

Scalable and Cooperative Deep Reinforcement Learning Approaches for Multi-UAV Systems: A Systematic Review

Abstract
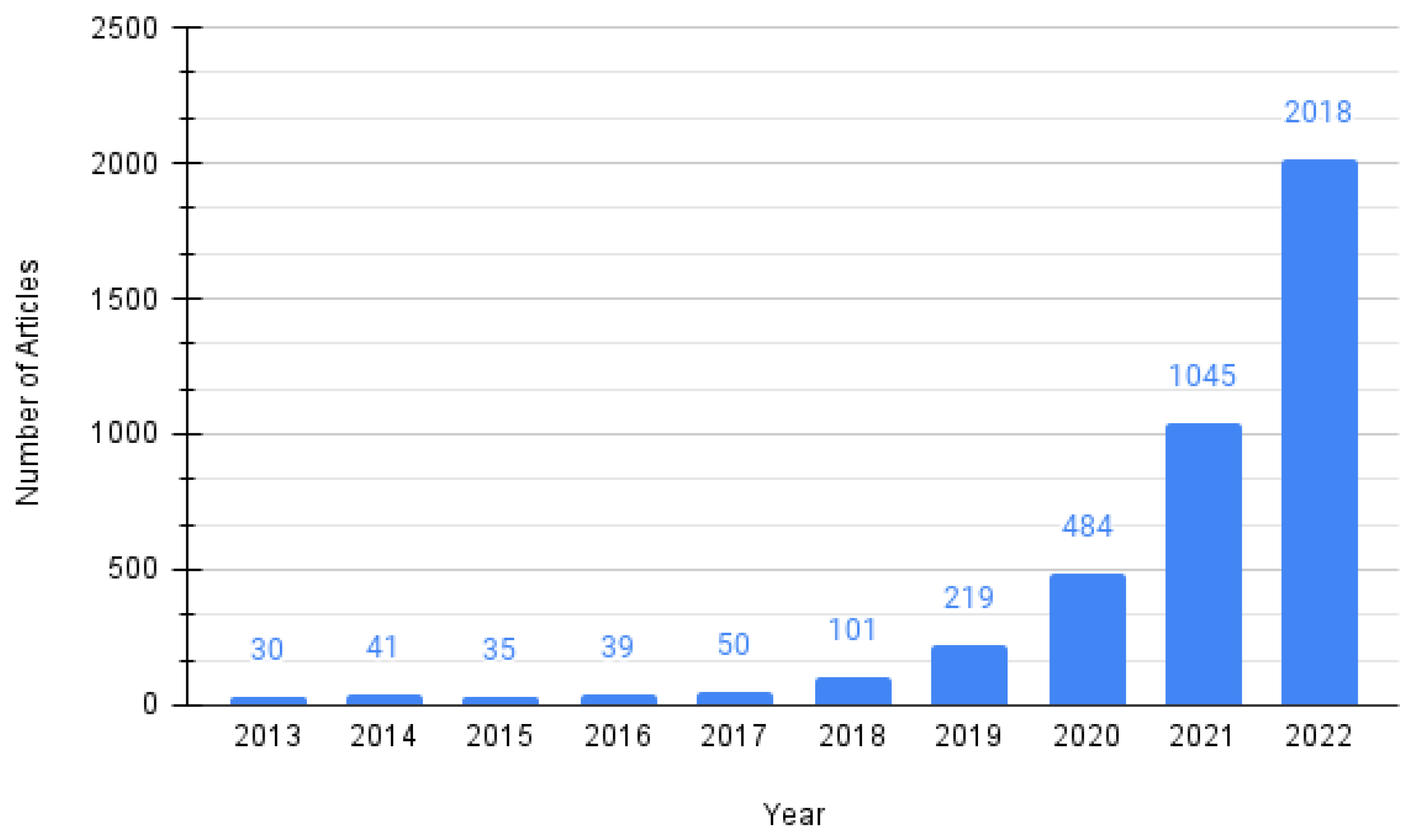
:1. Introduction
2. Background
2.1. Single-Agent Markov Decision Process
- is a set of states , with ;
- is the a set of actions with possible in each state s;
- is the probability transition matrix representing the probability of switching from the state s at time t to the state at time by picking the action a;
- is the reward function that returns the reward obtained by transitioning from state s to by picking action a.
2.2. Multi-Agent Markov Decision Process
- is the number of players (agents);
- is the set of environmental states shared by all the agents with ;
- is the set of joint actions with , where is the set of actions of agent i;
- is the probability transition matrix representing the probability of switching from the state s to by picking the joint action ;
- is the set of rewards , where is the reward function related to the agent i, which returns the reward obtained by transitioning from the state s to the state by taking the action .
2.3. Single-Agent Reinforcement Learning (SARL)
- Policy-based methods. The agent learns an explicit representation of a policy during the learning process;
- Value-based methods. The agent learns a value function to derive an implicit policy . The selected actions are the ones that maximize the value function;
- Actor–critic methods. The agent learns both a policy function and a value function. These methods are mainly related to deep reinforcement learning and can be considered a mix of the previous ones.
- Past State Independence. Future states depend only on the current state;
- Full Observability. The MDP is often considered to be a FOMDP;
- Stationary Environment. and are constant over time.
2.4. Multi-Agent Reinforcement Learning (MARL)
- Centralized training with centralized execution (CTCE) provides a single-cooperative system policy but relies on stable communication among all the agents. The need for a centralized unit makes this approach unmanageable when the number of agents becomes large. Standard SARL algorithms may be adapted to work in this setting;
- Decentralized training with decentralized execution (DTDE) allows independent agents to perform their policies without neither communication nor cooperation. This paradigm is sometimes referred to as independent learning, and SARL algorithms (just as in the previous case) can be used for any individual agent;
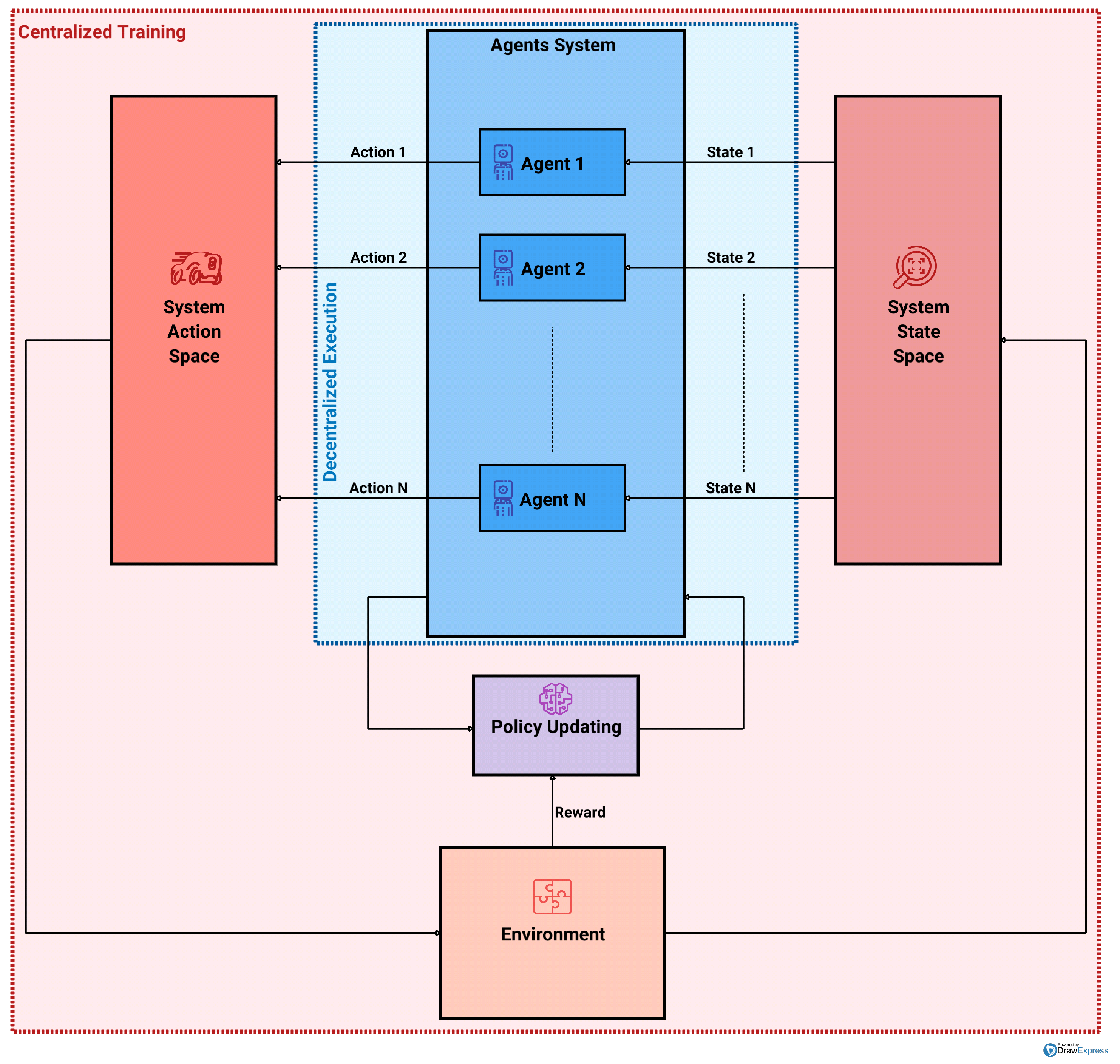
- Centralized training with decentralized execution (CTDE), where the agents can access global info during the training time but not at the execution time. The system cooperation is ensured by the centralized training, while the distributed agents execution can be performed without the need for communication, hence providing a more adaptive behavior with respect to the non-stationarity of the environment (see Figure 2 for a schematic visualization);
- Fully Cooperative. Each agent receives the same reward at each time step
- Fully Competitive (or zero-sum). The sum of the rewards of all the agents is zero
- Partially Cooperative. A part of the reward is shared among agents, but they could have additional individual rewards, i.e., , where is the shared part of the reward and represents the individual reward associated with agent i;
- Mixed. No specific constraint on the structure of the reward function.
