1. Introduction
UAVs have received significant attention and utilization in both civilian and military domains [
1]. UAVs are autonomous or remotely controlled aircrafts that offer numerous advantages over manned aircraft, including cost-effectiveness, flexibility, and the ability to operate in challenging or hazardous environments. In the civilian sector, UAVs have revolutionized various fields, such as agricultural crop protection [
2,
3], aerial photography [
4], express transportation [
5,
6], and ocean remote sensing [
7]. In the military sector, they have become vital assets for intelligence gathering [
8], reconnaissance surveillance [
9], and other complex and dangerous missions. The role of UAVs in the delivery of essential supplies during seismic disaster relief operations in mountainous areas is of particular interest. Mountainous regions often involve challenges such as complex geological conditions and limited transportation options, which impede traditional supply/delivery methods. UAVs, with their speed and agility, can effectively transport relief materials to disaster-stricken areas, providing crucial support for rescue operations [
10].
One fundamental requirement for a UAV to effectively accomplish its intended mission is effective path planning [
11]. The path planning problem for UAVs involves generating a collision-free trajectory from the starting point to the target point that accounts for the given flight conditions and environmental constraints. The planned path should minimize the cost and comply with the relevant constraints. Due to the complexity of optimization problems with multiple constraints, traditional optimization strategies often face challenges in finding the best solution [
12].
Sampling-oriented path planning algorithms have been widely studied and applied because of their low computational complexity when solving complex, high-dimensional problems. Tan Liguo uses the RRT algorithm to extend the node to address the time consumption and low success rate of UAV path planning in complex blockage environments [
13]. The path planning solutions of RRT have better adaptability than traditional strategies, allowing them to cope with obstacle changes in dynamic environments and find feasible paths more quickly [
14,
15], but these methods may run indefinitely when paths do not exist.
In contrast, nature-inspired optimization algorithms offer distinct advantages when addressing intricate optimization problems like path planning. Unlike traditional gradient-based algorithms, natural heuristic algorithms do not rely on the gradient information of the objective function but search by directly evaluating the objective function values. These algorithms are not constrained by mathematical conditions such as continuous differentiability and can be applied to discrete optimization problems such as integer programming [
16]. Even in nonlinear control systems, natural heuristic algorithms are effective for parameter estimation and control optimization [
17,
18]. Notable examples of these common heuristic algorithms encompass particle swarm optimization (PSO) [
19,
20,
21], ant colony optimization (ACO) [
22,
23], artificial bee colony (ABC) [
24,
25,
26], the genetic algorithm (GA) [
27,
28,
29], beetle antennae search algorithm (BAS) [
16], and Harris hawks optimization (HHO) [
30], among others. Ref. [
31] proposes a novel path planning approach integrating Voronoi diagram generation and Dijkstra’s shortest path algorithm, introducing an efficient PSO metaheuristic algorithm that improves solution quality compared to traditional PSO by simulating real-world scenarios, with enhancements ranging from 5% to 22% under different wind conditions. Ref. [
32] explores the impact of common U-shaped obstacles in 3D space on path planning for UAVs and presents a self-heuristic ACO-based method. This method defines the entire space by constructing a grid workspace model and designing two different search strategies for selecting the next path node to avoid ACO algorithm deadlock, effectively addressing the path planning problem for UAVs encountering U-shaped obstacles in 3D space. Ref. [
25] proposes an improved ABC algorithm based on multi-strategy synthesis for UAV path planning in complex urban environments and provides rapid and optimal paths. A feasible approach was proposed in [
33] to solve the real-time path planning problem for UAVs, which meets the requirements of flight safety and improves the efficiency of path planning, especially in dynamic obstacle avoidance.
The methods proposed in the above literature include problems such as unrealistic map settings, ease of falling into local optimums, and unreasonable path optimization. Notably, the artificial fish swarm algorithm (AFSA) in the population intelligence algorithm is widely used for optimization because of its flexibility, insensitivity to initial parameter settings, and global search capability [
34]. It stimulates the preying, following, and swarming behaviors of fish, utilizing multiple fish to collaboratively search and optimize functions or solve problems. Within AFSA, each fish makes various behavioral decisions based on the objective function information within their field of vision. Different fish interact through information exchange to achieve synergy, ultimately leading the fish population toward the optimal state. In comparison to the BAS algorithm, AFSA offers greater flexibility in adjusting search step lengths and striking a balance between local and global search through various behaviors. BAS, on the other hand, relies more on antenna length parameters. In contrast to HHO, AFSA features autonomous individuals within the fish population and lacks a distinct tracking-evading relationship, which helps prevent falling into local optima. In the context of the problem at hand, AFSA achieves collaborative search through information dissemination, while PSO depends on velocity to maintain search direction. The local interactions within AFSA can provide richer search information. Ref. [
35] proposed incorporating directional operators and probabilistic weighting factors to enhance the path quality of autonomous surface vessels (ASVs). Ref. [
36] addresses the path planning problem of ASVs under complete constraints by employing a cost expansion strategy. Ref. [
37] introduces a novel approach combining an artificial fish school algorithm with continuous segmented Bessel curves to generate low-precision, high-quality paths with minimal inflection points and reduced length for robots.
