
GO-E-MON: A New Online Platform for Decentralized Cognitive Science


Abstract
:1. Introduction
1.1. Online Experiment Platform
1.2. Personal Data Stores
2. Materials and Methods
2.1. Architecture
2.2. Case Studies
Sample Tasks for the Case Studies
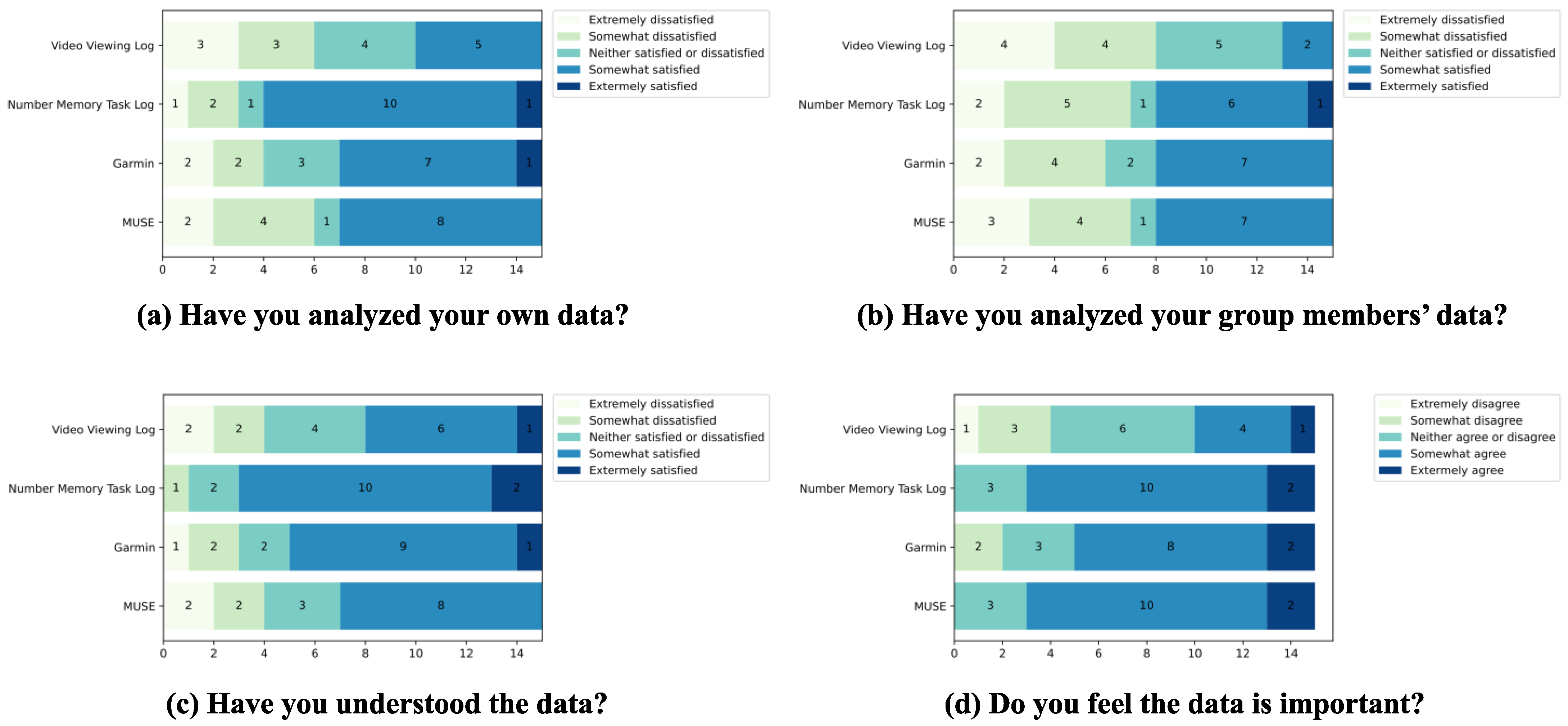
3. Results
3.1. Collection of Video Viewing Behaviors: Collection of Experimental Data by the Experimenter
3.2. Experimental Data Collection and Analysis by Students: Collection and Analysis by the Subjects Themselves
4. Discussion
4.1. The Importance of the Data Transmission Function to the Experimenter
4.2. Countermeasures against Host Cracking
4.3. Safety of the Experimental Script
4.4. Paradigm Shift in Behavioral Big Data Accumulation and the Need for Digital Citizenship Education
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lazer, D.; Pentland, A.S.; Adamic, L.; Aral, S.; Barabasi, A.-L.; Brewer, D.; Christakis, N.; Contractor, N.; Fowler, J.; Gutmann, M.; et al. Social science: Computational Social Science. Science 2009, 323, 721–723. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schwab, K.; Marcus, A.; Oyola, J.; Hoffman, W.; Luzi, M. Personal Data: The Emergence of a New Asset Class. Available online: https://www.weforum.org/reports/personal-data-emergence-new-asset-class (accessed on 16 August 2021).
