
AI Based Emotion Detection for Textual Big Data: Techniques and Contribution

 ,
,  ,
,  and
and 
Abstract
:1. Introduction
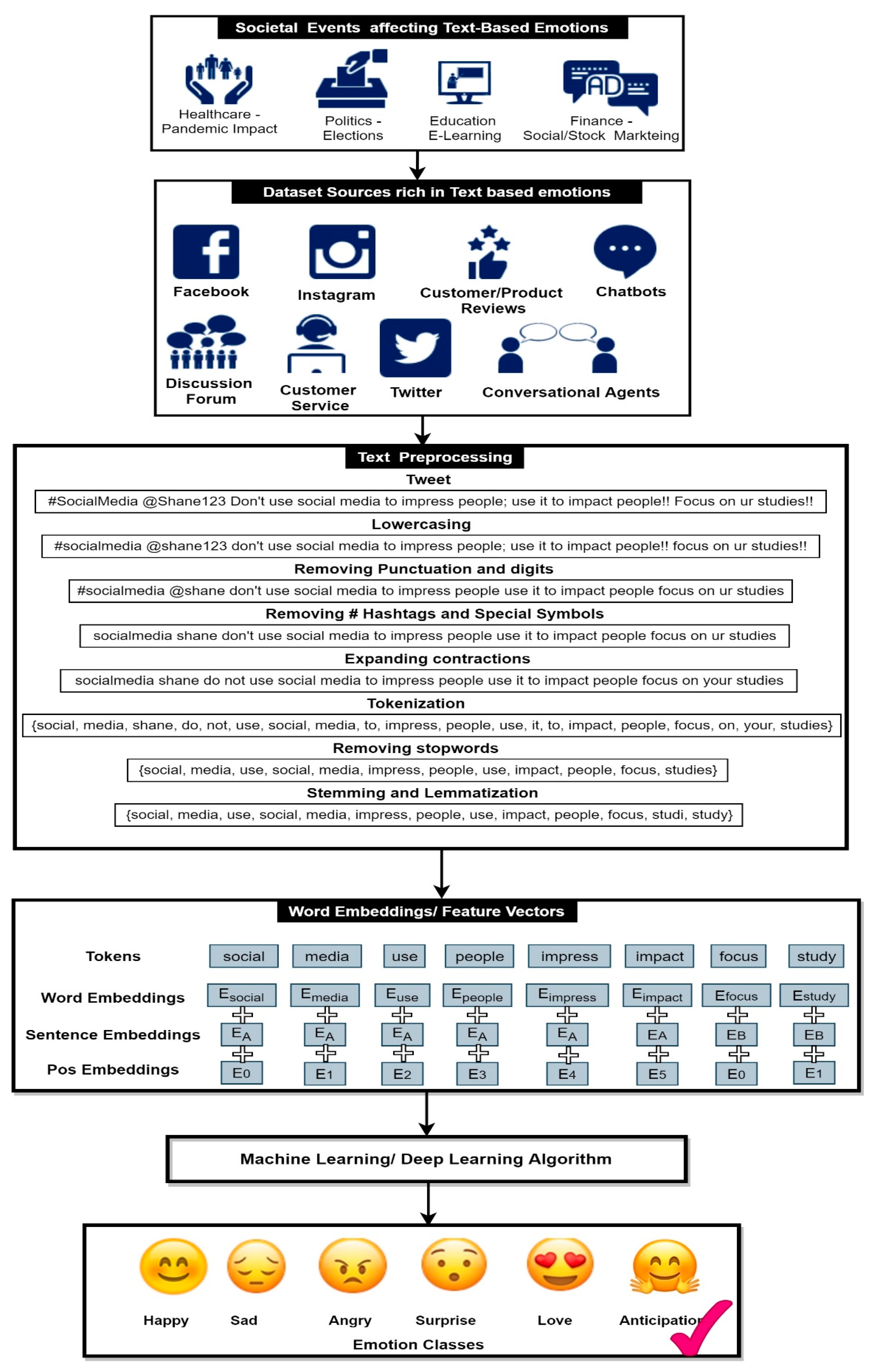
Text-Based Emotion Detection: Overview
- To represent the qualitative analysis of the relevant research work which is carried out in the last 15 years.
- To review the emotion modeling approaches for the text-based sources.
- To survey existing AI approaches and publicly available datasets for text-based emotion detection.
- To perform bibliometric analysis of text-based emotion detection using artificial intelligence by employing Scopus and web of science databases.
2. Qualitative Analysis—Techniques Overview