However, relatively few reports discuss applying AFSAs to the path planning problem of UAV 3D environments. By analyzing and organizing the above literature, an improved artificial fish swarming algorithm (IAFSA) is proposed to address this problem and obtain the optimal path more effectively than other algorithms. The following are the contributions to this paper:
A multi-strategy fusion IAFSA is proposed to improve the original AFSA. Specifically, the refractive opposition learning (ROL) strategy is introduced to address the issue of the uneven distribution of the fish swarm. Then, the adaptive spiral strategy (ASS) is employed to balance the trade-off between exploration and exploitation of the algorithm. Finally, the adaptive elimination and regeneration (AER) mechanism is implemented to effectively prevent the algorithm from converging to local optima. Through the integration of these strategies, the improved algorithm achieves superior performance compared to the original AFSA.
The proposed algorithm is compared on the cec2020 benchmark function with PSO, the original AFSA, the improved strategy IAFSA1 proposed in Ref. [
35], and the improved strategy IAFSA2 proposed in Ref. [
38], and the experimental results are analyzed.
Experiments on the effectiveness of the strategy are performed for the UAV path planning issue, and the experimental results are analyzed. Then, the suggested algorithm is compared with itself in maps of different complexity to explore the effect of the algorithm.
This manuscript is structured as follows:
Section 2 describes the problem of UAV path planning.
Section 3 introduces the standard AFSA, the proposed optimization idea, and the improvement method of the IAFSA.
Section 4 presents the validation experiment, the strategy effectiveness experiment, and the algorithm comparison experiment on the test function.
Section 5 presents the conclusions.
2. Problem Description for Path Planning
In this section, a mountainous environment model for UAVs is established, along with a corresponding UAV path planning model. A dual-objective model is formulated that accounts for both the minimization of UAV path length and the optimization of flight energy consumption. Additionally, trajectory optimization methods for UAVs are introduced.
2.1. 3D Scene Setting
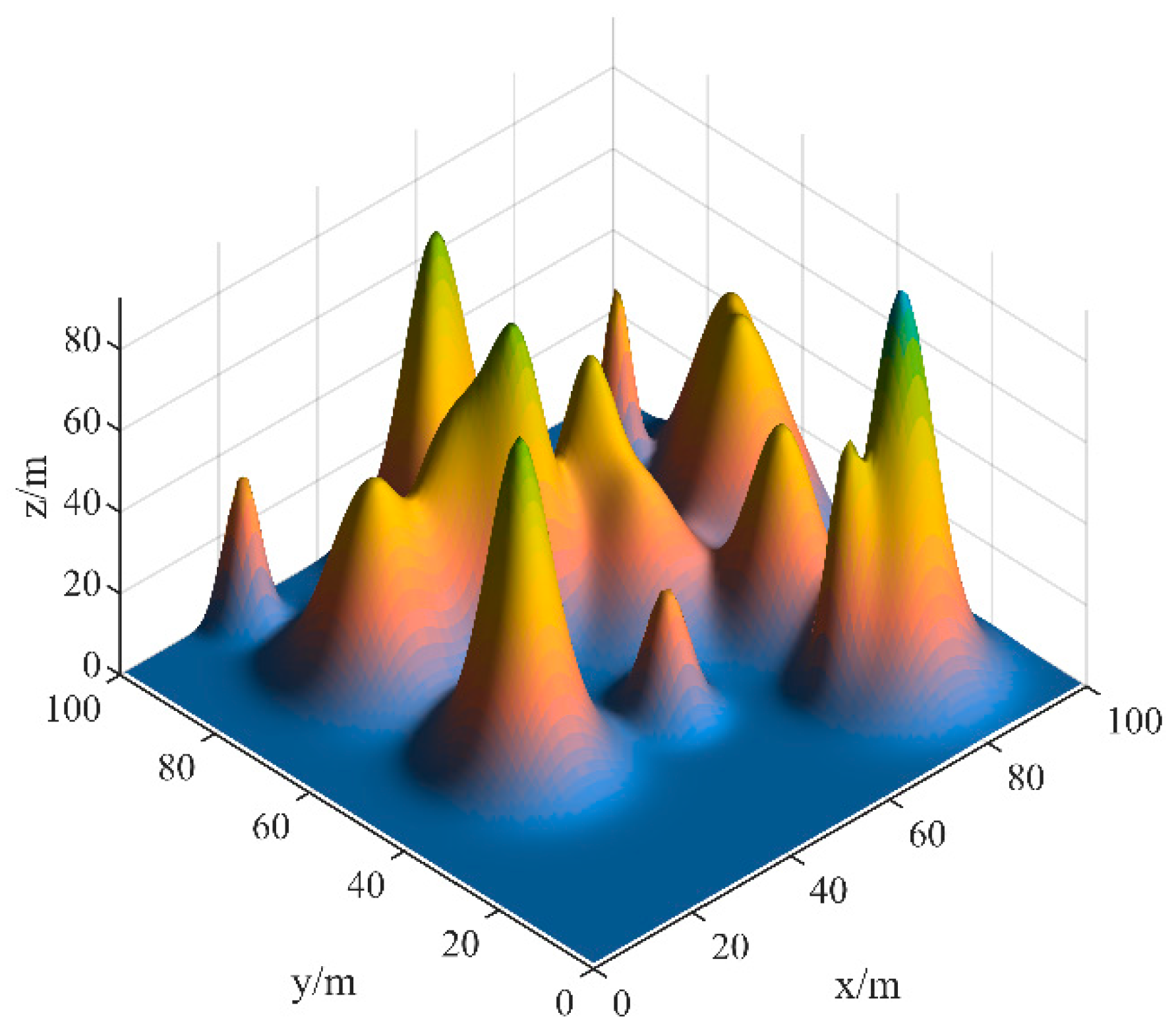
UAVs often operate in complex terrains in practical scenarios such as coastal search and disaster relief. The terrain model serves as a fundamental basis for UAV path planning. To better simulate real-world conditions, the complex 3D terrain can be described using the following exponential (1) function [
39]:
The coordinates are utilized to represent the position in the two-dimensional plane. denotes the number of generated peaks, where correspond to the height control parameter and central coordinates of the respective peak. represents the rate of change in the peak along the -axis, while denotes the rate of change along the -axis. Additionally, denotes the exponential function.
This formulation enables multiple peaks to be created and manipulated within the given plane. The parameters , , , , and collectively contribute to the diverse and intricate landscape generated by the peaks.
Based on the model (1) formulation, ten randomly generated peaks were created within a 3D space of dimensions
, as illustrated in
Figure 1.
2.2. Establishment of the Multiobjective Fitness Function
Let the coordinates of the starting point in the aforementioned complex 3D environment be and the coordinates of the destination point be . The coordinates of the intermediate node are denoted as , where .
