
Ensemble-Based Short Text Similarity: An Easy Approach for Multilingual Datasets Using Transformers and WordNet in Real-World Scenarios


Abstract
:1. Introduction
- (a)
- Pre-trained Models: there exist transformers language models pre-trained on large corpora, saving time and resources compared to training Word2Vec or GloVe embeddings from scratch, and more efficient than the pre-trained models.
- (b)
- Out-of-Vocabulary Handling: Transformers can handle out-of-vocabulary words better than Word2Vec or GloVe because they use sub-word tokenization methods (as used in this paper). This allows them to represent and work with words, not in the training data belonging to a niche context or domain.
- (c)
- Multi-lingual Support: Many pre-trained transformer models support multiple languages, making them suitable for multilingual NLP tasks. Word2Vec and GloVe models are typically language-specific.
- Unsupervised pipeline: Once hyperparameters and transformation models are optimized, the entire process becomes unsupervised. We use pre-trained models carefully chosen, eliminating the need to train the networks on specific data.
- Mitigation of the lack of context: the integration of different methods (neural network transformers, dictionary-based and syntactic) allows the mitigation of the lack of context of keywords and the definition of final similarity scores.
- Scalability: Using pre-trained language models, the approach can efficiently handle even archives with hundreds of elements.
- Multilingual support: The use of pre-trained multilingual text models enables the approach to efficiently manage archives containing documents in different languages, such as English, French, Italian, and others.
- Real-world scenarios: The experiments performed for this article demonstrate the ability of the method to adapt to real data without having to adapt it to a specific context. The use of ensemble methods makes it possible to overcome any critical problems that may arise due to unfamiliar words or different languages.
- (1)
- Provide an overview of different approaches that can be adapted to identify overall similarities of 1- or n-gram tags.
- (2)
- Evaluate and compare the performance of different pre-trained language models on short texts/keywords, which are self-contained.
- (3)
- Define methods that can overcome limitations through integrated approaches after analyzing the results of individual methods.
2. Related Works
3. Materials and Methods
3.1. Materials
3.2. Language Identification and Preprocessing
3.3. Single Methods Similarity
- The shortest path length measure computes the length of the shortest path between two synsets in the WordNet graph, representing the minimum number of hypernym links required to connect the synsets. This measure assigns a higher similarity score to word pairs with a shorter path length, indicating a closer semantic relationship. It will be referred to as a path.
- Wu-Palmer Similarity: The Wu-Palmer similarity measure utilizes the depth of the LCS (Lowest Common Subsumer—the most specific common ancestor of two synsets in WordNet’s hierarchy) and the shortest path length to assess the relatedness between synsets. By considering the depth of the LCS in relation to the depths of the synsets being compared, this measure aims to capture the conceptual similarity based on the position of the common ancestor in the WordNet hierarchy. It will be referred to as wu.
- Measure based on distance: analogously to the shortest path length, this measure is also based on the minimum distance between 2 synsets. This measure, hand-crafted by the authors, considers that the shorter the distance, the greater the similarity. In this case, the similarity measure is calculated using this equation:
3.4. Ensemble Methods
- n pretrained language models: as we will see in the experimentation part, the datasets we tested our approach can be monolingual (English or Italian, so far) or multilingual (English, Italian or French, in the experiments). It is, therefore, necessary to identify the models that best represent the specificity of the data under consideration.
- semantic relatedness: three different methods of calculating the representative vector to be evaluated must be compared.
- WordNet-based similarity: again, there are three different ways of calculating the similarity between words.
3.5. Evaluation of the Results
- Recall: Recall measures the proportion of relevant items correctly identified or retrieved by a model. It focuses on the ability to find all positive instances and is calculated as the ratio of true positives to the sum of true positives and false negatives.
- Precision: Precision measures the proportion of retrieved items that are relevant or correct. It focuses on the accuracy of the retrieved items and is calculated as the ratio of true positives to the sum of true positives and false positives.
- F1 score: The F1 score combines precision and recall into a single metric. It is the harmonic mean of precision and recall and provides a balanced measure of a model’s performance. The F1 score ranges from 0 to 1, with 1 being the best performance. It is calculated as 2 × (precision × recall)/(precision + recall).
- Dice coefficient: The Dice coefficient is a metric commonly used for measuring the similarity between two sets. Natural language processing is often employed for evaluating the similarity between predicted and reference sets, such as in entity extraction or document clustering. The Dice coefficient ranges from 0 to 1, with 1 indicating a perfect match. It is calculated as 2 × (intersection of sets)/(sum of set sizes).
- Jaccard coefficient: The Jaccard coefficient, also known as the Jaccard similarity index, measures the similarity between two sets. It is commonly used for tasks like clustering, document similarity, or measuring the overlap between predicted and reference sets. The Jaccard coefficient ranges from 0 to 1, with 1 indicating a complete match. It is calculated as the ratio of the intersection of sets to the union of sets.
4. The Experimentation
4.1. Datasets
- During the search phase, the query is to include all tags that surpass a predetermined similarity threshold. This expansion allows for a broader search scope, encompassing tags semantically similar to the original query. By including such tags, we aim to enhance the search results by considering related keywords.
- During the fruition stage, suggest elements that contain similar keywords to enhance the user experience. By identifying and recommending elements that share similar keywords, we provide users with relevant and related content. This approach enables users to explore and access information beyond their initial query, promoting a comprehensive and enriched browsing experience.
4.2. Dataset Preparation
4.3. Single Methods Similarity
- Determining the best similarity measure: Various similarity assessment methods were utilized to calculate similarity scores between tags. The evaluation aimed to identify the similarity algorithm that best captured the semantic similarity between the given tag and other tags in the datasets.
- Identifying the single tag with the highest similarity: Based on the calculated similarity scores, the tags that exhibited the highest similarity to the given tag were identified, one for each similarity measure.
- Identifying the three most similar features: In addition to finding the single tag with the highest similarity, the evaluation process also focused on identifying the three most similar features. These features are the elements (1-gram or n-grams) that demonstrated high similarity to the given tag.
- Not all WordNet synsets have been translated into all languages. This implies that some synsets may not be available in certain languages, which can affect the matching process.
- By employing machine translation on tags, we can increase the likelihood of finding a corresponding synset. This strategy helps overcome language barriers and enhances the chances of locating relevant synsets.
4.4. Ensemble Methods Similarity/Relatedness
- Single Model Ensemble: This ensemble approach considered the best similarity score for each pre-trained model by combining the results of the various similarity evaluation techniques. Using the weighted voting mechanism (see Table 3a, rows 14–17), the ensemble evaluation aimed to capture the overall similarity between the tags while considering the specific evaluation techniques employed. On the other hand, using the majority voting techniques (see Table 3b, rows 1–4), we can consider the consensus among various approaches.
