
Typical Fault Detection on Drone Images of Transmission Lines Based on Lightweight Structure and Feature-Balanced Network


Abstract
:1. Introduction
1.1. Research Background
1.2. Methods Based on Deep Learning and Its Limitations
1.3. This Work
2. Materials and Methods
2.1. Datasets
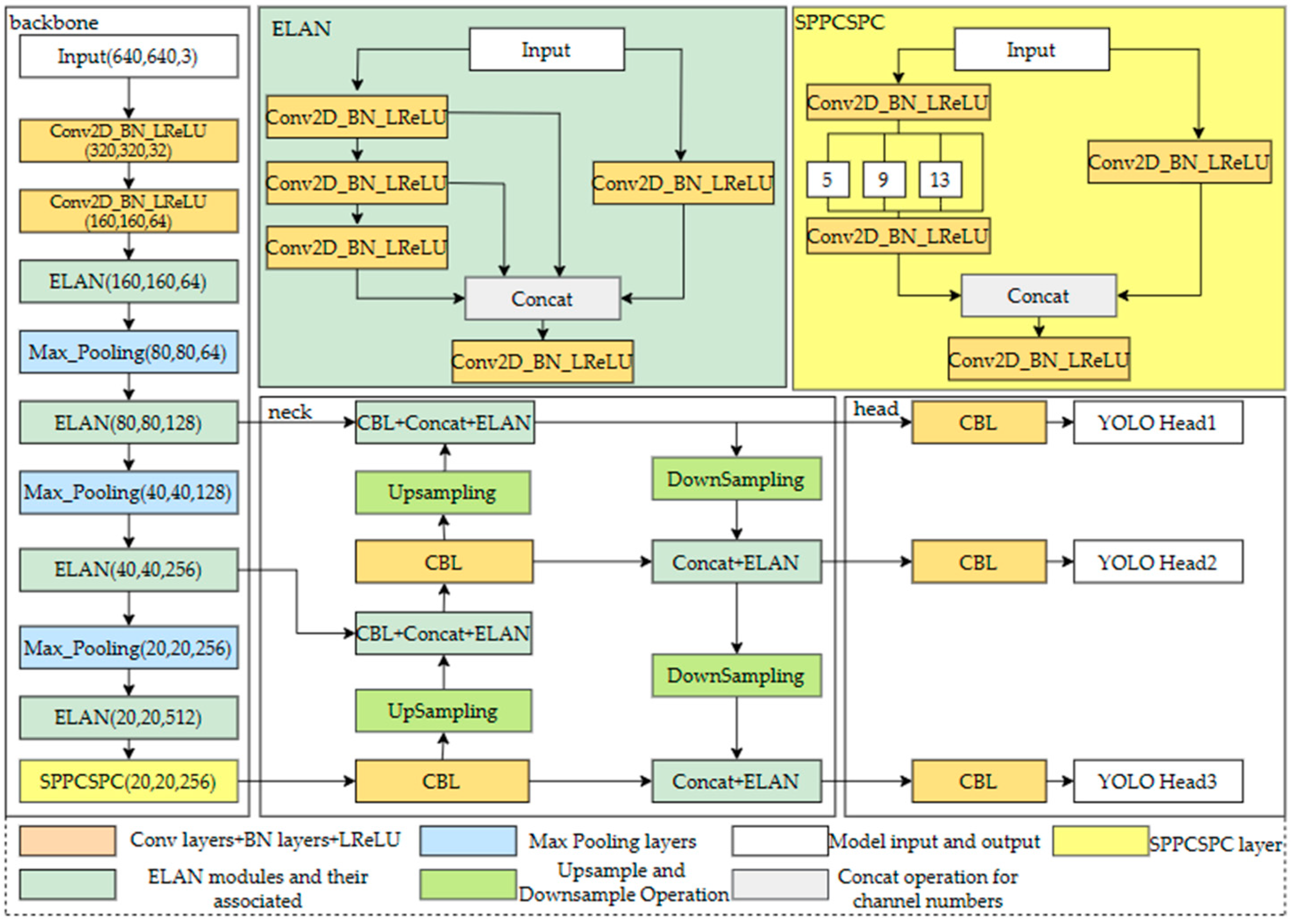
2.2. Overview of YOLOv7 Methods
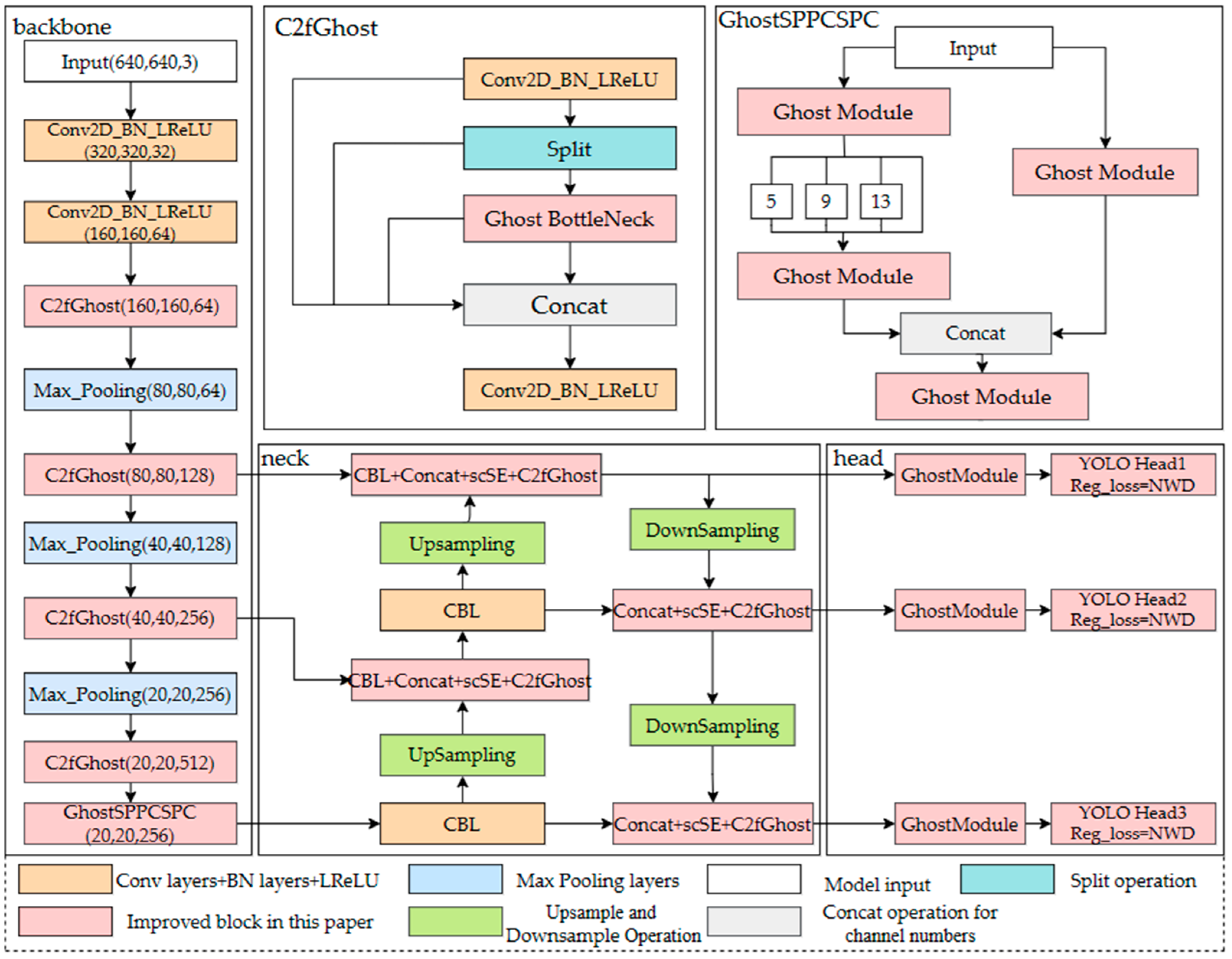
2.3. The Overall Architecture of TD-YOLO
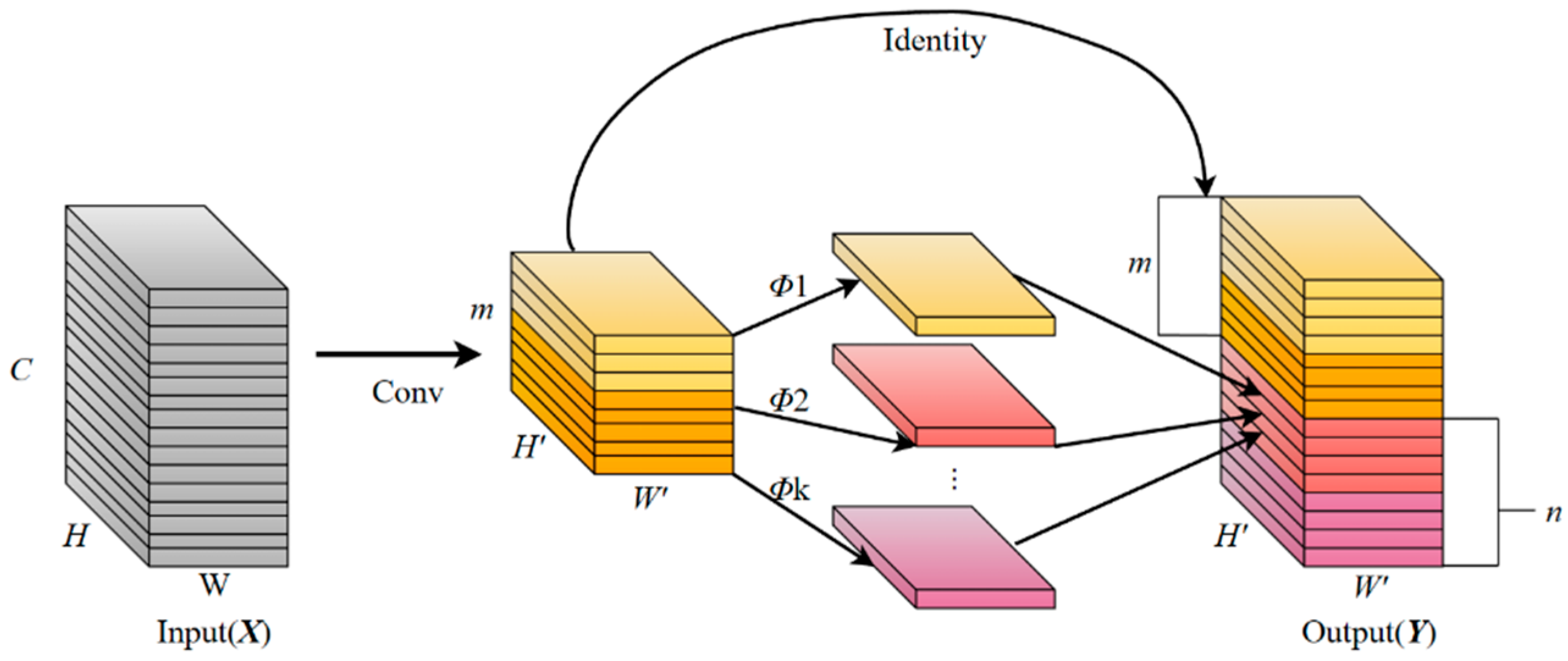
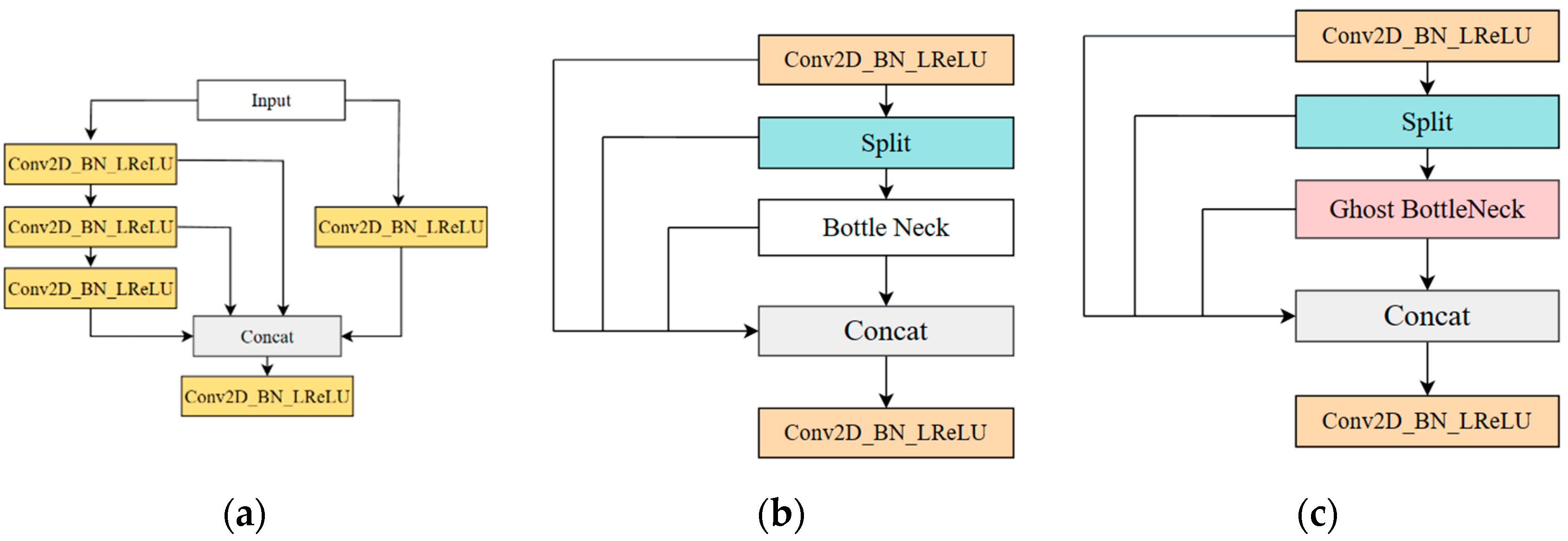
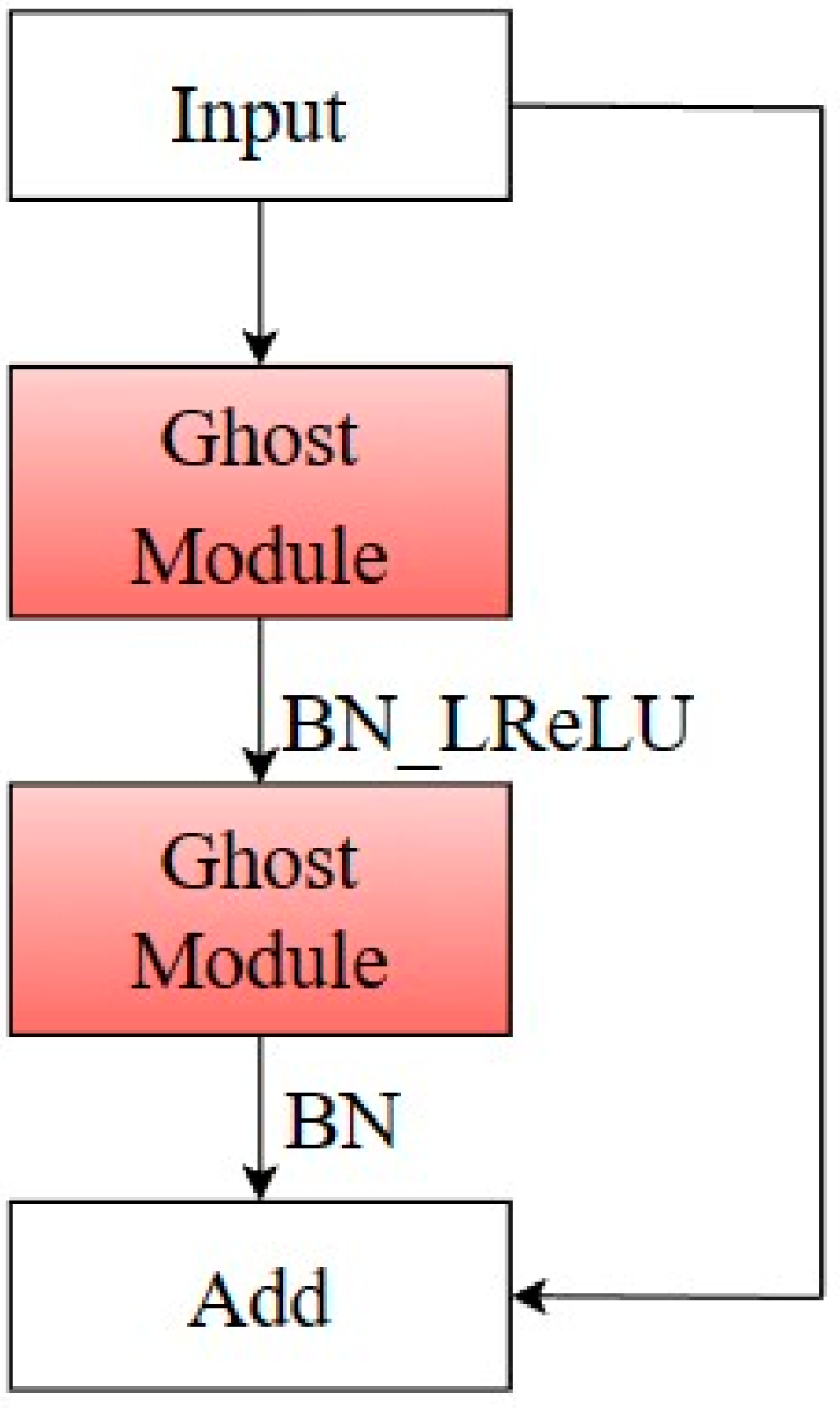
2.3.1. Various Improvements of Model Lightweight Based on the Ghost Module
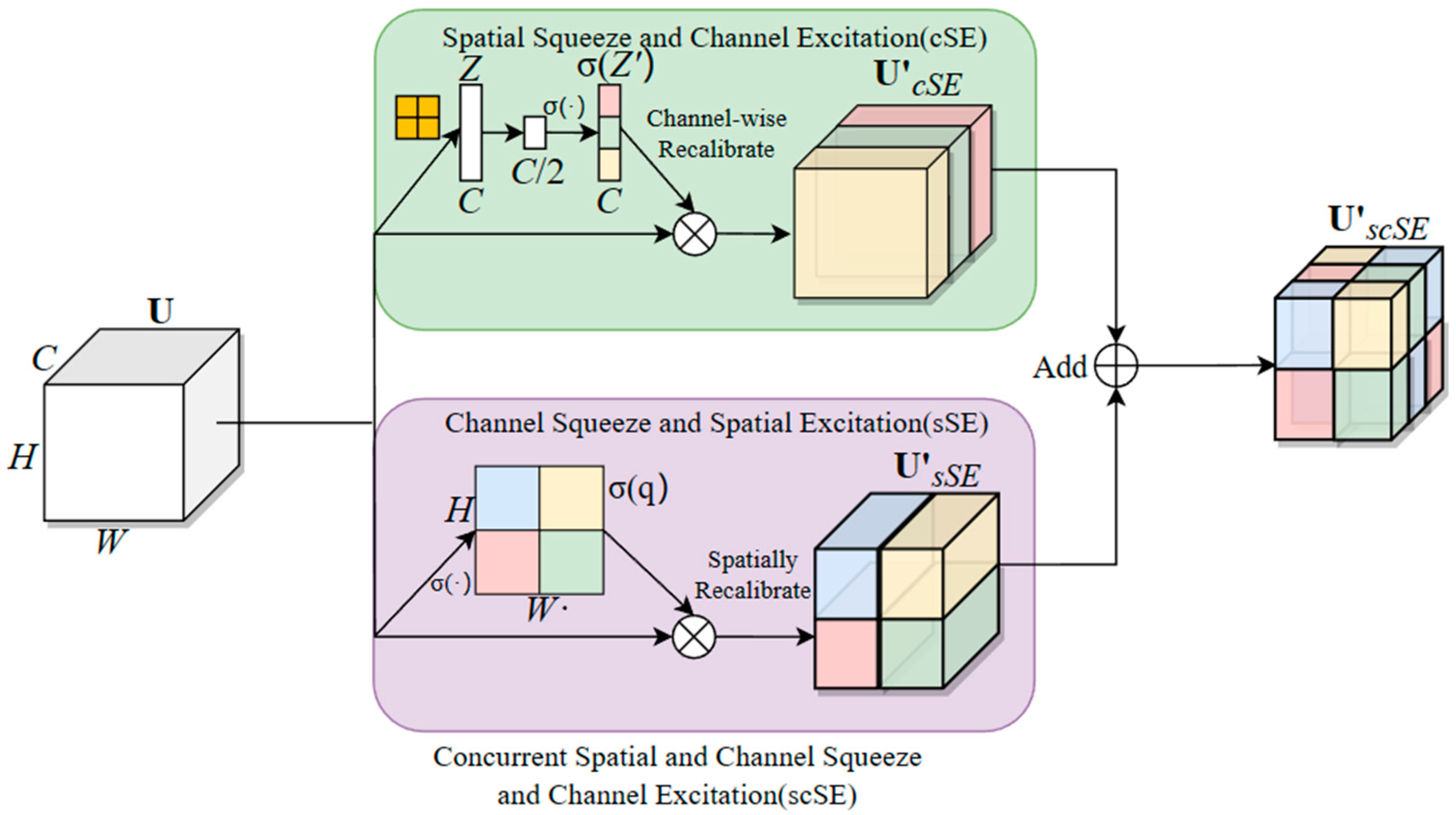
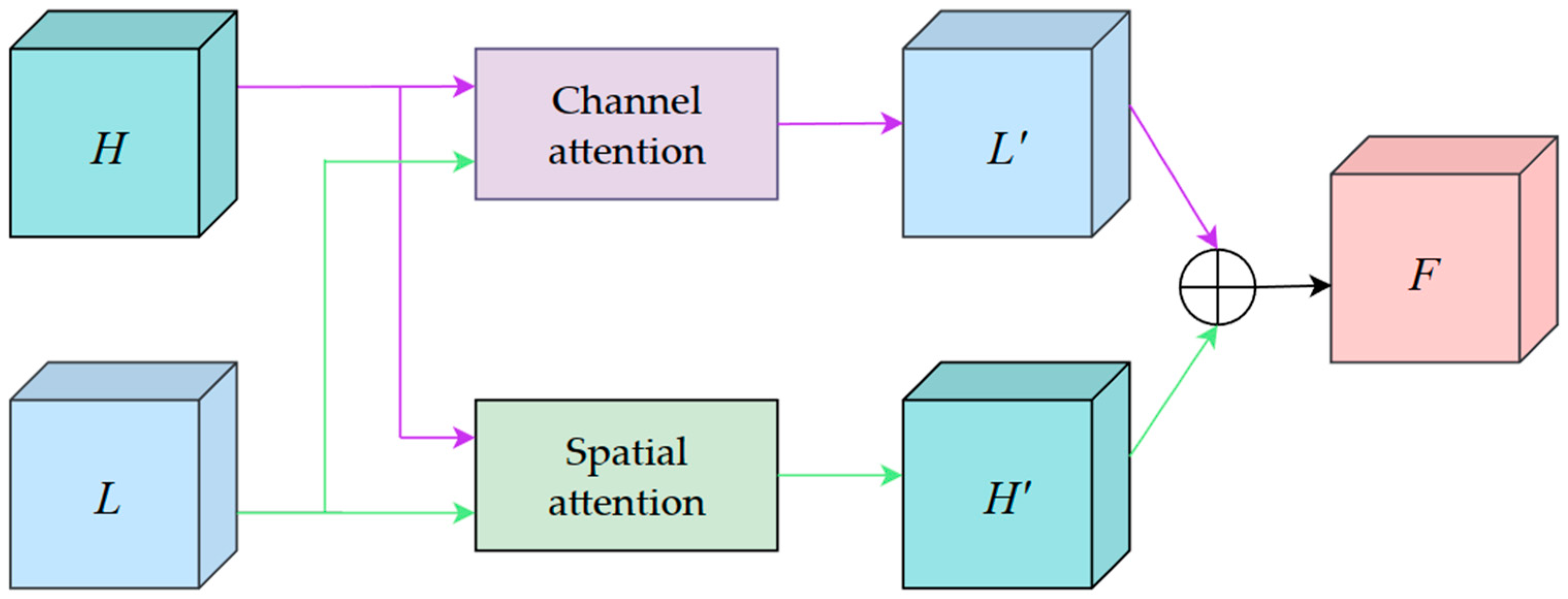
2.3.2. Improvement of Multi-Scale Feature Fusion Based on Feature-Balanced Network
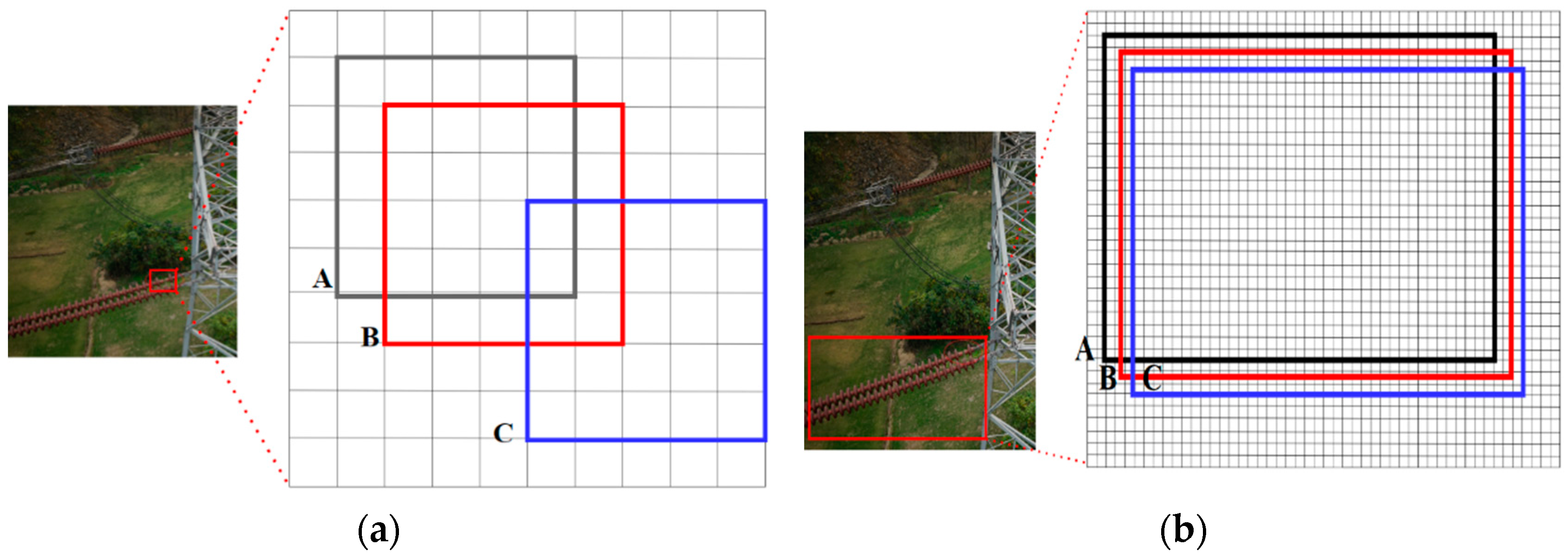
2.3.3. Small Target Detection Optimization Based on NWD Loss Function
3. Experimental Results
3.1. Experimental Environment
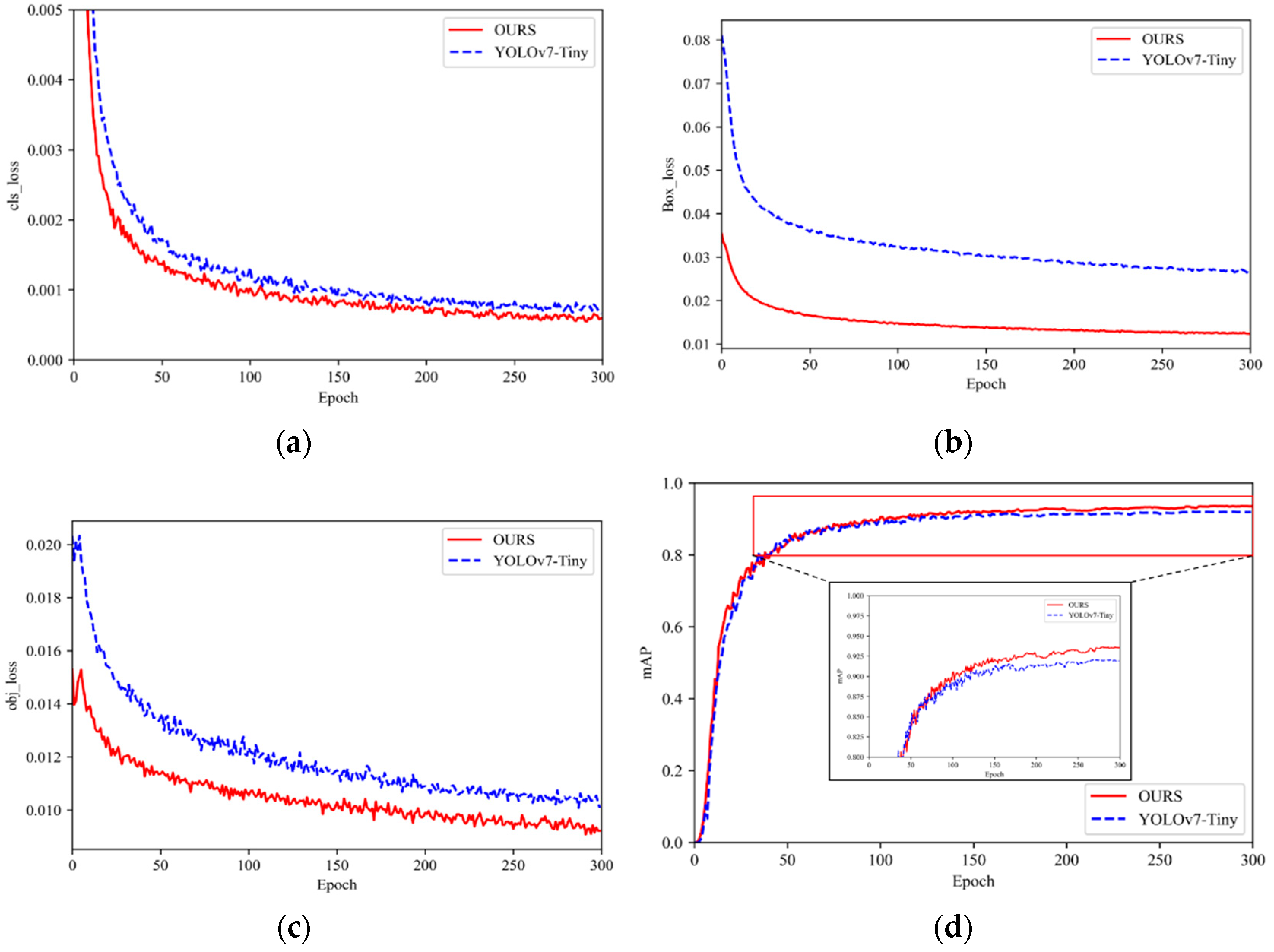
3.2. Training Process and Parameter Settings
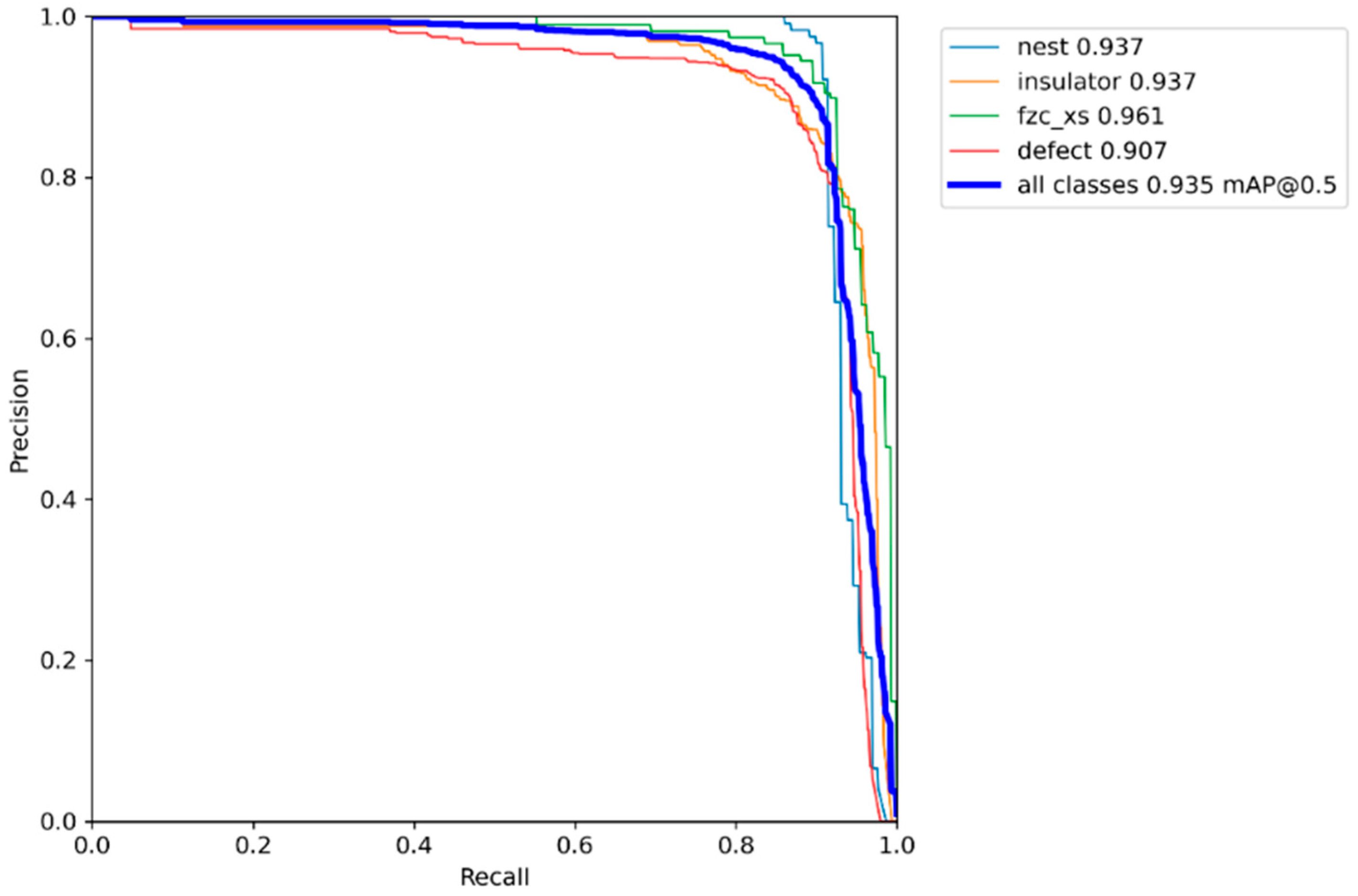
3.3. Performance Evaluation Indicators
4. Experimental Discussion
4.1. Validation of Model Lightweight Effects
4.2. Validation of Feature-Balanced Network Validity and Comparison of Similar Attention Mechanisms
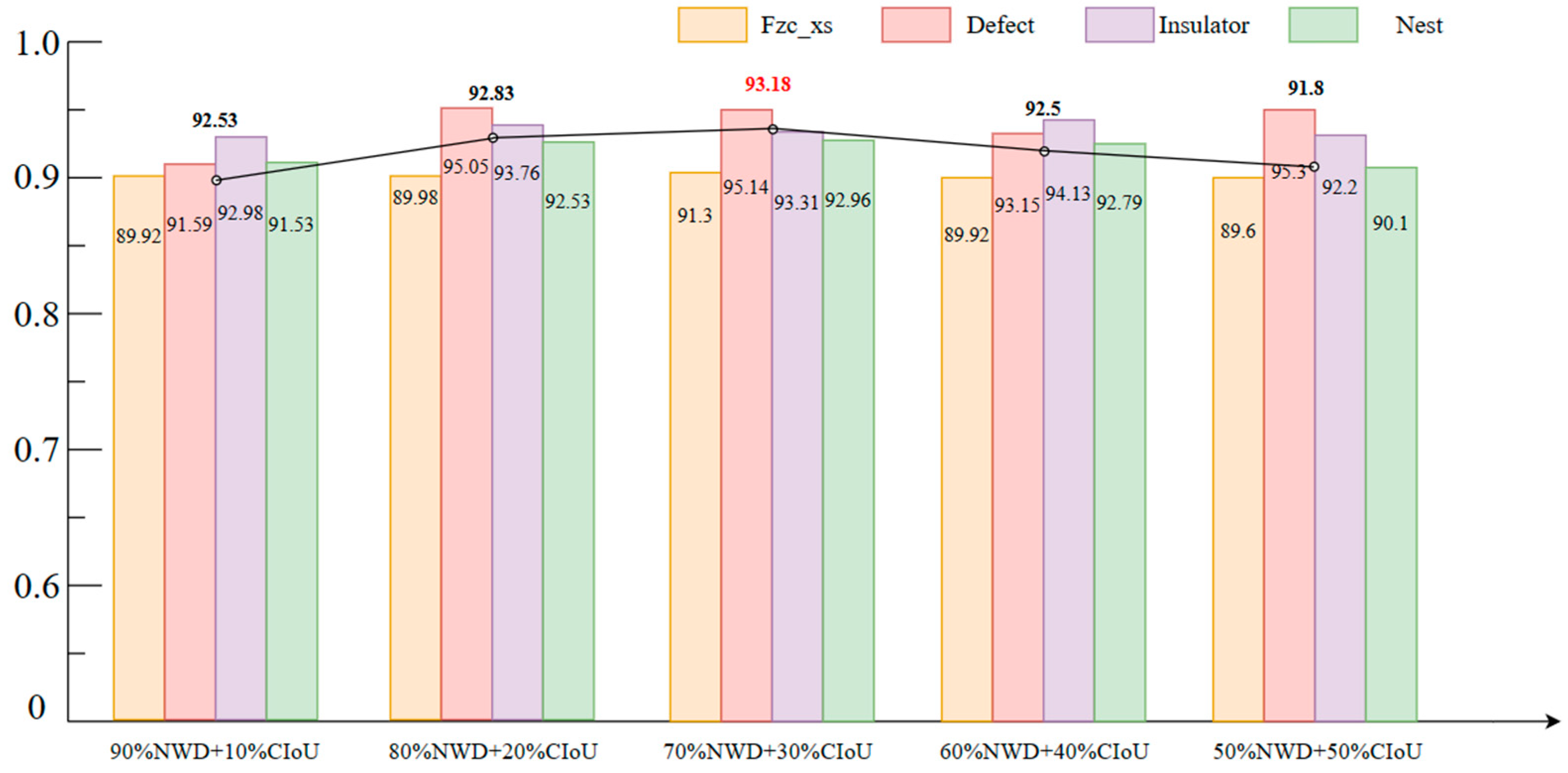
4.3. Validation of the Effect of NWD Loss Function and the Effect of NWD on the Model with Different Fusion Ratios
