
Machine Learning Techniques for Chronic Kidney Disease Risk Prediction



Abstract
:1. Introduction
- A data preprocessing step that exploits the Synthetic Minority Oversampling Technique (SMOTE), which is essential to ensure that the dataset instances are distributed in a balanced way and, thus, designs effective classification models to predict the risk for CKD occurrence.
- A features analysis, which includes three specific sub-steps: (i) numerical attributes statistical description, (ii) order of importance measurement by employing three different methods, and (iii) capturing nominal features frequency of occurrence in tabular form.
- A comparative evaluation of various models’ performance is presented considering the most common metrics, such as Precision, Recall, F-Measure, Accuracy and AUC.
- A performance evaluation is demonstrated, where all models demonstrated exceptionally high outcomes, with Rotation Forest achieving the highest results in all metrics, thus constituting the main suggestion of this analysis.
2. Related Work
3. Materials and Methods
3.1. Dataset Description
- Diastolic Blood Pressure (Bp - mmHg) [39]: This feature shows the participator’s diastolic blood pressure.
- Specific Gravity (Sg) [40]: This feature captures the participator’s specific gravity value.
- Albumin (Al) [41]: This attribute captures the participator’s albumin level. It has three categories (72.25% normal, 21.5% above normal and 6.25% well above normal).
- Glucose (Su) [42]: This attribute denotes the participator’s glucose level. It has three categories (88% normal, 8% above normal and 4% well above normal).
- Red Blood Cell (Rbc) [43]: This attribute captures whether the participator’s Red Blood Cell is normal or not. It has two categories (88.25% normal and 11.75% abnormal).
- Blood Urea (Bu - mmol/L) [44]: This feature captures the amount of urea found in the participant’s blood. Blood Urea is measured in millimoles per liter (mmol/L).
- Serum Creatinine (Sc - mg/dL) [45]: This feature measures the amount of serum creatinine found in the participant’s blood. Serum creatinine is reported as milligrams of creatinine to a deciliter of blood (mg/dL).
- Sodium (Sod - mEq/L) [46]: This feature measures the amount of sodium found in the participant’s blood. Sodium is a type of electrolyte and is reported as milliequivalents per liter (mEq/L).
- Potassium (Pot - mmol/L) [47]: This feature measures the amount of potassium found in the participant’s blood and is reported as millimoles per liter (mmol/L).
- Hemoglobin (Hemo - gm/dL) [48]: This feature measures the amount of hemoglobin found in the participant’s blood and is reported as grams per deciliter (gm/dL).
- White Blood Cell Count (Wbcc) [49]: This feature measures the number of white cells in the participant’s blood and is reported as Wbc per microliter.
- Red Blood Cell Count (Rbcc) [43]: This feature measures the number of red blood cells in the participant’s blood and is reported as a million red blood cells per microliter (mcL) of blood.
- Hypertension (Htn) [50]: This attribute refers to whether the participant has hypertension or not. A total of 36.75% of participants have hypertension.
- Chronic Kidney Disease (CKD): This feature denotes whether the participant suffers from CKD or not. A total of 62.5% of participants have been diagnosed with CKD.
