1. Introduction
Big data are increasingly becoming an integral part of almost all fields. The rapidity with which data is generated and piled up in the era of disruptive digital technologies is astounding [
1]. Such big data have necessitated the need for efficient data management tools and techniques to deal with the bulk of data. Recently, a great deal of focus has been dedicated to using, storing, and managing big data in various fields [
2]. The rise of interest in big data is associated with the easy availability of technology such as smartphones and computers across the globe [
3]. The bulk of data generated daily through these technologies has made various researchers interested in using the data for innovative purposes and moving away from traditional time-consuming questionnaire-based approaches for data collection to more digital data management. Algorithm development, machine learning (ML), statistical analysis, and computational model development are among the various techniques that depend on data that can be easily gathered by day-to-day usage gadgets [
4,
5]. The presence of bulks of data makes it possible for researchers to make informed decisions and conduct relevant analyses for their field of study.
Construction is a data-intensive sector where the bulk of data is generated and not capitalized on adequately due to slow technology adoption [
6]. Accordingly, it is not surprising to see the construction sector lagging behind the technology curve by more than five years which is rather slow considering the day-to-day innovations and disruptions brought about by the booming information technology industry [
7]. Moreover, big data, a relatively new technology, are not properly adopted by construction. In fact, construction big data management is in its nascency and has a long way to go to mature. However, multiple studies [
6,
8] show that the potential is enormous if construction big data are fully utilized.
There are various steps involved in using big data, including data acquisition, storage, classification, and refining [
8]. These steps are handled through various software programs to refine the associated big data and make it usable for research and practical purposes [
9,
10,
11]. The biggest challenge in big data management is identifying which data is useful and vice versa through data refinement [
12,
13]. The immense amounts of data easily available make it hard to identify the datasets used for a particular purpose. Moreover, the available data format may not be ready for use or easily readable for the intended purpose [
14,
15]. These barriers to accessing, understanding, and utilizing big data make it important to develop systems for extracting key information and analyzing it [
16]. In addition, the strategic sorting and analysis of big data have opened up new avenues of research by widening the need to use data appropriately [
17]. In the case of construction, some barriers to big data adoption include latency, data privacy, data availability, data governance, poor broadband connectivity at construction sites, and cost implication for long-term use. For instance, big data adoption in construction may have latency issues with lower transfer rate and response time required due to software issues or network problems which may be a hurdle for some time-sensitive construction applications [
18].
Furthermore, there is an increase in vulnerability in technology adoption due to the fluidity of security parameters. Storing construction design and financial information in shared resources concerns the construction industry [
19]. Afolabi et al. [
20] assessed the economies of big data in project delivery and included poor network connect among the threats to adoption by the construction industry.
Sorting big data requires developing database designs that would automate picking the most useful data for a given purpose [
21]. Identifying a design that works best for data sorting is an entire research area on its own and has helped expand big data research by a great deal [
22]. Currently, the biggest question concerning researchers in the field of big data is to find a way that creates seamless coordination between database systems such that they can hold big data, help process it, and possibly lead to an error-free statistical analysis [
23]. Removing the current limitations in understanding big data will enable scientists to utilize the readily available data and make better decisions.
The construction industry is also benefiting from big data in a way that has revolutionized its traditional operational methods to a more automated process. The presence of digital tools and technologies for designing and executing construction projects has made the construction industry take enormous leaps in the last two decades. The possibility of modeling building structures and identifying the functionality of those structures before they are built has led to industrial investments in big data and related technologies [
24,
25]. Computer-aided design (CAD), such as building information modelling (BIM), is a term now synonymous with the construction industry [
26]. The three-dimensional modeling of buildings and other construction infrastructures leads to the generation of digital files which can be stored in various formats, leading to a bulk of data generation [
27]. Other digital innovations such as digital twins, 3D laser scanning, and advanced wearable gadgets incorporated in hats, shoes, gloves, and other sensor-based tools have revolutionized the construction industry and helped generate useful big data.
Big data in the construction industry can accumulate quickly and become storage heavy due to the large size of the 3D modeling files and a huge amount of daily data generated by wearable gadgets [
28]. Management of such big data is a hectic but essential task as the usefulness of the models lies in ensuring that they are available for viewing and leveraging as and when needed. Apart from providing the ease of modeling infrastructure, big data also provide the opportunity to develop sustainable structures by using test models before actual constructions. These are made possible by using digital twins, geographical information systems (GIS)-based 3D point cloud structures, and other cloud-based scanning systems. Furthermore, the software that enables CAD and BIM further feeds into the databases and contributes to big data. All these variables lead to the possibility of utilizing technology for sustainable construction and associated development in line with the United Nations sustainable development goals and other local development initiatives.
The applications of big data in the construction industry are immense. Identifying how big data can be applied to the construction industry remains the real challenge. Since each construction project leads to more data generation, it is crucial to analyze and sort the data accordingly. Some of the key features within the construction industry that can benefit from big data include construction safety, efficiency, waste minimization, productivity, competitive advantage, and pollution management [
29]. The strategic and operational benefits of big data in the construction industry have further been explored by Atuahene et al. [
30]. The major benefits of big data were found to be project management, management of claims, and procurement. These aspects of big data application are crucial for managing construction projects. However, many other aspects and applications of big data within the construction industry still need to be explored. While these different aspects of construction projects benefit from big data, it is important to understand how big data can be analyzed and utilized for different projects. Furthermore, the algorithms and frameworks that can integrate big data in the construction industry remain largely unexplored.
Today, studies on construction and its management in relation to big data are scarce, presenting a gap in research. This provides opportunities for further research that can greatly benefit the construction industry in the long run. This gap is targeted in the current study, where the papers published in construction fields focused on big data since 2010 are studied. The key takeaways of these studies are presented here to help the construction researchers build upon these studies and advance the state of research related to big data in construction.
In terms of implications, this study will help both the construction researchers and practitioners, where the former will have the current state of research on big data and can see opportunities for further research. Similarly, the practitioners can ascertain the software and hardware requirements for incorporating big-data-based opportunities in construction and create implementation models and gadgets. This paper is divided into sections exploring big data engineering (BDE), databases, use of big data in construction, the application of big-data-based statistics in construction, and future opportunities for big data in construction.
Research Questions
This study aims to identify ways in which big data can be used for construction and its management based on the review of existing literature. The existing literature on big data does not provide detailed solutions for construction management, which creates a gap in the literature concerning the use of big data in the construction industry. The research questions set for this study are as follows:
How can we use big data for research in construction engineering and management?
How is construction big data managed and stored?
How can big data be used for planning construction projects in a futuristic way?
The rest of the paper is organized as follows.
Section 2 presents the method and materials used in the study.
Section 3 presents the preliminary analyses conducted in the study. This is followed by
Section 4, where the BDE and its subcomponents, including big data processing, big data storage, and big data analytics (BDA), are presented and discussed. Similarly, the 10 vs. of big data and ML techniques are also presented in this section.
Section 5 presents the future opportunities for big data in construction. Finally,
Section 6 concludes the study and presents the key takeaways, limitations, and future expansion directions based on the current study.
2. Materials and Methods
This study follows a multi-stepped approach for reviewing the studies on big data in construction. First, a comprehensive literature retrieval mechanism is adopted from published literature and modified accordingly to retrieve pertinent literature on big data in construction. This is followed by analyses of the retrieved articles in the shape of preliminary analyses, BDE, processing, storage, analytics, and statistical and data mining approaches in relation to the construction industry. These steps are subsequently explained.
An extensive literature search was carried out to identify peer-reviewed papers related to big data and construction since 2010, following the approaches adopted in recent studies [
31,
32]. This was conducted in order to keep a recent focus and study current articles on big data in construction. Some preliminary analyses, as subsequently discussed, highlighted that big data in construction received more attention in 2010 and onwards; hence, the review period of 2010 and onwards makes sense. A number of scholarly research platforms, including Google Scholar, Scopus, Science Direct, Springer, Elsevier, and IEEE Explore, were consulted for literature search based on the high volume of high-quality research papers available on these platforms following recent studies [
33,
34,
35]. Once the search engines were selected, a combination of different keywords was developed to identify the most useful publications for this study in the next step. The keyword combinations were developed in a tier-based approach, such that terms related to big data, such as “big data”, “big data analysis”, “big data volume”, and “big data analysis tools” fell into category 1 (S1).
Similarly, all keywords pertaining to construction, such as “construction”, “construction management”, and “construction industry”, were classified into category 2 (S2). Different combinations of keywords from both categories were used to retrieve the most relevant publications. Examples of keyword combinations include big data in construction, big data for construction management, construction management, and big data, etc.
Search category was further restricted by including only those papers that were published in 2010 or later years. Since big data technology was used robustly in the last decade, research publications prior to 2010 were left out. Concept papers, editorials, notes, perspectives, closures, discussions, conference papers, and others were also excluded from the search to ensure the inclusion of original research papers only. Other publications dealing with classical definitions were also excluded.
Using different combinations of the keywords to identify papers published from 2010 onwards led to a total of more than 10,000 papers being retrieved from the mentioned search engines. The list of articles was narrowed down using the detailed inclusion criteria set for this study. This included removing duplicates and other exclusions, as previously mentioned, which brought the search results down to around 4000 papers. This was further narrowed down in a stepwise manner to ensure that only those papers were included that fit the scope of the current study. In the final step, the content of the papers was analyzed to determine their suitability for this study, resulting in a total of 156 papers.
