
On-Shore Plastic Waste Detection with YOLOv5 and RGB-Near-Infrared Fusion: A State-of-the-Art Solution for Accurate and Efficient Environmental Monitoring

 , , ,
, , ,  , and
, and
Abstract
:1. Introduction
- Two datasets of plastic waste were established, one comprising the RGB color space, and the other comprising their corresponding RGNIR color space. Additionally, a dataset of background images devoid of plastic waste in both the RGB and RGNIR color spaces was compiled.
- The present research provides a systematic comparison of the performance of two color spaces, RGB and RGNIR, when used in a YOLOv5-based system for detecting plastic waste. Our study offers a comprehensive evaluation of the effectiveness of these color spaces in this context. The analysis aims to provide insight into the effectiveness of these two approaches in detecting plastic waste and to identify any potential advantages or disadvantages of each method. Through this comparison, we hope to contribute to the understanding of the role of color space in the effectiveness of object detection systems.
2. Related Works
3. Proposed Method
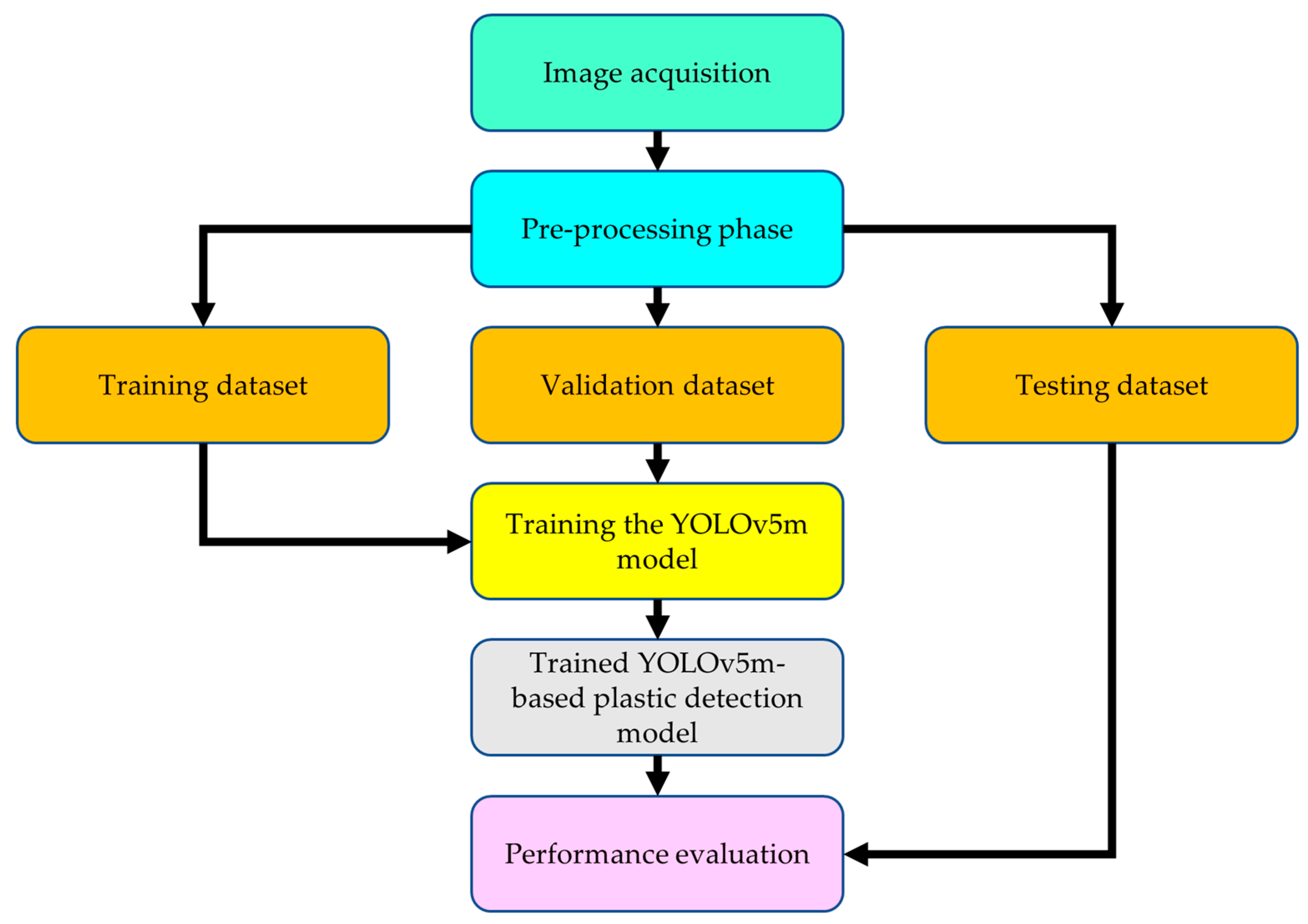
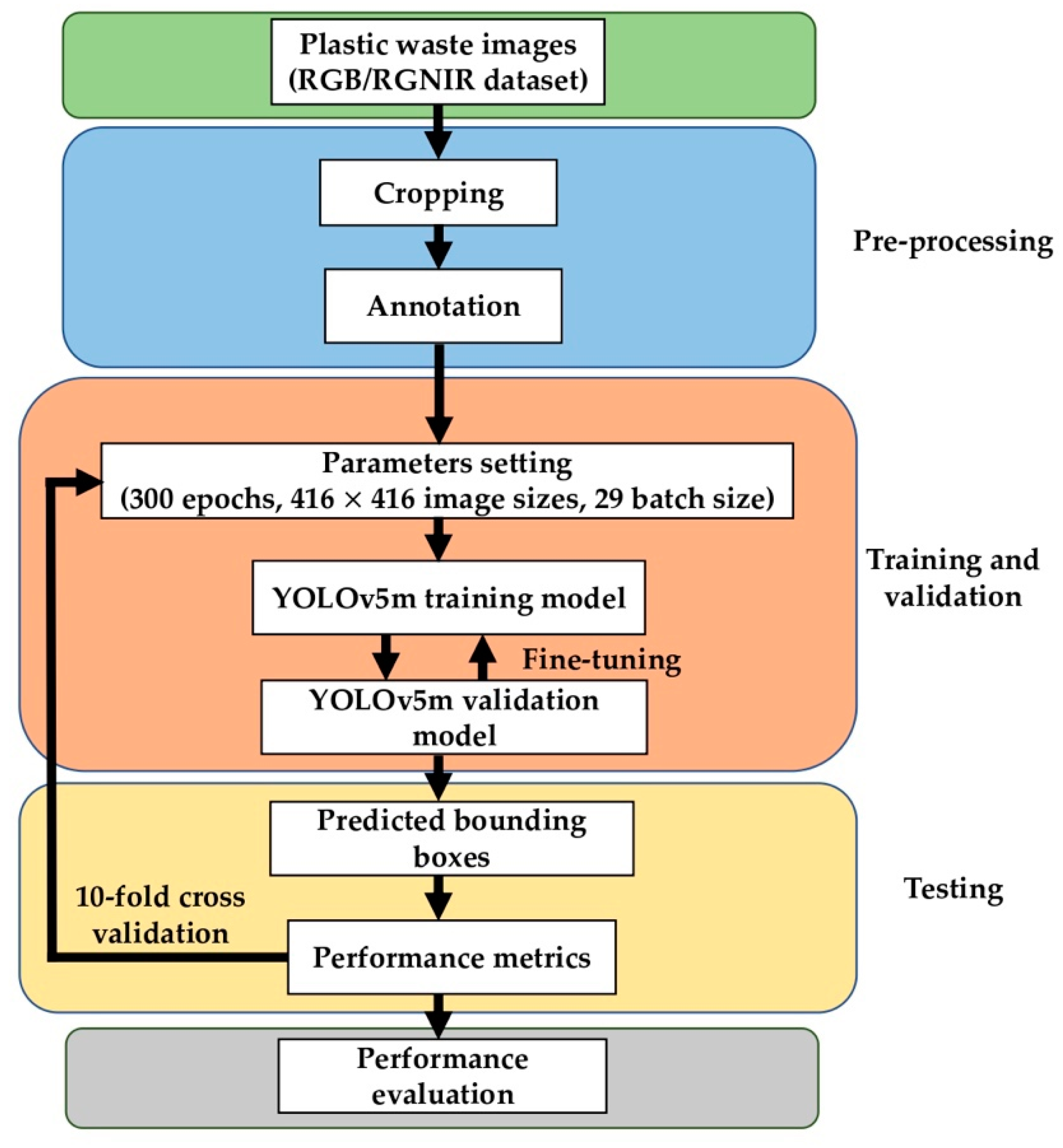
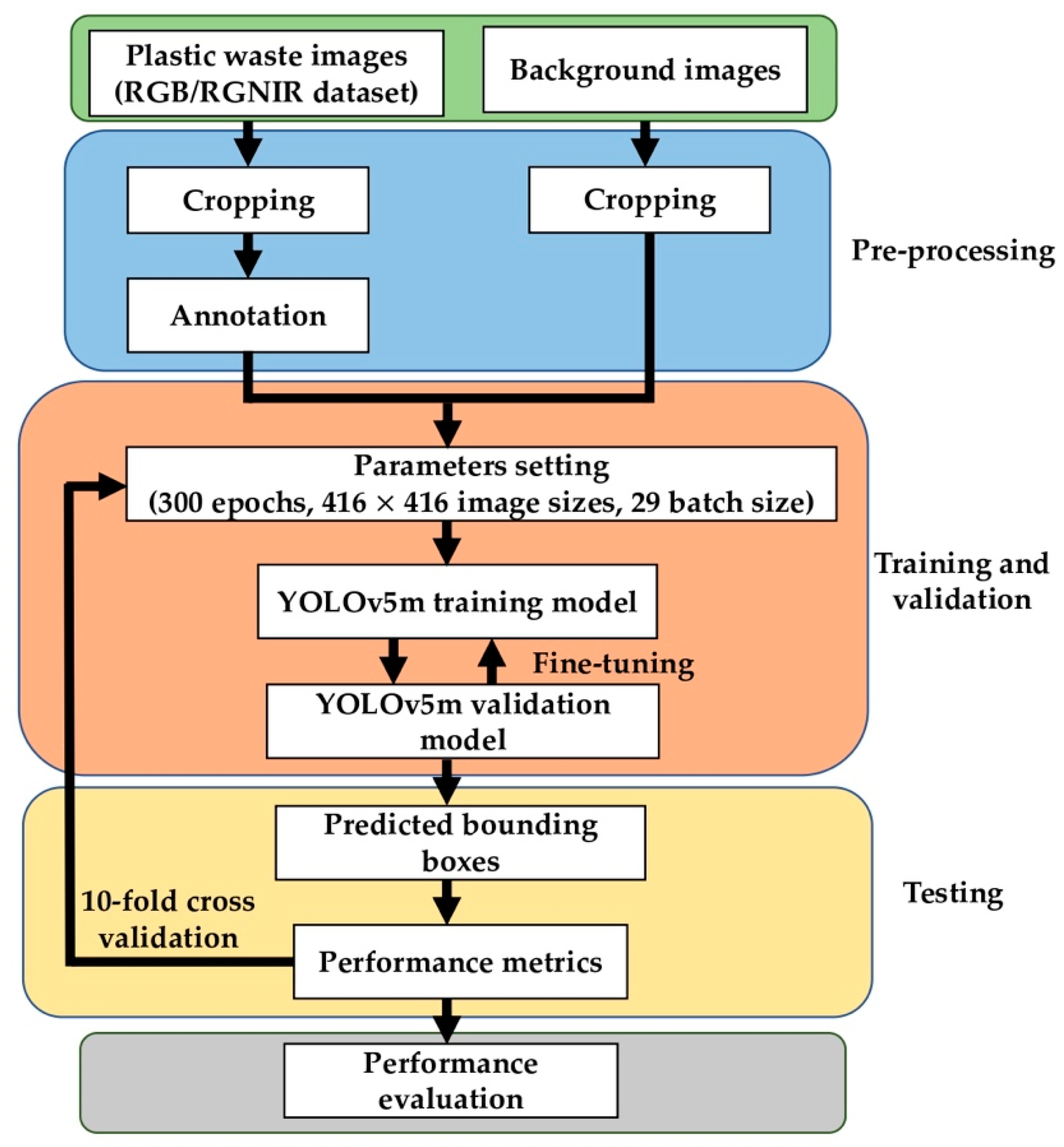
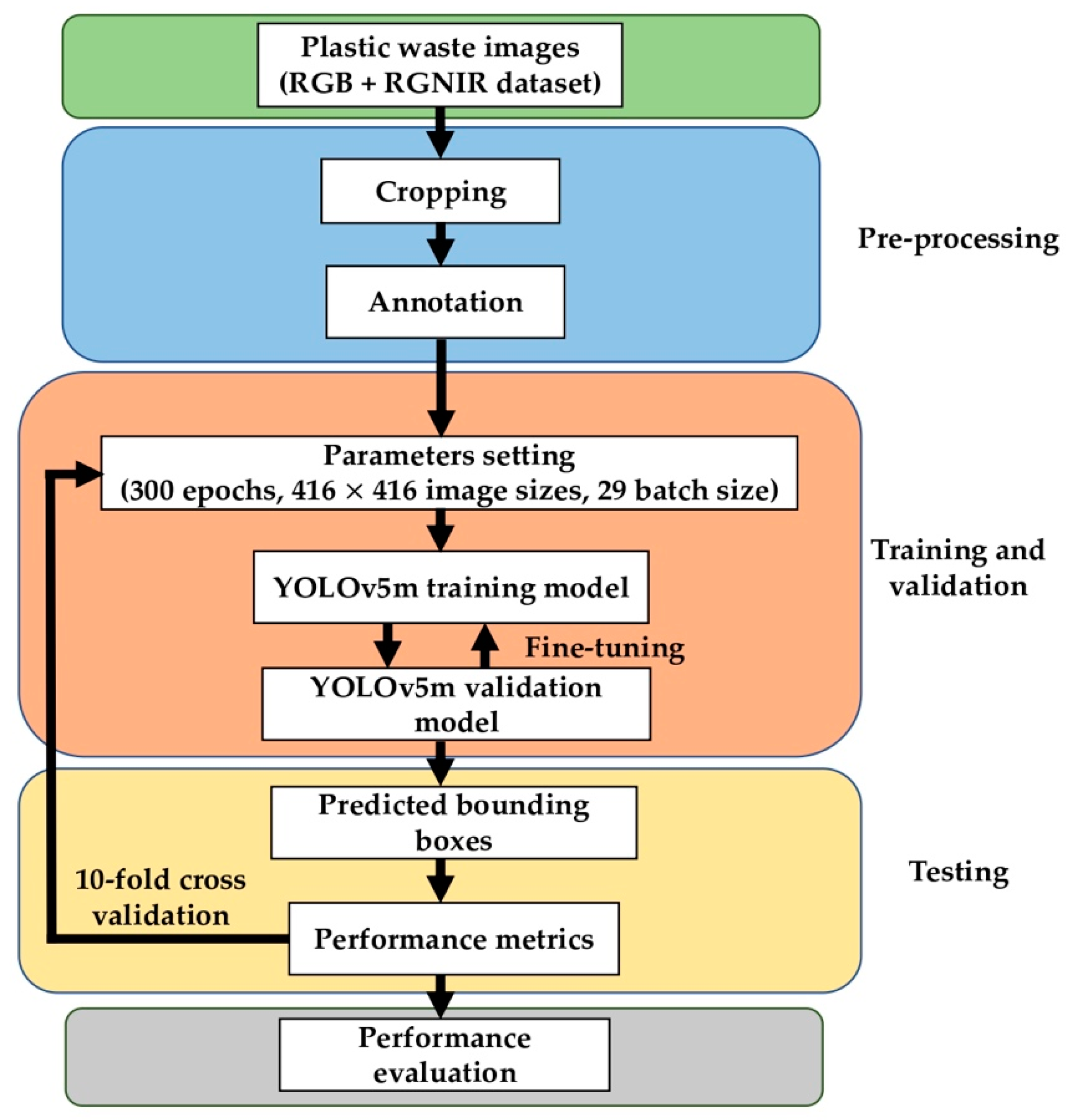
3.1. Research Overview
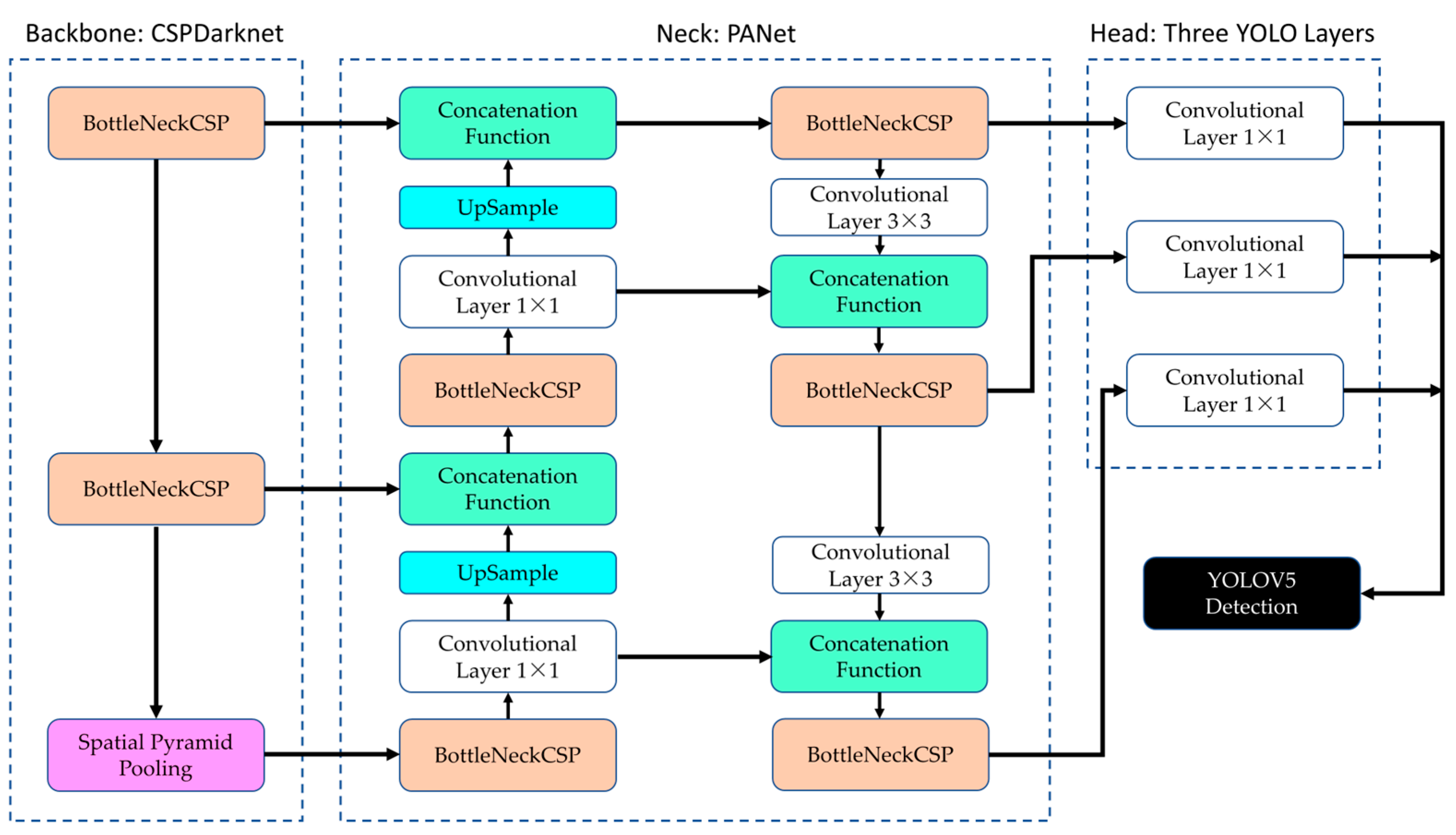
3.2. Object Detection Model
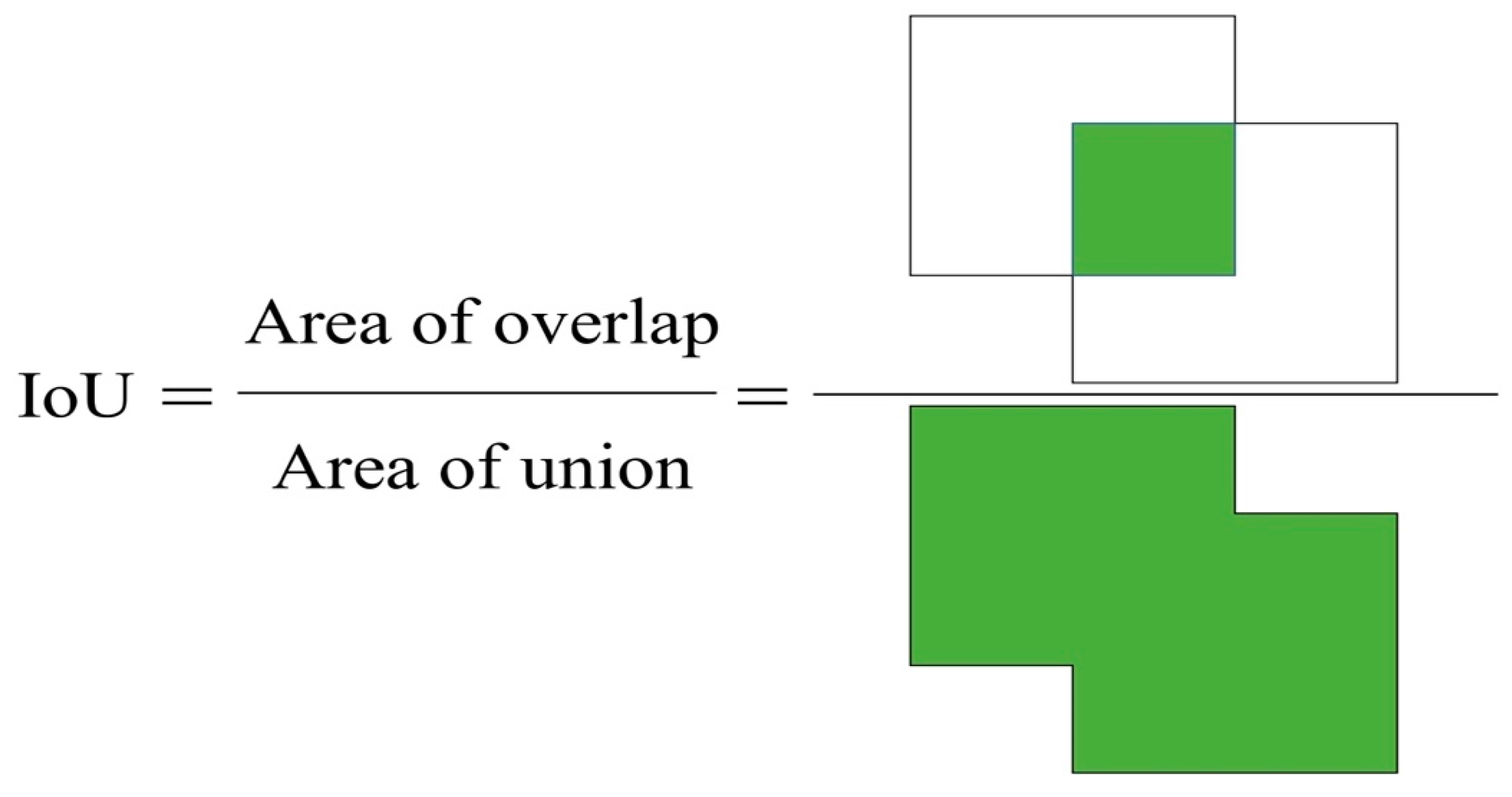
3.3. Performance Metrics
4. Dataset
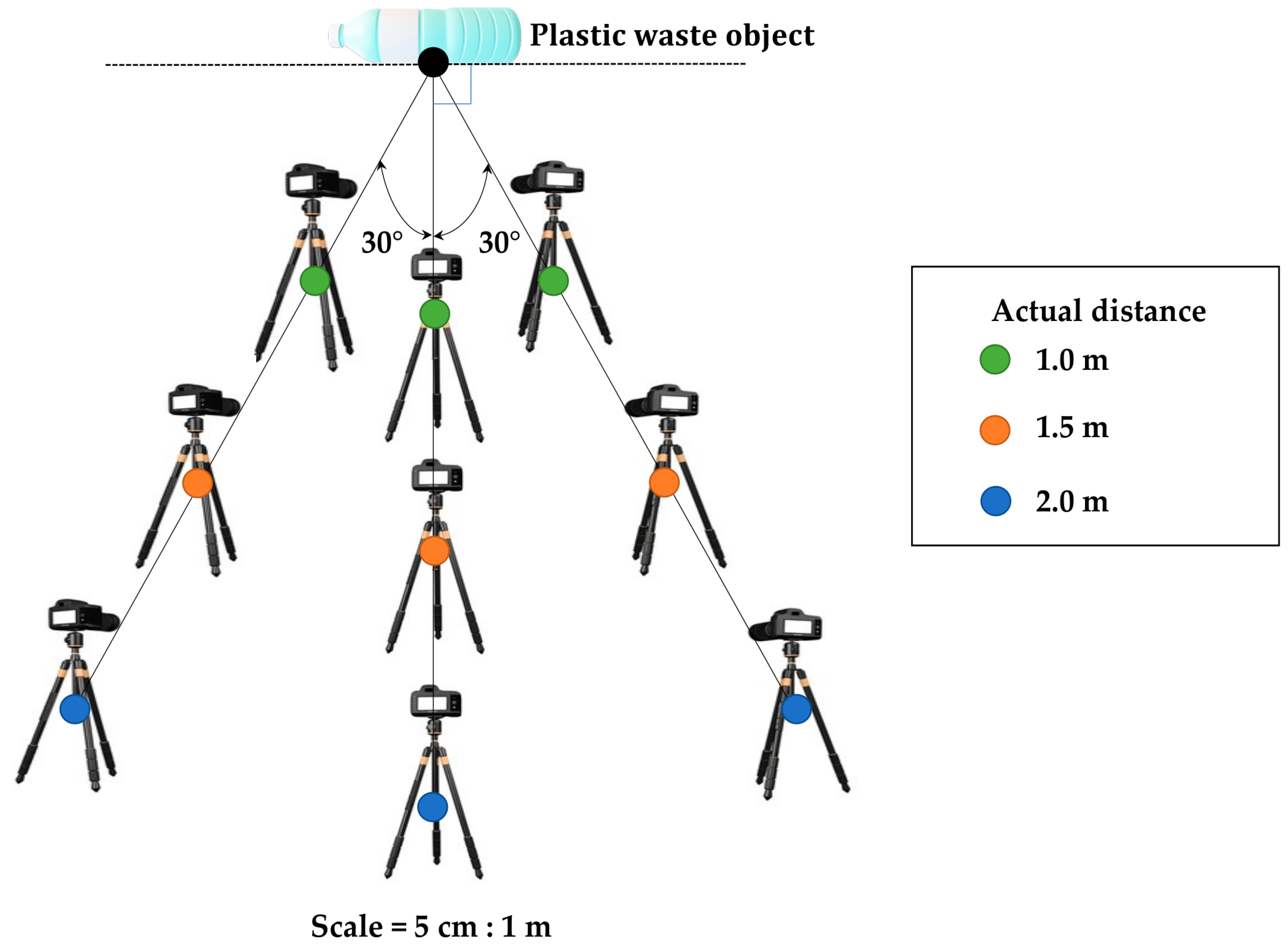
4.1. Data Acquisition
4.2. Background Images
4.3. Pre-Processing
4.4. Dataset Partition
