The Potential of the SP System in Machine Learning and Data Analysis for Image Processing


Abstract
:
{kind=link}
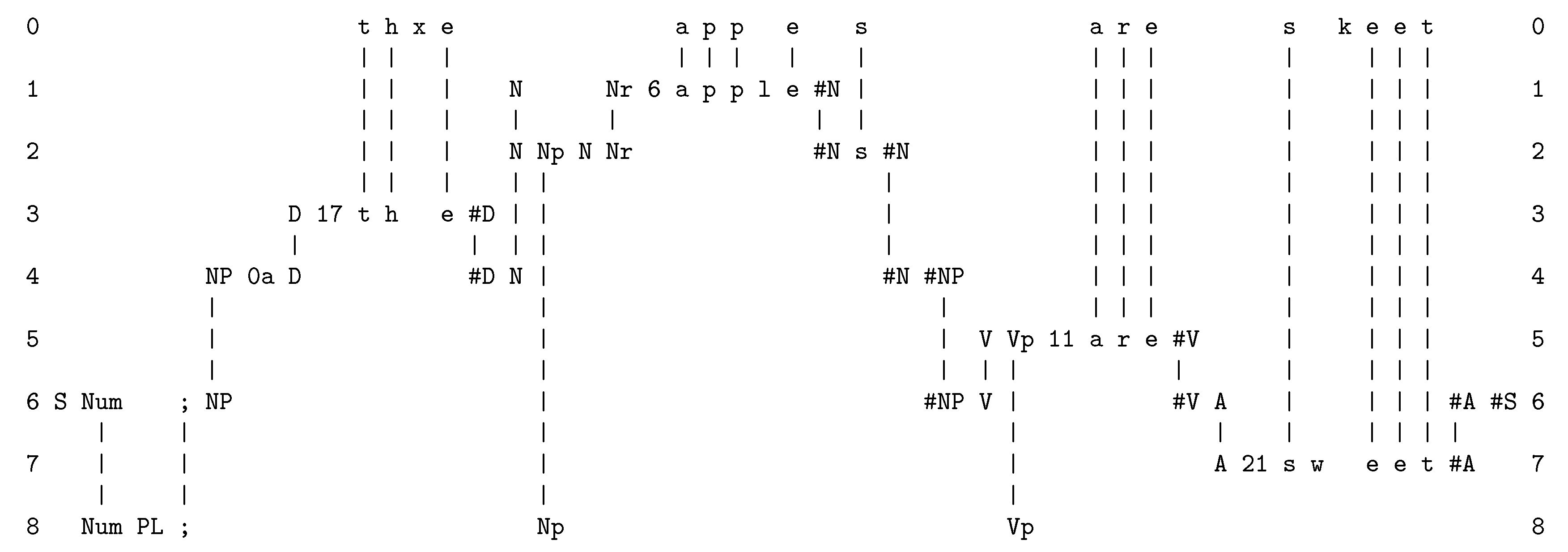{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
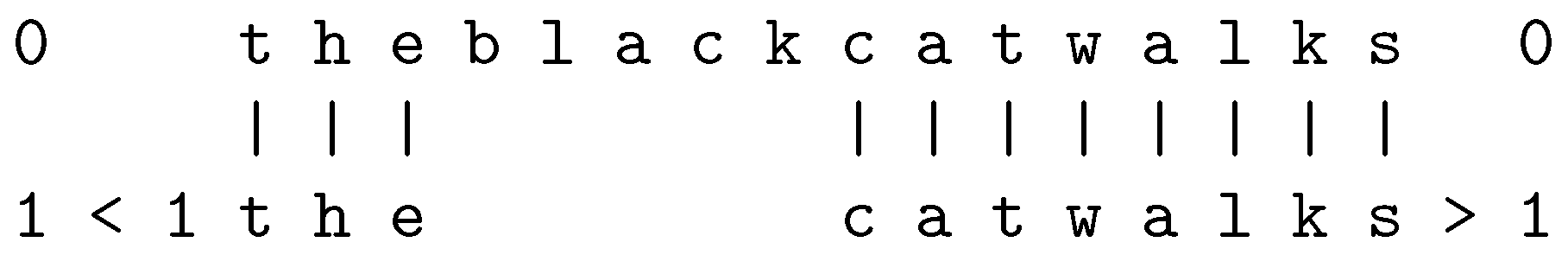{kind=link}
{kind=link}
1. Introduction
- It is widely acknowledged that, while computer-based techniques for image processing have advantages compared with people in that they do not suffer from boredom, they do not get drunk, and they do not fall asleep, they fall far short of people in terms of the subtlety and intelligence that can be applied.
