1. Introduction
In the last decade, research has been exponentially increasing in the domains of flight control, path planning, and obstacle avoidance of unmanned aerial vehicles (UAVs) [
1,
2,
3]. The analyses get increasingly complex when dealing with multiple UAVs in different formations. The natural behaviors of birds, ants, and fishes have been proven to be significant in formulating successful bio-inspired algorithms for the formation control, route planning, and trajectory tracking of a swarm of multiple UAVs [
4,
5,
6]. Some of the important algorithms inspired by nature include ant colony optimization [
7], pigeon-inspired optimization [
8], and particle swarm optimization [
9].
The primary inspiration for this study is to utilize the knowledge obtained from studying the natural flocking and swarming activities of ants and use them for controlling UAVs. Researchers have used these nature-inspired algorithms for numerous purposes including cooperative path planning of multiple UAVs [
10], distributed UAV flocking among obstacles [
11], and forest fire fighting missions [
12]. We also find multiple studies that hybridize a bio-inspired algorithm with another method to increase its efficiency [
13,
14,
15].
There are many existing solutions regarding the problems of path planning and multi-UAV cooperation. One such research study [
16] deals with the inspection of an oilfield using multiple UAVs while avoiding obstacles. The researchers achieve this using an improved version of Non-Dominated Sorting Genetic Algorithm (NSGA). Another existing solution to tackle a multi-objective optimization is addressed in reference [
17]. In [
17], the researchers use a hybrid of NSGA and local fruit fly optimization to solve interval multi-objective optimization problems. In reference [
18], academics use a modified particle swarm optimization algorithm for the dynamic target tracking of multiple UAVs.
Our proposed method consists of many concepts, which are explained as follows:
Ant colony optimization (ACO) is an optimization technique used by ant colonies to find the shortest route to take to get to their food [
19]. Using pheromones left behind from earlier ants, the ACO mimics ants looking for food. The path used by the most ants contains the most pheromones, which aids the next ant in choosing the shortest way [
20]. The ACO technique is used in a variety of applications, such as the routing of autonomous vehicles and robots, which need to find the shortest path to a destination, and the design of computer algorithms, which need to find the optimal solution for a given problem.
Sometimes, however, the ACO is slow to converge and falls into the local optimum. To help solve these issues, researchers introduced a modified version of ACO called max-min ant colony optimization (MMACO). It operates by controlling the maximum and minimum amounts of pheromone that can be left on each possible trial [
21]. The range of possible pheromone amounts on each possible route is limited to avoid stagnation in the search process.
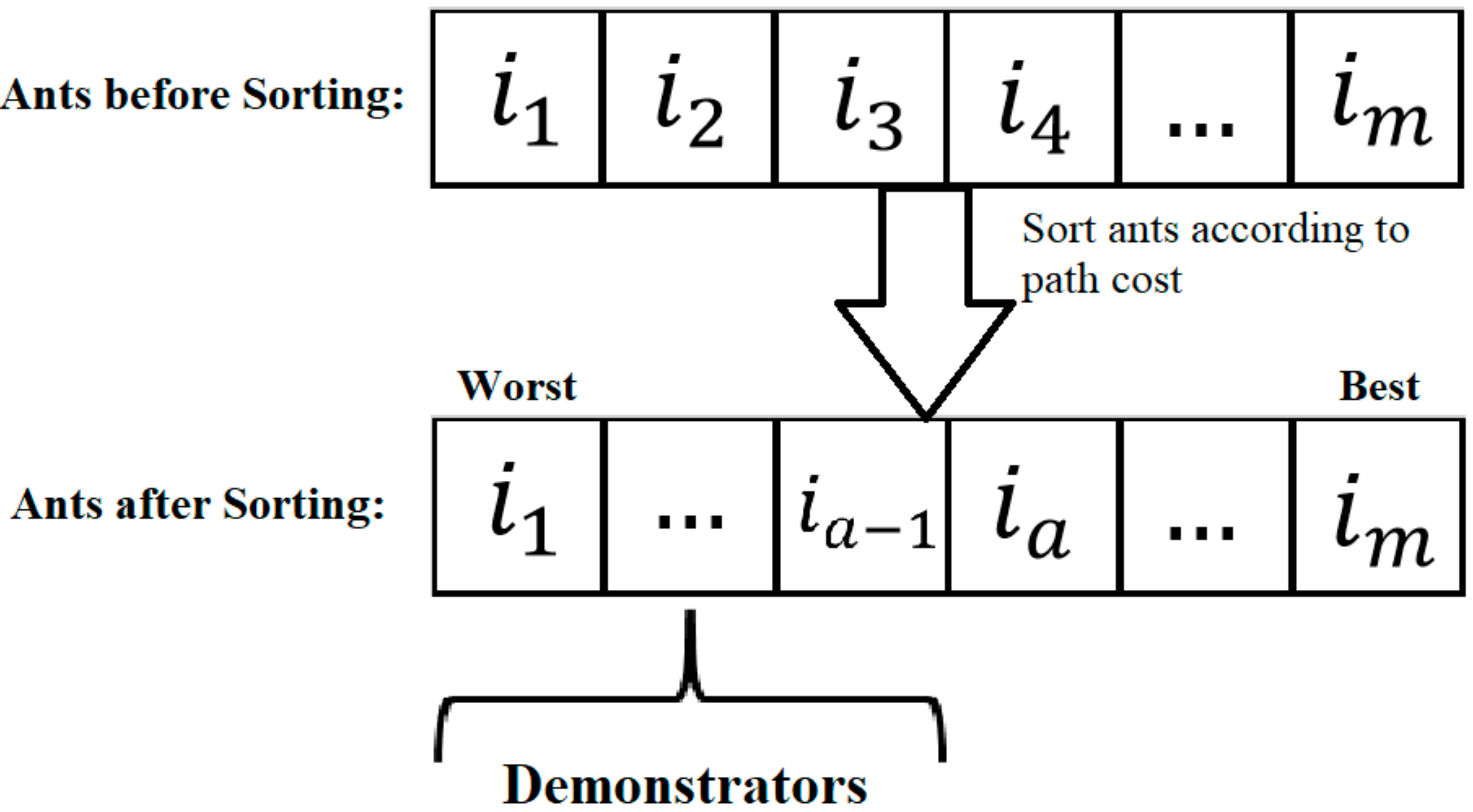
In social animals, social learning plays a significant part in behavior learning. Social learning, as opposed to asocial (individual) learning, allows individuals to learn from the actions of others without experiencing the costs of individual trials and errors [
22]. That is why this study incorporates social learning mechanisms into MMACO. Unlike traditional MMACO variations, which update ants based on past data, each ant in the proposed SL-MMACO learns from any better ants (called demonstrators) in the present swarm.
Some of the state-of-the-art work in the field of optimization algorithms include research [
23] that proposes the use of social learning-based particle swarm optimization (SL-PSO) for integrated circuits manufacturing. The SL-PSO is used to increase the imaging performance in extreme ultraviolet lithography. Results showed that the errors were reduced significantly compared to conventional methods. Similarly, another recent study [
24] uses improved ant colony optimization (IACO) for human gait recognition. The IACO is used to enhance the extracted features, which are then passed on to the classifier. Compared with current methods, the IACO technique in [
24] is more accurate and takes less time to compute.
