



Contemporary Art Authentication with Large-Scale Classification



Abstract
:1. Introduction
2. Materials and Methods
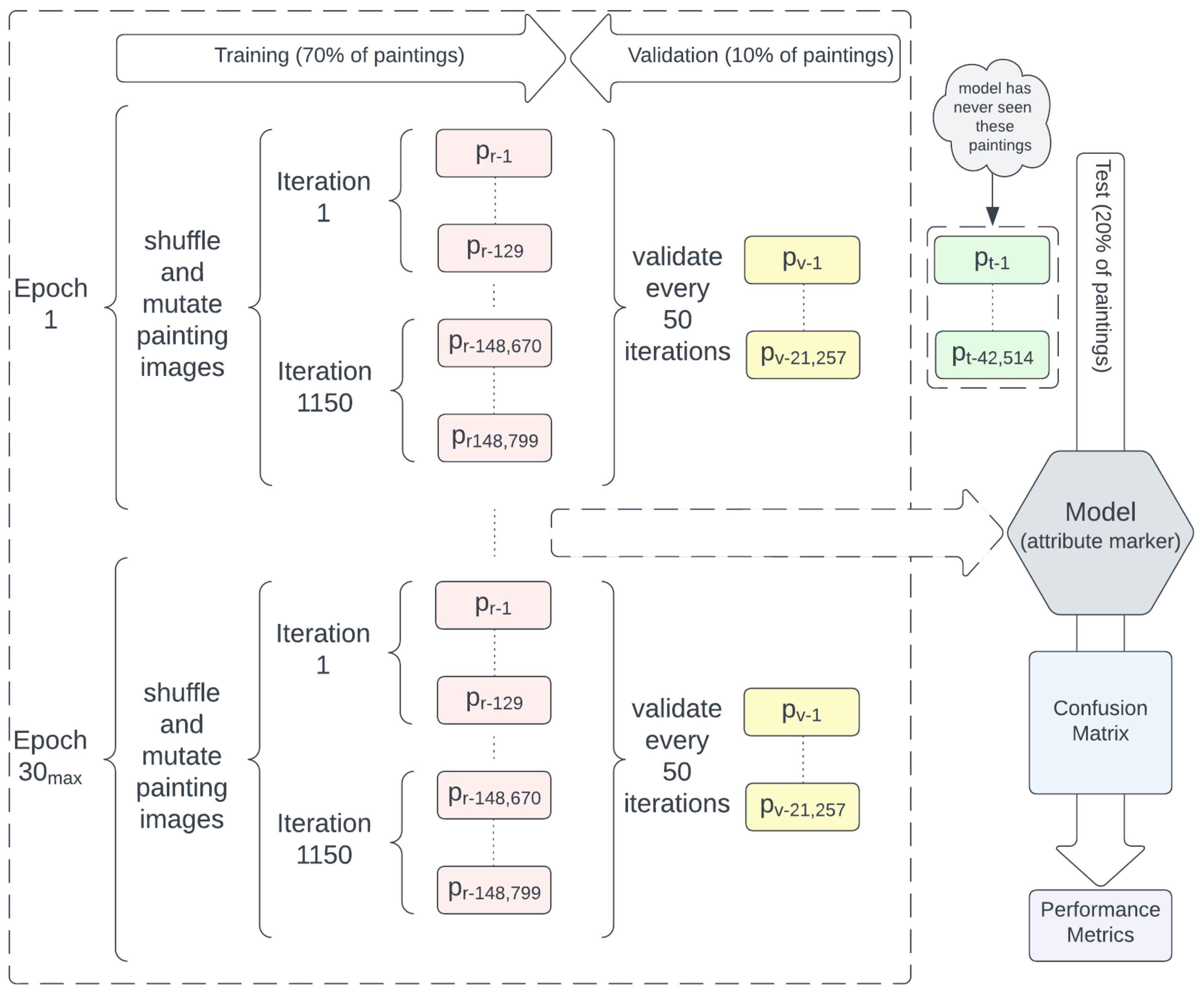
2.1. Machine Learning Development and Evaluation
2.2. Training, Validation and Testing Datasets
2.3. Model Selection
2.4. ResNet Architecture
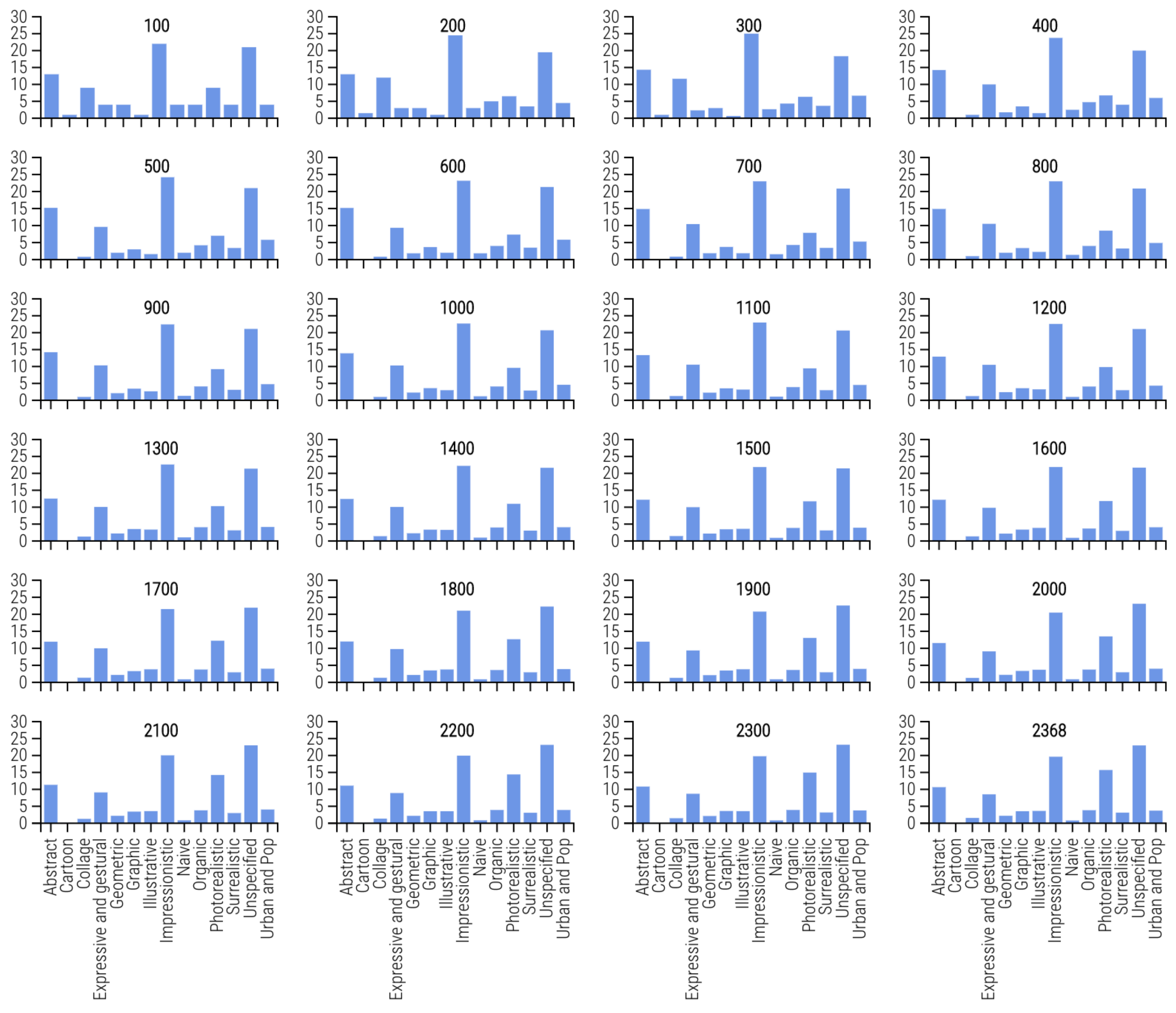
2.5. Artist Selection
2.6. Evaluation Using the Testing Set
2.7. Limitations with Image-Based Art Authentication
Data Source
3. Results
3.1. Confusion Matrix
3.2. Accuracy
4. Discussion
4.1. Multiclass Classifier as Binary Classifier
4.2. True Negatives
4.3. Contemporary Art Performance
4.4. Artist Style
4.5. Uniqueness
5. Conclusions
Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | machine learning |
| SVM | support vector machine |
| k-NN | k-nearest neighbor |
| PCA | principal component analysis |
| OCT | optical coherence tomography |
References
- Lyu, S.; Rockmore, D.; Farid, H. A digital technique for art authentication. Proc. Natl. Acad. Sci. USA 2004, 101, 17006–17010. [Google Scholar] [CrossRef] [PubMed]
- Polak, A.; Kelman, T.; Murray, P.; Marshall, S.; Stothard, D.J.; Eastaugh, N.; Eastaugh, F. Hyperspectral imaging combined with data classification techniques as an aid for artwork authentication. J. Cult. Herit. 2017, 26, 1–11. [Google Scholar] [CrossRef]
- Dobbs, T.; Benedict, A.; Ras, Z. Jumping into the artistic deep end: Building the catalogue raisonné. AI Soc. 2022, 37, 873–889. [Google Scholar] [CrossRef]
- Dobbs, T.; Ras, Z. On art authentication and the Rijksmuseum challenge: A residual neural network approach. Expert Syst. Appl. 2022, 200, 116933. [Google Scholar] [CrossRef]
- Leonarduzzi, R.; Liu, H.; Wang, Y. Scattering transform and sparse linear classifiers for art authentication. Signal Process. 2018, 150, 11–19. [Google Scholar] [CrossRef]
- ydżba-Kopczyńska, B.I.; Szwabiński, J. Attribution Markers and Data Mining in Art Authentication. Molecules 2021, 27, 70. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Park, S.M.; Bak, S.; Kim, G.H.; Kim, C.S.; Kim, C.E.; Kim, K. Advanced Art Authentication in Oil Paintings Using Precise 3D Morphological Analysis of Craquelure Patterns. Res. Sq. 2021. preprint. [Google Scholar] [CrossRef]
