


Comparative Study of Mortality Rate Prediction Using Data-Driven Recurrent Neural Networks and the Lee–Carter Model

Abstract
:1. Literature Review
2. Introduction
3. Recurrent Neural Networks
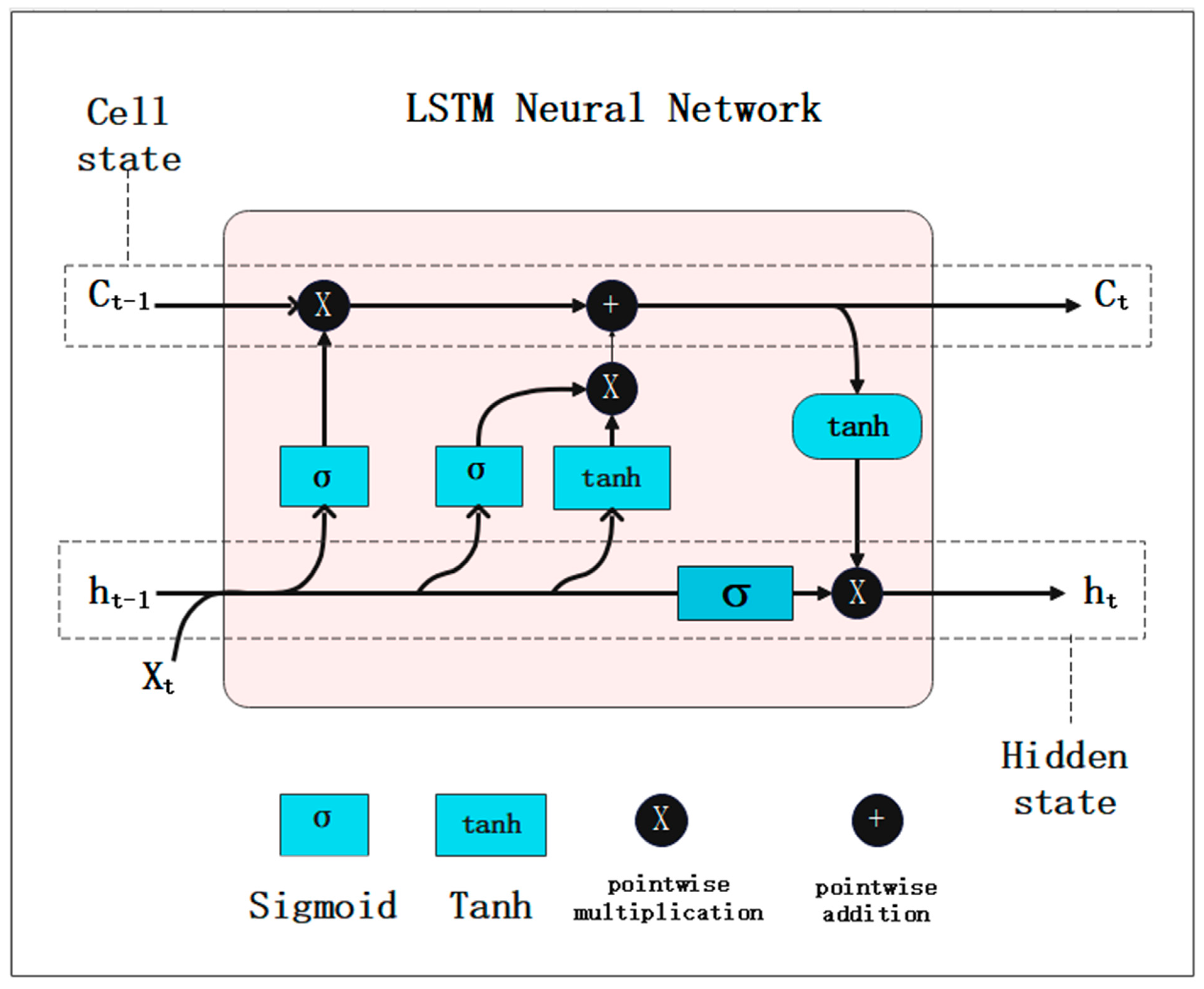
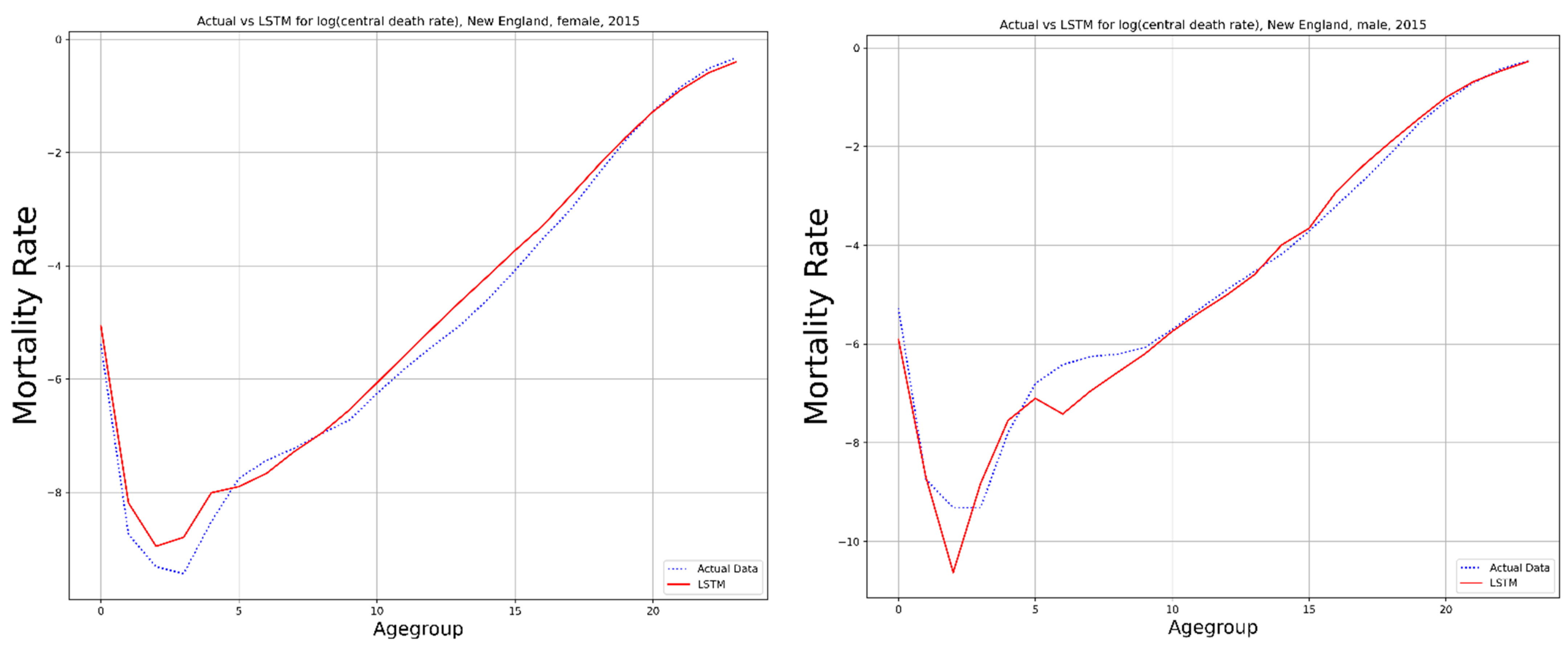
3.1. Long Short-Term Memory
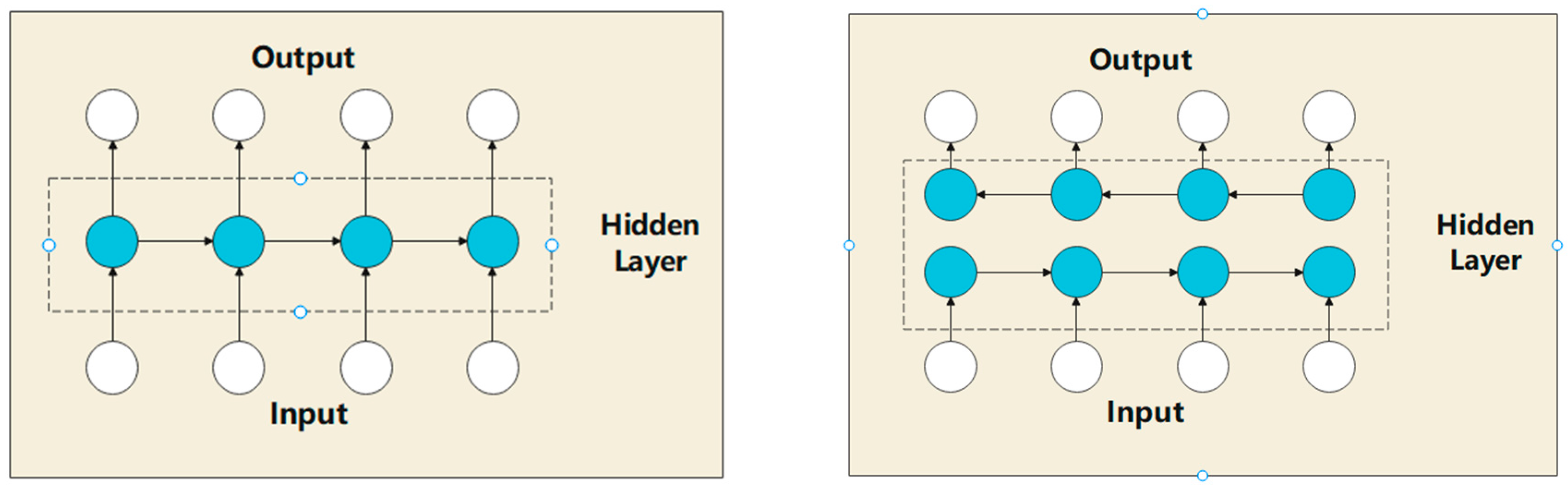
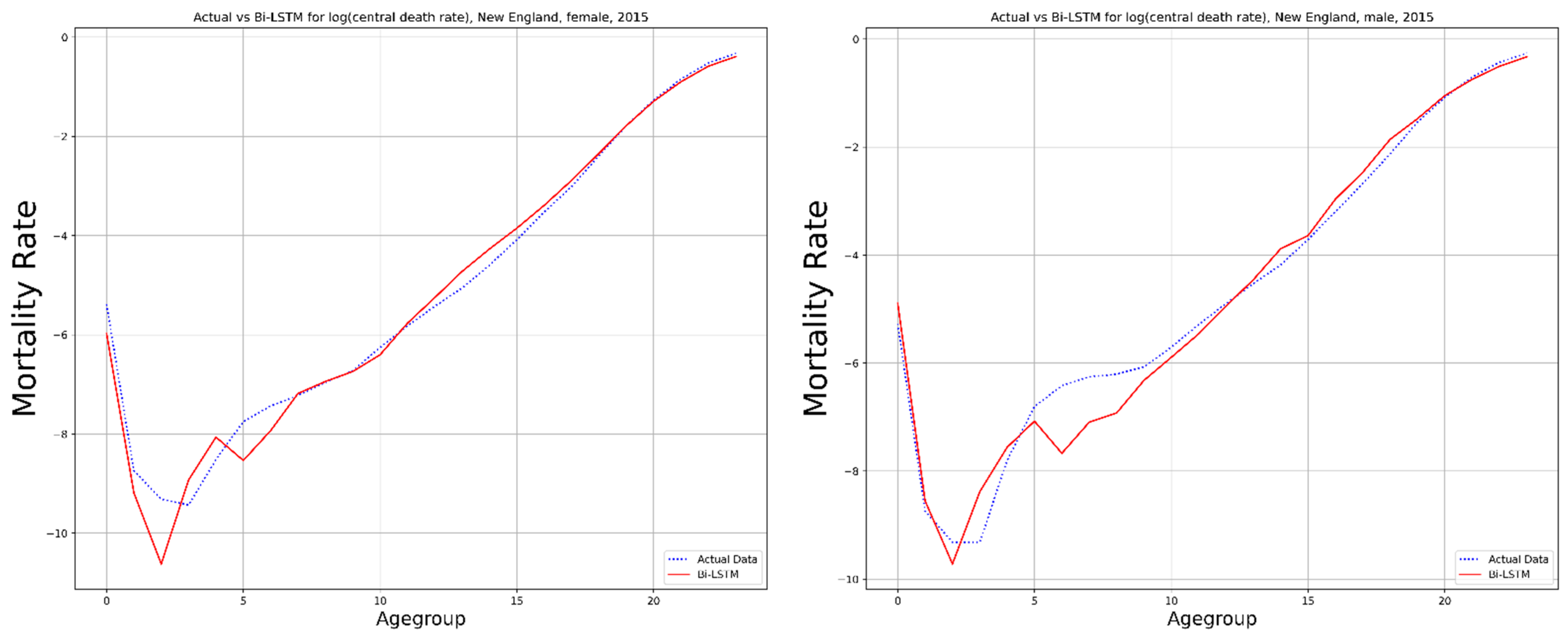
3.2. Bi-directional Long Short-Term Memory
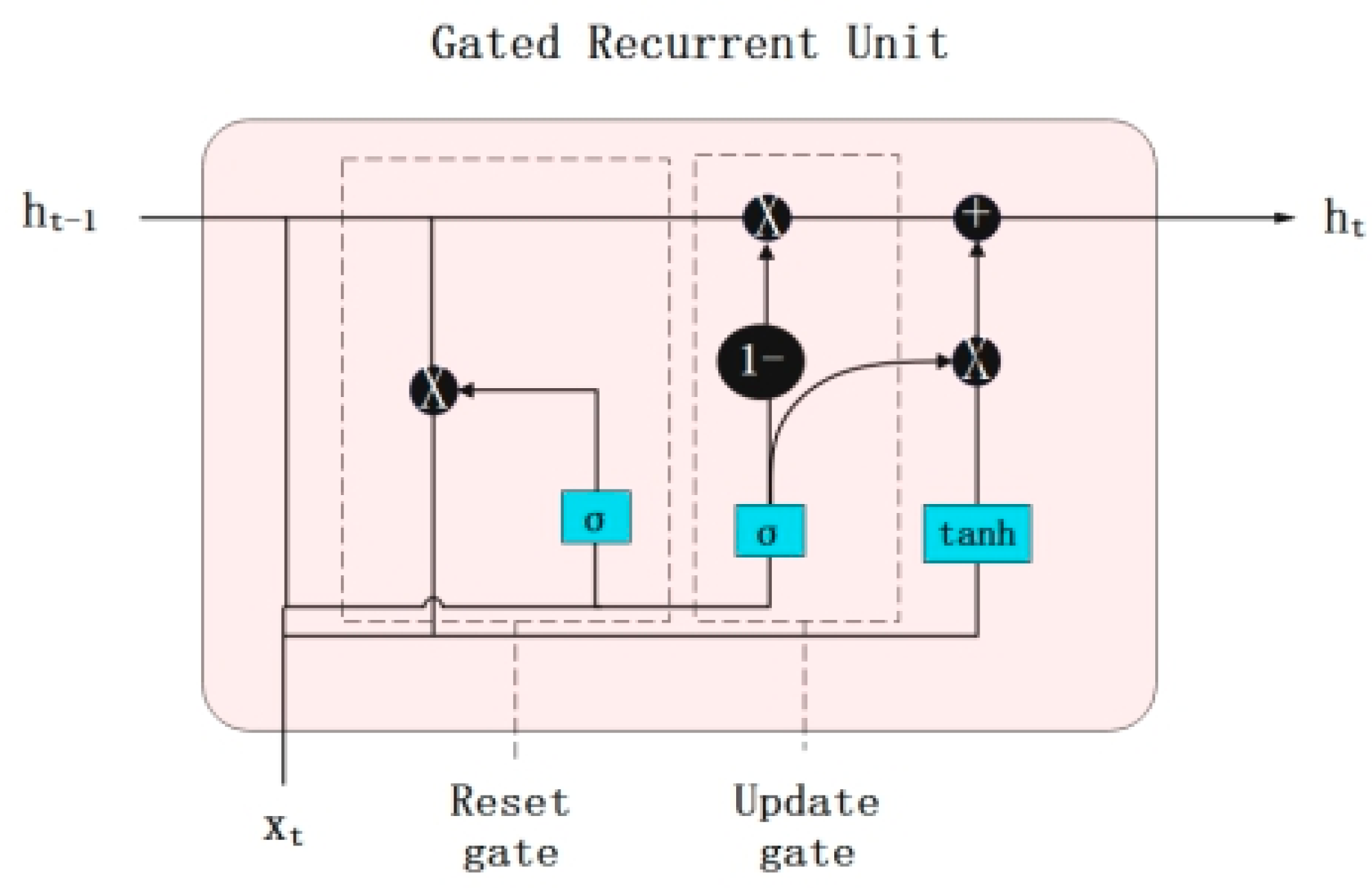
3.3. Gated Recurrent Unit
