
An Information System Supporting Insurance Use Cases by Automated Anomaly Detection

 , , , , , and
, , , , , and
Abstract
:1. Introduction and Motivation
2. Related Work
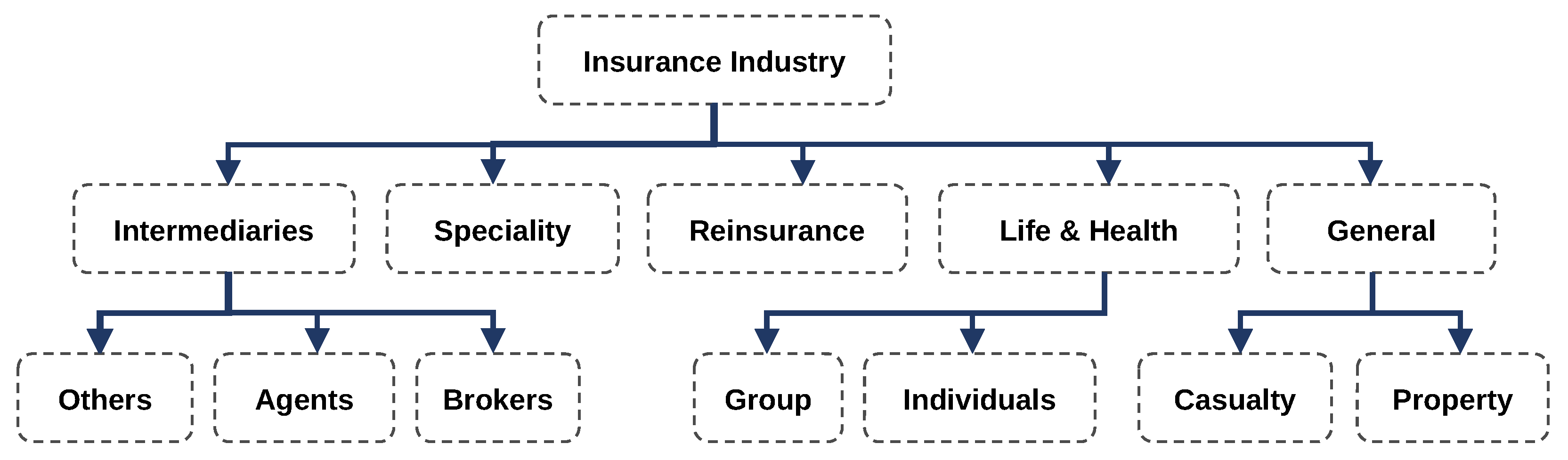
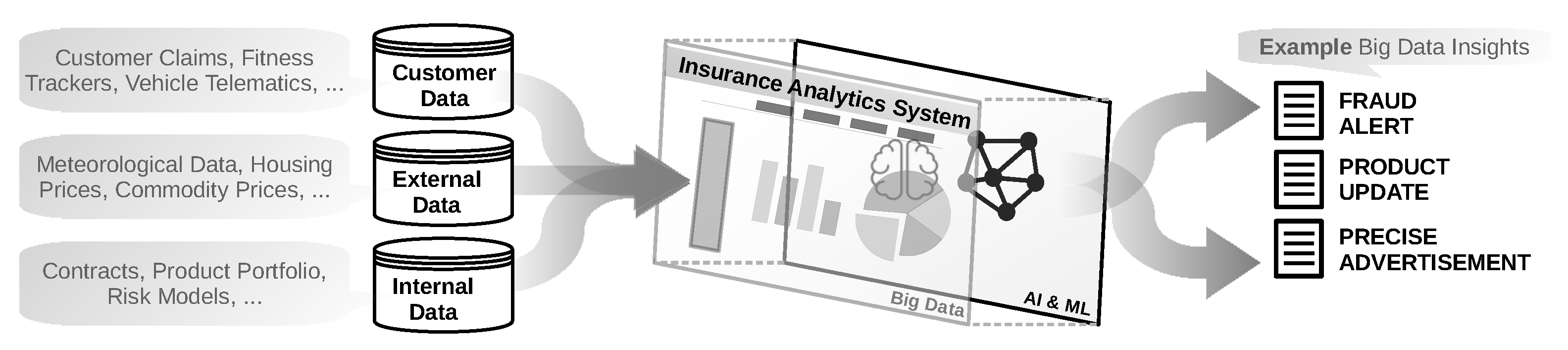
2.1. Data Analytics for Insurance Companies
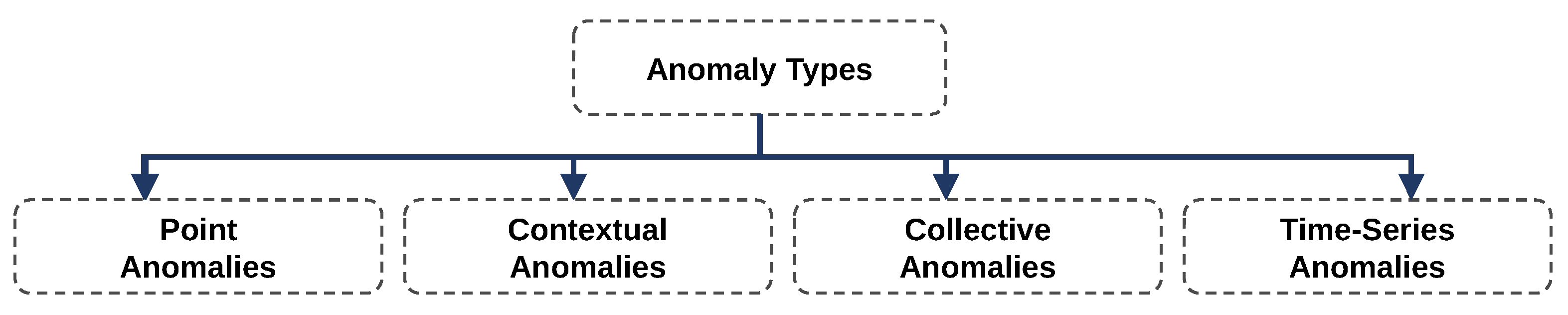
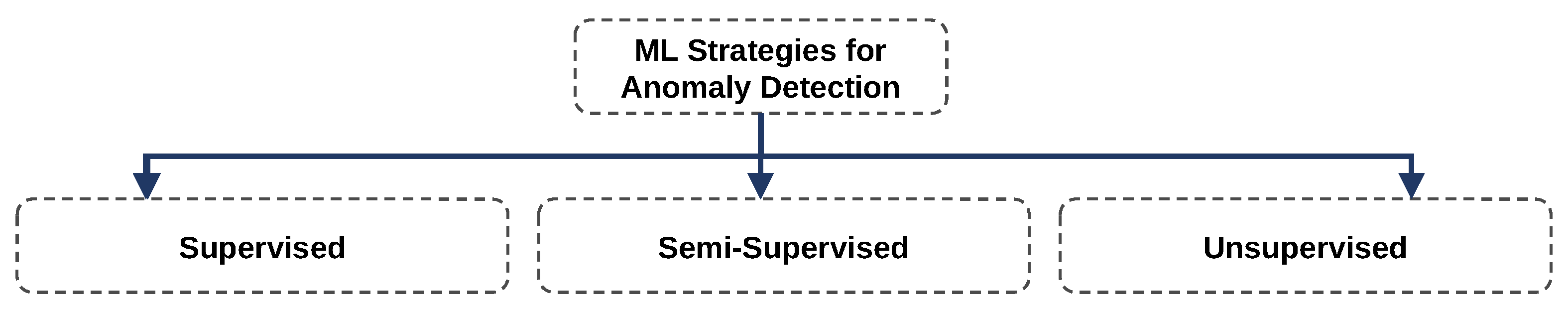
2.2. Anomaly Detection
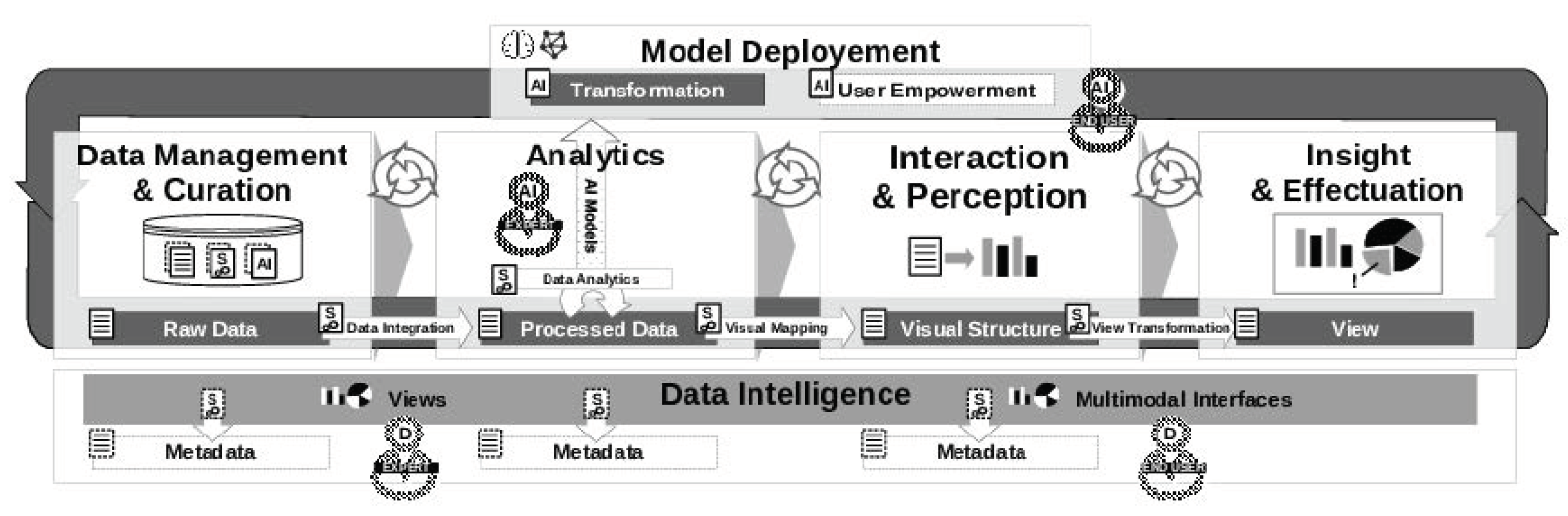
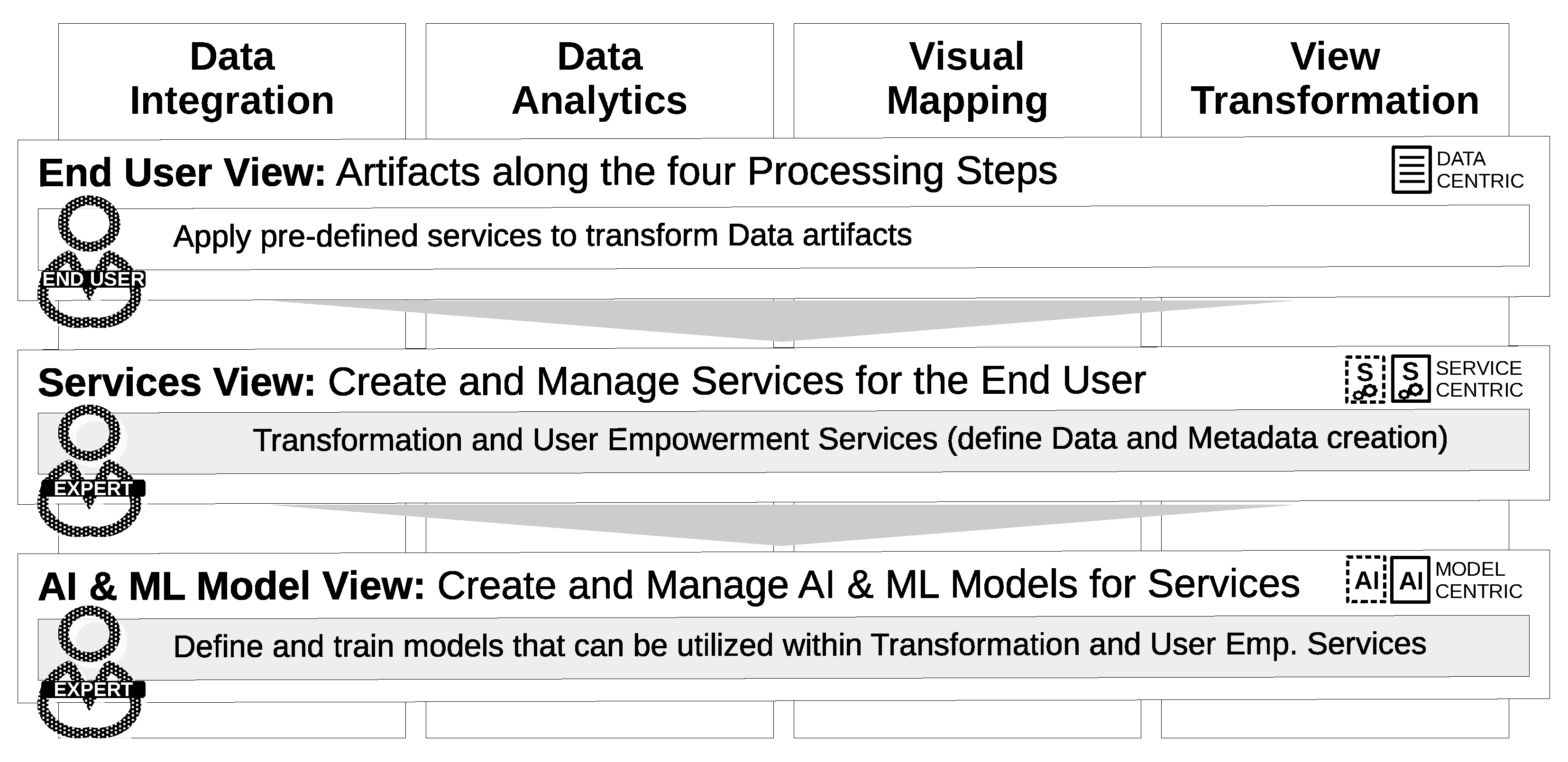
2.3. AI2VIS4BigData Reference Model and Architecture
2.4. Discussion and Remaining Challenges
- RC1. It is unclear whether the already data-driven insurance industry requires support for analyzing big data.
- RC2. There exists no IS that supports end users in detecting anomalies.
- RC3. The state of the art lacks a AI2VIS4BigData reference implementation for ML-based user empowerment.
3. Conceptual Modeling
- For RC1, a pre-study addresses an unclear demand for such a system in the insurance industry in Section 3.1;
- For RC2, Section 3.2 and Section 3.3 address the design of an IS; and
- For RC3, Section 3.4 addresses the AI2VIS4BigData reference implementation.
