1. Introduction
Person re-identification is the process of retrieving the best matching person in a video sequence across the views of multiple overlapping cameras. It is an essential step in many important applications such as surveillance systems, object tracking, and activity analysis. Re-identifying a person involves simply assigning a unique identifier to pedestrians captured within multiple camera settings. However, it is very challenging due to occlusion, large intra-class and small inter-class variation, pose variation, viewpoint change, etc.
Person re-identification is conducted on images [
1,
2,
3,
4,
5,
6,
7] or videos [
8,
9,
10,
11,
12,
13,
14]. Early approaches to this process can be classified into two main branches: either to develop handcrafted features or to develop machine learning solutions for optimizing parameters. Recently, the use of deep learning feature extraction has become very popular due to its success in many vision problems.
Nowadays, videos have gained more attention because they make use of the benefits of rich temporal information rather than using static images which suffer from limited content. Several related works have extracted frame features and aggregated them into maximum or average pooling [
11,
15], while other studies using temporal information have used temporal aggregates such as long- and short-term memory (LSTM) or recurrent neural networks (RNNs) [
8,
9,
16,
17].
Lately, “attention” has attracted more interest due to its strength in retaining important features and removing irrelevant ones. Several works have been designed using spatial-temporal attention [
12,
15] or recurrent attention [
9,
18,
19], or have developed functions to re-weight frames [
13,
20] or use 3D convolution neural networks (CNNs), such as in [
21].
Several studies have focused on developing part-based models, combined with global features [
1,
4,
5,
7,
15]. Some works have also used an auxiliary dataset [
22] to define an attribute [
1,
7] or have used pose estimation [
6,
15], while others have extracted features on a multi-scale [
2,
3].
Self-attention was introduced by Ashish et al. [
23] in 2017. It complements CNNs and helps systems with multi-level dependencies to focus on important features. It has successfully achieved better performance in many linguistic tasks such as summarization, translation, reading comprehension, and sentence representation.
In this study, inspired by research on attention and a combination of studies on global and local features extraction, we have developed a multi-part feature extractor with a multi-attention framework. As such, the contributions of our study can be summarized as follows:
Developing multilevel local features representation to overcome missing parts and misalignment in global representation. The integration between multi-local partitions makes the representation more generalizable, as the person is viewed with multiple granularities.
Proposing a novel way to use self-attention in an image using a block of convolution layers to capture the most generalized information.
Using channel attention in addition to spatial attention to capture correlation in all directions. This uses the relation between channels instead of only a spatial aspect.
Introducing self-part attention between the multi-levels of features to benefit from the relationships between the parts in multi-granularities and produce better representations of each part.
The rest of the paper is organized as follows: The related works are discussed in
Section 2; the proposed approach in
Section 3; the experimental results in
Section 4; and the conclusion and our intended future studies in
Section 5.
2. Related Works
Person re-identification focuses on developing a discriminative feature set to represent a person. Early studies in this area have developed handcrafted features such as the local binary pattern (LBP) histogram [
24], histogram of gradient (HOG) [
25], and local-maximal-occurrence (LOMO) [
26]. Other studies use a combination of different features [
27,
28].
After that, various deep learning models have been presented and show better performance compared to handcrafted features. For example, Shangxuan et al. [
29] combined handcrafted features (ensemble of local features—ELF) with features extracted from CNNs, thereby making the CNN features more robust.
Video-based re-identification research focuses on three topics: feature extraction, temporal aggregation, and the attention function. Feature extraction refers to selecting the best features—global, part-based, or a combination of both—that represent a person. Temporal aggregation is the method by which each frame’s features are aggregated to construct video-sequence features. The attention function is used to learn how important features can be strengthened and irrelevant ones suppressed.