- All Models Ensemble: In this case, the ensemble is measured by pooling the results from all the language models considered. In this case, greater importance is attributed to the identified term than the similarity value, thereby expanding the range of similar terms, including those with some level of relatedness. What is taken into consideration is the frequency of term selection (Table 3b, rows 5–8).
- Most Frequent Terms Ensemble: The combined results considering all pre-trained models, with the majority voting mechanism applied only to the most frequent terms, capture the collective decision of multiple language models (Table 3b, rows 9–12).
- -
- Eliminate the word: If no suitable term could be found, the annotators could exclude the word from the annotation process due to the unavailability of appropriate alternatives.
- -
- Make an extremely bland association: In cases where the annotators faced significant difficulty finding similar terms, they could make a less precise or less contextually relevant association. This option aimed to capture any resemblance or connection, even if it was not an ideal match.
5. Results and Discussion
5.1. Datasets Used
- Keywords extracted dynamically in QueryLab. The interesting thing is that QueryLab’s archives are multilingual, and almost all of them can respond with English terms. When tested, however, different languages coexist, e.g., RMN or DPLA. Here are the results of the queries:
- (1)
- mariage on Europeana and RMN, using respectively 120 and 100 items;
- (2)
- wedding on Victoria & Albert Museum and DPLA., using 100 items for both archives.
- 2.
- Intangible heritage-related tag lists extracted from QueryLab. These lists are hand-built by experienced ethnographers. The tags we compare are those defined for the Archives of Ethnographies and Social History AESS and its transnational version for the inventory of the intangible cultural heritage of some regions in Northern Italy, some cantons in Switzerland and some traditions in Germany, France and Austria [38] and those of UNESCO [39], imported in QueryLab. The language is the same (English), but there are extremely specialized terms, making it difficult to assess similarity. This dataset is called ICH_TAGS and comprises 300 elements for both lists.
- 3.
- tag lists referring to cooking and ingredients, in Italian, again taken from QueryLab. The interest is to handle data belonging to a specific domain in a language other than English, both for semantic and dictionary-based similarity. The pretrained models used are those for Italian. A comparison was made with a multilingual model. In the following, called Cook_IT, it is composed of 100 and 300 items.
- 4.
- WordSim363, the gold standard.
5.2. Results Evaluation
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Recall | Precision | F1 | Dice | Jaccard |
|---|---|---|---|---|---|
| s1s.[CLS] | 0.346667 | 0.590909 | 0.436975 | 0.310606 | 0.215909 |
| s1s.[AVG] | 0.26506 | 0.5 | 0.346457 | 0.265152 | 0.185606 |
| s1s.[MAXS] | 0.394366 | 0.636364 | 0.486957 | 0.333333 | 0.231061 |
| s1w.path | 0.294872 | 0.522727 | 0.377049 | 0.261364 | 0.174242 |
| s1w.wu | 0.576271 | 0.772727 | 0.660194 | 0.397727 | 0.268939 |
| s1w.min_dist | 0.576271 | 0.772727 | 0.660194 | 0.397727 | 0.268939 |
| s.Jaro | 0.034483 | 0.090909 | 0.05 | 0.045455 | 0.030303 |
| s3s.[CLS] | 0.379032 | 0.152597 | 0.217593 | 0.216414 | 0.128923 |
| s3s.[AVG] | 0.370968 | 0.149351 | 0.212963 | 0.210732 | 0.125045 |
| s3s.[MAXS] | 0.354839 | 0.142857 | 0.203704 | 0.201641 | 0.119363 |
| s3w.path | 0.330645 | 0.138514 | 0.195238 | 0.187879 | 0.114313 |
| s3w.wu | 0.693548 | 0.296552 | 0.415459 | 0.393434 | 0.267181 |
| s3w.min_dist | 0.685484 | 0.293103 | 0.410628 | 0.389394 | 0.262716 |
| e1.model | 0.698113 | 0.840909 | 0.762887 | 0.431818 | 0.291667 |
| e3.model | 0.935484 | 0.127753 | 0.224806 | 0.226294 | 0.129223 |
| e1s.model | 0.394366 | 0.636364 | 0.486957 | 0.333333 | 0.231061 |
| e3s.model | 0.41129 | 0.141274 | 0.210309 | 0.211033 | 0.123785 |
| Method | Recall | Precision | F1 | Dice | Jaccard |
|---|---|---|---|---|---|
| s1s.[CLS] | 0.5 | 0.704545 | 0.584906 | 0.352273 | 0.234848 |
| s1s.[AVG] | 0.5 | 0.704545 | 0.584906 | 0.352273 | 0.234848 |
| s1s.[MAXS] | 0.568966 | 0.75 | 0.647059 | 0.375 | 0.25 |
| s1w.path | 0.294872 | 0.522727 | 0.377049 | 0.261364 | 0.174242 |
| s1w.wu | 0.576271 | 0.772727 | 0.660194 | 0.397727 | 0.268939 |
| s1w.min_dist | 0.576271 | 0.772727 | 0.660194 | 0.397727 | 0.268939 |
| s.Jaro | 0.034483 | 0.090909 | 0.05 | 0.045455 | 0.030303 |
| s3s.[CLS] | 0.5 | 0.201299 | 0.287037 | 0.283965 | 0.174874 |
