
Event-Triggered Hierarchical Planner for Autonomous Navigation in Unknown Environment




Abstract
:1. Introduction
2. Preliminaries
2.1. Hierarchical Reinforcement Learning
2.2. Hindsight Transitions Experience
2.3. Deep Deterministic Policy Gradient
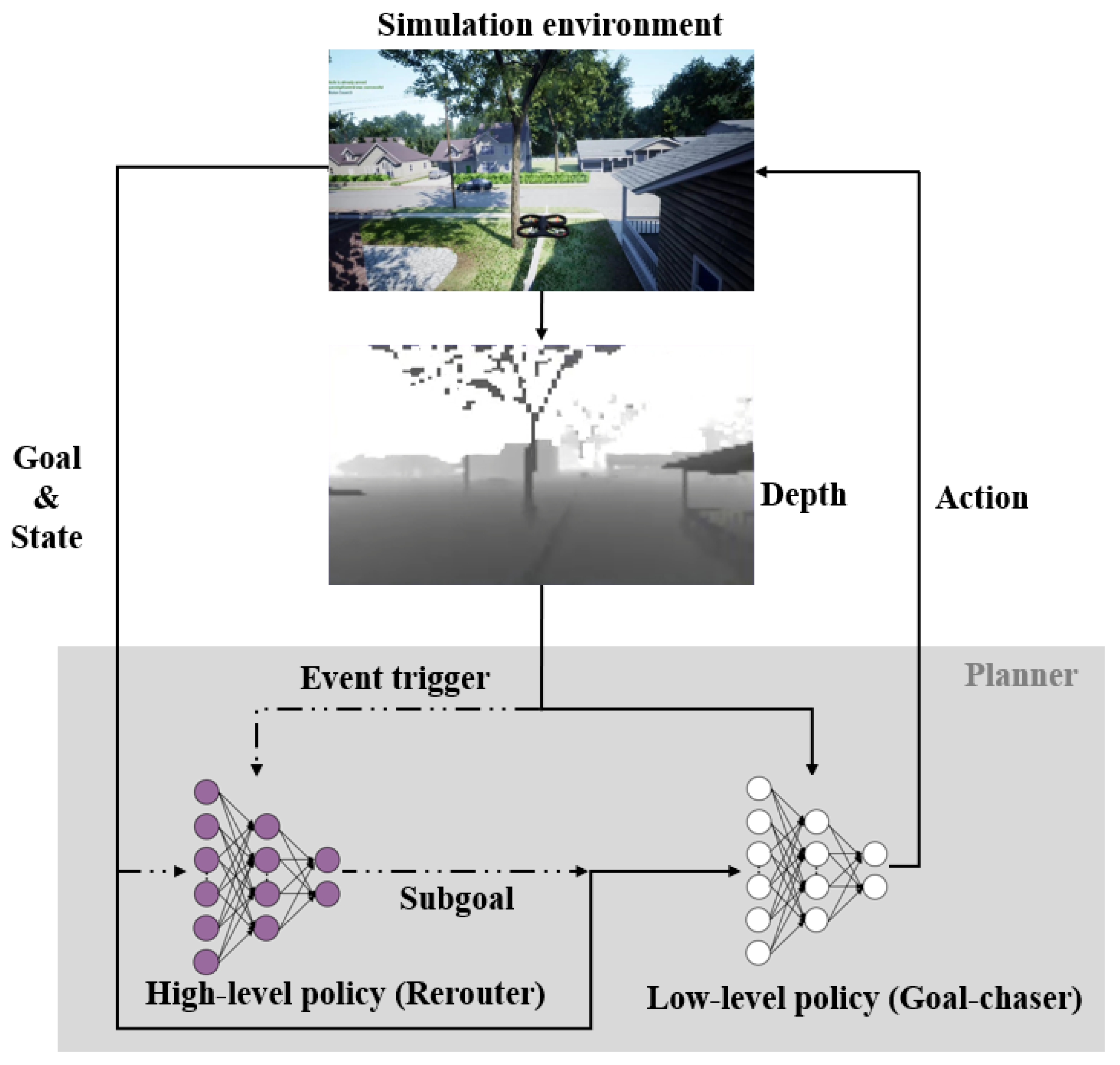
3. Event-Triggered Bi-Level Hierarchical Planner (ETHP)
| Algorithm 1: ETHP |
 |
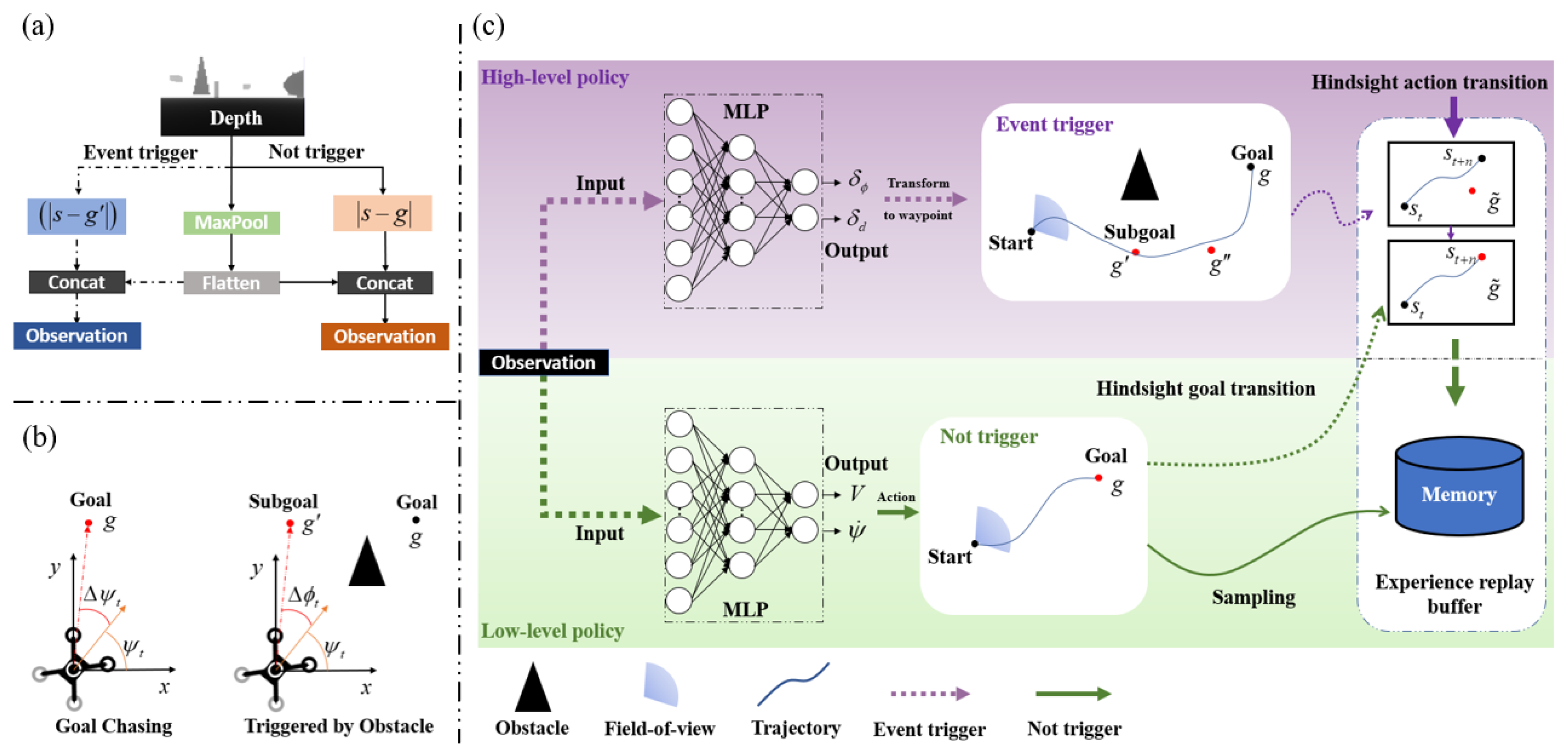
3.1. The Low-Level Policy (Goal Chaser)
3.2. The High-Level Policy (Rerouter)
3.3. Hindsight Transitions for Bi-Level Hierarchical Planner
4. Experiment
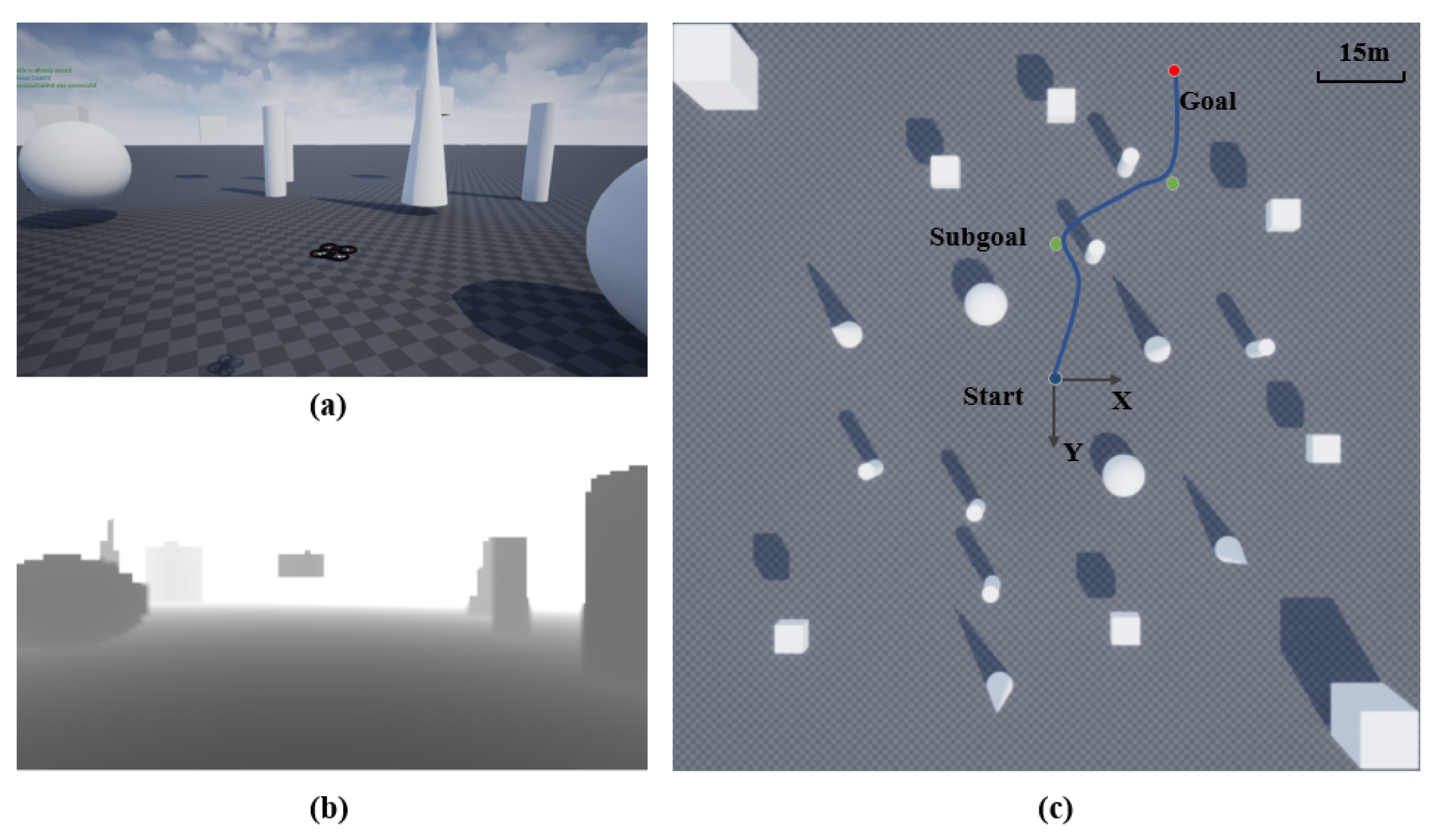
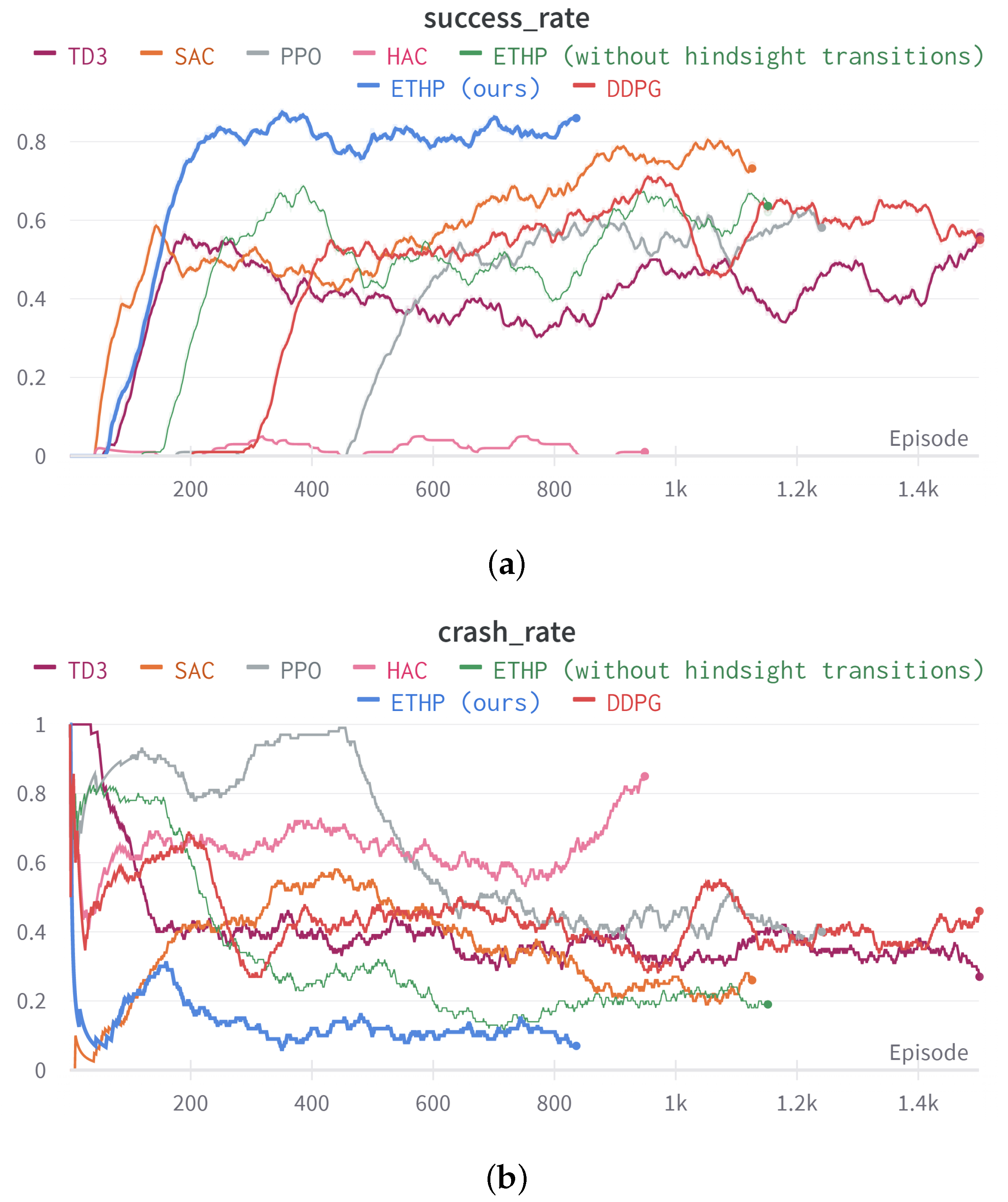
4.1. Comparison Experiment
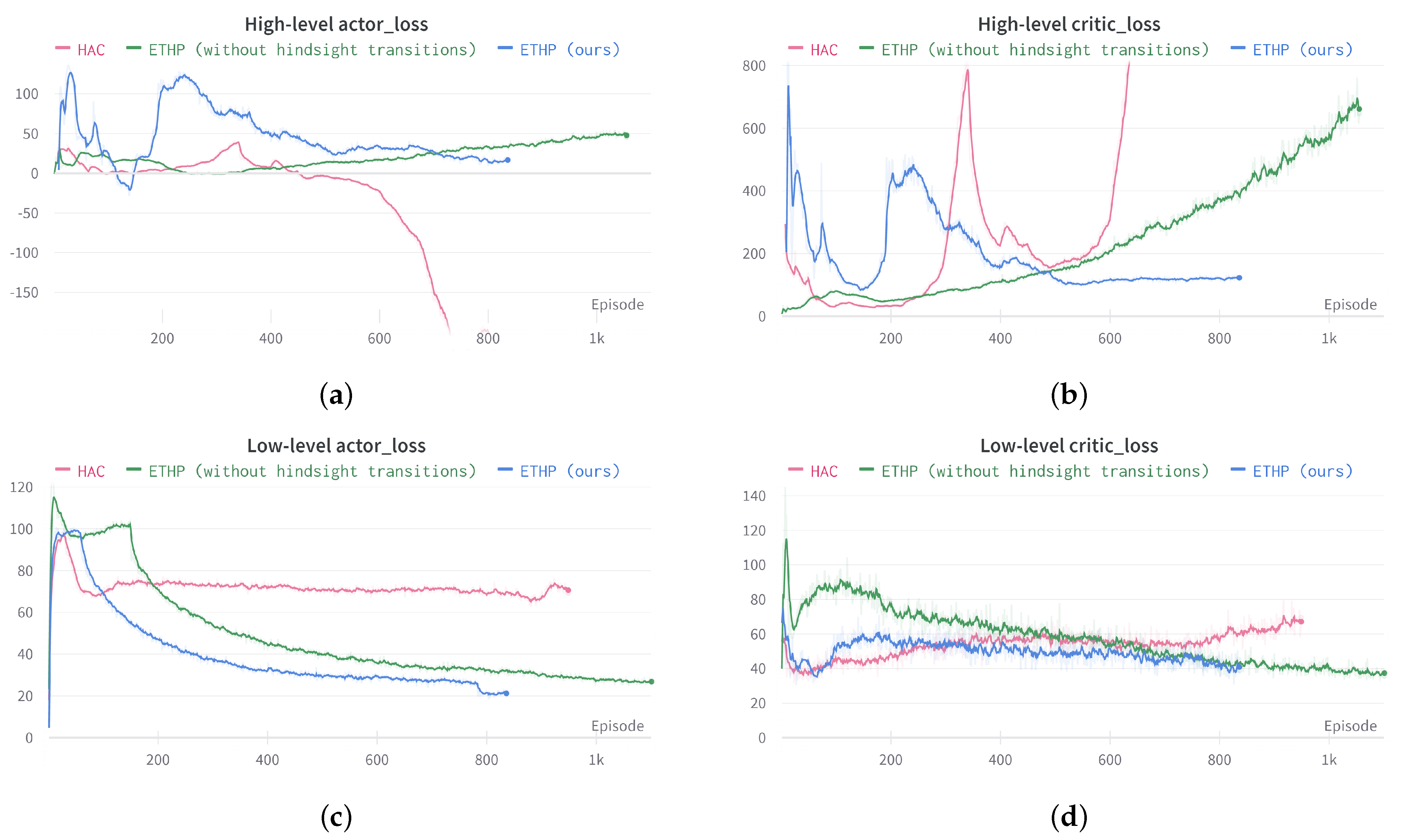
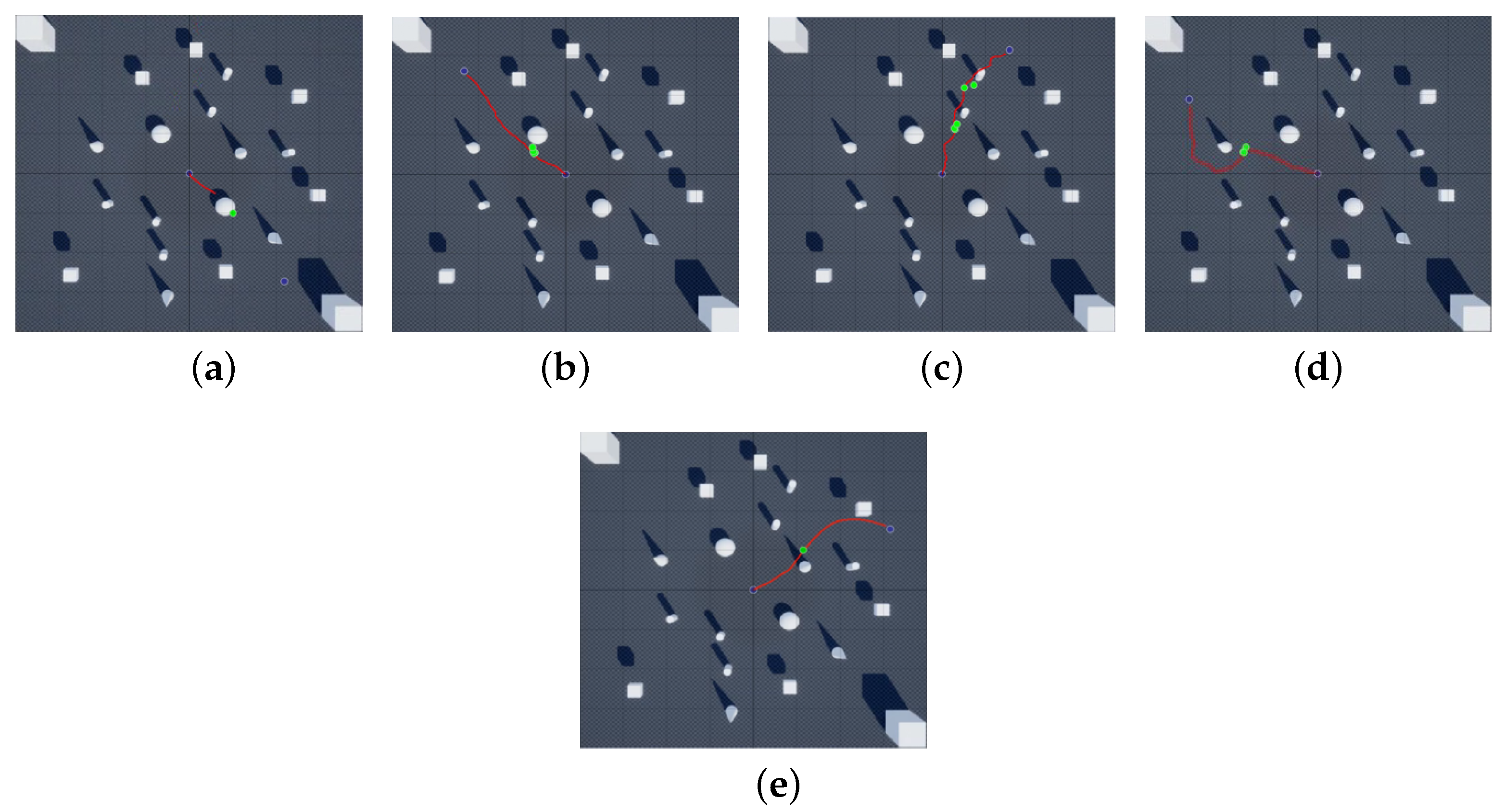
4.2. Evaluation Experiments
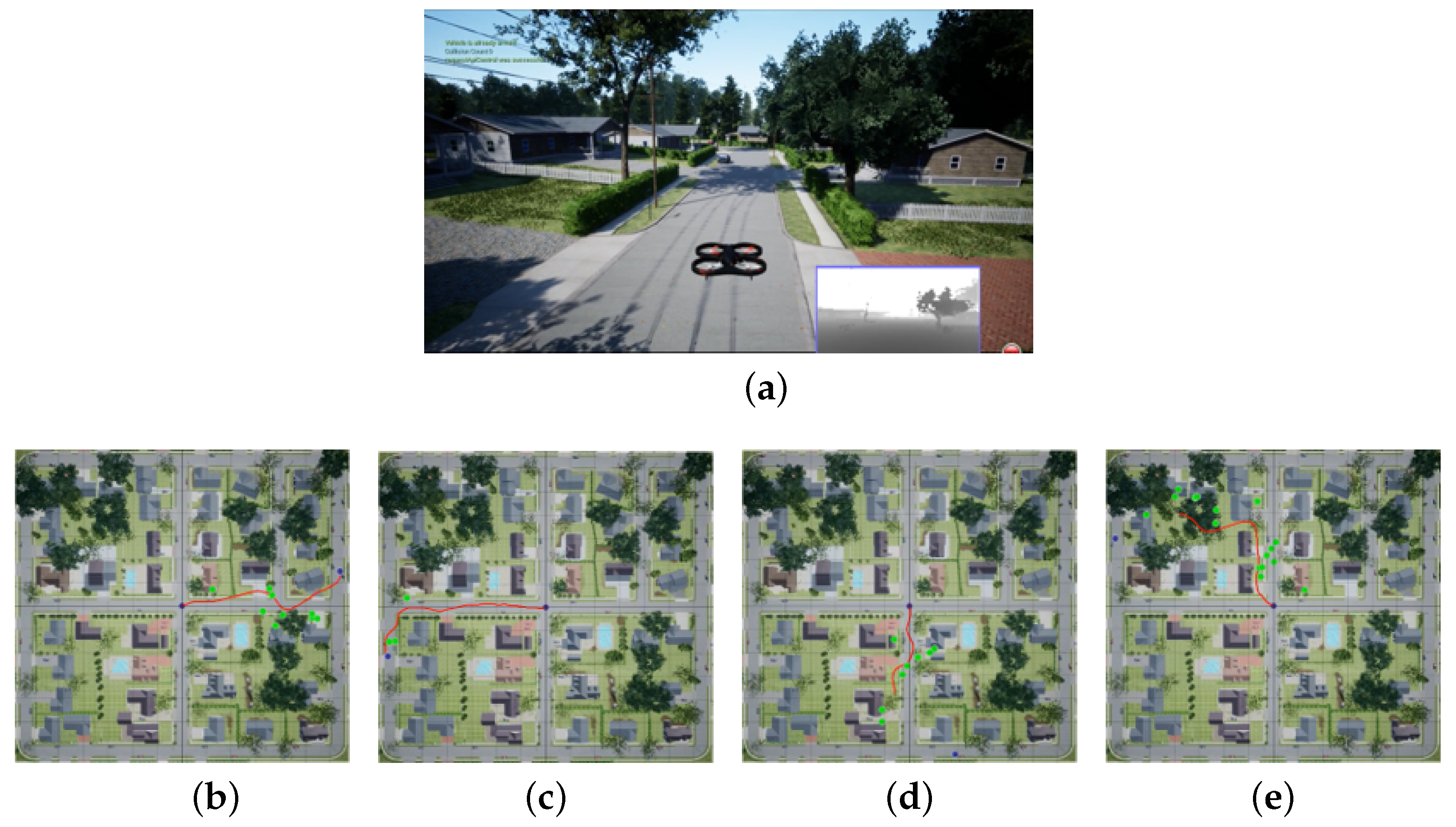
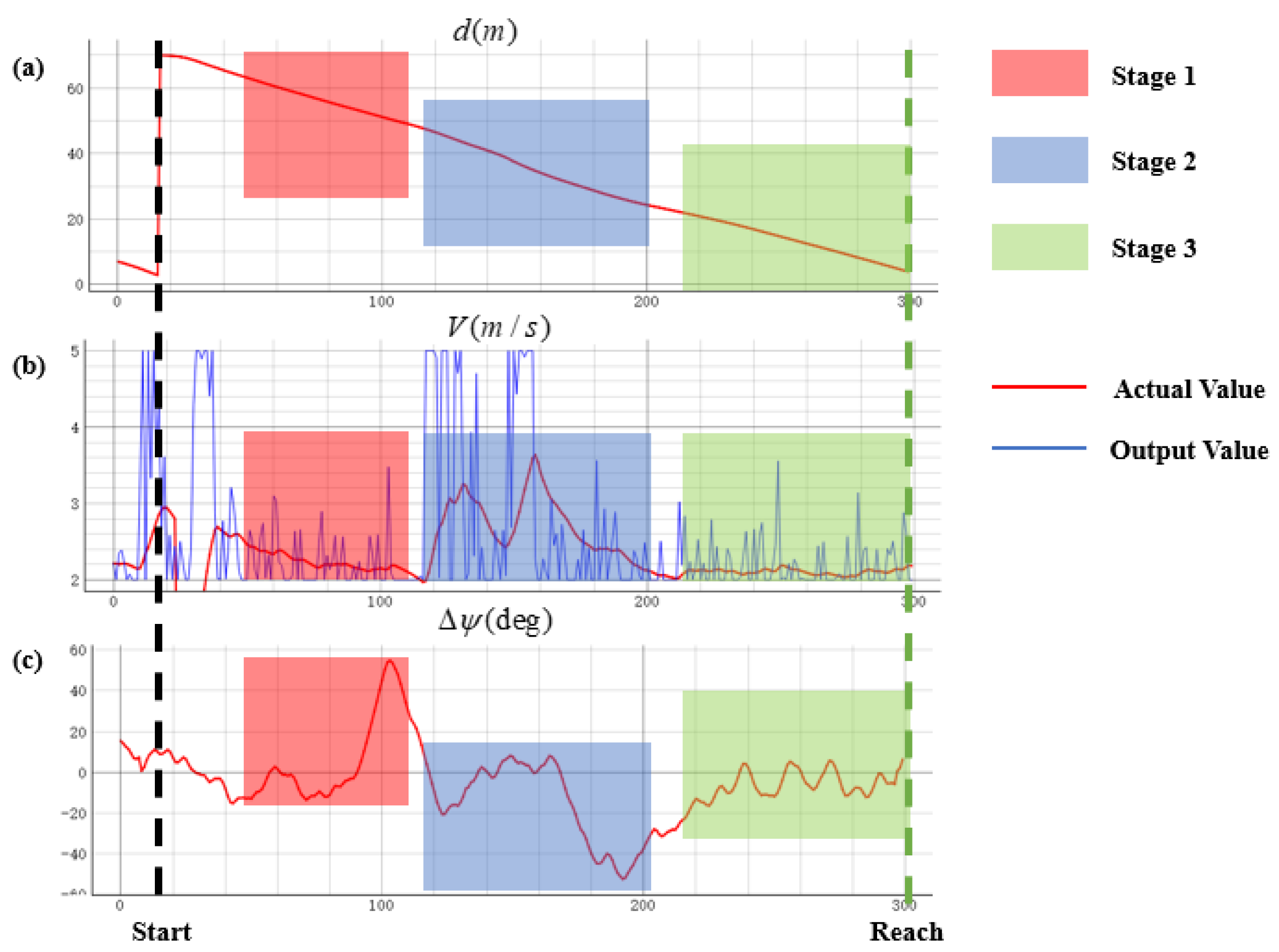
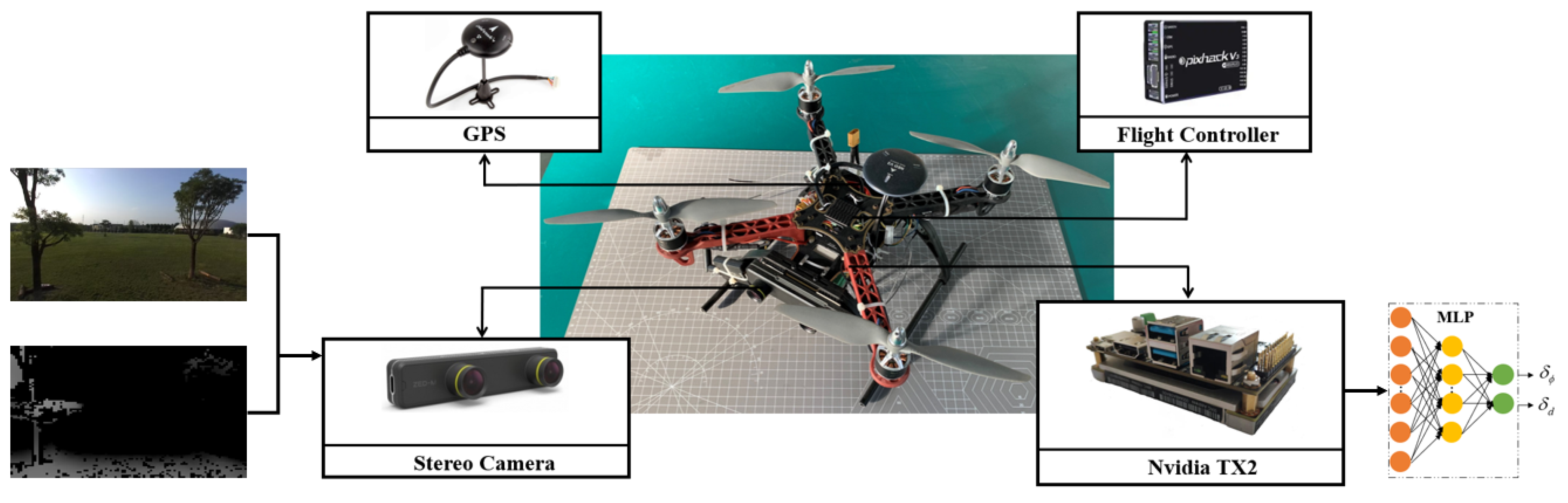
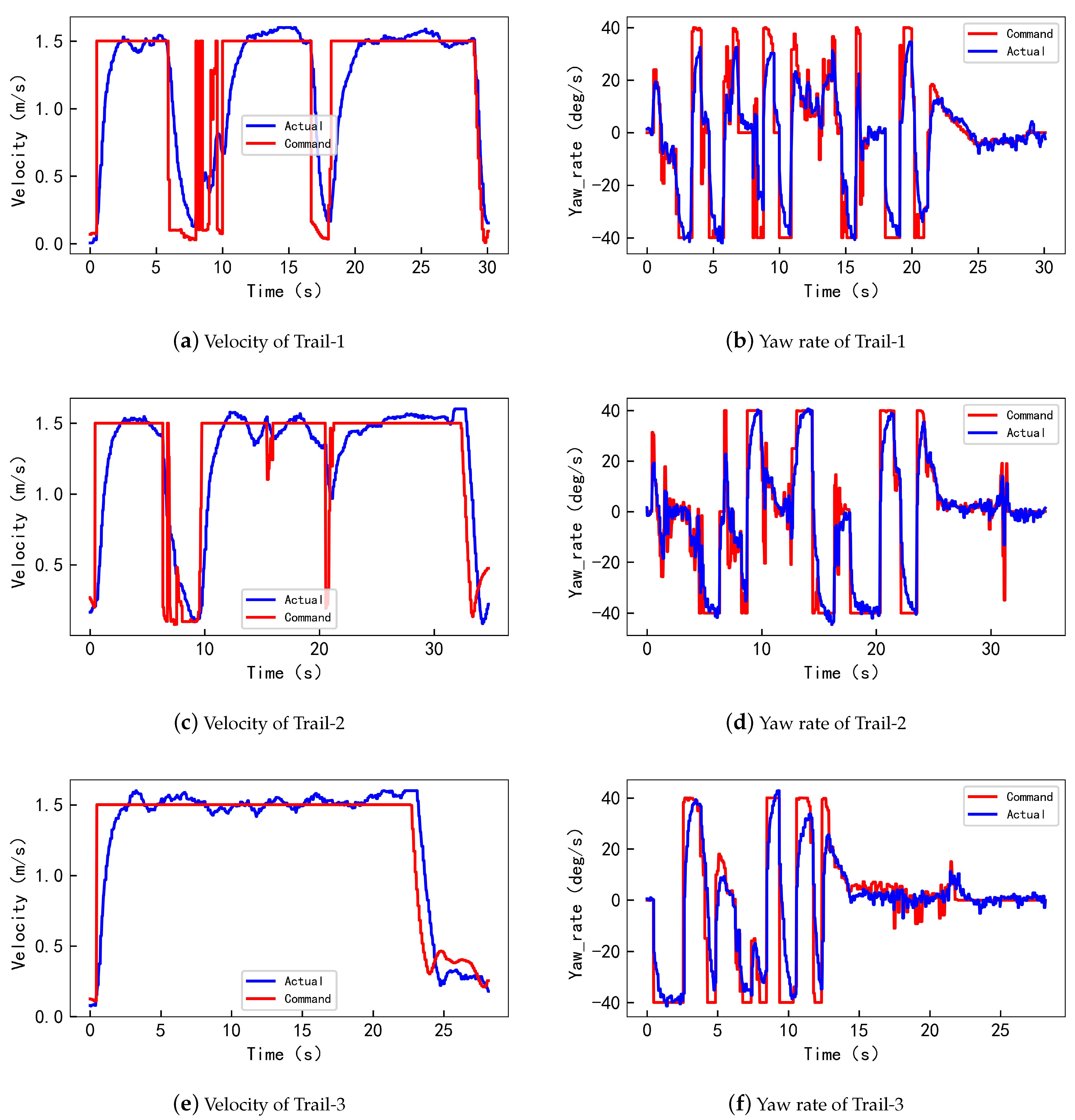
