2019, 19, 4654. [Google Scholar] [CrossRef] [Green Version]
- Hewitt, S.; Tiropanis, T.; Bokhove, C. The Problem of Identifying Misogynist Language on Twitter (and Other Online Social Spaces). In WebSci’16. Proceedings of the 2016 ACM Web Science Conference; Nejdl, W., Hall, W., Parigi, P., Staab, S., Eds.; ACM: New York, NY, USA, 2016. [Google Scholar]
- Ahluwalia, R.; Shcherbinina, E.; Callow, E.; Anderson, C.; Nascimento, A.; De Cock, M. Detecting Misogynous Tweets. In Proceedings of the Third Workshop on Evaluation of Human Language Technologies for Iberian Languages (IberEval), Sevilla, Spain, 18 September 2018. [Google Scholar]
- Anzovino, M.; Fersini, E.; Rosso, P. Automatic Identification and Classification of Misogynistic Language on Twitter. In Natural Language Processing and Information Systems. NLDB 2018. Lecture Notes in Computer Science; Silberztein, M., Atigui, F., Kornyshova, E., Métais, E., Meziane, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10859. [Google Scholar] [CrossRef]
- Şahi, H.; Kılıç, Y.; Saǧlam, R.B. Automated Detection of Hate Speech towards Woman on Twitter. In Proceedings of the 3rd International Conference on Computer Science and Engineering (UBMK), Sarajevo, Bosnia and Herzegovina, 20–23 September 2018; pp. 533–536. [Google Scholar] [CrossRef]
- Basile, V.; Bosco, C.; Fersini, E.; Nozza, D.; Patti, V.; Rangel, F.; Rosso, P.; Sanguinetti, M. Semeval-2019 task 5: Multilingual detection of hate speech against immigrants and women in twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation, Association for Computational Linguistics, Minneapolis, Minnesota, USA, 6 June 2019; pp. 54–63. [Google Scholar]
- Fuchs, T.; Schäfer, F. Normalizing misogyny: Hate speech and verbal abuse of female politicians on Japanese Twitter. Jpn. Forum 2020. [Google Scholar] [CrossRef]
- Southern, R.; Harmer, E. Twitter, Incivility and “Everyday” Gendered Othering: An Analysis of Tweets Sent to UK Members of Parliament. Soc. Sci. Comput. Rev. 2019, 39, 259–275. [Google Scholar] [CrossRef]
- Gallego, M.; Gualda, E.; Rebollo, C. Women and Refugees in Twitter: Rhetorics on Abuse, Vulnerability and Violence from a Gender Perspective. J. Mediterr. Knowl. 2017, 2, 37–58. [Google Scholar] [CrossRef]
- Núñoz Puente, S.; Fernández Romero, D. Posverdad y victimización en Twitter ante el caso de La Manada: Propuesta de un marco analítico a partir del testimonio ético. Investig. Fem. 2019, 10, 385–398. [Google Scholar] [CrossRef]
- Villar-Aguilés, A.; Pecourt Gracia, J. Antifeminismo y troleo de género en Twitter. Estudio de la subcultura trol a través de #STOPfeminazis. Teknocultura 2021, 18, 33–44. [Google Scholar]
- Alden, H.L.; Parker, K.F. Gender role ideology, homophobia and hate crime: Linking attitudes to macro-level anti-gay and lesbian hate crimes. Deviant Behav. 2005, 26, 321–343. [Google Scholar] [CrossRef]
- Carratalá, A. Audiencias críticas en Twitter frente a coberturas tránsfobas: La identidad de género como nuevo derecho y su tratamiento periodístico. In Más Sobre Periodismo y Derechos Humanos Emergentes; Gómez y Méndez, J.M., Turón-Padial, M.C., Cartes Barroso, M.J., Eds.; Universidad de Sevilla: Sevilla, Spain, 2020; pp. 64–78. [Google Scholar]
- Blondeel, K.; De Vasconcelos, S.; García-Moreno, C.; Stephenson, R.; Temmerman, M.; Toskin, I. Violence motivated by perception of sexual orientation and gender identity: A systematic review. Bull. World Health Organ. 2018, 96, 29–41. [Google Scholar] [CrossRef]
- Burnap, P.; Williams, M.L. Us and them: Identifying cyber hate on Twitter across multiple protected characteristics. EPJ Data Sci. 2016, 5, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Lingiardi, V.; Carone, N.; Semeraro, G.; Musto, C.; D’Amico, M.; Brena, S. Mapping Twitter hate speech towards social and sexual minorities: A lexicon-based approach to semantic content analysis. Behav. Inf. Technol. 2020, 39, 711–721. [Google Scholar] [CrossRef]
- Cai, J.; Li, J.; Li, W.; Wang, J. Deep learning model used in text classification. In Proceedings of the 15th International Computer Conference on Wavelet Active Media Technology and Information Proccessing, Chengdu, China, 14–16 December 2018; pp. 123–126. [Google Scholar]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A survey on text classification: From shallow to deep learning. arXiv 2020, arXiv:2008.00364. [Google Scholar]
- Miró-Llinares, F. Taxonomía de la comunicación violenta y el discurso del odio en Internet. IDP Rev. Internet Derecho Política 2016, 22, 82–107. [Google Scholar] [CrossRef] [Green Version]
- Kalampokis, E.; Tambouris, E.; Tarabanis, K. Understanding the predictive power of social media. Internet Res. 2013, 23, 544–559. [Google Scholar] [CrossRef]
- Martini, S.; Torcal, M. Trust across political conflicts: Evidence from a survey experiment in divided societies. Party Politics 2016, 25, 126–139. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arcila-Calderón, C.; Amores, J.J.; Sánchez-Holgado, P.; Blanco-Herrero, D. Using Shallow and Deep Learning to Automatically Detect Hate Motivated by Gender and Sexual Orientation on Twitter in Spanish. Multimodal Technol. Interact. 2021, 5, 63. https://doi.org/10.3390/mti5100063
Arcila-Calderón C, Amores JJ, Sánchez-Holgado P, Blanco-Herrero D. Using Shallow and Deep Learning to Automatically Detect Hate Motivated by Gender and Sexual Orientation on Twitter in Spanish. Multimodal Technologies and Interaction. 2021; 5(10):63. https://doi.org/10.3390/mti5100063
Chicago/Turabian StyleArcila-Calderón, Carlos, Javier J. Amores, Patricia Sánchez-Holgado, and David Blanco-Herrero. 2021. "Using Shallow and Deep Learning to Automatically Detect Hate Motivated by Gender and Sexual Orientation on Twitter in Spanish" Multimodal Technologies and Interaction 5, no. 10: 63. https://doi.org/10.3390/mti5100063
APA StyleArcila-Calderón, C., Amores, J. J., Sánchez-Holgado, P., & Blanco-Herrero, D. (2021). Using Shallow and Deep Learning to Automatically Detect Hate Motivated by Gender and Sexual Orientation on Twitter in Spanish. Multimodal Technologies and Interaction, 5(10), 63. https://doi.org/10.3390/mti5100063