| s3s.[AVG] | 0.491935 | 0.198052 | 0.282407 | 0.278914 | 0.173205 |
| s3s.[MAXS] | 0.491935 | 0.198052 | 0.282407 | 0.280556 | 0.172078 |
| s3w.path | 0.330645 | 0.138514 | 0.195238 | 0.187879 | 0.114313 |
| s3w.wu | 0.693548 | 0.296552 | 0.415459 | 0.393434 | 0.267181 |
| s3w.min_dist | 0.685484 | 0.293103 | 0.410628 | 0.389394 | 0.262716 |
| e1.model | 0.698113 | 0.840909 | 0.762887 | 0.431818 | 0.291667 |
| e3.model | 0.951613 | 0.133033 | 0.233432 | 0.235696 | 0.135516 |
| e1s.model | 0.568966 | 0.75 | 0.647059 | 0.375 | 0.25 |
| e3s.model | 0.580645 | 0.2 | 0.297521 | 0.296103 | 0.183816 |
| Method | Recall | Precision | F1 |
|---|---|---|---|
| e1.llukas22_mpnet_base | 0.70297 | 0.669811 | 0.68599 |
| e1.tgsc_para_multi | 0.752577 | 0.715686 | 0.733668 |
| e3.llukas22_mpnet_base | 0.935484 | 0.127753 | 0.224806 |
| e3.tgsc_para_multi | 0.951613 | 0.133033 | 0.233432 |
| e3s.llukas22_mpnet_base | 0.362903 | 0.148026 | 0.21028 |
| e3s.tgsc_para_multi | 0.491935 | 0.203333 | 0.287736 |
| e3w.llukas22_mpnet_base | 0.754098 | 0.239583 | 0.363636 |
| e3w.tgsc_para_multi | 0.754098 | 0.239583 | 0.363636 |
| e1.all | 0.805556 | 0.644444 | 0.716049 |
| e3.all | 0.983871 | 0.122367 | 0.217663 |
| e3s.all | 0.620968 | 0.186893 | 0.287313 |
| e3w.all | 0.754098 | 0.239583 | 0.363636 |
| e1.max | 0.710843 | 0.766234 | 0.7375 |
| e3.max | 0.903226 | 0.140351 | 0.24295 |
| e3s.max | 0.233871 | 0.151042 | 0.183544 |
| e3w.max | 0.754098 | 0.239583 | 0.363636 |
| Method | Recall | Precision | F1 | Dice | Jaccard |
|---|---|---|---|---|---|
| s1s.[CLS] | 0.65625 | 0.807692 | 0.724138 | 0.429487 | 0.294872 |
| s1s.[AVG] | 0.606061 | 0.769231 | 0.677966 | 0.403846 | 0.275641 |
| s1s.[MAXS] | 0.527778 | 0.730769 | 0.612903 | 0.391026 | 0.269231 |
| s1w.path | 0.414634 | 0.653846 | 0.507463 | 0.358974 | 0.25 |
| s1w.wu | 0.461538 | 0.692308 | 0.553846 | 0.384615 | 0.275641 |
| s1w.min_dist | 0.461538 | 0.692308 | 0.553846 | 0.384615 | 0.275641 |
| s.Jaro | 0.142857 | 0.307692 | 0.195122 | 0.166667 | 0.115385 |
| s3s.[CLS] | 0.59375 | 0.22619 | 0.327586 | 0.324306 | 0.207672 |
| s3s.[AVG] | 0.609375 | 0.232143 | 0.336207 | 0.332639 | 0.211806 |
| s3s.[MAXS] | 0.59375 | 0.22619 | 0.327586 | 0.324306 | 0.206019 |
| s3w.path | 0.4375 | 0.166667 | 0.241379 | 0.240741 | 0.145833 |
| s3w.wu | 0.671875 | 0.255952 | 0.37069 | 0.36875 | 0.241154 |
| s3w.min_dist | 0.671875 | 0.255952 | 0.37069 | 0.369676 | 0.236111 |
| e1.model | 0.59375 | 0.791667 | 0.678571 | 0.444444 | 0.319444 |
| e3.model | 0.984375 | 0.145833 | 0.254032 | 0.256155 | 0.148334 |
| e1s.model | 0.633333 | 0.791667 | 0.703704 | 0.423611 | 0.291667 |
| e3s.model | 0.65625 | 0.21 | 0.318182 | 0.322807 | 0.203907 |
| Method | Recall | Precision | F1 | Dice | Jaccard |
|---|---|---|---|---|---|
| s1s.[CLS] | 0.5 | 0.704545 | 0.584906 | 0.352273 | 0.234848 |
| s1s.[AVG] | 0.5 | 0.704545 | 0.584906 | 0.352273 | 0.234848 |
| s1s.[MAXS] | 0.568966 | 0.75 | 0.647059 | 0.375 | 0.25 |
| s1w.path | 0.294872 | 0.522727 | 0.377049 | 0.261364 | 0.174242 |
| s1w.wu | 0.576271 | 0.772727 | 0.660194 | 0.397727 | 0.268939 |
| s1w.min_dist | 0.576271 | 0.772727 | 0.660194 | 0.397727 | 0.268939 |
| s.Jaro | 0.034483 | 0.090909 | 0.05 | 0.045455 | 0.030303 |
| s3s.[CLS] | 0.5 | 0.201299 | 0.287037 | 0.283965 | 0.174874 |
| s3s.[AVG] | 0.491935 | 0.198052 | 0.282407 | 0.278914 | 0.173205 |
| s3s.[MAXS] | 0.491935 | 0.198052 | 0.282407 | 0.280556 | 0.172078 |
| s3w.path | 0.330645 | 0.138514 | 0.195238 | 0.187879 | 0.114313 |
| s3w.wu | 0.693548 | 0.296552 | 0.415459 | 0.393434 | 0.267181 |
| s3w.min_dist | 0.685484 | 0.293103 | 0.410628 | 0.389394 | 0.262716 |
| e1.model | 0.698113 | 0.840909 | 0.762887 | 0.431818 | 0.291667 |
| e3.model | 0.951613 | 0.133033 | 0.233432 | 0.235696 | 0.135516 |
| e1s.model | 0.568966 | 0.75 | 0.647059 | 0.375 | 0.25 |
| e3s.model | 0.580645 | 0.2 | 0.297521 | 0.296103 | 0.183816 |
| Method | Recall | Precision | F1 |
|---|---|---|---|
| e1.llukas22_mpnet_base | 0.722222 | 0.661017 | 0.690265 |
| e1.tgsc_para_multi | 0.692308 | 0.610169 | 0.648649 |
| e3.llukas22_mpnet_base | 0.984375 | 0.145833 | 0.254032 |
| e3.tgsc_para_multi | 0.984375 | 0.146512 | 0.255061 |
| e3s.llukas22_mpnet_base | 0.578125 | 0.226994 | 0.325991 |
| e3s.tgsc_para_multi | 0.5625 | 0.219512 | 0.315789 |
| e3w.llukas22_mpnet_base | 0.703125 | 0.197368 | 0.308219 |
| e3w.tgsc_para_multi | 0.703125 | 0.197368 | 0.308219 |
| e1.all | 0.775862 | 0.616438 | 0.687023 |
| e3.all | 1 | 0.131959 | 0.233151 |
| e3s.all | 0.640625 | 0.199029 | 0.303704 |
| e3w.all | 0.703125 | 0.197368 | 0.308219 |
| e1.max | 0.625 | 0.666667 | 0.645161 |
| e3.max | 0.96875 | 0.164456 | 0.281179 |
