
A Cooperative Decision-Making Approach Based on a Soar Cognitive Architecture for Multi-Unmanned Vehicles

 , ,
, ,
Abstract
:1. Introduction
2. System Design Based on Soar Cognitive Architecture
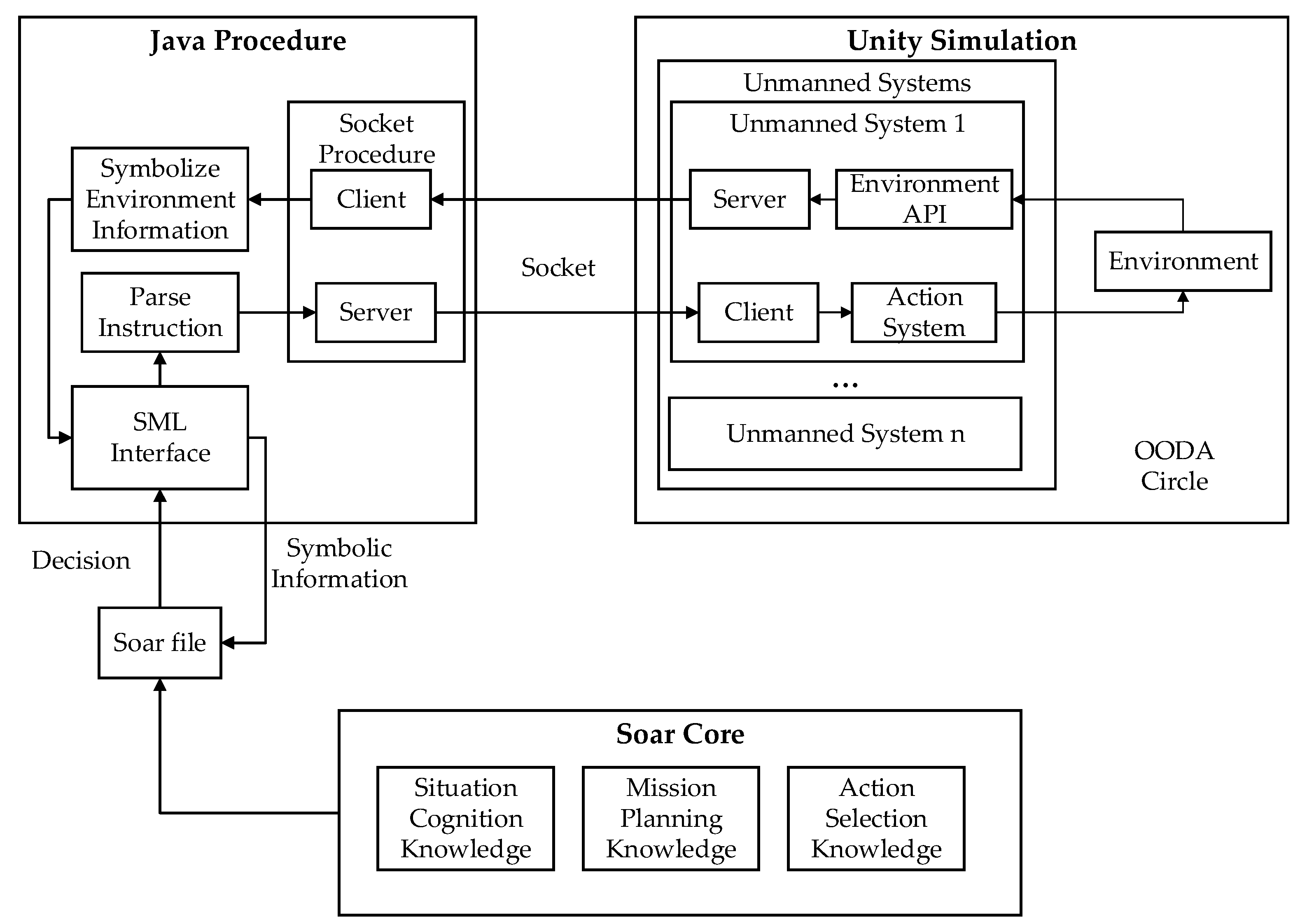
2.1. Overall Framework Design
2.2. Interface
2.3. Knowledge Establishment
3. Game Setting
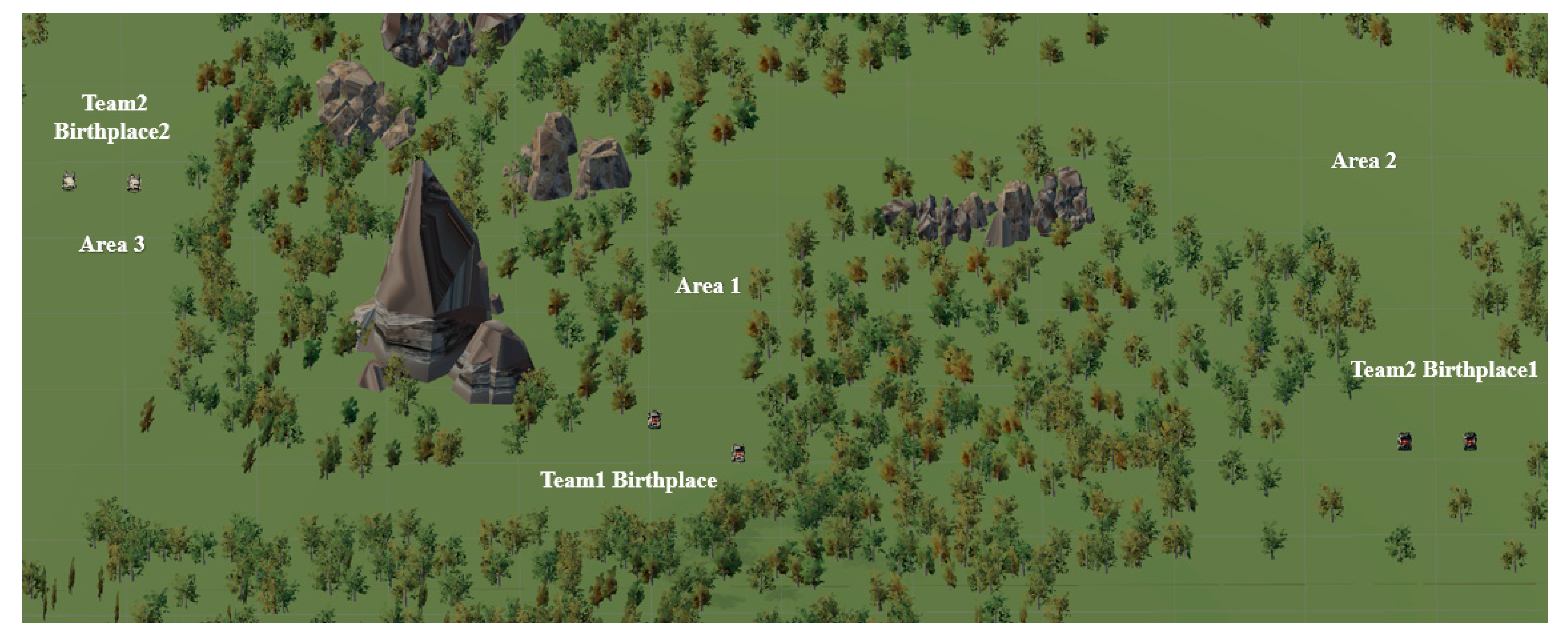
3.1. Scene
3.2. Team Configuration
3.3. Game Flow
- (1)
- Initialize: Initialize scene and unmanned system properties, establish the connection between the client and server, send information to the server, and start client reception.
- (2)
- Step: Unmanned systems choose actions to execute at each time step, affecting the environment and various properties of all unmanned systems.
- (3)
- Monitor: Monitor the environment and various data to determine whether the termination condition is met.
- (4)
- Game Done: The combat experiment terminates when the number of unmanned systems for either side reaches 0 or reaches the maximum number of combat steps (10,000). If one side achieves victory, record one victory for the winning side. If both sides fail to eliminate each other, then record one draw.
