The problematization fields to which I refer below are not exhaustive; they have been selected based on those that, for the moment, I consider to require more attention, although I am aware that it may be a very subjective decision.
3.1. Vectorized Culture and Cultural Vectorization
The phenomenon of «cultural vectorization» (and its associated concepts and practices) has interesting epistemological, critical and narrative implications, as will be argued later. However, it is the transformation of the representational order of cultural heritage that it is producing what must be addressed in the very first place. As aforementioned, cultural objects (whether words, images, texts, sounds, etc.) are no longer only rematerialized in numerical information but also encoded in vectors, which thus become the new representational entities of cultural heritage that, therefore, remains numerically encoded according to certain characteristics or values. Likewise, the high-dimensional vector space models produced using deep learning neural networks constitute a vectorization of the entire cultural domain under analysis. In other words, the totality of the vectors represents the totality of the structure of the dataset such that the vector space stands as «a» model that represents and describes the cultural domain in its entirety.
If we take into account the fact that vectorization processes are highly increasingly common phenomena that result from the growing use of deep learning technologies in linguistic and visual analysis, it can be affirmed that we are witnessing a transformation in how cultural heritage is recorded, preserved and transmitted and, with that, the set of knowledge, beliefs, values and ideas that cultural objects convey. In a strict sense, it could be said that vectors and high-dimensional vector spaces are being instituted (in our computational society shaped by AI) as the new models for recording and ordering the memory of culture, thus displacing what, until now, were considered the fundamental models: the book, archive and database artifacts.
Simultaneously, a reconfiguration of the concept and meaning of what a cultural object is and of the nature of the conceptual categories used for its description, ordering and interpretation is taking place. If cultural objects are translated into strictly commensurable values, the primary question that arises is about the limits of the commensurability since it is one of the epistemological assumptions embedded in computational approaches. That is, we need to discuss whether it is epistemologically possible that all the dimensions and characteristics of cultural objects can be translated into numbers and codified in vectors, or instead there is some margin for the incommensurable, that is, for what cannot be numerically codified. Even if being epistemologically feasible, this scenario also prompts us to inquire what kind of reductionism would imply the prevalence of a vectorized culture.
Likewise, and given that the logic underneath AI applications can be understood as a process of extraction and production of statistical distribution of patterns, the concept of pattern (or, better said, of techno-pattern, as produced by AI) becomes a central issue that demands an examination of what implies to instantiate cultural objects, processes and phenomena in sets of techno-patterns; what it means to understand cultural domains as sets of techno-patterns correlated in some way; what epistemological assumptions are embedded and how they determine research and interpretation modalities; what convergences and divergences emerge when this idea of a tecno-pattern is put in relation to other concepts of cultural patterns formulated over the past.
A modification in the nature of the analytical and interpretative categories hitherto used is also in fieri. As explained above, a techno-pattern is a distribution of patterns that constitute a model. Consequently, art-historical concepts such as style, genre, period or authorship are no longer intellectual elaborations but statistical models of characteristics in the domain of computational art history. For the same reason, from an algorithmic point of view, classifying or giving order to cultural production is to determine whether a numerical data structure is more or less similar to the pattern encoded in a model. Within this framework, there are no longer cultural objects that «are» baroque (just to put an example), but objects (as a set of characteristics) more or less close to a pattern which has been generated by statistical induction. These classificatory or ordering logics need to be discussed in relation with the empirical-based classificatory methods, also known as inductive classification, phenomenal classification or extensional classification, as well as with the Eleanor Rosch’s prototype theory and its further developments. This question, however, falls outside the scope of this paper. So logical categories are replaced by probabilistic ranges. These changes in the nature of objects and conceptual categories entail interesting epistemological derivations, as we will see as follows.
3.2. Spatiality: Geometry, Form and Topology
If the concept of an n-dimensional space implies the problematization and reconsideration of some kind of concept, it is precisely the notion of «space» itself. In this sense, I believe that the toy examples of the previous section, although simple, adequately illustrate the fact that these spaces do not act as containers or supports in the traditional sense of the term—that is, spaces where cultural objects, visual contents or writing signs are located, arranged or situated—but are generated by them once they have been transformed into numerical information. Sign and space constitute an indissoluble unity: space is sign and sign is space, and this lack of distinction shifts us from the traditional concept of Euclidean space—according to which space is a pre-existing category, different from what is located in it (it is another dimension, extrinsic to the object)—to the topological concept of space, according to which space is an a posteriori that is generated by and imbricated in the objects themselves.