- Almuhimedi, H.; Schaub, F.; Sadeh, N.; Adjerid, I.; Acquisti, A.; Gluck, J.; Cranor, F.L.; Agarwal, Y. Your Location has been Shared 5,398. Times! A Field Study on Mobile App Privacy Nudging. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 787–796. [Google Scholar] [CrossRef]
- Eagle, N.; Macy, M.; Claxton, R. Network diversity and economic development. Science 2010, 328, 1029–1031. [Google Scholar] [CrossRef] [PubMed]
- de Montjoye, Y.A.; Hidalgo, C.A.; Verleysen, M.; Blondel, V.D. Unique in the crowd: The privacy bounds of human mobility. Sci. Rep. 2013, 3, 1376. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Narayanan, A.; Shmatikov, V. Robust de-anonymization of large sparse datasets. In Proceedings of the 2008 IEEE Symposium on Security and Privacy (sp 2008), Oakland, CA, USA, 18–22 May 2008; pp. 111–125. [Google Scholar]
- de Montjoye, Y.A.; Shmueli, E.; Wang, S.S.; Pentland, A.S. openpds: Protecting the Privacy of Metadata through SafeAnswers. PLoS ONE 2014, 9, e98790. [Google Scholar] [CrossRef] [Green Version]
- Hasida, K. Personal life repository as a distributed PDS and its dissemination strategy for healthcare services. In Proceedings of the 2014 AAAI Spring Symposium Series Big Data Becomes Personal: Knowledge into Meaning, Palo Alto, CA, USA, 24 March 2014; pp. 10–11. [Google Scholar]
- Baker, M. 1500 Scientists lift the lid on reproducibility. Nature 2016, 533, 452–454. [Google Scholar] [CrossRef] [Green Version]
- Open Science Collaboration. Estimating the reproducibility of psychological science. Science 2015, 349, aac4716. [Google Scholar] [CrossRef] [Green Version]
- Camerer, C.F.; Dreber, A.; Holzmeister, F.; Ho, T.H.; Huber, J.; Johannesson, M.; Kirchler, M.; Nave, G.; Nosek, B.A.; Pfeiffer, T.; et al. Evaluating the replicability of social science experiments in Nature and Science between 2010 and 2015. Nat. Hum. Behav. 2018, 2, 637–644. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, Y.; Youyou, W.; Uzzi, B. Estimating the deep replicability of scientific findings using human and artificial intelligence. Proc. Natl. Acad. Sci. USA 2020, 117, 10762–10768. [Google Scholar] [CrossRef]
- Center for Open Science. OSF. Available online: https://osf.io/ (accessed on 16 August 2021).
