

Recognizing Similar Musical Instruments with YOLO Models




Abstract
:1. Introduction
2. Related Works
2.1. Identifing Similar Musical Instruments with CNN
2.2. YOLOv5 and YOLOv7
3. Methodology
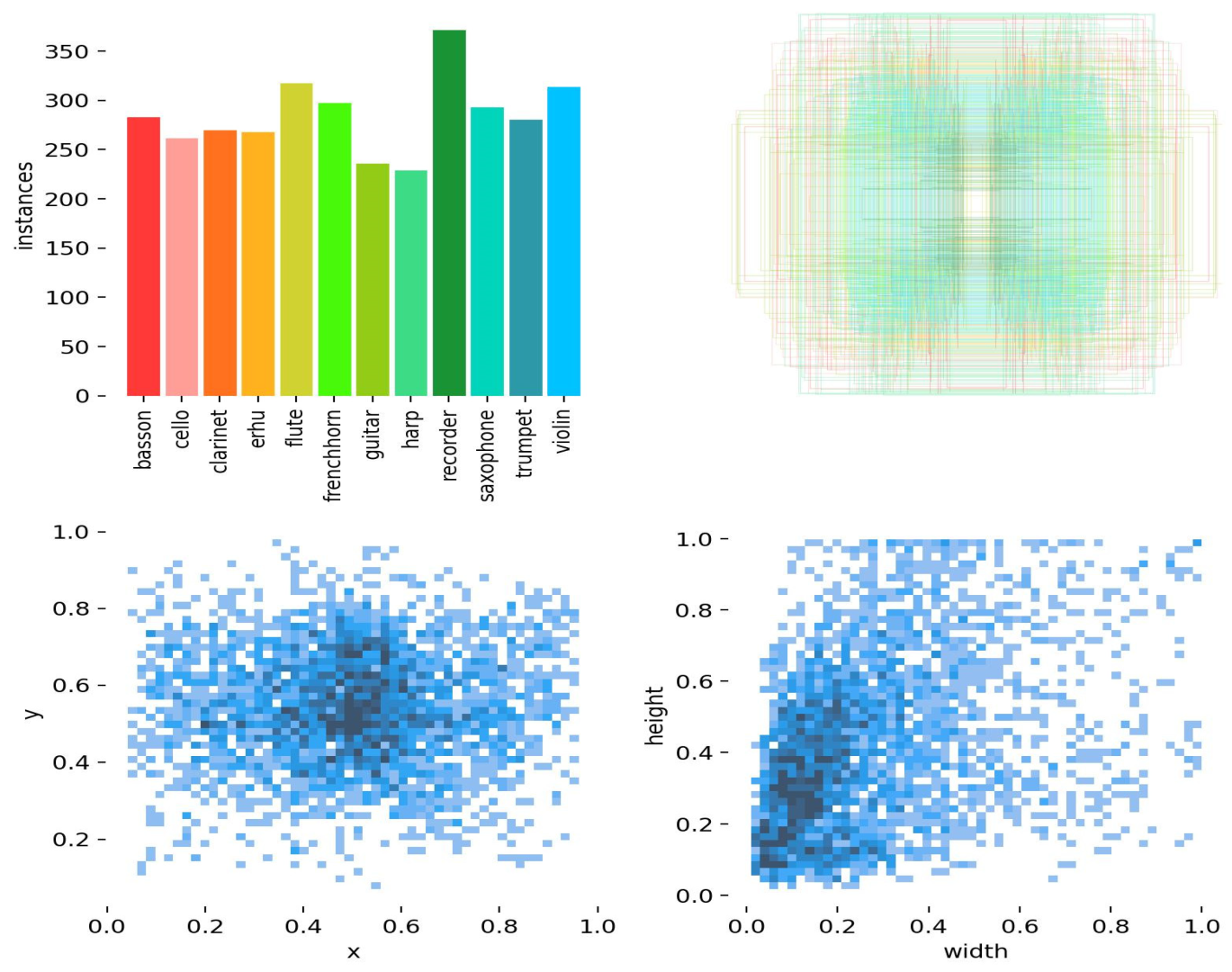
3.1. Dataset
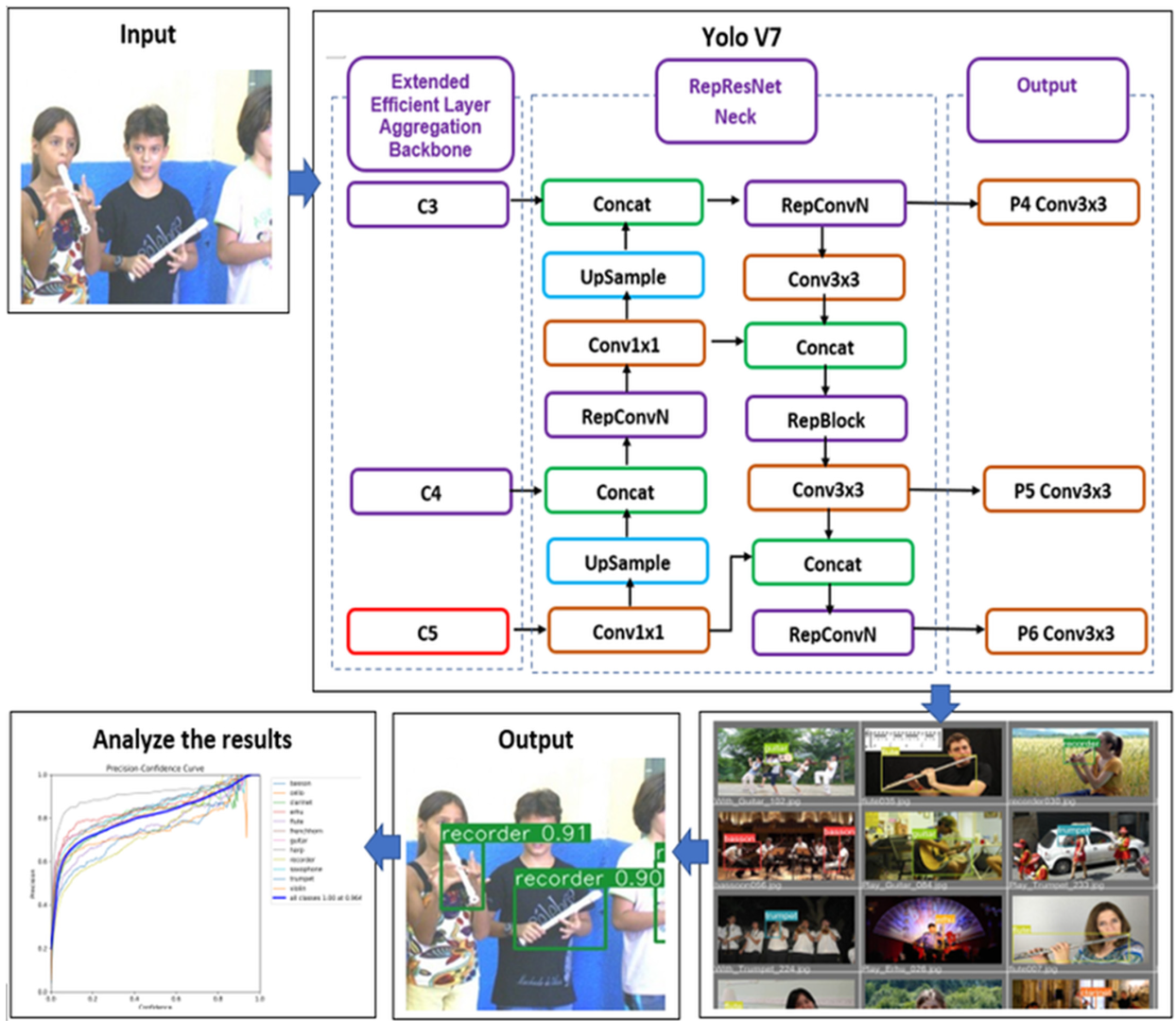
3.2. YOLOv7
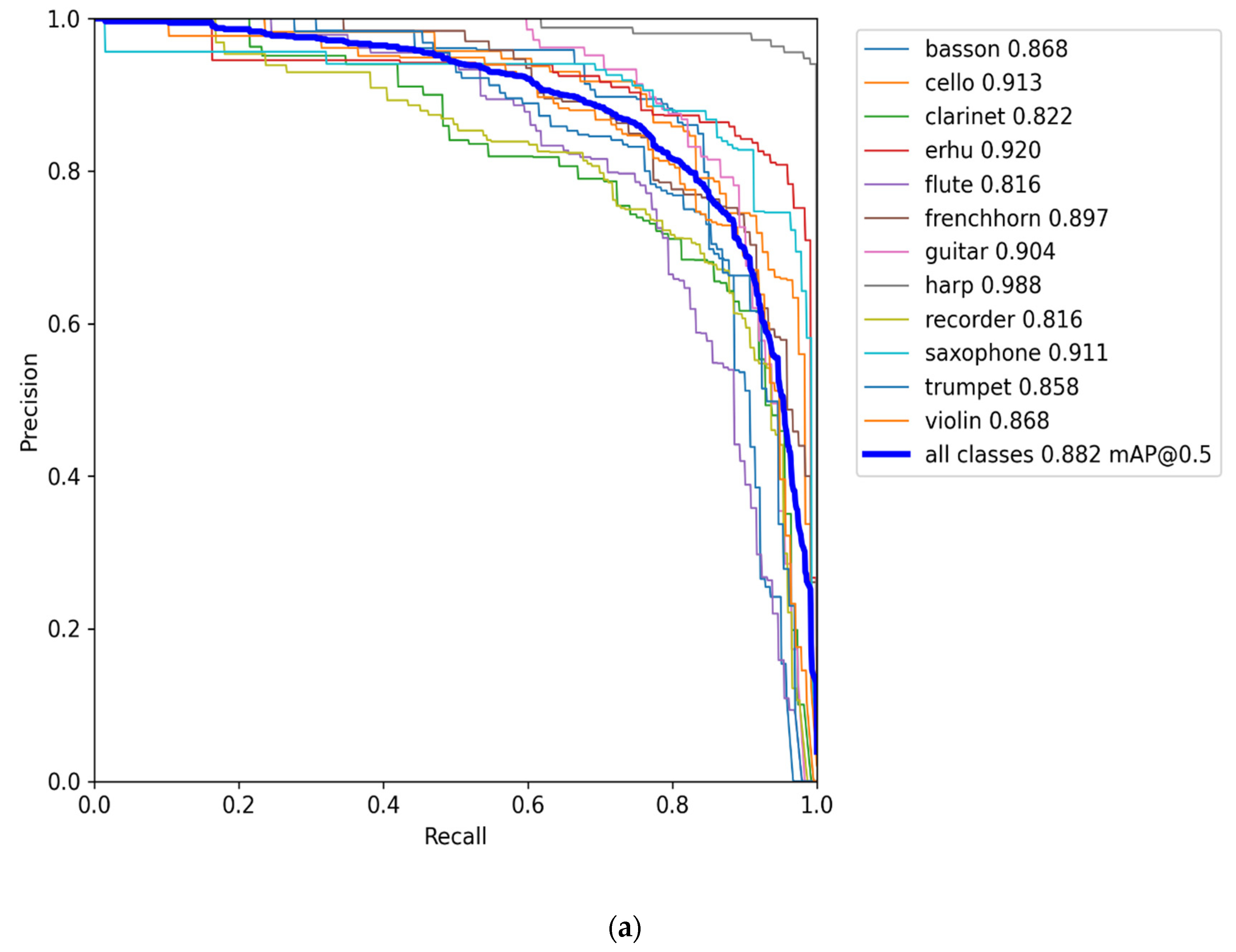
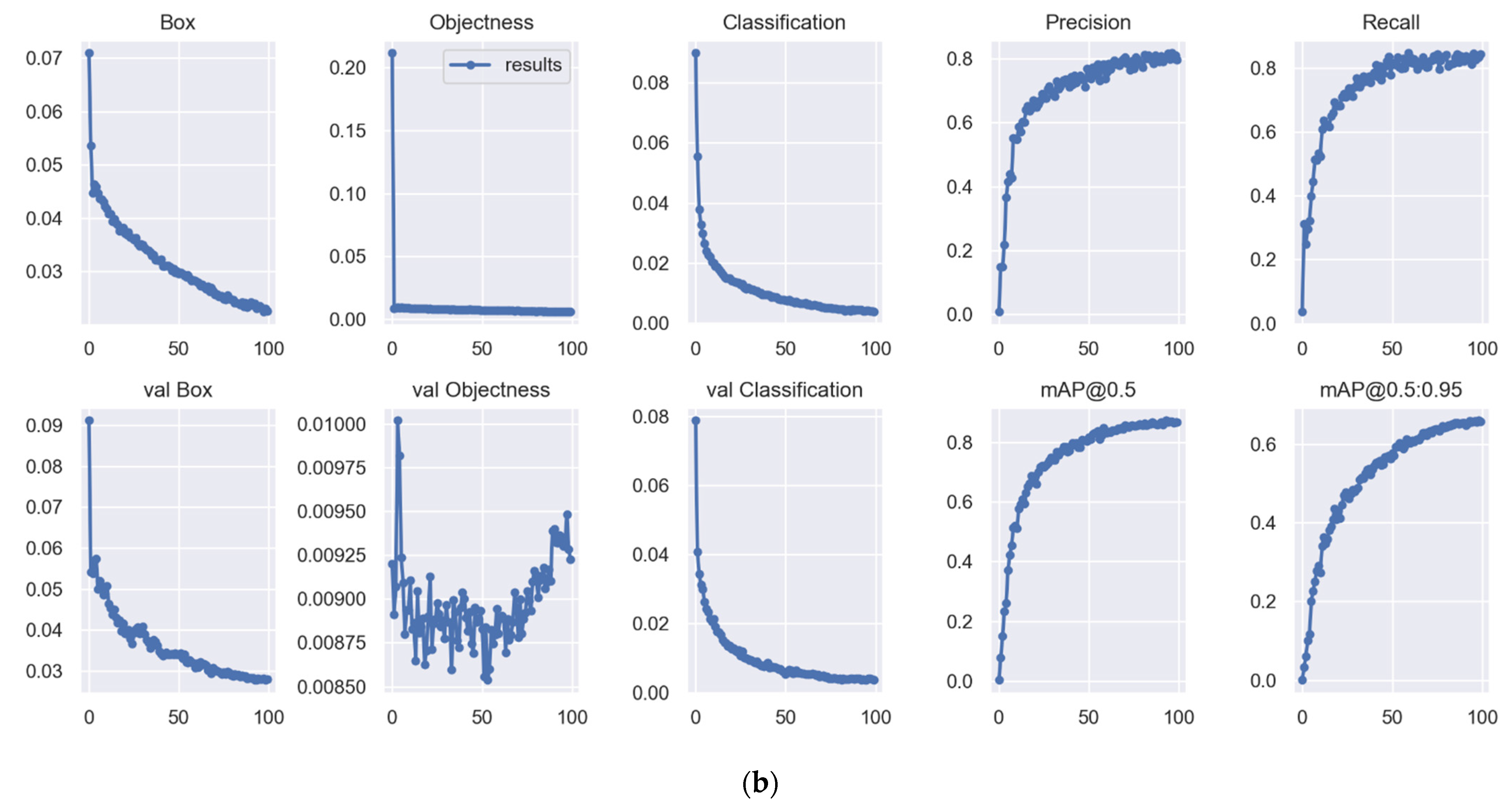
3.3. Training Results
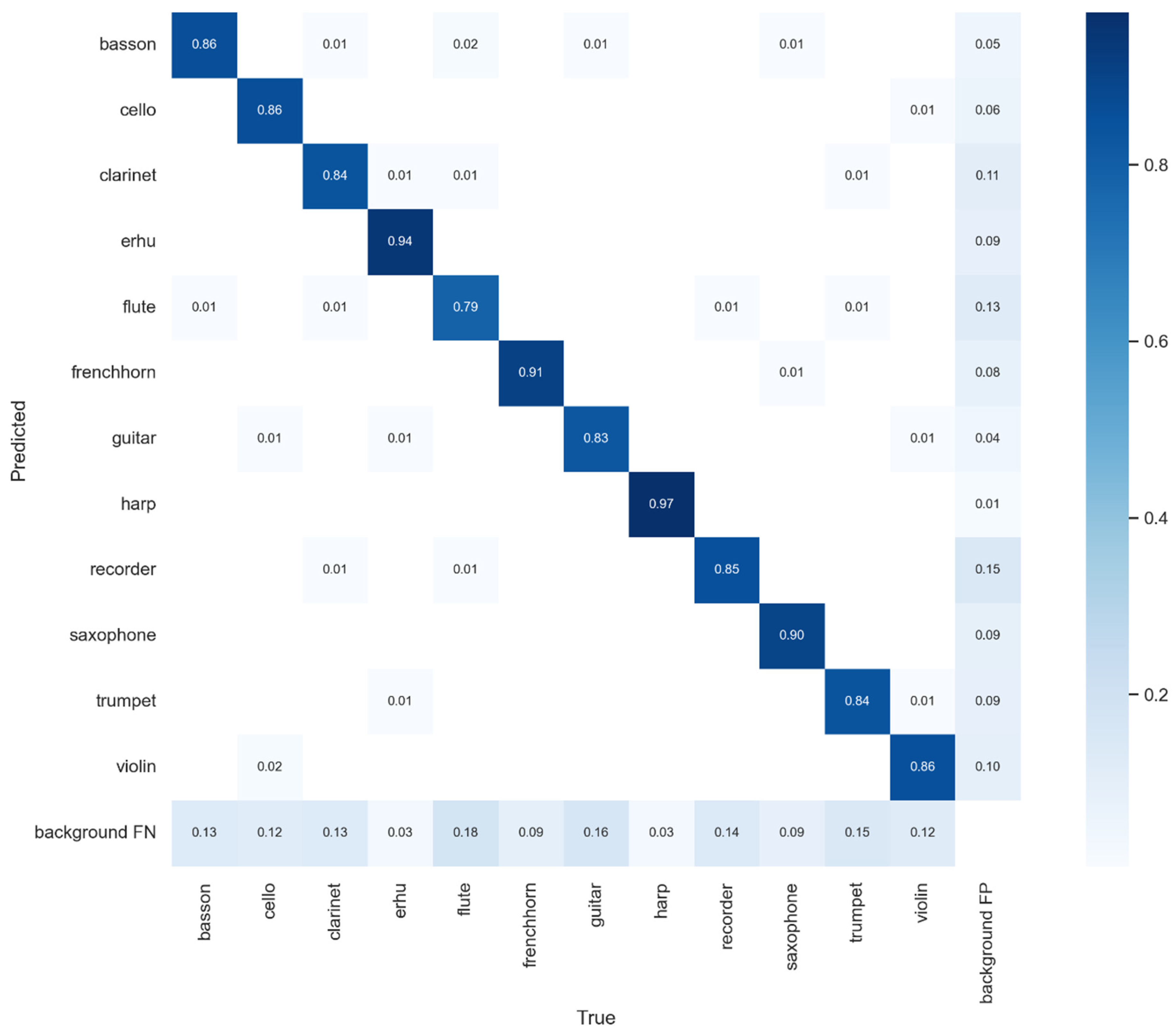
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wetzel, J.; Laubenheimer, A.; Heizmann, M. Joint Probabilistic People Detection in Overlapping Depth Images. IEEE Access 2020, 8, 28349–28359. [Google Scholar] [CrossRef]
- Saponara, S.; Elhanashi, A.; Gagliardi, A. Implementing a Real-Time, AI-Based, People Detection and Social Distancing Measuring System for COVID-19. J. Real Time Image Process. 2021, 18, 1937–1947. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, A.C.M.; Scharlach, R.C.; Pinheiro, M.M.C. Assessment of Temporal Aspects in Popular Singers. CODAS 2015, 27, 520–525. [Google Scholar] [CrossRef] [PubMed]
