Data-Assisted Persona Construction Using Social Media Data




Abstract
:1. Introduction
- Creating personas is a costly and lengthy process,
- Personas may be biased by their creators,
- Personas may be non-verifiable and untrustworthy when they depend on the information used for their creation,
- Personas may become inaccurate over time.
2. Related Work
3. Motivation
4. Experimental Setup and Method
4.1. Data
4.2. Participants
5. Persona Construction
6. User Evaluation
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Guo, A.; Ma, J. Archetype-Based Modeling of Persona for Comprehensive Personality Computing from Personal Big Data. Sensors 2018, 18, 684. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miaskiewicz, T.; Kozar, K.A. Personas and user-centered design: How can personas benefit product design processes? Des. Stud. 2011, 32, 417–430. [Google Scholar] [CrossRef]
- Dittmar, A.; Forbrig, P. Integrating Personas and Use Case Models. In Proceedings of the Human-Computer Interaction—INTERACT 2019, Paphos, Cyprus, 2–6 September 2019; Lamas, D., Loizides, F., Nacke, L., Petrie, H., Winckler, M., Zaphiris, P., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 666–686. [Google Scholar]
- Nielsen, L. Personas in Use. In Personas—User Focused Design; Nielsen, L., Ed.; Springer: London, UK, 2019; pp. 83–115. ISBN 978-1-4471-7427-1. [Google Scholar]
- Nielsen, L. Making Your Personas Live. In Personas—User Focused Design; Nielsen, L., Ed.; Springer: London, UK, 2019; pp. 161–170. ISBN 978-1-4471-7427-1. [Google Scholar]
- Pruitt, J.; Grudin, J. Personas: Practice and Theory. In Proceedings of the 2003 Conference on Designing for User Experiences—DUX ’03, San Francisco, CA, USA, 6–7 June 2003; ACM Press: New York, NY, USA, 2003; pp. 1–15. [Google Scholar]
- Salminen, J.; Jansen, B.J.; An, J.; Kwak, H.; Jung, S. Are personas done? Evaluating their usefulness in the age of digital analytics. Pers. Stud. 2018, 4, 47–65. [Google Scholar] [CrossRef] [Green Version]
- Jansen, B.J.; Salminen, J.O.; Jung, S.-G. Data-Driven Personas for Enhanced User Understanding: Combining Empathy with Rationality for Better Insights to Analytics. Data Inf. Manag. 2020, 4, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Jung, S.G.; Salminen, J.; An, J.; Kwak, H.; Jansen, B.J. Automatically Conceptualizing Social Media Analytics Data via Personas. In Proceedings of the International AAAI Conference on Web and Social Media, Stanford, CA, USA, 15 June 2018. [Google Scholar]