This shift involves a theoretical perspective that addresses the notion of space as a dimension intrinsically implicated in the definition and production of cultural objects. It also implies bringing back to the center of the debate the notion of spatiality as a category for analysis and interpretation and, more specifically, the «reincorporation» into the cultural and humanistic epistemology of concepts taken from geometry and topology. Neither geometry nor topology constitutes new conceptual frameworks in the field of cultural and humanistic interpretation. In fact, the very conceptualization of the contemporary world as a system of distributed nodes connected by networks, ontologically constituted as a continuity of interweaved and entangled heterogeneous entities, which is moreover in a state of continuous transformation, has favored the new impulse that topology has acquired in recent years as a cultural category [
21].
However, in the context of the high-dimensional vector spaces produced and explored by AI technologies, geometry and topology, in addition to providing us with a theoretical and conceptual framework to interpret sociocultural phenomena (which have become topological), also offer us specific mathematical instruments to analyze the geometric and topological structures of data in high-dimensional vector space, whose results, moreover, are visually materialized in certain spatial configurations that facilitate its intelligibility. Before continuing, it is important to notice that, although this paper focuses on high-dimensional vectors spaces as topological and geometrical structures, they can also be algebraic structures.
Tthe spatial distribution of images and works that we observe, for example, in
Figure 4 and
Figure 5, although reduced to two or three dimensions, responds to the structure that emanates from the computationally established positions and distances of visual and/or linguistic data that are translated into numbers in a vector space. It is just this spatial structure that is meaningful since the implicit knowledge extracted from computation (statistical distribution of patterns) is expressed in the vector space itself (in its configuration and structure). In other words, the sense and meaning of the cultural domain under analysis are codified in terms of distances and spatial structures (or formations). It can be said, then, that a topological–morphological order comes into play since it is precisely the form and spatial structure resulting from data computation that are the fundamental parameters of interpretation.
Thus, geometry and topology, beyond providing us with a theoretical or conceptual framework to think about cultural objects and phenomena, become a device (in Foucault’s sense) or artifact, material and concrete, that is generated by the technology itself. It can be said, then, that our spatio-topological imagination is mediated and somehow produced by the analytical methodologies that govern the operating logics of AI, by its epistemological assumptions and, especially, by the indispensable visualizations that we need to make intelligible the structures of high-dimensional vector spaces. This is why I consider we can speak in terms of a techno-spatio-topology and affirm that a spatio-topology, in this framework of computational exploration, becomes a techno-concept and a techno-object. This circumstance entails an approach to geometric and topological concepts from the double perspective of a techno-concept as both a possibility of opening and widening the epistemological and critical horizon for the analysis and interpretation of cultural phenomena and processes, as well as a problem that, as a mode of cultural analysis and interpretation, must be critically discussed to become aware of how these spatio-topological devices determine and model our imagination and, therefore, the narratives that may be derived from them.