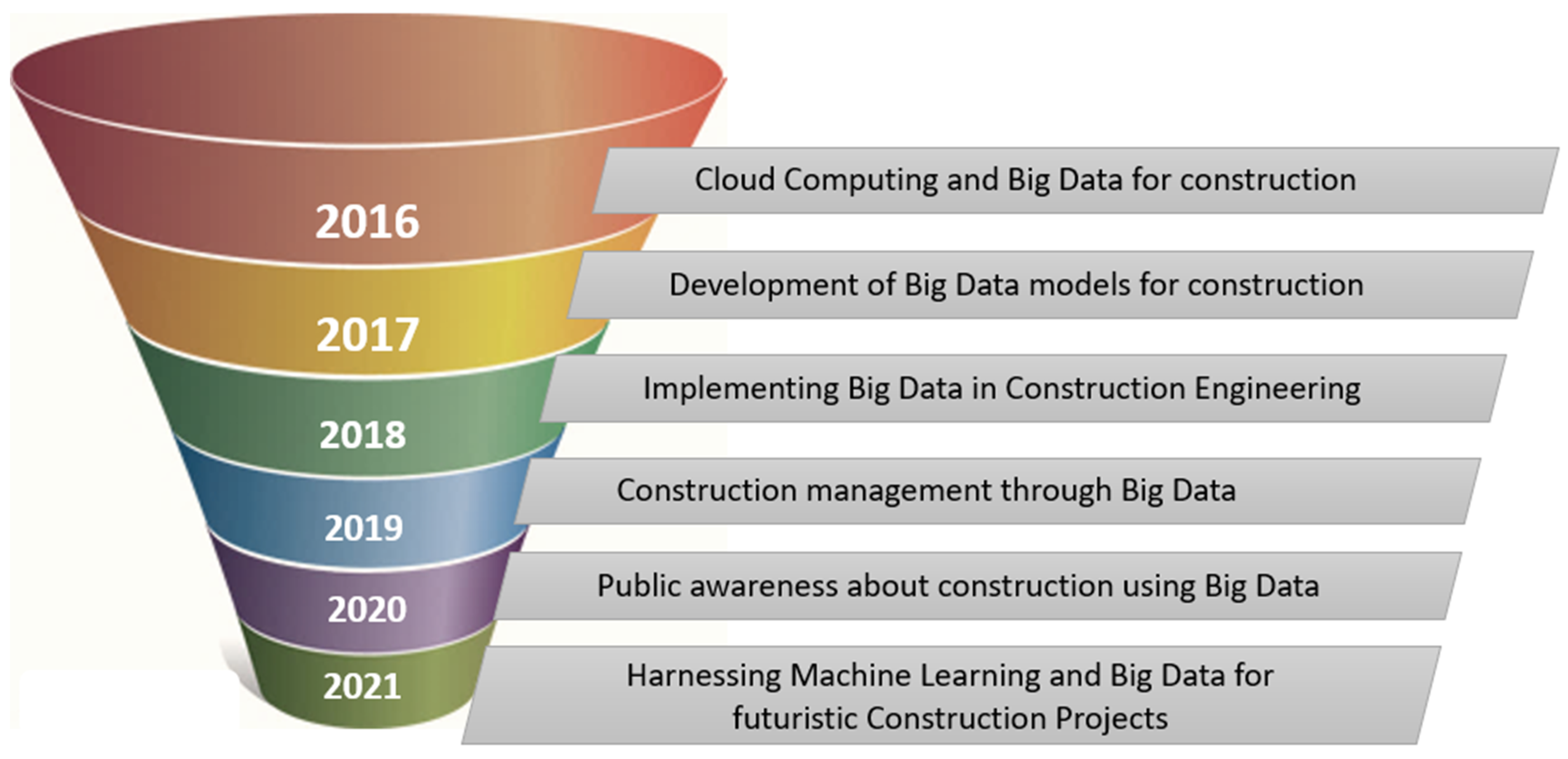
Figure 1 shows an overview of the different ways in which research studies have addressed the use of big data in construction. There has been a rise in the interest in big data usage for the construction industry since 2016. However, the interest has been limited in terms of analyses scope as the trends have remained steady. As shown in
Figure 1, the publications on this topic have followed similar terms and research themes over the last few years, leading to gradual evolution. For example, in 2016, most papers related to big data and construction focused on the use of cloud computing, while 2017 saw a trend of developing models and frameworks for implementing big data in the construction industry. Similarly, in 2018 and 2019, researchers have mainly explored how different big data models could be implemented within the construction industry. Recently, the research focus has shifted to using big data in real-time construction projects and identifying how these technologies could be harnessed for developing futuristic construction projects.
In addition to big data, some other technologies and methods have been researched in the last couple of years for improving the construction industry. There is a great overlap in the types of technologies studied simultaneously for developing models that could guide future research in the construction industry.
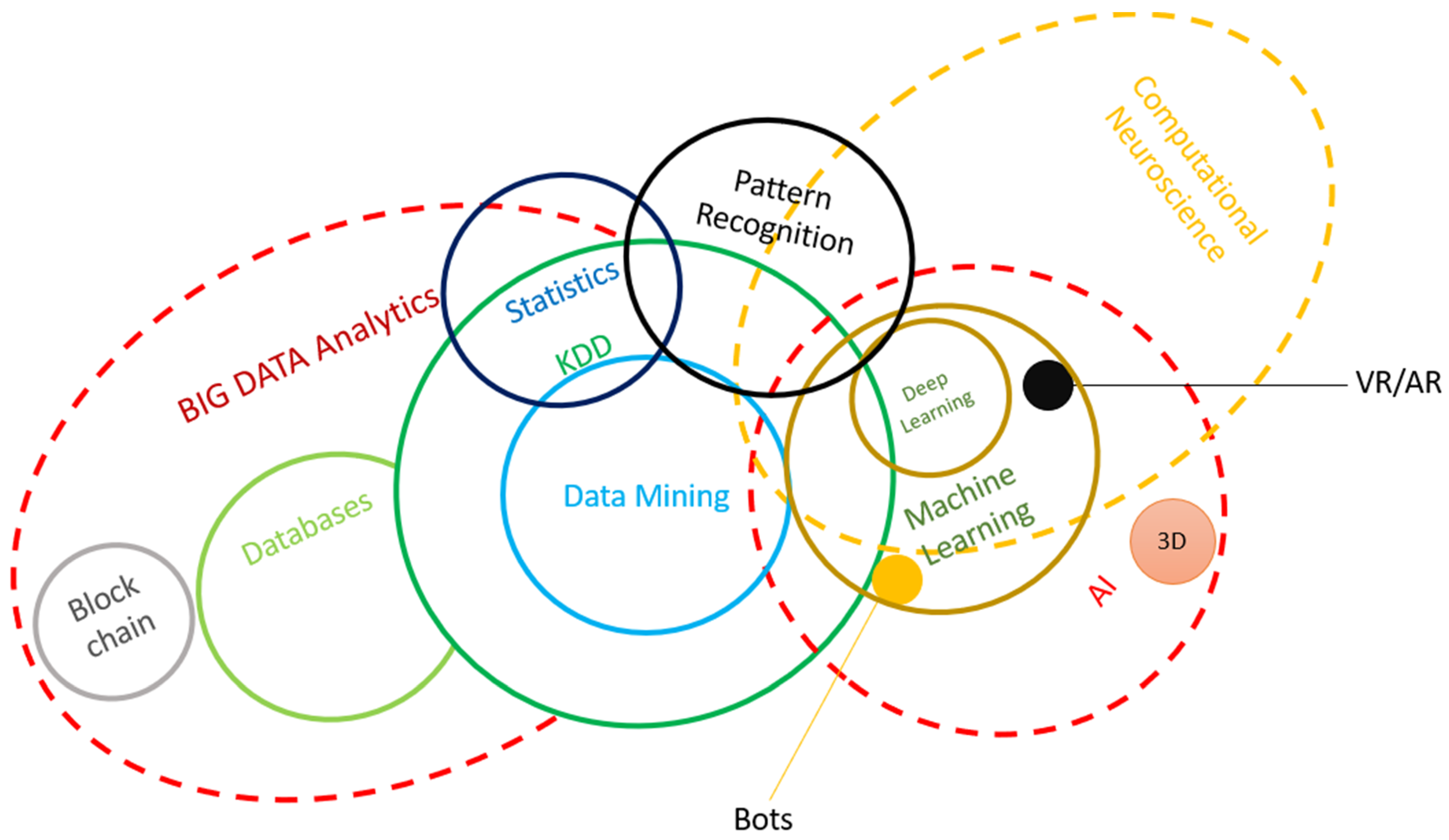
Figure 2 shows the overlapping tools and technologies identified from recent literature. It can be observed that big data is not standalone; rather, it depends on other tools and methods, including data analytics, ML, pattern recognition, statistics, deep learning, and artificial intelligence (AI). All these tools and technologies are used in different combinations for developing models that could be used in real time for construction projects. The reliance of all these tools on each other is an important factor to consider when developing construction projects as the computational aspects of the project can only be as good and true and the depth of research is performed for developing and testing the algorithms and frameworks. The construction industry greatly benefits from the overlapping fields of big data technologies. The use of big data requires data mining which generates enormous datasets. The bulk of construction-related data makes the use of statistics inevitable.
Along with data management, statistical analysis, and big data analytics, several different techniques and resources come into use. For example, machine learning tools and artificial intelligence play a crucial role in the construction industry in conjunction with big data. The overlap of all the different fields shown in
Figure 2 shows how the field of construction is laden with the use of different technologies, each of which is somehow associated with big data. The use of computational models, databases, deep learning, pattern recognition, virtual reality, bots, and augmented reality contributes to the application of big data in the construction industry. An in-depth analysis of the big data applications and the use of technology in the construction industry results in a much more complex overlap than shown here. However, the core aim of using different technologies is to simplify how datasets can be used to guide future construction projects. Recognizing data patterns and understanding how each dataset fits the needs of a construction project is only possible if the dataset has been analyzed, critically appraised, and classified for its specific usage. The guiding principle here is to use modern technology to upgrade and update the ways in which information could be streamlined for the benefit of different projects. For example, identifying the materials that best suit a particular structure, developing project timelines, and streamlining the resources can become much more straightforward if the construction projects are developed with the help of big data technologies.
As shown in
Figure 2, different technologies in the construction industry overlap in different ways. Integrating big data in the construction industry is possible through the combined use of other technologies such as machine learning, AI, VR, AR, pattern recognition, and other such methods.