A multi-agent system (MAS) is a collection of agents that interact with each other and the environment to achieve a common goal. The main function of the MAS is to tackle issues that a single agent would find difficult to solve. To achieve its objective, another important function of the MAS is to be able to interact with each agent and respond accordingly. In MAS, each agent can determine its state and behavior based on the state and behavior of its neighbors [
25]. MAS has multiple uses in fields such as robotics, computer vision, and transportation [
26,
27,
28]. In most MAS scenarios, an external entity is required to direct the agents toward the destination [
29].
A leader is an agent that can alter the states of the follower agents. A leader can be outside or inside the MAS or can even be virtual. A large swarm of UAVs can be controlled more efficiently by selecting fewer leaders than follower agents. For example, when we want to control a fleet of UAVs, we can select a few leader agents, let the remaining UAVs follow the leader, and use the leading UAVs to control the state of the system.
The major contributions of this study are as follows:
Designing a novel hybrid algorithm that combines MMACO with the social learning mechanism to enhance its performance.
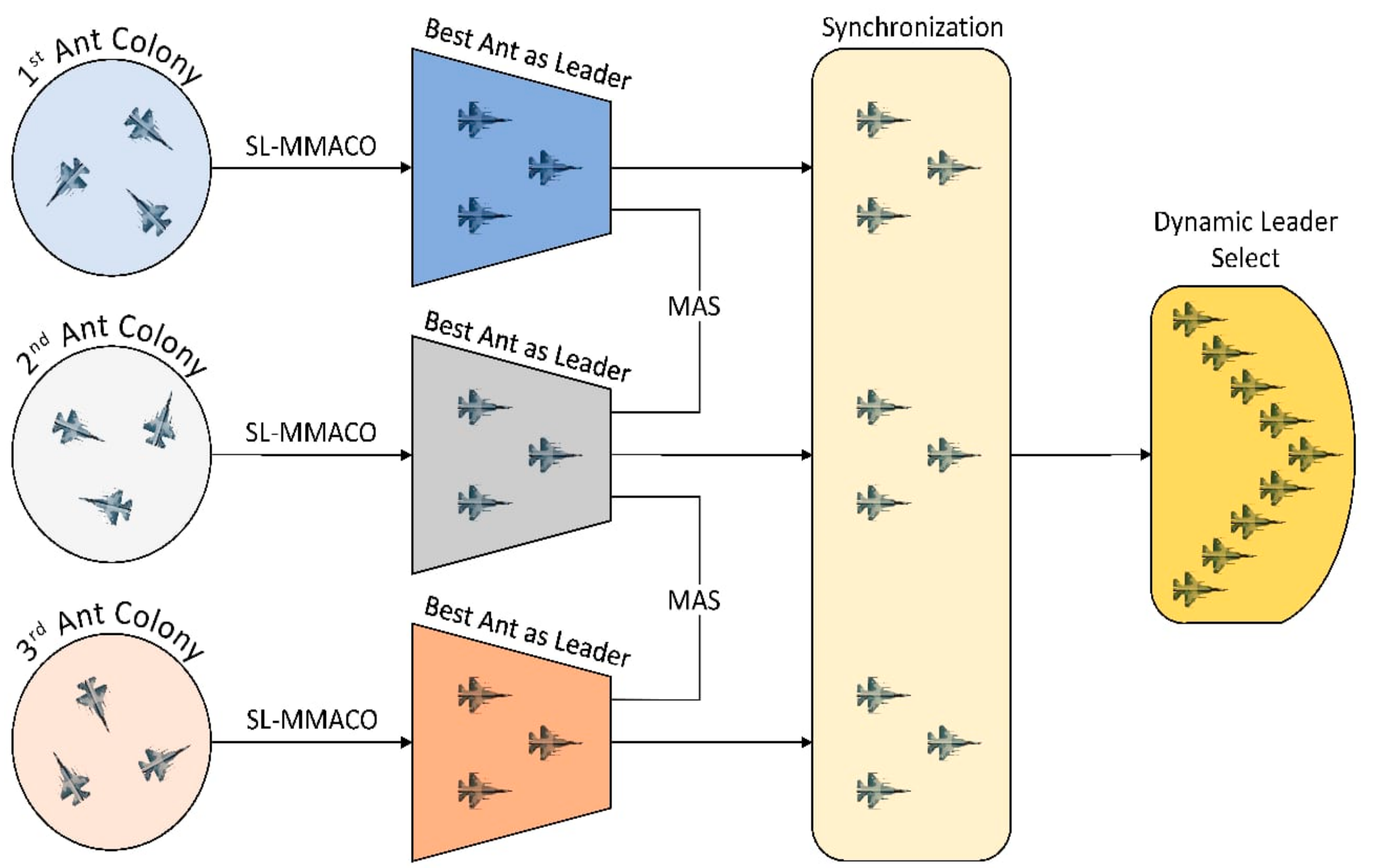
Using the designed algorithm in tandem with the MAS and dynamic leader selection to connect the three colonies.
Achieving the self-organization of the three colonies and synchronizing them into one swarm.
Demonstrating the validity of the designed method by performing computer simulations that mimic real-life scenarios.
The paper is organized into seven sections.
Section 1 presents the introduction and the literature review. In
Section 2, we break down the problem into three scenarios and describe each one in detail.
Section 3 provides the framework of the proposed solution.
Section 4 defines the proposed method with each of its constituent parts discussed at length and offers the algorithm and the flowchart. In
Section 5, we discuss the simulations and their outcomes.
Section 6 presents the conclusion of the study.
