The Next Generation Cognitive Security Operations Center: Network Flow Forensics Using Cybersecurity Intelligence

 ,
, 
 and
and 
Abstract
:1. Introduction
2. Related Work
3. Proposed Framework
4. Methodology
4.1. Ensemble Learning
4.2. Ensemble Size
4.3. Model Selection
4.4. Identification of the Weights of Different Models of Ensemble
4.5. Reliability of Ensemble
4.6. Importance of Ensemble
5. Ensemble of Algorithms
5.1. Support Vector Machine (SVM)
5.2. Artificial Neural Network (ANN)
- Calculate the inputs:
- Calculate the output for each hidden node:
- Calculate the overall outputs:
5.3. Random Forest (RF)
- (1)
- Draw n tree bootstrap samples from the source dataset.
- (2)
- At each node of the bootstrap samples, grow an unpruned predictor tree and choose the best split between variables.
- (3)
- Predict new data by aggregating the predictions of the n trees and estimate the error at each iteration using the “out-of-bag” method.
5.4. k-Nearest Neighbors (k-NN)
- A positive integer k is definite, along with a new sample.
- The closest k entries are selected.
- The most usual classification of these entries is determined and given to the new sample.
6. Datasets
6.1. Features Extraction
6.2. Data
7. Results
8. Conclusions
8.1. Discussion
8.2. Innovation
8.3. Synopsis
8.4. Future Works
Author Contributions
Funding
Conflicts of Interest
References
- CISCO. WAN and Application Optimization Solution Guide; Cisco Validated Design Document; Version 1.1; CISCO Press: Hoboken, NJ, USA, 2008; Available online: www.cisco.com/c/en/us/td/docs/nsite/enterprise/wan/wan_optimization/wan_opt_sg.pdf (accessed on 1 October 2018).
- Wang, W.; Zhang, X.; Shi, W.; Lian, S.; Feng, D. Network traffic monitoring, analysis and anomaly detection [Guest Editorial]. IEEE Netw. 2011, 25, 6–7. [Google Scholar] [CrossRef] [Green Version]
- Rudd, E.; Rozsa, A.; Gunther, M.; Boult, T. A Survey of Stealth Malware: Attacks, Mitigation Measures, and Steps Toward Autonomous Open World Solutions. arXiv, 2016; arXiv:1603.06028. [Google Scholar]
- Zhang, H.; Papadopoulos, C.; Massey, D. Detecting encrypted botnet traffic. In Proceedings of the 2013 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Turin, Italy, 14–19 April 2013; pp. 3453–1358. [Google Scholar] [CrossRef]
- William, H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Section 16.5. Support Vector Machines. In Numerical Recipes: The Art of Scientific Computing, 3rd ed.; Cambridge University Press: New York, NY, USA, 2007; ISBN 978-0-521-88068-8. [Google Scholar]
- Hubel, D.H.; Wiesel, T.N. Brain and Visual Perception: The Story of a 25-Year Collaboration; Oxford University Press: Oxford, UK, 2005; p. 106. ISBN 978-0-19-517618-6. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hall, P.; Park, B.U.; Samworth, R.J. Choice of neighbor order in nearest-neighbor classification. Ann. Stat. 2008, 36, 2135–2152. [Google Scholar] [CrossRef]
- Demertzis, K.; Iliadis, L.; Anezakis, V. Commentary: Aedes albopictus and Aedes japonicus—Two invasive mosquito species with different temperature niches in Europe. Front. Environ. Sci. 2017, 5, 85. [Google Scholar] [CrossRef]
