Large Scale Fault Data Analysis and OSS Reliability Assessment Based on Quantification Method of the First Type


Abstract
:1. Introduction
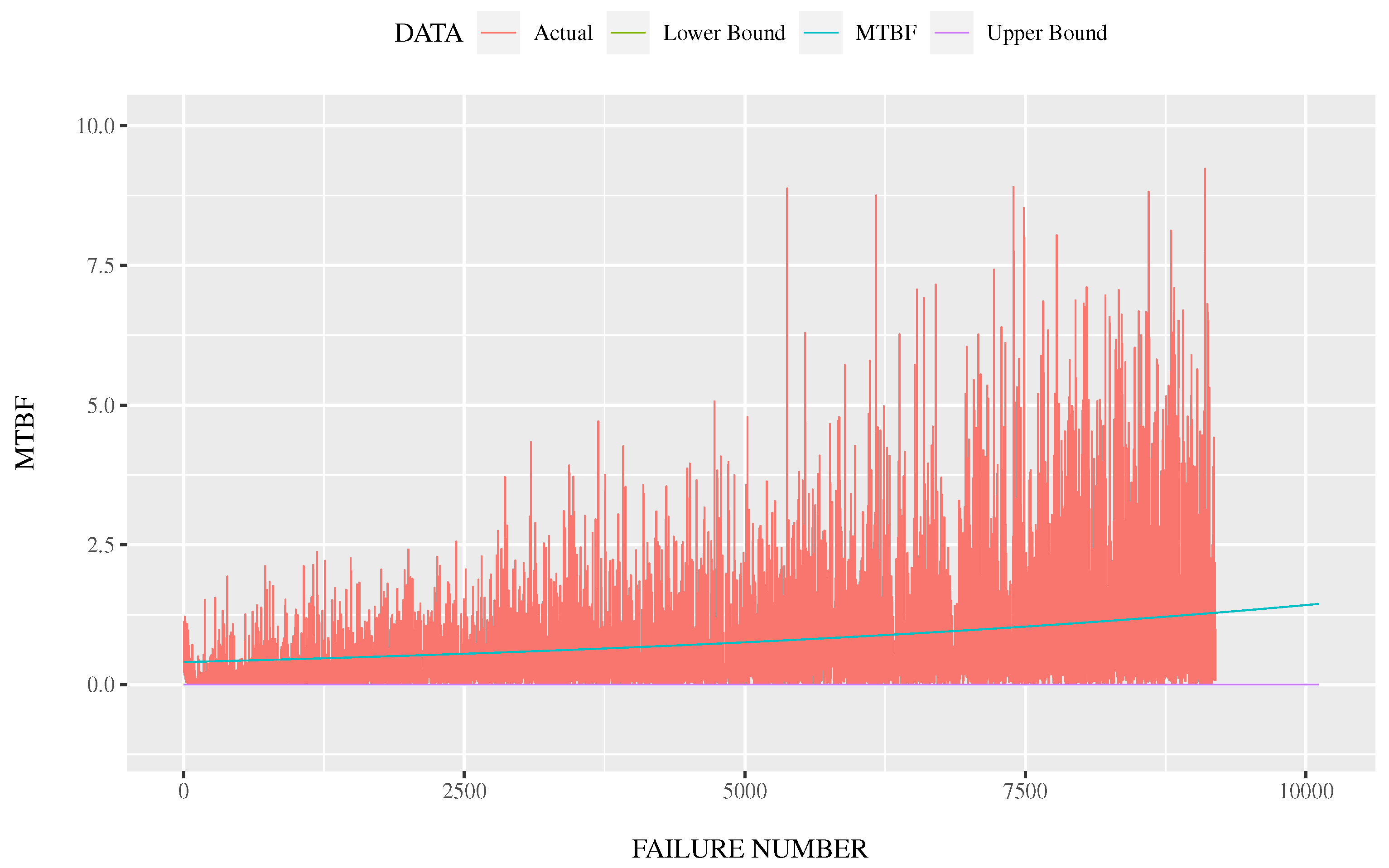
2. Fault Data Analysis
- Non-homogeneous Poisson process (NHPP) model (Fault Count Type).
