
Population Forecast of China’s Rural Community Based on CFANGBM and Improved Aquila Optimizer Algorithm

Abstract
:1. Introduction
- In this study, an improved Aquila Optimizer (namely, IAO) was proposed, which combines quasi-opposition learning and wavelet mutation strategy to improve the solution accuracy and convergence speed of the algorithm. The performance of the IAO was tested on the CEC2017 test set.
- A consistent fractional accumulation nonhomogeneous grey Bernoulli model named the CFANGBM(1, 1, b, c) for predicting rural population in China was established. The proposed IAO algorithm was used to solve the model parameters. The fitting error of the CFANGBM(1, 1, b, c) on population data was compared with other grey prediction models: GM(1, 1), DGM(1, 1), TRGM, and FTDGM. The rural population of China in 2020–2024 was forecast.
2. Improved Aquila Optimizer
2.1. Aquila Optimizer
2.1.1. The Process of Initialization
2.1.2. Expanded Exploration (X1)
2.1.3. Narrowed Exploration (X2)
2.1.4. Expanded Exploitation (X3)
2.1.5. Narrowed Exploitation (X4)
2.2. The Proposed Improved Aquila Optimizer
| Algorithm 1: Aquila Optimizer |
| Input: Aquila population X and related parameters (i.e., , , etc.) |
| Output: The optimal value fit(Xbest) |
| While (t < T) |
| Calculate the fitness values of population, and record the best solution (Xbest) |
| Update the parameters such as x, y, QF, G1, G2, etc. |
| if |
| if |
| Expanded exploration (X1): |
| Update the current solution based on Equation (2) |
| When fit(X1(t + 1)) < fit(X(t)), replace X(t) by X1(t + 1) |
| else |
| Narrowed exploration (X2): |
| Update the current solution based on Equation (4) |
| When fit(X2(t + 1)) < fit(X(t)), replace X(t) by X2(t + 1) |
| end if |
| else |
| if |
| Expanded exploitation (X3): |
| Update the current solution based on Equation (11) |
| When fit(X3(t + 1)) < fit(X(t)), replace X(t) by X3(t + 1) |
| else |
| Narrowed exploitation (X4): |
| Update the current solution based on Equation (12) |
| When fit(X4(t + 1)) < fit(X(t)), replace X(t) by X4(t + 1) |
| end if |
| end if |
| t = t + 1 |
| End While |
2.2.1. Quasi-Opposition Learning Strategy
2.2.2. Wavelet Mutation Strategy
2.2.3. Overview of Improved Aquila Optimizer
| Algorithm 2: The Proposed IAO |
| Initialize the population X randomly and set parameters such as , , etc. |
| Calculate quasi-opposition individual of current individual Xi based on Equation (17) |
| Select the N individuals with better fitness value from as the current population |
| While (t < T) |
| Judge whether the individual position is beyond the boundary |
| Calculate the fitness values of population, and update the best solution (Xbest) |
| Update the parameters such as QF, G1, G2, etc. |
| for i = 1, 2, …, N do |
| if |
| if //Expanded exploration |
| if fit(X1) < fit(X) |
| X1 = X |
| end if |
| else //Narrowed exploration |
| if fit(X2) < fit(X) |
| X2 = X |
| end if |
| end if |
| else |
| if //Expanded exploitation |
| if fit(X3) < fit(X) |
| X3 = X |
| end if |
| else //Narrowed exploitation |
| if fit(X4) < fit(X) |
| X4 = X |
| end if |
| end if |
| end if |
| if rand < 0.5 //wavelet mutation |
| if fit() < fit() |
| = |
| end if |
| end if |
| end for |
| t = t + 1 |
| End While |
| Return: The optimal value fit(Xbest) |
2.3. Computational Complexity of the Improved Aquila Optimizer
3. Comparison of Improved Aquila Optimizer with Other Algorithms
4. The Solving of China’s Rural Community Population Forecast Model Using Improved Aquila Optimizer
4.1. China’s Rural Population Forecasting Model
4.2. The Steps of Improved Aquila Optimizer Solving China’s Rural Population Forecasting Model
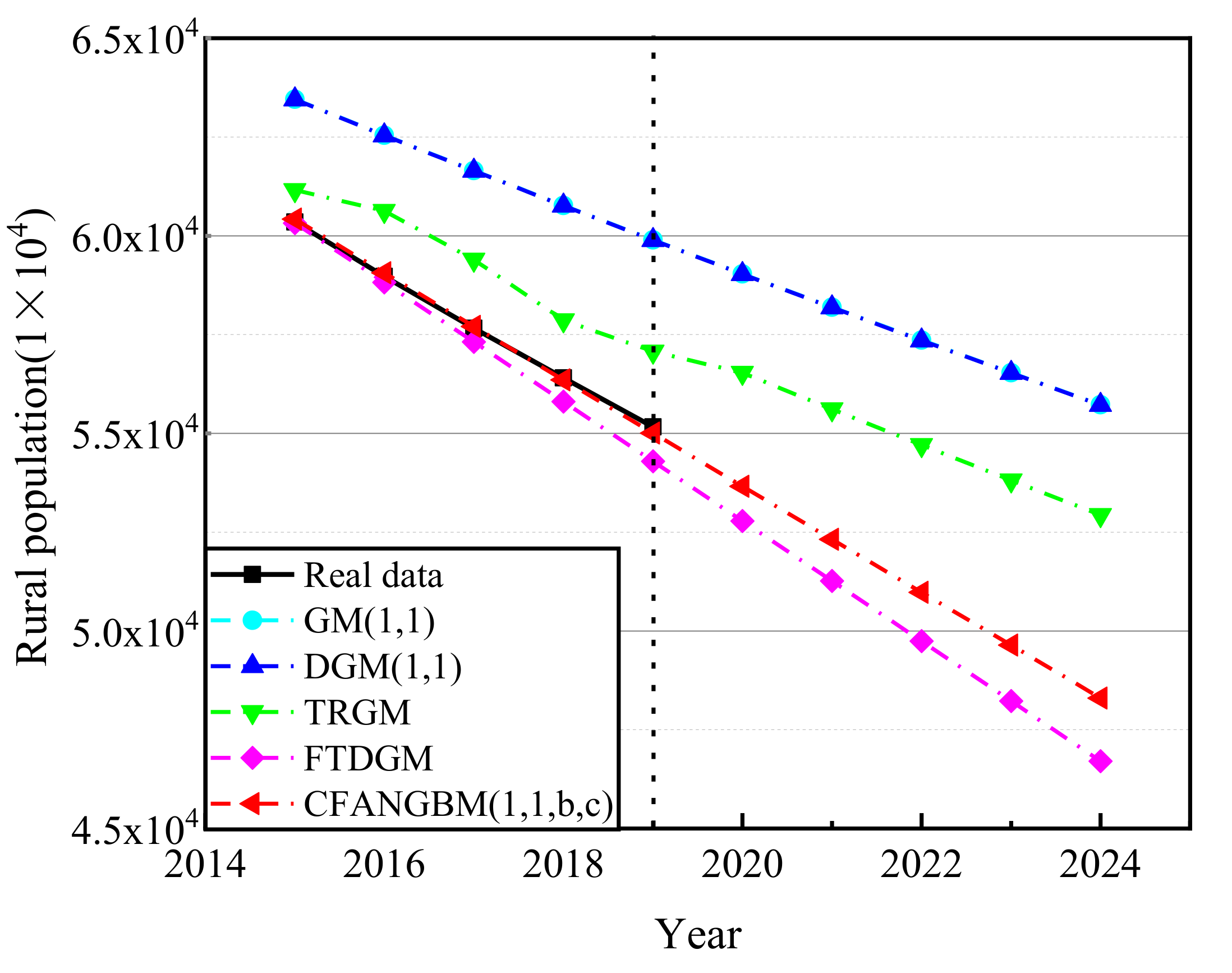
4.3. Experimental Result Analysis of China’s Rural Population Forecasting Model
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, C.F.; Chen, T.M.; Mao, X.Y.; Zhou, Y. Economic transition, urbanization and population redistribution in China. Habitat Int. 2016, 51, 39–47. [Google Scholar] [CrossRef]
- Yan, J.H.; Zhu, S. Rural population transferring trend and spatial direction. China Popul. Resour. Environ. 2017, 27, 146–152. [Google Scholar]
- Lv, Z.; Xu, X.L.; Wan, X.R. Rural Population Prediction from the Perspective of “Rural-Urban” Dynamic Migration—Take Heilongjiang Province as an Example. J. Dalian Univ. 2019, 40, 87–95. [Google Scholar]
- Guan, Y.; Li, X.Y.; Zhu, J.M. Prediction and Analysis of Rural Population in China based on ARIMA Model. J. Shandong Agric. Eng. Univ. 2019, 36, 15–20. [Google Scholar]
- Xuan, H.Y.; Zhang, A.Q.; Yang, N.N. A Model in Chinese Population Growth Prediction. Applied Mechanics and Materials; Trans Tech Publications, Ltd.: Bäch, Switzerland, 2014; Volume 556–562, pp. 6811–6814. [Google Scholar]