The objective function is to minimize the cost of the drone’s travel and energy consumption while executing the mission. Assuming that the total cost of completing a single mission by the drone is
, the following equation is obtained.
where
represent the cost of travel and energy consumption, respectively.
and
denote the weights assigned to these costs and satisfy the condition
.
2.2.1. Cost of Travel
The flight distance covered by a UAV while completing each mission is determined by summing the Euclidean distances between adjacent path nodes, denoted as
. The UAV departs from the starting point
, passes through node
, and reaches the destination point
, with the expression of the cost of flight distance denoted as
.
Equation (3) can be reformulated as follows:
2.2.2. Energy Consumption
Under constant velocity, power is primarily proportional to weight. Weight consists of three main components: airframe, battery, and payload. Therefore, increasing payload increases the overall weight of the aircraft, resulting in higher power consumption. Energy consumption is a crucial factor that limits the performance of UAVs as different behaviors of the aircraft result in differing amounts of power consumption. If the payload influence is not accounted for, the planned flight path may not be achievable in practical missions. Hence, an effective payload penalty coefficient, denoted as , is introduced.
According to research conducted by Song et al. [
40], the flight time and energy consumption of UAVs increase linearly with the mass of the loaded product. Therefore, the effective payload penalty coefficient
for logistics UAVs during delivery missions is assumed to be directly proportional to the payload quantity
.
represents the maximum payload capacity of the logistics UAVs, while
represents the maximum value of the effective payload penalty coefficient.
Then, the effective payload penalty coefficient is expressed as follows:
The energy cost
can be described as follows:
where
and
indicate the energy spent by UAVs during horizontal and vertical flight, respectively. The number
represents the energy consumption per unit distance for horizontal flight.
denotes the energy consumption generated per unit distance for vertical height. It is worth noting that in this model, a simplification of the same power consumption for ascent and descent has been made for the sake of reserving safe power.
2.3. Restrictions and Path Smoothing
To guarantee that the UAV’s flight route remains within the defined airspace, the following constraints must be satisfied:
where
is the restricted space range.
In drone path planning, it is common to impose navigation angle constraints on unmanned aerial vehicles to restrict their flight direction and orientation [
41,
42,
43].
The current position of the UAV is
, and under the condition
, the UAV following the turning angle
can be described by Equation (10). In Equation (11),
is the climb angle of the current position.
where
is the maximum angle of turning, and
is the maximum climb angle.
The use of mathematical expression constraints in UAV path planning poses significant challenges. These constraints make it challenging to precisely describe complex paths, often resulting in path discontinuities and a lack of smoothness. Simultaneously satisfying various constraints becomes a complex task, ultimately restricting path choices and hindering optimization. In contrast, spline curve methods offer a more optimized, smoother, and continuous approach to path planning. Spline curves reduce UAV vibrations and bumps, enhancing comfort and stability. They also provide a better simulation of natural curves, ensuring path harmonization. Utilizing optimization algorithms, these methods can efficiently identify optimal paths within specified constraints, significantly improving efficiency.