- Partial Observability. Action selection takes place under incomplete assumptions;
- Scalability. The state and action spaces increase exponentially with the number of agents;
- Non-stationarity. All the agents learn and change their policies at the same time;
- Credit Assignment. Every agent needs to understand its contribution to the joint system reward.
2.5. Additional Techniques
3. Articles Selection Methodology
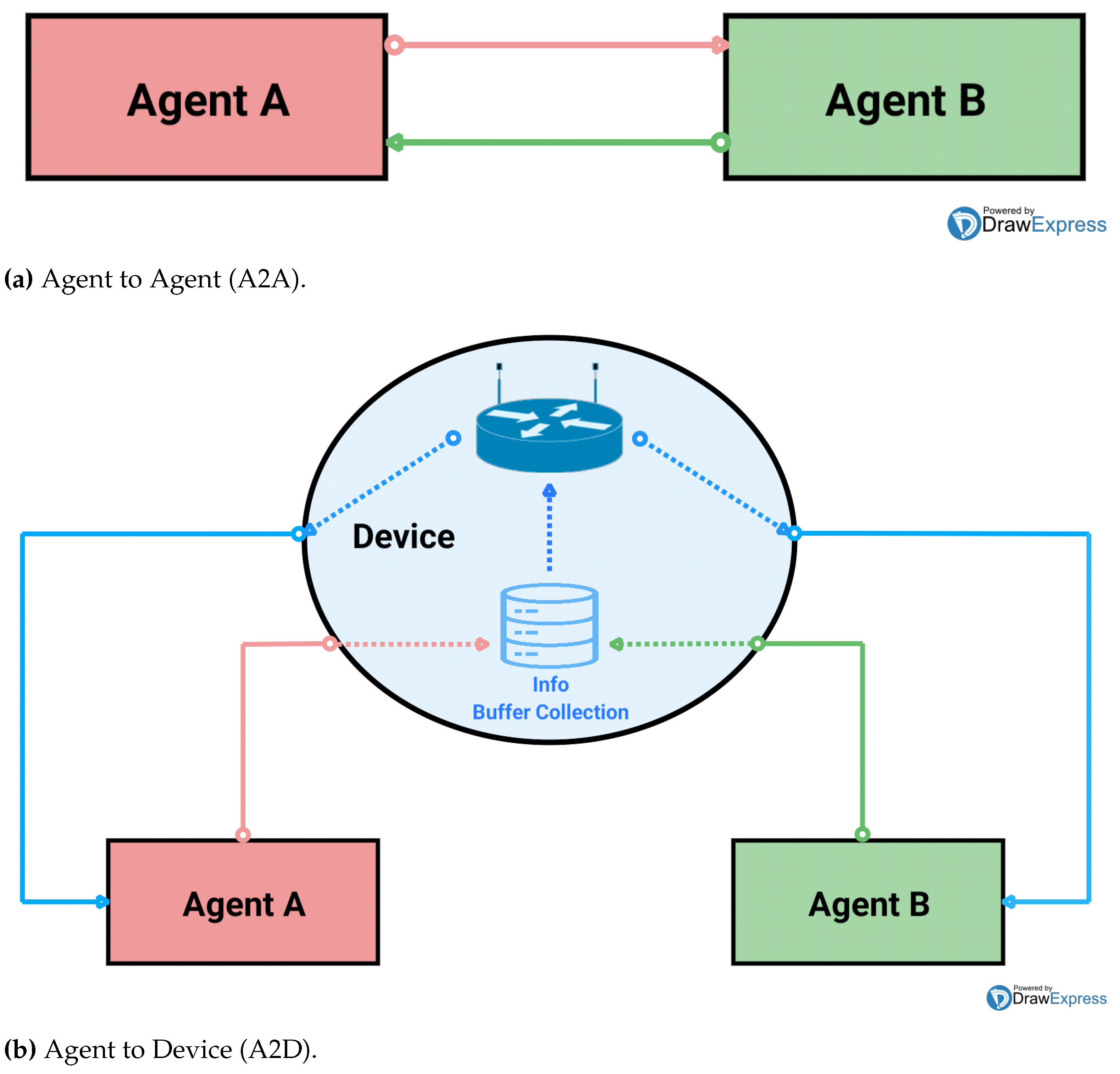
- Scalable and cooperative approaches. The multi-agent reinforcement learning solution should use either a centralized training decentralized execution (CTDE) scheme (see Section 2.4 for more details) or even a fully decentralized (FD) approach. However, in the latter case, it should be augmented through communication and/or a shared reward (SR) among the agents. When the reward is shared, communication cannot even be present. When the agents are sharing a reward (even if partially), they can learn to collaborate without communication and solve the non-stationarity issue. All the works using either only a centralized training/centralized execution or a decentralized training/decentralized execution paradigm will not be considered: we want our agents to be able to act individually and to cooperate at the same time without being necessarily constrained to the global (and maybe not always accessible) state system information during the execution phase unless a specific communication method is provided. We will also not take into account any works in which the training phase is performed sequentially by keeping fixed the policy of all the other UAVs involved during the learning step and, thus, actually not solving the non-stationary online problem (see Section 2 for more details). Collaboration can be considered as such only if all the UAVs can obtain either the same reward or different rewards but share some common observations through direct (Figure 3a) or indirect (Figure 3b) communication. The observation communicated can result either from the concatenation of all the agents’ individual observations (i.e., global communication, referred to as GC) or from a local and/or partial info exchange (i.e., local communication, referred as LC): if the shared observations are local, they should not necessarily be partial. Info exchange can be about any feature (e.g., sensor detections, gradients, and q-values). When the training phase is centralized, then cooperation is intrinsically guaranteed. Even if the communication module is not based on a real transmission protocol, this is still a valid feature for UAVs’ cooperation. Our criteria reject all the cases where there is no clear info about how the global observations are supposed to be locally available on the agent side at execution time. Even though some works study multi-UAV systems resulting in a final collaborative task, they were not selected if the agents involved are not aware of each other and, thus, every time that the cooperation could be implicitly derived only from the interaction between the environment objects and the agents. For example, the latter case could happen in some specific application scenarios where different users can be served only by one agent at a time; these specific interactions implicitly lead to cooperation among agents, which will then avoid all the already served users. These first filtering choices are meant to be focused on scalable solutions (i.e., without a central control unit at execution time) and cooperative approaches through the usage of shared resources or communications. Indeed, it is well known that completely centralized approaches suffer from the curse of dimensionality;
- Deep RL. We only consider reinforcement learning approaches that use function approximators based on deep neural networks. This choice is guided by the fact that we want to focus on generalizable solutions: in real environments, some unpredictable events which are not experienced during the learning phase can occur, and RL techniques cannot handle them as smoothly as DRL approaches can;
- Number of UAVs. The number of UAVs effectively used in the experiments should be at least greater than two (comparison analyses including a number of drones ranging from 2 to N, with N > 2, have still been taken into account). For the sake of clarity, we highlight that we filtered an article out even though it was focused on a system (which could be heterogeneous) made up of a number of agents equal to or greater than three (but with a number of UAVs involved in the considered system not greater than two). In addition, we did not select any papers where the agents are not represented by the UAVs even if UAVs are somehow involved (indeed, sometimes, it could happen that the agents are represented by a central controller such as a server or a base station);
- Clear description of the framework. The MDP and the framework structure must be explicitly defined. If not, their main features (i.e., state space, action space, or reward function) must be clearly or easily derivable from the context or figures.