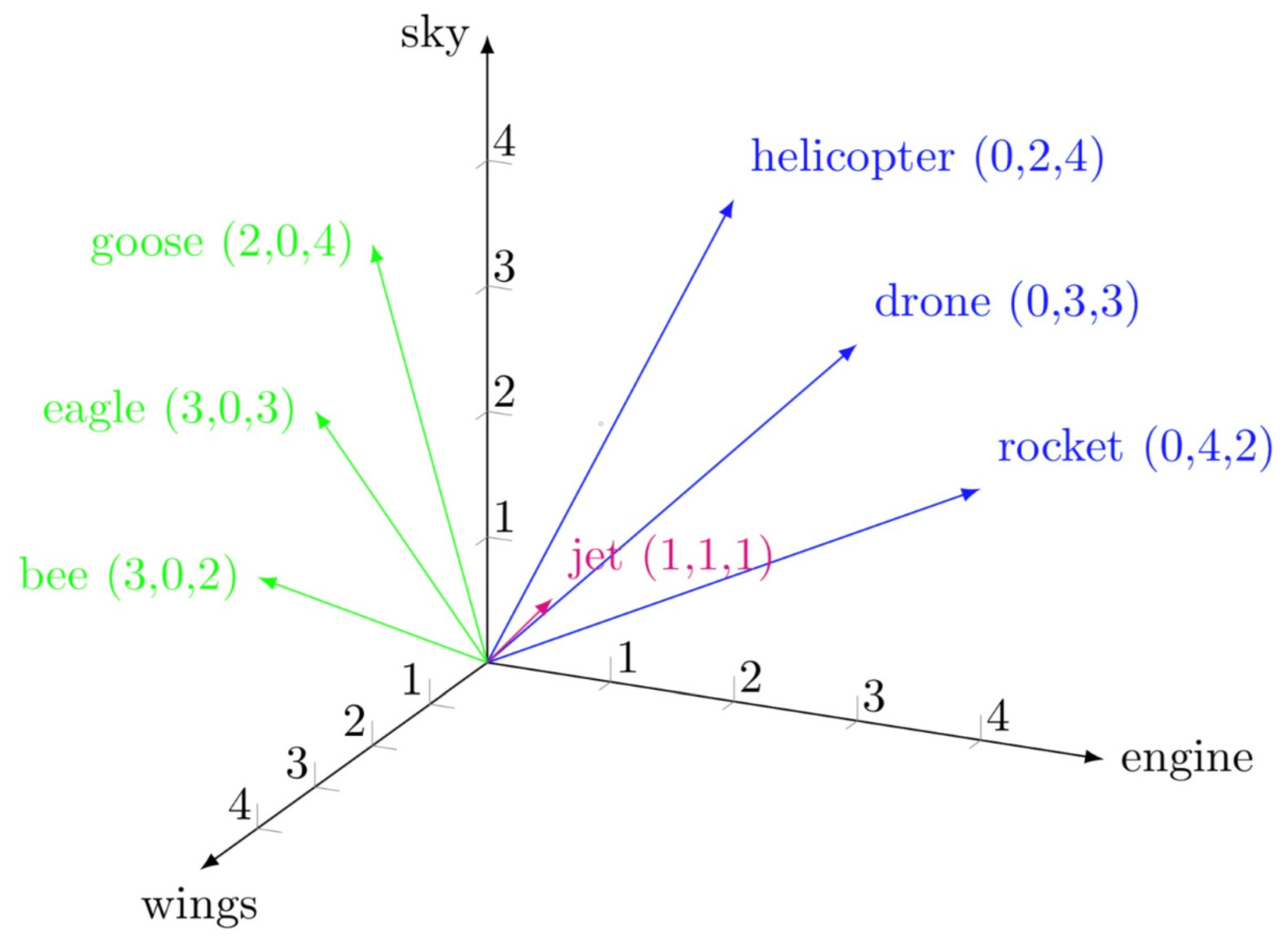
Consider, for example, the concept of distance, which is a key concept in cultural interpretation that has been the subject of different conceptualizations and definitions over time. In a vector space, distance becomes a mathematical distance. This issue is well illustrated by the so-called cosine similarity, which is one of the basic operations taken from linear algebra that consists of calculating the similarity between two vectors by taking, as a measure, the cosine of the angle between them (
Figure 6).
The mathematical interpretation is that the smaller the cosine angle between two vectors, the greater the similarity between these vectors within the vector space. This calculation is used to detect degrees of similarity between cultural elements (transformed into vectors) and to build large-scale cartographies of cultural domains. These large-scale cartographies foster modes of interpretations of cultural domains (visual or linguistic) that take as primary basis their arrangement into groups of similar elements, which in turn underpins modes of narrative based on contiguity and resemblance (I will come back to this issue later on). Likewise, this also implies that the concept of mathematical distance becomes a category of analysis and interpretation since in vector space, as we have seen, distance is not an empty notion but a measure of the degree of similarity between cultural elements (in the form of vectors). In summary, a process of cultural semantization of the concept of mathematical distance takes place; cosine similarity (the algebraic calculus) becomes an interpretative tool; and the result, namely, the similarity between cultural elements, is redefined as a measure of the degree of distance, mathematically computed, in the vector space.
The most obvious consequence of this semantization process is the adoption of a quantitatively based concept of similarity as a parameter of cultural ordering. Although this mathematical similarity intuitively works very well since, once projected onto the two-dimensional space, we can directly perceive the «resemblance» between the neighboring cultural objects under examination (see
Figure 7), this must also be (and is being) discussed in terms of its divergence from the forms of similarity that are proper to human cognition and its possible reductionisms (see, for example, [
22]).