- Ioannidis, J.P. Anticipating consequences of sharing raw data and code and of awarding badges for sharing. J. Clin. Epidemiol. 2016, 70, 258–260. [Google Scholar] [CrossRef]
- Doleman, B.; Williams, J.P.; Lund, J. Why most published meta-analysis findings are false. Tech. Coloproctology 2019, 23, 925–928. [Google Scholar] [CrossRef]
- Hajek, T.; Kopecek, M.; Alda, M.; Uher, R.; Höschl, C. Why negative meta-analyses may be false? Eur. Neuropsychopharmacol. 2013, 23, 1307–1309. [Google Scholar] [CrossRef]
- Trampe, D.; Quoidbach, J.; Taquet, M. Emotions in everyday life. PLoS ONE 2015, 10, e0145450. [Google Scholar] [CrossRef] [Green Version]
- Fett, A.J.; Velthorst, E.; Reichenberg, A.; Ruggero, C.J.; Callahan, J.L.; Fochtmann, L.J.; Carlson, G.A.; Perlman, G.; Bromet, E.J.; Kotov, R.; et al. Long-term changes in cognitive functioning in individuals with psychotic disorders: Findings from the Suffolk County Mental Health Project. JAMA Psychiatry 2020, 77, 387–396. [Google Scholar] [CrossRef] [PubMed]
- Cragg, L.; Kovacevic, N.; McIntosh, A.R.; Poulsen, C.; Martinu, K.; Leonard, G.; Paus, T. Maturation of EEG power spectra in early adolescence: A longitudinal study. Dev. Sci. 2011, 14, 935–943. [Google Scholar] [CrossRef]
- Hohmann, M.R.; Konieczny, L.; Hackl, M.; Wirth, B.; Zaman, T.; Enficiaud, R.; Grosse-Wentrup, M.; Schölkopf, B. MYND: Unsupervised Evaluation of Novel BCI Control Strategies on Consumer Hardware. arXiv 2020, arXiv:2002.11754v1. [Google Scholar]
- Johnson-Laird, P.N.; Savary, F. Illusory inferences: A novel class of erroneous deductions. Cognition 1999, 71, 191–229. [Google Scholar] [CrossRef]
- de Leeuw, J.R. jsPsych: A JavaScript library for creating behavioral experiments in a web browser. Behav. Res. Method 2015, 47, 1–12. [Google Scholar] [CrossRef]
- Peirce, J.; Gray, J.R.; Simpson, S.; MacAskill, M.; Höchenberger, R.; Sogo, H.; Grosse-Wentrup, M.; Schölkopf, B. PsychoPy2: Experiments in behavior made easy. Behav. Res. Method 2019, 51, 195–203. [Google Scholar] [CrossRef] [Green Version]
- Stegman, P.; Crawford, C.; Gray, J. WebBCI: An electroencephalography toolkit built on modern web technologies. Lect. Note Comput. Sci. 2018, 10915, 212–221. [Google Scholar] [CrossRef]
- Amazon Mechanical Turk, Inc. Amazon Mechanical Turk. Available online: https://www.mturk.com/ (accessed on 16 August 2021).
- Stoet, G. PsyToolkit: A novel web-based method for running online questionnaires and reaction-time experiments. Teach. Psychol. 2017, 44, 24–31. [Google Scholar] [CrossRef]
- Yazawa, S.; Yoshimoto, H.; Hiraki, K. Learning with Wearable Devices reveals Learners’ Best Time to Learn. In Proceedings of the 2018 2nd International Conference on Education and e-Learning, Bali, Indonesia, 5–7 November 2018; Association for Computing Machinery: New York, NY, USA; pp. 87–92. [Google Scholar] [CrossRef]
- Okano, K.; Kaczmarzyk, J.R.; Dave, N.; Gabrieli, J.D.; Grossman, J.C. Sleep quality, duration, and consistency are associated with better academic performance in college students. NPJ Sci. Learn. 2019, 4, 16. [Google Scholar] [CrossRef] [Green Version]
- Poulsen, A.T.; Kamronn, S.; Dmochowski, J.; Parra, L.C.; Hansen, L.K. EEG in the classroom: Synchronised neural recordings during video presentation. Sci. Rep. 2017, 7, 43916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sawangjai, P.; Hompoonsup, S.; Leelaarporn, P.; Kongwudhikunakorn, S.; Wilaiprasitporn, T. Consumer Grade EEG measuring sensors as research tools: A review. IEEE Sens. J. 2020, 20, 3996–4024. [Google Scholar] [CrossRef]
- Anwyl-Irvine, A.L.; Massonnié, J.; Flitton, A.; Kirkham, N.; Evershed, J.K. Gorilla in our midst: An online behavioral experiment builder. Behav. Res. Method 2020, 52, 388–407. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ecma International. ECMAscript® Specification Suite. Available online: https://www.ecma-international.org/ (accessed on 27 July 2021).
