We wanted to investigate the achievements of the suggested approaches; thus, we executed experiments on the quantitative (
Section 8.3) and qualitative (
Section 8.4) characteristics of our retrieved facts. For the challenge of retrieving fact structures in Wikipedia, we did not find related work sources containing an exhaustive list of real-world facts. Nevertheless, we discovered several sources attempting to provide a comprehensive list in our research study: (i) the Wikipedia Current Event Portal (cited later as WikiPortal) aggregating and exposing human generated event descriptions; (ii) YAGO2 database [
4] representing each fact as a set of entities connections. These approaches are restricted in terms of the number of facts and their degree of abstraction. Furthermore, considering that a complete facts repository was not yet released, computing recall for fact retrieval strategies is infeasible. Hence, we completed a manual evaluation as follows. Retrieved facts have been manually judged by five examiners who had to determine if they were similar to real occasions. For every retrieved fact, the annotators have been asked to check all concerned entities and to pick out a real-global occasion with the aid of inspecting internet-based assets (Wikipedia, legitimate home pages, search engines such as Google, etc.) that best described the co-incidence of those entities in the fact for the duration of the chronological period. For each set of entities, a label
true or
false was assigned for describing the association to a real world occasion.
8.1. Dataset
Our dataset was created by using English Wikipedia. Due to the fact that Wikipedia also incorporates pages that do not describe entities (e.g., “register of physicists”), we decided to select pages related to entities registered in YAGO2 and those that are a part of the following categories: humans, locations, corporations, and artefacts. In general we retrieved 1,843,665 pages, each related to one entity. We selected a chronological period starting from 18 January 2011 until 9 February 2011, because it covers critical actual-global events which include the Arab Spring rebellion, the Australian Open, and so on. We opted for a relatively short period, since it is easier for humans to match the facts retrieved by our system with real-world occasions by checking the Web. Considering the fact that using days as smallest time unit proved to efficiently seize news-associated facts in both social media and news systems [
42], we used day granularity in addition to sampling time. We call the entire dataset containing all pages
Dataset A. Moreover, we extracted a sample, referred to as
Dataset B, by deciding on entities that have been actively edited (more than 50 instances) in our temporal window. The idea behind this is that a huge amount of edits can be generated by a fact. Therefore, this sample carries only 3837 pages.
8.2. Implementation Details
Entity Edits Indexing. We used the JWPL Wikipedia Revision Toolkit [
43] to save the entire Wikipedia edit records dump and to pick out the edits.
Similarity. In order to retrieve the ancestors of a specific entity, we utilized the YAGO2 knowledge base [
4], which is an ontology that was constructed from Wikipedia infoboxes and mixed with Wordnet and GeoNames, to obtain 10 million entities and 120 million records. We observed facts with
subClassOf and
typeOf predicates to extract the ancestors of entities. We bounded the retrieval to three tiers, considering the fact that we determined that approaching a higher degree would entail considering many extremely abstract classes. This diminished the discriminating overall performance of the similarity dimension.
