
Without Data Quality, There Is No Data Migration



Abstract
:1. Introduction
2. Concept of Data Migration
2.1. Definition of Data Migration
2.2. Requirements
2.3. Goals of Data Migration
- To analyze and clean up the existing data and documents (by the project and the core organization),
- Correct automated, semi-automated, and manual migrations of the relevant data and documents, including linking the business objects with the documents,
- Understand the migration and validate the results obtained. The data protection requirements must be observed.
2.4. Types of Data Migration
2.5. Strategies of Data Migration
- The new system offers full functionality but is only available to a limited group of users. New and old systems run in parallel. The group of users is expanded with each level. The problem here is the parallel use of the old and the new system and, in particular, the maintenance of data consistency.
- Another type of introduction is the provision of partial functions for all users. The users work in parallel on new and old systems. With each step, the functionality of the new system is expanded until the old system has been completely replaced.
3. Data Quality and Its Impact on Data Migration
- The consolidation and quality improvement takes place before the project of introducing new software. The separation of these two projects is an important success factor.
- As part of the analysis of the existing data landscape, requirements for the new system are identified, which flow into the selection or the initial adjustment of this system.
- Data consolidation and data quality improvement is a project with some factors that cannot be precisely planned in terms of time. By separating the process from the actual migration project, it is easier to plan and be more successful.
- Since the project pressure of the implementation process is largely eliminated, the data can be better prepared with more time and brought to a significantly higher level.
- Data quality methods and tools rank the errors with the greatest impact on the overall result first. Therefore, the time available for error corrections can be used more efficiently.
- The time span between replacing the old documentation and using the new system is optimized. The target system is filled from a data source. Errors due to different versions and errors in links were transparent and cleared up in advance.
- Direct and indirect costs are saved through good data quality in data migration projects (e.g., waste of budgets, costs due to wrong decisions and lost sales, etc.).
- Data collection: Data collection is often the greatest source of errors in terms of data quality. This includes the incorrect use of input masks both by internal employees and by customers who enter information in incorrect input areas (e.g., confusion of first and last name fields). Typing errors, phonetically similar sounds (e.g., ai and ei in Maier or Meier) or inadequate inquiries from service employees are also potential sources of error. Many of these errors can only occur due to a poor design or poor mandatory field protection or plausibility checks in the input masks. However, the import of inadequate external data such as purchased address or customer data can also lead to deterioration in data quality.
- Processes: Processes become the cause of poor data quality if they are incorrect or incomplete (e.g., incorrect processing of existing data or missing check routines).
- Data architecture: Data architecture describes the data processing technologies (e.g., various application software) and the data flow between these technologies. Many of these programs require their own, special data representation, such as formatting or the order of the input and output arguments. Therefore, a conversion of the data is often necessary, which can lead to inconsistencies and thus poor data quality.
- Data definitions: In order for large companies to work effectively, there must be a common understanding of frequently used terms. For example, there is often no uniform scheme for calculating sales or different views as to which data are used. These heterogeneous interpretations can lead to inconsistent data descriptions, table definitions, and field formats.
- Use of data: Errors in application programs can give a user the impression of poor data quality, although the underlying operational system provides almost perfect data in terms of content. Such an impression can occur on the one hand through incorrect interpretation of the data by the user or the creator of the application program from the source system. A supposed correction resulting from this could, contrary to the original intention, introduce new errors into the information system. Apart from an incorrect interpretation, ready-made rules should be created and adhered to for the correction process, such as that data corrections are always made in the source systems and not in the application programs.
- Data expiration: This factor occurs automatically in some areas, as certain data can lose their validity after a certain period. This mainly includes address and telephone data, but also bank details, price lists, and many other areas are affected by data deterioration, which obviously also limits the data quality.
4. Relationship between Data Quality and Data Migration
- Have you already worked on a data migration project? Or are you currently on a data migration project?
- How important is the data quality in the context of the data migration project?
- Was it a goal to improve and increase the data quality in the course of the data migration?
