A Multi-Modality Deep Network for Cold-Start Recommendation

Abstract
:1. Introduction
2. Related Work
3. Methods
3.1. Problem Definition and Model Overview
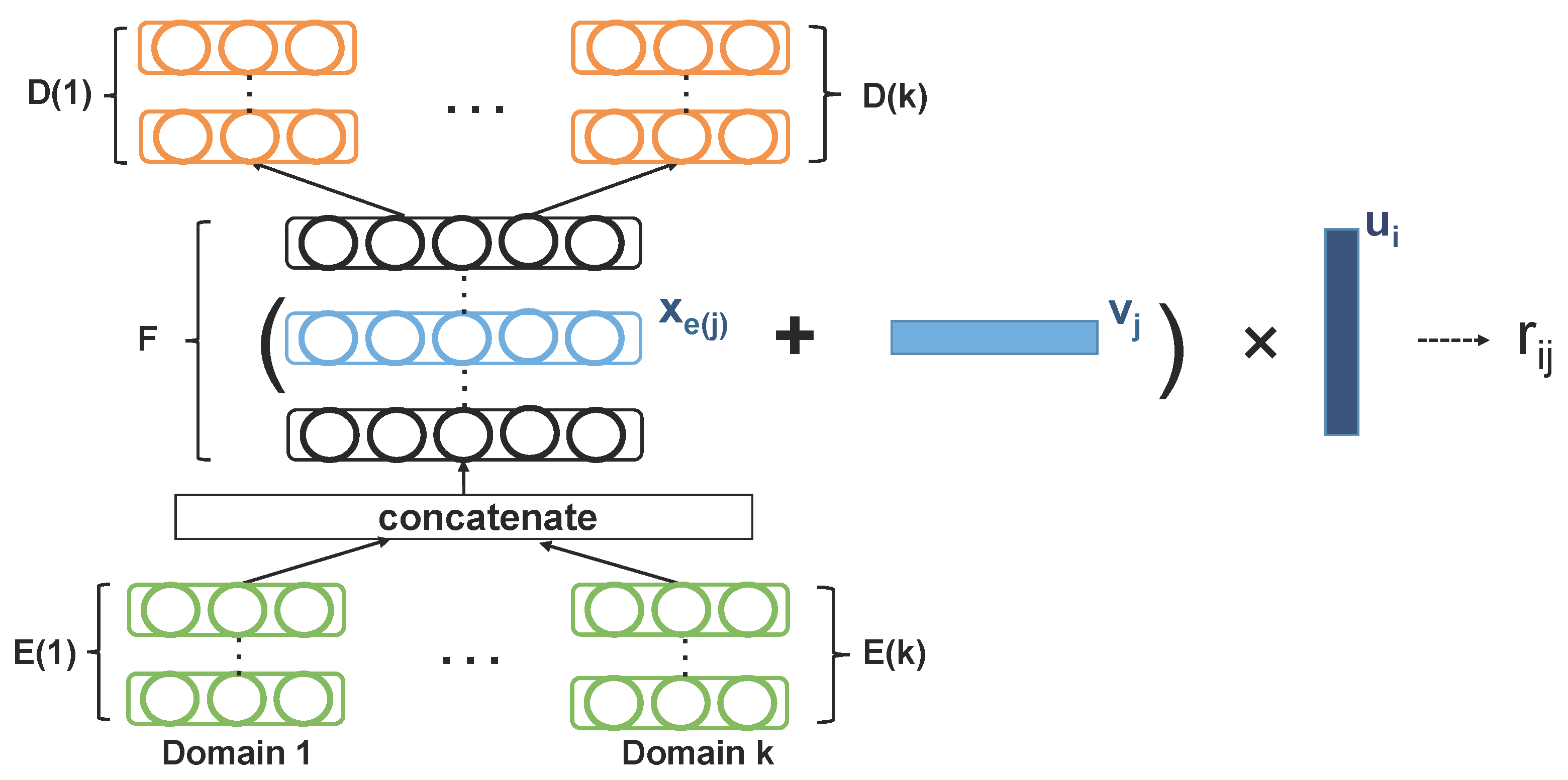
3.2. Deep Fusion for Multimodal Embedding
| Algorithm 1: Computing and for a single item. |
 |
3.3. Heterogeneous Domain-Specific Encoders and Decoders
3.4. Learning Rating Prediction with Deep Fusion
4. Experiments
4.1. Datasets
4.2. Models Used in Experiments
4.3. Evaluation Scheme
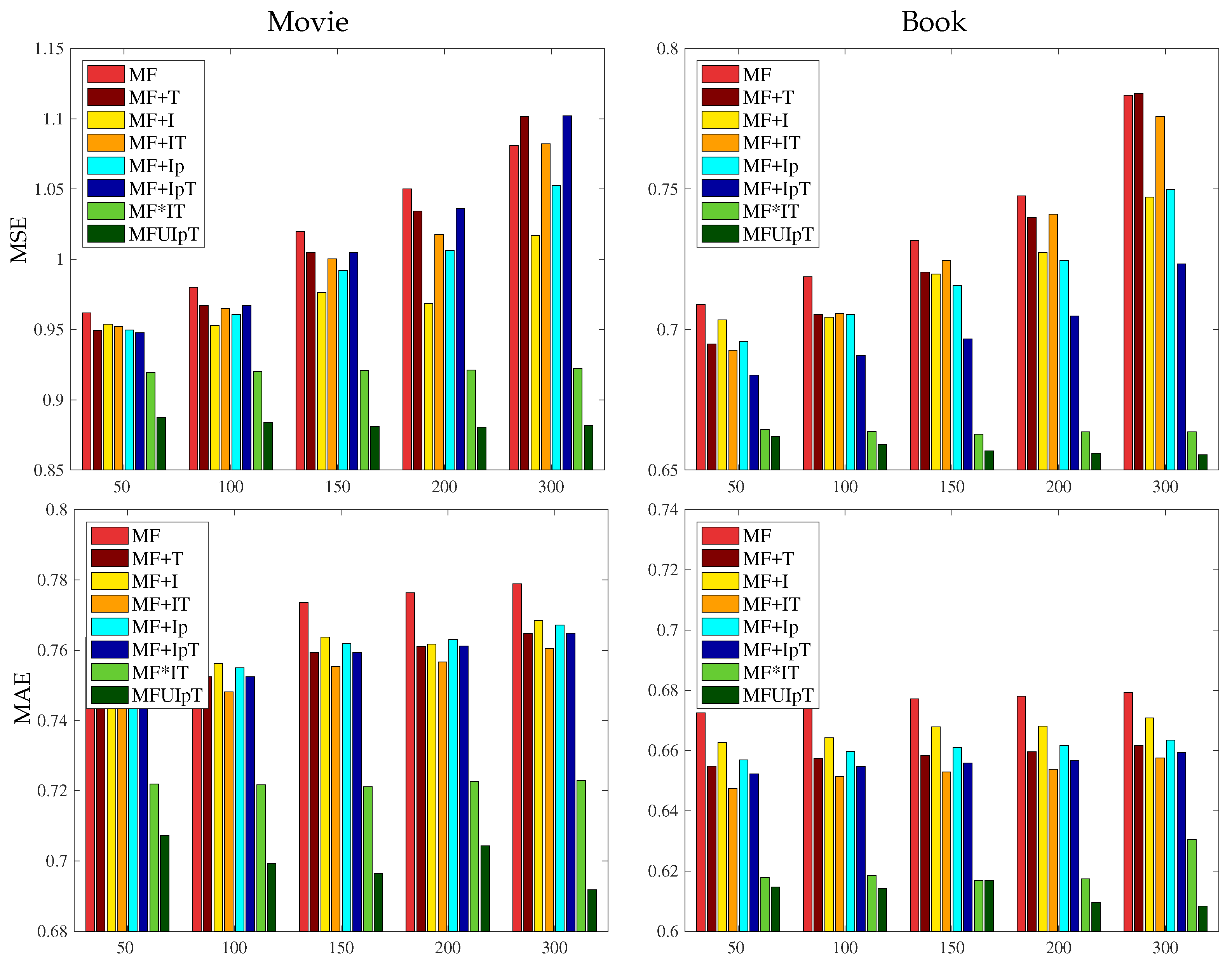
5. Results and Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Koren, Y. Factor in the neighbors: Scalable and accurate collaborative filtering. ACM Trans. Knowl. Discov. Data 2010, 4, 1–24. [Google Scholar] [CrossRef]
- Liu, B.; Fu, Y.; Yao, Z.; Xiong, H. Learning geographical preferences for point-of-interest recommendation. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1043–1051. [Google Scholar]
- Chen, X.; Zhang, Y.; Ai, Q.; Xu, H.; Yan, J.; Qin, Z. Personalized key frame recommendation. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 315–324. [Google Scholar]
- Sun, M.; Li, C.; Zha, H. Inferring Private Demographics of New Users in Recommender Systems. In Proceedings of the ACM International Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, Miami, FL, USA, 21–25 November 2017. [Google Scholar]
- Hofmann, T. Latent semantic models for collaborative filtering. ACM Trans. Inf. Syst. 2004, 22, 89–115. [Google Scholar] [CrossRef]
- Pennock, D.M.; Horvitz, E.; Lawrence, S.; Giles, C.L. Collaborative filtering by personality diagnosis: A hybrid memory- and model-based approach. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, San Francisco, CA, USA, 30 June–3 July 2000; pp. 473–480. [Google Scholar]
- Lee, J.; Sun, M.; Kim, S.; Lebanon, G. Automatic Feature Induction for Stagewise Collaborative Filtering. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Lee, J.; Sun, M.; Lebanon, G. PREA: Personalized Recommendation Algorithms Toolkit. J. Mach. Learn. Res. 2012, 13, 2699–2703. [Google Scholar]
- Li, L.; Chu, W.; Langford, J.; Schapire, R.E. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 661–670. [Google Scholar]
- Yang, Y.; Yoo, S.; Zhang, J.; Kisiel, B. Robustness of adaptive filtering methods in a cross-benchmark evaluation. In Proceedings of the ACM SIGIR Conference, Salvador, Brazil, 15–19 August 2005; pp. 98–105. [Google Scholar]