4.4. Comparison of Ablation Experiments
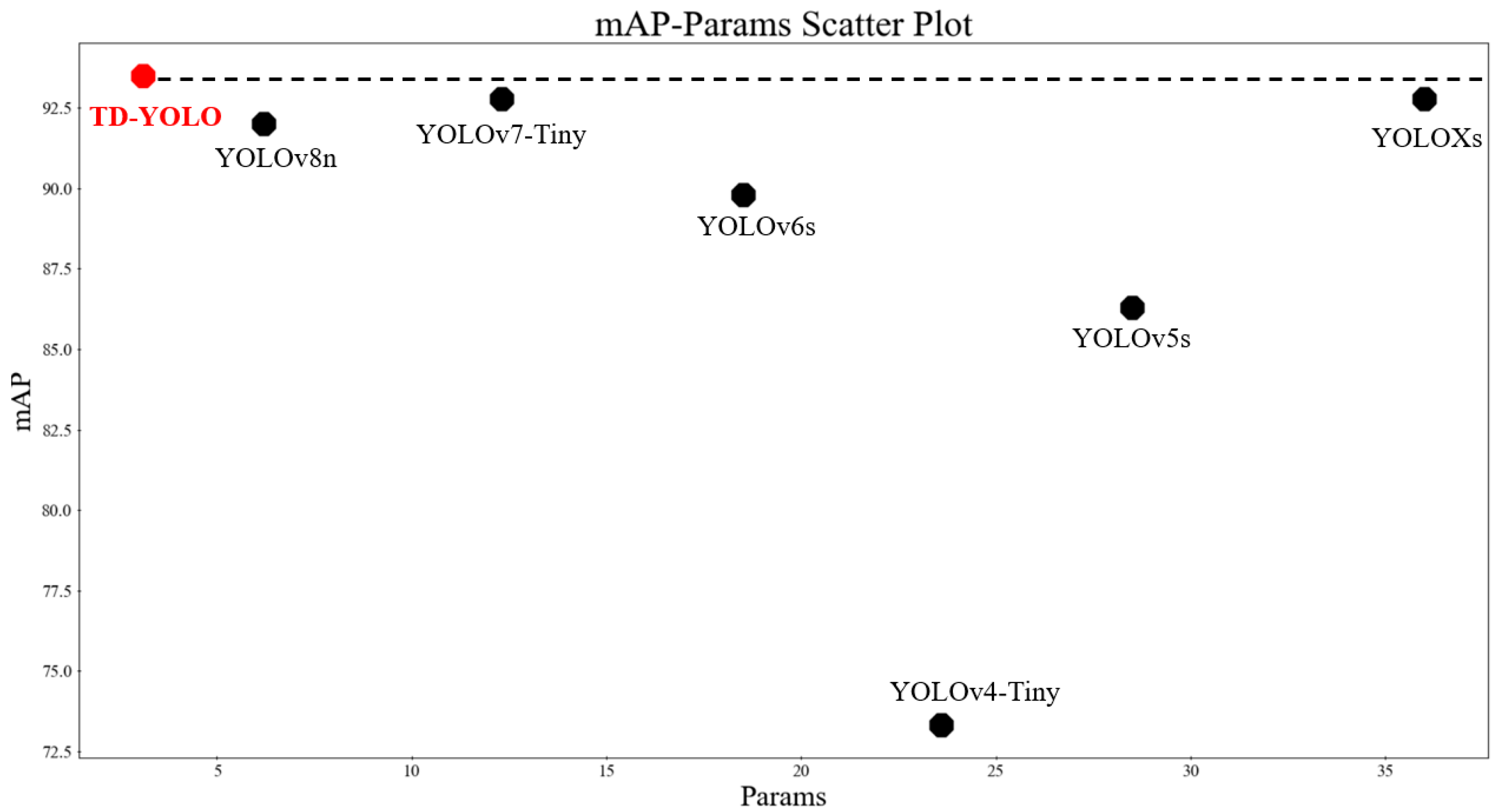
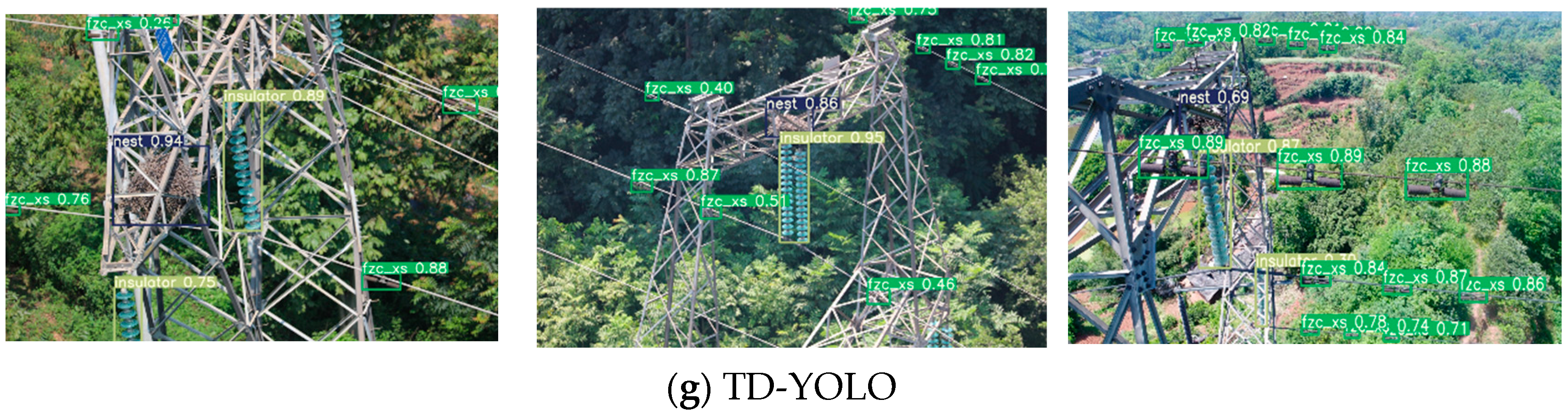
4.5. Horizontal Comparison of Experimental Results
5. Edge-Side Deployment
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Code
Test Videos
References
- He, M.; Qin, L.; Deng, X. Transmission Line Segmentation Solutions for UAV Aerial Photography Based on Improved UNet. Drones 2023, 7, 274. [Google Scholar] [CrossRef]
- Sui, Y.; Ning, P.; Niu, P. Review on Mounted UAV for Transmission Line Inspection. Power Syst. Technol. 2021, 9, 3636–3648. [Google Scholar]
- Lunze, J.; Richter, J. Reconfigurable Fault-tolerant Control: A Tutorial Introduction. Eur. J. Control 2008, 14, 359–386. [Google Scholar] [CrossRef]
- Merrill, W.; DeLaat, J.; Bruton, W. Advanced detection, isolation, and accommodation of sensor failures–Real-time evaluation. J. Guid. Control Dyn. 1988, 11, 517–526. [Google Scholar] [CrossRef]
- Liu, C.; Wu, Y. Research progress of vision detection methods based on deep learning for transmission lines. Proc. CSEE 2022, 8, 31. [Google Scholar]
- Khodayar, M.; Liu, G.; Wang, J. Deep learning in power systems research: A review. CSEE J. Power Energy Syst. 2021, 3, 209–220. [Google Scholar]
