
Special Vehicle Detection from UAV Perspective via YOLO-GNS Based Deep Learning Network

Abstract
:1. Introduction
2. Materials and Methods
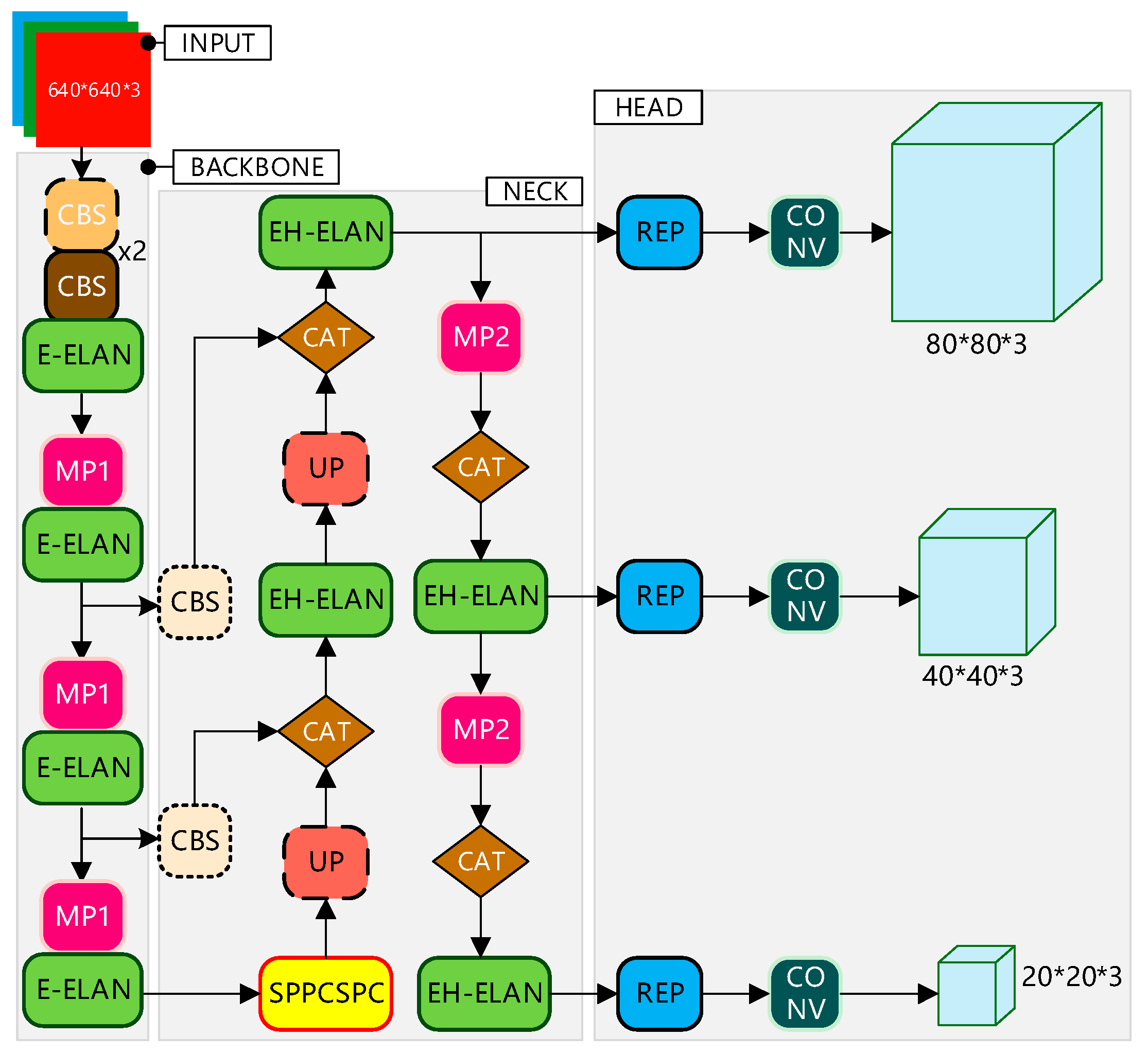
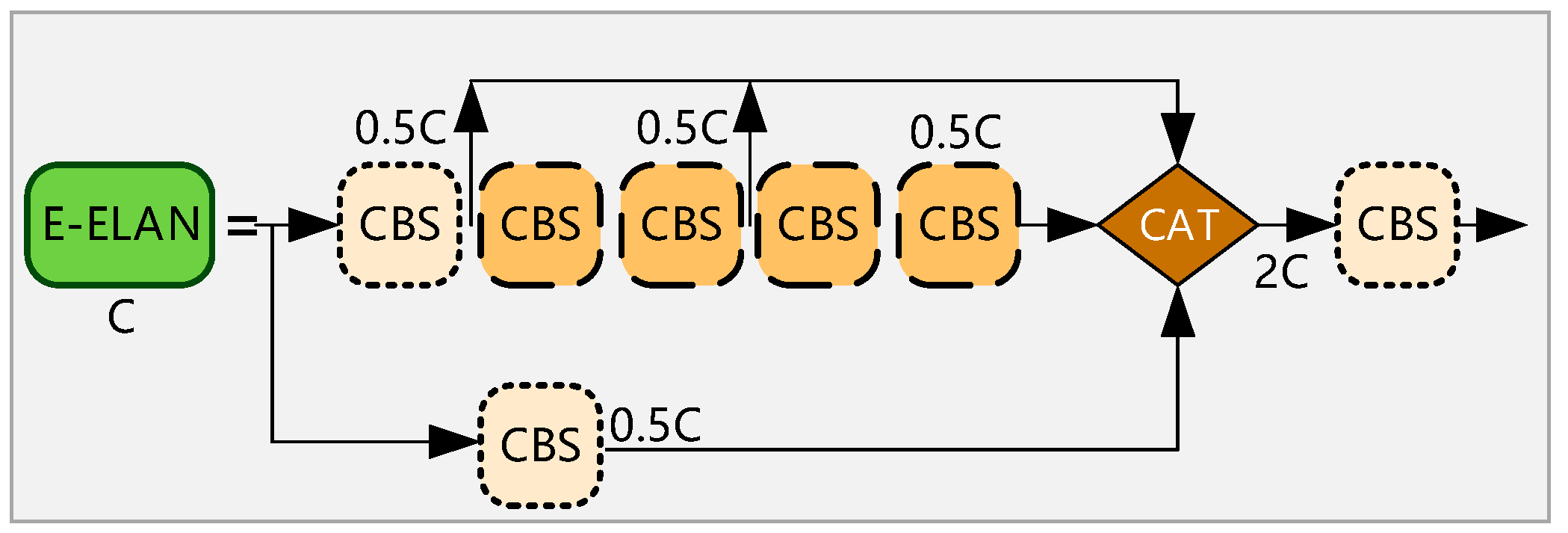
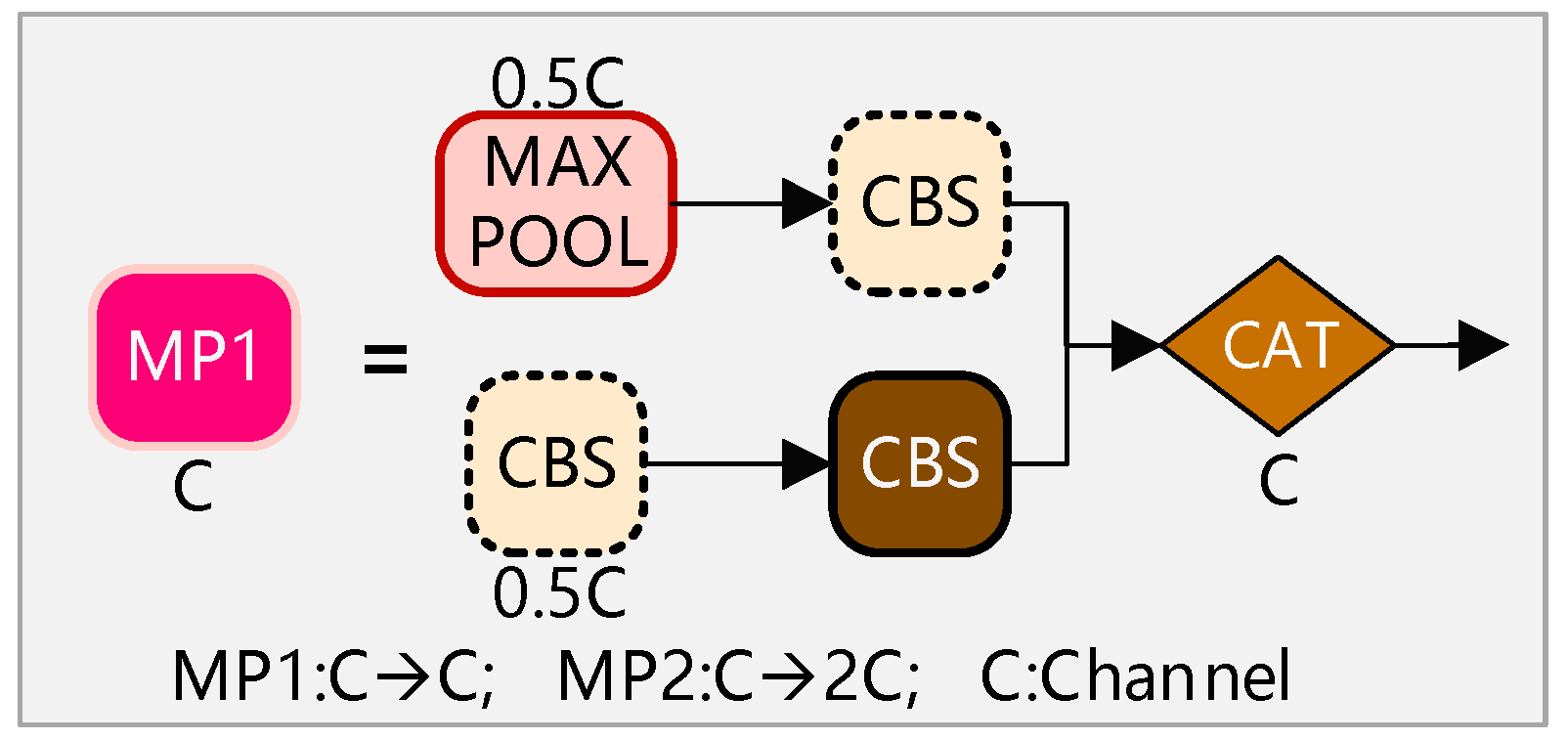
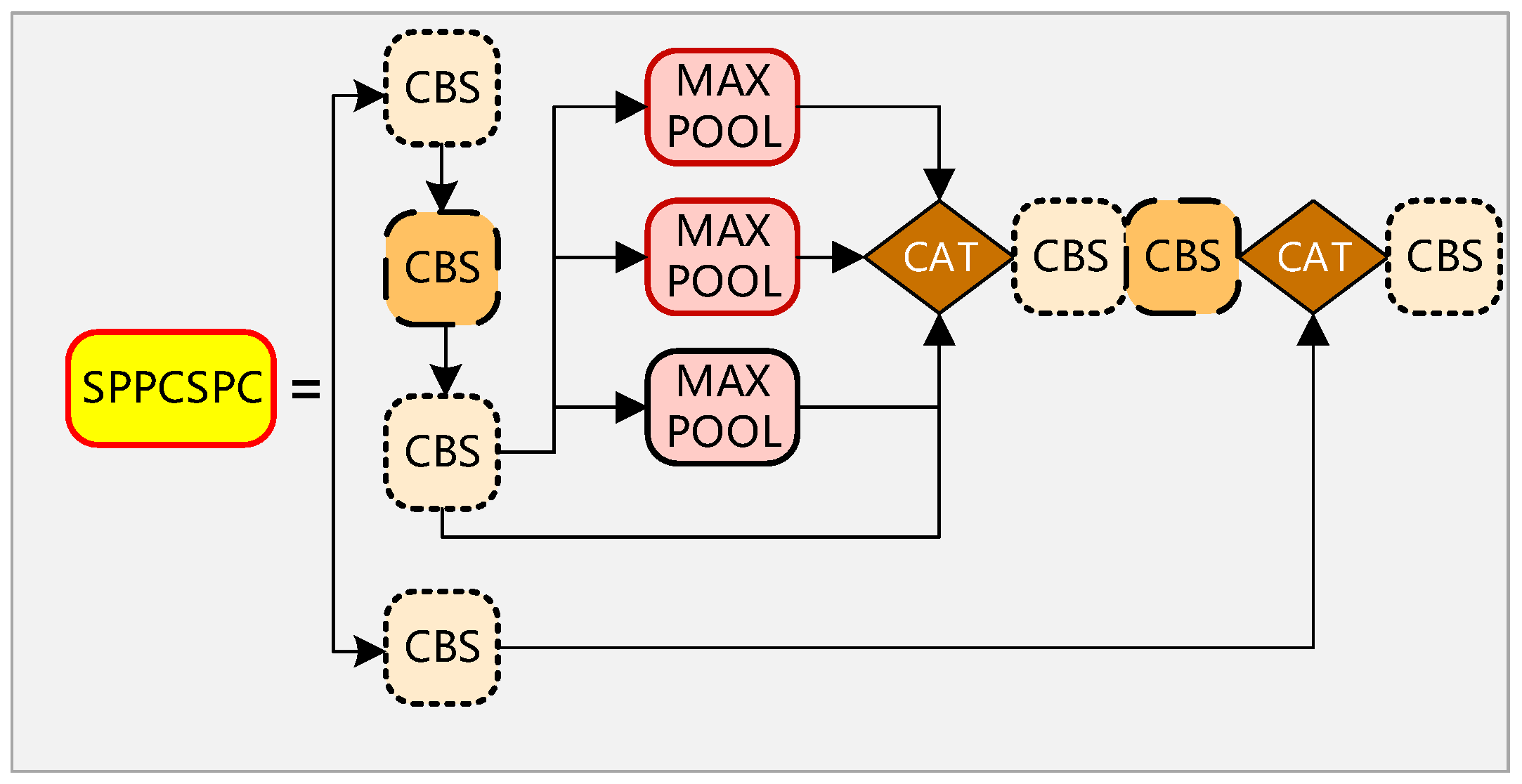
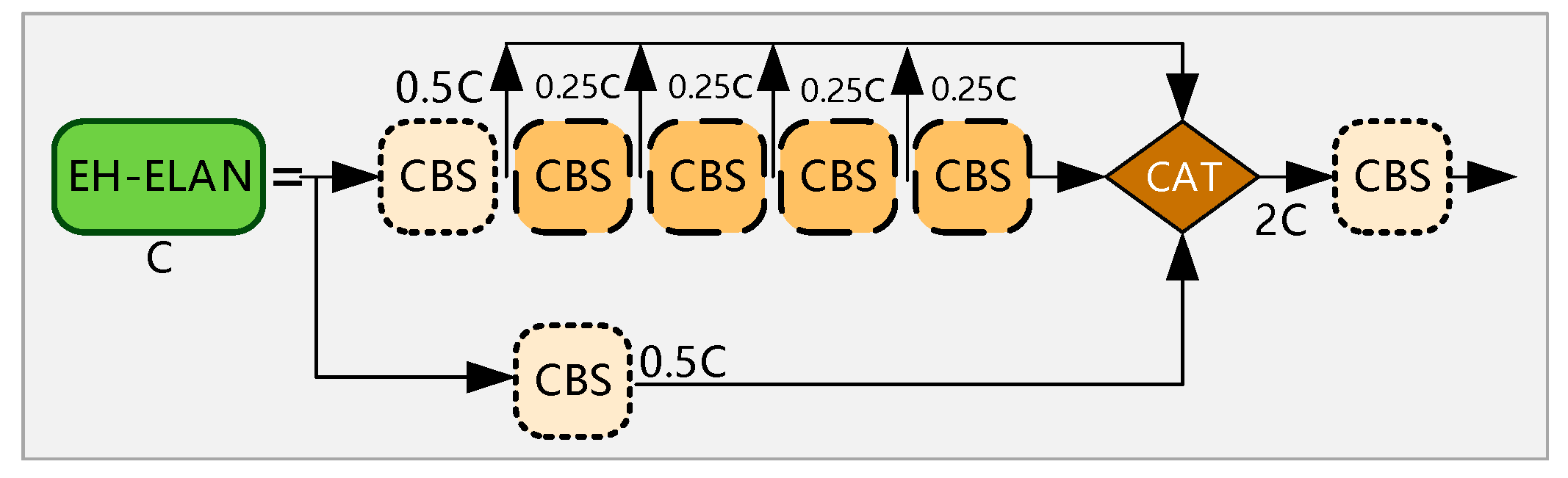
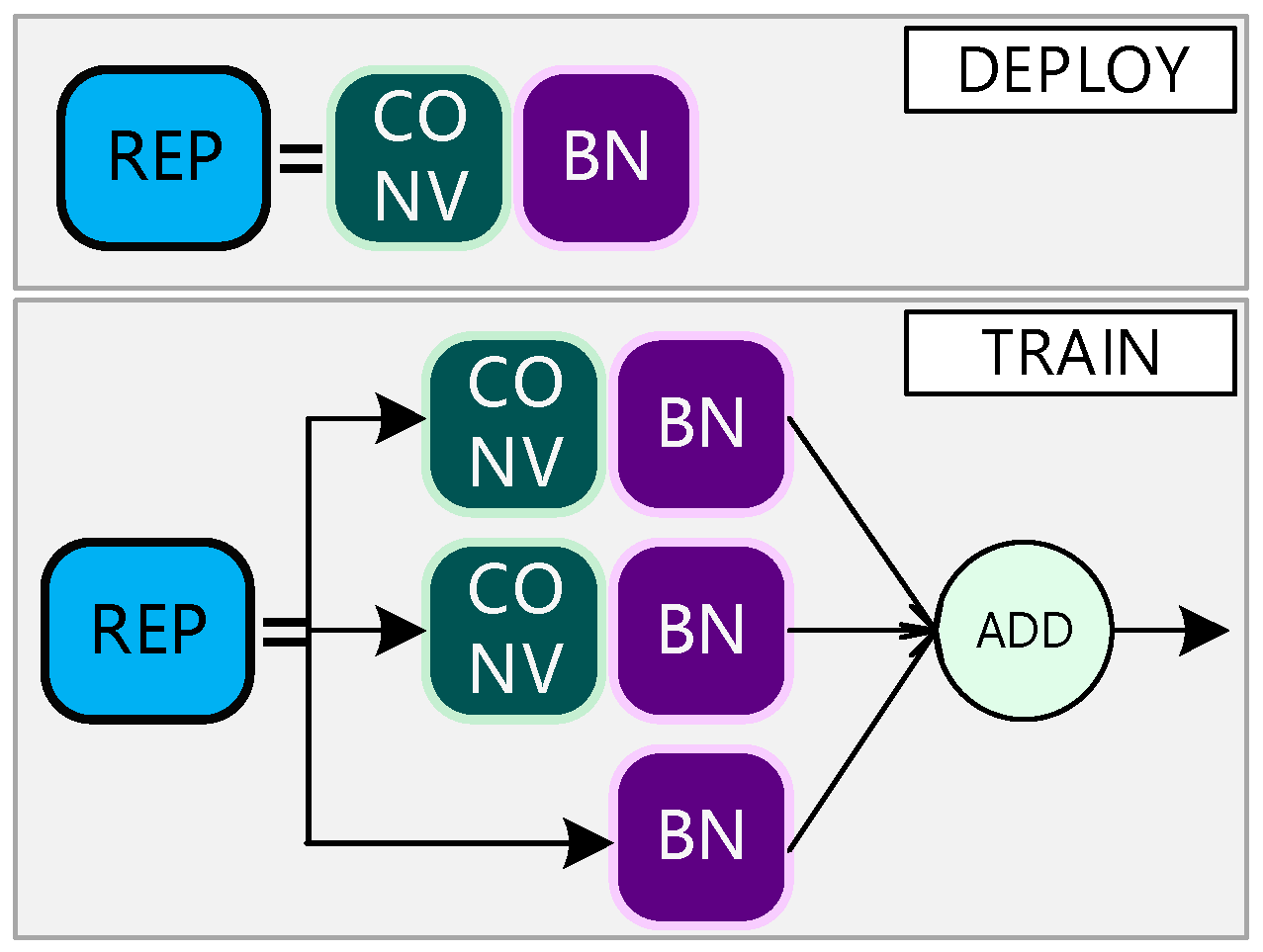
2.1. Principle of YOLOv7 Network Structure
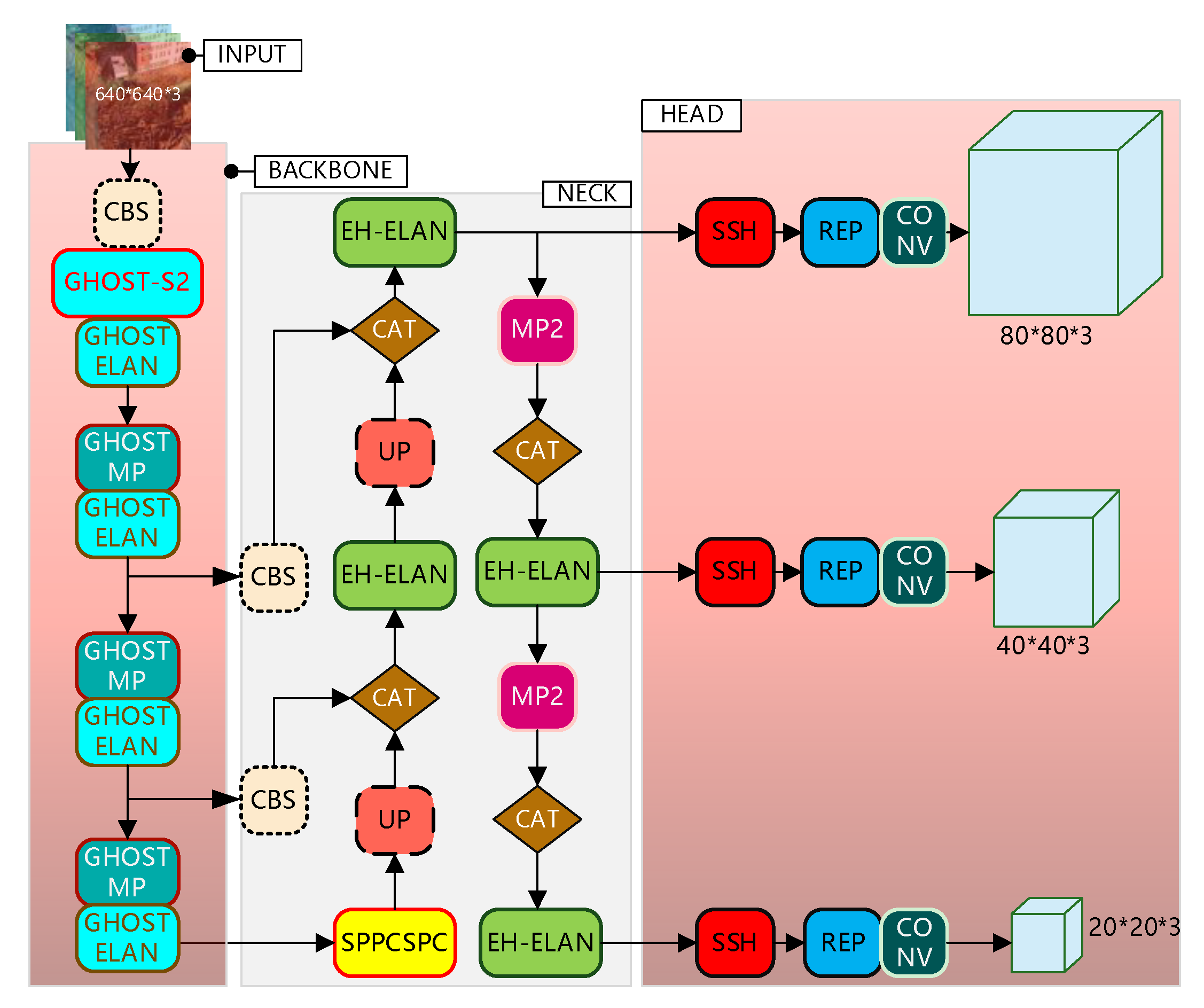
2.2. YOLO-GNS Algorithm
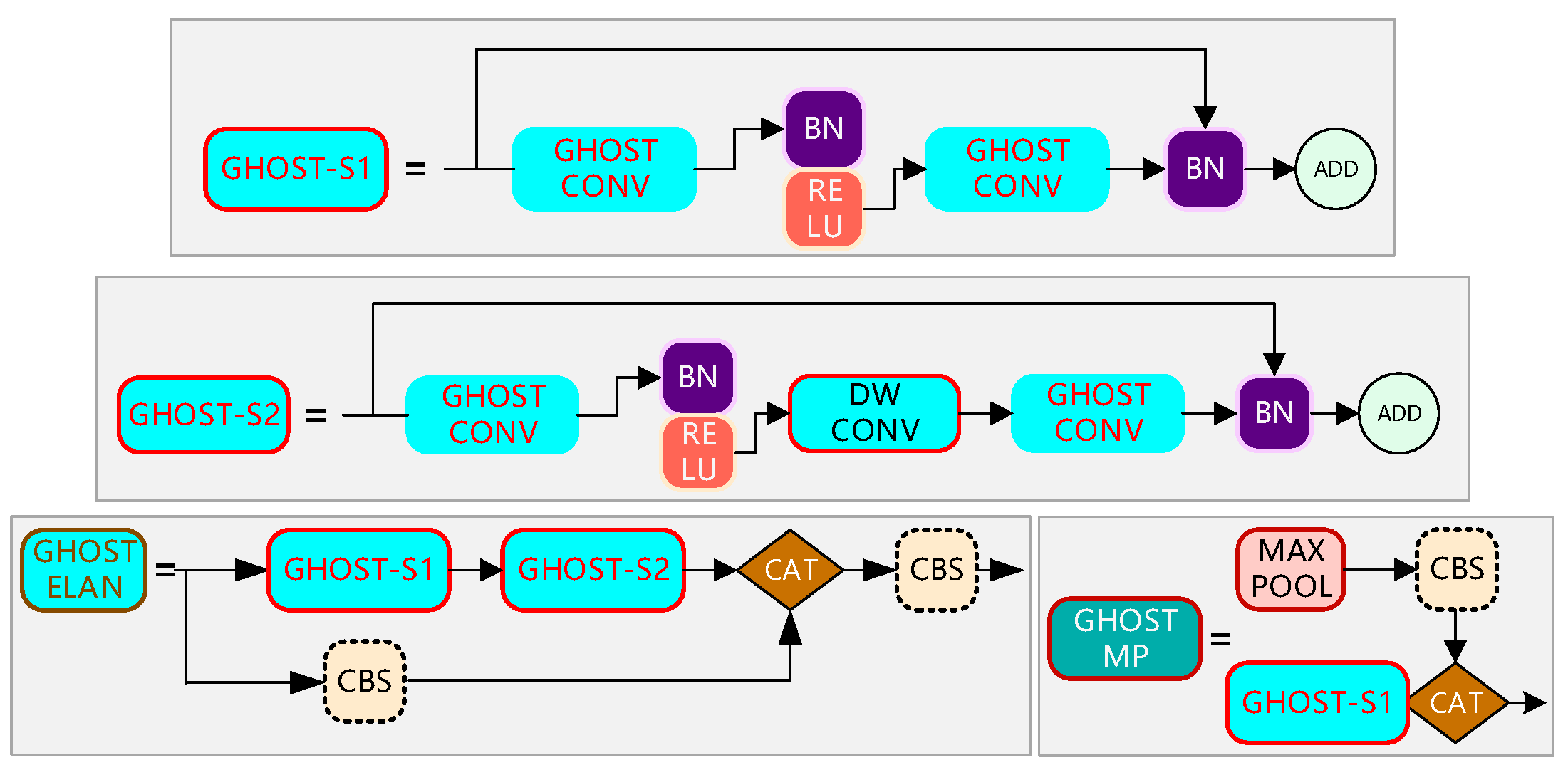
2.2.1. Improvement of Backbone Network Based on GhostNet
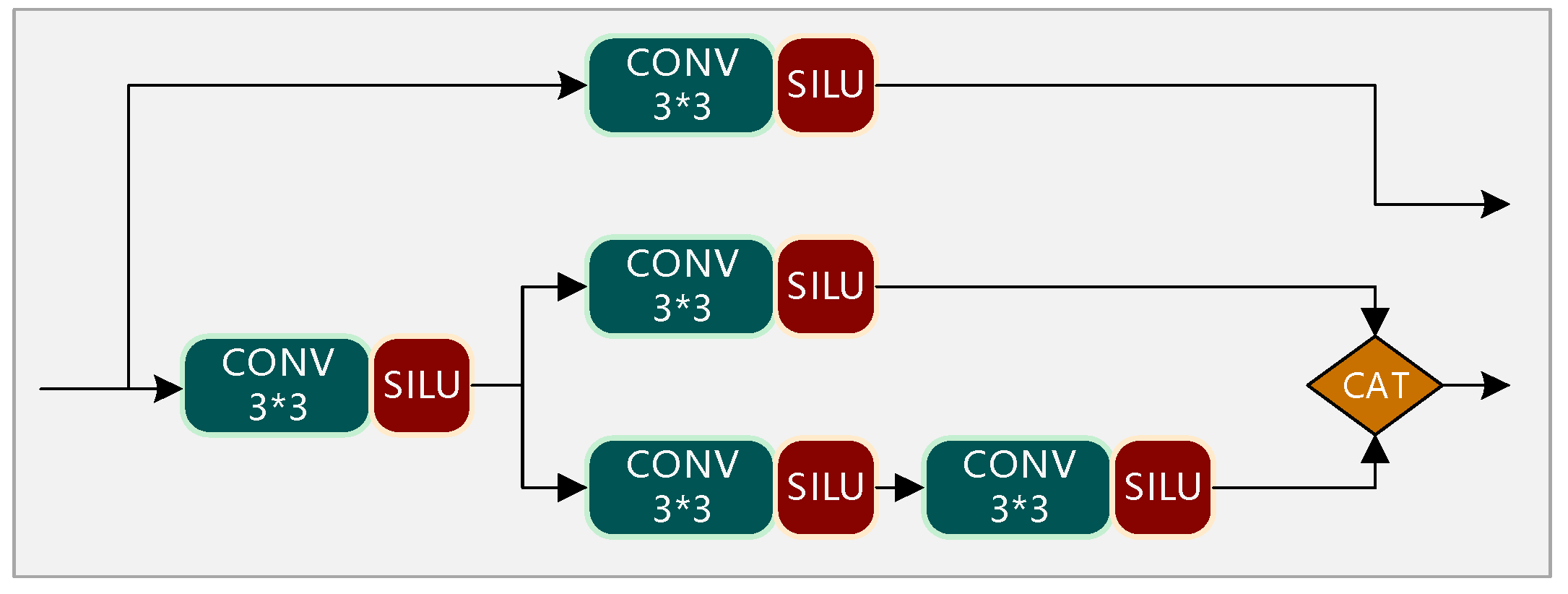
2.2.2. Prediction Optimization Based on SSH Structure
3. Results
3.1. Special Vehicle Dataset
3.2. Experimental Environment and Settings
3.3. Experimental Results and Analysis
3.3.1. Experiments on SEVE Dataset
3.3.2. Experiments on COCO Datasets
3.3.3. Ablation Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Q.; Ban, X.; Wu, H. Design of Informationized Operation and Maintenance System for Long-Distance