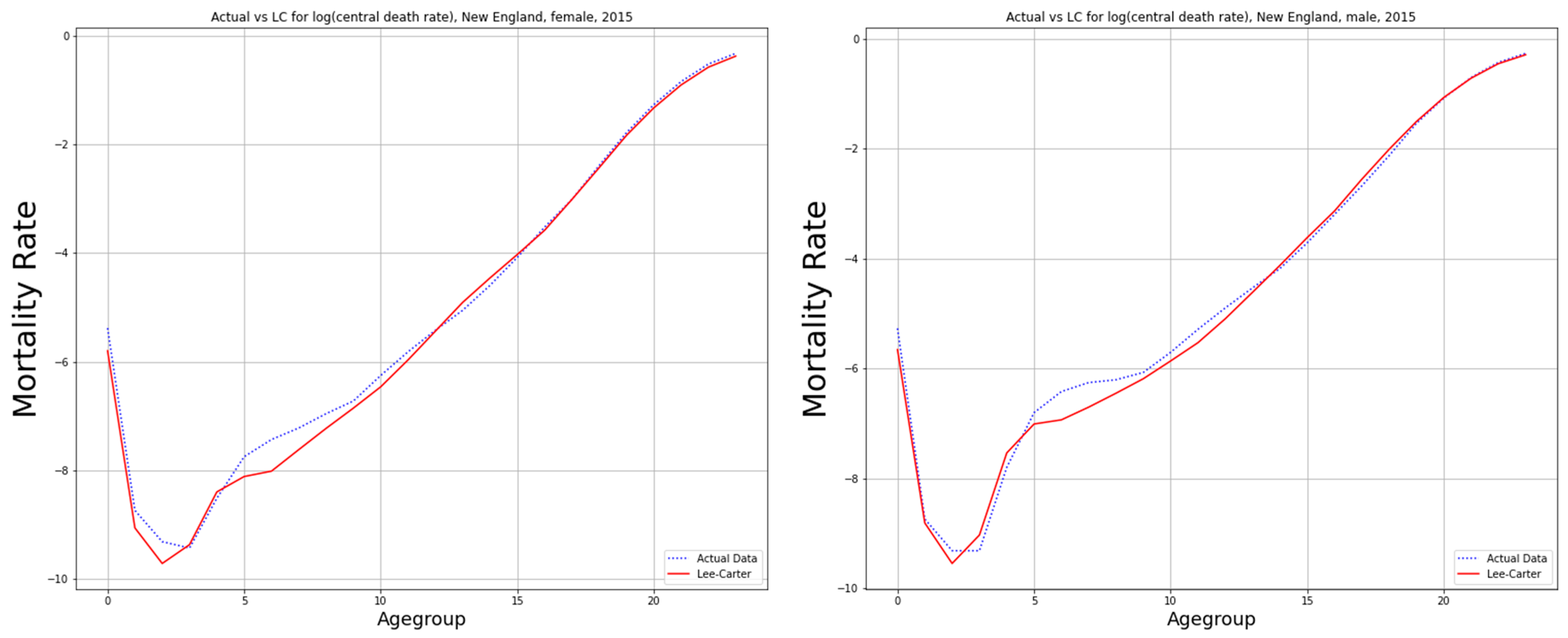
4. Lee–Carter Model
5. Data
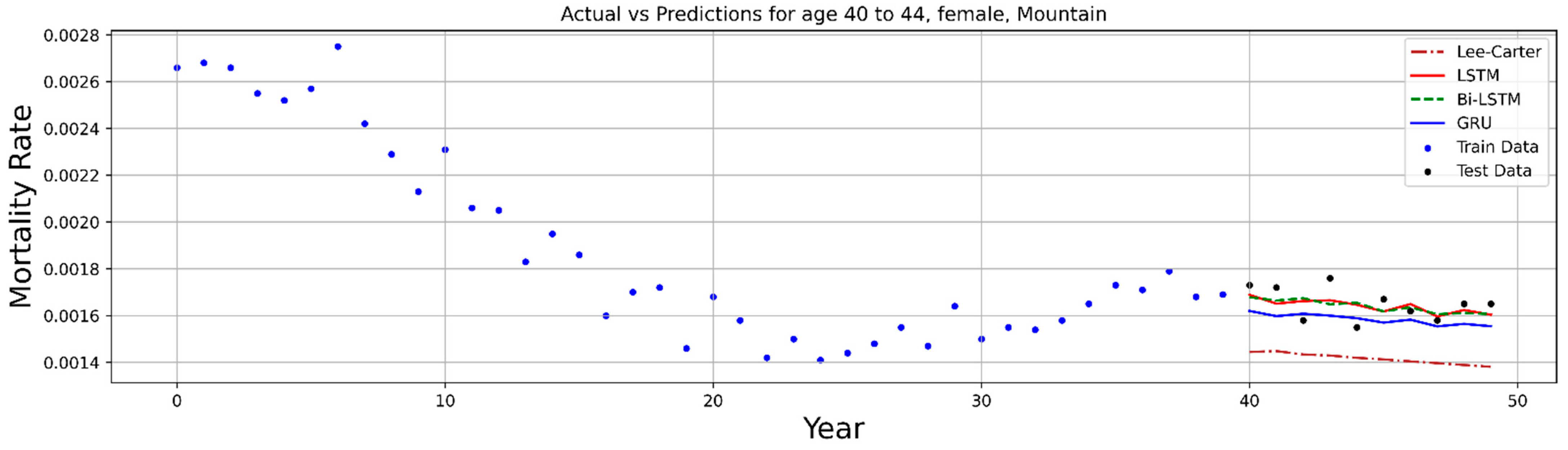
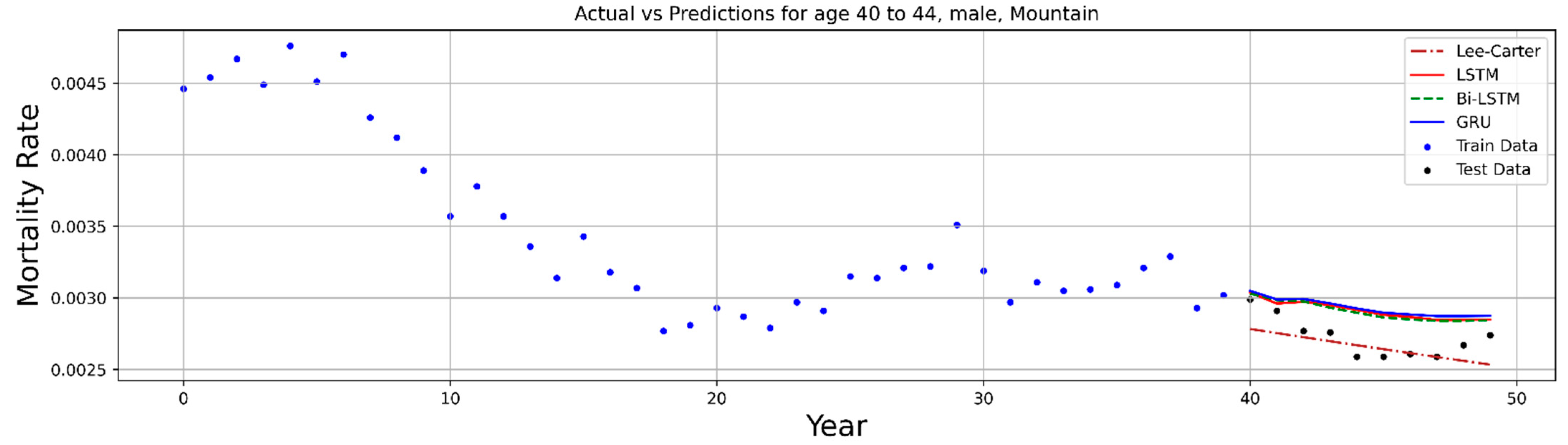
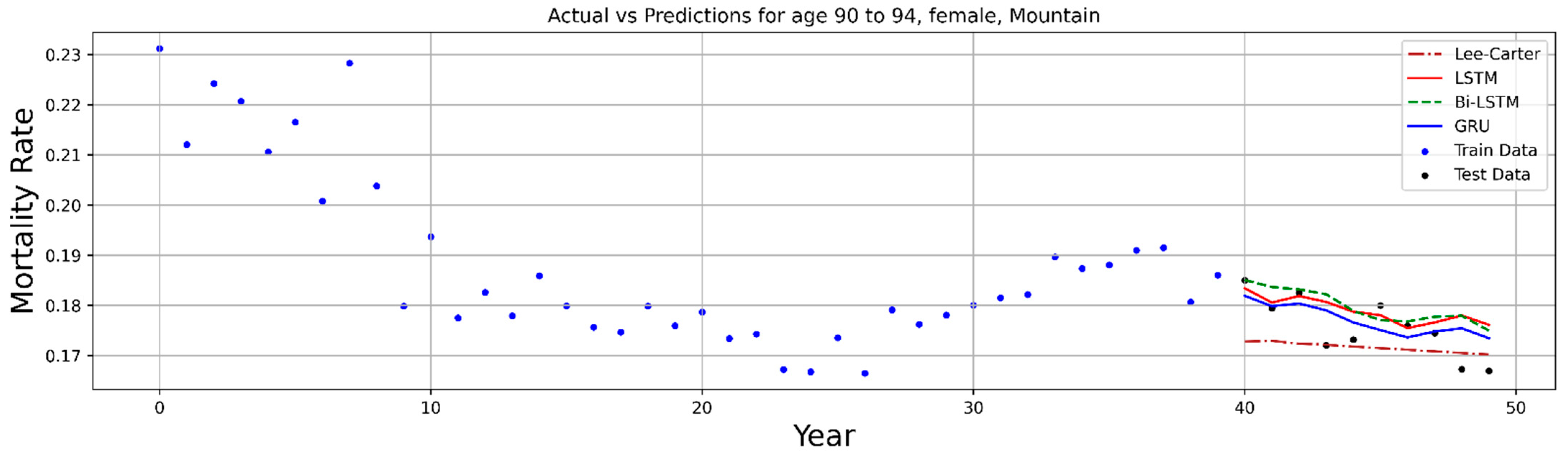
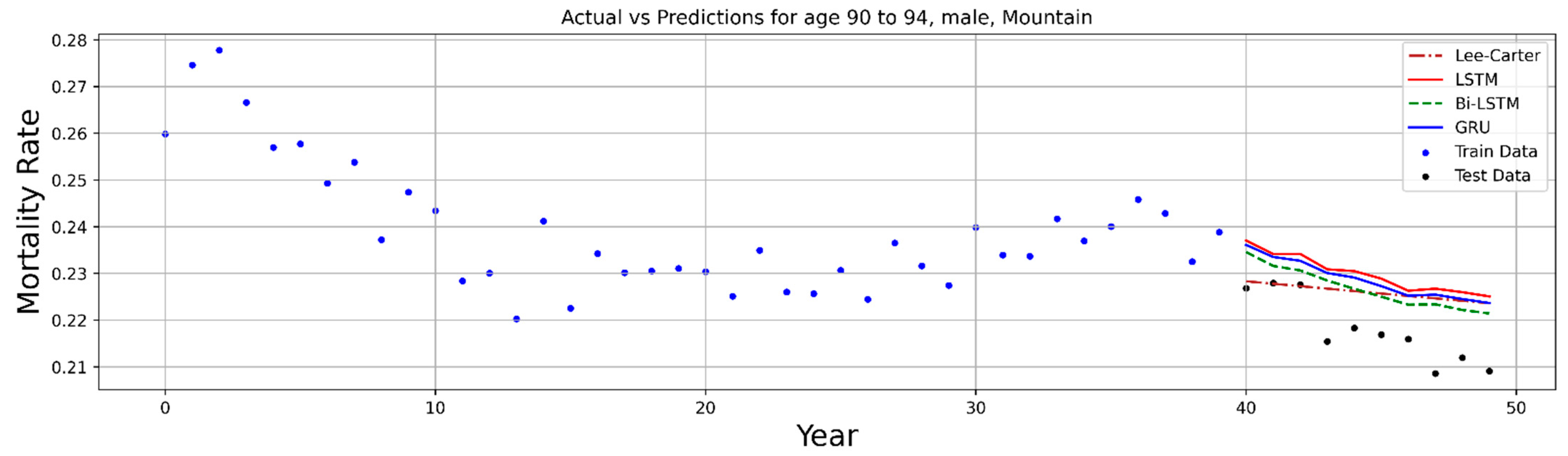
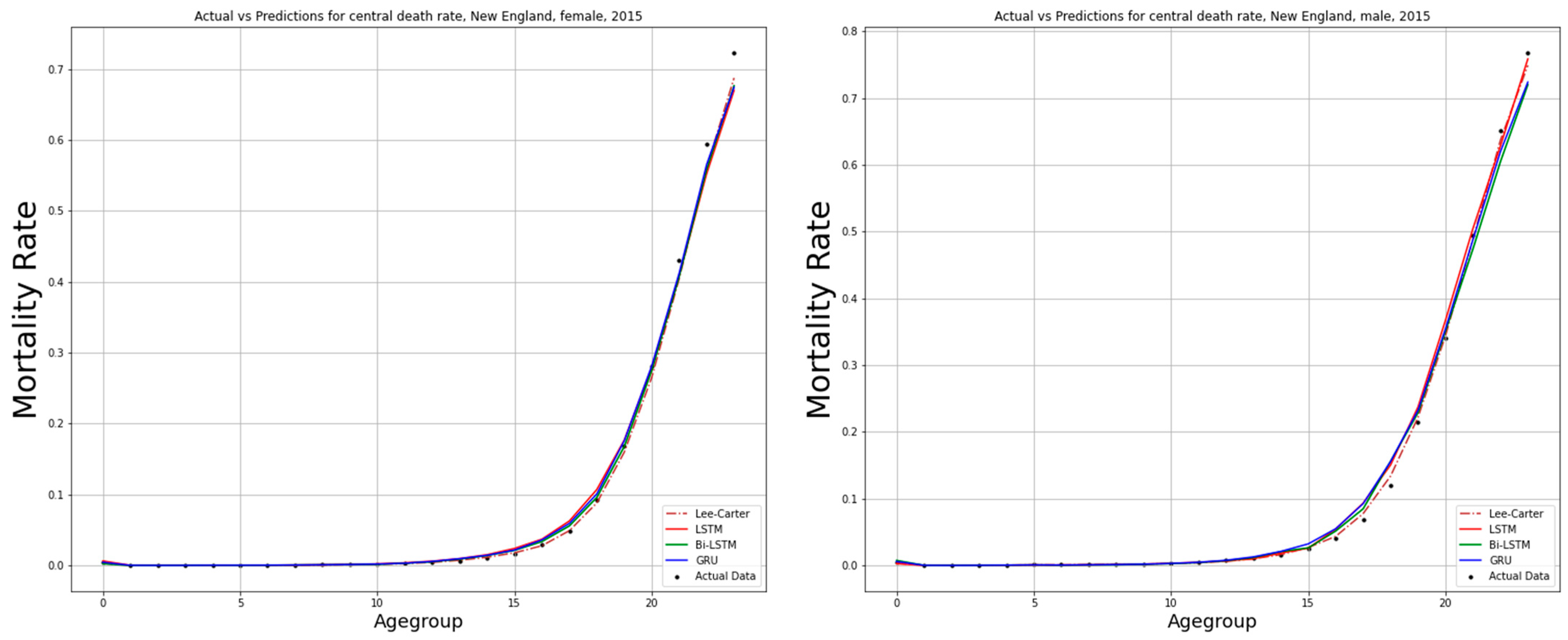
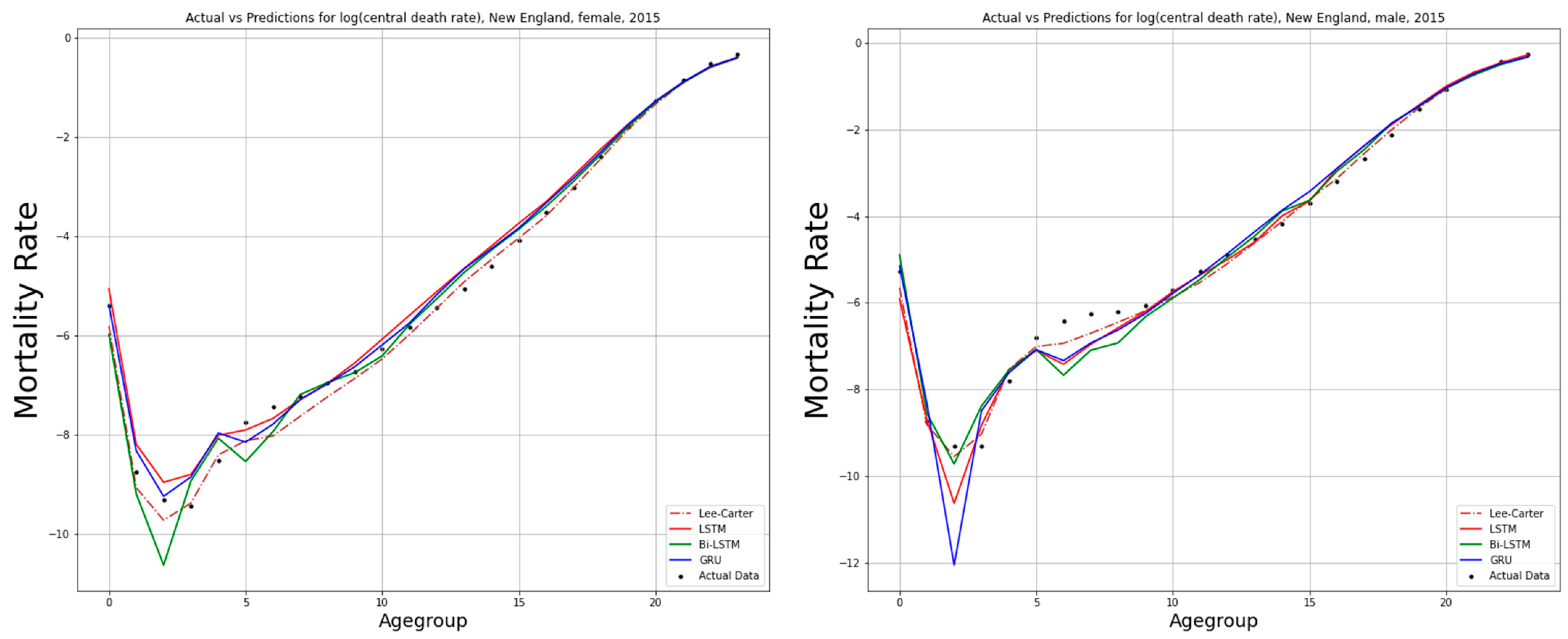
6. Numerical Process
7. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, R.; Carter, L. Modeling and Forecasting U.S. Mortality. J. Am. Stat. Assoc. 1992, 87, 659–671. [Google Scholar] [CrossRef]