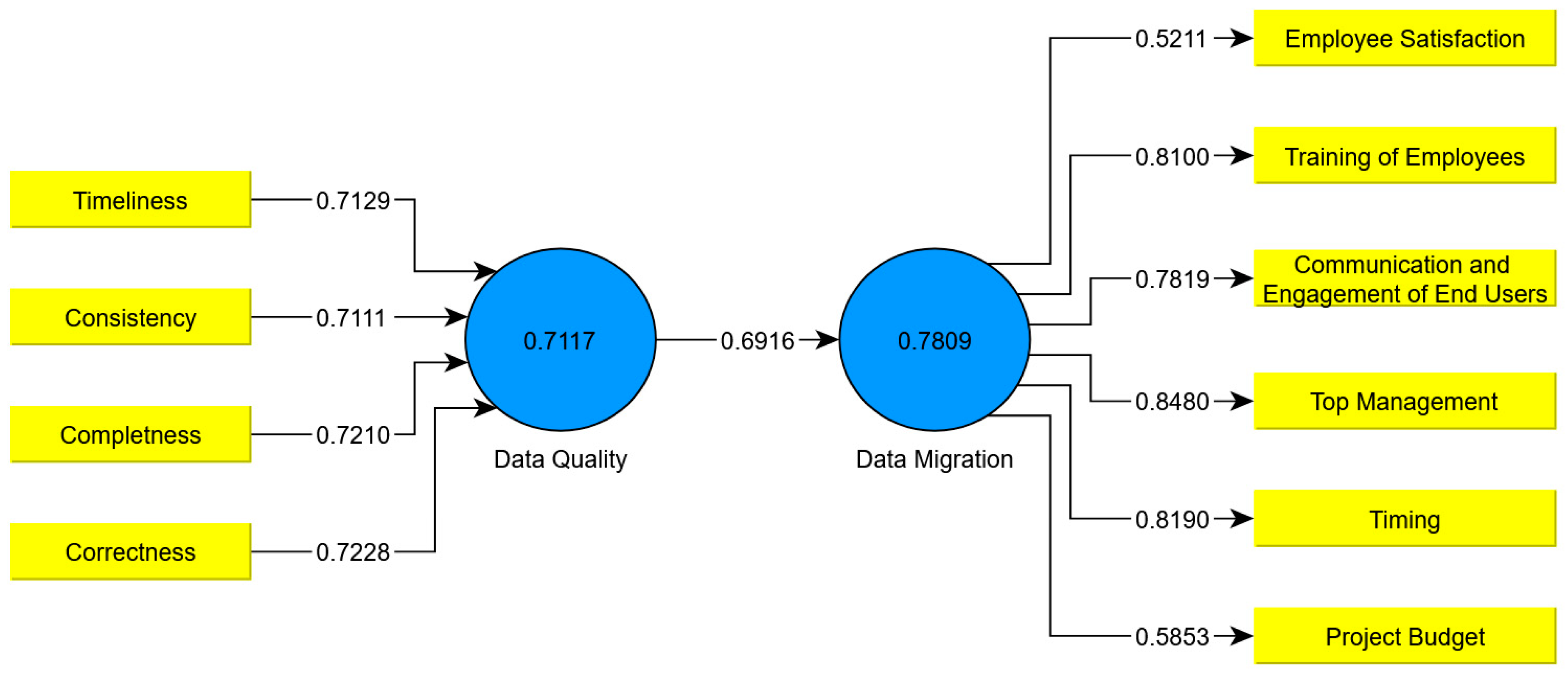
- Which data quality criteria [correctness, completeness, consistency and timeliness] are taken into account in the data migration project? How do you rate the degree of fulfillment of the following criteria in relation to the quality of the data at the time or after the data migration project is completed?
- Which data quality criteria do you take into account as part of the data migration project in order to control and improve the quality?
- What methods and tools do you use in the data migration project to clean up the dirty data?
- How do you rate the degree of fulfillment of the following success criteria [project budget, timing, top management, communication and involvement with the end user, training of employees, and employee satisfaction] with regard to the data migration project? Which success criteria do you also consider in the context of the data migration project?
- Correctness: The data must match the reality.
- Completeness: Attributes must contain all the necessary data.
- Consistency: A data record must not have any contradictions in itself or with other data records.
- Timeliness: All data records must correspond to the current state of the depicted reality.
- A migration project always has a budget. The budget contains all the cost-effective resources necessary to achieve the goals.
- A migration project always has an end. It is often carried out under great time pressure.
- An efficient and successful migration can be difficult without the support of top management. Migration often changes processes and behavior. Top management must commit to change and be ready to take risks. If the decision to migrate to a new system is not made by top management, this is not very motivating for everyone involved. The complexity of exchanging a system is very high, and the advantages of exchanging only become apparent after its introduction.
- Open communication and involvement with the end user is an important factor right from the start, because the new system must be accepted in order to be successful. The decision to replace the old system may not be easy for everyone to understand. End users need to understand why the existing system is being replaced so there is no aversion to the new system. Therefore, the involvement of end users in the migration project is an important factor.
- In order for end users to be able to use the new software right from the start and to feel safe, it must be ensured that employees are trained in relation to the new system at an early stage.
