Forecasting Plant and Crop Disease: An Explorative Study on Current Algorithms



Abstract
:1. Introduction
2. Materials and Methods
2.1. Methodology
2.2. Factors Involved in Plant and Crop Disease Outbreak
- Disease intensity is a general term used to describe the amount of disease present in a population [36];
- Disease prevalence is the proportion (or percentage) of fields, counties, states, etc. in which the disease is detected, and reveals the disease at a grander scale than incidence [36];
- Disease severity is the area (relative or absolute) of the sampling unit (leaf, fruit, etc.) showing symptoms of disease. It is most often expressed as a percentage or proportion [36].
2.3. Crop and Plant Disease Prediction
2.3.1. Data Sources
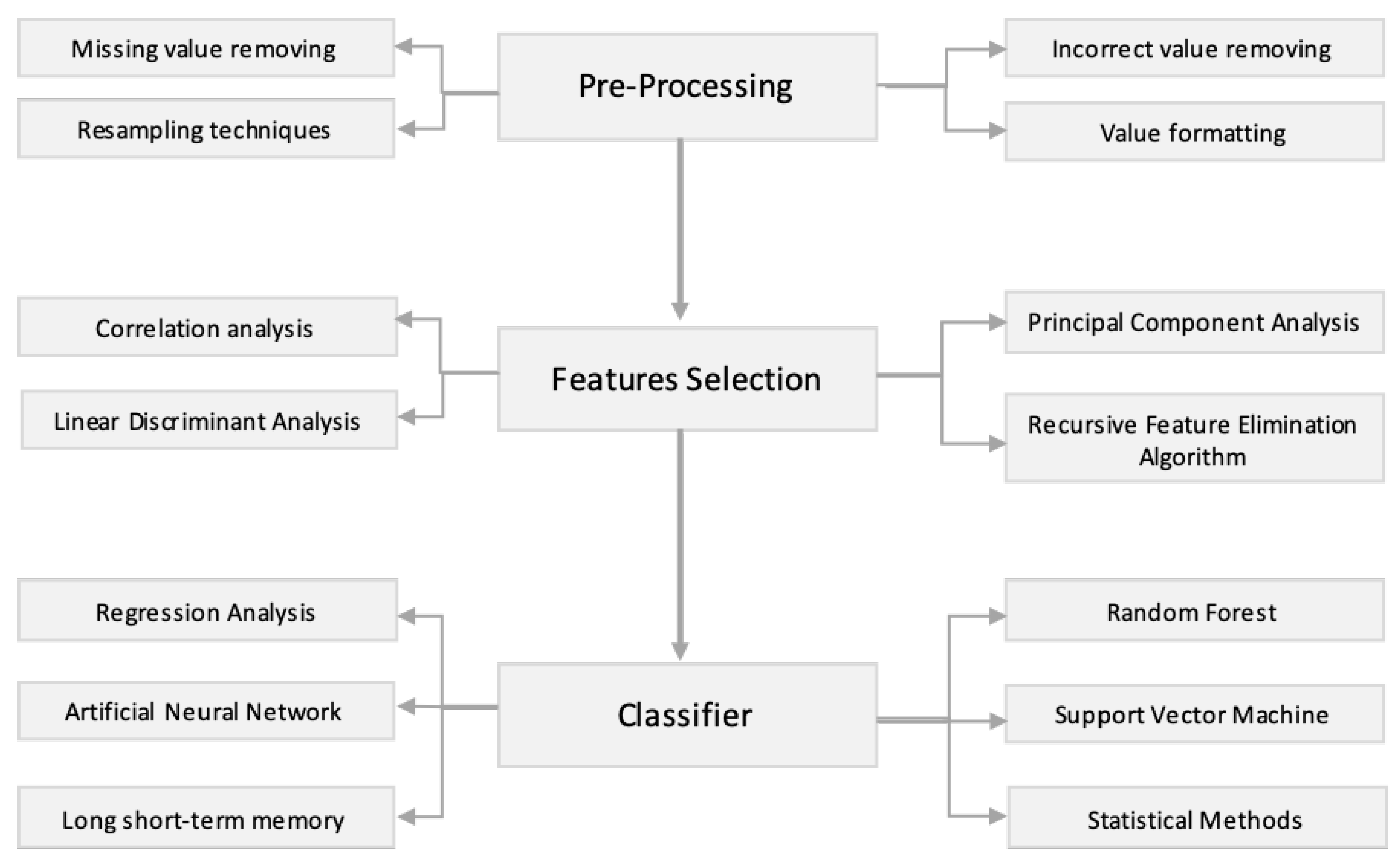
2.3.2. Pre-Processing
2.3.3. Techniques and Methods
- Forecast models based on weather data;
- Forecast models based on image processing;
- Forecast models based on the distinct types of data originating from various heterogeneous sources.
2.3.4. Predicted Outputs
2.3.5. Performance Metrics
2.3.6. Data Analysis Frameworks
- Matlab: https://www.mathworks.com/;
- Python: https://www.python.org/;
- Waikato Environment for Knowledge Analysis (WEKA): https://www.cs.waikato.ac.nz/ml/weka/;
- Scikit-learn: https://scikit-learn.org/;
- Keras: https://keras.io/;
- Tensorflow: https://www.tensorflow.org/.
