
UAV Air Game Maneuver Decision-Making Using Dueling Double Deep Q Network with Expert Experience Storage Mechanism


Abstract
:1. Introduction
2. Air Game Environment Modeling
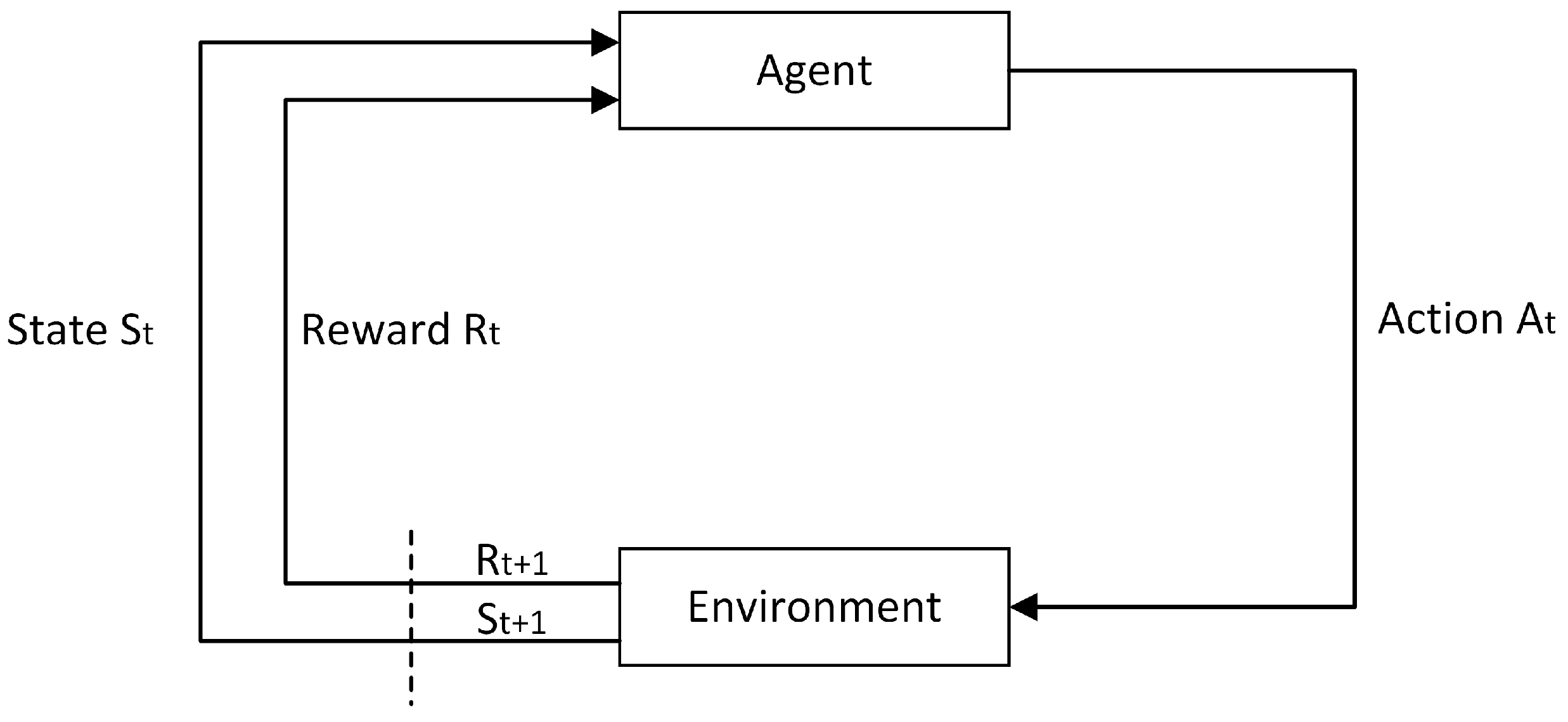
2.1. Markov Decision Process
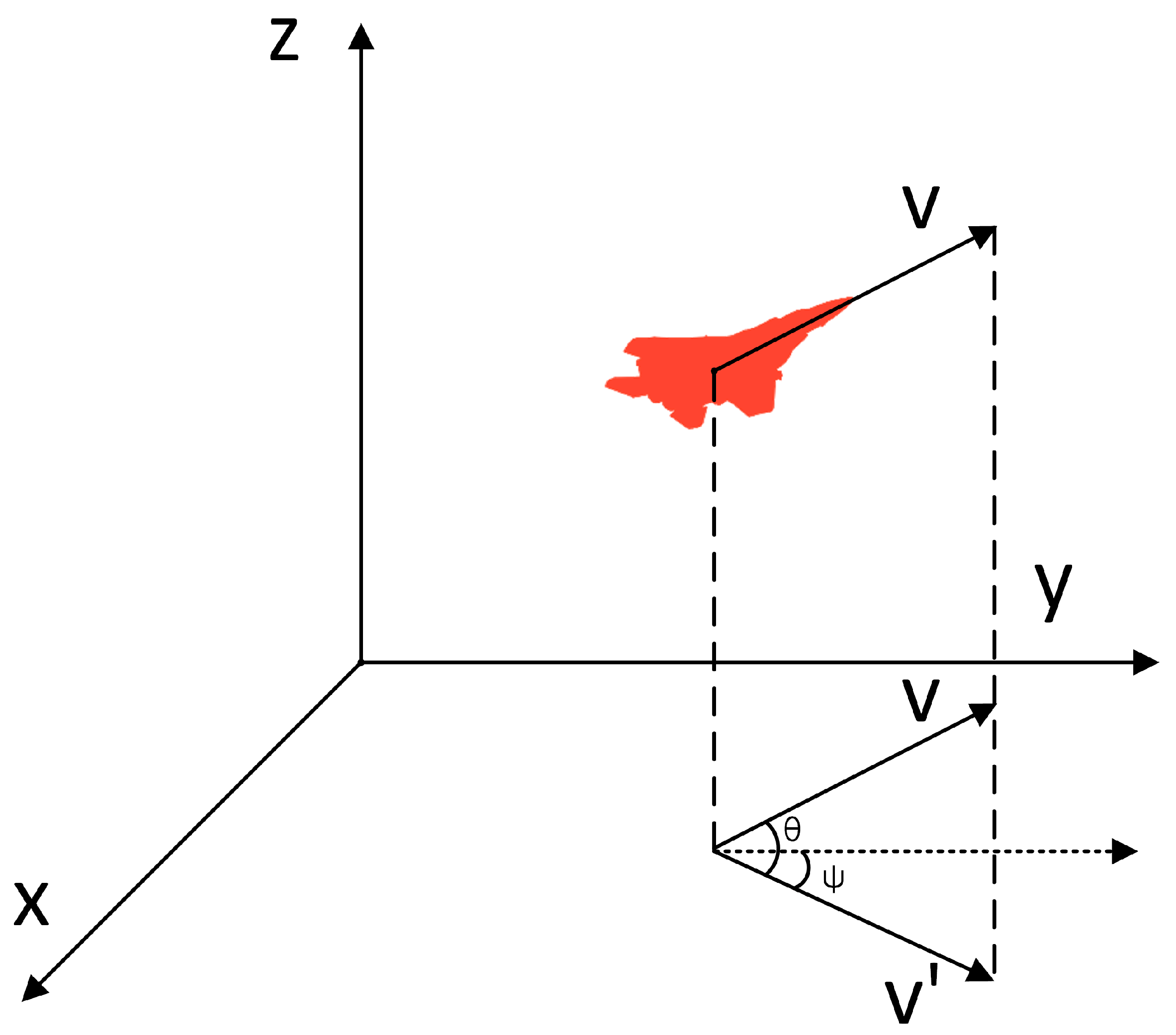
2.2. Aircraft Motion Modeling
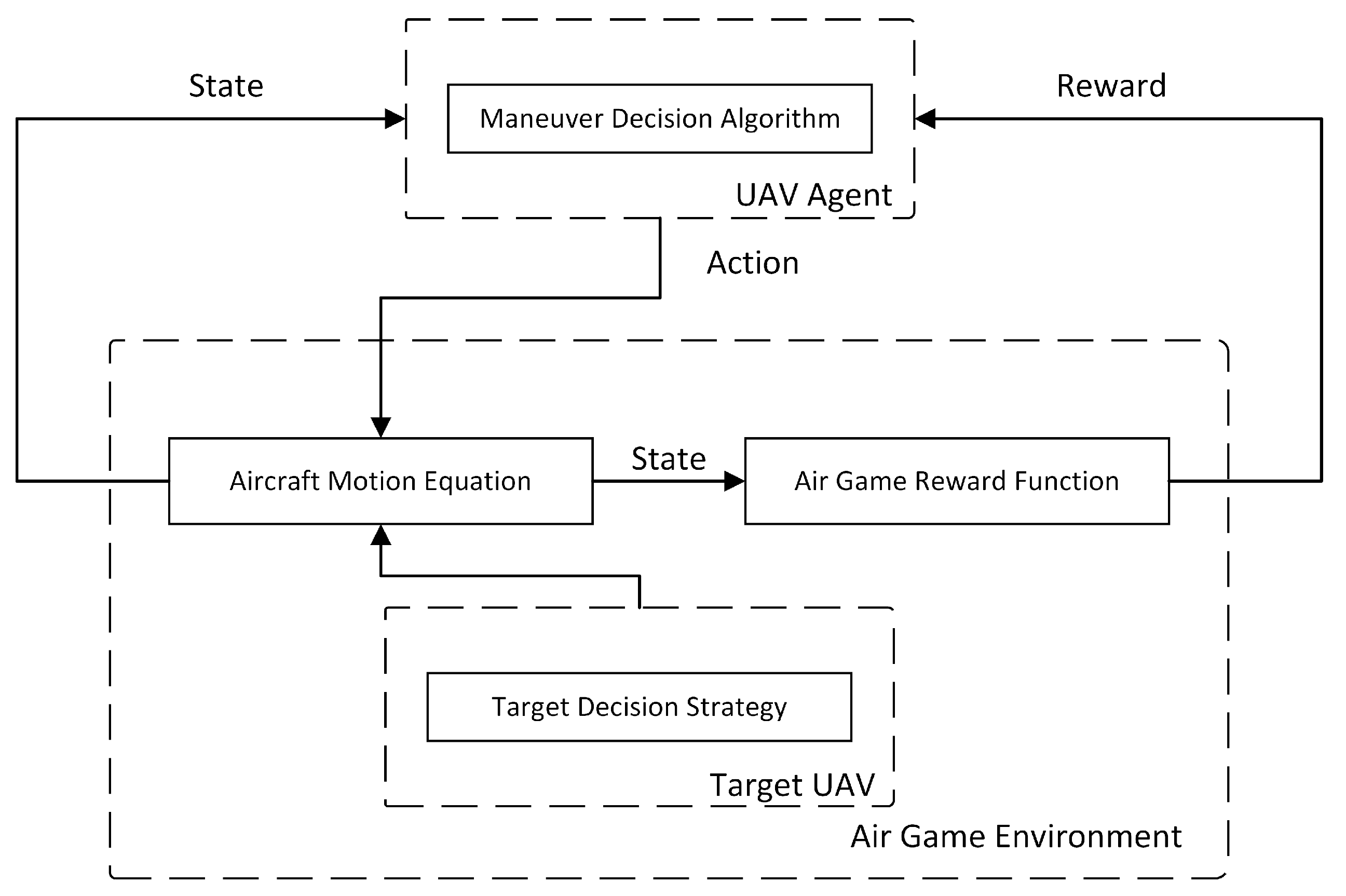
2.3. Maneuver Decision Modeling by Deep Reinforcement Learning
