4.1. Determining the Support Theoretical Tools
Our approach to evaluate the eWoM Power of Reddit posts takes into account the information about the posts, authors, and subreddits provided by Reddit through
pushshift.io (accessed on 21 November 2022) and described in detail in
Section 3. Clearly, not all the fields of our dataset contribute directly to the estimation of the eWoM Power of a post. Therefore, we first had to analyze the semantics of these fields to determine which of them can contribute to this estimation. At the end of this analysis, we identified the following candidate fields: (i) for posts:
num_comments,
num_crossposts,
score,
total_award, and
title (evaluated through its sentiment polarity); (ii) for authors:
karma and
created_utc; (iii) for subreddits:
subscribers and
description (evaluated through its sentiment polarity). In order to decide whether these candidate fields can contribute to the eWoM Power of a post and, in the affirmative case, to identify how they contribute, we studied the distribution of the posts, authors, and subreddits of our dataset against all these fields. This study is essential to define a function that models this contribution. In fact, suppose that, for a candidate field, say the
score of posts, the distribution follows a power law. This distribution describes the relationship between two variables, where one variable is proportional to a power of the other one. It can be expressed as
. In this formula, the exponent
is a measure of the steepness of the power law, and so, the higher
is, the higher the steepness of the curve. Instead,
is an offset parameter that shifts the distribution along the x-axis. When
is positive, the distribution is shifted to the right; when
is negative, the distribution is shifted to the left. Power law distributions are characterized by a long tail of rare events, meaning that the distribution has a high frequency of small values and a low frequency of large values. In our scenario, taking the
score parameter into consideration, this means that many posts have a low score, while a few posts have a high score. Therefore, with this type of distribution, having a high score is extremely difficult for a post. On the other side, a post that achieves this goal acquires a “competitive advantage” over other posts. This advantage ultimately results in an increase of its eWoM Power.
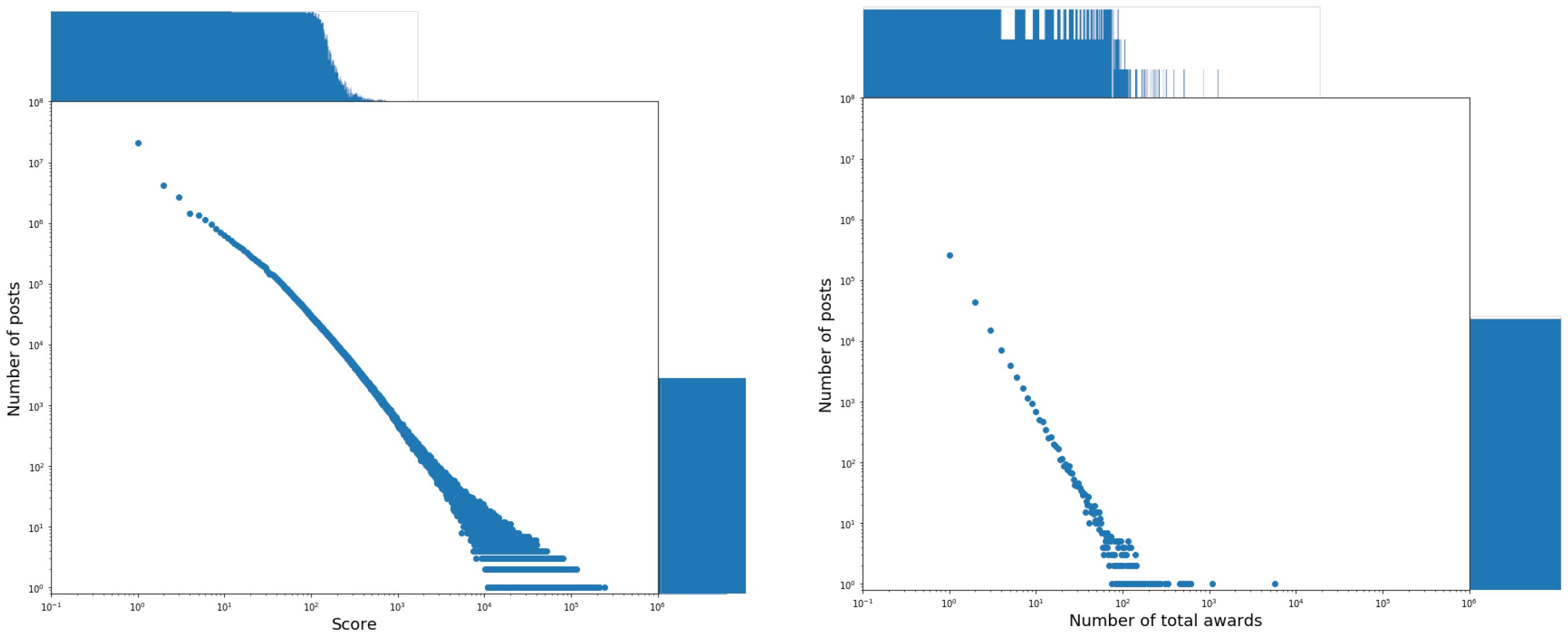
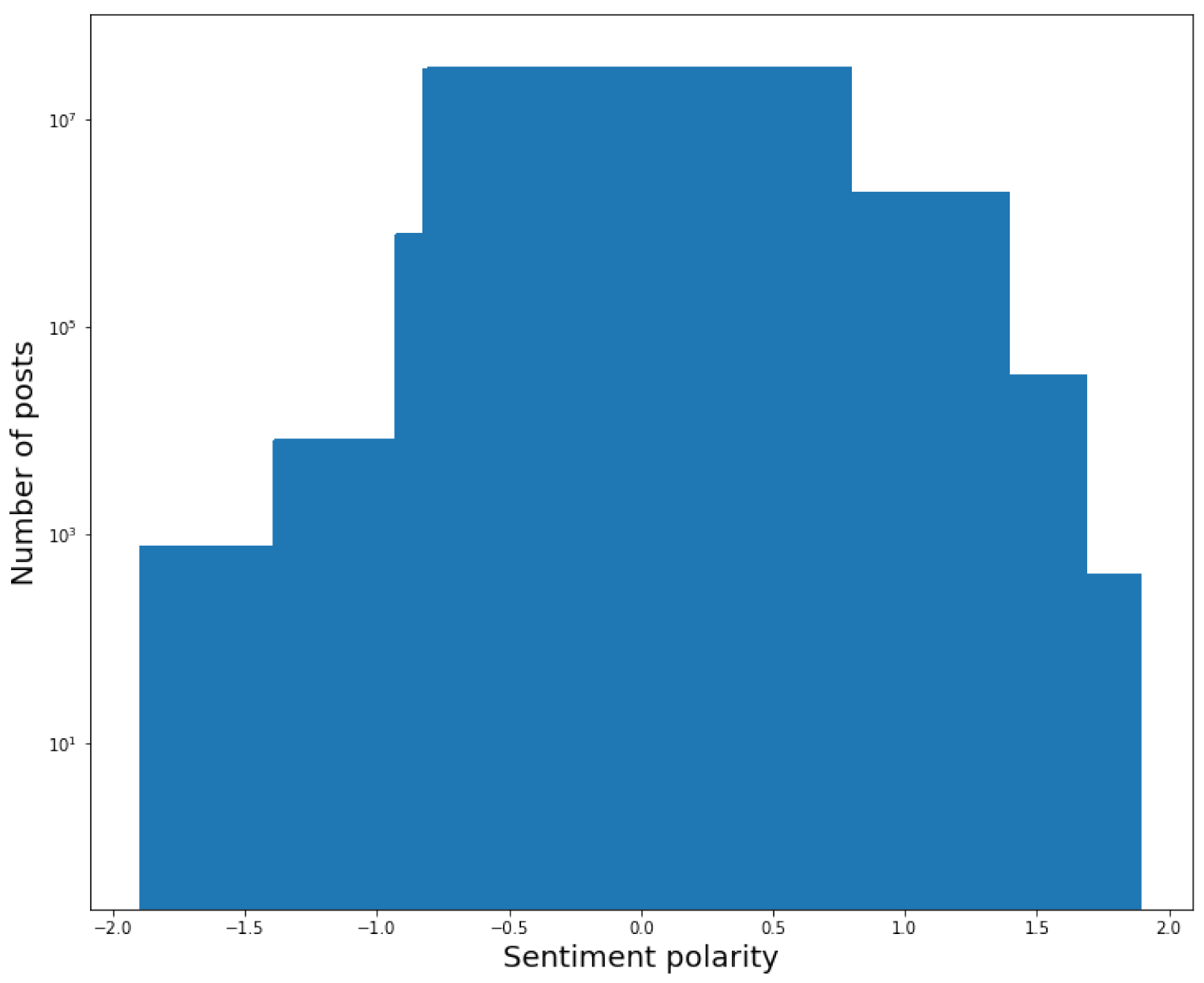