2.3.7. Overall Performance and Comparison
2.4. Discussion
3. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ML | Machine Learning |
| DL | Deep Learning |
| RM | Regression Model |
| ANN | Artificial Neural Network |
| DSS | Decision Support System |
| LSTM | Long Short-Term Memory |
| SVM | Support Vector Machine |
| SVR | Support Vector Regression |
| RF | Random Forest |
| ELM | Extreme Learning Machine |
| MLR | Multi-Linear Regression |
| MLP | Multi-layer Perceptron |
| CNN | Convolutional Neural Network |
| DT | Decision-Tree |
| BN | Bayesian Network |
| LR | Logistic Regression |
| HMM | Hidden Markov Model |
| KNN | K-Nearest Neighbors |
| RBF | Radial Basis Function |
| LVQ | Learning Vector Quantization |
| LDA | Linear Discriminant Analysis |
| QDA | Quadratic Discriminant Analysis |
| NB | Naïve Bayes |
| PLD | Pseudo Linear Discriminant |
| CCT | Compact Classification Tree |
| VI | Vegetation Indices |
| NDVI | Normalized Difference Vegetation Index |
| TVI | Triangular Vegetation Index |
| SAVI | Soil Adjusted Vegetation Index |
| DSWI | Disease Water Stress Index Shortwave |
| SIWSI | Infrared Water Stress Index |
| LST | Land Surface Temperature |
| VIS-NIR | Visible and Near Infrared Spectroradiometery |
| LAI | Leaf Area Index |
| KNR | K Neighbors Regressor |
| HSI | Hyperspectral Imaging |
| Green Band | |
| Red Band | |
| Near-infrared Band | |
| UAV | Unmanned Aerial Vehicles |
| PM | Powdery Mildew |
| Acc | Accuracy |
| Prec | Precision |
| Rec | Recall |
| MAE | Mean Absolute Error |
| MSE | Mean Squared Error |
| RMSE | Root Mean Squared Error |
| R2 | R Squared |
| ROC | Receiver Operating Characteristic Curve |
| AUC | Area under the ROC Curve |
| TEMP | Temperature |
| HUM | Humidity |
| RA | Rainfall |
| min. | Minimum |
| max. | Maximum |
References
- Food and Agriculture Organization of the United Nations. Plant Health and Food Security; International Plant Protection Convention: Roma, Itay, 2017. [Google Scholar]
- Food and Agriculture Organization of the United Nations. The State of the World’s Land and Water Resources for Food and Agriculture: Managing Systems at Risk; Earthscan: London, UK, 2011. [Google Scholar]
- Fenu, G.; Malloci, F.M. Artificial Intelligence Technique in Crop Disease Forecasting: A Case Study on Potato Late Blight Prediction. In International Conference on Intelligent Decision Technologies (IDT); Springer: Singapore, 2020; Volume 193, pp. 79–89. [Google Scholar] [CrossRef]
- Rong, L.; Liu, D.; Pedersen, E.F.; Zhang, G. The effect of wind speed and direction and surrounding maize on hybrid ventilation in a dairy cow building in Denmark. Energy Build. 2015, 86, 25–34. [Google Scholar] [CrossRef]
- Das, T.; Majumdar, M.H.D.; Devi, R.T.; Rajesh, T. Climate change impacts on plant diseases. SAARC J. Agric. 2016, 14, 200–209. [Google Scholar] [CrossRef] [Green Version]
- Newbery, F.; Qi, A.; Fitt, B.D. Modelling impacts of climate change on arable crop diseases: Progress, challenges and applications. Curr. Opin. Plant Biol. 2016, 32, 101–109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Donatelli, M.; Magarey, R.D.; Bregaglio, S.; Willocquet, L.; Whish, J.P.; Savary, S. Modelling the impacts of pests and diseases on agricultural systems. Agric. Syst. 2017, 155, 213–224. [Google Scholar] [CrossRef] [PubMed]
- Raza, A.; Razzaq, A.; Mehmood, S.S.; Zou, X.; Zhang, X.; Lv, Y.; Xu, J. Impact of climate change on crops adaptation and strategies to tackle its outcome: A review. Plants 2019, 8, 34. [Google Scholar] [CrossRef] [Green Version]
- Boursianis, A.D.; Papadopoulou, M.S.; Diamantoulakis, P.; Liopa-Tsakalidi, A.; Barouchas, P.; Salahas, G.; Karagiannidis, G.; Wan, S.; Goudos, S.K. Internet of Things (IoT) and Agricultural Unmanned Aerial Vehicles (UAVs) in Smart Farming: A Comprehensive Review. Internet Things 2020, 100–187. [Google Scholar] [CrossRef]
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111–402. [Google Scholar] [CrossRef]
- Mekala, M.S.; Viswanathan, P. A Survey: Smart agriculture IoT with cloud computing. In Proceedings of the 2017 International Conference on Microelectronic Devices, Circuits and Systems (ICMDCS), Vellore, India, 10–12 August 2017; pp. 1–7. [Google Scholar]