2. Research Design
We broke our problem into three different scenarios to help make it easier. In the first scenario, the UAVs are in random positions and then using our proposed algorithm, they organize themselves into a formation. In the second scenario, we navigate the newly organized formations through some obstacles. In the last scenario, we combine the three formations into one swarm and then navigate it through the same environment. Below, we describe each scenario in detail:
Scenario 1:
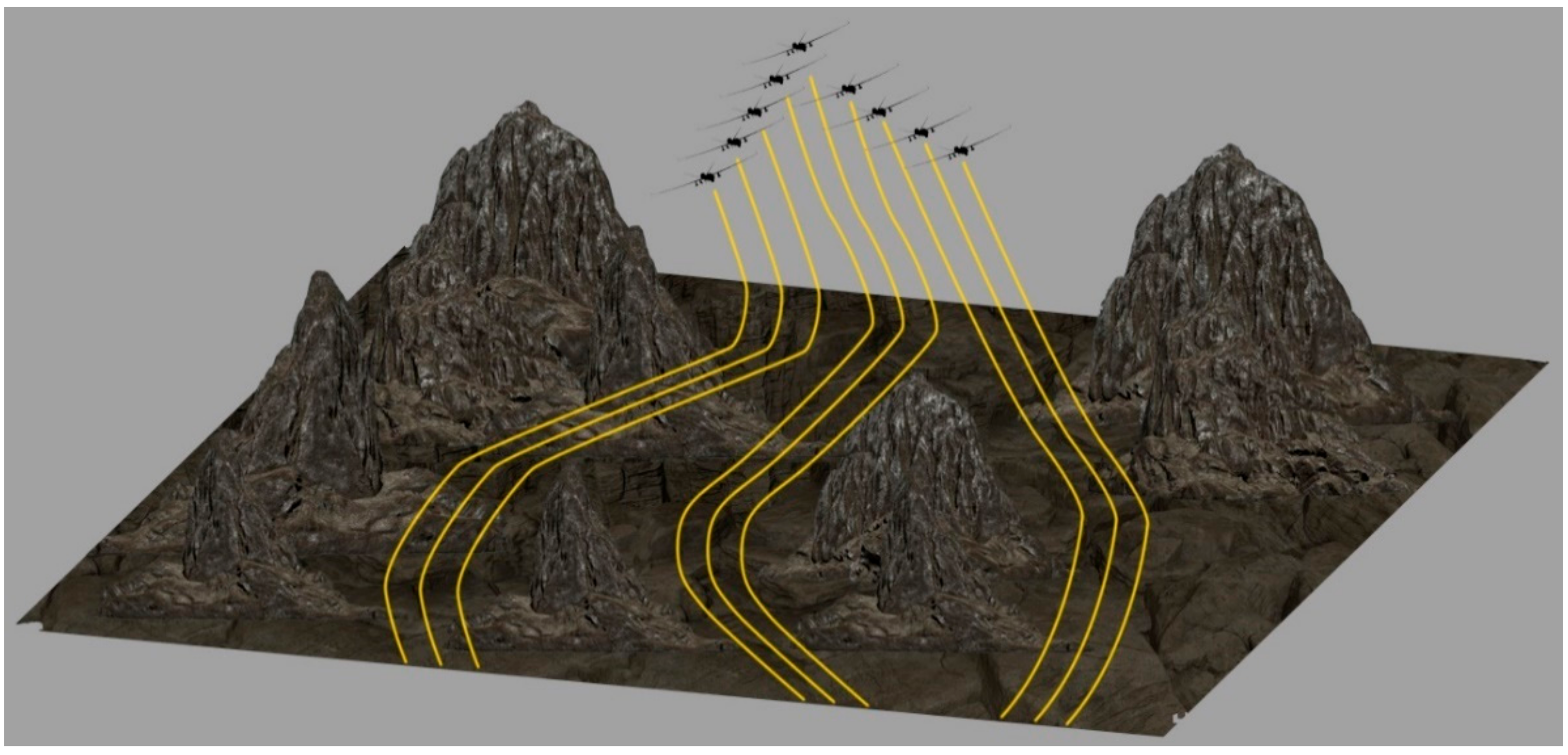
Figure 1 presents the first scenario. In this scenario, there are three UAVs in three different colonies and the UAVs are placed at random positions within each colony. The environment contains different obstacles like mountains and rough terrain. The goal is to reach the target using the shortest route possible without colliding with other UAVs. The main objective here is to maintain the formation throughout the journey.