Features are extracted from each frame and aggregated using the temporal average pooling, as provided in [
30]. An RNN is designed to extract features from each frame and capture information across all time steps to get final feature representation [
11]. Two stream networks, one for motion and the other for appearance, are used together for aggregating with the RNN [
14]. Handcrafted features such as color, texture, and LBP with LSTM are used to prove the importance of LSTM in capturing temporal information. LSTM is used to build a timestamped frame-wise sequence of pedestrian representation that allows discriminative features to be accumulated to the deepest node and prevents non-discriminative ones from reaching it [
9]. Thus, two CONV-LSTM are proposed: one for getting spatial information and the other for capturing temporal information [
18].
The global features are combined with six local attributes learned from the predefined RAP dataset [
22]. Then, the frames are aggregated by re-weighting each frame using the attribute confidence function [
31]. Co-segmentation [
32] detects salient features across frames by calculating the correlation between multiple frames of the same tracklet and aggregating the frames using temporal attention. Multi-level spatial pyramid pooling is used to determine an important region in the spatial dimension and uses RNNs to capture temporal information [
16]. A tracklet is divided into multiple snippets and learns co-attention between them [
12]. The self and collaborative attention network (SCAN) [
10] uses the self-attention sub-network (SAN) to select information from frames in the same video, and the collaborative attention sub-network (CAN) obtains the across-camera features. TAM is designed for generating weights that represent the importance of each frame, and the spatial recurrent model (SRM) is responsible for capturing spatial information and aggregating frames by RNN [
13].
Spatial-Temporal Attention-Aware Learning (STAL) [
15] presents a model that extracts global and local features, which is trained on the MPII human pose dataset [
33] for learning body joints and attention branch for learning STAL. The relation module (RM) is designed to determine the relation between each spatial position and all other positions. It obtains the temporal relation among all frames according to the defined relational guided spatial attention (RGSA) and relational guided spatial attention (RGTR) [
34]. The multi-hypergraph can be defined as multi-nodes where each node is in a different spatial granularity [
35]. Attentive feature aggregation is presented to explore features along channel dimensions in different granularities and divides into groups. Each group has a different granularity than the attentive aggregate used [
36]. Finally, intra/inter frame attention is proposed for re-weighting each frame [
20].
