1. Introduction
Recently there has been debate [
1,
2,
3,
4,
5,
6] as to whether Species Distribution Models (SDM) are appropriate tools in the study of the COVID-19 pandemic. Of course, such a debate raises the important question of when and under what circumstances an SDM, or an Ecological Niche Model (ENM), are likely to be valid and/or useful in the study of disease in general? Just which diseases, or aspects of diseases, can be usefully studied using SDM/ENMs? Which pathogens have ecological niches and which do not? In addition, if some do not, why do they not? Taking the broad view: If ecology is the study of the relations between organisms, both among themselves and with their environment, and an ecological niche is the full set of biotic and abiotic factors that favour the presence of an organism [
7,
8], then clearly all disease pathogens must have an ecological niche. The question, rather, is: how is that niche to be characterised and quantified? What are the appropriate niche dimensions and can a meaningful and useful ENM and, consequently an SDM, be constructed?
Although there is controversy as to the application of ENMs and SDMs to the case of COVID-19, there have been varying degrees of success in applying them to other human diseases. In particular, to zoonoses [
9,
10], where non-human species are involved in the transmission cycle. The principal applications have been to the creation of ENMs and SDMs for important agents in the transmission cycle of the zoonosis, such as known vectors [
11] and hosts [
12], considered as risk factors, as well as the pathogen itself [
13]. In all these cases the corresponding niche variables were abiotic—climate and environmental layers—in spite of the fact that biotic factors clearly play an important role as niche variables for the disease itself. Biotic factors were successfully incorporated into ENMs and SDMs for zoonoses in [
14,
15,
16,
17,
18,
19,
20] Importantly, the capacity to include biotic factors into ENMs and SDMs led not only to the creation of more predictive and explainable models but also, for example, to the prediction and confirmation of multiple new hosts of several zoonoses [
16]. However, all these models, independently of the inclusion of biotic factors, were based on presence–absence data and on the implicit assumption that the system was in “equilibrium” [
21].
In all of these cases of human disease there has been a component that is considered “ecological”, either in the targets of the ENM/SDM, such as vectors or hosts of a zoonosis, as well as in the niche variables themselves, such as climatic and other environmental variables, as well as potential hosts and vectors. However, in the case of a disease such as COVID-19, which is based on human-to-human transmission, there is a question as to the relevance of such factors. Additionally, abundance, rather than just presence–absence is a fundamental concern. Finally, it is clear that for epidemics or pandemics of this nature in no way is an equilibrium assumption valid. It is these criticisms, among others, that have led to the questioning of an ecological ENM/SDM approach and to the conclusion that an epidemiological rather than ecological approach is to be preferred, which leads us to a further question: when is an ecological versus an epidemiological approach more appropriate? The difference between the two is stated quite clearly in the epidemiological literature [
22,
23]. Put simply, ecological models are naturally associated with the “where” of a disease, while epidemiological models are more concerned with the “who”. This difference is aptly captured in [
24] with the question: “Is it better to have a heart attack in the United States or Canada?”, the emphasis being that this type of question is of an ecological nature, whereas the question: How many people out of a cohort of individuals diagnosed with COVID-19 will subsequently die? is an epidemiological question. Indeed, this ecological “where” perspective has a long history in the social sciences as a whole [
25,
26]. From a modelling viewpoint, the difference between the two approaches lies in what statistical ensemble will be used to draw inferences. Epidemiological models use an ensemble of “individuals”, while ecological models use an ensemble of “places”, where each place is associated, either explicitly or implicitly, with a population. The “places” can vary depending on context: from countries and other political units, to eco-regions, any fixed-area spatial cells, and to pixels on a raster.
Additionally, there is a subsequent question of “when”, that is relevant for both the ecological and epidemiological points of view. Standard SIR-type modelling [
27], for instance, is associated with the “who” and the “when”, with the “who” being associated with a fixed-number of states—susceptible, infected, etc. that are associated with individuals [
28]. It is the “when” and, relatedly, “how many” that has dominated the modelling of the COVID-19 pandemic, with standard SIR models, and variations thereof [
29,
30,
31], playing an important role [
32,
33]. However, more sophisticated techniques, such as deep learning, have also been used [
34]. All these methods however, are based on modelling the time series of the data to be predicted, such as cases or deaths. In no way can they account for the high degree of multi-factoriality involved in the evolution in space and time of the pandemic. In other words, they cannot account for the “whys” that accrue from the direct and indirect causes of this evolution. Thus, although such dynamical models can be extended to consider “place” by constructing a SIR-type model for a particular place [
35,
36]; such models, however, do not account for the distinguishing features of that particular “place”, as does an SDM/ENM. On the other hand, currently, SDM/ENMs do not account for the dynamics of a disease and are also unnecessarily restrictive in the set of niche variables considered. Finally, there is, behind the “who”, “where”, and “when”, the “why” that explains them. This, we argue, is the most important role for the use of ENMs in the study of human disease.
In this paper, we show that an ecological approach, using SDM/ENMs, can be usefully applied to any human or non-human disease, transmissible or not, taking as a specific example the spatio-temporal distribution of COVID-19 in Mexico to answer in the affirmative that a respiratory virus does, indeed, have an ecological niche, and that it can be mapped. We show that a wide variety of habitat variables, both environmental, behavioural, and social, and of different types and spatio-temporal resolutions, can be included, to yield a deeper understanding of the factors that drive the COVID-19 pandemic. Moreover, we show how to generalise SDM/ENMs to incorporate and predict the dynamics of the disease. Finally, we show how the formalism can be used to disentangle the complex causal chains that are a fundamental part of a complex adaptive system.
2. Materials and Methods
Several of the methodological elements used in this paper have been used previously for creating ENM/SDMs in multiple contexts [
15,
16,
17,
18]. Further details can be found in these papers and in the
Supplementary Material.
2.1. Defining a Spatial Grid
All SDM/ENMs are based on the notion of co-occurrence between a target,
C, and, one or more, predictors/habitat variables,
. Normally, co-occurrence is considered purely in spatial terms, although the concept can be extended to co-occurrences in time. In either case, to specify whether there is a co-occurrence or not requires a specification of a grid that divides a spatio-temporal region into cells. A spatial grid can consist of cells of arbitrary shape, as long as they form a partition; i.e., each spatial point is a member of one and only one cell. A partition may be uniform, such as formed by rectangular cells of a given area, or irregular, as is the case for political/administrative units, such as municipalities, counties, states, etc. In standard SDM/ENM modelling [
37] this partition is implicit, corresponding, for example, to the pixels of environmental rasters. Such a partition, however, creates a barrier when wishing to include biotic factors, such as point collection data, that cannot be naturally represented as a raster. In short, we may wish to ask: what is the relative importance of average annual temperature, as taken from WorldClim, versus the presence of a prey species in an SDM/ENM for a vagile carnivore?