Scenario 2:
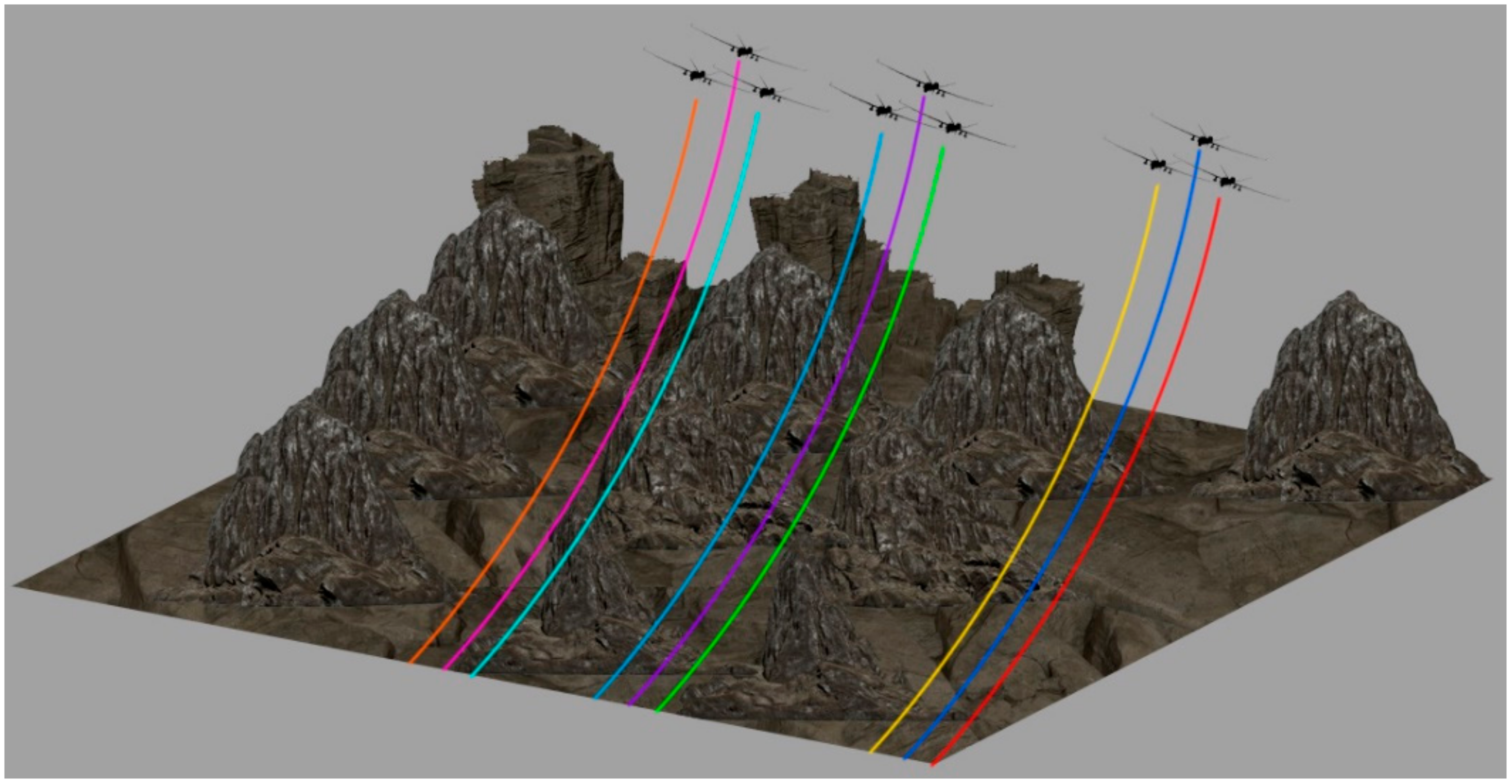
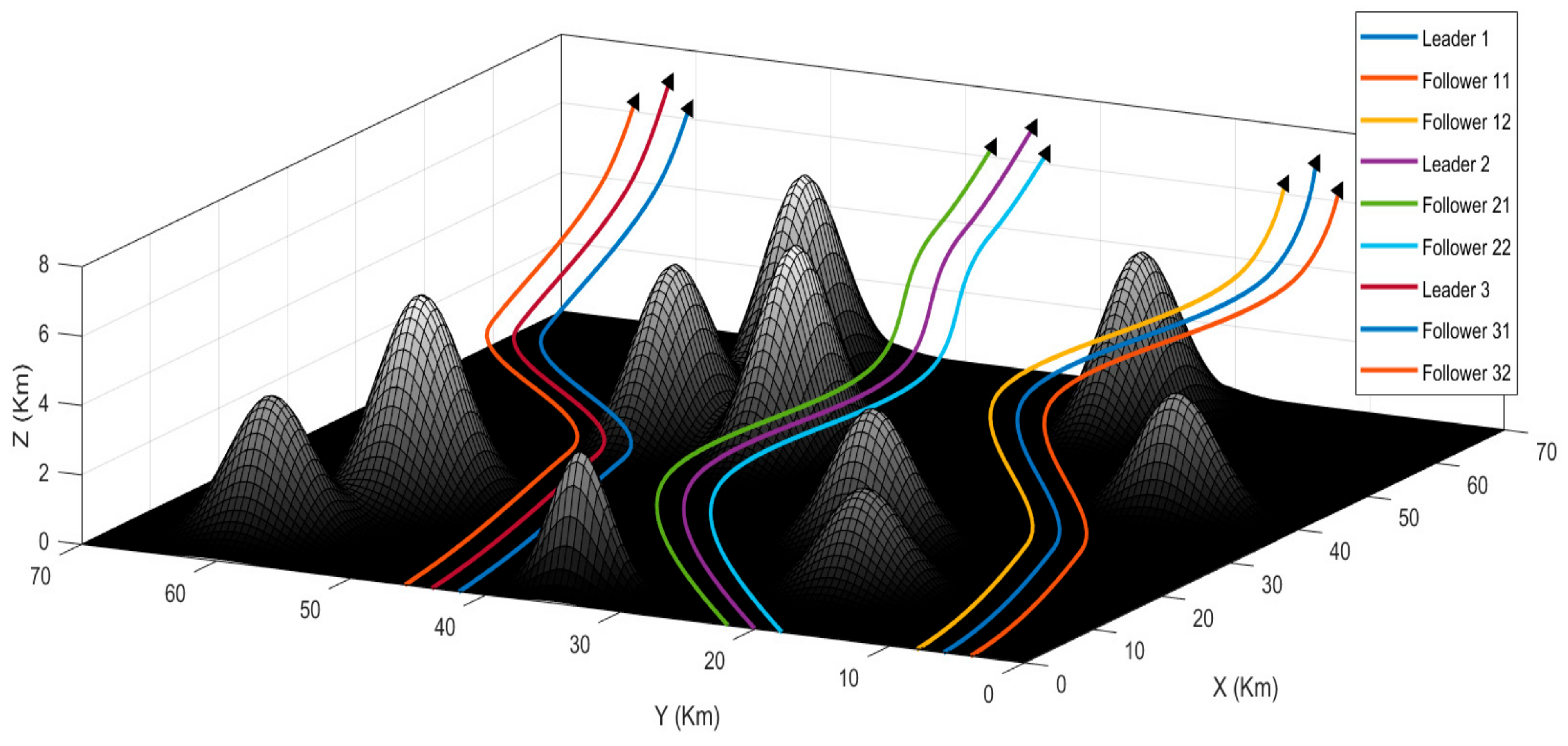
Figure 2 illustrates the second scenario. In this scenario, there are again three UAVs in three different colonies and the UAVs are placed at random positions within each colony. The environment is also the same. The goal is to reach the target using the shortest route possible without colliding with the obstacles or other UAVs. The main distinction between the first and the second scenario is that, in the first task, we only had to demonstrate the ability of the algorithm to maintain a formation. However, the second task also requires navigating through the obstacles without any collision.
Scenario 3:
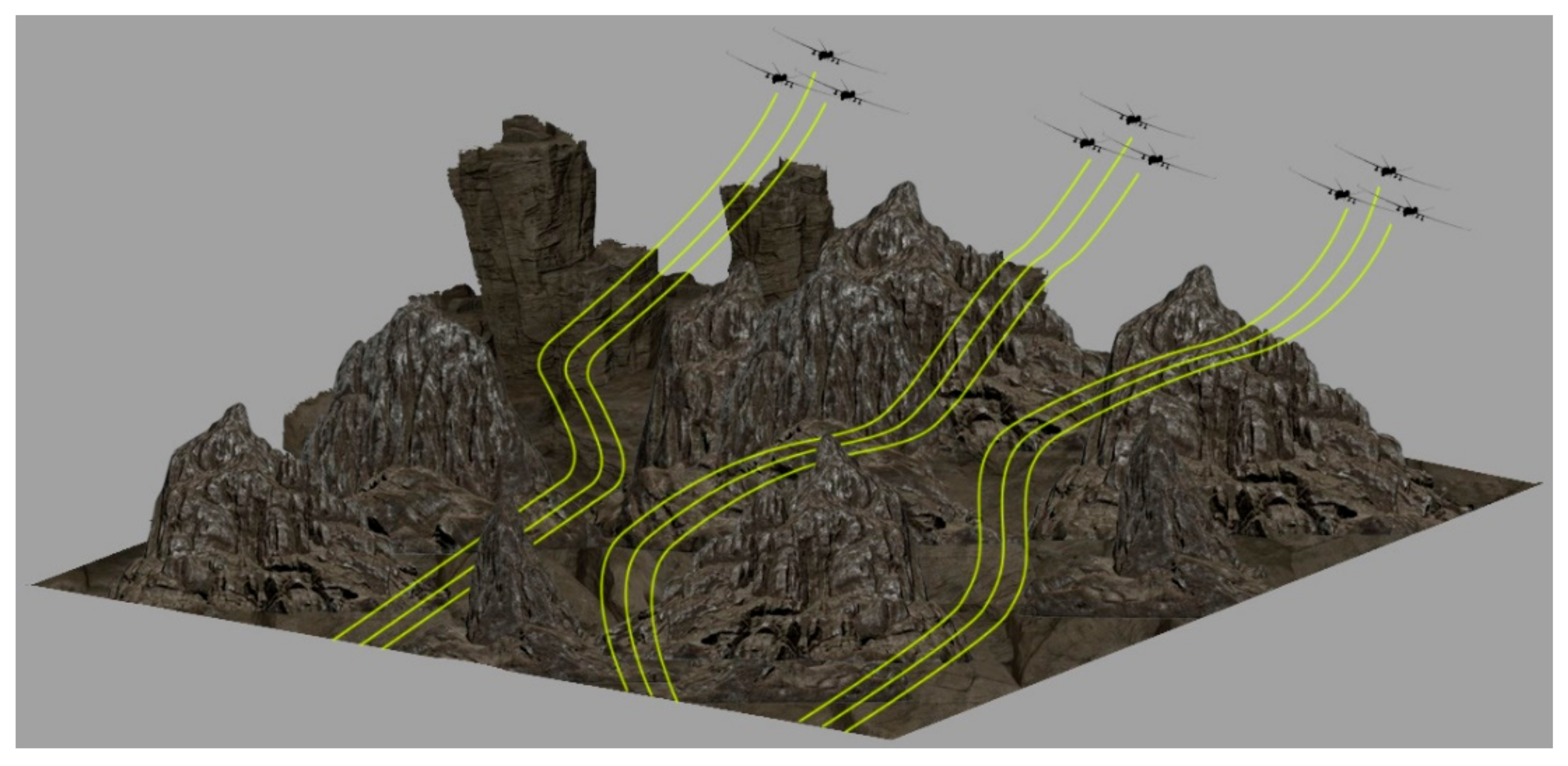
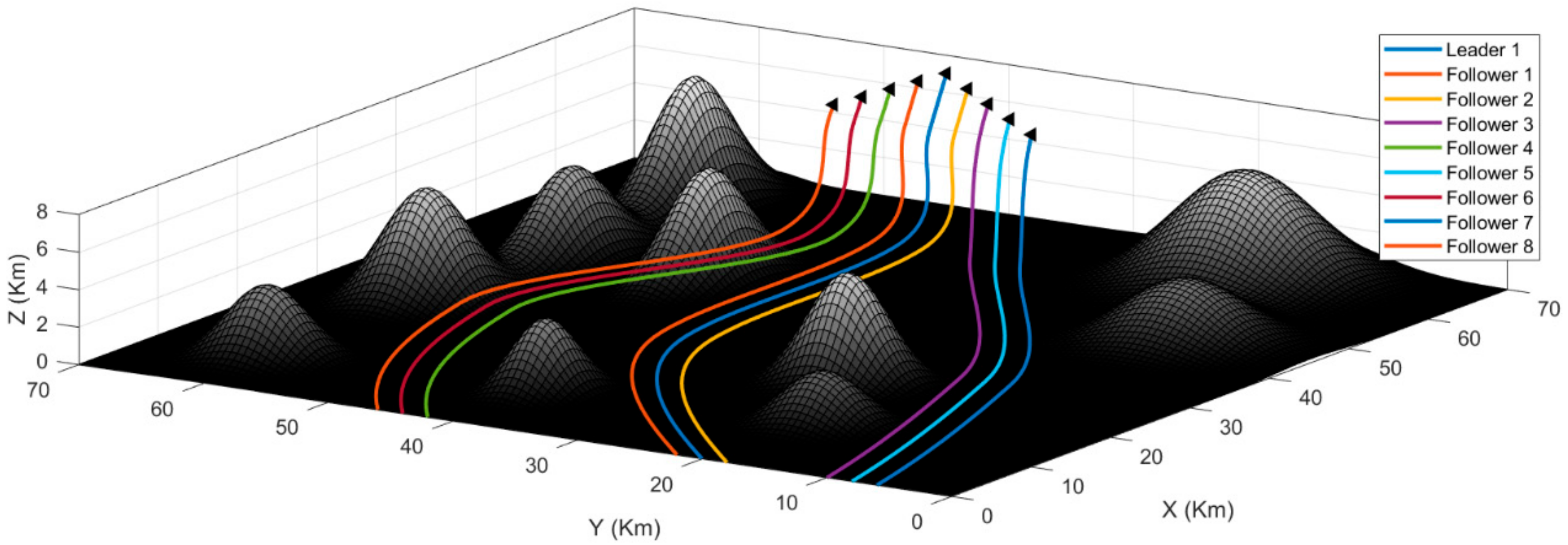