5. Experiments
- i.
- The first set of experiments consists of only plastic waste images. This experiment aims to compare the performance of the RGB and RGNIR datasets without the background images.
- ii.
- The second set of experiments fuses the plastic waste images with the background images. This experiment aims to compare the performance of the RGB and RGNIR dataset with the background images. The background images are only added to the training dataset and are not used as part of the validation and testing dataset.
- iii.
- The third experiment fuses both the RGB and RGNIR datasets to create more training samples. This experiment aims to investigate whether the model performs better in plastic waste detection that learns the RGB and RGNIR datasets features at the same time.
6. Results and Discussion
6.1. First Experiment: Training Dataset without Background Images
6.1.1. Recall and Precision Results Using Training Dataset without Background Images
6.1.2. Model mAP Results without Background Images in the Training Dataset
6.2. Second Experiment: Training Dataset with Background Images
6.2.1. Recall and Precision Results Using Training Dataset with Background Images
6.2.2. Model mAP Results with Background Images in the Training Dataset
6.3. Third Experiment: Training Dataset That Consists of Images from a Fused RGB and RGNIR Datasets
6.3.1. Recall and Precision Results from Training on Fused RGB and RGNIR Image Datasets
6.3.2. Model mAP Results from Training on Fused RGB and RGNIR Image Datasets
6.4. Fourth Experiment: A Comparison of Faster R-CNN and YOLOv5m with Fused RGB and RGNIR Image Dataset