| e3s.max | 0.5 | 0.264463 | 0.345946 |
| e3w.max | 0.703125 | 0.197368 | 0.308219 |
| Method | Recall | Precision | F1 | Dice | Jaccard |
|---|---|---|---|---|---|
| s1s.[CLS] | 0.460177 | 0.693333 | 0.553191 | 0.351111 | 0.235556 |
| s1s.[AVG] | 0.447368 | 0.68 | 0.539683 | 0.342222 | 0.228889 |
| s1s.[MAXS] | 0.477477 | 0.706667 | 0.569892 | 0.357778 | 0.24 |
| s1w.path | 0.320611 | 0.56 | 0.407767 | 0.28 | 0.186667 |
| s1w.wu | 0.504673 | 0.72 | 0.593407 | 0.36 | 0.24 |
| s1w.min_dist | 0.504673 | 0.72 | 0.593407 | 0.36 | 0.24 |
| s.Jaro | 0.121387 | 0.28 | 0.169355 | 0.14 | 0.093333 |
| s3s.[CLS] | 0.466346 | 0.19246 | 0.272472 | 0.271373 | 0.166336 |
| s3s.[AVG] | 0.485577 | 0.200397 | 0.283708 | 0.282793 | 0.173473 |
| s3s.[MAXS] | 0.480769 | 0.198413 | 0.280899 | 0.279707 | 0.172564 |
| s3w.path | 0.346154 | 0.142857 | 0.202247 | 0.200617 | 0.121142 |
| s3w.wu | 0.677885 | 0.279762 | 0.396067 | 0.392593 | 0.260444 |
| s3w.min_dist | 0.644231 | 0.265873 | 0.376404 | 0.37284 | 0.244819 |
| e1.model | 0.59375 | 0.791667 | 0.678571 | 0.400463 | 0.268519 |
| e3.model | 0.961538 | 0.135227 | 0.237107 | 0.242837 | 0.139389 |
| e1s.model | 0.454545 | 0.694444 | 0.549451 | 0.351852 | 0.236111 |
| e3s.model | 0.576923 | 0.169492 | 0.262009 | 0.269189 | 0.162208 |
| Method | Recall | Precision | F1 | Dice | Jaccard |
|---|---|---|---|---|---|
| s1s.[CLS] | 0.346154 | 0.6 | 0.439024 | 0.313333 | 0.215556 |
| s1s.[AVG] | 0.390244 | 0.64 | 0.484848 | 0.331111 | 0.226667 |
| s1s.[MAXS] | 0.341085 | 0.586667 | 0.431373 | 0.297778 | 0.2 |
| s1w.path | 0.320611 | 0.56 | 0.407767 | 0.28 | 0.186667 |
| s1w.wu | 0.504673 | 0.72 | 0.593407 | 0.36 | 0.24 |
| s1w.min_dist | 0.504673 | 0.72 | 0.593407 | 0.36 | 0.24 |
| s.Jaro | 0.121387 | 0.28 | 0.169355 | 0.14 | 0.093333 |
| s3s.[CLS] | 0.389423 | 0.160714 | 0.227528 | 0.226929 | 0.135362 |
| s3s.[AVG] | 0.432692 | 0.178571 | 0.252809 | 0.252238 | 0.15264 |
| s3s.[MAXS] | 0.442308 | 0.18254 | 0.258427 | 0.257485 | 0.157132 |
| s3w.path | 0.346154 | 0.142857 | 0.202247 | 0.200617 | 0.121142 |
| s3w.wu | 0.677885 | 0.279762 | 0.396067 | 0.392593 | 0.260444 |
| s3w.min_dist | 0.644231 | 0.265873 | 0.376404 | 0.37284 | 0.244819 |
| e1.model | 0.583333 | 0.777778 | 0.666667 | 0.388889 | 0.259259 |
| e3.model | 0.951923 | 0.139437 | 0.243243 | 0.247863 | 0.142883 |
| e1s.model | 0.333333 | 0.583333 | 0.424242 | 0.296296 | 0.199074 |
| e3s.model | 0.480769 | 0.160514 | 0.240674 | 0.244501 | 0.146704 |
| Method | Recall | Precision | F1 | Dice | Jaccard |
|---|---|---|---|---|---|
| s1s.[CLS] | 0.390244 | 0.64 | 0.484848 | 0.331111 | 0.226667 |
| s1s.[AVG] | 0.518519 | 0.746667 | 0.612022 | 0.386667 | 0.264444 |
| s1s.[MAXS] | 0.420168 | 0.666667 | 0.515464 | 0.344444 | 0.235556 |
| s1w.path | 0.320611 | 0.56 | 0.407767 | 0.28 | 0.186667 |
| s1w.wu | 0.504673 | 0.72 | 0.593407 | 0.36 | 0.24 |
| s1w.min_dist | 0.504673 | 0.72 | 0.593407 | 0.36 | 0.24 |
| s.Jaro | 0.121387 | 0.28 | 0.169355 | 0.14 | 0.093333 |
| s3s.[CLS] | 0.480769 | 0.198413 | 0.280899 | 0.280324 | 0.171682 |
| s3s.[AVG] | 0.504808 | 0.208333 | 0.294944 | 0.294213 | 0.182429 |
| s3s.[MAXS] | 0.466346 | 0.19246 | 0.272472 | 0.271373 | 0.167879 |
| s3w.path | 0.346154 | 0.142857 | 0.202247 | 0.200617 | 0.121142 |
| s3w.wu | 0.677885 | 0.279762 | 0.396067 | 0.392593 | 0.260444 |
| s3w.min_dist | 0.644231 | 0.265873 | 0.376404 | 0.37284 | 0.244819 |
| e1.model | 0.519608 | 0.736111 | 0.609195 | 0.368056 | 0.24537 |
| e3.model | 0.942308 | 0.142029 | 0.246851 | 0.250538 | 0.144767 |
| e1s.model | 0.413793 | 0.666667 | 0.510638 | 0.344907 | 0.236111 |
| e3s.model | 0.528846 | 0.190972 | 0.280612 | 0.28209 | 0.172596 |
| Method | Recall | Precision | F1 |
|---|---|---|---|
| e1.para-MiniLM_l6-v2 | 0.672414 | 0.62234 | 0.646409 |
| e1.flax_mpnet_base | 0.620112 | 0.593583 | 0.606557 |
| e1.tgsc_para_multi | 0.625731 | 0.601124 | 0.613181 |
| e3.para-MiniLM_l6-v2 | 0.961538 | 0.135227 | 0.237107 |
| e3.flax_mpnet_base | 0.951923 | 0.139437 | 0.243243 |
| e3.tgsc_para_multi | 0.942308 | 0.142029 | 0.246851 |
| e3s.para-MiniLM_l6-v2 | 0.485577 | 0.221491 | 0.304217 |
| e3s.flax_mpnet_base | 0.423077 | 0.183716 | 0.256186 |
| e3s.tgsc_para_multi | 0.490385 | 0.204819 | 0.288952 |
| e3w.para-MiniLM_l6-v2 | 0.677885 | 0.206745 | 0.316854 |
| e3w.flax_mpnet_base | 0.677885 | 0.206745 | 0.316854 |
| e3w.tgsc_para_multi | 0.677885 | 0.206745 | 0.316854 |
| e1.all | 0.771277 | 0.516014 | 0.618337 |
| e3.all | 0.985577 | 0.113135 | 0.20297 |
| e3s.all | 0.615385 | 0.175824 | 0.273504 |
| e3w.all | 0.677885 | 0.206745 | 0.316854 |
| e1.max | 0.611511 | 0.714286 | 0.658915 |