- Brouns, N.; Denuit, M.; Vermunt, J. A Poisson log-bilinear regression approach to the construction of projected lifetables. Insur. Math. Econ. 2002, 31, 373–393. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, R.J.; Ullah, M.S. Robust forecasting of mortality and fertility rates: A functional data approach. Comput. Stat. Data Anal. 2007, 51, 4942–4956. [Google Scholar] [CrossRef] [Green Version]
- Shang, H.L. Dynamic principal component regression: Application to age-specific mortality forecasting. ASTIN Bull. 2019, 49, 619–645. [Google Scholar] [CrossRef] [Green Version]
- Cairns, A.; Blake, D.; Dowd, K. A Two-Factor Model for Stochastic Mortality with Parameter Uncertainty: Theory and Calibration. J. Risk Insur. 2006, 73, 687–718. [Google Scholar] [CrossRef]
- Renshaw, A.; Haberman, S. A cohort-based extension to the Lee–Carter model for mortality reduction factors. Insur. Math. Econ. 2006, 38, 556–570. [Google Scholar] [CrossRef]
- Deprez, P.; Shevchenko, P.; Wüthrich, M. Machine learning techniques for mortality modeling. Eur. Actuar. J. 2017, 7, 337–352. [Google Scholar] [CrossRef]
- Levantesi, S.; Pizzorusso, V. Application of Machine Learning to Mortality Modeling and Forecasting. Risks 2019, 7, 26. [Google Scholar] [CrossRef] [Green Version]
- Hassani, H.; Unger, S.; Beneki, C. Big Data and Actuarial Science. Big Data Cogn. Comput. 2020, 4, 40. [Google Scholar] [CrossRef]
- Richman, R. AI in Actuarial Science. 24 July 2018. Available online: https://ssrn.com/abstract=3218082 (accessed on 10 October 2022).