- (5)
- Reset: Reset the game. Set the step count back to 0, kill all systems, and regenerate two teams of unmanned systems.
4. Result Analysis
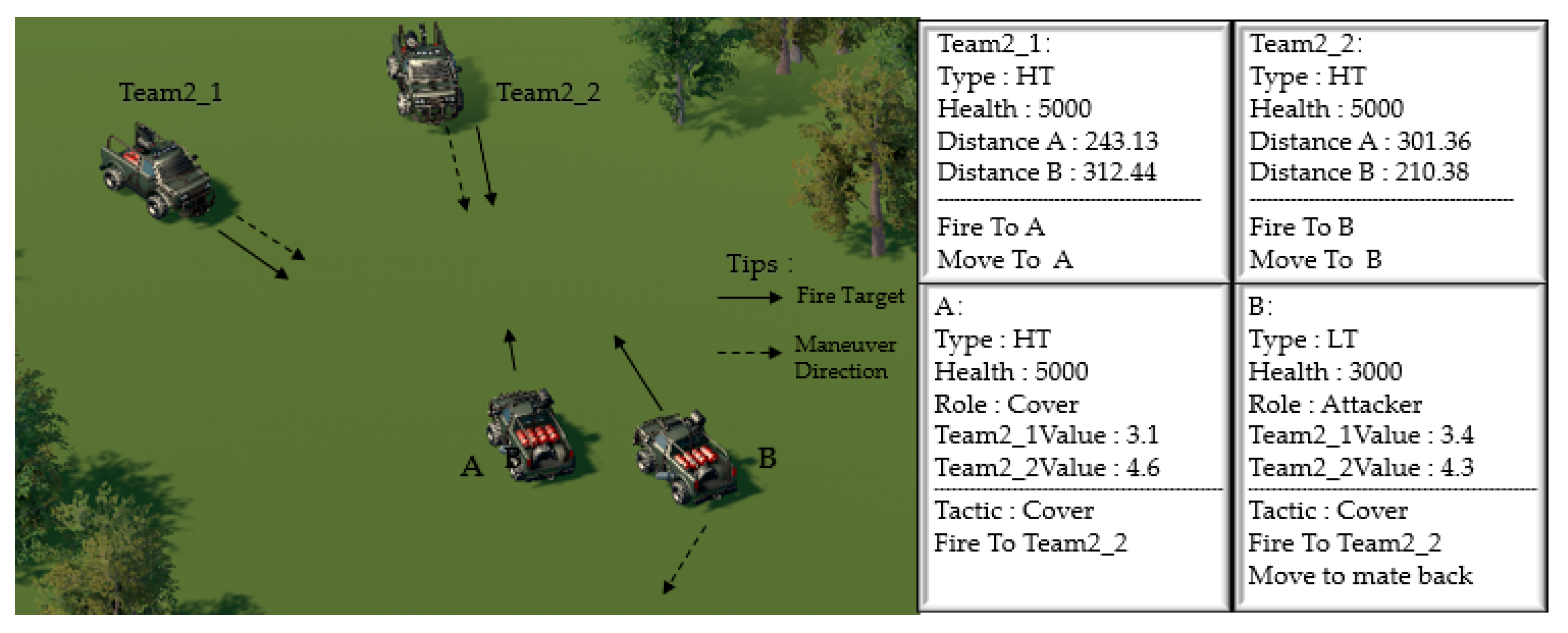
4.1. Real-Time Analysis
4.2. Decision Analysis
4.3. Performance from Past Outcomes
4.4. Performance during the Game
- In Area 2, when applying the Cover strategy, obstacles not only block rival attacks but sometimes hinder Team 1’s attacks as well, resulting in a longer overall testing time. Further refinement of the attack actions is needed, including the addition of criteria to assess whether there are obstacles in the attack direction.
- In Area 3, when facing the situation of 2HT VS 2LT, the outcome of the confrontation is closely related to the positions of Team 1 and Team 2. When the distance between the two sides is close, the advantage of the Kiting tactic is not fully utilized because Team 1 remains within the rival’s attack range for an extended period. This may lead to a decrease in Team 1’s win rate.