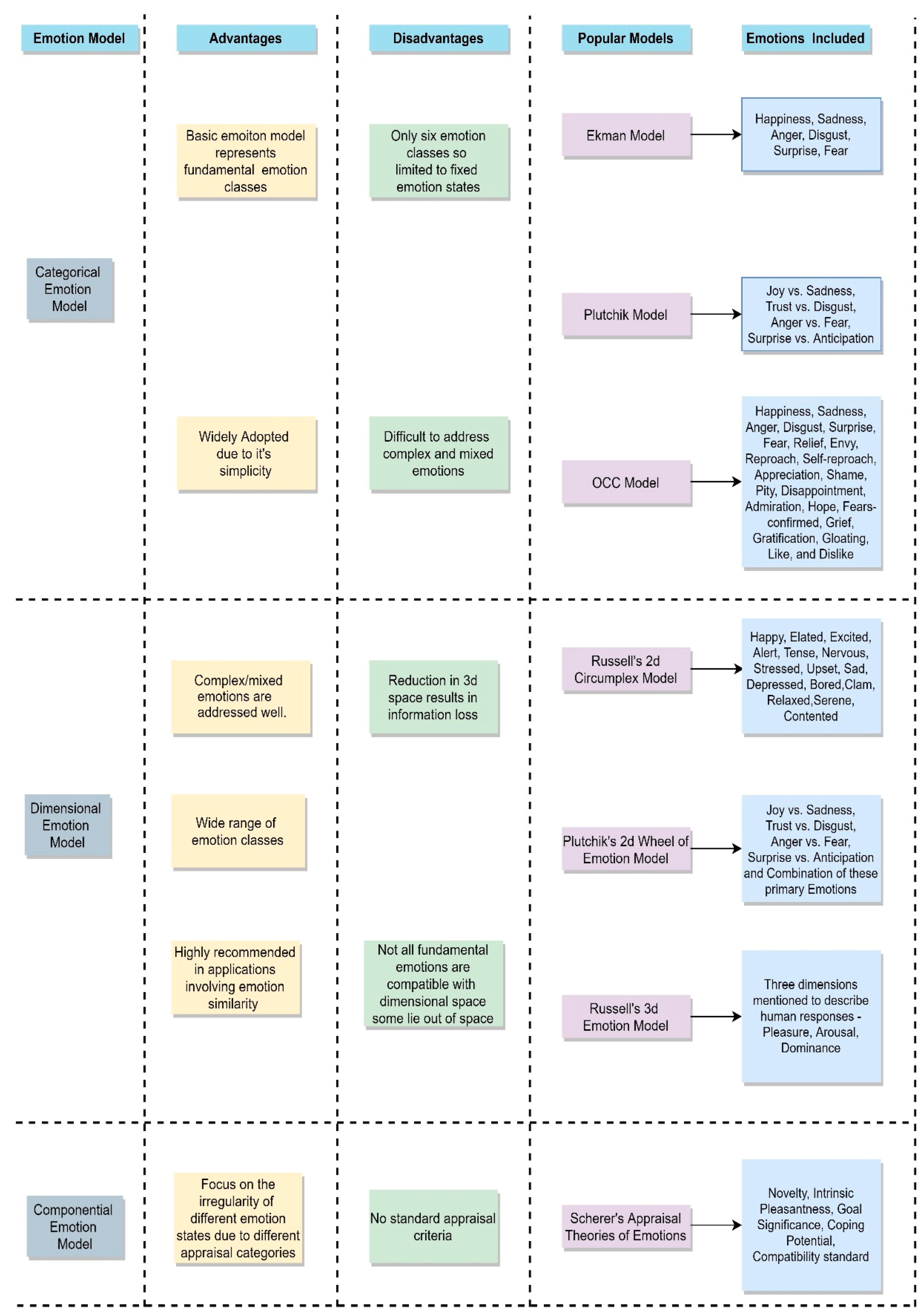
2.1. Emotion Models—Brief Overview
- Valence—This dimension states that emotion is positive or negative.
- Arousal—This dimension states emotion is exited or apathetic.
- Power—This dimension states degree of emotion.
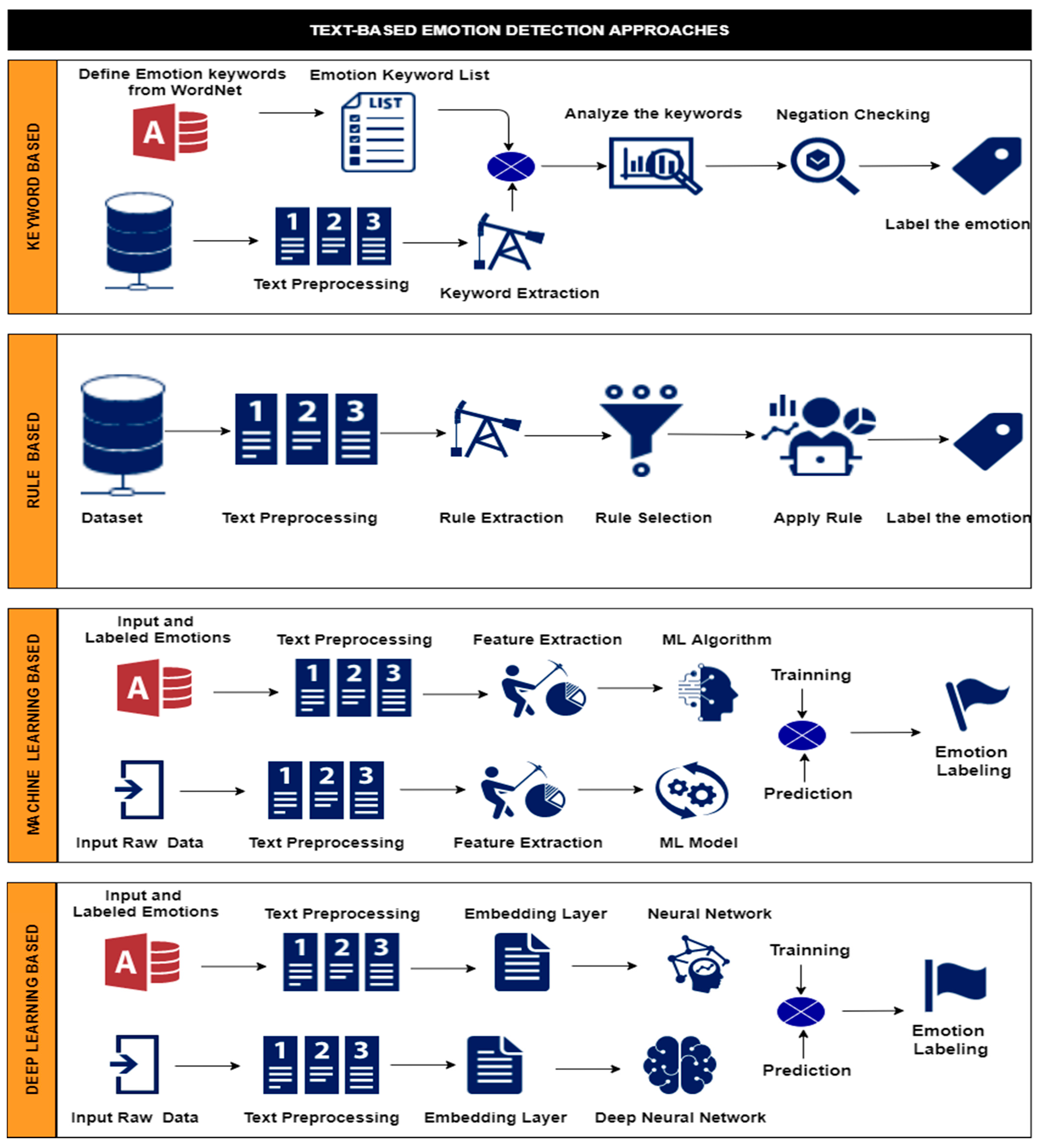
2.2. Text-Based Emotion Detection Approaches
2.3. Dataset/Corpora
3. Quantitative Analysis—Bibliometric Contributions Analysis
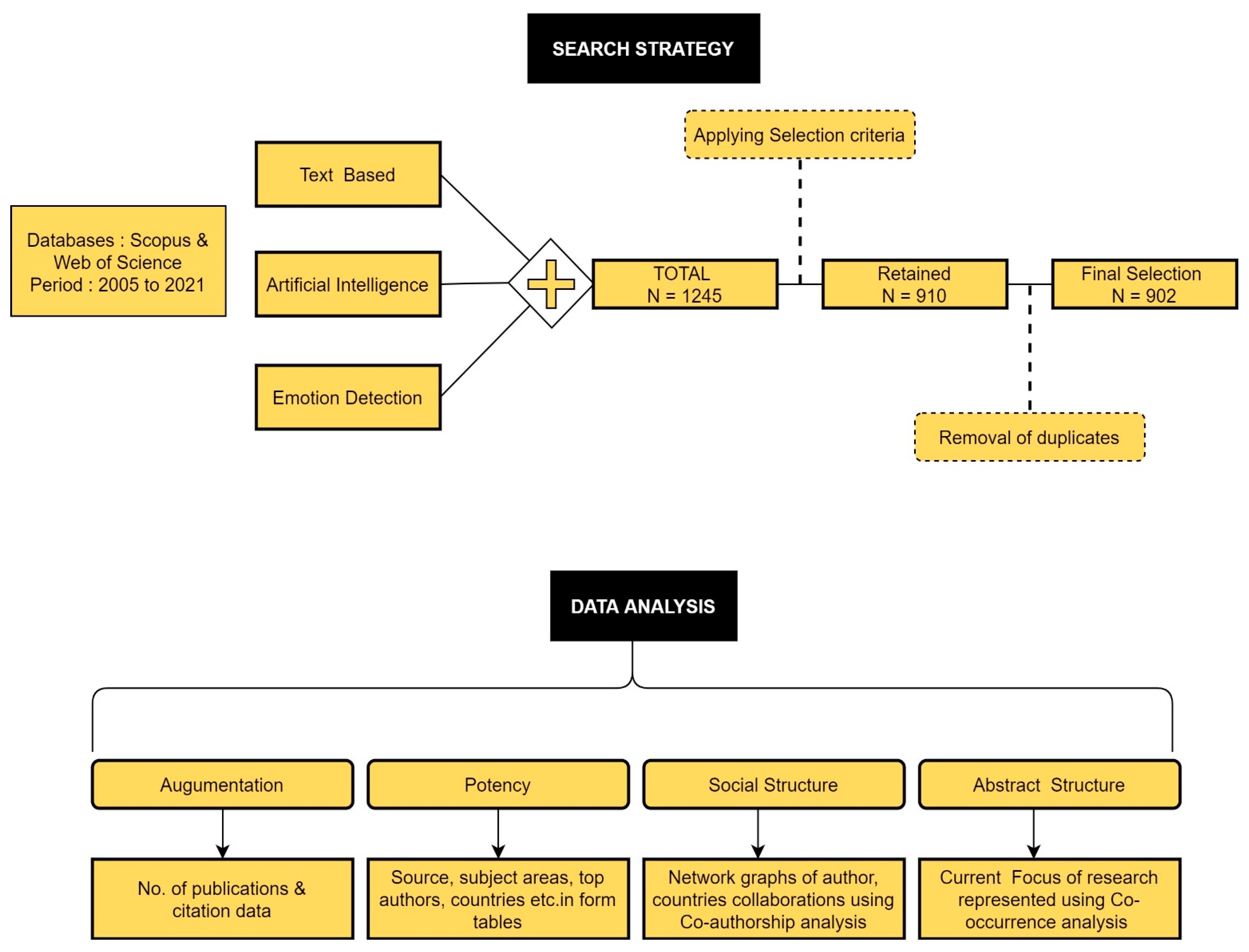
3.1. Search Strategy
3.2. Data Analysis Procedure
3.3. Data Collection
3.3.1. Initial Search Results
3.3.2. Analysis Based on Yearly Publication Distribution
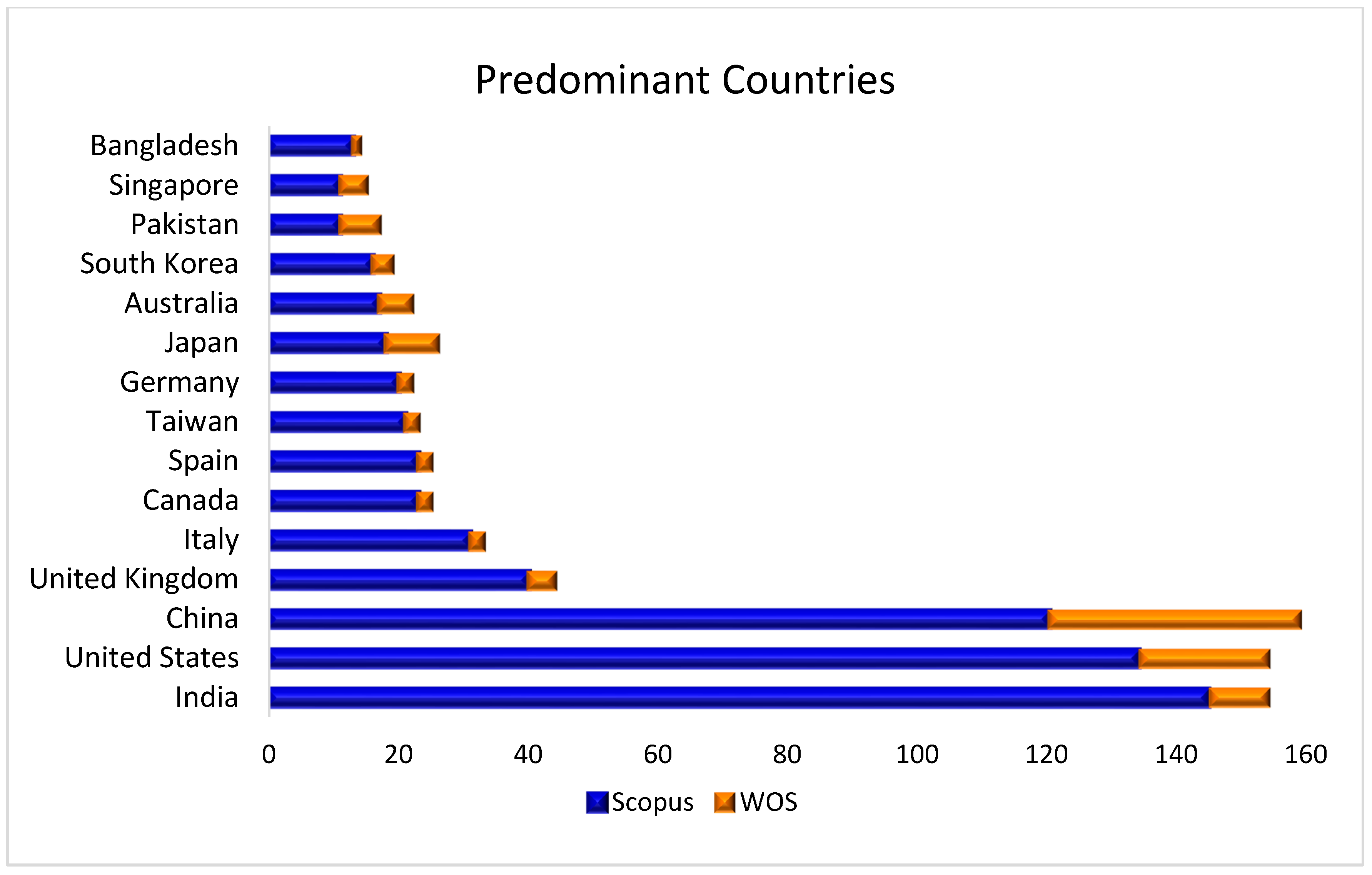
