
Deep Deterministic Policy Gradient (DDPG) Agent-Based Sliding Mode Control for Quadrotor Attitudes


Abstract
:1. Introduction
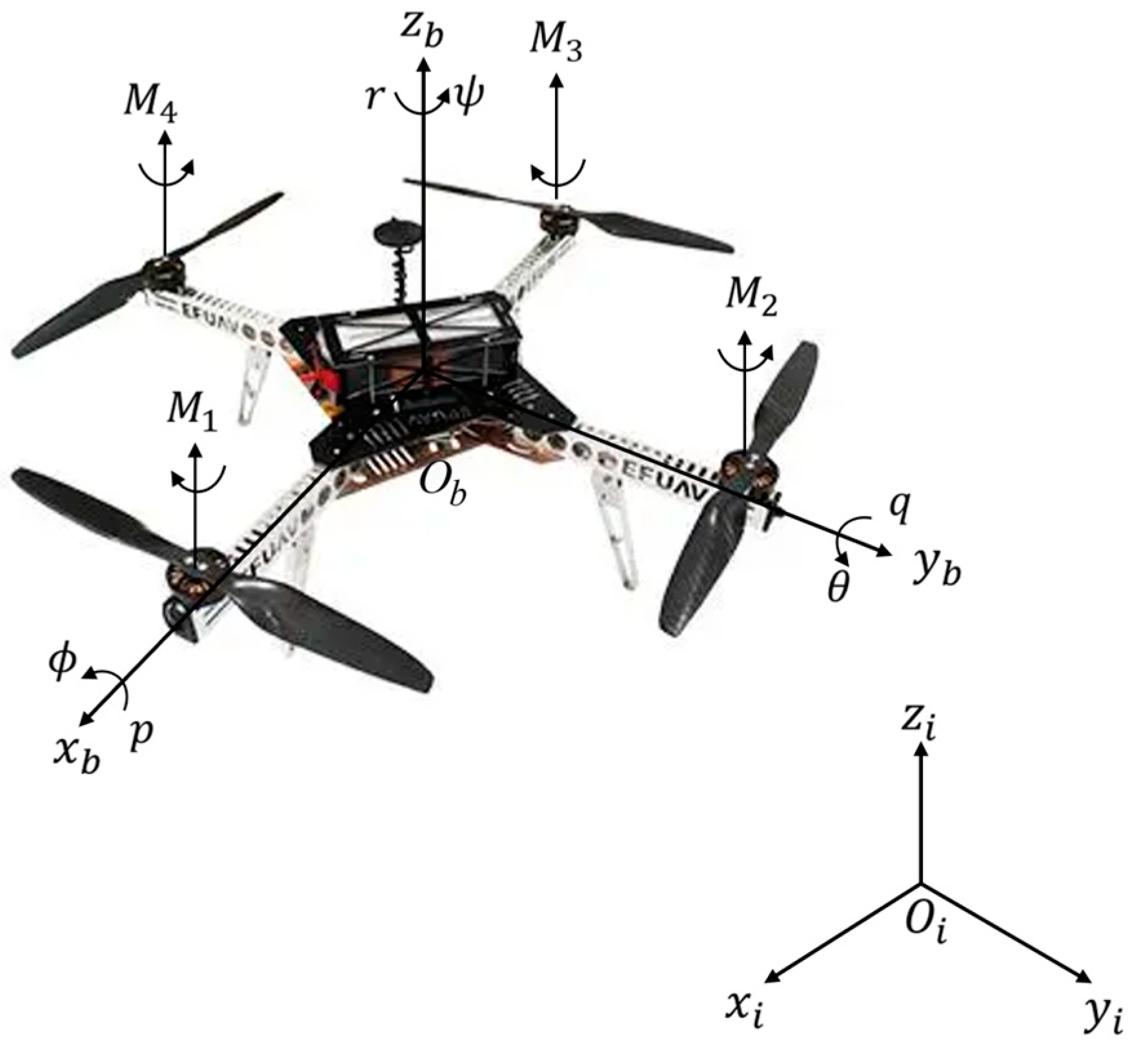
2. Attitude Dynamics Modeling for Quadrotor UAV
3. Control Design for Attitude Control
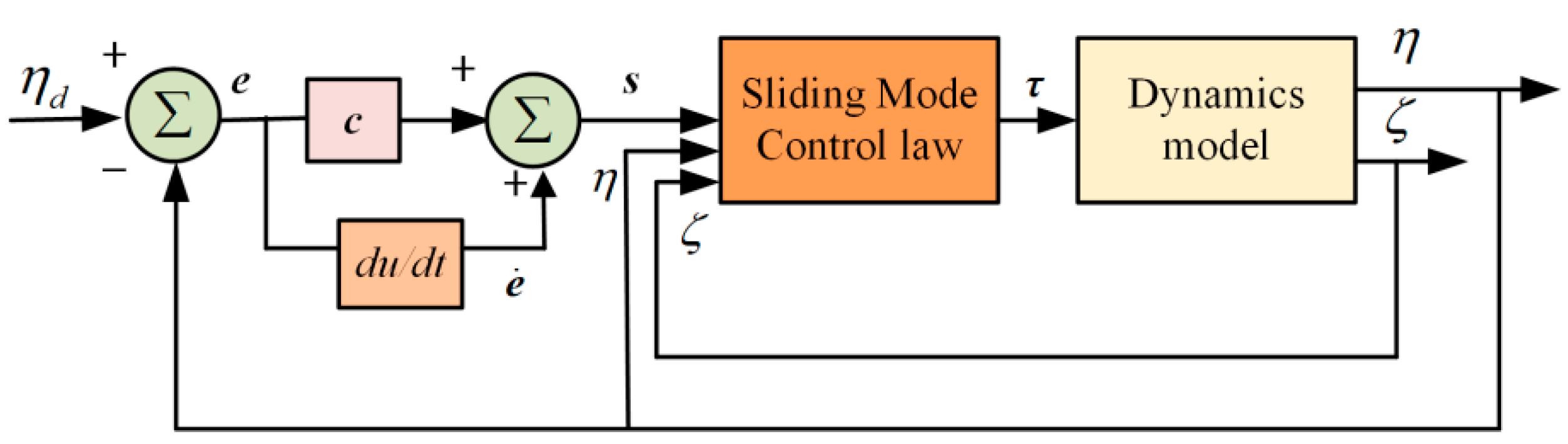
3.1. SMC Design
| Algorithm 1. Design Methodology of SMC. |
| Input: (1) Desired attitude angles (2) Actual attitude angles (3) Model parameters of the quadrotor Output: Control signals for the attitude dynamics model Step 1: Design of the control signal (a) Define the sliding mode surface s (b) Select the reaching law (c) Compute the control signal Step 2: Proof of the stability of the closed-loop system (a) Select a Lyapunov candidate function (b) Calculate the first-order derivative of (c) Analyze the sign of the above derivative of (d) Conclude the convergence of the attitude motion Step 3: Termination If the attitude control errors meet the requirements, conduct the algorithm termination and output the control signal . Otherwise, carry out Step 1 until convergence of the control errors. |
3.2. DDPG-SMC Design
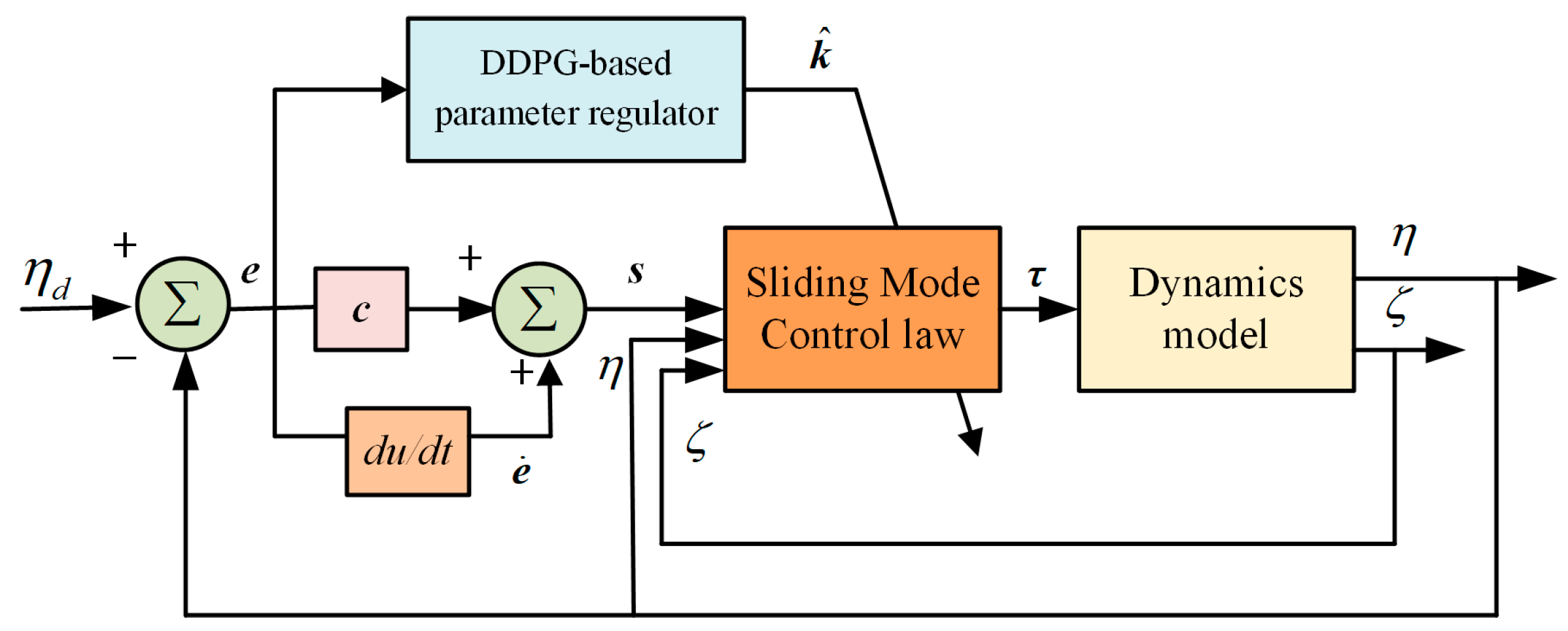
3.2.1. The Architectural Design of DDPG-SMC
3.2.2. The Basic Principle of the DDPG Algorithm
| Algorithm 2. DDPG Algorithm. |