- When dealing with the situation of HTLT VS 2HT in Area 3, adopting the Cover strategy has a higher win rate than the Focus Fire strategy. Furthermore, statistics show that during confrontations, the Focus Fire strategy can lead to victories but is also accompanied by mate losses. The probability of losing one mate system constitutes 90% of the total victories. In contrast, when employing the Cover strategy, the loss of one mate system accounts for only 20% of the total victories.
- In tests with asymmetric quantities, the Focus Fire strategy is employed when Team1 has a numerical advantage, while the Kiting tactic is chosen in case of a numerical disadvantage. In tests where there is a numerical disadvantage, the frequency of draws increases due to multiple instances of reaching the maximum time steps.
- There is a correlation between the decision speed of the Soar system and the number of rules. In this paper, the knowledge set was around 200 rules, and, excluding the first decision, the maximum time for a single decision was kept within 7 milliseconds, meeting real-time requirements. However, when dealing with a higher magnitude of rules, it is crucial to focus on testing and controlling decision-making times.
5. Conclusions and Future Work
- Constructing knowledge of cooperative and adversarial cognitive decision models for multi-unmanned systems by designing Situation Cognition Knowledge, Mission Planning Knowledge, and Action Selection Knowledge to assist unmanned systems in adversarial tasks. Situational Awareness Knowledge assists systems in internal cognition, Mission Planning Knowledge utilizes hierarchical thought to decompose adversarial tasks into subtasks related to strategies and defines the execution actions under each strategy, helping system devise fully hierarchical autonomous task planning, while Action Selection Knowledge assists in selecting appropriate strategies for application.
- Providing a complex forest simulation environment based on Unity, along with communication interfaces for connecting and testing cognitive decision models. The decision-making outcomes are intuitively displayed in the visualized scenarios. This establishes a foundation for the subsequent development of multi-domain collaborative unmanned systems.
- The positive performance validates the feasibility and effectiveness of Soar cognitive architecture application to multi-unmanned systems. The system demonstrated the decision-making capabilities of Soar in complex and dynamic environments, showcasing its ability to make appropriate decisions in various complex scenarios. These results confirm the effectiveness of the Soar architecture in collaborative decision-making for multi-unmanned systems.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gao, J.; Wang, G.; Gao, L. LSTM-MADDPG multi-agent Cooperative Decision Algorithm based on asynchronous cooperative updating. J. Jilin Univ. (Engin. Technol. Ed.) 2022, 7, 1–9. [Google Scholar]
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.S.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.; Schrittwieser, J.; et al. StarCraft II: A New Challenge for Reinforcement Learning. arXiv 2017, arXiv:1708.04782. [Google Scholar]
- Ecoffet, A.; Huizinga, J.; Lehman, J.; Stanley, K.O.; Clune, J. First return, then explore. Nature 2021, 590, 580–586. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Singh, S.; Precup, D.; Sutton, R.S. Reward is enough. Artif. Intell. 2021, 299, 103535. [Google Scholar] [CrossRef]
