


An End-to-End Online Traffic-Risk Incident Prediction in First-Person Dash Camera Videos


Abstract
:1. Introduction
- We proposed two-stage algorithms based on unsupervised and supervised learning to predict traffic-risk incidents from dash camera videos based on the human perception of driving.
- We extracted the information from dash camera videos based on a combination of visual driver attention and object tracking of other moving objects appearing on the video to localize where precisely the accident’s risky regions will happen and to calculate a safety distance between them for predicting traffic incidents from a dash camera.
- We classified unsafe event collections produced by the first stage using supervised learning and mixed them with the metadata to enrich the classification event type by bringing the metadata from the first stage result for long-term capturing driving events to handle limited data annotation.
2. Related Works
2.1. Incident Dataset
2.2. Incident Detection and Predictions
3. Methods
3.1. Proposed Method Overview
3.2. Traffic Risk Prediction
- The driver’s perspective focuses more on specific areas than others.
- If one of the moving objects is closer to the driver than their attention, it must be a near miss or incident if no action is taken.
3.2.1. Ego-Vehicle Features
3.2.2. Other Moving Object Features
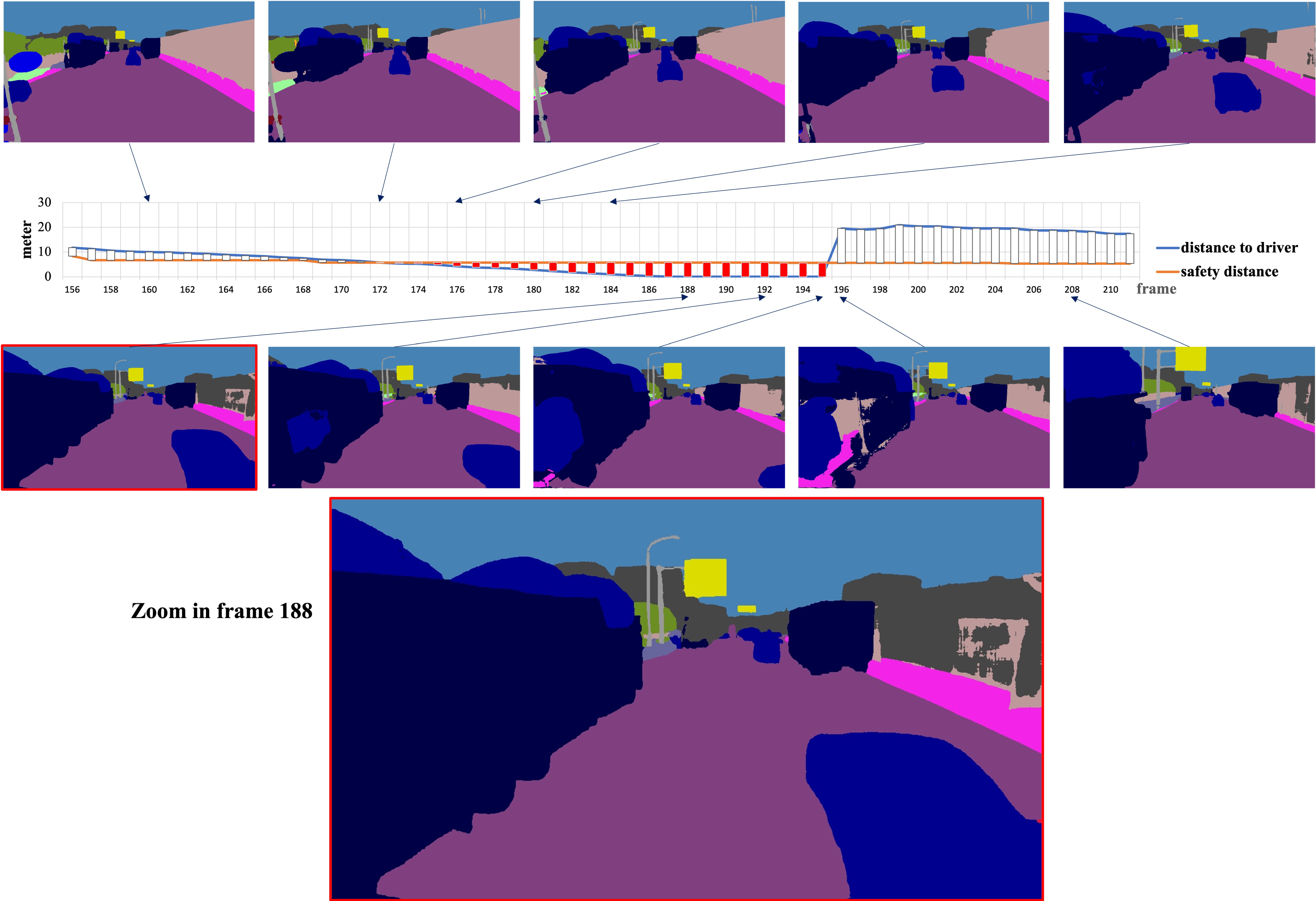
- If the attention map indicates the moving object constantly moving away from the ego-vehicle for a continuous duration of three seconds, there will be a shift in the focus of attention towards another object. Throughout this period, the driver and moving object will try to avoid a potential collision, as illustrated in Figure 2, implying that the object’s movement and trajectory will be monitored. If it is observed that it is moving away for an extended duration, then it will no longer be considered a priority for attention. Instead, attention will be redirected toward objects requiring more immediate attention, such as those closer to the ego-vehicle.