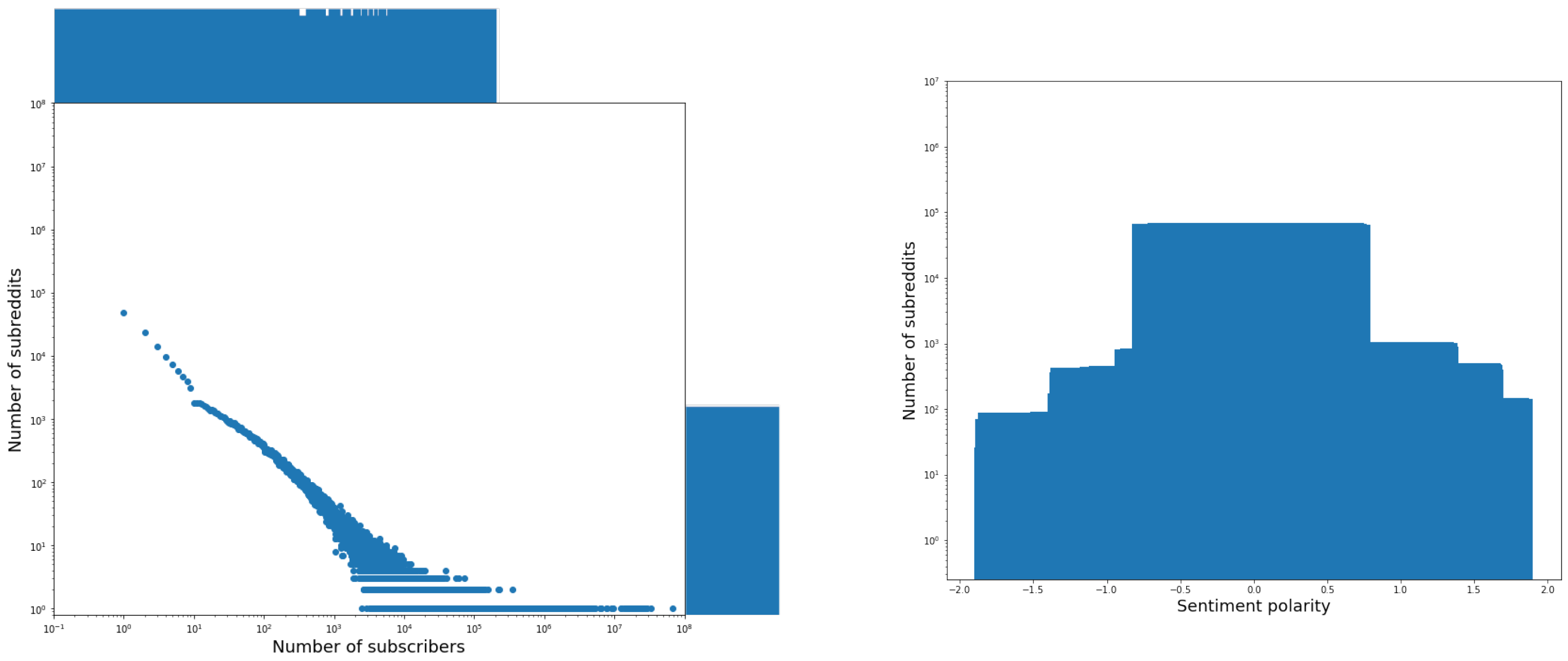
The distributions of the posts, the authors, or the subreddits against the candidate fields are shown in
Figure 1,
Figure 2,
Figure 3,
Figure 4 and
Figure 5. From the analysis of these figures, we can observe the following:
The distributions of posts against the fields
num_comments,
num_crossposts,
total_ awards, and
score follow a power law. The values of the parameters
and
of these distributions, together with the maximum values of the corresponding fields in our dataset, are shown in
Table 4.
The distribution of posts against the sentiment polarity of the field title is centered on the value of 0. It highlights that almost all the titles of the posts (in particular, 91% of them) have a null sentiment polarity. Furthermore, the very few posts having a different behavior are distributed quite uniformly on the right and left of 0, and in any case, most of the corresponding sentiment polarity values are very close to 0. This allowed us to conclude that the sentiment polarity of the titles does not contribute significantly to characterizing the posts and, ultimately, that the field title does not provide a significant contribution to the eWoM Power of a post.
