



Unsupervised Deep Learning for Structural Health Monitoring


 and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials
2.1.1. Data from Numerical Simulations
- -
- The braces were modeled using T-profile truss elements;
- -
- Piers were modeled using 4-node shell elements (ASDShellQ4);
- -
- The ballast was modeled using springs;
- -
- Tracks were modeled using IPE beam elements;
- -
- Both top and bottom chords were modeled using double-T beam elements;
- -
- Verticals were modeled using IPE300 beam elements;
- -
- Diagonals were modeled using double-C beam elements.
2.1.2. Real-World Data
- -
- Three temperature time series labeled as follows:
- -
- : The air temperature (in Celsius) measured by a sensor placed outside the tower;
- -
- : The core temperature of the masonry measured by a sensor placed within the wall at a depth of 15 cm from the external surface;
- -
- : The air temperature measured by a sensor placed inside the tower.
- -
- Two inclinometer time series labeled as follows:
- -
- : The inclination of the tower along the east–west direction (x axis) measured at a height of 21.0 m from the ground;
- -
- : The inclination of the tower along the north–south direction (y axis) measured at the same height.
2.2. Methods
2.2.1. Flow chart of the Proposed Approach
2.2.2. Gap Filling and Trend Removal
2.2.3. Feature Extraction and Aggregation
- For any 1-d time series (i.e., for each physical quantity), a set of temporal, spectral, and statistical quantities is computed. Following the work of [16], we exploited the TSFEL library for Python in our setup for feature extraction [17] (See 1 May 2023, https://tsfel.readthedocs.io/en/latest/ for a complete list of computed features), cutting all