Unlike the use of spatial and temporal attention in the previous methods, we propose the use of multiple attention for mining tensor vectors. Thus, we use the correlation from multiple directions and the advantages of channel dimension and part interaction to select important features from various dimensions. Taking advantage of multi-scale approaches, we propose a multi-part pyramid for exploring a person from multiple views that aims to extract discriminative and robust features.
3. Our Approach
Our model aims to explore pedestrians using the pyramid multi-part features with multi-attention (PMP-MA) for video re-identification. Pyramid multi-part features (PMP) detects pedestrians with multiple granularities to capture different details. Multiple Attention (MA) is applied to obtain the most important features in multiple domains. The combined approach gets the most robust features in multi-granularity levels and multiple domains. We start with a discussion of the overall architecture, followed by the details of the different model parts.
3.1. Overall Architecture
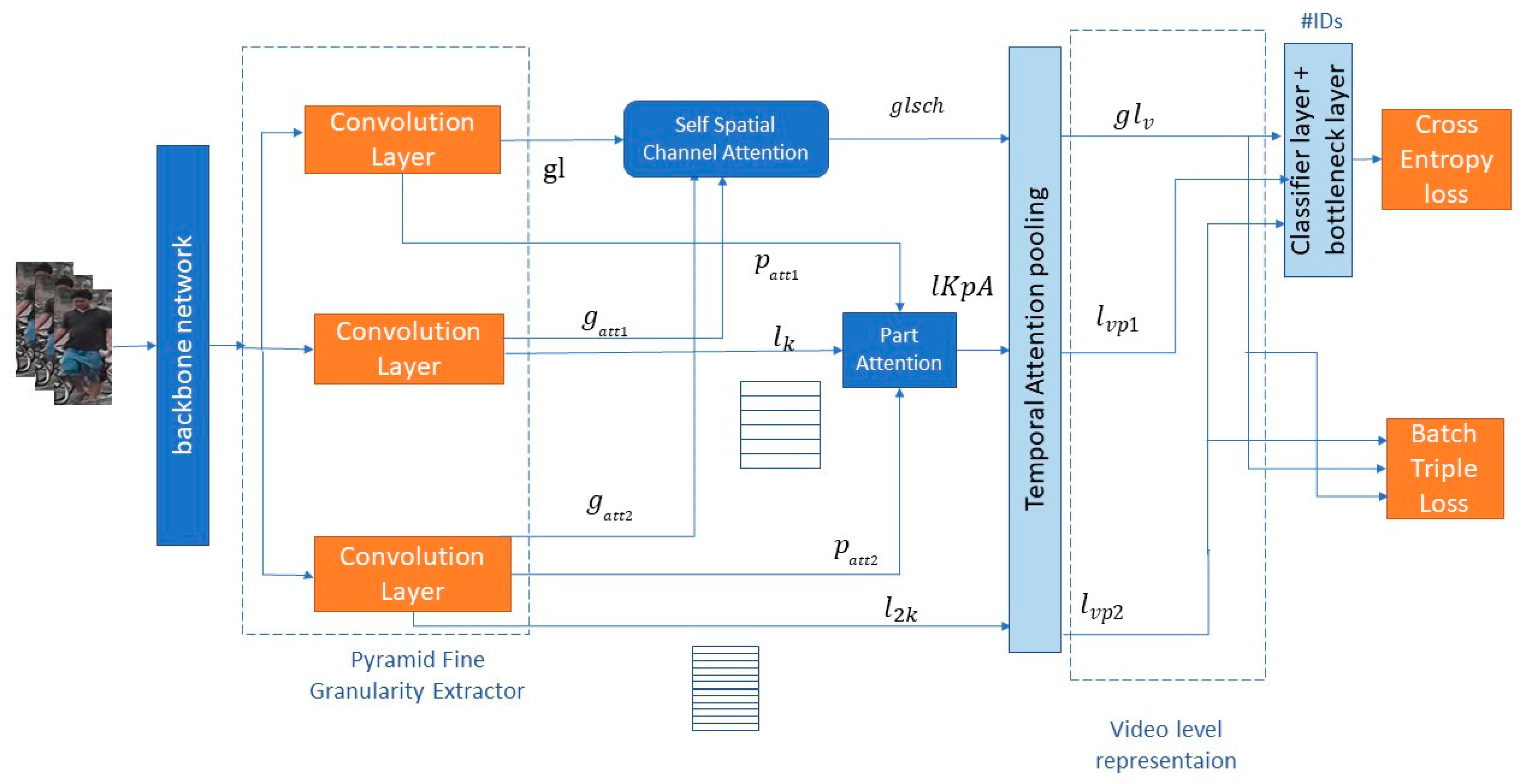
Initially, a group of pedestrian videos is fed into a backbone network X = {xt}1:T, where T is the number of frames. The backbone network is based on ResNet50. The output of the backbone is split into three independent branches; each branch represents a different granular level, as shown in
Figure 1. Then, we apply self-spatial and channel attention to improve the feature extraction and obtain the best spatial channel and part attention to obtain the relation between parts in multiple granularities. Subsequently, the outcomes of the three branches are concatenated to learn the most robust features for representing a person at multiple levels. After that, we apply temporal attention pooling (TAP) [
30] to aggregate the frame-level features and temporal information into a video-sequence feature representation. Finally, we use a classification layer with an intermediate bottleneck layer to generalize the representation among the set of tracklets used in training before loss function. Two loss functions are used: triple loss and cross-entropy.
3.2. Pyramid Feature Extractor
To enhance the representation of person-reidentification, this model uses a pyramid feature extractor to represent a pedestrian with multi-granularities level for each frame. It represents the pedestrian by three granularities: global representation , coarse-grained part representation and fine-grained part representation . The feature map of global representation is where h, w, and c represent the height, width, and channel size of the feature map. The features of the multi-part branches are partitioned into K and 2*K horizontal parts where k represents the number of horizontal parts. Initially, the backbone network extracts an initial feature map. Then, it splits into three branches and extracts three different feature maps to represent the same person through separate convolution layers (based on Resnet50). Besides that, it extracts complementary features to use as attention features.