| Input: Experience replay buffer , initial critic networks’ Q-function parameters , actor networks’ policy parameters , target networks and Initialize the target network parameters: for episode = 1 to M do Initialize stochastic process to add exploration to the action. Observe initial state for time step = 1 to T do Select action Perform action and transfer to next state , then acquire the reward value and the termination signal Store the state transition data in experience replay buffer Calculate the target function: Update the critic network using the minimized loss function: Update the actor network using the policy gradient method: Update target networks: end for end for |
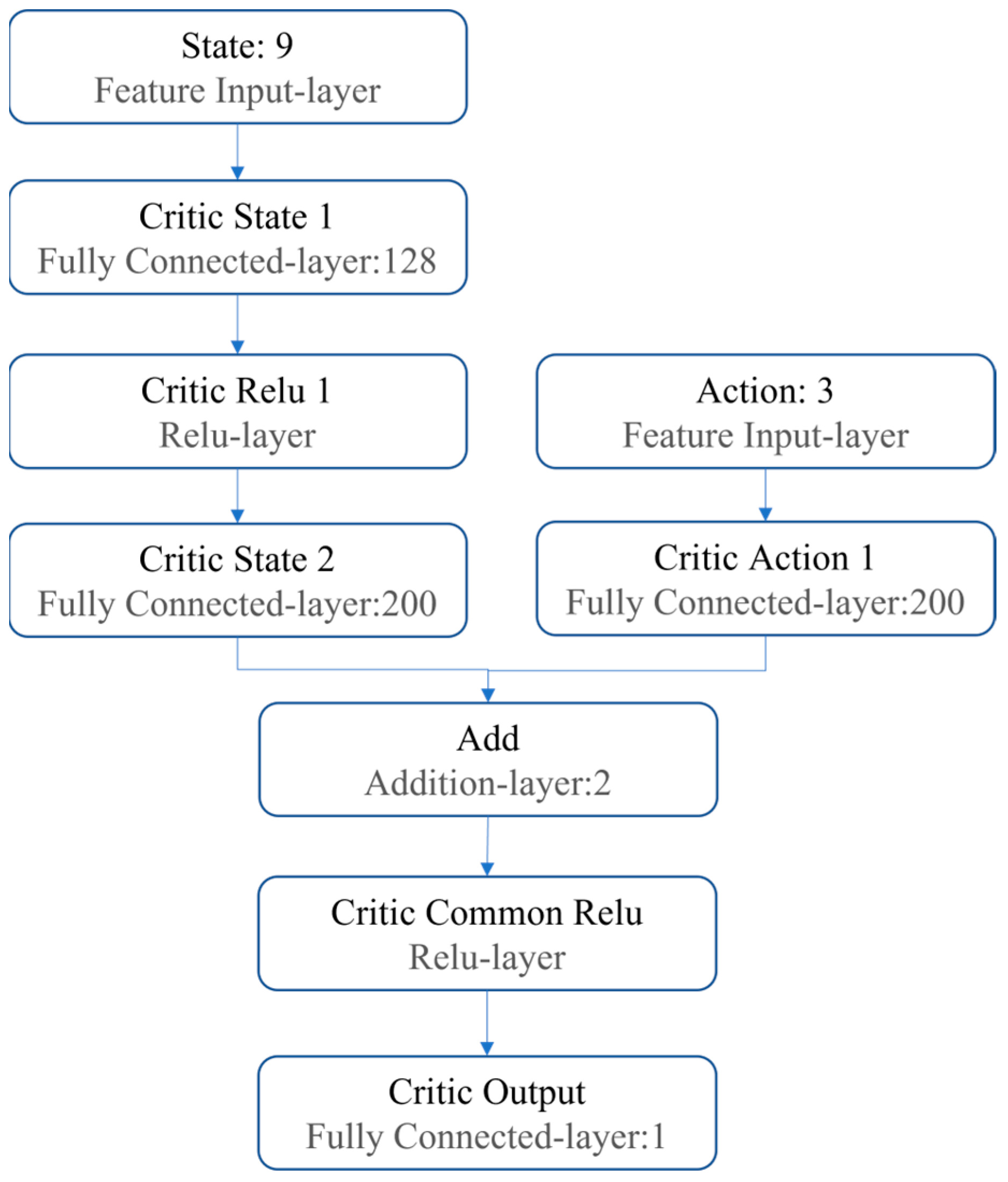
3.2.3. Design of the Neural Network and Parameters Related to DDPG
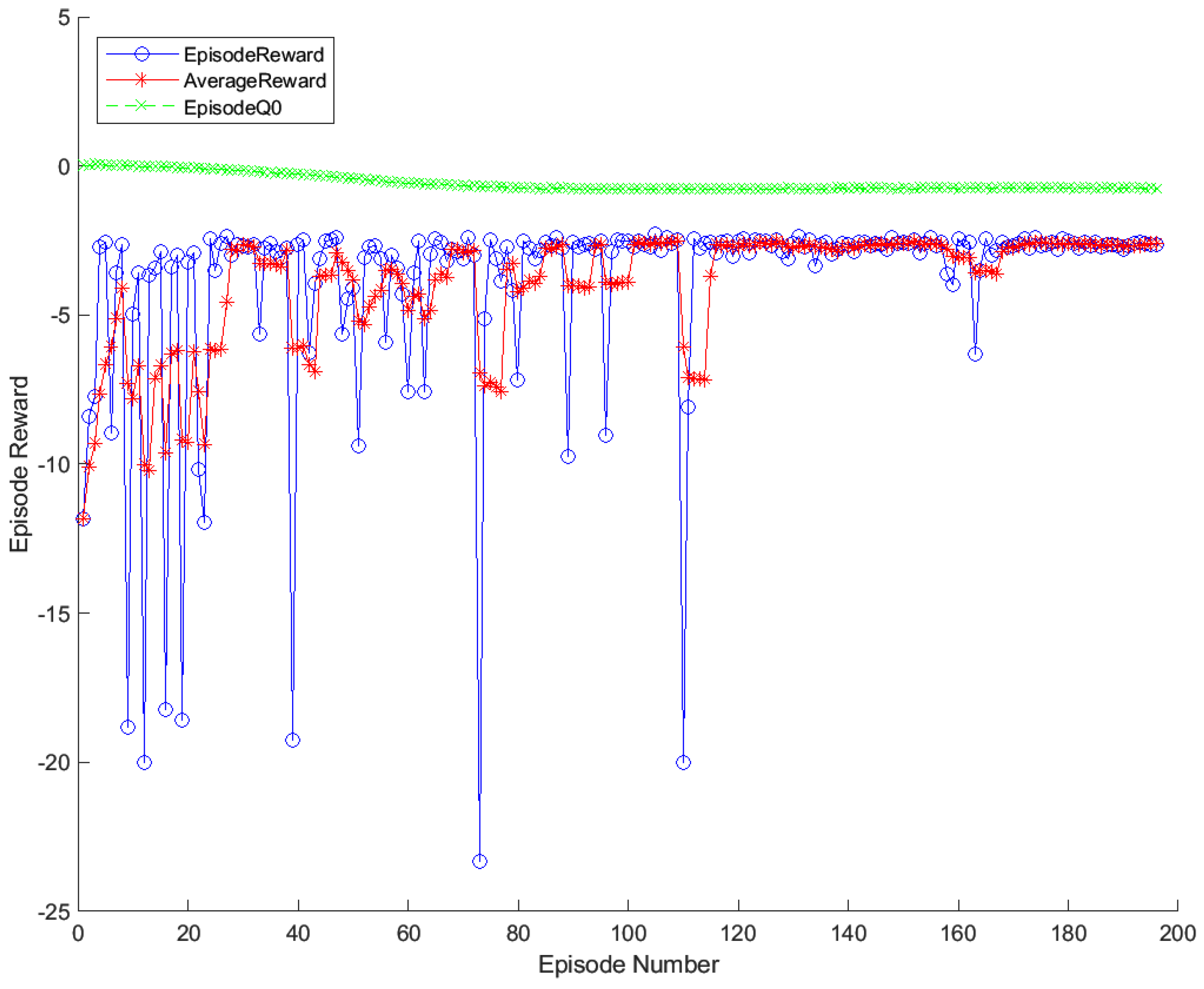
3.2.4. The Training Results of DDPG
4. Simulation Results
4.1. Simulation Results of SMC
4.2. Simulation Results of AFGS-SMC
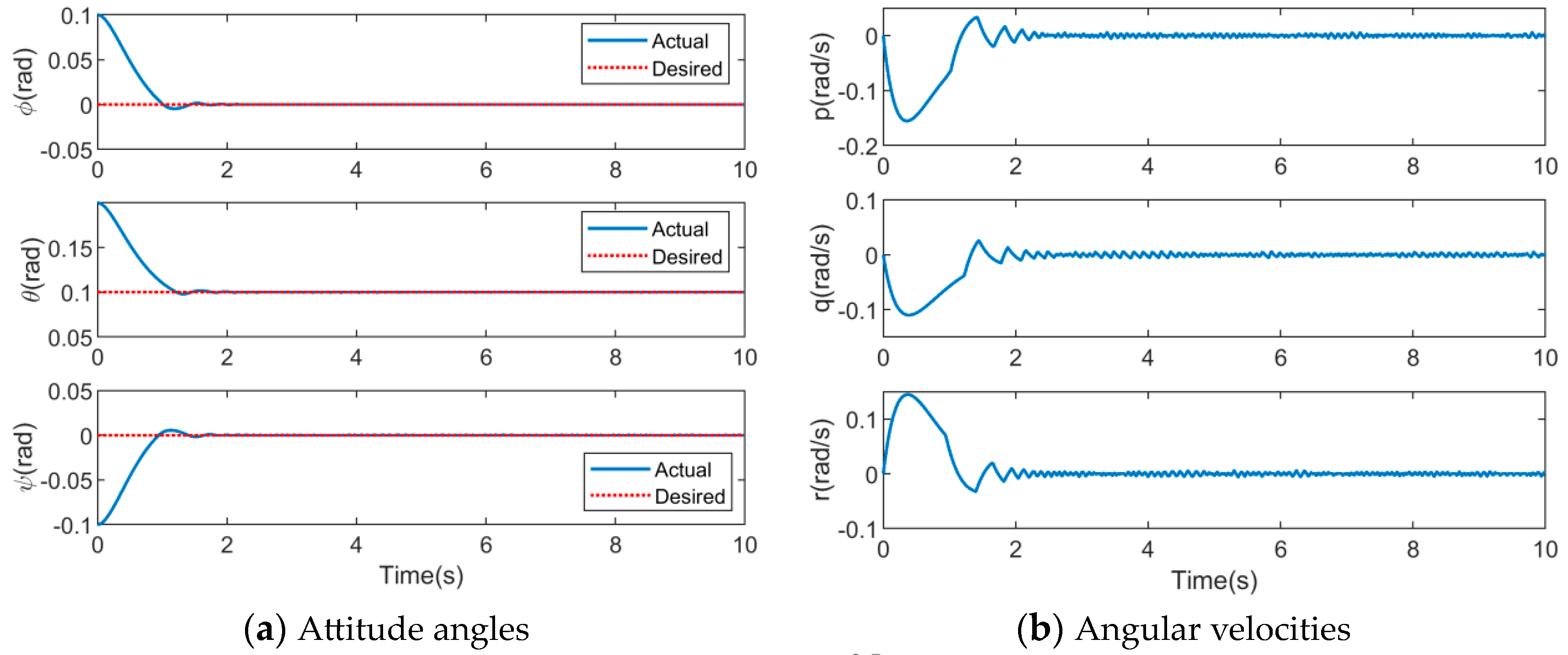
4.3. Simulation Results of DDPG-SMC
4.4. Comparative Analysis of Simulation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Grima, S.; Lin, M.; Meng, Z.; Luo, C.; Chen, Y. The application of unmanned aerial vehicle oblique photography technology in online tourism design. PLoS ONE 2023, 18, e0289653. [Google Scholar]
- Clarke, R. Understanding the drone epidemic. Comput. Law Secur. Rev. 2014, 30, 230–246. [Google Scholar] [CrossRef]
- Xu, B.; Wang, W.; Falzon, G.; Kwan, P.; Guo, L.; Chen, G.; Tait, A.; Schneider, D. Automated cattle counting using Mask R-CNN in quadcopter vision system. Comput. Electron. Agric. 2020, 171, 105300. [Google Scholar] [CrossRef]