- There are now many studies that demonstrate that, although deep neural networks (DNNs) can be quite good at recognising things, they can make surprisingly silly mistakes (see, for example, [6,7,8]). Mistakes like these can be a serious problem when there is a risk of death or injury to people, or when expensive equipment may be damaged or destroyed.
- It is sometimes simpler and more effective for recognition tasks to be done by human “clickworkers”, earning money for skills which currently exceed what computers can do (see, for example, item 24 in https://tinyurl.com/y6yfrkqp, accessed on 22 February 2021).
- Some websites aim to exclude web-crawling bots by setting recognition tasks which require human knowledge and intelligence. Examples include such tasks as identifying all the pictures within a set which show all or part of a shop front, or of a car, and so on.
- In a similar way, “captcha” tasks—such as the recognition of highly irregular and obscured letters and numbers—are used with the aim of separating humans from bots.
Abbreviations
- Artificial intelligence: AI.
- Information compression: IC.
- SP computer model: SPCM.
- SP-multiple-alignment: SPMA.
- The SP system is intended, in itself, to combine simplicity with descriptive and explanatory power.
- Additionally, because the SP system works entirely by compression of information, which may be seen as a process that creates structures that combine conceptual simplicity with descriptive and explanatory power.
2. Preamble
2.1. Introduction to the SP System
2.2. The SP Computer Model
2.3. The SP System as a Foundation for the Development of Artificial General Intelligence
- There is good evidence, described in [12], that the SP system may help to solve 20 significant problems in AI research. There appears to be no other system with this potential.
- Although the SP system is conceptually simple, it demonstrates strengths and potential across several different aspects of intelligence, as described in [9,10]. Those strengths and that potential are summarised in Appendix A.6.
3. Pattern Recognition and Scene Analysis
4. Robust Analysis in the Face of Errors
5. Seeing Things That Are Not Objectively There
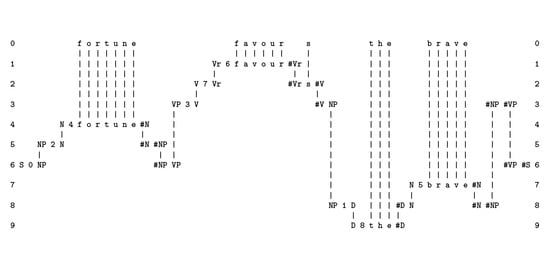
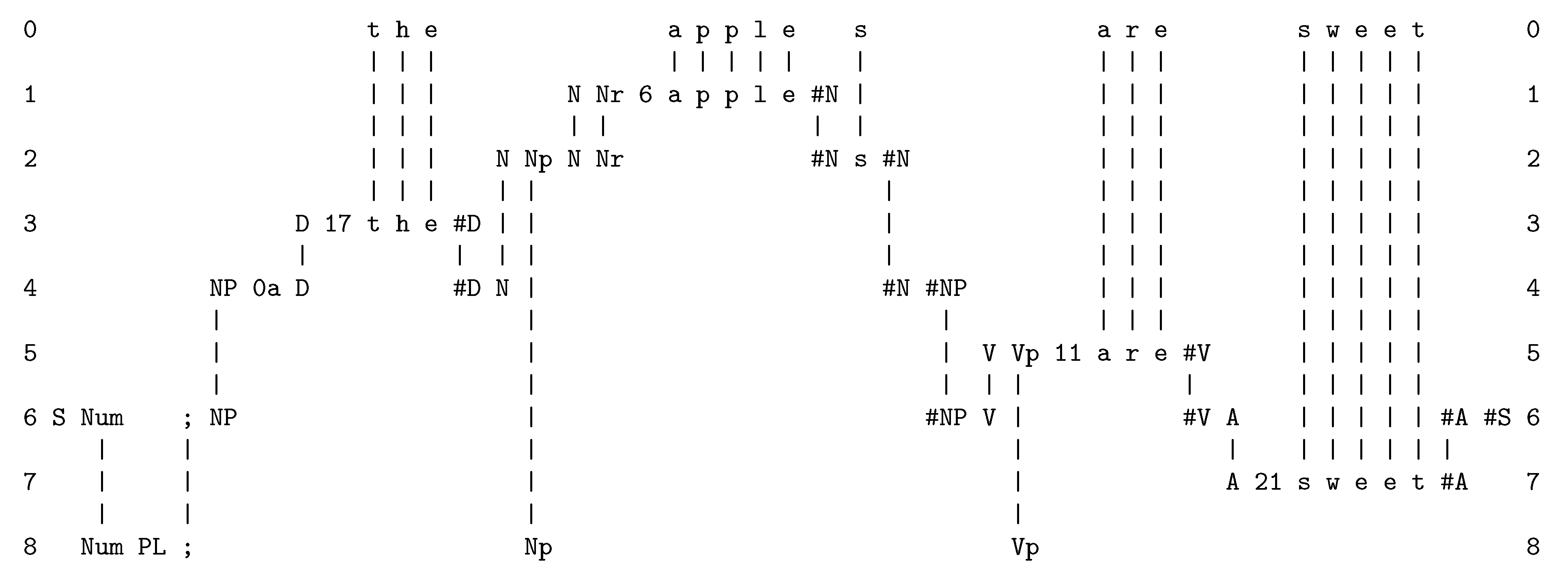