- Zhang, Y.N.; Li, W.; Qiu, B.B.; Tan, H.Z.; Luo, Z.Y. UK population forecast using twice-pruning Chebyshev-polynomial WASD neuronet. In Proceedings of the 2016 Chinese Control and Decision Conference (CCDC), Yinchuan, China, 28–30 May 2016; pp. 3029–3034. [Google Scholar]
- Wang, C.Y.; Lee, S.J. Regional Population Forecast and Analysis Based on Machine Learning Strategy. Entropy 2021, 23, 656. [Google Scholar] [CrossRef]
- Fernandes, R.; Campos, P.; Gaio, A.R. An Agent-Based MicMac Model for Forecasting of the Portuguese Population, Portuguese Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2015; pp. 702–707. [Google Scholar]
- Gao, H.; Yao, T.; Kang, X. Population forecast of Anhui province based on the GM (1, 1) model. Grey Syst. 2017, 7, 19–30. [Google Scholar] [CrossRef]
- Wei, Z. Study of Differential Equation Application in the Forecast of Population Growth. Comput. Simul. 2011, 28, 358–362. [Google Scholar]
- Wang, Z.X.; Li, D.D.; Zheng, H.H. Model comparison of GM (1, 1) and DGM (1, 1) based on Monte-Carlo simulation. Phys. A. 2020, 542, 123341. [Google Scholar] [CrossRef]
- Zhou, P.; Ang, B.W.; Poh, K.L. A trigonometric grey prediction approach to forecasting electricity demand. Energy 2006, 31, 2839–2847. [Google Scholar] [CrossRef]
- Xie, N.; Liu, S. Discrete grey forecasting model and its optimization. Appl. Math. Model. 2009, 33, 1173–1186. [Google Scholar] [CrossRef]
- Ma, X.; Mei, X.; Wu, W.Q.; Wu, X.X.; Zeng, B. A novel fractional time delayed grey model with Grey Wolf Optimizer and its applications in forecasting the natural gas and coal consumption in Chongqing China. Energy 2019, 178, 487–507. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R.C. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Yang, X.S.; Gandomi, A.H. Bat Algorithm: A Novel Approach for Global Engineering Optimization. Eng. Comput. 2012, 29, 464–483. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl.-Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Soft. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Soft. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.S. Firefly Algorithm, Stochastic Test Functions and Design Optimization. Int. J. Bio-Inspir. Com. 2010, 2, 78–84. [Google Scholar] [CrossRef]
- Saremi, S.; Mirjalili, S.; Lewis, A. Grasshopper Optimisation Algorithm: Theory and application. Adv. Eng. Softw. 2017, 105, 30–47. [Google Scholar] [CrossRef] [Green Version]
- Heidari, A.; Mirjalili, S.; Farris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comp. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Sulaiman, M.H.; Mustaffa, Z.; Saari, M.M.; Daniyal, H. Barnacles mating optimizer: A new bio-inspired algorithm for solving engineering optimization problems. Eng. Appl. Artif. Intell. 2020, 87, 103330. [Google Scholar] [CrossRef]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp swarm algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Soft. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Zhao, W.G.; Zhang, Z.X.; Wang, L.Y. Manta ray foraging optimization: An effective bio-inspired optimizer for engineering applications. Eng. Appl. Artif. Intell. 2020, 87, 103300. [Google Scholar] [CrossRef]
- Faramarzi, A.; Heidarinejad, M.; Mirjalil, S.; Gandomi, A.H. Marine Predators Algorithm: A nature-inspired metaheuristic. Expert Syst. Appl. 2020, 152, 113377. [Google Scholar] [CrossRef]
- Khishe, M.; Mosavi, M.R. Chimp optimization algorithm. Expert Syst. Appl. 2020, 149, 113338. [Google Scholar] [CrossRef]
- Li, S.M.; Chen, H.L.; Wang, M.J.; Heidari, A.A.; Mirjalili, S. Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comp. Syst. 2020, 111, 300–323. [Google Scholar] [CrossRef]
- Maciel, O.; Cuevas, E.; Navarro, M.A.; Zaldívar, D.; Hinojosa, S. Side-blotched lizard algorithm: A polymorphic population approach. Appl. Soft Comput. 2020, 88, 106039. [Google Scholar] [CrossRef]
- Abdollahzadeh, B.; Gharehchopogh, F.S.; Mirjalili, S. African vultures optimization algorithm: A new nature-inspired metaheuristic algorithm for global optimization problems. Comput. Ind. Eng. 2021, 158, 107408. [Google Scholar] [CrossRef]
- Abdollahzadeh, B.; Gharehchopogh, F.S.; Mirjalili, S. Artificial gorilla troops optimizer: A new nature-inspired metaheuristic algorithm for global optimization problems. Int. J. Intell. Syst. 2021, 36, 5887–5958. [Google Scholar] [CrossRef]
- Abualigah, L.; Yousri, D.; Elaziz, M.A.; Ewees, A.A.; Al-qaness, M.A.A.; Gandomi, A. Aquila Optimizer: A novel meta-heuristic optimization algorithm. Comput. Ind. Eng. 2021, 157, 107250. [Google Scholar] [CrossRef]