- Mar, B. Experts’ Role in Art Authentication; Seton Hall University eRepository: South Orange, NJ, USA, 2021. [Google Scholar]
- The MathWorks Inc. Optimization Toolbox Version: 9.4 (R2022b); The MathWorks Inc.: Natick, MA, USA, 2022. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Kai, L.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Viswanathan, N. Artist Identification with Convolutional Neural Networks. In Standford193CS231N Report; Art Computer Science: Stanford, CA, USA, 2017. [Google Scholar]
- Chen, J. Comparison of Machine Learning Techniques for Artist Identification. In Standford193CS231N Report; Art Computer Science: Stanford, CA, USA, 2018. [Google Scholar]
- Cetinic, E.; Lipic, T.; Grgic, S. Fine-tuning Convolutional Neural Networks for fine art classification. Expert Syst. Appl. 2018, 114, 107–118. [Google Scholar] [CrossRef]
- Mensink, T.; van Gemert, J. The Rijksmuseum Challenge: Museum-Centered Visual Recognition. In Proceedings of the International Conference on Multimedia Retrieval. Association for Computing Machinery, ICMR ’14, Glasgow, UK, 1–4 April 2014. [Google Scholar] [CrossRef]
- van Noord, N.; Hendriks, E.; Postma, E. Toward Discovery of the Artist’s Style: Learning to recognize artists by their artworks. IEEE Signal Process. Mag. 2015, 32, 46–54. [Google Scholar] [CrossRef]
- Strezoski, G.; Worring, M. OmniArt: Multi-task Deep Learning for Artistic Data Analysis. arXiv 2017, arXiv:1708.00684. [Google Scholar]
- Kondo, K.; Hasegawa, T. CNN-based Criteria for Classifying Artists by Illustration Style. In Proceedings of the 2020 2nd International Conference on Image, Video and Signal Processing, Singapore, 20–22 March 2020; pp. 93–98. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Philipp, G.; Song, D.; Carbonell, J.G. The exploding gradient problem demystified-definition, prevalence, impact, origin, tradeoffs, 363 and solutions. arXiv 2017, arXiv:1712.05577. [Google Scholar] [CrossRef]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2008, arXiv:2008.05756. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Powell, L.; Gelich, A.; Ras, Z.W. How to raise artwork prices using action rules, personalization and artwork visual features. J. Intell. Inf. Syst. 2021, 57, 583–599. [Google Scholar] [CrossRef]