- Hazard rate model (Time Interval of Fault Detection).
- Stochastic differential equation model (Fault Count Type).
- Logistic curve model (Fault Count Type).
3. Multiple Regression Analysis
- Step 1:
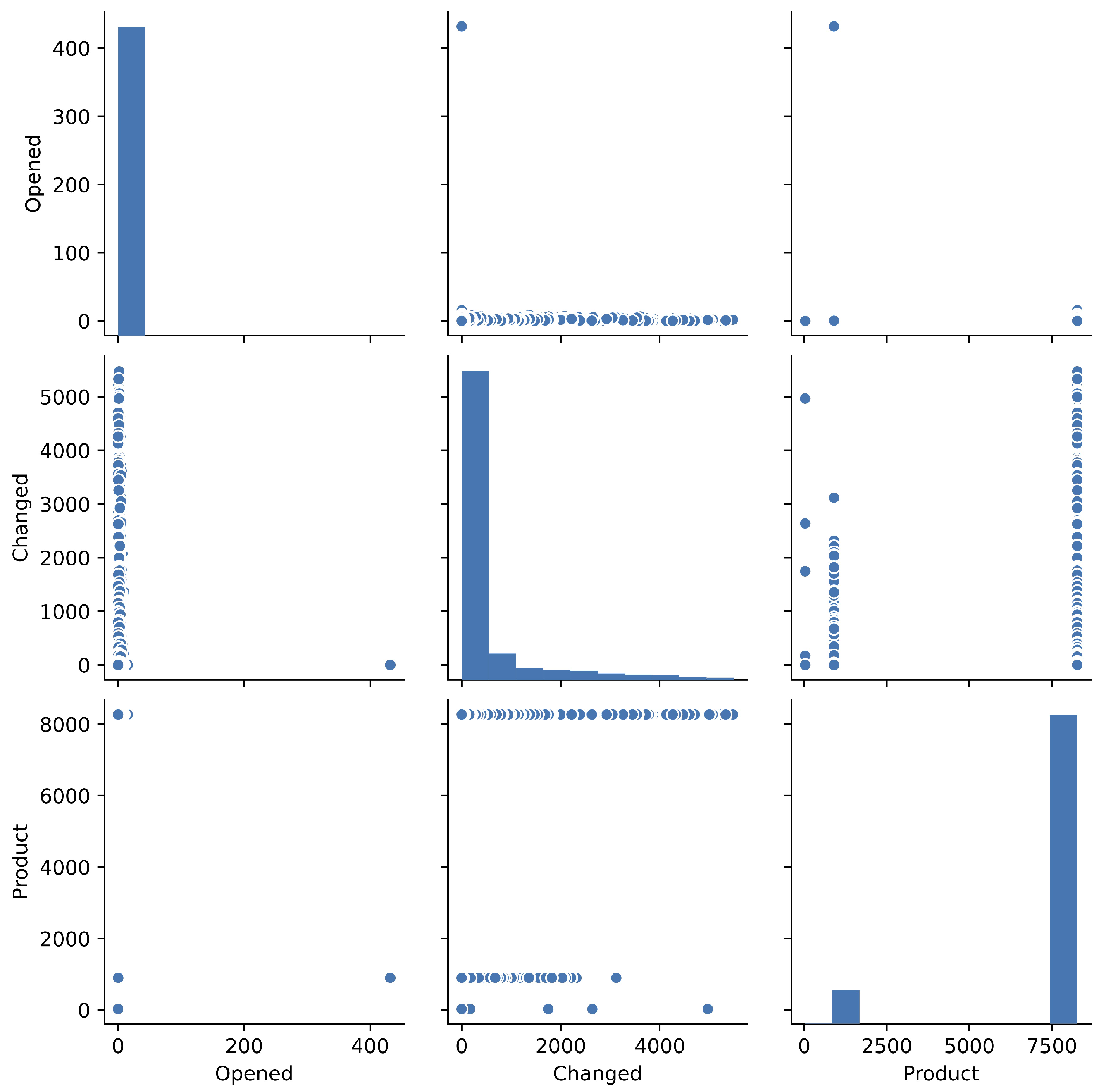
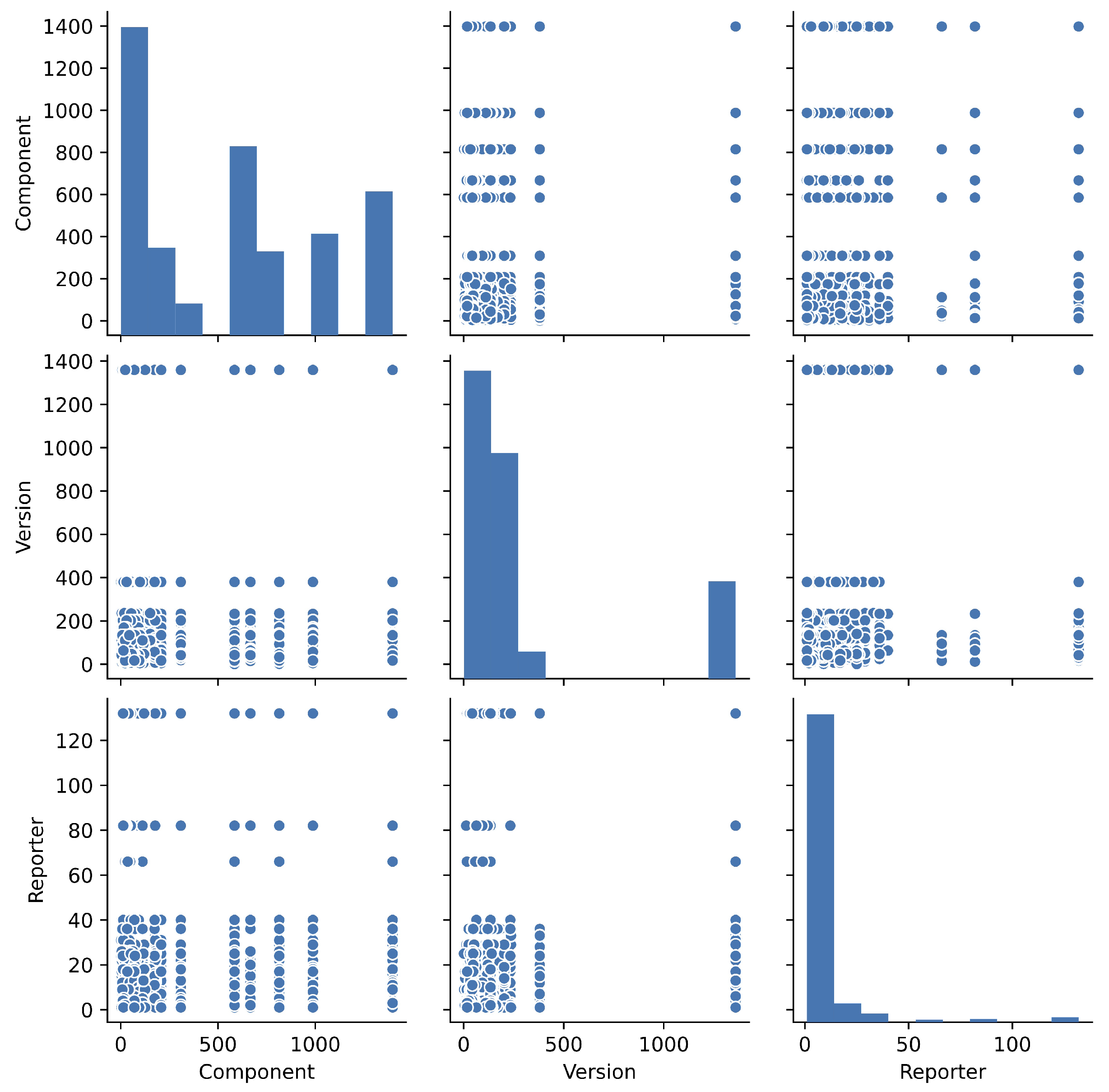
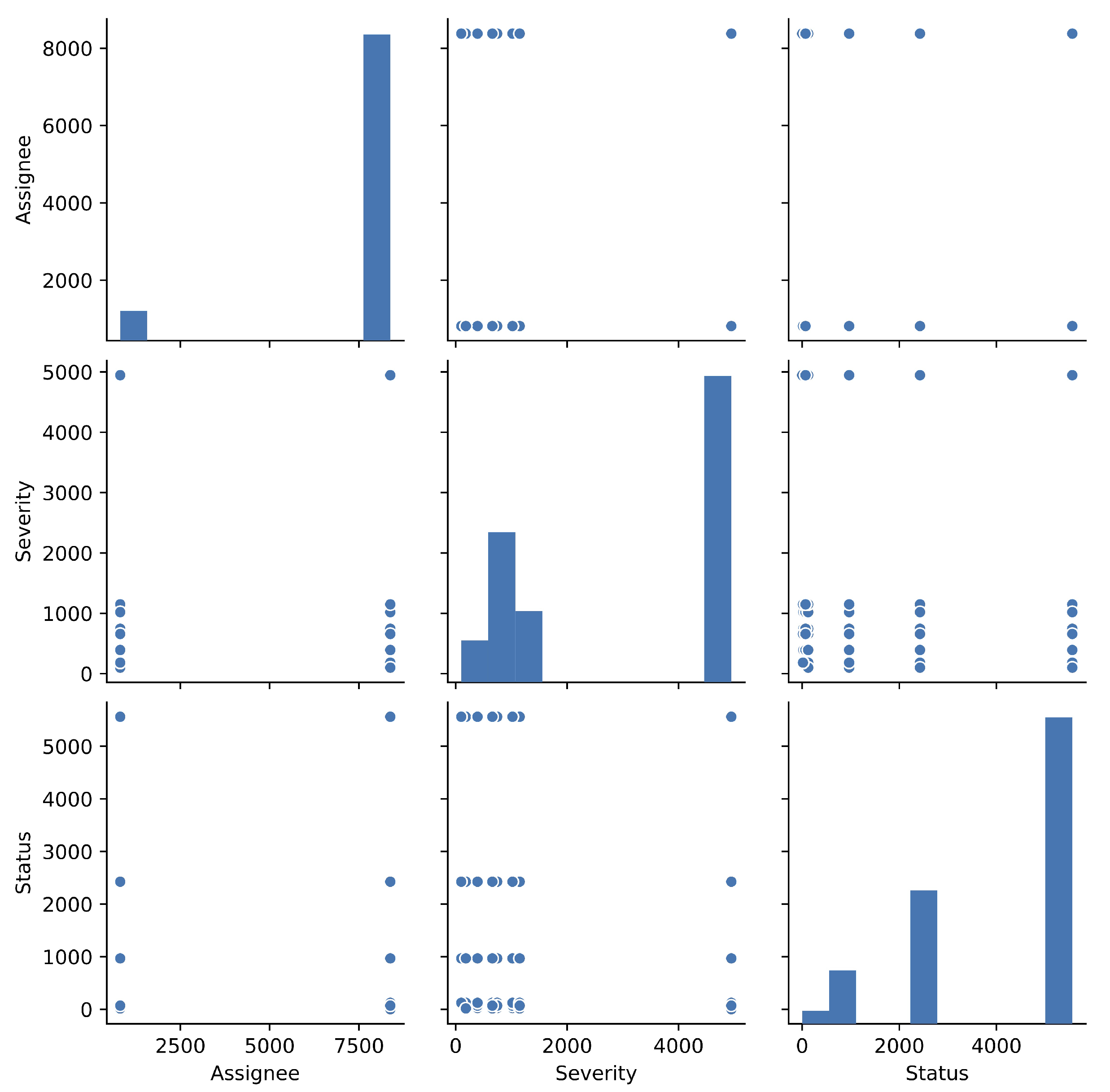
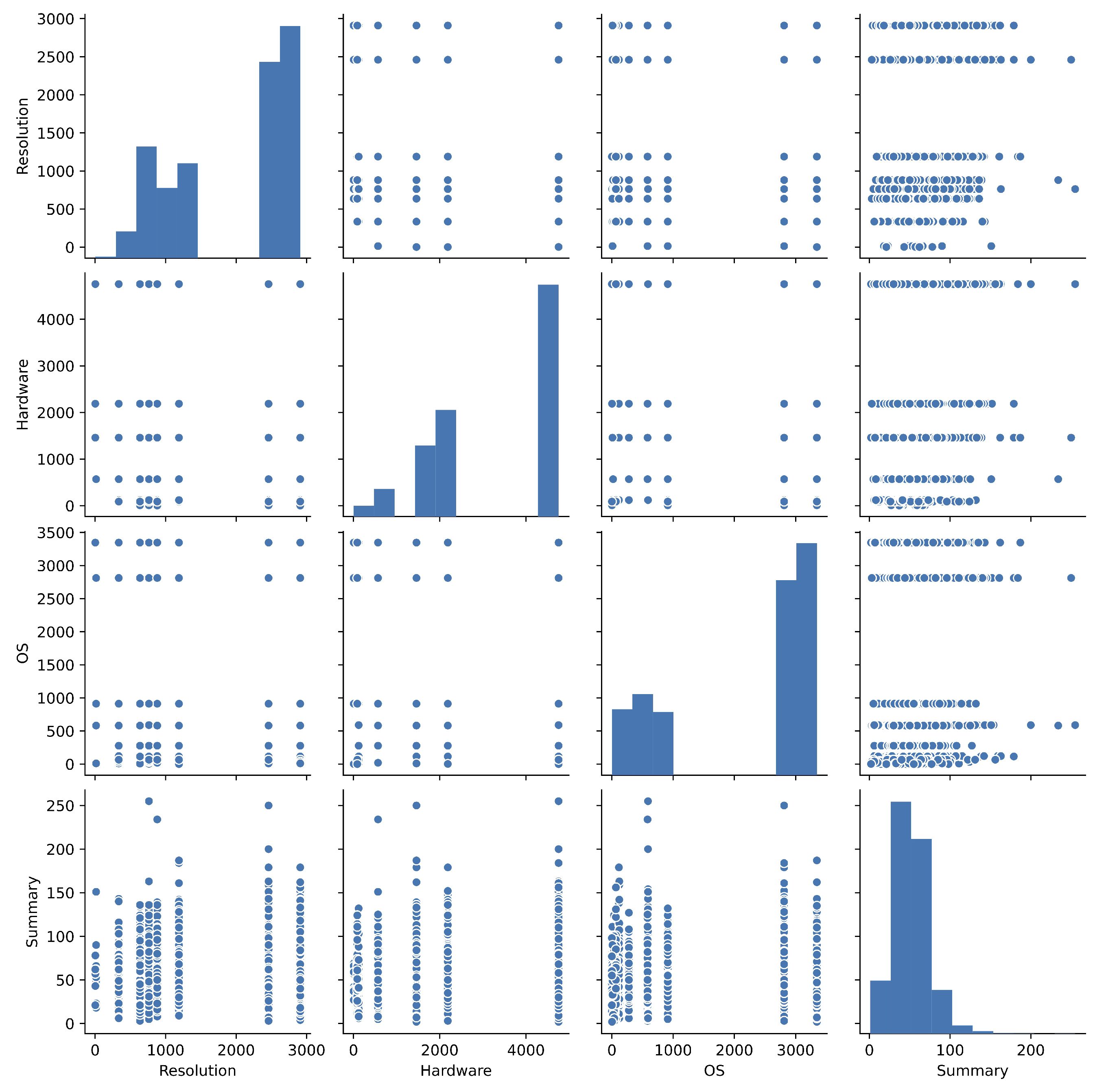
- The pairplots for each factor are used in order to overlooking the fault big data.