3. Preliminary Analyses
As mentioned in the method, some preliminary analyses were conducted on the retrieved articles, including the keywords analysis and the countries of origin of the articles following recently published articles [
31,
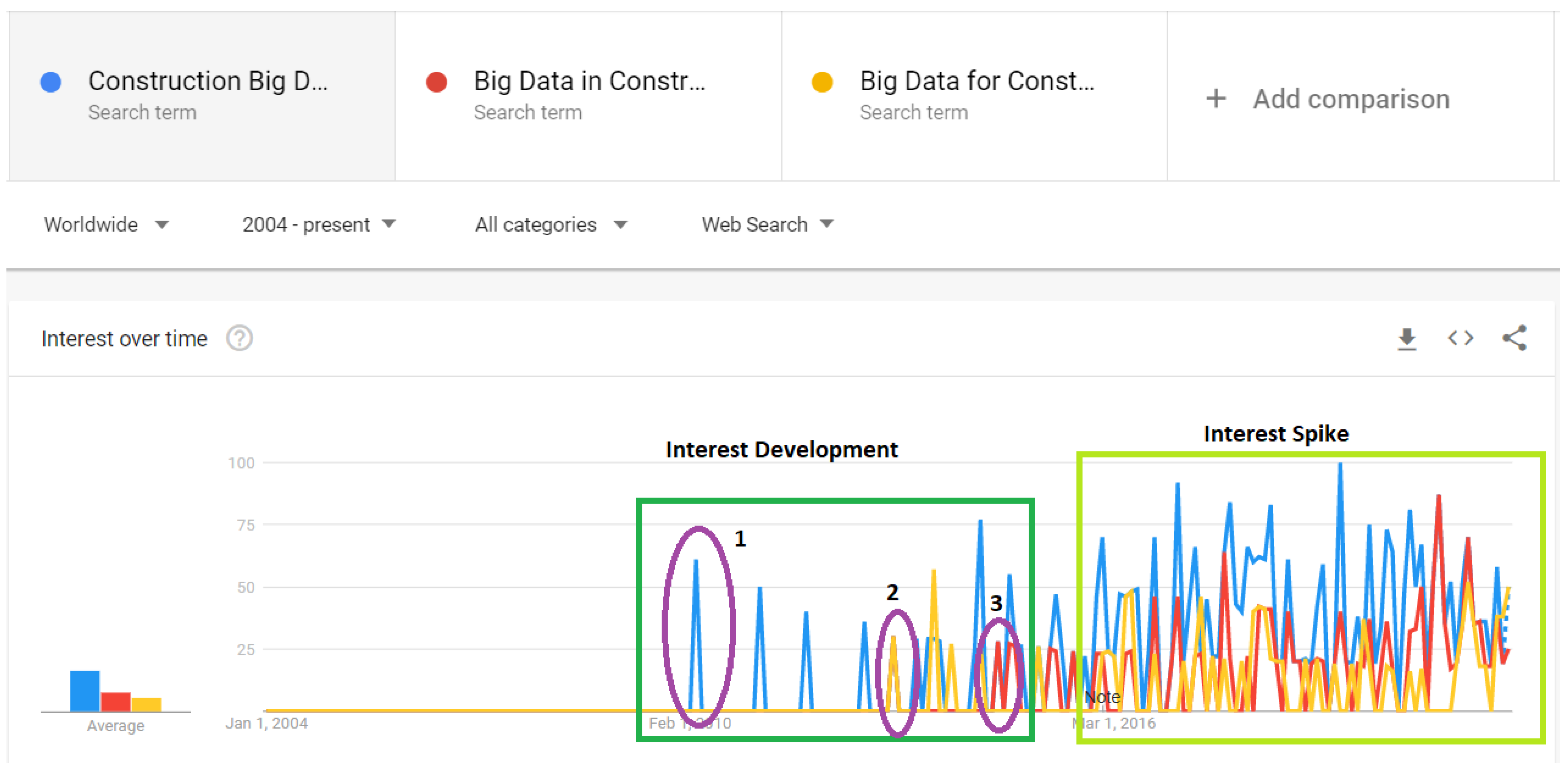
35]. Before this, a basic Google Trend (r) search was conducted using trends.google.com (accessed on 20 November 2021). A comparison was made for three iterations of the keywords previously mentioned. These included construction big data (keyword 1), big data in construction (keyword 2), and big data for construction management (keyword 3). As shown in
Figure 3, the earliest attention paid to big data in construction was reported in 2010. This was reported for keyword 1, followed by keyword 2 in 2013 and keyword 3 in 2014. Two clusters are clearly visible from
Figure 3. The initial interest cluster showed when big data focused on construction and the spike in interest cluster. The first cluster is evident in 2010–2014, whereas the spike in interest cluster started in 2016. This shows the hotness or relevance of the topic under investigation in the current study.
After the Google Trend analyses, the retrieved articles were analyzed using Vos Viewer
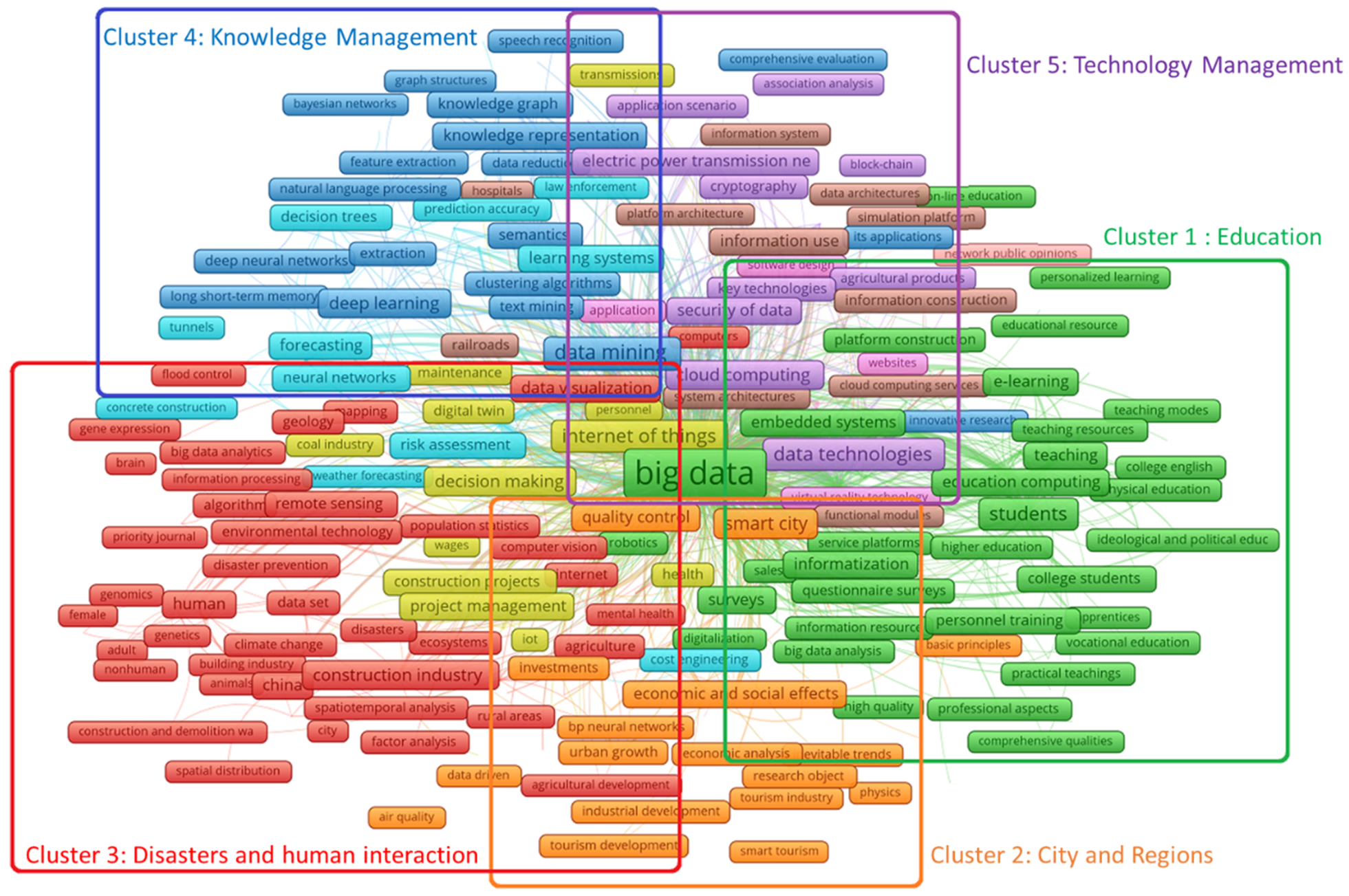
® tool. The first analysis was that of keywords. The natural distribution of keywords retrieved from the articles shows five distinct clusters: education, city and region, disaster and human interactions, knowledge management, and technology management in relation to construction, as given in
Figure 4. The overall top keywords in order of priority retrieved from these articles included big data, information management, AI, data mining, internet of things, ML, advanced analytics, data technologies, students, data handling, digital storage, colleges and universities, smart city, decision making, cloud computing, construction industry, and others. These are based on the appearance of the keywords in the titles, abstract, and keywords of a minimum of 30 papers. These keywords are in line with the natural clusters highlighted in
Figure 4.
