
SR-DeblurUGAN: An End-to-End Super-Resolution and Deblurring Model with High Performance

Abstract
:1. Introduction
- The model is still inadequate in extracting subtle features and cannot capture subtle differences in color and shape in images.
- Image repair sometimes produces distorted parts that cannot be strictly embedded with the surrounding pixels.
- Inability to generate reasonable images that achieve good results in repairing large gaps.
2. Related Works
2.1. Overall
2.1.1. CGAN
2.1.2. ACGAN
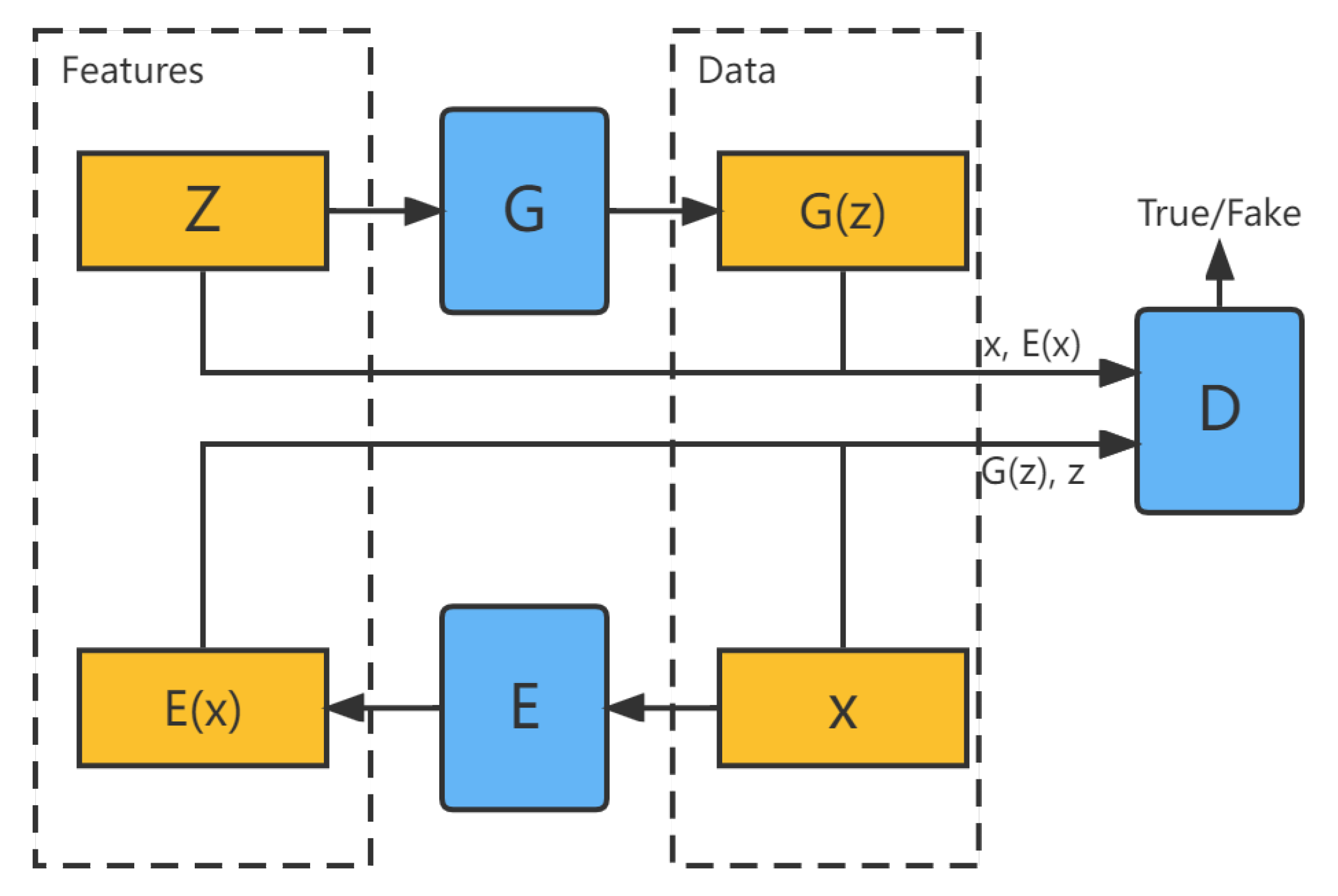
2.1.3. GAN Combined with Encoder
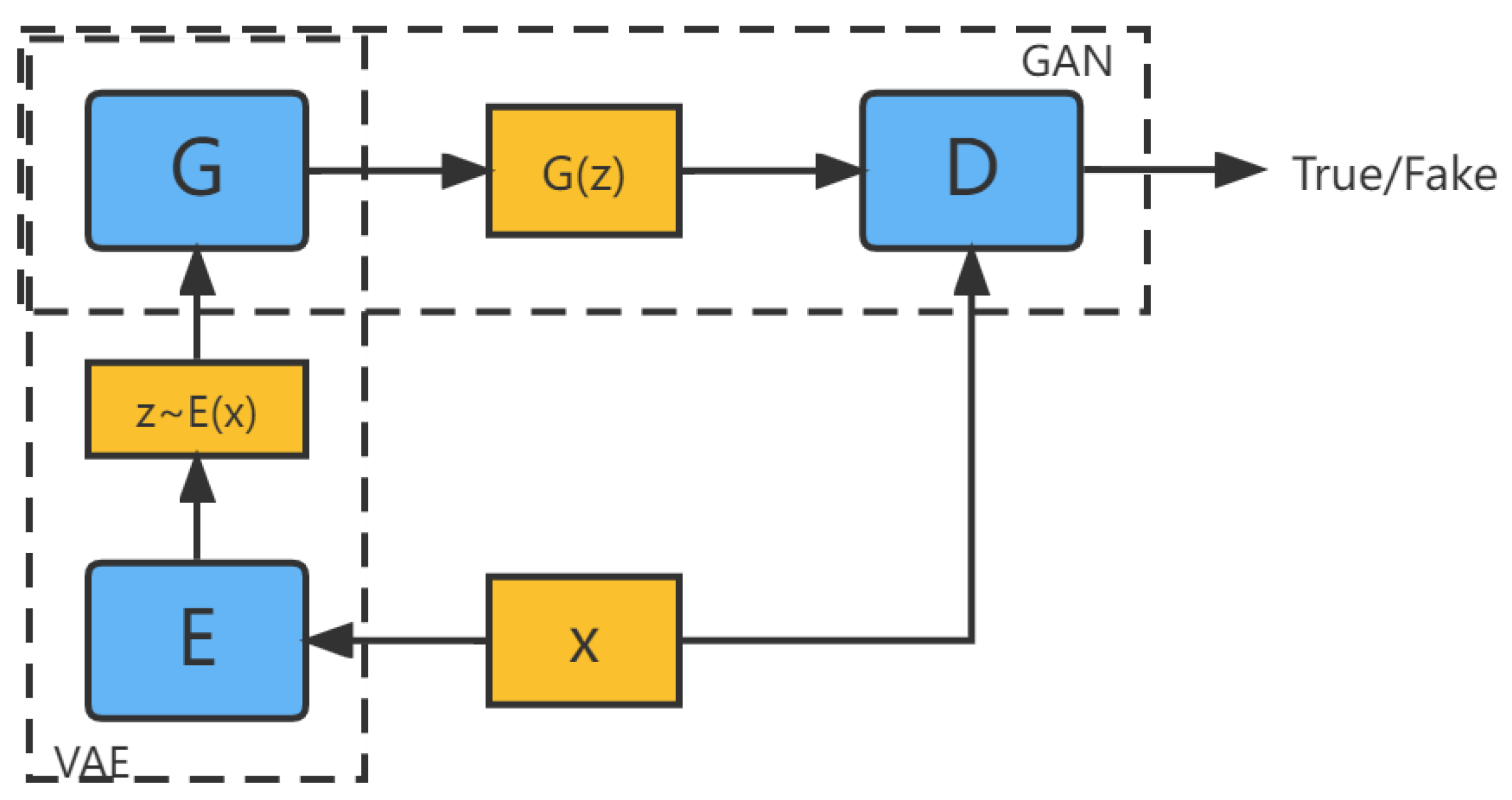
2.1.4. VAE-GAN
2.2. GAN in Image Generation Tasks
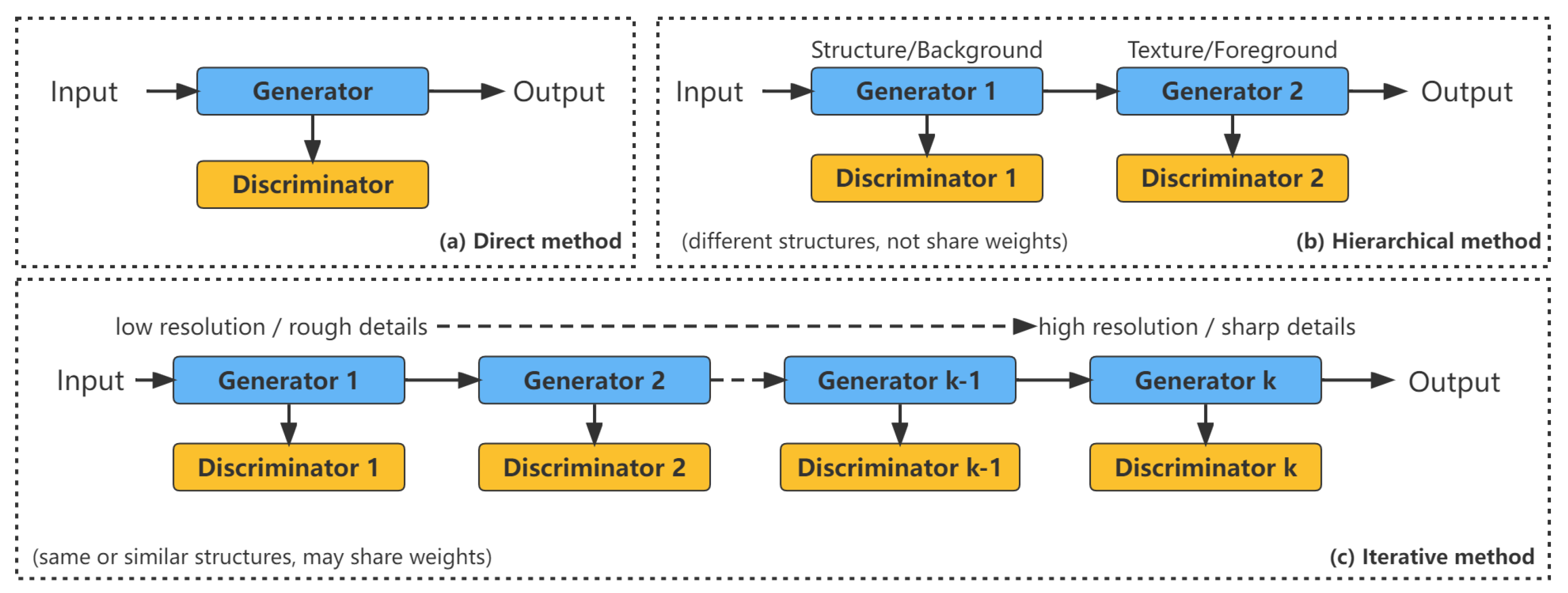
2.2.1. Direct Methods
2.2.2. Hierarchical Methods
2.2.3. Iterative Methods
2.2.4. Other Methods
3. Materials and Methods
3.1. Dataset Analysis