3.3.3. Analysis Based on Geographical/Country Wise
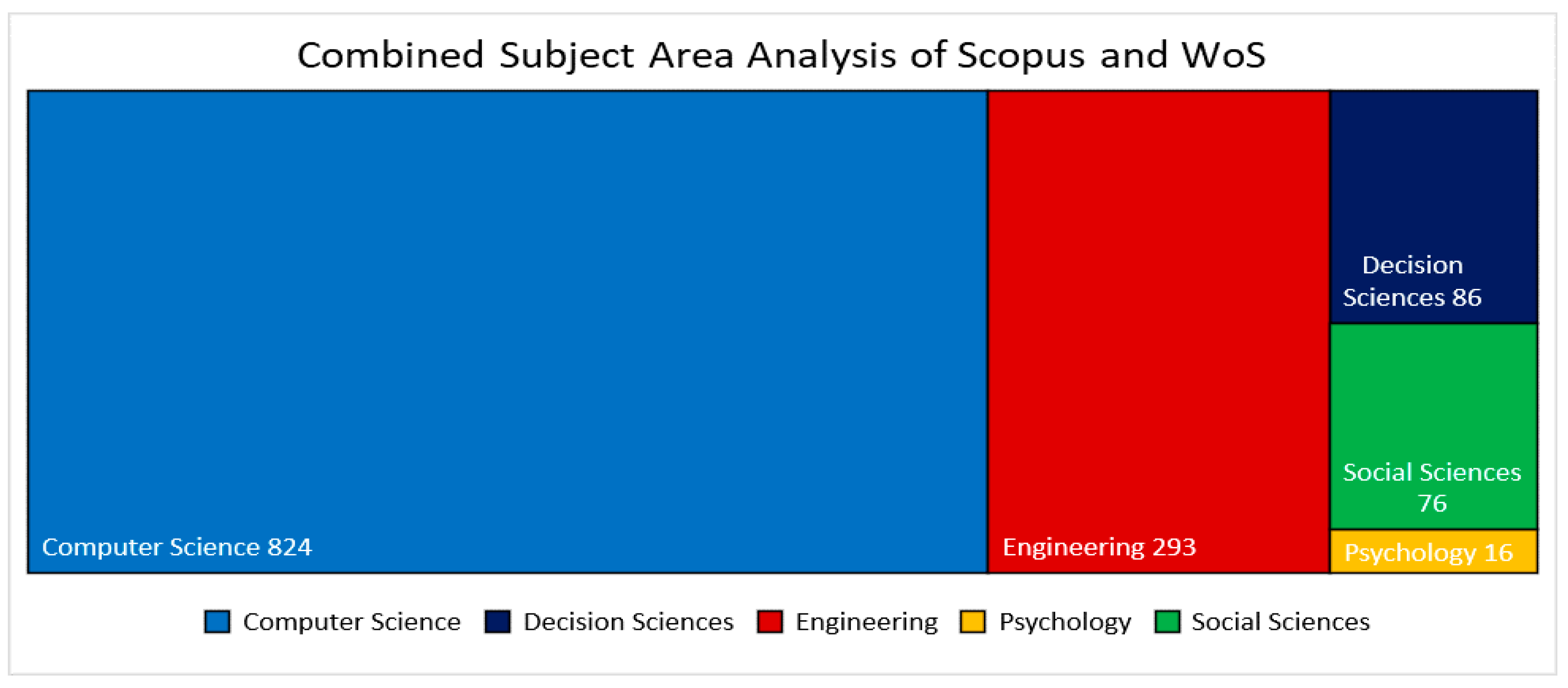
3.3.4. Analysis Based on Subject Area
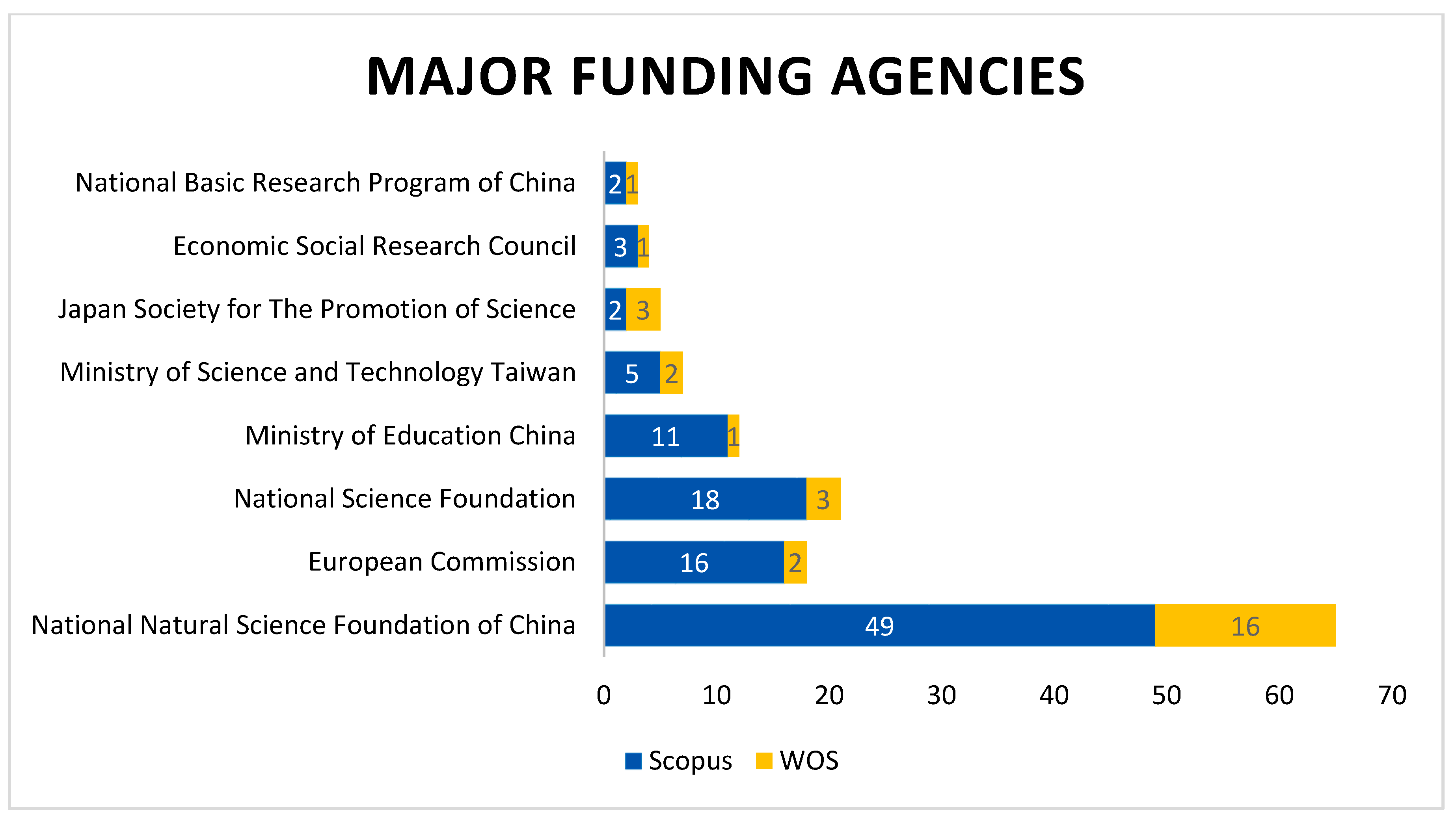
3.3.5. Analysis Based on Funding Agencies
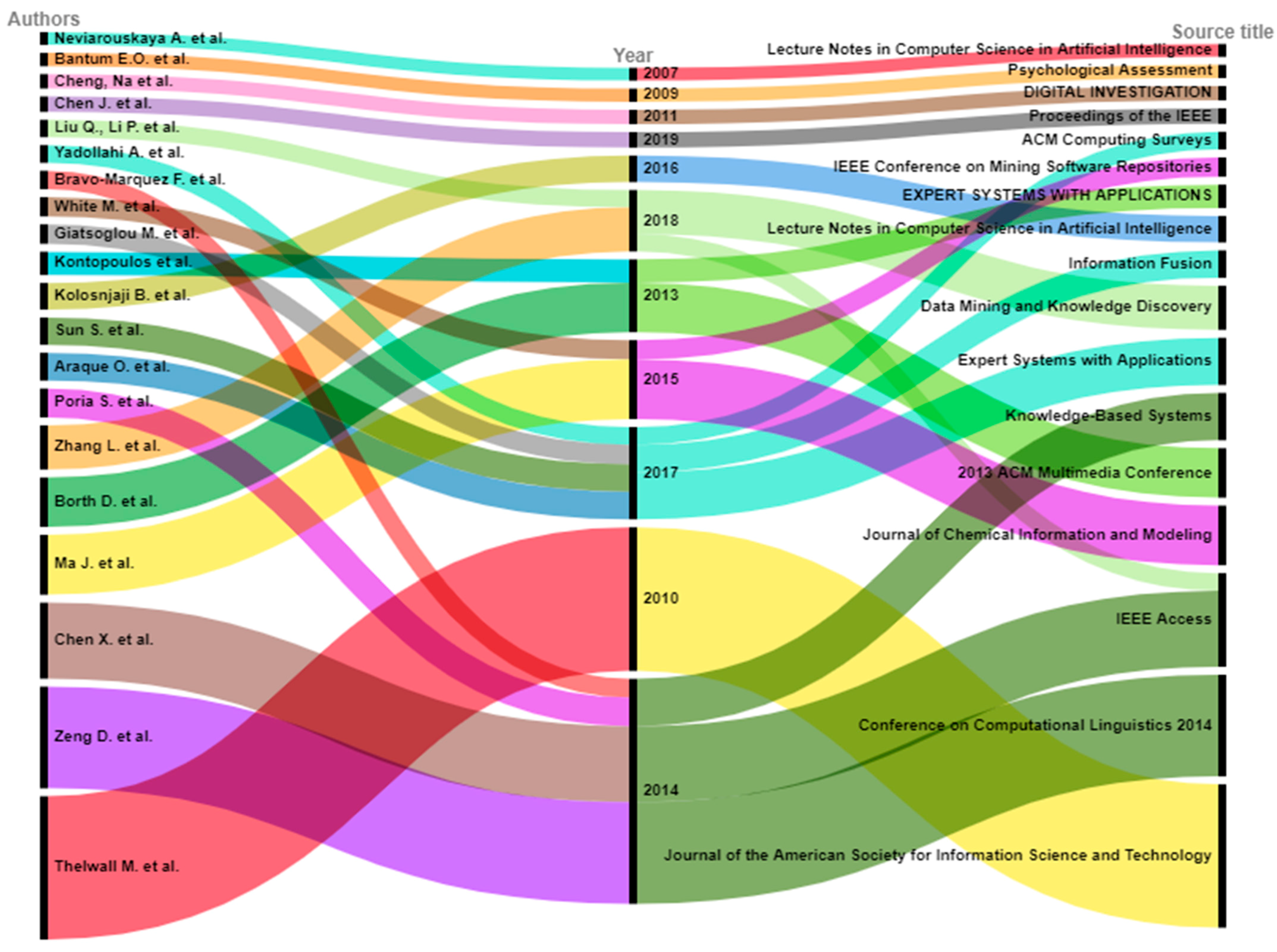
3.3.6. Analysis Based on Source Titles/Publication Source
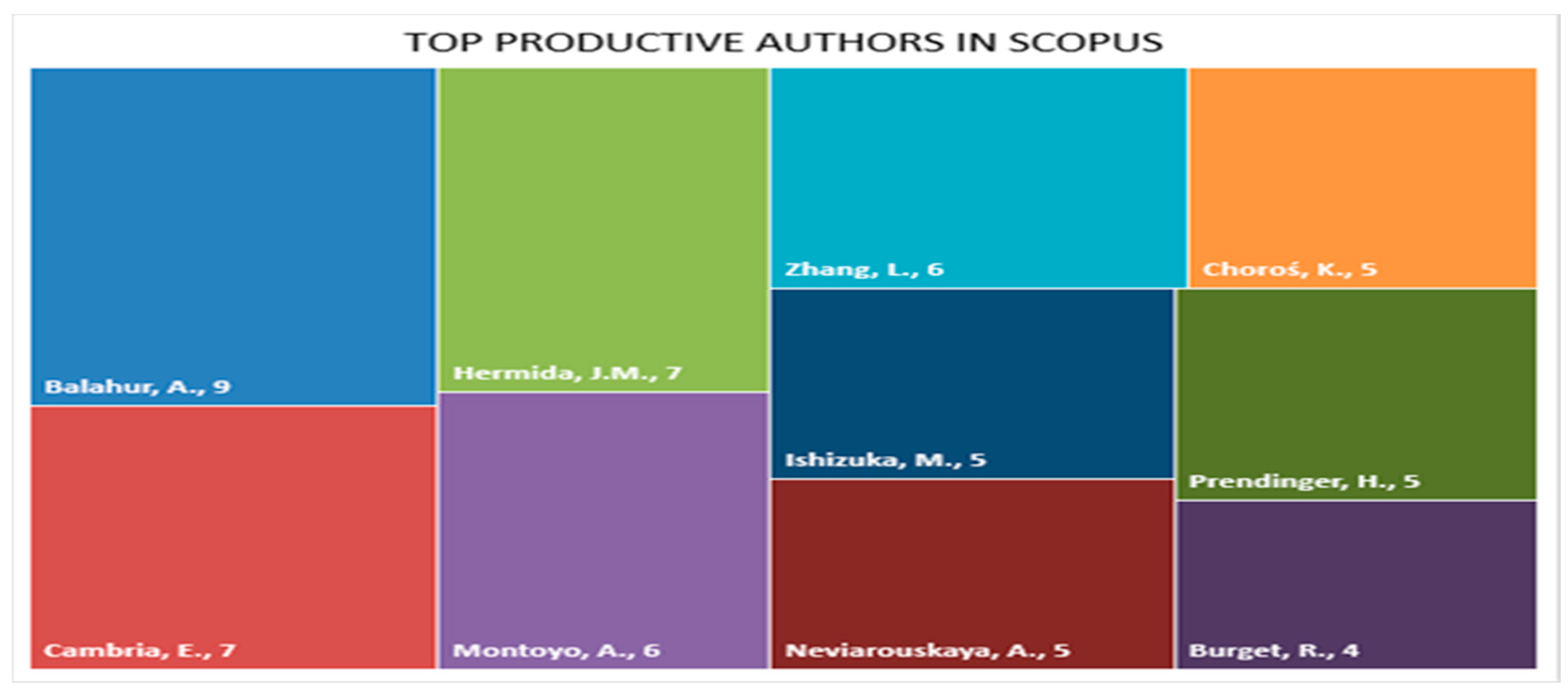
3.3.7. Analysis Based on Author
3.4. Network Analysis
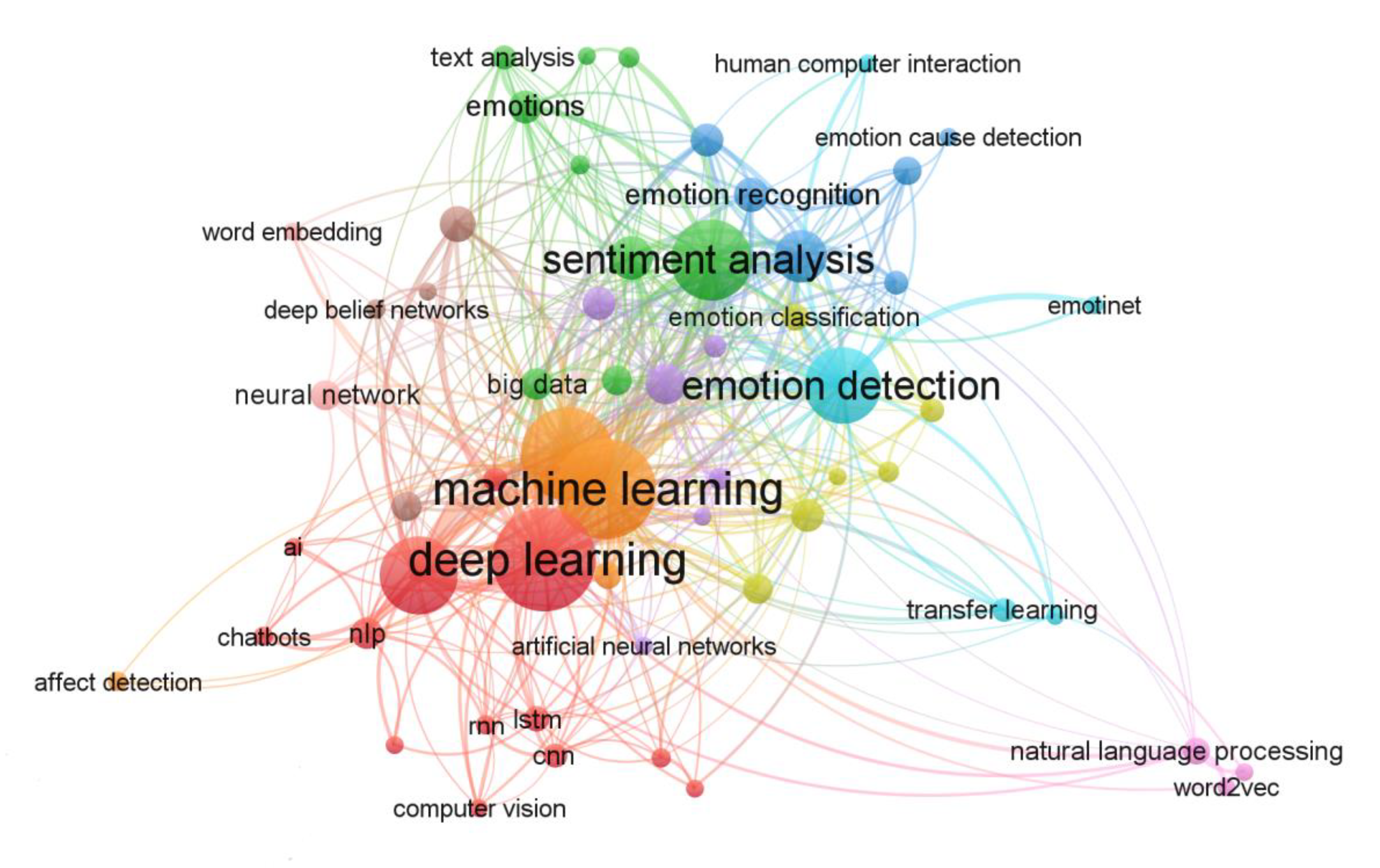
3.4.1. Analysis Based on Author Keyword Co-Occurrence
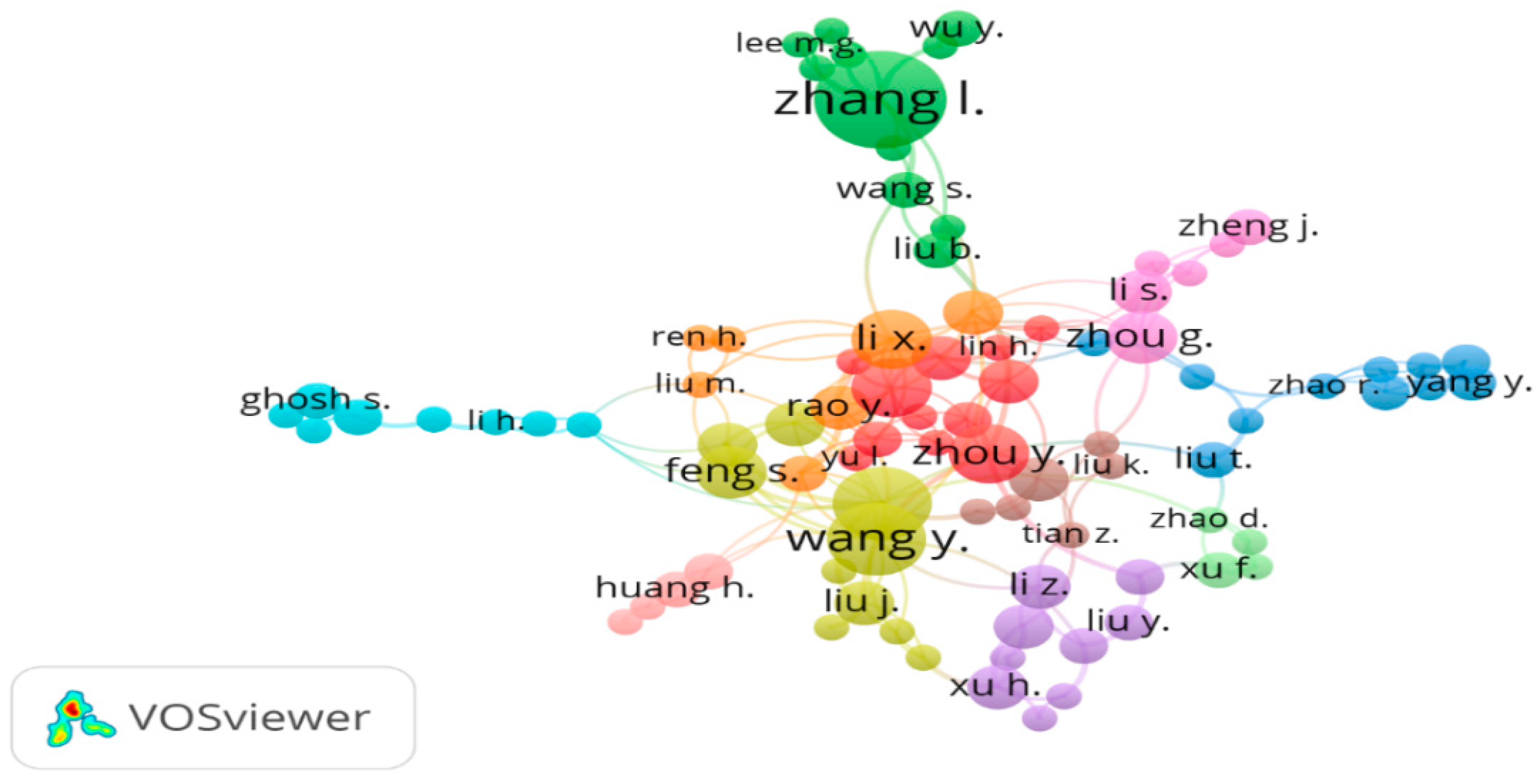
3.4.2. Analysis Based on Co-Authorship
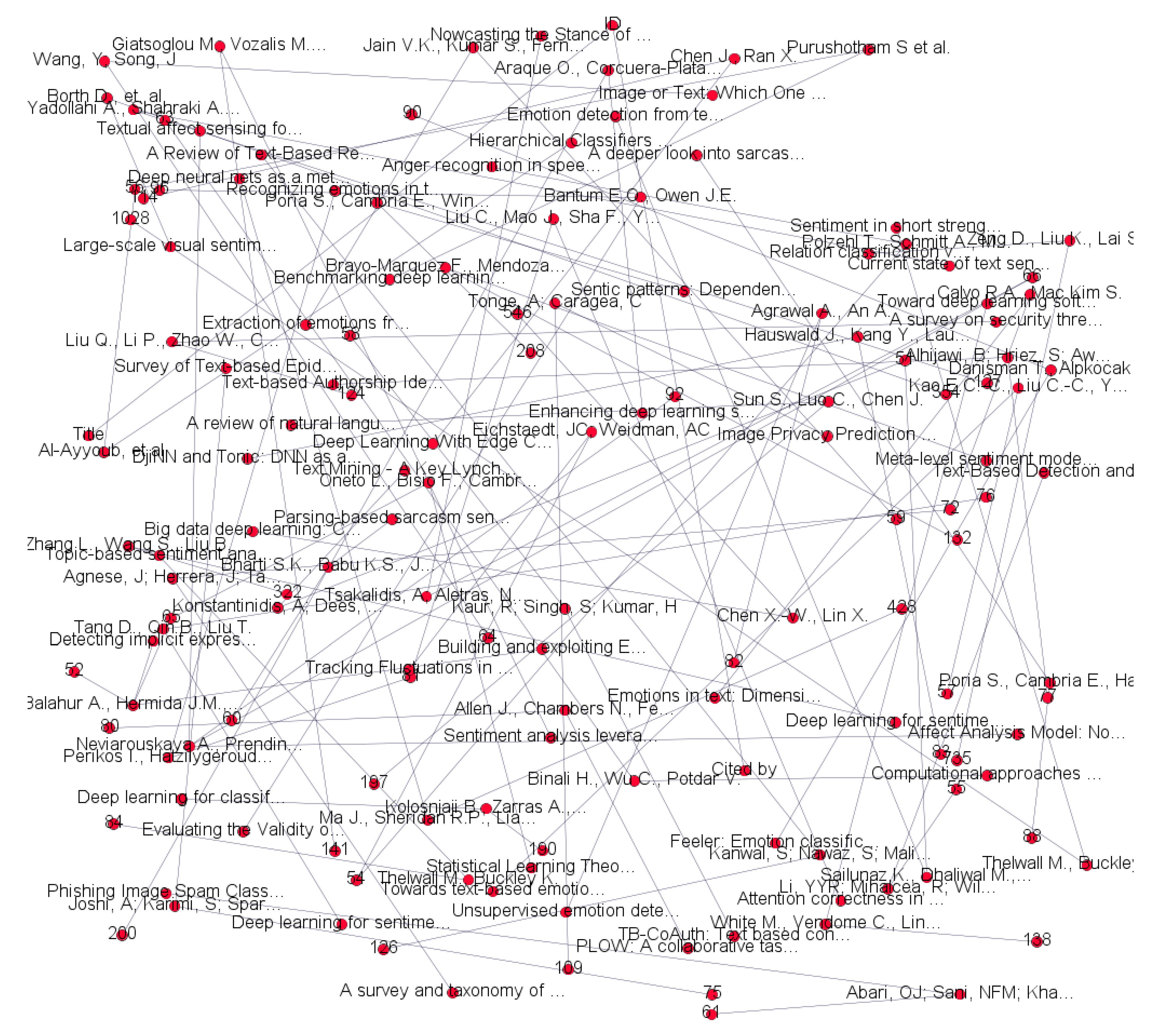
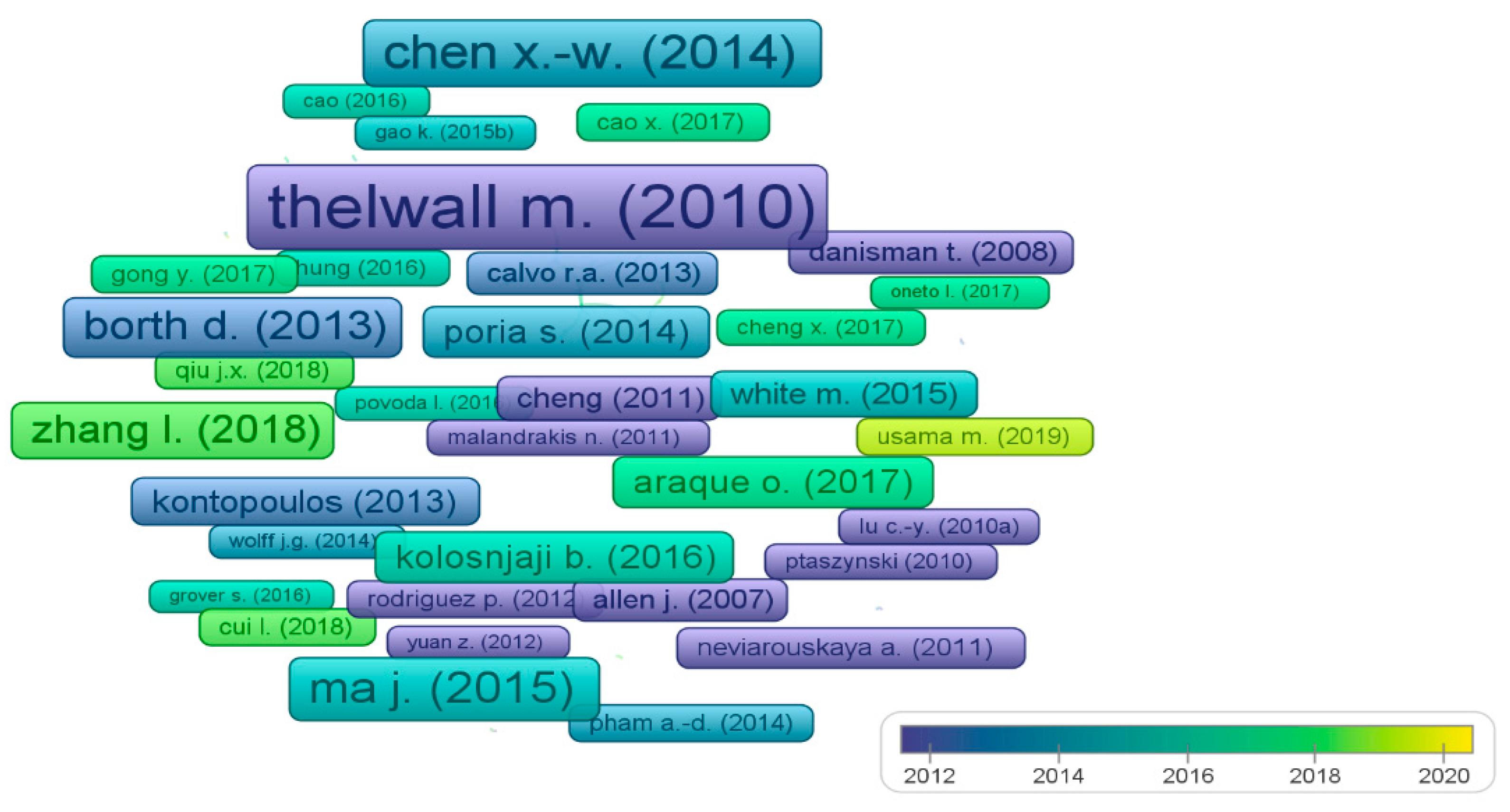
3.4.3. Analysis Based on Citations