Spline Function Definition: Given an existing function , which satisfies a third-degree polynomial definition within each interval , where . The function is referred to as a spline function with nodes . If at the node , there exists an equation and the equation holds true throughout, then is termed a spline interpolation function.
In each subinterval
satisfying the following:
where
are the coefficient to be determined.
Faction
has second-order continuous derivatives in the interval
and thus satisfies at the
nodes.
The boundary condition can be described as follows:
3. Algorithm Description
In the previous section, we built a 3D environment and established a fitness function that considers UAV path planning. We also proposed using spline interpolation to generate a smooth path. Among these, the process points between the start and end points are especially important, because the process points directly affect the final path quality. In order to obtain optimized process points, this section will introduce an IAFSA.
In this section, an overview of the traditional AFSA is provided, followed by a discussion on the four key improvements made in the IAFSA for UAV trajectory planning. The improvements include generating the initial population using an ROL strategy, enhancing convergence speed through adaptive spiral vision, incorporating social experience locations to reinforce following behavior, and implementing population regeneration to avoid local optima. Finally, the specific implementation steps of the IAFSA for UAV path planning are presented.
3.1. Traditional AFSA
The AFSA is a population intelligence algorithm that seeks optimization by imitating the feeding behavior of fish in a specified search area space. The AFSA uses a local-to-whole optimization approach. First, each artificial fish in a group of artificial fish performs a local optimization search and information transfer according to a set perceptual range and behavioral mechanism. Then, the overall optimization is achieved based on the distribution of fish locations.
In a school of fish, represents the state of the fish, and denotes the dimension of each individual. denotes the current food concentration, and two-norm represents the distance between two fish.
The AFSA consists of four main behaviors: prey behavior, swarming behavior, following behavior, and random behavior.
Figure 2 shows the main behavioral mechanisms of a traditional AFSA. These behaviors are specifically described as follows:
3.1.1. Preying Behavior
In the traditional AFSA algorithm, the artificial fish randomly chooses a position within the visual range based on the current position . If the food concentration , the artificial fish moves one step size toward . Otherwise, it randomly chooses another position to compare the food concentration. After exploring for the maximum number of preying attempts times, if the conditions for advancement are not met, a random step is taken.
The position
can be defined as (16) and provides a random position state in the visual range next to the current fish.
The fish moves toward
if the food concentration
. This is accomplished by the following:
3.1.2. Following Behavior
In the
field of view, position
corresponds to the food concentration
, and the state of the position satisfies
. This indicates that a fish in the school finds a better position, assuming that there are
artificial fish in the
field of view where
, indicating that the position is not crowded.
then moves toward (18).
The AFSA will engage in prey behavior if no neighbors are located in the field of view or the requirements are not met.
3.1.3. Swarming Behavior
The behavior of the artificial fish mimics the natural aggregation patterns observed in real fish, where they strive to move toward a central location during each iteration. This movement strategy enables artificial fish to concentrate in areas with high food density, facilitating efficient local exploitation. One method used to determine the central location is illustrated in Equation (19):
The artificial fish moves toward the central position as expressed in (20) if the food concentration
and
.
Otherwise, the artificial fish executes prey behavior.
3.1.4. Random Behavior
To mitigate the risk of becoming trapped in local optima, the artificial fish adopts a random behavior when it is unable to execute other predefined behaviors. This random behavior involves the artificial fish randomly selecting a state or position within its visual field and then swimming toward the chosen location. This procedure can be expressed as follows:
3.2. Improved AFSA
3.2.1. ROL Initialization Strategy
In the context of UAV path planning, finding the globally optimal path faces challenges in complex environments. During the early stages of algorithm evolution, exploration takes precedence over exploitation, as global exploration of the search space helps prevent premature convergence or becoming trapped in local optima. Therefore, to address this issue, the ROL strategy was introduced, aiming to expand the search range and prevent the algorithm from prematurely converging to local optima.
The ROL strategy is a mathematical idea inspired by the natural phenomenon of light deflection in the propagation direction due to different refractive indices in two media [
44,
45]. In the analogy between ray refraction and path planning, both involve the process of finding the optimal path in a target space. During light propagation, refraction occurs when interfaces with different refractive indices are encountered, thus changing the direction of propagation. Similarly, in path planning, when a better path is found, the path direction needs to be adjusted in time. The “refraction effect” occurs when an unobstructed region of space exists when generating the initial school of fish. This effect refracts the initial set of points as a target into a new set of points, ensuring correlation between the old and new sets of points. In contrast, randomized methods do not ensure this correlation because the new points may not be correlated at all. This helps avoid revisiting previously explored regions and extends the path to unexplored regions. This ensures that a more evenly distributed initial population of fish is generated, thus improving the performance of the algorithm.