- Lavinia, Y.; Vo, H.; Verma, A. New Colour Fusion Deep Learning Model for Large-Scale Action Recognition. Int. J. Comput. Vis. Robot. 2020, 10, 41–60. [Google Scholar] [CrossRef]
- Bai, T.; Pang, Y.; Wang, J.; Han, K.; Luo, J.; Wang, H.; Lin, J.; Wu, J.; Zhang, H. An Optimized Faster R-CNN Method Based on DRNet and RoI Align for Building Detection in Remote Sensing Images. Remote Sens. 2020, 12, 762. [Google Scholar] [CrossRef] [Green Version]
- Dewi, C.; Chen, R.C.; Yu, H. Weight Analysis for Various Prohibitory Sign Detection and Recognition Using Deep Learning. Multimed. Tools Appl. 2020, 79, 32897–32915. [Google Scholar] [CrossRef]
- Xi, X.; Yu, Z.; Zhan, Z.; Yin, Y.; Tian, C. Multi-Task Cost-Sensitive-Convolutional Neural Network for Car Detection. IEEE Access 2019, 7, 98061–98068. [Google Scholar] [CrossRef]
- Qin, S.; Liu, S. Towards End-to-End Car License Plate Location and Recognition in Unconstrained Scenarios. Neural Comput. Appl. 2021, 34, 21551–21566. [Google Scholar] [CrossRef]