- Agricultural dataset collected in Shahe Town, Laizhou City, Yantai City, Shandong Province, China, at 09:00–14:00 and 16:00–18:00 on 8 April 2022. The collected images are shown in Figure 5A. A drone was equipped with a Canon 5D camera (stabilized by a tripod). This camera acquires solid color images at 8-bit resolution. The acquisition is performed automatically at a predetermined cadence during flight preparation. The system uses autonomous ultrasonic sensor flight technology to reduce the risk of accidents. The system includes a ground control radio connected to a smartphone with a range of 5 km (without obstacles) under normal conditions.
- The Urban100 dataset contains 100 images of urban scenes. It is commonly used as a test set to evaluate the performance of super-resolution models.
- The BSD 100 dataset is a dataset that provides an empirical basis for the study of image segmentation and boundary detection, containing 1000 hand-labeled segments of 1000 Corel dataset images from 30 human subjects, half of which were obtained by presenting color images to the subjects; the other half were obtained by presenting grayscale images. A common benchmark based on these data includes all grayscale and color segmentations of the 300 images. The BSD 300 dataset is divided into 200 training images and 100 side views, and the ground truth is divided into two folders, color and gray, which in turn have subfolders named after the marker id (uid), containing segmentation information provided by each marker. These folders have subfolders named by marker id (uid), which contain segmentation information provided by each marker, named by image id, and saved as .seg files. The dataset was released in 2001 by the University of California, Berkeley.