- Chen, C.; Zheng, Z.; Xu, T.; Guo, S.; Feng, S.; Yao, W.; Lan, Y. YOLO-Based UAV Technology: A Review of the Research and Its Applications. Drones 2023, 7, 190. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W. SSD: Single Shot MultiBox Detector. In Computer Vision-ECCV; Lecture Notes in Computer Science, 9905; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farrhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farrhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 23 July 2023).
- Li, C.; Li, L.; Jiang, H. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.; Bochkovskiy, A. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Bai, J.; Zhao, R.; Gu, F. Multi-target Detection and Fault Recognition Image Processing Method. High Volt. Eng. 2019, 11, 3504–3511. [Google Scholar]
- Hao, S.; Ma, R.; Zhao, X. Fault Detection of YOLOv3 Transmission Line Based on Convolutional Block Attention Model. Power Syst. Technol. 2021, 8, 2979–2987. [Google Scholar]
- Hao, S.; Yang, L.; Ma, X. YOLOv5 Transmission Line Fault Detection Based on Attention Mechanism and Cross-scale Feature Fusion. Proc. CSEE 2023, 6, 2319–2331. [Google Scholar]
- Hao, S.; Zhang, X.; Ma, X. Small Target Fault Detection Method for Transmission Line Based on PKAMNet. High Volt. Eng. 2023, 3, 1–10. [Google Scholar]
- Qiu, Z.; Zhu, X.; Liao, C. A Lightweight YOLOv4-EDAM Model for Accurate and Real-time Detection of Foreign Objects Suspended on Power Lines. IEEE Trans. Power Deliv. 2022, 38, 1329–1340. [Google Scholar] [CrossRef]
- Deng, F.; Xie, Z.; Mao, W. Research on edge intelligent recognition method oriented to transmission line insulator fault detection. Int. J. Electr. Power Energy Syst. 2022, 139, 108054. [Google Scholar] [CrossRef]