At the same time, however, we can also appropriate this concept of spatial similarity based on mathematically computed distances to explore innovative ways of relating to cultural objects (which is not quantitatively based). This was one of the goals of the immersive project
Poscatálogo (2020) developed by iArtHis_Lab [
23,
24,
25]. Taking the concrete materialization of a high-dimensional vector space generated from the processing of a corpus of images with an Inception CNN as a base, we set out to explore how a notion as counterintuitive as that of high-dimensional vector space could be made to be physically experienced. For that, the two-dimensional manifold resulting from computational processing was transformed into an immersive three-dimensional space (
Figure 8).
In this way, the vector space, reconverted into an inhabitable, walkable environment in which the mathematical distances between the images are translated into physical distances that can be physically traversed, makes it possible to become aware of the existing gradational visual relationship between the images and their degree of similarity as the subject walks through the space; put another way, a spatial exploration of visual similarity is produced, not quantitatively but subjectively, as it is experienced with the whole body. Likewise, the bodily exploration of similarity through this performative exercise based on the traversing of physical distances between images materializes forms that are alternative to oculocentrism, that is, to the prevalence of the eye in our relationship with cultural objects in Western culture. Ultimately, my point is that while this geometric–mathematical-based epistemology can shape cultural interpretations and while, for that reason, it must be thoroughly discussed, it might or should also be the object of appropriation and reinterpretation in itself so that new (or renewed) cultural concepts can be explored. I believe that in this back-and-forth path lies the epistemological and critical broadening that these techno-concepts and techno-objects can offer us.
Spatial Forms and Structures/Morphology. As has been said (and can be clearly observed in
Figure 4 and
Figure 5), in the analyses carried out in high-dimensional vector spaces, the visual, linguistic, textual, etc., production becomes a problem of spatial distribution, which is the factor that determines the definition of cultural objects (for example, their greater or lesser degree of similarity respect to other cultural elements) and the cultural domain in itself; meanwhile, the space acquires a certain form and structure from the positions and distances that are established between the vectors that represents the cultural elements. Thus, the concepts of spatial structure and form become central categories for cultural analysis and interpretation.
Concerning the exploration of the structures underling high-dimensional vector spaces, topological data analysis (TDA) is a newly emerging domain comprising topology-based techniques to infer relevant features that have proved to be effective in supporting, enhancing, and augmenting both classical machine learning and deep learning models. TDA aims at providing well-founded mathematical, statistical and algorithmic methods to infer, analyze and exploit the complex topological and geometric structures underlying data that are often represented as point clouds in metric spaces [
26,
27]. The examination of the implications that this approach may have for cultural research and interpretation is still at a very early stage, although everything seems to point to the fact that these computational methods could provide interesting contributions. In addition to that, it cannot be disregarded that the application of these sorts of techniques oriented to explore the structures underlying data also involves the epistemological assumption that every phenomenon can be reconfigured as a structure and can be explained and interpreted in terms of structure. How this new structuralism will inform further cultural interpretations should also be an issue under discussion.
Nevertheless, my focus in this paper is exclusively on the visual configurations in which high-dimensional vector spaces materialize. In this regard, it is important to differentiate between the structure of high-dimensional space, which we do not see, and its materialization in a given visual form, which is the one we see, and, for this very reason, is the one that most strongly shapes our topo-morphological imagination. As these visual forms become discovery spaces and object knowledge in themselves, it is, therefore, essential to be aware of the distortions and deviations that these visualizations imply regarding the «real» structure of vector space; their inherent biases; the pareidolic phenomena that can occur when we try to unravel their meaning; and the epistemological assumptions that, embedded in them, endorse certain interpretations [
17,
28,
29]. Consequently, these visualizations constitute in themselves a space for problematization, and as shapers of imaginaries and activators of certain forms of cultural understanding, they must be systematically incorporated into critical studies on contemporary visual culture. However, and without undermining this question, what interests me in this paper is their potential epistemological productivity.