- Demertzis, K.; Iliadis, L. Ladon: A Cyber-Threat Bio-Inspired Intelligence Management System. J. Appl. Math. Bioinform. 2016, 3, 45–64. [Google Scholar]
- Demertzis, K.; Iliadis, L. Evolving Computational Intelligence System for Malware Detection. In Advanced Information Systems Engineering Workshops; Lecture Notes in Business Information Processing; Springer: Cham, Switzerland, 2014; Volume 178, pp. 322–334. [Google Scholar] [CrossRef]
- Llopis, S.; Hingant, J.; Pérez, I.; Esteve, M.; Carvajal, F.; Mees, W.; Debatty, T. A comparative analysis of visualisation techniques to achieve cyber situational awareness in the military. In Proceedings of the 2018 International Conference on Military Communications and Information Systems (ICMCIS), Warsaw, Poland, 22–23 May 2018. [Google Scholar] [CrossRef]
- Xu, C.; Chen, S.; Su, J.; Yiu, S.M.; Hui, L.C. A Survey on Regular Expression Matching for Deep Packet Inspection: Applications, Algorithms, and Hardware Platforms. IEEE Commun. Surv. Tutor. 2016, 18, 2991–3029. [Google Scholar] [CrossRef]
- Demertzis, K.; Iliadis, L. Evolving Smart URL Filter in a Zone-based Policy Firewall for Detecting Algorithmically Generated Malicious Domains. In Statistical Learning and Data Sciences; Lecture Notes in Computer Science; Gammerman, A., Vovk, V., Papadopoulos, H., Eds.; Springer: Cham, Switzerland, 2015; Volume 9047. [Google Scholar]
- Yadav, S.; Reddy, A.K.K.; Reddy, A.L.N.; Ranjan, S. Detecting Algorithmically Generated Domain-Flux Attacks with DNS Traffic Analysis. IEEE/ACM Trans. Netw. 2012, 20, 1663–1677. [Google Scholar] [CrossRef]
- Hayes, J. Traffic Confirmation Attacks Despite Noise. arXiv, 2016; arXiv:1601.04893. [Google Scholar]
- Mercaldo, F.; Martinelli, F. Tor traffic analysis and identification. In Proceedings of the 2017 AEIT International Annual Conference, Cagliari, Italy, 20–22 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Montieri, A.; Ciuonzo, D.; Aceto, G.; Pescapé, A. Anonymity Services Tor, I2P, JonDonym: Classifying in the Dark. In Proceedings of the 2017 29th International Teletraffic Congress (ITC 29), Genoa, Italy, 4–8 September 2017; pp. 81–89. [Google Scholar] [CrossRef]
- Backes, M.; Goldberg, I.; Kate, A.; Mohammadi, E. Provably secure and practical onion routing. In Proceedings of the 2012 IEEE 25th Computer Security Foundations Symposium (CSF), Cambridge, MA, USA, 25–27 June 2012. [Google Scholar]
- Deepika, B.; Sethi, P.; Kataria, S. Secure Socket Layer and its Security Analysis. Netw. Commun. Eng. 2015, 7, 255–259. [Google Scholar]
- Demertzis, K.; Iliadis, L. A Hybrid Network Anomaly and Intrusion Detection Approach Based on Evolving Spiking Neural Network Classification. In E-Democracy, Security, Privacy and Trust in a Digital World; Sideridis, A., Kardasiadou, Z., Yialouris, C., Zorkadis, V., Eds.; e-Democracy 2013; Communications in Computer and Information Science; Springer: Cham, Switzerland, 2014; Volume 441. [Google Scholar]