- Step 2:
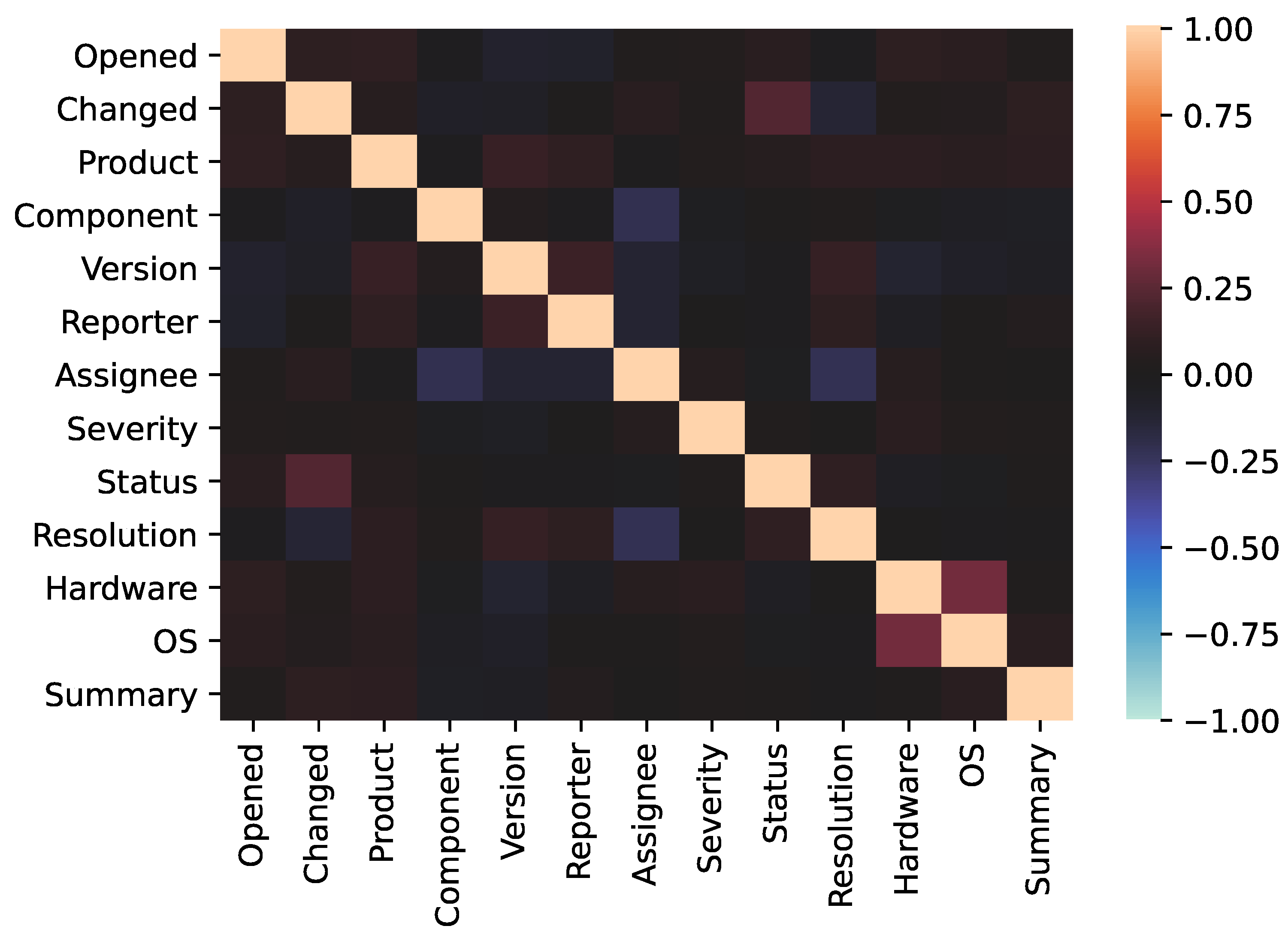
- We apply the heatmap to the decision of the objective variable
- Step 3:
- The explanatory variables are narrowed by using the forward-backward stepwise selection method. Then, the degree of freedom is decided by the number of explanatory variables.
- Step 4:
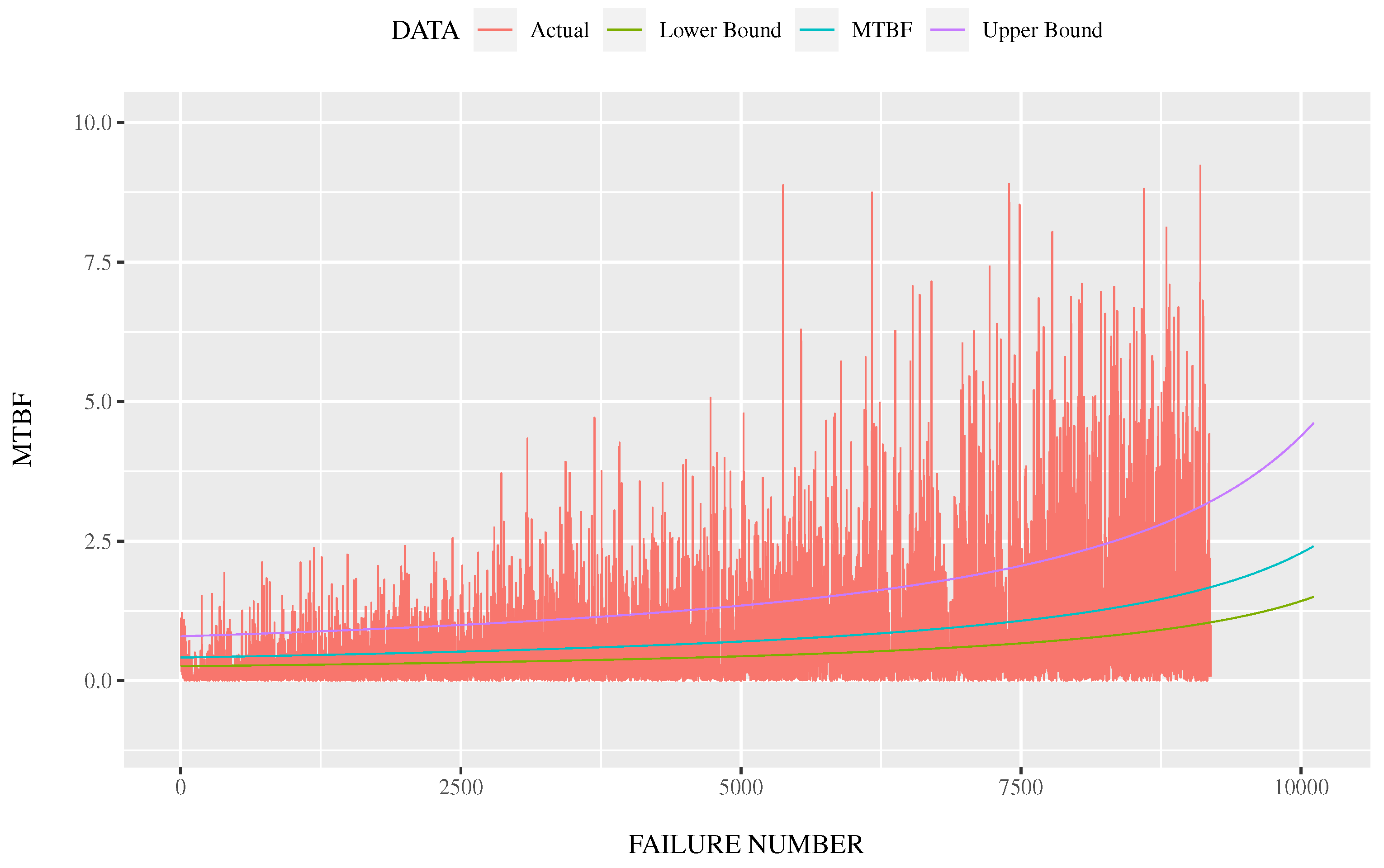
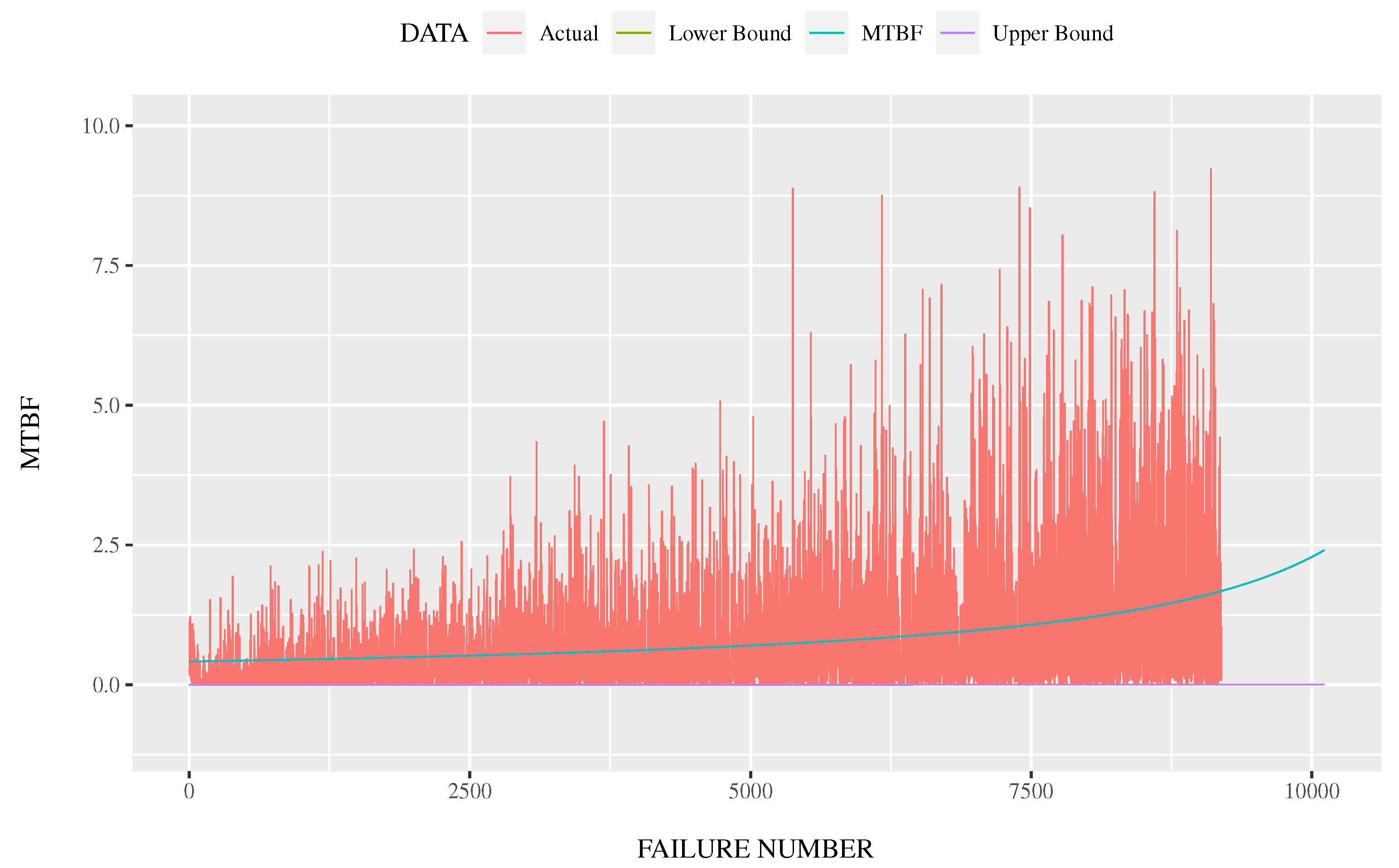
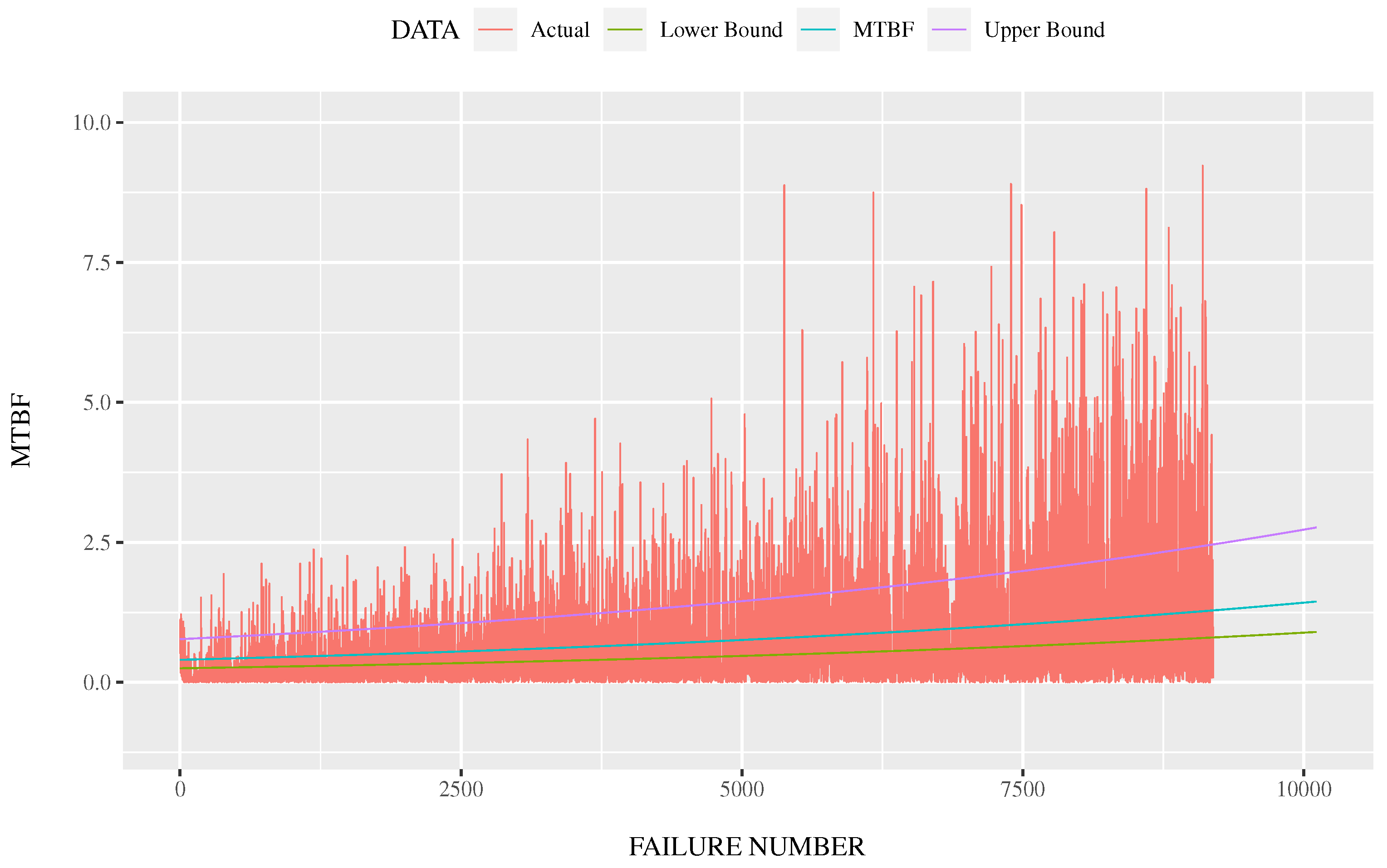
- The upper and lower bounds are estimated from the stochastic model and the degree of freedom in place of the number of explanatory variables.
| Opened: | The date and time recorded on the bug tracking system, |
| Changed: | The modified date and time. |
| Product: | The name of product included in OSS. |
| Component: | The name of component included in OSS. |
| Version: | The version number of OSS. |
| Reporter: | The nickname of fault reporter. |
| Assignee: | The nickname of fault assignee. |
| Severity: | The level of fault. |
| Status: | The fixing status of fault. |
| Resolution: | The status of resolution of fault. |
| Hardware: | The name of hardware under fault occurrence. |
| OS: | The name of operating system under fault occurrence. |
| Summary: | The brief contents of fault. |
4. Forward-Backward Stepwise Selection Method
- Step 1:
- All explanatory variables are analyzed by the multiple regression.
- Step 2:
- As the results of step 1, the explanatory variable is removed if p-value becomes large than 0.01.
- Step 3:
- The selected explanatory variables are analyzed by the multiple regression again.
- Step 4:
- The above steps 1 and 2 are continued until there is no p-value of explanatory variable larger than 0.01.