- Gabrilovich, E.; Dumais, S.; Horvitz, E. Newsjunkie: Providing personalized newsfeeds via analysis of information novelty. In Proceedings of the International Conference on World Wide Web, New Yrok, NY, USA, 17–22 May 2004; pp. 482–490. [Google Scholar]
- Chu, W.; Park, S.T. Personalized recommendation on dynamic content using predictive bilinear models. In Proceedings of the International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; pp. 691–700. [Google Scholar]
- Breese, J.; Heckerman, D.; Kadie, C. Empirical analysis of predictive algorithms for collaborative filtering. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Madison, WI, USA, 24–26 July 1998; pp. 43–52. [Google Scholar]
- Herlocker, J.L.; Konstan, J.A.; Borchers, A.; Riedl, J. An algorithmic framework for performing collaborative filtering. In Proceedings of the ACM SIGIR Conference, Berkeley, CA, USA, 15–19 August 1999; pp. 230–237. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Rennie, J.; Srebro, N. Fast maximum margin matrix factorization for collaborative prediction. In Proceedings of the International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 713–719. [Google Scholar]
- Sun, M.; Lebanon, G.; Kidwell, P. Estimating Probabilities in Recommendation Systems. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 734–742. [Google Scholar]
- Sun, M.; Lebanon, G.; Kidwell, P. Estimating Probabilities in Recommendation Systems. J. R. Stat. Soc. Ser. C 2012, 61, 471–492. [Google Scholar] [CrossRef]
- Sun, M.; Li, F.; Lee, J.; Zhou, K.; Lebanon, G.; Zha, H. Learning multiple-question decision trees for cold-start recommendation. In Proceedings of the Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013. [Google Scholar]
- Agarwal, D.; Chen, B. Regression-based latent factor models. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 19–28. [Google Scholar]
- Gunawardana, A.; Meek, C. Tied boltzmann machines for cold start recommendations. In Proceedings of the 2008 ACM Conference on Recommender Systems, Lausanne, Switzerland, 23–25 October 2008; pp. 19–26. [Google Scholar]
- Schein, A.I.; Popescul, A.; Ungar, L.H.; Pennock, D.M. Methods and metrics for cold-start recommendations. In Proceedings of the ACM SIGIR Conference, Tampere, Finland, 11–15 August 2002; pp. 253–260. [Google Scholar]
- Wang, C.; Blei, D.M. Collaborative topic modeling for recommending scientific articles. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 448–456. [Google Scholar]
