1. Introduction
The fashion industry is responsible for creating approximately 40 million tons of textile waste worldwide, most of which ends up in landfill or incinerated [
1]. The issue of clothing waste is prevalent in developed and developing countries [
2]. A major contributor to the accumulation of clothing waste is the tendency of most consumers to dispose of clothes that no longer serve their purpose, compounded by the poor quality of clothing products and their short lifespan [
3]. The pressure on clothing companies to prioritize the scale and speed of production over product quality has exacerbated the situation in response to heightened consumer demand in a highly competitive market. This phenomenon, known as “fast fashion”, entails the mass production of clothing items quickly and in large volumes, resulting in a decline in product quality for consumers [
4].
The shift of clothing companies towards e-commerce platforms has also contributed to the speed and scale of production. By embracing e-commerce, clothing companies have gained access to new market segments and an opportunity to increase their profits [
5]. The fashion industry has the largest B2C e-commerce market segment, and its global size is estimated to reach USD 752.5 billion by 2020. This market is expected to grow further by 9.1% per annum and reach a total market size of USD 1164.7 billion by the end of the year. The United States market was valued at USD 155.6 billion in 2020, with one of its most prominent players being Amazon [
6].
Customers with knowledge of a particular product, such as clothing, are valuable feedback resources [
3]. We can collect user-generated content (UGC), such as consumer reviews from social media, online forum discussions, and review sections on e-commerce websites. Clothing companies can leverage consumer reviews as an invaluable data source to gather product feedback and ideas for further product development [
7].
Product development aims to create durable items, minimizing waste and resource depletion. Analyzing e-commerce reviews is a valuable approach, but it requires advanced techniques. Multilabel classification is a necessary machine-learning method that assigns multiple labels to reviews, going beyond single-category classification. The method allows a detailed evaluation of products, considering various characteristics and customer feedback dimensions. This analytical approach is crucial for evolving products that meet diverse consumer needs. By decoding multifaceted customer feedback, development teams gain insights into material handling. This effort leads to the optimized use of material, efficient handling, reduced waste, and a clear integration of sustainability in product development.
In the context of clothing, it can be useful to utilize machine learning to gain insight to improve product quality. Research by [
8] employs sentiment analysis on e-commerce product reviews, using data collection programs to gather comments and a sentiment classifier to categorize feedback automatically. Furthermore, research by [
9] utilizes supervised machine learning to extend existing life-cycle assessment studies and create a tailored model for assessing clothing products’ environmental sustainability throughout their life cycles. In addition, classifying clothing dimensions and knowing the topic from a review can enhance the understanding of the market and pave the way to more sustainable business.
The deep-learning model BERT (Bidirectional Encoder Representations from Transformers) stands out for its capability to comprehend sentences contextually, making it an ideal choice for label prediction on multilabel classification tasks [
10]. The BERT model has been utilized in research in diverse areas, such as detecting fake news on the Internet [
11] and identifying one’s behavior based on the nature of extraversion and neuroticism of personality dimensions [
12]. In this study, we have chosen the RoBERTa model, which is trained on a larger dataset and can contextualize words better than BERT [
13]. The BERT model can also be implemented on topic modeling tasks called BERTopic. We will use RoBERTa, and BERTopic to map product quality problems in the fashion industry, especially clothing, to help clothing companies produce quality products to reduce clothing waste.
Despite the advancements in applying deep-learning methodologies to the fashion industry, a discernible gap persists in utilizing robust language models for classifying clothing quality. Previous research endeavors have predominantly focused on employing deep learning for categorizing types of clothing products [
14]. Furthermore, research conducted by Dirting et al. (2022) innovatively leveraged the BERT model for a multilabel classification task to discern hate speech [
15]. The specific application of language models like BERT and its derivatives to classify and evaluate clothing quality remains absent from the existing literature. The RoBERTa model, an optimized version of BERT, showcases potential in this domain due to its enhanced training and preprocessing technique. It could arguably facilitate a more nuanced understanding and classification of textual descriptions and reviews related to clothing quality. This research contribution integrates innovative machine-learning methodologies, particularly multilabel classification and utilizing advanced models such as RoBERTa and BERTopic, within the scope of fashion industry analysis.
Section 2 covers theories related to clothing waste management, the significance of quality-focused product development, and the application of machine learning for consumer review insights.
Section 3 shows the research framework, data preparation, and model evaluation metrics.
Section 4 discusses model results and their potential for enhancing clothing product quality. Finally,
Section 5 provides research implications, limitations, and future directions.
3. Research Framework
Selecting an appropriate NLP model is crucial for optimal results in any task. RoBERTa is chosen for the multilabel classification task, given its suitability and superior performance compared to other models considered. The primary objective of this study is to enhance the quality of clothing products while also addressing sustainability issues through implementing a multilabel classification and topic modeling approach, employing state-of-the-art models like RoBERTa and BERTopic. By combining the power of multilabel classification and topic modeling, the research aims to identify and classify various quality dimensions associated with clothing products, enabling a comprehensive assessment of their overall quality.
In addition to improving product quality, the study seeks to integrate sustainability considerations into the classification and topic modeling process. The incorporation of sustainability issues is vital in today’s environmentally conscious world, where the fashion industry faces increasing pressure to adopt eco-friendly practices.