3.4.4. Analysis of Highly Cited Publications
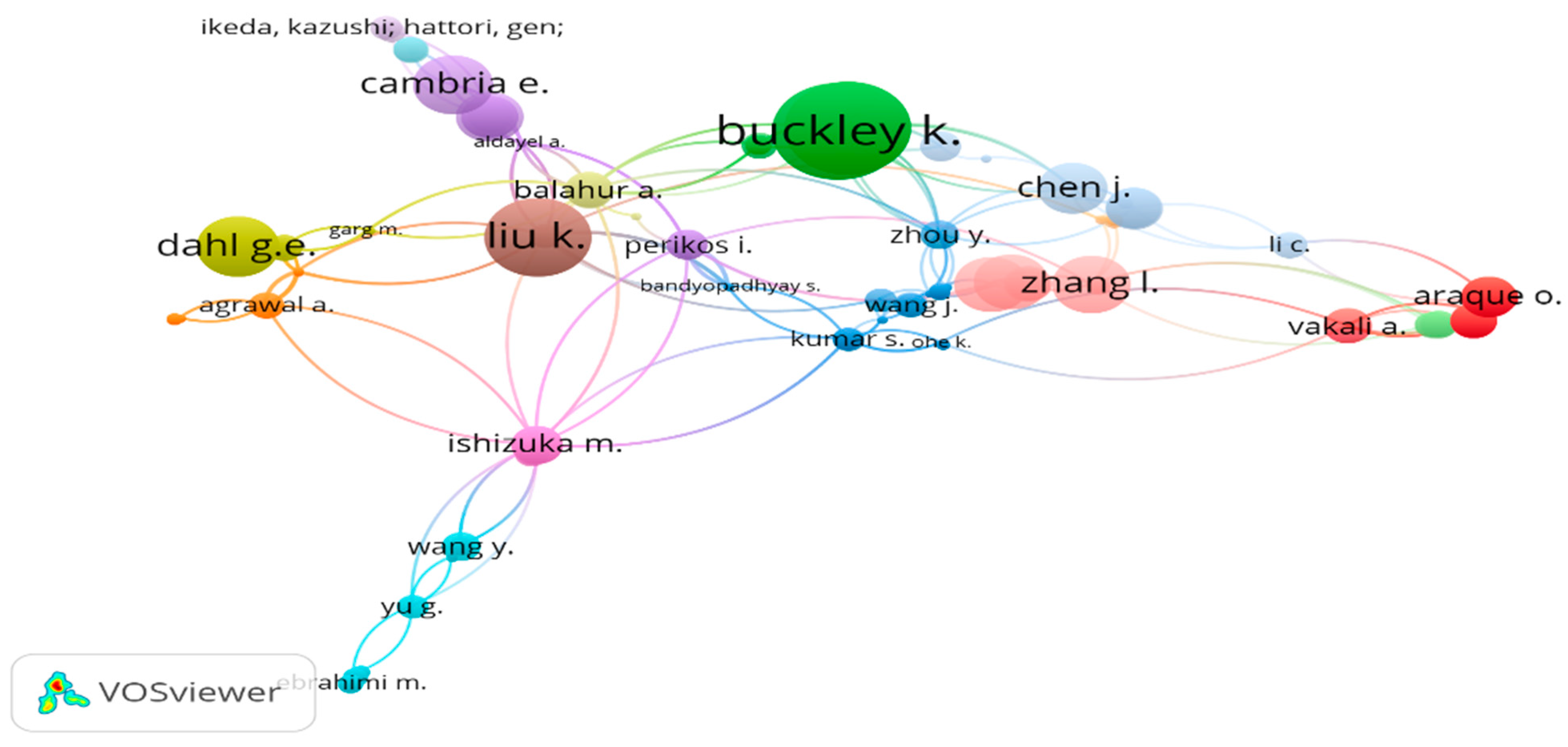
3.4.5. Analysis of Highly Cited Authors
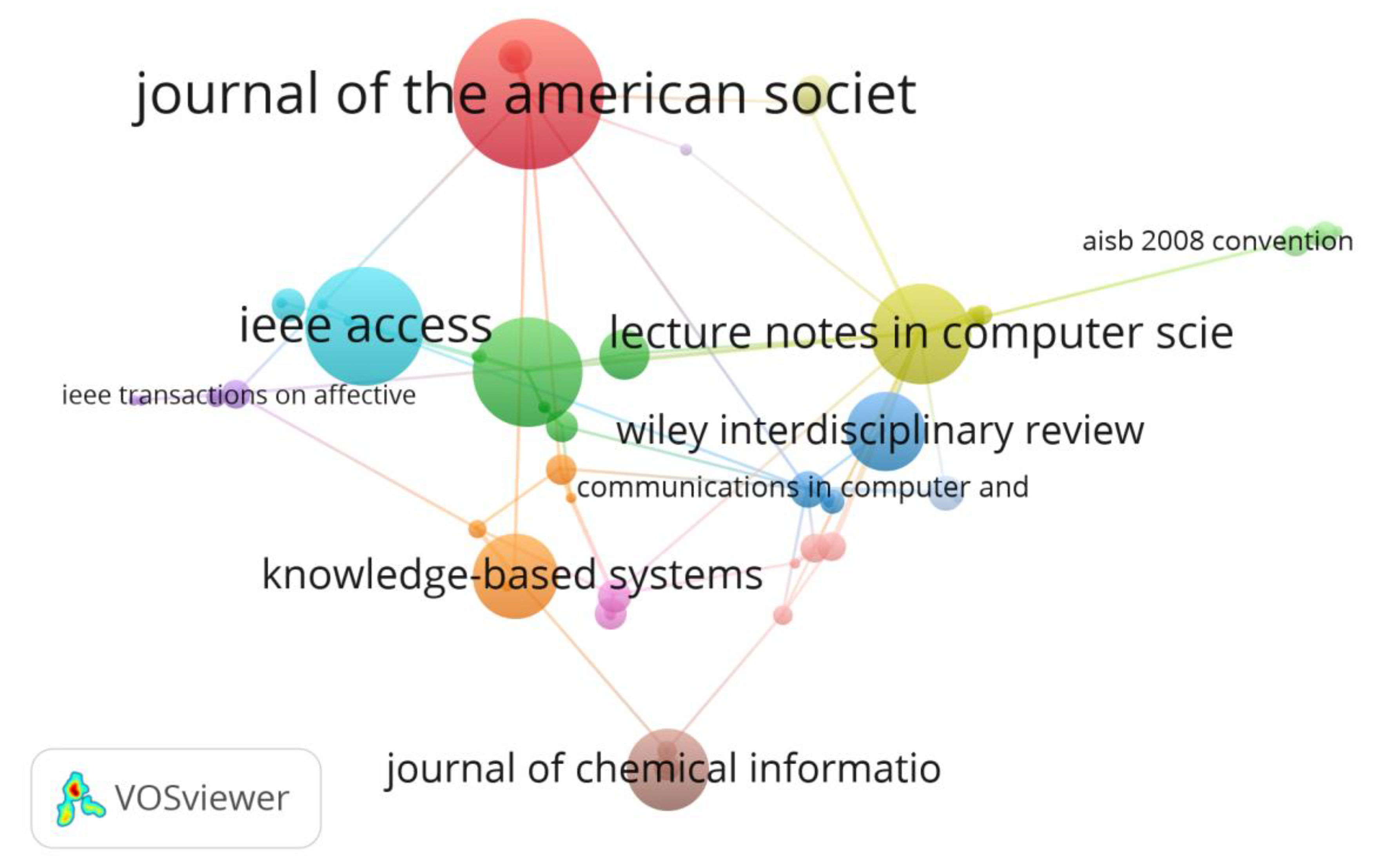
3.4.6. Analysis of Highly Cited Sources
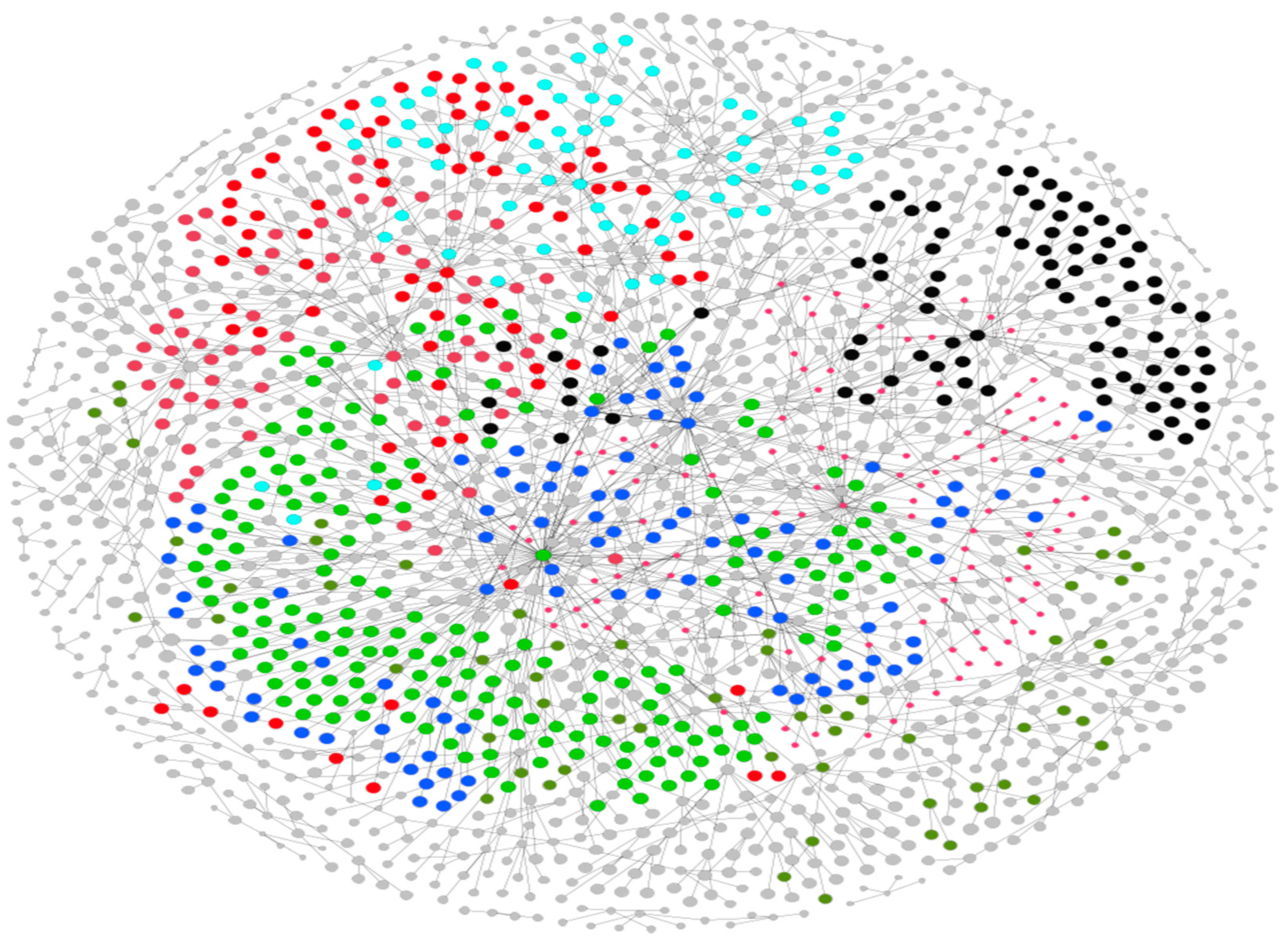
3.4.7. Analysis Based on Author Bibliographic Coupling
3.4.8. Analysis Based on Source Bibliographic Coupling
3.4.9. Analysis Based on Countries Bibliographic Coupling
4. Summarizing Comments on Bibliometric Analysis of Text-Based Emotion Detection Using Artificial Intelligence
- The majority of publications in this area are conference papers accompanied by articles on Scopus, whereas on Web of Science, most publications are articles.