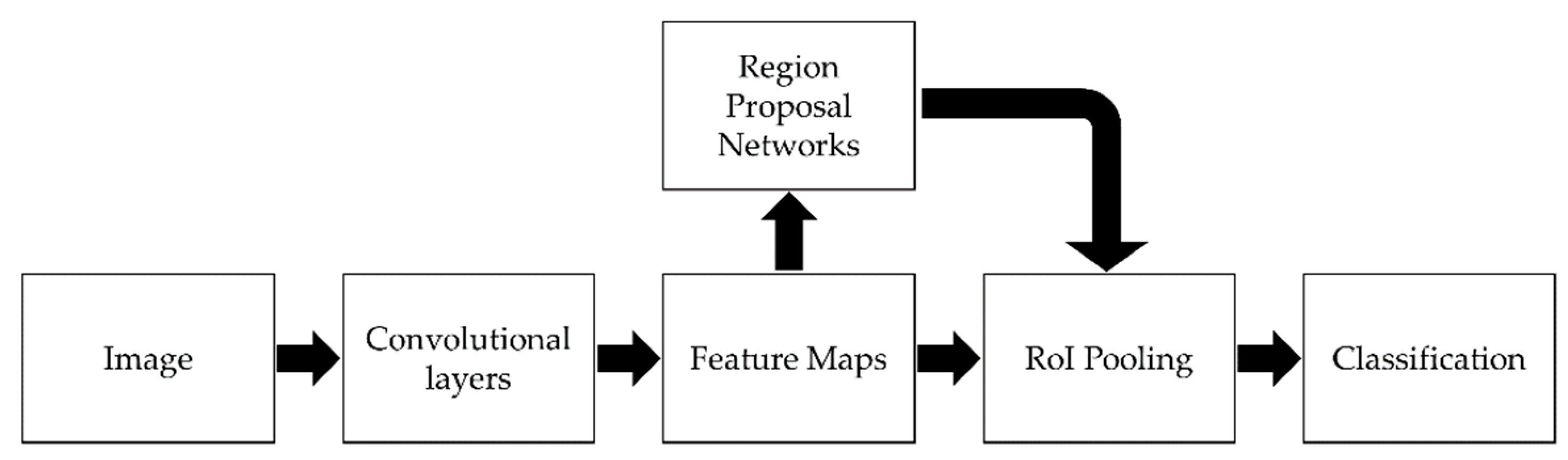
6.4.1. Faster R-CNN as Object Detection Model
6.4.2. Faster R-CNN and YOLOv5m mAP Results from Training on Fused RGB and RGNIR Image Datasets
6.5. Comparison with State-of-the-Art Approaches
7. Conclusions
8. Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Borrelle, S.B.; Ringma, J.; Law, K.L.; Monnahan, C.C.; Lebreton, L.; McGivern, A.; Murphy, E.; Jambeck, J.; Leonard, G.H.; Hilleary, M.A.; et al. Predicted growth in plastic waste exceeds efforts to mitigate plastic pollution. Science 2020, 369, 1515–1518. [Google Scholar] [CrossRef] [PubMed]
- Geyer, R.; Jambeck, J.R.; Law, K.L. Production, use, and fate of all plastics ever made. Sci. Adv. 2017, 3, e1700782. [Google Scholar] [CrossRef] [PubMed]
- Cesetti, M.; Nicolosi, P. Waste processing: New near infrared technologies for material identification and selection. J. Instrum. 2016, 11, C09002. [Google Scholar] [CrossRef]
- Wu, X.; Li, J.; Yao, L.; Xu, Z. Auto-sorting commonly recovered plastics from waste household appliances and electronics using near-infrared spectroscopy. J. Clean. Prod. 2020, 246, 118732. [Google Scholar] [CrossRef]
- Rani, M.; Marchesi, C.; Federici, S.; Rovelli, G.; Alessandri, I.; Vassalini, I.; Ducoli, S.; Borgese, L.; Zacco, A.; Bilo, F.; et al. Miniaturized near-infrared (MicroNIR) spectrometer in plastic waste sorting. Materials 2019, 12, 2740. [Google Scholar] [CrossRef]
- Moshtaghi, M.; Knaeps, E.; Sterckx, S.; Garaba, S.; Meire, D. Spectral reflectance of marine macroplastics in the VNIR and SWIR measured in a controlled environment. Sci. Rep. 2021, 11, 5436. [Google Scholar] [CrossRef]