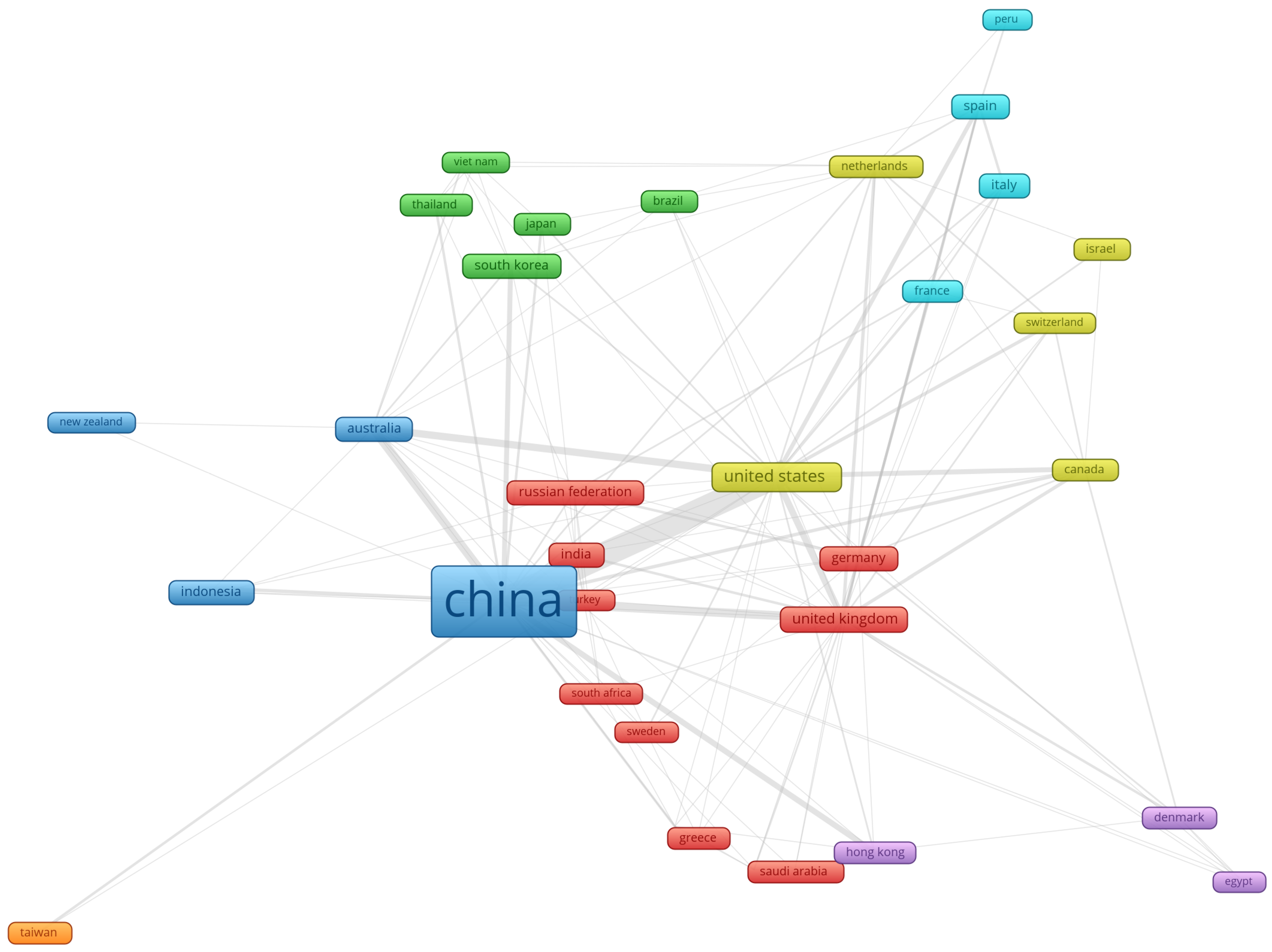
In another analysis, the top 10 contributing countries to big data research in construction were investigated. These are China, United States, United Kingdom, Russian Federation, Australia, India, South Korea, Germany, Spain, and Italy in terms of the number of contributions as shown in
Figure 5. The colors in the country box show the countries with the strongest collaborations, whereas the size of the box refers to the number of papers. For example, most of the papers authored by Chinese authors are in collaboration with authors from Australia, New Zealand, and Indonesia.
4. Big Data Engineering (BDE)
Big data analytics (BDA) is supported by BDE that provides a framework to conduct it. BDE has tremendous applications in construction. It has been used for BIM to improve project management [
36]. It has also been used to improve building design and for effective performance monitoring [
37], project management, safety, energy management, decision-making design frameworks, resource management [
38], quality management, waste management, and others [
24].
To understand BDE, it is important to discuss big data platforms. These platforms are divided into two groups based on variations in their inherent characteristics. These include horizontal scaling platforms (HSP) and vertical scaling platforms (VSP). HSP utilizes multiple servers by distributing processing across them and bringing new machines into the cluster. VSPs are single-server-based configurations that achieve the scaling by upgrading the hardware of the related server. In construction, HSPs have been used for waste management [
25], profitability performance [
39], smart road construction, and others [
40]. Similarly, VSPs have been reported in one-off construction projects [
41], transportation [
42], and others. This paper focuses on HSPs, particularly Berkeley Data Analytics Stack (BDAS) and Hadoop.
Recently, BDAS has been in the limelight since it has greater performance gains over Hadoop. However, as it is quite recent, it suffers the drawback of limitation in available supporting tools. On the other side, Hadoop has been widely utilized in big data applications. The tools offered by these platforms are useful in the storage and processing of big data. For instance, Bilal et al. [
39] investigated the profitability performance of construction projects using big data and used Hadoop Distributed File System (HDFS) for managing the data within the staging area while employing Resource Description Framework (RDF)-enabled Network Data Model (NDM) for storing the persistent data. Similarly, Jun Ying et al. [
43] investigated the development and implementation of BDAS by the relevant building authorities in Singapore, which has enhanced knowledge and expertise in buildability. An overview of big data classification into BDE and BDA is shown in
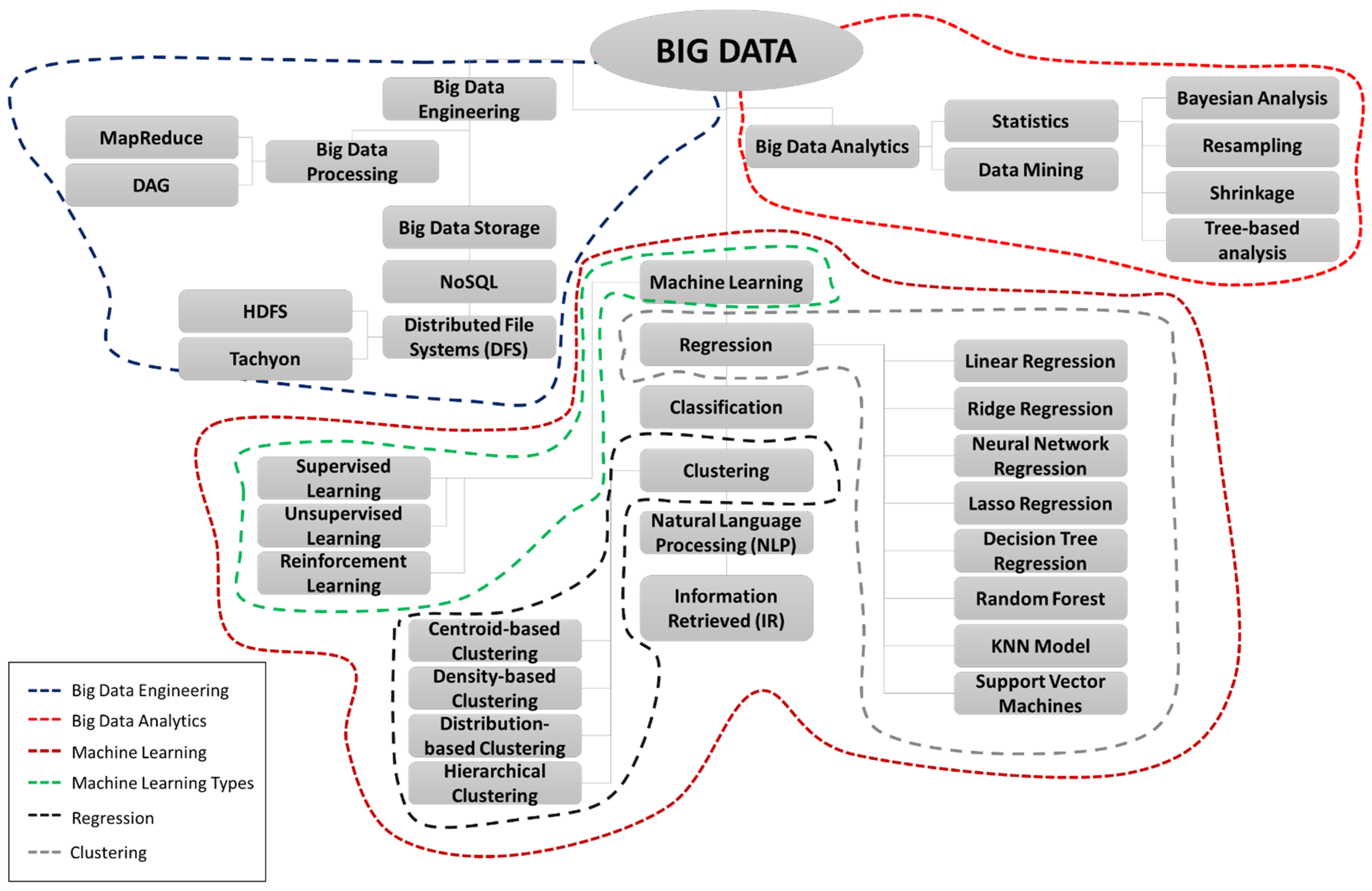
Figure 6 and subsequently explained.
Big data are classified into two major domains: BDE and BDA. These two main domains are further divided into many classes and subclasses. A third domain that comes under the canopy of big data is ML. The use of ML is inevitable in big data as the data need to be organized, analyzed, and used through ML tools and models such as deep learning and neural networks. Some of the key ML tools and models associated with big data directly or indirectly include regression analysis, clustering, classification, information retrieved (R), and natural language processing (NLP). Some examples of ML in construction include deep-learning-based flood detection and damage assessment [
44], projects delay risk prediction [
45], construction site safety [
46], construction site monitoring [
47], neural network models to predict concrete properties [
48], and others.
The various algorithms and methods shown in
Figure 6 all contribute towards big data in some way. The use of supervised and unsupervised learning approaches is determined depending on the type of datasets available. The major difference between supervised learning and unsupervised learning is that the algorithm for supervised learning utilizes labeled datasets while the unsupervised data do not use labeled data. The supervised and unsupervised algorithms further have different methods and examples. For instance, regression, linear regression, neural network regression, random forest, Naïve Bayes, and lasso regression are examples of supervised learning.
Similarly, clustering, Natural Language Processing (NLP), and KNN are examples of unsupervised learning. The applications of each of these algorithms can differ and hence their integration in the construction industry can vary. The regression models are used in engineering for analyzing trends and correlations between different variables. In the construction industry, these models play a crucial role as the statistical analysis and correlation development between different variables are made easy through linear regression and other similar algorithms. Similarly, machine learning models have made it possible to ensure that construction projects are developed considering safety, time management, and quality.