- Idrissi, M.; Salami, M.; Annaz, F. A review of quadrotor unmanned aerial vehicles: Applications, architectural design and control algorithms. J. Intell. Robot. Syst. 2022, 104, 22. [Google Scholar] [CrossRef]
- Adiguzel, F.; Mumcu, T.V. Robust discrete-time nonlinear attitude stabilization of a quadrotor UAV subject to time-varying disturbances. Elektron. Elektrotechnika 2021, 27, 4–12. [Google Scholar] [CrossRef]
- Shen, J.; Wang, B.; Chen, B.M.; Bu, R.; Jin, B. Review on wind resistance for quadrotor UAVs: Modeling and controller design. Unmanned Syst. 2022, 11, 5–15. [Google Scholar] [CrossRef]
- Gün, A. Attitude control of a quadrotor using PID controller based on differential evolution algorithm. Expert Syst. Appl. 2023, 229, 120518. [Google Scholar] [CrossRef]
- Zhou, L.; Pljonkin, A.; Singh, P.K. Modeling and PID control of quadrotor UAV based on machine learning. J. Intell. Syst. 2022, 31, 1112–1122. [Google Scholar] [CrossRef]
- Khatoon, S.; Nasiruddin, I.; Shahid, M. Design and simulation of a hybrid PD-ANFIS controller for attitude tracking control of a quadrotor UAV. Arab. J. Sci. Eng. 2017, 42, 5211–5229. [Google Scholar] [CrossRef]
- Landry, B.; Deits, R.; Florence, P.R.; Tedrake, R. Aggressive quadrotor flight through cluttered environments using mixed integer programming. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016. [Google Scholar]
- Bouabdallah, S.; Noth, A.; Siegwart, R. PID vs LQ control techniques applied to an indoor micro quadrotor. In Proceedings of the 2004 1EEE/RSJ Internationel Conference On Intelligent Robots and Systems, Sendal, Japan, 28 September–2 October 2004. [Google Scholar]