5. Multiple Regression Analysis with Application to Reliability Assessment
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yamada, S. Software Reliability Modeling: Fundamentals and Applications; Springer: Tokyo, Japan; Heidelberg, Germany, 2014. [Google Scholar]
- Kapur, P.K.; Pham, H.; Gupta, A.; Jha, P.C. Software Reliability Assessment with OR Applications; Springer: London, UK, 2011. [Google Scholar]
- Yamada, S.; Tamura, Y. OSS Reliability Measurement and Assessment; Springer International Publishing: Basel, Switzerland, 2016. [Google Scholar]
- Zhou, Y.; Davis, J. Open source software reliability model: An empirical approach. In Proceedings of the Fifth Workshop on Open Source Software Engineering (5-WOSSE), St Louis, MO, USA, 17 May 2005; pp. 1–6. [Google Scholar] [CrossRef]
- Norris, J. Mission-critical development with open source software. IEEE Softw. Mag. 2004, 21, 42–49. [Google Scholar] [CrossRef]
- Janczarek, P.; Sosnowski, J. Investigating software testing and maintenance reports: Case study. Inf. Softw. Technol. 2015, 58, 272–288. [Google Scholar] [CrossRef]
- Li, Q.; Pham, H. A Generalized Software Reliability Growth Model With Consideration of the Uncertainty of Operating Environments. IEEE Access 2019, 7, 84253–84267. [Google Scholar] [CrossRef]
- Tariq, I.; Maqsood, T.B.; Hayat, B.; Hameed, K.; Nasir, M.; Jahangir, M. The comprehensive study on software reliability. In Proceedings of the 2018 International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 3–4 March 2018; pp. 1–7. [Google Scholar]
- Korpalski, M.; Sosnowski, J. Correlating software metrics with software defects. In Proceedings of the Photonics Applications in Astronomy, Communications, Industry, and High-Energy Physics Experiments, Wilga, Poland, 27 May–5 June 2018. [Google Scholar] [CrossRef]