4.3. Real Flight Test
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tomic, T.; Schmid, K.; Lutz, P.; Domel, A.; Kassecker, M.; Mair, E.; Grixa, I.L.; Ruess, F.; Suppa, M.; Burschka, D. Toward a fully autonomous UAV: Research platform for indoor and outdoor urban search and rescue. IEEE Robot. Autom. Mag. 2012, 19, 46–56. [Google Scholar] [CrossRef]
- Özaslan, T.; Loianno, G.; Keller, J.; Taylor, C.J.; Kumar, V.; Wozencraft, J.M.; Hood, T. Autonomous navigation and mapping for inspection of penstocks and tunnels with MAVs. IEEE Robot. Autom. Lett. 2017, 2, 1740–1747. [Google Scholar] [CrossRef]
- Loianno, G.; Spurny, V.; Thomas, J.; Baca, T.; Thakur, D.; Hert, D.; Penicka, R.; Krajnik, T.; Zhou, A.; Cho, A.; et al. Localization, grasping, and transportation of magnetic objects by a team of mavs in challenging desert-like environments. IEEE Robot. Autom. Lett. 2018, 3, 1576–1583. [Google Scholar] [CrossRef]
- Liu, X.; Chen, S.W.; Nardari, G.V.; Qu, C.; Ojeda, F.C.; Taylor, C.J.; Kumar, V. Challenges and Opportunities for Autonomous Micro-UAVs in Precision Agriculture. IEEE Micro 2022, 42, 61–68. [Google Scholar] [CrossRef]
- Ma, Z.; Wang, Z.; Ma, A.; Liu, Y.; Niu, Y. A Low-Altitude Obstacle Avoidance Method for UAVs Based on Polyhedral Flight Corridor. Drones 2023, 7, 588. [Google Scholar] [CrossRef]
- Zhao, S.; Zhu, J.; Bao, W.; Li, X.; Sun, H. A Multi-Constraint Guidance and Maneuvering Penetration Strategy via Meta Deep Reinforcement Learning. Drones 2023, 7, 626. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, G.; Da, Q.; Lu, D.; Zhao, Y.; Li, S.; Lang, D. Multiple Unmanned Aerial Vehicle Autonomous Path Planning Algorithm Based on Whale-Inspired Deep Q-Network. Drones 2023, 7, 572. [Google Scholar] [CrossRef]