- Chien-Yao, W.; Bochkovskiy, A.; Hong-Yuan, L.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Yao, B.; Li, F. Grouplet: A Structured Image Representation for Recognizing Human and Object Interactions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Zhang, X.; Wan, F.; Liu, C.; Ji, X.; Ye, Q. Learning to Match Anchors for Visual Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3096–3109. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Kuala Lumpur, Malaysia, 10 June 2016; pp. 21–37. [Google Scholar]
- Ju, M.; Moon, S.; Yoo, C.D. Object Detection for Similar Appearance Objects Based on Entropy. In Proceedings of the 2019 7th International Conference on Robot Intelligence Technology and Applications, RiTA 2019, Daejeon, Republic of Korea, 1–3 November 2019. [Google Scholar]
- Song, S.; Que, Z.; Hou, J.; Du, S.; Song, Y. An Efficient Convolutional Neural Network for Small Traffic Sign Detection. J. Syst. Archit. 2019, 97, 269–277. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Hendry; Liu, Y.T. Similar Music Instrument Detection via Deep Convolution YOLO-Generative Adversarial Network. In Proceedings of the 2019 IEEE 10th International Conference on Awareness Science and Technology, iCAST 2019-Proceedings, Morioka, Japan, 23–25 October 2019. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Chen, H.; He, Z.; Shi, B.; Zhong, T. Research on Recognition Method of Electrical Components Based on YOLO V3. IEEE Access 2019, 7, 157818–157829. [Google Scholar] [CrossRef]
- Zhao, L.; Li, S. Object Detection Algorithm Based on Improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef] [Green Version]
- Bochkovskiy, A.; Wang, C.-Y.; Mark Liao, H.-Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.; Liao, H.M.; Wu, Y.; Chen, P. CSPNet: A New Backbone That Can Enhance Learning Capability of Cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR Workshop), Seattle, WA, USA, 14–19 June 2020; p. 2. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Misra, D. Mish: A Self Regularized Non-Monotonic Neural Activation Function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Li, Z.; Tian, X.; Liu, X.; Liu, Y.; Shi, X. A Two-Stage Industrial Defect Detection Framework Based on Improved-YOLOv5 and Optimized-Inception-ResnetV2 Models. Appl. Sci. 2022, 12, 834. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2124. [Google Scholar]
- Li, Y.; Pei, X.; Huang, Q.; Jiao, L.; Shang, R.; Marturi, N. Anchor-Free Single Stage Detector in Remote Sensing Images Based on Multiscale Dense Path Aggregation Feature Pyramid Network. IEEE Access 2020, 8, 63121–63133. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, A.P.S.; Christanto, H.J. Deep Learning for Highly Accurate Hand Recognition Based on Yolov7 Model. Big Data Cogn. Comput. 2023, 7, 53. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef] [PubMed]
- Hu, M.; Li, Y.; Fang, L.; Wang, S. A2-FPN: Attention Aggregation Based Feature Pyramid Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Huang, G.; Li, Y.; Pleiss, G.; Liu, Z.; Hopcroft, J.E.; Weinberger, K.Q. Snapshot Ensembles: Train 1, Get M for Free. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017—Conference Track Proceedings, Toulon, France, 24–26 April 2017. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; Volume 2016. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 10–15 June 2019; Volume 2019. [Google Scholar]
- Ultralytics Yolo V5. Available online: https://github.com/ultralytics/yolov5 (accessed on 13 January 2021).