3.2. Chronic Kidney Disease Risk Prediction
3.2.1. Data Preprocessing
3.2.2. Features Analysis
3.3. Machine Learning Models
3.3.1. Naive Bayes
3.3.2. Bayesian Network
3.3.3. Support Vector Machine
3.3.4. Logistic Regression
3.3.5. Artificial Neural Network
3.3.6. k-Nearest Neighbors
3.3.7. J48
3.3.8. Logistic Model Tree
3.3.9. Random Forest
3.3.10. Random Tree
3.3.11. Reduced Error Pruning Tree
3.3.12. Rotation Forest
3.3.13. AdaBoostM1
3.3.14. Stochastic Gradient Descent
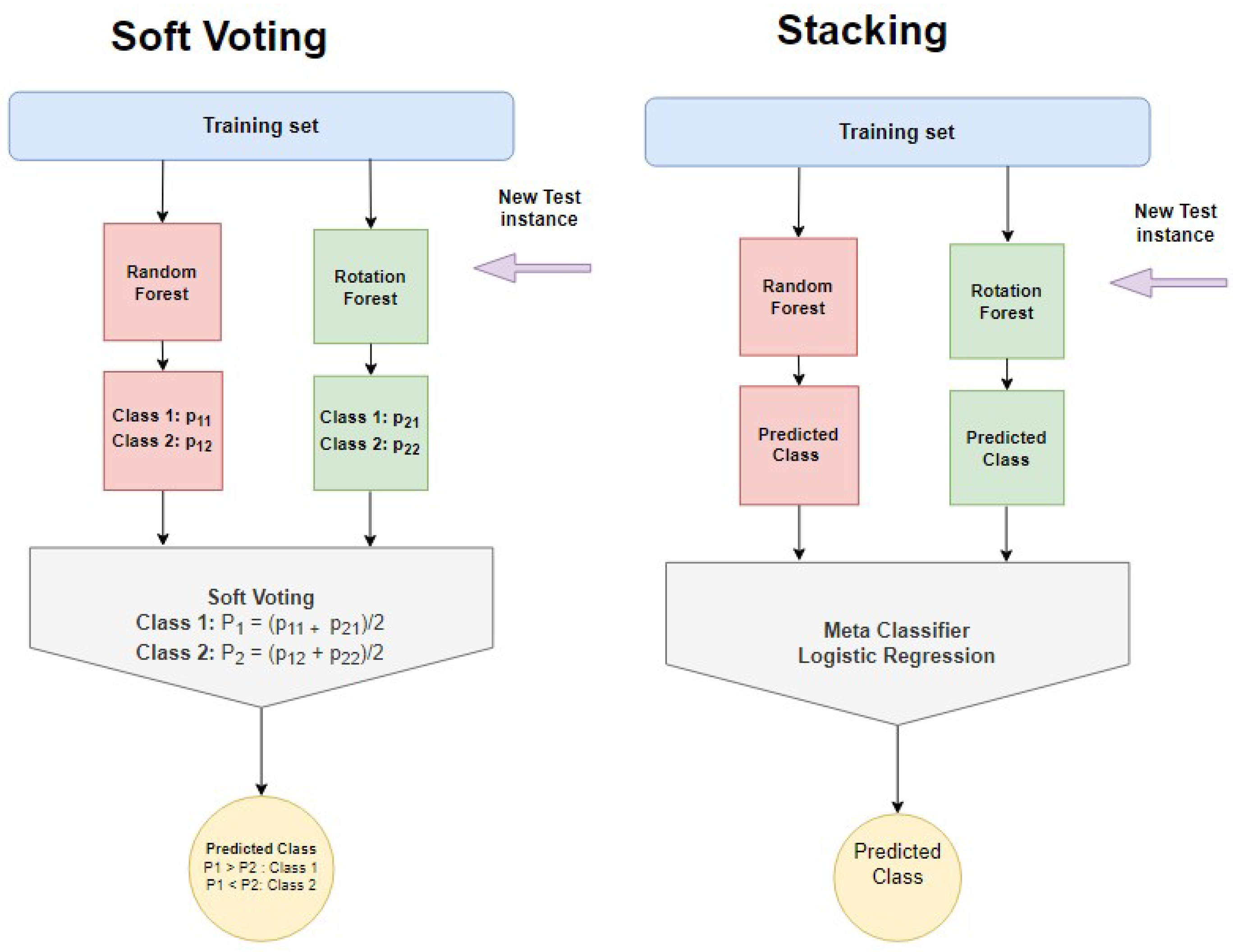
3.3.15. Ensemble Learning
3.4. Evaluation Metrics
4. Results and Discussion
4.1. Experiments Setup
4.2. Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mahadevan, V. Anatomy of the kidney and ureter. Surgery 2019, 37, 359–364. [Google Scholar] [CrossRef]
- Levey, A.S.; Coresh, J. Chronic kidney disease. Lancet 2012, 379, 165–180. [Google Scholar] [CrossRef]
- Koye, D.N.; Magliano, D.J.; Nelson, R.G.; Pavkov, M.E. The global epidemiology of diabetes and kidney disease. Adv. Chronic Kidney Dis. 2018, 25, 121–132. [Google Scholar] [CrossRef] [PubMed]
- CKD. Available online: https://www.urologyhealth.org/urology-a-z/k/kidney-(renal)-failure (accessed on 27 June 2022).