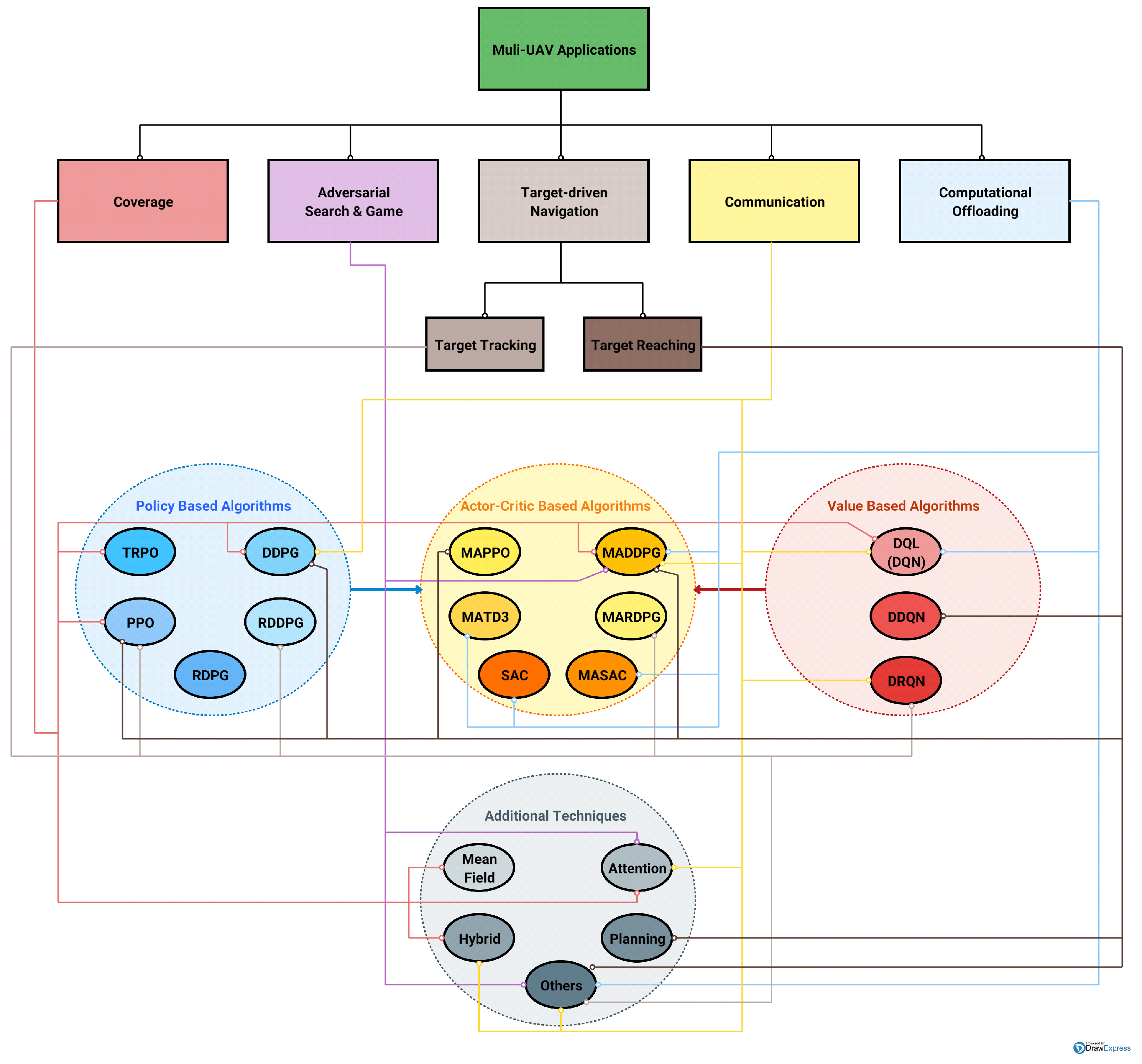
4. DRL-Based Multi-UAV Applications
- Coverage;
- Adversarial Search and Game;
- Computational Offloading;
- Communication;
- Target-Driven Navigation.
- Algorithm indicates the algorithm used by the authors;
- Paradigm refers to the learning paradigm used:
- -
- Centralized training with decentralized execution (CTDE);
- -
- Fully decentralized (FD) with either local communication (FDLC), global communication (FDGC), or shared reward (FDSR). A combination of some or all the previous ones is also possible (e.g., FDLCSR or FDGCSR);
- No. of UAVs points out the number of UAVs considered in the experiments;
- Collision avoidance is specified by a flag value (either a check mark or a cross) indicating whether collision avoidance is taken into account;
- Action space is associated with a categorical value, i.e., it can be specified by discrete (D), continuous (C), or hybrid (H) in order to indicate the value type of the considered action space. The type of action space is not indicated whenever the authors do not clearly define it or not smoothly inferrable (a cross will be present in this particular case);
- State space: as for the action space, but here, it is referred to as the state space;
- 3D is a flag value indicating if the UAVs can move in a three-dimensional space or not (i.e., only 2D);
- UAV dynamic model shows whether a UAV dynamic model is used (a check mark will be present) or not (a cross will be reported even if the UAV dynamic model is either not specified or not clearly inferable). The dynamic model must include low-level control inputs such as forces and/or torques and, thus, take into account also the mass of the UAVs. All the works using a simulator provided with realistic UAVs models, e.g., AirSim [22] and Gazebo [23], will be considered as solutions that include the UAV dynamic model by default. This feature does not apply to any studies using the dynamic model of a material point, even when including the forces and/or torques applied on the UAVs’ center of mass;
- Propulsion energy consumption is specified by a flag value (either a check mark or a cross), indicating whether the energy consumption due to the flight phase is considered or not.
- i-j points out that a number of UAVs between i and j (it could also include all the integer numbers among them) is used for the considered case;
- i, j, k,… indicates instead that a number of UAVs respectively and exactly equal to i, j, k,… is tested for the specific considered case.
4.1. Coverage

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Algorithm | Par. | No. of UAVs | Col. Av. | Prop. Eg. | Action Space | State Space | 3D | UAV Dyn. | PoI Model |
|---|---|---|---|---|---|---|---|---|---|---|
| [24] | EDICS | CTDE | 2–5 | ✓ | ✓ | C | H | X | X | X |
| [27] | DDPG | FDGCSR | 3–8 | X | ✓ | C | C | X | X | X |
| [26] | MADDPG | CTDE | 3, 4 | ✓ | ✓ | C | H | X | X | X |
| [28] | PPO | FDSR | 3, 4 | X | ✓ | D | C | X | X | ✓ |
| [29] | HGAT | FDLC | 10, 20, 30, 40 | X | ✓ | D | C | X | X | X |
| [30] | SBG-AC | FDSR | 3–9 | ✓ | ✓ | D | C | ✓ | X | X |
| [25] | DRL-eFresh | CTDE | up to 50 | ✓ | ✓ | C | H | X | X | X |
| [31] | MFTRPO | FDLC | 5–10 | X | ✓ | C | H | X | X | X |
| [32] | SDQN | CTDE | 10 | X | X | D | D | X | X | X |
4.2. Adversarial Search and Game
4.3. Computation Offloading
4.4. Communication
4.5. Target-Driven Navigation
4.5.1. Target Tracking
4.5.2. Target Reaching
5. Discussion
5.1. Technical Considerations
- Observation delay. Some observations can be delayed (e.g., [86]), and this may occur in real multi-UAV systems either for sensing or communication reasons;
- Action delay. In multi-UAV applications, some actions could take some time before being accomplished, resulting in a system affected by delayed actions [87].