- Interpolation via parsing. In Figure A2, the new SP-pattern in row 0 does not contain anything to mark the boundary between any pair of neighbouring words. However, the process of parsing has the effect of splitting up the sentence into its constituent words, and it also marks the morpheme boundary between “a p p l e” and “s”.
- Interpolation via error correction. It appears that, in the same way that the SPCM has interpolated the missing “l” in the sequence “a p p e s” within the new SP-pattern; as described in Section 4, the human brain interpolates part of the edge of the upper leaf in Marr’s photo, although in a literal interpretation of the photo, that part of the edge is missing.
6. Recognition at Multiple Levels of Abstraction
7. Recognition in Terms of Part-Whole Categories, and Hybrid Recognition
8. Learning and Perception of Three-Dimensional Structures
9. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Outline of the SP System

Appendix A.1. SP-Patterns and SP-Symbols
Appendix A.2. Biology, Psychology, and Compression of Information
Appendix A.3. IC via the Matching and Unification of Patterns
Appendix A.4. IC via SP-Multiple-Alignment

- At the beginning of processing, the SPCM has a store of old SP-patterns including those shown in rows 1 to 8 (one SP-pattern per row), and many others. When the SPCM is more fully developed, those old SP-patterns would have been learned from raw data as outlined in Appendix A.5, but for now they are supplied to the program by the user.
- The next step is to read in the new SP-pattern, “t h e a p p l e s a r e s w e e t”.
- Then the program searches for “good” matches between SP-patterns, where “good” means matches that yield relatively high levels of compression of the new SP-pattern in terms of old SP-patterns with which it has been unified. The details of relevant calculations are given in ([10], Section 4.1) and ([9], Section 3.5).
- As can be seen in the figure, matches are identified at early stages between (parts of) the new SP-pattern and (parts of) the old SP-patterns “D 17 t h e #D”, “N Nr 6 a p p l e #N”, “V Vp 11 a r e #V”, and “A 21 s w e e t #A”.
- Each of these matches may be seen as a partial SPMA. For example, the match between “t h e” in the new SP-pattern and the old SP-pattern “D 17 t h e #D” may be seen as an SPMA between the SP-pattern in row 0 and the SP-pattern in row 3.