- English is the preferred language for publications. However, some publications are available in the Chinese language and very few in Turkish.
- The top three countries/territories that made significant contributions to this field are India, the United States, and China both on Scopus and on Web of Science.
- The majority of researchers in the subject area chose Computer Science and Engineering as their field of study.
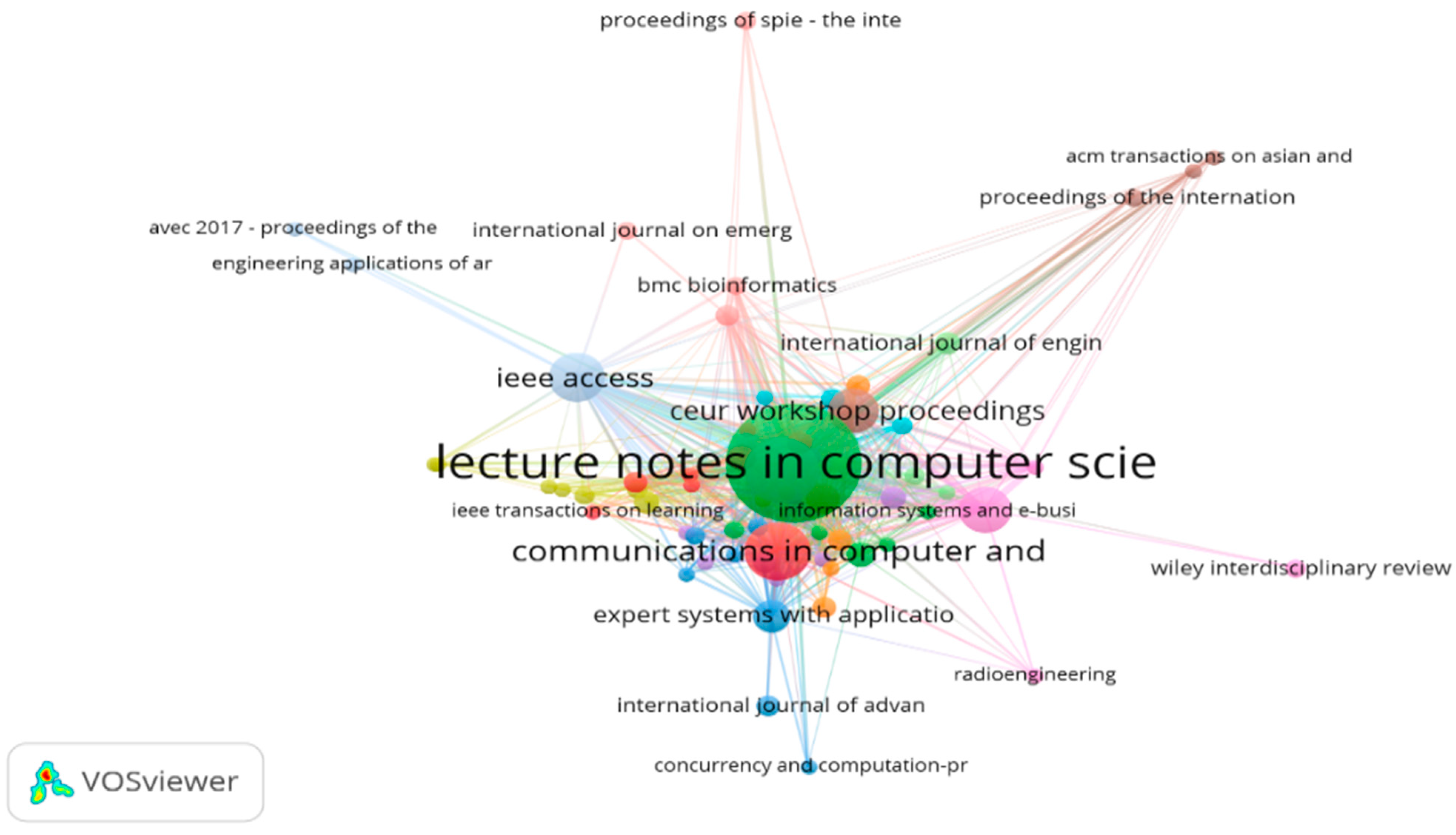
- The maximum number of publications of this area are available in “Lecture Notes in Computer Science” on the Scopus database and “IEEE access” on Web of Science.
- “Buckley K.” is a well-known author who has made significant contributions in the field.
- Most cited paper in this field is “Sentiment in short strength detection informal text.”
- The maximum research fund was provided by the “National Natural Science Foundation of China” in this field.
5. Summarizing Comments on Qualitative Analysis of Text-Based Emotion Detection Using Artificial Intelligence
- (1).
- Difficulties in detecting implicit emotions. One challenge is identifying emotions in the text when no emotion keywords or phrases have been used. Words and sentences used in the text can have different meanings. A single sentence can contain multiple emotions and views, which makes it difficult to detect multiple emotions. This issue needs to be addressed to improve the performance or accuracy of automated emotion detection systems.
- (2).
- Difficulty in extracting the semantic information. Many words in written text such as negations and modals affect emotion detection. Words and phrases used in different contexts convey different emotions. So, word semantic ambiguity is one of the issues in identifying correct emotion from the text.
- (3).
- Inefficient and Time-Consuming feature extraction and labeling. Most machine learning algorithms require efficient feature extraction to efficiently recognize emotions. However, manual feature extraction is time-consuming and an error-prone task. In addition, mislabeling of emotions may occur in the manual labeling process, making it a difficult task. Therefore, inefficient feature extraction and labeling can directly affect the accuracy of text-based emotion detection.
- (4).
- Classifying emotions according to their intensities. Written text can have words or phrases of varying degrees of associations with respect to sentiments and emotions. In detecting emotions from text, the strength of association with a word or a phrase helps to assign emotion scores/intensities to text. Thus, it becomes easy to annotate/label the text with intensities.
- (5).
- Detecting emotions from non-standard language. Users on online social platforms use sarcasm, irony, humor, etc., to express emotions. However, social media texts also contain informal words, slang words, misspellings, hashtags, emoticons, abbreviations, etc. Therefore, it becomes difficult to interpret such creative text for automatic text-based emotion detection systems.
- (6).
- Performance of existing systems. Major work in text-based emotion detection has been done using machine learning and deep learning techniques. However, most machine learning techniques require annotated datasets, which is time-consuming and dependent on human efficiency, affecting machine learning techniques’ performance. On the other hand, deep learning techniques are complex techniques it requires a large amount of data for training.
- (7).
- Imbalanced datasets. Very few datasets are available for research purposes, and most of the datasets are limited labeled imbalanced datasets. These datasets are built for specific experiments, and so are dependent on application domains. Machine learning and deep learning require large datasets, so these few imbalanced datasets restrict the work in text-based emotion detection.
6. Future Directions for Text-Based Emotion Detection Using Artificial Intelligence
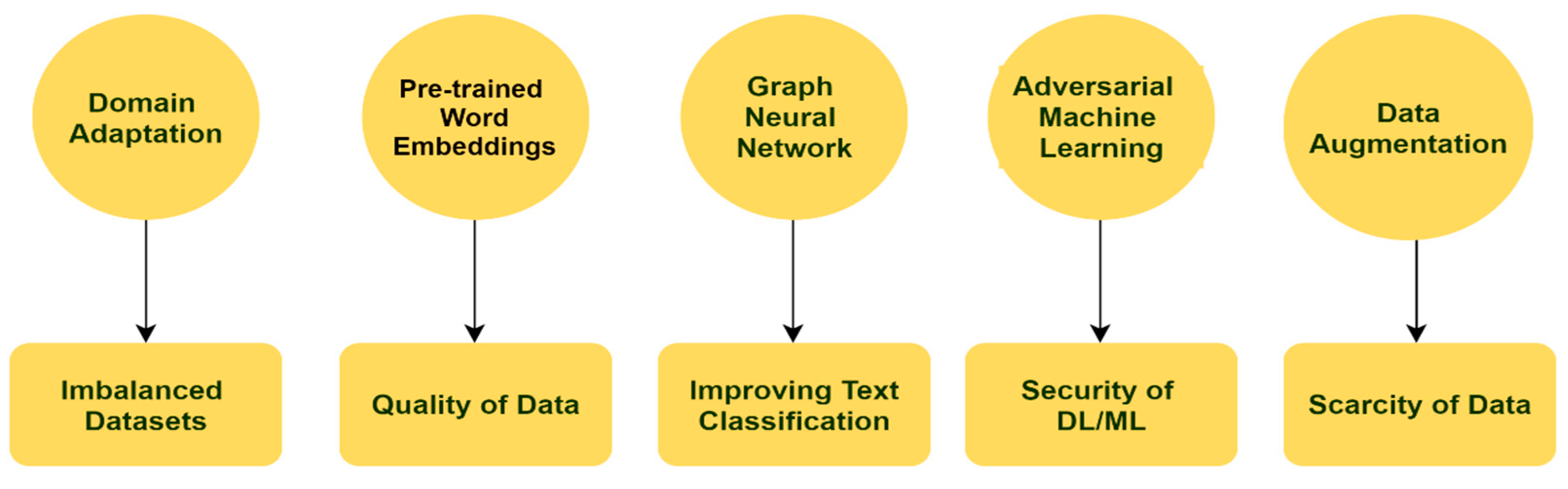
- Imbalanced Datasets—Problems with presently available datasets are limited labeled data, domain-dependent datasets, and imbalanced datasets. Solutions to these problems are domain adaptation and transfer learning. In domain adaptation, the deep learning model is trained in one kind of environment and tested in a different environment. Another possible solution is semi-supervised machine learning or deep learning algorithms.
- Accuracy of Existing systems/Models—Ensemble methods with deep learning models can be used to improve existing systems’ performance, and accuracy. Ensemble learning combines the predictions from multiple neural network models. Moreover, performance can be improved by training models on large, domain-specific datasets.
- Quality of data (Slang words/Emoticons)—A major problem with online social media texts are the use of informal language by users like sarcasm, irony, misspellings, grammatical mistakes, hashtags, emoticons, etc. Pretrained word embeddings or transformer-based word embeddings can be used to solve these problems.
- Improving Text classification—One more problem is text classification, where deep learning techniques like Graph Neural Network (GNN) can be used to improve text classification.
- Security of Machine Learning/Deep Learning Models—Another issue is the security of machine learning or deep learning models. The solution to this is adversarial machine learning. The machine learning algorithm is provided with malicious input that is misrepresentative or inaccurate data to misguide the algorithm to verify the algorithm’s security.
- Scarcity of labeled/annotated data—Deep learning is hungry for data. However, it requires a large amount of data to train the deep learning models. Therefore, more data can produce better performance in deep learning models. Unavailability of labeled data can be solved with data augmentation techniques. Data augmentation techniques like back translation or a thesaurus can be used to solve the scarcity of data.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Global Socially-Led Creative Agency-We Are Social. Available online: www.wearesocial.com (accessed on 30 March 2021).
- Acheampong, F.A.; Wenyu, C.; Nunoo-Mensah, H. Text-based emotion detection: Advances, challenges, and opportunities. Eng. Rep. 2020, 2, 12189. [Google Scholar] [CrossRef]
- Alswaidan, N.; Menai, M.E.B. A survey of state-of-the-art approaches for emotion recognition in text. Knowl. Inf. Syst. 2020, 62, 2937–2987. [Google Scholar] [CrossRef]
- Chaturvedi, I.; Cambria, E.; Cavallari, S.; Welsch, R.E. Genetic Programming for Domain Adaptation in Product Reviews. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Topal, K.; Ozsoyoglu, G. Movie review analysis: Emotion analysis of IMDb movie reviews. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016; pp. 1170–1176. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, X.; Chan, J.; Rosso, P. Irony detection via sentiment-based transfer learning. J. Inf. Process. Manag. 2018, 56, 1633–1644. [Google Scholar] [CrossRef]
- Chronopoulou, A.; Baziotis, C.; Potamianos, A. An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models. In Proceedings of the 2019 Conference of the North, Rockhampton, QLD, Australia, 16–19 January 2019. [Google Scholar]
- Basile, A.; Franco-Salvador, M.; Pawar, N.; Štajner, S.; China Rios, M.; Benajiba, Y. Combined neural models for emotion clas-sification in human chatbot conversations. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 330–334. [Google Scholar]
- Patil, S.; Joshi, S. Demystifying User Data Privacy in the World of IOT. Regul. Issue 2019, 8, 4412–4418. [Google Scholar] [CrossRef]
- Patil, S.G.; Joshi, S.; Patil, D. Enhanced Privacy Preservation Using Anonymization in IOT-Enabled Smart Homes. In Intelligent Decision Technologies 2016; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2019; pp. 439–454. [Google Scholar]
- Shaikh, A.; Patil, S. A survey on privacy enhanced role-based data aggregation via differential pri-vacy. In Proceedings of the 2018 International Conference on Advances in Communication and Computing Technology (ICACCT), Sangamner, India, 8–9 February 2018; pp. 285–290. [Google Scholar]
- Plutchik, R. A General Psycho Evolutionary Theory of Emotion; Elsevier: Amsterdam, The Netherlands, 1980; pp. 3–33. [Google Scholar]
- Lugovic, S.; Dunder, I.; Horvat, M. Techniques and applications of emotion recognition in speech. In Proceedings of the 2016 39th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 30 May–3 June 2016; pp. 1278–1283. [Google Scholar]
- Ekman, P. Basic emotions. Handb. Cogn. Emot. 1999, 98, 16. [Google Scholar]
- Colby, B.N.; Ortony, A.; Clore, G.L.; Collins, A. The Cognitive Structure of Emotions. Contemp. Sociol. A J. Rev. 1989, 18, 957. [Google Scholar] [CrossRef]
- Russell, J.A. A circumplex model of affect. J. Pers. Soc. Psychol. 1980, 39, 1161. [Google Scholar] [CrossRef]
- Russell, J.A.; Mehrabian, A. Evidence for a three-factor theory of emotions. J. Res. Pers. 1977, 11, 273–294. [Google Scholar] [CrossRef]
- Scherer, K.R. Appraisal theory. In Handbook of Cognition and Emotion; Dalgleish, T., Power, M.J., Eds.; Wiley: New York, NY, USA, 2005; pp. 637–663. [Google Scholar]
- Balahur, A.; Hermida, J.M.; Montoyo, A. Building and Exploiting EmotiNet, a Knowledge Base for Emotion Detection Based on the Appraisal Theory Model. IEEE Trans. Affect. Comput. 2011, 3, 88–101. [Google Scholar] [CrossRef]
- Carlo, S.; Alessandro, W. WordNet-Affect: An Affective Extension of WordNet. In Proceedings of the Fourth International Conference on Language Resources and Evaluation (LREC’04). 2004, Volume 4. Available online: http://www.lrec-conf.org/proceedings/lrec2004/pdf/369.pdf (accessed on 11 May 2021).