- Papoutsaki, A.; Sangkloy, P.; Laskey, J.; Daskalova, N.; Huang, J.; Hays, J. WebGazer: Scalable webcam eye tracking using user interactions. In Proceedings of the 25th International Joint Conference on Artificial Intelligence (IJCAI), New York, NY, USA, 9 July 2016; pp. 3839–3845. Available online: http://cs.brown.edu/people/apapouts/papers/ijcai2016webgazer.pdf (accessed on 12 December 2021).
- Web Bluetooth Community Group. Web Bluetooth Draft Community Group Report, 21 July 2021. Available online: https://webbluetoothcg.github.io/web-bluetooth/ (accessed on 27 July 2021).
- W3C. Cascading Style Sheets Specification. Available online: https://www.w3.org/Style/CSS/Overview.en.html (accessed on 27 July 2021).
- Impey, C.; Formanek, M. MOOCS and 100 days of COVID: Enrollment surges in massive open online astronomy classes during the coronavirus pandemic. Soc. Sci. Humanit. Open 2021, 4, 100177. [Google Scholar] [CrossRef] [PubMed]
- Jordan, K. MOOC Completion Rates: The Data. Available online: http://www.katyjordan.com/MOOCproject.html (accessed on 15 August 2021).
- Kim, J.; Guo, P.J.; Seaton, D.T.; Mitros, P.; Gajos, K.Z.; Miller, R.C. Understanding in-video dropouts and interaction peaks in online lecture videos. In Proceedings of the First ACM Conference on Learning @ Scale Conference (L@S ’14), New York, NY, USA, 4 March 2014; pp. 31–40. [Google Scholar] [CrossRef] [Green Version]
- Liang, J.; Li, C.; Zheng, L. Machine learning application in MOOCs: Dropout prediction. In Proceedings of the 11th International Conference on Computer Science & Education (ICCSE), Nagoya, Japan, 23–25 August 2016; pp. 52–57. [Google Scholar] [CrossRef]
- Garmin Japan. Garmin Vívosmart® 4. Available online: https://www.garmin.co.jp/products/intosports/vivosmart-4-black-r/ (accessed on 27 July 2021).
- InteraXon, Inc. Muse 2: Brain Sensing Headband. Available online: https://choosemuse.com/muse-2/ (accessed on 27 July 2021).
- Donoghue, T.; Voytek, B.; Ellis, S.E. Teaching creative and practical data science at scale. J. Stat. Data Sci. Educ. 2021, 29 (Suppl. 1), S27–S39. [Google Scholar] [CrossRef]
- Millman, K.J.; Brett, M.; Barnowski, R.; Poline, J.B. Teaching computational reproducibility for neuroimaging. Front. Neurosci. 2018, 12, 727. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Google Developers. Youtube IFrame Player API. Available online: https://developers.google.com/youtube/iframe_api_reference (accessed on 28 July 2021).
- Open JS Foundation. jQuery: The Write Less, Do More, Javascript Library. Available online: http://jquery.com/ (accessed on 28 July 2021).