- After unification of the matching symbols, each such SPMA may be seen as a single SP-pattern. So the unification of “t h e” with “D 17 t h e #D” yields the unified SP-pattern “D 17 t h e #D”, with exactly the same sequence of SP-symbols as the second of the two SP-patterns from which it was derived.
- As processing proceeds, similar pair-wise matches and unifications eventually lead to the creation of SP-multiple-alignments like that shown in Figure A2. At every stage, all the SP-multiple-alignments that have been created are evaluated in terms of IC, and then the best SP-multiple-alignments are retained and the remainder are discarded. In this case, the overall “winner” is the SPMA shown in Figure A2.
- This process of searching for good SP-multiple-alignments in stages, with selection of good partial solutions at each stage, is an example of heuristic search. This kind of search is necessary because there are too many possibilities for anything useful to be achieved by exhaustive search. By contrast, heuristic search can normally deliver results that are reasonably good within a reasonable time, but it cannot guarantee that the best possible solution has been found.
Appendix A.5. IC via Unsupervised Learning
“Unsupervised learning represents one of the most promising avenues for progress in AI. [...] However, it is also one of the most difficult challenges facing the field. A breakthrough that allowed machines to efficiently learn in a truly unsupervised way would likely be considered one of the biggest events in AI so far, and an important waypoint on the road to AGI.”Martin Ford ([23], pp. 11–12), emphasis added.
Appendix A.5.1. Learning with a Tabula Rasa
“We can imagine systems that can learn by themselves without the need for huge volumes of labeled training data.”Martin Ford ([23], p. 12).
“... the first time you train a convolutional network you train it with thousands, possibly even millions of images of various categories.”Yann LeCun ([23], p. 124).
Appendix A.5.2. Learning with Previously-Stored Knowledge