The distribution of authors against the fields
karma and
created_utc follows a power law (see
Table 4 for the values of
and
). The distribution of authors against
created_utc should be interpreted as follows. On the abscissae axis, we put the registration seniority of the authors to Reddit, grouped by bimesters. As for author seniority, we point out that, in our dataset, the youngest author registered on 8 March 2020 (and, therefore, has a seniority of 0 bimesters), whereas the oldest one registered on Reddit on 19 January 2006 (and, therefore, has a seniority of 84 bimesters).
The distribution of subreddits against the field
subscribers follows a power law (see
Table 4 for the values of
and
).
The distribution of subreddits against the field description is centered on the value of 0 of its sentiment polarity; its overall trend is analogous to the one of the distribution of posts against the field title. Therefore, also in this case, we can conclude that this field does not contribute to eWoM Power.
In accordance with the above reasoning, we can conclude that two of the field candidates for the contribution to to eWoM Power should be discarded. All the others, instead, should be selected. Interestingly, each selected field shows a power law distribution. We conclude this parameter selection activity with the consideration that we believe important because it highlights the strengths and limitations of our way of proceeding in this paper. In the Introduction, we mentioned that posts and comments on Reddit are generally made with a cool head and not impulsively. Therefore, already, the parameters (which, ultimately, reflect the frequency of posts, the seniority of their publishers on Reddit, and their polarity) are very good indicators for eWoM Power evaluation on Reddit. Actually, we are aware that a very in-depth semantic analysis of post contents could provide additional insights for an even more accurate evaluation of the eWoM Power of Reddit posts. However, as we said, this paper wants to be just a first step in this direction. We hope that it can serve as encouragement to other authors to deepen this study.
Finally, we point out that some of the parameters identified are specific to Reddit, while others are more generic and can be found to be almost identical on other social networks. Some of the specific parameters may have corresponding ones, with a similar or close semantic, on social networks such as Facebook and Twitter. This makes our approach replicable on other social networks, after having modified it appropriately. However, we want to emphasize again that the real difference between the adoption of these parameters, or similar ones, on Facebook and Twitter, on the one hand, and on Reddit, on the other hand, lies in the different way users behave on this social medium, as we discussed in the Introduction. This gives these parameters much more weight and relevance on Reddit than on platforms that encourage users to submit many short posts and comments on the fly.
In order to model the contribution that each selected field can provide to the eWoM Power of a post, it is necessary to start from the main feature of the power law distribution, according to which most of the elements involved in it have a low value and only few of them have a high value. To model the contribution to the eWoM Power of a field, say
x, characterized by this type of distribution, we need a function that returns low values and has a slow growth against
x for low values of this parameter. On the contrary, when
x is higher than a certain threshold, this function must start to return higher values, and its growth against
x must be faster. A function with these characteristics, well known in the literature, especially in the context of deep learning, is the Rectified Linear Unit (ReLU) function. A very general formulation of it is the following:
The functions
f,
g, and
h are used to decide the two growth rates of
R and the point at which this growth increases.
z and
w are suitable parameters that can be related to the trend of
x; they could also coincide. For example, if
x has associated a power law distribution,
z and/or
w could coincide with the corresponding
parameter. The definition of the ReLU function introduced above is extremely general. A specific formulation of the ReLU function typically used in the deep learning context is Leaky ReLU [
52], which is defined as follows:
We chose to adopt Leaky ReLU in our approach because it is a function that has a small negative slope for negative inputs, while, in the classical definition of ReLU, all the input values below zero are set to zero. In this way, using Leaky ReLU, the signal of
x, when
, is mitigated through
and is not discarded. Starting from it, a specialization of
R, which takes all the previous observations and needs into account, and which, therefore, may be able to estimate the contribution of a parameter
x to the eWoM Power of a post, is the following:
In this formula,
is a normalization function for
x; it receives an actual value of this parameter and returns a normalized value of it, belonging to the real interval
. A possible formulation of
is the following:
where
is the maximum value of it in the dataset.
The proposed definition of R reaches the goals we were aiming for. In fact, in the power law distribution, the steeper the curve, the higher the value of is. On the other hand, as the curve steepness increases, the highest values of x should be increasingly “rewarded” with a higher eWoM Power. However, in order to counterbalance the tendency to excessively reward a very small number of elements, as grows, moves increasingly to the left of the point where passes from a low slope to a high one. In the definition of R, we also decided to use the normalized value of x, and not the actual one, because we will adopt R to model the contribution to the eWoM Power of many fields with very heterogeneous ranges of values. Normalization allowed us to homogenize the values returned by the Leaky ReLU functions associated with the various fields, so that they can be combined in appropriate expressions in the next steps of our approach.