2.3.1. Framework of Model
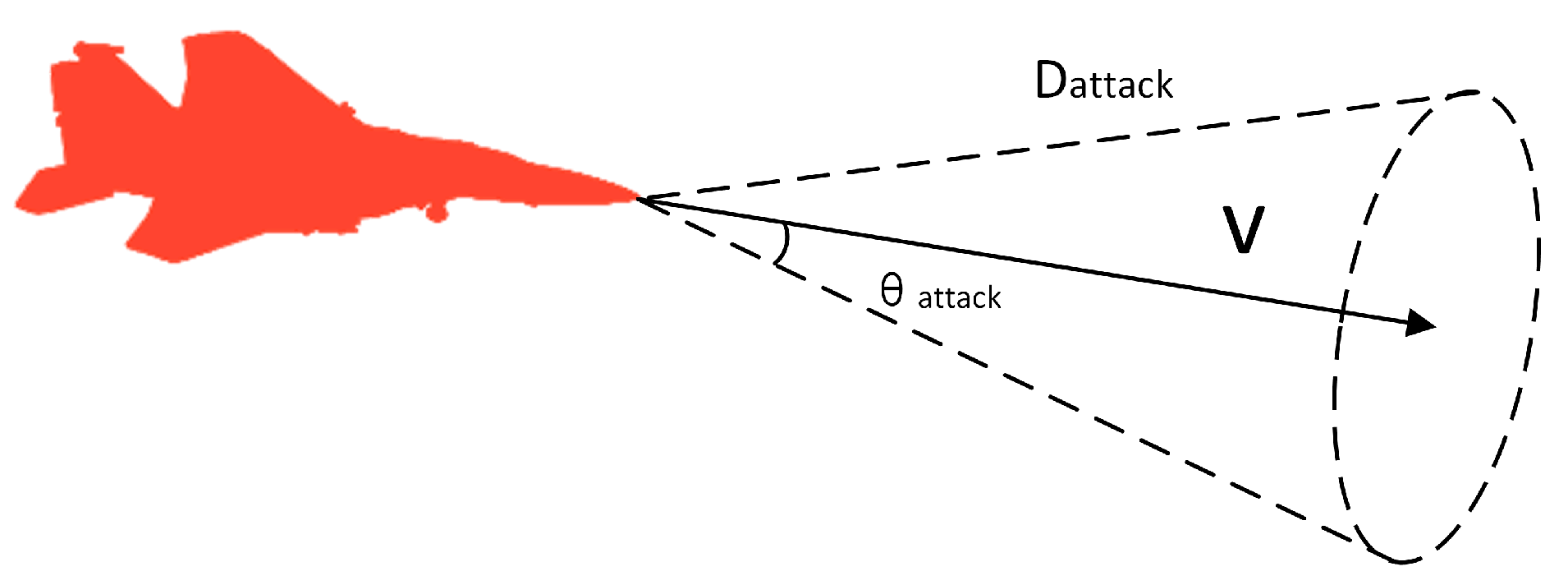
2.3.2. Attack Determination Model
2.3.3. State Definition
2.3.4. Action Definition
2.3.5. Reward Function Definition
- The distance between the UAV and the target should be within the attack range;
- The angle between the UAV and the target should be outside the attack angle of the target;
- The angle between the UAV and the target should be within the attack angle of the UAV.