- Hainaut, D. A neural-network analyzer for mortality forecast. ASTIN Bull. 2018, 48, 481–508. [Google Scholar] [CrossRef]
- Perla, F.; Richman, R.; Scognamiglio, S.; Wüthrich, M.V. Time-series forecasting of mortality rates using deep learning. Scand. Actuar. J. 2021, 2021, 572–598. [Google Scholar] [CrossRef]
- Human Mortality Database. University of California, Berkeley (USA) and Max Planck Institute for Demographic Research (Germany). Available online: http://www.mortality.org (accessed on 10 October 2022).
- Nigri, A.; Levantesi, S.; Marino, M.; Scognamiglio, S.; Perla, F. A Deep Learning Integrated Lee–Carter Model. Risks 2019, 7, 33. [Google Scholar] [CrossRef] [Green Version]
- Nigri, A.; Levantesi, S.; Marino, M. Life expectancy and lifespan disparity forecasting: A long short-term memory approach. Scand. Actuar. J. 2020, 2021, 110–133. [Google Scholar] [CrossRef]
- Marino, M.; Levantesi, S. Measuring Longevity Risk through a Neural Network Lee-Carter Model. 15 March 2020. Available online: https://ssrn.com/abstract=3599821 (accessed on 10 October 2022).
- Richman, R.; Wuthrich, M.V. Lee and Carter Go Machine Learning: Recurrent Neural Networks. 22 August 2019. Available online: https://ssrn.com/abstract=3441030 (accessed on 10 October 2022).
- Castellani, G.; Fiore, U.; Marino, Z.; Passalacqua, L.; Perla, F.; Scognamiglio, S.; Zanetti, P. An Investigation of Machine Learning Approaches in the Solvency II Valuation Framework. 2018. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3303296 (accessed on 10 October 2022).
- Hong, W.H.; Yap, J.H.; Selvachandran, G.; Thong, P.H.; Son, L.H. Forecasting mortality rates using hybrid Lee–Carter model, artificial neural network and random forest. Complex Intell. Syst. 2021, 7, 163–189. [Google Scholar] [CrossRef]
- Richman, R.; Wuthrich, M.V. A Neural Network Extension of the Lee-Carter Model to Multiple Populations. 22 October 2018. Available online: https://ssrn.com/abstract=3270877 (accessed on 10 October 2022).
- Gabrielli, A.; Wüthrich, M.V. An Individual Claims History Simulation Machine. Risks 2018, 6, 29. [Google Scholar] [CrossRef] [Green Version]
- Petneházi, G.; Gáll, J. Mortality rate forecasting: Can recurrent neural networks beat the Lee-Carter model? arXiv 2022. [Google Scholar] [CrossRef]
- Hocreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Hyndman, R.J.; Khandakar, Y. Automatic Time Series Forecasting: The forecast Package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Bergeron-Boucher, M.-P.; Canudas-Romo, V.; Oeppen, J.E.; Vaupel, J. Coherent forecasts of mortality with compositional data analysis. Demogr. Res. 2017, 37, 527–566. [Google Scholar] [CrossRef]
- Booth, H.; Hyndman, R.J.; Tickle, L.; De Jong, P. Lee-Carter mortality forecasting: A multi-country comparison of variants and extensions. Demogr. Res. 2006, 15, 289–310. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Booth, H. Stochastic population forecasts using functional data models for mortality, fertility and migration. Int. J. Forecast. 2008, 24, 323–342. [Google Scholar] [CrossRef]
- Tuljapurkar, S.; Li, N.; Boe, C. A universal pattern of mortality decline in the G7 countries. Nature 2000, 405, 789–792. [Google Scholar] [CrossRef] [PubMed]
- Lee, R.D.; Miller, T. Evaluating the Performance of the Lee-Carter Method for Forecasting Mortality. Demography 2001, 38, 537–549. [Google Scholar] [CrossRef]
- Keren, G.; Cummins, N.; Schuller, B. Calibrated Prediction Intervals for Neural Network Regressors. IEEE Access 2018, 6, 54033–54041. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Comprehensive Review of Neural Network-Based Prediction Intervals and New Advances. IEEE Trans. Neural Netw. 2011, 22, 1341–1356. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R. Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy. Stat. Sci. 1986, 1, 54–75. [Google Scholar] [CrossRef]
- Dietterich, T. Ensemble learning. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Heskes, T. Practical confidence and prediction intervals. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1997; pp. 176–182. [Google Scholar]