- Stai, E.; Kafetzoglou, S.; Tsiropoulou, E.E.; Papavassiliou, S. A holistic approach for personalization, relevance feedback & recommendation in enriched multimedia content. Multimedia Tools Appl. 2018, 77, 283–326. [Google Scholar]
- Pouli, V.; Kafetzoglou, S.; Tsiropoulou, E.E.; Dimitriou, A.; Papavassiliou, S. Personalized multimedia content retrieval through relevance feedback techniques for enhanced user experience. In Proceedings of the 2015 13th International Conference on IEEE Telecommunications (ConTEL), Graz, Austria, 13–15 July 2015; pp. 1–8. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Salakhutdinov, R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Andrew, G.; Arora, R.; Bilmes, J.; Livescu, K. Deep canonical correlation analysis. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1247–1255. [Google Scholar]
- Wang, W.; Arora, R.; Livescu, K.; Bilmes, J. On deep multi-view representation learning. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1083–1092. [Google Scholar]
- Wang, Q.; Sun, M.; Zhan, L.; Thompson, P.; Ji, S.; Zhou, J. Multi-Modality Disease Modeling via Collective Deep Matrix Factorization. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1155–1164. [Google Scholar]
- Salakhutdinov, R.; Mnih, A.; Hinton, G. Restricted Boltzmann machines for collaborative filtering. In Proceedings of the International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 791–798. [Google Scholar]
- Li, S.; Kawale, J.; Fu, Y. Deep collaborative filtering via marginalized denoising auto-encoder. In Proceedings of the ACM International Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 811–820. [Google Scholar]
- Wang, H.; Wang, N.; Yeung, D.Y. Collaborative deep learning for recommender systems. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Melbourne, Australia, 19–23 October 2015; pp. 1235–1244. [Google Scholar]
- Elkahky, A.M.; Song, Y.; He, X. A multi-view deep learning approach for cross domain user modeling in recommendation systems. In Proceedings of the International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 278–288. [Google Scholar]
- McAuley, J.; Targett, C.; Shi, Q.; Van den Hengel, A. Image-based recommendations on styles and substitutes. In Proceedings of the ACM SIGIR Conference, Santiago, Chile, 9–13 August 2015; pp. 43–52. [Google Scholar]
- He, R.; McAuley, J. VBPR: Visual Bayesian personalized ranking from implicit feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 144–150. [Google Scholar]