- Cong, C. Research on Multi-Agent Cooperative Decision Making Method Based on Deep Reinforcement Learning. Master’s Thesis, University of Chinese Academy of Sciences, Beijing, China, 2022. [Google Scholar]
- Shi, D.; Yan, X.; Gong, L.; Zhang, J.; Guan, D.; Wei, M. Reinforcement learning driven multi-agent cooperative combat simulation algorithm for naval battle field. J. Syst. Simul. 2023, 35, 786–796. [Google Scholar]
- Zhang, J.; He, Y.; Peng, Y.; Li, G. Path planning of cooperative game based on neural network and artificial potential field. Acta Aeronaut. Astronaut. Sin. 2019, 40, 228–238. [Google Scholar]
- Xing, Y.; Liu, H.; Li, B. Research on intelligent evolution of joint fire strike tactics. J. Ordnance Equip. Eng. 2021, 42, 189–195. [Google Scholar]
- Xu, J.; Zhu, X. Collaborative decision algorithm based on multi-agent reinforcement learning. J. Ningxia Norm. Univ. 2023, 44, 71–79. [Google Scholar]
- Ge, F. Swarm Cooperative Solution Algorithm Based on Chaotic Ants and Its Application. Ph.D. Thesis, Hefei University of Technology, Hefei, China, 2012. [Google Scholar]
- Song, W.X.; Zhang, F.; Liu, R.T. Mathematical models in research of metapopulation theory. J. Gansu Agric. Univ. 2009, 44, 133–139. [Google Scholar]
- Alfonso, R.H.; Pedro, J.T. Effects of diffusion on total biomass in simple metacommunities. J. Theor. Biol. 2018, 3, 12–24. [Google Scholar]
- Schmitt, F.; Schulte, A. Mixed-initiative mission planning using planning strategy models in military manned-unmanned teaming missions. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1391–1396. [Google Scholar]
- Yang, J.H.; Kapolka, M.; Chung, T.H. Autonomy balancing in a manned-unmanned teaming (MUT) swarm attack. In Robot Intelligence Technology and Applications 2012; Springer: Berlin/Heidelberg, Germany, 2013; pp. 561–569. [Google Scholar]
- Puranam, P. Human–AI collaborative decision-making as an organization design problem. J. Org. Des. 2021, 10, 75–80. [Google Scholar] [CrossRef]
- Aickelin, U.; Maadi, M.; Khorshidi, H.A. Expert–Machine Collaborative Decision Making: We Need Healthy Competition. IEEE Intell. Syst. 2022, 37, 28–31. [Google Scholar] [CrossRef]
- Maadi, M.; Khorshidi, H.A.; Aickelin, U. Collaborative Human-ML Decision Making Using Experts’ Privileged Information Under Uncertainty. In Proceedings of the AAAI 2021 Fall Symposium on Human Partnership with Medical AI: Design, Operationalization, and Ethics (AAAI-HUMAN 2021), Virtual Event, 4–6 November 2021. [Google Scholar]
- Zytek, A.; Liu, D.; Vaithianathan, R.; Veeramachaneni, K. Sibyl: Understanding and Addressing the Usability Challenges of Machine Learning In High-Stakes Decision Making. IEEE Trans. Visual. Comput. Graph. 2022, 28, 1161–1171. [Google Scholar] [CrossRef] [PubMed]
- Doshi-Velez, F.; Kim, B. Towards A Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Laird John, E., III; Robert; Wray, E.; Yongjia, W.; Nate, D.; Andrew, M.N.; Samuel, W.; Marinier, I.I.R.P.; Nicholas, G.; Joseph, X. The Soar Cognitive Architecture; The MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Laird, J.; Newell, A.; Rosenbloom, P. Soar: An Architecture for General Intelligence. Artif. Intell. 1987, 33, 1–64. [Google Scholar] [CrossRef]
- Wray, R.E.; Jones, R.M. An Introduction to Soar as an Agent Architecture. In Cognition and Multi-Agent Interaction: From Cognitive Modeling to Social Simulation; Sun, R., Ed.; Cambridge Univ. Press: Cambridge, UK, 2005; pp. 53–78. [Google Scholar]
- Laird, J.E. Introduction to SOAR. arXiv 2022, arXiv:2205.03854. Available online: http://arxiv.org/abs/2205.03854 (accessed on 8 May 2022).