- Demertzis, K.; Iliadis, L. Bio-Inspired Hybrid Artificial Intelligence Framework for Cyber Security. In Computation, Cryptography, and Network Security; Daras, N., Rassias, M., Eds.; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Demertzis, K.; Iliadis, L. Bio-Inspired Hybrid Intelligent Method for Detecting Android Malware. In Advanced Information Systems Engineering Workshops; Iliadis, L., Papazoglou, M., Pohl, K., Eds.; CAiSE 2014. Lecture Notes in Business Information Processing; Springer: Cham, Switzerland, 2014; Volume 178. [Google Scholar]
- Demertzis, K.; Iliadis, L. SAME: An Intelligent Anti-Malware Extension for Android ART Virtual Machine. In Computational Collective Intelligence; Núñez, M., Nguyen, N., Camacho, D., Trawiński, B., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9330. [Google Scholar]
- Demertzis, K.; Iliadis, L. Computational Intelligence Anti-Malware Framework for Android OS. Vietnam J. Comput. Sci. 2017, 4, 245. [Google Scholar] [CrossRef]
- Demertzis, K.; Iliadis, L.S.; Iliadis, V.-D. Anezakis, An innovative soft computing system for smart energy grids cybersecurity. Adv. Build. Energy Res. 2018, 12, 3–24. [Google Scholar] [CrossRef]
- Scandariato, R.; Walden, J. Predicting vulnerable classes in an android application. In Proceedings of the 4th International Workshop on Security Measurements and Metrics, Lund, Sweden, 21 September 2012. [Google Scholar]
- Chin, E.; Felt, A.; Greenwood, K.; Wagner, D. Analyzing inter-application communication in android. In Proceedings of the 9th International Conference on Mobile Systems, Applications, and Services, Bethesda, MD, USA, 28 June–1 July 2011; pp. 239–252. [Google Scholar]
- Burguera, I.; Zurutuza, U.; Nadjm-Tehrani, S. Crowdroid: Behavior-based malware detection system for android. In Proceedings of the 1st ACM Workshop on Security and Privacy in Smartphones and Mobile Devices, Chicago, IL, USA, 17 October 2011; pp. 15–26. [Google Scholar]
- Glodek, W.; Harang, R.R. Permissions-based Detection and Analysis of Mobile Malware Using Random Decision Forests. In Proceedings of the 2013 IEEE Military Communications Conference, San Diego, CA, USA, 18–20 November 2013. [Google Scholar]
- Zhang, J.; Chen, C.; Xiang, Y.; Zhou, W.; Vasilakos, A.V. An effective network traffic classification method with unknown flow detection. IEEE Trans. Netw. Serv. Manag. 2013, 10, 133–147. [Google Scholar] [CrossRef]
- Joseph, G.; Nagaraja, S. On the reliability of network measurement techniques used for malware traffic analysis. In Cambridge International Workshop on Security Protocols; Springer: Cham, Switzerland, 2014; pp. 321–333. [Google Scholar]
- Wang, H.T.; Mao, C.H.; Wu, K.P.; Lee, H.M. Real-time fast-flux identification via localized spatial geolocation detection. In Proceedings of the IEEE Computer Software and Applications Conference (COMPSAC), Izmir, Turkey, 16–20 July 2012. [Google Scholar]
- Tu, T.D.; Guang, C.; Xin, L.Y. Detecting bot-infected machines based on analyzing the similar periodic DNS queries. In Proceedings of the IEEE 2015 International Conference on Communications, Management and Telecommunications (ComManTel), DaNang, Vietnam, 28–30 December 2015. [Google Scholar]
- Soltanaghaei, E.; Kharrazi, M. Detection of fast-flux botnets through DNS traffic analysis. Sci. Iranica Trans. D Comput. Sci. Eng. Electr. 2015, 22, 2389. [Google Scholar]