These visual configurations have been the subject of different conceptualizations. Thus, they have been interpreted as a technological version of Tom Mitchell’s concept of the metapicture (
Picture Theory, 1994), as they constitute images that «talk» to us about other images, an image-within-an-image that produces a metavisual visualization [
17,
30,
31]. Maria Giulia Dondero [
31] has also evoked the concept of the self-aware image and the meta-painting proposed by Victor Stoichita for early modern paintings (
The self-aware image: An insight into early modern meta-painting, 1997). Elsewhere [
14,
32], I defined these visualizations as a human–machine interface, i.e., as the intermediate space in which algorithmic logic becomes partially visible to the human subject that endows it with meaning through an interpretative process. From this point of view, it is not so much the direct correspondence that may exist between what we see and the real structure of the vector space that is decisive but its capacity to expand the epistemological imagination, raise new questions or activate intuitions toward new hypotheses, in other words, its heuristic rather than its hermeneutic capacity.
Semantic vector space models offer some examples that may adequately illustrate this argument. As their name suggests, semantic vector spaces are those that, through certain vectorization technologies, capture and encode the semantic relationships between words. The semantic vector space model is based in Zelling Harris and John Firht’s distributional hypothesis, according to which words, signs, syntagms, etc., expressing similar meaning tend to be used in similar environments. Consequently, the meaning of signs can be induced through the combinatorial patterns of their co-appearances in a corpus. According to the operating logic of vector space models, t is assumed that the words that are spatially closer are those that maintain stronger semantic relationships with each other and, thus, are configured by their proximity in conceptual or semantic regions. In this sense, concepts (as semantic regions) can be understood as structures (or formations defined by a certain morphology) that result from the paradigmatic relations between words that co-appear with a given frequency (
Figure 9).
Consider another example taken from LSA (latent semantic analysis), which is one of the foundational techniques of what is popularly known as topic modeling. Topic modeling is used for detecting latent topics in sets of documents by adopting, as a criterion, the frequent co-occurrence of words in the same context. In
Figure 10, the uncomputed matrix does not seem to have an apparent meaning; when it is computed, however, we observe that this matrix is reorganized, acquiring a certain structure that is modeled by aggregational forms that correspond to the frequent co-appearances of words. Therefore, strictly speaking, it can be said that in this visualization, latent topics themselves manifest as forms or spatial structures.
The piece
Multiplicity (2017) (
Figure 11), which is an interactive installation devised and designed by Moritz Stefaner on the occasion of the exhibition
123 data (2017), may also be illustrative. This installation actually constitutes a collective photographic portrait of the city of Paris constructed from hundreds of thousands of photographs that were shared on social media and were computed using a CNN and clustering algorithm that spatially distributed and grouped them according to their mathematically computed visual similarity [
33]. These clusters could then be considered as latent visual themes that are embedded in the social photographic production of the city of Paris; these are clusters that, as a whole, gave a certain shape to this particular iconosphere.
Without undermining the fact that the epistemological logic, in all cases, is the distribution of patterns and that these visual «formations» are mediated by the algorithm that produces them, these topo-morphological configurations that are now the concepts (linguistic or visual) allow us to study them as morphologies that emerge at a given moment. We can thus identify where and when they appear and how they are transformed over time by attending to how they change morphologically or how the shape of the vector space is modified owing to their trajectories and changes in position. Moreover, and more interestingly for the point of view of my argument, this exploratory context invites us to wonder about the possibility (and convenience) of developing a type of morphological semantic (linguistic and visual). For example, we could explore the association of certain topo-structures with certain types of concepts, and thus, developing a conceptual typology derived from the topological behavior of semantic domains. Given that they now have a visible form, we could also elaborate upon an iconology of concepts (visual or linguistic), and taking the comparison of their topo-structures as a basis, comparative semantics between traditionally separated domains of reality (cultural, physical, biological, etc.) could be developed, which might facilitate a more holistic understanding of the configuration of the world.
It should be stated that this proposal is far from new. In this regard, it is worth remembering that in his 1981 article
Spatial Form in Literature: Toward a General Theory, Tom Mitchell reiterated that «the concept of spatial form has unquestionably been central to modern criticism […] Indeed, the consistent goal of the natural and human sciences in the twentieth century has been the discovery and/or construction of synchronic structural models to account for concrete phenomena» [
34] (p. 539). Following this reminder, Mitchell delved into what a general theory of literature based on a spatial form could consist of. Just one year later, he proposed the development of a diagrammatology, which was defined as the systematic and historical study of the operative forms in the literary tradition [
35]. Likewise, Maria Giulia Dondero, within the framework of her semiotic approach to these techno-images, proposed the concept of diagramma of images (or diagrammatic images), taking as a basis the notion of the diagram in the perspectives of Charles Sanders Peirce, Gilles Deleuze and Nelson Goodman [
36].