In Stephens et al. [
38], a methodology has been developed for incorporating spatial data layers of arbitrary type and spatial resolution. A spatial grid is overlaid on a chosen spatial region and co-occurrences defined with respect to a given cell. Thus, if there is a co-occurrence between
C and a particular variable,
, in a particular cell, then
. In the case of a continuous variable, such as species abundance, temperature, or precipitation, the variable,
, is coarse grained into a set of
n discrete bins, leading to
n discrete “presence/absence” variables. Thus,
represents the presence/absence in a cell,
, of values of
in the range defined by the
mth bin. Any categorical variable can be left as is, or also coarse grained into a smaller number of categories, if necessary. The criterion for fixing the bin distribution of a variable are that it allows for the best discrimination—dependence of
C on
—while maintaining an appropriate degree of statistical significance—number of cells associated with a given
. Furthermore, the target
C can also be discretised if necessary in the same way, with bins
. In summary, all variables become categorical, with each category being associated with a binary variable. An advantage of this categorisation is that no relation is assumed between one bin and another, as would be the case in a regression-based approach for example. Using a non-uniform grid however, can introduce some bias, as some municipalities are bigger than others. We have, however, used spatially uniform grids without substantial changes in our results.
2.2. Constructing SDMs and ENMs
Having transformed all variables to this binomial form, counts, , can be made over the region of interest, corresponding to the number of cells that contain a presence of the target and the variable . The number of cells associated with a given and/or may be fixed or varying depending on the target class. For instance, if we define the class using a relative measure, such as the 10% of cells with the highest abundance for a given species, or the highest number of confirmed cases or deaths in the case of COVID-19, then the class will always be associated with 10% of the cells, independently of time. However, if the class is based on an absolute measure, such as presence/absence of the species, or confirmed cases of a disease, the number of cells in the class may vary in time as, for example, in the case of an invasive species, or an emerging epidemic. Similar considerations hold for . If it represents a relative measure, such as the 10% of cells with highest average annual temperature, then it will always cover 10% of cells. However, if it represents the presence/absence of an invasive species, the number of associated cells will change. We will consider these cases in more detail below.
From the co-occurrence counts, probability distributions may be calculated, such as
,
, and
, which are related through Bayes theorem. These distributions can be compared to a null hypothesis and a binomial test used, for instance, to determine the statistical significance of the deviation from this hypothesis. For example, for the posterior, a natural null hypothesis is
(This is equivalent to the null hypothesis of type SIM2 in the classification of Gotelli [
39]. This null hypothesis is one that leads to lower rates of Type I errors and corresponds, in the framework of presence–absence matrices, to keeping the number of observations fixed but randomising their location.) and a statistical diagnostic for determining if the habitat variable
is significant or not is
In the case that the binomial distribution can be approximated by a normal distribution,
is equivalent to the 95% confidence interval. For a multivariate niche the corresponding distributions of interest are:
,
, and
. Although these exist formally from a frequentist perspective, i.e.,
, in the case of a high-dimensional habitat, both
and
, which means that a direct statistical estimation is impossible. To overcome this problem, in [
40], the likelihood
has been estimated by assuming a factorisation of the form
where
is a combination of a small number of variables. Thus, the abiotic and biotic habitat variables are partitioned into a set of
non-overlapping combinations. In the case that
, this corresponds to the well known Naive Bayes approximation [
41] (Although a complete factorisation of the likelihood may seem a strong assumption, the Naive Bayes approximation has been shown to be a robust performer even in cases where there are strong correlations between variables. An explanation for its surprisingly good performance can be found in [
41]). Usually, in order to calculate
, as the evidence function
is independent of
C, to omit it, the following “score” function is often used
where
is the set complement of
C, with
, and
is the contribution (“score”) to the overall
from the variable
. If
then the factor
contributes positively/negatively to the occurrence of
C. Everything now is based on simple cell counts:
,
,
, where
is the number of cells with a presence of the target
C,
is the number of cells with a presence of the variable
and
is the total number of cells in the spatial grid.
can be determined directly from
by deriving the relation
, discretizing the score range into bins and then counting how many cells in a given score range also have a presence of the target.
is a measure of how niche-like the conditions specified by
are. The most niche-like conditions,
, are those where
reaches its maximum value, while we can term those conditions,
, where
reaches its minimum value, as the most “anti-niche” like.
represents a height function for a given point in an
N-dimensional Hutchinsonian ecological niche space. The corresponding “Niche Landscape” is our ENM. As every spatial cell
can be assigned a corresponding niche profile,
,
for different spatial cells also now yields an SDM over our spatial region of interest.
A significant advantage of assuming a factorisation of the likelihood is that the subsequent model is completely transparent, with each factor contributing separately, so that each factor can be compared and contrasted with the rest. Moreover, the same applies for groups of factors, so we can compare the relative predictive and discriminative value of climate factors versus socio-economic factors, or air contamination versus mobility.
Of fundamental importance in the construction of is the statistical ensemble from which the counts will be made. Although we consider a spatial ensemble, the data assigned to each cell invariably have a temporal dimension. In the case of standard SDM/ENM, with a target class defined through point collection data, each data point, , is associated with a spatial specification, usually latitude and longitude, and a collection date, t. Similarly, abiotic factors are also time-stamped. A model for assumes that the distributions in time of both C and are both statistically constant and representative.
In the case that the target variable is metric, such as number of cases, , the classifier can also be used to predict for a given spatial cell and over a particular time period. In the case of a spatial model, the cells may be divided up into training and test sets. The points for each cell, , of the training set can then be plotted, and a regression performed to determine the relationship . This relation can now be used to predict for any cell in the test set given we have there.
2.3. Dynamical ENMs and SDMs
A key aspect of the COVID-19 pandemic is its highly dynamic nature, which can manifest itself in several different ways. First of all, the habitat variables themselves may be time dependent,
. Secondly, the target itself may be dynamical,
. In the latter case, this may represent the fact that a disease or a species/disease is present at a given spatial point at one point in time but not another. Thus, the case of an invasive species would fit into this category. In the former, the disappearance of food resources or climate change would naturally fit. In general, we wish to model
. It is important to point out that there is a difference, however, between having a ENM that is dynamical versus just considering a different configuration of the habitat variables substituted into a given model. In the case of climate change, for instance, this is usually performed [
42] by determining a static ENM, equivalent to
, which can be applied to any spatial point,
, then using a climate change model to determine
for some future time
. In other words, we assume the ENM does not change, only the spatial distribution of the habitat variables, which is then used to determine the new spatial distribution of the target with the same original model. In other words, we determine an SDM at
using an ENM derived at time
t.
To move beyond this limited context, we must return to the question of spatio-temporal cells as opposed to just a spatial grid. Considering a timespan T, we divide T into intervals. We now have a total of spatio-temporal cells. The simplest division is into uniform intervals, such as a year into 12 months. In a static setting, the interpretation of is that it represents an equilibrium relation between C and , even though the data used to calculate it, more often than not, spans substantial and, effectively, non-commensurate time periods. For example, using WorldClim data from a given year as habitat variables for a niche model of a species represented by collection data taken from a 150-year time period. Without assuming equilibrium we should calculate . However, we may also consider calculating , i.e., to predict the effect of the habitat variables at time on our target . Of course, an important question at the heart of this is: how are changes in reflected in ? This requires longitudinal observations and/or an understanding of the underlying causal relationships between the and C.