Fourier coefficients above 30 Hz. By default, TSFEL computes a rich list of univariate indicators, which are split into temporal, statistical, and spectral features. Table 1 reports the features the user can extract from a single time series. Some of them are composed of multiple coefficients. In that list, ECDF stands for empirical cumulative distribution function, FFT refers to fast Fourier transform, MFCC stands for mel frequency cepstrum coefficient, and LPCC refers to linear predictive cepstrum coefficient.
- Alternatively, features are arranged as follows:
- -
- Unpacked: To construct independent classifiers, features extracted from different devices are kept apart to feed separate algorithms;
- -
- Compacted together: Information from devices is mixed to feed a single algorithm;
- Temperature (and any other information about environmental conditions, if measured) is added to features in both cases.
2.2.4. Feature Standardization and Reduction
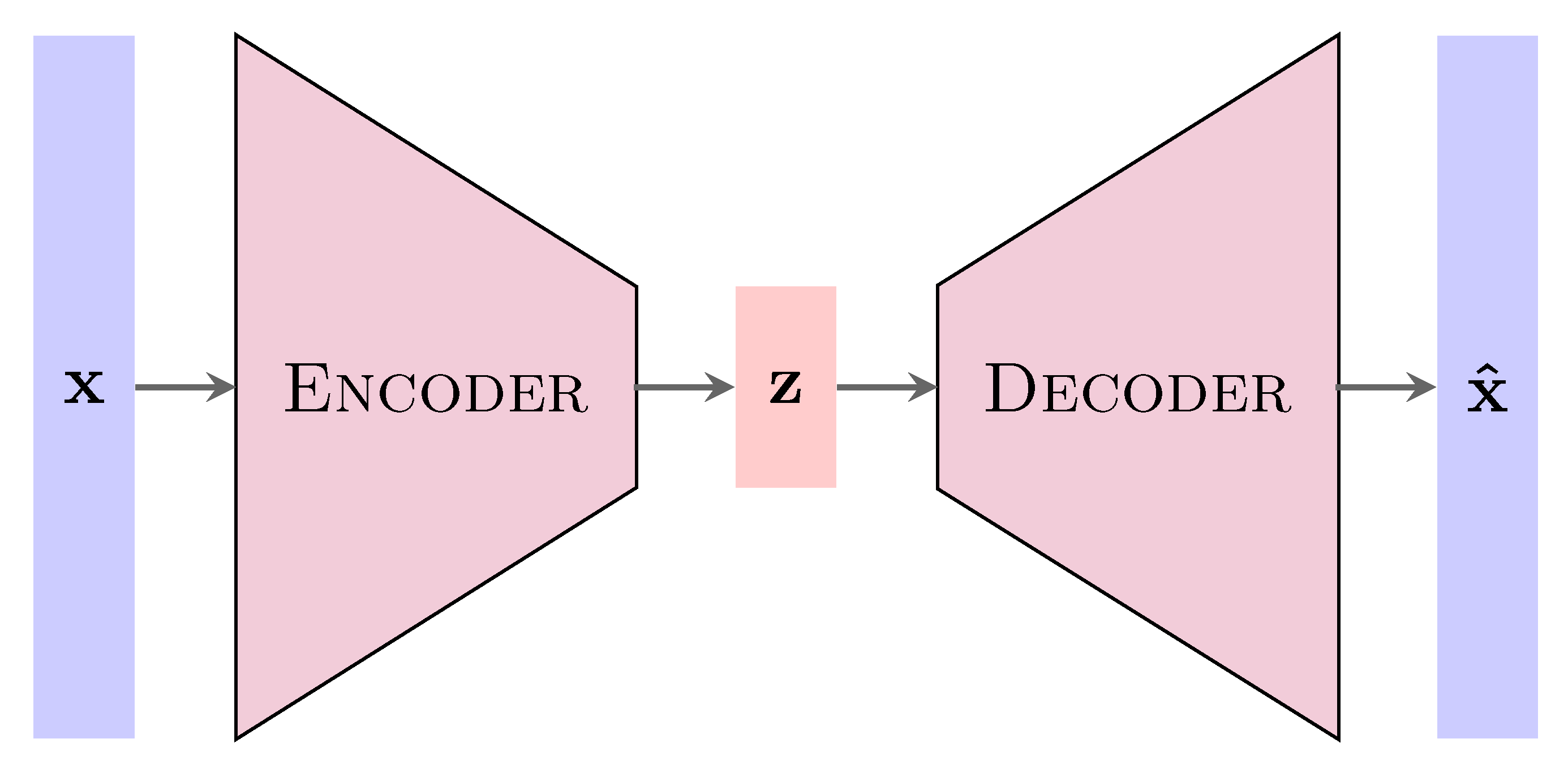
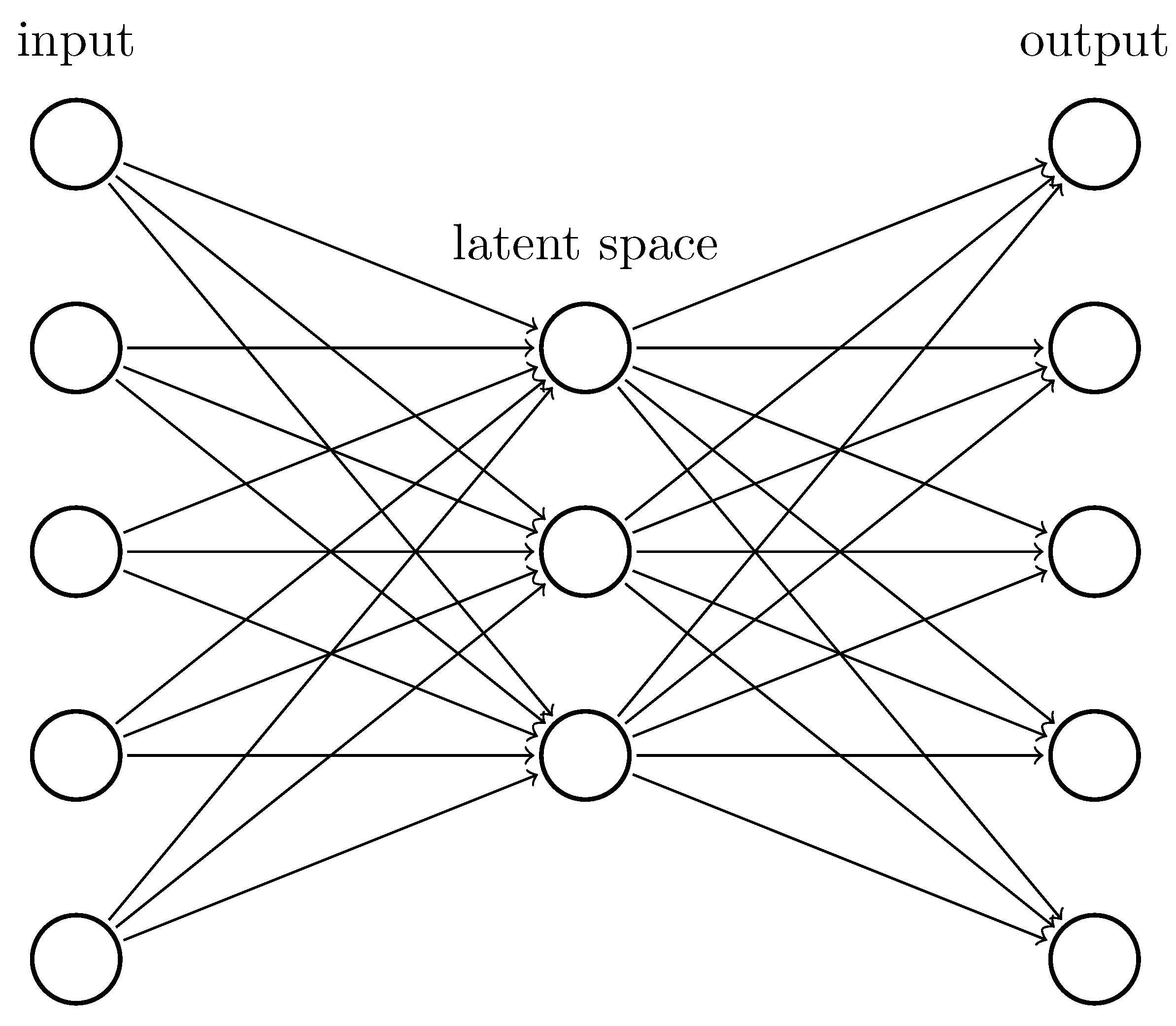
2.2.5. Autoencoder Neural Networks
2.2.6. Statistics of the Reconstruction Error
3. Results
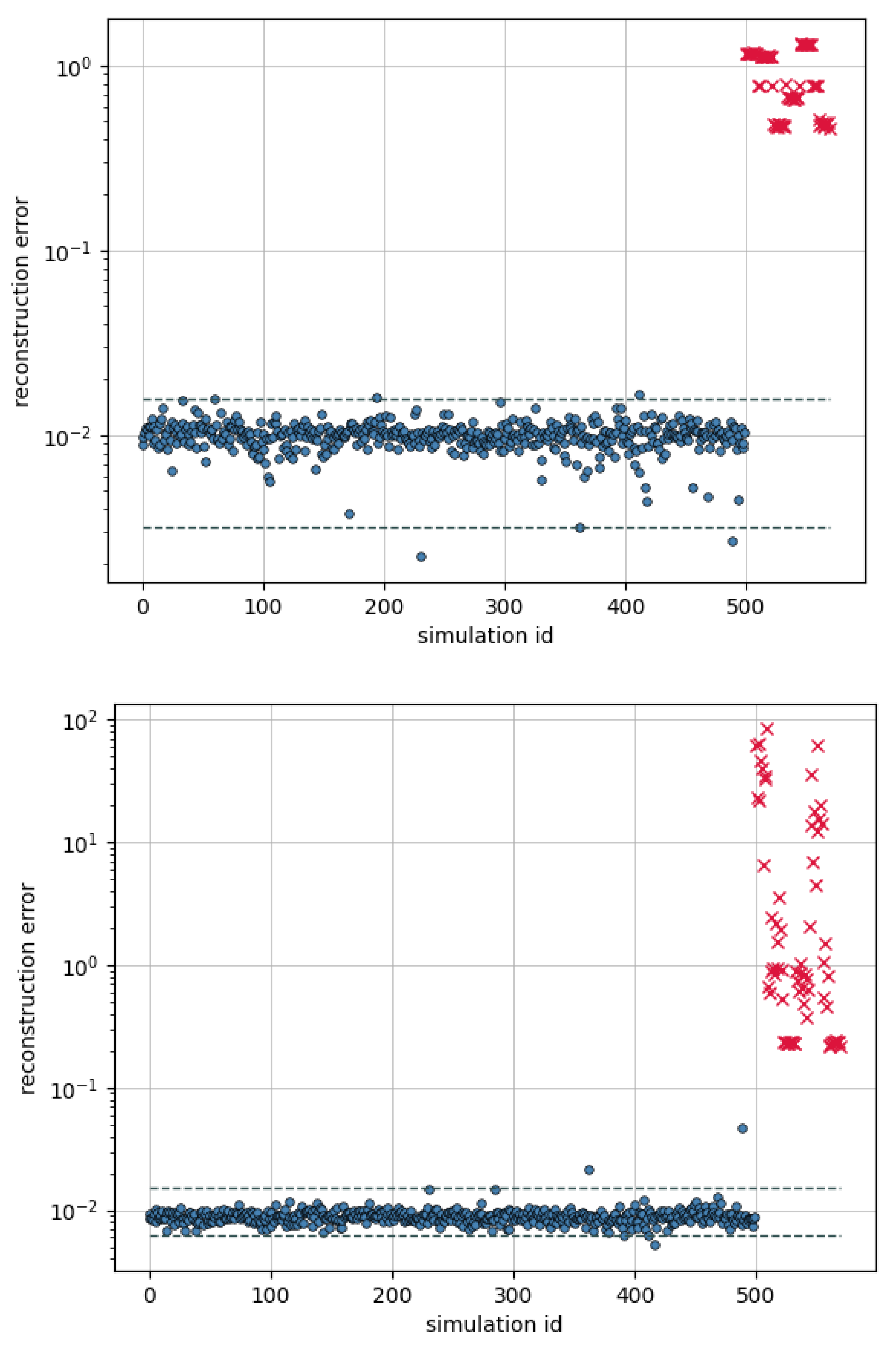
3.1. Results for the Railway Bridge Model
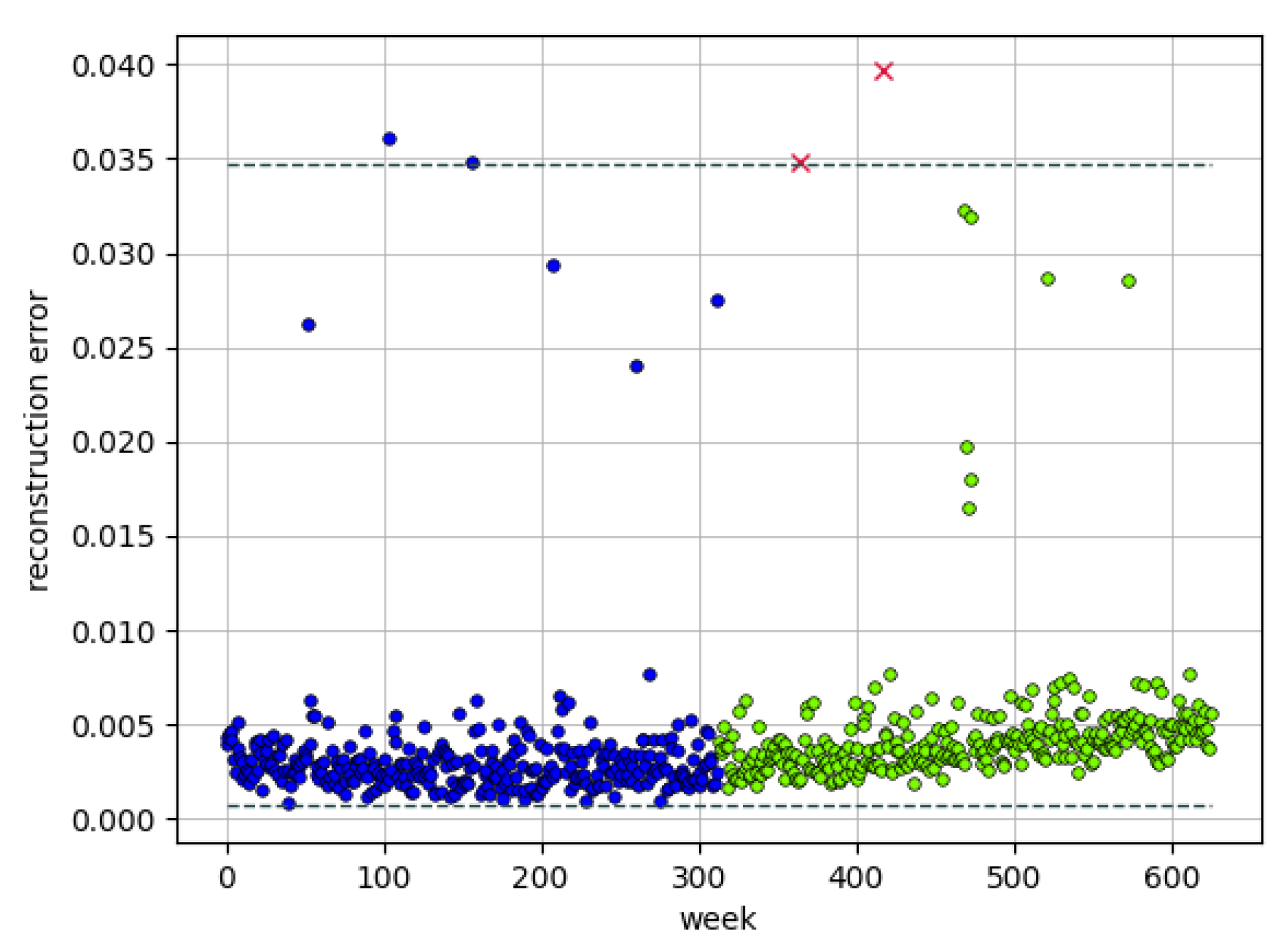
3.2. Results for the Tower Data
3.3. Comparison Results
- -
- The algorithm is trained using the available instances;
- -
- A score is obtained for each instance belonging to the training set in order to construct a prevision method in a way similar to that defined previously, although the underlying pdf is different from that describing the autoencoder’s reconstruction errors;
- -
- A threshold of is fixed to reject test instances (x) with a probability that is estimated to be less than to be observed.