- Han, G.; He, M. Insulator detection and damage identification based on improved lightweight YOLOv4 network. Energy Rep. 2021, 7, 187–197. [Google Scholar] [CrossRef]
- Li, X.; Liu, H.; Liu, G. Transmission Line Pin Defect Detection Based on Deep Learning. Power Syst. Technol. 2021, 8, 2988–2995. [Google Scholar]
- Zhang, H.; Qi, Q.; Zhang, J. Bird nest detection method for transmission lines based on improved YOLOv5. Power Syst. Prot. Control 2023, 2, 151–159. [Google Scholar]
- Zhao, W.; Xu, M.; Cheng, X. An Insulator in Transmission Lines Recognition and Fault Detection Model Based on Improved Faster RCNN. IEEE Trans. Instrum. Meas. 2021, 70, 1–8. [Google Scholar] [CrossRef]
- Chen, K.; Liu, X.; Jia, L. Insulator Defect Detection Based on Lightweight Network and Enhanced Multi-scale Feature Fusion. High Volt. Eng. 2023, 2, 1–12. [Google Scholar]
- Kang, J.; Wang, Q.; Liu, W. Detection Model of Aerial Photo Insulator Multi-defect by Integrating CAT-BiFPN and Attention Mechanism. High Volt. Eng. 2023, 2, 1–15. [Google Scholar]
- Li, H.; Dong, Y.; Liu, Y.; Ai, J. Design and Implementation of UAVs for Bird’s Nest Inspection on Transmission Lines Based on Deep Learning. Drones 2022, 6, 252. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Ren, D. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. arXiv 2020, arXiv:2005.03572v4. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q. GhostNet: More Features From Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Roy, A.; Navab, N.; Wachinger, C. Recalibrating Fully Convolutional Networks with Spatial and Channel’ Squeeze & Excitation’ Blocks. IEEE Trans. Med. Imaging 2019, 2, 540–549. [Google Scholar]
- Woo, S.; Park, J.; Lee, J. Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Dong, G.; Xie, W.; Huang, X. Review of Small Object Detection Algorithms Based on Deep Learning. Comput. Eng. Appl. 2023, 11, 16–27. [Google Scholar]
- Wang, J.; Xu, C.; Yang, W. A Normalized Gaussian Wasserstein Distance for Tiny Object Detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]
- Blanke, M.; Kinnaert, M.; Lunze, J.; Staroswiecki, M. Diagnosis and Fault-Tolerant Control; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Han, G.; Wang, R.; Yuan, Q.; Li, S.; Zhao, L.; He, M.; Yang, S.; Qin, L. Detection of Bird Nests on Transmission Towers in Aerial Images Based on Improved YOLOv5s. Machines 2023, 11, 257. [Google Scholar] [CrossRef]
- Ding, S. Model-Based Fault Diagnosis Techniques; Springer: London, UK, 2013. [Google Scholar] [CrossRef]
- Frank, P.; Ding, S.; Marcu, T. Model-based fault diagnosis in technical processes. Trans. Inst. Meas. Control 2000, 22, 57–101. [Google Scholar] [CrossRef]
- Li, Y.; Fan, Q.; Huang, H.; Han, Z.; Gu, Q. A Modified YOLOv8 Detection Network for UAV Aerial Image Recognition. Drones 2023, 7, 304. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Abbreviation | Insulator | Defect | Nest | Fzc_xs |