| e3.max | 0.889423 | 0.157046 | 0.266955 |
| e3s.max | 0.307692 | 0.20915 | 0.249027 |
| e3w.max | 0.677885 | 0.206745 | 0.316854 |
| Method | Recall | Precision | F1 | Dice | Jaccard |
|---|---|---|---|---|---|
| s1s.[CLS] | 0.275862 | 0.380952 | 0.32 | 0.261905 | 0.214286 |
| s1s.[AVG] | 0.333333 | 0.428571 | 0.375 | 0.285714 | 0.230159 |
| s1s.[MAXS] | 0.275862 | 0.380952 | 0.32 | 0.261905 | 0.214286 |
| s1w.path | 0.321429 | 0.428571 | 0.367347 | 0.301587 | 0.253968 |
| s1w.wu | 0.37037 | 0.47619 | 0.416667 | 0.333333 | 0.277778 |
| s1w.min_dist | 0.37037 | 0.47619 | 0.416667 | 0.333333 | 0.277778 |
| s.Jaro | 0.258065 | 0.380952 | 0.307692 | 0.285714 | 0.246032 |
| s3s.[CLS] | 0.289474 | 0.079137 | 0.124294 | 0.124565 | 0.072184 |
| s3s.[AVG] | 0.315789 | 0.084507 | 0.133333 | 0.130385 | 0.075113 |
| s3s.[MAXS] | 0.289474 | 0.078571 | 0.123596 | 0.122184 | 0.070673 |
| s3w.path | 0.421053 | 0.153846 | 0.225352 | 0.175737 | 0.111111 |
| s3w.wu | 0.5 | 0.197917 | 0.283582 | 0.243764 | 0.166667 |
| s3w.min_dist | 0.5 | 0.2 | 0.285714 | 0.245881 | 0.168367 |
| e1.model | 0.423077 | 0.52381 | 0.468085 | 0.365079 | 0.301587 |
| e3.model | 0.631579 | 0.086331 | 0.151899 | 0.140513 | 0.081068 |
| e1s.model | 0.333333 | 0.428571 | 0.375 | 0.285714 | 0.230159 |
| e3s.model | 0.315789 | 0.07362 | 0.119403 | 0.122151 | 0.069766 |
| Method | Recall | Precision | F1 | Dice | Jaccard |
|---|---|---|---|---|---|
| s1s.[CLS] | 0.428571 | 0.571429 | 0.489796 | 0.436508 | 0.380952 |
| s1s.[AVG] | 0.392857 | 0.52381 | 0.44898 | 0.388889 | 0.333333 |
| s1s.[MAXS] | 0.423077 | 0.52381 | 0.468085 | 0.365079 | 0.301587 |
| s1w.path | 0.321429 | 0.428571 | 0.367347 | 0.301587 | 0.253968 |
| s1w.wu | 0.37037 | 0.47619 | 0.416667 | 0.333333 | 0.277778 |
| s1w.min_dist | 0.37037 | 0.47619 | 0.416667 | 0.333333 | 0.277778 |
| s.Jaro | 0.258065 | 0.380952 | 0.307692 | 0.285714 | 0.246032 |
| s3s.[CLS] | 0.578947 | 0.152778 | 0.241758 | 0.241081 | 0.145597 |
| s3s.[AVG] | 0.578947 | 0.153846 | 0.243094 | 0.241081 | 0.145597 |
| s3s.[MAXS] | 0.605263 | 0.159722 | 0.252747 | 0.250605 | 0.150888 |
| s3w.path | 0.421053 | 0.153846 | 0.225352 | 0.175737 | 0.111111 |
| s3w.wu | 0.5 | 0.197917 | 0.283582 | 0.243764 | 0.166667 |
| s3w.min_dist | 0.5 | 0.2 | 0.285714 | 0.245881 | 0.168367 |
| e1.model | 0.461538 | 0.571429 | 0.510638 | 0.412698 | 0.349206 |
| e3.model | 0.789474 | 0.109091 | 0.191693 | 0.190999 | 0.110799 |
| e1s.model | 0.461538 | 0.571429 | 0.510638 | 0.412698 | 0.349206 |
| e3s.model | 0.605263 | 0.138554 | 0.22549 | 0.229733 | 0.136675 |
| Method | Recall | Precision | F1 |
|---|---|---|---|
| e1.nickprock_ita | 0.566667 | 0.395349 | 0.465753 |
| e1.tgsc_para_multi | 0.5 | 0.365854 | 0.422535 |
| e3.nickprock_ita | 0.789474 | 0.109091 | 0.191693 |
| e3.tgsc_para_multi | 0.631579 | 0.086331 | 0.151899 |
| e3s.nickprock_ita | 0.578947 | 0.157143 | 0.247191 |
| e3s.tgsc_para_multi | 0.315789 | 0.086331 | 0.135593 |
| e3w.nickprock_ita | 0.714286 | 0.183486 | 0.291971 |
| e3w.tgsc_para_multi | 0.714286 | 0.183486 | 0.291971 |
| e1.all | 0.645161 | 0.322581 | 0.430108 |
| e3.all | 0.868421 | 0.092697 | 0.167513 |
| e3s.all | 0.657895 | 0.123153 | 0.207469 |
| e3w.all | 0.714286 | 0.183486 | 0.291971 |
| e1.max | 0.428571 | 0.363636 | 0.393443 |
| e3.max | 0.552632 | 0.106599 | 0.178723 |
| e3s.max | 0.236842 | 0.118421 | 0.157895 |
| e3w.max | 0.714286 | 0.183486 | 0.291971 |
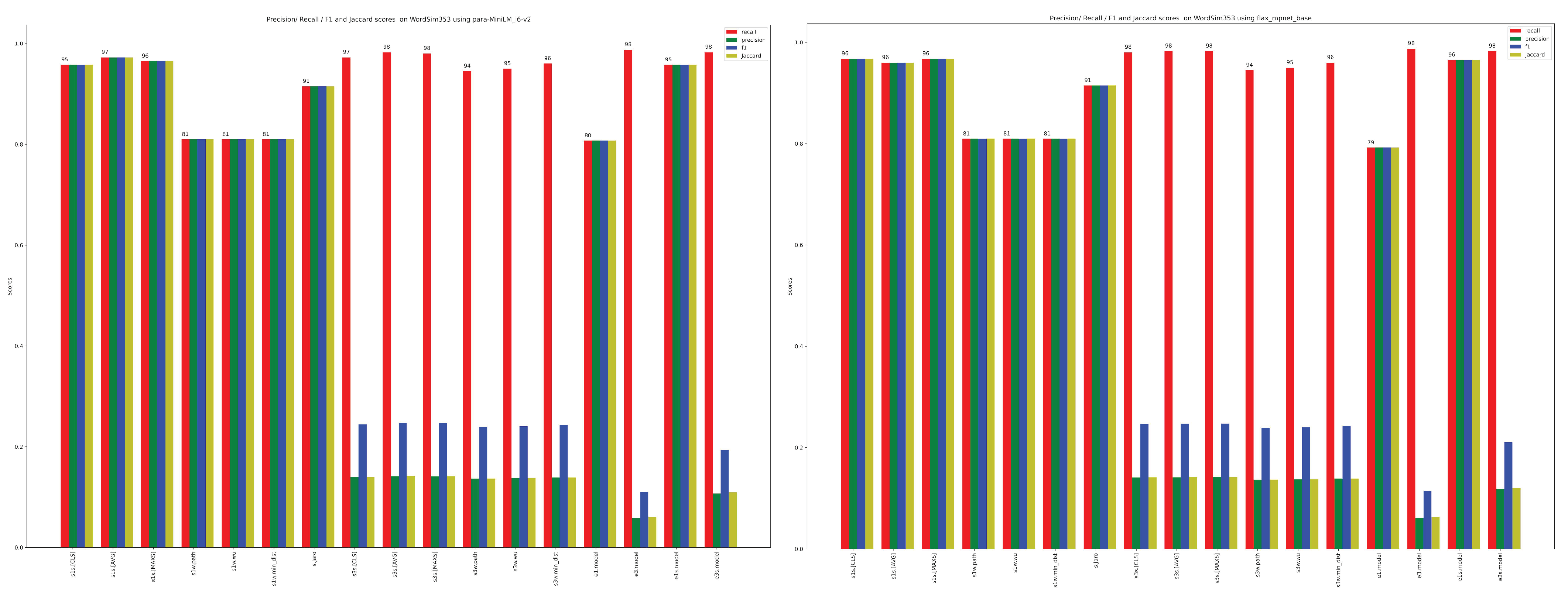
| Method | Recall | Precision | F1 | Dice | Jaccard |
|---|---|---|---|---|---|
| s1s.[CLS] | 0.9575 | 0.9575 | 0.9575 | 0.9575 | 0.9575 |
| s1s.[AVG] | 0.9725 | 0.9725 | 0.9725 | 0.9725 | 0.9725 |
| s1s.[MAXS] | 0.965 | 0.965 | 0.965 | 0.965 | 0.965 |
| s1w.path | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 |
| s1w.wu | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 |
| s1w.min_dist | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 |
| s.Jaro | 0.915 | 0.915 | 0.915 | 0.915 | 0.915 |
| s3s.[CLS] | 0.9725 | 0.139777 | 0.244423 | 0.244643 | 0.13994 |
| s3s.[AVG] | 0.9825 | 0.141367 | 0.24717 | 0.247321 | 0.141488 |
| s3s.[MAXS] | 0.98 | 0.14116 | 0.246774 | 0.246964 | 0.14131 |
| s3w.path | 0.945 | 0.136758 | 0.238938 | 0.23881 | 0.136714 |
| s3w.wu | 0.95 | 0.137532 | 0.240278 | 0.240149 | 0.137488 |
| s3w.min_dist | 0.96 | 0.138929 | 0.242731 | 0.24256 | 0.138857 |
| e1.model | 0.8075 | 0.8075 | 0.8075 | 0.8075 | 0.8075 |
| e3.model | 0.9875 | 0.058277 | 0.110059 | 0.1137 | 0.060448 |
| e1s.model | 0.9575 | 0.9575 | 0.9575 | 0.9575 | 0.9575 |
| e3s.model | 0.9825 | 0.107026 | 0.193026 | 0.196602 | 0.109461 |
| Method | Recall | Precision | F1 | Dice | Jaccard |