- Loquercio, A.; Kaufmann, E.; Ranftl, R.; Müller, M.; Koltun, V.; Scaramuzza, D. Learning high-speed flight in the wild. Sci. Robot. 2021, 6, eabg5810. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Aouf, N.; Whidborne, J.F.; Song, B. Integrated moment-based LGMD and deep reinforcement learning for UAV obstacle avoidance. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 7491–7497. [Google Scholar]
- Pham, H.X.; La, H.M.; Feil-Seifer, D.; Nguyen, L.V. Autonomous uav navigation using reinforcement learning. arXiv 2018, arXiv:1801.05086. [Google Scholar]
- Loquercio, A.; Maqueda, A.I.; Del-Blanco, C.R.; Scaramuzza, D. Dronet: Learning to fly by driving. IEEE Robot. Autom. Lett. 2018, 3, 1088–1095. [Google Scholar] [CrossRef]
- Nachum, O.; Gu, S.S.; Lee, H.; Levine, S. Data-efficient hierarchical reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Pieter Abbeel, O.; Zaremba, W. Hindsight experience replay. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Pateria, S.; Subagdja, B.; Tan, A.h.; Quek, C. Hierarchical reinforcement learning: A comprehensive survey. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Dayan, P.; Daw, N.D. Decision theory, reinforcement learning, and the brain. Cogn. Affect. Behav. Neurosci. 2008, 8, 429–453. [Google Scholar] [CrossRef] [PubMed]
- Barto, A.G.; Mahadevan, S. Recent advances in hierarchical reinforcement learning. Discret. Event Dyn. Syst. 2003, 13, 41–77. [Google Scholar] [CrossRef]
- Dayan, P.; Hinton, G.E. Feudal reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems, San Francisco, CA, USA, 30 November–3 December 1992; Volume 5. [Google Scholar]
- Sutton, R.S.; Precup, D.; Singh, S. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artif. Intell. 1999, 112, 181–211. [Google Scholar] [CrossRef]
- Sun, P.; Sun, X.; Han, L.; Xiong, J.; Wang, Q.; Li, B.; Zheng, Y.; Liu, J.; Liu, Y.; Liu, H.; et al. Tstarbots: Defeating the cheating level builtin ai in starcraft ii in the full game. arXiv 2018, arXiv:1809.07193. [Google Scholar]