- Miranda-Colorado, R.; Aguilar, L.T. Robust PID control of quadrotors with power reduction analysis. ISA Trans. 2020, 98, 47–62. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zhao, J.; Cai, Z.; Wang, Y.; Liu, N. Onboard actuator model-based incremental nonlinear dynamic inversion for quadrotor attitude control: Method and application. Chin. J. Aeronaut. 2021, 34, 216–227. [Google Scholar] [CrossRef]
- Smeur, E.J.J.; Chu, Q.; de Croon, G.C.H.E. Adaptive incremental nonlinear dynamic inversion for attitude control of micro air vehicles. J. Guid. Control. Dyn. 2016, 39, 450–461. [Google Scholar] [CrossRef]
- da Costa, R.R.; Chu, Q.P.; Mulder, J.A. Reentry flight controller design using nonlinear dynamic inversion. J. Spacecr. Rocket. 2003, 40, 64–71. [Google Scholar] [CrossRef]
- Yang, J.; Cai, Z.; Zhao, J.; Wang, Z.; Ding, Y.; Wang, Y. INDI-based aggressive quadrotor flight control with position and attitude constraints. Robot. Auton. Syst. 2023, 159, 104292. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, Y.; Zhang, W. A composite adaptive fault-tolerant attitude control for a quadrotor UAV with multiple uncertainties. J. Syst. Sci. Complex. 2022, 35, 81–104. [Google Scholar] [CrossRef]
- Huang, T.; Li, T.; Chen, C.L.P.; Li, Y. Attitude stabilization for a quadrotor using adaptive control algorithm. IEEE Trans. Aerosp. Electron. Syst. 2023, 60, 334–347. [Google Scholar] [CrossRef]