As shown in
Figure 6, the two major big data domains rely on statistics, data processing, and data management. All these features, in turn, are heavily dependent on ML tools and methods. For example, BDE requires data processing and storage, which in turn require regression models, NoSQL, and MapReduce, all of which are different types of computational tools that enable the different applications of big data management. Similarly, BDA heavily depends on ML tools that can use data and statistics to provide organized data solutions. The use of tree-based analysis, Bayesian analysis, and shrinkage are all examples of ML integration in the field of BDA. A wide variety of ML tools have been explored over the years and have been directly or indirectly associated with big data management and analysis. Tools such as linear regression, vector machines, KNN models, clustering, and decision tree regression are among the few examples which enable the use of big data coherently. Furthermore, the classification tree of big data is likely to be further expanded as the ML algorithms are further developed and more analysis methods are added to the list. Therefore, the constant expansion of the big data analysis tools can enable the use of these tools in the construction industry for improving construction projects in the future. Yang and Yu [
49] investigated the application of heterogeneous networks oriented to NoSQL database in optimal post-evaluation indexes of construction projects. NoSQL database is scalable with a powerful and flexible data model and a large amount of data and has increasing application potential in the memory field. Sanni-Anibire et al. [
50] investigated the increase in delays and abandonment of tall buildings and developed a machine learning model for delay risk assessment. Methods such as K-Nearest Neighbors (KNN), Artificial Neural Networks (ANN), Support Vector Machines (SVM), and Ensemble methods were considered. The model developed for predicting the risk of delay was based on ANN with a classification accuracy of 93.75%. The key components of big data from
Figure 6 for its management are discussed below.
4.1. Big Data Processing
Distributed and parallel computation is present in the core of BDE. In construction, big data processing has been utilized for waste management [
51], prefabricated construction project management [
52], profitability analyses, and other construction management applications [
39]. For processing information, a considerable number of models are developed. Some of the key big data models are discussed below.
4.1.1. MapReduce (MR)
MapReduce was developed for the handling of big data. It utilizes a distributed processing model in which two functions, as indicated by the name itself, map and reduce, are employed to write analytical tasks. Mappers and reducers are the processes that collect the data from these functions for further processing. Initially, mappers collect and read the input information to process it for subsequent results generation. The output of mappers is used by reducers which give the results that are ultimately stored in the file system. MR has been used by Jiao et al. [
53] to develop an augmented framework for BIM. Similarly, it has also been used in construction knowledge maps [
54] and other big data applications [
54].
The use of MapReduce in the construction industry is inevitable due to the big data applications within the construction industry. The usability of the MapReduce framework in the construction industry relies on the management of big data in a particular way. Accordingly, the datasets are analyzed and divided into categories to reduce clutter and present an easy-to-understand data output. The basic framework of MapReduce includes data input, data chunks, decomposition mappers, decomposed output, linear mappers, linear reducers, and combined output. The exact series and number of components in the framework can vary depending on the version used. However, the overall features and application of MapReduce remain the same, i.e., reduction of data into manageable chunks. The use of MapReduce not only distributes data into smaller chunks but also helps develop datasets that present a more analytic view of big data. Having organized datasets within the construction industry is of key importance as it can greatly increase the efficiency of data management and decision making based on data analysis.
Hadoop was the popular and first big data platform that introduced and made it easy for people to work on MR by executing its programs successfully. For tasks requiring batch processing, MR proved itself to be an effective tool as a typical cluster contains interlinked mappers and reducers that assist by running MR programs side by side at the same time. Though it has its benefits, these are not devoid of the drawbacks. These drawbacks include running some applications for graph generation and real-time and iterative processing. By dissociating the rest of the ecosystem from the processing of MR, Hadoop’s latest versions have tried to sort out the problem. Yet another resource negotiator (YARN) has also been introduced, which functions by providing resource management and scheduling related functions of MR and has made it easy to implement innovative applications by Hadoop.
Hadoop models have been used in construction for smart buildings and disaster management [
55], failure prediction of construction firms [
56], workers’ safe behaviors in a metro construction project [
57], and other relevant applications. The overall platform design architecture of Hadoop offers high reliability; adopt cluster technology, multi-copy technology, independent backup technology, and other means to reduce the data failure rate effectively and build a reliable data application service platform. First, the processing of big data into batches and simultaneous reduction and refining of the data are carried out using MR. Next, data are batched into similar items to streamline the analyses. This step further reduces noise or datasets that do not align with a particular batch of data. Finally, a dataset is obtained, which is refined and aligned with the original search purpose.
4.1.2. Directed Acyclic Graph
Big data platforms also use Directed Acyclic Graph (DAG) which is an alternative processing model. In comparison with MR, DAG works by relaxing map-then-reduce, the style of MR, which is supported by Spark. Spark is widely accepted for reactive and iterative applications due to its supremacy over MR in high expressiveness and in-memory computation. Disk-resident and memory-resident tasks are conducted ten and one hundred times faster using Spark than MR. DAGs show relationships among variables, making them easier to understand. DAGs provide major advantages that enable experts and researchers to construct complex causal relationships in which nodes represent stochastic variables, and directed edges (arrows) indicate direct probabilistic dependencies among the relevant variables. DAGs are also able to encode deterministic as well as probabilistic relationships among the variables. The usage of Spark and associated DAGs has been reported for construction profitability analysis [
39], waste management [
25], energy monitoring service on smart campuses [
58], and others.
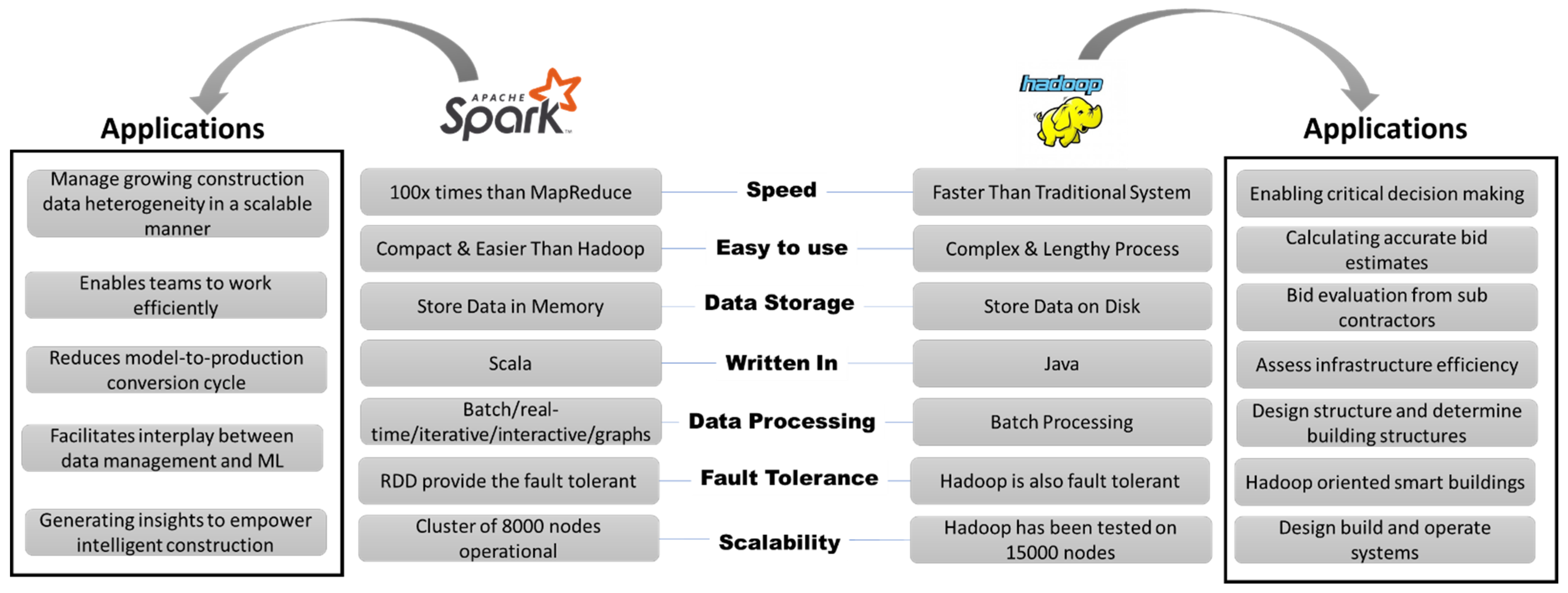
Spark and Hadoop are among the ML tools with enormous potential in construction engineering and management.
Figure 7 compares the two tools that can inform research in construction. The speed of both these systems is better than other algorithms and ML tools currently in use in the construction industry. Moreover, fault tolerance in both these systems is also high and has greater scalability than existing models. The data storage in these systems is slightly different in that Spark uses a memory system while Hadoop utilizes a disk for data storage. The language for both these tools is also different since Spark is written in Scala while Hadoop has been developed using JavaScript. Despite the slight differences, both these tools provide the opportunity to process data in the form of batches and at a higher speed than previously existing models, making them potential tools for futuristic model developments in construction engineering and management. JavaScript has been used in construction to anticipate building material reuse [
59], automated progress control coupled with laser scanning [
60], shared virtual reality for design and management [
61], construction information mining [
62], and others. Similarly, Scala has been used for the process information modeling concept for on-site construction management [
63].
4.1.3. Big Data Processing in Construction
Big data processing has been effectively utilized in the construction industry for failure prediction data [
56], construction waste analytics [
25], profitability data [
39], modular and prefabricated construction [
52], fire incident management [
64], smart campus energy monitoring [
58], healthier cities management [
28], smart road management [
40], and others.
Though MR and Spark have their own significance, these are less frequently employed in the construction industry to process big data such as BIM-associated data. Partial BIM models’ retrieval was optimized by MR by Bilal, et al. [
65] and Chang and Tsai [
66]. The authors found a loop in the Hadoop MR logic of data distribution. For overcoming the query problem, a few steps of prepartitioning and processing are introduced for relevant BIM data parts that are later stored in Hadoop clusters. Node multi-threading during data analysis helped by making the CPU work its maximum. This helped in customizing Hadoop for BIM data while the YARN application implemented querying components. YARN applications are further utilized to develop a BIM system for quantity estimation and clash detection that can execute required tasks with the performance improved many-fold.