- Abdel-Kader, K. Symptoms with or because of Kidney Failure? Clin. J. Am. Soc. Nephrol. 2022, 17, 475–477. [Google Scholar] [CrossRef]
- Webster, A.C.; Nagler, E.V.; Morton, R.L.; Masson, P. Chronic kidney disease. Lancet 2017, 389, 1238–1252. [Google Scholar] [CrossRef]
- Wang, Y.N.; Ma, S.X.; Chen, Y.Y.; Chen, L.; Liu, B.L.; Liu, Q.Q.; Zhao, Y.Y. Chronic kidney disease: Biomarker diagnosis to therapeutic targets. Clin. Chim. Acta 2019, 499, 54–63. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. A study of fall detection in assisted living: Identifying and improving the optimal machine learning method. J. Sens. Actuator Netw. 2021, 10, 39. [Google Scholar] [CrossRef]
- Alexiou, S.; Dritsas, E.; Kocsis, O.; Moustakas, K.; Fakotakis, N. An approach for Personalized Continuous Glucose Prediction with Regression Trees. In Proceedings of the 2021 6th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM), Preveza, Greece, 24–26 September 2021; pp. 1–6. [Google Scholar]
- Dritsas, E.; Alexiou, S.; Konstantoulas, I.; Moustakas, K. Short-term Glucose Prediction based on Oral Glucose Tolerance Test Values. In Proceedings of the International Joint Conference on Biomedical Engineering Systems and Technologies-HEALTHINF, Online, 9–11 February 2022; Volume 5, pp. 249–255. [Google Scholar]
- Dritsas, E.; Trigka, M. Data-Driven Machine-Learning Methods for Diabetes Risk Prediction. Sensors 2022, 22, 5304. [Google Scholar] [CrossRef]
- Dritsas, E.; Fazakis, N.; Kocsis, O.; Fakotakis, N.; Moustakas, K. Long-Term Hypertension Risk Prediction with ML Techniques in ELSA Database. In Proceedings of the International Conference on Learning and Intelligent Optimization, Athens, Greece, 20–25 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 113–120. [Google Scholar]
- Fazakis, N.; Dritsas, E.; Kocsis, O.; Fakotakis, N.; Moustakas, K. Long-Term Cholesterol Risk Prediction with Machine Learning Techniques in ELSA Database. In Proceedings of the 13th International Joint Conference on Computational Intelligence (IJCCI), SCIPTRESS, Valletta, Malta, 25–27 October 2021; pp. 445–450. [Google Scholar]
- Dritsas, E.; Trigka, M. Machine Learning Methods for Hypercholesterolemia Long-Term Risk Prediction. Sensors 2022, 22, 5365. [Google Scholar] [CrossRef]
- Alballa, N.; Al-Turaiki, I. Machine learning approaches in COVID-19 diagnosis, mortality, and severity risk prediction: A review. Inform. Med. Unlocked 2021, 24, 100564. [Google Scholar] [CrossRef]
- Dritsas, E.; Alexiou, S.; Moustakas, K. COPD Severity Prediction in Elderly with ML Techniques. In Proceedings of the 15th International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 29 June–1 July 2022; pp. 185–189. [Google Scholar]
- Dritsas, E.; Trigka, M. Stroke Risk Prediction with Machine Learning Techniques. Sensors 2022, 22, 4670. [Google Scholar] [CrossRef] [PubMed]
- Dritsas, E.; Alexiou, S.; Moustakas, K. Cardiovascular Disease Risk Prediction with Supervised Machine Learning Techniques. In Proceedings of the ICT4AWE, Prague, Czech Republic, 23–25 April 2022; pp. 315–321. [Google Scholar]
- Zhang, D.; Gong, Y. The comparison of LightGBM and XGBoost coupling factor analysis and prediagnosis of acute liver failure. IEEE Access 2020, 8, 220990–221003. [Google Scholar] [CrossRef]
- Das, P.K.; Pradhan, A.; Meher, S. Detection of acute lymphoblastic leukemia using machine learning techniques. In Machine Learning, Deep Learning and Computational Intelligence for Wireless Communication; Springer: Berlin/Heidelberg, Germany, 2021; pp. 425–437. [Google Scholar]
- Konstantoulas, I.; Kocsis, O.; Dritsas, E.; Fakotakis, N.; Moustakas, K. Sleep Quality Monitoring with Human Assisted Corrections. In Proceedings of the International Joint Conference on Computational Intelligence (IJCCI). SCIPTRESS, Virtual, 19–26 August 2021; pp. 435–444. [Google Scholar]
- Yarasuri, V.K.; Indukuri, G.K.; Nair, A.K. Prediction of hepatitis disease using machine learning technique. In Proceedings of the 2019 Third International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud)(I-SMAC), Palladam, India, 12–14 December 2019; pp. 265–269. [Google Scholar]