- Brezočnik, L.; Fister, I.; Podgorelec, V. Swarm Intelligence Algorithms for Feature Selection: A Review. Appl. Sci. 2018, 8, 1521. [Google Scholar] [CrossRef] [Green Version]
- Rahnamayan, S.; Tizhoosh, H.R.; Salama, M.M.A. Quasi-oppositional Differential Evolution. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25 September 2021; IEEE: Singapore, 2007; pp. 2229–2236. [Google Scholar]
- Chatterjee, A.; Ghoshal, S.P.; Mukherjee, V. Craziness-based PSO with wavelet mutation for transient performance augmentation of thermal system connected to grid. Expert Syst Appl. 2011, 38, 7784–7794. [Google Scholar] [CrossRef]
- Hu, G.; Zhu, X.N.; Wei, G.; Chang, C.T. An improved marine predators algorithm for shape optimization of developable Ball surfaces. Eng. Appl. Artif. Intell. 2021, 105, 104417. [Google Scholar] [CrossRef]
- Awad, N.H.; Ali, M.Z.; Liang, J.J.; Qu, B.Y.; Suganthan, P.N. Problem Definitions and Evaluation Criteria for the CEC 2017 Special Session and Competition on Single Objective Real-Parameter Numerical Optimization; Nanyang Technological Univ.: Singapore, 2016. [Google Scholar]
- Hashim, F.A.; Hussain, K.; Houssein, E.H.; Mai, S.M.; Ai-Atabany, W. Archimedes optimization algorithm: A new metaheuristic algorithm for solving optimization problems. Appl. Intell. 2021, 51, 1531–1551. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A Sine Cosine Algorithm for Solving Optimization Problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | No. | Function Name | Optimal Value |
|---|---|---|---|
| Unimodal Functions | F1 | Shifted and Rotated Bent Cigar Function | 100 |
| F3 | Shifted and Rotated Zakharov Function | 300 | |
| Multimodal Functions | F4 | Shifted and Rotated Rosenbrock’s Function | 400 |
| F5 | Shifted and Rotated Rastrigin’s Function | 500 | |
| F6 | Shifted and Rotated Expanded Scaffer’s F6 Function | 600 | |
| F7 | Shifted and Rotated Lunacek Bi_Rastrigin Function | 700 | |
| F8 | Shifted and Rotated Non-Continuous Rastrigin’s Function | 800 | |
| F9 | Shifted and Rotated Levy Function | 900 | |
| F10 | Shifted and Rotated Schwefel’s Function | 1000 | |
| Hybrid Functions | F11 | Hybrid Function of Zakharov, Rosenbrock, and Rastrigin’s | 1100 |
| F12 | Hybrid Function of High Conditioned Elliptic, Modified Schwefel, and Bent Cigar | 1200 | |
| F13 | Hybrid Function of Bent Cigar, Rosenbrock, and Lunacek Bi_Rastrigin | 1300 | |
| F14 | Hybrid Function of Elliptic, Ackley, Schaffer, and Rastrigin | 1400 | |
| F15 | Hybrid Function of Bent Cigar, HGBat, Rastrigin, and Rosenbrock | 1500 | |
| F16 | Hybrid Function of Expanded Schaffer, HGBat, Rosenbrock, and Modified Schwefel | 1600 | |
| F17 | Hybrid Function of Katsuura, Ackley, Expanded Griewank plus Rosenbrock, Modified Schwefel, and Rastrigin | 1700 | |
| F18 | Hybrid Function of high conditioned Elliptic, Ackley, Rastrigin, HGBat, and Discus | 1800 | |
| F19 | Hybrid Function of Bent Cigar, Rastrigin, Expanded Griewank plus Rosenbrock, Weierstrass, and expanded Schaffer | 1900 | |
| F20 | Hybrid Function of HappyCat, Katsuura, Ackley, Rastrigin, Modified Schwefel, and Schaffer | 2000 | |
| Composition Functions | F21 | Composition Function of Rosenbrock, High Conditioned Elliptic, and Rastrigin | 2100 |
| F22 | Composition Function of Rastrigin, Griewank, and Modified Schwefel | 2200 | |
| F23 | Composition Function of Rosenbrock, Ackley, Modified Schwefel, and Rastrigin | 2300 | |
| F24 | Composition Function of Ackley, High Conditioned Elliptic, Griewank, and Rastrigin | 2400 | |
| F25 | Composition Function of Rastrigin, HappyCat, Ackley, Discus, and Rosenbrock | 2500 | |
| F26 | Composition Function of Expanded Scaffer, Modified Schwefel, Griewank, Rosenbrock, and Rastrigin | 2600 | |
| F27 | Composition Function of HGBat, Rastrigin, Modified Schwefel, Bent-Cigar, High Conditioned Elliptic, and Expanded Scaffer | 2700 | |
| F28 | Composition Function of Ackley, Griewank, Discus, Rosenbrock, HappyCat, and Expanded Scaffer | 2800 | |
| F29 | Composition Function of shifted and rotated Rastrigin, Expanded Scaffer, and Lunacek Bi_Rastrigin | 2900 | |
| F30 | Composition Function of shifted and rotated Rastrigin, Non-Continuous Rastrigin, and Levy Function | 3000 | |
| Search Range: [−100, 100]D | |||
| Algorithm | Parameter Value |
|---|---|
| AO | Exploitation adjustment parameters: α 0.1, δ = 0.1 |
| AOA | Constant parameters: C1 = 2, C2 = 6, C3 = 1, C4 = 2 |
| PSO | Velocity range: 0.5 times the variable range |
| Cognitive and social factors: c1 = 2, c2 = 2.5 | |
| HHO | The value of E0 = [−1,1] |
| SCA | Constant value = 2 |
| WOA | variable linearly decreases from 2 to 0 |
| ACO | Pheromone evaporation coefficient: Rho = 0.95 Pheromones increase intensity: Q = 1 Speed of ant: Lambda = 0.5 |