- The Sun-Hays 80 dataset is a dataset that has been used for super-resolution image studies to compare and find relevant scenes in image databases using global scene descriptions that provide ideal example textures to constrain image sampling to problems that are more predictive of explicit scene matching compared to internal image statistics for super-resolution tasks. We used patch-based texture transfer techniques and generated phantom texture details after comparing the publisher’s super-resolution images with other methods to draw conclusions. This dataset was released institutionally by Brown University in 2012.
3.2. Dataset Augmentation
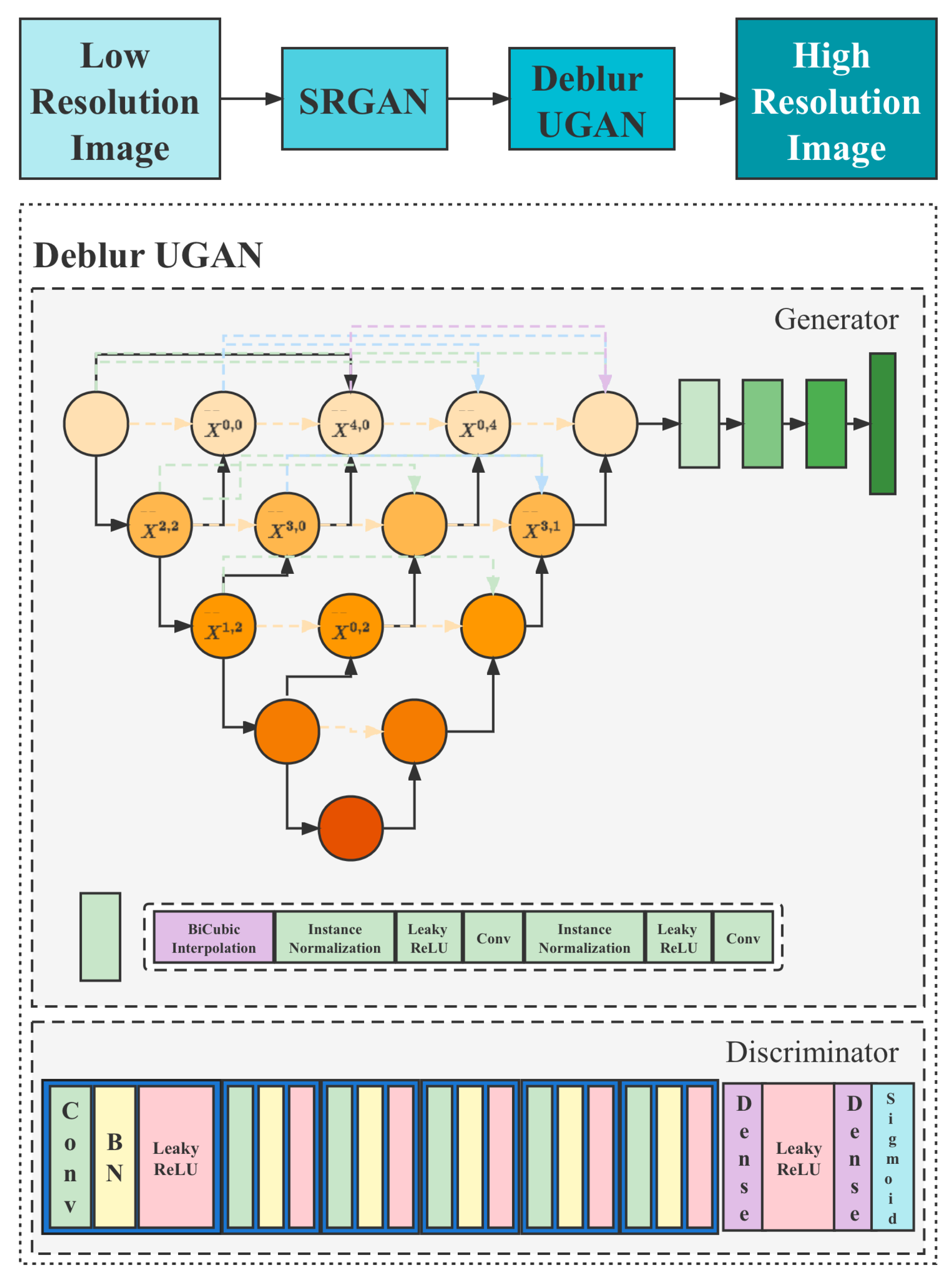
3.3. Proposed Model
3.3.1. Generator
- Adding a batch normalization layer after the convolutional layer but not for the output layer, which is beneficial to the rapid convergence of the deep network and, to a certain extent, to the effect of regularization, reducing the risk of overfitting, etc.