- Saba, T. Recent advancement in cancer detection using machine learning: Systematic survey of decades, comparisons and challenges. J. Infect. Public Health 2020, 13, 1274–1289. [Google Scholar] [CrossRef]
- Yu, C.S.; Lin, Y.J.; Lin, C.H.; Wang, S.T.; Lin, S.Y.; Lin, S.H.; Wu, J.L.; Chang, S.S. Predicting metabolic syndrome with machine learning models using a decision tree algorithm: Retrospective cohort study. JMIR Med. Inform. 2020, 8, e17110. [Google Scholar] [CrossRef] [PubMed]
- Xiao, J.; Ding, R.; Xu, X.; Guan, H.; Feng, X.; Sun, T.; Zhu, S.; Ye, Z. Comparison and development of machine learning tools in the prediction of chronic kidney disease progression. J. Transl. Med. 2019, 17, 119. [Google Scholar] [CrossRef]
- Ghosh, P.; Shamrat, F.J.M.; Shultana, S.; Afrin, S.; Anjum, A.A.; Khan, A.A. Optimization of prediction method of chronic kidney disease using machine learning algorithm. In Proceedings of the 2020 15th International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP), Bangkok, Thailand, 18–20 November 2020; pp. 1–6. [Google Scholar]
- Ifraz, G.M.; Rashid, M.H.; Tazin, T.; Bourouis, S.; Khan, M.M. Comparative Analysis for Prediction of Kidney Disease Using Intelligent Machine Learning Methods. Comput. Math. Methods Med. 2021, 2021, 6141470. [Google Scholar] [CrossRef]
- CKD Prediction Dataset. Available online: https://www.kaggle.com/datasets/abhia1999/chronic-kidney-disease (accessed on 27 June 2022).
- Islam, M.A.; Akter, S.; Hossen, M.S.; Keya, S.A.; Tisha, S.A.; Hossain, S. Risk factor prediction of chronic kidney disease based on machine learning algorithms. In Proceedings of the 2020 3rd International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 3–5 December 2020; pp. 952–957. [Google Scholar]
- Yashfi, S.Y.; Islam, M.A.; Sakib, N.; Islam, T.; Shahbaaz, M.; Pantho, S.S. Risk prediction of chronic kidney disease using machine learning algorithms. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–5. [Google Scholar]
- Chittora, P.; Chaurasia, S.; Chakrabarti, P.; Kumawat, G.; Chakrabarti, T.; Leonowicz, Z.; Jasiński, M.; Jasiński, Ł.; Gono, R.; Jasińska, E.; et al. Prediction of chronic kidney disease-a machine learning perspective. IEEE Access 2021, 9, 17312–17334. [Google Scholar] [CrossRef]
- Revathy, S.; Bharathi, B.; Jeyanthi, P.; Ramesh, M. Chronic kidney disease prediction using machine learning models. Int. J. Eng. Adv. Technol. (IJEAT) 2019, 9, 6364–6367. [Google Scholar] [CrossRef]
- Yadav, D.C.; Pal, S. Performance based Evaluation of Algorithmson Chronic Kidney Disease using Hybrid Ensemble Model in Machine Learning. Biomed. Pharmacol. J. 2021, 14, 1633–1646. [Google Scholar] [CrossRef]
- Baidya, D.; Umaima, U.; Islam, M.N.; Shamrat, F.J.M.; Pramanik, A.; Rahman, M.S. A Deep Prediction of Chronic Kidney Disease by Employing Machine Learning Method. In Proceedings of the 2022 6th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 28–30 April 2022; pp. 1305–1310. [Google Scholar]
- Izonin, I.; Tkachenko, R.; Dronyuk, I.; Tkachenko, P.; Gregus, M.; Rashkevych, M. Predictive modeling based on small data in clinical medicine: RBF-based additive input-doubling method. Math. Biosci. Eng. 2021, 18, 2599–2613. [Google Scholar] [CrossRef]
- Izonin, I.; Tkachenko, R.; Fedushko, S.; Koziy, D.; Zub, K.; Vovk, O. RBF-Based Input Doubling Method for Small Medical Data Processing. In Proceedings of the International Conference on Artificial Intelligence and Logistics Engineering, Kyiv, Ukraine, 20–22 February 2022; Springer: Berlin/Heidelberg, Germany, 2021; pp. 23–31. [Google Scholar]
- Bhattacharya, D.; Banerjee, S.; Bhattacharya, S.; Uma Shankar, B.; Mitra, S. GAN-based novel approach for data augmentation with improved disease classification. In Advancement of Machine Intelligence in Interactive Medical Image Analysis; Springer: Berlin/Heidelberg, Germany, 2020; pp. 229–239. [Google Scholar]