| GA | Crossover probability: Pc = 0.95 Mutation probability: Pm = 0.001 Select probability: Er = 0.2 |
| IAO | Mutation probability is 0.5, constant s = 10,000 |
| Result | Algorithms | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| IAO | AO | AOA | PSO | HHO | SCA | WOA | ACO | GA | ||
| F1 | Best | 2.05E+05 | 6.55E+05 | 3.83E+09 | 2.91E+06 | 1.48E+05 | 3.20E+06 | 2.38E+06 | 1.62E+09 | 1.43E+09 |
| Mean | 4.25E+05 | 2.48E+06 | 7.97E+09 | 3.62E+07 | 5.32E+05 | 6.07E+07 | 1.46E+07 | 3.99E+09 | 2.61E+09 | |
| Worst | 7.26E+05 | 1.04E+07 | 1.45E+10 | 7.68E+07 | 1.52E+06 | 4.06E+08 | 8.05E+07 | 7.45E+09 | 4.46E+09 | |
| Std | 1.52E+05 | 2.10E+06 | 2.85E+09 | 2.03E+07 | 3.39E+05 | 1.19E+08 | 1.91E+07 | 1.58E+09 | 7.32E+08 | |
| Rank | 1 | 3 | 9 | 5 | 2 | 6 | 4 | 8 | 7 | |
| F3 | Best | 3.01E+02 | 3.26E+02 | 1.49E+03 | 5.23E+02 | 3.04E+02 | 7.66E+03 | 6.87E+02 | 1.07E+05 | 1.17E+04 |
| Mean | 3.08E+02 | 1.19E+03 | 3.94E+03 | 1.64E+03 | 3.54E+02 | 5.27E+04 | 3.49E+03 | 4.17E+05 | 2.95E+05 | |
| Worst | 3.28E+02 | 3.05E+03 | 9.15E+03 | 2.78E+03 | 5.77E+02 | 2.03E+05 | 1.46E+04 | 1.08E+06 | 1.83E+06 | |
| Std | 8.61E+00 | 7.11E+02 | 1.98E+03 | 6.00E+02 | 7.12E+01 | 4.90E+04 | 4.23E+03 | 2.23E+05 | 5.91E+05 | |
| Rank | 1 | 3 | 6 | 4 | 2 | 7 | 5 | 9 | 8 | |
| F4 | Best | 4.03E+02 | 4.04E+02 | 5.81E+02 | 4.07E+02 | 4.00E+02 | 4.05E+02 | 4.06E+02 | 5.13E+02 | 5.40E+02 |
| Mean | 4.05E+02 | 4.32E+02 | 7.79E+02 | 4.16E+02 | 4.19E+02 | 4.14E+02 | 4.56E+02 | 7.33E+02 | 7.67E+02 | |
| Worst | 4.08E+02 | 4.85E+02 | 1.10E+03 | 4.89E+02 | 4.89E+02 | 4.47E+02 | 5.78E+02 | 1.26E+03 | 1.23E+03 | |
| Std | 1.20E+00 | 3.46E+01 | 1.60E+02 | 1.80E+01 | 2.69E+01 | 9.81E+00 | 5.67E+01 | 1.95E+02 | 1.72E+02 | |
| Rank | 1 | 5 | 9 | 3 | 4 | 2 | 6 | 7 | 8 | |
| F5 | Best | 5.05E+02 | 5.12E+02 | 5.58E+02 | 5.22E+02 | 5.17E+02 | 5.16E+02 | 5.30E+02 | 5.63E+02 | 5.20E+02 |
| Mean | 5.13E+02 | 5.31E+02 | 5.70E+02 | 5.31E+02 | 5.52E+02 | 5.27E+02 | 5.51E+02 | 5.85E+02 | 5.32E+02 | |
| Worst | 5.28E+02 | 5.46E+02 | 5.81E+02 | 5.44E+02 | 5.83E+02 | 5.40E+02 | 6.02E+02 | 6.04E+02 | 5.53E+02 | |
| Std | 6.44E+00 | 9.69E+00 | 7.18E+00 | 5.35E+00 | 1.66E+01 | 8.28E+00 | 1.81E+01 | 1.08E+01 | 7.74E+00 | |
| Rank | 1 | 4 | 8 | 3 | 7 | 2 | 6 | 9 | 5 | |
| F6 | Best | 6.00E+02 | 6.07E+02 | 6.29E+02 | 6.02E+02 | 6.14E+02 | 6.02E+02 | 6.11E+02 | 6.34E+02 | 6.02E+02 |
| Mean | 6.02E+02 | 6.17E+02 | 6.37E+02 | 6.04E+02 | 6.38E+02 | 6.05E+02 | 6.35E+02 | 6.49E+02 | 6.08E+02 | |
| Worst | 6.06E+02 | 6.37E+02 | 6.47E+02 | 6.06E+02 | 6.60E+02 | 6.11E+02 | 6.70E+02 | 6.67E+02 | 6.19E+02 | |
| Std | 1.63E+00 | 7.39E+00 | 5.63E+00 | 1.26E+00 | 1.29E+01 | 2.47E+00 | 1.57E+01 | 9.59E+00 | 4.85E+00 | |
| Rank | 1 | 5 | 7 | 2 | 8 | 3 | 6 | 9 | 4 | |
| F7 | Best | 7.21E+02 | 7.34E+02 | 7.58E+02 | 7.42E+02 | 7.42E+02 | 7.26E+02 | 7.31E+02 | 8.32E+02 | 7.27E+02 |
| Mean | 7.34E+02 | 7.57E+02 | 7.82E+02 | 7.62E+02 | 7.84E+02 | 7.38E+02 | 7.77E+02 | 9.05E+02 | 7.40E+02 | |
| Worst | 7.59E+02 | 7.86E+02 | 8.16E+02 | 7.87E+02 | 8.27E+02 | 7.55E+02 | 8.29E+02 | 9.64E+02 | 7.59E+02 | |
| Std | 1.15E+01 | 1.46E+01 | 1.50E+01 | 1.42E+01 | 2.55E+01 | 8.63E+00 | 2.51E+01 | 3.19E+01 | 8.44E+00 | |
| Rank | 1 | 4 | 7 | 5 | 8 | 2 | 6 | 9 | 3 | |
| F8 | Best | 8.07E+02 | 8.11E+02 | 8.26E+02 | 8.24E+02 | 8.13E+02 | 8.11E+02 | 8.17E+02 | 8.72E+02 | 8.12E+02 |
| Mean | 8.18E+02 | 8.23E+02 | 8.39E+02 | 8.34E+02 | 8.28E+02 | 8.20E+02 | 8.39E+02 | 8.93E+02 | 8.20E+02 | |
| Worst | 8.40E+02 | 8.36E+02 | 8.50E+02 | 8.51E+02 | 8.42E+02 | 8.27E+02 | 8.70E+02 | 9.06E+02 | 8.29E+02 | |
| Std | 9.02E+00 | 6.83E+00 | 6.85E+00 | 7.08E+00 | 9.24E+00 | 4.72E+00 | 1.47E+01 | 8.24E+00 | 4.68E+00 | |
| Rank | 1 | 4 | 8 | 6 | 5 | 2 | 7 | 9 | 3 | |
| F9 | Best | 9.00E+02 | 9.17E+02 | 9.98E+02 | 9.12E+02 | 1.02E+03 | 9.02E+02 | 1.00E+03 | 1.80E+03 | 1.02E+03 |
| Mean | 9.00E+02 | 1.03E+03 | 1.19E+03 | 9.55E+02 | 1.50E+03 | 9.39E+02 | 1.52E+03 | 2.48E+03 | 1.38E+03 | |
| Worst | 9.01E+02 | 1.26E+03 | 1.39E+03 | 1.04E+03 | 1.90E+03 | 1.12E+03 | 3.72E+03 | 3.53E+03 | 2.31E+03 | |
| Std | 2.50E-01 | 9.56E+01 | 9.51E+01 | 3.83E+01 | 2.45E+02 | 5.16E+01 | 6.03E+02 | 5.27E+02 | 3.34E+02 | |
| Rank | 1 | 4 | 5 | 3 | 7 | 2 | 8 | 9 | 6 | |
| F10 | Best | 1.24E+03 | 1.53E+03 | 1.99E+03 | 1.70E+03 | 1.48E+03 | 1.50E+03 | 1.32E+03 | 2.25E+03 | 1.55E+03 |
| Mean | 1.52E+03 | 1.97E+03 | 2.50E+03 | 2.26E+03 | 2.03E+03 | 2.15E+03 | 2.06E+03 | 2.46E+03 | 1.97E+03 | |
| Worst | 1.82E+03 | 2.55E+03 | 2.86E+03 | 2.60E+03 | 2.46E+03 | 2.89E+03 | 2.81E+03 | 3.32E+03 | 2.52E+03 | |
| Std | 1.93E+02 | 2.73E+02 | 2.15E+02 | 2.60E+02 | 2.91E+02 | 3.80E+02 | 4.46E+02 | 1.28E+03 | 2.70E+02 | |
| Rank | 1 | 2 | 9 | 7 | 4 | 6 | 5 | 8 | 3 | |