Figure 3 illustrates the third scenario. In this scenario, we pick up where the second scenario left off, i.e., the three colonies are now in the desired formations. The environment is the same as in the second scenario. The goal is to first synchronize the three colonies into one big swarm, and then, while maintaining the swarm, reach the target using the shortest route possible without colliding with the obstacles or other UAVs.
4. Proposed Algorithm
This section introduces the different concepts and theories that we used for the development of our proposed algorithm. In this research paper, we are using a graph-based approach.
4.1. Ant Colony Optimization
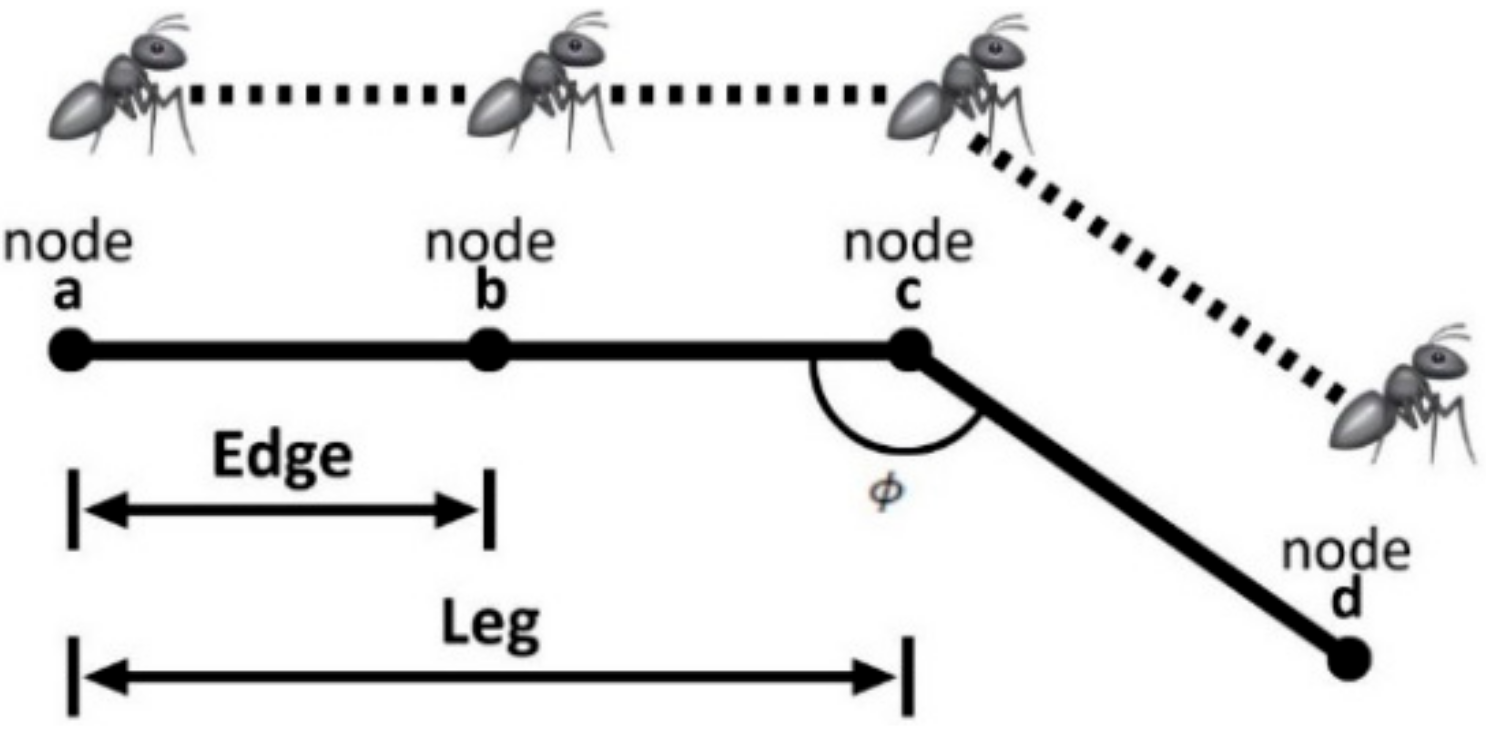
Here, we are using a graph-based approach. The concept of nodes, edges, and legs is important to understand path planning using ant colony optimization (ACO).