- The number of feature maps is halved, which significantly reduces the number of network parameters, saves computational resources, improves training and prediction speed, and allows inputting larger sample batches for training.
3.3.2. Discriminator
4. Experiments
4.1. Overall
4.2. Experiment Parameters and Platform
4.3. Experiment Metrics
4.3.1. Peak Signal-to-Noise Ratio (PSNR)
4.3.2. Structural Similarity Index
5. Results and Discussion
5.1. Results
- More effective recovery of image details;
- Lower deblurring processing time.
5.2. Validation on More Channels
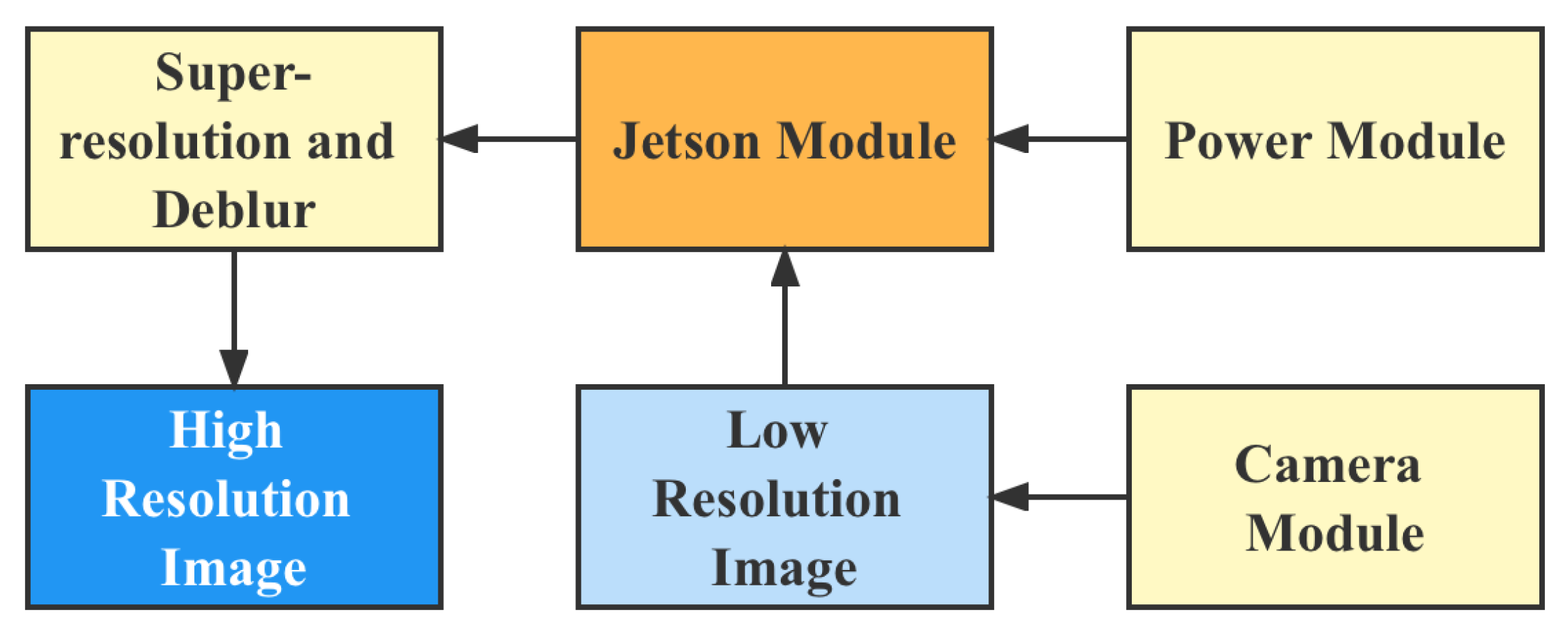
5.3. Application on Edge Computing
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Porras, D.; Carrasco, J.; Carrasco, P.; Alfageme, S.; Gonzalez-Aguilera, D.; Lopez Guijarro, R. Drone Magnetometry in Mining Research. An Application in the Study of Triassic Cu;Co;Ni Mineralizations in the Estancias Mountain Range, Almería (Spain). Drones 2021, 5, 151. [Google Scholar] [CrossRef]
- Liu, X.; Lian, X.; Yang, W.; Wang, F.; Han, Y.; Zhang, Y. Accuracy Assessment of a UAV Direct Georeferencing Method and Impact of the Configuration of Ground Control Points. Drones 2022, 6, 30. [Google Scholar] [CrossRef]
- Shelekhov, A.; Afanasiev, A.; Shelekhova, E.; Kobzev, A.; Tel’minov, A.; Molchunov, A.; Poplevina, O. Low-Altitude Sensing of Urban Atmospheric Turbulence with UAV. Drones 2022, 6, 61. [Google Scholar] [CrossRef]
- Orsini, C.; Benozzi, E.; Williams, V.; Rossi, P.; Mancini, F. UAV Photogrammetry and GIS Interpretations of Extended Archaeological Contexts: The Case of Tacuil in the Calchaquiacute; Area (Argentina). Drones 2022, 6, 31. [Google Scholar] [CrossRef]
- Fiz, J.I.; Martín, P.M.; Cuesta, R.; Subías, E.; Codina, D.; Cartes, A. Examples and Results of Aerial Photogrammetry in Archeology with UAV: Geometric Documentation, High Resolution Multispectral Analysis, Models and 3D Printing. Drones 2022, 6, 59. [Google Scholar] [CrossRef]
- Bollard, B.; Doshi, A.; Gilbert, N.; Poirot, C.; Gillman, L. Drone Technology for Monitoring Protected Areas in Remote and Fragile Environments. Drones 2022, 6, 42. [Google Scholar] [CrossRef]
- Pádua, L.; Antao-Geraldes, A.M.; Sousa, J.J.; Rodrigues, M.A.; Oliveira, V.; Santos, D.; Miguens, M.F.P.; Castro, J.P. Water Hyacinth (Eichhornia crassipes) Detection Using Coarse and High Resolution Multispectral Data. Drones 2022, 6, 47. [Google Scholar] [CrossRef]
- Miller, Z.; Hupy, J.; Hubbard, S.; Shao, G. Precise Quantification of Land Cover before and after Planned Disturbance Events with UAS-Derived Imagery. Drones 2022, 6, 52. [Google Scholar] [CrossRef]