- Becker, W.; Sachsenheimer, K.; Klemenz, M. Detection of black plastics in the middle infrared spectrum (MIR) using photon up-conversion technique for polymer recycling purposes. Polymers 2017, 9, 435. [Google Scholar] [CrossRef] [PubMed]
- Jacquin, L.; Imoussaten, A.; Trousset, F.; Perrin, D.; Montmain, J. Control of waste fragment sorting process based on MIR imaging coupled with cautious classification. Resour. Conserv. Recycl. 2021, 168, 105258. [Google Scholar] [CrossRef]
- Razali, M.N.; Moung, E.G.; Yahya, F.; Hou, C.J.; Hanapi, R.; Mohamed, R.; Hashem, I.A.T. Indigenous food recognition model based on various convolutional neural network architectures for gastronomic tourism business analytics. Information 2021, 12, 322. [Google Scholar] [CrossRef]
- Moung, E.G.; Wooi, C.C.; Sufian, M.M.; On, C.K.; Dargham, J.A. Ensemble-based face expression recognition approach for image sentiment analysis. Int. J. Electr. Comput. Eng. 2022, 12, 2588–2600. [Google Scholar]
- Dargham, J.A.; Chekima, A.; Moung, E.G.; Omatu, S. The effect of training data selection on face recognition in surveillance application. Adv. Intell. Syst. Comput. 2015, 373, 227–234. [Google Scholar] [CrossRef]
- Sufian, M.M.; Moung, E.G.; Hou, C.J.; Farzamnia, A. Deep learning feature extraction for COVID19 detection algorithm using computerized tomography scan. In Proceedings of the ICCKE 2021—11th International Conference on Computer Engineering and Knowledge, Mashhad, Iran, 28–29 October 2021; pp. 92–97. [Google Scholar] [CrossRef]