- DDPG and PPO are the most used policy-based algorithms;
- The most used value-based algorithm is DQN;
- MADDPG, which is off policy and mainly associated with a continuous action space, is instead the unique algorithm used in all the macro multi-UAV applications;
- The most used techniques combined with DRL methods are the others, namely all methods varying the reward and/or gradient sharing and processing, and more generally not included in all the other additional techniques specified and shown in Figure 4;

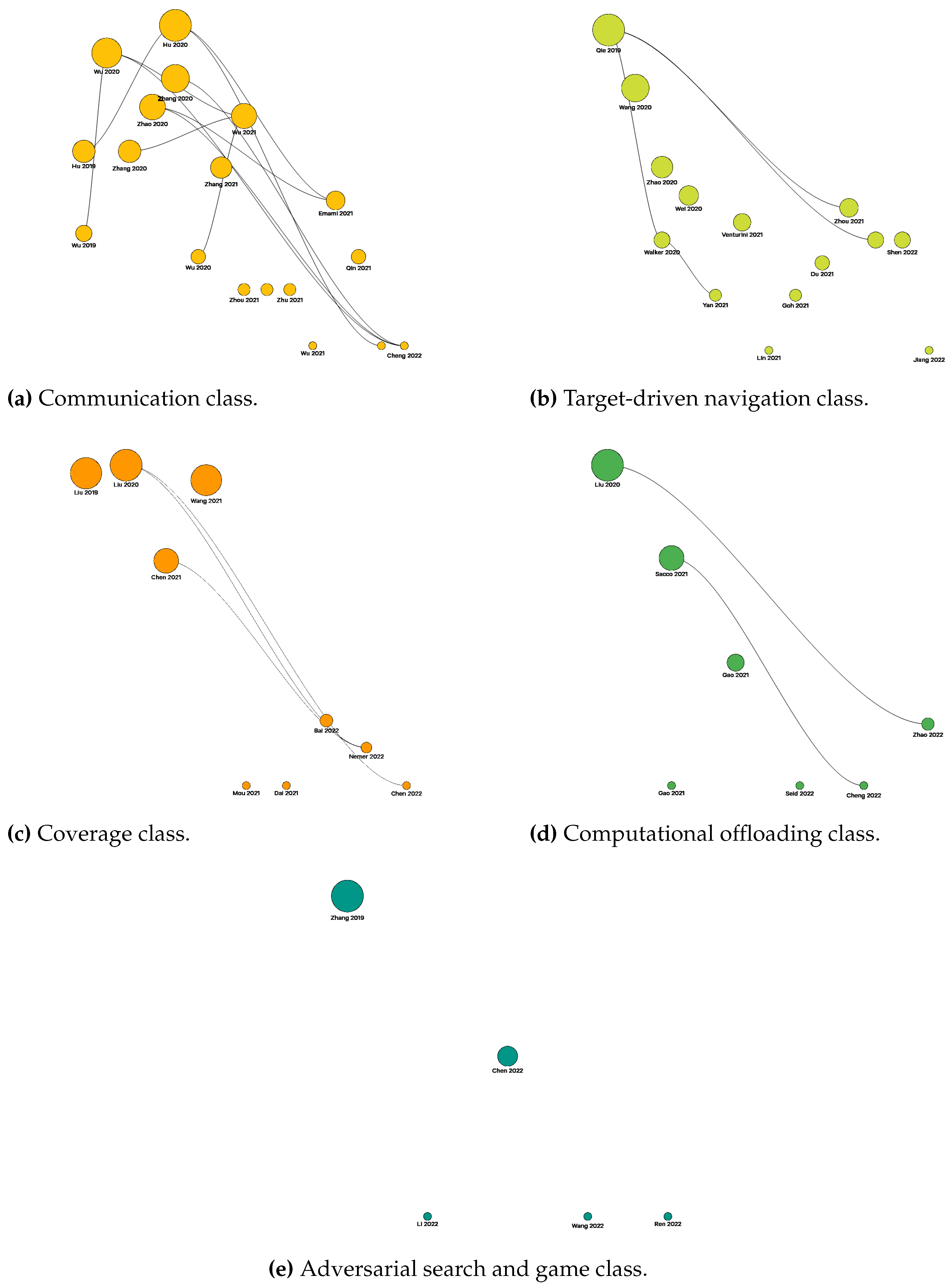
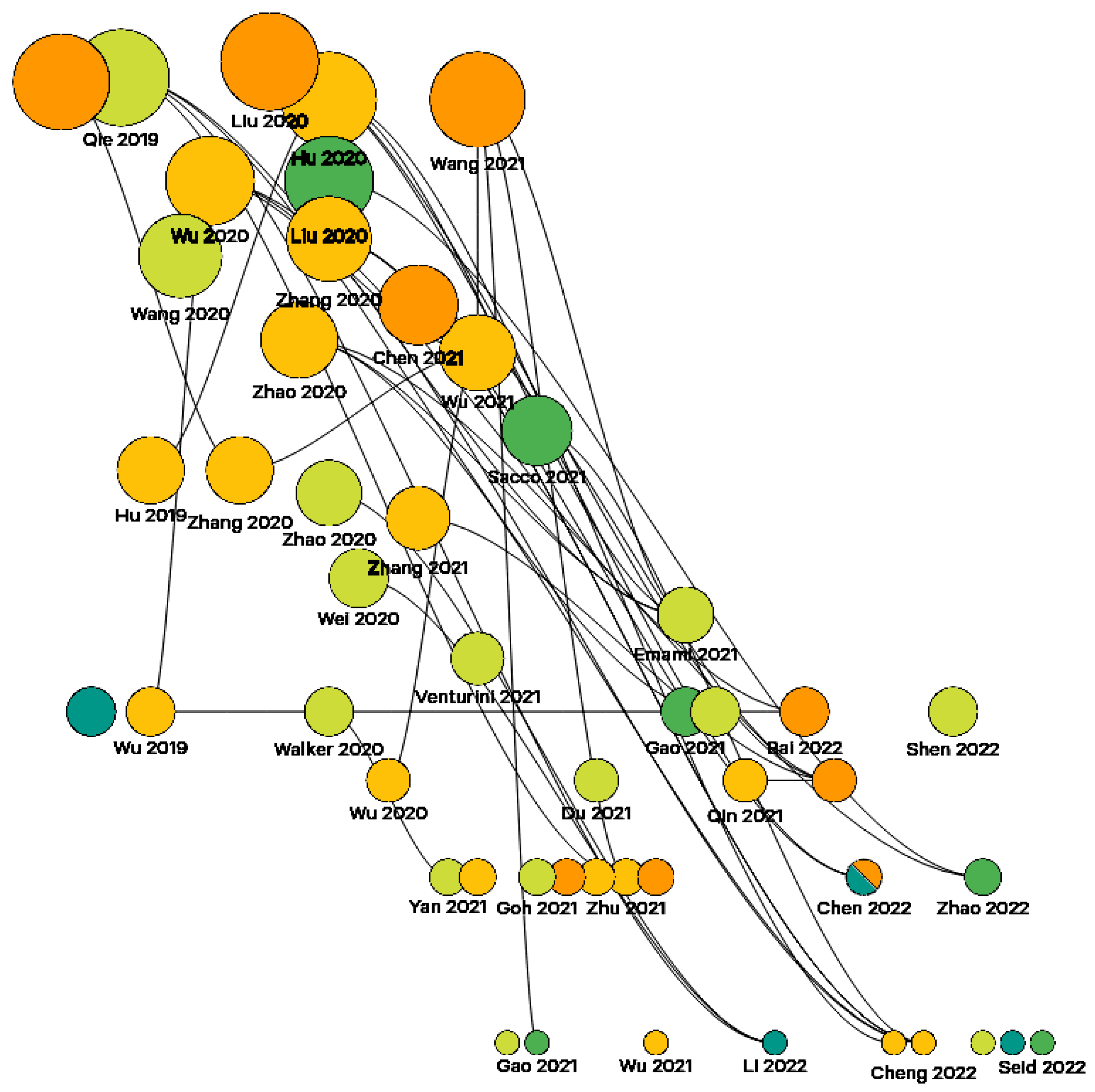
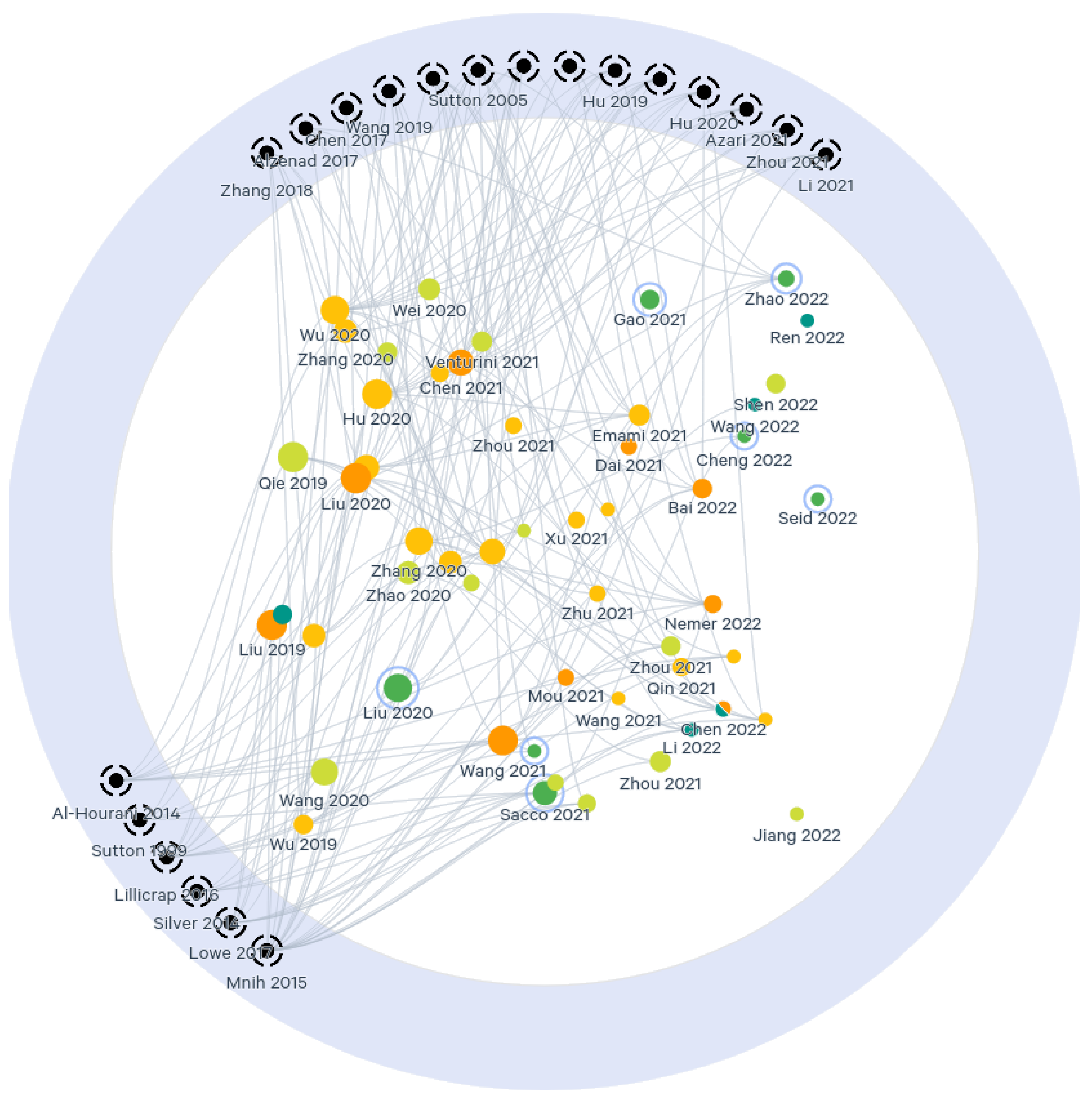
5.2. Driving Works and Links Analysis
5.3. General Considerations on Current and Future Developments
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| Algorithms | |
| CA2C | Compound-Action Actor–Critic |
| CAA-MADDPG | Continuous Action Attention Multi-Agent Deep Deterministic Policy Gradient |
| COM-MADDPG | Communication Multi-Agent Deep Deterministic Policy Gradient |
| D3QN | Dueling Double Deep Q-Network |
| DDPG | Deep Deterministic Policy Gradient |
| DHDRL | Decomposed Heterogeneous Deep Reinforcement Learning |
| DQL | Deep Q-Learning |
| DQN | Deep Q-Network |
| DRL | Deep Reinforcement Learning |
| DRQN | Deep Recurrent Q-Network |
| De-MADDPG | Decomposed MADDPG |
| FNN | Feedforward Neural Network |
| GA | Genetic Algorithm |
| HGAT | Hierarchical Graph Attention |
| MAAC-R | Reciprocal Reward Multi-Agent Actor–Critic |
| MADDPG | Multi-Agent Deep Deterministic Policy Gradient |
| MADRL-SA | Multi-UAV Deep Reinforcement Learning-Based Scheduling Algorithm |
| MAHDRL | Multi-Agent Hybrid Deep Reinforcement Learning |
| MAJPPO | Multi-Agent Joint Proximal Policy Optimization |
| MARL AC | Multi-Agent Reinforcement Learning Actor–Critic |
| MASAC | Multi-Agent Soft Actor–Critic |
| MATD3 | Multi-Agent Twin Delayed Deep Deterministic Policy Gradient |
| MAUC | Multi-Agent UAV Control |
| MFTRPO | Mean-Field Trust Region Policy Optimization |
| PPO | Proximal Policy Optimization |
| RDDPG | Recurrent Deep Deterministic Policy Gradient |
| RL | Reinforcement Learning |
| RRT | Rapidly Exploring Random Tree |
| SGB-AC | State-Based Game with Actor–Critic |
| STAPP | Simultaneous Target Assignment and Path Planning |
| TRPO | Trust Region Policy Optimization |
| WMFAC | Weighted Mean Field Actor–Critic |
| WMFQ | Weighted Mean Field Q-learning |
| cDQN | Constrained Deep Q-Network |
| Paradigms | |
| CTDE | Centralized Training with Decentralized Execution |
| FD | Fully Decentralized |
| GC | Global Communication |
| LC | Local Communication |
| PS | Parameter Sharing |
| SR | Shared Reward |
| RL Terminology and Domain-Dependent Terms | |
| Action Sp./Act Sp. | Action Space |
| Alg. | Algorithm |
| BS | Base Station |
| CNN | Convolutional Neural Network |
| Col. Av. | Collision Avoidance |
| Eg | Energy |
| FOMDP | Fully Observable Markovian Decision Process |
| HJB/FBP | Hamilton–Jacobi–Bellman/Fokker–Planck–Kolmogorov |
| LSTM | Long Short-Term Memory |
| MARL | Multi-Agent Reinforcement Learning |
| MCS | Mobile Crowd Sensing |
| MDP | Markovian Decision Process |
| MEC | Mobile Edge Computing |
| MFE | Mean Field Equilibrium |
| MFG | Mean Field Game |
| MOMDP | Mixed Observability Markovian Decision Process |
| MT | Mobile Terminal |
| POMDP | Partially Observable Markovian Decision Process |
| Par. | Paradigm |
| PoI | Points of Interest |
| Prop. Eg | Propulsion Energy |
| QoS | Quality of Service |
| RNN | Recurrent Neural Network |
| Ref. | Reference |
| SARL | Single-Agent Reinforcement Learning |