3. UAV Maneuver Decision Algorithm
3.1. Expert Experience Storage Mechanism
| Algorithm 1: Expert Experience Storage Mechanism |
Input: a reinforcement learning off-policy algorithm , self-learning time k, storage constant h, and expert replay buffer size N Initialize Initialize replay buffer R Initialize expert replay buffer for do Initialize transition sequence Initialize state for do Select action using the policy from Excute action and observe reward and Store transition in the replay buffer R Add transition to the transition sequence Sample a minibatch transition from the replay buffer R Update weights through a minibatch transition and end if goal achieved then Store transition sequence in the expert replay buffer if then for do Sample a minibatch transition from the replay buffer Update weights through a minibatch transition and end end end end |
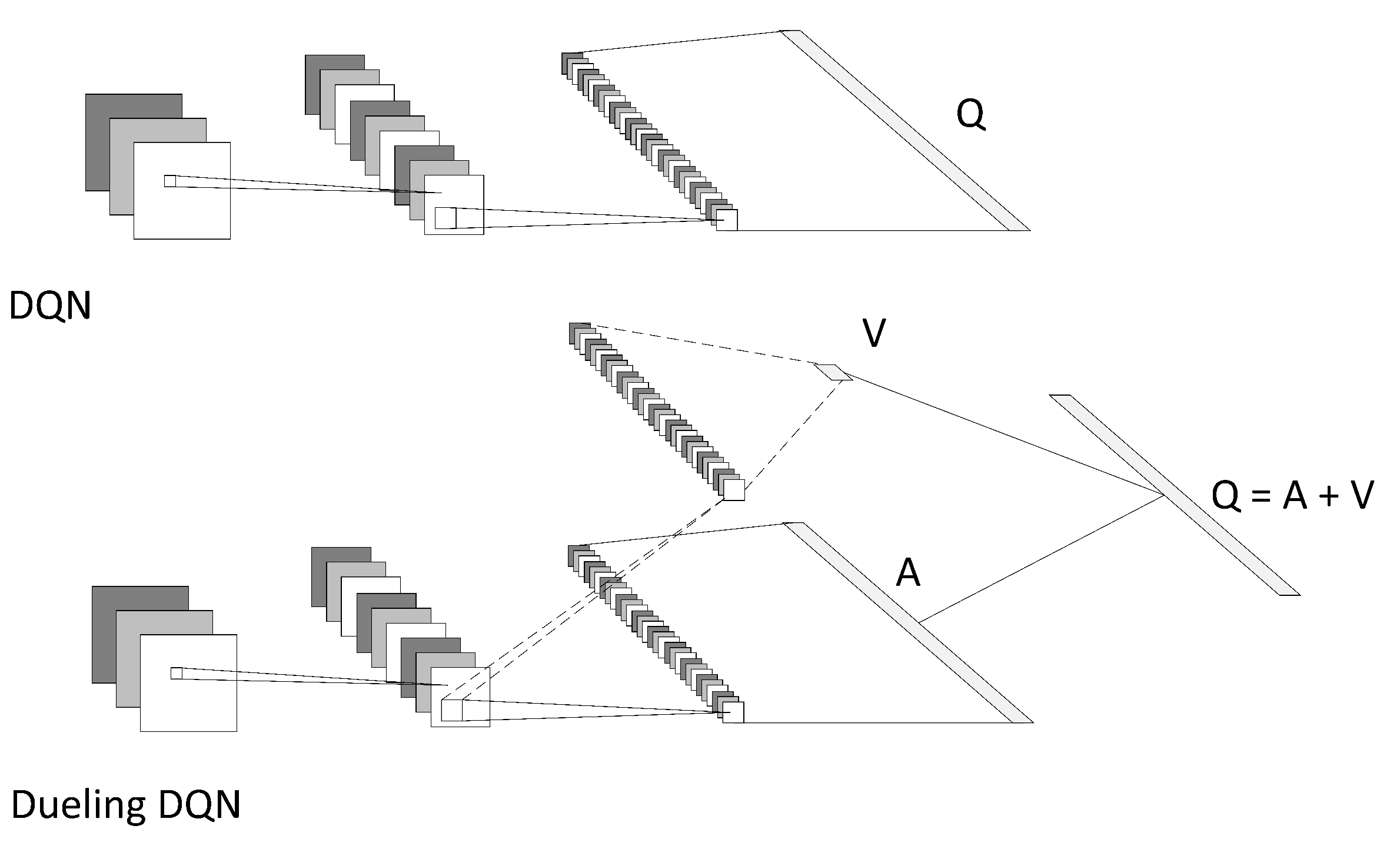
3.2. Dueling Double Deep Q Network Algorithm
3.3. Maneuver Decision Algorithm Based on Dueling Double Deep Q Network with Expert Experience Storage Mechanism
| Algorithm 2: UAV Maneuver Decision Algorithm |