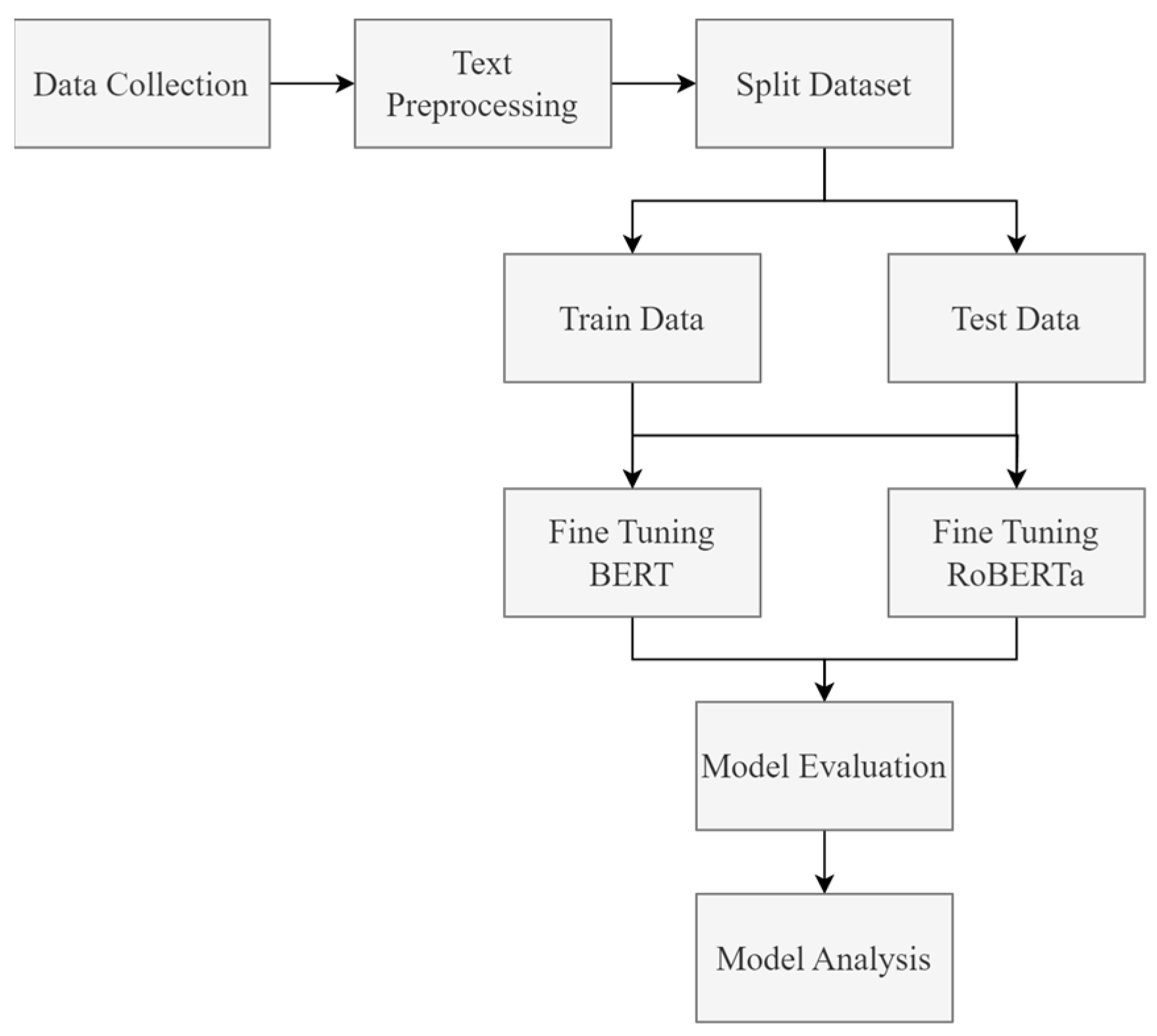
Figure 1 represents the construction of the multilabel classification model using BERT and RoBERTa, spanning from data collection through model analysis. The model must be trained and evaluated to identify patterns in the training data for evaluation using testing data. A well-performing model is then chosen and subsequently fine-tuned for practical application in various conditions.