- Dobbs, B.T.; Ras, Z.W. Machine Learning Approach to Art Authentication. In Encyclopedia of Data Science and Machine Learning; IGI Global: Hershey, PA, USA, 2023; pp. 1500–1513. [Google Scholar] [CrossRef]
- Abramovich, F.; Pensky, M. Classification with many classes: Challenges and pluses. J. Multivar. Anal. 2019, 174, 104536. [Google Scholar] [CrossRef]
- Honeine, P.; Noumir, Z.; Richard, C. Multiclass classification machines with the complexity of a single binary classifier. Signal Process. 2013, 93, 1013–1026. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Purpose |
|---|---|---|
| Image Size | 224 × 224 × 3 | Resize to match network input |
| Training | 70% | Baseline value |
| Validation | 10% | Baseline value |
| Test | 20% | Baseline value; performance measure source |
| Image Rotation | random | prevent overfitting |
| Image Scaling | random | prevent overfitting |
| Image Reflection | random | prevent overfitting |
| Image Batch | 128 | Based on total image count and available resources |
| Maximum Epochs | 30 | Training Governor |
| Validation | 50 iterations | Training Governor |
| Image shuffle | each epoch | Handles indivisible image partition |
| Initial Input Weight | ImageNet TL | Initial weights for neural network |
| Solver | SGDM | Algorithm that updates weights and biases to minimize the loss function |
| Learning Rate | 0.01 | Tuned to ensure training does not take too long or results do not diverge |
| Momentum | 0.9 | Parameter contribution of the previous iteration to the current iteration |
| Weight Decay Regularization | 0.0001 | Reduces overfitting |
| Artists | Val Acc | Test Acc () | Test Acc (M) |
|---|---|---|---|
| 2368 | 67.62% | 65.33% | 48.97% |
| 2300 | 68.09% | 66.02% | 50.93% |
| 2200 | 68.67% | 67.20% | 52.88% |
| 2100 | 69.15% | 67.63% | 54.84% |
| 2000 | 69.71% | 68.37% | 57.35% |
| 1900 | 70.49% | 68.95% | 59.35% |
| 1800 | 71.42% | 70.23% | 61.05% |
| 1700 | 72.49% | 71.47% | 63.66% |