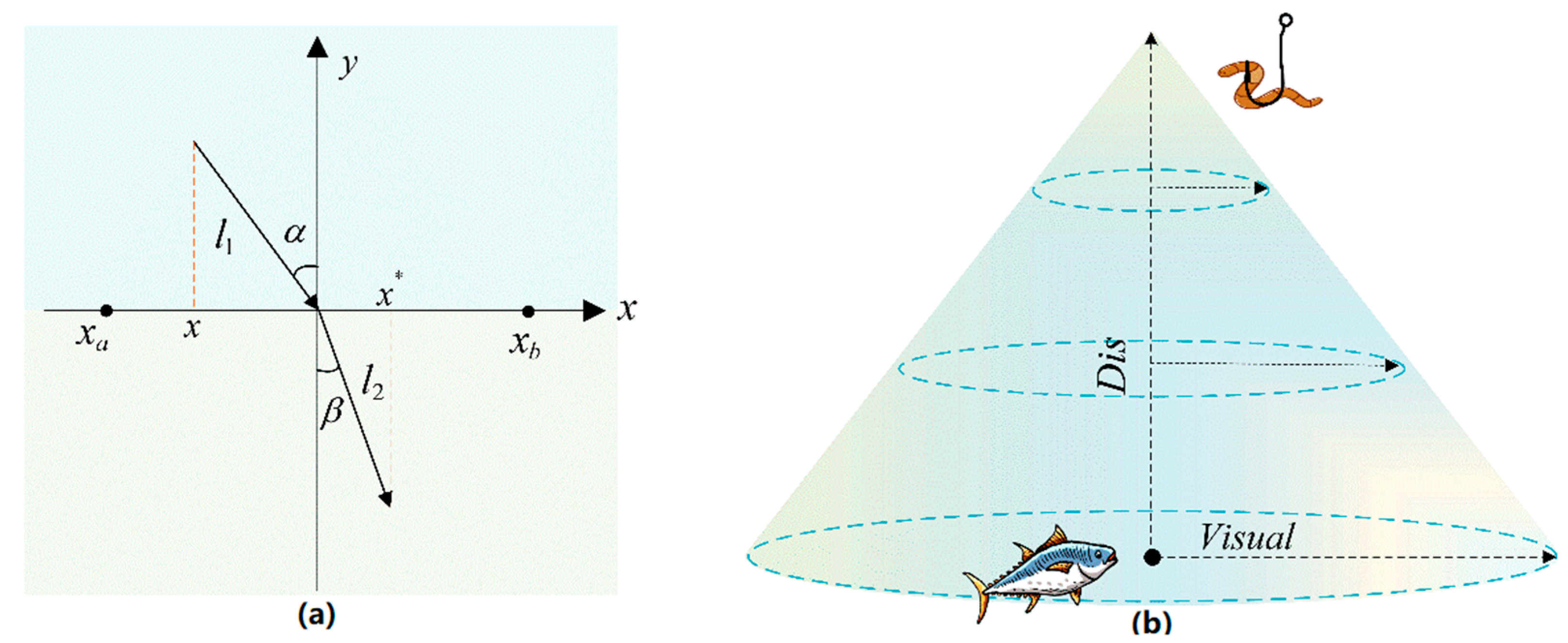
An optimization method is used to retain the more adaptive individual from the current set of solutions and from the set of opposing solutions. The concept of the ROL initialization strategy is illustrated in
Figure 3a.
In
Figure 3a, the
-axis depicts the division between two distinct media, while the
-axis represents the normal direction perpendicular to the
-axis. The search range is denoted as
, and the angles of incidence and refraction are represented by
and
, respectively, while
and
denote the lengths of the incident and refracted light, respectively. The point
symbolizes a position within the incident region
, while
denotes the position of point
after refraction. The lines depicted in
Figure 3a illustrate the following geometric relationships:
Equation (24) defines the refraction rate
.
Given
, combining (24), we obtain the following, as shown in (25):
By taking
in the general case and modifying Equation (25) to address the D-dimensional space problem, we obtain the following:
where
is the position of the
dimension of the
individual.
is refracted by
through the refractive opposition method.
In the initialization process of the algorithm, the generated initial population
is considered the incident light, and the population
after refraction, where
is the population size. The composition of the initial population
can be expressed by (27):
The fitness of and is calculated to filter out the iterative population with high fitness, thereby improving global search ability and population diversity.
3.2.2. ASS Strategy
In UAV path planning, the path needs to be quickly adjusted in complex and dynamic environments. The IAFSA simulates the intelligent behaviors of fish in different environments, enabling dynamic path adjustments to suit various scenarios.
In this subsection, the ASS strategy is introduced to enhances the algorithm’s adaptability and improve the convergence speed and accuracy of the AFSA. This strategy adopts a spiral-shaped search path, which gradually decreases the step size in the search process and helps to approach the optimal solution quickly. This strategy has a large field of view in the initial search phase, and the field of view gradually decreases as the search proceeds striking a balance between global optimality and real-time responsiveness.