- -
- At fixed M, find as the unique value such that for any , the algorithm detects one or more anomalies in the training set, and for any , no anomalies are identified.
- -
- For any instance in the test set:
- -
- Add the new instance to the training set;
- -
- Launch the DBSCAN algorithm with parameters M and and check if the new instance is labeled as an anomaly.
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hoshyarmanesh, H.; Abbasi, A.; Moein, P.; Ghodsi, M.; Zareinia, K. Design and implementation of an accurate, portable, and time-efficient impedance-based transceiver for structural health monitoring. IEEE/ASME Trans. Mechatron. 2017, 22, 2089–2814. [Google Scholar] [CrossRef]
- Sohn, H.; Farrar, C.R.; Hemez, F.M.; Czamecki, J.J. A Review of Structural Health Review of Structural Health Monitoring Literature 1996–2001. In Proceedings of the Third World Conference on Structural Control, Como, Italy, 7–12 April 2002. [Google Scholar]
- Rytter, A. Vibrational Based Inspection of Civil Engineering Structures. Ph.D. Thesis, Aalborg University, Aalborg, Denmark, 1993. [Google Scholar]
- Farrar, C.R.; Worden, K. Structural Health Monitoring: A Machine Learning Perspective; Wiley: Oxford, UK, 2013. [Google Scholar]
- Tibaduiza Burgos, D.A.; Gomez Vargas, R.C.; Pedraza, C.; Agis, D.; Pozo, F. Damage identification in structural health monitoring: A brief review from its implementation to the use of data-driven applications. Sensors 2020, 20, 733. [Google Scholar] [CrossRef] [PubMed]
- Nick, W.; Shelton, J.; Asamene, K.; Esterline, A.C. A Study of Supervised Machine Learning Techniques for Structural Health Monitoring. MAICS 2015, 1353, 36. [Google Scholar]