Oil and Gas Pipelines. In Proceedings of the International Conference on Computer Science and Application Engineering, Sanya, China, 22–24 October 2019. [Google Scholar] [CrossRef]
- Bao, W.; Ren, Y.; Wang, N.; Hu, G.; Yang, X. Detection of Abnormal Vibration Dampers on Transmission Lines in UAV Remote Sensing Images with PMA-YOLO. Remote Sens. 2021, 13, 4134. [Google Scholar] [CrossRef]
- Jiang, Y.; Huang, Y.; Liu, J.; Li, D.; Li, S.; Nie, W.; Chung, I.-H. Automatic Volume Calculation and Mapping of Construction and Demolition Debris Using Drones, Deep Learning, and GIS. Drones 2022, 6, 279. [Google Scholar] [CrossRef]
- Mittal, P.; Singh, R.; Sharma, A. Deep Learning-Based Object Detection in Low-Altitude UAV Datasets: A Survey. Image Vis. Comput. 2020, 104, 104046. [Google Scholar] [CrossRef]
- Bouguettaya, A.; Zarzour, H.; Kechida, A.; Taberkit, A.M. Vehicle Detection From UAV Imagery with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6047–6067. [Google Scholar] [CrossRef]
- Srivastava, S.; Narayan, S.; Mittal, S. A Survey of Deep Learning Techniques for Vehicle Detection from UAV Images. J. Syst. Archit. 2021, 117, 102152. [Google Scholar] [CrossRef]
- Liu, W.; Quijano, K.; Crawford, M.M. YOLOv5-Tassel: Detecting Tassels in RGB UAV Imagery with Improved YOLOv5 Based on Transfer Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8085–8094. [Google Scholar] [CrossRef]
- Zhou, H.; Ma, A.; Niu, Y.; Ma, Z. Small-Object Detection for UAV-Based Images Using a Distance Metric Method. Drones 2022, 6, 308. [Google Scholar] [CrossRef]
- Wang, J.; Shao, F.; He, X.; Lu, G. A Novel Method of Small Object Detection in UAV Remote Sensing Images Based on Feature Alignment of Candidate Regions. Drones 2022, 6, 292. [Google Scholar] [CrossRef]
- Li, Q.; Mou, L.; Xu, Q.; Zhang, Y.; Zhu, X.X. R3-Net: A Deep Network for Multioriented Vehicle Detection in Aerial Images and Videos. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5028–5042. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Yuan, H.; Wang, Y.; Xiao, C. GGT-YOLO: A Novel Object Detection Algorithm for Drone-Based Maritime Cruising. Drones 2022, 6, 335. [Google Scholar] [CrossRef]