| SPDE | Stochastic Partial Differential Equations |
| State Sp./St. Sp. | State Space |
| U2D | UAV-to-Device |
| U2U | UAV-to-UAV |
| UAV | Unmanned Aerial Vehicle |
| UAV Dyn. | UAV Dynamic model |
| UE | User Equipment |
References
- Akhloufi, M.A.; Couturier, A.; Castro, N.A. Unmanned Aerial Vehicles for Wildland Fires: Sensing, Perception, Cooperation and Assistance. Drones 2021, 5, 15. [Google Scholar] [CrossRef]
- Hayat, S.; Yanmaz, E.; Brown, T.X.; Bettstetter, C. Multi-objective UAV path planning for search and rescue. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 5569–5574. [Google Scholar] [CrossRef]
- Aurambout Jean-Philippe, G.K.C.B. Last mile delivery by drones: An estimation of viable market potential and access to citizens across European cities. Eur. Transp. Res. Rev. 2019, 11, 30. [Google Scholar] [CrossRef]
- Salhaoui, M.; Guerrero-González, A.; Arioua, M.; Ortiz, F.J.; El Oualkadi, A.; Torregrosa, C.L. Smart Industrial IoT Monitoring and Control System Based on UAV and Cloud Computing Applied to a Concrete Plant. Sensors 2019, 19, 3316. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C.; He, H.; Yang, P.; Lyu, F.; Wu, W.; Cheng, N.; Shen, X. Deep RL-based Trajectory Planning for AoI Minimization in UAV-assisted IoT. In Proceedings of the 2019 11th International Conference on Wireless Communications and Signal Processing (WCSP), Xi’an, China, 23–25 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Chakareski, J. UAV-IoT for Next Generation Virtual Reality. IEEE Trans. Image Process. 2019, 28, 5977–5990. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Berner, C.; Brockman, G.; Chan, B.; Cheung,, V.; Dębiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with Large Scale Deep Reinforcement Learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- OpenAI; Akkaya, I.; Andrychowicz, M.; Chociej, M.; Litwin, M.; McGrew, B.; Petron, A.; Paino, A.; Plappert, M.; Powell, G.; et al. Solving Rubik’s Cube with a Robot Hand. arXiv 2019, arXiv:1910.07113. [Google Scholar]
- Bithas, P.S.; Michailidis, E.T.; Nomikos, N.; Vouyioukas, D.; Kanatas, A.G. A Survey on Machine-Learning Techniques for UAV-Based Communications. Sensors 2019, 19, 5170. [Google Scholar] [CrossRef]
- Ben Aissa, S.; Ben Letaifa, A. UAV Communications with Machine Learning: Challenges, Applications and Open Issues. Arab. J. Sci. Eng. 2022, 47, 1559–1579. [Google Scholar] [CrossRef]
- Puente-Castro, A.; Rivero, D.; Pazos, A.; Fernandez-Blanco, E. A review of artificial intelligence applied to path planning in UAV swarms. Neural Comput. Appl. 2022, 34, 153–170. [Google Scholar] [CrossRef]
- Pakrooh, R.; Bohlooli, A. A Survey on Unmanned Aerial Vehicles-Assisted Internet of Things: A Service-Oriented Classification. Wirel. Pers. Commun. 2021, 119, 1541–1575. [Google Scholar] [CrossRef]
- Azar, A.T.; Koubaa, A.; Ali Mohamed, N.; Ibrahim, H.A.; Ibrahim, Z.F.; Kazim, M.; Ammar, A.; Benjdira, B.; Khamis, A.M.; Hameed, I.A.; et al. Drone Deep Reinforcement Learning: A Review. Electronics 2021, 10, 999. [Google Scholar] [CrossRef]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction. IEEE Trans. Neural Netw. 1998, 9, 1054. [Google Scholar] [CrossRef]
- Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. Mach. Learn. Proc. 1994, 157–163. [Google Scholar] [CrossRef]
- Gronauer, S.; Diepold, K. Multi-agent deep reinforcement learning: A survey. Artif. Intell. Rev. 2021, 55, 895–943. [Google Scholar] [CrossRef]
- DrawExpress Lite [Gesture-Recognition Diagram Application]. Available online: https://drawexpress.com/ (accessed on 27 February 2023).