- Madeyski, L.; Jureczko, M. Which process metrics can significantly improve defect prediction models? An empirical study. Softw. Qual. J. 2015, 23, 393–422. [Google Scholar] [CrossRef] [Green Version]
- Park, N.J.; George, K.M.; Park, N. A multiple regression model for trend change prediction. In Proceedings of the 2010 International Conference on Financial Theory and Engineering, Dubai, UAE, 18–20 June 2010; pp. 22–26. [Google Scholar] [CrossRef]
- Aiyin, W.; Yanmei, X. Multiple Linear Regression Analysis of Real Estate Price. In Proceedings of the 2018 International Conference on Robots & Intelligent System (ICRIS), Changsha, China, 26–27 May 2018; pp. 564–568. [Google Scholar] [CrossRef]
- Rahil, A.; Mbarek, N.; Togni, O.; Atieh, M.; Fouladkar, A. Statistical learning and multiple linear regression model for network selection using MIH. In Proceedings of the Third International Conference on e-Technologies and Networks for Development (ICeND2014), Beirut, Lebanon, 29 April–1 May 2014; pp. 189–194. [Google Scholar] [CrossRef]
- Singh, V.B.; Sharma, M.; Pham, H. Entropy based software reliability analysis of multi-version open source software. IEEE Trans. Softw. Eng. 2017. [Google Scholar] [CrossRef]
- Lavazza, L.; Morasca, S.; Taibi, D.; Tosi, D. An empirical investigation of perceived reliability of open source Java programs. In Proceedings of the 27th Annual ACM Symposium on Applied Computing (SAC ’12), Trento, Italy, 26–30 March 2012; pp. 1109–1114. [Google Scholar] [CrossRef]
- The Apache Software Foundation, The Apache HTTP Server Project. Available online: http://httpd.apache.org/ (accessed on 14 October 2020).