- After the introduction of a new system, the satisfaction of the employees can be a criterion for the success of the migration project. The goal with a new system is to give employees a new system that makes their work easier.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jha, S.; Jha, M.; O’Brien, L.; Wells, M. Integrating legacy system into big data solutions: Time to make the change. In Proceedings of the Asia-Pacific World Congress on Computer Science and Engineering, Nadi, Fiji, 4–5 November 2014; pp. 1–10. [Google Scholar] [CrossRef]
- Jha, S.; Jha, M.; O’Brien, L.; Cowling, M.; Wells, M. Leveraging the Organisational Legacy: Understanding How Businesses Integrate Legacy Data into Their Big Data Plans. Big Data Cogn. Comput. 2020, 4, 15. [Google Scholar] [CrossRef]
- Matthes, F.; Schulz, C.; Haller, K. Testing & quality assurance in data migration projects. In Proceedings of the 27th IEEE International Conference on Software Maintenance (ICSM’11), Williamsburg, VA, USA, 25–30 September 2011; pp. 438–447. [Google Scholar]
- Azeroual, O.; Saake, G.; Abuosba, M. Data quality measures and data cleansing for research information systems. J. Digit. Inf. Manag. 2018, 16, 12–21. [Google Scholar]
- Verhulst, S.G.; Young, A. The Potential and Practice of Data Collaboratives for Migration. In Guide to Mobile Data Analytics in Refugee Scenarios; Salah, A., Pentland, A., Lepri, B., Letouzé, E., Eds.; Springer: Cham, Switzerland, 2019; pp. 465–476. [Google Scholar]
- Leloup, F. Migration, a complex phenomenon. Int. J. Anthropol. 1996, 11, 101–115. [Google Scholar] [CrossRef]
- Stahlknecht, P.; Hasenkamp, U. Einführung in die Wirtschaftsinformatik; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Meier, A.; Mercerat, J.; Muriset, A.; Untersinger, J.; Eckerlin, R.; Ferrara, F. Hierarchical to Relational Database Migration. IEEE Softw. 1994, 11, 21–27. [Google Scholar] [CrossRef]
- Meier, A. Providing Database Migration Tools—A Practicioner’s Approach. In Proceedings of the 21th International Conference on Very Large Data Bases (VLDB’95), Zürich, Switzerland, 11–15 September 1995; pp. 635–641. [Google Scholar]
- Sarmah, S.S. Data Migration. Sci. Technol. 2018, 8, 1–10. [Google Scholar]
- Khajeh-Hosseini, A.; Sommerville, I.; Bogaerts, J.; Teregowda, P. Decision Support Tools for Cloud Migration in the Enterprise. In Proceedings of the 2011 IEEE 4th International Conference on Cloud Computing, Washington, DC, USA, 4–9 July 2011; pp. 541–548. [Google Scholar] [CrossRef] [Green Version]
- McAdam, J. The concept of crisis migration. Forced Migr. Rev. 2014, 45, 10–11. [Google Scholar]
- Morris, J. Practical Data Migration, 3rd ed.; British Informatics Society Ltd.: Swindon, UK, 2006. [Google Scholar]
- Derr, E.; Bugiel, S.; Fahl, S.; Acar, Y.; Backes, M. Keep me Updated: An Empirical Study of Third-Party Library Updatability on Android. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS ‘17); Association for Computing Machinery: New York, NY, USA, 2017; pp. 2187–2200. [Google Scholar]
- Laranjeiro, N.; Soydemir, S.N.; Bernardino, J. A Survey on Data Quality: Classifying Poor Data. In Proceedings of the 21st IEEE Pacific Rim International Symposium on Dependable Computing, (PRDC 2015), Zhangjiajie, China, 18–20 November 2015; pp. 179–188. [Google Scholar]
- Morris, J. Practical Data Migration; BCS, The Chartered Institute: Swindon, UK, 2012; Available online: https://ws1.nbni.co.uk/fusion/v2.0/supplement/5d6e240d646eb18c10cb4e84.pdf (accessed on 17 May 2021).
- Karnitis, G.; Arnicans, G. Migration of Relational Database to Document-Oriented Database: Structure Denormalization and Data Transformation. In Proceedings of the 7th International Conference on Computational Intelligence, Communication Systems and Networks, Riga, Latvia, 3–5 June 2015; pp. 113–118. [Google Scholar] [CrossRef]
- Hudicka, J.R. An Overview of Data Migration Methodology. 1998. Available online: https://dulcian.com/articles/overview_data_migration_methodology.htm (accessed on 22 March 2021).
- Latt, W.Z. Data Migration Process Strategies. Available online: https://onlineresource.ucsy.edu.mm/handle/123456789/1226 (accessed on 17 May 2021).