The ASS strategy is unique because it combines the characteristics of randomness and determinism, thus maintaining diversity in the search process. It can not only perform an accurate local search but also step out of local optimal solutions and search in the direction of the global optimal solution.
Figure 3b shows a schematic diagram of the spiral field of the visual range.
Figure 4a illustrates the preying behavior of the spiral field of the ASS strategy.
The ellipse in
Figure 4a indicate that the range of an individual’s visual field varies in a spiral pattern. In the early stage of the algorithm, the range of field of view is larger, which is favorable for global search; in the later stage, the range of field of view gradually decreases, which is favorable for local fine search, and as the number of iterations increases, the range of the field of view and the step size of the fish individuals will gradually decrease when they are close to the local optimal solution. This realizes the adaptive transformation from global to local. In
Figure 4b, the traditional AFSA fish will move directly toward the position closest to the food in the field of view. In IAFSA, the effect of the current global optimal solution (social experience position) is introduced while moving toward the optimal position in the field of view. The fish will move in the direction of the synthesis of the optimal position in the field of view and the socio-experiential position. This increases the ability to utilize global information.
represents the distance from the current artificial fish to the global optimum , and the value of the global optimum decreases as the exploration deepens. It is worth noting that the global optimal mentioned here refers to the optimal algorithm within the explored solution space, not the absolute optimal mathematical solution. is the spiral-shaped parameter, is the random number between , and is the initial field of view value.
3.2.3. Behavioral Enhancement
In the original pursuit behavior, the pursuit relied solely on the information of artificial fish within its visual range. However, when the visual range is limited, the artificial fish are prone to becoming trapped in local optima. In contrast, incorporating the social experience location broadens the search range, facilitating global exploration for the fish swarm. The social experience position refers to the potential global optimal solutions in the current number of iterations. These positions are selected based on the number of iterations of the algorithm and the current search state, one position at a time.
Compared to local information within the visual range, social experience offers comprehensive spatial distribution information. Therefore, by incorporating social experience positions into the pursuit behavior and integrating local and global information, fine-grained and broad-scale searches are combined.
Additionally, introducing moderate random perturbations enhances exploratory behavior, effectively improving the algorithm’s capability for global optimization. This modification adapts to the optimization needs of complex multimodal problems better than the original pursuit behavior that relied solely on local information. The enhanced following behavior is shown in
Figure 4b.
The updated equation for the improved pursuit behavior’s position update is as follows:
where
denotes the adaptive step factor.
3.2.4. AER Mechanism
In UAV planning, aiming for a global optimal path instead of a local one is essential, but achieving a globally optimal path search in complex environments is notably challenging.
During the search process, the mechanism randomly updates individual positions, preserving differentiation among individuals in the fish population. This approach prevents the algorithm from prematurely converging to a specific local optimum, enabling a balanced exploration of the entire search space. Maintaining diversity allows the algorithm to adapt better to complex problems and diverse environments, thereby improving global search effectiveness.
Specifically, this mechanism is triggered when the algorithm reaches a threshold value of
iterations being trapped in local optima during the optimization process. The total number
of individuals to be replaced is calculated according to Equation (32).
Here, the operation is used to round a number to the nearest integer. represents the current iteration count, and represents two positive real numbers. These parameters determine the proportions for updating the population.
Using the logistic mapping method shown in Equation (33), a random number sequence between
is generated and mapped to integers in the range
, where
represents the population size, to determine which populations will be replaced.
represents the initial value.
The population is updated with the new generation using Equation (34).
where
denotes the position of the
individual, while
denotes the updated position of the population. The random operator
is generated using the t-distribution, and the global best value is denoted as
.
3.2.5. IAFSA Implementation in UAV Path Planning
The previous section introduced the UAV route planning issue and the improvement strategy of IAFSA. This section discusses how to tackle the path planning problem using IAFSA in conjunction with the spline curve approach. To be more specific, the path comprises a series of interpolation points and control points, forming an ordered spline curve. The sequence starts from the initial point, followed by interpolation points, then control points, followed by interpolation points, then control points, and finally ends with interpolation points. These control points are determined through an iterative optimization process of the algorithm. The following is the specific interpolation process for generating a path:
Use IAFSA to obtain interpolating nodes , and the sequence is given as an equivalent sequence .
Split the coordinates of the M interpolated points into three sequences , ,
Find the coordinate set and set , and calculate the corresponding spline interpolation function , , and .
Calculate the corresponding values of , , and on to achieve values , , .
is the desired path.
In the algorithm implementation, individual fish are defined with attributes, including position, path, and fitness. Position represents the location information of control points, and the initial positions are selected through the ROL strategy. Path represents the candidate path, which is obtained through the methods described above. Fitness indicates the fitness value, and once the path is obtained, we calculate the fitness value for each fish based on the objective function and accordingly update their fitness. The detailed steps of the algorithm are as follows:
- 1
Given the initial position and the end position, generate the complex landscape map.