|---|---|---|---|---|---|
| s1s.[CLS] | 0.9675 | 0.9675 | 0.9675 | 0.9675 | 0.9675 |
| s1s.[AVG] | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| s1s.[MAXS] | 0.9675 | 0.9675 | 0.9675 | 0.9675 | 0.9675 |
| s1w.path | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 |
| s1w.wu | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 |
| s1w.min_dist | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 |
| s.Jaro | 0.915 | 0.915 | 0.915 | 0.915 | 0.915 |
| s3s.[CLS] | 0.98 | 0.141109 | 0.246696 | 0.246964 | 0.14131 |
| s3s.[AVG] | 0.9825 | 0.141316 | 0.247092 | 0.247321 | 0.141488 |
| s3s.[MAXS] | 0.9825 | 0.14152 | 0.247403 | 0.247679 | 0.141726 |
| s3w.path | 0.945 | 0.136758 | 0.238938 | 0.23881 | 0.136714 |
| s3w.wu | 0.95 | 0.137532 | 0.240278 | 0.240149 | 0.137488 |
| s3w.min_dist | 0.96 | 0.138929 | 0.242731 | 0.24256 | 0.138857 |
| e1.model | 0.7925 | 0.7925 | 0.7925 | 0.7925 | 0.7925 |
| e3.model | 0.9875 | 0.060713 | 0.114393 | 0.117832 | 0.062778 |
| e1s.model | 0.965 | 0.965 | 0.965 | 0.965 | 0.965 |
| e3s.model | 0.9825 | 0.117947 | 0.210611 | 0.213335 | 0.119866 |
| Method | Recall | Precision | F1 | Dice | Jaccard |
|---|---|---|---|---|---|
| s1s.[CLS] | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 |
| s1s.[AVG] | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 |
| s1s.[MAXS] | 0.9675 | 0.9675 | 0.9675 | 0.9675 | 0.9675 |
| s1w.path | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 |
| s1w.wu | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 |
| s1w.min_dist | 0.81 | 0.81 | 0.81 | 0.81 | 0.81 |
| s.Jaro | 0.915 | 0.915 | 0.915 | 0.915 | 0.915 |
| s3s.[CLS] | 0.9825 | 0.141469 | 0.247325 | 0.247589 | 0.141667 |
| s3s.[AVG] | 0.9825 | 0.141622 | 0.247559 | 0.247857 | 0.141845 |
| s3s.[MAXS] | 0.9825 | 0.141469 | 0.247325 | 0.247589 | 0.141667 |
| s3w.path | 0.945 | 0.136758 | 0.238938 | 0.23881 | 0.136714 |
| s3w.wu | 0.95 | 0.137532 | 0.240278 | 0.240149 | 0.137488 |
| s3w.min_dist | 0.96 | 0.138929 | 0.242731 | 0.24256 | 0.138857 |
| e1.model | 0.8175 | 0.8175 | 0.8175 | 0.8175 | 0.8175 |
| e3.model | 0.99 | 0.063604 | 0.119529 | 0.123139 | 0.065788 |
| e1s.model | 0.9675 | 0.9675 | 0.9675 | 0.9675 | 0.9675 |
| e3s.model | 0.9825 | 0.12793 | 0.226382 | 0.22864 | 0.129532 |
| Method | Recall | Precision | F1 |
|---|---|---|---|
| e1.para-MiniLM_l6-v2 | 0.975 | 0.761719 | 0.855263 |
| e1.flax_mpnet_base | 0.9775 | 0.771203 | 0.862183 |
| e1.tgsc_para_multi | 0.98 | 0.777778 | 0.867257 |
| e3.para-MiniLM_l6-v2 | 0.9875 | 0.058277 | 0.110059 |
| e3.flax_mpnet_base | 0.9875 | 0.060713 | 0.114393 |
| e3.tgsc_para_multi | 0.99 | 0.063604 | 0.119529 |
| e3s.para-MiniLM_l6-v2 | 0.98 | 0.151002 | 0.261682 |
| e3s.flax_mpnet_base | 0.9825 | 0.146151 | 0.254451 |
| e3s.tgsc_para_multi | 0.9825 | 0.14265 | 0.249128 |
| e3w.para-MiniLM_l6-v2 | 0.964912 | 0.122651 | 0.217637 |
| e3w.flax_mpnet_base | 0.964912 | 0.122651 | 0.217637 |
| e3w.tgsc_para_multi | 0.964912 | 0.122651 | 0.217637 |
| e1.all | 0.9825 | 0.722426 | 0.832627 |
| e3.all | 0.9925 | 0.047953 | 0.091485 |
| e3s.all | 0.9875 | 0.103268 | 0.186982 |
| e3w.all | 0.964912 | 0.122651 | 0.217637 |
| e1.max | 0.97 | 0.804979 | 0.879819 |
| e3.max | 0.9825 | 0.07328 | 0.136387 |
| e3s.max | 0.9725 | 0.206695 | 0.340929 |
| e3w.max | 0.964912 | 0.122651 | 0.217637 |
References
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Van Rijsbergen, C. Information Retrieval; Butterworths: Boston, MA, USA, 1979. [Google Scholar]
- Jones, K.S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 2004, 60, 493–502. [Google Scholar] [CrossRef]
- Artese, M.T.; Gagliardi, I. Integrating, Indexing and Querying the Tangible and Intangible Cultural Heritage Available Online: The QueryLab Portal. Information 2022, 13, 260. [Google Scholar] [CrossRef]
- Atoum, I.; Otoom, A. A Comprehensive Comparative Study of Word and Sentence Similarity Measures. Int. J. Comput. Appl. 2016, 975, 8887. [Google Scholar] [CrossRef]
- Gomaa, W.H.; Fahmy, A.A. A survey of text similarity approaches. Int. J. Comput. Appl. 2013, 68, 13–18. [Google Scholar]
- Gupta, A.; Kumar, A.; Gautam, J.; Gupta, A.; Kumar, M.A.; Gautam, J. A survey on semantic similarity measures. Int. J. Innov. Res. Sci. Technol. 2017, 3, 243–247. [Google Scholar]
- Sunilkumar, P.; Shaji, A.P. A survey on semantic similarity. In Proceedings of the 2019 International Conference on Advances in Computing, Communication and Control (ICAC3), Mumbai, India, 20–21 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Wang, J.; Dong, Y. Measurement of text similarity: A survey. Information 2020, 11, 421. [Google Scholar] [CrossRef]