There are four distinct paths to incorporating time into the SDM/ENM: (i) assume equilibrium, and thereby ignore time dependence; (ii) construct a model using a time slice/history to predict a spatial distribution on that time slice, as a function of the habitat variables on the same time slice; (iii) predict in time, assuming niche conservatism, i.e., construct and use it to predict the spatial distribution, at some later time using the habitat ; (iv) predict in time, without assuming niche conservatism, by constructing , where . Models of type (i) and (ii), we term spatial prediction models. They are analogous to standard SDM/ENMs, in that they predict a spatial distribution. However, in distinction, in case (ii) they do so using a time slice of data that permits us to compare and contrast , and over time. For instance, we may use data only from May 2021 and compare with data from May 2020, or we may consider data from all of 2021, etc. Models of type (iii) and (iv) we term time prediction models. In this case they are an ENM/SDM equivalent to a SIR-type model, predicting the evolution of “where” in time, as opposed to “who”. The case with niche conservatism would be equivalent to a SIR type model, where the parameters of the model do not change, whereas the non-conservative case would correspond to the case where they do change and are fitted to dynamic data.
The notion of a time prediction model also naturally leads us to consider ENM/SDMs that are associated with changes in the distribution of a species/disease. For instance, we may consider the set of cells, , that have a presence in the time interval and the set of cells, , that have a presence in the time interval t. may then represent those cells that had a presence/absence at and, in contrast, an absence/presence at t. This could, for example, model the range expansion of a species. In this case, an ENM represents a model for predicting changes in the distribution due to the habitat variables. This model can then be applied to produce an SDM using the habitat variables at t and predicting the change in distribution between t and .
We give more details about how to construct the different spatio-temporal models in the
Supplementary Material. As discussed above, spatially, we used a grid corresponding to the municipalities of Mexico. For the temporal partition, we chose a month, though any other timescale of interest could have been used.
2.4. Testing Model Performance
The way in which our models are tested depends on the type of statistical ensemble that is used to train and then test the model. In the case of an ENM on a given time slice,
, the model will be created on a training set that corresponds to a randomly chosen fraction,
, of spatial cells with data associated with a time period
t. The model is then tested on the remaining fraction of cells
from the same time period. The test and train sets can be chosen in multiple ways. Here, we consider a 70%/30% split. Standard performance statistics can then be determined, such as from a confusion matrix or from the area under the ROC, among others [
43,
44]. However, we can also use the ENM
trained on 100% of spatial cells and apply it to a future time period
. In this case, the entire set of spatial cells at
is the test set. The luxury of a problem such as COVID-19 is that we have relatively accurate data about the spatial distribution of the disease as a function of time. In this case, the ENM
is used by substituting at
,
for each spatial cell,
, to obtain for that cell
. We can now test the quality of the prediction using any of the above standard metrics, given that
is a classifier, and we can compare with the actual distribution
. We will expect the time
t ENM to yield good performance at
only if the niche is conserved over this time period.
Aside from the pure assumption of niche conservatism, where we apply the ENM , we can compare and contrast ENMs from different time slices to determine the degree to which they are changing. This would correspond to determining if the niche is actually changing over time. This can be performed for each habitat variable by comparing with . If the niche is changing then we must consider just how fast it is changing. This can be deduced by comparing the across time. If for two time periods t and , then the niche is conserved over the interval . If they differ substantially, then we may reduce and determine how much change there has been over this shorter interval.
For time prediction models that do not assume niche conservatism, the training set consists of choosing two time periods and t. An ENM is created on all spatial cells. This model is then applied to all spatial cells for the time periods t and as test set. Thus, we use the ENM , substituting to create the SDM for prediction of . We can then apply any of the above standard metrics to evaluate the performance of this ENM/SDM.
2.5. Predicting Abundances
ENMs that are based on presence/no presence are, naturally, binary classification models. Although a metric variable, such as abundance, can be treated as such by considering multiple classes, it is also possible to use a binary prediction model, such as the top 10% of municipalities with highest confirmed cases, to construct a relation, between the score, , and the number of cases on a training set. This model can then be applied to a test set, predicting the expected number of cases for a given cell, , using its habitat profile . This procedure can be used for both spatial and time prediction models. In the former case, the abundance predictions are associated with a given time slice t using a split of the cells into training and test sets, while for the latter we predict from a training set that consists of all cells on a time slice t to predict abundances on a test set of all cells on a time slice .
2.6. Inferring Causality in ENMs
Another criticism of the application of standard SDM/ENMs to the pandemia has been the lack of plausibility of the relation between, say, infection rates and habitat variables, such as climate or contamination. As pointed out in [
40], this is a problem with correlative approaches in general. This criticism however, can be applied to a phenomenological study of any complex adaptive system, where cause–effect relations are multi-layered and, therefore, often indirect. Epidemiology and medicine in general are rife with problems of causal inference and there are two basic approaches to it: a “classic” approach [
45] and a “modern” approach [
46,
47,
48]. An important criterion from our perspective is that of “strength of association” [
45], where, although a small association does not mean that there is no causal effect, the larger the association, the more likely that it is causal. This is key to our use and understanding of both
and
and their multi-factorial counterparts
and
. Thus, for two niche factors,
and
, if
, then we will judge
to be causally closer to
C than
. An illustrative example of this would be a food chain: carnivore → herbivore → plant food → climate, as considered in [
40].
In [
40,
49], we have proposed a formalism for examining causality that is particularly natural for application to ENMs. If we have two niche factors
and
, we can better understand their potential causal relations with a target
C by considering the following relations
where
represents the null hypothesis with respect to which we will determine the predictability of the combination
. If
we are gauging the consistency of
with the null hypothesis that the distribution of the target species is independent of the variable combination
. However, we may also choose as null hypotheses
or
, in which case the null hypothesis is that
is independent of
and
, respectively. With this approach, we can determine the degree to which
confounds
or vice versa. For example, if
and
, we can conclude that within a 95% confidence interval that
is not consistent with the null hypothesis and therefore the habitat variable
is predictive of the distribution of
C beyond what is explained by the habitat variable
. As
may be a biotic variable and
an abiotic one, we have used this to show that, very often, biotic factors are confounders for abiotic factors and not vice versa [
40]. Although, here, we are concentrating on causal relations and confounding with respect to pairs of habitat variables the formalism naturally extends to larger numbers of variables.
In any spatial cell we may determine if there is a presence or absence of a given coarse grained bin for either variable, and . For example, would represent a presence of bin 4 of variable 8 and a presence of bin 2 of variable 10 in the cell , while would represent an absence of bin 4 of variable 8 and a presence of bin 2 of variable 10 in the cell. Thus, there are 4 possible combinations for any pair of habitat variables: presence–presence = 11, presence–absence = 10, absence–presence = 01, absence–absence = 00. By comparing and contrasting the different combinations, we may determine, for example, if presence of one habitat variable is more predictive than the other. Note does not imply absence of the variable itself in the cell, just the range denoted by the nth coarse grained bin.