- Wang, J.; Ding, J.; Guo, H.; Cheng, W.; Pan, T.; Yang, W. Mask OBB: A Semantic Attention-Based Mask Oriented Bounding Box Representation for Multi-Category Object Detection in Aerial Images. Remote Sens. 2019, 11, 2930. [Google Scholar] [CrossRef]
- Mantau, A.J.; Widayat, I.W.; Leu, J.-S.; Köppen, M. A Human-Detection Method Based on YOLOv5 and Transfer Learning Using Thermal Image Data from UAV Perspective for Surveillance System. Drones 2022, 6, 290. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Zou, H. Toward Fast and Accurate Vehicle Detection in Aerial Images Using Coupled Region-Based Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3652–3664. [Google Scholar] [CrossRef]
- Tian, G.; Liu, J.; Yang, W. A Dual Neural Network for Object Detection in UAV Images. Neurocomputing 2021, 443, 292–301. [Google Scholar] [CrossRef]
- Xie, J.; Wang, D.; Guo, J.; Han, P.; Fang, J.; Xu, Z. An Anchor-Free Detector Based on Residual Feature Enhancement Pyramid Network for UAV Vehicle Detection. In Proceedings of the 2021 4th International Conference on Artificial Intelligence and Pattern Recognition, Xiamen, China, 24–26 September 2021; ACM: New York, NY, USA, 2021; pp. 287–294. [Google Scholar]
- Wan, Y.; Zhong, Y.; Huang, Y.; Han, Y.; Cui, Y.; Yang, Q.; Li, Z.; Yuan, Z.; Li, Q. ARSD: An Adaptive Region Selection Object Detection Framework for UAV Images. Drones 2022, 6, 228. [Google Scholar] [CrossRef]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Y.; Liu, T.; Lin, Z.; Wang, S. DAGN: A Real-Time UAV Remote Sensing Image Vehicle Detection Framework. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1884–1888. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, C.; Chang, F.; Song, Y. Multi-Scale and Occlusion Aware Network for Vehicle Detection and Segmentation on UAV Aerial Images. Remote Sens. 2020, 12, 1760. [Google Scholar] [CrossRef]