- Karur, K.; Sharma, N.; Dharmatti, C.; Siegel, J.E. A Survey of Path Planning Algorithms for Mobile Robots. Vehicles 2021, 3, 448–468. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. arXiv 2017, arXiv:1705.05065. [Google Scholar]
- Koenig, N.; Howard, A. Design and use paradigms for Gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No.04CH37566), Sendai, Japan, 28 September–2 October 2004; Volume 3, pp. 2149–2154. [Google Scholar] [CrossRef]
- Liu, C.H.; Chen, Z.; Zhan, Y. Energy-Efficient Distributed Mobile Crowd Sensing: A Deep Learning Approach. IEEE J. Sel. Areas Commun. 2019, 37, 1262–1276. [Google Scholar] [CrossRef]
- Dai, Z.; Liu, C.H.; Han, R.; Wang, G.; Leung, K.; Tang, J. Delay-Sensitive Energy-Efficient UAV Crowdsensing by Deep Reinforcement Learning. IEEE Trans. Mob. Comput. 2021, 1233, 1–15. [Google Scholar] [CrossRef]
- Wang, L.; Wang, K.; Pan, C.; Xu, W.; Aslam, N.; Hanzo, L. Multi-Agent Deep Reinforcement Learning-Based Trajectory Planning for Multi-UAV Assisted Mobile Edge Computing. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 73–84. [Google Scholar] [CrossRef]
- Liu, C.H.; Ma, X.; Gao, X.; Tang, J. Distributed Energy-Efficient Multi-UAV Navigation for Long-Term Communication Coverage by Deep Reinforcement Learning. IEEE Trans. Mob. Comput. 2020, 19, 1274–1285. [Google Scholar] [CrossRef]
- Bai, C.; Yan, P.; Yu, X.; Guo, J. Learning-based resilience guarantee for multi-UAV collaborative QoS management. Pattern Recognit. 2022, 122, 108166. [Google Scholar] [CrossRef]
- Chen, Y.; Song, G.; Ye, Z.; Jiang, X. Scalable and Transferable Reinforcement Learning for Multi-Agent Mixed Cooperative-Competitive Environments Based on Hierarchical Graph Attention. Entropy 2022, 24, 563. [Google Scholar] [CrossRef] [PubMed]
- Nemer, I.A.; Sheltami, T.R.; Belhaiza, S.; Mahmoud, A.S. Energy-Efficient UAV Movement Control for Fair Communication Coverage: A Deep Reinforcement Learning Approach. Sensors 2022, 22, 1919. [Google Scholar] [CrossRef] [PubMed]
- Chen, D.; Qi, Q.; Zhuang, Z.; Wang, J.; Liao, J.; Han, Z. Mean Field Deep Reinforcement Learning for Fair and Efficient UAV Control. IEEE Internet Things J. 2021, 8, 813–828. [Google Scholar] [CrossRef]
- Mou, Z.; Zhang, Y.; Gao, F.; Wang, H.; Zhang, T.; Han, Z. Three-Dimensional Area Coverage with UAV Swarm based on Deep Reinforcement Learning. IEEE Int. Conf. Commun. 2021, 39, 3160–3176. [Google Scholar] [CrossRef]
- Liu, C.H.; Chen, Z.; Tang, J.; Xu, J.; Piao, C. Energy-efficient UAV control for effective and fair communication coverage: A deep reinforcement learning approach. IEEE J. Sel. Areas Commun. 2018, 36, 2059–2070. [Google Scholar] [CrossRef]
- Li, S.; Jia, Y.; Yang, F.; Qin, Q.; Gao, H.; Zhou, Y. Collaborative Decision-Making Method for Multi-UAV Based on Multiagent Reinforcement Learning. IEEE Access 2022, 10, 91385–91396. [Google Scholar] [CrossRef]
- Ren, Z.; Zhang, D.; Tang, S.; Xiong, W.; Yang, S.H. Cooperative maneuver decision making for multi-UAV air combat based on incomplete information dynamic game. Def. Technol. 2022. [CrossRef]
- Wang, B.; Li, S.; Gao, X.; Xie, T. Weighted mean field reinforcement learning for large-scale UAV swarm confrontation. Appl. Intell. 2022, 1–16. [Google Scholar] [CrossRef]
- Zhang, G.; Li, Y.; Xu, X.; Dai, H. Multiagent reinforcement learning for swarm confrontation environments. In Proceedings of the 12th International Conference, ICIRA 2019, Shenyang, China, 8–11 August 2019; Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Springer: Berlin/Heidelberg, Germany, 2019; Volume 11742 LNAI, pp. 533–543. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Zhao, N.; Ye, Z.; Pei, Y.; Liang, Y.C.; Niyato, D. Multi-Agent Deep Reinforcement Learning for Task Offloading in UAV-Assisted Mobile Edge Computing. IEEE Trans. Wirel. Commun. 2022, 21, 6949–6960. [Google Scholar] [CrossRef]
- Liu, Y.; Xie, S.; Zhang, Y. Cooperative Offloading and Resource Management for UAV-Enabled Mobile Edge Computing in Power IoT System. IEEE Trans. Veh. Technol. 2020, 69, 12229–12239. [Google Scholar] [CrossRef]
- Cheng, Z.; Liwang, M.; Chen, N.; Huang, L.; Du, X.; Guizani, M. Deep reinforcement learning-based joint task and energy offloading in UAV-aided 6G intelligent edge networks. Comput. Commun. 2022, 192, 234–244. [Google Scholar] [CrossRef]
- Sacco, A.; Esposito, F.; Marchetto, G.; Montuschi, P. Sustainable Task Offloading in UAV Networks via Multi-Agent Reinforcement Learning. IEEE Trans. Veh. Technol. 2021, 70, 5003–5015. [Google Scholar] [CrossRef]
- Gao, A.; Wang, Q.; Liang, W.; Ding, Z. Game Combined Multi-Agent Reinforcement Learning Approach for UAV Assisted Offloading. IEEE Trans. Veh. Technol. 2021, 70, 12888–12901. [Google Scholar] [CrossRef]
- Seid, A.M.; Lu, J.; Abishu, H.N.; Ayall, T.A. Blockchain-Enabled Task Offloading With Energy Harvesting in Multi-UAV-Assisted IoT Networks: A Multi-Agent DRL Approach. IEEE J. Sel. Areas Commun. 2022, 40, 3517–3532. [Google Scholar] [CrossRef]
- Gao, A.; Wang, Q.; Chen, K.; Liang, W. Multi-UAV Assisted Offloading Optimization: A Game Combined Reinforcement Learning Approach. IEEE Commun. Lett. 2021, 25, 2629–2633. [Google Scholar] [CrossRef]
- Qin, Z.; Liu, Z.; Han, G.; Lin, C.; Guo, L.; Xie, L. Distributed UAV-BSs Trajectory Optimization for User-Level Fair Communication Service With Multi-Agent Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2021, 70, 12290–12301. [Google Scholar] [CrossRef]
- Xu, W.; Lei, H.; Shang, J. Joint topology construction and power adjustment for UAV networks: A deep reinforcement learning based approach. China Commun. 2021, 18, 265–283. [Google Scholar] [CrossRef]
- Cheng, Z.; Liwang, M.; Chen, N.; Huang, L.; Guizani, N.; Du, X. Learning-based user association and dynamic resource allocation in multi-connectivity enabled unmanned aerial vehicle networks. Digit. Commun. Netw. 2022. [Google Scholar] [CrossRef]
- Zhu, Z.; Xie, N.; Zong, K.; Chen, L. Building a Connected Communication Network for UAV Clusters Using DE-MADDPG. Symmetry 2021, 13, 1537. [Google Scholar] [CrossRef]
- Zhou, Y.; Ma, X.; Hu, S.; Zhou, D.; Cheng, N.; Lu, N. QoE-Driven Adaptive Deployment Strategy of Multi-UAV Networks Based on Hybrid Deep Reinforcement Learning. IEEE Internet Things J. 2022, 9, 5868–5881. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, Q.; Liu, X.; Liu, Y.; Chen, Y. Three-Dimension Trajectory Design for Multi-UAV Wireless Network with Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2021, 70, 600–612. [Google Scholar] [CrossRef]
- Zhao, N.; Liu, Z.; Cheng, Y. Multi-Agent Deep Reinforcement Learning for Trajectory Design and Power Allocation in Multi-UAV Networks. IEEE Access 2020, 8, 139670–139679. [Google Scholar] [CrossRef]
- Wu, F.; Zhang, H.; Wu, J.; Song, L. Cellular UAV-to-Device Communications: Trajectory Design and Mode Selection by Multi-Agent Deep Reinforcement Learning. IEEE Trans. Commun. 2020, 68, 4175–4189. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, H.; Song, L.; Schober, R.; Poor, H.V. Cooperative Internet of UAVs: Distributed Trajectory Design by Multi-Agent Deep Reinforcement Learning. IEEE Trans. Commun. 2020, 68, 6807–6821. [Google Scholar] [CrossRef]
- Emami, Y.; Wei, B.; Li, K.; Ni, W.; Tovar, E. Joint Communication Scheduling and Velocity Control in Multi-UAV-Assisted Sensor Networks: A Deep Reinforcement Learning Approach. IEEE Trans. Veh. Technol. 2021, 70, 10986–10998. [Google Scholar] [CrossRef]