2.7. Data and Habitat Variables
In this paper, considering the evolution of the pandemia in Mexico, we used an irregular spatial partition consisting of the 2458 municipalities of Mexico. The advantage of this partition is that it is most aligned with publicly available socio-demographic and socio-economic factors that can serve as corresponding niche variables. Its disadvantage is that there is a potential bias in the spatial distribution of different municipalities according to their area. For the epidemiological data, used to define the target classes, we used data from the General Directorate of Epidemiology, Secretariat of Health in Mexico [
50]. For the socio-demographic and socio-economic data, we used 124 variables taken from the 2010 Mexican Census [
51] at the municipality level. For mobility data, we used 12 variables provided by the Institute of Geography of UNAM, that represent the average, daily labour flows between a pair of municipalities. For the air contamination factors, we used three atmospheric pollutants (formaldehyde (HCHO) nitrogen dioxide (NO
), sulphur dioxide (SO
)) [
52,
53,
54], while for climactic data, we used 19 bioclimatic variables from the WorldClim database (
www.worldclim.org (accessed on March 2022)) with a spatial resolution of 30 arc-seconds (≈1 km) [
55], which includes 11 temperature and eight precipitation indices that express annual trends (e.g., annual mean temperature and precipitation), seasonality (e.g., annual temperature and precipitation ranges), and environmental extremes (e.g., highest and lowest values of temperature for the warmest and coolest months).
As all the socio-demographic, socio-economic, and mobility data were metric and continuous, for each variable, we ranked the 2458 municipalities from highest to lowest value then divided the ranked list into deciles, with 10% of all municipalities in each decile. By doing this, as opposed to dividing the metric interval for the variable into equal parts, we assure equal statistical weight to each coarse grained category. For the air pollution variables, we divided each raster layer into 20 ranges, which were chosen to have roughly equal number of pixels in each one. Climate variables were also divided into 20 ranges. Thus, in this way we mapped both target class and habitat variables in their entirety into a set of binomial presence/absence variables for each cell on our grid. We also included in as a habitat variable the decile of confirmed cases associated with a given municipality, but at period , as opposed to the target variable which was associated with period t. In this way, we could show, in principle, how the history of the habitat can also be included as a predictor. Indeed, this is the first step at showing how the present methodology may be developed to include SIRs-type modelling properties.
4. Discussion
Our goal in this article was to demonstrate that the questions: “Does a respiratory virus have an ecological niche, and if so, can it be mapped?” can be answered in the affirmative. We have explicitly created several ENMs and SDMs for COVID-19 that are both predictive and contain habitat factors that are more causally plausible than climate, for instance. In order to achieve this, we introduced several innovations compared to standard niche and species distribution modelling. Firstly, we showed how to extend niche and species distribution modelling to “non-equilibrium” situations, where both target and niche variables are potentially time varying, as well as the relation between them. Secondly, we created models with habitat variables that were represented by quite different data types and associated spatial resolutions. Finally, we showed how causal relations and confounding can be better understood by introducing a hierarchy of conditional probabilities and the associated intuition that a more causally direct factor should have a bigger effect than an indirect one.
We constructed ENMs as Niche Landscapes,
- Bayesian posteriors which serve as a height function on a Hutchinsonian ecological space with 2749 dimensions, spanning air pollution, climate, mobility, socio-economic, and socio-demographic data. Usually in ENM/SDMs, the target class,
C, is a binary variable, such as presence/no presence of a species. In Coro [
5], the corresponding variable was “high” infection rate, defined in a binary fashion with respect to a reference infection rate. We too, have used binary class variables, by choosing a particular subgroup of spatial cells, corresponding to presence/absence of confirmed cases, or if a spatial cell was in the top 10% of highest total infections (In the EpI-PUMA system, publicly available in a Platform-as-a-Service environment (
http://covid19.c3.unam.mx, accessed on 5 April 2021), 72 different SDM/ENMs are available that use the methodology described in this paper.). However, the binary nature of the target variable is a choice rather than a restriction. For instance, taking infection rate as a continuous variable, this can be divided into as many quantiles as we please, say
. The target variable now consists of
“presence/absence” variables, each with its own ENM/SDM,
,
. Even in the case of a binary decomposition of a continuous variable; however, the metric nature of the variable leaves an imprint on
, such that higher score, as a continuous metric variable, corresponds to higher infection rate or number of cases, as we have demonstrated, leading to a model that can predict abundances.