| F11 | Best | 1.11E+03 | 1.13E+03 | 1.20E+03 | 1.12E+03 | 1.13E+03 | 1.12E+03 | 1.13E+03 | 3.89E+03 | 2.62E+03 |
| Mean | 1.13E+03 | 1.18E+03 | 1.63E+03 | 1.14E+03 | 1.19E+03 | 1.16E+03 | 1.23E+03 | 9.97E+03 | 1.76E+04 | |
| Worst | 1.16E+03 | 1.34E+03 | 3.44E+03 | 1.36E+03 | 1.31E+03 | 1.33E+03 | 1.52E+03 | 2.55E+04 | 6.86E+04 | |
| Std | 1.50E+01 | 6.16E+01 | 5.66E+02 | 5.20E+01 | 5.18E+01 | 4.66E+01 | 9.11E+01 | 5.53E+03 | 1.48E+04 | |
| Rank | 1 | 4 | 7 | 2 | 5 | 3 | 6 | 8 | 9 | |
| F12 | Best | 1.70E+04 | 8.54E+04 | 4.25E+05 | 2.71E+05 | 8.13E+03 | 2.10E+04 | 8.48E+04 | 2.53E+07 | 2.99E+07 |
| Mean | 3.92E+05 | 3.83E+06 | 1.21E+07 | 2.20E+06 | 3.53E+06 | 1.82E+06 | 6.73E+06 | 1.83E+08 | 2.37E+08 | |
| Worst | 2.50E+06 | 1.69E+07 | 5.72E+07 | 8.49E+06 | 1.31E+07 | 1.49E+07 | 1.92E+07 | 4.76E+08 | 4.78E+08 | |
| Std | 6.11E+05 | 4.42E+06 | 1.64E+07 | 2.03E+06 | 3.40E+06 | 3.67E+06 | 5.98E+06 | 1.23E+08 | 1.30E+08 | |
| Rank | 1 | 5 | 7 | 3 | 4 | 2 | 6 | 8 | 9 | |
| F13 | Best | 2.34E+03 | 3.60E+03 | 8.60E+03 | 1.69E+03 | 1.83E+03 | 5.30E+03 | 1.84E+03 | 1.69E+05 | 1.56E+06 |
| Mean | 7.70E+03 | 1.69E+04 | 8.92E+04 | 9.69E+03 | 2.39E+04 | 9.98E+04 | 1.58E+04 | 3.49E+06 | 6.33E+07 | |
| Worst | 1.98E+04 | 4.86E+04 | 9.36E+05 | 2.78E+04 | 8.49E+04 | 2.98E+05 | 3.89E+04 | 9.28E+06 | 2.98E+08 | |
| Std | 4.31E+03 | 1.23E+04 | 2.09E+05 | 8.43E+03 | 1.78E+04 | 7.66E+04 | 1.19E+04 | 2.60E+06 | 6.74E+07 | |
| Rank | 1 | 4 | 6 | 2 | 5 | 7 | 3 | 8 | 9 | |
| F14 | Best | 1.47E+03 | 1.49E+03 | 1.46E+03 | 1.43E+03 | 1.47E+03 | 1.72E+03 | 1.47E+03 | 1.61E+03 | 2.40E+03 |
| Mean | 1.53E+03 | 2.72E+03 | 1.85E+03 | 1.57E+03 | 1.59E+03 | 8.68E+03 | 1.88E+03 | 2.42E+03 | 6.93E+05 | |
| Worst | 1.75E+03 | 7.25E+03 | 5.26E+03 | 2.44E+03 | 1.90E+03 | 3.55E+04 | 2.58E+03 | 4.48E+03 | 3.17E+06 | |
| Std | 6.32E+01 | 1.40E+03 | 8.61E+02 | 2.27E+02 | 1.16E+02 | 8.83E+03 | 3.71E+02 | 8.62E+02 | 9.86E+05 | |
| Rank | 1 | 7 | 4 | 2 | 3 | 8 | 5 | 6 | 9 | |
| F15 | Best | 1.62E+03 | 2.06E+03 | 1.70E+03 | 1.58E+03 | 1.72E+03 | 8.67E+03 | 1.63E+03 | 3.09E+03 | 2.51E+04 |
| Mean | 3.84E+03 | 9.12E+03 | 3.42E+03 | 2.16E+03 | 6.15E+03 | 5.11E+04 | 7.96E+03 | 9.81E+03 | 2.06E+06 | |
| Worst | 7.53E+03 | 3.43E+04 | 7.43E+03 | 3.36E+03 | 1.08E+04 | 4.04E+05 | 1.57E+04 | 2.68E+04 | 1.84E+07 | |
| Std | 2.02E+03 | 6.82E+03 | 1.65E+03 | 5.40E+02 | 3.23E+03 | 9.75E+04 | 3.97E+03 | 6.31E+03 | 4.07E+06 | |
| Rank | 3 | 6 | 2 | 1 | 4 | 8 | 5 | 7 | 9 | |
| F16 | Best | 1.60E+03 | 1.64E+03 | 1.73E+03 | 1.60E+03 | 1.77E+03 | 1.63E+03 | 1.65E+03 | 1.83E+03 | 2.05E+03 |
| Mean | 1.70E+03 | 1.80E+03 | 1.95E+03 | 1.66E+03 | 1.96E+03 | 1.76E+03 | 1.92E+03 | 2.19E+03 | 2.37E+03 | |
| Worst | 1.97E+03 | 2.04E+03 | 2.17E+03 | 1.76E+03 | 2.15E+03 | 1.93E+03 | 2.22E+03 | 2.51E+03 | 2.76E+03 | |
| Std | 1.32E+02 | 1.19E+02 | 1.24E+02 | 6.15E+01 | 1.06E+02 | 9.19E+01 | 1.67E+02 | 1.73E+02 | 1.85E+02 | |
| Rank | 2 | 4 | 6 | 1 | 7 | 3 | 5 | 8 | 9 | |
| F17 | Best | 1.72E+03 | 1.73E+03 | 1.76E+03 | 1.73E+03 | 1.75E+03 | 1.74E+03 | 1.76E+03 | 1.88E+03 | 1.87E+03 |
| Mean | 1.76E+03 | 1.77E+03 | 1.80E+03 | 1.77E+03 | 1.77E+03 | 1.77E+03 | 1.83E+03 | 2.02E+03 | 2.33E+03 | |
| Worst | 1.81E+03 | 1.85E+03 | 1.85E+03 | 1.86E+03 | 1.82E+03 | 1.89E+03 | 1.99E+03 | 2.25E+03 | 2.81E+03 | |
| Std | 2.05E+01 | 2.90E+01 | 2.42E+01 | 3.91E+01 | 2.16E+01 | 3.08E+01 | 6.87E+01 | 1.04E+02 | 2.61E+02 | |
| Rank | 1 | 5 | 6 | 2 | 4 | 3 | 7 | 8 | 9 | |
| F18 | Best | 2.88E+03 | 5.32E+03 | 3.29E+03 | 3.10E+03 | 4.27E+03 | 5.66E+03 | 2.26E+03 | 4.35E+05 | 8.26E+06 |
| Mean | 1.09E+04 | 2.69E+04 | 3.83E+06 | 1.15E+04 | 1.64E+04 | 8.98E+04 | 1.58E+04 | 3.83E+06 | 3.12E+08 | |
| Worst | 2.29E+04 | 7.29E+04 | 4.55E+07 | 2.68E+04 | 3.76E+04 | 5.92E+05 | 3.90E+04 | 7.79E+06 | 8.05E+08 | |
| Std | 6.28E+03 | 1.50E+04 | 1.11E+07 | 8.09E+03 | 1.05E+04 | 1.31E+05 | 1.27E+04 | 2.11E+06 | 2.99E+08 | |
| Rank | 1 | 5 | 7 | 2 | 4 | 6 | 3 | 8 | 9 | |
| F19 | Best | 1.93E+03 | 2.13E+03 | 2.15E+03 | 1.92E+03 | 2.38E+03 | 2.04E+03 | 2.17E+03 | 1.22E+04 | 5.22E+04 |
| Mean | 3.60E+03 | 2.24E+04 | 4.80E+04 | 3.00E+03 | 1.11E+04 | 2.24E+04 | 7.51E+04 | 2.44E+05 | 1.88E+07 | |
| Worst | 1.59E+04 | 2.22E+05 | 4.18E+05 | 9.67E+03 | 3.81E+04 | 1.43E+05 | 4.69E+05 | 1.38E+06 | 6.09E+07 | |
| Std | 3.14E+03 | 4.78E+04 | 9.84E+04 | 1.92E+03 | 1.06E+04 | 3.40E+04 | 1.21E+05 | 3.32E+05 | 1.88E+07 | |
| Rank | 2 | 4 | 6 | 1 | 3 | 5 | 7 | 8 | 9 | |
| F20 | Best | 2.02E+03 | 2.04E+03 | 2.09E+03 | 2.02E+03 | 2.05E+03 | 2.04E+03 | 2.07E+03 | 2.14E+03 | 2.01E+03 |
| Mean | 2.04E+03 | 2.12E+03 | 2.14E+03 | 2.05E+03 | 2.17E+03 | 2.08E+03 | 2.18E+03 | 2.25E+03 | 2.06E+03 | |
| Worst | 2.06E+03 | 2.20E+03 | 2.24E+03 | 2.19E+03 | 2.34E+03 | 2.20E+03 | 2.34E+03 | 2.33E+03 | 2.16E+03 | |