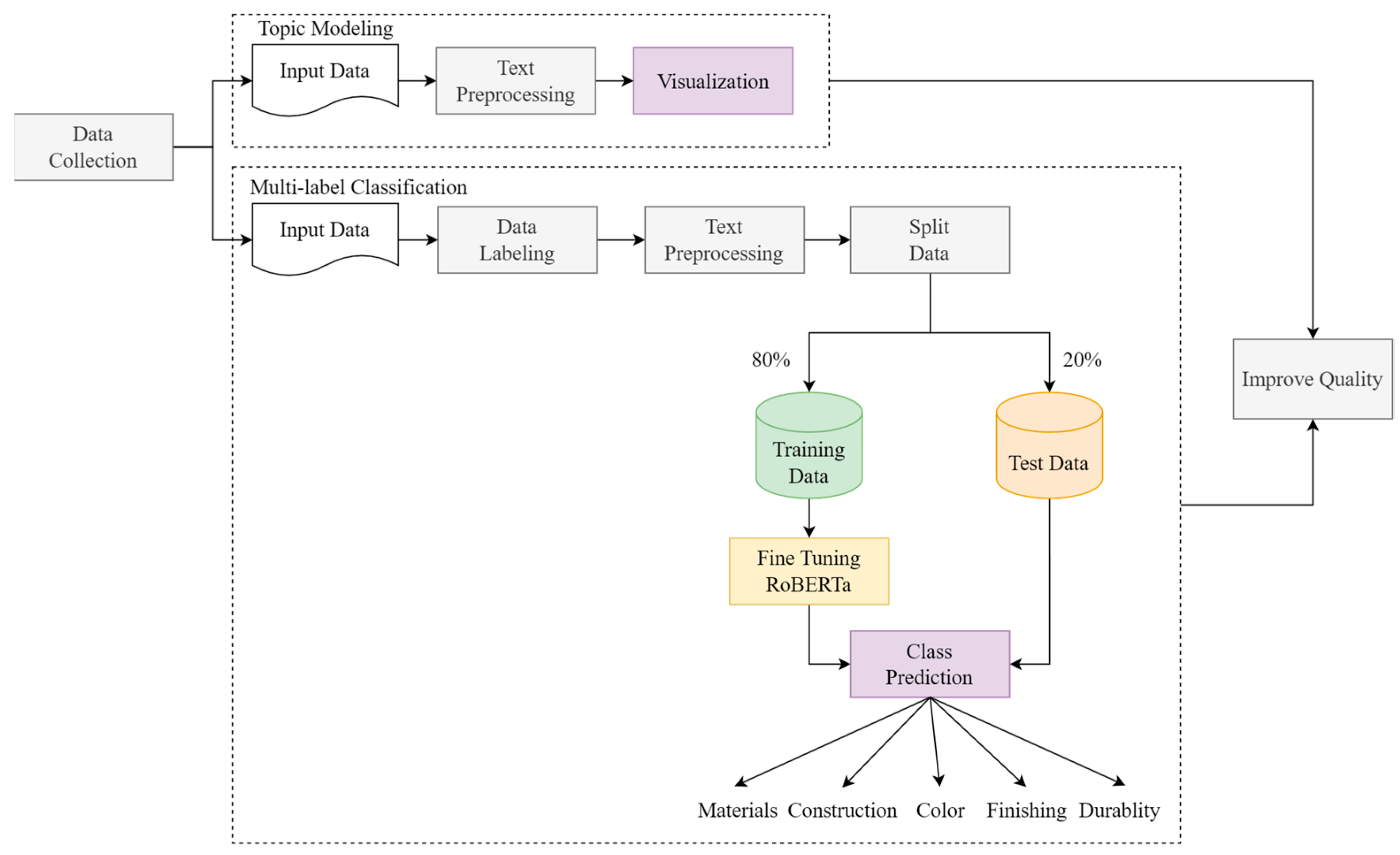
Figure 2 shows the processes of model construction for topic modeling. It includes data preparation (data collection and preprocessing) and a preliminary step for topic modeling.
The research workflow consists of two approaches, namely topic modeling and multilabel classification. These approaches are done in parallel; multilabel classification is utilized to classify the issue of clothing quality, whereas topic modeling can provide insight into the public voice. This comprehensive approach ensures a holistic understanding of clothing quality concerns and the multifaceted voices of consumers in this domain.
Figure 3 provides a comprehensive depiction of the research workflow, encompassing a series of tasks that collectively contribute to the study’s methodology. These tasks include steps such as data labeling, a crucial process to assign appropriate labels to the dataset’s components, ensuring accurate representation, and subsequent analysis. The preprocessing phase is undertaken to eliminate noise and standardize text, resulting in a cleaner and more coherent dataset for the model. Furthermore, the workflow involves the crucial step of splitting the dataset into distinct subsets, with 80% of the data designated for the training set and the remaining 20% allocated for model testing. As for topic modeling tasks, the first step is preprocessing, followed by visualization of the topic. A detailed explanation is given in the next section.
3.1. Data Source, Data Collection, and Dataset
There are two data sources. The first is the data collected using the AMZReviews tool to obtain Amazon reviews [
67]. It is the primary data for this research [
68]. The data we gather contain customer reviews for clothing products with 27,683 data points. Furthermore, to enrich our datasets, we added a dataset from Kaggle consisting of 23,486 clothing review data [
69]. The combined dataset comprises 51,169 data points.
Table 6 comprises six columns, each with its own description. The sample for the User column is “R2S3IVS12Y6RC4”, the Rate column holds user ratings ranging from 1 to 5, with the sample rating as “5”, and the Format column describes product attributes, such as size and color. The “Title” column contains review headings like “Quality Baseball Pants”. The Content column presents detailed user reviews, in this case, about the fit of baseball pants for a child. The “Helpful” column indicates the number of users who found the review helpful. This structure is outlined in
Table 6.
We concentrate on one primary feature in
Table 6, Content, which offers insights into textual expression and sentiment. Furthermore, we include five Boolean features tied to the five quality dimensions listed in
Table 1. Boolean feature is assigned a value of 0 if absent or 1 if present in the review. For instance, a review containing the “Materials” dimension receives a value of 1. There are, in total, nine features for the final dataset [
67]. The final structure of the dataset is as follows: Title, Content, Rate, Class Name, Materials, Construction, Color, Finishing, and Durability. This final dataset serves as input for RoBERTa and BERTopic neural network models, employed in multilabel classification, RoBERTa fine-tuning, and BERT-based topic modeling.