- Giglioli, V.; Venanzi, V.; Poggioni, I.; Milani, A.; Ubertini, F. Autoencoders for unsupervised real-time bridge health assessment. Comput. Civ. Infrastruct. Eng. 2023, 38, 959–974. [Google Scholar] [CrossRef]
- Ma, X.; Lin, Y.; Nie, Z.; Ma, H. Structural damage identification based on unsupervised feature-extraction via Variational Auto-encoder. Measurement 2020, 160, 107811. [Google Scholar] [CrossRef]
- Pollastro, A.; Testa, G.; Bilotta, A.; Prevete, R. Unsupervised detection of structural damage using Variational Autoencoder and a One-Class Support Vector Machine. arXiv 2022, arXiv:2210.05674. [Google Scholar]
- Cauteruccio, F.; Fortino, G.; Guerrieri, A.; Terracina, G. Discovery of Hidden Correlations between Heterogeneous Wireless Sensor Data Streams. In Internet and Distributed Computing Systems, Proceedings of the 7th International Conference, IDCS 2014, Calabria, Italy, 22–24 September 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 383–395. [Google Scholar] [CrossRef]
- Cauteruccio, F.; Fortino, G.; Guerrieri, A.; Liotta, A.; Mocanu, D.C.; Perra, C.; Terracina, G.; Torres Vega, M. Short-long term anomaly detection in wireless sensor networks based on machine learning and multi-parameterized edit distance. Inf. Fusion 2019, 52, 13–30. [Google Scholar] [CrossRef]
- Petracca, M.; Candeloro, F.; Camata, G. STKO User Manual; ASDEA Software Technology: Pescara, Italy, 2017. [Google Scholar]
- Ubertini, F.; Gentile, C.; Materazzi, A.L. Automated modal identification in operational conditions and its application to bridges. Eng. Struct. 2013, 46, 264–278. [Google Scholar] [CrossRef]
- Parisi, F.; Mangini, A.M.; Fanti, M.P.; Adam, J.M. Automated location of steel truss bridge damage using machine learning and raw strain sensor data. Autom. Constr. 2022, 138, 104249. [Google Scholar] [CrossRef]