- Chen, J.; Jia, K.; Chen, W.; Lv, Z.; Zhang, R. A Real-Time and High-Precision Method for Small Traffic-Signs Recognition. Neural Comput. Appl. 2022, 34, 2233–2245. [Google Scholar] [CrossRef]
- Bbox Label Tool. Available online: https://github.com/puzzledqs/BBox-Label-Tool (accessed on 13 January 2022).
- Long, J.W.; Yan, Z.R.; Peng, L.; Li, T. The Geometric Attention-Aware Network for Lane Detection in Complex Road Scenes. PLoS ONE 2021, 16, e0254521. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.; Xiong, Z.; Wang, Q. An Incremental Framework for Video-Based Traffic Sign Detection, Tracking, and Recognition. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1918–1929. [Google Scholar] [CrossRef]
- Kang, H.; Chen, C. Fast Implementation of Real-Time Fruit Detection in Apple Orchards Using Deep Learning. Comput. Electron. Agric. 2020, 168, 105–108. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C. Combination of Resnet and Spatial Pyramid Pooling for Musical Instrument Identification. Cybern. Inf. Technol. 2022, 22, 104. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Accuracy (mAP 0.5) | Params (Million) | GPU Time (ms) | CPU Time (ms) |
|---|---|---|---|---|
| YOLOv5n | 45.7 | 1.9 | 6.3 | 45 |
| YOLOv5s | 56.8 | 7.2 | 6.4 | 98 |
| YOLOv5m | 64.1 | 21.2 | 8.2 | 224 |
| YOLOv7 | 51.4 | 36.9 | - | - |
| YOLOv7x | 53.1 | 71.3 | - | - |
| Class Name | Testing | Training | Total Images |
|---|---|---|---|
| Bassoon | 109 | 253 | 362 |
| Cello | 97 | 225 | 322 |
| Clarinet | 95 | 221 | 316 |
| Erhu | 101 | 236 | 337 |
| Flute | 95 | 221 | 315 |
| French horn | 98 | 229 | 327 |
| Guitar | 98 | 228 | 326 |
| Harp | 100 | 232 | 332 |
| Recorder | 93 | 216 | 309 |
| Saxophone | 98 | 228 | 326 |
| Trumpet | 99 | 231 | 330 |
| Violin | 102 | 238 | 340 |
| Total Images | 1183 | 2759 | 3942 |
| Class | Images | Labels | YOLOv7 | YOLOv7x | ||||
|---|---|---|---|---|---|---|---|---|
| P | R | [email protected] | P | R | [email protected] | |||
| All | 1182 | 1543 | 0.795 | 0.843 | 0.866 | 0.804 | 0.84 | 0.882 |
| Bassoon | 1182 | 140 | 0.838 | 0.812 | 0.856 | 0.858 | 0.82 | 0.868 |
| Cello | 1182 | 119 | 0.735 | 0.857 | 0.869 | 0.821 | 0.832 | 0.913 |
| Clarinet | 1182 | 112 | 0.775 | 0.862 | 0.853 | 0.72 | 0.786 | 0.822 |
| Erhu | 1182 | 123 | 0.84 | 0.935 | 0.911 | 0.806 | 0.959 | 0.92 |
| Flute | 1182 | 131 | 0.762 | 0.806 | 0.826 | 0.75 | 0.779 | 0.816 |
| French horn | 1182 | 119 | 0.687 | 0.866 | 0.862 | 0.767 | 0.84 | 0.897 |
| Guitar | 1182 | 112 | 0.856 | 0.821 | 0.885 | 0.887 | 0.786 | 0.904 |
| Harp | 1182 | 110 | 0.938 | 0.963 | 0.976 | 0.955 | 0.958 | 0.988 |
| Recorder | 1182 | 173 | 0.75 | 0.798 | 0.808 | 0.721 | 0.792 | 0.816 |
| Saxophone | 1182 | 137 | 0.839 | 0.861 | 0.916 | 0.826 | 0.901 | 0.911 |
| Trumpet | 1182 | 130 | 0.743 | 0.715 | 0.804 | 0.772 | 0.792 | 0.858 |
| Violin | 1182 | 137 | 0.783 | 0.817 | 0.827 | 0.765 | 0.832 | 0.868 |
| Class | Images | Labels | YOLOv5m | YOLOv5n | YOLOv5s | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | [email protected] | P | R | [email protected] | P | R | [email protected] | |||