Input: self-learning time K, storage constant h, expert replay buffer size N, discount factor , batch size B, learning rate l, copy network step C, , and Initialize predict Q network parameter Initialize target Q network parameter Initialize replay buffer R Initialize expert replay buffer for do Initialize transition sequence Initialize state for do Calculate the Q value through the predict Q network Select action using -greedy policy Excute action and observe reward and Store transition in the replay buffer R Add transition to the transition sequence Sample a minibatch transition from the replay buffer R for do Compute TD-error Update weights end Every C steps, copy weights into target network end if goal achieved then Store transition sequence in the expert replay buffer if then for do Sample a minibatch transition from the replay buffer for do Compute TD-error Update weights end end end end end |
4. Simulation Experiment and Analysis
4.1. Simulation Experiment Basic Setup
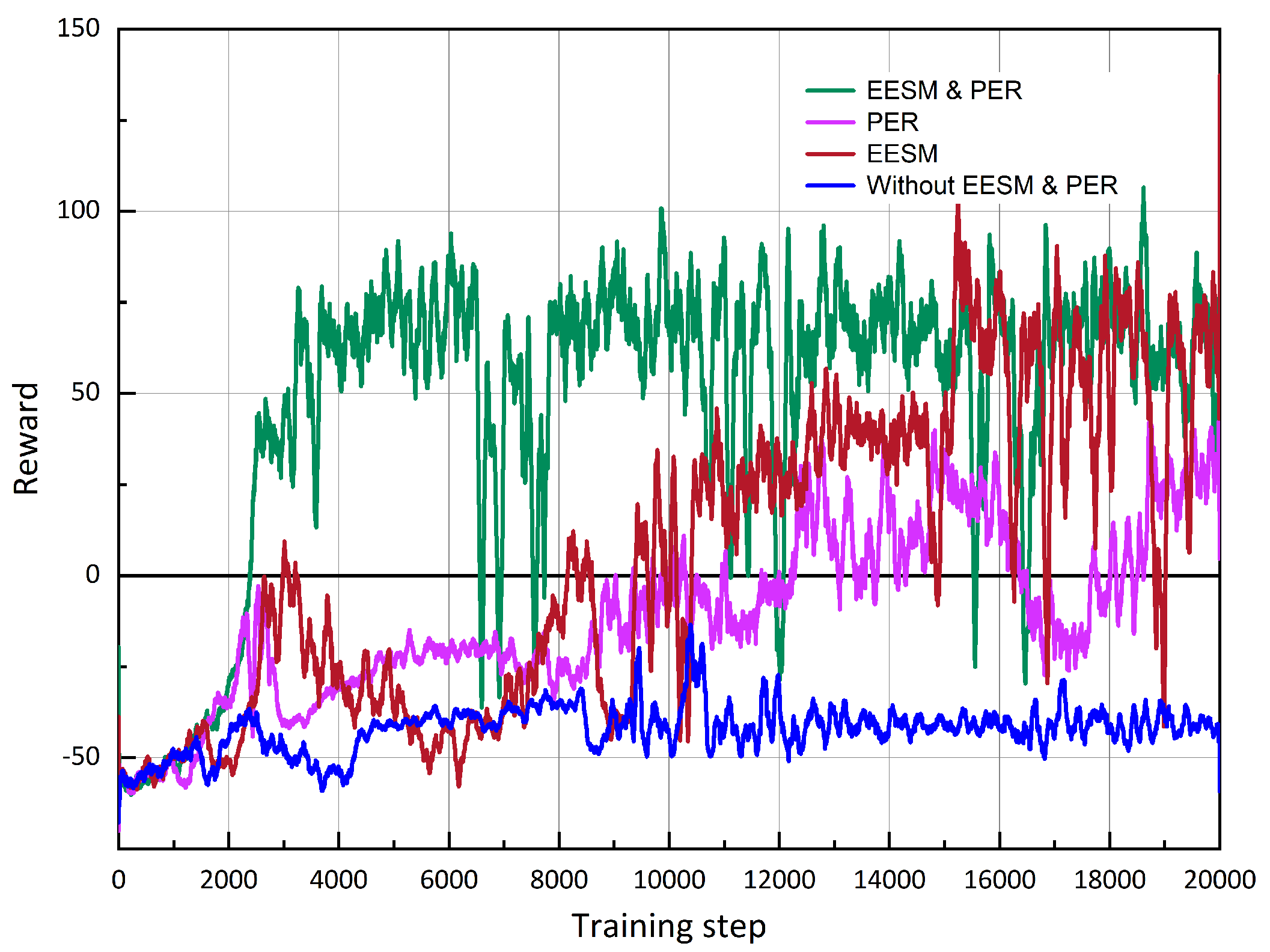
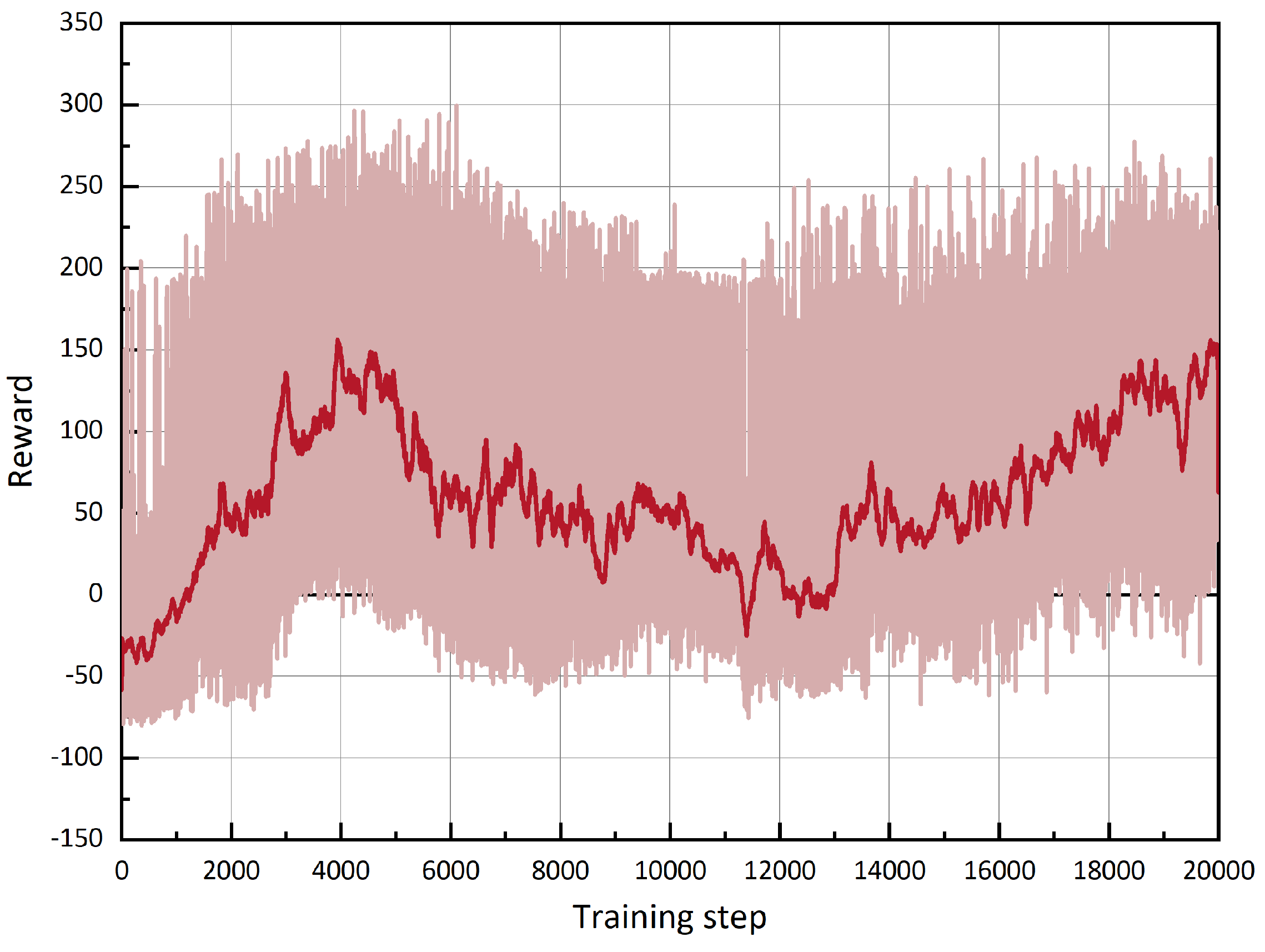
4.2. Expert Experience Storage Mechanism Ablation Experiment
- Training and testing with both PER and the expert experience storage mechanism;
- Training and testing with only PER and without the expert experience storage mechanism;
- Training and testing with only the expert experience storage mechanism and without PER;
- Training and testing without either PER or the expert experience storage mechanism.