- Ulyah, S.M.; Mardianto, M.F.F. Comparing the Performance of Seasonal ARIMAX Model and Nonparametric Regression Model in Predicting Claim Reserve of Education Insurance. J. Phys. Conf. Ser. 2019, 1397, 012074. [Google Scholar] [CrossRef]
- Buckley, T.; Bidisha, G.; Pakrashi, V. A feature extraction & selection benchmark for structural health monitoring. Struct. Health Monit. 2023, 22, 2082–2127. [Google Scholar]
- Barandas, M.; Folgado, D.; Fernandes, L.; Santos, S.; Abreu, M.; Bota, P.; Liu, H.; Schultz, T.; Gamboa, H. TSFEL: Time Series Feature Extraction Library. SoftwareX 2020, 11, 100456. [Google Scholar] [CrossRef]
- Ringnér, M. What is principal component analysis? Nat. Biotechnol. 2008, 26, 303–304. [Google Scholar] [CrossRef] [PubMed]
- Bank, D.; Koenigstein, N.; Giryes, R. Autoencoders. arXiv 2020, arXiv:2003.05991. [Google Scholar]
- Jin, F.; Sengupta, A.; Cao, S. mmFall: Fall Detection Using 4-D mmWave Radar and a Hybrid Variational RNN AutoEncoder. IEEE Trans. Autom. Sci. Eng. 2022, 19, 1245–1257. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Ding, Z.; Fei, M. An Anomaly Detection Approach Based on Isolation Forest Algorithm for Streaming Data using Sliding Window. IFAC Proc. Vol. 2013, 46, 12–17. [Google Scholar] [CrossRef]
- Emadi, H.S.; Mazinani, S.M. A Novel Anomaly Detection Algorithm Using DBSCAN and SVM in Wireless Sensor Networks. Wirel. Pers. Commun. 2018, 98, 2025–2035. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, Portland, OR, USA, 2–4 August 1996; AAAI Press: Washington, DC, USA, 1996; pp. 226–231. [Google Scholar]
