Traffic Sign Recognition based on Synthesised Training Data




Abstract
:1. Introduction
2. Related Work
2.1. Early Methods
2.2. Deep Learning Methods
3. Generation of Synthetic Training Data
3.1. Resources
- Warning signs with their characteristics being their triangular shape, with red borders.
- Regulatory signs, which are usually found to have a circular shape, with varying colours (direction indicators or vehicles restrictions).
- Speed limits, which are circular with a red lining (for maximum speed), or blue (minimum speed).
3.2. Generating Novel Training Images from Templates
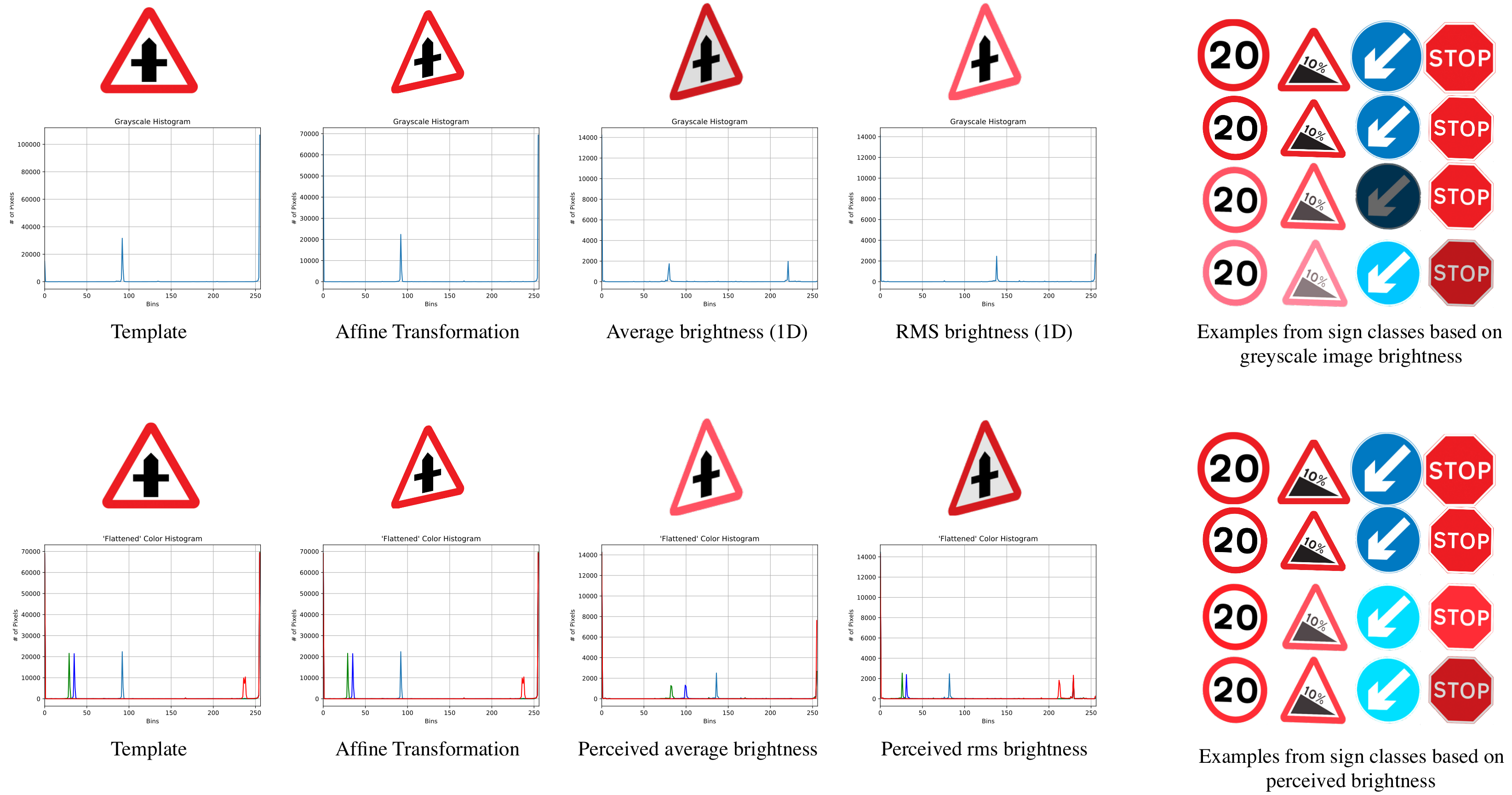
3.3. Dataset Normalisation
4. Classification Scheme
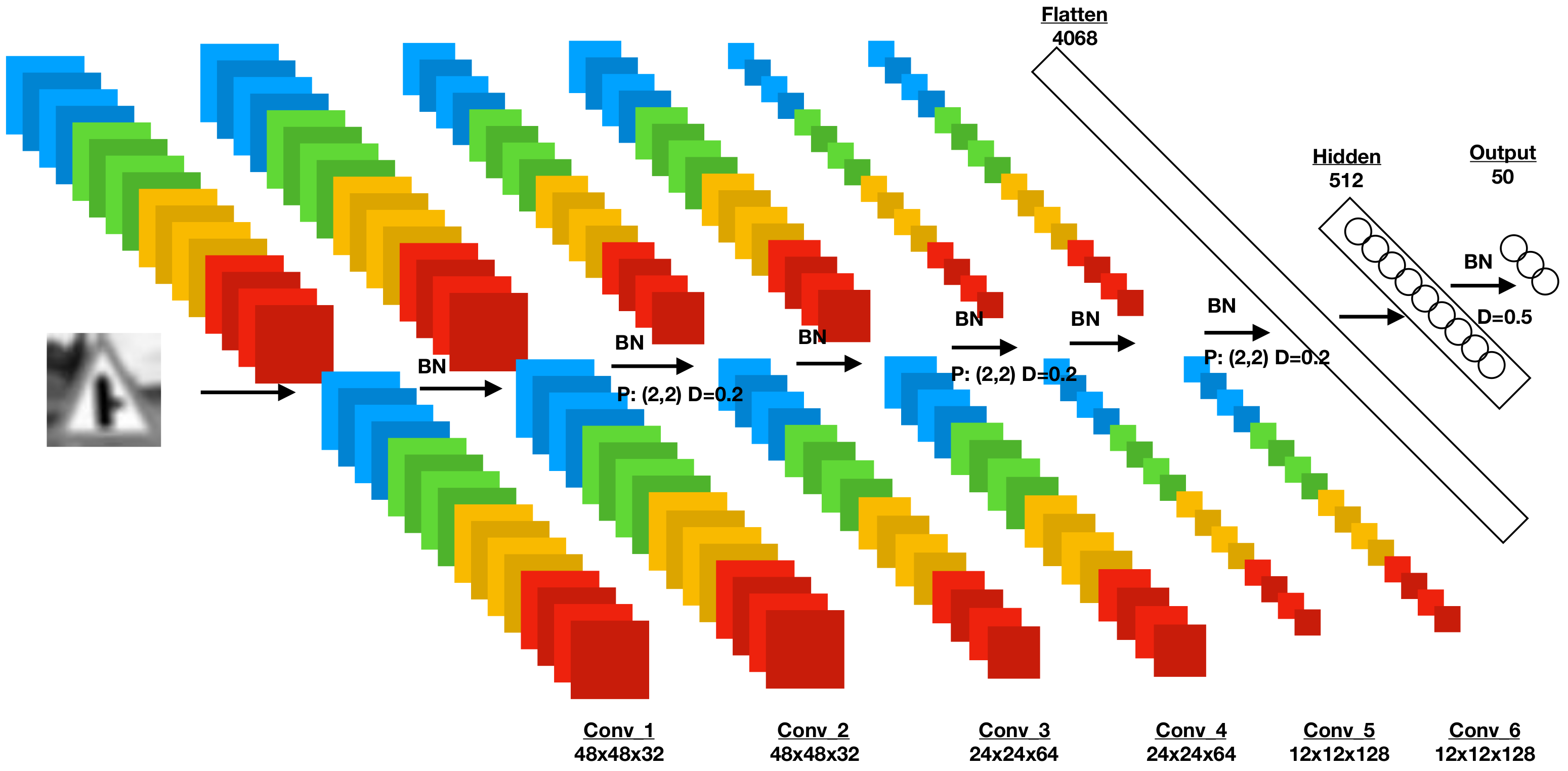
4.1. CNNs and Three-Dimensional Image Depth
4.2. Utilising Exponential Linear Units
4.3. Normalisation
4.4. Sample-Based Discretisation
- The size of the filter to be used. Most filters in max pooling are either of size 2 × 2 or 3 × 3, as based on these values, the kernel will traverse the entire image matrix. Furthermore, taking into account the use of the mean or max value at each traverse, the system will compute and output the suitable value.