- Salminen, J.; Sengün, S.; Jung, S.; Jansen, B.J. Design Issues in Automatically Generated Persona Profiles: A Qualitative Analysis from 38 Think-Aloud Transcripts. In Proceedings of the 2019 Conference on Human Information Interaction and Retrieval, Glasgow, Scotland, UK, 10–14 March 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 225–229. [Google Scholar]
- Jung, S.; Salminen, J.; Jansen, B.J. Personas Changing Over Time: Analyzing Variations of Data-Driven Personas During a Two-Year Period. In Proceedings of the Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar]
- Jansen, B.J.; Jung, S.; Salminen, J. Capturing the change in topical interests of personas over time. Proc. Assoc. Inf. Sci. Technol. 2019, 56, 127–136. [Google Scholar] [CrossRef]
- Kouroupetroglou, G.; Spiliotopoulos, D. Usability methodologies for real-life voice user interfaces. Int. J. Inf. Technol. Web Eng. 2009, 4, 78–94. [Google Scholar] [CrossRef] [Green Version]
- Jung, S.-G.; Salminen, J.; Jansen, B.J. Giving Faces to Data: Creating Data-Driven Personas from Personified Big Data. In Proceedings of the 25th International Conference on Intelligent User Interfaces Companion, Cagliari, Italy, 17–20 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 132–133. [Google Scholar]
- An, J.; Cho, H.; Kwak, H.; Hassen, M.Z.; Jansen, B.J. Towards Automatic Persona Generation Using Social Media. In Proceedings of the 2016 IEEE 4th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Vienna, Austria, 22–24 August 2016; pp. 206–211. [Google Scholar]
- Chang, Y.; Lim, Y.; Stolterman, E. Personas: From theory to practices. In Proceedings of the 5th Nordic conference on Human-computer interaction building bridges—NordiCHI ’08, Lund, Sweden, 20–22 October 2008; ACM Press: New York, NY, USA, 2008; pp. 439–442. [Google Scholar]
- Schefbech, G.; Spiliotopoulos, D.; Risse, T. The Recent Challenge in Web Archiving: Archiving the Social Web. In Proceedings of the International Council on Archives Congress, Brisbane, Australia, 20–25 August 2012; pp. 1–5. [Google Scholar]
- Aivazoglou, M.; Roussos, A.O.; Margaris, D.; Vassilakis, C.; Ioannidis, S.; Polakis, J.; Spiliotopoulos, D. A fine-grained social network recommender system. Soc. Netw. Anal. Min. 2020, 10, 8. [Google Scholar] [CrossRef]