The first branch is the global extractor that captures the global features of each pedestrian. It represents the whole frame with one vector and produces attention vector for part attention. The second branch divides the feature map into K parts to capture the local features for each part, captures the coarse-grained parts of each pedestrian , and represents the frame with K vectors. Beside that, it produces attention vector for spatial and channel attention. The third branch divides the map into 2*K parts. It captures the fine parts of each pedestrian and represents a frame with 2*K vectors and produces the attention vectors and . The model extracts global, coarse parts and fine parts features from the three branches and fuses them to obtain the most robust features.
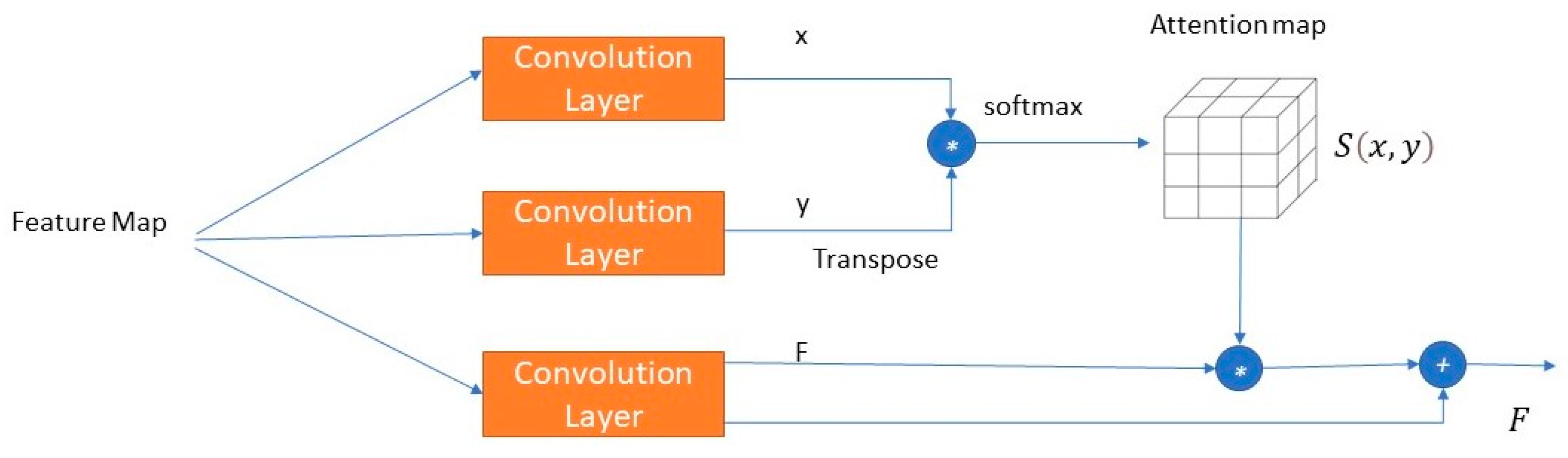
3.3. Self-Spatial Channel Attention
Self-attention is an intra-attention mechanism to re-weight feature
F with an attention score matrix
S(
x,
y) for strengthening the discriminative feature. It is designed to learn the correlation between one pixel and all other positions. It can explicitly capture global interdependencies. There are different techniques for calculating the attention score; in this work, the attention score
S is calculated by computing the relation and interdependencies of two attention branches using the attention dot-product [
21]. We compute the tensor-matrix-multiplication of
x and
y, where
x and
y are two feature attention vectors, and apply the
softmax function to get
S (Equation (1)), as shown in
Figure 2. Self-attention is used as a residual block [
37], which sums the output of
S *
F to the original
F. Equation (2) expresses the output of the self-attention block
f_att. where x, y, F→ feature vectors.