| Std | 1.18E+01 | 4.80E+01 | 4.13E+01 | 4.39E+01 | 7.71E+01 | 4.46E+01 | 6.90E+01 | 5.59E+01 | 5.07E+01 | |
| Rank | 1 | 5 | 6 | 2 | 7 | 4 | 8 | 9 | 3 | |
| F21 | Best | 2.20E+03 | 2.20E+03 | 2.22E+03 | 2.20E+03 | 2.20E+03 | 2.21E+03 | 2.22E+03 | 2.37E+03 | 2.21E+03 |
| Mean | 2.26E+03 | 2.32E+03 | 2.32E+03 | 2.32E+03 | 2.32E+03 | 2.30E+03 | 2.33E+03 | 2.39E+03 | 2.29E+03 | |
| Worst | 2.33E+03 | 2.35E+03 | 2.38E+03 | 2.34E+03 | 2.39E+03 | 2.33E+03 | 2.38E+03 | 2.40E+03 | 2.35E+03 | |
| Std | 5.88E+01 | 3.71E+01 | 5.62E+01 | 3.94E+01 | 6.13E+01 | 4.28E+01 | 4.92E+01 | 7.09E+00 | 5.00E+01 | |
| Rank | 1 | 5 | 4 | 6 | 7 | 3 | 8 | 9 | 2 | |
| F22 | Best | 2.30E+03 | 2.27E+03 | 2.35E+03 | 2.31E+03 | 2.31E+03 | 2.30E+03 | 2.31E+03 | 2.31E+03 | 2.31E+03 |
| Mean | 2.31E+03 | 2.31E+03 | 2.54E+03 | 2.32E+03 | 2.32E+03 | 2.73E+03 | 2.32E+03 | 3.52E+03 | 2.32E+03 | |
| Worst | 2.31E+03 | 2.32E+03 | 2.88E+03 | 2.33E+03 | 2.33E+03 | 4.20E+03 | 2.34E+03 | 4.69E+03 | 2.34E+03 | |
| Std | 1.22E+00 | 1.11E+01 | 1.44E+02 | 5.09E+00 | 5.05E+00 | 6.30E+02 | 9.05E+00 | 1.81E+03 | 8.82E+00 | |
| Rank | 1 | 2 | 7 | 4 | 3 | 8 | 6 | 9 | 5 | |
| F23 | Best | 2.61E+03 | 2.62E+03 | 2.67E+03 | 2.62E+03 | 2.62E+03 | 2.62E+03 | 2.62E+03 | 2.70E+03 | 2.62E+03 |
| Mean | 2.61E+03 | 2.65E+03 | 2.71E+03 | 2.63E+03 | 2.67E+03 | 2.63E+03 | 2.66E+03 | 2.78E+03 | 2.66E+03 | |
| Worst | 2.62E+03 | 2.67E+03 | 2.75E+03 | 2.64E+03 | 2.71E+03 | 2.66E+03 | 2.72E+03 | 2.86E+03 | 2.74E+03 | |
| Std | 4.33E+00 | 1.49E+01 | 2.35E+01 | 7.11E+00 | 3.01E+01 | 9.60E+00 | 2.87E+01 | 3.39E+01 | 2.89E+01 | |
| Rank | 1 | 4 | 8 | 2 | 7 | 3 | 5 | 9 | 6 | |
| F24 | Best | 2.50E+03 | 2.50E+03 | 2.59E+03 | 2.53E+03 | 2.50E+03 | 2.74E+03 | 2.56E+03 | 2.74E+03 | 2.54E+03 |
| Mean | 2.68E+03 | 2.75E+03 | 2.77E+03 | 2.74E+03 | 2.81E+03 | 2.76E+03 | 2.79E+03 | 2.84E+03 | 2.71E+03 | |
| Worst | 2.75E+03 | 2.81E+03 | 2.89E+03 | 2.76E+03 | 2.91E+03 | 2.78E+03 | 2.83E+03 | 2.87E+03 | 2.83E+03 | |
| Std | 1.07E+02 | 8.65E+01 | 8.92E+01 | 6.78E+01 | 8.02E+01 | 1.03E+01 | 5.67E+01 | 2.59E+01 | 1.13E+02 | |
| Rank | 1 | 4 | 6 | 3 | 8 | 5 | 7 | 9 | 2 | |
| F25 | Best | 2.90E+03 | 2.90E+03 | 3.06E+03 | 2.90E+03 | 2.90E+03 | 2.91E+03 | 2.90E+03 | 3.00E+03 | 2.92E+03 |
| Mean | 2.91E+03 | 2.93E+03 | 3.22E+03 | 2.94E+03 | 2.94E+03 | 2.93E+03 | 2.95E+03 | 3.17E+03 | 2.96E+03 | |
| Worst | 2.94E+03 | 2.96E+03 | 3.43E+03 | 2.95E+03 | 3.03E+03 | 2.95E+03 | 3.03E+03 | 3.30E+03 | 3.03E+03 | |
| Std | 2.12E+01 | 2.28E+01 | 1.03E+02 | 1.98E+01 | 2.95E+01 | 1.09E+01 | 3.13E+01 | 7.29E+01 | 2.34E+01 | |
| Rank | 1 | 3 | 9 | 4 | 5 | 2 | 6 | 8 | 7 | |
| F26 | Best | 2.82E+03 | 2.62E+03 | 3.27E+03 | 2.92E+03 | 2.82E+03 | 2.84E+03 | 2.96E+03 | 3.33E+03 | 2.87E+03 |
| Mean | 2.89E+03 | 3.06E+03 | 3.58E+03 | 3.00E+03 | 3.25E+03 | 3.17E+03 | 3.34E+03 | 3.70E+03 | 3.25E+03 | |
| Worst | 2.95E+03 | 3.75E+03 | 3.93E+03 | 4.13E+03 | 4.15E+03 | 3.47E+03 | 4.46E+03 | 4.09E+03 | 4.11E+03 | |
| Std | 3.13E+01 | 2.16E+02 | 1.93E+02 | 2.66E+02 | 3.68E+02 | 1.76E+02 | 4.36E+02 | 1.81E+02 | 3.19E+02 | |
| Rank | 1 | 3 | 8 | 2 | 5 | 4 | 7 | 9 | 6 | |
| F27 | Best | 3.09E+03 | 3.09E+03 | 3.14E+03 | 3.10E+03 | 3.10E+03 | 3.08E+03 | 3.10E+03 | 3.15E+03 | 3.11E+03 |
| Mean | 3.09E+03 | 3.11E+03 | 3.21E+03 | 3.11E+03 | 3.17E+03 | 3.18E+03 | 3.14E+03 | 3.18E+03 | 3.16E+03 | |
| Worst | 3.10E+03 | 3.12E+03 | 3.32E+03 | 3.17E+03 | 3.27E+03 | 3.20E+03 | 3.22E+03 | 3.21E+03 | 3.23E+03 | |
| Std | 2.37E+00 | 7.78E+00 | 3.54E+01 | 1.50E+01 | 4.08E+01 | 3.92E+01 | 4.37E+01 | 1.73E+01 | 3.24E+01 | |
| Rank | 1 | 2 | 9 | 3 | 6 | 8 | 4 | 7 | 5 | |
| F28 | Best | 3.10E+03 | 3.10E+03 | 3.28E+03 | 3.13E+03 | 3.10E+03 | 3.27E+03 | 3.18E+03 | 3.47E+03 | 3.12E+03 |
| Mean | 3.26E+03 | 3.37E+03 | 3.39E+03 | 3.31E+03 | 3.38E+03 | 3.29E+03 | 3.38E+03 | 3.54E+03 | 3.48E+03 | |
| Worst | 3.41E+03 | 3.48E+03 | 3.77E+03 | 3.45E+03 | 3.75E+03 | 3.30E+03 | 3.74E+03 | 3.63E+03 | 3.72E+03 | |
| Std | 1.50E+02 | 1.18E+02 | 1.74E+02 | 1.34E+02 | 1.79E+02 | 9.88E+00 | 1.37E+02 | 4.45E+01 | 2.02E+02 | |
| Rank | 1 | 4 | 7 | 3 | 5 | 2 | 6 | 9 | 8 | |
| F29 | Best | 3.15E+03 | 3.18E+03 | 3.26E+03 | 3.17E+03 | 3.24E+03 | 3.15E+03 | 3.22E+03 | 3.35E+03 | 3.55E+03 |
| Mean | 3.18E+03 | 3.26E+03 | 3.34E+03 | 3.21E+03 | 3.35E+03 | 3.26E+03 | 3.34E+03 | 3.46E+03 | 3.90E+03 | |
| Worst | 3.24E+03 | 3.38E+03 | 3.49E+03 | 3.35E+03 | 3.52E+03 | 3.36E+03 | 3.53E+03 | 3.56E+03 | 4.36E+03 | |
| Std | 2.17E+01 | 5.39E+01 | 5.67E+01 | 4.11E+01 | 7.74E+01 | 4.75E+01 | 8.17E+01 | 6.86E+01 | 2.06E+02 | |
| Rank | 1 | 4 | 5 | 2 | 7 | 3 | 6 | 8 | 9 | |
| F30 | Best | 6.82E+03 | 4.65E+03 | 1.12E+04 | 2.56E+04 | 7.54E+03 | 3.26E+03 | 1.67E+04 | 4.94E+05 | 1.19E+07 |