- Laird, J.E. Intelligence, Knowledge & Human-like Intelligence. J. Artif. Gen. Intell. 2020, 11, 41–44. [Google Scholar] [CrossRef]
- Kennedy, W.G.; De Jong, K.A. Characteristics of Long-term Learning in Soar and Its Application to the Utility Problem. In Proceedings of the 20th International Conference on Machine Learning, Washington, DC, USA, 21–24 August; ICML: Honolulu, HI, USA, 2003; pp. 337–344. [Google Scholar]
- Nason, S.; Laird, J.E.; Soar, R.L. Integrating Reinforcement Learning with Soar. Cogn. Syst. Res. 2005, 6, 51–59. [Google Scholar] [CrossRef]
- Nuxoll, A.M.; Laird, J.E. A Cognitive Model of Episodic Memory Integrated with a General Cognitive Architecture. In Proceedings of the International Conference on Cognitive Modeling, Pittsburgh, PA, USA, 30 July–1 August 2004; ICCM: Warwick, UK, 2004; pp. 220–225. [Google Scholar]
- Hanford, S.D. A cognitive robotic system based on the Soar cognitive architecture for mobile robot navigation, search, and mapping missions. In Dissertations & Theses Gradworks; The Pennsylvania State University: State College, PA, USA, 2011. [Google Scholar]
- Gunetti, P.; Dodd, T.; Thompson, H. Simulation of a Soar-Based Autonomous Mission Management System for Unmanned Aircraft. J. Aerosp. Comput. Inf. Commun. 2013, 10, 53–70. [Google Scholar] [CrossRef]
- Laird, J.E.; Yager, E.S.; Hucka, M.; Tuck, C.M. Robo-Soar: An integration of external interaction, planning, and learning, using Soar. IEEE Robot. Auton. Syst. 1991, 8, 113–129. [Google Scholar] [CrossRef]
- Van Dang, C.; Tran, T.T.; Pham, T.X.; Gil, K.-J.; Shin, Y.-B.; Kim, J.-W. Implementation of a Refusable Human-Robot Interaction Task with Humanoid Robot by Connecting Soar and ROS. J. Korea Robot. Soc. 2017, 12, 55–64. [Google Scholar] [CrossRef]
- Pfeiffer, S.; Angulo, C. Gesture learning and execution in a humanoid robot via dynamic movement primitives. Pattern Recognit. Lett. 2015, 67, 100–107. [Google Scholar] [CrossRef]
- Wu, T.; Sun, X.; Zhao, S. Application of Soar in the construction of Air defense Decision Behavior Model of Surface Ship CGF. Command Control Simul. 2013, 2, 108–112. [Google Scholar]
- Zhao, Y.; Derbinsky, N.; Wong, L.Y.; Sonnenshein, J.; Kendall, T. Continual and real-time learning for modeling combat identification in a tactical environment. In Proceedings of the NIPS 2018 Workshop on Continual Learning, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Luo, F.; Zhou, Q.; Fuentes, J.; Ding, W.; Gu, C. A Soar-Based Space Exploration Algorithm for Mobile Robots. Entropy J. 2022, 24, 426. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Wu, H.; Tang, L.; Wang, W. An intrusion prevention system with cognitive function. J. Henan Univ. Sci. Technol. (Nat. Sci. Ed.) 2017, 38. 49–53+6. [Google Scholar] [CrossRef]
- Czuba, A. Target Detection in Changing Noisy Environment Using Coherent Radar Model Integrated with Soar Cognitive Architecture. In Proceedings of the 2022 IEEE 21st International Conference on Cognitive Informatics & Cognitive Computing (ICCI*CC), Toronto, ON, Canada, 8–10 December 2022; pp. 64–71. [Google Scholar] [CrossRef]
- Mininger, A.; Laird, J.E. A Demonstration of Compositional, Hierarchical Interactive Task Learning. Proc. AAAI Conf. Artif. Intell. 2022, 36, 13203–13205. [Google Scholar] [CrossRef]
- Jones, R.M.; Laird, J.E.; Nielsen, P.E.; Coulter, K.J.; Kenny, P.; Koss, F.V. Automated Intelligent Pilots for Combat Flight Simulation. AI Mag. 1999, 20, 27–41. [Google Scholar]
- Laird, J.E. Toward cognitive robotics. In Proceedings of the SPIE, Orlando, FL, USA, 14–15 April 2009. [Google Scholar]
- Wray, R.E.; Laird, J.E.; Nuxoll, A.; Stokes, D.; Kerfoot, A. Synthetic Adversaries for Urban Combat Training. AI Mag. 2005, 26, 82–92. Available online: https://search.ebscohost.com/login.aspx?direct=true&db=edsbl&AN=RN176366008&site=eds-live (accessed on 20 February 2024).