In summary, these techno-images (or techno-forms), as boundary entities between the computational rationale and the human thought-/imagination, the visible and the invisible, the mathematical structure and the visual form, constitute an interesting space for interdisciplinary exploration in which machine learning, visual studies, visual semiotics and morphology should converge. Likewise, they constitute an interesting context in which to explore the epistemological potentialities of previous theoretical frameworks for the configuration of a possible topo-morphological epistemology.
3.3. Topological Narratives
The spatialization of the forms of reasoning that are inherent to high-dimensional vector spaces, their algorithmic logic based on the detection of patterns (and the distribution of vectors according to their similarity with the pattern encoded in a model) and their materialization in topo-morphological images lead to topological modalities of narratives, where concepts such as connectivity, relationality, continuity, proximity gradients and transformation (among others) prevail. All of these are concepts that are associated with topology, which are adopted (explicitly or implicitly) as categories of analysis and interpretation when dealing with high-dimensional vector spaces. As indicated in previous paragraphs, topological thinking is not new in the field of art historical and/or cultural interpretation; however, the growing «topologization» of discourses and narratives around cultural heritage associated with the phenomenon of cultural vectorization and its computational processes demands that it be given a new centrality in the theoretical–critical discussion, taking into account, moreover, that our horizon of reflection is now a techno-topology. In this regard, it is important to bear two issues in mind. On the one hand, it is necessary to explore the epistemological continuities and discontinuities regarding previous topological approaches in the field of art history and cultural heritage. For example, the visual similarity between Warburg’s tafeln and the visual feature spaces in which high-dimensional vector spaces materialize, and the fact that neural networks used in computer vision are capable to detect invariant patrons over time, cannot make us lose sight of the fact that Warburg’s topological thinking about the persistence and transformation of images is completely different from the algorithmic logic of deep learning technologies, no matter how much we try to interpret them from the Warburgian perspective. On the other hand, it is necessary to detect the problematization fields to which these topological narratives give rise. Let us consider two examples.
Neighborhood/Proximity/Affinity/Similarity. As has been repeated throughout this paper, the logic underlying high-dimensional vector spaces makes it possible to materialize the concept of neighborhood (semantic, visual, linguistic), which tends toward a study of cultural phenomena in terms of contiguity and affinity. The reorganization of visual or linguistic production, based on neighborhoods of related elements, undoubtedly contributes to a diverse understanding of cultural production by emphasizing contiguity beyond traditional classificatory schemes, which enables interconnections between cultural objects that are sometimes located in very different places in those epistemological systems built according to traditional categories of ordering and classification. These cultural reorganizations also provide interesting materials to propose alternative narratives to the traditional chronotope regime (geospatial and linear–chronological) by allowing us to inquire into nonlinear temporalities and spatial relations differently from those that are geographical or geopolitical. In this sense, the concept of contiguity, which is associated with the idea of neighborhood, also encourages the development of horizontal narratives, which favors a very productive context for experimenting with transchronological, de-hierarchical and nonstemmatic (or nongenealogical) narratives. The forms of contiguity and proximity also support, as Remedios Zafra claims [
37], thinking in terms of affinity and gradient as opposed to the «identitarian, dual and excluding forms» (p. 121) that are characteristic of those classification systems that divide or separate. For Zafra, the phenomena of erosion, fusion and confluence constitute the distinctive forms of our fluid and networked culture, which demands other forms of thought that make integration and conciliation possible.
However, we must not forget that these narratives of affinity and contiguity are, in reality, narratives of similarity and resemblance since, as we have seen, the proximities in a vector space are nothing other than degrees of similarity. As we know, the concept of similarity is plural and the analysis of the similarity that relate cultural objects, processes and phenomena to each other can respond to different dimensions depending on the research interests. However, the algorithmic modeling of similarity imposes the same logic in all cases: mathematically measured proximity to a pattern or model. Instead, human similarity does not operate only from the recognition of patterns, it also works by evocation and resonance, it is culturally modeled, and it puts into play other complex forms of similarity, such as metaphor.