3.1. Insurance Analyst Expert Interview as Pre-Study
3.2. Use Context Empowering Insurance Analysts
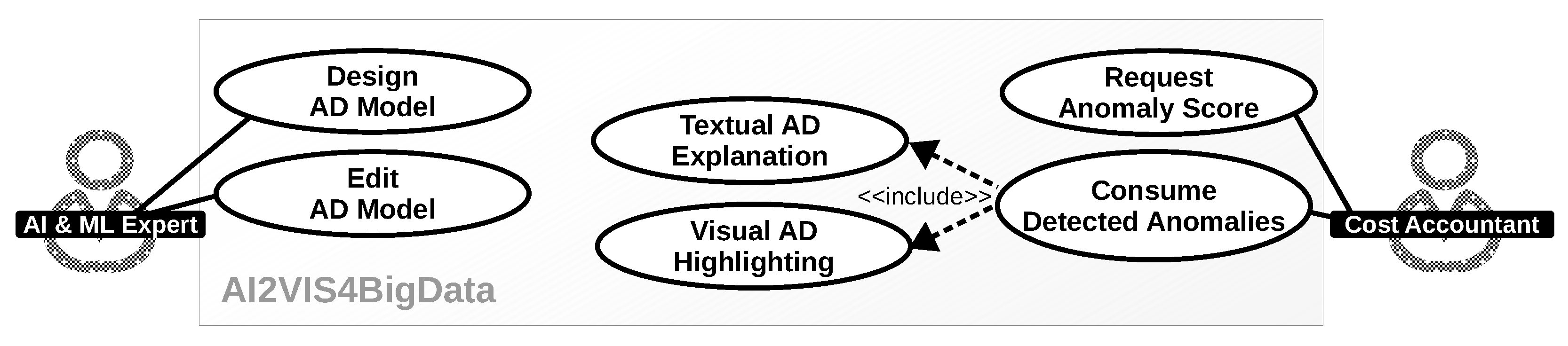
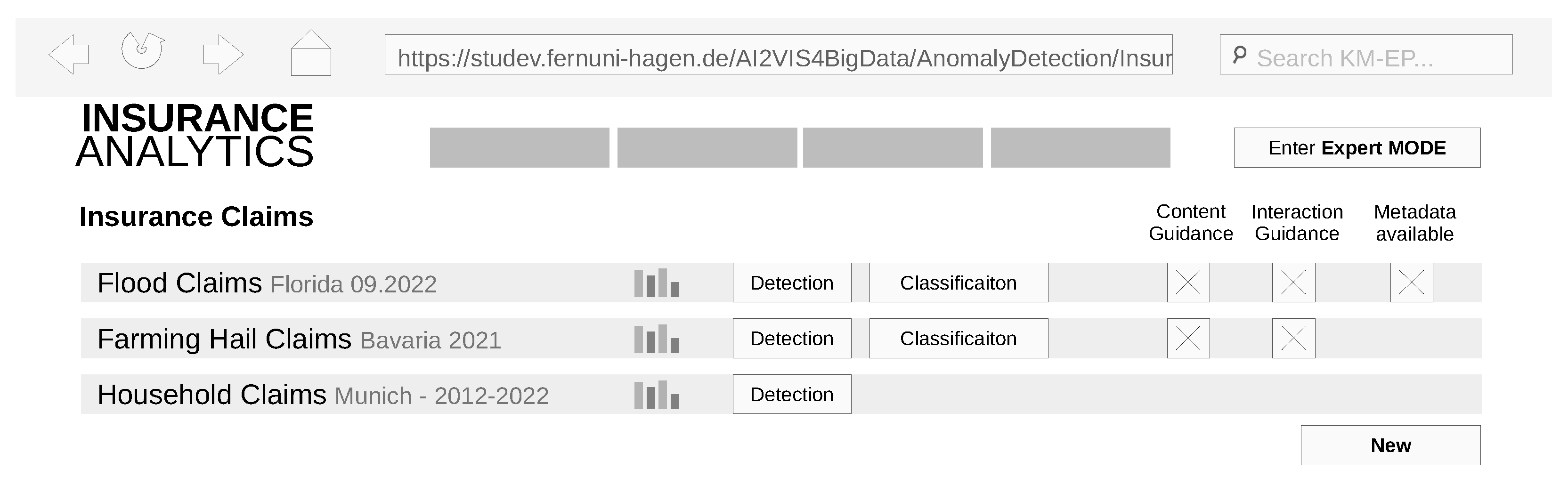
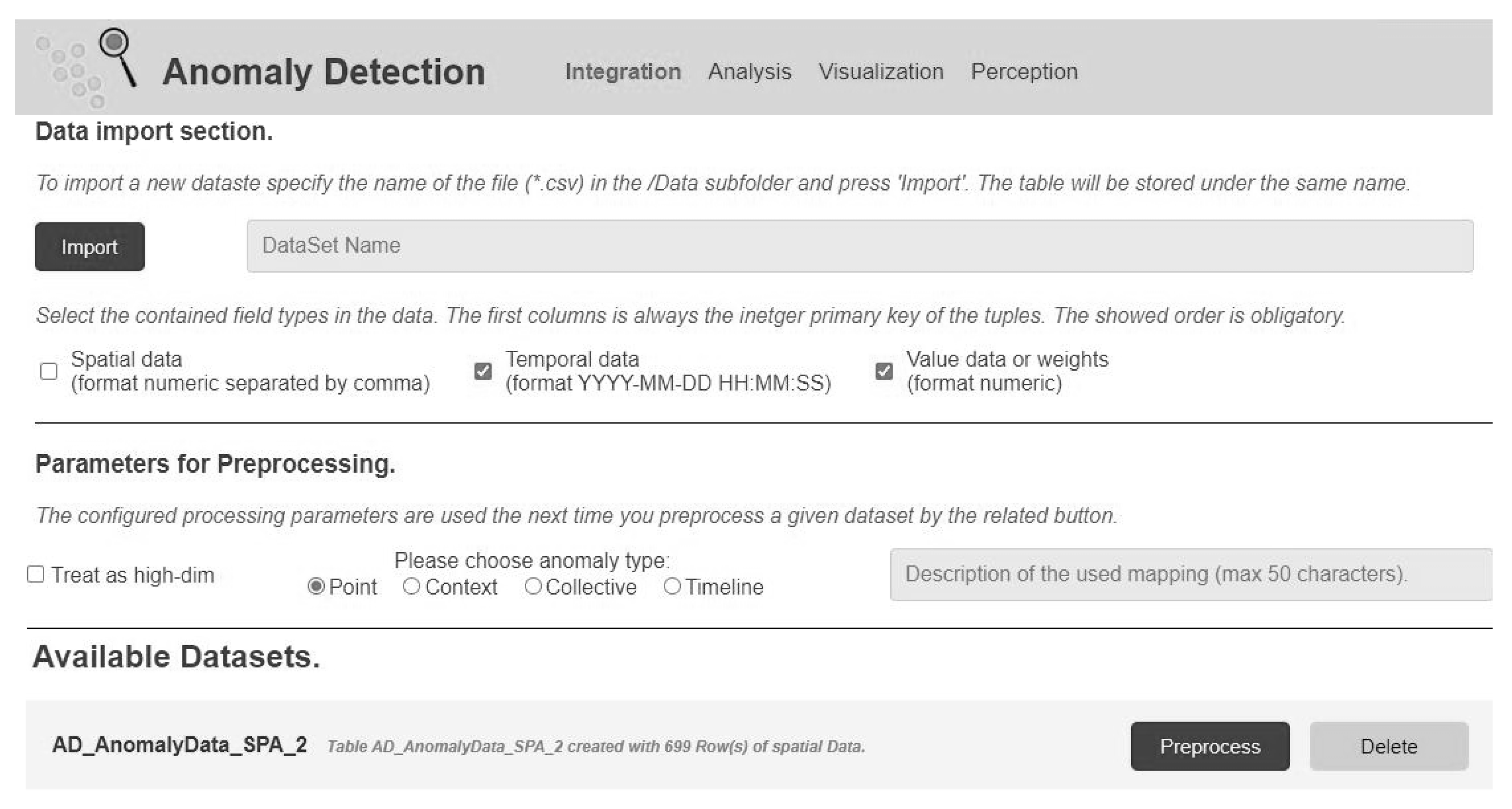
- (REQ1) Two independent views: The target system shall provide two independent views that reflect the different skills and demands by both user stereotypes as they use the system for disjunct use cases. These views shall focus on the AD models (AD model view for the AI & ML expert) and the actual data analytics with anomaly presentation (data analytics view for the cost accountant).