- 2
Set the initialization parameters, including the number of fish , the initialization factor , the initial field of view , the adaptive step factor , the maximum number of preying tries , the crowding factor , and the maximum number of iterations .
- 3
Randomly generate the artificial fish population according to Equation (26) to generate the opposing population , where represents the location information. Calculate the fitness value of each artificial fish corresponding to the path, filter the iterative population , and update the global optimal position .
- 4
Calculate the field of view of the spiral search using Equation (28), with determined by Equation (31).
- 5
Execute the swarming behavior; select each artificial fish in turn, and determine the number of artificial fish within the current artificial fish field of view and find the central location . Determine whether the location is crowded. If it is not crowded according to Equation (20), move one step toward ; otherwise, execute preying behavior.
- 6
Perform the following behavior; determine the social experience position and the local optimal position . Determine whether the position is crowded. If it is not crowded according to Equation (30), update the current position; otherwise, perform foraging behavior.
- 7
Compare the swarming behavior with the following behavior: update the optimal position, and obtain the target path.
- 8
Determine whether collision occurs with the mountain. If collision occurs, expand the fitness value appropriately.
- 9
Determine whether the population regeneration threshold is reached. If not, reach the threshold by Formulas (32)–(34) to update the population, and continue from step 4; otherwise, continue to execute steps 4–8 until the maximum number of iterations pass. End the iterations to find the optimal path.
- 10
The IAFSA pseudocode is shown in Algorithm A1,
Appendix A.
3.2.6. Time Complexity
The time complexity of this algorithm primarily consists of two main components: the ROL initialization strategy and the original AFSA. As previously explained, represents the population size, denotes the number of decision variables in the problem being solved, and represents the maximum number of algorithm iterations.
In the ROL initialization strategy, an opposing population is generated for the original population, and the individuals with the lowest fitness values are selected as the initial population. The time complexity of the initialization process comprises two parts: computing fitness values and sorting the population. Therefore, the time complexity of the initialization process can be expressed as .
The time complexity of the original AFSA mainly consists of three parts: the move step, the neighborhood search, and the fitness evaluation. In one iteration, both the moving step and the neighborhood search have a worst-case time complexity of , while the fitness evaluation has a time complexity of . Therefore, the time complexity of the original AFSA can be calculated as .
In summary, the time complexity of this algorithm is .
4. Experimental Results and Analysis
In this section, the effectiveness of the proposed IAFSA algorithm is evaluated using the 10 benchmark functions in CEC2020. The strategy effectiveness of the algorithm is also evaluated. In addition, the proposed model is simulated using the improved algorithm; for comprehensive analysis and validation, this algorithm is compared with various other algorithms based on the experimental results.
4.1. CEC2020 Experiments
The newest and most challenging numerical optimization contest, the CEC2020 benchmark function (see
Table 1), was chosen for evaluating the performance of the IAFSA. This choice allows the capabilities of the proposed algorithm to be further observed. The benchmark test consists of 10 different functions categorized into single-mode, multimode, hybrid and combinatorial functions.
Numerical experiments were performed under
conditions, and the proposed algorithm was compared with the original AFSA, PSO, IAFSA1 with probability weighting factors, IASA2 with integrated survey behavior, and IAFSA3 with an initialization strategy and adaptive strategy [
47]. The experiments were conducted under the same conditions to attempt to provide a fair and reliable assessment of the performance of the algorithms. The experiments were conducted in a controlled environment using MATLAB 2021b on a Windows 10 operating system with an Intel(R) Core(TM) i9-12500H @ 3.1 GHz CPU and 16 GB RAM
The experimental parameters were set as follows: the number of populations was
, the number of iterations was
, the inertia weight of the PSO was set to
, the social and cognitive weights were set to
, and the particle velocity was set to
. The following are IAFSA parameter settings: the factor
, initial field of view
, adaptive step factor
, maximum number of preying tries
, crowding factor
, and spiral-shaped parameter
. The main simulation parameters of AFSA were set as follows:
; the field of view
; the maximum number of prey trials
; and the crowding factor was set to
. The other comparison algorithms were set to the same level as that of the AFSA, and the parameter settings were kept the same as those of the AFSA.
Figure 5 shows the convergence curve on CEC2020.
Table 2 reflects the experimental results of 30 iterations.
4.2. Strategy Validity Experiments
To assess the potential proposed strategy enhancement on the effectiveness of the AFSA in 3D path planning problems, a systematic investigation was conducted by selectively retaining specific improvement strategies or mechanisms. The aim of this investigation was to evaluate the impact of the retained strategies on the overall path planning effectiveness and to ascertain the individual contributions and significance of each component within the IAFSA framework.
The following IAFSA variations were considered for evaluation:
IAFSA_S1: Exclusively employing the ROL initialization strategy.