- Fellbaum, C. WordNet. In Theory and Applications of Ontology: Computer Applications; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2010; pp. 231–243. [Google Scholar]
- Tao, J. Context-based emotion detection from text input. In Proceedings of the 8th International Conference on Spoken Language Processing (ICSLP), Jeju Island, Korea, 4–8 October 2004; pp. 1337–1340. [Google Scholar]
- Ma, C.; Prendinger, H.; Ishizuka, M. Emotion estimation and reasoning based on affective textual interaction. In Affective Computing and Intelligent Interaction; Tao, J., Tieniu, T., Picard, R.W., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 622–628. [Google Scholar]
- Perikos, I.; Hatzilygeroudis, I. Recognizing emotion presence in natural language sentences. In Engineering Applications of Neural Networks; Iliadis, L., Papado-poulos, H., Jayne, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 30–39. [Google Scholar]
- Shivhare, S.N.; Garg, S.; Mishra, A. EmotionFinder: Detecting emotion from blogs and textual documents. In Proceedings of the International Conference on Computing, Communication & Automation, Greater Noida, India, 15–16 May 2015; pp. 52–57. [Google Scholar]
- Lee, S.Y.M.; Chen, Y.; Huang, C.R. A text-driven rule-based system for emotion cause detection. In Proceedings of the NAACLHLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, CAA-GET’10; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 45–53. [Google Scholar]
- Udochukwu, O.; He, Y. A rule-based approach to implicit emotion detection in text. In Natural Language Processing and Information Systems. Lecture Notes in Computer Science; Biemann, C., Handschuh, S., Freitas, A., Meziane, F., Métais, E., Eds.; Springer: Cham, Switzerland, 2015; pp. 197–203. [Google Scholar]
- Nina, R.; Aleksandra, R. Business Sentiment Analysis. Concept and Method for Perceived Anticipated Effort Identification. In Proceedings of the 28th International Conference on Information Systems Development (ISD2019), Toulon, France, 28–30 August 2019. [Google Scholar]
- Kolekar, N.V.; Rao, G.; Dey, S.; Mane, M.; Jadhav, V.; Patil, S. Sentiment analysis and classification using lexi-con-based approach and addressing polarity shift problem. J. Theor. Appl. Inf. Technol. 2016, 90, 118–125. [Google Scholar]
- Aman, S.; Szpakowicz, S. Identifying Expressions of Emotion in Text. In Proceedings of the Text, Speech and Dialogue; Springer International Publishing: Berlin/Heidelberg, Germany, 2007; pp. 196–205. [Google Scholar]
- Ghazi, D.; Inkpen, D.; Szpakowicz, S. Hierarchical versus flat classification of emotions in text. In Proceedings of the NAACLHLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, CAAGET’10, Los Angeles, CA, USA, 5 June 2010; pp. 140–146. [Google Scholar]
- De Bruyne, L.; De Clercq, O.; Hoste, V. LT3 at SemEval-2018 task 1: A classifier chain to detect emotions in tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 123–127. [Google Scholar]
- Suhasini, M.; Srinivasu, B. Emotion Detection Framework for Twitter Data Using Supervised Classifiers; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2020; pp. 565–576. [Google Scholar]
- Singh, L.; Singh, S.; Aggarwal, N. Two-stage text feature selection method for human emotion recognition. In Proceedings of 2nd International Conference on Communication, Computing and Networking, Lecture Notes in Networks and Systems; Springer: Singapore, 2019; Volume 46, pp. 531–538. [Google Scholar]
- Allouch, M.; Azaria, A.; Azoulay, R.; Ben-Izchak, E.; Zwilling, M.; Zachor, D.A. Automatic Detection of Insulting Sentences in Conversation. In Proceedings of the 2018 IEEE International Conference on the Science of Electrical Engineering in Israel (ICSEE), Eilat, Israel, 12–14 December 2018; Volume 2018, pp. 1–4. [Google Scholar]
- Baziotis, C.; Pelekis, N.; Doulkeridis, C. DataStories at SemEval-2017 Task 4: Deep LSTM with Attention for Message-Level and Topic-based Sentiment Analysis. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 747–754. [Google Scholar]
- Ezen-Can, A.; Can, E.F. RNN for Affects at SemEval-2018 Task 1: Formulating Affect Identification as a Binary Classification Problem. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 162–166. [Google Scholar]
- Shrivastava, K.; Kumar, S.; Jain, D.K. An effective approach for emotion detection in multimedia text data using se-quence-based convolutional neural network. Multimed. Tools Appl. 2019, 78, 29607–29639. [Google Scholar] [CrossRef]
- Xiao, J. Figure Eight at SemEval-2019 Task 3: Ensemble of Transfer Learning Methods for Contextual Emotion Detection. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 220–224. [Google Scholar]
- Rathnayaka, P.; Abeysinghe, S.; Samarajeewa, C.; Manchanayake, I.; Walpola, M.J.; Nawaratne, R.; Bandaragoda, T.; Alahakoon, D. Gated recurrent neural network approach for multi-label emotion detection in microblogs. arXiv 2019, arXiv:1907.07653. [Google Scholar]
- Krommyda, M.; Rigos, A.; Bouklas, K.; Amditis, A. An Experimental Analysis of Data Annotation Methodologies for Emotion Detection in Short Text Posted on Social Media. Informatics 2021, 8, 19. [Google Scholar] [CrossRef]
- Kratzwald, B.; Ilić, S.; Kraus, M.; Feuerriegel, S.; Prendinger, H. Deep learning for affective computing: Text-based emotion recognition in decision support. Decis. Support Syst. 2018, 115, 24–35. [Google Scholar] [CrossRef] [Green Version]
- Choudrie, J.; Patil, S.; Kotecha, K.; Matta, N.; Pappas, I. Applying and Understanding an Advanced, Novel Deep Learning Approach: A Covid 19, Text Based, Emotions Analysis Study. Inf. Syst. Front. 2021, 1–35. [Google Scholar] [CrossRef]
- Scherer, K.R.; Wallbott, H.G. Evidence for universality and cultural variation of differential emotion response patterning. J. Pers. Soc. Psychol. 1994, 66, 310–328. [Google Scholar] [CrossRef]
- Alm, E.C.O. Affect in Text and Speech. Citeseer; The University of Illinois at Urbana-Champaign: Urbana, IL, USA, 2008. [Google Scholar]
- Rosenthal, S.; Farra, N.; Nakov, P. SemEval-2017 task 4: Sentiment analysis in Twitter. arXiv 2019, arXiv:1912.00741. [Google Scholar]
- Ghazi, D.; Inkpen, D.; Szpakowicz, S. Detecting Emotion Stimuli in Emotion-Bearing Sentences. Lect. Notes Comput. Sci. 2015, 2015, 152–165. [Google Scholar] [CrossRef]
- Mohammad, S.; Bravo-Marquez, F. WASSA-2017 Shared Task on Emotion Intensity. In Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Copenhagen, Denmark, 8 September 2017. [Google Scholar]
- Buechel, S.; Hahn, U.; Schneider, N.; Xue, N. Readers vs. Writers vs. Texts: Coping with Different Perspectives of Text Understanding in Emotion Annotation. In Proceedings of the 11th Linguistic Annotation Workshop, Valencia, Spain, 3 April 2017; Volume 2017, pp. 1–12. [Google Scholar]
- Preoţiuc-Pietro, D.; Schwartz, H.A.; Park, G.; Eichstaedt, J.; Kern, M.; Ungar, L.; Shulman, E. Modelling Valence and Arousal in Facebook posts. In Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, San Diego, CA, USA, 16 June 2016; Volume 2016, pp. 9–15. [Google Scholar]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. MELD: A multimodal multi-party dataset for emo-tion recognition in conversations. arXiv 2018, arXiv:1810.02508. [Google Scholar]
- Demszky, D.; Movshovitz-Attias, D.; Ko, J.; Cowen, A.; Nemade, G.; Ravi, S. GoEmotions: A Dataset of Fine-Grained Emotions. In Proceedings of the Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online. 5–10 July 2020; pp. 4040–4054. [Google Scholar]
- Kumar, S.; Patil, S.; Bongale, A.; Kotecha, K.; Bongale, A.K.M. Demystifying Artifificial Intelligence Based Digital Twins in Manufacturing-A Bibliometric Analysis of Trends and Techniques. Available online: https://digitalcommons.unl.edu/libphilprac/4541/ (accessed on 11 May 2021).
- Zeynu, S.; Patil, S. Survey on prediction of chronic kidney disease using data mining classification techniques and feature selection. Int. J. Pure Appl. Math. 2018, 118, 149–156. [Google Scholar]
- VOSviewer. Available online: www.vosviwer.com (accessed on 5 April 2021).
- van Eck, N.J.; Waltman, L. Visualizing Bibliometric Networks, in Measuring Scholarly Impact: Methods and practice. In Measuring Scholarly Impact; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Ortega, M.G.S.; Rodríguez, L.-F.; Gutierrez-Garcia, J.O. Towards emotion recognition from contextual information using machine learning. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 3187–3207. [Google Scholar] [CrossRef]
- Lai, Y.; Zhang, L.; Han, D.; Zhou, R.; Wang, G. Fine-grained emotion classification of Chinese microblogs based on graph convolution networks. World Wide Web 2020, 23, 2771–2787. [Google Scholar] [CrossRef]
- Acheampong, F.A.; Nunoo-Mensah, H.; Chen, W. Transformer models for text-based emotion detection: A review of BERT-based approaches. Artif. Intell. Rev. 2021, 1–41. [Google Scholar] [CrossRef]
- Huang, C.; Trabelsi, A.; Zaïane, O. ANA at SemEval-2019 Task 3: Contextual Emotion detection in Conversations through hierarchical LSTMs and BERT. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019. [Google Scholar]
- Huang, Y.-H.; Lee, S.-R.; Ma, M.-Y.; Chen, Y.-H.; Yu, Y.-W.; Chen, Y.-S. EmotionX-IDEA: Emotion BERT–An affectional model for conversation. arXiv 2019, arXiv:1908.06264. [Google Scholar]
- Mohammad, S.; Bravo-Marquez, F. Emotion Intensities in Tweets. In Proceedings of the 6th Joint Conference on Lexical and Computational Semantics (*SEM 2017), Vancouver, BC, USA, 3–4 August 2017. [Google Scholar]
- Bouazizi, M.; Ohtsuki, T.O. A Pattern-Based Approach for Sarcasm Detection on Twitter. IEEE Access 2016, 4, 5477–5488. [Google Scholar] [CrossRef]
- Rendalkar, S.; Chandankhede, C. Sarcasm Detection of Online Comments Using Emotion Detection. In Proceedings of the 2018 International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 11–12 July 2018; pp. 1244–1249. [Google Scholar]
- Majumder, N.; Poria, S.; Peng, H.; Chhaya, N.; Cambria, E.; Gelbukh, A. Sentiment and Sarcasm Classification with Multitask Learning. IEEE Intell. Syst. 2019, 34, 38–43. [Google Scholar] [CrossRef] [Green Version]
- Rajadesingan, A.; Zafarani, R.; Liu, H. Sarcasm Detection on Twitter. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Huston, TX, USA, Shanghai, China, 31 January–6 February 2015; pp. 97–106. [Google Scholar]
- Kumar, A.; Garg, G. Empirical study of shallow and deep learning models for sarcasm detection using context in benchmark datasets. J. Ambient. Intell. Humaniz. Comput. 2019. [Google Scholar] [CrossRef]
- Ahanin, Z.; Ismail, M.A. Feature extraction based on fuzzy clustering and emoji embeddings for emotion classification. Int. J. Tech. Manag. Inf. Syst. 2020, 2, 102–112. [Google Scholar]
- Huang, F.; Li, X.; Yuan, C.; Zhang, S.; Zhang, J.; Qiao, S. Attention-Emotion-Enhanced Convolutional LSTM for Sentiment Analysis. IEEE Trans. Neural Networks Learn. Syst. 2021, 1–14. [Google Scholar] [CrossRef]
- Kouw, W.M.; Loog, M. An introduction to domain adaptation and transfer learning. arXiv 2019, arXiv:1812.11806v2. [Google Scholar]
- Ahmad, Z.; Jindal, R.; Ekbal, A.; Bhattachharyya, P. Borrow from rich cousin: Transfer learning for emotion detection using cross lingual embedding. Expert Syst. Appl. 2020, 139, 112851. [Google Scholar] [CrossRef]
- Li, H.; Guevara, N.; Herndon, N.; Caragea, D.; Neppalli, K.; Caragea, V.; Squicciarini, A.; Tapia, A.H. Twitter Mining for Disaster Response: A Domain Adaptation Approach, Short Paper–Social Media Studies. In Proceedings of the 12th International Conference on Information Systems for Crisis Response and Management, Kristiansand, Norway, 24–27 May 2015. [Google Scholar]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef] [Green Version]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application Domain | Details | References |
|---|---|---|
| Product Reviews | Emotion detection on Amazon product reviews for different products and in different languages using deep learning techniques. | [4] |
| Movie Review | Introduced the concept of movie emotion maps based on movie reviews using machine learning techniques. | [5] |
| Social Media | Proposed a model based on transfer learning and attention-based neural network, used to identify context inconsistency for detecting irony in Twitter. | [6] |
| Discussion Forum | Proposed simple transfer learning approach using pre-trained models for text classification tasks. | [7] |
| Chatbots/ Conversational systems | Developed a model to detect English textual conversations between a chatbot and a human using deep learning techniques. | [8] |
| Paper | Emotion Model | Dataset | Algorithm/Technique/ Method | Objective | Advantages | Disadvantages | Evaluation Measures (%) | Emotions Detected |
|---|---|---|---|---|---|---|---|---|
| Public Monitoring | ||||||||
| [22] (2004) | Categorical Emotion Model— OCC Model | Speech corpus | Keyword-based Approach | Emotion Detection for Chinese dataset | Simple Approach | Many mis- labeled emotions | NA | Joy, Fear, Anger, Hate, Sadness, Surprise |