- Pierce, F.J.; Nowak, P. Aspects of precision agriculture. In Advances in Agronomy; Elsevier: Amsterdam, The Netherlands, 1999; Volume 67, pp. 1–85. [Google Scholar]
- Semmens, K.; Anderson, M.C.; Kustas, W.P.; Gao, F.; Alfieri, J.G.; McKee, L.G.; Prueger, J.H.; Hain, C.R.; Cammalleri, C.; Yang, Y.; et al. Monitoring daily evapotranspiration over two California vineyards using Landsat 8 in a multi-sensor data fusion approach. Remote Sens. Environ. 2016, 185, 155–170. [Google Scholar] [CrossRef] [Green Version]
- Fenu, G.; Malloci, F.M. LANDS DSS: A Decision Support System For Forecasting Crop Disease In Southern Sardinia. Int. J. Decis. Support Syst. Technol. IJDSST 2021, 13, 21–33. [Google Scholar] [CrossRef]
- Kamilaris, A.; Kartakoullis, A.; Prenafeta-Boldú, F.X. A review on the practice of big data analysis in agriculture. Comput. Electron. Agric. 2017, 143, 23–37. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Milioto, A.; Lottes, P.; Stachniss, C. Real-Time Semantic Segmentation of Crop and Weed for Precision Agriculture Robots Leveraging Background Knowledge in CNNs. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2229–2235. [Google Scholar]
- Fu, L.; Feng, Y.; Majeed, Y.; Zhang, X.; Zhang, J.; Karkee, M.; Zhang, Q. Kiwifruit detection in field images using Faster R-CNN with ZFNet. IFAC Pap. 2018, 51, 45–50. [Google Scholar] [CrossRef]
- Cheema, M.J.M.; Khan, M.A. Information Technology for Sustainable Agriculture. In Innovations in Sustainable Agriculture; Springer: Berlin/Heidelberg, Germany, 2019; pp. 585–597. [Google Scholar]
- Fenu, G.; Malloci, F.M. An Application of Machine Learning Technique in Forecasting Crop Disease. In Proceedings of the 2019 3rd International Conference on Big Data Research, Paris, France, 20–22 November 2019; pp. 76–82. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Eastburn, D.; McElrone, A.; Bilgin, D. Influence of atmospheric and climatic change on plant–pathogen interactions. Plant Pathol. 2011, 60, 54–69. [Google Scholar] [CrossRef]
- Juroszek, P.; von Tiedemann, A. Linking plant disease models to climate change scenarios to project future risks of crop diseases: A review. J. Plant Dis. Prot. 2015, 122, 3–15. [Google Scholar] [CrossRef]
- Classen, A.T.; Sundqvist, M.K.; Henning, J.A.; Newman, G.S.; Moore, J.A.; Cregger, M.A.; Moorhead, L.C.; Patterson, C.M. Direct and indirect effects of climate change on soil microbial and soil microbial-plant interactions: What lies ahead? Ecosphere 2015, 6, 1–21. [Google Scholar] [CrossRef]
- Kim, Y.H.; Yoo, S.J.; Gu, Y.H.; Lim, J.H.; Han, D.; Baik, S.W. Crop Pests Prediction Method Using Regression and Machine Learning Technology: Survey. IERI Procedia 2014, 6, 52–56. [Google Scholar] [CrossRef] [Green Version]
- Yandun Narvaez, F.; Reina, G.; Torres-Torriti, M.; Kantor, G.; Cheein, F.A. A Survey of Ranging and Imaging Techniques for Precision Agriculture Phenotyping. IEEE/ASME Trans. Mechatron. 2017, 22, 2428–2439. [Google Scholar] [CrossRef]
- Elavarasan, D.; Vincent, D.R.; Sharma, V.; Zomaya, A.Y.; Srinivasan, K. Forecasting yield by integrating agrarian factors and machine learning models: A survey. Comput. Electron. Agric. 2018, 155, 257–282. [Google Scholar] [CrossRef]
- Kaur, S.; Pandey, S.; Goel, S. Plants disease identification and classification through leaf images: A survey. Arch. Comput. Methods Eng. 2019, 26, 507–530. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent advances of hyperspectral imaging technology and applications in agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Stevens, R. An Advanced Treatise. Plant Pathol. 1960, 3, 357–429. [Google Scholar]
- Francl, L. The Disease Triangle: A plant pathological paradigm revisited. Plant Health Instr. 2001. [Google Scholar] [CrossRef]
- Agrios, G.N. Introduction to plant pathology. In Plant Pathology, 3rd ed.; Academic Press: San Diego, CA, USA, 1988; pp. 3–40. [Google Scholar]
- Bock, C.H.; Poole, G.H.; Parker, P.E.; Gottwald, T.R. Plant Disease Severity Estimated Visually, by Digital Photography and Image Analysis, and by Hyperspectral Imaging. Crit. Rev. Plant Sci. 2010, 29, 59–107. [Google Scholar] [CrossRef]
- Madden, L.V.; Hughes, G.; Van Den Bosch, F. The Study of Plant Disease Epidemics; The American Phytopatological Society: Saint Paul, MN, USA, 2007. [Google Scholar]