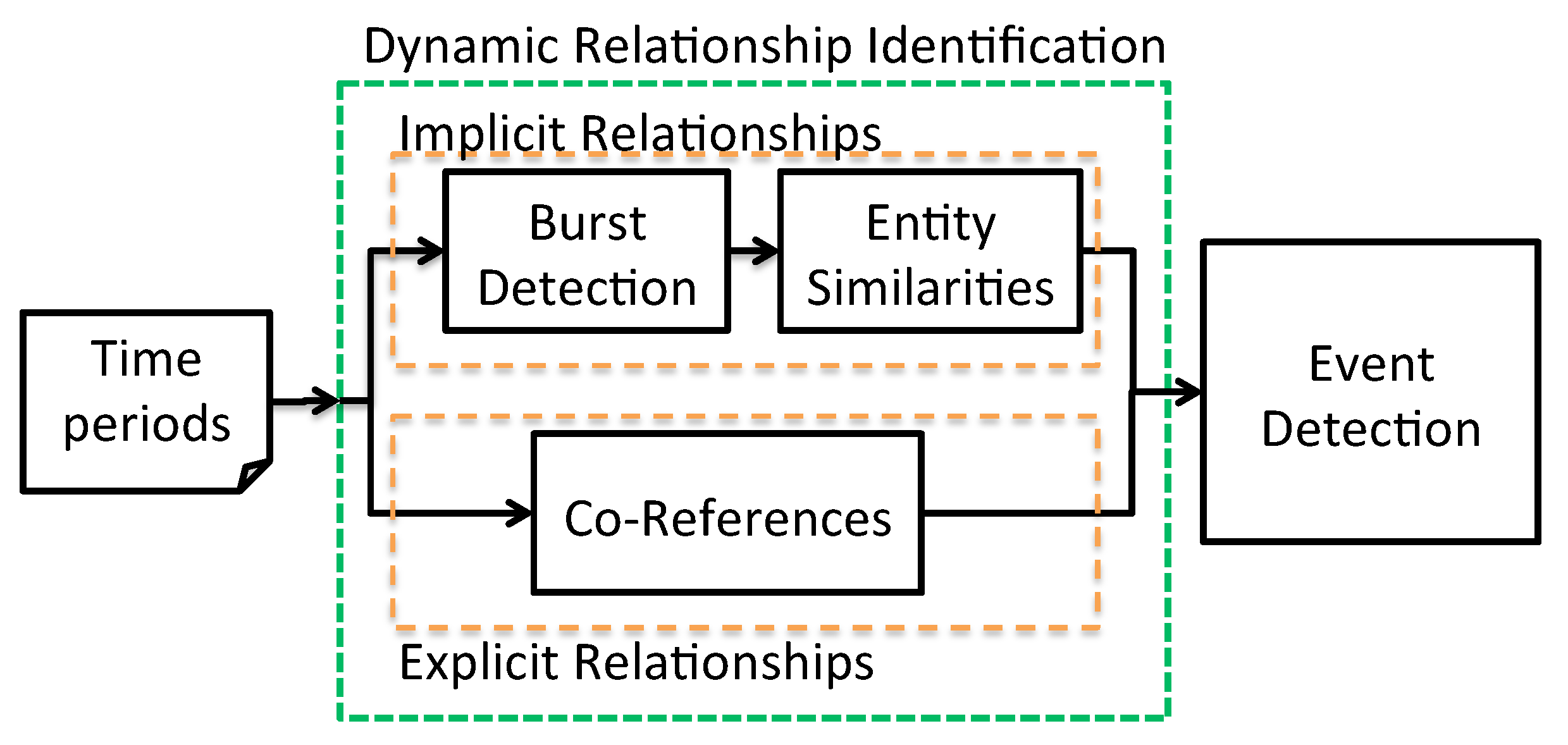
Burst Detection and Event Detection. We applied Kleinberg’s algorithm by using the modified version of CShell toolkit (
http://wiki.cns.iu.edu/display/CISHELL/Burst+Detection (accessed on the 21 March 2011)). We imposed the density scaling to
, the default variety of burst states to 3, and the transition cost to
(for extra details, read [
44]). We noticed that changing the parameters of the burst detection no longer had an effect on the order of overall performance between specific fact retrieval strategies. For the dynamic connections, we imposed the temporal lag parameter
to 7 days and
to
, as those values achieved the best outcomes in our experimentation.
8.3. Quantitative Analysis
The purpose of this phase is to numerically assess our strategy below the (i) total quantity of retrieved facts and (ii) the precision, i.e., the proportion of real facts. For the parameters’ choice, be aware that the graph created is completely based on the exact method and exposes no weights on its connections. On the other hand, the implied approach generates a weighted graph primarily based at the similarities, and the temporal graph clustering depends on the edge for filtering entity pairs of low maximum similarity. We tried different values of and observed that decreasing it ended in a bigger wide variety of entity pairs that coalesced right into a low quantity of big facts. These facts having multiple entities could not be recognized as actual facts. Consequently, we used for the following experiments.