- Petneházi, G. Recurrent Neural Networks for Time Series Forecasting. arXiv 2018, arXiv:1901.00069. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
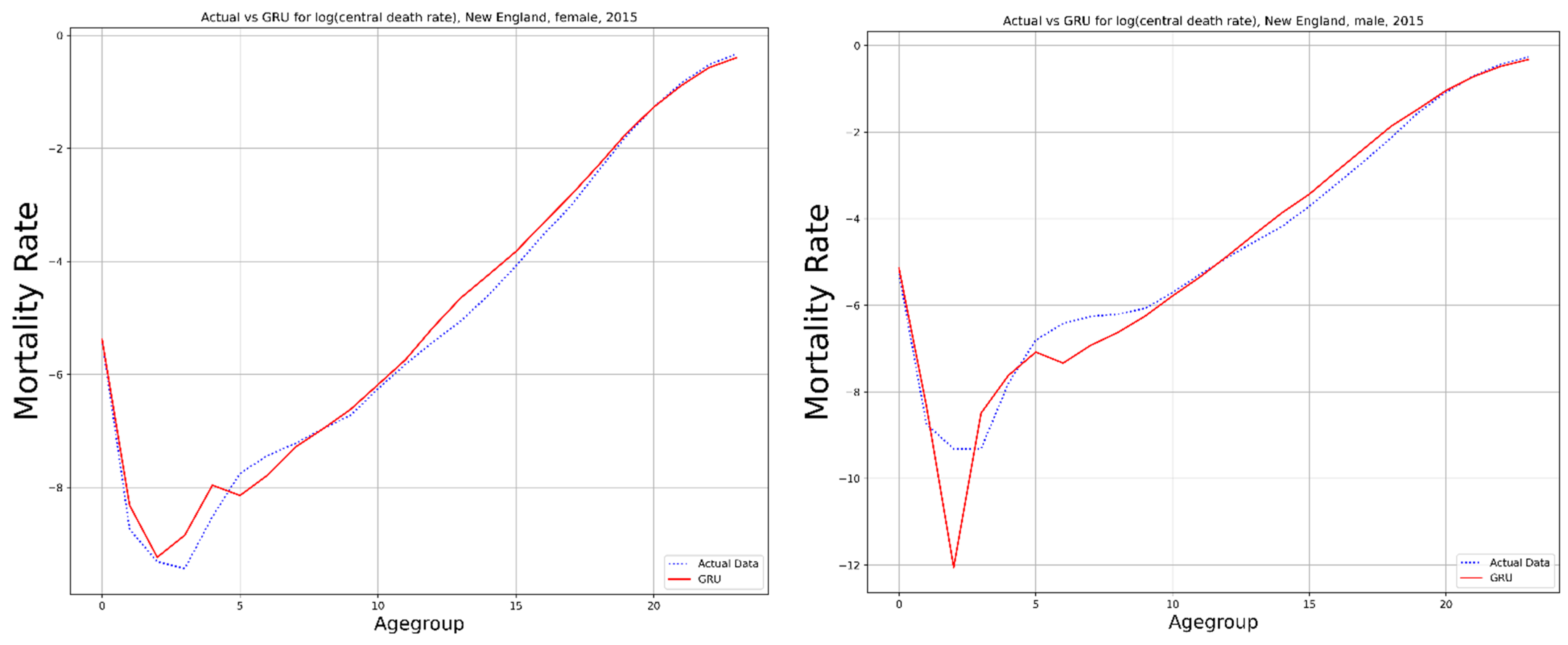{kind=link}
| Census Division | Total Years | Testing Set Years |
|---|---|---|
| New England | 1966–2015 | 2006–2015 |
| Middle Atlantic | 1966–2015 | 2006–2015 |
| East North Central | 1966–2015 | 2006–2015 |
| West North Central | 1966–2015 | 2006–2015 |
| South Atlantic | 1966–2015 | 2006–2015 |
| East South Central | 1966–2015 | 2006–2015 |
| West South Central | 1966–2015 | 2006–2015 |
| Mountain | 1966–2015 | 2006–2015 |
| Pacific | 1966–2015 | 2006–2015 |
| Age Group | Male | Female |
|---|---|---|
| 0 | 0.0103184 | 0.008126 |
| 1–4 | 0.0003978 | 0.0003192 |
| 5–9 | 0.000224 | 0.0001586 |
| 10–14 | 0.00024 | 0.0001582 |
| 15–19 | 0.0008736 | 0.0003356 |
| 20–24 | 0.0012676 | 0.0004144 |
| 25–29 | 0.0012794 | 0.0004938 |
| 30–34 | 0.0014682 | 0.0006756 |
| 35–39 | 0.0019484 | 0.0010024 |
| 40–44 | 0.0028846 | 0.0015864 |
| 45–49 | 0.004514 | 0.0025628 |
| 50–54 | 0.0071644 | 0.0039904 |
| 55–59 | 0.011396 | 0.0061842 |
| 60–64 | 0.0179772 | 0.0097272 |
| 65–69 | 0.0277216 | 0.0151632 |
| 70–74 | 0.0425512 | 0.0242644 |
| 75–79 | 0.065019 | 0.0394208 |
| 80–84 | 0.100258 | 0.065534 |
| 85–89 | 0.1565726 | 0.111995 |
| 90–94 | 0.2401684 | 0.1854848 |
| 95–99 | 0.3470992 | 0.289526 |
| 100–104 | 0.4723096 | 0.4209162 |
| 105–109 | 0.601285 | 0.5649978 |
| 110+ | 0.7013268 | 0.680411 |
| Census Division | Best ARIMA(p,d,q) |
|---|---|
| New England | ARIMA(1,1,1) |
| Middle Atlantic | ARIMA(2,1,0) |
| East North Central | ARIMA(0,1,0) |
| West North Central | ARIMA(1,1,2) |
| South Atlantic | ARIMA(0,1,0) |
| East South Central | ARIMA(2,2,1) |
| West South Central | ARIMA(0,1,1) |
| Mountain | ARIMA(1,2,1) |
| Pacific | ARIMA(0,1,0) |
| Census Division | Best ARIMA(p,d,q) |
|---|---|
| New England | ARIMA(0,1,0) |
| Middle Atlantic | ARIMA(0,1,0) |
| East North Central | ARIMA(0,1,0) |
| West North Central | ARIMA(1,1,0) |
| South Atlantic | ARIMA(0,1,0) |
| East South Central | ARIMA(0,1,0) |
| West South Central | ARIMA(0,1,0) |
| Mountain | ARIMA(0,1,0) |
| Pacific | ARIMA(0,1,0) |
| Census Division | Neurons | Batch Size | Epochs | Dropout |
|---|---|---|---|---|
| New England | ||||
| LSTM | 128 | 32 | 50 | 20% |
| Bi-LSTM | 128 | 32 | 50 | 20% |
| GRU | 128 | 32 | 50 | 20% |
| Middle Atlantic | ||||
| LSTM | 64 | 32 | 100 | 30% |
| Bi-LSTM | 64 | 32 | 100 | 30% |
| GRU | 64 | 64 | 300 | 30% |
| East North Central | ||||
| LSTM | 64 | 16 | 150 | 10% |
| Bi-LSTM | 64 | 16 | 150 | 10% |
| GRU | 64 | 16 | 150 | 10% |
| West North Central | ||||
| LSTM | 128 | 32 | 50 | 20% |
| Bi-LSTM | 128 | 32 | 50 | 20% |
| GRU | 128 | 32 | 50 | 20% |
| South Atlantic | ||||
| LSTM | 128 | 16 | 150 | 10% |
| Bi-LSTM | 128 | 16 | 150 | 10% |
| GRU | 128 | 16 | 300 | 20% |
| East South Central | ||||
| LSTM | 128 | 32 | 300 | 10% |
| Bi-LSTM | 128 | 32 | 300 | 30% |
| GRU | 128 | 32 | 300 | 10% |
| West South Central | ||||
| LSTM | 128 | 64 | 300 | 10% |
| Bi-LSTM | 64 | 64 | 300 | 10% |
| GRU | 128 | 16 | 300 | 10% |
| Mountain | ||||
| LSTM | 128 | 32 | 50 | 20% |
| Bi-LSTM | 128 | 32 | 50 | 20% |
| GRU | 128 | 32 | 50 | 20% |
| Pacific | ||||
| LSTM | 128 | 32 | 100 | 20% |
| Bi-LSTM | 128 | 32 | 100 | 20% |
| GRU | 128 | 32 | 100 | 20% |
| Census Division | Neurons | Batch Size | Epochs | Dropout |
|---|---|---|---|---|
| New England | ||||
| LSTM | 32 | 16 | 300 | 10% |
| Bi-LSTM | 32 | 16 | 300 | 10% |
| GRU | 128 | 32 | 150 | 20% |
| Middle Atlantic | ||||
| LSTM | 128 | 32 | 60 | 30% |
| Bi-LSTM | 64 | 32 | 60 | 30% |
| GRU | 64 | 16 | 100 | 30% |
| East North Central | ||||
| LSTM | 128 | 64 | 50 | 10% |
| Bi-LSTM | 128 | 64 | 50 | 10% |
| GRU | 128 | 64 | 50 | 10% |
| West North Central | ||||
| LSTM | 64 | 16 | 150 | 30% |
| Bi-LSTM | 128 | 32 | 150 | 30% |
| GRU | 64 | 32 | 150 | 30% |
| South Atlantic | ||||
| LSTM | 64 | 32 | 300 | 10% |
| Bi-LSTM | 64 | 32 | 300 | 10% |
| GRU | 64 | 32 | 300 | 10% |
| East South Central | ||||
| LSTM | 128 | 16 | 50 | 30% |
| Bi-LSTM | 128 | 32 | 50 | 30% |
| GRU | 64 | 32 | 300 | 30% |
| West South Central | ||||