- Bobulski, J.; Kubanek, M. Deep learning for plastic waste classification system. Appl. Comput. Intell. Soft Comput. 2021, 2021, 6626948. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Thuan, D. Evolution of Yolo Algorithm and yolov5: The State-of-the-Art Object Detection Algorithm. Bachelor’s Thesis, Oulu University, Oulu, Finland, 2021. [Google Scholar]
- Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs. Sensors 2022, 22, 464. [Google Scholar] [CrossRef] [PubMed]
- Tamin, O.; Moung, E.G.; Dargham, J.A.; Yahya, F.; Omatu, S.; Angeline, L. A comparison of RGB and RGNIR color spaces for plastic waste detection using the YOLOv5 architecture. In Proceedings of the 4th IEEE International Conference on Artificial Intelligence in Engineering and Technology, IICAIET 2022, Kota Kinabalu, Malaysia, 13–15 September 2022. [Google Scholar] [CrossRef]
- Tamin, O.; Moung, E.G.; Dargham, J.A.; Yahya, F.; Omatu, S. A review of hyperspectral imaging-based plastic waste detection state-of-the-arts. Int. J. Electr. Comput. Eng. 2023, 13, 3407–3419. [Google Scholar] [CrossRef]
- Tamin, O.; Moung, E.G.; Ahmad Dargham, J.; Yahya, F.; Omatu, S.; Angeline, L. Machine learning for plastic waste detection: State-of-the-art, challenges, and solutions. In Proceedings of the 2022 International Conference on Communications, Information, Electronic and Energy Systems, CIEES 2022, Veliko Tarnovo, Bulgaria, 24–26 November 2022. [Google Scholar] [CrossRef]
- Córdova, M.; Pinto, A.; Hellevik, C.C.; Alaliyat, S.A.A.; Hameed, I.A.; Pedrini, H.; Torres, R.D.S. Litter Detection with Deep Learning: A Comparative Study. Sensors 2022, 22, 548. [Google Scholar] [CrossRef]