- Patnaik, K.; Zhang, W. Adaptive attitude control for foldable quadrotors. IEEE Control. Syst. Lett. 2023, 7, 1291–1296. [Google Scholar] [CrossRef]
- Chen, J.; Long, Y.; Li, T.; Huang, T. Attitude tracking control for quadrotor based on time-varying gain extended state observer. Proc. Inst. Mech. Eng. Part I J. Syst. Control. Eng. 2022, 237, 585–595. [Google Scholar] [CrossRef]
- Zheng, Z.; Su, X.; Jiang, T.; Huang, J. Robust dynamic geofencing attitude control for quadrotor systems. IEEE Trans. Ind. Electron. 2023, 70, 1861–1869. [Google Scholar] [CrossRef]
- Yang, Y.; Yan, Y. Attitude regulation for unmanned quadrotors using adaptive fuzzy gain-scheduling sliding mode control. Aerosp. Sci. Technol. 2016, 54, 208–217. [Google Scholar] [CrossRef]
- Chen, X.; Li, Y.; Ma, H.; Tang, H.; Xie, Y. A novel variable exponential discrete time sliding mode reaching law. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 2518–2522. [Google Scholar] [CrossRef]
- Lian, S.; Meng, W.; Lin, Z.; Shao, K.; Zheng, J.; Li, H.; Lu, R. Adaptive attitude control of a quadrotor using fast nonsingular terminal sliding mode. IEEE Trans. Ind. Electron. 2022, 69, 1597–1607. [Google Scholar] [CrossRef]
- Sun, H.; Li, J.; Wang, R.; Yang, K. Attitude control of the quadrotor UAV with mismatched disturbances based on the fractional-order sliding mode and backstepping control subject to actuator faults. Fractal Fract. 2023, 7, 227. [Google Scholar] [CrossRef]