- Tkachenko, R.; Izonin, I.; Vitynskyi, P.; Lotoshynska, N.; Pavlyuk, O. Development of the non-iterative supervised learning predictor based on the ito decomposition and SGTM neural-like structure for managing medical insurance costs. Data 2018, 3, 46. [Google Scholar] [CrossRef]
- Plantinga, L.C.; Miller III, E.R.; Stevens, L.A.; Saran, R.; Messer, K.; Flowers, N.; Geiss, L.; Powe, N.R. Blood pressure control among persons without and with chronic kidney disease: US trends and risk factors 1999–2006. Hypertension 2009, 54, 47–56. [Google Scholar] [CrossRef] [PubMed]
- Shaikh, N.; Shope, M.F.; Kurs-Lasky, M. Urine specific gravity and the accuracy of urinalysis. Pediatrics 2019, 144. [Google Scholar] [CrossRef] [PubMed]
- Erstad, B.L. Serum albumin levels: Who needs them? Ann. Pharmacother. 2021, 55, 798–804. [Google Scholar] [CrossRef]
- Zelnick, L.R.; Batacchi, Z.O.; Ahmad, I.; Dighe, A.; Little, R.R.; Trence, D.L.; Hirsch, I.B.; de Boer, I.H. Continuous glucose monitoring and use of alternative markers to assess glycemia in chronic kidney disease. Diabetes Care 2020, 43, 2379–2387. [Google Scholar] [CrossRef]
- Qiang, Y.; Liu, J.; Dao, M.; Suresh, S.; Du, E. Mechanical fatigue of human red blood cells. Proc. Natl. Acad. Sci. USA 2019, 116, 19828–19834. [Google Scholar] [CrossRef]
- Seki, M.; Nakayama, M.; Sakoh, T.; Yoshitomi, R.; Fukui, A.; Katafuchi, E.; Tsuda, S.; Nakano, T.; Tsuruya, K.; Kitazono, T. Blood urea nitrogen is independently associated with renal outcomes in Japanese patients with stage 3–5 chronic kidney disease: A prospective observational study. BMC Nephrol. 2019, 20, 1–10. [Google Scholar] [CrossRef]
- Lin, Y.L.; Chen, S.Y.; Lai, Y.H.; Wang, C.H.; Kuo, C.H.; Liou, H.H.; Hsu, B.G. Serum creatinine to cystatin C ratio predicts skeletal muscle mass and strength in patients with non-dialysis chronic kidney disease. Clin. Nutr. 2020, 39, 2435–2441. [Google Scholar] [CrossRef]
- Borrelli, S.; Provenzano, M.; Gagliardi, I.; Ashour, M.; Liberti, M.E.; De Nicola, L.; Conte, G.; Garofalo, C.; Andreucci, M. Sodium intake and chronic kidney disease. Int. J. Mol. Sci. 2020, 21, 4744. [Google Scholar] [CrossRef]
- Kovesdy, C.P.; Matsushita, K.; Sang, Y.; Brunskill, N.J.; Carrero, J.J.; Chodick, G.; Hasegawa, T.; Heerspink, H.L.; Hirayama, A.; Landman, G.W.; et al. Serum potassium and adverse outcomes across the range of kidney function: A CKD Prognosis Consortium meta-analysis. Eur. Heart J. 2018, 39, 1535–1542. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.S.; Choi, S.; Lee, G.; Cho, Y.; Park, S.M. Association of hemoglobin level with fracture: A nationwide cohort study. J. Bone Miner. Metab. 2021, 39, 833–842. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Jiang, L.; Shao, X. Predictive value of procalcitonin for diagnosis of infections in patients with chronic kidney disease: A comparison with traditional inflammatory markers C-reactive protein, white blood cell count, and neutrophil percentage. Int. Urol. Nephrol. 2017, 49, 2205–2216. [Google Scholar] [CrossRef] [PubMed]
- Ku, E.; Lee, B.J.; Wei, J.; Weir, M.R. Hypertension in CKD: Core curriculum 2019. Am. J. Kidney Dis. 2019, 74, 120–131. [Google Scholar] [CrossRef] [PubMed]
- Maldonado, S.; López, J.; Vairetti, C. An alternative SMOTE oversampling strategy for high-dimensional datasets. Appl. Soft Comput. 2019, 76, 380–389. [Google Scholar] [CrossRef]
- Obilor, E.I.; Amadi, E.C. Test for significance of Pearson’s correlation coefficient. Int. J. Innov. Math. Stat. Energy Policies 2018, 6, 11–23. [Google Scholar]
- Gnanambal, S.; Thangaraj, M.; Meenatchi, V.; Gayathri, V. Classification algorithms with attribute selection: An evaluation study using WEKA. Int. J. Adv. Netw. Appl. 2018, 9, 3640–3644. [Google Scholar]
- Disha, R.A.; Waheed, S. Performance analysis of machine learning models for intrusion detection system using Gini Impurity-based Weighted Random Forest (GIWRF) feature selection technique. Cybersecurity 2022, 5, 1. [Google Scholar] [CrossRef]