- Nutter, F., Jr.; Teng, P.; Shokes, F. Disease assessment terms and concepts. Plant Dis. 1991, 75, 1187–1188. [Google Scholar] [CrossRef]
- Zhang, J.; Yuan, L.; Nie, C.; Wei, L.; Yang, G. Forecasting of powdery mildew disease with multi-sources of remote sensing information. In Proceedings of the 2014 The Third International Conference on Agro-Geoinformatics, Beijing, China, 11–14 August 2014; pp. 1–5. [Google Scholar]
- Duarte-Carvajalino, J.M.; Alzate, D.F.; Ramirez, A.A.; Santa-Sepulveda, J.D.; Fajardo-Rojas, A.E.; Soto-Suárez, M. Evaluating late blight severity in potato crops using unmanned aerial vehicles and machine learning algorithms. Remote Sens. 2018, 10, 1513. [Google Scholar] [CrossRef] [Green Version]
- Sannakki, S.; Rajpurohit, V.; Sumira, F.; Venkatesh, H. A neural network approach for disease forecasting in grapes using weather parameters. In Proceedings of the 2013 Fourth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Tiruchengode, India, 4–6 July 2013; pp. 1–5. [Google Scholar]
- Wang, H.; Ma, Z. Prediction of wheat stripe rust based on support vector machine. In Proceedings of the 2011 Seventh International Conference on Natural Computation, Shanghai, China, 26–28 July 2011; Volume 1, pp. 378–382. [Google Scholar]
- Ahmed, N.; Khan, M.; Khan, N.; Ali, M. Prediction of potato late blight disease based upon environmental factors in Faisalabad. Pak. J. Plant Pathol. Microbiol. S 2015, 3. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Q.; Li, W.; Chen, P.; Wang, B. Prediction of Crop Pests and Diseases in Cotton by Long Short Term Memory Network. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 11–16. [Google Scholar]
- Jawade, P.; Chaugule, D.; Patil, D.; Shinde, H. Disease Prediction of Mango Crop Using Machine Learning and IoT. In International Conference on E-Business and Telecommunications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 254–260. [Google Scholar] [CrossRef]
- Patil, S.S.; Thorat, S.A. Early detection of grapes diseases using machine learning and IoT. In Proceedings of the 2016 Second International Conference on Cognitive Computing and Information Processing (CCIP), Mysore, India, 12–13 August 2016; pp. 1–5. [Google Scholar]
- Toroitich, P.K.; Orero, J. Real-time monitoring model for early detection of crop diseases. In Pan African Conference on Science, Computing and Telecommunications (PACT); Strathmore University: Nairobi, Kenya, 2017. [Google Scholar]
- Malicdem, A.R.; Fernandez, P.L. Rice blast disease forecasting for northern Philippines. WSEAS Trans. Inf. Sci. Appl. 2015, 12, 120–129. [Google Scholar]
- Gu, Y.; Yoo, S.; Park, C.; Kim, Y.; Park, S.; Kim, J.; Lim, J. BLITE-SVR: New forecasting model for late blight on potato using support-vector regression. Comput. Electron. Agric. 2016, 130, 169–176. [Google Scholar] [CrossRef]
- Kim, Y.; Roh, J.H.; Kim, H.Y. Early forecasting of Rice blast disease using long short-term memory recurrent neural networks. Sustainability 2018, 10, 34. [Google Scholar] [CrossRef] [Green Version]
- Gibert, K.; Sànchez–Marrè, M.; Izquierdo, J. A survey on pre-processing techniques: Relevant issues in the context of environmental data mining. AI Commun. 2016, 29, 627–663. [Google Scholar] [CrossRef] [Green Version]
- Sharma, P.; Singh, B.; Singh, R. Prediction of Potato Late Blight Disease Based Upon Weather Parameters Using Artificial Neural Network Approach. In Proceedings of the 2018 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, 10–12 July 2018; pp. 1–13. [Google Scholar]
- Singh, B.; Singh, R.; Bisen, T.; Kharayat, S. Disease Manifestation Prediction from Weather Data Using Extreme Learning Machine. In Proceedings of the 2018 3rd International Conference On Internet of Things: Smart Innovation and Usages (IoT-SIU), Nainital, India, 24–25 February 2018; pp. 1–6. [Google Scholar]
- Ghaffari, R.; Zhang, F.; Iliescu, D.; Hines, E.; Leeson, M.; Napier, R.; Clarkson, J. Early detection of diseases in tomato crops: An Electronic Nose and intelligent systems approach. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010. [Google Scholar] [CrossRef]
- de Oliveira Aparecido, L.E.; de Souza Rolim, G.; da Silva Cabral De Moraes, J.R.; Costa, C.T.S.; de Souza, P.S. Machine learning algorithms for forecasting the incidence of Coffea arabica pests and diseases. Int. J. Biometeorol. 2020, 64, 671–688. [Google Scholar] [CrossRef] [PubMed]