Another research group worked for naive and expert BIM users by developing a system for BIM data storage and retrieval [
67]. The authors developed a system for cloud BIM to retrieve and represent big data intelligently. This system helped develop an interactive interface to maximize the usability and utility of construction big data. Complex BIM data are retrieved by processing proposed natural languages after reformulating user queries. This data are then visualized by mapping on various visualizations. Before query evaluation, two BIM collections are merged to optimize the process of query execution. Using this technology, a 40% reduction in response time has been witnessed compared to other traditional technologies. Currently, the utilization of BIM is limited across the construction and facilities management stages. The real intent of BIM could only be achieved once applied at each stage of the building lifecycle.
4.2. Big Data Storage
Big data storage is also an important aspect of BDE. In construction, big data storage has been explored for forecasting the success of construction projects [
68], smart buildings data storage [
69], tender price evaluation [
70], and others. Despite the availability of BIM data storage, the current applications in construction still require successful implementation. Social BIM, proposed by Das et al. [
71], captures building models and the social interactions among the users. The authors developed BIMCloud based on the distributed BIM framework.
Similarly, a two-tiered hybrid data infrastructure was proposed by Jeong et al. [
72] for data management and monitoring of bridges. In this model, the client tier efficiently completes some analytical tasks by storing structured data momentarily using MongoDB, while the central tier stores sensor data permanently using Apache Cassandra. Lin et al. [
67] also used MongoDB to store BIM data obtained through building models.
Overall big data storage is provided by either emerging NoSQL databases or distributed file systems, as explained subsequently.
4.2.1. Distributed File Systems
The distributed file systems consist of Hadoop Distributed File System (HDFS) and Tachyon. HDFS is designed to deal with large and complex databases such as those related to BIM, waste, and other construction big data sources. It operates with the commodity servers grouped together in a cluster. As it utilizes several servers, the probability of hardware failure also increases. To overcome this problem, HDFS introduces fault tolerance achieved through the distribution of data and their replication. However, in situations where low-latency data access is required, HDFS is not a suitable option as it shows inferior performance. Moreover, it is also troublesome to save many small files due to issues in managing meta-data. Moreover, it is not useful if modifications must be made concurrently at random locations in the data. Nevertheless, HDFS has been utilized by construction researchers for observing construction workers’ behavior [
73], improving road performance [
39], and investigating profitability performance [
39]. Furthermore, based on the distributed input from HDFS, it facilitates building predictive models for conducting building simulations that give output in a predictive model markup language.
Tachyon is a distributed file system designed to extend HDFS benefits by providing access to the distributed data across the cluster at memory speed. It provides better performance through in-memory data caching and backward compatibility allows MR and Spark tasks to run without changing the codes required in those programs. Tachyon has been utilized in construction for handling unstructured documents [
65] and file storage [
74]. The Tachyon performs better than HDFS, is backward compatible and can handle the MapReduce jobs without any further modifications.
4.2.2. NoSQL Databases
Relational databases have been common for data management in past decades. However, new applications were designed for better performance, scalability, and flexibility as the technology emerged. Relational databases lag because of their special processing and storage needs. As a result, new systems were devised to fill this technology gap. One such system is the “Not only SQL” system that has optimized data management in several ways. For achieving flexibility, it supports schemaless storage rather than schema-oriented storage. NoSQL has been widely used in different industries, including construction, due to its fragmented nature. Some examples of NoSQL in construction include integration of lessons learned knowledge in BIM [
75], web service framework for construction supply chain collaboration and management [
76], and Social BIMCloud implementation [
71]. NoSQL systems store schemaless data in a non-relational model. It does not set too many restrictions on value and allows easy product determination. Generally, when NoSQL databases are set to key values, they carry out only specific tasks without evaluating specific values. The key-value database is mainly tailored to the business accessed through the primary key. These systems have four data models that are briefly discussed below.
This is the simplest data model used for unstructured data storage. However, the data lack self-description. It has been used for knowledge management in construction [
77] and integration of lessons learned knowledge in BIM [
75]. BIM provides positive outcomes on project success, such as cost and time reduction, communication and coordination improvement, and increased quality. Big data utilization in BIM can be beneficial to discover root causes of poor building performance, perform real-time data queries, improve the decision-making process, improve productivity, and reveal new designs and services in the construction industry, as is the case in every industry.
This model can store self-describing data. However, this model can lag in terms of efficiency. It has been used for unified lifecycle data management in architecture, engineering, construction, and facilities management through BIM integration [
78].
Aggregated columns, grouped sub-columns, and sparse data can be stored by using this model. It has been used for integrating digital construction through the internet of things [
79] and smart archiving of energy and petroleum construction projects [
80].
This model works well for property-graph-based huge datasets in relationship traversal. It has been used for the 4D construction management information model of prefabricated buildings [
81] and the development of a BIM-enabled software tool for facility management [
82].
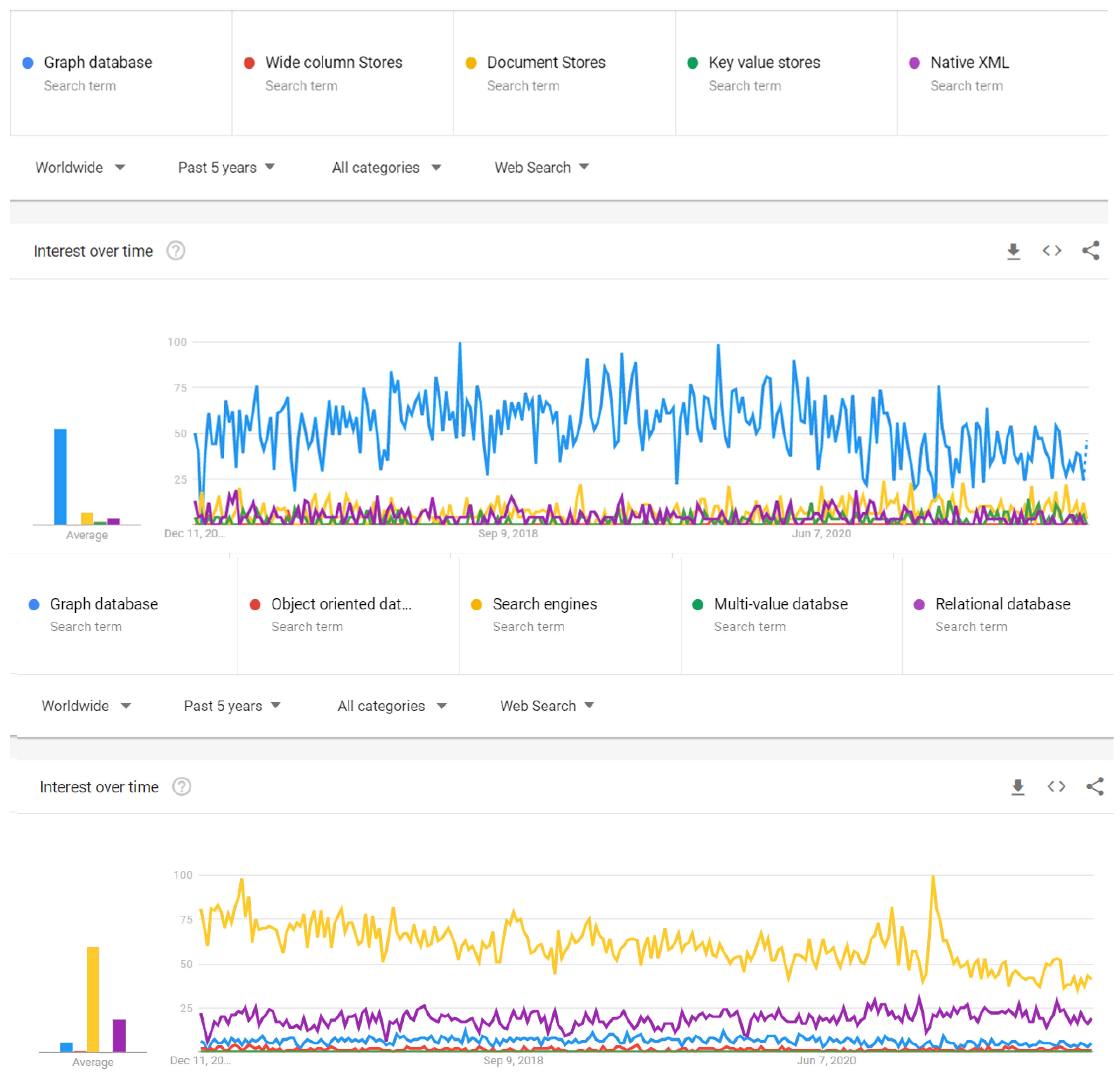
Databases concerning big data storage and management are widely used worldwide for research on various topics. The construction industry also relies on big data sources and databases, observed throughout the last five years to a decade. As shown in
Figure 8, the search engine is among the most widely searched database in the last five years, followed by relational and graph DBMS. Until the time of analyzing data for this review, i.e., November 2021, other heavily used databases for extracting and using big data for the construction industry include document stores, native XML, key-value stores, and wide column stores. Object-oriented DBMS and multivalued DBMS search are considerably lower than relational DBMS and graph DBMS, whereas the search engines outperform all other DBMS. These different databases provide data sources for BIM and computational sources for developing structures that could guide larger construction projects. The rising trend in using big data sources shows the increasing interest among the construction industries in big data. For example, exchanging and reusing information is critical for engineering and construction project management. The issues pertaining to data exchange have been minimized with the Extensible Markup Language (XML) application. Such an XML-based Distributed Construction Estimating System (XDCES) has been helpful to reduce the overload of cost-estimating information exchange. Similarly, construction-based DBMS enables all construction companies to build and maintain a database easily. It allows supervisors and workers to capture information using a mobile or tablet device, and then all of that information is stored in the cloud and accessible via a desktop version.
4.3. Big Data Analytics (BDA)
BDA gathers information from a variety of disciplines. All these disciplines have one thing in common: to find out data patterns. Some of these related disciplines are data mining, statistics, business analytics, predictive analytics, data analytics, knowledge discovery from data, and the most recent one, big data. Big data use the previous techniques to broaden the field of data analytics. For BDA, some of the ML-based tools are developed. In construction projects, BDA has been used for improving building design and effective performance monitoring [
37], project safety, energy, resource, overall management and decision-making frameworks [
38], and quality and waste management [
24]. Big data analytics has been taken a step further by developing predictive analysis techniques. Ngo et al. [
83] used a factor-based big data predictive analytic tool for analyzing the capacity of construction industries to deal with big data. This tool was tested and validated on four different construction organizations to ensure that the predictive analytic method could improve how the construction industry can use big data. The integration of big data in the construction industry remains an avenue that requires further research in terms of big data analytics. The gaps in this area were explored by Atuahene et al. [
30] and Atuahene et al. [
84]. It was identified that the management and processing of data by firms led to the generation of more data, which made data analysis an uphill task. Developing an integrated framework for managing big data and sorting the useful datasets can greatly increase the usability and application of big data in the construction industry. Overall, data analytics is conducted through statistical, data mining, and regression techniques, as explained below.