- Palaka, E.; Grandy, S.; van Haalen, H.; McEwan, P.; Darlington, O. The impact of CKD anaemia on patients: Incidence, risk factors, and clinical outcomes—A systematic literature review. Int. J. Nephrol. 2020, 2020, 7692376. [Google Scholar] [CrossRef]
- Feng, X.; Li, S.; Yuan, C.; Zeng, P.; Sun, Y. Prediction of slope stability using naive Bayes classifier. KSCE J. Civ. Eng. 2018, 22, 941–950. [Google Scholar] [CrossRef]
- Marcot, B.G.; Penman, T.D. Advances in Bayesian network modelling: Integration of modelling technologies. Environ. Model. Softw. 2019, 111, 386–393. [Google Scholar] [CrossRef]
- Pisner, D.A.; Schnyer, D.M. Support vector machine. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 101–121. [Google Scholar]
- Nusinovici, S.; Tham, Y.C.; Yan, M.Y.C.; Ting, D.S.W.; Li, J.; Sabanayagam, C.; Wong, T.Y.; Cheng, C.Y. Logistic regression was as good as machine learning for predicting major chronic diseases. J. Clin. Epidemiol. 2020, 122, 56–69. [Google Scholar] [CrossRef] [PubMed]
- Morariu, D.; Crețulescu, R.; Breazu, M. The WEKA multilayer perceptron classifier. Int. J. Adv. Stat. It&C Econ. Life Sci. 2017, 7, 1. [Google Scholar]
- Ali, N.; Neagu, D.; Trundle, P. Evaluation of k-nearest neighbour classifier performance for heterogeneous data sets. SN Appl. Sci. 2019, 1, 1559. [Google Scholar] [CrossRef] [Green Version]
- Ihya, R.; Namir, A.; Filali, S.E.; Daoud, M.A.; Guerss, F.Z. J48 algorithms of machine learning for predicting user’s the acceptance of an E-orientation systems. In Proceedings of the 4th International Conference on Smart City Applications, Casablanca, Morocco, 2–4 October 2019; pp. 1–8. [Google Scholar]
- Abedini, M.; Ghasemian, B.; Shirzadi, A.; Bui, D.T. A comparative study of support vector machine and logistic model tree classifiers for shallow landslide susceptibility modeling. Environ. Earth Sci. 2019, 78, 560. [Google Scholar] [CrossRef]
- Reis, I.; Baron, D.; Shahaf, S. Probabilistic random forest: A machine learning algorithm for noisy data sets. Astron. J. 2018, 157, 16. [Google Scholar] [CrossRef]
- Alsharif, N. Ensembling PCA-based Feature Selection with Random Tree Classifier for Intrusion Detection on IoT Network. In Proceedings of the 2021 8th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Semarang, Indonesia, 20–21 October 2021; pp. 317–321. [Google Scholar]
- Mohamed, W.N.H.W.; Salleh, M.N.M.; Omar, A.H. A comparative study of reduced error pruning method in decision tree algorithms. In Proceedings of the 2012 IEEE International Conference on Control System, Computing and Engineering, Penang, Malaysia, 23–25 November 2012; pp. 392–397. [Google Scholar]
- Lu, H.; Meng, Y.; Yan, K.; Gao, Z. Kernel principal component analysis combining rotation forest method for linearly inseparable data. Cogn. Syst. Res. 2019, 53, 111–122. [Google Scholar] [CrossRef]
- Polat, K.; Sentürk, U. A novel ML approach to prediction of breast cancer: Combining of mad normalization, KMC based feature weighting and AdaBoostM1 classifier. In Proceedings of the 2018 2nd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 19–21 October 2018; pp. 1–4. [Google Scholar]
- Zhang, Y.; Saxe, A.M.; Advani, M.S.; Lee, A.A. Energy–entropy competition and the effectiveness of stochastic gradient descent in machine learning. Mol. Phys. 2018, 116, 3214–3223. [Google Scholar] [CrossRef]
- Burka, D.; Puppe, C.; Szepesváry, L.; Tasnádi, A. Voting: A machine learning approach. Eur. J. Oper. Res. 2022, 299, 1003–1017. [Google Scholar] [CrossRef]
- Pavlyshenko, B. Using stacking approaches for machine learning models. In Proceedings of the 2018 IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018; pp. 255–258. [Google Scholar]
- Moccia, S.; De Momi, E.; El Hadji, S.; Mattos, L.S. Blood vessel segmentation algorithms—Review of methods, datasets and evaluation metrics. Comput. Methods Programs Biomed. 2018, 158, 71–91. [Google Scholar] [CrossRef]
- WEKA Tool. Available online: https://www.weka.io/ (accessed on 27 June 2022).