IAFSA_S2: Exclusively employing the ASS strategy.
IAFSA_S3: Incorporating the behavioral reinforcement mechanism.
IAFSA_S4: Implementing the AER mechanisms.
To obtain fair experimental results, the common parameters were set to be consistent across the variations: the start point coordinates were ; the end point coordinates were ; the number of populations was ; the maximum number of iterations was ; the initial field of view range was ; the maximum number of preying trials was ; and the crowding degree factor was . The adaptive step factor of IAFSA was . The spiral-shaped parameter was . The inertia weight of the particle swarm algorithm was ; the social weight and the cognitive weight were ; and the particle velocity was .
Figure 6 illustrates the comparative effectiveness of the proposed improvement strategy. The introduced strategies exhibit varying degrees of enhancement on the original algorithm. Among these variations, the IAFSA method, which combines each strategy, demonstrates the highest convergence speed and the strongest global search capability. The data on the longest path, shortest path, average path length, and standard deviation after employing the specified parameters and conducting 20 independent experiments are tabulated in
Table 3.
The performance of the AFSA and the four improved schemes is compared using the data described in
Table 3. The AFSA exhibits relatively large values of 178.6125 and 157.7066 for the worst and average fitness, respectively, with a standard deviation of 12.9958. This indicates that the algorithm is prone to local optimization, resulting in suboptimal and unstable path performance.
In contrast, the algorithms in the four improvement schemes exhibit different degrees of optimization in terms of fitness values and standard deviations. Specifically, the worst adaptation, the average adaptation, and the standard deviation of IAFSA_S1 are all better than those of the AFSA. These findings suggest that employing the improvement strategy enhances the search capability of the algorithm, which improves path quality and stability. IAFSA_S2, IAFSA_S2, and IAFSA_S4 also exhibit some reduction in adaptation, but the standard deviation is not significantly impacted.
Ultimately, the IAFSA incorporates multiple improvement strategies and exhibits the best performance, with the average path length reduced to approximately 26.5% of the AFSA value and the standard deviation reduced to 0.012. These results highlight that integrating these strategies significantly enhances the performance of the algorithm, which significantly increases the probability of finding the optimal path.
Synergy exists among the various mechanisms of the IAFSA; the optimal effect cannot be achieved by using only one mechanism. The design of the IAFSA is reasonable and necessary for its performance. The adopted comprehensive improvement strategy effectively enables the algorithm to achieve excellent performance and discover solutions with high stability.
4.3. Algorithm Comparison Experiment
In the previous section, the effectiveness of the proposed strategy was experimentally verified. To better present the advantages of the improved algorithm, it is compared with the AFSA, AFSA1, IAFSA2, and PSO in this section.
To verify the stability and effectiveness of the proposed algorithm parameters, three landscapes with different levels of complexity were selected for testing: scenario 1, scenario 2, and scenario 3. The parameter settings of IAFSA1 and IAFSA2 follow those of the previous section. The inertia weight of the particle swarm algorithm was ; the social weight and the cognitive weight were ; and the particle velocity was .
Figure 7,
Figure 8 and
Figure 9 reflect the path planning capabilities of each algorithm in different scenarios. It can be intuitively observed that all tested algorithms are capable of accomplishing the path planning task. However, the proposed IAFSA exhibits superior performance under all scenario maps, indicating that the algorithm is more robust and converges faster than the comparison algorithms in all tested cases.
The data in
Table 4 illustrate that IAFSA consistently outperforms other methods in all scenarios, as it exhibits the lowest mean fitness values and standard deviations. This signifies that IAFSA excels at finding optimal solutions with high stability. In the simple scenario, IAFSA achieves a mean fitness of 111.9639, with its best and worst results recorded as 111.9465 and 112.0492, respectively, as well as a relatively low standard deviation of 0.0217. In contrast, AFSA achieves a higher mean fitness value of 134.9919 and a larger standard deviation of 1.3386.
IAFSA continues to demonstrate its effectiveness in the relatively complex scenario, where it yields a mean fitness of 114.9252. The best and worst results obtained are 110.9471 and 117.9821, respectively, and the standard deviation increases to 2.9398. Conversely, AFSA exhibits a lower mean fitness of 126.2389 but a higher standard deviation of 6.4789.
In complex scenarios, IAFSA maintains its strong performance, achieving a mean fitness of 112.6264. The best and worst results obtained are 110.9471 and 112.6554, respectively, with an impressively low standard deviation of 0.0095.
IAFSA1 performs well in simple scenarios, but its performance deteriorates significantly in complex scenarios, resulting in a mean path length of 137.3709 and a high standard deviation of 17.6507. These findings suggest that IAFSA1 is less adaptable to complex problems. Conversely, IAFSA2 demonstrates superior average fitness and standard deviation values, delivering competitive results. Additionally, PSO maintains stable performance across all scenarios, exhibiting mean path lengths ranging from 129.6669 to 138.0377 and moderate standard deviations.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}