4.3.1. Statistics
Statistics has wide applications in the construction industry. Statistical techniques including Monte Carlo simulation, Gaussian distribution, non-Bayesian methods, correlation analysis, factor analysis, decision trees, Naïve Bayes, and others have been reported by various studies in construction [
85,
86]. Some of the areas that benefitted from statistics include learning from post-project reviews, identifying causes of construction delays, analyzing buildings for structural damages, construction litigation, and identifying and recognizing heavy machinery and workers. Other examples of statistics in construction are those of bidding statistics to predict completed construction cost [
87], accidents statistics [
88], quality control [
89], and six sigma for project success [
90,
91]. From measuring the bid-to-win ratio to how much a project is over budget or schedule, and KPIs, the more numbers you can put behind your work, the better. Data not only allow for more visibility into the state of a particular project, but relevant industry statistics and facts can provide valuable information needed to make important future decisions regarding preconstruction and planning, productivity tools, risk assessment, and workforce and operational efficiency.
Table 1 presents some uses of statistical models in construction.
4.3.2. Data Mining
Data mining is used to extract meaningful patterns in the data. It has been an integral part of all big data management systems. It employs the techniques used in pattern recognition, ML, and statistics. Several models are assessed, and the ones with the best tolerance and high accuracy are selected and used for obtaining predictive results. In construction, data mining has been reported in waste management [
97], BIM-based construction engineering quality management [
98], and other relevant areas. Data mining detects useful regularities and information necessary for decision making for construction management projects. A data mining method such as cluster analysis is important for the construction industry, as it combines different construction objects into homogeneous groups and investigates them.
Data mining is supported through data warehousing. Specially structured data is stored in data warehousing for querying and analysis. Extract, transform and load (ETL) is a program that allows the collation of transactional data and operational data. Warehouse data analysis is conducted using Online Analytical Processing (OLAP), which performs better than SQL in computing breakdown and data summaries. OLAP has been used for cost data management in construction cost estimates by Moon et al. [
99]. OLAP technology deals with the operational data and data obtained using big data technology. OLAP is presented as a multidimensional cube that rapidly processes datasets.
Similarly, different data mining techniques have been used to identify construction delays. For analyzing construction datasets, Kim et al. [
12] presented a framework of knowledge discovery in databases (KDD). In the KDD, the most time-consuming and challenging step is data preprocessing. Nevertheless, KDD is a powerful tool for identifying casual relationships in construction projects and reducing construction variability by identifying and eliminating causes for possible deviations. With the application of KDD, randomness of construction projects and novel patterns can be determined. Other techniques include dimensional matrix analysis, link analysis, and text analysis [
100]. Other datasets with information related to delay causes, BIM-based knowledge discovery, intelligent learning, and the prevention of occupational injuries can be easily extended in the domain of data mining.
4.3.3. Regression Techniques
Based on an input variable, regression predicts the value of the target variable. It is a supervised ML method. Regression is categorized into simple linear and multiple linear regression based on explanatory variables. In simple linear regression, the relationship between two variables (an explanatory variable x and a dependent variable y) is modeled using ML. While in multiple linear regression, two or more explanatory variables are used and their relationship with the dependent variable is modeled. The more common regression technique is multiple linear regression.
Regression has been extensively used in construction research. For example, it has been used to predict properties of concrete cured under hot weather [
48], predicting final cost for competitive bids on construction projects [
101], determining contingency in international construction projects [
102], estimating performance time for construction projects [
103], and others. Moreover, regression has been used for cost estimation, which is a difficult task in the early stages of the project. Adoption of parametric methods such as regression and multiple regression can be applied as both analytical and predictive techniques to estimate the overall reliability of the cost estimation.
4.4. The 10 vs. of Big Data
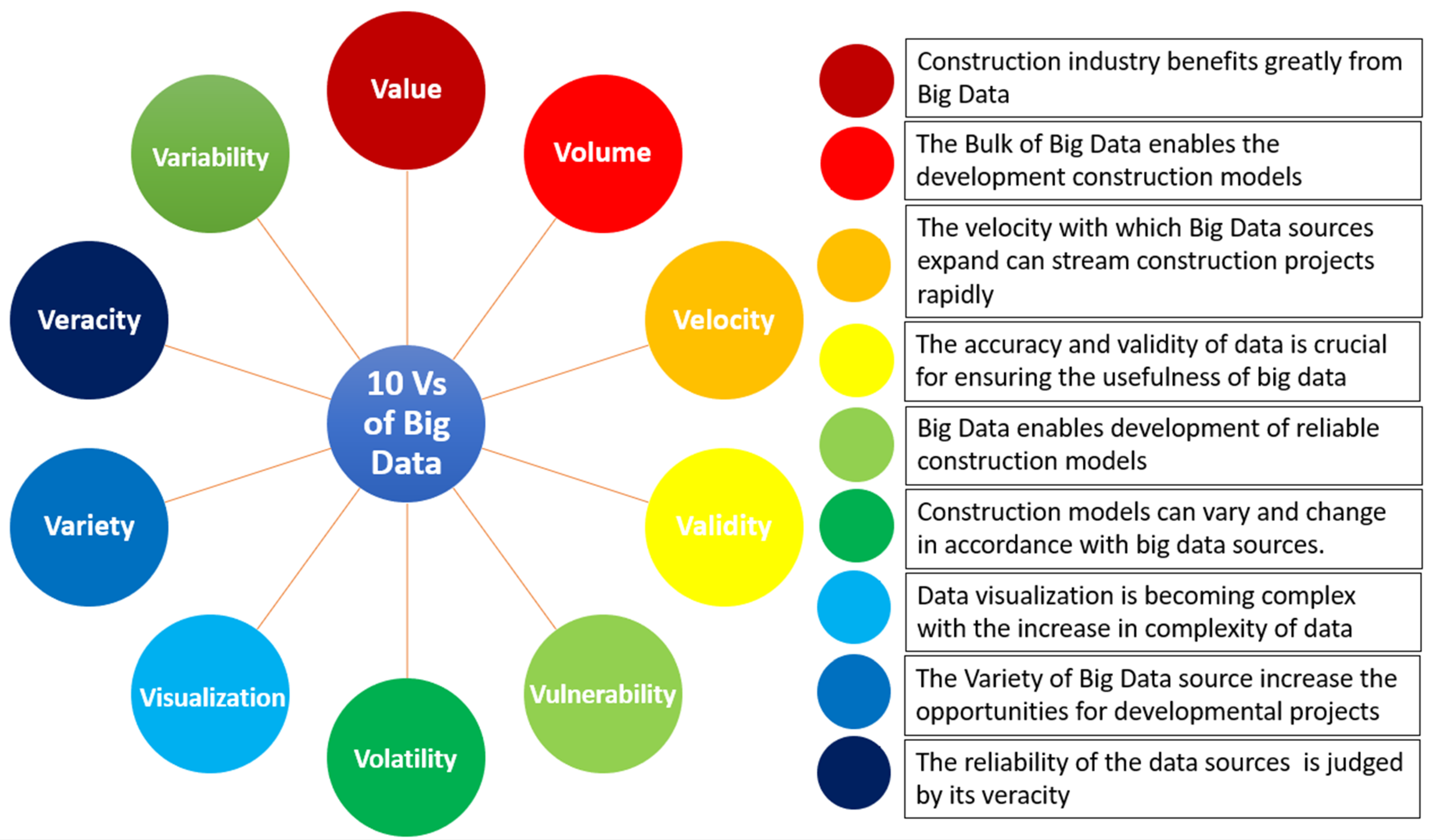
The bulk and variety of big data gathering enormously each day make it virtually impossible to deal with the data sources seamlessly. On the other hand, the enormity of big data gives it many characteristics that further expand the potential of big data and its applications in different research fields.
Figure 9 provides an overview of some of the crucial characteristics of big data, also known as the vs. of big data. The 10 vs. of big data have been discussed in
Figure 9. Understanding these characteristics of big data enables the identification of opportunities and challenges. The most crucial properties of big data include their value, volume, velocity, variety, veracity, volatility, validity, variability, vulnerability, and visualization, also known as the 10 vs. of big data [
104]. These characteristics of vs. are used to guide research in different areas and fields.
In terms of the use of big data in the field of construction, analyzing the vs. can help explore how big data can be used for developing better construction models in the future. Firstly, big data provide great value using various databases and sources that inform the research studies and algorithm developments related to computational models of different building structures. In addition to the value of research, big data also provide a bulk of information needed for research simply through the ever-increasing volume of data that becomes available each day. Furthermore, the velocity with which databases expand each day adds variety to the sort of data available for utilization in fields like construction. The variety of data present is not varying just in terms of the data sources but also the types of data. For example, big data can be present in the form of written text, graphs, pictures, and various other formats to help manage construction project schedules and progress reporting. The increasing amounts of data make the visualization process quite complex. Therefore, it is crucial to develop new ways for data visualization and analysis to keep with the volatility of big data.
The 10 vs. of big data are among the crucial characteristics representing the true picture of big data as a field of research. The applications of big data in the construction industry are innumerable and they can all be categorized and managed through understanding the characteristic features (or Vs) of big data. The construction industry benefits immensely as a business by integrating big data technologies. The correlation with the business side of the construction industry has been explored in light of the 10 vs. of big data and it has been found that these characteristics provide an immense business growth potential. Starting from the core attributes of volume, variety and velocity, big data have come a long way in terms of their applications and trends. Today, there are 10 characteristics that define big data and are also crucial for implementing big data into different fields. It is crucial to understand that these 10 vs. of big data can be explained in a context-dependent manner considering the field of research. As for the construction industry, the variety and volume of big data are immense, but there is also a great deal of variability in the data present. For example, the choice of building materials and the suitability of the selected materials in different projects depend on several different factors. In this case, analyzing the applicability of big data is possible through data-visualizing techniques that can help deal with the volatility and variability of big data. Similarly, the validity and veracity of big data in construction can be judged only after analyzing the value that the data sources bring and the authenticity that these sources present. Therefore, the increasing velocity of big data is not useful as an independent factor. Instead, the application of big data in the construction industry depends on the 10 different characteristics (Vs) which are associated with big data and are explained in
Figure 9.