- Garmin Ltd. Garmin Health API. Available online: http://developer.garmin.com/garmin-connect-api/overview/ (accessed on 28 July 2021).
- Shaked, U. EEG Explorer. Available online: https://github.com/urish/eeg-explorer (accessed on 28 July 2021).
- Project Jupyter Team. JupyterHub. Available online: https://jupyterhub.readthedocs.io/ (accessed on 28 July 2021).
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A publishing format for reproducible computational workflows. In Positioning and Power in Academic Publishing: Players, Agents and Agendas; IOS Press: Amsterdam, The Netherlands, 2016; pp. 87–90. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Method 2020, 17, 261–272. [Google Scholar] [CrossRef] [Green Version]
- McKinney, W. Pandas: A Foundational Python Library for Data Analysis and Statistics. Python High Perform. Sci. Comput. 2011, 14, 1–9. [Google Scholar]
- Powale, P. YouTube Engineering and Developers Blog Variable Speed Playback on Mobile. Available online: https://youtube-eng.googleblog.com/2017/09/variable-speed-playback-on-mobile.html (accessed on 15 August 2021).
- Lang, D.; Chen, G.; Mirzaei, K.; Paepcke, A. Is faster better? A study of video playback speed. In Proceedings of the Tenth International Conference on Learning Analytics & Knowledge (LAK ’20), Frankfurt, Germany, 23–27 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 260–269. [Google Scholar] [CrossRef] [Green Version]
- ZDNET. Google: G Suite Now Has 2 Billion Users. 13 March 2020. Available online: https://www.zdnet.com/article/google-g-suite-now-has-2-billion-users/ (accessed on 28 July 2021).
- Statistics Bureau, Ministry of Internal Affairs and Communications of Japan. Diffusion of the Internet Ministry of Internal affairs and Communications in Japan, Statistical Handbook of Japan. Available online: https://www.stat.go.jp/english/data/handbook/c0117.html (accessed on 27 July 2021).
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl. -Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Terrace, J.; Beard, S.R.; Katta, N.P. JavaScript in JavaScript (js.js): Sandboxing Third-Party Scripts. In Proceedings of the 3rd USENIX conference on Web Application Development (WebApps’12), Boston, MA, USA, 13 June 2012; p. 9. Available online: https://www.usenix.org/conference/webapps12/technical-sessions/presentation/terrace (accessed on 12 December 2021).
- Huang, D.Y.; Dharmdasani, H.; Meiklejohn, S.; Dave, V.; Grier, C.; McCoy, D.; Savage, S.; Weaver, N.; Snoeren, A.C.; Levchenko, K. Botcoin: Monetizing stolen cycles. In Proceedings of the Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 23 February 2014. [Google Scholar] [CrossRef] [Green Version]
- ReversingLabs. Groundhog Day: NPM Package Caught Stealing Browser Passwords. 21 July 2021. Available online: https://blog.secure.software/groundhog-day-npm-package-caught-stealing-browser-passwords (accessed on 28 July 2021).
- Curtsinger, C.; Zorn, B.; Seifert, C. ZOZZLE: Fast and Precise in-Browser JavaScript Malware Detection. In Proceedings of the 20th USENIX Secur. Symp. (USENIX Secur. 11), San Francisco, CA, USA, 12 August 2011; Available online: https://www.usenix.org/conference/usenix-security-11/zozzle-fast-and-precise-browser-javascript-malware-detection (accessed on 12 December 2021).