| LSTM | 64 | 16 | 30 | 10% |
| Bi-LSTM | 32 | 16 | 30 | 10% |
| GRU | 64 | 16 | 100 | 30% |
| Mountain | ||||
| LSTM | 128 | 32 | 100 | 20% |
| Bi-LSTM | 128 | 32 | 100 | 20% |
| GRU | 128 | 32 | 100 | 20% |
| Pacific | ||||
| LSTM | 32 | 32 | 300 | 30% |
| Bi-LSTM | 32 | 16 | 50 | 30% |
| GRU | 64 | 32 | 300 | 30% |
| Census Division | Female | Male | ||
|---|---|---|---|---|
| New England | MAE | RMSE | MAE | RMSE |
| LC | 0.003580 | 0.0085774 | 0.0038145 | 0.007061 |
| LSTM | 0.003333 | 0.0077581 | 0.003602 | 0.007446 |
| Bi-LSTM | 0.003559 | 0.0084523 | 0.004280 | 0.008178 |
| GRU | 0.003222 | 0.007591 | 0.004250 | 0.009505 |
| Middle Atlantic | MAE | RMSE | MAE | RMSE |
| LC | 0.002296 | 0.0055494 | 0.003419 | 0.0064182 |
| LSTM | 0.005479 | 0.012104 | 0.0036423 | 0.0070882 |
| Bi-LSTM | 0.004609 | 0.0107834 | 0.0045392 | 0.0093438 |
| GRU | 0.004957 | 0.0115375 | 0.0024576 | 0.0048186 |
| East North Central | MAE | RMSE | MAE | RMSE |
| LC | 0.004458 | 0.0106013 | 0.0042796 | 0.0081338 |
| LSTM | 0.002742 | 0.0054024 | 0.0050855 | 0.0117587 |
| Bi-LSTM | 0.002667 | 0.0056034 | 0.0056478 | 0.0103892 |
| GRU | 0.003531 | 0.0080238 | 0.0045146 | 0.0104677 |
| West North Central | MAE | RMSE | MAE | RMSE |
| LC | 0.006313 | 0.0147076 | 0.0058709 | 0.0123197 |
| LSTM | 0.004541 | 0.0104502 | 0.0050320 | 0.0095187 |
| Bi-LSTM | 0.004225 | 0.0100399 | 0.0038613 | 0.0073576 |
| GRU | 0.004378 | 0.0104372 | 0.0029962 | 0.0055895 |
| South Atlantic | MAE | RMSE | MAE | RMSE |
| LC | 0.004249 | 0.0100673 | 0.0043421 | 0.007902 |
| LSTM | 0.004162 | 0.0096163 | 0.0065645 | 0.0129754 |
| Bi-LSTM | 0.003537 | 0.0079331 | 0.0041443 | 0.0077775 |
| GRU | 0.004525 | 0.0103644 | 0.0042279 | 0.0087472 |
| East South Central | MAE | RMSE | MAE | RMSE |
| LC | 0.005919 | 0.0137948 | 0.006056 | 0.0121139 |
| LSTM | 0.006389 | 0.0154277 | 0.0062494 | 0.0135819 |
| Bi-LSTM | 0.006630 | 0.0161339 | 0.0043764 | 0.0091593 |
| GRU | 0.006237 | 0.0150568 | 0.003344 | 0.0074549 |
| West South Central | MAE | RMSE | MAE | RMSE |
| LC | 0.003881 | 0.0094994 | 0.004401 | 0.008112 |
| LSTM | 0.002977 | 0.0067081 | 0.008326 | 0.0186121 |
| Bi-LSTM | 0.002770 | 0.0061035 | 0.0088042 | 0.0187601 |
| GRU | 0.003814 | 0.0089701 | 0.0031701 | 0.0062397 |
| Mountain | MAE | RMSE | MAE | RMSE |
| LC | 0.005875 | 0.0136075 | 0.0058631 | 0.0116347 |
| LSTM | 0.005474 | 0.0129507 | 0.0055829 | 0.0130083 |
| Bi-LSTM | 0.005256 | 0.0124847 | 0.0037339 | 0.0076257 |
| GRU | 0.005158 | 0.0123561 | 0.0048700 | 0.0112312 |
| Pacific | MAE | RMSE | MAE | RMSE |
| LC | 0.00303 | 0.0063291 | 0.0038562 | 0.0073431 |
| LSTM | 0.00337 | 0.0069403 | 0.0045788 | 0.0090681 |
| Bi-LSTM | 0.002647 | 0.0054352 | 0.0055415 | 0.0105694 |
| GRU | 0.002453 | 0.0056640 | 0.0029244 | 0.0056143 |
| Model | MAE Female | MAE Male | RMSE Female | RMSE Male | Averaged MAE | Averaged RMSE |
|---|---|---|---|---|---|---|
| LC | 0.0044 | 0.04656 | 0.010304 | 0.009004 | 0.004528 | 0.009654 |
| LSTM | 0.004274 | 0.005407 | 0.009706 | 0.011451 | 0.004841 | 0.010579 |
| Bi-LSTM | 0.003989 | 0.004992 | 0.009219 | 0.009907 | 0.00449 | 0.009563 |
| GRU | 0.004253 | 0.003639 | 0.010000 | 0.007741 | 0.003946 | 0.008871 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Khaliq, A.Q.M. Comparative Study of Mortality Rate Prediction Using Data-Driven Recurrent Neural Networks and the Lee–Carter Model. Big Data Cogn. Comput. 2022, 6, 134. https://doi.org/10.3390/bdcc6040134
Chen Y, Khaliq AQM. Comparative Study of Mortality Rate Prediction Using Data-Driven Recurrent Neural Networks and the Lee–Carter Model. Big Data and Cognitive Computing. 2022; 6(4):134. https://doi.org/10.3390/bdcc6040134
Chicago/Turabian StyleChen, Yuan, and Abdul Q. M. Khaliq. 2022. "Comparative Study of Mortality Rate Prediction Using Data-Driven Recurrent Neural Networks and the Lee–Carter Model" Big Data and Cognitive Computing 6, no. 4: 134. https://doi.org/10.3390/bdcc6040134
APA StyleChen, Y., & Khaliq, A. Q. M. (2022). Comparative Study of Mortality Rate Prediction Using Data-Driven Recurrent Neural Networks and the Lee–Carter Model. Big Data and Cognitive Computing, 6(4), 134. https://doi.org/10.3390/bdcc6040134