- Proença, P.F.; Simões, P. Taco: Trash annotations in context for litter detection. arXiv 2020, arXiv:2003.06975. [Google Scholar] [CrossRef]
- Lv, Z.; Li, H.; Liu, Y. Garbage detection and classification method based on YoloV5 algorithm. In Proceedings of the Fourteenth International Conference on Machine Vision (ICMV 2021), Rome, Italy, 8–12 November 2021; Volume 12084, pp. 11–18. [Google Scholar] [CrossRef]
- Wu, Z.; Zhang, D.; Shao, Y.; Zhang, X.; Zhang, X.; Feng, Y.; Cui, P. Using YOLOv5 for Garbage Classification. In Proceedings of the 2021 4th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Yibin, China, 20–22 August 2021; pp. 35–38. [Google Scholar]
- Jiang, X.; Hu, H.; Qin, Y.; Hu, Y.; Ma, S.; Ding, R. A real-time rural domestic garbage detection algorithm with an improved YOLOv5s network model. Sci. Rep. 2022, 12, 16802. [Google Scholar] [CrossRef]
- Lin, F.; Hou, T.; Jin, Q.; You, A. Improved YOLO Based Detection Algorithm for Floating Debris in Waterway. Entropy 2021, 23, 1111. [Google Scholar] [CrossRef]
- Zang, H.; Wang, Y.; Ru, L.; Zhou, M.; Chen, D.; Zhao, Q.; Zhang, J.; Li, G.; Zheng, G. Detection method of wheat spike improved YOLOv5s based on the attention mechanism. Front. Plant Sci. 2022, 13, 993244. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A forest fire detection system based on ensemble learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- PyTorch. Available online: https://pytorch.org/hub/ultralytics_yolov5 (accessed on 5 July 2022).