- Wright, M.K.; Adler, M.; Levine, B.N.; Shields, C. An analysis of the degradation of anonymous protocols. In Proceedings of the Network and Distributed Security Symposium, San Diego, CA, USA, 6–8 February 2002. [Google Scholar]
- Shmatikov, V.; Wang, M.H. Timing analysis in low-latency mix networks: Attacks and defenses. In Proceedings of the ESORICS, Hamburg, Germany, 18–20 September 2006. [Google Scholar]
- Hsu, C.-H.; Huang, C.-Y.; Chen, K.-T. Fast-flux bot detection in real time. In International Workshop on Recent Advances in Intrusion Detection; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Haffner, P.; Sen, S.; Spatscheck, O.; Wang, D. ACAS: Auto-mated Construction of Application Signatures. In Proceedings of the ACM SIGCOMM, Philadelphia, PA, USA, 22–26 August 2005; pp. 197–202. [Google Scholar]
- Alshammari, R.; Zincir-Heywood, N.A. A flow-based approach for SSH traffic detection, Cybernetics, ISIC. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Montreal, QC, Canada, 7–10 October 2007; pp. 296–301. [Google Scholar]
- Holz, T.; Gorecki, C.; Rieck, K.; Freiling, F. Measuring and detecting fast-flux service networks. In Proceedings of the Network & Distributed System Security Symposium, San Diego, CA, USA, 10–13 February 2008. [Google Scholar]
- Almubayed, A.; Hadi, A.; Atoum, J. A Model for Detecting Tor Encrypted Traffic using Supervised Machine Learning. Int. J. Comput. Netw. Inf. Secur. 2015, 7, 10–23. [Google Scholar] [CrossRef] [Green Version]
- Chaabane, A.; Manils, P.; Kaafar, M.A. Digging into Anonymous Traffic: A Deep Analysis of the Tor Anonymizing Network. In Proceedings of the 4th International Conference on Network and System Security (NSS), Helsinki, Finland, 21–23 August 2010; pp. 167–174. [Google Scholar]
- Chakravarty, S.; Stavrou, A.; Keromytis, A.D. Traffic analysis against low-latency anonymity networks using available bandwidth estimation. In European Symposium on Research in Computer Security; Springer: Berlin/Heidelberg, Germany, 2010; pp. 249–267. [Google Scholar]
- Chakravarty, S.; Stavrou, A.; Keromytis, A.D. Identifying Proxy Nodes in a Tor Anonymization Circuit. In Proceedings of the 2nd Workshop on Security and Privacy in Telecommunications and Information Systems (SePTIS), Bali, Indonesia, 30 November–3 December 2008; pp. 633–639. [Google Scholar]
- Mees, W.; Llopis, S.; Debatty, T. Achieving cyber situation awareness through a multi-aspect 3D operational picture. In Proceedings of the NATO IST-148 Symposium on Cyber Defense Situational Awareness, Sofia, Bulgaria, 3–4 October 2016. [Google Scholar]
- Bonab, R.H.; Can, F. A Theoretical Framework on the Ideal Number of Classifiers for Online Ensembles in Data Streams. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; p. 2053. [Google Scholar]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Kuncheva, L. Combining Pattern Classifiers: Methods and Algorithms; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]
- Dietterich, T.G. Ensemble methods in machine learning. In Multiple Classifier Systems; Kittler, J., Roli, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; Volume 1857, pp. 1–15. [Google Scholar]