Figure 5 presents the relationship between the nodes, edges, and legs. The ACO generates intermediary points between the initial and final positions. These intermediate points are called the nodes. An edge is a link between two nodes. For instance, edge (b,c) is the length from edge b to c, whereas a leg is generated whenever a UAV turns.
Suppose that the
mth ant is at node
i on time
t, the probability of transition can be written as:
where the probability of transition from node
i to node
j of the
mth ant is
, the pheromone on the edge (
i,
) is
, the transit feasibility from node
i to node
j is
, the set of nodes that are neighboring
i is
, the constant influencing the
is
, and the constant influencing the
is
.
After the method begins, the starting pheromone rate varies according to the edges. The pheromone rate is then reset by each ant that generated the result, which starts the next cycle of the process.
on the edge (
is:
where the rate of pheromone evaporation is
(
, total ants are represented by
, and the pheromone rate of the edge
is
.
can be further defined as
where the length of the route built by the
mth ant is
and
is the constant.
4.2. Max-Min Ant Colony Optimization
We need to improve the traditional method to ensure that the ACO converges quickly. MMACO delivers some remarkable results in this area by restricting the pheromones on each route. To understand MMACO, we must first examine the path’s cost. The average cost of path
can be given as:
Note that the mth ant only updates the pheromone when the cost of path of the mth ant in the tth iteration fulfill .
The MMACO updates the route using Equation (3) after every iteration. After each iteration, the algorithm determines the most optimum and least optimal paths. To improve the probability of discovering the global best route, it discards the least optimum route. As a result, Equation (3) may be revised as follows:
In the above equation, is the most optimal route and is the current iteration’s worst route. The quantity of pheromone produced by MMACO is limited to specified values. This limitation aids in accelerating convergence and avoiding stagnation.
The algorithm restricts the pheromone on each route to a specified minimum and maximum value, denoted by
and
, respectively. This can be represented mathematically as:
4.3. Social Learning Mechanism
The conduct of a person to learn from their surroundings is referred to as social learning. You should learn not just from the top students in class, but also from students who are better than you. Most biological groups follow the same idea. Initially, for the map and compass process, locations and velocities of the ants are produced at random and are indicated as
Xi and
Vi (
i = 1, 2, …,
m). At the next iteration, the new location Xi and velocity Vi are calculated by the formula [
30]:
where
R represents the map and compass factor, which is between 0 and 1,
is the current number of iterations,
c1 the learning factor,
Xmod the demonstrator ant superior to the current ant, and
m is the total number of ants. Each follows the ant better than itself, and this is known as the learning behavior.
Figure 6 illustrates the process for the selection of demonstrator
Xmod.
For the landmark operation, the social behavior occurs when ants from the center are removed, and other ants migrate toward the center. The procedure can be given as:
where the social influence factor is
c2, and
is called the social coefficient.
4.4. Multiple Agent Systems
The multi-agent system comprises
n independent agents that move with the same absolute velocity. Every agent’s direction is updated to its neighbor’s status. At time
t, the neighbors of an agent
A (1 ≤
A ≤
n) are those who are located within a circle of radius
r (
r > 0) centered on the position of agent
a. At time
t, the neighbor of the agent
a is
Na(
t),
where the Pythagorean Theorem can be used to compute
.
The coordinates of the agent at time
t are (
xa(
t),
ya(
t)), where agent
a is a neighbor to agent
b. The absolute velocity
v (
v > 0) of each agent in the system is the same.
At time
t, the heading angle of agent
a is
θa(
t). The following equation is used by the algorithm to update the heading angle:
The equation above is used to discover obstructions by examining their surroundings. If a missing node in the neighbor (i.e., a hurdle) exists, the heading angle will be changed to prevent colliding with the obstruction.
We can analyze this algorithm using basic graph theory. Please note that each agent’s neighbors are not always the same. The undirected graph set } is used for agent coordination. Where the set containing every agent is = {1, 2, ···, N}, and the time-varying edge set is . A graph is connected if any two of its vertices are connected.
Equation (16) can be modified as:
To further simplify Equation (17), we use a matrix,
where
. For the graph
, the weighted average matrix is
.
For the synchronization, we study the linear model of Equation (16) as follows:
where the number of elements in
is
. Equation (18) can be rewritten as,
where
, and the entries of the matrix
are,
4.5. Synchronization and Connectivity
To continue the study of the synchronization of the designed algorithm and the connectivity of the associated neighboring graphs, we should formally describe synchronization. If the headings of each agent match the following criteria, the system will achieve synchronization.
where
θ varies to the starting values
and the system parameters
v, and
r. Considering the model in Equations (14)–(16), let
, and assume that the neighbor at the start,
is connected. Therefore, to achieve synchronization, the system will have to satisfy,
whereas the number of agents is represented by
N. Meanwhile,
Considering the models in Equations (14), (15) and (20)
, let
θa(
0) ∈ [0, 2
π), and let us assume that the starting neighbor graph is connected. Therefore, to achieve synchronization, the system will have to satisfy,
whereas
d is the same as described in Equation (26).
4.6. Dynamic Leader Selection
Due to communication problems between agents, the formation structure of multi-agent systems might occasionally change. Considering a random failure of communication, each connection (
a,b)∊
E fails independently with probability
p. Let
be the graph topology and
be the expected convergence time for this model of communication failure, while
denotes the argument’s expectation across the group of network structures represented by
. The convergence rate will be maximized by reducing
). As a result, the formula for choosing a leader
k to maximize the convergence rate is as follows:
So that it meets the below conditions,
As such, the objective function is in line with the projected convergence rate for potential network topologies. Where is a convex function of Y.
4.7. B-Spline Path Smoothing
The hybrid algorithm’s route consists mostly of a combination of line segments. The B-spline curve method is utilized to ensure the smoothness of the route created. The B-spline method is an improvement over the Bezier approach that preserves the convexity and geometrical invariability.