- Wu, F.; Zhang, H.; Wu, J.; Han, Z.; Poor, H.V.; Song, L. UAV-to-Device Underlay Communications: Age of Information Minimization by Multi-Agent Deep Reinforcement Learning. IEEE Trans. Commun. 2021, 69, 4461–4475. [Google Scholar] [CrossRef]
- Chen, B.; Liu, D.; Hanzo, L. Decentralized Trajectory and Power Control Based on Multi-Agent Deep Reinforcement Learning in UAV Networks. IEEE Int. Conf. Commun. 2022, 3983–3988. [Google Scholar] [CrossRef]
- Wang, W.; Lin, Y. Trajectory Design and Bandwidth Assignment for UAVs-enabled Communication Network with Multi - Agent Deep Reinforcement Learning. In Proceedings of the 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall), Norman, OK, USA, 27–30 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Zhou, Y.; Jin, Z.; Shi, H.; Wang, Z.; Lu, N.; Liu, F. UAV-Assisted Fair Communication for Mobile Networks: A Multi-Agent Deep Reinforcement Learning Approach. Remote Sens. 2022, 14, 5662. [Google Scholar] [CrossRef]
- Zhang, Y.; Mou, Z.; Gao, F.; Jiang, J.; Ding, R.; Han, Z. UAV-Enabled Secure Communications by Multi-Agent Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2020, 69, 11599–11611. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Hu, S.; Zhou, D.; Zhou, Y.; Lu, N. Adaptive Deployment of UAV-Aided Networks Based on Hybrid Deep Reinforcement Learning. In Proceedings of the 2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall), Victoria, BC, Canada, 18 November–16 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Wu, J.; Cheng, X.; Ma, X.; Li, W.; Zhou, Y. A Time-Efficient and Attention-Aware Deployment Strategy for UAV Networks Driven by Deep Reinforcement Learning. In Proceedings of the 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall), Norman, OK, USA, 27–30 September 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, R.; Lim, T.J. Wireless communications with unmanned aerial vehicles: Opportunities and challenges. IEEE Commun. Mag. 2016, 54, 36–42. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, H.; Bian, K.; Song, L.; Han, Z. Distributed trajectory design for cooperative internet of UAVs using deep reinforcement learning. In Proceedings of the 2019 IEEE Global Communications Conference, GLOBECOM 2019-Proceedings, Waikoloa, HI, USA, 9–13 December 2019. [Google Scholar] [CrossRef]
- Wu, F.; Zhang, H.; Wu, J.; Song, L.; Han, Z.; Poor, H.V. AoI Minimization for UAV-to-Device Underlay Communication by Multi-agent Deep Reinforcement Learning. In Proceedings of the GLOBECOM 2020-2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Wu, F.; Zhang, H.; Wu, J.; Song, L. Trajectory Design for Overlay UAV-to-Device Communications by Deep Reinforcement Learning. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhuang, Z.; Gao, F.; Wang, J.; Han, Z. Multi-Agent Deep Reinforcement Learning for Secure UAV Communications. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Republic of Korea, 25–28 May 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Goh, K.C.; Ng, R.B.; Wong, Y.K.; Ho, N.J.; Chua, M.C. Aerial filming with synchronized drones using reinforcement learning Multimedia Tools and Applications. Multimed. Tools Appl. 2021, 80, 18125–18150. [Google Scholar] [CrossRef]
- Du, W.; Guo, T.; Chen, J.; Li, B.; Zhu, G.; Cao, X. Cooperative pursuit of unauthorized UAVs in urban airspace via Multi-agent reinforcement learning. Transp. Res. Part Emerg. Technol. 2021, 128, 103122. [Google Scholar] [CrossRef]
- ZHOU, W.; LI, J.; LIU, Z.; SHEN, L. Improving multi-target cooperative tracking guidance for UAV swarms using multi-agent reinforcement learning. Chin. J. Aeronaut. 2022, 35, 100–112. [Google Scholar] [CrossRef]
- Yan, P.; Jia, T.; Bai, C. Searching and Tracking an Unknown Number of Targets: A Learning-Based Method Enhanced with Maps Merging. Sensors 2021, 21, 1076. [Google Scholar] [CrossRef]
- Jiang, L.; Wei, R.; Wang, D. UAVs rounding up inspired by communication multi-agent depth deterministic policy gradient. Appl. Intell. 2022. [Google Scholar] [CrossRef]
- Wei, X.; Yang, L.; Cao, G.; Lu, T.; Wang, B. Recurrent MADDPG for Object Detection and Assignment in Combat Tasks. IEEE Access 2020, 8, 163334–163343. [Google Scholar] [CrossRef]
- Zhou, W.; Liu, Z.; Li, J.; Xu, X.; Shen, L. Multi-target tracking for unmanned aerial vehicle swarms using deep reinforcement learning. Neurocomputing 2021, 466, 285–297. [Google Scholar] [CrossRef]
- Qie, H.; Shi, D.; Shen, T.; Xu, X.; Li, Y.; Wang, L. Joint Optimization of Multi-UAV Target Assignment and Path Planning Based on Multi-Agent Reinforcement Learning. IEEE Access 2019, 7, 146264–146272. [Google Scholar] [CrossRef]
- Zhao, W.; Chu, H.; Miao, X.; Guo, L.; Shen, H.; Zhu, C.; Zhang, F.; Liang, D. Research on the multiagent joint proximal policy optimization algorithm controlling cooperative fixed-wing uav obstacle avoidance. Sensors 2020, 20, 4546. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.S.; Chiu, H.T.; Gau, R.H. Decentralized Planning-Assisted Deep Reinforcement Learning for Collision and Obstacle Avoidance in UAV Networks. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Helsinki, Finland, 25–28 April 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Shen, G.; Lei, L.; Li, Z.; Cai, S.; Zhang, L.; Cao, P.; Liu, X. Deep Reinforcement Learning for Flocking Motion of Multi-UAV Systems: Learn From a Digital Twin. IEEE Internet Things J. 2022, 9, 11141–11153. [Google Scholar] [CrossRef]
- Wang, D.; Fan, T.; Han, T.; Pan, J. A Two-Stage Reinforcement Learning Approach for Multi-UAV Collision Avoidance under Imperfect Sensing. IEEE Robot. Autom. Lett. 2020, 5, 3098–3105. [Google Scholar] [CrossRef]
- Venturini, F.; Mason, F.; Pase, F.; Chiariotti, F.; Testolin, A.; Zanella, A.; Zorzi, M. Distributed Reinforcement Learning for Flexible and Efficient UAV Swarm Control. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 955–969. [Google Scholar] [CrossRef]
- Walker, O.; Vanegas, F.; Gonzalez, F. A Framework for Multi-Agent UAV Exploration and Target-Finding in GPS-Denied and Partially Observable Environments. Sensors 2020, 20, 4739. [Google Scholar] [CrossRef] [PubMed]
- Katsikopoulos, K.; Engelbrecht, S. Markov decision processes with delays and asynchronous cost collection. IEEE Trans. Autom. Control. 2003, 48, 568–574. [Google Scholar] [CrossRef]
- Arjona-Medina, J.A.; Gillhofer, M.; Widrich, M.; Unterthiner, T.; Hochreiter, S. RUDDER: Return Decomposition for Delayed Rewards. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Kim, K. Multi-Agent Deep Q Network to Enhance the Reinforcement Learning for Delayed Reward System. Appl. Sci. 2022, 12, 3520. [Google Scholar] [CrossRef]
- Agarwal, M.; Aggarwal, V. Blind Decision Making: Reinforcement Learning with Delayed Observations. Proc. Int. Conf. Autom. Plan. Sched. 2021, 31, 2–6. [Google Scholar] [CrossRef]
- Chen, B.; Xu, M.; Li, L.; Zhao, D. Delay-aware model-based reinforcement learning for continuous control. Neurocomputing 2021, 450, 119–128. [Google Scholar] [CrossRef]
- Patrizi, N.; Fragkos, G.; Tsiropoulou, E.E.; Papavassiliou, S. Contract-Theoretic Resource Control in Wireless Powered Communication Public Safety Systems. In Proceedings of the GLOBECOM 2020-2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, Y.; Mou, Z.; Gao, F.; Xing, L.; Jiang, J.; Han, Z. Hierarchical Deep Reinforcement Learning for Backscattering Data Collection With Multiple UAVs. IEEE Internet Things J. 2021, 8, 3786–3800. [Google Scholar] [CrossRef]
- Litmaps [Computer Software]. 2023. Available online: https://www.litmaps.com/spotlight-articles/litmaps-2023-redesign (accessed on 27 February 2023).