In addition to delve into what similarity means in algorithmic terms, it is also necessary to discuss what it means to rely on narratives that are based primarily on similarity and resemblance. As José Luis Brea pointed out some years ago [
38] (pp. 82–83), AI imposes a logic of resemblance or, in other words, of recognition through mere resemblance. Rather than being different, cultural objects (transformed into vectors) «seems» to be more or less similar in the high-dimensional vector space. In this respect, I think it could be interesting to establish a distinction between the notions of dissimilarity and difference. Dissimilarity can be qualified according to the degree of resemblance between the things under analysis (objects can be more or less dissimilar); difference, instead, according to their specificity and singularity. This circumstance, together with the fact that models produced by the AI technologies are the materialization of invariant feature structures extracted from heterogeneous datasets, raises the crucial problem of how to approach the difference. These models are extremely valuable for analyzing the not-immediately-evident communality underlying cultural productions and processes. This potential explains their increasing use to extract the set of shared, recurrent characteristics that shape cultural and visual production but, at the same time, complicate the recognition of diversity, the new, the unique, the uncommon and the disruptive [
9]. This is why, together with the algorithmicity of the concept of similarity (and its potential reductionism), the relationship between similarity and difference, as well as the notion of difference in a vectorized culture, constitutes one of the epistemological problems that must be addressed.
Continuity/Transformation/Transition/Transductivity. The topological narratives underpinned by high-dimensional vector spaces also advocate an approach to the study and interpretation of culture in terms of continuity or, more specifically, of continuity «in» transformation. It must be kept in mind that in the high-dimensional vector space, cultural objects are no longer perfectly delimited entities, with each located in the box that corresponds to it according to its inherent, fixed and stable properties (as in the grid model at the basis of the traditional concept of archive); rather, they become a set of (numerical) characteristics that represent a point in a space that is made up of continuous dimensions. There (not as an object, but as such a set of characteristics) they maintain relations of degree with the rest of the points. That is why high dimensional vector spaces facilitate the exploration of the fuzzy boundaries that exist between cultural elements (words, images, concepts, etc.) that are not breaks but are more or less continuous transitions. These topological narratives thus constitute a suggestive (although not new) alternative to narrative modalities based on polarization, delimitation and bounding.
Figure 12, for example, shows us the evolution of Western pictorial production as a single topological form made up of regions and intermediate spaces that operate as continuous transitions between them. The image of art history as a sequential evolution of periods, styles, isms, poetics, etc., vanishes to become a unique space of characteristics, which has been explored unevenly over time by artistic practices but without discontinuity or rupture. Moreover, this vision of the totality in a synchronic manner is not timeless but spatiotemporal since time (inscribed in the process of transformation) is spatially modulated, or it can also be said that space is modulated in the temporality of what is transformed. Thus, the possibility of developing more complex temporalities that escape chronological regulation also emerge in the context of high-dimensional vector spaces.
Nevertheless, and regardless of the research potentialities involved in these approaches, the question about the extent to which introducing continuity into the discrete entails heuristic values and to what extent this leads us an unfertile distortion cannot be obliterated. Likewise, thinking in terms of continuity also involves bringing to the center of the debate its counterpart, discontinuity. Therefore, it is the dialectic between continuity and discontinuity as behavioral logics of cultural phenomena that truly becomes epistemologically productive.
If we take into account the fact that latent vector spaces are, in reality, regions of encoded features, it is easy to infer that the movement through a latent vector space entails a progressive transformation of the observed characteristics. If we examine it, for example, in the realm of images, the iconosphere is presented to us as a visual continuum that transforms in a progressive and nonlinear way, as we observe in
Figure 13, where images progressively transform from left to right. This transformative imagery raises a new order of questions; for example, what properties or characteristics could be considered critical to determining that a visual form is constituted as a distinct entity? What is the threshold that leads us to recognize forms as distinct entities?