- Belgacem, K.; Mezouar, A.; Essounbouli, N. Design and analysis of adaptive sliding mode with exponential reaching law control for double-fed induction generator based wind turbine. Int. J. Power Electron. Drive Syst. 2018, 9, 1534–1544. [Google Scholar] [CrossRef]
- Mechali, O.; Xu, L.; Xie, X.; Iqbal, J. Fixed-time nonlinear homogeneous sliding mode approach for robust tracking control of multirotor aircraft: Experimental validation. J. Frankl. Inst. 2022, 359, 1971–2029. [Google Scholar] [CrossRef]
- Kelkoul, B.; Boumediene, A. Stability analysis and study between classical sliding mode control (SMC) and super twisting algorithm (STA) for doubly fed induction generator (DFIG) under wind turbine. Energy 2021, 214, 118871. [Google Scholar] [CrossRef]
- Danesh, M.; Jalalaei, A.; Derakhshan, R.E. Auto-landing algorithm for quadrotor UAV using super-twisting second-order sliding mode control in the presence of external disturbances. Int. J. Dyn. Control 2023, 11, 2940–2957. [Google Scholar] [CrossRef]
- Siddique, N.; Rehman, F.U.; Raoof, U.; Iqbal, S.; Rashad, M. Robust hybrid synchronization control of chaotic 3-cell CNN with uncertain parameters using smooth super twisting algorithm. Bull. Pol. Acad. Sci. Tech. Sci. 2023, 71, 1–8. [Google Scholar] [CrossRef]
- Chen, Y.; Cai, B.; Cui, G. The Design of Adaptive Sliding Mode Controller Based on RBFNN Approximation for Suspension Control of MVAWT; 2020 Chinese Automation Congress (CAC): Shanghai, China, 2020. [Google Scholar]