- Christoforakos, L.; Tretter, S.; Diefenbach, S.; Bibi, S.-A.; Fröhner, M.; Kohler, K.; Madden, D.; Marx, T.; Pfeiffer, T.; Pfeiffer-Leßmann, N.; et al. Potential and Challenges of Prototyping in Product Development and Innovation. i-com 2019, 18, 179–187. [Google Scholar] [CrossRef]
- Schoch, E.; Choi, A.M.L.A.; Lee, H.; Connor, S.; Rose, E.J. The Food Locker: An Innovative, User-Centered Approach to Address Food Insecurity on Campus. In Proceedings of the 37th ACM International Conference on the Design of Communication, Portland, OR, USA, 4–6 October 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar]
- Ozkan, D.S.; Reeping, D.; McNair, L.D.; Martin, T.L.; Harrison, S.; Lester, L.; Knapp, B.; Wisnioski, M.; Patrick, A.; Baum, L. Using Personas as Curricular Design Tools: Engaging the Boundaries of Engineering Culture. In Proceedings of the 2019 IEEE Frontiers in Education Conference (FIE), Covington, KY, USA, 16–19 October 2019; pp. 1–7. [Google Scholar]
- Niskanen, K.; Bosch, M.; Wils, K. Scientific Personas in Theory and Practice—Ways of Creating Scientific, Scholarly, and Artistic Identities. Pers. Stud. 2018, 4, 1–5. [Google Scholar] [CrossRef]
- Bosch, M. Looking at Laboratory Life, Writing a Scientific Persona: Marianne van Herwerden’s Travel Letters from the United States, 1920. L’Homme 2018, 29, 15–34. [Google Scholar] [CrossRef]
- Salminen, J.; Jung, S.-G.; Jansen, B.J. Detecting Demographic Bias in Automatically Generated Personas. In Proceedings of the Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar]
- Salminen, J.; Jung, S.; Jansen, B.J. The Future of Data-driven Personas: A Marriage of Online Analytics Numbers and Human Attributes. In Proceedings of the 21st International Conference on Enterprise Information Systems—Volume 1: ICEIS, Heraklion, Crete, Greece, 3–5 May 2019; SciTePress: Setúbal Municipality, Portugal, 2019; pp. 608–615. [Google Scholar]
- Jung, S.-G.; An, J.; Kwak, H.; Ahmad, M.; Nielsen, L.; Jansen, B.J. Persona Generation from Aggregated Social Media Data. In Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1748–1755. [Google Scholar]
- An, J.; Kwak, H.; Jung, S.; Salminen, J.; Jansen, B.J. Customer segmentation using online platforms: Isolating behavioral and demographic segments for persona creation via aggregated user data. Soc. Netw. Anal. Min. 2018, 8, 54. [Google Scholar] [CrossRef]