- The focus of attention will be shifted when the object being monitored by the attention map is no longer being tracked. This can happen when the object disappears from the dash camera video view, as shown in Figure 3. In such cases, the attention map will stop displaying information about the object and instead shift its focus to other moving objects currently within the camera’s view.
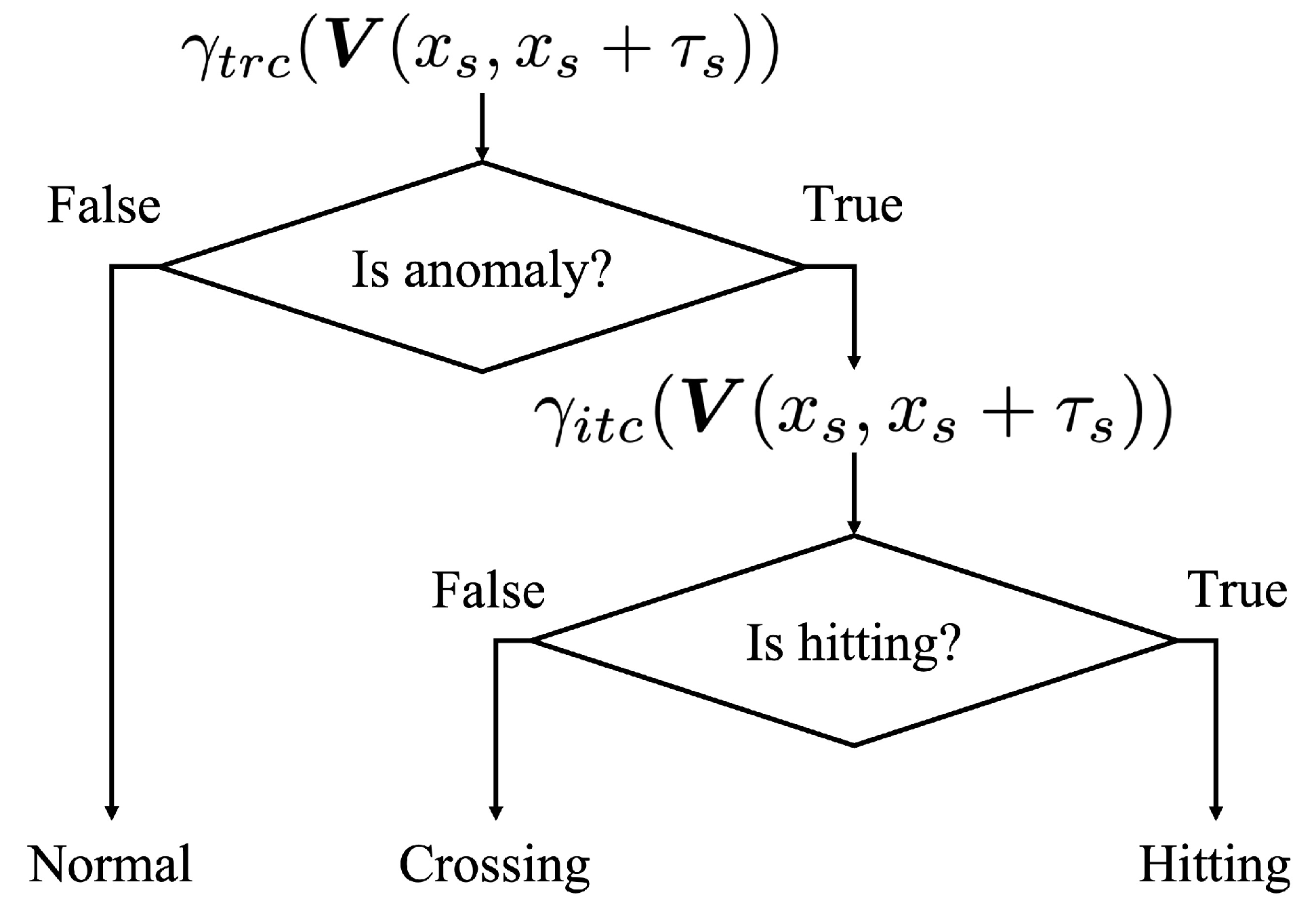
3.3. Traffic-Risk and Incident Type Classification
4. Experimental Results
4.1. Datasets
4.1.1. Re-Annotated State-of-the-Art Traffic Risk Dataset
CST-S3D Dataset to Build the Model of
CST-S3D Dataset to Build the Model of
4.1.2. Real Driving
4.2. Result
4.2.1. The First Stage Results
4.2.2. The Second Stage Result
4.3. Computational Time
5. Theoretical and Managerial Implication
6. Conclusions and Discussion
7. Limitation and Future Works
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Katrakazas, C.; Quddus, M.; Chen, W.H.; Deka, L. Real-time motion planning methods for autonomous on-road driving: State-of-the-art and future research directions. Transp. Res. Part Emerg. Technol. 2015, 60, 416–442. [Google Scholar] [CrossRef]
- Sahoo, G.K.; Patro, S.A.; Pradhan, P.K.; Das, S.K.; Singh, P. An IoT-Based Intimation and Path Tracing of a Vehicle Involved in Road Traffic Crashes. In Proceedings of the 2020 IEEE-HYDCON, Hyderabad, India, 11–12 September 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Bzai, J.; Alam, F.; Dhafer, A.; Bojović, M.; Altowaijri, S.M.; Niazi, I.K.; Mehmood, R. Machine Learning-Enabled Internet of Things (IoT): Data, Applications, and Industry Perspective. Electronics 2022, 11, 2676. [Google Scholar] [CrossRef]
- Katreddi, S.; Kasani, S.; Thiruvengadam, A. A Review of Applications of Artificial Intelligence in Heavy Duty Trucks. Energies 2022, 15, 7457. [Google Scholar] [CrossRef]
- Schwarz, D.M.; Rolland, L.; Johnston, J.B. Why We should be Careful when Using Self-driving Vehicle Features! In Proceedings of the 2021 IEEE International Conference on Engineering, Technology and Innovation (ICE/ITMC), Cardiff, UK, 21–23 June 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Li, Z.; Chen, L.; Nie, L.; Yang, S.X. A Novel Learning Model of Driver Fatigue Features Representation for Steering Wheel Angle. IEEE Trans. Veh. Technol. 2022, 71, 269–281. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Liu, Y.T.; Tai, S.K. Synthetic Data generation using DCGAN for improved traffic sign recognition. Neural Comput. Appl. 2021, 34, 1–16. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Jiang, X.; Yu, H. Deep convolutional neural network for enhancing traffic sign recognition developed on Yolo V4. Multimed. Tools Appl. 2022, 81, 1–25. [Google Scholar] [CrossRef]