- Luo, X.; Tian, X.; Zhang, H.; Hou, W.; Leng, G.; Xu, W.; Jia, H.; He, X.; Wang, M.; Zhang, J. Fast Automatic Vehicle Detection in UAV Images Using Convolutional Neural Networks. Remote Sens. 2020, 12, 1994. [Google Scholar] [CrossRef]
- Balamuralidhar, N.; Tilon, S.; Nex, F. MultEYE: Monitoring System for Real-Time Vehicle Detection, Tracking and Speed Estimation from UAV Imagery on Edge-Computing Platforms. Remote Sens. 2021, 13, 573. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 November 2020).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Han, K.; Wang, Y.; Xu, C.; Guo, J.; Xu, C.; Wu, E.; Tian, Q. GhostNets on Heterogeneous Devices via Cheap Operations. Int. J. Comput. Vis. 2022, 130, 1050–1069. [Google Scholar] [CrossRef]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L. SSH: Single Stage Headless Face Detector. arXiv 2017, arXiv:1708.03979. [Google Scholar]

















{kind=link}
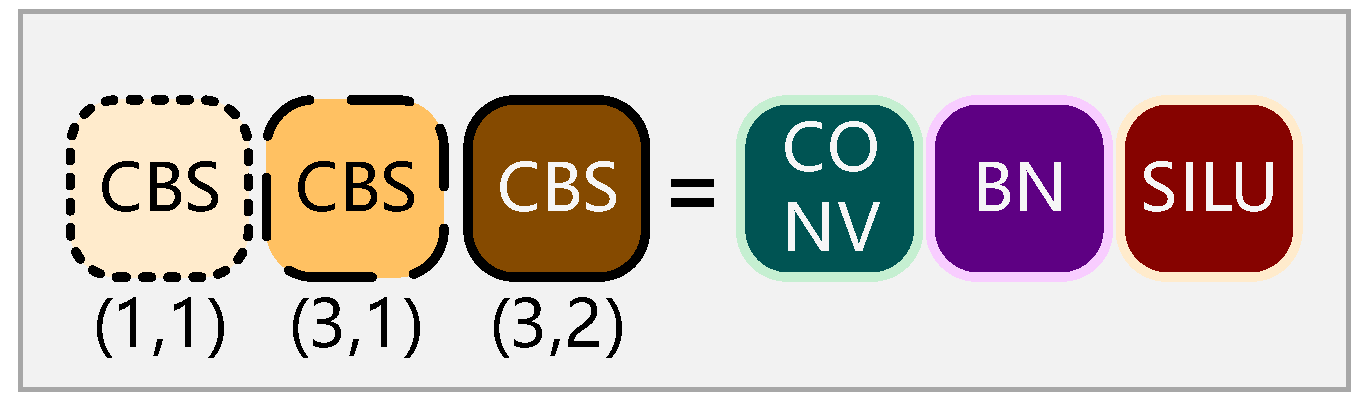{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
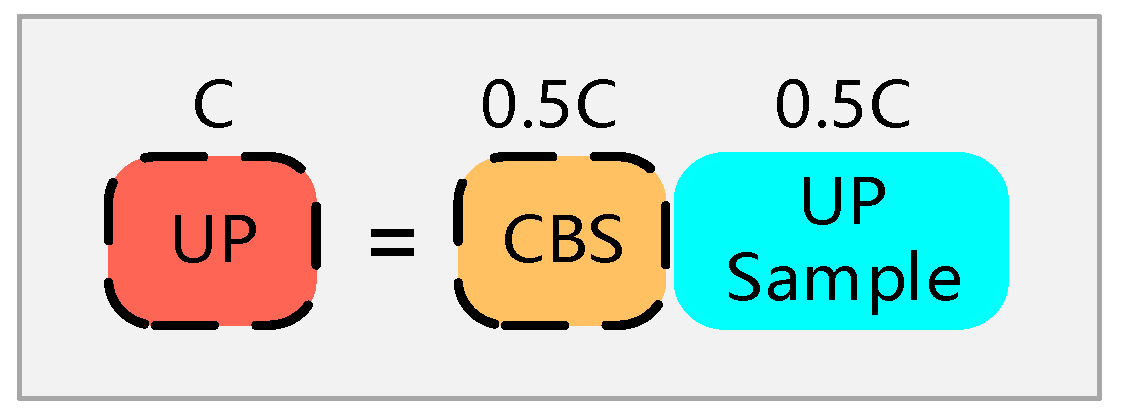{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | [email protected](%) | [email protected] (%) | Params(M) | FPS | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C | L | T | M | F | P | R | EL | EX | ||||