3.2. Data Preprocessing
Preprocessing significantly impacts text classification success and topic modeling for enhanced insights [
70]. BERT in multilabel classification task automatically preprocesses text data. The steps comprise tokenization with special tokens such as [CLS] for classification tasks and [SEP] to separate input segments. Input sequences are then padded or truncated to a fixed length, ensuring a uniform shape for efficient training and inference. Lastly, masking is employed, where BERT randomly replaces tokens with [MASK] during pretraining to learn bidirectional representations [
13].
In contrast, BERTopic requires manual preprocessing, comprising tokenization, stop-word removal, lowercase conversion, stemming, and lemmatization, eliminating extraneous information and reducing text complexity [
71]. BERTopic was employed to create embeddings for each document in our dataset, utilizing a pre-trained BERT model.
3.3. Multilabel Classification Process
The first step of the process is labeling the data, which will be explained in
Section 3.1. After the input data are labeled and preprocessed by the embedded tokenizer, the model is then fine-tuned to our specific dataset. We then conducted an extensive hyperparameter search to intricately optimize the model’s performance. This comprehensive endeavor encompassed fine-tuning crucial parameters, such as learning rates, batch sizes, and the number of training epochs. The objective is to attain the most favorable outcomes tuned precisely to our specific task.
3.3.1. Data Labeling
Data labeling is vital for model construction, enabling accurate pattern learning. This process classifies raw data into correct classes and matches content with quality dimensions. With multilabel classification in mind, we added five columns to the dataset based on
Table 1, namely Materials, Construction, Color, Finishing, and Durability, and filled them with numbers 0 or 1 based on data relevance. The labeled data comprised 3318 instances for clothing quality and 466 unrelated instances. To avoid bias, under-sampling balanced the dataset by selecting 1208 instances from the least-represented label—Durability.
Annotators assign one or more labels from a predefined set of labels to each data instance. This type of annotation allows for the simultaneous assignment of multiple labels to a single data point, reflecting the fact that the data instance may belong to multiple categories or classes. As an illustration, consider the following review: “The colors are gorgeous, but there was a tear in the seam of the dress I had not worn it yet.” This review contextually indicates a concern related to durability, as the mention of tearing is commonly associated with the garment’s resistance to wear and damage. Consequently, we fill the “Color” and “Durability” columns with a value of 1, signifying the presence of durability-related feedback, while the remaining columns are populated with 0 to indicate the absence of such feedback.
3.3.2. Fine-Tuning
The accuracy of model predictions depends on various factors, including the training data size and learning algorithms. A large enough training data size is crucial to achieving high accuracy values, but errors can still occur if there is insufficient data. In this study, we used the Random Split strategy to divide the data randomly [
72]. The data have been split into a ratio of 80:20, where 80% of the data are allocated for training and 20% for testing. The total number of training data is 3029, while the number of test data is 758.
The BERT and RoBERTa models are pre-trained, which allows researchers to focus on fine-tuning them for specific datasets. The initial step entails establishing a scheduler to ascertain the optimal learning rate, ultimately contributing to improved model performance. Determining the model’s hyperparameters is crucial. The “Dropout” parameter, set at 0.1, suggests the use of dropout regularization with a rate of 10%, a common practice to prevent overfitting. The “Batch Size” is configured as 12, indicating that the model processes data in batches of 12 during training. The “Learning Rate (AdamW)” is specified as 0.0001, which controls the step size in the optimization process, with lower values often indicating a cautious learning approach. The “Epoch” parameter is set to 5, representing the number of complete passes through the training dataset. “Hidden Size” is noted as 758, potentially denoting the dimensionality of the hidden layers in the model architecture. Lastly, “Max Position Embeddings” is listed as 512, indicating the maximum positional information the model can consider, which is essential for tasks involving sequential data.
Dropout is a technique used in deep-learning model training to prevent overfitting by randomly disabling nodes. Batch size, the number of samples used in each epoch, affects performance; improper sizes may yield suboptimal results or extended epoch durations with minimal accuracy gains [
73]. The learning rate impacts model accuracy and convergence [
74,
75]. An epoch, a single pass through the training data, indicates how often a dataset is trained on a model. Hidden size refers to the number of embedding representations, while maximum position embedding denotes the maximum number of words in a sentence eligible for embedding [
11].
3.4. Topic Modeling Process
BERTopic, a method for topic modeling, was employed to harness the capabilities of BERT (Bidirectional Encoder Representations from Transformers) in extracting meaningful topics from textual data. The preprocessed data can be input data for BERTopic. The next step is the optimization of BERTopic’s performance for our specific research objective, which entailed the fine-tuning of hyperparameters, encompassing critical adjustments such as determining the optimal number of topics and creating a meaningful topic.