- Lin, C.Y. Migrating to Relational Systems: Problems, Methods, and Strategies. Contemp. Manag. Res. 2008, 4, 369–380. [Google Scholar] [CrossRef] [Green Version]
- English, L.P. Improving Data Warehouse and Business Information Quality: Methods for Reducing Costs and Increasing Profits; Wiley: New York, NY, USA, 1999. [Google Scholar]
- Würthele, V. Datenqualitätsmetrik für Informationsprozesse: Datenqualitätsmanagement Mittels Ganzheitlicher Messung der Datenqualität; ETH Zurich: Zurich, Switzerland, 2003. [Google Scholar]
- Apel, D.; Behme, W.; Eberlein, R.; Merighi, C. Datenqualität Erfolgreich Steuern: Praxislösungen für Business-Intelligence-Projekte, 3rd Revised and Extended Edition; dpunkt.verlag: Heidelberg, Germany, 2015. [Google Scholar]
- Eppler, M.J. Managing Information Quality: Increasing the Value of Information in Knowledge-Intensive Products and Processes; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Haller, K. Towards the industrialization of data migration: Concepts and patterns for standard software implementation projects. In Proceedings of the 21st International Conference on Advanced Information Systems Engineering (CAISE), Amsterdam, The Netherlands, 8–12 June 2009; pp. 63–78. [Google Scholar]
- Manjunath, T.N.; Hegadi, R.S.; Archana, R.A. A study on sampling techniques for data testing. Int. J. Comput. Sci. Commun. 2012, 3, 13–16. [Google Scholar]
- Paygude, P.; Devale, P.R. Automated data validation testing tool for data migration quality assurance. Int. J. Mod. Eng. Res. 2013, 3, 599–603. [Google Scholar]
- Clément, D.; Ben Hassine-Guetari, S.; Laboisse, B. Data Quality as a Key Success Factor for Migration Projects. In Proceedings of the 15th International Conference on Information Quality (ICIQ) 2010, Little Rock, AR, USA, 12–14 November 2010. [Google Scholar]
- Kreis, L. Datenqualität als kritischer Erfolgsfaktor bei Datenmigrationen. Bachelor’s Thesis, Zurich University of Applied Sciences, Zurich, Switzerland, 2017. [Google Scholar]
- Azeroual, O.; Saake, G.; Abuosba, M.; Schöpfel, J. Data Quality as a Critical Success Factor for User Acceptance of Research Information Systems. Data 2020, 5, 35. [Google Scholar] [CrossRef] [Green Version]
- Hoyle, R.H. The structural equation modeling approach: Basic concepts and fundamental issues. In Structural Equation Modeling: Concepts, Issues, and Applications; Hoyle, R.H., Ed.; Sage Publications, Inc.: Washington, DC, USA, 1995; pp. 1–15. Available online: https://psycnet.apa.org/record/1995-97753-001 (accessed on 17 May 2021).


{kind=link}
| Indicators | Cronbach Alpha | Factor Loading | Eigenvalues | (%) of Variance |
|---|---|---|---|---|
| Correctness | 0.9105 | 0.7228 | 6.997 | 36.751 |
| Completeness | 0.9244 | 0.7210 | ||
| Consistency | 0.9160 | 0.7111 | ||
| Timeliness | 0.9090 | 0.7129 | ||
| Project Budget | 0.9174 | 0.5853 | 11.012 | 63.249 |
| Timing | 0.9064 | 0.8190 | ||
| Top Management | 0.9183 | 0.8480 | ||
| Communication and Engagement of End Users | 0.9152 | 0.7819 | ||
| Training of Employees | 0.9111 | 0.8100 | ||
| Employee Satisfaction | 0.9044 | 0.5211 | ||
| Total Cronbachs Alpha | 0.9120 | Kaiser–Meyer–Olkin Criterion (KMO) | 1.000 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azeroual, O.; Jha, M. Without Data Quality, There Is No Data Migration. Big Data Cogn. Comput. 2021, 5, 24. https://doi.org/10.3390/bdcc5020024
Azeroual O, Jha M. Without Data Quality, There Is No Data Migration. Big Data and Cognitive Computing. 2021; 5(2):24. https://doi.org/10.3390/bdcc5020024
Chicago/Turabian StyleAzeroual, Otmane, and Meena Jha. 2021. "Without Data Quality, There Is No Data Migration" Big Data and Cognitive Computing 5, no. 2: 24. https://doi.org/10.3390/bdcc5020024
APA StyleAzeroual, O., & Jha, M. (2021). Without Data Quality, There Is No Data Migration. Big Data and Cognitive Computing, 5(2), 24. https://doi.org/10.3390/bdcc5020024