- Neate, T.; Bourazeri, A.; Roper, A.; Stumpf, S.; Wilson, S. Co-Created Personas: Engaging and Empowering Users with Diverse Needs Within the Design Process. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar]
- Li, B.; Segonds, F.; Mateev, C.; Lou, R.; Merienne, F. Design in context of use: An experiment with a multi-view and multi-representation system for collaborative design. Comput. Ind. 2018, 103, 28–37. [Google Scholar] [CrossRef] [Green Version]
- Sim, G.; Shrivastava, A.; Horton, M.; Agarwal, S.; Haasini, P.S.; Kondeti, C.S.; McKnight, L. Child-Generated Personas to Aid Design Across Cultures. In Proceedings of the Human-Computer Interaction—INTERACT 2019, Paphos, Cyprus, 2–6 September 2019; Lamas, D., Loizides, F., Nacke, L., Petrie, H., Winckler, M., Zaphiris, P., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 112–131. [Google Scholar]
- Salminen, J.; Liu, Y.-H.; Engün, S.; Santos, J.M.; Jung, S.; Jansen, B.J. The Effect of Numerical and Textual Information on Visual Engagement and Perceptions of AI-Driven Persona Interfaces. In Proceedings of the 25th International Conference on Intelligent User Interfaces, Cagliari, Italy, 17–20 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 357–368. [Google Scholar]
- Salminen, J.; Santos, J.M.; Jung, S.-G.; Eslami, M.; Jansen, B.J. Persona Transparency: Analyzing the Impact of Explanations on Perceptions of Data-Driven Personas. Int. J. Hum. Comput. Interact. 2019, 36, 788–800. [Google Scholar]
- Jansen, B.J.; Jung, S.; Salminen, J. Creating Manageable Persona Sets from Large User Populations. In Proceedings of the Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar]
- McGinn, J.; Kotamraju, N. Data-Driven Persona Development. In Proceedings of the Twenty-Sixth Annual CHI Conference on Human Factors in Computing Systems—CHI ’08, Florence, Italy, 5–10 April 2008; ACM Press: New York, NY, USA, 2008; pp. 1521–1524. [Google Scholar]
- Xu, Y.; Lee, M.J. Identifying Personas in Online Shopping Communities. Multimodal Technol. Interact. 2020, 4, 1–19. [Google Scholar]
- Salminen, J.; Jung, S.-G.; Santos, J.M.; Jansen, B.J. Does a Smile Matter if the Person Is Not Real? The Effect of a Smile and Stock Photos on Persona Perceptions. Int. J. Hum. Comput. Interact. 2020, 36, 568–590. [Google Scholar]