- Webb, G.I.; Zheng, Z. Multistrategy ensemble learning: Reducing error by combining ensemble learning techniques. IEEE Trans. Knowl. Data Eng. 2004, 16, 980–991. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Angelis, L.; Vlahavas, I.P. Selective fusion of heterogeneous classifiers. Intell. Data Anal. 2005, 9, 511–525. [Google Scholar] [CrossRef]
- Mao, J.; Jain, A.K.; Duin, P.W. Statistical pattern recognition: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 4–37. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. In Pattern Recognition Letters; Elsevier Science Inc.: Amsterdam, The Netherlands, 2006; Volume 27, pp. 861–874. [Google Scholar] [CrossRef]
- Haining, W.; Danlu, Z.; Kang, G.S. Detecting SYN flooding attacks. In Proceedings of the Twenty-First Annual Joint Conference of the IEEE Computer and Communications Societies, New York, NY, USA, 23–27 June 2002; volume 3, pp. 1530–1539. [Google Scholar]
- Arndt, D.J.; Zincir-Heywood, A.N. A Comparison of Three Machine Learning Techniques for Encrypted Network Traffic Analysis. In Proceedings of the 2011 IEEE Symposium on Computational Intelligence for Security and Defense Applications (CISDA), Paris, France, 11–15 April 2011; pp. 107–114. [Google Scholar]
- Contagiodump. Available online: http://contagiodump.blogspot.com/ (accessed on 16 June 2018).
- Usma. Available online: https://www.usma.edu (accessed on 20 July 2018).
- Netresec. Available online: https://www.netresec.com (accessed on 25 July 2018).
- NetFlow. Available online: https://dan.arndt.ca (accessed on 6 June 2018).
- Sagduyu, E.; Ephremides, A. A Game-Theoretic Analysis of Denial of Service Attacks in Wireless Random Access. In Proceedings of the 2007 5th International Symposium on Modeling and Optimization in Mobile, Ad Hoc and Wireless Networks and Workshops, Limassol, Cyprus, 16–20 April 2007; pp. 1–10. [Google Scholar] [CrossRef]
- Sagduyu, Y.E.; Berryt, R.A.; Ephremidesi, A. Wireless jamming attacks under dynamic traffic uncertainty. In Proceedings of the 8th International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks, Avignon, France, 31 May–4 June 2010; pp. 303–312. [Google Scholar]
- Tsiropoulou, E.E.; Baras, J.S.; Papavassiliou, S.; Qu, G. On the Mitigation of Interference Imposed by Intruders in Passive RFID Networks. In Decision and Game Theory for Security; Zhu, Q., Alpcan, T., Panaousis, E., Tambe, M., Casey, W., Eds.; GameSec 2016; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9996. [Google Scholar]


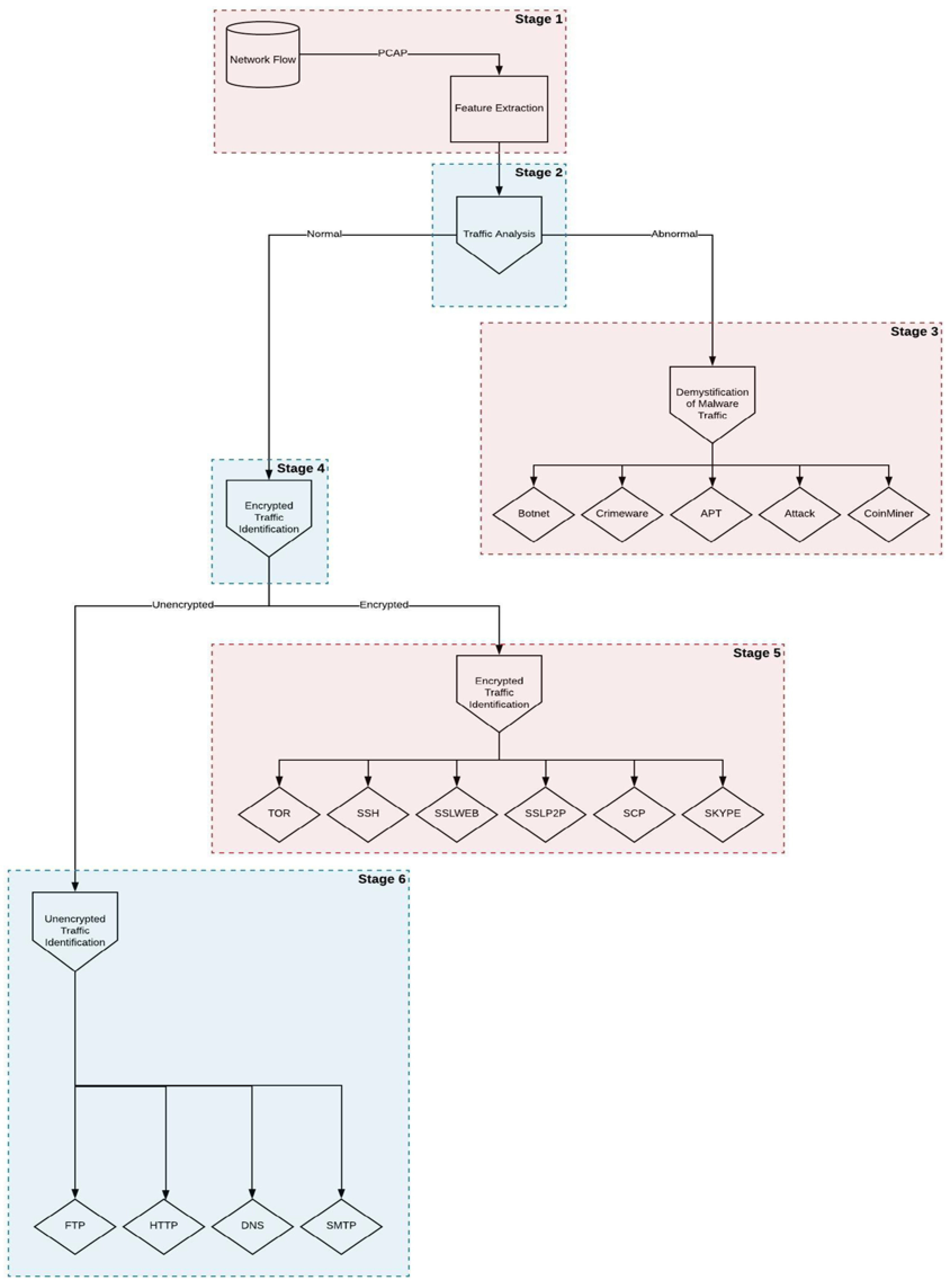{kind=link}
| Network Traffic Analysis (Binary) (208.629 Instances) | ||||||
|---|---|---|---|---|---|---|
| Classifier | Classification Accuracy & Performance Metrics | |||||
| TAC | RMSE | PRE | REC | F-Score | ROC_Area | |
| SVM | 98.01% | 0.1309 | 0.980 | 0.980 | 0.980 | 0.980 |
| MLFF ANN | 98.13% | 0.1295 | 0.981 | 0.981 | 0.981 | 0.994 |
| k-NN | 96.86% | 0.1412 | 0.970 | 0.970 | 0.970 | 0.970 |
| RF | 97.12% | 0.1389 | 0.972 | 0.971 | 0.971 | 0.971 |
| Ensemble | 97.53% | 0.1351 | 0.976 | 0.975 | 0.975 | 0.979 |
| Demystification of Malware Traffic (Multiclass) (168.501 Instances) | ||||||
|---|---|---|---|---|---|---|