| Mean | 1.37E+05 | 1.37E+06 | 1.46E+06 | 1.07E+06 | 1.28E+06 | 1.53E+04 | 1.51E+06 | 1.39E+06 | 6.63E+07 | |
| Worst | 1.45E+06 | 3.66E+06 | 4.30E+06 | 2.95E+06 | 5.13E+06 | 7.42E+04 | 7.17E+06 | 2.20E+06 | 1.42E+08 | |
| Std | 3.59E+05 | 1.28E+06 | 1.19E+06 | 1.14E+06 | 1.48E+06 | 1.77E+04 | 1.81E+06 | 5.67E+05 | 3.75E+07 | |
| Rank | 2 | 5 | 7 | 3 | 4 | 1 | 8 | 6 | 9 | |
| Mean Rank | 1.1724 | 4.1034 | 6.7241 | 3.0345 | 5.1724 | 4.1379 | 5.8966 | 8.2069 | 6.5517 | |
| Runtime(s) | 0.4300 | 0.2980 | 0.1404 | 0.0551 | 0.3092 | 0.0848 | 0.1146 | 1.3843 | 15.2474 | |
| AO | AOA | PSO | HHO | SCA | WOA | ACO | GA | |
|---|---|---|---|---|---|---|---|---|
| F1 | 9.17E-08/+ | 6.80E-08/+ | 6.80E-08/+ | 4.25E-01/= | 6.80E-08/+ | 6.80E-08/+ | 6.80E-08/+ | 6.80E-08/+ |
| F3 | 9.17E-08/+ | 6.80E-08/+ | 6.80E-08/+ | 9.28E-05/+ | 6.80E-08/+ | 6.80E-08/+ | 6.80E-08/+ | 6.80E-08/+ |
| F4 | 8.36E-04/+ | 6.80E-08/+ | 9.17E-08/+ | 6.01E-02/= | 9.13E-07/+ | 1.20E-06/+ | 6.80E-08/+ | 6.80E-08/+ |
| F5 | 3.07E-06/+ | 6.80E-08/+ | 2.22E-07/+ | 1.66E-07/+ | 1.41E-05/+ | 6.80E-08/+ | 6.80E-08/+ | 2.56E-07/+ |
| F6 | 6.80E-08/+ | 6.80E-08/+ | 4.68E-05/+ | 6.80E-08/+ | 1.41E-05/+ | 6.80E-08/+ | 6.80E-08/+ | 2.69E-06/+ |
| F7 | 1.41E-05/+ | 7.90E-08/+ | 1.80E-06/+ | 3.94E-07/+ | 1.26E-01/= | 2.06E-06/+ | 6.80E-08/+ | 3.85E-02/+ |
| F8 | 1.33E-02/+ | 1.20E-06/+ | 8.60E-06/+ | 2.34E-03/+ | 1.26E-01/= | 1.81E-05/+ | 6.80E-08/+ | 1.14E-01/= |
| F9 | 6.80E-08/+ | 6.80E-08/+ | 6.80E-08/+ | 6.80E-08/+ | 6.80E-08/+ | 6.80E-08/+ | 6.80E-08/+ | 6.80E-08/+ |
| F10 | 1.60E-05/+ | 6.80E-08/+ | 2.22E-07/+ | 2.69E-06/+ | 1.80E-06/+ | 1.29E-04/+ | 1.22E-03/+ | 3.50E-06/+ |
| F11 | 2.75E-04/+ | 6.80E-08/+ | 5.79E-01/= | 1.10E-05/+ | 3.34E-03/+ | 2.06E-06/+ | 6.80E-08/+ | 6.80E-08/+ |
| F12 | 5.87E-06/+ | 2.96E-07/+ | 1.25E-05/+ | 7.41E-05/+ | 2.75E-02/+ | 2.69E-06/+ | 6.80E-08/+ | 6.80E-08/+ |
| F13 | 1.78E-03/+ | 3.07E-06/+ | 7.76E-01/= | 7.41E-05/+ | 3.50E-06/+ | 6.79E-02/= | 6.80E-08/+ | 6.80E-08/+ |
| F14 | 1.20E-06/+ | 1.48E-01/= | 1.64E-01/= | 4.39E-02/+ | 7.90E-08/+ | 2.47E-04/+ | 1.92E-07/+ | 6.80E-08/+ |
| F15 | 1.44E-04/+ | 7.56E-01/= | 9.05E-03/− | 2.23E-02/+ | 6.80E-08/+ | 3.75E-04/+ | 9.28E-05/+ | 6.80E-08/+ |
| F16 | 4.70E-03/+ | 4.68E-05/+ | 3.51E-01/= | 4.54E-06/+ | 1.33E-02/+ | 1.29E-04/+ | 1.92E-07/+ | 6.80E-08/+ |
| F17 | 2.85E-01/= | 3.99E-06/+ | 8.60E-01/= | 9.62E-02/= | 2.18E-01/= | 2.36E-06/+ | 6.80E-08/+ | 6.80E-08/+ |
| F18 | 5.90E-05/+ | 3.85E-02/+ | 9.46E-01/= | 8.59E-02/= | 9.75E-06/+ | 5.25E-01/= | 6.80E-08/+ | 6.80E-08/+ |
| F19 | 4.68E-05/+ | 9.28E-05/+ | 2.62E-01/= | 8.36E-04/+ | 5.25E-05/+ | 2.36E-06/+ | 7.90E-08/+ | 6.80E-08/+ |
| F20 | 2.06E-06/+ | 6.80E-08/+ | 8.82E-01/= | 2.96E-07/+ | 1.79E-04/+ | 6.80E-08/+ | 6.80E-08/+ | 8.60E-01/= |
| F21 | 6.04E-03/+ | 1.04E-04/+ | 6.87E-04/+ | 7.41E-05/+ | 8.36E-04/+ | 1.67E-02/+ | 8.35E-04/+ | 2.56E-03/+ |
| F22 | 2.00E-04/+ | 6.80E-08/+ | 6.80E-08/+ | 6.92E-07/+ | 4.60E-04/+ | 1.06E-07/+ | 1.22E-03/+ | 1.38E-06/+ |
| F23 | 1.66E-07/+ | 6.80E-08/+ | 5.23E-07/+ | 6.80E-08/+ | 2.22E-07/+ | 1.92E-07/+ | 6.80E-08/+ | 1.43E-07/+ |
| F24 | 1.41E-05/+ | 2.75E-02/+ | 6.67E-06/+ | 6.92E-07/+ | 6.01E-07/+ | 6.01E-07/+ | 1.23E-07/+ | 3.15E-02/+ |
| F25 | 5.90E-05/+ | 6.80E-08/+ | 2.04E-05/+ | 4.68E-05/+ | 3.34E-03/+ | 4.54E-06/+ | 6.80E-08/+ | 9.13E-07/+ |
| F26 | 8.29E-05/+ | 6.80E-08/+ | 6.92E-07/+ | 2.04E-05/+ | 9.13E-07/+ | 6.80E-08/+ | 6.80E-08/+ | 9.13E-07/+ |
| F27 | 6.92E-07/+ | 6.80E-08/+ | 6.80E-08/+ | 6.80E-08/+ | 4.54E-06/+ | 6.80E-08/+ | 6.80E-08/+ | 6.80E-08/+ |
| F28 | 1.12E-03/+ | 2.85E-01/= | 4.11E-02/+ | 2.94E-02/+ | 1.00E+00/= | 3.97E-03/+ | 6.80E-08/+ | 2.75E-04/+ |
| F29 | 6.67E-06/+ | 6.80E-08/+ | 3.15E-02/+ | 7.90E-08/+ | 3.07E-06/+ | 7.90E-08/+ | 6.80E-08/+ | 6.80E-08/+ |
| F30 | 8.29E-05/+ | 1.10E-05/+ | 5.17E-06/+ | 1.81E-05/+ | 2.80E-03/+ | 5.17E-06/+ | 5.23E-07/+ | 6.80E-08/+ |
| +/=/− | 28/1/0 | 26/3/0 | 20/8/1 | 25/4/0 | 25/4/0 | 27/2/0 | 29/0/0 | 27/2/0 |
| Year | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 |
|---|---|---|---|---|---|---|---|---|---|---|
| Rural population (×104) | 84,138 | 84,620 | 84,996 | 85,344 | 85,681 | 85,947 | 85,085 | 84,177 | 83,153 | 82,038 |
| Year | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 |
|---|---|---|---|---|---|---|---|---|---|---|
| Rural population (×104) | 80,837 | 79,563 | 78,241 | 76,851 | 75,705 | 74,544 | 73,160 | 71,496 | 70,399 | 68,938 |
| Year | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 |
|---|---|---|---|---|---|---|---|---|---|---|
| Rural population (×104) | 67,113 | 65,656 | 64,222 | 62,961 | 61,866 | 60,346 | 58,973 | 57,661 | 56,401 | 55,162 |