- Tamura, Y.; Yamada, S. Dependability analysis tool based on multi-dimensional stochastic noisy model for cloud computing with big data. Int. J. Math. Eng. Manag. Sci. 2017, 2, 273–287. [Google Scholar] [CrossRef]
- Tamura, Y.; Yamada, S. Open source software cost analysis with fault severity levels based on stochastic differential equation models. J. Life Cycle Reliab. Saf. Eng. 2017, 6, 31–35. [Google Scholar] [CrossRef]
- Tamura, Y.; Yamada, S. Dependability analysis tool considering the optimal data partitioning in a mobile cloud. In Reliability Modeling with Computer and Maintenance Applications; World Scientific: Singapore, 2017; pp. 45–60. [Google Scholar]
- Tamura, Y.; Yamada, S. Multi-dimensional software tool for OSS project management considering cloud with big data. Int. J. Reliab. Qual. Saf. Eng. 2018, 25, 1850014-1–1850014-16. [Google Scholar] [CrossRef]
- Tamura, Y.; Yamada, S. Maintenance effort management based on double jump diffusion model for OSS project. Ann. Oper. Res. 2019, 1–16. [Google Scholar] [CrossRef]
- Jelinski, Z.; Moranda, P.B. Software Reliability Research, in Statistical Computer Performance Evaluation; Freiberger, W., Ed.; Academic Press: New York, NY, USA, 1972; pp. 465–484. [Google Scholar]
- Yin, L.; Trivedi, K.S. Confidence interval estimation of NHPP-based software reliability models. In Proceedings of the 10th International Symposium on Software Reliability Engineering (Cat. No.PR00443), Boca Raton, FL, USA, 1–4 November 1999; pp. 6–11. [Google Scholar] [CrossRef]
- Okamura, H.; Grottke, M.; Dohi, T.; Trivedi, K.S. Variational Bayesian Approach for Interval Estimation of NHPP-Based Software Reliability Models. In Proceedings of the 37th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN’07), Edinburgh, UK, 25–28 June 2007; pp. 698–707. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Opened | Product | Component | Version | Reporter | Assignee |
| 0.83895 | Apache httpd-1.3 | Documentation | 1.3.23 | rineau+apachebugzilla | docs |
| 1.12118 | Apache httpd-1.3 | Other mods | 1.3.24 | siegfried.delwiche | bugs |
| 0.17191 | Apache httpd-1.3 | Documentation | 1.3.23 | dard | bugs |
| 0.40766 | Apache httpd-1.3 | Other | 1.3.23 | bernard.l.dubreuil | docs |
| 0.51352 | Apache httpd-1.3 | Other | 1.3.23 | george | bugs |
| Severity | Status | Resolution | Hardware | OS | |
| normal | CLOSED | FIXED | Other | other | |
| blocker | CLOSED | FIXED | PC | Linux | |
| normal | CLOSED | FIXED | All | FreeBSD | |
| minor | CLOSED | FIXED | All | All | |
| normal | CLOSED | WORKSFORME | PC | Linux |
| Opened | Product | Component | Version | Reporter | Assignee |
| 0.83895 | 898 | 815 | 95 | 1 | 815 |
| 1.12118 | 898 | 91 | 62 | 1 | 8378 |
| 0.17191 | 898 | 815 | 95 | 1 | 8378 |
| 0.40766 | 898 | 141 | 95 | 2 | 815 |
| 0.51352 | 898 | 141 | 95 | 1 | 8378 |
| Severity | Status | Resolution | Hardware | OS | |
| 4946 | 2426 | 2910 | 1460 | 912 | |
| 392 | 2426 | 2910 | 4755 | 3347 | |
| 4946 | 2426 | 2910 | 2188 | 278 | |
| 658 | 2426 | 2910 | 2188 | 2812 | |
| 4946 | 2426 | 335 | 4755 | 3347 |
| Hardware | Estimate | Std. Error | t Value | p Value |
| Intercept | 1645.720058 | 114.700127 | 14.348 | 0 |
| Opened | 2.791757 | 3.498686 | 0.7979 | 0.424923 |
| Changed | −0.067763 | 0.017142 | −3.9531 | 0.000078 |
| Product | 0.051574 | 0.005491 | 9.3933 | 0 |
| Component | −0.008983 | 0.032654 | −0.2751 | 0.783246 |
| Version | −0.131288 | 0.037497 | −3.5013 | 0.000465 |
| Reporter | −0.146627 | 0.873514 | −0.1679 | 0.866698 |
| Assignee | 0.058349 | 0.005035 | 11.5888 | 0 |
| Severity | 0.063834 | 0.00753 | 8.4776 | 0 |
| Status | −0.02625 | 0.008096 | −3.2424 | 0.00119 |
| Resolution | 0.003068 | 0.016816 | 0.1824 | 0.855249 |
| OS | 0.342187 | 0.012378 | 27.6439 | 0 |
| Summary | −0.452142 | 0.712837 | −0.6343 | 0.525911 |
| OS | Estimate | Std. Error | t Value | pValue |
| Intercept | 1765.506001 | 86.557174 | 20.397 | 0 |
| Opened | 0.546647 | 2.669727 | 0.2048 | 0.837766 |
| Changed | 0.042945 | 0.013078 | 3.2837 | 0.001028 |
| Product | 0.020329 | 0.004211 | 4.8277 | 0.000001 |
| Component | −0.072043 | 0.024922 | −2.8908 | 0.003852 |
| Version | 0.162994 | 0.028514 | 5.7162 | 0 |
| Reporter | 0.040314 | 0.666462 | 0.0605 | 0.951767 |
| Assignee | −0.035459 | 0.003937 | −9.0061 | 0 |
| Severity | −0.010353 | 0.005781 | −1.7908 | 0.073361 |
| Status | −0.038089 | 0.006183 | −6.1603 | 0 |
| Resolution | −0.028639 | 0.012835 | −2.2314 | 0.02568 |
| Hardware | 0.199227 | 0.007261 | 27.4381 | 0 |
| Summary | 3.442676 | 0.539452 | 6.3818 | 0 |
| Changed | Estimate | Std. Error | t Value | pValue |
| Intercept | 159.274647 | 69.47537 | 2.2925 | 0.021897 |