4.2. A Naive Formulation of the eWoM Power of Reddit Posts
After choosing to use
R for evaluating the contribution that
x can give to the eWoM Power of a post, we can define a first “naive” version of the function
, which computes the eWoM Power of a post
p on Reddit. This function can be defined as:
Here: (i)
is the contribution provided by
num_comments; (ii)
is the contribution given by
num_crossposts; (iii)
is the contribution of the
score of
p; (iv)
is the contribution given by the parameter
total_awards; (v)
is the contribution provided by the
karma of the author of
p; (vi)
is the contribution given by the parameter
created_utc of the author of
p (we recall that this parameter denotes the seniority of the author of
p in Reddit); (viii)
is the contribution given by the parameter
subscribers.
If a post has just been created, the corresponding values of , , , and are set to 0. If an author has just registered to Reddit, the corresponding values of and are set to 0. If a subreddit has just been created, the corresponding value of is set to 0. Finally, if a post p is new, its author has just registered to Reddit, and the subreddit in which it is published has just been created, it is assumed that the eWoM Power of p is 0. These last observations highlight a very important property of eWoM Power that we mentioned in the Introduction. In fact, the eWoM Power of a post is not static and immutable over time. On the contrary, it is in continuous evolution. As the values of the parameters mentioned above increase, the eWoM Power grows because it receives positive contributions from them. However, there is a fundamental aspect that works in the opposite direction: it is the “time” factor. In fact, as time goes by, a post becomes obsolete, and this provides a continuous negative contribution to its eWoM Power. Therefore, the positive and negative contributions represent two contrasting and dynamic forces acting in the eWoM Power of a post. As a consequence, the naive version of must be refined, taking the contribution of time into account.
One might argue that this formula is simple. Regarding this potential objection, we would like to point out the following:
It represents only the starting point for the computation of the refined eWoM Power, which, instead, is characterized by a more sophisticated formulation.
The adoption of a weighted mean gives our definition of naive eWoM Power a great flexibility because changing the weights makes it possible to model very different situations, starting from the same simple common formulation.
The adoption of a weighted mean gives our definition of naive eWoM Power a great extensibility, making both the addition of new parameters that one wants to consider and the modeling of scenarios different from those initially envisaged easy (see
Section 5.1 for some of them). In this last case, as we will see below, it will be enough to define a new combination of weights that is well fit to the scenario that one wants to model.
4.3. A Refined Formulation of eWoM Power of Reddit Posts
To perform this task, it is first necessary to understand how the value of a post changes over time. To the best of our knowledge, in the past literature, no attempt to perform this analysis for Reddit posts has been made. However, some authors analyzed this problem with reference to content on Twitter and found that their value decays according to a power law function [