| Error | Abbreviation | Concrete Expression |
|---|---|---|
| Mean Absolute Percentage Error | MAPE | |
| Root Mean Square Percentage Error | RMSPE | |
| Mean Square Error | MSE | |
| Mean Absolute Error | MAE |
| Year | Real Data | GM(1, 1) | DGM(1, 1) | TRGM | FTDGM | CFANGBM (1, 1, b, c) |
|---|---|---|---|---|---|---|
| 1990 | 84,138 | 84,138.0 | 84,138.0 | 84,138.0 | 84,138.0 | 84,138.0 |
| 1991 | 84,620 | 89,704.7 | 89,712.5 | 90,599.5 | 85009.1 | 84,405.9 |
| 1992 | 84,996 | 88,419.9 | 88,427.0 | 89,696.5 | 85,484.0 | 85,157.3 |
| 1993 | 85,344 | 87,153.5 | 87,159.8 | 88,090.9 | 85,628.4 | 85,609.5 |
| 1994 | 85,681 | 85,905.2 | 85,910.8 | 86,194.6 | 85,496.6 | 85,681.0 |
| 1995 | 85,947 | 84,674.8 | 84,679.8 | 85,037.3 | 85,134.4 | 85,411.9 |
| 1996 | 85,085 | 83,462.0 | 83,466.3 | 84,206.5 | 84,579.8 | 84,863.5 |
| 1997 | 84,177 | 82,266.6 | 82,270.2 | 82,671.9 | 83,864.6 | 84,094.0 |
| 1998 | 83,153 | 81,088.3 | 81,091.3 | 80,845.7 | 83,015.3 | 83,153.1 |
| 1999 | 82,038 | 79,926.9 | 79,929.3 | 79,757.5 | 82,054.0 | 82,081.1 |
| 2000 | 80,837 | 78,782.1 | 78,783.9 | 78,994.7 | 80,999.3 | 80,910.3 |
| 2001 | 79,563 | 77,653.7 | 77,655.0 | 77,527.3 | 79,866.5 | 79,666.1 |
| 2002 | 78,241 | 76,541.5 | 76,542.2 | 75,767.2 | 78,668.7 | 78,368.2 |
| 2003 | 76,851 | 75,445.2 | 75,445.3 | 74,744.1 | 77,416.4 | 77,032.0 |
| 2004 | 75,705 | 74,364.6 | 74,364.2 | 74,045.6 | 76,118.7 | 75,669.4 |
| 2005 | 74,544 | 73,299.5 | 73,298.6 | 72,641.5 | 74,783.2 | 74,289.4 |
| 2006 | 73,160 | 72,249.6 | 72,248.2 | 70,943.8 | 73,416.0 | 72,898.8 |
| 2007 | 71,496 | 71,214.8 | 71,212.9 | 69,982.3 | 72,022.3 | 71,502.8 |
| 2008 | 70,399 | 70,194.8 | 70,192.5 | 69,344.5 | 70,606.7 | 70,105.1 |
| 2009 | 68,938 | 69,189.4 | 69,186.6 | 68,000.1 | 69,172.6 | 68,708.6 |
| 2010 | 67,113 | 68,198.4 | 68,195.2 | 66,361.4 | 67,723.1 | 67,315.0 |
| 2011 | 65,656 | 67,221.6 | 67,217.9 | 65,458.0 | 66,260.8 | 65,925.7 |
| 2012 | 64,222 | 66,258.8 | 66,254.7 | 64,877.3 | 64,787.8 | 64,541.6 |
| 2013 | 62,961 | 65,309.8 | 65,305.3 | 63,589.4 | 63,305.9 | 63,162.9 |
| 2014 | 61,866 | 64,374.4 | 64,369.5 | 62,006.3 | 61,816.5 | 61,790.0 |
| Error | GM(1, 1) | DGM(1, 1) | TRGM | FTDGM | CFANGBM (1, 1, b, c) |
|---|---|---|---|---|---|
| MAE | 1.6148E+07 | 1.3233E+07 | 1.6143E+07 | 3.4565E+06 | 1.6636E+06 |
| MAPE(%) | 2.198626 | 1.738619 | 2.197725 | 0.477928 | 0.231867 |
| MSE | 3.7681E+14 | 2.6103E+14 | 3.7681E+14 | 1.6026E+13 | 4.3480E+12 |
| RMSPE(%) | 2.510064 | 2.001781 | 2.509359 | 0.535274 | 0.277700 |
| Year | Real Data | GM(1, 1) | DGM(1, 1) | TRGM | FTDGM | CFANGBM (1, 1, b, c) |
|---|---|---|---|---|---|---|
| 2015 | 60,346 | 63,452.4 | 63,447.1 | 61,157.7 | 60,320.9 | 60,422.7 |
| 2016 | 58,973 | 62,543.5 | 62,537.9 | 60,631.1 | 58,820.0 | 59,060.7 |
| 2017 | 57,661 | 61,647.7 | 61,641.7 | 59,396.5 | 57,314.8 | 57,703.8 |
| 2018 | 56,401 | 60,764.8 | 60,758.4 | 57,865.9 | 55,806.0 | 56,351.4 |
| 2019 | 55,162 | 59,894.4 | 59,887.8 | 57,069.0 | 54,294.2 | 55,003.1 |
| Error | GM(1, 1) | DGM(1, 1) | TRGM | FTDGM | CFANGBM (1, 1, b, c) |
|---|---|---|---|---|---|
| MAE | 3.9520E+07 | 5.5452E+07 | 3.9460E+07 | 3.9743E+06 | 8.3145E+05 |
| MAPE(%) | 8.608105 | 10.303898 | 8.595082 | 0.882413 | 0.181523 |
| MSE | 1.5946E+15 | 3.2963E+15 | 1.5898E+15 | 2.5021E+13 | 8.6257E+11 |
| RMSPE(%) | 6.991762 | 9.755137 | 6.981294 | 0.896381 | 0.164034 |
| Year | GM(1, 1) | DGM(1, 1) | TRGM | FTDGM | CFANGBM (1, 1, b, c) |
|---|---|---|---|---|---|
| 2020 | 59,036.6 | 59,029.6 | 56,532.6 | 52,779.8 | 53,658.2 |
| 2021 | 58,191.0 | 58,183.7 | 55,611.3 | 51,263.3 | 52,316.1 |
| 2022 | 57,357.6 | 57,349.9 | 54,705.0 | 49,745.1 | 50,976.3 |
| 2023 | 56,536.0 | 56,528.1 | 53,813.4 | 48,225.4 | 49,638.1 |
| 2024 | 55,726.3 | 55,718.1 | 52,936.4 | 46,704.4 | 48,300.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, L.; Li, J.; Zhao, Y. Population Forecast of China’s Rural Community Based on CFANGBM and Improved Aquila Optimizer Algorithm. Fractal Fract. 2021, 5, 190. https://doi.org/10.3390/fractalfract5040190
Ma L, Li J, Zhao Y. Population Forecast of China’s Rural Community Based on CFANGBM and Improved Aquila Optimizer Algorithm. Fractal and Fractional. 2021; 5(4):190. https://doi.org/10.3390/fractalfract5040190
Chicago/Turabian StyleMa, Lin, Jun Li, and Ye Zhao. 2021. "Population Forecast of China’s Rural Community Based on CFANGBM and Improved Aquila Optimizer Algorithm" Fractal and Fractional 5, no. 4: 190. https://doi.org/10.3390/fractalfract5040190
APA StyleMa, L., Li, J., & Zhao, Y. (2021). Population Forecast of China’s Rural Community Based on CFANGBM and Improved Aquila Optimizer Algorithm. Fractal and Fractional, 5(4), 190. https://doi.org/10.3390/fractalfract5040190