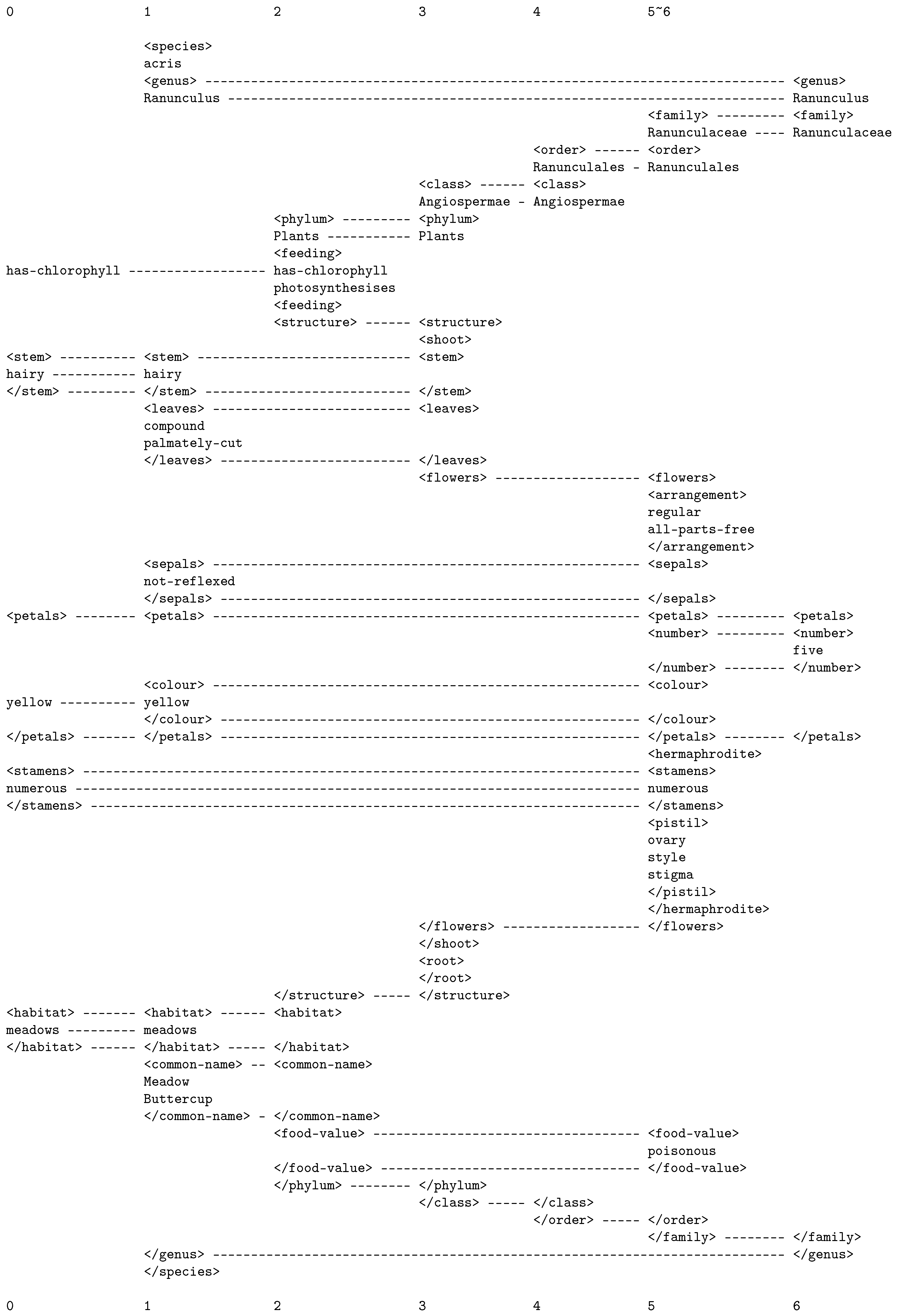
- The new information is interpreted via SPMA in terms of the old information, as described in Appendix A.4. The example illustrated in Figure A2 is of a purely syntactic analysis, but with the SPCM, semantic analysis is feasible too (Section 5.7 in [9]).
- Partial matches between new and old SP-patterns may lead to the creation of additional old SP-patterns, as outlined next.

Appendix A.5.3. Unsupervised Learning of SP-Grammars
Appendix A.5.4. Future Developments
Appendix A.5.5. The DONSVIC Principle
Appendix A.6. Strengths and Potential of the SP System in AI-Related Functions
Appendix A.7. SP-Neural
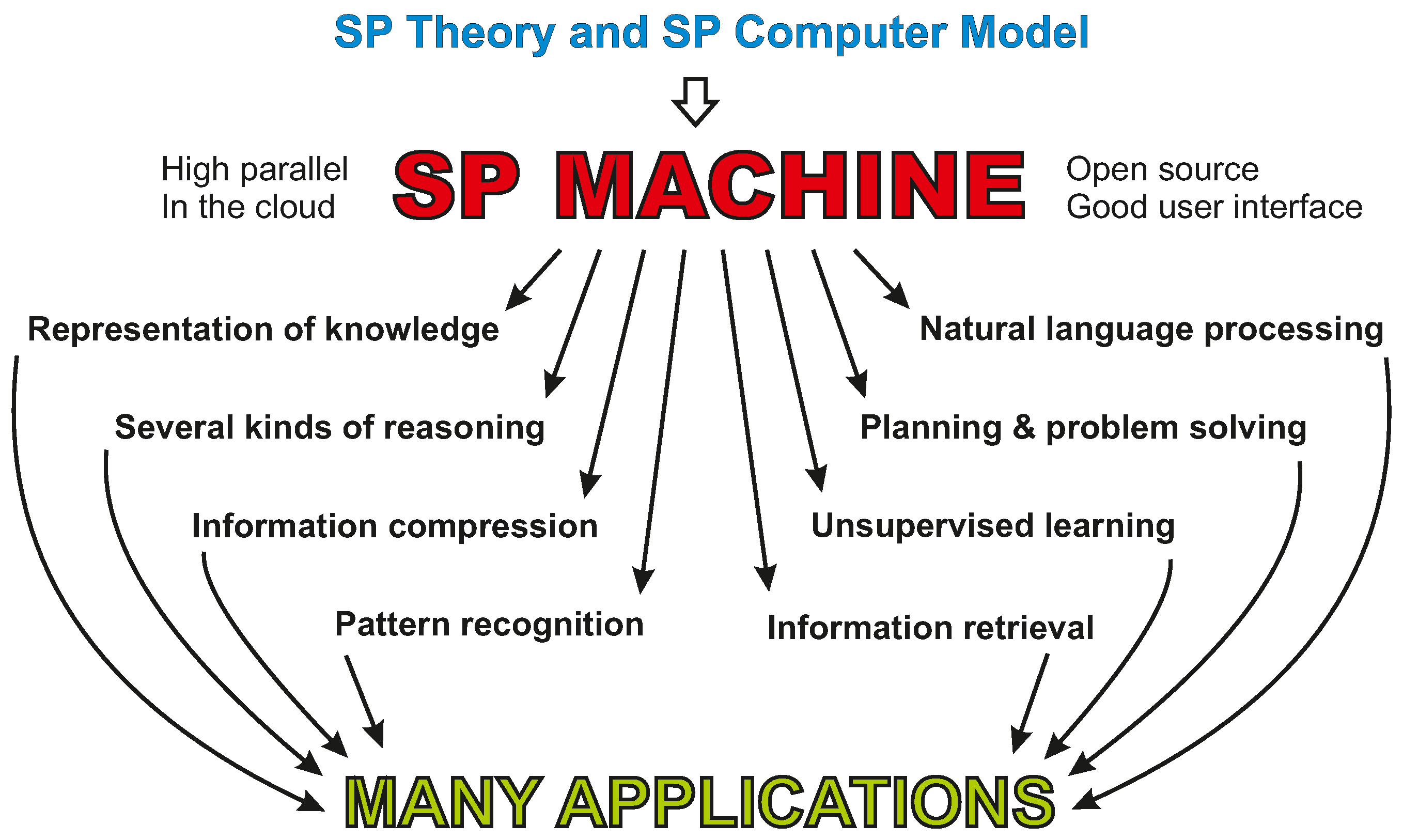
Appendix A.8. Development of an “SP Machine”

References
- Hayani, S.; Benaddy, M.; Meslouhi, O.E.; Kardouchi, M. Arab sign language recognition with convolutional neural networks. In Proceedings of the International Conference of Computer Science and Renewable Energies, Agadir, Morocco, 22–24 July 2019; pp. 1–4. [Google Scholar]
- Akhloufi, M.; Guyon, Y.; Ibarra-Castanedo, C.; Bendada, A.H. Three-dimensional thermography for nondestructive testing and evaluation. Quant. Infrared Thermogr. J. 2017, 14, 79–106. [Google Scholar] [CrossRef]
- Elgarrai, Z.; Elmeslouhi, O.; Kardouchi, M.; Allali, H.; Selouani, S.-A. Offline face recognition system based on gabor-fisher descriptors and hidden markov models. Int. J. Interact. Multimed. Artif. Intell. 2016, 4, 11–14. [Google Scholar] [CrossRef] [Green Version]
- Wadham-Gagnon, M.; Bolduc, D.; Akhloufi, M.; Petersen, J.; Friedrich, H.; Camion, A. Monitoring icing events with remote cameras and image analysis. In Proceedings of the International Wind Energy Conference in Winterwind, Barcelona, Spain, 10–13 March 2014. [Google Scholar]
- Yoon, S.; Jain, A.K. Longitudinal study of fingerprint recognition. Proc. Natl. Acad. Sci. USA 2015, 112, 8555–8560. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heaven, D. Why deep-learning AIs are so easy to fool. Nature 2019, 574, 163–166. [Google Scholar] [CrossRef]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2014, arXiv:1312.6199v4. [Google Scholar]