- Kim, E.; Yoon, J.; Kwon, J.; Liaw, T.; Agogino, A.M. From Innocent Irene to Parental Patrick: Framing User Characteristics and Personas to Design for Cybersecurity. Proc. Des. Soc. Int. Conf. Eng. Des. 2019, 1, 1773–1782. [Google Scholar] [CrossRef] [Green Version]
- Margaris, D.; Kobusinska, A.; Spiliotopoulos, D.; Vassilakis, C. An Adaptive Social Network-Aware Collaborative Filtering Algorithm for Improved Rating Prediction Accuracy. IEEE Access 2020, 8, 68301–68310. [Google Scholar] [CrossRef]
- Kizgin, H.; Dey, B.L.; Dwivedi, Y.K.; Hughes, L.; Jamal, A.; Jones, P.; Kronemann, B.; Laroche, M.; Peñaloza, L.; Richard, M.-O.; et al. The impact of social media on consumer acculturation: Current challenges, opportunities, and an agenda for research and practice. Int. J. Inf. Manag. 2020, 51, 102026. [Google Scholar] [CrossRef]
- Matthews, T.; Judge, T.; Whittaker, S. How Do Designers and User Experience Professionals Actually Perceive and Use Personas? In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; Association for Computing Machinery: New York, NY, USA, 2012; pp. 1219–1228. [Google Scholar]
- Risse, T.; Demidova, E.; Dietze, S.; Peters, W.; Papailiou, N.; Doka, K.; Stavrakas, Y.; Plachouras, V.; Senellart, P.; Carpentier, F.; et al. The ARCOMEM Architecture for Social- and Semantic-Driven Web Archiving. Futur. Internet 2014, 6, 688–716. [Google Scholar] [CrossRef] [Green Version]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Antonakaki, D.; Spiliotopoulos, D.; Samaras, C.V.; Pratikakis, P.; Ioannidis, S.; Fragopoulou, P. Social media analysis during political turbulence. PLoS ONE 2017, 12, e0186836. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chorley, M.J.; Colombo, G.B.; Allen, S.M.; Whitaker, R.M. Human content filtering in Twitter: The influence of metadata. Int. J. Hum. Comput. Stud. 2015, 74, 32–40. [Google Scholar] [CrossRef] [Green Version]
- Salminen, J.; Kwak, H.; Santos, J.M.; Jung, S.-G.; An, J.; Jansen, B.J. Persona Perception Scale: Developing and Validating an Instrument for Human-Like Representations of Data. In Proceedings of the Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar]
- Salminen, J.; Sengun, S.; Kwak, H.; Jansen, B.; An, J.; Jung, S.-G.; Vieweg, S.; Harrell, D.F. Generating Cultural Personas from Social Data: A Perspective of Middle Eastern Users. In Proceedings of the 2017 5th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Prague, Czech Republic, 21–23 August 2017; IEEE: New York, NY, USA, 2017; pp. 120–125. [Google Scholar]