- Wang, D.; Shen, Y.; Sha, Q. Adaptive DDPG design-based sliding-mode control for autonomous underwater vehicles at different speeds. In Proceedings of the 2019 IEEE Underwater Technology (UT), Kaohsiung, Taiwan, 16–19 April 2019. [Google Scholar]
- Nicola, M.; Nicola, C.-I.; Selișteanu, D. Improvement of the control of a grid connected photovoltaic system based on synergetic and sliding mode controllers using a reinforcement learning deep deterministic policy gradient agent. Energies 2022, 15, 2392. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Mechali, O.; Xu, L.; Huang, Y.; Shi, M.; Xie, X. Observer-based fixed-time continuous nonsingular terminal sliding mode control of quadrotor aircraft under uncertainties and disturbances for robust trajectory tracking: Theory and experiment. Control. Eng. Pract. 2021, 111, 104806. [Google Scholar] [CrossRef]
- Tang, P.; Lin, D.; Zheng, D.; Fan, S.; Ye, J. Observer based finite-time fault tolerant quadrotor attitude control with actuator faults. Aerosp. Sci. Technol. 2020, 104, 105968. [Google Scholar] [CrossRef]
- Nasiri, A.; Kiong Nguang, S.; Swain, A. Adaptive sliding mode control for a class of MIMO nonlinear systems with uncertainties. J. Frankl. Inst. 2014, 351, 2048–2061. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N. Deterministic policy gradient algorithms. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| State dimension of the input layer | 9 |
| Action dimension of the output layer | 3 |
| Reward discount factor | 0.995 |
| Minimum batch size | 128 |
| Max steps per episode | 500 |
| Max episodes | 200 |
| Agent sample time | 0.02 s |