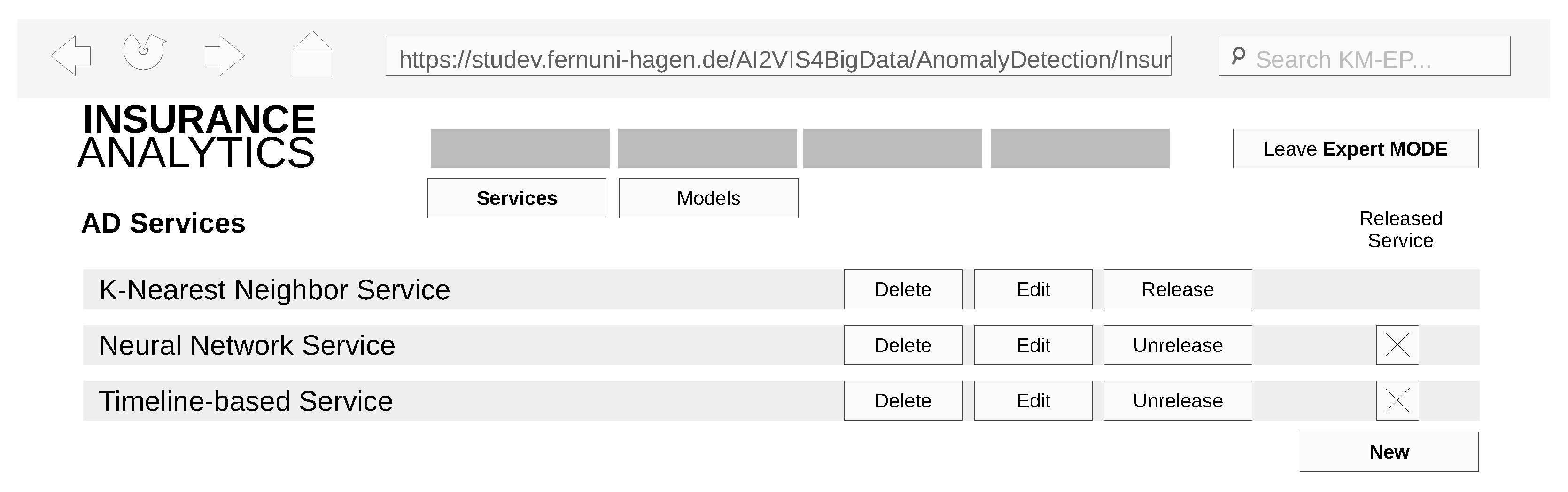
- (REQ2) Design AD models: The AD model view shall support the design and integration of an AD model. The design consists of selecting an AD algorithm, defining input data and preprocessings, parameterizing an AD algorithm and training AD algorithms (for supervised or semisupervised ML).
- (REQ3) Edit AD models: The AD model view shall support editing existing AD models and refactoring of their content.
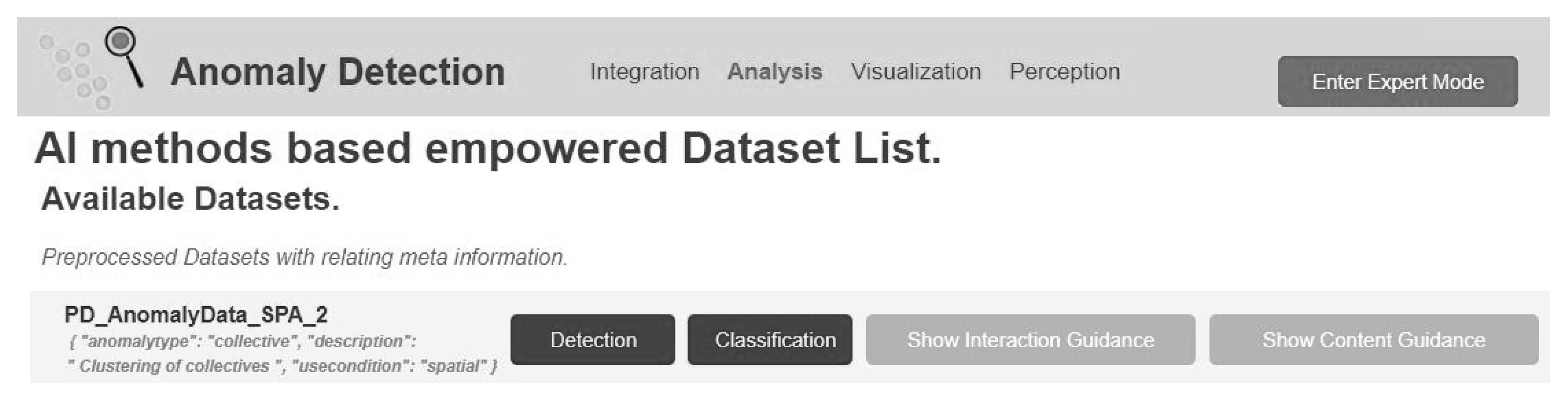
- (REQ4) Consume detected anomalies: The data analytics view shall inform the cost accountant about anomalies in datasets that are of relevance. The detection of these anomalies shall be performed automatically without the user’s active request.
- (REQ5) Textual AD explanations: Detected anomalies shall be presented to the user in a textual form. The text shall include information on the anomaly type, anomaly score, and the applied algorithm.
- (REQ6) Visual AD explanations: Detected anomalies shall be presented to the user in a visual form as a graphic. The graphic shall highlight abnormal data instances and differentiate them from normal ones.
- (REQ7) Request anomaly score: The data analytics view shall provide the function of actively requesting an anomaly score for verifying or falsifying hypotheses. The anomaly score shall be provided for selected data instances within a dataset.