- Without using the EESM and PER mechanisms, although the experience replay time of the algorithm is less, the UAV intelligent agent has difficulty learning an effective strategy for attacking the target UAV.
- The UAV intelligent agent can achieve a certain training effect when only using the PER mechanism, but the replay experience time is greatly increased. The algorithm’s performance is further improved after introducing the proposed EESM mechanism.
- The EESM mechanism proposed in this study can significantly improve the performance of the algorithm with less replay time: it reduces the replay time of the algorithm by 81.3% compared to the PER mechanism and makes the UAV intelligent agent obtain a higher maximum average reward value.
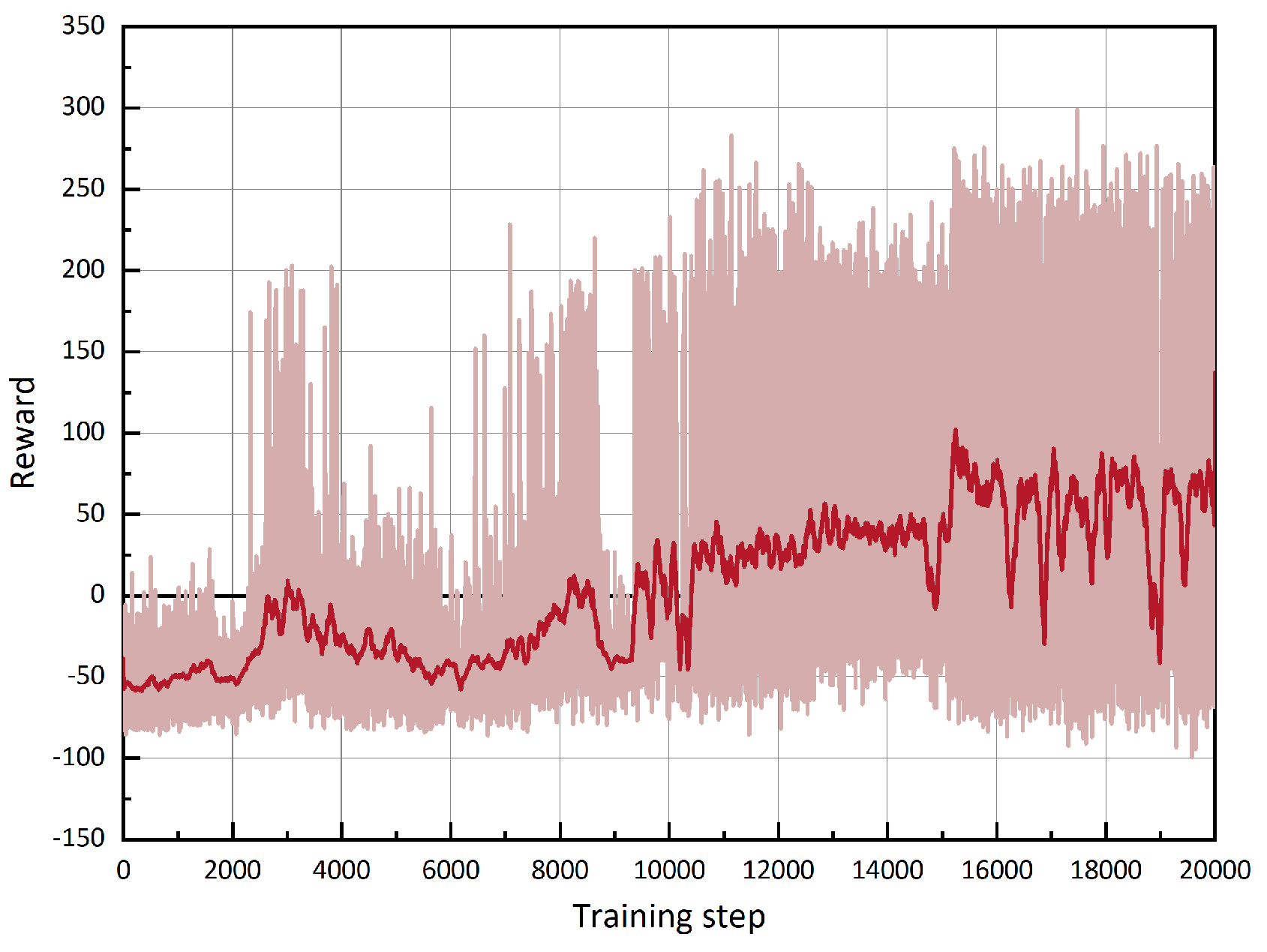
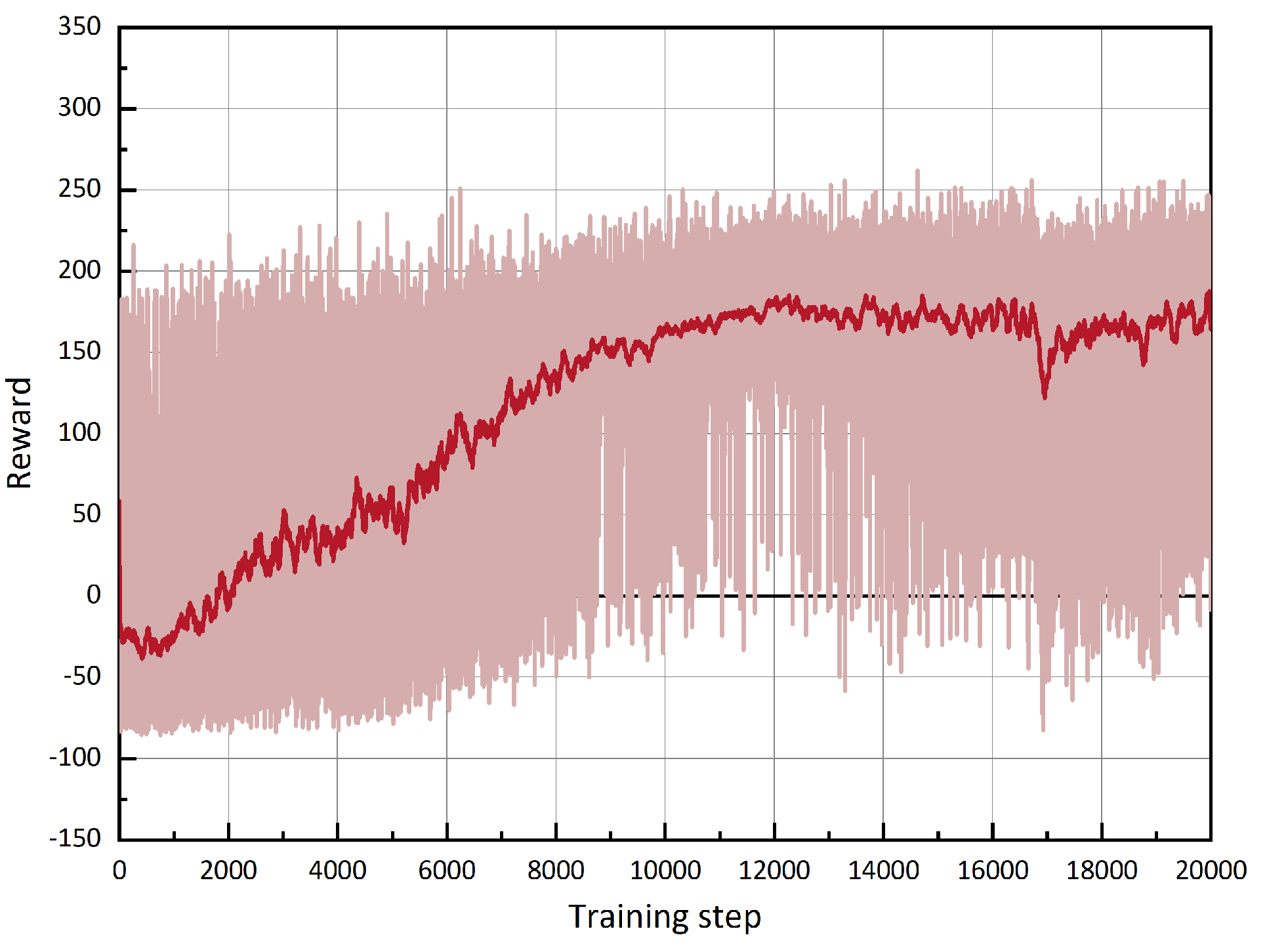
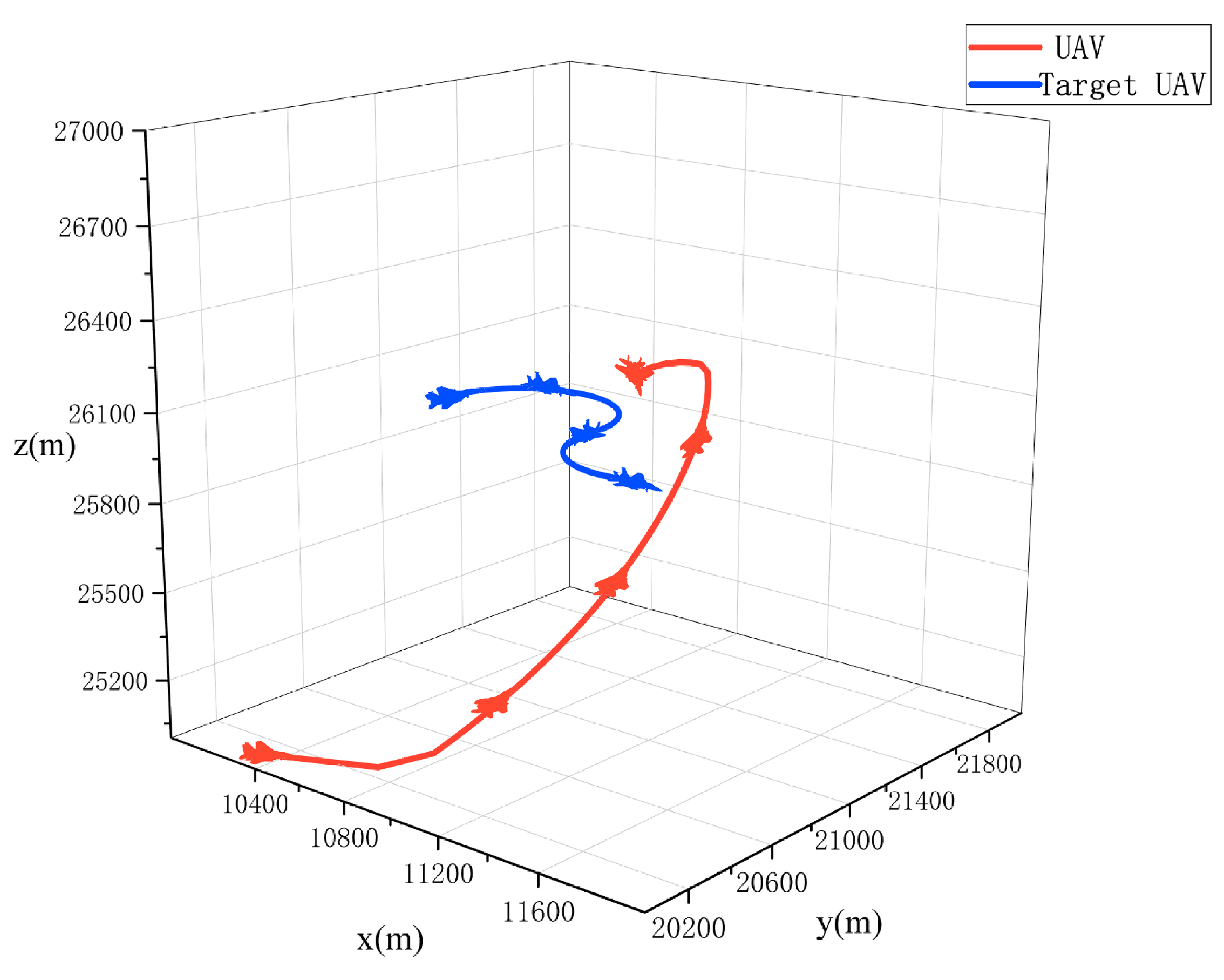
4.3. Air Game Simulation Experiment Based on Maneuver Decision Algorithm
- Uniform speed and direct flight: Target UAV executes in the action space.