| Classifier | Classification Accuracy & Performance Metrics | |||||
| TAC | RMSE | PRE | REC | F-Score | ROC_Area | |
| SVM | 96.63% | 0.1509 | 0.967 | 0.967 | 0.968 | 0.970 |
| MLFF ANN | 96.50% | 0.1528 | 0.981 | 0.981 | 0.981 | 0.965 |
| k-NN | 94.95% | 0.1602 | 0.970 | 0.970 | 0.970 | 0.950 |
| RF | 95.91% | 0.1591 | 0.972 | 0.971 | 0.971 | 0.960 |
| Ensemble | 95.99% | 0.1557 | 0.972 | 0.972 | 0.973 | 0.961 |
| Encrypted Traffic Analysis (Binary) (166.874 Instances) | ||||||
|---|---|---|---|---|---|---|
| Classifier | Classification Accuracy & Performance Metrics | |||||
| TAC | RMSE | PRE | REC | F-Score | ROC_Area | |
| SVM | 98.99% | 0.1109 | 0.989 | 0.990 | 0.990 | 0.990 |
| MLFF ANN | 99.12% | 0.1086 | 0.998 | 0.998 | 0.998 | 0.998 |
| k-NN | 97.84% | 0.1372 | 0.975 | 0.975 | 0.978 | 0.980 |
| RF | 98.96% | 0.1107 | 0.989 | 0.989 | 0.989 | 0.990 |
| Ensemble | 98.72% | 0.1168 | 0.987 | 0.987 | 0.988 | 0.989 |
| Encrypted Traffic Identification (Multiclass) (214.155 Instances) | ||||||
|---|---|---|---|---|---|---|
| Classifier | Classification Accuracy & Performance Metrics | |||||
| TAC | RMSE | PRE | REC | F-Score | ROC_Area | |
| SVM | 90.31% | 0.1906 | 0.905 | 0.905 | 0.906 | 0.950 |
| MLFF ANN | 92.67% | 0.1811 | 0.930 | 0.930 | 0.928 | 0.960 |
| k-NN | 85.19% | 0.2032 | 0.890 | 0.890 | 0.890 | 0.935 |
| RF | 91.56% | 0.1800 | 0.920 | 0.916 | 0.916 | 0.930 |
| Ensemble | 89.93% | 0.1887 | 0.911 | 0.910 | 0.910 | 0.943 |
| Unencrypted Traffic Identification (Multiclass) (186.541 Instances) | ||||||
|---|---|---|---|---|---|---|
| Classifier | Classification Accuracy & Performance Metrics | |||||
| TAC | RMSE | PRE | REC | F-Score | ROC_Area | |
| SVM | 99.92% | 0.1003 | 0.999 | 0.999 | 0.999 | 0.999 |
| MLFF ANN | 99.91% | 0.1008 | 0.999 | 0.999 | 0.999 | 0.999 |
| k-NN | 98.98% | 0.1020 | 0.989 | 0.989 | 0.990 | 0.995 |
| RF | 99.93% | 0.1001 | 0.999 | 0.999 | 0.999 | 0.999 |
| Ensemble | 99.68% | 0.1008 | 0.996 | 0.996 | 0.997 | 0.998 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Demertzis, K.; Kikiras, P.; Tziritas, N.; Sanchez, S.L.; Iliadis, L. The Next Generation Cognitive Security Operations Center: Network Flow Forensics Using Cybersecurity Intelligence. Big Data Cogn. Comput. 2018, 2, 35. https://doi.org/10.3390/bdcc2040035
Demertzis K, Kikiras P, Tziritas N, Sanchez SL, Iliadis L. The Next Generation Cognitive Security Operations Center: Network Flow Forensics Using Cybersecurity Intelligence. Big Data and Cognitive Computing. 2018; 2(4):35. https://doi.org/10.3390/bdcc2040035
Chicago/Turabian StyleDemertzis, Konstantinos, Panayiotis Kikiras, Nikos Tziritas, Salvador Llopis Sanchez, and Lazaros Iliadis. 2018. "The Next Generation Cognitive Security Operations Center: Network Flow Forensics Using Cybersecurity Intelligence" Big Data and Cognitive Computing 2, no. 4: 35. https://doi.org/10.3390/bdcc2040035
APA StyleDemertzis, K., Kikiras, P., Tziritas, N., Sanchez, S. L., & Iliadis, L. (2018). The Next Generation Cognitive Security Operations Center: Network Flow Forensics Using Cybersecurity Intelligence. Big Data and Cognitive Computing, 2(4), 35. https://doi.org/10.3390/bdcc2040035