- Meng, L.; Huang, R.; Gu, J. A review of semantic similarity measures in WordNet. Int. J. Hybrid Inf. Technol. 2013, 6, 1–12. [Google Scholar]
- Atoum, I.; Otoom, A. Efficient hybrid semantic text similarity using WordNet and a corpus. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 124–130. [Google Scholar] [CrossRef]
- Ensor, T.M.; MacMillan, M.B.; Neath, I.; Surprenant, A.M. Calculating semantic relatedness of lists of nouns using WordNet path length. Behav. Res. Methods 2021, 53, 2430–2438. [Google Scholar] [CrossRef]
- Kenter, T.; De Rijke, M. Short text similarity with word embeddings. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 1411–1420. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Chandrasekaran, D.; Mago, V. Evolution of semantic similarity—A survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Zad, S.; Heidari, M.; Hajibabaee, P.; Malekzadeh, M. A survey of deep learning methods on semantic similarity and sentence modeling. In Proceedings of the 2021 IEEE 12th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 27–30 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 0466–0472. [Google Scholar]
- Arslan, Y.; Allix, K.; Veiber, L.; Lothritz, C.; Bissyandé, T.F.; Klein, J.; Goujon, A. A comparison of pre-trained language models for multi-class text classification in the financial domain. In Proceedings of the Companion Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 260–268. [Google Scholar]
- Li, Y.; Wehbe, R.M.; Ahmad, F.S.; Wang, H.; Luo, Y. A comparative study of pretrained language models for long clinical text. J. Am. Med. Inform. Assoc. 2023, 30, 340–347. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Li, J.; Wu, H.; Hovy, E.; Sun, Y. Pre-Trained Language Models and Their Applications. Engineering 2022. [Google Scholar] [CrossRef]
- Guo, T. A Comprehensive Comparison of Pre-training Language Models (Version 7). TechRxiv. 2021. [Google Scholar] [CrossRef]
- Hugging Face Model for Sentence Similarity. Available online: https://huggingface.co/models?pipeline_tag=sentence-similarity (accessed on 6 September 2023).
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Xu, C. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30; Neural Information Processing Systems Foundation, Inc. (NeurIPS): Long Beach, CA, USA, 2017. [Google Scholar]
- Fellbaum, C. WordNet. In Theory and Applications of Ontology: Computer Applications; Springer: Dordrecht, The Netherlands, 2010; pp. 231–243. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Soni, K.K.; Vyas, R.; Sinhal, A. Importance of string matching in real world problems. Int. J. Eng. Comput. Sci. 2014, 3, 6371–6375. [Google Scholar]
- Wang, Y.; Qin, J.; Wang, W. Efficient approximate entity matching using Jaro-Winkler distance. In Web Information Systems Engineering–WISE 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 231–239. [Google Scholar]
- Hassan, B.; Abdelrahman, S.E.; Bahgat, R.; Farag, I. UESTS: An unsupervised ensemble semantic textual similarity method. IEEE Access 2019, 7, 85462–85482. [Google Scholar] [CrossRef]
- Rychalska, B.; Pakulska, K.; Chodorowska, K.; Walczak, W.; Andruszkiewicz, P. Samsung Poland NLP Team at SemEval-2016 Task 1: Necessity for diversity; combining recursive autoencoders, WordNet and ensemble methods to measure semantic similarity. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 602–608. [Google Scholar]
- Kim, S.Y.; Upneja, A. Majority voting ensemble with a decision trees for business failure prediction during economic downturns. J. Innov. Knowl. 2021, 6, 112–123. [Google Scholar] [CrossRef]
- Anand, V.; Gupta, S.; Gupta, D.; Gulzar, Y.; Xin, Q.; Juneja, S.; Shah, A.; Shaikh, A. Weighted Average Ensemble Deep Learning Model for Stratification of Brain Tumor in MRI Images. Diagnostics 2023, 13, 1320. [Google Scholar] [CrossRef]
- Dogan, A.; Birant, D. A weighted majority voting ensemble approach for classification. In Proceedings of the 2019 4th International Conference on Computer Science and Engineering (UBMK), Samsun, Turkey, 11–15 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Upadhyay, A.; Nguyen, T.T.; Massie, S.; McCall, J. WEC: Weighted ensemble of text classifiers. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–8. [Google Scholar]
- Finkelstein, L.; Gabrilovich, E.; Matias, Y.; Rivlin, E.; Solan, Z.; Wolfman, G.; Ruppin, E. Placing search in context: The concept revisited. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, 1–5 April 2001; pp. 406–414. [Google Scholar]
- WordSim353 and SimLex999 Datasets. Available online: https://github.com/kliegr/word_similarity_relatedness_datasets (accessed on 6 September 2023).