The value of each parameter is based on the recommendation stated in BERTopic. Parameters specific to the BERTopic model, a method primarily used for topic modeling. “stop_words” are defined as “english”, specifying the removal of common English stop words during the analysis, which can enhance the focus on more meaningful content. “top_n_words” is set at 5, signifying that the model focuses on the top five most important words within each document, based on the optimal number of terms is below 30 and TF-IDF score, contributing to the overall representation. “min_topic_size” is established as 20, designating the minimum number of documents required for a topic to be considered valid, with smaller topics potentially excluded. “nr_topics” is specified as 10, indicating the intended number of topics to be extracted from the text data, influencing the granularity of the topic modeling [
59].
3.5. Model Evaluation
The model necessitates evaluation to assess its performance following fine-tuning with training data to assess the performance of multilabel classification and topic modeling tasks.
We utilize the metrics presented in
Table 2 for multilabel classification. These metrics serve as an essential indicator of the model’s effectiveness in handling multiple labels and provide a thorough evaluation of its overall performance [
76,
77].
BERTopic can be evaluated using coherence score, perplexity, and topic diversity. Coherence scores assess how semantically related the words within each topic are, essentially quantifying how well the words co-occur and form coherent topics. Higher coherence scores indicate more coherent and interpretable topics, implying that the words within each topic are closely related and represent a cohesive theme [
76]. These scores are designed to distinguish between topics that are readily understood. On the other hand, perplexity scores measure how well a topic model can predict a set of documents or text data [
78,
79]. As for topic diversity, it captures the variety and distinctiveness of topics in a corpus. The goal of this study is to help clothing companies improve the product’s quality by understanding the consumer’s feedback thoroughly [
59].
3.6. Multilabel Classification Task Model Selection
To substantiate the rationale for selecting RoBERTa, a comparative analysis of BERT and RoBERTa’s performance is conducted utilizing our dataset. As depicted in
Figure 1, the methodology for comparing these two models is outlined. Macro and micro metrics are employed for evaluation. The resulting macro and micro F1 scores reveal that BERT yields a score of 0.86, while RoBERTa achieves a score of 0.87. Based on these findings, the study adopts the RoBERTa model for the multilabel classification.
4. Results and Discussion
4.1. Multilabel Classification Results
This section describes the results of multilabel classification by fine-tuning RoBERTa. We use five epochs to fine-tune the model. Evaluation metrics are used on each label and the model’s overall training process over five epochs. It records the training loss, validation loss, and the time taken during each epoch. In the initial epoch, the training loss begins at 0.39 and gradually decreases to 0.06 in the final epoch. This diminishing training loss indicates a reduction in the prediction errors made by the model as it is being trained on the dataset. Similarly, the validation loss commences at 0.34, experiences fluctuations, and stabilizes at 0.24 in the fourth and fifth epochs. The time taken for each epoch remains relatively consistent, ranging between 4 min and 33 s to 4 min and 35 s. This consistency suggests efficient model training without significant variations in the time required for each epoch.
Table 7 provides a comprehensive overview of the model’s performance metrics, showcasing results for both the training and test datasets. These metrics are instrumental in evaluating the model’s efficiency in making predictions or classifications. In the training phase, “MicroP” (Micro Precision) indicates a Precision rate of 0.86, highlighting that, on average, the model’s predictions are accurate around 86% of the time. This Precision remains consistent in the test phase, affirming the model’s reliability. “MacroP” (Macro Precision) emphasizes class-specific Precision scores, with 0.88 in the training phase, demonstrating the model’s consistent Precision across individual classes. Although it slightly decreases to 0.86 in the test phase, the Precision level remains high. “MicroR” (Micro Recall) attains a score of 0.87 in both training and test phases, signifying that, on average, the model successfully recalls about 87% of relevant instances. “MacroR” (Macro Recall) showcases robust Recall across individual classes, reaching 0.86 in the training phase and increasing to 0.88 in the test phase. “MicroF1” (Micro F1 Score) achieves a high balance between Precision and Recall with a score of 0.89 in the training phase and maintains strength at 0.87 in the test phase. “MacroF1” (Macro F1 Score) affirms a consistent trade-off between Precision and Recall across various classes in both training and test phases, with a score of 0.87. “Accuracy” signifies the model’s overall correctness, achieving 0.90 in the training phase and improving to 0.91 in the test phase, demonstrating high accuracy in predicting instances within the test dataset.
The noteworthy observation in this evaluation’s context is that all the performance metrics considered have consistently surpassed the critical threshold of 0.8. Established as a benchmark, this threshold carries profound implications as it signifies a significant level of model performance. The model’s ability to consistently achieve metrics exceeding this threshold implies a remarkable proficiency in sentence prediction, with an error rate well below 20%. This achievement highlights the model’s robustness and reliability in natural language processing tasks, particularly in its role as an indispensable tool for effectively classifying issues related to the quality of clothing products. These exemplary results affirm the model’s efficacy and underscore its invaluable utility, positioning it as a highly dependable resource in addressing and categorizing concerns about clothing quality.