- Bustamam, A.; Musti, M.I.; Hartomo, S.; Aprilia, S.; Tampubolon, P.P.; Lestari, D. Performance of rotation forest ensemble classifier and feature extractor in predicting protein interactions using amino acid sequences. BMC Genom. 2019, 20, 950. [Google Scholar] [CrossRef]
- Jukic, S.; Saracevic, M.; Subasi, A.; Kevric, J. Comparison of ensemble machine learning methods for automated classification of focal and non-focal epileptic EEG signals. Mathematics 2020, 8, 1481. [Google Scholar] [CrossRef]


{kind=link}
| Stage of CKD | Description | GFR (mL/min/1.73 m2) |
|---|---|---|
| Stage 1 | Normal | ≥90 |
| Stage 2 | Mild CKD | 60–89 |
| Stage 3 | Moderate CKD | 30–59 |
| Stage 4 | Severe CKD | 15–29 |
| Stage 5 | End Stage CKD | <15 |
| Feature | Min | Max | Mean ± std |
|---|---|---|---|
| Hemo | 3.1 | 17.8 | 13.04 ± 2.68 |
| Sg | 1.005 | 1.025 | 1.019 ± 0.005 |
| Rbcc | 2.1 | 8 | 4.84 ± 0.82 |
| Bu | 1.5 | 391 | 52.59 ± 45.34 |
| Sod | 4.5 | 163 | 138.44 ± 8.64 |
| Sc | 0.4 | 76 | 2.65 ± 5.09 |
| Bp | 50 | 180 | 75.4 ± 12.6 |
| Wbcc | 2200 | 26,400 | 8310.7 ± 2394.2 |
| Pot | 2.5 | 47 | 4.56 ± 2.53 |
| Pearson CC | Gain Ratio | Random Forest | |||
|---|---|---|---|---|---|
| Feature | Ranking | Feature | Ranking | Feature | Ranking |
| Hemo | 0.763 | Sc | 0.532 | Hemo | 0.449 |
| Sg | 0.699 | Htn | 0.441 | Rbcc | 0.439 |
| Htn | 0.645 | Hemo | 0.381 | Sc | 0.429 |
| Rbcc | 0.621 | Sg | 0.338 | Sg | 0.401 |
| Al | 0.506 | Rbcc | 0.337 | Sod | 0.388 |
| Bu | 0.419 | Bp | 0.295 | Pot | 0.374 |
| Sod | 0.387 | Al | 0.287 | Bp | 0.309 |
| Sc | 0.334 | Bu | 0.270 | Bu | 0.292 |
| Rbc | 0.322 | Rbc | 0.225 | Htn | 0.277 |
| Bp | 0.321 | Su | 0.190 | Wbcc | 0.232 |
| Su | 0.317 | Sod | 0.170 | Al | 0.211 |
| Wbcc | 0.207 | Wbcc | 0.141 | Su | 0.088 |
| Pot | 0.092 | Pot | 0.136 | Rbc | 0.086 |
| Albumin | CKD = No | CKD = Yes |
|---|---|---|
| Above normal | 0.00% | 17.20% |
| Well above normal | 0.00% | 5.00% |
| Normal | 50.00% | 27.80% |
| Glucose | CKD = No | CKD = Yes |
| Above normal | 0.00% | 6.40% |
| Normal | 50.00% | 40.40% |
| Well above normal | 0.00% | 3.20% |
| Hypertension | CKD = No | CKD = Yes |
| No | 50.00% | 20.60% |
| Yes | 0.00% | 29.40% |
| Red blood cell | CKD = No | CKD = Yes |
| Abnormal | 0.00% | 9.40% |
| Normal | 50.00% | 40.60% |
| Models | Parameters |
|---|---|
| BayesNet | estimator: simpleEstimator searchAlgorithm: K2 useADTree: False |
| NB | useKernelEstimator: False useSupervisedDiscretization: True |
| SVM | eps = 0.001 gamma = 0.0 kernel type: linear loss = 0.1 |
| LR | ridge = useConjugateGradientDescent: False |