| All | 1314 | 1748 | 0.798 | 0.825 | 0.825 | 0.725 | 0.735 | 0.75 | 0.761 | 0.802 | 0.813 |
| Bassoon | 1314 | 149 | 0.837 | 0.828 | 0.869 | 0.828 | 0.745 | 0.8 | 0.818 | 0.785 | 0.811 |
| Cello | 1314 | 124 | 0.811 | 0.887 | 0.896 | 0.772 | 0.831 | 0.816 | 0.737 | 0.871 | 0.841 |
| Clarinet | 1314 | 136 | 0.836 | 0.757 | 0.793 | 0.693 | 0.625 | 0.649 | 0.781 | 0.733 | 0.809 |
| Erhu | 1314 | 135 | 0.83 | 0.889 | 0.913 | 0.743 | 0.785 | 0.804 | 0.782 | 0.85 | 0.864 |
| Flute | 1314 | 163 | 0.727 | 0.785 | 0.799 | 0.746 | 0.62 | 0.69 | 0.708 | 0.767 | 0.733 |
| French horn | 1314 | 140 | 0.844 | 0.812 | 0.902 | 0.713 | 0.829 | 0.84 | 0.8 | 0.836 | 0.877 |
| Guitar | 1314 | 123 | 0.806 | 0.756 | 0.819 | 0.784 | 0.715 | 0.799 | 0.805 | 0.748 | 0.784 |
| Harp | 1314 | 114 | 0.913 | 0.974 | 0.982 | 0.883 | 0.93 | 0.949 | 0.907 | 0.956 | 0.969 |
| Recorder | 1314 | 209 | 0.702 | 0.745 | 0.782 | 0.57 | 0.565 | 0.572 | 0.649 | 0.703 | 0.721 |
| Saxophone | 1314 | 144 | 0.815 | 0.875 | 0.902 | 0.712 | 0.84 | 0.83 | 0.751 | 0.879 | 0.876 |
| Trumpet | 1314 | 140 | 0.729 | 0.721 | 0.733 | 0.606 | 0.586 | 0.561 | 0.718 | 0.692 | 0.698 |
| Violin | 1314 | 171 | 0.722 | 0.865 | 0.828 | 0.645 | 0.754 | 0.685 | 0.683 | 0.801 | 0.771 |
| Class | Images | Labels | YOLOv7 | YOLOv7x | ||||
|---|---|---|---|---|---|---|---|---|
| P | R | [email protected] | P | R | [email protected] | |||
| All | 1182 | 1543 | 0.808 | 0.833 | 0.867 | 0.771 | 0.826 | 0.861 |
| Bassoon | 1182 | 140 | 0.826 | 0.816 | 0.853 | 0.876 | 0.757 | 0.849 |
| Cello | 1182 | 119 | 0.751 | 0.849 | 0.862 | 0.778 | 0.823 | 0.871 |
| Clarinet | 1182 | 112 | 0.749 | 0.857 | 0.821 | 0.678 | 0.772 | 0.774 |
| Erhu | 1182 | 123 | 0.832 | 0.927 | 0.91 | 0.784 | 0.946 | 0.905 |
| Flute | 1182 | 131 | 0.799 | 0.771 | 0.831 | 0.663 | 0.802 | 0.814 |
| French horn | 1182 | 119 | 0.757 | 0.849 | 0.871 | 0.673 | 0.84 | 0.873 |
| Guitar | 1182 | 112 | 0.842 | 0.806 | 0.877 | 0.836 | 0.776 | 0.85 |
| Harp | 1182 | 110 | 0.951 | 0.955 | 0.973 | 0.95 | 0.863 | 0.968 |
| Recorder | 1182 | 173 | 0.807 | 0.751 | 0.835 | 0.716 | 0.815 | 0.801 |
| Saxophone | 1182 | 137 | 0.853 | 0.861 | 0.912 | 0.786 | 0.885 | 0.9 |
| Trumpet | 1182 | 130 | 0.738 | 0.736 | 0.811 | 0.767 | 0.784 | 0.853 |
| Violin | 1182 | 137 | 0.789 | 0.818 | 0.844 | 0.748 | 0.854 | 0.871 |
| Class | Images | Labels | YOLOv5m | YOLOv5n | YOLOv5s | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | [email protected] | P | R | [email protected] | P | R | [email protected] | |||
| All | 1314 | 1748 | 0.739 | 0.793 | 0.805 | 0.61 | 0.689 | 0.64 | 0.688 | 0.752 | 0.726 |
| Bassoon | 1314 | 149 | 0.762 | 0.745 | 0.791 | 0.69 | 0.626 | 0.643 | 0.706 | 0.664 | 0.719 |
| Cello | 1314 | 124 | 0.743 | 0.782 | 0.772 | 0.633 | 0.653 | 0.616 | 0.656 | 0.758 | 0.691 |
| Clarinet | 1314 | 136 | 0.751 | 0.775 | 0.784 | 0.583 | 0.684 | 0.618 | 0.7 | 0.755 | 0.727 |
| Erhu | 1314 | 135 | 0.817 | 0.829 | 0.866 | 0.676 | 0.622 | 0.681 | 0.71 | 0.817 | 0.776 |
| Flute | 1314 | 163 | 0.637 | 0.804 | 0.767 | 0.563 | 0.644 | 0.568 | 0.707 | 0.748 | 0.696 |
| French horn | 1314 | 140 | 0.826 | 0.849 | 0.895 | 0.597 | 0.847 | 0.747 | 0.723 | 0.82 | 0.79 |