- Zou, Y.; Ding, L.; Zhang, H.; Zhu, T.; Wu, L. Vehicle Acceleration Prediction Based on Machine Learning Models and Driving Behavior Analysis. Appl. Sci. 2022, 12, 5259. [Google Scholar] [CrossRef]
- Park, R.; Hong, E. Urban traffic accident risk prediction for knowledge-based mobile multimedia service. Pers. Ubiquitous Comput. 2022, 26, 417–427. [Google Scholar] [CrossRef]
- Satrawala, A.; Mazumdar, A.P.; Vipparthi, S.K. Distributed Adaptive Recommendation & Time-stamp based Estimation of Driver-Behaviour. In Proceedings of the 2022 IEEE Region 10 Symposium (TENSYMP), Mumbai, India, 1–3 July 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Chowdhury, A.; Kaisar, S.; Khoda, M.E.; Naha, R.; Khoshkholghi, M.A.; Aiash, M. IoT-Based Emergency Vehicle Services in Intelligent Transportation System. Sensors 2023, 23, 5324. [Google Scholar] [CrossRef] [PubMed]
- Matsui, Y.; Oikawa, S. Characteristics of Dangerous Scenarios between Vehicles Turning Right and Pedestrians under Left-Hand Traffic. Appl. Sci. 2023, 13, 4189. [Google Scholar] [CrossRef]
- Pradana, H.; Dao, M.S.; Zettsu, K. Augmenting Ego-Vehicle for Traffic Near-Miss and Accident Classification Dataset using Manipulating Conditional Style Translation. In Proceedings of the 2022 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Sydney, Australia, 30 November–2 December 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Zámečník, P.; Havlíčková, D.; Gregorovič, A.; Trepáčová, M. Blind Spot in DUI Countermeasures-Dependent Drivers Are Out of Traffic Safety System Measures. In Proceedings of the Advances in Human Aspects of Transportation; Stanton, N., Ed.; Springer International Publishing: Cham, Switzerland, 2021; pp. 54–62. [Google Scholar]
- Zeng, K.H.; Chou, S.H.; Chan, F.H.; Carlos Niebles, J.; Sun, M. Agent-Centric Risk Assessment: Accident Anticipation and Risky Region Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Bao, W.; Yu, Q.; Kong, Y. Uncertainty-Based Traffic Accident Anticipation with Spatio-Temporal Relational Learning. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 2682–2690. [Google Scholar]
- Bao, W.; Yu, Q.; Kong, Y. DRIVE: Deep Reinforced Accident Anticipation with Visual Explanation. arXiv 2021, arXiv:2107.10189. [Google Scholar]
- Chan, F.H.; Chen, Y.T.; Xiang, Y.; Sun, M. Anticipating accidents in dashcam videos. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 136–153. [Google Scholar]