In criticising ENM/SDMs as a useful tool for the COVID-19 pandemic, or any other, it is important to distinguish between applicability of ENM/SDMs in general versus a particular instance of an ENM/SDM. It is appropriate to criticise a model that includes climate, and which has been used to infer a corresponding causal effect on the pandemic, without any analysis of possible confounders. This does not mean, however, that with appropriate habitat variables and a methodology for disentangling confounding, that useful ENM/SDMs cannot be constructed, as we have shown here. Our results clearly show that models for predicting where the highest number of cases will be, that are built on mobility, socio-demographic and socio-economic data, are much more predictive than models built on climate and/or air contamination, as can be seen in the results of
Figure 1, and that this has been true throughout the pandemic. As seen in
Table 1, the most important niche/anti-niche factors for this target are all associated with the highest/lowest levels of mobility, as proxied by inter- and intra-municipal labour flows, and a particular socio-economic profile. The fact that a climate model can exhibit some degree of predictability does not mean that climate is the direct driver. On the contrary, we can ask if any apparent predictability due to climate factors is confounded by human-based factors. As we have shown in
Figure 7 and
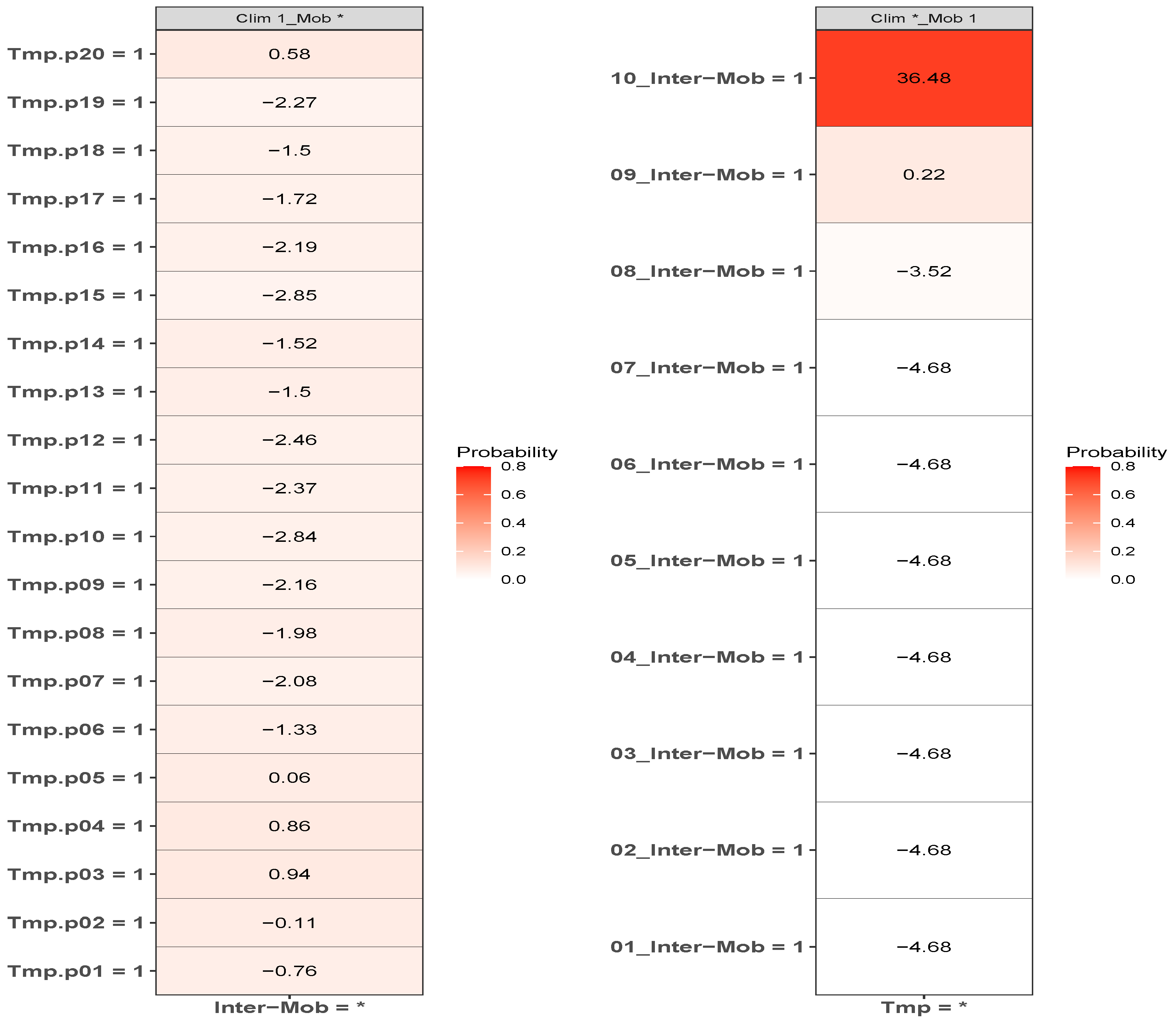
Figure 8, this is indeed the case. Just the distribution of the habitat variable scores themselves tells us that if there is confounding then it is the human factors that confound climate and not vice versa, as a confounder should be causally closer to its effect than the confounded variable and therefore have a higher score, as is implicit in the Bradford–Hill criteria.
With respect to the socio-demographic and socio-economic factors, we see that they have a similar predictive power to the mobility factors and reflect the socio-demographic and socio-economic conditions where COVID-19 cases are highest. For instance, the habitat variables
% of households that have a computer and
% of households that have internet access are both significant niche factors, as are other factors that correspond to a more educated population with higher economic status. Of course, the interpretation of these factors is not as intuitive as mobility and we certainly do not wish to attribute direct causality to them. However, there are a variety of relevant factors for COVID-19 that can be related to internet access and computer usage for example, such as age, educational status, population density [
56], as urban areas have better infrastructure, and mobility itself [
57,
58]. As with any epidemiological or ecological model, the interpretation of the predictors as representing direct versus indirect interactions is highly non-trivial. The formalism we have introduced for disentangling confounding can help in this regard.
The places where COVID-19 is in highest abundance represent one particular characterisation of the spatio-temporal distribution of the COVID-19 “species” and its associated ecological niche. Where it is present and where it will be in the future compared to where it is now are two others. Hutchinson [
7,
59] defined niche as that region of ecological space where the net growth rate of the species is
at low density. For a pathogen that is not capable of free movement and is dependent on a host, there are two natural growth rates: one associated with the pathogenic load within a host and another that is measured by the number of infected hosts. Obviously, in this paper we are concerned with the latter, where the growth rate is characterised by the basic reproduction rate,
, or the effective reproduction rate,
[
60]. If we defined niche for COVID-19 through an analogue of
, such as
, we would clearly be in a situation where we were passing from “niche” to “anti-niche” (
) and vice versa, continuously in space and time due to a multitude of factors, including public health interventions, such as lockdowns and vaccinations, as well as resistance to vaccinations, new variants, and a host of others. That these factors alter the ecological conditions in a certain place at a certain time is undeniable. However, to keep track of such changes and how they impinge on how niche-like conditions are in a certain spatio-temporal cell,
, requires the corresponding data. Here, we have preferred to use characteristics of the pathogen distribution that are easier to measure—number or presence of cases—but with which we can characterise the concept of niche, and a set of habitat variables that go beyond those previously considered. We take highest case abundance to distinguish those conditions in ecological space, and in geographical space and time, that favour higher abundance of the pathogen, as proxied by abundance of cases. This is a
relative measure, as it may be that a municipality,
, has
but such that it is higher than any other.
Holt [
61] has suggested that besides an “Establishment Niche”, that corresponds to the original Hutchinsonian niche, a “Population Persistence Niche”, associated with the range of niche space in which populations above some threshold density,
, can persist, is a complementary notion. We take where COVID-19 is in highest abundance to be closer to this Population Persistence Niche, whereas where it is present is closer to the original Hutchinsonian characterisation and, especially, as it is portrayed in the majority of ENM/SDMs [
37], where presence/absence is used to characterise both. On the other hand, where it is now versus in the past corresponds to neither, but is taken to reflect the potential range expansion/contraction of the species. We believe that these examples, and more, show that there are multiple characteristics of a species distribution that can and should be modelled and can be used to characterise complementary notions of niche.