- Vezhnevets, A.S.; Osindero, S.; Schaul, T.; Heess, N.; Jaderberg, M.; Silver, D.; Kavukcuoglu, K. Feudal networks for hierarchical reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 3540–3549. [Google Scholar]
- Levy, A.; Konidaris, G.; Platt, R.; Saenko, K. Learning multi-level hierarchies with hindsight. arXiv 2017, arXiv:1712.00948. [Google Scholar]
- Schaul, T.; Horgan, D.; Gregor, K.; Silver, D. Universal value function approximators. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 1312–1320. [Google Scholar]
- Kulkarni, T.D.; Narasimhan, K.; Saeedi, A.; Tenenbaum, J. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 22–24 June 2014; pp. 387–395. [Google Scholar]
- Peters, J.; Schaal, S. Natural actor-critic. Neurocomputing 2008, 71, 1180–1190. [Google Scholar] [CrossRef]
- Tedrake, R.; Zhang, T.W.; Seung, H.S. Stochastic policy gradient reinforcement learning on a simple 3D biped. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No. 04CH37566), Sendai, Japan, 28 September–2 October 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 3, pp. 2849–2854. [Google Scholar]
- Mugnai, M.; Teppati Losé, M.; Herrera-Alarcón, E.P.; Baris, G.; Satler, M.; Avizzano, C.A. An Efficient Framework for Autonomous UAV Missions in Partially-Unknown GNSS-Denied Environments. Drones 2023, 7, 471. [Google Scholar] [CrossRef]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. Airsim: High-fidelity visual and physical simulation for autonomous vehicles. In Proceedings of the Field and Service Robotics, Zurich, Switzerland, 12–15 September 2017; Springer: Cham, Switzerland, 2018; pp. 621–635. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Success Rate | Crash Rate |
|---|---|---|
| ETHP (ours) | 91% | 5% |
| ETHP (wht) | 62% | 19% |
| SAC | 73% | 24% |
| PPO | 58% | 39% |
| TD3 | 56% | 28% |
| DDPG | 53% | 47% |
| HAC | 3% | 88% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Song, B.; Fu, Q.; Xue, D.; He, L. Event-Triggered Hierarchical Planner for Autonomous Navigation in Unknown Environment. Drones 2023, 7, 690. https://doi.org/10.3390/drones7120690
Chen C, Song B, Fu Q, Xue D, He L. Event-Triggered Hierarchical Planner for Autonomous Navigation in Unknown Environment. Drones. 2023; 7(12):690. https://doi.org/10.3390/drones7120690
Chicago/Turabian StyleChen, Changhao, Bifeng Song, Qiang Fu, Dong Xue, and Lei He. 2023. "Event-Triggered Hierarchical Planner for Autonomous Navigation in Unknown Environment" Drones 7, no. 12: 690. https://doi.org/10.3390/drones7120690
APA StyleChen, C., Song, B., Fu, Q., Xue, D., & He, L. (2023). Event-Triggered Hierarchical Planner for Autonomous Navigation in Unknown Environment. Drones, 7(12), 690. https://doi.org/10.3390/drones7120690