- Suzuki, T.; Kataoka, H.; Aoki, Y.; Satoh, Y. Anticipating Traffic Accidents With Adaptive Loss and Large-Scale Incident DB. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yao, Y.; Xu, M.; Wang, Y.; Crandall, D.J.; Atkins, E.M. Unsupervised Traffic Accident Detection in First-Person Videos. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 273–280. [Google Scholar] [CrossRef]
- Huang, X.; He, P.; Rangarajan, A.; Ranka, S. Intelligent Intersection: Two-Stream Convolutional Networks for Real-Time Near-Accident Detection in Traffic Video. ACM Trans. Spat. Algorithms Syst. 2020, 6, 1–28. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. arXiv 2014, arXiv:1412.0767. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification. arXiv 2017, arXiv:1712.04851. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. arXiv 2017, arXiv:1705.07750. [Google Scholar]
- Tian, Y.; Pang, G.; Chen, Y.; Singh, R.; Verjans, J.W.; Carneiro, G. Weakly-supervised Video Anomaly Detection with Robust Temporal Feature Magnitude Learning. arXiv 2021, arXiv:2101.10030. [Google Scholar]
- Wu, J.C.; Hsieh, H.Y.; Chen, D.J.; Fuh, C.S.; Liu, T.L. Self-Supervised Sparse Representation for Video Anomaly Detection. In Proceedings of the ECCV, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Fang, J.; Yan, D.; Qiao, J.; Xue, J.; Wang, H.; Li, S. DADA-2000: Can Driving Accident be Predicted by Driver Attentionƒ Analyzed by A Benchmark. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 4303–4309. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar] [CrossRef]
- Min, K.; Corso, J.J. TASED-Net: Temporally-Aggregating Spatial Encoder-Decoder Network for Video Saliency Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2394–2403. [Google Scholar]
- Zhou, Z.; Dong, X.; Li, Z.; Yu, K.; Ding, C.; Yang, Y. Spatio-Temporal Feature Encoding for Traffic Accident Detection in VANET Environment. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19772–19781. [Google Scholar] [CrossRef]
- Mateen, A.; Hanif, M.Z.; Khatri, N.; Lee, S.; Nam, S.Y. Smart Roads for Autonomous Accident Detection and Warnings. Sensors 2022, 22, 2077. [Google Scholar] [CrossRef] [PubMed]
- Brostrom, M. Real-Time Multi-Object Tracker Using YOLOv5 and Deep Sort. 2020. Available online: https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch (accessed on 30 June 2022).
- GitHub—Geopy/Geopy: Geocoding Library for Python.— github.com. Available online: https://github.com/geopy/geopy (accessed on 23 January 2023).
- Mackenzie, J.; Anderson, R. The Potential Effects of Electronic Stability Control Interventions on Rural Road Crashes in Australia: Simulation of Real World Crashes. 2009. Available online: https://trid.trb.org/view/1151354 (accessed on 18 January 2023).