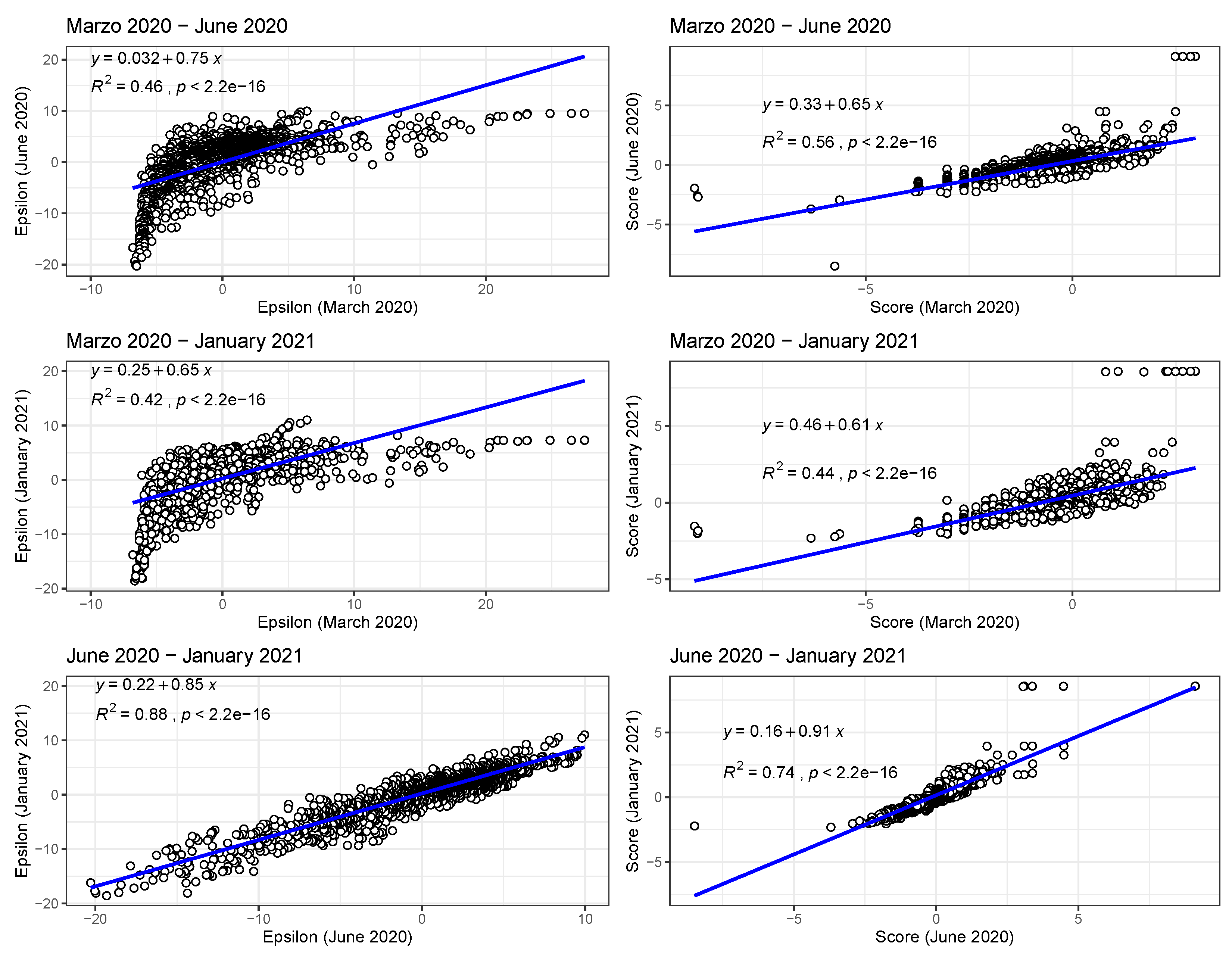
The methods we have exhibited and the corresponding examples also allow us to understand to what degree a niche is conserved. In the case of species abundance, we saw that the niche associated with those places where the relative number of COVID-19 cases was highest was highly conserved, with very little difference across the entire pandemic. Moreover, we showed how this conservatism could be quantified using our statistical diagnostic and the score functions, , associated with the habitat variables , with the time dependence of the associated score function reflecting the relationship between target and habitat variables. For example, if is strongly positive at one time, t, and not another, , then we may say that the variable is niche-like with respect to C at time t, but not at . Niche conservatism with respect to is then quantified by . This niche conservatism is also manifest in that an ENM created at time t provides a SDM that is just as predictive at a later time as at t. Thus, from a Hutchinsonian perspective, the relation may be conserved in ecological space, even though the spatial distribution of and/or could change in time.
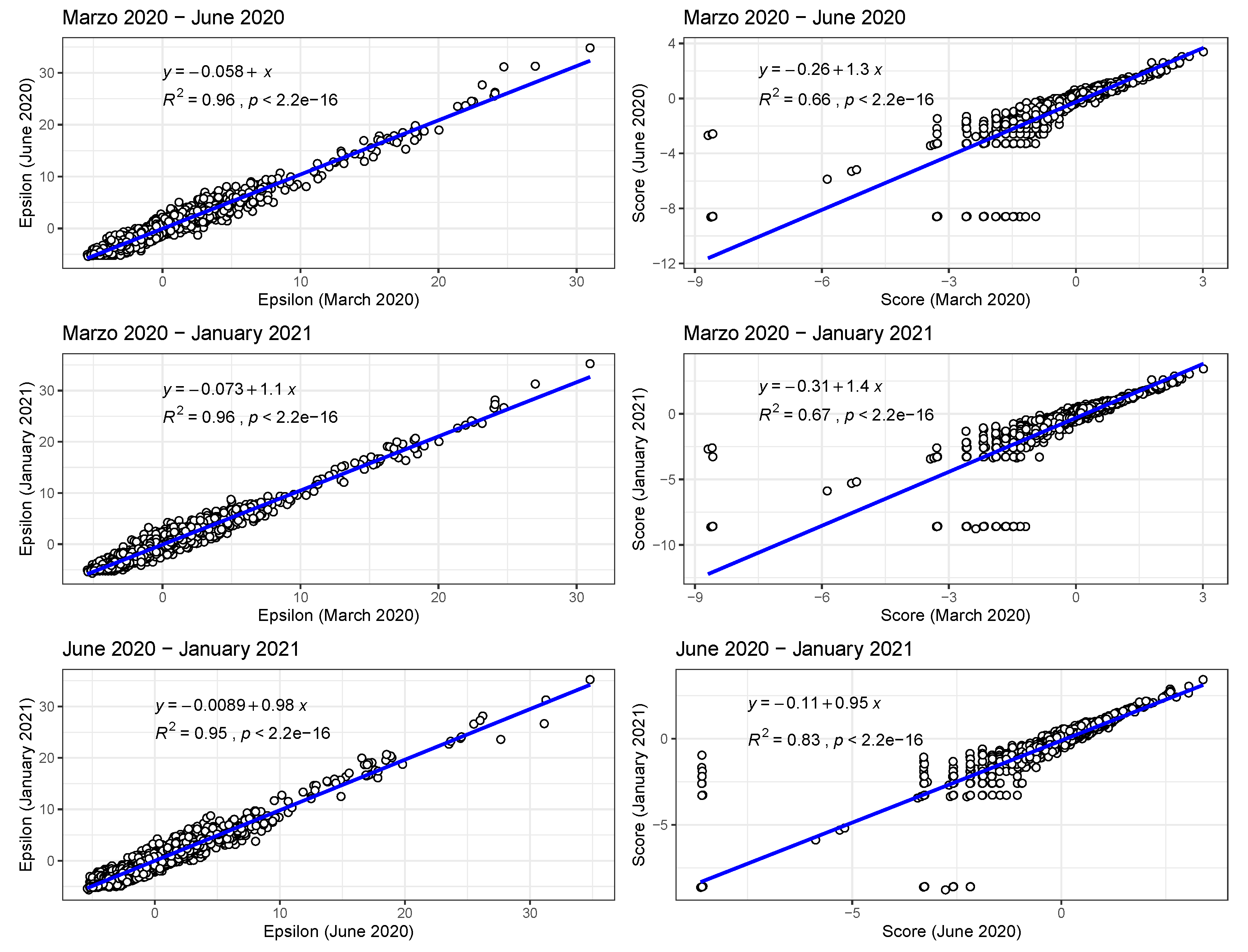
In the case of presence/absence as target class, the corresponding realised niche is not conserved, in that
. This is seen in
Figure 5, when compared to
Figure 3, where the regression slopes for the March 2020–June 2020 and March 2020–January 2021 comparisons have lower
values and also slopes
, indicating that the scores in January or June are only about 60% of their values in March. The
values and slopes for the
comparisons in the same figures show the same effect. These differences just reflect the range expansion of COVID-19, where it has been argued that: “there is no unsuitable habitat” for COVID-19 [