| Experience replay buffer | 1 × 106 |
| Target smooth factor | 1 × 10−3 |
| Parameter | Value |
|---|---|
| Mass m/kg | 3.350 |
| Inertia moment about obxb Jx/(kg·m2) | 0.0588 |
| Inertia moment about obyb Jy/(kg·m2) | 0.0588 |
| Inertia moment about obzb Jz/(kg·m2) | 0.1076 |
| Lift factor b | 8.159 × 10−5 |
| Drag factor d | 2.143 × 10−6 |
| Distance between the center of mass and the rotation axis of any propeller l/m | 0.195 |
| Performance Indicators | SMC | AFGS-SMC | DDPG-SMC |
|---|---|---|---|
| Convergence time (s) | 2.1 | 2.5 | 2.0 |
| Steady-state errors (%) | 2 | 5 | 1 |
| Chattering amplitudes (N·m) | (−0.018, 0.024) | (−0.006, 0.006) | (−0.005, 0.005) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, W.; Yang, Y.; Liu, Z. Deep Deterministic Policy Gradient (DDPG) Agent-Based Sliding Mode Control for Quadrotor Attitudes. Drones 2024, 8, 95. https://doi.org/10.3390/drones8030095
Hu W, Yang Y, Liu Z. Deep Deterministic Policy Gradient (DDPG) Agent-Based Sliding Mode Control for Quadrotor Attitudes. Drones. 2024; 8(3):95. https://doi.org/10.3390/drones8030095
Chicago/Turabian StyleHu, Wenjun, Yueneng Yang, and Zhiyang Liu. 2024. "Deep Deterministic Policy Gradient (DDPG) Agent-Based Sliding Mode Control for Quadrotor Attitudes" Drones 8, no. 3: 95. https://doi.org/10.3390/drones8030095
APA StyleHu, W., Yang, Y., & Liu, Z. (2024). Deep Deterministic Policy Gradient (DDPG) Agent-Based Sliding Mode Control for Quadrotor Attitudes. Drones, 8(3), 95. https://doi.org/10.3390/drones8030095