- Uniform speed and hovering: Target UAV executes in the action space.
- Uniform speed and serpentine maneuver: Target UAV executes and periodically, with the period being 35 simulation steps.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Sample Availability
References
- Kong, W.; Zhou, D.; Yang, Z.; Zhao, Y.; Zhang, K. UAV autonomous aerial combat maneuver strategy generation with observation error based on state-adversarial deep deterministic policy gradient and inverse reinforcement learning. Electronics 2020, 9, 1121. [Google Scholar] [CrossRef]
- Yang, Q.; Zhang, J.; Shi, G.; Hu, J.; Wu, Y. Maneuver decision of UAV in short-range air combat based on deep reinforcement learning. IEEE Access 2019, 8, 363–378. [Google Scholar] [CrossRef]
- Myerson, R.B. Game Theory: Analysis of Conflict; Harvard University Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Shachter, R.D. Evaluating influence diagrams. Oper. Res. 1986, 34, 871–882. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Li, Q.; Sun, Y. Key technologies for air combat intelligent decision based on game confrontation. Command. Inf. Syst. Technol. 2021, 12, 1–6. [Google Scholar]
- Virtanen, K.; Karelahti, J.; Raivio, T. Modeling air combat by a moving horizon influence diagram game. J. Guid. Control. Dyn. 2006, 29, 1080–1091. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.; Ming’an, T.; Wei, Z.; Shengyun, Z. Sequential maneuvering decisions based on multi-stage influence diagram in air combat. J. Syst. Eng. Electron. 2007, 18, 551–555. [Google Scholar] [CrossRef]
- Pan, Q.; Zhou, D.; Huang, J.; Lv, X.; Yang, Z.; Zhang, K.; Li, X. Maneuver decision for cooperative close-range air combat based on state predicted influence diagram. In Proceedings of the 2017 IEEE International Conference on Information and Automation (ICIA), Macau, China, 18–20 July 2017; pp. 726–731. [Google Scholar]
- Xie, R.Z.; Li, J.Y.; Luo, D.L. Research on maneuvering decisions for multi-UAVs Air combat. In Proceedings of the 11th IEEE International Conference on Control & Automation (ICCA), Taichung, Taiwan, 18–20 June 2014; pp. 767–772. [Google Scholar]
- Weintraub, I.E.; Pachter, M.; Garcia, E. An introduction to pursuit-evasion differential games. In Proceedings of the 2020 American Control Conference (ACC), Online, 1–3 July 2020; pp. 1049–1066. [Google Scholar]
- Mukai, H.; Tanikawa, A.; Tunay, I.; Ozcan, I.; Katz, I.; Schättler, H.; Rinaldi, P.; Wang, G.; Yang, L.; Sawada, Y. Sequential linear-quadratic method for differential games with air combat applications. Comput. Optim. Appl. 2003, 25, 193–222. [Google Scholar] [CrossRef]
- Fu, L.; Wang, X. The short-range dogfight combat model of modern fighter based on differential games. In Proceedings of the 2011 Chinese Control and Decision Conference (CCDC), Mianyang, China, 23–25 May 2011; pp. 4082–4084. [Google Scholar]
- Park, H.; Lee, B.Y.; Tahk, M.J.; Yoo, D.W. Differential game based air combat maneuver generation using scoring function matrix. Int. J. Aeronaut. Space Sci. 2016, 17, 204–213. [Google Scholar] [CrossRef] [Green Version]
- Başpınar, B.; Koyuncu, E. Assessment of aerial combat game via optimization-based receding horizon control. IEEE Access 2020, 8, 35853–35863. [Google Scholar] [CrossRef]
- He, M.; Wang, X. Nonlinear Differential Game Guidance Law for Guarding a Target. In Proceedings of the 2020 6th International Conference on Control, Automation and Robotics (ICCAR), Singapore, 20–23 April 2020; pp. 713–721. [Google Scholar]
- Smith, R.E.; Dike, B.; Mehra, R.; Ravichandran, B.; El-Fallah, A. Classifier systems in combat: Two-sided learning of maneuvers for advanced fighter aircraft. Comput. Methods Appl. Mech. Eng. 2000, 186, 421–437. [Google Scholar] [CrossRef]
- Sprinkle, J.; Eklund, J.M.; Kim, H.J.; Sastry, S. Encoding aerial pursuit/evasion games with fixed wing aircraft into a nonlinear model predictive tracking controller. In Proceedings of the 2004 43rd IEEE Conference on Decision and Control (CDC) (IEEE Cat. No. 04CH37601), Nassau, The Bahamas, 14–17 December 2004; Volume 3, pp. 2609–2614. [Google Scholar]
- McGrew, J.S.; How, J.P.; Williams, B.; Roy, N. Air-combat strategy using approximate dynamic programming. J. Guid. Control. Dyn. 2010, 33, 1641–1654. [Google Scholar] [CrossRef] [Green Version]
- Duan, H.; Li, P.; Yu, Y. A predator-prey particle swarm optimization approach to multiple UCAV air combat modeled by dynamic game theory. IEEE/CAA J. Autom. Sin. 2015, 2, 11–18. [Google Scholar]
- Ji, H.; Yu, M.; Han, Q.; Yang, J. Research on the air combat countermeasure generation based on improved TIMS model. IOP J. Phys. Conf. Ser. 2018, 1069, 012039. [Google Scholar] [CrossRef] [Green Version]
- Han, T.; Wang, X.; Liang, Y.; Ku, S. Study on UCAV robust maneuvering decision in automatic air combat based on target accessible domain. IOP J. Phys. Conf. Ser. 2019, 1213, 052004. [Google Scholar] [CrossRef]
- Tan, M.; Tang, A.; Ding, D.; Xie, L.; Huang, C. Autonomous Air Combat Maneuvering Decision Method of UCAV Based on LSHADE-TSO-MPC under Enemy Trajectory Prediction. Electronics 2022, 11, 3383. [Google Scholar] [CrossRef]
- Ruan, W.; Duan, H.; Deng, Y. Autonomous Maneuver Decisions via Transfer Learning Pigeon-Inspired Optimization for UCAVs in Dogfight Engagements. IEEE/CAA J. Autom. Sin. 2022, 9, 1639–1657. [Google Scholar] [CrossRef]
- Machmudah, A.; Shanmugavel, M.; Parman, S.; Manan, T.S.A.; Dutykh, D.; Beddu, S.; Rajabi, A. Flight trajectories optimization of fixed-wing UAV by bank-turn mechanism. Drones 2022, 6, 69. [Google Scholar] [CrossRef]
- Rodin, E.Y.; Amin, S.M. Maneuver prediction in air combat via artificial neural networks. Comput. Math. Appl. 1992, 24, 95–112. [Google Scholar] [CrossRef] [Green Version]