- Padilla, R.; Netto, S.L.; Da Silva, E.A. A survey on performance metrics for object-detection algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar] [CrossRef]
- Qin, G.; Vrusias, B.; Gillam, L. Background filtering for improving of object detection in images. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 922–925. [Google Scholar] [CrossRef]
- Liu, B.; Zhao, W.; Sun, Q. Study of object detection based on Faster R-CNN. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 6233–6236. [Google Scholar] [CrossRef]
- Wu, Y.; Shen, X.; Liu, Q.; Xiao, F.; Li, C. A Garbage Detection and Classification Method Based on Visual Scene Understanding in the Home Environment. Complexity 2021, 2021, 1055604. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Models Used | Dataset | Performance Metrics | Findings |
|---|---|---|---|---|
| Córdova et al., 2022 [22] | YOLOv5, RetinaNet, EfficientDet, Faster R-CNN, Mask R-CNN | TACO | Speed, Accuracy | YOLOv5 outperformed other CNN architectures in terms of speed and accuracy in detecting litter, suggesting it may be a valuable tool in litter detection applications. |
| Proença and Simões, 2020 [23] | Unspecified | TACO | Unspecified | The TACO dataset consisted of 1500 images with image sizes ranging from 842 × 474 to 6000 × 4000 pixels of 60 litter categories involving 4784 annotations. |
| Lv et al., 2022 [24] | YOLOv5 | TACO | Detection speed, mAP | YOLOv5 had superior performance compared to YOLOv3, with a detection speed of 5.52 frames per second and a mean average precision of 97.62%. |
| Wu et al., 2021 [25] | GC-YOLOv5 | Unspecified | Accuracy, Recall, [email protected] | GC-YOLOv5 demonstrated high accuracy and recall rates, and [email protected] values indicated accurate detection of a high percentage of objects with varying levels of overlap. |
| Jiang et al., [26] | YOLOv5s | Unspecified | Accuracy, Recall, [email protected] | YOLOv5s-based garbage classification and detection model in rural areas improved background network structure by adding an attention combination mechanism, leading to better feature representation and potentially enhancing accuracy and effectiveness of the model. The model achieved high accuracy, recall, and [email protected] rates. |
| Lin et al., 2021 [27] | YOLOv5s | Floating objects | [email protected] | The addition of feature map attention (FMA) at the end of the backbone layer improved feature extraction ability in detecting floating waste categories, and the model achieved an [email protected] of 79.41% on the testing dataset. |
| Zang et al., 2022 [28] | YOLOv5m | Images, Videos | [email protected] | YOLOv5m improved feature extraction ability by adding a supervised attention mechanism combined with a multimodal knowledge graph to improve garbage detection in real-scene images and videos, achieving an [email protected] of 72.8%. |
| Camera | Number of Images | Number of Annotations | |
|---|---|---|---|
| Without Background | With Background | ||
| iPhone 12 | 405 | 567 | 1344 |
| Mapir Survey 3W | 405 | 567 | 1344 |
| Dataset | Number of Images | |||
|---|---|---|---|---|
| Training | Validation | Testing | ||
| Without Background | With Background | |||
| RGB | 284 | 446 | 81 | 40 |
| RGNIR | 284 | 446 | 81 | 40 |
| Training Dataset | Recall | Precision |
|---|---|---|
| RGB without Background Images | 90.52% ± 3.26% | 91.40% ± 2.86% |
| RGNIR without Background Images | 87.98% ± 4.00% | 93.91% ± 3.50% |
| Fold No. | RGB without Background Images | RGNIR without Background Images | ||||
|---|---|---|---|---|---|---|
| [email protected] | [email protected]:0.95 | WMS | [email protected] | [email protected]:0.95 | WMS | |
| 1 | 90.32% | 63.59% | 66.27% | 90.08% | 68.65% | 70.79% |
| 2 | 95.22% | 71.23% | 73.63% | 94.33% | 70.49% | 72.87% |
| 3 | 93.58% | 67.94% | 70.50% | 90.94% | 65.99% | 68.48% |
| 4 | 97.61% | 70.51% | 73.22% | 98.80% | 77.62% | 79.74% |
| 5 | 92.88% | 68.19% | 70.66% | 90.65% | 64.65% | 67.25% |
| 6 | 94.59% | 72.65% | 74.84% | 93.31% | 72.48% | 74.57% |
| 7 | 90.83% | 62.78% | 65.59% | 86.94% | 63.31% | 65.67% |
| 8 | 95.47% | 68.42% | 71.12% | 93.08% | 69.67% | 72.01% |
| 9 | 91.36% | 68.33% | 70.63% | 92.09% | 68.88% | 71.20% |
| 10 | 91.24% | 66.28% | 68.77% | 92.16% | 70.60% | 72.75% |
| Mean | 93.31% | 67.99% | 70.52% | 92.24% | 69.23% | 71.53% |
| Training Dataset | [email protected] | [email protected]:0.95 | WMS |
|---|---|---|---|
| RGB without Background Images | 93.31% ± 2.28% | 67.99% ± 2.97% | 70.52% ± 2.86% |
| RGNIR without Background Images | 92.24% ± 2.94% | 69.23% ± 3.89% | 71.53% ± 3.78% |
| Training Dataset | Recall | Precision |
|---|---|---|
| RGB with Background Images | 89.17% ± 2.75% | 93.51% ± 2.42% |
| RGNIR with Background Images | 88.64% ± 2.95% | 93.05% ± 3.17% |
| Fold No. | RGB with Background Images | RGNIR with Background Images | ||||
|---|---|---|---|---|---|---|
| [email protected] | [email protected]:0.95 | WMS | [email protected] | [email protected]:0.95 | WMS | |
| 1 | 90.47% | 63.69% | 66.36% | 90.36% | 68.30% | 70.51% |
| 2 | 95.49% | 71.10% | 73.54% | 94.71% | 71.24% | 73.59% |