The B-spline path smoothing can be written as:
Considering Equation (31), are control points, and are the normalized b-order functions of the B-spline. These can be described as:
The essential functions of the B-spline curve are determined by the parametric knots . In contrast to the Bezier curve, the B-spline curve is unaffected by altering a single control point. Another benefit of the control points over the Bezier curve is that the degree of polynomials does not increase when the control points are increased.
4.8. Flowchart and Algorithm
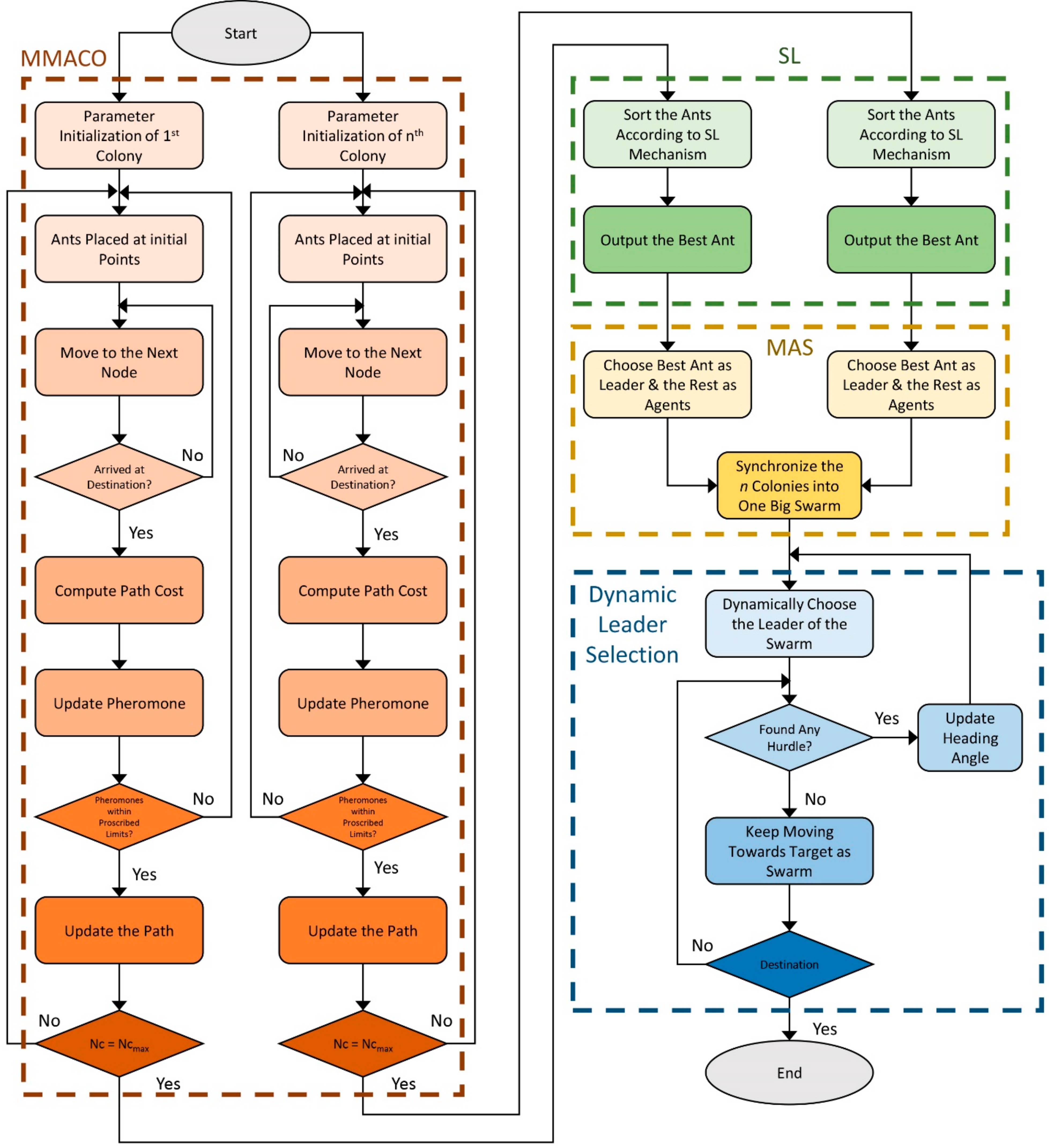
Figure 7 illustrates the flowchart of the whole system. As we can see, the system first initializes the parameters in all colonies and places ants at the starting random positions. Then, the ants keep moving to the next node until they reach the destination. Hereinafter, they compute the path cost and update the pheromone. However, the system only updates the path if the pheromone is within the desired range. This process is repeated for the predefined number of iterations. Next, the social learning mechanism sorts the ants from best to worst according to the path cost, and the algorithm assigns the best ant to be the leader of each colony and the remaining ants to be agents. Finally, all the colonies are synchronized into one big swarm, and the system dynamically selects its leader.
| Algorithm 1 Designed Strategy is Given As. |
![Drones 06 00104 i001]() |
5. Simulation Results
In this section, we verify the effectiveness of the proposed strategy by applying it to a MATLAB simulation. The conclusions that we want to verify are the following: firstly, we apply the algorithm to three colonies with each having three UAVs, and see if they can organize themselves into desired formations. For the second scenario, we navigate these newly organized formations through some obstacles to see if they can maintain their formations. Lastly, we validate if the designed strategy can successfully synchronize and connect the three colonies into one swarm.
First Scenario:
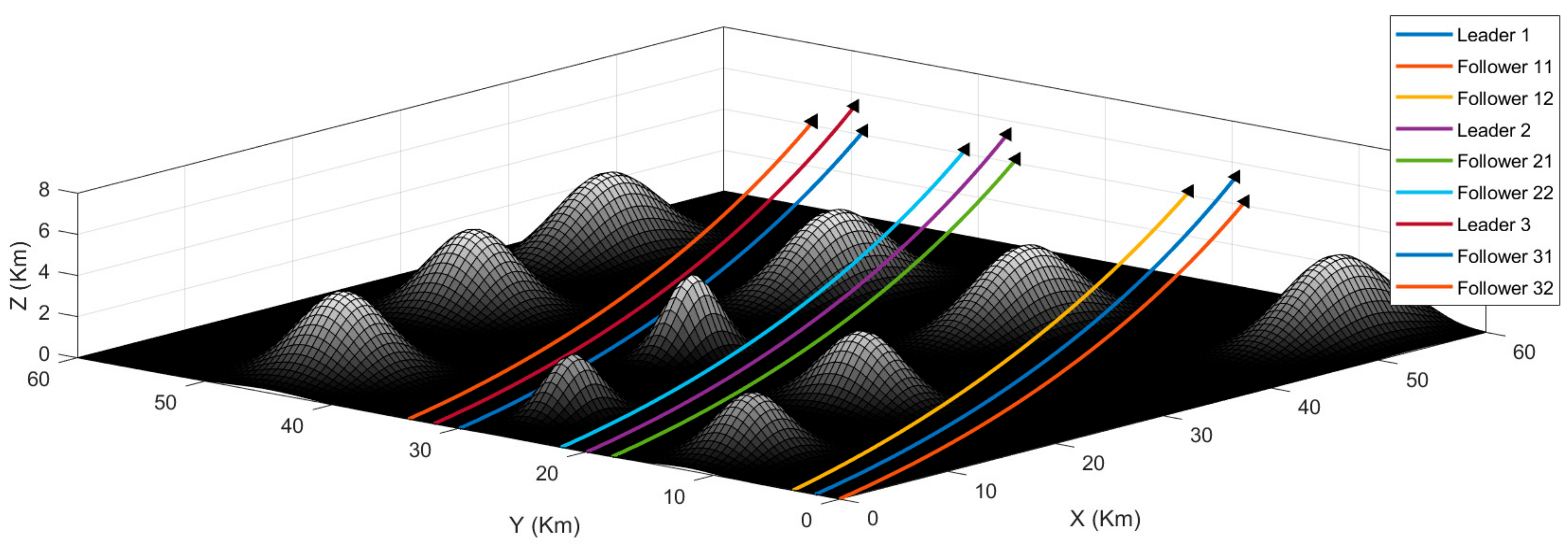
For the first scenario, the UAVs are at random positions within each colony. The objective is to arrange the UAVs into the desired formations and then reach the target using the shortest possible path.