- The stride of the kernel, as it defines the step that is used while passing through the image vector. A larger stride will resolve in a smaller output, since less pixels will overlap between kernel steps. For example, a 2 × 2 filter with a stride of two will resolve in non-overlapping pixels in the final output down-scaled feature vector.
4.5. Regularisation
5. Experimental Results
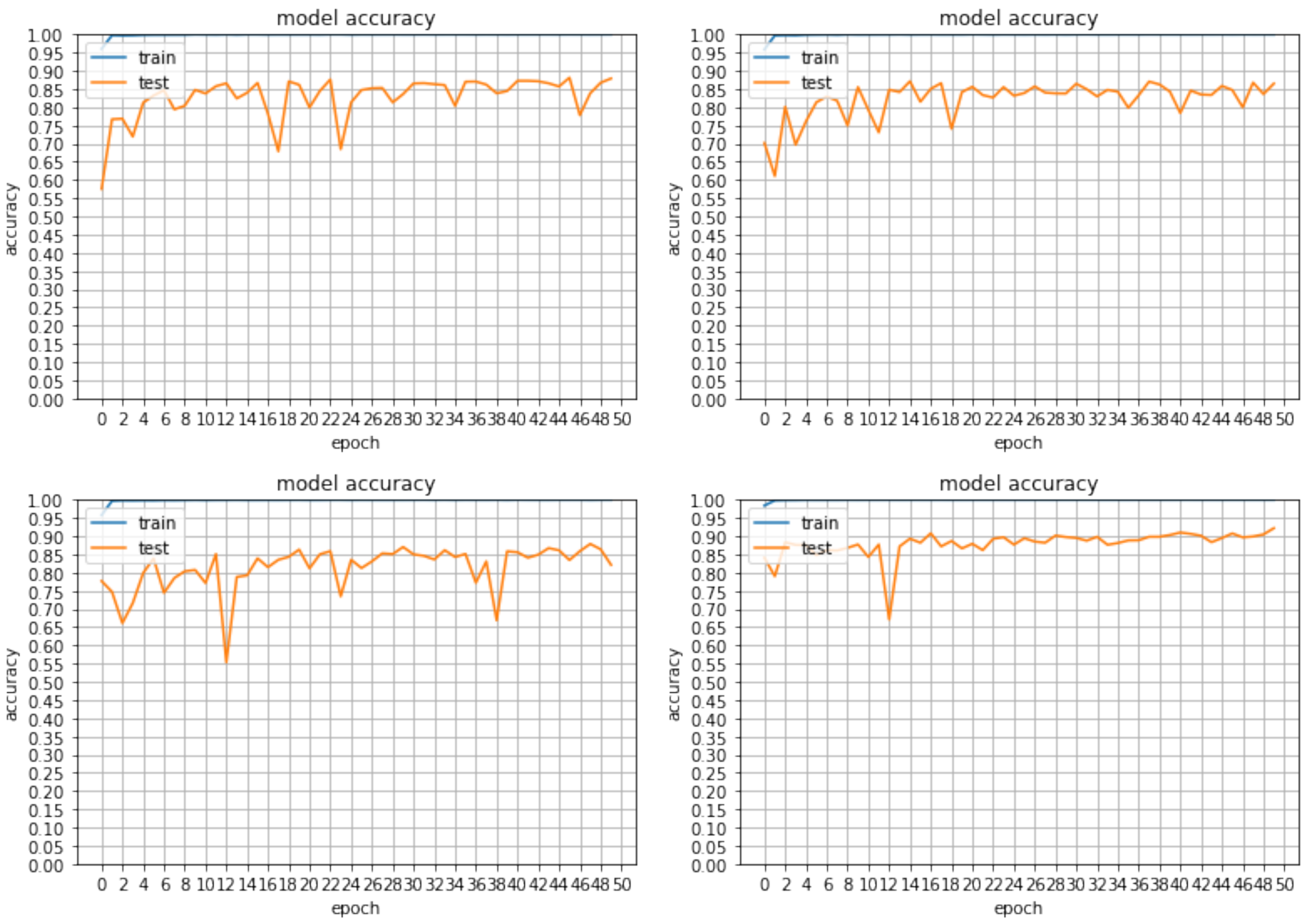
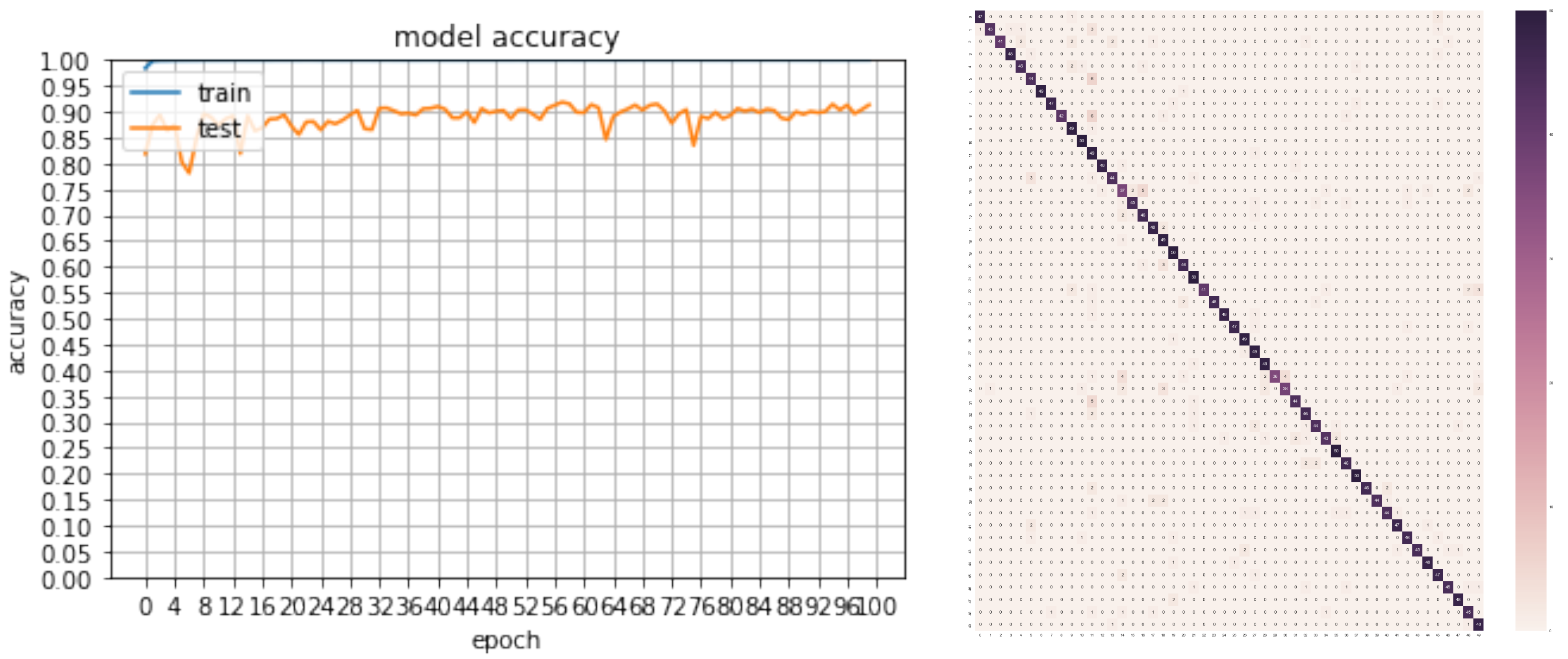
5.1. Implementation Details
5.2. Classification Results
6. Conclusions and Future Work
Author Contributions
Conflicts of Interest
References
- Fu, M.Y.; Huang, Y.S. A survey of traffic sign recognition. In Proceedings of the IEEE International Conference on Wavelet Analysis and Pattern Recognition (ICWAPR), Qingdao, China, 11–14 July 2010; pp. 119–124. [Google Scholar]
- Miura, J.; Kanda, T.; Nakatani, S.; Shirai, Y. An active vision system for on-line traffic sign recognition. IEICE Trans. Inf. Syst. 2002, 85, 1784–1792. [Google Scholar]
- Sermanet, P.; LeCun, Y. Traffic sign recognition with multi-scale convolutional networks. In Proceedings of the 2011 IEEE International Joint Conference on Neural Networks (IJCNN), San Jose, CA, USA, 31 July–5 August 2011; pp. 2809–2813. [Google Scholar]
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. The German traffic sign recognition benchmark: A multi-class classification competition. In Proceedings of the 2011 IEEE International Joint Conference on Neural Networks (IJCNN), San Jose, CA, USA, 31 July–5 August 2011; pp. 1453–1460. [Google Scholar]