|---|---|---|---|---|
| Numbers | 4556 | 1333 | 1525 | 7287 |
| mAP (%) | FLOPs (G) | Params (MB) | |
|---|---|---|---|
| YOLOv7-Tiny | 92.79 | 13 | 12.3 |
| YOLOv7-Tiny-C2fGhost | 92.93 | 7.5 | 7.3 |
| YOLOv7-Tiny-GhostSPPCSPC | 92.84 | 10.3 | 9.5 |
| YOLOv7-GhostConv(Head) | 92.81 | 10.3 | 9.3 |
| YOLOv7-Tiny-C2fGhost -GhostSPPCSPC | 92.55 | 7 | 6.15 |
| YOLOv7-Tiny-C2fGhost -GhostConv(Head) | 92.74 | 4.7 | 4.3 |
| YOLOv7-Tiny-C2fGhost- GhostSPPCSPC-GhostConv(Head) | 91.98 | 4.1 | 3 |
| Models | Map (%) | FLOPs (G) | Params (MB) |
|---|---|---|---|
| YOLOv7-Tiny-Ghost | 91.98 | 4.1 | 3 |
| YOLOv7-Tiny-Ghost-FBN(CBAM) [40] | 92.18 | 4.4 | 3.1 |
| YOLOv7-Tiny-Ghost-FBN(scSE) | 92.31 | 4.2 | 3.1 |
| Models | Training Time /(h) | mAP /(%) | Miss Rate (Fzc_xs)/(%) | Miss Rate (Defect)/(%) |
|---|---|---|---|---|
| YOLOv7-Tiny-Ghost | 11.2 | 91.98 | 16.96 | 23.07 |
| −(100%NWD) | 24.5 | 92.92 | 11.03 | 10.24 |
| −(90%NWD + 10%CIoU) | 23 | 92.53 | 14.23 | 13.84 |
| −(80%NWD + 20%CIoU) | 21.5 | 92.83 | 14.35 | 11.31 |
| −(70%NWD + 30%CIoU) | 20 | 93.18 | 10.20 | 8.46 |
| −(60%NWD + 40%CIoU) | 18.5 | 92.5 | 13.04 | 12.3 |
| −(50%NWD + 50%CIoU) | 17 | 91.8 | 13.99 | 14.6 |
| Models | Ghost | FBN | NWD | Fzc_xs (AP%) | Defect (AP%) | Insulator (AP%) | Nest (AP%) | mAP (%) | Parmas (MB) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|---|---|