- Schvaneveldt, R.W.; Goldsmith, T.E.; Benson, A.E.; Waag, W.L. Neural Network Models of Air Combat Maneuvering; Technical Report; New Mexico State University: Las Cruces, NM, USA, 1992. [Google Scholar]
- Teng, T.H.; Tan, A.H.; Tan, Y.S.; Yeo, A. Self-organizing neural networks for learning air combat maneuvers. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar]
- Geng, W.X.; Ma, D.Q. Study on tactical decision of UAV medium-range air combat. In Proceedings of the 26th Chinese Control and Decision Conference (2014 CCDC), Changsha, China, 31 May–2 June 2014; pp. 135–139. [Google Scholar]
- Wu, A.; Yang, R.; Liang, X.; Zhang, J.; Qi, D.; Wang, N. Visual range maneuver decision of unmanned combat aerial vehicle based on fuzzy reasoning. Int. J. Fuzzy Syst. 2022, 24, 519–536. [Google Scholar] [CrossRef]
- Çintaş, E.; Özyer, B.; Şimşek, E. Vision-based moving UAV tracking by another UAV on low-cost hardware and a new ground control station. IEEE Access 2020, 8, 194601–194611. [Google Scholar] [CrossRef]
- Li, Y.; Lyu, Y.; Shi, J.; Li, W. Autonomous Maneuver Decision of Air Combat Based on Simulated Operation Command and FRV-DDPG Algorithm. Aerospace 2022, 9, 658. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Wan, K.; Gao, X.; Hu, Z.; Wu, G. Robust motion control for UAV in dynamic uncertain environments using deep reinforcement learning. Remote Sens. 2020, 12, 640. [Google Scholar] [CrossRef] [Green Version]
- Yang, K.; Dong, W.; Cai, M.; Jia, S.; Liu, R. UCAV air combat maneuver decisions based on a proximal policy optimization algorithm with situation reward shaping. Electronics 2022, 11, 2602. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Zhang, H.; Wei, Y.; Zhou, H.; Huang, C. Maneuver Decision-Making for Autonomous Air Combat Based on FRE-PPO. Appl. Sci. 2022, 12, 10230. [Google Scholar] [CrossRef]
- Fan, Z.; Xu, Y.; Kang, Y.; Luo, D. Air Combat Maneuver Decision Method Based on A3C Deep Reinforcement Learning. Machines 2022, 10, 1033. [Google Scholar] [CrossRef]
- Cao, Y.; Kou, Y.X.; Li, Z.W.; Xu, A. Autonomous Maneuver Decision of UCAV Air Combat Based on Double Deep Q Network Algorithm and Stochastic Game Theory. Int. J. Aerosp. Eng. 2023, 2023, 3657814. [Google Scholar] [CrossRef]
- Li, B.; Huang, J.; Bai, S.; Gan, Z.; Liang, S.; Evgeny, N.; Yao, S. Autonomous air combat decision-making of UAV based on parallel self-play reinforcement learning. CAAI Trans. Intell. Technol. 2022, 8, 64–81. [Google Scholar] [CrossRef]
- Li, B.; Bai, S.; Liang, S.; Ma, R.; Neretin, E.; Huang, J. Manoeuvre decision-making of unmanned aerial vehicles in air combat based on an expert actor-based soft actor critic algorithm. CAAI Trans. Intell. Technol. 2023. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Austin, F.; Carbone, G.; Falco, M.; Hinz, H.; Lewis, M. Automated maneuvering decisions for air-to-air combat. In Proceedings of the Guidance, Navigation and Control Conference, Monterey, CA, USA, 17–19 August 1987; p. 2393. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Fedus, W.; Ramachandran, P.; Agarwal, R.; Bengio, Y.; Larochelle, H.; Rowland, M.; Dabney, W. Revisiting fundamentals of experience replay. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 13–18 July 2020; pp. 3061–3071. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Karimpanal, T.G.; Bouffanais, R. Experience replay using transition sequences. Front. Neurorobot. 2018, 12, 32. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 1995–2003. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | Definition | State | Definition |
|---|---|---|---|
| Action | Definition | |||
|---|---|---|---|---|
| straight flight | 0 | 1 | 0 | |
| acceleration | 2 | 1 | 0 | |
| deceleration | −2 | 1 | 0 | |
| left turn | 0 | 8 | ||
| right turn | 0 | 8 | ||
| upward flight | 0 | 8 | 0 | |
| downward flight | 0 | 8 |
| Parameter | Value |
|---|---|
| Threshold distance | 5000 m |
| State space normalization parameter | 20 m/s |
| State space normalization parameter | 80 m/s |
| UAV velocity range | [60 m/s, 100 m/s] |
| attack distance | 500 m |
| learning rate l | |
| initial greedy coefficient | 1 |
| greedy coefficient decay rate | |
| discount factor | |
| reward factor | |
| reward factor | |
| reward factor | |
| replay buffer size | |
| batch size | 256 |
| storage constant h | 10 |
| self-learning time k | 10 |
| number of hidden layers | 2 |
| number of network cells in each layer | 256 |
| Initial Position | v (m/s) | ||||
|---|---|---|---|---|---|
| Our UAV | (10,300, 20,000, 25,000) | 60 | 0 | 0 | 0 |
| Target UAV | (11,300, 21,000, 26,000) | 60 | 0 | 0 | 0 |
| PER | EESM | Experience Replay Time | Max Average Reward | |
|---|---|---|---|---|
| Experiment 1 | ✓ | ✓ | 1577.0 ms | 106.6 |
| Experiment 2 | ✓ | 1149.2 ms | 42.5 | |
| Experiment 3 | ✓ | 178.5 ms | 102.3 | |
| Experiment 4 | 101.0 ms | −13.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Meng, Z.; He, J.; Wang, Z.; Liu, L. UAV Air Game Maneuver Decision-Making Using Dueling Double Deep Q Network with Expert Experience Storage Mechanism. Drones 2023, 7, 385. https://doi.org/10.3390/drones7060385
Zhang J, Meng Z, He J, Wang Z, Liu L. UAV Air Game Maneuver Decision-Making Using Dueling Double Deep Q Network with Expert Experience Storage Mechanism. Drones. 2023; 7(6):385. https://doi.org/10.3390/drones7060385
Chicago/Turabian StyleZhang, Jiahui, Zhijun Meng, Jiazheng He, Zichen Wang, and Lulu Liu. 2023. "UAV Air Game Maneuver Decision-Making Using Dueling Double Deep Q Network with Expert Experience Storage Mechanism" Drones 7, no. 6: 385. https://doi.org/10.3390/drones7060385
APA StyleZhang, J., Meng, Z., He, J., Wang, Z., & Liu, L. (2023). UAV Air Game Maneuver Decision-Making Using Dueling Double Deep Q Network with Expert Experience Storage Mechanism. Drones, 7(6), 385. https://doi.org/10.3390/drones7060385