We compared methods for the implied connection retrieval strategies described in
Section 5.2, known as the following
techniques:
Textual,
Entities,
Ancestors, and
PMI, as well as for the exact method as described in
Section 5.1 that is referred to as the
Co-References method. The outcomes are provided in
Table 1 and
Table 2 where the number of retrieved facts and their precision are reported in the third and fourth columns, respectively. As predicted, we suggest that there are more events in
Dataset A as in
Dataset B because of the higher number of entities taken into consideration. The biggest wide variety of retrieved facts is supplied by
Co-references in each datasets. That is attributed to the parameter-free nature of the exact method, while, with the implied method, a portion of facts are removed by using a threshold. Comparing the methods utilized by the implied approach,
PMI retrieves more facts than other methods. This is due to the difference in computing the entity similarity
.
PMI considers the sets of incoming links that account for relevant feedback to our
and
from all the other entities. This derives more abundant entity pairs and more definite consistent facts, while the other implied strategies generally tend to aggregate entities in bigger but lesser facts.
Textual,
Entities, and
Ancestors calculate
starting from the edited contents of two entities at a specific chronological point. A huge amount of content regarding entities, which might no longer be explicitly related to
and
, might be considered, rendering the value of
lower. Therefore, using the same value for
as for the
PMI creates a lower number of entity pairs and, consequently, of retrieved occasions.
The precision of each setup, i.e., the percentage of authentic retrieved occasions, is summarized in the fourth column of
Table 1 and
Table 2. Considering the various implicit strategy methods, we denoted a clear advantage of using similarities that take semantics into account (
Entities,
Ancestors, and
PMI) over string similarity (
Textual).
Ancestors play worse than
Entities in each datasets, showing that the addition of ancestor entities introduces extra noise rather than clarifying the relationships among the edited entities.
Entities achieves comparable performances on both datasets.
PMI achieves better performance in
Dataset B than compared to the other implicit similarities given that it are exploiting the structure of in-out links among Wikipedia articles. However,
PMI plays worse on
Dataset A because of the higher variety of inactive entities taken into consideration, introducing noisy links.
In the end, Co-References outperforms all the implied techniques on both datasets. Usually, all approaches carried out better or similar to one another on Dataset B versus Dataset A, indicating that choosing only the entities which might be edited more frequently improves our strategies. Even though less facts are retrieved in Dataset B, the majority of them correspond to actual existence facts.
8.4. Qualitative Analysis
Here, we conduct a qualitative analysis of the facts retrieved in
Dataset A. We concentrate on a number of facts retrieved by our first-class approach,
Co-References (
Section 8.3). Then, we evaluate some cases wherein our techniques performed poorly and we suggest the possible reasons for the poor performance.
In
Table 3, we present some retrieved facts by our best method,
Co-References, by matching real-world occasions and we relate the entities, the chronological period, and a human readable explanation of the detected fact from web sources for each of them. The Table shows that the behaviour of our methods does not depend on the domain of the entities involved in the events, as we have a good coverage over different fields. In particular, we can observe that sport events are easier to detect because of the highly connected entities and the similar terminology used in the articles of the involved entities. Furthermore, we report the graph structure of two true retrieved facts:
Example 1. We describe the connections to the true occasion called Friday of Anger during the Egyptian rebellion in Figure 2a. On 28 January 2011, thousands of people crammed the Egyptian streets to protest against the government. One of the primary demonstrations happened in Cairo. Protests became organized with the help of social media networks and smartphones, and some of the organizers included the April 6 Youth Movement and the National Democratic Party. The aviation minister and previous chief of Air workforce Ahmed Shafiq and Gamal Mubarak are determined as the possible successors of Hosni Mubarak by means of the authorities. Example 2. The graph structure of some other exceptional actual global occasion that is detected: The declaration of the nominees for the 83rd Academy Awards on 25 January 2011 is shown in Figure 2b. The most crucial node is the 83rd Academy Awards and, as a secondary node, the Academy Award for Best Actor having True Grit and Biutiful as the connecting nodes, which were been nominated for more classes. We depict some errors of our strategies to retrieve actual-world facts in
Table 4, together with the reasons that result in such faulty final results. Depending on the technique, we can identify unique patterns that motive false positives. The
entity based similarity generally fails due to updates containing several entities that are not involved in any important event. The usage of the
ancestor-based similarity can provide false facts because some entities, which can be very comparable and have a wide variety of ancestors, have coincidentally concurrent edit peaks in the temporal window under observation. The
PMI shows poor results because of comparable reasons: Entities share several incoming links to the entities contained in the edits conducted on the same day. In the end, the
Co-References method appears to fail when the reciprocal mentions originate in connections which are unbiased of any fact.