Table 8 presents each label’s Precision, Recall, and F1-score values. Notably, despite having an equal number of labels, each label exhibits distinct evaluation metric values. The Precision values for the labels are as follows: Materials at 0.85, Construction at 0.84, Color at 0.87, Finishing with the lowest value of 0.83, and Durability with the highest score of 0.92. The Recall scores are 0.81 for Materials (the lowest Recall value), 0.85 for Construction, 0.95 for Color, 0.82 for Finishing, and 0.95 for Durability, with Color and Durability achieving the highest Recall scores. The F1 scores for the labels are 0.81 for Materials, 0.84 for Construction, 0.91 for Color, 0.83 for Finishing, and 0.94 for Durability, where Materials labels receive the lowest F1 score, and Durability obtains the highest F1 score. Although the differences are slight, they may be attributed to factors such as variations in label combinations within the data and the number of sentences. The difference in the Precision, Recall, and F1 score values necessitate the utilization of specialized multilabel classification metrics to evaluate the model’s comprehensive performance.
The findings of the RoBERTa model demonstrate a commendable score using a relatively small dataset consisting of merely 3784 customer reviews. It is crucial to acknowledge that this dataset is considered modest in size, yet the RoBERTa model demonstrates its effectiveness even when the training dataset is constrained. This assertion is substantiated by the evaluation results, showing that the model’s score surpasses 0.5 for individual quality dimensions and overall performance. This finding strongly suggests that the RoBERTa model holds the potential to reliably function as a valuable instrument for pinpointing product quality weaknesses in clothing companies. Additionally, the RoBERTa model’s successful performance with a modest-sized dataset ensures promising implications for other NLP tasks. If the RoBERTa model demonstrates such impressive outcomes with a smaller dataset, it assures that performance can be further enhanced with extensive training data. This assurance could prove particularly valuable for industries or domains where acquiring extensive quantities of labeled data is essential.
The integration of RoBERTa can facilitate a proactive approach to the feedback loop. Manufacturers can utilize the model to predict potential material handling issues before they escalate, enabling preemptive measures that enhance the quality of products and their handling attributes. This predictive capability is especially valuable in optimizing logistics, as manufacturers can swiftly identify potential bottlenecks or vulnerabilities in the material handling process and take corrective actions.
4.2. Topic Modeling Results
This segment presents the top ten topics derived from topic modeling, determined by their highest frequency. To assess the performance of BERTopic in this study, we employ the coherence score metric. The model achieved a coherence score of 0.67 in 20 topics. We experimented with min_topic_size ranging from 10 to 22. We experiment with this set of numbers based on the minimum optimal value recommended by the author of BERTopic [
59].
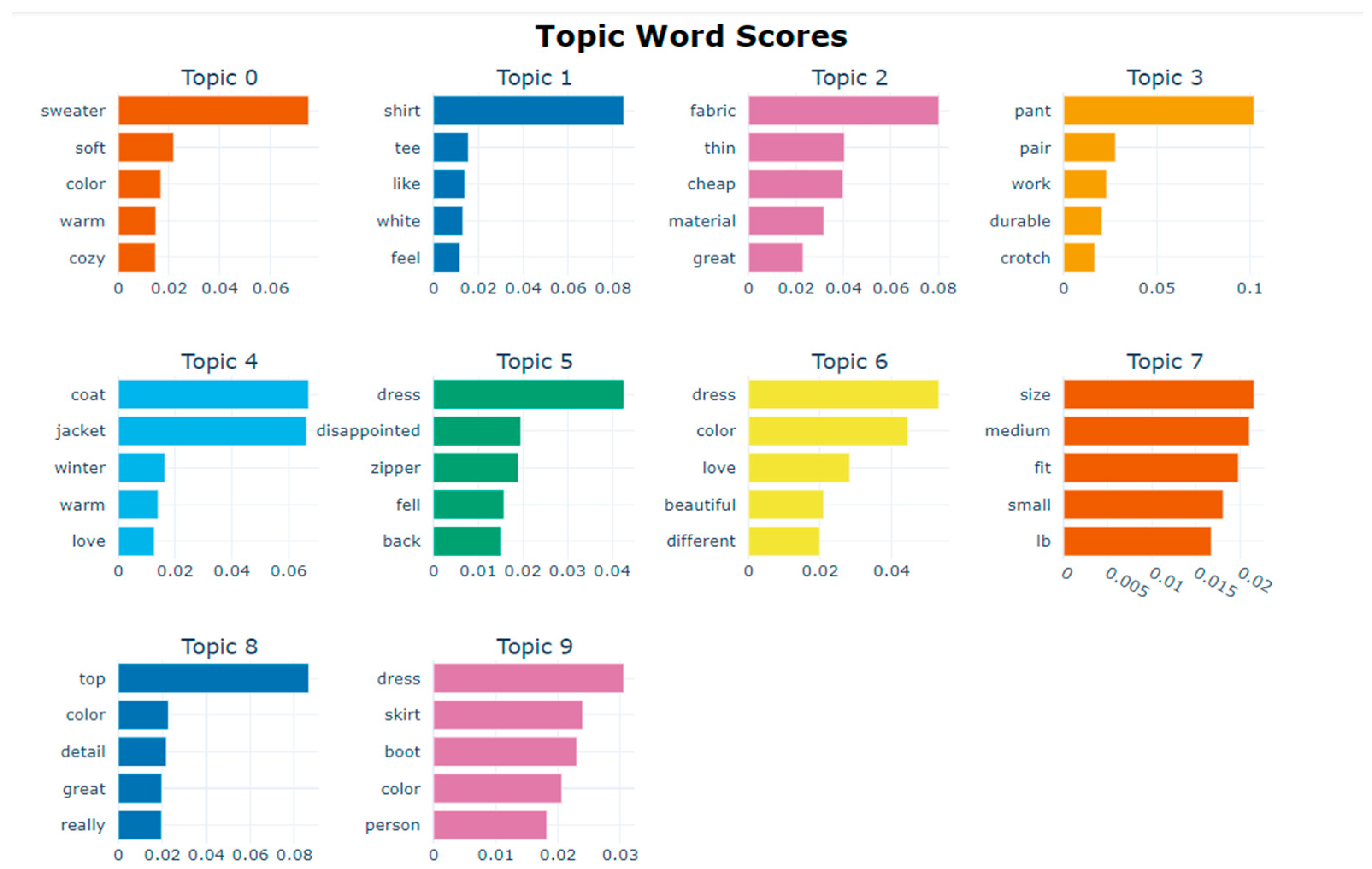
We reduce the topic to 10 to remove redundant or overlapping topics to represent most consumer reviews. To visualize the topics, we use five Topic Word Scores based on TF-IDF to find keywords in a particular topic and a Similarity Matrix to find the correlation between topics. It helps multiple issues to be addressed with one solution. BERTopic manages to give a decent coherence score, and it is above 0.5. The highest coherence score means BERTopic can produce a cluster of words that form topics.