- Suin, M.; Purohit, K.; Rajagopalan, A.N. Adaptive Image Inpainting. arXiv 2022, arXiv:2201.00177. [Google Scholar]
- Chen, J.; Ng, M.K. Color Image Inpainting via Robust Pure Quaternion Matrix Completion: Error Bound and Weighted Loss. arXiv 2022, arXiv:2202.02063. [Google Scholar]
- Qiu, Z.; Yuan, L.; Liu, L.; Yuan, Z.; Chen, T.; Xiao, Z. Generative Image Inpainting with Dilated Deformable Convolution. J. Circuits Syst. Comput. 2022, 31, 2250114. [Google Scholar] [CrossRef]
- Kumar, A.; Tamboli, D.; Pande, S.; Banerjee, B. RSINet: Inpainting Remotely Sensed Images Using Triple GAN Framework. arXiv 2022, arXiv:2202.05988. [Google Scholar]
- Jam, J.; Kendrick, C.; Drouard, V.; Walker, K.; Yap, M.H. V-LinkNet: Learning Contextual Inpainting Across Latent Space of Generative Adversarial Network. arXiv 2022, arXiv:2201.00323. [Google Scholar]
- Dervishaj, E.; Cremonesi, P. GAN-based Matrix Factorization for Recommender Systems. In Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing, Virtual Event, 25–29 April 2022. [Google Scholar]
- Park, G.; Park, K.; Song, B.; Lee, H. Analyzing Impact of Types of UAV-Derived Images on the Object-Based Classification of Land Cover in an Urban Area. Drones 2022, 6, 71. [Google Scholar] [CrossRef]
- Zheng, H.; Lin, Z.; Lu, J.; Cohen, S.; Shechtman, E.; Barnes, C.; Zhang, J.; Xu, N.; Amirghodsi, S.; Luo, J. CM-GAN: Image Inpainting with Cascaded Modulation GAN and Object-Aware Training. arXiv 2022, arXiv:2203.11947. [Google Scholar]
- Dogan, Y.; Keles, H.Y. Iterative facial image inpainting based on an encoder-generator architecture. Neural Comput. Appl. 2022, 34, 10001–10021. [Google Scholar] [CrossRef]
- Zhao, Y.; Barnes, C.; Zhou, Y.; Shechtman, E.; Amirghodsi, S.; Fowlkes, C. GeoFill: Reference-Based Image Inpainting of Scenes with Complex Geometry. arXiv 2022, arXiv:2201.08131. [Google Scholar]
- Rezki, A.M.; Serir, A.; Beghdadi, A. Blind image inpainting quality assessment using local features continuity. Multimed. Tools Appl. 2022, 81, 9225–9244. [Google Scholar] [CrossRef]
- Hudagi, M.R.; Soma, S.; Biradar, R.L. Bayes-Probabilistic-Based Fusion Method for Image Inpainting. Int. J. Pattern Recognit. Artif. Intell. 2022, 36, 2254008. [Google Scholar] [CrossRef]