2]. This is linked, however, to the notion of presence, not to abundance. The fact that the score and
contributions are diminishing in the presence model from March 2020 to June 2020 and January 2021 is due to the fact that the habitat variables are less able to discriminate between those cells where cases are present versus absent. The differences between June 2020 and January 2021 are much less as, by this time, a large majority of municipalities now had confirmed cases. We can also see this niche non-conservation in
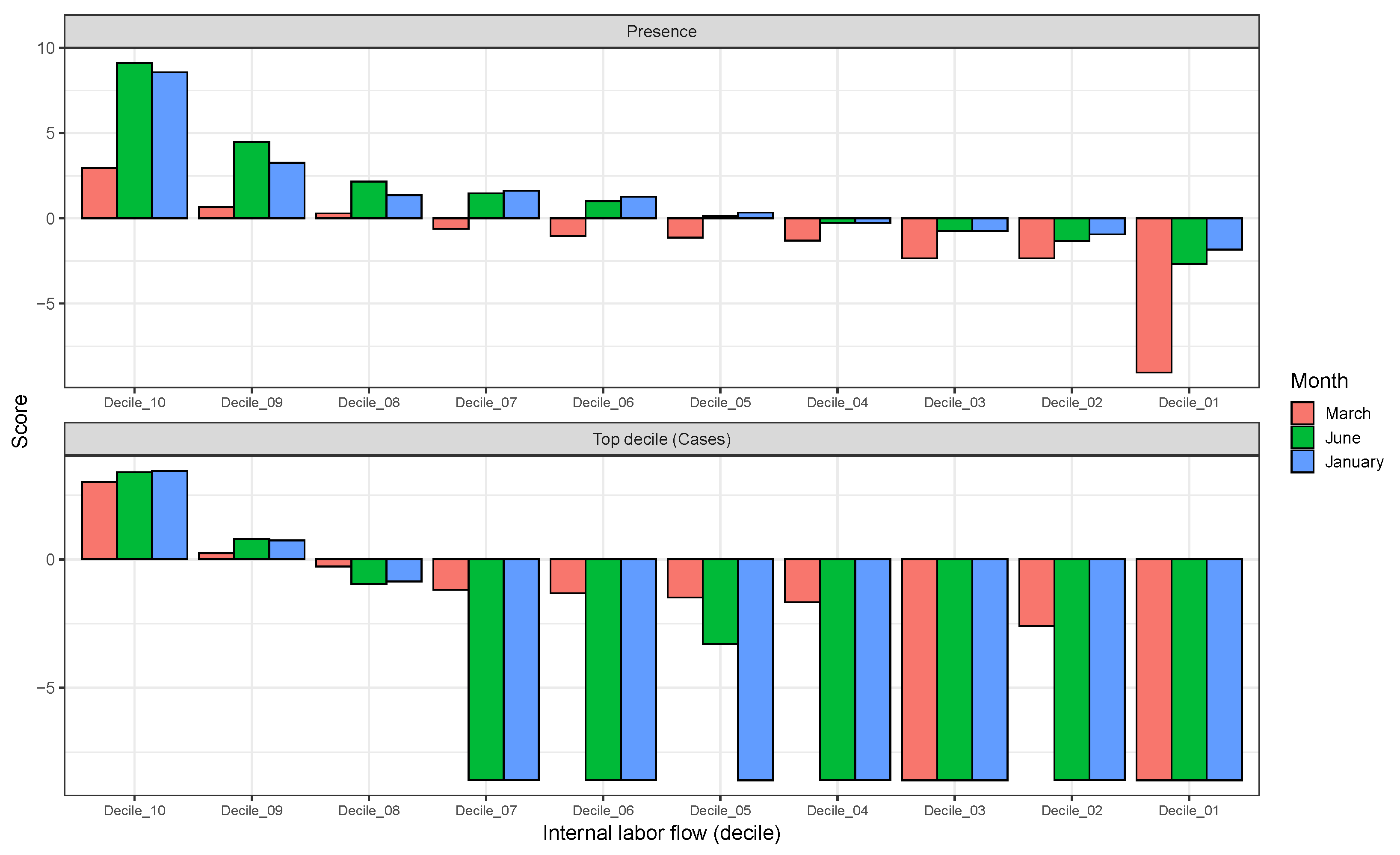
Figure 3 (top), using as an example the variable
Internal labour flow of the municipality. We see that in March 2020 only the first three deciles of municipalities ranked by that score are associated with a positive score—niche-like—whereas in June 2020 and January 2021 60% have positive scores. Similarly, we see that in the most anti-niche-like deciles,
and
, the scores are becoming less negative, indicating that those municipalities with the lowest internal labour flows are becoming less anti-niche-like. If the pandemic had a presence in
every municipality, then every
, corresponding to the fact that there can be no discrimination between where the species is present and where it is absent. Everywhere is niche-like. This would not be the case, however, for abundance, as is seen in
Figure 3 (bottom), where the change is due to the fact that our relative abundance measure is associated with the top 10% of municipalities with the highest number of cases. The range expansion of COVID-19 presence also has an impact on the performance of the corresponding SDMs, as seen in
Figure 4, where we see that for the all, socio-demographic, and mobility models, the corresponding AUC for the presence/absence spatial models is much less than their abundance counterparts.