- Wolff, J.G. Unifying Computing and Cognition: The SP Theory and Its Applications; CognitionResearch.org: Menai Bridge, UK, 2006. [Google Scholar]
- Wolff, J.G. The SP Theory of Intelligence: An overview. Information 2013, 4, 283–341. [Google Scholar] [CrossRef] [Green Version]
- Wolff, J.G. Information compression as a unifying principle in human learning, perception, and cognition. Complexity 2019, 38. [Google Scholar] [CrossRef]
- Wolff, J.G. Problems in AI research and how the SP System may help to solve them. arXiv 2009, arXiv:2009.09079. [Google Scholar]
- Jeong, C.Y.; Yang, S.H.; Moon, K.D. Horizon detection in maritime images using scene parsing network. Electron. Lett. 2018, 54, 760–762. [Google Scholar] [CrossRef]
- Shi, Q.Y.; Fu, K.-S. Parsing and translation of (attributed) expansive graph languages for scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1983. [Google Scholar] [CrossRef] [PubMed]
- Zellers, R.; Yatskar, M.; Thomson, S.; Choi, Y. Neural motifs: Scene graph parsing with global context. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5831–5840. [Google Scholar]
- Wolff, J.G. Big data and the SP Theory of Intelligence. IEEE Access 2014, 2, 301–315. [Google Scholar] [CrossRef] [Green Version]
- Marr, D. Vision: A Computational Investigation into the Human Representation and Processing of Visual Information; W.H. Freeman: San Francisco, CA, USA, 1982. [Google Scholar]
- Wolff, J.G. Application of the SP Theory of Intelligence to the understanding of natural vision and the development of computer vision. SpringerPlus 2014, 3, 552–570. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Palade, V.; Wolff, J.G. A roadmap for the development of the ‘SP Machine’ for artificial intelligence. Comput. J. 2019, 62, 1584–1604. [Google Scholar] [CrossRef]
- Attneave, F. Some informational aspects of visual perception. Psychol. Rev. 1954, 61, 183–193. [Google Scholar] [CrossRef] [PubMed]