8]. They also measured the value of the coefficient
of this function and found that it is equal to 1. This result is totally in line with the data analytics theory, according to which the value of the data decreases exponentially over time [
19].
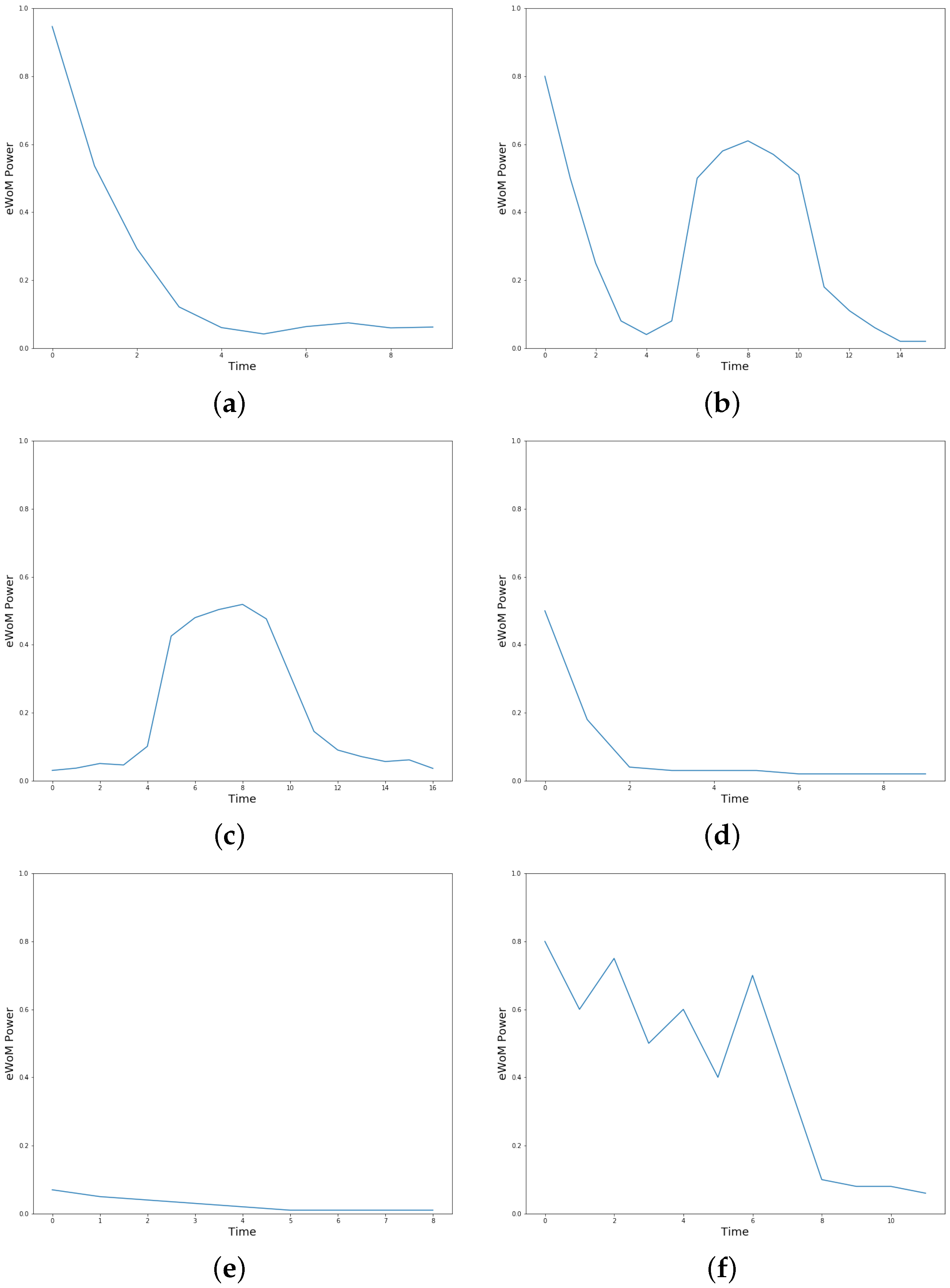
The results described in [
8] and especially the data analytics theory [
19] allow us to assume that, in the long run, the value of a post always decays exponentially. Actually, it could happen that, in some cases, this value stops decaying and even starts to increase again, for a certain period [
53,
54,
55]. This fact could also happen several times in the lifetime of a post. However, if we analyze the phenomenon in the long run, without considering this “noise” that could be present in some moments, we can certainly say that the value of a post decays over time [
8,
19]. This theoretical result was also confirmed experimentally on Reddit, as we will see later in this paper. Indeed, we will see that there are several templates modeling the possible trends of the value of a post on Reddit, but all of them, eventually, in the long run, lead to a decrease toward zero. In data analytics theory, the concept of the “value” of data is generic. However, it is clear that there is a relationship between eWoM Power and value, and it is exactly on this idea that we will rely following this discussion. Now, since:
The decay law of the value of a post over time is similar to all the distribution functions related to the other parameters of interest for eWoM Power;
We have seen that, in those cases, the Leaky ReLU function is well suited to express the contribution of each of those parameters to eWoM Power;
It seems reasonable to use the Leaky ReLU function also to model the role of the “time” factor in determining the eWoM Power of a post.
A final reasoning is necessary before defining a refined version of eWoM Power. In fact, the naive version , previously defined, assumes that all parameters cannot vary over time. Instead, a more refined modeling of eWoM Power must consider that these parameters can change over time. For this reason, the refined eWoM Power should be computed through a function , which returns the eWoM Power of a post p at the time instant t.
In order to formalize the function , it is necessary to introduce two support functions, which we call and . They play a key role in the definition of . Let t be a time instant:
The function returns the value of at t.
is the Leaky ReLU function at t. As for it, we note that:
- –
When is smaller than , the decrease caused by the “time” factor is low and grows slowly over time.
- –
When is higher than or equal to , the decrease becomes consistent and grows quickly over time.
- –
In the definition of the normalization function associated with , we assumed that the maximum value of t is equal to the number of seconds elapsed between t and the time instant in which p was published.
We now have all the necessary elements to formalize
. In particular:














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}