| [24] (2013) | Categorical Emotion Model— Ekman Model | Self- created | Keyword-based approach, Sentence Splitting, Sentence dependency graph | Detect emotional state of sentence | Specify the emotional word strength. | Used self-corpus. can be extended to detect complex emotions | NA | Happiness, Anger, Sadness, Disgust, Fear, Surprise |
| [34] (2019) | Categorical Emotion Model— Ekman Model | ISEAR | Machine Learning approach, Used Chi-square, and POS tagger, SVM classification | Recognize the human emotions from the unstructured text documents | Solved the long-standing semantic extraction problem, Performance improvement | Ignored relation between features | 72.43 (Accuracy) | Happiness, Sadness, Anger, Fear, Disgust, Surprise |
| [28] (2020) | -- | Self- Created | Rule based approach with unsupervised machine learning algorithm | Presented a concept of business sentiment to interpret the contextual intricacy of business process worker | Used valence rules based on semantic and syntactic information. Improved performance | Small dataset used | NA | Positive, Neutral, Negative. |
| [43] (2021) | -- | CrowdFlower | Advanced deep learning based RoBERTa model | To study emotions expressed by people in early months of Covid-19 | Performance improvement | Limited hashtags used for data collection. Limited period data used. | 80.33 (Accuracy) | happiness, fear anger, anxiety, joy, sadness |
| Chatbots/Conversational Systems | ||||||||
| [23] (2005) | Categorical Emotion Model— Ekman Model | Chat system | Keyword Spotting technique at Sentence Level | Emotion recognition from the text-based chat system | Easy Approach | Weak strategy used for negation | NA | Happiness, Anger, Sadness, Fear, Disgust, Surprise |
| [8] (2019) | -- | SemEval-2019 | BERT, USE, Bi-LSTM with deep attention process at the sentence level. | To detect emotions conversations between a human and a Chatbot | Use of different deep learning sub-models | Accuracy for happy is smaller than angry, sad | 77.00 (F-Score) | Sad, Happy, Angry, and Others |
| [39] (2019) | -- | SemEval-2019 | Deep Learning approach, Pretrained language models ULMFiT, BERT, OpenAI’s GPT | The proposed approach for contextual emotion detection | Informal writing considered in preprocessing, Use of semantic information | Accuracy for happy is smaller than angry, sad | 76.86 (F-Score)) | Happy, Sad, Angry, Or Others |
| [35] (2018) | -- | Manually built | Machine Learning approach, Classifiers SVM, decision tree, NB, and the tree bagger | Proposed a system to aid children to detect insulting words | SVM provided the highest accuracy. | Ignoring contextual information resulted in misclassification. -No semantic representation in the model. | 76.9 (Accuracy) | Clearly Insulting Clearly Non- Insulting, Sentences - Insulting Or Non-Insulting |
| Social Media | ||||||||
| [25] (2015) | Categorical Emotion Model— Parrot Model | Blogs | Ontology, hierarchy based with keyword spotting technique | Detect emotions from blogs and textual documents | Improved accuracy as compared to other techniques | -Does not overcome all limitations. -No use of semantic information | 79.75 (Accuracy) | Love, Anger, Sadness, Joy, Fear, Surprise, |
| [26] (2010) | Dimensional Emotion Model Turner’s Model | Sina Weibo | Linguistic Rule-Based | Rule-based emotion cause detection for Chinese microblogging site | Linguistic rules constructed | Showed poor performance | 47.95 (F-Score) | Anger, Fear, Happiness, Sadness, Surprise. |
| [27] (2015) | Categorical Emotion Model— OCC Model | ISEAR, SemEval-2007, Alm | Rule-Based Approach using lexicon and syntactic information. | Detect implicit emotions | Syntactic and lexicon Information used | Sensitive to the content of the text, Poor performance for Emotion Label—Fear | 51.3/57.3/65.5 (F-Score) | Joy/Happy, Fear/Fearful, Anger/Angry- Disgusted sadness/Sad, Disgust |
| [30] (2007) | Categorical Emotion Model— Ekman Model | Aman | Machine Learning approach, Naïve Bayes and SVM Algorithm | Emotion detection on a corpus of the blog post | -Used emoticons information -SVM performed better | Did not use semantic, syntactic, features | 73.89 (Accuracy) | Happiness, Anger, Sadness, Surprise, Disgust, Fear |
| [31] (2010) | Categorical Emotion Model— Ekman Model | Aman | Machine Learning approach, Hierarchical approach 2-Level, and 3-Level, SVM Algorithm | Proposed a hierarchical approach for highly imbalanced structure datasets | -Reduced influence of the class size on performance -Hierarchical is better than flat class | Did not utilize semantic, syntactic, features | 50.86 (F-Score) | Happiness, Anger Sadness, Disgust, Fear, Surprise |
| [33] (2020) | Dimensional Emotion model— Russell’s Circumplex Model | Twitter (Sentiment 140) | NB and K-NN Machine Learning techniques. | Proposed a system to detect expressed emotions based on their tweets | NB showed high accuracy compared to KNN. | Contextual information extraction in sentences is low | 72.06 (Accuracy) | Happy-Active Class Happy-Inactive Class Unhappy-Active Class Unhappy-Inactive Class |
| [32] (2018) | Categorical Emotion Model— Ekman Model | SemEval-2018 | Machine Learning algorithms SVM, linear SVM, logistic regression, and RF | Developed a multi-class emotion classification system for English tweets | -Utilized broad range of features -For each feature, a customized model built. | Unbalanced data set impacted performance | 52.00 (Jaccard Accuracy) | Anger, fear, joy, disgust, surprise, pessimism, trust, love anticipation, sadness, optimism |
| [36] (2017) | -- | SemEval-2018 | Deep Learning approach, Bi-LSTM with deep attention mechanism at Message Level and Topic Level | Multi-label emotion detection in English tweets | -The vocabulary and expressions preservation, spell correction performed | Out-of-vocabulary words problem | 58.80 (Jaccard Accuracy) | Positive, Negative, Neutral |
| [37] (2018) | Categorical Emotion Model | SemEval-2018 | Deep Learning approach using Bi-GRU | Proposed multi binary classification to model various affective categories of Twitter post | Use of binary models to handle unbalanced data. Use of emoji embeddings | No use of affect lexicons | 39.80 (Jaccard Accuracy) | Fear, Anger, Joy, Surprise, Disgust, Pessimism, Trust, Love Anticipation, Sadness, Optimism. |
| [40] (2019) | -- | SemEval-2018 | Deep learning approach using Bi-GRU with pyramid attention network | Proposed emotion detection in microblogs using Pyramid Attention Network based model | Capture multiple emotions in a single text. Use of semantics and context features | Low recognition of understated classes | 58.90 (F-Score) | Anger, Trust, Joy Fear, Anticipation, Disgust, Optimism, Love, Sadness, Surprise, Pessimism |
| [41] (2021) | Dimensional Emotion Model—Plutchik’s Wheel of Emotions | Tweets_ Annotated _to_ emotions | Deep learning and Machine learning approach using LSTM, SVM-SGD XGBoost, Naive Bayes, Decision Tree, Random forest | To detect the emotions in a short text post from Online Social Media | Fully annotated dataset created for Tweets | Accuracy of anticipation, trust emotions low compared to other emotions. | 91.9 (Accuracy) | Anger, Joy, Trust, Fear, Disgust, Sadness, Surprise, Anticipation |
| [19] (2012) | Componential Emotion Model— Appraisal Model | ISEAR SemEval – 2007 | Deep Learning approach using LSTM | Presented a new knowledge base—EmotiNet for storing and representing affective reaction and evaluated the same using deep learning algorithms | Appraisal based model proved flexible in terms of accuracy | Limited in domain knowledge | 42.2 (Precision) | Anger, Disgust, Guilt, Fear, Sadness, Joy, And Shame |
| [42] (2018) | Categorical Emotion Model and Dimensional Emotion Model | Alm, ISEAR, | Machine learning algorithms, Random Forest, SVM, and Deep Learning technique Bi-LSTM with pre-trained models | Proposed text-based emotion detection in decision support systems using multi-class classification | Performance improvement over traditional methods | The system evaluated on the small dataset | 23.2 (F-Score) | Joy, Trust, Sadness, Disgust, Fear, Anger, Anticipation, Surprise |
| [29] (2016) | -- | Reviews from customized shopping portal | Machine learning with bag-of-words (BoW) model | Proposed a system to classify sentiments in product reviews | Addressed polarity shift problem by using modifying negations | Used customized dataset | -- | Positive, Negative, Neutral |
| Multimedia Systems | ||||||||
| [38] (2019) | Categorical Emotion Model— Ekman Model | TV transcript | Deep Learning approach using Convolutional neural networks with max pooling. | Detecting emotions in multimedia text | Learning semantics and context features | Ambiguity between classes like anger and disgust, happiness and surprise | 72.48 (F-Score) | Happiness, Fear, Sadness, Anger, Disgust, Surprise |
| Sr. No. | Emotion Datasets | Collection Platform Used | Emotions Labeled | Link |
|---|---|---|---|---|
| 1 | ISEAR (1997) [44] | Obtained in cross-cultural studies from 37 countries | Joy, Fear, Anger, Guilt, Sadness, Shame, And Disgust | https://www.kaggle.com/shrishrivas/isears-dataset (accessed on 5 July 2021) |
| 2 | Cecilia Oves dotter Alm’s Affect data (2005) [45] | Constructed from story Tales | Angry, Fearful, Sad, Happy, Surprise, And Disgusted | http://people.rc.rit.edu/~coagla/affectdata/index.html (accessed on 5 July 2021) |
| 3 | Crowdflower (2007) | Constructed from 40,000 tweets | Surprise, Sadness, Happiness, Fun, Anger, Love, Worry, Boredom, Hate, Relief Enthusiasm, Neutral, Empty | https://www.crowdflower.com/wpcontent/uploads/2016/07/text_emotion.csv (accessed on 6 July 2021) |
| 4 | SemEval (2012) [46] | Three variations according to data from google news, news headlines, major newspapers, tweets, conversations | Joy, Sadness, Fear, Anger, Surprise, Disgust | http://web.eecs.umich.edu/~mihalcea/downloads.html (accessed on 6 July 2021) |
| 5 | Emotion-Stimulus data (2015) [47] | Contains 1594 emotion-labeled sentences, Frame Nets’ annotated data. | Joy, Sadness, Fear, Anger, Surprise, Disgust | http://www.site.uottawa.ca/~diana/resources/emotion_stimulus_data (accessed on 5 July 2021) |
| 6 | Aman (2016) [30] | Constructed from blog posts | Happiness, Disgust, Sadness, Fear, Anger, Surprise, No Emotion, Mixed Emotion | Available on request |
| 7 | WASSA-2017 [48] | Constructed from tweets | Joy, Sadness, Fear, And Anger | http://saifmohammad.com/WebPages/EmotionIntensity-SharedTask.html (accessed on 6 July 2021) |
| 8 | Emobank (2017) [49] | News headline, blogs, newspapers, essays, fiction, travel guides, and letters | Joy, Fear, Sadness, Anger, Surprise, Disgust | https://github.com/JULIELab/EmoBank (accessed on 6 July 2021) |
| 9 | The Valence and Arousal Facebook data (2018) [50] | Built from 2895 Facebook posts | Joy, Fear, Sadness, Anger, Surprise, Disgust | http://wwbp.org/downloads/public_data/dataset-fb-valence-arousal-anon.csv (accessed on 6 July 2021) |
| 10 | MELD dataset (2018) [51] | Friends TV show’s dialogues and utterances were used to compile this dataset. | Joy, Fear, Anger, Sadness, Disgust, Surprise, Neutral | https://github.com/SenticNet/MELD (accessed on 7 July 2021) |
| 11 | GoEmotions (2020) [52] | 58k carefully curated comments extracted from | Amusement, Disgust, Remorse, Sadness, Admiration, Grief, Anger, Gratitude, Love, Pride, Annoyance, Approval, Caring, Confusion, Desire, Optimism, Disappointment, Disapproval, Embarrassment, Excitement, Curiosity, Fear, Joy, Nervousness, Realization, Relief, Surprise, | https://github.com/google-research/google-research/tree/master/goemotions (accessed on 7 July 2021) |
| Search Query | “Text-Based*” AND “Artificial Intelligence*” OR “Deep Learning*” OR “Machine Learning*” OR “Natural Language Processing*.” AND “Emotion Detection*” OR “Sentiment analysis*” OR “Emotion Analysis*” OR “Emotion Recognition*” OR “Chatbots,” OR “Conversational agents*” OR “Social Media*” OR “Twitter” OR “Facebook” OR “Reddit” OR “Instagram” OR “Reviews” | |
| Scopus 1011 | Web of Science 234 | |
| Selection Criteria | Paper Language—English Document Types—Conference Paper, Article, Review, Conference Review Publication Years—2005 to 2021 Research Areas—Computer Science, Engineering, Psychology, Decision Sciences, Social Sciences | |
| Scopus 827 | Web of Science 83 | |
| Removing Duplicates | Total 910 Duplicates 08 | |
| Publications for analysis | Combined from Scopus and Web of Science 902 | |
| Publication Language | Scopus | Web of Science |
|---|---|---|
| English | 827 | 83 |
| Chinese | 20 | 2 |
| Portuguese | 1 | - |
| Slovenian | 1 | - |
| Spanish | 1 | - |
| Turkish | 1 | 3 |
| Korean | - | 4 |
| Russian | - | 1 |
| Publication Type | Scopus | Web of Science |
|---|---|---|
| Conference Paper | 454 | - |
| Article | 231 | 83 |
| Conference Review | 131 | - |
| Review | 11 | - |
| Year | Publication Count N (%) | |
|---|---|---|