Figure 8 presents the simulation result of the first scenario. As we can see, the algorithm successfully arranges the UAVs into formations, and they maintain these formations throughout the journey. The environment contains different obstacles like mountains and rough terrain. Please note that in this scenario, we are only testing the capability of the algorithm to maintain formations, and hence, we fly the UAV formations in an upward trajectory and not through the obstacles. The second and the third scenarios deal with passing the formations through the obstacles.
Second Scenario:
In this scenario, after the algorithm successfully maintains the formation, and we check whether it is also capable of obstacle avoidance. The environment contains different obstacles like mountains and rough terrain. The goal is to reach the target using the shortest route possible without colliding with the obstacles or other UAVs.
Figure 9 illustrates the simulation result of the second scenario. It is evident from the result that the algorithm achieved the desired goal, and we can see that the three colonies navigated the obstacles while maintaining formations.
Third Scenario:
In this scenario, we pick up where the second scenario left off, i.e., the three colonies are now in the desired formations. The environment contains different obstacles like mountains and rough terrain. The goal is to first synchronize the three colonies into one big swarm, and then while maintaining the swarm, reach the target using the shortest route possible without colliding with the obstacles or other UAVs.
Figure 10 illustrates the simulation result of the third scenario. Again, we see that the algorithm successfully synchronized the three colonies into one swarm, and it reaches its target without any collision.
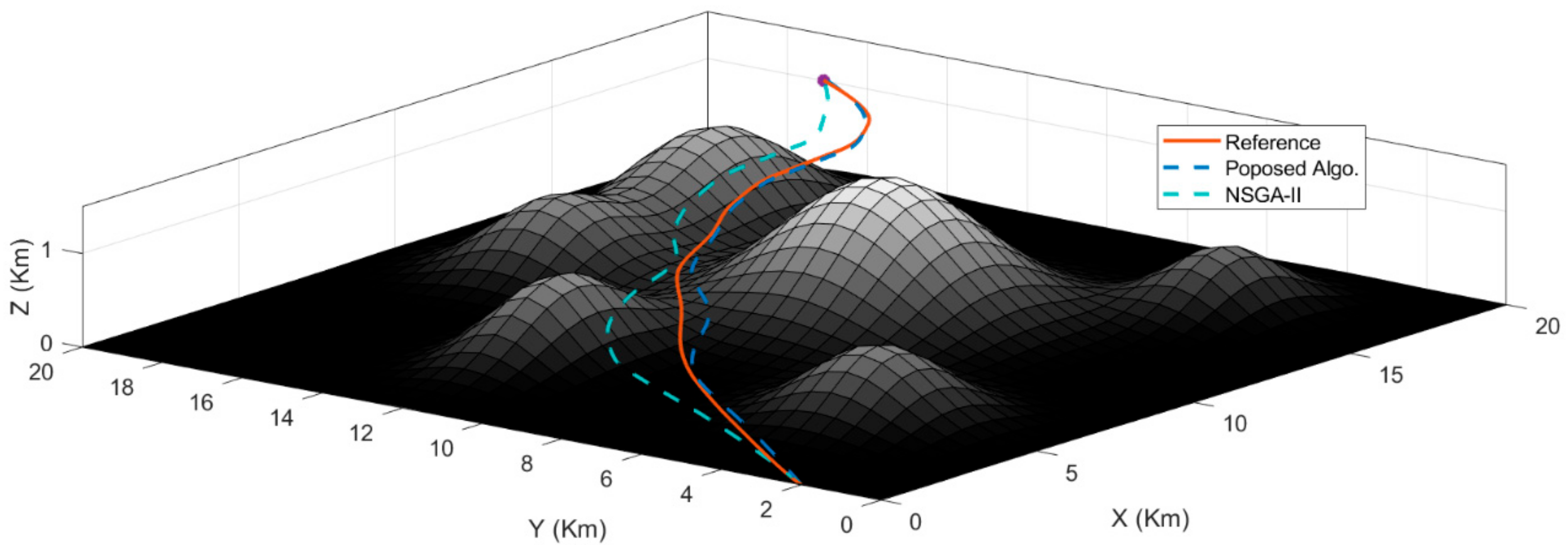
Comparison with NSGA-II:
Lastly, we also compare our proposed algorithm with the Non-Dominated Sorting Genetic Algorithm II (NSGA II). We compare our proposed method with the NSGA II because it is a fast multi-objective genetic algorithm and is a highly regarded evolutionary algorithm.
Figure 11 compares our proposed method with NSGA-II. Here, we can see that our designed strategy stays close to the reference while NSGA-II sometimes strays too far. Additionally, our strategy follows a shorter and quicker path to the target.
6. Conclusions
This research presents a strategy for the self-organization of a swarm of UAVs consisting of three colonies with three UAVs each. To plan the path of each colony to the target, we used max-min ant colony optimization (MMACO), and we used the social learning mechanism to sort the ants from worst to best. To organize the randomly positioned UAVs into different formations, this study used the multi-agent system (MAS). The designed algorithm also synchronized and connected the three colonies into a swarm with the help of dynamic leader selection. The proposed algorithm completed the given objectives in the simulation results.
The salient results and the findings in this research include successfully maintaining the formations in the first scenario. In the second scenario, the algorithm not only maintained the formations, but also navigated them through the obstacles. In the third scenario, the algorithm merged the three formations into one big swarm and then successfully navigated the swarm through the obstacles. By comparing the proposed method with the Non-Dominated Sorting Genetic Algorithm II (NSGA-II), it was clear that our strategy offered better convergence, optimized routes, and reached the destination using a shorter route than NSGA-II.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