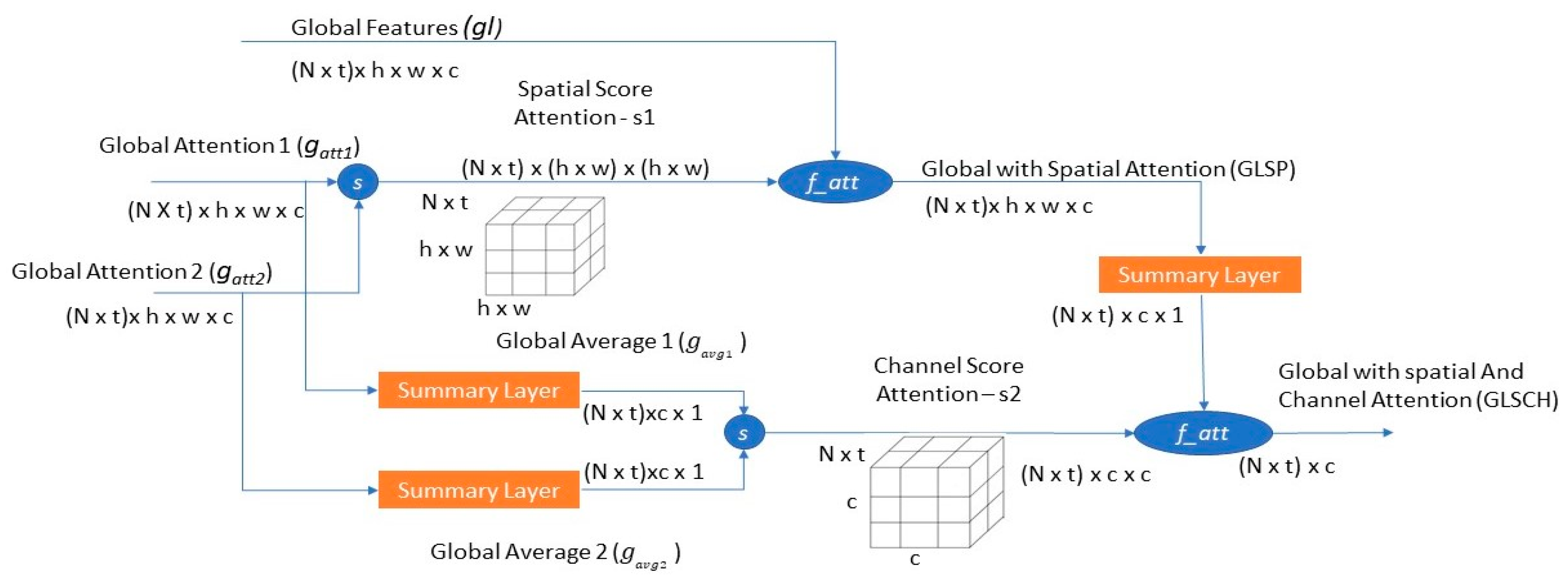
Using three branches satisfies the need of self-attention. Spatial-channel self-attention uses
for building an attention map that represents the relation between spatial and channel. Spatial attention enriches the spatial relationship. Let
gatt1 and
gatt2 be attention branches; when rearranged
(gatt1,
gatt2 Rhw*c,
Rhw*c), each spatial position is described by the
c channel. Hence, the spatial attention score after applying function
S is
s1
R hw*hw (Equation (3)), which represents the relation between each position and all positions. Then, we apply the
f_att function for
gl (Equation (4)).
At this step, we construct global self-channel attention. This type of attention aims to strengthen the weight of important channels and suppress less important ones. First, we apply a summary layer over the three branches (
) to sum all spatial position and focus on the channel feature for each branch. For the global attention branches, we calculate
Rc*1 (Equations (5)–(7)) and then compute the channel attention score by applying function
S for
(Equation (8)); the result is the channel score
(s2
R c*c). The
s2 score represents the relation between channels. Finally, we apply the
f_att function over channel score
s2 and the third branch
and compute the self-spatial with channel attention
(Equation (9)). The flow of the whole process is shown in
Figure 3, where N is the number of pedestrians in each batch and t is the number of frames describing each pedestrian.