- Available online: https://soar.eecs.umich.edu/articles/articles/soar-markup-language-sml/78-sml-quick-start-guide (accessed on 15 August 2014).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Action | Description |
|---|---|
| Cross formation | When the team advances to a narrow road, a formation is designed to ensure safety both in the front and on both sides. |
| Vertical formation | When the team advances to a very narrow pathway allowing only single-person passage, a formation is designed for safe progression. |
| Horizontal formation | When the team advances to a wide area, a formation is designed to ensure the full utilization of firepower. |
| Focus fire | Both sides of the team maintain a horizontal alignment and launch a joint attack. |
| Kiting | The kiting tactic involves launching attacks by leveraging the advantages of range and speed. |
| Cover(tactic) | The cover strategy protects the attacker and completes the assault. |
| Move | Autonomous navigation to the corresponding point. |
| Retreat | Quick location of nearby large obstacles and resistance to rival attacks. |
| Fire | Firing at the target, but only one target can be attacked at a time. There is a certain cooldown period after firing. |
| Hide | Seeking cover while changing ammunition (no offensive capability). |
| Cover(action) | When there is not enough cover on the front lines, roles are switched to provide cover for teammates. |
| Speed up | When team members are distant, members positioned at the rear of the team accelerate to catch up. |
| Slow down | When team members are widely spaced, members positioned at the front of the team slow down. |
| Situation | Focus Fire | Cover | Kiting | Retreat |
|---|---|---|---|---|
| Both teams have similar configurations. | 4 | 3 | 2 | 1 |
| Team 1 has a significant speed advantage. | 3 | 2 | 4 | 1 |
| Team 1 possesses a distinct power advantage. | 3 | 4 | 2 | 1 |
| Team 1 has critically low health. | 1 | 2 | 3 | 4 |
| Type | ATK | HP | CD | Attack Range | Field of View | Speed Range | Tag |
|---|---|---|---|---|---|---|---|
| HT | 500 | 5000 | 5 | 220 | 350 | 15–25 | Team 1/Team 2 |
| LT | 300 | 3000 | 3 | 280 | 350 | 25–35 | Team 1/Team 2 |
| Confrontation Scenario | Both Parties’ Configurations and Strategies | Team 1 Wins | Team 2 Wins | Draws | Team 1’s Win Rate |
|---|---|---|---|---|---|
| Area 2 | 2HT VS 2LT (Cover) | 36 | 16 | 2 | 66.67% |
| Area 3 | 2HT VS 2LT (Kiting) | 39 | 17 | 1 | 68.42% |
| HTLT VS 2LT (Kiting) | 33 | 18 | 4 | 60% | |
| 2HT VS HTLT (Kiting) | 28 | 16 | 0 | 63% | |
| HTLT VS 2HT (Focus Fire) | 42 | 9 | 0 | 82.35%% | |
| HTLT VS 2HT (Cover) | 43 | 0 | 2 | 95.56% | |
| HT VS 2LT (Focus Fire) | 25 | 0 | 0 | 100% | |
| 3HT VS 2LT (Kiting) | 28 | 15 | 7 | 56% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, L.; Tang, Y.; Wang, T.; Xie, T.; Huang, P.; Yang, B. A Cooperative Decision-Making Approach Based on a Soar Cognitive Architecture for Multi-Unmanned Vehicles. Drones 2024, 8, 155. https://doi.org/10.3390/drones8040155
Ding L, Tang Y, Wang T, Xie T, Huang P, Yang B. A Cooperative Decision-Making Approach Based on a Soar Cognitive Architecture for Multi-Unmanned Vehicles. Drones. 2024; 8(4):155. https://doi.org/10.3390/drones8040155
Chicago/Turabian StyleDing, Lin, Yong Tang, Tao Wang, Tianle Xie, Peihao Huang, and Bingsan Yang. 2024. "A Cooperative Decision-Making Approach Based on a Soar Cognitive Architecture for Multi-Unmanned Vehicles" Drones 8, no. 4: 155. https://doi.org/10.3390/drones8040155
APA StyleDing, L., Tang, Y., Wang, T., Xie, T., Huang, P., & Yang, B. (2024). A Cooperative Decision-Making Approach Based on a Soar Cognitive Architecture for Multi-Unmanned Vehicles. Drones, 8(4), 155. https://doi.org/10.3390/drones8040155