- Bascón, S.M.; Rodríguez, J.A.; Arroyo, S.L.; Caballero, A.F.; López-Ferreras, F. An optimization on pictogram identification for the road-sign recognition task using SVMs. Comput. Vis. Image Underst. 2010, 114, 373–383. [Google Scholar] [CrossRef]
- Larsson, F.; Felsberg, M. Using Fourier descriptors and spatial models for traffic sign recognition. In Proceedings of the Scandinavian Conference on Image Analysis, Ystad, Sweden, 23–27 May 2011; pp. 238–249. [Google Scholar]
- Timofte, R.; Zimmermann, K.; Van Gool, L. Multi-view traffic sign detection, recognition, and 3D localisation. Mach. Vis. Appl. 2014, 25, 633–647. [Google Scholar] [CrossRef]
- Akatsuka, H.; Imai, S. Road Signposts Recognition System. SAE Trans. 1987, 96, 936–943. [Google Scholar]
- de Saint Blancard, M. Road sign recognition. In Vision-Based Vehicle Guidance; Springer: Berlin, Germany, 1992; pp. 162–172. [Google Scholar]
- Zaklouta, F.; Stanciulescu, B. Real-time traffic sign recognition in three stages. Robot. Auton. Syst. 2014, 62, 16–24. [Google Scholar] [CrossRef]
- Yao, C.; Wu, F.; Chen, H.J.; Hao, X.L.; Shen, Y. Traffic sign recognition using HOG-SVM and grid search. In Proceedings of the IEEE 2014 12th International Conference on Signal Processing (ICSP), Hangzhou, China, 19–23 October 2014; pp. 962–965. [Google Scholar]
- Cireşan, D.; Meier, U.; Masci, J.; Schmidhuber, J. Multi-column deep neural network for traffic sign classification. Neural Netw. 2012, 32, 333–338. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of pooling operations in convolutional architectures for object recognition. In Proceedings of the International Conference on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010; pp. 92–101. [Google Scholar]
- Ueda, N. Optimal linear combination of neural networks for improving classification performance. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 207–215. [Google Scholar] [CrossRef]
- Meier, U.; Ciresan, D.C.; Gambardella, L.M.; Schmidhuber, J. Better digit recognition with a committee of simple neural nets. In Proceedings of the IEEE 2011 International Conference on Document Analysis and Recognition (ICDAR), Beijing, China, 18–21 September 2011; pp. 1250–1254. [Google Scholar]
- Haloi, M. Traffic Sign Classification Using Deep Inception Based Convolutional Networks. arXiv 2015, arXiv:1511.02992. [Google Scholar]
- Jin, J.; Fu, K.; Zhang, C. Traffic sign recognition with hinge loss trained convolutional neural networks. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1991–2000. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Traffic Sign Images. Available online: https://www.gov.uk/guidance/traffic-sign-images (accessed on 17 January 2018).