- Barlow, H.B. Sensory mechanisms, the reduction of redundancy, and intelligence. In The Mechanisation of Thought Processes; HMSO, Ed.; Her Majesty’s Stationery Office: London, UK, 1959; pp. 535–559. [Google Scholar]
- Barlow, H.B. Trigger features, adaptation and economy of impulses. In Information Processes in the Nervous System; Leibovic, K.N., Ed.; Springer: New York, NY, USA, 1969; pp. 209–230. [Google Scholar]
- Ford, M. Architects of Intelligence: The Truth About AI From the People Building It, Kindle ed.; Packt Publishing: Birmingham, UK, 2018. [Google Scholar]
- Wolff, J.G. Learning syntax and meanings through optimization and distributional analysis. In Categories and Processes in Language Acquisition; Levy, Y., Schlesinger, I.M., Braine, M.D.S., Eds.; Lawrence Erlbaum: Hillsdale, NJ, USA, 1988; pp. 179–215. [Google Scholar]
- Wolff, J.G. The SP Theory of Intelligence: Its distinctive features and advantages. IEEE Access 2016, 4, 216–246. [Google Scholar] [CrossRef]
- Wolff, J.G. Information compression, multiple alignment, and the representation and processing of knowledge in the brain. Front. Psychol. 2016, 7, 1584. [Google Scholar] [CrossRef] [PubMed] [Green Version]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wolff, J.G. The Potential of the SP System in Machine Learning and Data Analysis for Image Processing. Big Data Cogn. Comput. 2021, 5, 7. https://doi.org/10.3390/bdcc5010007
Wolff JG. The Potential of the SP System in Machine Learning and Data Analysis for Image Processing. Big Data and Cognitive Computing. 2021; 5(1):7. https://doi.org/10.3390/bdcc5010007
Chicago/Turabian StyleWolff, J. Gerard. 2021. "The Potential of the SP System in Machine Learning and Data Analysis for Image Processing" Big Data and Cognitive Computing 5, no. 1: 7. https://doi.org/10.3390/bdcc5010007
APA StyleWolff, J. G. (2021). The Potential of the SP System in Machine Learning and Data Analysis for Image Processing. Big Data and Cognitive Computing, 5(1), 7. https://doi.org/10.3390/bdcc5010007