| Algorithm 1 | 90.81 | 94.67 | 92.85 | 92.84 | 92.79 | 12.3 | 13 | |||
| Algorithm 2 | √ | 89.35 | 92.87 | 93.15 | 92.55 | 91.98 | 3 | 4.2 | ||
| Algorithm 3 | √ | √ | 89.38 | 93.4 | 93.9 | 92.71 | 92.31 | 3.1 | 4.2 | |
| Algorithm 4 | √ | √ | 89.7 | 95.94 | 93.18 | 91.07 | 92.47 | 3 | 4.2 | |
| Algorithm 5 | √ | √ | √ | 90.7 | 96.1 | 93.7 | 93.7 | 93.5 | 3.1 | 4.3 |
| Models | Fzc_xs (AP%) | Defect (AP%) | Insulator (AP%) | Nest (AP%) | mAP (%) | Inference (ms) | Params (MB) |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | 55.72 | 85.76 | 89.34 | 80.18 | 77.75 | 78 | 114 |
| YOLOv4 | 83.74 | 86.48 | 91.87 | 81.89 | 86 | 22.8 | 256 |
| YOLOv4-Tiny | 62.58 | 75.33 | 84.15 | 71.18 | 73.31 | 6.28 | 23.6 |
| YOLOv5s | 87.86 | 83.94 | 91.33 | 82.05 | 86.3 | 13 | 28.5 |
| YOLOXs | 90.84 | 95.42 | 96.18 | 88.63 | 92.77 | 15 | 36 |
| YOLOv6s | 89.6 | 88.1 | 92.6 | 88.8 | 89.8 | 9 | 18.5 |
| YOLOv7-Tiny | 90.81 | 94.67 | 92.85 | 92.84 | 92.79 | 5 | 12.3 |
| YOLOv8n | 90.6 | 93.8 | 92.8 | 90.9 | 92 | 4 | 6.2 |
| TD-YOLO | 90.7 | 96.1 | 93.7 | 93.7 | 93.5 | 3.5 | 3.1 |
| Models | Inference (ms) | NMS (ms) | Speed (FPS) | mAP (%) |
|---|---|---|---|---|
| Algorithm 1 | 50 ± 4 | 4.5 ± 1.5 | 18.3 ± 1.8 | 92.79 |
| Algorithm 2 | 33 ± 3 | 4.5 ± 1.5 | 26.7 ± 2.3 | 91.98 |
| Algorithm 3 | 35.7 ± 2.8 | 4.5 ± 1.5 | 24.8 ± 2.4 | 92.31 |
| Algorithm 4 | 34.9 ± 2.1 | 4.5 ± 1.5 | 25.3 ± 2.2 | 92.47 |