- Ardila, C.E.C.; Ramirez, L.A.; Ortiz, F.A.P. Spectral analysis for the early detection of anthracnose in fruits of Sugar Mango (Mangifera indica). Comput. Electron. Agric. 2020, 173, 105357. [Google Scholar] [CrossRef]
- Hsieh, J.Y.; Huang, W.; Yang, H.T.; Lin, C.C.; Fan, Y.C.; Chen, H. Building the Rice Blast Disease Prediction Model based on Machine Learning and Neural Networks; Technical Report; EasyChair: Manchester, UK, 2019. [Google Scholar]
- Bhatia, A.; Chug, A.; Singh, A.P. Hybrid SVM-LR Classifier for Powdery Mildew Disease Prediction in Tomato Plant. In Proceedings of the 2020 7th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 27–28 February 2020. [Google Scholar] [CrossRef]
- Bhatia, A.; Chug, A.; Singh, A.P. Application of extreme learning machine in plant disease prediction for highly imbalanced dataset. J. Stat. Manag. Syst. 2020, 23, 1059–1068. [Google Scholar] [CrossRef]
- Berger, R. Description and application of some general models for plant disease epidemics. Plant Dis. Epidemiol. 1989, 2, 125–149. [Google Scholar]
- Bhagawati, R.; Bhagawati, K.; Singh, A.; Nongthombam, R.; Sarmah, R.; Bhagawati, G. Artificial neural network assisted weather based plant disease forecasting system. Int. J. Recent Innov. Trends Comput. Commun. 2015, 3, 4168–4173. [Google Scholar]
- Katsantonis, D.; Kadoglidou, K.; Dramalis, C.; Puigdollers, P. Rice blast forecasting models and their practical value: A review. Phytopathol. Mediterr. 2017, 56, 187–216. [Google Scholar]
- University of Caifornia and Resources. California PestCast: Disease Model Database. Available online: http://ipm.ucanr.edu/DISEASE/DATABASE/diseasemodeldatabase.htm (accessed on 11 January 2021).
- Nettleton, D.F.; Katsantonis, D.; Kalaitzidis, A.; Sarafijanovic-Djukic, N.; Puigdollers, P.; Confalonieri, R. Predicting rice blast disease: Machine learning versus process-based models. BMC Bioinform. 2019, 20. [Google Scholar] [CrossRef]
- Ahmadi, P.; Muharam, F.M.; Ahmad, K.; Mansor, S.; Seman, I.A. Early Detection of Ganoderma Basal Stem Rot of Oil Palms Using Artificial Neural Network Spectral Analysis. Plant Dis. 2017, 101, 1009–1016. [Google Scholar] [CrossRef] [Green Version]
- Yeh, Y.H.; Chung, W.C.; Liao, J.Y.; Chung, C.L.; Kuo, Y.F.; Lin, T.T. Strawberry foliar anthracnose assessment by hyperspectral imaging. Comput. Electron. Agric. 2016, 122, 1–9. [Google Scholar] [CrossRef]
- Rumpf, T.; Mahlein, A.K.; Steiner, U.; Oerke, E.C.; Dehne, H.W.; Plümer, L. Early detection and classification of plant diseases with Support Vector Machines based on hyperspectral reflectance. Comput. Electron. Agric. 2010, 74, 91–99. [Google Scholar] [CrossRef]
- Zhu, H.; Chu, B.; Zhang, C.; Liu, F.; Jiang, L.; He, Y. Hyperspectral Imaging for Presymptomatic Detection of Tobacco Disease with Successive Projections Algorithm and Machine-learning Classifiers. Sci. Rep. 2017, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, J.; Pu, R.; Yuan, L.; Huang, W.; Nie, C.; Yang, G. Integrating Remotely Sensed and Meteorological Observations to Forecast Wheat Powdery Mildew at a Regional Scale. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4328–4339. [Google Scholar] [CrossRef]
- Zhao, J.; Xu, C.; Xu, J.; Huang, L.; Zhang, D.; Liang, D. Forecasting the wheat powdery mildew (Blumeria graminis f. Sp. tritici) using a remote sensing-based decision-tree classification at a provincial scale. Australas. Plant Pathol. 2018, 47, 53–61. [Google Scholar] [CrossRef]
- Kaur, K.; Kaur, M. Prediction of plant disease from weather forecasting using data mining. Int. J. Future Revolut. Comput. Sci. Commun. Eng. 2018, 4, 685–688. [Google Scholar] [CrossRef]
- Badnakhe, M.R.; Durbha, S.S.; Jagarlapudi, A.; Gade, R.M. Evaluation of Citrus Gummosis disease dynamics and predictions with weather and inversion based leaf optical model. Comput. Electron. Agric. 2018, 155, 130–141. [Google Scholar] [CrossRef]
- Lu, W.; Newlands, N.K.; Carisse, O.; Atkinson, D.E.; Cannon, A.J. Disease Risk Forecasting with Bayesian Learning Networks: Application to Grape Powdery Mildew (Erysiphe necator) in Vineyards. Agronomy 2020, 10, 622. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, S.; Shao, Y.; Zhang, Y. Plant Disease Forecasting Based on Wavelet Transformation and Support Vector Machine. Int. J. Res. Agric. Sci. 2018, 5, 90–94. [Google Scholar]