| Guitar | 1314 | 123 | 0.76 | 0.675 | 0.747 | 0.695 | 0.629 | 0.659 | 0.715 | 0.675 | 0.688 |
| Harp | 1314 | 114 | 0.861 | 0.912 | 0.914 | 0.752 | 0.825 | 0.824 | 0.851 | 0.746 | 0.839 |
| Recorder | 1314 | 209 | 0.658 | 0.732 | 0.739 | 0.483 | 0.67 | 0.535 | 0.59 | 0.718 | 0.659 |
| Saxophone | 1314 | 144 | 0.743 | 0.854 | 0.873 | 0.617 | 0.778 | 0.702 | 0.656 | 0.847 | 0.797 |
| Trumpet | 1314 | 140 | 0.628 | 0.714 | 0.709 | 0.505 | 0.571 | 0.478 | 0.59 | 0.664 | 0.595 |
| Violin | 1314 | 171 | 0.681 | 0.849 | 0.798 | 0.529 | 0.719 | 0.615 | 0.65 | 0.813 | 0.734 |
| Class Name | Class ID | Grouplet [10] | Resnet 50 SPP [41] | YOLOv7 | YOLOv7x |
|---|---|---|---|---|---|
| Bassoon | 0 | 78.50% | 85.00% | 85.30% | 84.90% |
| Cello | 1 | 87.60% | 81.00% | 86.20% | 87.10% |
| Clarinet | 2 | 95.70% | 89.00% | 82.10% | 77.40% |
| Erhu | 3 | 84.00% | 81.00% | 91.00% | 90.50% |
| Flute | 4 | 87.70% | 82.00% | 83.10% | 81.40% |
| French horn | 5 | 87.70% | 78.00% | 87.10% | 87.30% |
| Guitar | 6 | 93.00% | 79.00% | 87.70% | 85.00% |
| Harp | 7 | 76.30% | 98.00% | 97.30% | 96.80% |
| Recorder | 8 | 84.60% | 85.00% | 83.50% | 80.10% |
| Saxophone | 9 | 82.30% | 93.00% | 91.20% | 90.00% |
| Trumpet | 10 | 87.10% | 85.00% | 81.10% | 85.30% |
| Violin | 11 | 76.50% | 80.00% | 84.40% | 87.10% |
| Average | 85.10% | 84.64% | 86.70% | 86.10% |
| Class Name | YOLOv5n | YOLOv5s | YOLOv5m | YOLOv7 | YOLOv7x | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc (%) | Time (s) | Acc (%) | Time (s) | Acc (%) | Time (s) | Acc (%) | Time (s) | Acc (%) | Time (s) | |
| Clarinet | 0.609 | 0.031 | 0.660 | 0.061 | 0.701 | 0.118 | 0.744 | 0.022 | 0.648 | 0.021 |
| Flute | 0.560 | 0.031 | 0.703 | 0.061 | 0.632 | 0.116 | 0.667 | 0.012 | 0.561 | 0.020 |
| Guitar | 0.499 | 0.031 | 0.632 | 0.060 | 0.750 | 0.116 | 0.675 | 0.012 | 0.635 | 0.020 |
| Harp | 0.713 | 0.030 | 0.656 | 0.060 | 0.875 | 0.116 | 0.753 | 0.012 | 0.457 | 0.020 |
| Trumpet | 0.579 | 0.030 | 0.621 | 0.060 | 0.685 | 0.116 | 0.793 | 0.012 | 0.791 | 0.020 |
| Saxophone | 0.668 | 0.030 | 0.644 | 0.060 | 0.625 | 0.118 | 0.638 | 0.012 | 0.817 | 0.020 |
| Violin | 0.689 | 0.031 | 0.798 | 0.060 | 0.693 | 0.116 | 0.763 | 0.012 | 0.652 | 0.020 |
| Average | 0.617 | 0.030 | 0.673 | 0.060 | 0.709 | 0.117 | 0.719 | 0.014 | 0.652 | 0.020 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dewi, C.; Chen, A.P.S.; Christanto, H.J. Recognizing Similar Musical Instruments with YOLO Models. Big Data Cogn. Comput. 2023, 7, 94. https://doi.org/10.3390/bdcc7020094
Dewi C, Chen APS, Christanto HJ. Recognizing Similar Musical Instruments with YOLO Models. Big Data and Cognitive Computing. 2023; 7(2):94. https://doi.org/10.3390/bdcc7020094
Chicago/Turabian StyleDewi, Christine, Abbott Po Shun Chen, and Henoch Juli Christanto. 2023. "Recognizing Similar Musical Instruments with YOLO Models" Big Data and Cognitive Computing 7, no. 2: 94. https://doi.org/10.3390/bdcc7020094
APA StyleDewi, C., Chen, A. P. S., & Christanto, H. J. (2023). Recognizing Similar Musical Instruments with YOLO Models. Big Data and Cognitive Computing, 7(2), 94. https://doi.org/10.3390/bdcc7020094