- Musch, M.; Wressnegger, C.; Johns, M.; Rieck, K. Web-based Cryptojacking in the wild. arXiv 2018, arXiv:abs/1808.09474. [Google Scholar]
- Soldatova, L.N.; King, R.D. An ontology of scientific experiments. J. R. Soc. Interface 2006, 3, 795–803. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ocheja, P.; Flanagan, B.; Ogata, H. Connecting decentralized learning records: A blockchain based learning analytics platform. In Proceedings of the 8th International Conference on Learning Analytics and Knowledge (LAK ’18), Sydney, Australia, 7–9 March 2018; Association for Computing Machinery: New York, NY, USA, 7 March 2018; pp. 265–269. [Google Scholar] [CrossRef]
- Nikiforakis, N.; Kapravelos, A.; Joosen, W.; Kruegel, C.; Piessens, F.; Vigna, G. Cookieless monster: Exploring the ecosystem of web-based device fingerprinting. In Proceedings of the 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 19–22 May 2013; pp. 541–555. [Google Scholar] [CrossRef] [Green Version]
- Formby, D.; Srinivasan, P.; Leonard, A.; Rogers, J.; Beyah, R. Who’s in control of your control system? Device fingerprinting for cyber-physical systems. In Proceedings of the 2016 Network and Distributed System Security Symposium, San Diego, CA, USA, 21 February 2016. [Google Scholar] [CrossRef] [Green Version]
- Merchant, K.; Revay, S.; Stantchev, G.; Nousain, B. Deep learning for RF device fingerprinting in cognitive communication networks. IEEE J. Sel. Top. Signal Process. 2018, 12, 160–167. [Google Scholar] [CrossRef]
- Publications Office of the European Union. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the Protection of Natural Persons with Regard to the Processing of Personal Data and on the Free Movement of such Data, and Repealing Directive 95/46/EC (General Data Protection Regulation). Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02016R0679-20160504&qid=1532348683434 (accessed on 28 July 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Viewing Task | Number Memory Task | Garmin Vivosmart 4 | MUSE-Classic (EEG) 1 | What to Analyze | |
|---|---|---|---|---|---|
| Group 1 | ✔ | ✔ | Relationship between brain waves and performance on a number memory task after waking and before bedtime | ||
| Group 2 | ✔ | ✔ | ✔ | Relationship between brain waves and heart rate and performance in a number memory task | |
| Group 3 | ✔ | Relationship between EEG and the execution of their original multi-digit calculation task | |||
| Group 4 | ✔ | Relationship between sleep and stress |
| No. | Questions | Answers |
|---|---|---|
| 1 | Please answer whether you feel that you were able to analyze your own data in this lecture. | 0: Extremely dissatisfied 1: Somewhat dissatisfied 2: Neither satisfied or dissatisfied 3: Somewhat satisfied 4: Extremely satisfied |
| 2 | Please answer whether you feel that you were able to analyze the group members’ data in this lecture. | |
| 3 | Please answer whether you feel you have understood each of the data obtained in this lecture. | |
| 4 | Please answer whether you feel that the data obtained in this lecture are important or not. | 0: Extremely disagree 1: Somewhat disagree 2: Neither agree or disagree 3: Somewhat agree 4: Extremely agree |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yazawa, S.; Sakaguchi, K.; Hiraki, K. GO-E-MON: A New Online Platform for Decentralized Cognitive Science. Big Data Cogn. Comput. 2021, 5, 76. https://doi.org/10.3390/bdcc5040076
Yazawa S, Sakaguchi K, Hiraki K. GO-E-MON: A New Online Platform for Decentralized Cognitive Science. Big Data and Cognitive Computing. 2021; 5(4):76. https://doi.org/10.3390/bdcc5040076
Chicago/Turabian StyleYazawa, Satoshi, Kikue Sakaguchi, and Kazuo Hiraki. 2021. "GO-E-MON: A New Online Platform for Decentralized Cognitive Science" Big Data and Cognitive Computing 5, no. 4: 76. https://doi.org/10.3390/bdcc5040076
APA StyleYazawa, S., Sakaguchi, K., & Hiraki, K. (2021). GO-E-MON: A New Online Platform for Decentralized Cognitive Science. Big Data and Cognitive Computing, 5(4), 76. https://doi.org/10.3390/bdcc5040076