- Yang, X.; Nie, C.; Zhang, J.; Feng, H.; Yang, G. A Bayesian Network Model for Yellow Rust Forecasting in Winter Wheat. In International Conference on Computer and Computing Technologies in Agriculture (CCTA); Springer: Berlin/Heidelberg, Germany, 2017; Volume 545, pp. 65–75. [Google Scholar] [CrossRef]
- Behmann, J.; Steinrücken, J.; Plümer, L. Detection of early plant stress responses in hyperspectral images. ISPRS J. Photogramm. Remote Sens. 2014, 93, 98–111. [Google Scholar] [CrossRef]
- Ilic, M.; Ilic, S.; Jovic, S.; Panic, S. Early cherry fruit pathogen disease detection based on data mining prediction. Comput. Electron. Agric. 2018, 150, 418–425. [Google Scholar] [CrossRef]
- Pérez-Ariza, C.B.; Nicholson, A.E.; Flores, M.J. Prediction of coffee rust disease using bayesian networks. In Proceedings of the Sixth European Workshop on Probabilistic Graphical Models, Granada, Spain, 19–21 September 2012; pp. 259–266. [Google Scholar]
- Chen, M.; Brun, F.; Raynal, M.; Makowski, D. Forecasting severe grape downy mildew attacks using machine learning. PLoS ONE 2020, 15, e0230254. [Google Scholar] [CrossRef] [PubMed]
- Alves, L.; Silva, R.R.; Bernardino, J. System to Predict Diseases in Vineyards and Olive Groves using Data Mining and Geolocation. In Proceedings of the 13th International Conference on Software Technologies (ICSOFT), Porto, Portugal, 26–28 July 2018; pp. 679–687. [Google Scholar] [CrossRef]
- Calderón, R.; Navas-Cortés, J.A.; Zarco-Tejada, P.J. Early detection and quantification of Verticillium wilt in olive using hyperspectral and thermal imagery over large areas. Remote Sens. 2015, 7, 5584–5610. [Google Scholar] [CrossRef] [Green Version]
- Liaghat, S.; Ehsani, R.; Mansor, S.; Shafri, H.Z.; Meon, S.; Sankaran, S.; Azam, S.H. Early detection of basal stem rot disease (Ganoderma) in oil palms based on hyperspectral reflectance data using pattern recognition algorithms. Int. J. Remote Sens. 2014, 35, 3427–3439. [Google Scholar] [CrossRef]
- Singh, B.K.; Singh, R.P.; Tiwari, P.; Kumar, N. Climate Based Factor Analysis and Epidemiology Prediction for Potato Late Blight Using Machine Learning Approaches. In Proceedings of the 2019 Women Institute of Technology Conference on Electrical and Computer Engineering (WITCON ECE), Dehradun, India, 22–23 November 2019. [Google Scholar] [CrossRef]
- Saha, M.; Chakraborty, A.; Bhattacharya, K. Aerobiology, epidemiology and disease forecasting of false smut disease of rice in West Bengal, India. Aerobiologia 2020, 36, 299–304. [Google Scholar] [CrossRef]
- Kodaty, S.C.; Halavath, B. A New Approach for Paddy Leaf Blast Disease Prediction Using Logistic Regression. In Advances in Information Communication Technology and Computing; Springer: Singapore, 2020; pp. 533–542. [Google Scholar] [CrossRef]
- Shi, M.W. Based on time series and RBF network plant disease forecasting. Procedia Eng. 2011, 15, 2384–2387. [Google Scholar] [CrossRef] [Green Version]
- Mahlein, A.K.; Kuska, M.T.; Behmann, J.; Polder, G.; Walter, A. Hyperspectral sensors and imaging technologies in phytopathology: State of the art. Annu. Rev. Phytopathol. 2018, 56, 535–558. [Google Scholar] [CrossRef]
- Rwanga, S.S.; Ndambuki, J.M. Accuracy assessment of land use/land cover classification using remote sensing and GIS. Int. J. Geosci. 2017, 8, 611. [Google Scholar] [CrossRef] [Green Version]
- Barbedo, J.G.A. Plant disease identification from individual lesions and spots using deep learning. Biosyst. Eng. 2019, 180, 96–107. [Google Scholar] [CrossRef]
- Rowlandson, T.; Gleason, M.; Sentelhas, P.; Gillespie, T.; Thomas, C.; Hornbuckle, B. Reconsidering leaf wetness duration determination for plant disease management. Plant Dis. 2015, 99, 310–319. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Plant/Crop | Diseases | Observed Features | Models/Algorithms | Metrics | Predicted Output |
|---|---|---|---|---|---|---|
| [74] | Barley | Drought stress | Hyperspectral images | SVM | Acc, Confusion Matrix | Drought stress |
| [75] | Cherry | Monilinia laxa, Coccomyces hiemalis | Min. temperature, max. temperature, mean temperature, mean humidity, RA, wind speed | LDA, QDA, PLD, CCT | Acc | Disease occurrence |