- Hill, F.; Reichart, R.; Korhonen, A. Simlex-999: Evaluating semantic models with (genuine) similarity estimation. Comput. Linguist. 2015, 41, 665–695. [Google Scholar] [CrossRef]
- Artese, M.T.; Gagliardi, I. Methods, Models and Tools for Improving the Quality of Textual Annotations. Modelling 2022, 3, 224–242. [Google Scholar] [CrossRef]
- Artese, M.T.; Gagliardi, I. Inventorying intangible cultural heritage on the web: A life-cycle approach. Int. J. Intang. Herit. 2017, 12, 112–138. [Google Scholar]
- Unesco ICH. Retrieved from Browse the Lists of Intangible Cultural Heritage and the Register of Good Safeguarding Practices. May 2023. Available online: https://ich.unesco.org/en/lists (accessed on 15 September 2023).
- Rehurek, R.; Sojka, P. Gensim–Python Framework for Vector Space Modelling; NLP Centre, Faculty of Informatics, Masaryk University: Brno, Czech Republic, 2011; Volume 3. [Google Scholar]













# Task 1: Dataset Preparation
|
| No. | Model Name | Pretrained Language |
|---|---|---|
| 1 | ‘sentence-transformers/paraphrase-MiniLM-L6-v2’ | English |
| 2 | ‘flax-sentence-embeddings/all_datasets_v3_mpnet-base’ | English |
| 3 | ‘tgsc/sentence-transformers_paraphrase-multilingual-mpnet-base-v2’ | English |
| 4 | ‘nickprock/sentence-bert-base-italian-xxl-uncased’ | Italian |
| 5 | ‘tgsc/sentence-transformers_paraphrase-multilingual-mpnet-base-v2’ | Italian |
| 6 | ‘LLukas22/paraphrase-multilingual-mpnet-base-v2-embedding-all’ | Multilingual |
| 7 | ‘tgsc/sentence-transformers_paraphrase-multilingual-mpnet-base-v2’ | Multilingual |
| (a) single similarity method result label | |||
| 1 | s1s.[CLS] | Single method using semantic similarity, taking the most similar element and respectively [CLS], [AVG] and [MAX] | individual similarity |
| 2 | s1s.[AVG] | ||
| 3 | s1s.[MAX] | ||
| 4 | s1w.path | Single method using WordNet-based similarity, taking the most similar element and respectively path, wu and min_dist | |
| 5 | s1w.wu | ||
| 6 | s1w.min_dist | ||
| 7 | s.Jaro | Single method using Jaro similarity | |
| 8 | s3s.[CLS] | Single method using semantic similarity, taking the most three similar elements and respectively [CLS], [AVG] and [MAX] | |
| 9 | s3s.[AVG] | ||
| 10 | s3s.[MAXS] | ||
| 11 | s3w.path | Single method using WordNet-based similarity, taking the most three similar elements and respectively path, wu and min_dist | |
| 12 | s3w.wu | ||
| 13 | s3w.min_dist | ||
| 14 | e1.model | Single method ensemble, using weighted voting mechanism respectively on the most and most three similar elements obtained by all single methods (for the specific language model) | Single model ensemble (see Section 4.4 point 1) |
| 15 | e3.model | ||
| 16 | e1s.model | Single method ensemble, using weighted voting mechanism respectively on the most and most three similar elements obtained by semantic methods (for the specific language model) | |
| 17 | e3s.model | ||
| (b) ensemble similarity method result label | |||
| 1 | e1.model | Single methods ensemble, using majority voting mechanism respectively on the most and most three similar elements obtained by all single methods, semantic (s) or WordNet-based algorithms (for the specific language model) | Single model ensemble |
| 2 | e3.model | ||
| 3 | e3s.model | ||
| 4 | e3w.model | ||
| 5 | e1.all | As mentioned above, combining the results obtained by each language model | All Models Ensemble(see Section 4.4 point 2) |
| 6 | e3.all | ||
| 7 | e3s.all | ||
| 8 | e3w.all | ||
| 9 | e1.max | As above, combining the results obtained by each language model, applied only to the most frequent terms | Most Frequent Terms Ensemble (see Section 4.4 point 3) |
| 10 | e3.max | ||
| 11 | e3s.max | ||
| 12 | e3w.max | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gagliardi, I.; Artese, M.T. Ensemble-Based Short Text Similarity: An Easy Approach for Multilingual Datasets Using Transformers and WordNet in Real-World Scenarios. Big Data Cogn. Comput. 2023, 7, 158. https://doi.org/10.3390/bdcc7040158
Gagliardi I, Artese MT. Ensemble-Based Short Text Similarity: An Easy Approach for Multilingual Datasets Using Transformers and WordNet in Real-World Scenarios. Big Data and Cognitive Computing. 2023; 7(4):158. https://doi.org/10.3390/bdcc7040158
Chicago/Turabian StyleGagliardi, Isabella, and Maria Teresa Artese. 2023. "Ensemble-Based Short Text Similarity: An Easy Approach for Multilingual Datasets Using Transformers and WordNet in Real-World Scenarios" Big Data and Cognitive Computing 7, no. 4: 158. https://doi.org/10.3390/bdcc7040158
APA StyleGagliardi, I., & Artese, M. T. (2023). Ensemble-Based Short Text Similarity: An Easy Approach for Multilingual Datasets Using Transformers and WordNet in Real-World Scenarios. Big Data and Cognitive Computing, 7(4), 158. https://doi.org/10.3390/bdcc7040158