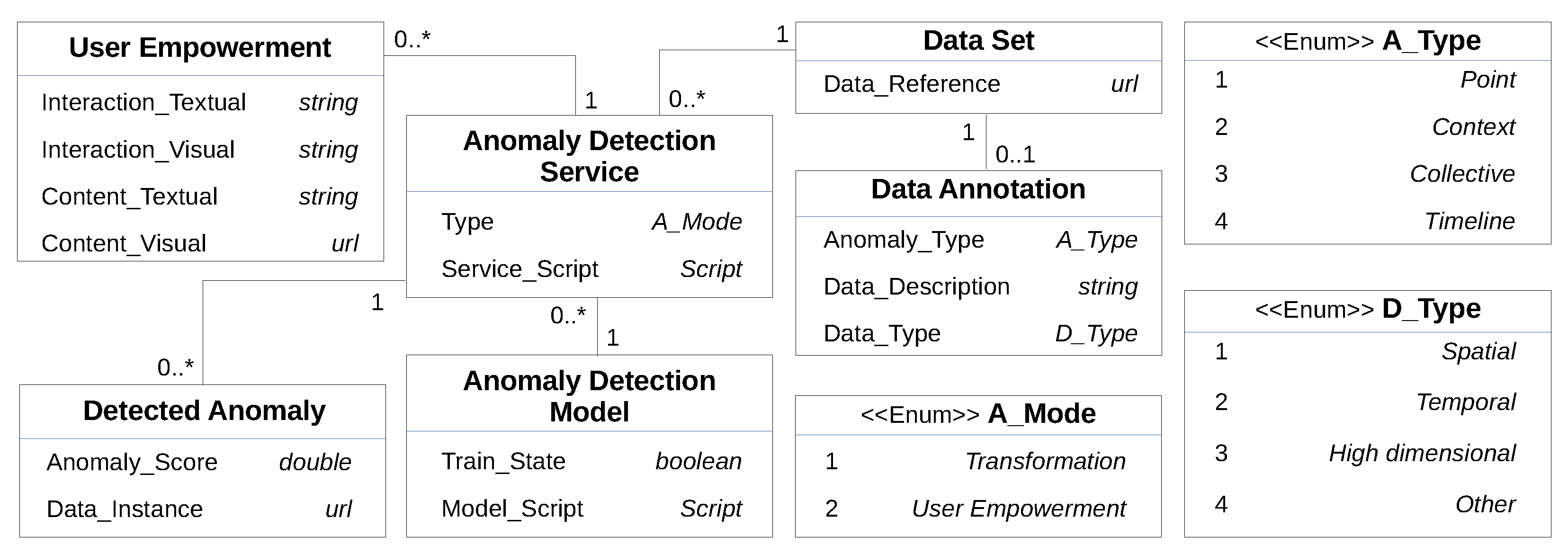
3.3. Modeling a User Empowering Anomaly Detection Component
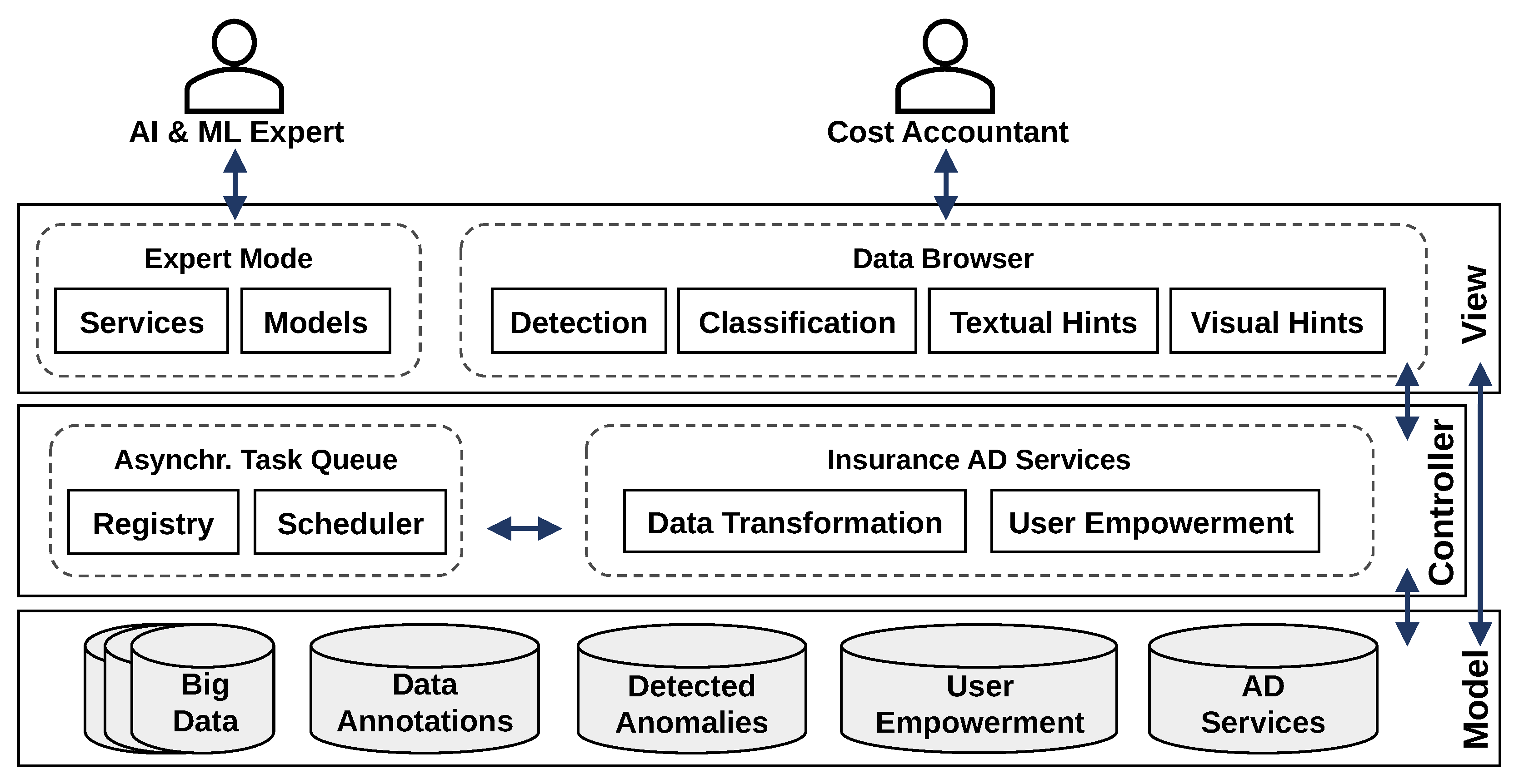
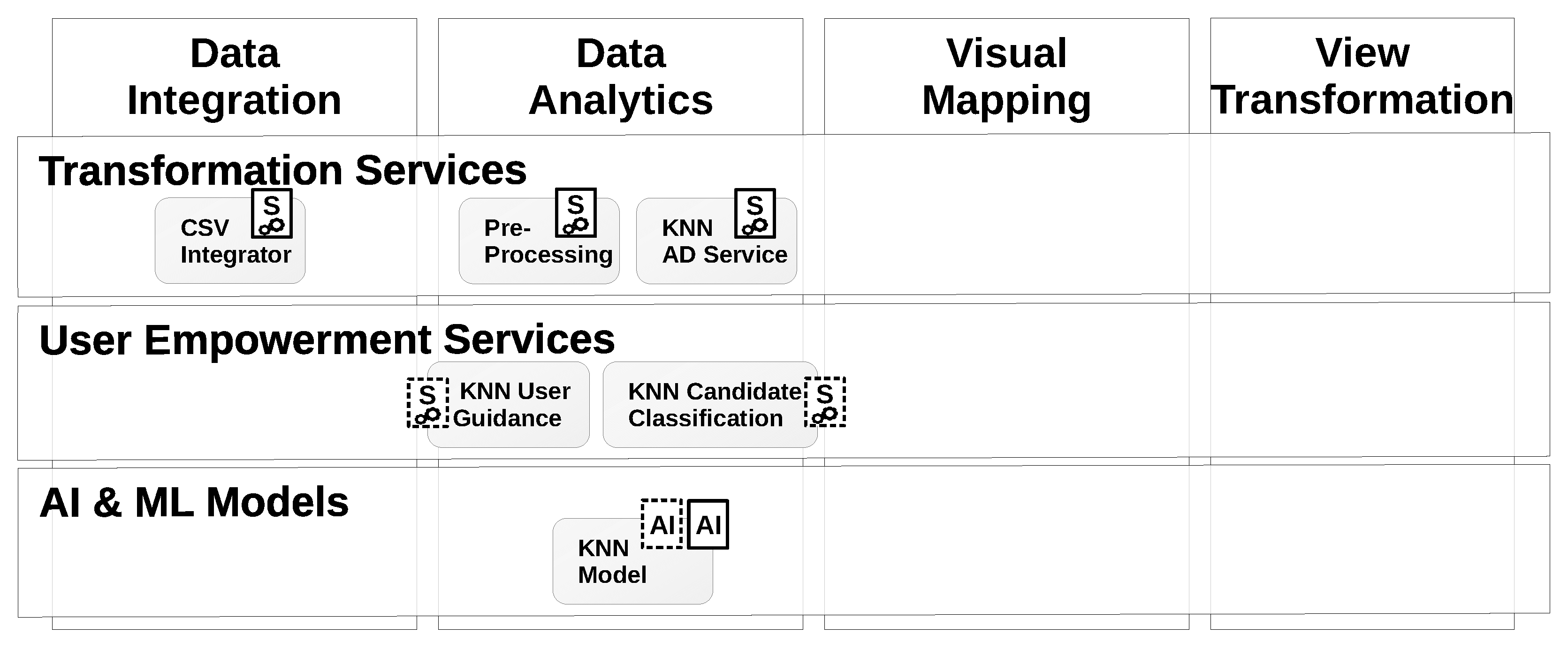
3.4. Extension of AI2VIS4BigData for ML-Based User Empowerment
4. Proof-of-Concept Implementation
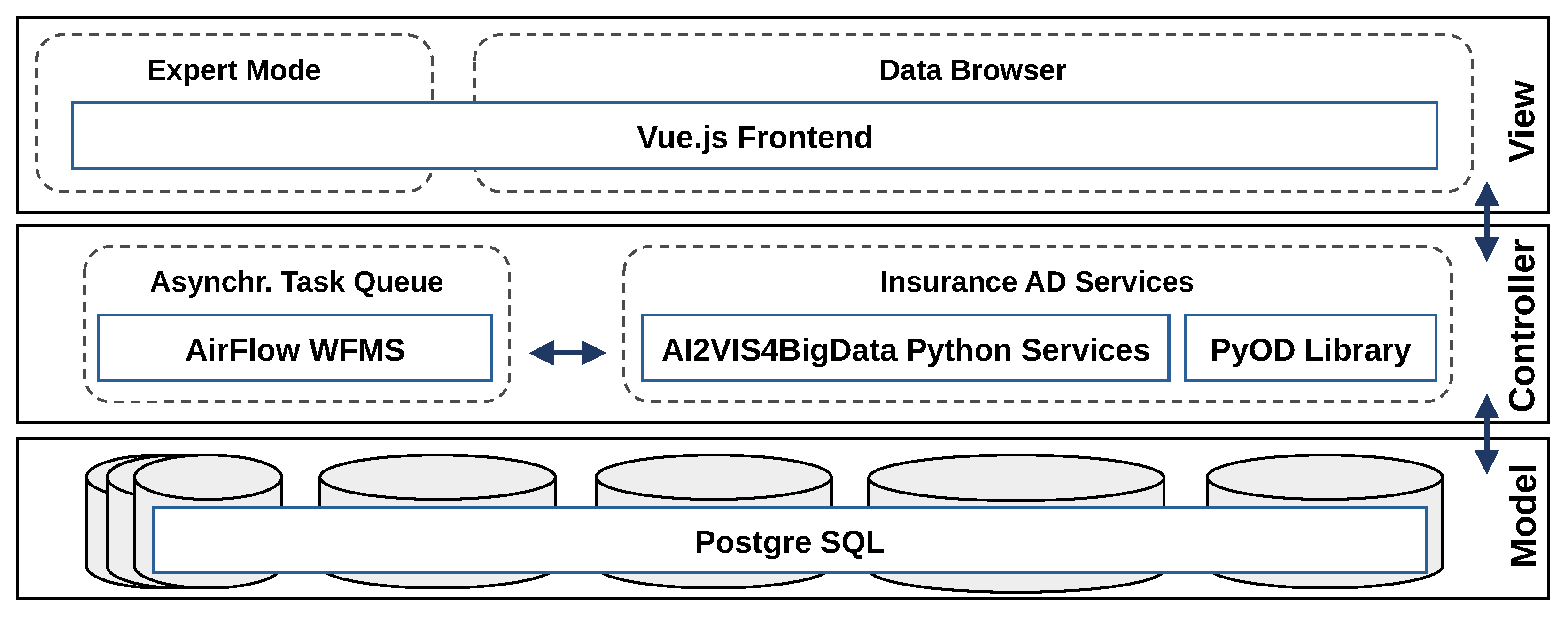
4.1. Implementation of the Anomaly Detection Component
4.2. Implementation of the Graphical User Interface
4.3. Implementation of the End User Use Case