| [70] | Citrus | Gummosis | Temperature, humidity, RA, soil moisture, soil temperature, LAI, chlorophyll | SVR, MLR | Acc, RMSE, R2 | Disease severity |
| [53] | Coffee | Cercospora, Rust | Min. temperature, max. temperature, RA, humidity, number of days with rainfall ≥1 mm and <9 mm, Number of days with rainfall ≥10 mm, number of days with relative humidity ≥90%, number of days with relative humidity ≥80% | MLR, KNN, RF, MLP | Acc, Willmott’s ‘d’, RMSE, Prec, R2 adj | Disease severity (%) |
| [76] | Coffee | Cercospora, Rust | monthly information of the incidence of the coffee rust, a daily summary of temperature, humidity, wind speed, solar radiation and amount of RA registered every 30 min. | BN, Naive Bayes, DT | Confusion Matrix, Error Rates | Disease incidence (three classes) |
| [72] | Cucumber | Downy mildew, leaf spot, anthracnose | 13 variables, divided into soil data, weather data, disease data | Wavelet Transformation, SVM | Prec | Disease occurrence (%) |
| [42] | Cotton | Bollworm, Whitefly, Jassid, Leaf blight | Max. temperature, min. temperature, humidity, RA, wind speed, sunshine hour, evaporation | LSTM | Acc, AUC, F1-score | Pest and disease occurrence |
| [39] | Grape | Downy mildew, powdery mildew, anthracnose | Max. temperature, min. temperature, pressure, humidity, RA, visibility medium, wind speed, max. wind speed | RM for crop disease forecasting. ANN with K-NN for weather forecasting | N/A | Disease outbreaks |
| [44] | Grape | Bacterial leaf spot, powdery mildew, downy mildew, anthracnose, bacterial cancer, rust | Temperature, humidity, leaf wetness | HMM | Acc, Prec, Rec, F-Measure | Disease occurrence |
| [77] | Grape | Downy mildew | Date of disease onset and/or average monthly temperature and RA | Linear models, Regularized Regression models, Gradient Boosting, RF | AUC | High disease severity and incidence |
| [71] | Grape | Powdery mildew | Environmental (weather, climate), pathogenic (development stages), and host (crop cultivar-specific susceptibility) factors | BN | MAE, RMSE | Disease risk |
| [43] | Mango | Thrips | Max. temperature, min temperature, mean temperature, humidity | RM | MAE, RMSE, MSE | Attack value ranging from 0.9 to 0.3 for each day |
| [54] | Mango | Anthracnose | Spectral analysis | RF, SVM | Acc | Healthy, asymptomatic, diseased |
| [69] | Orange | Black spot, greening, melanosa, greasy spot, scab, Alternaria brown spot, canker | Image of orange, temperature, rainfall, humidity | Deep Learning neural network with K-means | Acc | Disease name |
| [78] | Olive, grape | Downy mildew, powdery mildew, peacock spot, anthracnose | Temperature, humidity, accumulated heat, degree-days | RF | Acc | Disease occurrence |
| [79] | Olive | Verticillium wilt | Hyperspectral and thermal imagery | LDA, SVM | Acc, Kappa | Disease severity (scale from 1 to 4) |
| [80] | Oil palm | Ganoderma | VIS-NIR spectroscopy | LDA, KNN, QDA, NB | Acc, Analysis of Variance (ANOVA) | Disease severity |
| [63] | Oil palm | Ganoderma | Spectral analysis | ANN | Acc | Disease severity |
| [3] | Potato | Late Blight | Temperature, humidity, RA, wind speed, solar radiation | SVM | Acc, Prec, Rec, F1-score | Disease severity (healthy, low, medium, high) |
| [20] | Potato | Late Blight | Temperature, humidity, Blight Units | ANN, SVM | Acc, Prec, Rec, F1-score | Disease severity (high, medium, low) |
| [38] | Potato | Late blight | Multispectral images | MLP, CNN, RF, SVR | MAE, RMSE, R2 | Disease severity |
| [45] | Potato | Late Blight | Temperature, humidity | ANN | Acc, Prec, Rec, Confusion Matrix | Disease severity (high, medium, low) |
| [50] | Potato | Late blight | Max. temperature, min. temperature, max. humidity, min. humidity, RA, crop data | ANN | Prec, Rec, Confusion Matrix, ROC | Disease did not occur, disease occurred with low severity, disease occurred with high severity |
| [47] | Potato | Late blight | 13 types of climatic variables | SVR, Statistical Method | Acc | First date of occurrence |
| [41] | Potato | Late Blight | Max. temperature, min. temperature, humidity, RA, wind speed | Stepwise Regression Analysis | Acc, RMSE, R2, R2 adj, C(p) | Disease severity (%) |
| [51] | Potato | Late Blight | Max. temperature, min. temperature, RA, humidity | ELM | Confusion Matrix, ROC | No occurrence of disease (%), severity between 1–50 (%), severity between 51–100 (%) |