| Faster-RCNN | 73.2 | 75.5 | 76.1 | 80.2 | 78.1 | 81.3 | 56.3 | 45.5 | 21.3 | 65.3 | 186.3 | 16.8 |
| RetinaNet | 77.5 | 78.6 | 85.1 | 82.3 | 81.5 | 80.6 | 57.6 | 49.1 | 23.5 | 68.4 | 28.5 | 19.5 |
| YOLOV4 | 78.7 | 80.1 | 82.3 | 83.5 | 82.6 | 78.3 | 60.5 | 55.8 | 30.3 | 70.2 | 64.4 | 25.6 |
| YOLOV5-X | 79.8 | 78.1 | 85.6 | 83.9 | 83.1 | 82.5 | 59.1 | 58.3 | 32.5 | 71.4 | 86.7 | 29.2 |
| YOLOV7 | 80.5 | 82.3 | 86.4 | 88.6 | 85.3 | 86.4 | 65.3 | 60.8 | 45.8 | 75.7 | 36.9 | 31.5 |
| YOLO-GNS | 85.9 | 86.9 | 89.4 | 91.3 | 90.1 | 89.6 | 69.5 | 67.3 | 50.8 | 80.1 | 30.7 | 33.1 |
| Methods | Backbone | mAP0.5:0.95 | mAP0.5 | mAP0.75 |
|---|---|---|---|---|
| Faster-RCNN | ResNet50 | 36.2 | 59.2 | 39.1 |
| RetinaNet | ResNet50 | 36.9 | 56.3 | 39.3 |
| YOLOV4 | CSPDarknet-53 | 43.5 | 65.7 | 47.3 |
| YOLOV5-X | Modified CSP v5 | 50.4 | 68.8 | - |
| YOLOV7 | E-ELAN | 51.4 | 69.7 | 55.9 |
| YOLO-GNS | GhostELAN | 51.5 | 69.8 | 55.7 |