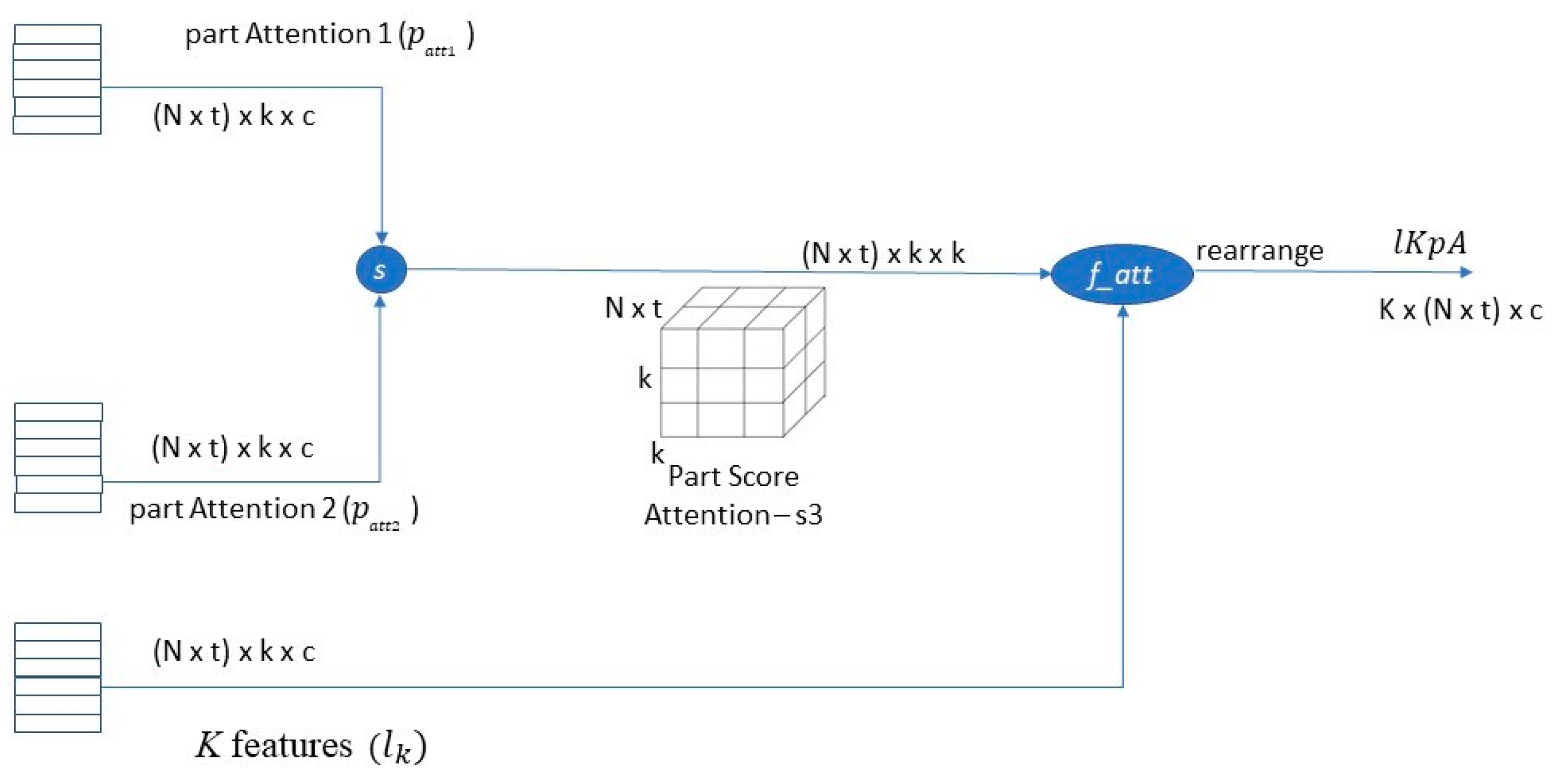
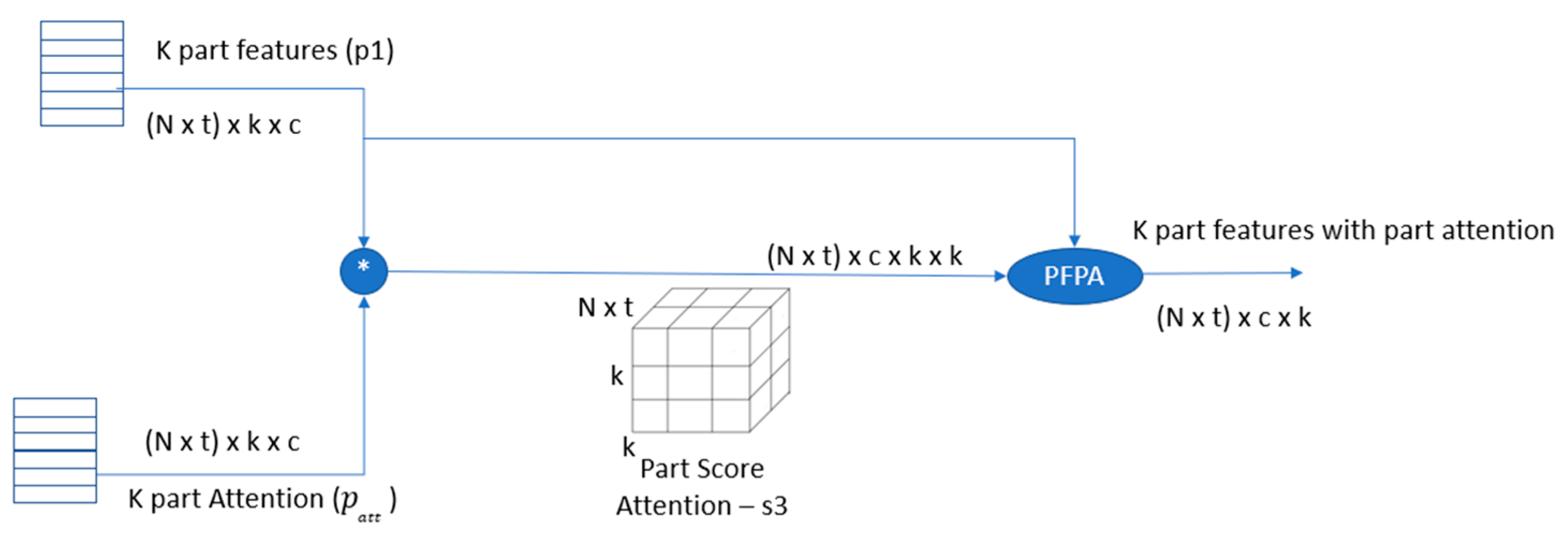
3.4. Self-Part Attention
The local feature extractor is better at learning specific parts than the global one. Pedestrians can be partitioned into several parts, and two local branches are used to see a pedestrian with coarse-grained and fine-grained parts. Part attention is then used to learn the robust features of each coarse part by computing the relationship among the parts in different branches. It applies the
S function over the attention vector from the global branch (
) and attention from fine parts (
. The
s3 score represents the relation between the two granularity parts. Then, the coarse part with attention (
is computed by applying
over
s and the
K features. After that, it rearranges
vector to let each part be represented by (N × t) × c. This results in enriching each part with discriminative features for each
k part, as shown in
Figure 4.