- Salminen, J.; Jansen, B.J.; An, J.; Kwak, H.; Jung, S.-G. Automatic Persona Generation for Online Content Creators: Conceptual Rationale and a Research Agenda. In Personas—User Focused Design; Nielsen, L., Ed.; Springer: London, UK, 2019; pp. 135–160. ISBN 978-1-4471-7427-1. [Google Scholar]
- Margaris, D.; Vassilakis, C.; Spiliotopoulos, D. Handling uncertainty in social media textual information for improving venue recommendation formulation quality in social networks. Soc. Netw. Anal. Min. 2019, 9, 64. [Google Scholar] [CrossRef]
- Margaris, D.; Vassilakis, C.; Spiliotopoulos, D. What makes a review a reliable rating in recommender systems? Inf. Process. Manag. 2020, 57, 102304. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
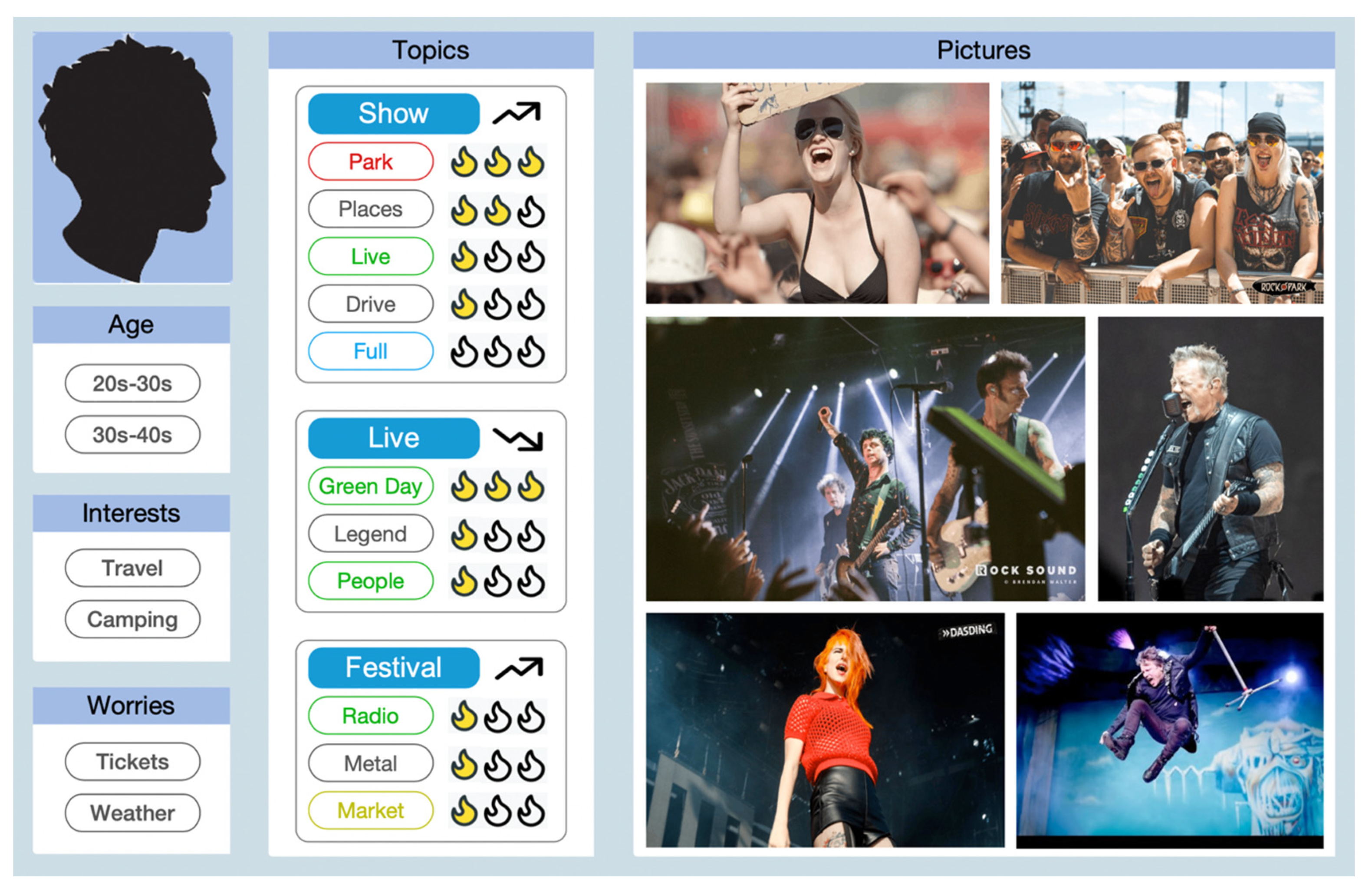{kind=link}
{kind=link}
{kind=link}
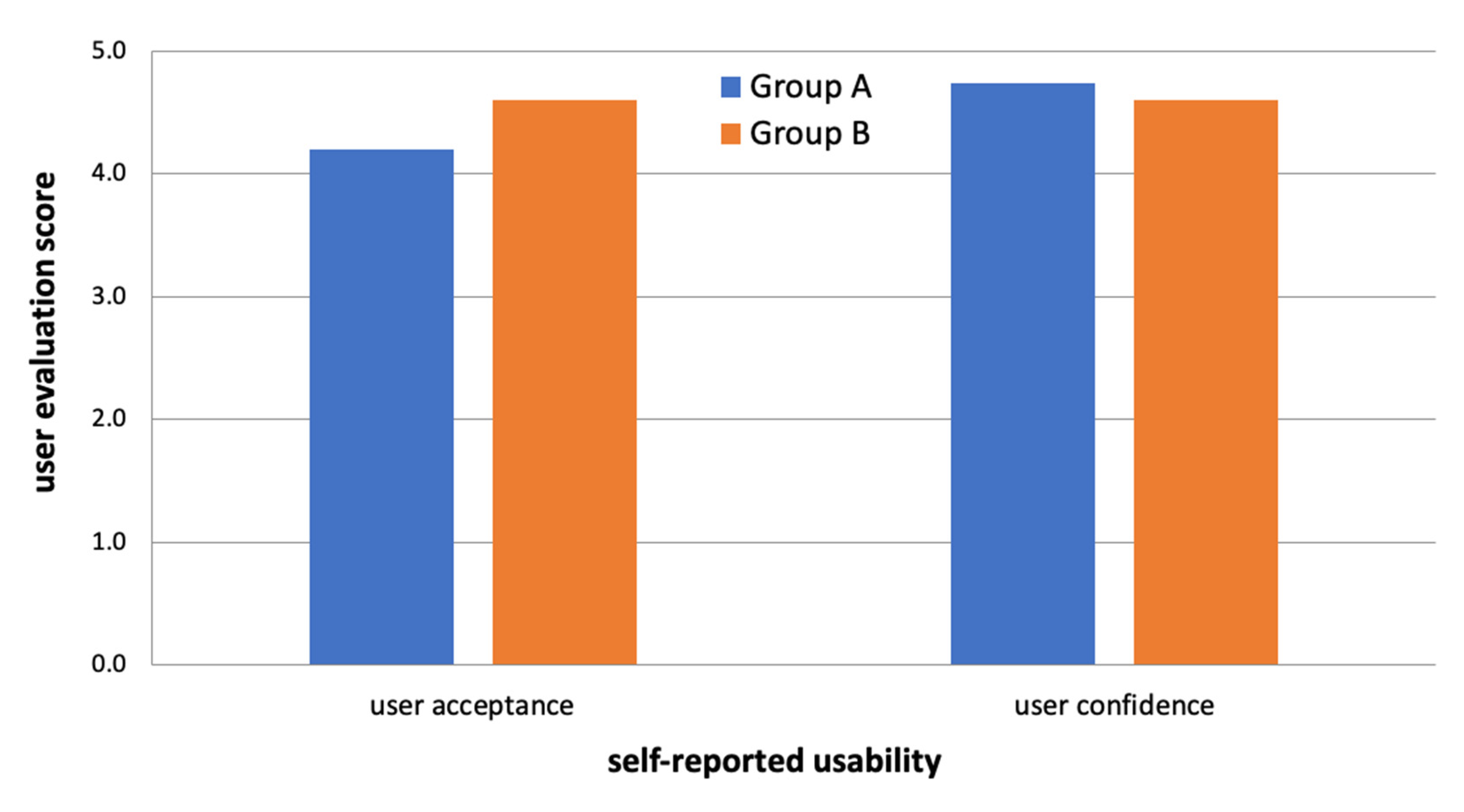{kind=link}
| Group | Task | Sources |
|---|---|---|
| A | create personas using topic modelling from twitter data | topic information |
| B | create personas using any information deemed useful | Twitter, analytics tools |
| A + B | evaluate personas of two random participants, one from each group | persona perception scale, usability evaluation questionnaire |
| Group | All Participants | Male Participants | Female Participants |
|---|---|---|---|
| A | 4.4 (std: 1.18) | 4.38 (std: 1.19) | 4.43 (std: 1.27) |
| B | 6.2 (std: 1.37) | 6.67 (std: 1.00) | 5.50 (std: 1.64) |
| A + B | 5.3 (std: 1.56) | 5.59 (std: 1.58) | 4.92 (std: 1.50) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Spiliotopoulos, D.; Margaris, D.; Vassilakis, C. Data-Assisted Persona Construction Using Social Media Data. Big Data Cogn. Comput. 2020, 4, 21. https://doi.org/10.3390/bdcc4030021
Spiliotopoulos D, Margaris D, Vassilakis C. Data-Assisted Persona Construction Using Social Media Data. Big Data and Cognitive Computing. 2020; 4(3):21. https://doi.org/10.3390/bdcc4030021
Chicago/Turabian StyleSpiliotopoulos, Dimitris, Dionisis Margaris, and Costas Vassilakis. 2020. "Data-Assisted Persona Construction Using Social Media Data" Big Data and Cognitive Computing 4, no. 3: 21. https://doi.org/10.3390/bdcc4030021
APA StyleSpiliotopoulos, D., Margaris, D., & Vassilakis, C. (2020). Data-Assisted Persona Construction Using Social Media Data. Big Data and Cognitive Computing, 4(3), 21. https://doi.org/10.3390/bdcc4030021