| [81] | Potato | Late Blight | Max. temperature, min. temperature, max. humidity, min. humidity, RA, Number of Rain days | ELM, SVM | Acc, Confusion Matrix, ROC | Class 1: <3%, Class 2: 4–10%, Class 3: 11–30%, Class 4: 31–60%, Class 5: >60% |
| [82] | Rice | False Smut | Atmospheric spore concentration | RM | R2 | Disease severity (from 0 to 9) |
| [48] | Rice | Blast | Mean temperature, humidity, sunshine hours | LSTM | Acc, F1-score | Resistance (0–3), moderate resistance (4–6), susceptibility (7–9), moderate resistance (4–6), susceptibility (7–9) |
| [46] | Rice | Blast | Evaporation, max. temperature, min. temperature, RA, solar radiation, brightness, wind speed, humidity | ANN, SVM | Acc, MSE, R2 | Disease occurrence, disease severity |
| [62] | Rice | Blast | Temperature, humidity, leaf wetness, previous 1, 3, 7 days of the daily max. and min. for air temperature, humidity and leaf wetness | M5Rules, LSTM | R, R, MAE, AUC | Disease Severity index (scale from 1 to 6) |
| [83] | Rice | Blast | RA, temperature, weed, nitrogen, seed resistance, crop phase | LR | F-test | Disease occurrence |
| [59] | Rice | Blast | Temperature, humidity, RA, wind speed | ANN | Acc | Disease risk |
| [55] | Rice | Blast | 17 variables: six atmospheric features, seven micro-climate features, four additional derived features | Auto-Sklearn Alghorithms, ANN | Acc, Rec, Prec | Disease occurrence |
| [64] | Strawberry | Anthracnose | Hyperspectral images | Spectral Angle Mapper (SAM), Stepwise Discriminant Analysis (SDA), Correlation Measure (CM) | Acc, confusion matrix | Disease stages |
| [65] | Sugar beet | Cercospora, rust, powdery mildew | Volatile organic compounds (VOCs), temperature, humidity | SVM | Acc, Rec, Confusion Matrix | Disease severity (%) |
| [66] | Tobacco | Tobacco mosaic virus | Hyperspectral images | Partial Least Squares-Discrimination Analysis (PLS-DA), RF, SVM, BPNN, ELM, Least Squares Support Vector Machine (LS-SVM) | Acc | Disease stages (healthy, 2DPI, 4DPI, 6DPI) |
| [52] | Tomato | Powdery mildew, spider mites | Volatile organic compounds (VOCs), temperature, humidity | RBF, LVQ, MLP | Acc | Healthy crop, diseased crop |
| [56] | Tomato | Powdery mildew | Temperature, humidity, leaf wetness, wind speed, global radiations | Hybrid of Support Vector Machine (SVM), LR | Acc, Confusion Matrix, F1-Score, AUC, ROC | Conducive classes, not conducive classes |
| [57] | Tomato | Powdery mildew | Temperature, humidity, leaf wetness, wind speed, global radiations | ELM | Accuracy, confusion matrix, F1-Score, AUC, ROC | Conducive class, not conducive class |
| [84] | Wheat | Sharp eyespot | - | GM(1,1), ANN | Acc, Prec, MSE | Disease occurrence |
| [40] | Wheat | Stripe rust | Mean temperature, mean RA | SVM, Regression Analysis | Acc | Five classes (0–5) |
| [67] | Wheat | Powdery mildew | RA, temperature, sun radiation, humidity, , , , TVI, SAVI, DSWI, SIWSI | LR | Statistical Measurement | Disease occurrence |
| [68] | Wheat | Powdery Mildew | MODIS images, NDVI, TEMP, RA, LST | Decision Tree | Acc | Four infection severities (healthy, mild, moderate and severe) |
| [73] | Wheat | Yellow Rust | Mean temperature, mean humidity, RA and sunshine duration, growth period | BN | Acc | Disease occurrence |
| [37] | Wheat | Powdery mildew | Optical remote sensing image, thermal remote sensing image | LR | Pearson correlation analysis, Acc | Disease occurrence |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fenu, G.; Malloci, F.M. Forecasting Plant and Crop Disease: An Explorative Study on Current Algorithms. Big Data Cogn. Comput. 2021, 5, 2. https://doi.org/10.3390/bdcc5010002
Fenu G, Malloci FM. Forecasting Plant and Crop Disease: An Explorative Study on Current Algorithms. Big Data and Cognitive Computing. 2021; 5(1):2. https://doi.org/10.3390/bdcc5010002
Chicago/Turabian StyleFenu, Gianni, and Francesca Maridina Malloci. 2021. "Forecasting Plant and Crop Disease: An Explorative Study on Current Algorithms" Big Data and Cognitive Computing 5, no. 1: 2. https://doi.org/10.3390/bdcc5010002
APA StyleFenu, G., & Malloci, F. M. (2021). Forecasting Plant and Crop Disease: An Explorative Study on Current Algorithms. Big Data and Cognitive Computing, 5(1), 2. https://doi.org/10.3390/bdcc5010002