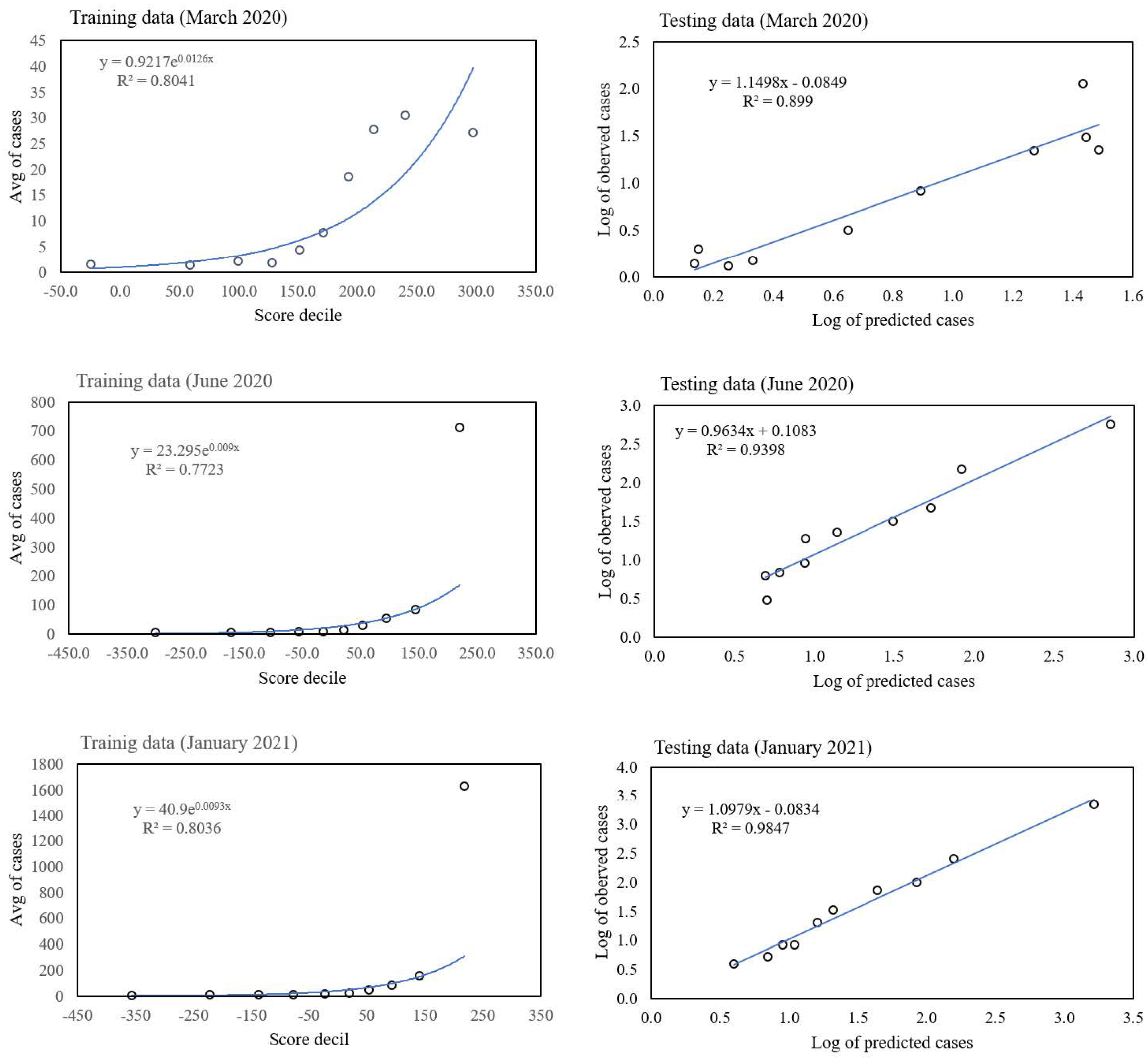
We have also shown how a classification-based ENM can be used to predict abundances, with an example being the number of confirmed cases of COVID-19 for a given month. We see that the score based on all habitat variables explains approximately 90% of the variance. We believe that the ENM/SDM formalism we have developed here has the capacity to be truly epi-ecological/eco-epidemiological given the right habitat variables. The static habitat variables we have chosen cannot account for the dynamic expansion and contraction that is characteristic of epidemics and which naturally emerges from a mechanistic SIR-type modelling formalism. What is required are habitat variables that are the analogue of what enters into a differential equations type modelling environment: changes in abundances from one time period to another, for example, or even changes in those changes, as it it these variables that account for the underlying dynamics. Indeed, an ENM built on a given time slice that does not explicitly account for such variables will either underestimate or overestimate abundances, depending on whether the epidemic is in an expansion or contraction phase. We will return to this in a future publication.
We have also shown how it is possible to distinguish confounding and how this can be used as a tool to disentangle causality. As a test case we considered combining a behavioural/socio-economic/socio-demographic variable—Internal labour flow of the municipality—and a climatic variable, showing how climate as an apparently predictive habitat variable is confounded by the more predictive socio-economic and mobility factors.
An apparent limitation of our work is that we have worked at a quite coarse-grained level, that of municipalities. This is a limitation of the data used, however, not the methodology. In principle, a much finer spatial resolution, at the level of “census blocks”, for instance, could be used if data were available at that resolution for the target class and habitat. In the same vein, dynamical data that represented both changes in the local environment, such as lockdowns and hospital occupation rates, or changes in behaviour, such as mask wearing compliance, cell phone data as a proxy for short-term mobility, or vaccination rates, or a host of other factors could also be included. It would be interesting for example to determine to what extent adaptations in the pathogen were potentially reflected as changes in its niche. There is also the question of the validity of the target class data as maintaining accurate counts of confirmed cases is difficult. However, this would have little to no impact on the overall conclusions of our ENM/SDMs.
In summary, the five principal advantages of our methodology relative to standard ENM/SDMs are: (i) First and foremost, our methodology can account for the highly multifactorial nature of COVID-19 as a complex adaptive system, where there are many directly or indirectly causal factors that affect both its spread and its magnitude; (ii) It is Bayesian in nature and therefore has the advantage of being adaptive, where the incorporation of new information can be achieved naturally using Bayes theorem, which, in addition, also allows for the incorporation of human expertise by means of Bayesian priors, as well as the addition of data-based evidence; (iii) By considering the incorporation of new information in time, any time variation in the relation between a target class C and its corresponding niche variables, can be tracked to determine how conserved the niche is; (iv) It permits a more profound analysis of causality and confounding through the consideration of a hierarchy of conditional probabilities; (v) It naturally permits the construction of niche models associated with different notions of niche – presence/absence, abundance, etc.—as these are simply representable as distinct classes of interest, C. The models we have presented can predict ”absolutes”, such as the number of cases in a given municipality, transversally, i.e., on the same time slice. Additionally, they can predict “relatives”, such as the relative number of cases in a given municipality longitudinally. We have shown that the corresponding models are accurate, with a high degree of correlation between predictions and actual numbers. Furthermore, that accuracy is intimately related to the incorporation of relevant niche variables such as mobility, socio-economic, and socio-demographic factors. Our goal here was not to offer a gold-standard model for prediction of the pandemic. As mentioned, there are more predictive and directly causal factors than we have included here. However, the niche of COVID-19 is immensely complex and adaptive and the incorporation of the vast array of relevant factors that determine it is a huge challenge in data collection and integration. What we have shown is that if that data can be represented in space and time, , then it may be incorporated into an ENM/SDM using the methodology we have shown here. Moreover, the innovations we have shown are independent of the specific use case of COVID-19 considered here. They represent general extensions of current niche and species distribution modelling, and can be applied to any ecological system, where they are necessary. In particular, they can be applied to situations where the target and/or niche variables are changing in time. Aside from disease dynamics, invasive species, habitat, and biodiversity loss are other prime areas where time dependence is crucial and where our approach can be used. Moreover, we believe that taken in its fullest sense, where a niche/anti-niche represents the complete set of both biotic and abiotic drivers that favour where a “species” is or is not, or at least should be, a universally applicable concept, with the SDM determining the “where” and the ENM the corresponding “why”. Indeed, its applicability is only restricted in an ecological setting by just what we mean by “ecological”. If we take ecology to cover any interaction between biota and the environment then we should accept factors as mask-wearing compliance as a potential niche factor for example. Furthermore, when thinking of a “Species” distribution model, we may encouraged to be liberal in our notion of “species”, where it may represent, for instance, cases of non-transmissable diseases, such as diabetes or heart disease.
In conclusion, there is a difference between stating that ENM/SDMs generally are inappropriate vehicles for modelling a dynamic phenomenon such as the COVID-19 pandemic versus stating that a particular ENM/SDM is inappropriate. We have shown that ENM/SDMs can be generated which overcome such criticisms.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}