- Li, W.; Lin, Z.; Zhou, K.; Qi, L.; Wang, Y.; Jia, J. MAT: Mask-Aware Transformer for Large Hole Image Inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Van den Oord, A.; Kalchbrenner, N.; Espeholt, L.; Vinyals, O.; Graves, A. Conditional image generation with pixelcnn decoders. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 9 December 2016; Volume 29. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative flow with invertible 1x1 convolutions. In Proceedings of the 2018 Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. In Advances in Neural Information Processing Systems; The MIT Press: London, UK, 2014; Volume 3, pp. 2672–2680. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1558–1566. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 9 December 2016; Volume 29. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 9 December 2016; Volume 29. [Google Scholar]
- Nowozin, S.; Cseke, B.; Tomioka, R. f-gan: Training generative neural samplers using variational divergence minimization. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 9 December 2016; Volume 29. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1060–1069. [Google Scholar]
- Nguyen, A.; Clune, J.; Bengio, Y.; Dosovitskiy, A.; Yosinski, J. Plug & play generative networks: Conditional iterative generation of images in latent space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4467–4477. [Google Scholar]
- Cho, S.; Jun, T.J.; Oh, B.; Kim, D. Dapas: Denoising autoencoder to prevent adversarial attack in semantic segmentation. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the ICML 2013, Atlanta, GA, USA, 16–21 June 2013; Volume 30, p. 3. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR | SSIM | FPS | Average Perceived Loss |
|---|---|---|---|---|
| deblurGAN | 26.15 | 0.75 | 20.2 | 21.63 |
| simDeblur | 27.33 | 0.81 | 18.5 | 19.63 |
| ours | 28.93 | 0.83 | 7.42 | 15.79 |
| Series | PSNR | SSIM | Input/Ouput |
|---|---|---|---|
| 1 | 28.617 | 0.981 | 32.4 |
| 2 | 28.815 | 0.981 | 33.4 |
| 3 | 27.958 | 0.982 | 34.8 |
| 4 | 21.758 | 0.981 | 35.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, Y.; Zhang, J.; Chen, W.; Wang, Y.; You, J.; Wang, Q. SR-DeblurUGAN: An End-to-End Super-Resolution and Deblurring Model with High Performance. Drones 2022, 6, 162. https://doi.org/10.3390/drones6070162
Xiao Y, Zhang J, Chen W, Wang Y, You J, Wang Q. SR-DeblurUGAN: An End-to-End Super-Resolution and Deblurring Model with High Performance. Drones. 2022; 6(7):162. https://doi.org/10.3390/drones6070162
Chicago/Turabian StyleXiao, Yuzhen, Jidong Zhang, Wei Chen, Yichen Wang, Jianing You, and Qing Wang. 2022. "SR-DeblurUGAN: An End-to-End Super-Resolution and Deblurring Model with High Performance" Drones 6, no. 7: 162. https://doi.org/10.3390/drones6070162
APA StyleXiao, Y., Zhang, J., Chen, W., Wang, Y., You, J., & Wang, Q. (2022). SR-DeblurUGAN: An End-to-End Super-Resolution and Deblurring Model with High Performance. Drones, 6(7), 162. https://doi.org/10.3390/drones6070162