Figure 4 presents ten topics, each featuring the top five words based on their highest TF-IDF scores, which indicate word relevance and provide insight into each topic’s general theme. Topic 0 addresses attributes like softness, warmth, and color consumers value in sweaters. Topic 1 focuses on the feel of white T-shirts. Topic 2 examines thin fabrics associated with inexpensive clothing. Topic 3 reviews work pants with high durability needs in the sensitive groin area. Topic 4 covers winter jackets and coats desired for warmth. Topic 5 reveals consumer disappointment with dresses featuring fragile back zippers. Topic 6 discusses color preferences for attractive dresses. Topic 7 highlights the common purchase of medium-sized clothing, though consumers often find it too small and lightweight. Topic 8 explores tank top attributes, such as color and detail. Topic 9 considers the appearance of consumers’ buttocks when wearing dresses and skirts. The topic encapsulates consumer desires and requirements in product reviews, assisting companies in achieving sustainability objectives. By integrating consumer feedback, businesses can develop products better tailored to meet needs, minimizing disposal and related environmental impacts. This strategy fosters sustainability and curbs the fashion industry’s waste generation. Concentrating on fulfilling consumers’ needs allows companies to decrease waste and promote eco-friendly production.
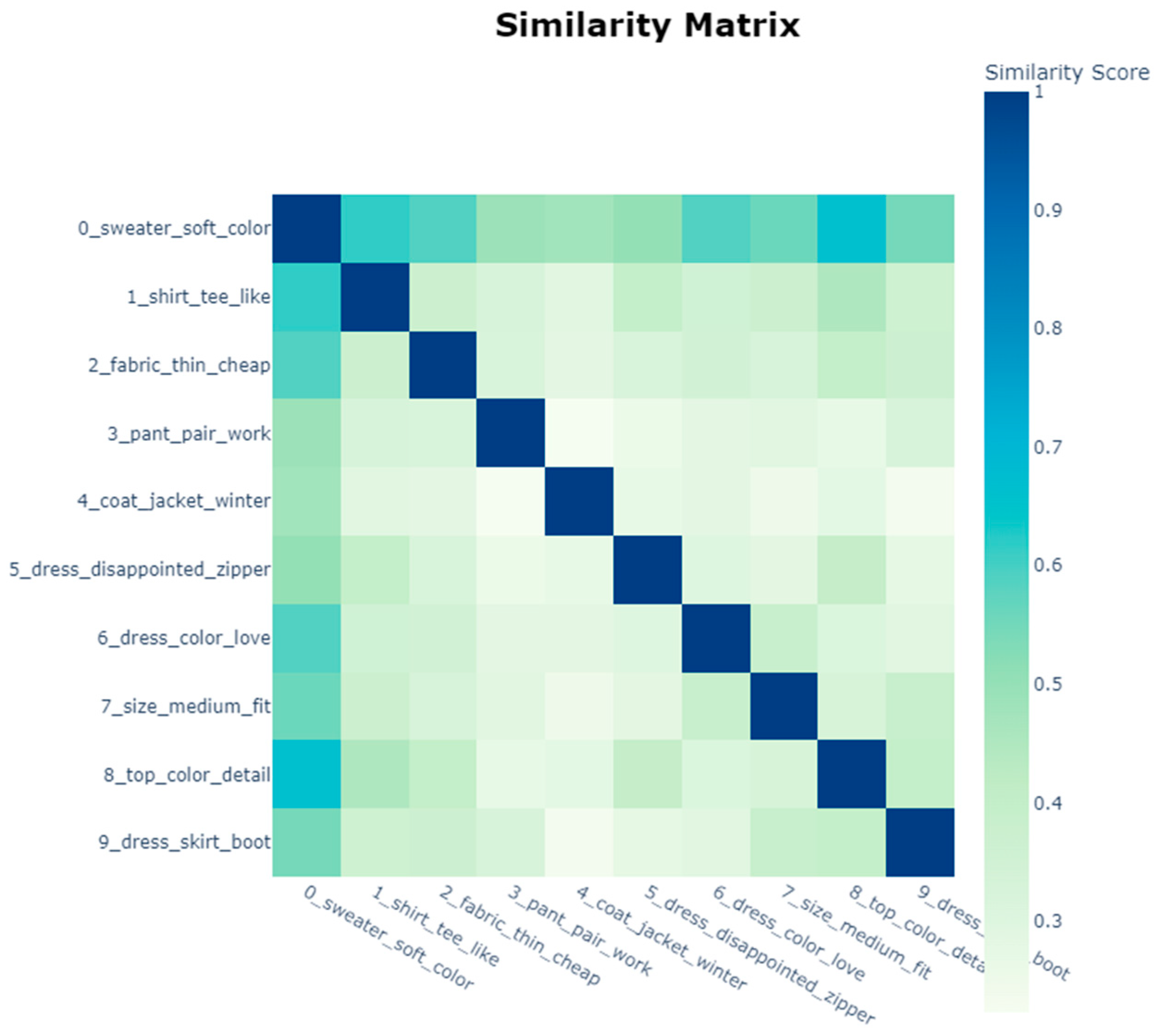
Figure 5 shows a similarity between topics. It is important to qualitatively analyze the words that appear on the topic based on domain experts. The highest similarity is between Topic 0 and Topic 8, with a similarity score of 0.66. As for the topic with the lowest similarity score between Topic 3 and Topic 4, these generally discuss the characteristics required by clothing, according to its function, for companies to be included in the top and sweater attributes. Topic 3 discusses the durability of work pants. In contrast, Topic 4 discusses whether winter jackets should provide warmth for users; these two topics each discuss clothing in different contexts, and Topic 3 discusses clothes worn in winter. In contrast, Topic 4 discusses clothing used while working. Another correlation worth mentioning is Topic 0 and 2, as it can be interpreted that a sweater that is made from fabric is often soft and thin with a lot of color variation while being cheap.
A higher similarity score’s importance lies in its ability to pinpoint sustainable solutions across various topics. Companies can create versatile solutions when there is a high degree of similarity between problems in different areas, reducing research and development costs. This method preserves resources and fosters sustainability by lessening the creation of potentially harmful products or processes. Employing a similarity-focused approach helps companies lower their environmental impact and foster a sustainable future. Thus, a high similarity score is valuable for its practical uses and for encouraging eco-friendly business practices. For example, topics 0 and 8 strongly correlate due to the word “color”. Companies can address related issues in both clothing categories using uniform color codes and natural dyes, ensuring color consistency without procuring additional raw materials. Additionally, Topics 0 and 2 are essential for incorporating improved material handling considerations into material selection, which is crucial for clothing manufacturers, particularly when dealing with diverse textiles, such as thin fabrics that cannot be made into sweaters. The materials require careful attention to ensure that the handling processes, from manufacturing to distribution, do not compromise their integrity or quality over time.