- Berger, M. Geometry I; Springer: Berlin, Germany, 2009. [Google Scholar]
- Jain, A.K. Fundamentals of Digital Image Processing; Prentice Hall: Englewood Cliffs, NJ, USA, 1989. [Google Scholar]
- Connolly, T.G.; Sluckin, W. Introduction to Statistics for the Social Sciences; Springer: Berlin, Germany, 1971. [Google Scholar]
- Finley, D. HSP Color Model— Alternative to HSV (HSB) and HSL. 2006. Available online: http://alienryderflex.com/hsp.html (accessed on 26 July 2018).
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (Elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Bengio, Y. Learning deep architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1026–1034. [Google Scholar]
- Jia, Y. Learning Semantic Image Representations at a Large Scale; University of California: Berkeley, CA, USA, 2014. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Povey, D.; Zhang, X.; Khudanpur, S. Parallel training of Deep Neural Networks with Natural Gradient and Parameter Averaging. arXiv 2014, arXiv:1410.7455. [Google Scholar]
- Wiesler, S.; Richard, A.; Schluter, R.; Ney, H. Mean-normalized stochastic gradient for large-scale deep learning. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 180–184. [Google Scholar]
- Gülçehre, Ç.; Bengio, Y. Knowledge matters: Importance of prior information for optimization. J. Mach. Learn. Res. 2016, 17, 226–257. [Google Scholar]
- Baldi, P.; Sadowski, P.J. Understanding Dropout. In Advances in Neural Information Processing Systems 26; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; pp. 2814–2822. [Google Scholar]
- Nitish, S.K.; Dheevatsa, M.; Jorge, N.; Mikhail, S.; Tang, P.T.P. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. arXiv 2016, arXiv:1609.04836. [Google Scholar]
Sample Availability: A sample of the code and results obtain can be found in: https://github.com/
alexandrosstergiou/Traffic-Sign-Recognition-basd-on-Synthesised-Training-Data. |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy |
|---|---|
| Spatial transform/inception [16] | 99.98% |
| MCDNN [12] | 99.46% |
| Human observations (best) | 99.22% |
| Human observations (average) | 98.84% |
| Multi-scale CNN [3] | 98.31% |
| Random forests [10] | 96.14% |
| LDA and HOG [4] | 95.68% |
| Classifier Type | Accuracy Rates (%) | Kappa Statistic |
|---|---|---|
| CNN w/Leaky ReLU—0 epochs | 87.88% | 0.8788 |
| CNN w/ PReLu, 50 epochs | 87.03% | 0.8703 |
| CNN w/ ELU—50 epochs | 87.88% | 0.8788 |
| CNN w/ ELU and BN, 50 epochs | 92.20% | 0.9219 |
| CNN w/ ELU and BN, 100 epochs, new data | 91.84% | 0.9183 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stergiou, A.; Kalliatakis, G.; Chrysoulas, C. Traffic Sign Recognition based on Synthesised Training Data. Big Data Cogn. Comput. 2018, 2, 19. https://doi.org/10.3390/bdcc2030019
Stergiou A, Kalliatakis G, Chrysoulas C. Traffic Sign Recognition based on Synthesised Training Data. Big Data and Cognitive Computing. 2018; 2(3):19. https://doi.org/10.3390/bdcc2030019
Chicago/Turabian StyleStergiou, Alexandros, Grigorios Kalliatakis, and Christos Chrysoulas. 2018. "Traffic Sign Recognition based on Synthesised Training Data" Big Data and Cognitive Computing 2, no. 3: 19. https://doi.org/10.3390/bdcc2030019
APA StyleStergiou, A., Kalliatakis, G., & Chrysoulas, C. (2018). Traffic Sign Recognition based on Synthesised Training Data. Big Data and Cognitive Computing, 2(3), 19. https://doi.org/10.3390/bdcc2030019