8.5. Comparative Analysis
We examine retrieved facts by means of our approach with facts reported in the WikiPortal inside the identical chronological period. Users in WikiPortal put up a brief summary of a fact in reaction to the incidence of actual-world occurrence and relate the entity mentioned with the corresponding Wikipedia pages. The occasion summary can also be clustered into larger “stories” (which include Egypt rebellion), or it can be prepared in one-of-a-kind class, such as politics, cinema, etc.
We performed the evaluation considering the 130 ( of 186) true retrieved facts by the Co-References approach on Dataset A, given that this is the setup that provided the biggest set of authentic facts.
We gathered 561 events from WikiPortal within the specific duration by clustering all occasions in the same story as representing a single fact. In addition, we took into consideration the best event descriptions annotated with a minimum of one entity contained within Dataset A, gathering 505 events. These facts can be retrieved via our approach.
Even though an entity can participate in an event without being explicitly annotated within the event description, we assume that the articles of the relevant entities participating in the event are annotated by the users of WikiPortal.
In order to evaluate the overlap between the two fact sets, we classify facts according to the following classes:
1. Class Green: The fact in one set, together with all its contributing entities, is reported in the other set either as a single or as multiple facts.
2. Class Yellow: The fact is partially reported in the other set, i.e., only a subset of its contributing entities is shown in one or more facts in the other set.
3. Class Red: The fact is not present in the other set.
We offer explanations for every class in
Table 3 in conjunction with causes of each class selection. We noticed two patterns for green class: (i) One occasion in
Co-References is spread over several facts in WikiPortal (as an example, the occasion concerning the candidacies for the
Fianna Fail party is indicated in WikiPortal via many facts and each one specializes in one single candidacy); (ii) one fact in
Co-References is related to one occasion in WikiPortal. The yellow class typically covers the case where a fact describes a non-stated aspect of a fact in WikiPortal. As an example, for the
Australian Open tennis event, only the men’s semi-final and very last matches are stated in WikiPortal without mentioning the other ones, which are suggested in
Co-References. In addition, the
Friday of Anger (Egyptian rebellion) and the
Academy Awards nominations are present in WikiPortal, but our retrieved facts are endowed with extra entities that do not appear inside the portal. In the end, the red class aggregates those occasions not mentioned in WikiPortal in any respect, which is similar to the
Royal Rumble wrestling match.
We observed that
of the facts retrieved by
Co-References are completely or partly reported inside the WikiPortal. For the sake of readability, in
Table 5, we provide a number of the events which can be found in WikiPortal, but that our technique was not able to retrieve, in conjunction with an explanation. The main patterns are the following: (i) the fact contains just one entity; (ii) the fact involves entities, which are highly unlikely to reference one another because of their extraordinary roles within the common facts.
In conclusion, Co-References and WikiPortal can be considered as complementary strategies for fact retrieval.









{kind=link}
{kind=link}
{kind=link}