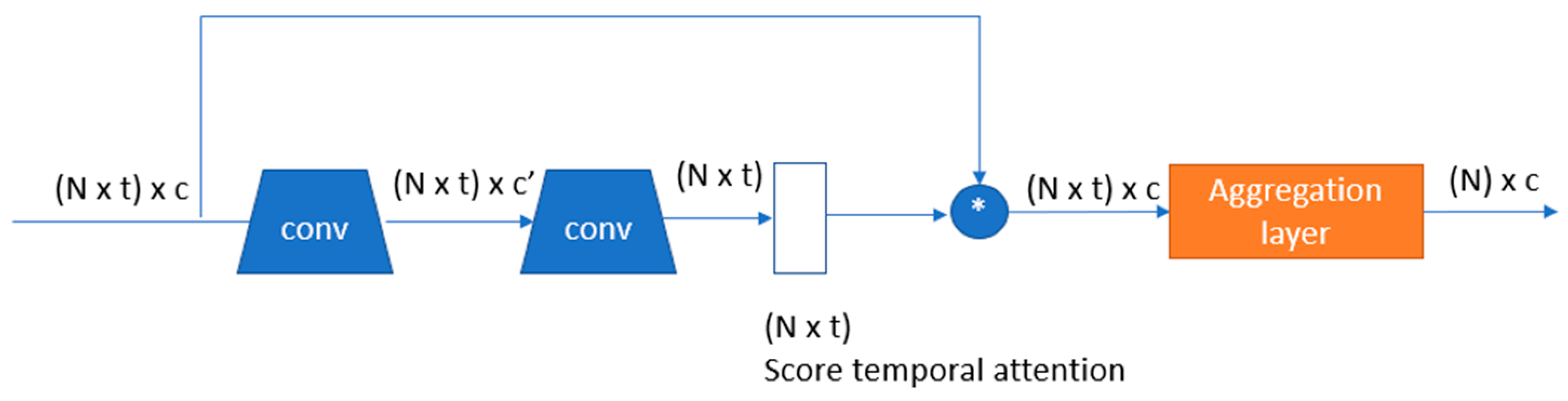
3.5. Temporal Attention
After extraction frame level features, temporal attention pooling (TAP) [
30] applies to generate video level representation. The global features after spatial-channel attention (
), each part in coarse-grained after part attention (
), and each part in fine-grained part representation (
are fed into TAP. Initially, the convolution layer is used to reduce the features from
c to
c′; thus, it is more generalized. Then, the other convolution layers with the
softmax function are used to calculate the attention scores as shown in
Figure 5. Finally, the aggregation layer directly takes each pedestrian described by t frames and aggregates the frames into a single generalized feature vector.
where
is a feature vector of global video representation,
is a feature vector of part
p in coarse-grained frame representation,
is a feature vector of part
p in fine-grained frame representation,
is a feature vector of part p in coarse-grained video representation,
is a feature vector of part p in fine-grained video representation.
3.6. Objective Function
Our objective function
is a combination of the hard triplet loss
and cross-entropy loss
in both the global features and each local part, as shown in Equation (11).
Further details of the functions used are as follows:
Triplet Loss : The distance between pairs from the same pedestrian is minimized (reduced intra-class), where the distance between pairs of different pedestrians is maximized (increased inter-class). We use the hard triplet loss that selects the hardest example for the positive and negative pairs, where are the anchor, positive features, and negative features, respectively.
For the classification layer in the cross-entropy function, we used the intermediate bottleneck to reduce dimension and make it more generalized.
5. Conclusions
This paper proposes a PMP-MA extractor for video-based re-identification. A multi-local model can learn generic and specific (multiple localization) features of each frame. To take full advantage of the pyramid model, we used self-spatial and channel attention, which enabled us to specify the quality of each spatial feature and channel to enrich the features vector. Multiple local parts were used to learn a specific part with two scales and part attention. The PMP system is complemented with TAP, which is used to extract temporal information among frames. The evaluation was done against four challenging datasets, where the proposed model achieved better performance in three datasets, that is, 2.4% over the iLIDs-VID, 2.7% over PRID2011, 0.9% over DukeMTMC-VideoReID, and 11.5% over the cross-dataset. The PMP-MA extractor is a well-designed extractor that can extract and fuse robust features from multiple granularities. Potential applications of this approach in other computer vision problems include object tracking and image segmentation or video object segmentation. In the future, we plan to add positional encoding to get the model to pay more attention to important frames. Moreover, we will try to enhance our pyramid model to reduce the complexity of the system components to overcome the necessity of having a GPU with a betterVRAM capacity.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}