| Scopus (N = 827) | Web of Science (N = 83) | |
| 2005 | 2 (0.24) | - |
| 2006 | 3 (0.36) | 1 (1.20) |
| 2007 | 5 (0.60) | - |
| 2008 | 6 (0.72) | 2 (2.40) |
| 2009 | 9 (1.08) | - |
| 2010 | 14 (1.69) | 1 (1.20) |
| 2011 | 15 (1.81) | 1 (1.20) |
| 2012 | 21 (2.53) | 1 (1.20) |
| 2013 | 27 (3.26) | 4 (4.81) |
| 2014 | 31 (3.74) | 2 (2.40) |
| 2015 | 40 (4.83) | 4 (4.81) |
| 2016 | 55 (6.65) | 7 (8.43) |
| 2017 | 55 (6.65) | 8 (9.63) |
| 2018 | 97 (11.72) | 12 (14.45) |
| 2019 | 127 (15.35) | 15 (18.07) |
| 2020 | 160 (19.34) | 23 (27.71) |
| 2021 | 184 (22.24) | 4 (4.81) |
| Country | Scopus | WOS |
|---|---|---|
| India | 145 | 9 |
| United States | 134 | 20 |
| China | 120 | 39 |
| United Kingdom | 40 | 4 |
| Italy | 31 | 2 |
| Canada | 23 | 2 |
| Spain | 23 | 2 |
| Taiwan | 21 | 2 |
| Germany | 20 | 2 |
| Japan | 18 | 8 |
| Australia | 17 | 5 |
| South Korea | 16 | 3 |
| Pakistan | 11 | 6 |
| Singapore | 11 | 4 |
| Bangladesh | 13 | 1 |
| Subject Area | Scopus | Web of Science | Total |
|---|---|---|---|
| Computer Science | 750 | 74 | 824 |
| Decision Sciences | 86 | - | 86 |
| Engineering | 266 | 27 | 293 |
| Psychology | 12 | 4 | 16 |
| Social Sciences | 66 | 10 | 76 |
| Funding Agencies | Scopus | WOS |
|---|---|---|
| National Natural Science Foundation of China | 49 | 16 |
| European Commission | 16 | 2 |
| National Science Foundation | 18 | 3 |
| Ministry of Education China | 11 | 1 |
| Ministry of Science and Technology Taiwan | 5 | 2 |
| Japan Society for The Promotion of Science | 2 | 3 |
| Economic Social Research Council | 3 | 1 |
| National Basic Research Program of China | 2 | 1 |
| Rank | Source Titles | Publication Count, N (%) |
|---|---|---|
| 1 | IEEE access | 11(13.25) |
| 2 | Expert systems with applications | 3(3.61) |
| 3 | International journal of advanced computer science and applications | 3(3.61) |
| 4 | Journal of intelligent fuzzy systems | 3(3.61) |
| 5 | Journal of intelligent fuzzy systems applications in engineering and technology | 3(3.61) |
| 6 | Concurrency and computation practice experience | 2(2.41) |
| 7 | Empirical software engineering | 2(2.41) |
| 8 | IEEE transactions on affective computing | 2(2.41) |
| 9 | Information processing management | 2(2.41) |
| 10 | Information systems and e business management | 2(2.41) |
| Rank | Source Titles | Publication Count, N (%) |
|---|---|---|
| 1 | Lecture Notes in Computer Science | 130 (15.71) |
| 2 | Advances in Intelligent Systems and Computing | 40 (4.83) |
| 3 | Communications in Computer and Information Science | 30 (3.62) |
| 4 | ACM International Conference Proceeding Series | 19 (2.29) |
| 5 | Ceur Workshop Proceedings | 19 (2.29) |
| 6 | IEEE Access | 11 (1.33) |
| 7 | Procedia Computer Science | 9 (1.08) |
| 8 | Expert Systems with Applications | 7 (0.84) |
| 9 | International Journal of Innovative Technology and Exploring Engineering | 7 (0.84) |
| 10 | Information Systems and E Business Management | 6 (0.72) |
| Authors | Publication Title | No. of Citations |
|---|---|---|
| Thelwall M. et al. | Sentiment in short strength detection informal text | 1028 |
| Borth D. et al. | Large-scale visual sentiment ontology and detectors using adjective-noun pairs | 354 |
| Zhang L. et al. | Deep learning for sentiment analysis: A survey | 322 |
| Poria S. et al. | Sentic patterns: Dependency-based rules for concept-level sentiment analysis | 208 |
| Araque O. et al. | Enhancing deep learning sentiment analysis with ensemble techniques in social applications | 200 |
| Sun S. et al. | A review of natural language processing techniques for opinion mining systems | 197 |
| Kolosnjaji B. et al. | Deep learning for classification of malware system call sequences | 190 |
| Giatsoglou M. et al. | Sentiment analysis leveraging emotions and word embeddings | 141 |
| Bravo-Marquez F. et al. | Meta-level sentiment models for big social data analysis | 132 |
| Yadollahi A. et al. | The current state of text sentiment analysis from opinion to emotion mining | 127 |
| Keyword | Links | Total Link Strength | Occurrences | Keyword | Links | Total Link Strength | Occurrences |
|---|---|---|---|---|---|---|---|
| Deep Learning | 40 | 130 | 155 | Emotion Recognition | 16 | 14 | 18 |
| Machine Learning | 45 | 134 | 147 | Affective Computing | 14 | 16 | 16 |
| Natural Language Processing | 39 | 118 | 124 | Text Classification | 17 | 13 | 16 |
| Sentiment Analysis | 39 | 81 | 94 | 17 | 13 | 16 | |
| Artificial Intelligence | 34 | 81 | 89 | Big Data | 14 | 13 | 15 |
| Emotion Detection | 34 | 57 | 86 | Convolutional Neural Network | 15 | 12 | 14 |
| Text Mining | 24 | 37 | 41 | Data Mining | 18 | 13 | 14 |
| Social Media | 24 | 24 | 28 | Deep Neural Networks | 10 | 11 | 13 |
| Opinion Mining | 28 | 22 | 24 | Neural Network | 13 | 11 | 13 |
| Emotion | 19 | 14 | 18 | Emotion Analysis | 13 | 9 | 12 |
| Authors | Links | Documents | Authors | Links | Documents |
|---|---|---|---|---|---|
| Zhang L. | 8 | 12 | Zhou y. | 7 | 6 |
| Wang Y. | 13 | 8 | feng s. | 6 | 5 |
| Zhang Y. | 12 | 8 | Zhou g. | 9 | 5 |
| Li X. | 13 | 6 | li s. | 7 | 4 |
| Zhang J. | 8 | 6 | li z. | 4 | 4 |
| Year | Citation Count Scopus | Citation Count Web of Science |
|---|---|---|
| 2015 | 2730 | 58 |
| 2016 | 5997 | 67 |
| 2017 | 10744 | 80 |
| 2018 | 20155 | 123 |
| 2019 | 35939 | 212 |
| 2020 | 51655 | 290 |
| 2021 | 15754 | 80 |
| Title | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | Sub Total | >2015 | Total Citations |
|---|---|---|---|---|---|---|---|---|---|---|
| Ontology-based sentiment analysis of twitter posts | 25 | 22 | 23 | 32 | 26 | 21 | 8 | 157 | 10 | 167 |
| Author gender identification from text | 13 | 14 | 19 | 14 | 12 | 9 | 0 | 81 | 22 | 103 |
| A survey of multimodal sentiment analysis | 0 | 0 | 0 | 12 | 36 | 22 | 10 | 80 | 0 | 80 |
| Twitter user profiling based on text and community mining for market analysis | 12 | 9 | 10 | 13 | 9 | 6 | 2 | 61 | 4 | 65 |
| Sentiment analysis of Chinese micro-blog text based on extended sentiment dictionary | 0 | 0 | 0 | 6 | 19 | 27 | 4 | 56 | 0 | 56 |
| Title | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | Sub Total | >2015 | Total Citations |
|---|---|---|---|---|---|---|---|---|---|---|
| Sentiment in short strength detection informal text | 114 | 114 | 124 | 135 | 136 | 136 | 29 | 788 | 238 | 1026 |
| Relation classification via convolutional deep neural network | 24 | 63 | 89 | 135 | 199 | 190 | 29 | 729 | 0 | 729 |
| Big data deep learning: Challenges and perspectives | 15 | 42 | 67 | 113 | 149 | 120 | 38 | 544 | 0 | 544 |
| Deep neural nets as a method for quantitative structure-activity relationships | 6 | 33 | 45 | 84 | 104 | 118 | 37 | 427 | 0 | 427 |
| Large-scale visual sentiment ontology and detectors using adjective noun pairs | 41 | 60 | 51 | 50 | 71 | 50 | 12 | 335 | 19 | 354 |
| Deep learning for sentiment analysis: A survey | 0 | 0 | 0 | 10 | 101 | 150 | 57 | 318 | 0 | 318 |
| Sentic patterns: Dependency-based rules for concept-level sentiment analysis | 35 | 38 | 27 | 30 | 40 | 19 | 13 | 202 | 5 | 207 |
| Enhancing deep learning sentiment analysis with ensemble techniques in social applications | 0 | 0 | 4 | 26 | 64 | 82 | 23 | 199 | 0 | 199 |
| A review of natural language processing techniques for opinion mining systems | 0 | 0 | 10 | 42 | 55 | 69 | 20 | 196 | 1 | 197 |
| Deep learning for classification of malware system call sequences | 0 | 0 | 8 | 38 | 72 | 64 | 8 | 190 | 0 | 190 |
| Authors | Links | Citations | Authors | Links | Citations |
|---|---|---|---|---|---|
| Buckley K. | 22 | 1109 | Liu K. | 2 | 730 |
| Thelwall M. | 22 | 1109 | Zhao J. | 2 | 730 |
| Cai D. | 19 | 1026 | Dahl G.E. | 8 | 427 |
| Kappas A. | 19 | 1026 | Liaw A. | 8 | 427 |
| Paltoglou G. | 19 | 1026 | Ma J. | 8 | 427 |
| Source | Links | Citations | Year |
|---|---|---|---|
| Journal Of The American Society For Information Science And Technology | 12 | 1109 | 2011 |
| IEEE Access | 6 | 761 | 2019 |
| Expert Systems With Applications | 10 | 670 | 2015 |
| Lecture Notes In Computer Science In Artificial Intelligence | 21 | 579 | 2016 |
| Knowledge-Based Systems | 4 | 454 | 2013 |
| Journal Of Chemical Information And Modeling | 2 | 427 | 2015 |
| Wiley Interdisciplinary Reviews: Data Mining And Knowledge Discovery | 2 | 400 | 2017 |
| Information Fusion | 2 | 196 | 2017 |
| Communications In Computer And Information Science | 8 | 117 | 2017 |
| Authors | Links | Total Strength Links | Citations |
|---|---|---|---|
| Zhang L. | 127 | 115 | 397 |
| Balahur A. | 91 | 211 | 154 |
| Wang Y. | 41 | 25 | 104 |
| Zhang Y. | 96 | 146 | 55 |
| Cambria E. | 77 | 261 | 407 |
| Hermida J.M. | 87 | 194 | 145 |
| Li X. | 46 | 172 | 19 |
| Montoya A. | 86 | 173 | 147 |
| Zhang J. | 70 | 98 | 39 |
| Zhou Y. | 40 | 96 | 105 |
| Source | Links | Total Strength Links | Documents |
|---|---|---|---|
| Lecture Notes In Computer Science in Artificial Intelligence | 63 | 480 | 129 |
| Advances In Intelligent Systems And Computing | 52 | 201 | 39 |
| Communications In Computer And Information Science | 54 | 132 | 30 |
| IEEE Access | 58 | 130 | 22 |
| ACM International Conference Proceeding Series | 50 | 105 | 19 |
| Ceur Workshop Proceedings | 51 | 141 | 18 |
| Expert Systems With Applications | 42 | 43 | 10 |
| Procedia Computer Science | 27 | 38 | 8 |
| Lecture Notes In Electrical Engineering | 33 | 30 | 6 |
| Multimedia Tools And Applications | 28 | 16 | 6 |
| Countries | Links | Total Strength Links | Documents | Citations |
|---|---|---|---|---|
| United States | 40 | 1957 | 133 | 2949 |
| China | 39 | 1259 | 121 | 2077 |
| India | 39 | 950 | 144 | 768 |
| Italy | 37 | 494 | 30 | 248 |
| Canada | 38 | 486 | 22 | 955 |
| United Kingdom | 39 | 464 | 40 | 1321 |
| Singapore | 32 | 436 | 11 | 441 |
| Spain | 38 | 346 | 23 | 445 |
| Malaysia | 35 | 235 | 9 | 91 |
| Saudi Arabia | 37 | 235 | 9 | 50 |
| Challenges | Implemented Solutions | References |
|---|---|---|
| Failure to detect implicit emotions Failure to extract the semantic information Inefficient and Time-Consuming feature extraction and labeling Classifying emotions according to their intensities | Transformer-based word embeddings for contextual information extraction. Improving classification accuracies using Machine learning algorithms. Applying Deep Learning algorithms like GNNs for improving classification. Best-Worst Scaling (BWS) Annotation Scheme. | [35,57,58,59,60,61,62] |
| Detecting sarcasm | A pattern-based approach using Part-Of-Speech tags and No. of interjection words. A Deep Neural Network-based Multitask Learning System. | [63,64,65,66,67] |
| Affected by text quality—Slang Words, Irony | Transfer learning—Transferring the knowledge base to enhance limited annotated irony datasets. | [6,61] |
| Unrobustness of some techniques Improve the accuracy of existing systems by optimizing them. | Ensemble of attention-based Deep neural networks and fuzzy clustering. | [6,59,68] |
| Imbalanced Datasets. | Domain Adaptation—Training a model on labeled data from a source domain and testing an unlabeled target domain. Transfer Learning—Transferring knowledge from a Large dataset to a Small dataset, thus improving the system’s accuracy. Attention Based Deep Learning Techniques. | [7,36,69,70,71,72,73] |
| Sr. No. | Research Gap | Future Directions |
|---|---|---|
| 1 | Unavailability of ready datasets/corpora covering all aspects of the data. Further, this field is lacking labeled/annotated datasets. | Domain Adaptation Transfer Learning Multi-Modality |
| 2 | There is a need to expand the research domain to detect implicit emotions, mislabeled emotions, inefficient and time-consuming feature extraction tasks. | Transformer-based word embeddings Improving classification accuracies using machine learning algorithms and deep learning algorithms like GNN’s |
| 3 | Reinforcing robustness of some techniques/algorithms and improving the accuracy of existing systems by optimizing them. | Ensemble methods Deep Learning methods |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kusal, S.; Patil, S.; Kotecha, K.; Aluvalu, R.; Varadarajan, V. AI Based Emotion Detection for Textual Big Data: Techniques and Contribution. Big Data Cogn. Comput. 2021, 5, 43. https://doi.org/10.3390/bdcc5030043
Kusal S, Patil S, Kotecha K, Aluvalu R, Varadarajan V. AI Based Emotion Detection for Textual Big Data: Techniques and Contribution. Big Data and Cognitive Computing. 2021; 5(3):43. https://doi.org/10.3390/bdcc5030043
Chicago/Turabian StyleKusal, Sheetal, Shruti Patil, Ketan Kotecha, Rajanikanth Aluvalu, and Vijayakumar Varadarajan. 2021. "AI Based Emotion Detection for Textual Big Data: Techniques and Contribution" Big Data and Cognitive Computing 5, no. 3: 43. https://doi.org/10.3390/bdcc5030043
APA StyleKusal, S., Patil, S., Kotecha, K., Aluvalu, R., & Varadarajan, V. (2021). AI Based Emotion Detection for Textual Big Data: Techniques and Contribution. Big Data and Cognitive Computing, 5(3), 43. https://doi.org/10.3390/bdcc5030043