| Methods | Backbone | GhostNet | SSH | [email protected](%) |
|---|---|---|---|---|
| YOLOV7 | E-ELAN | × | × | 75.7 |
| YOLOV7 | E-ELAN | × | √ | 78.9 |
| YOLOV7 | E-ELAN | √ | × | 79.2 |
| YOLOV7 | E-ELAN | √ | √ | 80.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Z.; Bai, H.; Chen, T. Special Vehicle Detection from UAV Perspective via YOLO-GNS Based Deep Learning Network. Drones 2023, 7, 117. https://doi.org/10.3390/drones7020117
Qiu Z, Bai H, Chen T. Special Vehicle Detection from UAV Perspective via YOLO-GNS Based Deep Learning Network. Drones. 2023; 7(2):117. https://doi.org/10.3390/drones7020117
Chicago/Turabian StyleQiu, Zifeng, Huihui Bai, and Taoyi Chen. 2023. "Special Vehicle Detection from UAV Perspective via YOLO-GNS Based Deep Learning Network" Drones 7, no. 2: 117. https://doi.org/10.3390/drones7020117
APA StyleQiu, Z., Bai, H., & Chen, T. (2023). Special Vehicle Detection from UAV Perspective via YOLO-GNS Based Deep Learning Network. Drones, 7(2), 117. https://doi.org/10.3390/drones7020117