- Hartmann, Y.; Liu, H.; Schultz, T. Feature Space Reduction for Multimodal Human Activity Recognition. In Proceedings of the 13th International Joint Conference on Biomedical Engineering Systems and Technologies, BIOSTEC 2020, Valletta, Malta, 24–26 February 2020; SCITEPRESS: Setúbal, Portugal, 2020; pp. 135–140. [Google Scholar] [CrossRef]
- Hui, L. Biosignal Processing and Activity Modeling for Multimodal Human Activity Recognition. Ph.D. Thesis, Universität Bremen, Bremen, Germany, 2021. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistical | Temporal | Spectral |
|---|---|---|
| ECDF | Absolute energy | FFT mean coefficients |
| ECDF percentile | Area under the curve | Fundamental frequency |
| ECDF percentile count | Autocorrelation | MFCC |
| ECDF slope | Centroid | LPCC |
| Histogram | Entropy | Max power spectrum |
| Interquantile range | Mean absolute difference | Maximum frequency |
| Kurtosis | Mean difference | Median frequency |
| Max | Median absolute difference | Power bandwidth |
| Mean | Median difference | Spectral centroid |
| Mean absolute deviation | Negative turning points | Spectral decrease |
| Median | Peak-to-peak distance | Spectral distance |
| Median absolute deviation | Positive turning points | Spectral entropy |
| Min | Signal distance | Spectral kurtosis |
| Root mean square | Slope | Spectral positive turning points |
| Skewness | Sum absolute difference | Spectral roll-off |
| Standard deviation | Total energy | Spectral roll-on |
| Variance | Zero crossing rate | Spectral skewness |
| Neighborhood peaks | Spectral slope | |
| Spectral spread | ||
| Spectral variation | ||
| Wavelet absolute mean | ||
| Wavelet energy | ||
| Wavelet standard deviation | ||
| Wavelet entropy | ||
| Wavelet variance |
| Feature | Sensor | |
|---|---|---|