The question of the transformation and permanence of cultural contents, objects and forms is a
topos of cultural research. High-dimensional vector space, however, propitiates a shift from the cultural production, that is, what is subject to change, to the process of transformation itself. The problem we confront (or should confront) is not a culture that transforms, trying to elucidate how we get from one point to another, but a «culture-in-transformation», so that it is the very process of transformation that becomes the object of exploration insofar transformation (in other words, the dynamics of change) is inherent to culture. This issue is illustrated when we understand vector space as a space in which multiple directions unfold. We must remember that a vector is also a trajectory and that a vector space has not only a magnitude but also a direction. The dimensions of the vector space specify the number of directions in the space. In addition, directions in the latent space can encode specific aspects of the cultural domain being analyzed. Therefore, the notion of direction can be used as an investigative tool in itself since the exploration of directions, i.e., the path between two points in the latent space, allows us to examine the chains of characteristic variations that unfold between them (
Figure 13 and
Figure 14). Thus, this quality of latent vector spaces facilitates an understanding of culture as a continuity «in» transformation, as a continual becoming, meanwhile placing the concepts of transitionality and transformativity at the center of the epistemological inquiry insofar as we can now materialize and «see», in a concrete way, the grade, scale, intensity and range of transformations operating between regions of cultural domains.
The continuity we have been discussing is also manifested from another point of view: multimodal continuity. This continuity can be seen as the result of the ontological equalization of different semiotic systems that are derived from the transformation of cultural objects into numerical information entities and vectors. From a computational point of view, there is no substantive, material or ontological difference between words, images, sounds, etc.—they all have the same materiality and mode of existence. In fact, strictly speaking, it could be said that multimodality itself vanishes in the vectorial continuity. This circumstance implies that vectors of images and words (for example) can coexist in the same vector space, making it possible to compare and analyze them together or even, due to the porosity of neural networks, making possible the production of texts from a given image or the generation of synthetic images from texts. See, for example [
39,
40,
41] regarding the production of captions and texts associated to artworks images. Perhaps, the most well-known models that handle with the task of image descriptions and text-to-image generation are OpenAI’s CLIP, DALL-E 2 and GLIDE, which have become very popular in recent times. Likewise, the so−called multimodal AI is based on the construction of exploratory systems that combine different analysis technologies (NLP, CV, etc.) and integrate multiple semiotic modalities to produce meanings that emerge from the synthesis between language, images, videos, etc. The operating logics and the outputs generated by these models really seems to lead us to a post-visual and post-linguistic era marked by a (post-human) transductivity between semiotic systems.
Although we are still at an early stage in the field of cultural heritage, this emerging scenario prompts us to inquire about what avenues of exploration are opening up and what areas of problematization are emerging beyond the possibility of producing image captions/descriptions or synthetic images. Undoubtedly, cultural vectorialization, high-dimensional vector spaces and latent spaces offer us a very valuable framework to explore transfers and transitions between images and words in a different way than we have done so far. From my point of view, one of the most striking projects regarding this question is
The Next Biennial Should be Curated by a Machine. Experiment: A-TNB (2021), designed and developed by Joasia Krysa, Leonardo Impett and Eva Cetinic [
42]. This experimental project uses CLIP (Contrastive Language–Image Pre-training) to explore cross-similarities between images and texts, so that a sort of transductive ecosystem is created in which synthetics images generated from texts and generative texts produced from images are related according to their degree of similarity. Since the generated images are created only from titles, the most similar generated images are therefore connected through the visual similarity of their (textual) titles. In the same way, since the images’ textual descriptions are generated from their visual features, the most similar texts are connected through the textual similarity of their (visual) appearance [
Figure 15 and
Figure 16]. Certainly, it is only an experiment, but it is compelling enough to invite us to reflect on what other dimensions of similarity exist (or can exist) that scape human intellectual and cognitive mechanisms, as well as involving approaching visual-textual transfers and transitions on another order of complexity.
The fluid boundaries between words and images (or, in other words, the linguisticity of the image and the visuality of the language) is a cornerstone of Tom Mitchell’s picture theory (to cite perhaps the most widely known example); therefore, here, we do not again confront an unprecedented paradigm of cultural interpretation. However, these models provide us with concrete tools to make transductivity a central category for cultural analysis and interpretation.
In summary, beyond narrative and research potentialities, the essential question at stake is how to re-operationalize these not-new concepts (continuity, transformativity, transitionality, transductivity), but now re-modeled by the techno-topologies generated by computational methods in order to produce truly relevant knowledge in the field of cultural research and interpretation. Likewise, these topological narratives also reposition in a new context the debate around the dialectical interplay between transformations and invariants, deformations and permanence, as well as the tension between continuity and discretization. How to go beyond the already known intellectual concerns associated to these dialectical interplays is also a crucial question.



.jpg)




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}