| Opened | 0.43598 | 2.096636 | 0.2079 | 0.835278 |
| Product | 0.027367 | 0.003366 | 8.1295 | 0 |
| Component | −0.093938 | 0.019572 | −4.7996 | 0.000002 |
| Version | −0.054772 | 0.022467 | −2.4379 | 0.014792 |
| Reporter | 0.53278 | 0.523398 | 1.0179 | 0.30874 |
| Assignee | 0.019791 | 0.003121 | 6.3411 | 0 |
| Severity | −0.003285 | 0.004545 | −0.7227 | 0.469904 |
| Status | 0.120565 | 0.004782 | 25.2141 | 0 |
| Resolution | −0.282455 | 0.009813 | −28.7829 | 0 |
| Hardware | −0.024331 | 0.005928 | −4.1044 | 0.000041 |
| OS | 0.026484 | 0.007756 | 3.4146 | 0.000642 |
| Summary | 1.344123 | 0.427139 | 3.1468 | 0.001656 |
| Status | Estimate | Std. Error | t Value | pValue |
| Intercept | 3191.460936 | 129.213128 | 24.6992 | 0 |
| Opened | −1.334526 | 4.025544 | −0.3315 | 0.740264 |
| Changed | 0.444458 | 0.019224 | 23.1196 | 0 |
| Product | 0.030289 | 0.006215 | 4.8737 | 0.000001 |
| Component | 0.069858 | 0.037401 | 1.8678 | 0.061817 |
| Version | −0.197055 | 0.043141 | −4.5677 | 0.000005 |
| Reporter | 0.366868 | 1.004787 | 0.3651 | 0.715031 |
| Assignee | −0.018191 | 0.005768 | −3.154 | 0.001616 |
| Severity | 0.025926 | 0.008674 | 2.9889 | 0.002807 |
| Resolution | 0.423487 | 0.018391 | 23.0264 | 0 |
| Hardware | −0.034746 | 0.011364 | −3.0576 | 0.002238 |
| OS | −0.086595 | 0.014885 | −5.8176 | 0 |
| Summary | 1.250057 | 0.816914 | 1.5302 | 0.125997 |
| Hardware | Estimate | Std. Error | t Value | p Value |
| Intercept | 1626.405219 | 97.43963 | 16.6914 | 0 |
| Changed | −0.068803 | 0.016619 | −4.1401 | 0.000035 |
| Product | 0.05123 | 0.00532 | 9.6292 | 0 |
| Version | −0.130621 | 0.037285 | −3.5033 | 0.000462 |
| Assignee | 0.058414 | 0.004989 | 11.7087 | 0 |
| Severity | 0.063954 | 0.007503 | 8.5233 | 0 |
| Status | −0.026041 | 0.007774 | −3.3498 | 0.000812 |
| OS | 0.341771 | 0.012315 | 27.7524 | 0 |
| OS | Estimate | Std. Error | t Value | pValue |
| Intercept | 1743.085854 | 85.250018 | 20.4468 | 0 |
| Changed | 0.043135 | 0.01308 | 3.2978 | 0.000978 |
| Product | 0.020108 | 0.004139 | 4.8586 | 0.000001 |
| Component | −0.071013 | 0.024916 | −2.8501 | 0.00438 |
| Version | 0.163322 | 0.028485 | 5.7336 | 0 |
| Assignee | −0.035639 | 0.00385 | −9.2573 | 0 |
| Status | −0.038459 | 0.006145 | −6.2587 | 0 |
| Resolution | −0.028896 | 0.012789 | −2.2595 | 0.023879 |
| Hardware | 0.198147 | 0.007192 | 27.5505 | 0 |
| Summary | 3.431072 | 0.537922 | 6.3784 | 0 |
| Changed | Estimate | Std. Error | t Value | pValue |
| Intercept | 156.810893 | 68.42801 | 2.2916 | 0.02195 |
| Product | 0.027344 | 0.003314 | 8.2522 | 0 |
| Component | −0.09417 | 0.019566 | −4.8129 | 0.000002 |
| Version | −0.051485 | 0.022444 | −2.2939 | 0.021816 |
| Assignee | 0.019413 | 0.003056 | 6.353 | 0 |
| Status | 0.120492 | 0.004752 | 25.3539 | 0 |
| Resolution | −0.282509 | 0.009778 | −28.8923 | 0 |
| Hardware | −0.024697 | 0.00588 | −4.2001 | 0.000027 |
| OS | 0.026598 | 0.007748 | 3.4327 | 0.0006 |
| Summary | 1.348889 | 0.425998 | 3.1664 | 0.001548 |
| Status | Estimate | Std. Error | t Value | pValue |
| Intercept | 3316.187141 | 116.49209 | 28.4671 | 0 |
| Changed | 0.444006 | 0.019226 | 23.0943 | 0 |
| Product | 0.03109 | 0.006181 | 5.0303 | 0 |
| Version | −0.198328 | 0.043107 | −4.6008 | 0.000004 |
| Assignee | −0.021023 | 0.005759 | −3.6502 | 0.000263 |
| Severity | 0.025704 | 0.008673 | 2.9637 | 0.003048 |
| Resolution | 0.422041 | 0.018285 | 23.0815 | 0 |
| Hardware | −0.034968 | 0.011359 | −3.0784 | 0.002087 |
| OS | −0.086049 | 0.014875 | −5.7846 | 0 |
| Factors Selected from All Objective Variables | Factors Removed from All Objective Variables |
|---|---|
| Product | Opened |
| Version | Reporter |
| Assignee | ———– |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tamura, Y.; Yamada, S. Large Scale Fault Data Analysis and OSS Reliability Assessment Based on Quantification Method of the First Type. Mach. Learn. Knowl. Extr. 2020, 2, 436-452. https://doi.org/10.3390/make2040024
Tamura Y, Yamada S. Large Scale Fault Data Analysis and OSS Reliability Assessment Based on Quantification Method of the First Type. Machine Learning and Knowledge Extraction. 2020; 2(4):436-452. https://doi.org/10.3390/make2040024
Chicago/Turabian StyleTamura, Yoshinobu, and Shigeru Yamada. 2020. "Large Scale Fault Data Analysis and OSS Reliability Assessment Based on Quantification Method of the First Type" Machine Learning and Knowledge Extraction 2, no. 4: 436-452. https://doi.org/10.3390/make2040024
APA StyleTamura, Y., & Yamada, S. (2020). Large Scale Fault Data Analysis and OSS Reliability Assessment Based on Quantification Method of the First Type. Machine Learning and Knowledge Extraction, 2(4), 436-452. https://doi.org/10.3390/make2040024