5. Conclusions
Companies should examine ever-growing and diverse consumer reviews for product development ideas to enhance quality and minimize waste. This study suggests a novel approach by merging multilabel classification using a modified RoBERTa model and topic modeling with BERTopic. The combination enables companies to comprehend customer feedback better, pinpoint improvement areas, and reduce waste by developing products in line with consumer preferences.
The research demonstrates RoBERTa’s powerful performance in multilabel classification tasks, separating consumer reviews based on clothing quality dimensions. Metrics such as micro and macro-averaged Precision, Recall, and F1 scores support these findings. Additionally, BERTopic’s topic modeling offers valuable insights, as each topic contains quality-related keywords frequently reviewed on Amazon’s e-commerce platform. We discovered that distinct clothing types have different topics and quality-related issues.
Integrating RoBERTa opens opportunities for a proactive approach to addressing product quality. Manufacturers can use the model to predict material handling issues before they escalate, allowing them to take swift corrective actions, which is particularly valuable in optimizing logistics. BERTopic for topic modeling offers a practical framework for extracting meaningful topics from consumer feedback. Its coherence score of 0.67 at 20 topics effectively captures vital aspects of clothing products valued or criticized by consumers. These insights empower businesses to tailor product development strategies, reducing waste and promoting eco-friendly production practices that align with sustainability goals. Analyzing topic similarities helps companies create versatile and sustainable solutions. High similarity scores between different problems guide the development of unified solutions, lowering research and development costs and reducing environmental impact. For instance, the correlation between topics discussing color consistency encourages the adoption of uniform color codes and natural dyes. Understanding topic relationships, such as those related to material handling, informs material choices to maintain quality during handling processes.
This study acknowledges certain limitations. First, the data quantity used for pretraining models and topic modeling may not fully encompass all clothing quality aspects, warranting more extensive data in future research. Second, this study did not compare other BERT variations or alternative language models. Despite these limitations, the research contributes to the understanding that the RoBERTa model effectively interprets clothing quality-related sentences and excels in multilabel classification tasks. Additionally, BERTopic can extract meaningful topics. Overall, clothing companies can utilize this model to improve product development by leveraging consumer reviews and identifying quality areas needing enhancement. The model boasts high accuracy and rapid analysis of vast data volumes.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