- Sabri, M.; Fauza, A. Analysis of vehicle braking behaviour and distance stopping. IOP Conf. Ser. Mater. Sci. Eng. 2018, 309, 012020. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # of Videos | # of Clipped Video (s) | |||
|---|---|---|---|---|---|
| Incident | Normal | Incident | Normal | ||
| CST-S3D | Training | 837 | 612 | 26,097 | 33,060 |
| Validating | 324 | 138 | 3264 | 3264 | |
| Testing | 132 | 69 | 7884 | 8724 | |
| Real driving | Testing | 231 | 204 | 5001 | 5274 |
| Dataset | Object Type | # of Videos | # of Clipped Video (s) | |||
|---|---|---|---|---|---|---|
| Hitting | Crossing | Hitting | Crossing | |||
| CST-S3D | Training | All objects | 384 | 366 | 11,052 | 9999 |
| Validating | 66 | 54 | 1602 | 1335 | ||
| Testing | 132 | 150 | 3987 | 2886 | ||
| Detail for Testing | Pedestrian | 6 | 15 | 24 | 156 | |
| Cyclist | 9 | 9 | 309 | 195 | ||
| Motorbike | 27 | 48 | 888 | 990 | ||
| Car | 15 | 6 | 729 | 174 | ||
| Truck | 75 | 72 | 2037 | 1371 | ||
| Real driving | Testing | All objects | 165 | 66 | 3885 | 1116 |
| Detail for Testing | Pedestrian | 0 | 0 | 0 | 0 | |
| Cyclist | 0 | 0 | 0 | 0 | ||
| Motorbike | 0 | 0 | 0 | 0 | ||
| Car | 54 | 39 | 1254 | 810 | ||
| Truck | 111 | 27 | 2631 | 306 | ||
| Model | Dataset | Precision | Recall | F1-Score |
|---|---|---|---|---|
| CST-S3D | 90.99 | 86.98 | 88.94 | |
| Real driving | 75.37 | 77.63 | 76.48 | |
| CST-S3D | 95.5 | 96.3 | 95.9 | |
| Real driving | 89.25 | 98.21 | 93.52 |
| Dataset | Object Type | Hitting | Crossing | ||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | ||
| CST-S3D | Pedestrian | 82.42 | 78.79 | 80.56 | 86.68 | 82.86 | 84.73 |
| Cyclist | 83.19 | 79.52 | 81.31 | 83.14 | 79.48 | 81.27 | |
| Motorbike | 82.61 | 78.97 | 80.75 | 86.03 | 82.23 | 84.09 | |
| Car | 82.20 | 78.57 | 80.35 | 84.87 | 81.13 | 82.95 | |
| Truck | 83.79 | 80.10 | 81.90 | 82.7 | 79.05 | 80.83 | |
| Average | 82.84 | 79.19 | 80.97 | 84.68 | 80.95 | 82.77 | |
| Real driving | Pedestrian | n/a | n/a | n/a | n/a | n/a | n/a |
| Cyclist | n/a | n/a | n/a | n/a | n/a | n/a | |
| Motorbike | n/a | n/a | n/a | n/a | n/a | n/a | |
| Car | 66.93 | 67.17 | 67.05 | 74.37 | 76.98 | 75.65 | |
| Truck | 75.37 | 75.63 | 75.5 | 75.58 | 75.46 | 75.52 | |
| Average | 71.15 | 71.4 | 71.28 | 74.98 | 76.22 | 75.59 | |
| Spesifications | ||
|---|---|---|
| Hardware | CPU | 11th Gen Intel(R) Core(TM) i9-11900K @ 3.50 GHz |
| RAM | 64 GB | |
| GPU | NVIDIA GeForce RTX 3090 | |
| Software | OS | Windows 11 Pro 22H2 |
| IDE | Microsoft Visual Studio Enterprise 2019 | |
| Language | Python 3.9.7 | |
| DL tools | Torch 1.10.1 + CUDA 11.3 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pradana, H. An End-to-End Online Traffic-Risk Incident Prediction in First-Person Dash Camera Videos. Big Data Cogn. Comput. 2023, 7, 129. https://doi.org/10.3390/bdcc7030129
Pradana H. An End-to-End Online Traffic-Risk Incident Prediction in First-Person Dash Camera Videos. Big Data and Cognitive Computing. 2023; 7(3):129. https://doi.org/10.3390/bdcc7030129
Chicago/Turabian StylePradana, Hilmil. 2023. "An End-to-End Online Traffic-Risk Incident Prediction in First-Person Dash Camera Videos" Big Data and Cognitive Computing 7, no. 3: 129. https://doi.org/10.3390/bdcc7030129
APA StylePradana, H. (2023). An End-to-End Online Traffic-Risk Incident Prediction in First-Person Dash Camera Videos. Big Data and Cognitive Computing, 7(3), 129. https://doi.org/10.3390/bdcc7030129