Similarly, these data types can be refined and unstructured, further adding variety to the type of data present for various reporting and research purposes. Veracity refers to the reliability of big data. This is guided by statistics as the enormity of big data makes it hard to identify reliable data sources. Therefore, validating data sources and ensuring that they can be reliably used to guide construction project developments is crucial for research. The veracity of data sources leads to another important characteristic of big data: variability. It is crucial to understand that big data can be highly variable depending on the sources used for extracting the datasets. Understanding these characteristics of big data and analyzing these characteristics given the use of big data in the construction industry can greatly enhance the potential of future construction projects.
Overall, multiple construction-related studies have reported the usage of vs. of big data. For example, velocity has been reported for high-speed construction data processing [
105]. Value has been reported for smarter universities and campuses [
106]. Volume has been reported for mass level offsite construction material and component production [
107]. Variety has been reported for investigating the profitability performance of construction projects [
39]. Veracity has been reported for forecasting the success of construction projects [
68]. Similarly, variability has been reported for modeling occupational accidents in construction projects [
108].
Big data necessitate cost-effective, innovative information processing forms for enhanced insights and decision making. Construction companies can analyze historical datasets and carry out predictive analytics to forecast future events. Data-driven decision making has the potential to reshape the entire business. Together, the 10 attributes or 10 vs. of big data play a crucial role in the construction industry. The volume of data and the velocity through which data are produced at high speed lead to the possibility of validating information related to construction projects. The ability to visualize big data, keep up with the variety of data, and accept the volatility, vulnerability, and variability that come with the veracity of data helps ensure that big data could be truly applicable in the construction industry. Therefore, the value of big data in the construction industry is high and it helps guide future projects.
4.5. Machine Learning Techniques
One AI subdomain is ML which can be used to learn from the data using computational systems. The tools used for big data ML are presented in
Table 2. ML is further categorized into: (i) supervised learning; (ii) unsupervised learning; (iii) association; and (iv) numeric prediction. ML has several applications in the construction industry. It uses different approaches, including rule-based learning approaches, case-based reasoning techniques, artificial neural networks, and hybrid methodologies.
ML has immense potential as a tool in the field of construction. Over the last two decades, several ML algorithms have been proposed to aid and improve the overall process of construction. For example, ML has been used to predict properties of concrete [
48], contract management [
109], site safety and injury prediction [
46], delay risks management [
45], BIM integrated on-demand site monitoring [
47], and other areas of construction engineering and management.
Various ML tools are integrated at different steps along with the construction management processes. Different ML interfaces such as PyTorch and Keras.io help develop computational models based on existing data for building futuristic construction models. BIM can also be improved by using big data and ML tools, as these technologies allow the opportunity to explore how technology could be applied to the construction industry [
110]. Over the last few years, different algorithms have been explored to predict various project phases and guide construction projects from inception to closure [
111]. Firstly, decision trees and similar tools are used for developing an overall project timeline to predict or determine construction project performance in various phases. Secondly, statistical analysis tools are used for analyzing previous projects and choosing guiding principles for future projects [
112]. Finally, design tools are integrated with ML algorithms to build 3D construction models and graphics for building models. These computational models enable analyzing construction projects by planning through look-up schedules and looking for ways to improve buildings and other structures [
113].
The combined use of big data, ML, and AI holds the potential to develop seamless construction projects and enable the development of structures that can withhold severe weather conditions and disasters. For example, one of the key uses of ML tools in futuristic construction projects can be the development of structures that can stand through natural disasters and provide safety nets to communities during floods and other disasters [
114]. Similarly, post-disaster evacuation and rescue of individuals can also be carried out more easily if the area contains structures such as roads and buildings built through the use of statistical modeling, thus providing safe routes for people [
115]. Although the automation of construction projects remains a future goal, the integration of different ML algorithms is already underway. Managing costs, timelines, and human resources on a construction project are areas guided by various algorithms and computational models [
116]. The ML approach can also be applied to develop leading indicators to classify sites according to their safety risk in construction projects.
Table 2.
Machine learning tools used for big data.
Table 2.
Machine learning tools used for big data.
| No. | Tool | Description | Supported Algorithm | Languages | Applications in Construction | Ref. |
|---|
| 1 | PyTorch | PyTorch is a free tool available for Windows, Mac OS, and Linux for developing ML programs | Regression
Classification
Clustering
Dimensionality reduction
Preprocessing | C, C++, Python | Object detection, analyzing buildings and other structures to develop better models | [117] |
| 2 | Apache Mahout | An open-source tool that allows high-performing and scalable applications using ML | Distributed Linear Algebra
Clustering
Regression
Preprocessing | Java, Scala | Processing big data for the development of building models and appropriate algorithms | [118,119] |
| 3 | Shogun | A diverse ML platform supporting various languages and platforms. Works well with Windows, Linux, and Mac OS | Classification
Regression
Dimensionality reduction
Online learning
Support vector machines | C++ | Provides a platform for analyzing data and developing strategies for construction projects using available information in the form of big data | [120] |
| 4 | SciKit Learn | A free, machine-learning tool that supports Windows, Mac OS, and Linux | Regression
Classification
Preprocessing
Clustering
Model selection | C, C++, Cython, Python | Enables statistical analysis for construction projects, particularly using existing data for developing suitable construction models | [121] |
| 5 | Keras.io | An ML software that can be used across different platforms | API for neural networks | Python | Provides training models which can be harnessed for improving BIM and creating confident models for construction projects | [122] |
5. Future Opportunities of Big Data in Construction
There is immense potential for the use of big data in the construction industry. The use of big data and ML can enable construction automation. These tools can also enhance the overall project by removing various hurdles and roadblocks that tend to slow down different projects. The construction industry is quite dynamic and demanding, with the need for labor strength and human resources to ensure the smooth running of projects. The constant challenge of keeping projects on track and ensuring that new buildings and structures are made up to modern standards puts much strain on the project management teams. These roadblocks can greatly be reduced with the use of big data and ML. The core aim of using big data in the construction industry is to enhance the project planning phases and speed up the overall construction process by predicting the possible timelines for particular projects and identifying what factors can be worked on to improve the overall process [
123].
The automation of the construction projects will require the combined use of big data, deep learning, and ML tools. One of the major concerns with such projects is ensuring workers’ safety and developing strategies for overcoming potential threats to the overall process. Safety of the workers and the structures is essential for the smoother development of construction projects. The use of big data and related tools can ensure that existing data and information can be used for drafting guiding principles and then building computational models accordingly. For example, using sensor-based wearable personal protective equipment, the big data of near misses, onsite accidents, hazards, and other issues can be generated for developing safety plans and management techniques. Similarly, big data, BIM, and cloud-powered simulations can help minimize project waste and help produce superior quality constructed facilities. Further, big data artifacts generated by 3D scanners for as-built drawing development are another key advantage whereby the rehabilitation plans of ancient heritage sites can be developed.
The future holds great potential for the construction industry through big data integration. Some of the key opportunities for the construction industries lie in using big data for business and environmental sustainability. The current roadblocks faced by the construction industry can be overcome in the future through the integration of information extracted through big data. The use of information gathered from past and present projects can help develop sustainable infrastructure in the long term. It is possible to avoid past mistakes and use better quality products guided by the information found through big data in construction. Future research directions in the field of construction rely heavily on big data as the presence of information sources can help in building better infrastructure and greatly improve building designs and the overall construction business. The construction industry must move towards automation and build upon the integration of technology to make the future use of big data seamless and hassle-free. The use of big data tools, BIM, and CAD can only be possible if the relevant support and integration systems are present [
107]. Hence, the future of the construction industry depends on upgrading the present environment gradually.
Overall, the role of big data in enabling the entire process of futuristic construction projects is undeniable. Data play a crucial role in developing training models and smoothly enabling the process of construction. Future developments in this field will also include the generation and use of more algorithms and models that rely on big data, owing to the need to train the models reliably.
6. Conclusions
The construction industry is yet to reap the true benefits of using big data aptly. Over the last two decades, the rapid growth of big data technologies has caused a spike in the number of models and platforms that have been developed for increasing digitalization across different fields. However, the same level of digitalization has not truly been harnessed or integrated by the construction industry. A critical overview of the existing literature points towards the bulk of existing resources and platforms that can easily be applied for construction management. However, the state of implantation of adoption in construction is below par. Therefore, the utilization and commercialization of big data to benefit the construction industry are crucial. An extensive literature review enabled us to identify the potential of big data in construction as the industry generates huge amounts of data daily and can greatly improve using the latest technologies. The development of online tools and software which enable infrastructure modeling and CAD is a crucial step in the right direction for futuristic constructions. Having explored the existing ML tools, we found that these tools, coupled with big data, can be applied in the construction industry. In this paper, we have discussed the existing tools used in big data, the use of statistics, big data storage, and BDE. Overlap between these variables further creates complications in that more data are present and the field of big data is ever-expanding.
The current study contributes to the body of knowledge by providing a state-of-the-art review of relevant articles focused on big data applications in construction published between 2010 and 2021. It further provides various current applications and future opportunities of big data in the construction industry for practitioners and researchers to ponder upon and initiates the necessary debate around practical implementation and adoption of big data applications in construction.
There are currently various gaps and pitfalls that act as barriers to using big data to its full potential. Firstly, data generation is much faster than the tools available for processing it. Moreover, big data integration into the construction industry is quite an uphill task even with the existing data processing tools.
The current study is limited to the literature published in the last decade and may not include all the available papers due to specific selection criteria developed in this study. Similarly, the search terms may not be holistic and thus not exhaustive; a study conducted in the future with slightly different search strings may produce different results. In the future, the researchers can expand upon and explore the five clusters identified in
Figure 4. The individual relations and adoption frameworks for big data in these clusters can be explored.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