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016-Conference Track Proceedings, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. Adv. Neural Inf. Process. Syst. 2017, 30, 6380–6391. [Google Scholar]
- Zhang, S.; Zhang, H.; He, Q.; Bian, K.; Song, L. Joint Trajectory and Power Optimization for UAV Relay Networks. IEEE Commun. Lett. 2018, 22, 161–164. [Google Scholar] [CrossRef]
- Zhang, H.; Song, L.; Han, Z.; Poor, H.V. Cooperation Techniques for a Cellular Internet of Unmanned Aerial Vehicles. IEEE Wirel. Commun. 2019, 26, 167–173. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, H.; Song, L. Reinforcement Learning for Decentralized Trajectory Design in Cellular UAV Networks with Sense-and-Send Protocol. IEEE Internet Things J. 2019, 6, 6177–6189. [Google Scholar] [CrossRef]






| Ref. | Algorithm | Par. | No. of UAVs | Act. Space | St. Space | 3D | UAV Dyn. | Col. Av. | Prop. Eg | Att. Mod. | Learn. Enem. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| [34] | MADDPG | CTDE | 4 | D | D | ✓ | X | X | X | ✓ | X |
| [35] | MADDPG | CTDE | 2, 3 | D | X | ✓ | X | X | X | ✓ | ✓ |
| [36] | WMFQ+ WMFAC | FDLC | 25, 50, 100 | D | D | X | X | X | X | ✓ | ✓ |
| [29] | HGAT | FDLC | 10, 20, 30, 4 | D | D | X | X | X | X | X | ✓ |
| [37] | MADDPG | CTDE | 3 | C | C | X | X | X | X | ✓ | ✓ |
| Ref. | Algorithm | Par. | No. of UAVs | Col. Av. | Act. Space | State Space | 3D | UAV Dyn. | Prop. Eg | OFLD Eg | OFLD | Trajs. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [39] | MATD3 | CTDE | 2, 3 | ✓ | C | C | ✓ | X | X | ✓ | ✓ | L |
| [40] | DQN | FDLC | 1–10 | X | C | C | X | X | X | X | X | F |
| [41] | MASAC | CTDE | 3–6 | X | C | C | X | X | ✓ | ✓ | ✓ | D |
| [42] | MARL AC | FDGC | 50, 100, 150, 200 | X | D | C | X | X | X | ✓ | ✓ | F |
| [43] | MADDPG | CTDE | 2, 3, 9 | ✓ | C | H | ✓ | X | ✓ | X | ✓ | L |
| [44] | MADDPG | CTDE | 1–6 | ✓ | C | H | ✓ | X | ✓ | X | ✓ | L |
| Ref. | Algorithm | Par. | No. of UAVs | Col. Av. | Act. Sp. | St. Sp. | 3D | UAV Dyn. | Prop. Eg | Com. Eg | U2U | U2D | Trajs. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [46] | MAUC | CTDE | 2–6 | ✓ | C | C | X | X | ✓ | X | X | ✓ | L |
| [47] | DHDRL | FDLC | 10, 15 | X | H | X | X | X | X | X | ✓ | ✓ | D |
| [48] | MAHDRL | CTDE | 3–7 | X | H | H | X | X | X | ✓ | X | ✓ | D |
| [49] | DE-MADDPG | CTDE | 8, 10, 12 | X | C | C | ✓ | X | X | X | ✓ | ✓ | L |
| [50] | HDRL | CTDE | 2–20 | ✓ | D | H | X | X | ✓ | X | X | ✓ | L |
| [51] | cDQN | FDGC | 3 | X | D | D | ✓ | X | X | X | ✓ | ✓ | L |
| [52] | MADDPG | FDGC | 1, 2, 3 | ✓ | C | D | ✓ | X | X | ✓ | X | ✓ | L |
| [53] | DQN | FDGC | 10 | X | D | D | X | X | X | X | X | ✓ | L |
| [54] | CA2C | FDGCSR | 2–6 | X | H | H | X | X | X | X | X | ✓ | L |
| [55] | MADRL-SA | FDLCSR | 2–10 | X | H | C | X | X | X | X | X | ✓ | D |
| [56] | DDPG | FDGC | 6, 8, 10, 12 | X | C | C | X | X | X | X | X | ✓ | L |
| [57] | DTPC | CTDE | 4 | ✓ | C | C | X | X | ✓ | ✓ | X | ✓ | L |
| [58] | MADRL-based | CTDE | 3 | ✓ | H | C | X | X | X | X | X | ✓ | L |
| [59] | UAFC | CTDE | 2, 3 | X | C | C | X | X | ✓ | ✓ | X | ✓ | L |
| [60] | CAA-MADDPG | CTDE | 3 | X | C | H | ✓ | X | X | X | X | ✓ | L |
| Ref. | Algorithm | Par. | No. of UAVs | Col. Av. | Action Space | State Space | 3D | UAV Dyn. | Prop. Eg | Multi-Target |
|---|---|---|---|---|---|---|---|---|---|---|
| [69] | DRQN-RDDPG | FDSR | 3 | ✓ | D | C | ✓ | ✓ | X | X |
| [70] | MAC | CTDE | 3 | ✓ | C | C | X | X | X | X |
| [71] | MAAC-R | FDLCSR | 5, 10, 20, 50, 100, 200, 1000 | X | D | C | X | X | X | ✓ |
| [72] | PPO | CTDE | 2, 5, 10, 15, 20 | X | D | H | X | X | X | ✓ |
| [73] | COM-MADDPG | CTDE | 3, 4 | ✓ | C | X | X | X | X | X |
| [74] | Fast-MARDPG | CTDE | 3, 4 | ✓ | C | C | X | X | X | ✓ |
| Ref. | Algorithm | Par. | No. of UAVs | Col. Av. | Action Space | State Space | 3D | UAV Dyn. | Prop. Eg | Multi-Target |
|---|---|---|---|---|---|---|---|---|---|---|
| [76] | STAPP | CTDE | 4, 5 | ✓ | X | X | ✓ | X | X | ✓ |
| [77] | MAJPPO | CTDE | 3 | ✓ | C | C | ✓ | ✓ | X | X |
| [80] | DDPG | FDLC | 10, 200 | ✓ | X | X | ✓ | ✓ | X | X |
| [82] | PPO | FDGC | 1–4 | ✓ | C | C | ✓ | ✓ | X | ✓ |
| [78] | MADDPG | CTDE | 3 | ✓ | D | C | X | X | X | ✓ |
| [79] | BCDDPG | CTDE | 6, 9, 12 | ✓ | C | C | X | X | X | X |
| [81] | DDQN | FDGC | 2, 3, 4 | ✓ | D | D | X | X | X | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frattolillo, F.; Brunori, D.; Iocchi, L. Scalable and Cooperative Deep Reinforcement Learning Approaches for Multi-UAV Systems: A Systematic Review. Drones 2023, 7, 236. https://doi.org/10.3390/drones7040236
Frattolillo F, Brunori D, Iocchi L. Scalable and Cooperative Deep Reinforcement Learning Approaches for Multi-UAV Systems: A Systematic Review. Drones. 2023; 7(4):236. https://doi.org/10.3390/drones7040236
Chicago/Turabian StyleFrattolillo, Francesco, Damiano Brunori, and Luca Iocchi. 2023. "Scalable and Cooperative Deep Reinforcement Learning Approaches for Multi-UAV Systems: A Systematic Review" Drones 7, no. 4: 236. https://doi.org/10.3390/drones7040236
APA StyleFrattolillo, F., Brunori, D., & Iocchi, L. (2023). Scalable and Cooperative Deep Reinforcement Learning Approaches for Multi-UAV Systems: A Systematic Review. Drones, 7(4), 236. https://doi.org/10.3390/drones7040236