| Algorithm 5 | 38 ± 3 | 4.5 ± 1.5 | 23.5 ± 2.2 | 93.5 |
| Indicators | Jeston Xavier NX | M300-RTK | Effective |
|---|---|---|---|
| Weight | 260 g | Maximum load of 2.7 kg | √ |
| Form Factor | 70 mm × 45 mm | 180 mm × 130 mm | √ |
| Power Consumption | Maximum 15 W | Rated power 17 W | √ |
| Frame Rate | 23.5 ± 2.2 FPS | Maximum 30 FPS | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, G.; Wang, R.; Yuan, Q.; Zhao, L.; Li, S.; Zhang, M.; He, M.; Qin, L. Typical Fault Detection on Drone Images of Transmission Lines Based on Lightweight Structure and Feature-Balanced Network. Drones 2023, 7, 638. https://doi.org/10.3390/drones7100638
Han G, Wang R, Yuan Q, Zhao L, Li S, Zhang M, He M, Qin L. Typical Fault Detection on Drone Images of Transmission Lines Based on Lightweight Structure and Feature-Balanced Network. Drones. 2023; 7(10):638. https://doi.org/10.3390/drones7100638
Chicago/Turabian StyleHan, Gujing, Ruijie Wang, Qiwei Yuan, Liu Zhao, Saidian Li, Ming Zhang, Min He, and Liang Qin. 2023. "Typical Fault Detection on Drone Images of Transmission Lines Based on Lightweight Structure and Feature-Balanced Network" Drones 7, no. 10: 638. https://doi.org/10.3390/drones7100638
APA StyleHan, G., Wang, R., Yuan, Q., Zhao, L., Li, S., Zhang, M., He, M., & Qin, L. (2023). Typical Fault Detection on Drone Images of Transmission Lines Based on Lightweight Structure and Feature-Balanced Network. Drones, 7(10), 638. https://doi.org/10.3390/drones7100638