| Listing 1: Parameters for PyOD KNN anomaly detection model. | |
| 1 n_neighbors = 5, | # five neighbors used for k neighbors queries |
| 2 method = ’mean’, | # average of all k neighbors as anomaly score |
| 3 metric = ’Euclidean’ | # euclidean distance as metric |
5. Evaluation
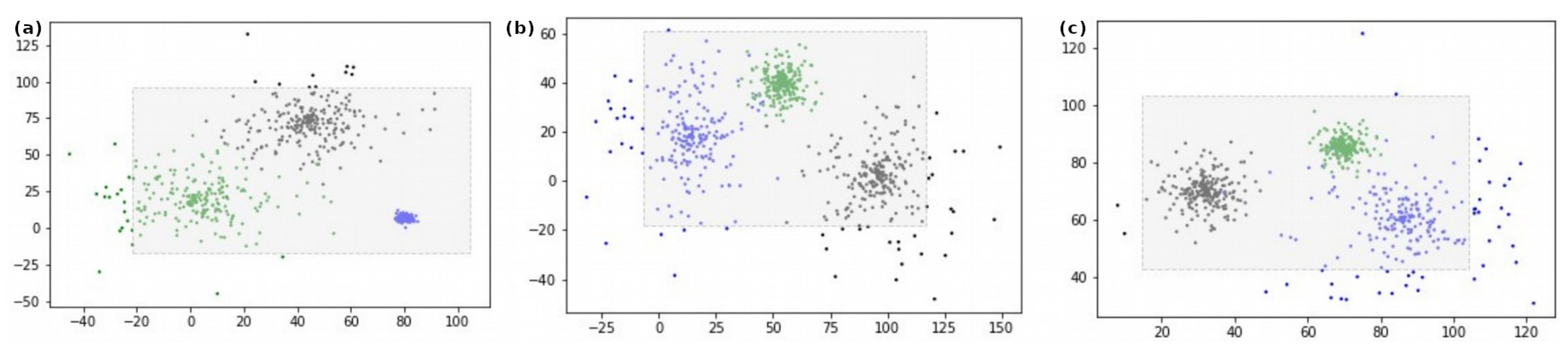
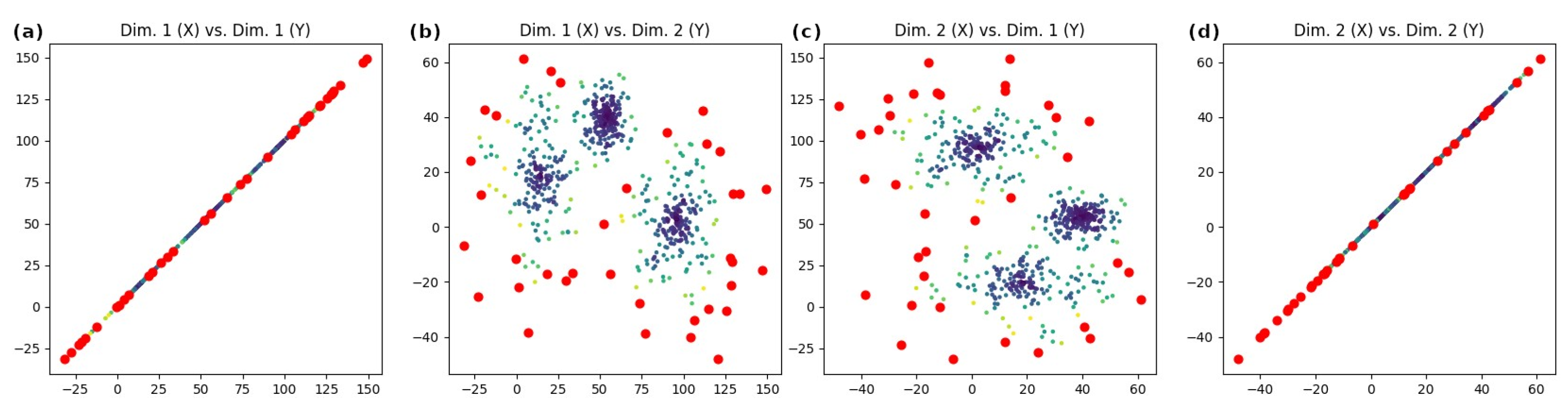
5.1. Qualitative Evaluation of Anomaly Detection
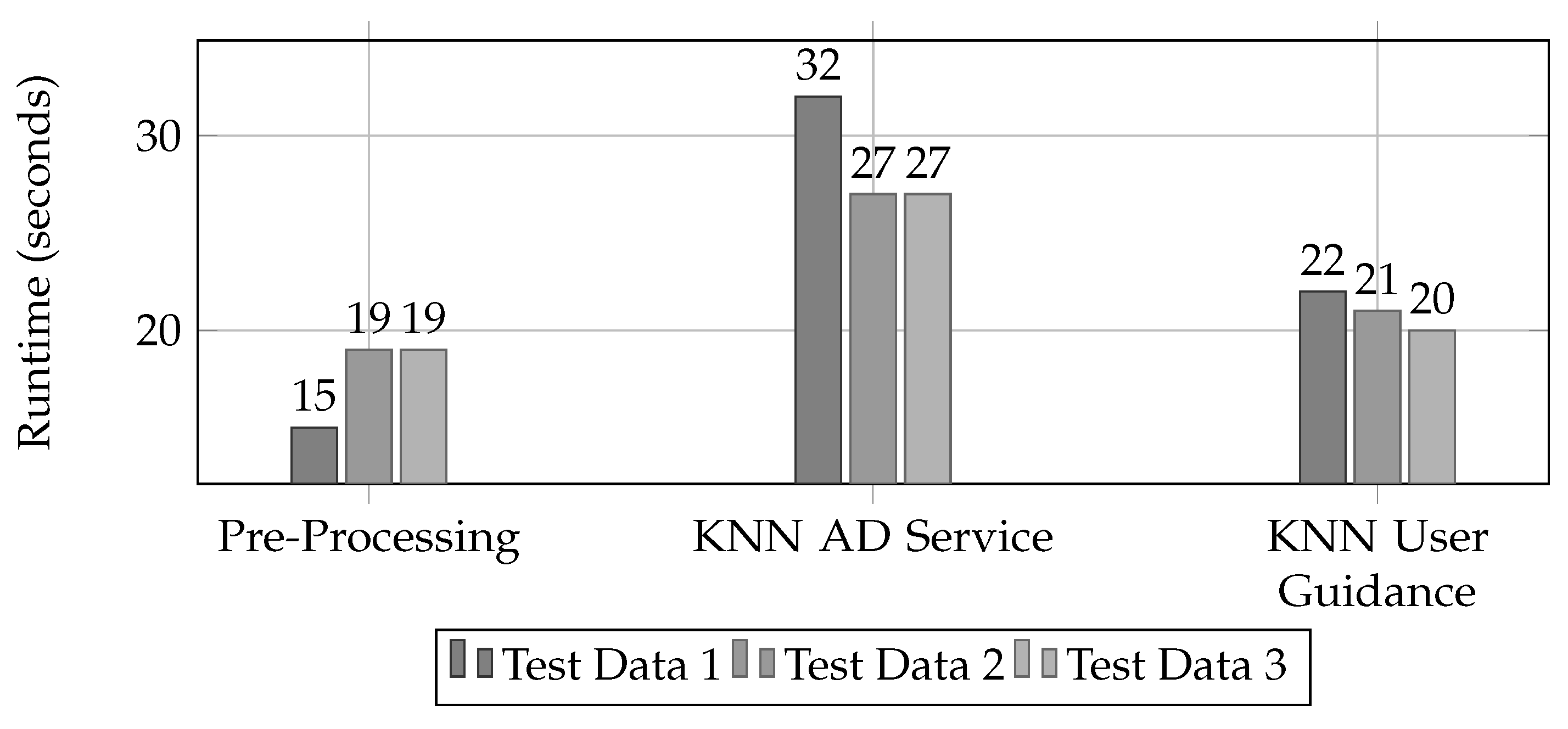
5.2. Quantitative Evaluation of the Anomaly-Detection Component
5.3. Qualitative Evaluation of the Insurance Analyst Use Case
- (1)
- perform a complete AD for a certain dataset;
- (2)
- review a data instance with an exceptional anomaly score; and
- (3)
- reclassify a data instance from the dataset with another AD service.
- (4)
- preprocess data and label its data and anomaly type;
- (5)
- identify and interpret the graphical anomaly content guidance; and
- (6)
- identify and interpret the textual anomaly interaction guidance.