| ANN | hidden layers: ‘a’ learning rate: 0.3 momentum: 0.2 training time: 500 |
| k-NN | k = 1 Search Algorithm: LinearNNSearch with Euclidean |
| J48 | reducedErrorPruning: False savelnstanceData: False subtreeRaising: True |
| LMT | errorOnProbabilities: False fastRegression: True numInstances = 15 useAIC: False |
| RF | maxDepth = 0 numIterations = 100 numFeatures = 0 |
| RT | maxDepth = 0 minNum = 1.0 minVarianceProp = 0.001 |
| DT (RepTree) | maxDepth = −1 minNum = 2.0 minVarianceProp = 0.001 |
| RotF | classifier: J48 numberOfGroups: False projectionFilter: PrincipalComponents |
| AdaBoostM1 | classifier: DecisionStump resume: False useResampling: False |
| SGD | epochs = 500 epsilon = 0.001 lamda = learningRate = 0.01 lossFunction: Hinge loss (SVM) |
| Stacking | classifiers: RF and RotF metaClassifier: LR numFolds = 10 |
| Soft Voting | classifiers: RF and RotF combinationRule: average of probabilities |
| Accuracy | Precision | Recall | F-Measure | AUC | |
|---|---|---|---|---|---|
| NB | 0.984 | 0.984 | 0.984 | 0.984 | 0.999 |
| BayesNet | 0.984 | 0.984 | 0.984 | 0.984 | 0.999 |
| SVM (linear) | 0.940 | 0.940 | 0.940 | 0.940 | 0.940 |
| LR | 0.974 | 0.974 | 0.974 | 0.974 | 0.982 |
| ANN | 0.968 | 0.968 | 0.968 | 0.968 | 0.990 |
| k-NN | 0.984 | 0.984 | 0.984 | 0.984 | 0.984 |
| AdaBoostM1 | 0.978 | 0.978 | 0.978 | 0.978 | 0.998 |
| SGD | 0.974 | 0.975 | 0.974 | 0.974 | 0.974 |
| RoF | 0.992 | 0.992 | 0.992 | 0.992 | 1 |
| J48 | 0.974 | 0.974 | 0.974 | 0.974 | 0.992 |
| LMT | 0.982 | 0.982 | 0.982 | 0.982 | 0.996 |
| RF | 0.989 | 0.989 | 0.989 | 0.989 | 0.999 |
| RT | 0.972 | 0.972 | 0.972 | 0.972 | 0.972 |
| DT | 0.974 | 0.974 | 0.974 | 0.974 | 0.980 |
| Stacking | 0.984 | 0.984 | 0.984 | 0.984 | 1 |
| Soft Voting | 0.990 | 0.990 | 0.990 | 0.990 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dritsas, E.; Trigka, M. Machine Learning Techniques for Chronic Kidney Disease Risk Prediction. Big Data Cogn. Comput. 2022, 6, 98. https://doi.org/10.3390/bdcc6030098
Dritsas E, Trigka M. Machine Learning Techniques for Chronic Kidney Disease Risk Prediction. Big Data and Cognitive Computing. 2022; 6(3):98. https://doi.org/10.3390/bdcc6030098
Chicago/Turabian StyleDritsas, Elias, and Maria Trigka. 2022. "Machine Learning Techniques for Chronic Kidney Disease Risk Prediction" Big Data and Cognitive Computing 6, no. 3: 98. https://doi.org/10.3390/bdcc6030098
APA StyleDritsas, E., & Trigka, M. (2022). Machine Learning Techniques for Chronic Kidney Disease Risk Prediction. Big Data and Cognitive Computing, 6(3), 98. https://doi.org/10.3390/bdcc6030098