| 1600 | 73.29% | 72.76% | 65.34% |
| 1500 | 74.29% | 73.41% | 66.80% |
| 1400 | 75.76% | 74.41% | 68.34% |
| 1300 | 76.66% | 75.93% | 70.51% |
| 1200 | 77.81% | 77.43% | 71.77% |
| 1100 | 78.83% | 78.46% | 74.01% |
| 1000 | 79.59% | 79.57% | 75.40% |
| 900 | 81.34% | 81.57% | 77.20% |
| 800 | 82.49% | 82.35% | 78.36% |
| 700 | 83.75% | 83.35% | 80.33% |
| 600 | 85.59% | 85.71% | 82.66% |
| 500 | 86.46% | 86.85% | 83.60% |
| 400 | 88.15% | 88.51% | 85.47% |
| 300 | 91.11% | 91.30% | 88.88% |
| 200 | 93.17% | 93.36% | 91.15% |
| 100 | 96.20% | 96.29% | 91.23% |
| Artists | Artfinder Acc | WikiArt Acc | Rijks Acc |
|---|---|---|---|
| 1200 | 71.77% | n/a | 32.40% |
| 1000 | 75.40% | n/a | 40.51% |
| 400 | 85.47% | n/a | 58.60% |
| 300 | 88.88% | n/a | 46.70% |
| 200 | 91.15% | n/a | 81.66% |
| 100 | 91.23% | 72.96% | 72.69% |
| Artists Count | Uniqueness Score |
|---|---|
| 2368 | 11.37% |
| 2300 | 10.76% |
| 2200 | 10.04% |
| 2100 | 9.32% |
| 2000 | 8.57% |
| 1900 | 8.00% |
| 1800 | 7.53% |
| 1700 | 6.99% |
| 1600 | 6.58% |
| 1500 | 6.19% |
| 1400 | 5.82% |
| 1300 | 5.56% |
| 1200 | 5.29% |
| 1100 | 4.85% |
| 1000 | 4.55% |
| 900 | 4.24% |
| 800 | 3.99% |
| 700 | 3.75% |
| 600 | 3.41% |
| 500 | 3.12% |
| 400 | 2.95% |
| 300 | 2.59% |
| 200 | 2.68% |
| 100 | 3.99% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dobbs, T.; Nayeem, A.-A.-R.; Cho, I.; Ras, Z. Contemporary Art Authentication with Large-Scale Classification. Big Data Cogn. Comput. 2023, 7, 162. https://doi.org/10.3390/bdcc7040162
Dobbs T, Nayeem A-A-R, Cho I, Ras Z. Contemporary Art Authentication with Large-Scale Classification. Big Data and Cognitive Computing. 2023; 7(4):162. https://doi.org/10.3390/bdcc7040162
Chicago/Turabian StyleDobbs, Todd, Abdullah-Al-Raihan Nayeem, Isaac Cho, and Zbigniew Ras. 2023. "Contemporary Art Authentication with Large-Scale Classification" Big Data and Cognitive Computing 7, no. 4: 162. https://doi.org/10.3390/bdcc7040162
APA StyleDobbs, T., Nayeem, A.-A.-R., Cho, I., & Ras, Z. (2023). Contemporary Art Authentication with Large-Scale Classification. Big Data and Cognitive Computing, 7(4), 162. https://doi.org/10.3390/bdcc7040162