- Geng, X.; Zhang, H.; Bian, J.; Chua, T.S. Learning image and user features for recommendation in social networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4274–4282. [Google Scholar]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.Y. Collaborative knowledge base embedding for recommender systems. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| u, v | user and item latent vector |
| user i’s rating on item j | |
| d | data domain |
| , | input and corrupted input from d |
| domain-specific encoding network for d | |
| domain-specific decoding network for d | |
| F | fusion network |
| computation done by network S | |
| reconstruction for domain d input | |
| the embedding vector | |
| parameters of network (E, D and F) |
| Method | Fused Embedding | Embedding Coupled Rating | Pretrained |
|---|---|---|---|
| MF | ✗ | ✗ | ✗ |
| MF + T | ✗ | ✗ | ✗ |
| CTR | ✗ | ✓ | ✗ |
| MF + I | ✗ | ✗ | ✗ |
| MF + IT | ✗ | ✗ | ✗ |
| MF * IT | ✗ | ✓ | ✗ |
| MF + I | ✗ | ✗ | ✓ |
| MF + IT | ✗ | ✗ | ✓ |
| MFUIT | ✓ | ✓ | ✓ |
| Movie Dataset | Book Dataset | |
|---|---|---|
| MF | m = 50, lr = 0.01, = 0.15 | m = 50, lr = 0.006, = 0.2 |
| m = 100, lr = 0.01, = 0.15 | m = 100, lr = 0.006, = 0.2 | |
| m = 150, lr = 0.015, = 0.15 | m = 150, lr = 0.003, = 0.2 | |
| m = 200, lr = 0.015, = 0.15 | m = 200, lr = 0.003, = 0.2 | |
| m = 300, lr = 0.015, = 0.15 | m = 300, lr = 0.003, = 0.2 | |
| FCAE | lr = 0.05, batch = 32, iter = 500 | lr = 0.05, batch = 32, iter = 500 |
| SCAE | lr = 0.01, batch = 32, iter = 100 | lr = 0.01, batch = 32, iter = 100 |
| Method | ||||
|---|---|---|---|---|
| MF * IT | ||||
| MFUIT | ||||
| CTR |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, M.; Li, F.; Zhang, J. A Multi-Modality Deep Network for Cold-Start Recommendation. Big Data Cogn. Comput. 2018, 2, 7. https://doi.org/10.3390/bdcc2010007
Sun M, Li F, Zhang J. A Multi-Modality Deep Network for Cold-Start Recommendation. Big Data and Cognitive Computing. 2018; 2(1):7. https://doi.org/10.3390/bdcc2010007
Chicago/Turabian StyleSun, Mingxuan, Fei Li, and Jian Zhang. 2018. "A Multi-Modality Deep Network for Cold-Start Recommendation" Big Data and Cognitive Computing 2, no. 1: 7. https://doi.org/10.3390/bdcc2010007
APA StyleSun, M., Li, F., & Zhang, J. (2018). A Multi-Modality Deep Network for Cold-Start Recommendation. Big Data and Cognitive Computing, 2(1), 7. https://doi.org/10.3390/bdcc2010007