6. Summary and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Koutsomitropoulos, D.A.; Kalou, A.K. A standards-based ontology and support for Big Data Analytics in the insurance industry. ICT Express 2017, 3, 57–61. [Google Scholar] [CrossRef]
- Boobier, T. Analytics for Insurance: The Real Business of Big Data; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Laney, D. 3D Data Management: Controlling Data Volume, Velocity, and Variety; Technical Report; META Group: Fort Myers, FL, USA, 2001. [Google Scholar]
- King, M.R.N.; Timms, P.D.; Rubin, T.H. Use of Big Data in Insurance. In The Palgrave Handbook of Technological Finance; Rau, R., Wardrop, R., Zingales, L., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 669–700. [Google Scholar] [CrossRef]
- Pugnetti, C.; Seitz, M. Data-driven services in insurance: Potential evolution and impact in the Swiss market. J. Risk Financ. Manag. 2021, 14, 227. [Google Scholar] [CrossRef]
- Reis, T.; Bornschlegl, M.X.; Hemmje, M.L. AI2VIS4BigData: Qualitative Evaluation of an AI-Based Big Data Analysis and Visualization Reference Model. In Advanced Visual Interfaces. Supporting Artificial Intelligence and Big Data Applications; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12585, pp. 136–162. [Google Scholar] [CrossRef]
- Reis, T.; Bornschlegl, M.X.; Hemmje, M.L. Toward a Reference Model for Artificial Intelligence Supporting Big Data Analysis. In Advances in Data Science and Information Engineering, Proceedings of the 2020 International Conference on Data Science (ICDATA’20), Las Vegas, NV USA, 27–30 July 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 561–572. [Google Scholar]
- Reis, T.; Steffl, A.; Bruchhaus, S.; Freund, F.; Bornschlegl, M.X.; Hemmje, M.L. A Service-based Information System for AI-supported Health Informatics. In Proceedings of the 2022 IEEE 5th International Conference on Big Data and Artificial Intelligence (BDAI), Fuzhou, China, 8–10 July 2022; pp. 99–104. [Google Scholar] [CrossRef]
- Sukamto, R.A.; Wibisono, Y.; Agitya, D.G. Enhancing The User Experience of Portal Website using User-Centered Design Method. In Proceedings of the 2020 6th International Conference on Science in Information Technology (ICSITech), Palu, Indonesia, 21–22 October 2020; pp. 171–175. [Google Scholar] [CrossRef]
- Hanafy, M.; Ming, R. Machine learning approaches for auto insurance big data. Risks 2021, 9, 42. [Google Scholar] [CrossRef]
- Grubbs, F.E. Procedures for detecting outlying observations in samples. Technometrics 1969, 11, 1–21. [Google Scholar] [CrossRef]
- Hawkins, D.M. Identification of Outliers; Springer: Berlin/Heidelberg, Germany, 1980; Volume 11. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41, 15. [Google Scholar] [CrossRef]
- Blázquez-García, A.; Conde, A.; Mori, U.; Lozano, J.A. A Review on Outlier/Anomaly Detection in Time Series Data. ACM Comput. Surv. 2021, 54, 56. [Google Scholar] [CrossRef]
- Marteau, P.F. Random partitioning forest for point-wise and collective anomaly detection—Application to network intrusion detection. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2157–2172. [Google Scholar] [CrossRef]
- Beggel, L.; Kausler, B.X.; Schiegg, M.; Pfeiffer, M.; Bischl, B. Time series anomaly detection based on shapelet learning. Comput. Stat. 2019, 34, 945–976. [Google Scholar] [CrossRef] [Green Version]
- Anand, G.; Nayak, R. Contextual Anomaly Detection in Spatio-Temporal Data Using Locally Dense Regions. In Proceedings of the 2018 IEEE 30th International Conference on Tools with Artificial Intelligence (ICTAI), Volos, Greece, 5–7 November 2018; pp. 963–967. [Google Scholar] [CrossRef]
- Reis, T.; Bornschlegl, M.X.; Hemmje, M.L. AI2VIS4BigData: A Reference Model for AI-based big data analysis and Visualization. In Advanced Visual Interfaces. Supporting Artificial Intelligence and Big Data Applications; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12585, pp. 1–18. [Google Scholar] [CrossRef]
- Reis, T.; Bornschlegl, M.X.; Hemmje, M.L. Towards a Reference Model for Artificial Intelligence Supporting Big Data Analysis. In Proceedings of the Advances in Data Science and Information Engineering; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Bornschlegl, M.X.; Berwind, K.; Kaufmann, M.; Engel, F.C.; Walsh, P.; Hemmje, M.L.; Riestra, R. IVIS4BigData: A reference model for advanced visual interfaces supporting big data analysis in virtual research environments. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2016, 10084 LNCS, 1–18. [Google Scholar] [CrossRef]
- Reis, T.; Bruchhaus, S.; Freund, F.; Bornschlegl, M.X.; Hemmje, M.L. AI-based User Empowering Use Cases for Visual big data analysis. In Proceedings of the Proceedings of the 7th Collaborative European Research Conference (CERC 2021), Cork, Ireland, 9–10 September 2021. [Google Scholar]
- Döringer, S. ‘The problem-centred expert interview’. Combining qualitative interviewing approaches for investigating implicit expert knowledge. Int. J. Soc. Res. Methodol. 2021, 24, 265–278. [Google Scholar] [CrossRef]
- Fowler, M. Patterns of Enterprise Application Architecture; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2002. [Google Scholar]
- Reis, T.; Bruchhaus, S.; Vu, B.; Bornschlegl, M.X.; Hemmje, M.L. Towards Modeling AI-based User Empowerment for Visual Big Data Analysis. In Proceedings of the Second Workshop on Bridging the Gap between Information Science, Information Retrieval and Data Science (BIRDS 2021), online, 19 March 2021; pp. 67–75. [Google Scholar]
- Van Rossum, G.; Drake, F.L. An Introduction to Python; Network Theory Ltd.: Bristol, UK, 2003. [Google Scholar]
- Wharton, C.; Rieman, J.; Lewis, C.; Polson, P. The cognitive walkthrough method: A practitioner’s guide. In Usability Inspection Methods; ACM: New York, NY, USA, 1994; pp. 105–140. [Google Scholar]
- Reis, T.; Funke, T.; Bruchhaus, S.; Freund, F.; Bornschlegl, M.X.; Hemmje, M.L. Supporting Meteorologists in Data Analysis through Knowledge-Based Recommendations. Big Data Cogn. Comput. 2022, 6, 103. [Google Scholar] [CrossRef]
- Ramaswamy, S.; Rastogi, R.; Shim, K. Efficient algorithms for mining outliers from large data sets. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 427–438. [Google Scholar]
- Lewis, C.; Polson, P.G.; Wharton, C.; Rieman, J. Testing a walkthrough methodology for theory-based design of walk-up-and-use interfaces. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Seattle, WA, USA, 1–5 April 1990; pp. 235–242. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Data | Average Processor Load [%] | |||
|---|---|---|---|---|
| Data Set | Data Points | Pre-Processing | KNN AD Service | KNN User Guidance |
| Test Data 1 | 681 | 41.51 | 45.82 | 37.73 |
| Test Data 2 | 699 | 38.77 | 45.68 | 37.73 |
| Test Data 3 | 697 | 38.52 | 42.97 | 38.53 |
| Task | Evaluation | |||
|---|---|---|---|---|
| Description | Required Actions | Identified Actions | Problems | Problem Rate |
| (1) Perform a complete AD for a certain data set | 4 | 4 | 0 | 0% |
| (2) Review a data instance with an exceptional anomaly score | 7 | 7 | 1 | 14% |
| (3) Reclassify a data instance from the data set with another AD service | 8 | 8 | 0 | 0% |
| (4) Pre-process data and label its data and anomaly type | 3 | 2 | 3 | 100% |
| (5) Identify and interpret the graphical anomaly content guidance | 3 | 3 | 1 | 33% |
| (6) Identify and interpret the textual anomaly interaction guidance | 3 | 3 | 0 | 0% |
| Total | 28 | 27 | 5 | 18% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reis, T.; Kreibich, A.; Bruchhaus, S.; Krause, T.; Freund, F.; Bornschlegl, M.X.; Hemmje, M.L. An Information System Supporting Insurance Use Cases by Automated Anomaly Detection. Big Data Cogn. Comput. 2023, 7, 4. https://doi.org/10.3390/bdcc7010004
Reis T, Kreibich A, Bruchhaus S, Krause T, Freund F, Bornschlegl MX, Hemmje ML. An Information System Supporting Insurance Use Cases by Automated Anomaly Detection. Big Data and Cognitive Computing. 2023; 7(1):4. https://doi.org/10.3390/bdcc7010004
Chicago/Turabian StyleReis, Thoralf, Alexander Kreibich, Sebastian Bruchhaus, Thomas Krause, Florian Freund, Marco X. Bornschlegl, and Matthias L. Hemmje. 2023. "An Information System Supporting Insurance Use Cases by Automated Anomaly Detection" Big Data and Cognitive Computing 7, no. 1: 4. https://doi.org/10.3390/bdcc7010004
APA StyleReis, T., Kreibich, A., Bruchhaus, S., Krause, T., Freund, F., Bornschlegl, M. X., & Hemmje, M. L. (2023). An Information System Supporting Insurance Use Cases by Automated Anomaly Detection. Big Data and Cognitive Computing, 7(1), 4. https://doi.org/10.3390/bdcc7010004