| 3 | 92.99% | 66.67% | 69.30% | 90.38% | 65.40% | 67.90% |
| 4 | 98.29% | 69.99% | 72.82% | 97.82% | 77.99% | 79.98% |
| 5 | 92.37% | 66.83% | 69.39% | 90.79% | 65.31% | 67.85% |
| 6 | 94.27% | 71.98% | 74.21% | 94.42% | 70.90% | 73.25% |
| 7 | 90.30% | 63.07% | 65.79% | 87.04% | 62.61% | 65.06% |
| 8 | 95.90% | 68.18% | 70.95% | 92.34% | 66.96% | 69.50% |
| 9 | 93.01% | 68.57% | 71.01% | 92.34% | 70.66% | 72.83% |
| 10 | 90.31% | 66.50% | 68.88% | 92.51% | 70.87% | 73.03% |
| Mean | 93.34% | 67.66% | 70.23% | 92.27% | 69.02% | 71.35% |
| Training Dataset | [email protected] | [email protected]:0.95 | WMS |
|---|---|---|---|
| RGB with Background Images | 93.34% ± 2.54% | 67.66% ± 2.77% | 70.23% ± 2.70% |
| RGNIR with Background Images | 92.27% ± 2.80% | 69.02% ± 4.10% | 71.35% ± 3.95% |
| Training Dataset | Recall | Precision |
|---|---|---|
| Fusion of RGB and RGNIR Dataset | 89.32% ± 3.79% | 93.06% ± 1.87% |
| Fold No. | Fusion of RGB and RGNIR Dataset | ||
|---|---|---|---|
| [email protected] | [email protected]:0.95 | WMS | |
| 1 | 90.84% | 65.87% | 68.37% |
| 2 | 95.52% | 72.41% | 74.72% |
| 3 | 92.68% | 68.49% | 70.91% |
| 4 | 98.07% | 74.40% | 76.77% |
| 5 | 91.53% | 67.24% | 69.67% |
| 6 | 94.68% | 73.97% | 76.04% |
| 7 | 88.55% | 64.50% | 66.91% |
| 8 | 94.32% | 69.32% | 71.82% |
| 9 | 92.89% | 69.17% | 71.54% |
| 10 | 90.54% | 69.34% | 71.46% |
| Mean | 92.96% | 69.47% | 71.82% |
| Training Dataset | [email protected] | [email protected]:0.95 | WMS |
|---|---|---|---|
| Fusion of RGB and RGNIR Dataset | 92.96% ± 2.63% | 69.47% ± 3.11% | 71.82% ± 3.04% |
| Experiment | Dataset | Recall | Precision | [email protected] | [email protected]:0.95 | WMS |
|---|---|---|---|---|---|---|
| First experiment | RGB without background images | 90.52% ± 3.26% | 91.40% ± 2.86% | 93.31% ± 2.28% | 67.99% ± 2.97% | 70.52% ± 2.86% |
| RGNIR without background images | 87.98% ± 4.00% | 93.91% ± 3.50% | 92.24% ± 2.94% | 69.23% ± 3.89% | 71.53% ± 3.78% | |
| Second experiment with background images | RGB with background images | 89.17% ± 2.75% | 93.51% ± 2.42% | 93.34% ± 2.54% | 67.66% ± 2.77% | 70.23% ± 2.70% |
| RGNIR with background images | 88.64% ± 2.95% | 93.05% ± 3.17% | 92.27% ± 2.80% | 69.02% ± 4.10% | 71.35% ± 3.95% | |
| Third experiment with a fusion of RGB and RGNIR datasets | Fusion of RGB and RGNIR dataset | 89.32% ± 3.79% | 93.06% ± 1.87% | 92.96% ± 2.63% | 69.47% ± 3.11% | 71.82% ± 3.04% |
| Experiment | [email protected] | [email protected]:0.95 | WMS |
|---|---|---|---|
| Faster R-CNN (ResNet50 as backbone) | 71.34% ± 3.93% | 44.05% ± 3.36% | 46.78% ± 3.39% |
| YOLOV5m | 92.96% ± 2.63% | 69.47% ± 3.11% | 71.82% ± 3.04% |
| Method | Color Space | [email protected] | [email protected]:0.95 | Waste Type |
|---|---|---|---|---|
| GC-YOLOv5 [25] | RGB | 99.59% | 64.70% | Electronics, fruits, papers, and plastics |
| YOLOv5-Attention-KG [34] | RGB | 73.20% | - | Recyclable, food, and hazardous |
| YOLOv5s-CSS [26] | RGB | 98.30% | - | Plastics |
| FMA-YOLOv5s [27] | RGB | 88.54% | - | Plastics |
| YOLOv5s [28] | RGB | 85.00% | - | Plastics |
| YOLOv5m (Proposed model) | RGB without background images | 93.31% ± 2.28% | 67.99% ± 2.97% | Plastics |
| YOLOv5m (Proposed model) | RGNIR without background images | 92.24% ± 2.94% | 69.23% ± 3.89% | Plastics |
| YOLOv5m (Proposed model) | RGB with background images | 93.34% ± 2.54% | 67.66% ± 2.77% | Plastics |
| YOLOv5m (Proposed model) | RGNIR with background images | 92.27% ± 2.80% | 69.02% ± 4.10% | Plastics |
| YOLOv5m (Proposed model) | Fusion of RGB and RGNIR dataset | 92.96% ± 2.63% | 69.47% ± 3.11% | Plastics |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tamin, O.; Moung, E.G.; Dargham, J.A.; Yahya, F.; Farzamnia, A.; Sia, F.; Naim, N.F.M.; Angeline, L. On-Shore Plastic Waste Detection with YOLOv5 and RGB-Near-Infrared Fusion: A State-of-the-Art Solution for Accurate and Efficient Environmental Monitoring. Big Data Cogn. Comput. 2023, 7, 103. https://doi.org/10.3390/bdcc7020103
Tamin O, Moung EG, Dargham JA, Yahya F, Farzamnia A, Sia F, Naim NFM, Angeline L. On-Shore Plastic Waste Detection with YOLOv5 and RGB-Near-Infrared Fusion: A State-of-the-Art Solution for Accurate and Efficient Environmental Monitoring. Big Data and Cognitive Computing. 2023; 7(2):103. https://doi.org/10.3390/bdcc7020103
Chicago/Turabian StyleTamin, Owen, Ervin Gubin Moung, Jamal Ahmad Dargham, Farashazillah Yahya, Ali Farzamnia, Florence Sia, Nur Faraha Mohd Naim, and Lorita Angeline. 2023. "On-Shore Plastic Waste Detection with YOLOv5 and RGB-Near-Infrared Fusion: A State-of-the-Art Solution for Accurate and Efficient Environmental Monitoring" Big Data and Cognitive Computing 7, no. 2: 103. https://doi.org/10.3390/bdcc7020103
APA StyleTamin, O., Moung, E. G., Dargham, J. A., Yahya, F., Farzamnia, A., Sia, F., Naim, N. F. M., & Angeline, L. (2023). On-Shore Plastic Waste Detection with YOLOv5 and RGB-Near-Infrared Fusion: A State-of-the-Art Solution for Accurate and Efficient Environmental Monitoring. Big Data and Cognitive Computing, 7(2), 103. https://doi.org/10.3390/bdcc7020103