| Wavelet variance 6 | 0.117 | |
| FFT mean coefficient 4 | 0.119 | |
| ECDF 4 | 0.119 | |
| FFT mean coefficient 8 | 0.119 | |
| FFT mean coefficient 5 | 0.123 | |
| FFT mean coefficient 11 | 0.125 | |
| Wavelet variance 7 | 0.127 | |
| Zero crossing rate | 0.127 | |
| ECDF 7 | 0.128 | |
| FFT mean coefficient 7 | 0.129 | |
| FFT mean coefficient 12 | 0.132 | |
| Entropy | 0.133 | |
| ECDF 9 | 0.134 | |
| FFT mean coefficient 1 | 0.135 | |
| ECDF 3 | 0.137 | |
| Autocorrelation | 0.137 | |
| ECDF 6 | 0.141 | |
| ECDF Percentile 1 | 0.145 | |
| ECDF 1 | 0.149 | |
| ECDF 4 | 0.150 |
| Angular Coefficient (2009–2015) | Angular Coefficient (2016–2021) | |
|---|---|---|
| Regular Data | Anomalous Data | |
|---|---|---|
| AE | 96% | 100% |
| VAE | 96% | 100% |
| IF | 100% | 100% |
| DBSCAN | 100% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boccagna, R.; Bottini, M.; Petracca, M.; Amelio, A.; Camata, G. Unsupervised Deep Learning for Structural Health Monitoring. Big Data Cogn. Comput. 2023, 7, 99. https://doi.org/10.3390/bdcc7020099
Boccagna R, Bottini M, Petracca M, Amelio A, Camata G. Unsupervised Deep Learning for Structural Health Monitoring. Big Data and Cognitive Computing. 2023; 7(2):99. https://doi.org/10.3390/bdcc7020099
Chicago/Turabian StyleBoccagna, Roberto, Maurizio Bottini, Massimo Petracca, Alessia Amelio, and Guido Camata. 2023. "Unsupervised Deep Learning for Structural Health Monitoring" Big Data and Cognitive Computing 7, no. 2: 99. https://doi.org/10.3390/bdcc7020099
APA StyleBoccagna, R., Bottini, M., Petracca, M., Amelio, A., & Camata, G. (2023). Unsupervised Deep Learning for Structural Health Monitoring. Big Data and Cognitive Computing, 7(2), 99. https://doi.org/10.3390/bdcc7020099